1. Introduction
In recent years, the development of increasingly sophisticated high-fidelity models (HFMs) has become crucial for simulating complex physical phenomena. One of the main computational challenges in HFMs is the need for very fine spatio-temporal resolutions, which results in extremely high-dimensional problems that can take weeks to solve, even on numerous parallelized computing cores. Therefore, it is vital to create methods that significantly reduce the computational time and resources required to enable the application of these models in time-sensitive scenarios, including real-time control systems, simulation-driven optimization and digital twins [
1,
2,
3].
To address these computational challenges, projection-based reduced-order models (ROMs) have emerged as a powerful strategy, allowing for rapid simulation by approximating the dynamics of the high-dimensional system within a lower-dimensional latent space [
4]. ROMs can be broadly classified as intrusive or non-intrusive, depending on how the reduced equations are derived. Intrusive ROMs project the governing equations directly onto a reduced space, typically via Galerkin projection [
5], Least-Squares Petrov–Galerkin (LSPG) projection [
6,
7,
8,
9], or related Petrov–Galerkin formulations [
10]. In contrast, non-intrusive ROMs avoid direct equation manipulation, instead employing supervised-learning methods like artificial neural networks (ANNs) or Gaussian processes to map parameters directly to reduced solutions, thereby fully decoupling the online computation from the original high-fidelity solver [
11,
12,
13,
14,
15].
Intrusive projection-based ROMs typically involve an offline–online decomposition. In the offline stage, a latent space is computed from a collection of high-fidelity solutions sampled over a defined parametric domain. Proper Orthogonal Decomposition (POD) is a common approach, relying on Singular Value Decomposition (SVD) to obtain an optimal linear basis that efficiently captures the dominant dynamics [
16,
17,
18]. The online stage then involves solving a reduced optimization problem within this latent space, resulting in dramatically reduced computational costs compared to the original HFM. Such strategies have demonstrated effectiveness in parametric linear problems [
19,
20] and nonlinear problems with moderate complexities [
21,
22].
Non-intrusive ROMs have attracted attention for scenarios where intrusive access to HFM operators is impractical or unavailable. Early successes include Gaussian processes and ANN regression models for aeroacoustic and structural problems [
13,
15], as well as neural networks for predicting flow coefficients in combustion dynamics [
11,
12]. Recent extensions leverage convolutional autoencoders for complex spatio-temporal predictions [
23] and generalized data-driven frameworks for nonlinear PDEs [
14]. Later work with graph neural networks [
24] has aimed at bypassing the need for structured meshes that convolutional autoencoders have. Despite their advantages in computational efficiency, these methods require large training datasets and their scale is still directly tied to the HFM’s dimensions.
Nevertheless, intrusive linear ROMs, particularly those using POD-Galerkin formulations, have been noted to exhibit accuracy degradation and stability issues in highly nonlinear or convection-dominated regimes. For example, spurious mode growth was reported in compressible flows [
21], stability issues have been examined from dynamical systems perspectives [
25], and convergence difficulties have been highlighted in reactive flow scenarios [
26]. These limitations have been attributed to the slow decay of the Kolmogorov n-width [
27], fundamentally restricting the representational power of linear subspaces.
Consequently, a growing body of research has focused on developing nonlinear ROM strategies to overcome these fundamental expressivity barriers. Within intrusive ROMs, the formal theory for generic nonlinear projection-based ROM was introduced in [
28], which was first demonstrated using a convolutional neural network to define a nonlinear mapping between the full and latent spaces. Despite several limitations—namely, limited scalability and the need for structured meshes—this architecture paved the way for further nonlinear architectures. These include methods based on quadratic manifolds [
29], piecewise linear manifolds via local POD approaches [
9,
30,
31], and the PROM-ANN architecture from [
32,
33], the latter essentially being a nonlinear approximation of POD using dense neural networks.
Another approach to deal with nonlinearizable dynamics is the use of spectral submanifolds [
34,
35], which are more mathematically sound than data-based ones. These type of nonlinear manifolds can be found under certain non-resonance conditions [
36], and their direct computation requires explicit knowledge of nonlinear coefficients in the equations of motion. Recent developments in [
34] present a non-intrusive and data-free method to obtain these spectral submanifolds, but are currently limited to mechanical systems with cubic order nonlinearities.
In this paper, we propose a novel residual-informed training approach for constructing nonlinear ROM operators. While existing projection-based ROMs construct their projection operators based exclusively on learning the reconstruction of solution snapshots, we propose incorporating the discrete residual of the FEM-based HFM—the same residual used during online ROM projection—into the training of these operators. The reason for this is that since the residual is the quantity to be optimized during ROM inference, its more accurate representation will improve the solutions of the ROMs, which is much needed.
Our methodology is inspired by Physics-Informed Neural Networks (PINNs) [
37] and their variants, e.g., [
38,
39]. PINNs are models based on neural networks that learn the solution function to a system of partial differential equations (PDEs) in their continuous form. This is achieved by embedding the governing PDEs directly into the loss function and taking advantage of the automatic differentiation capabilities of common machine learning libraries. However, their application in engineering workflows can be hindered by their difficulties to cope with irregular or discontinuous domains, complex PDEs due to spectral bias (which hinders their ability to handle high-frequency terms [
40]), discontinuities (such as shock waves [
41]), and plasticity (requiring significant effort to develop workarounds for these issues [
42]).
In contrast, the Finite Element Method (FEM) [
43], along with other HFMs like Finite Differences or Finite Volumes Methods, remains the gold standard for solving complex physical behaviors, particularly in engineering applications. This has led to recent efforts to bridge FEM and PINNs. For example, Refs. [
44,
45] proposed discrete PINNs that use FEM to compute residuals and their derivatives for backpropagation in linear problems. These approaches predict nodal values using neural networks that take simulation parameters as the only input. Meanwhile, the spatial discretization and boundary conditions are implicitly integrated via the FEM residual. While [
45] focuses exclusively on structural mechanics, Ref. [
44] generalizes the approach but only for linear PDEs. Another intermediate approach is presented in [
46], which introduces a physics-informed neural operator inference [
47] framework that takes a discretized, variational form of the PDE as the training loss. This variational form is based on the energy of the system and is closely related to the FEM one, although it is not generalizable to the same degree. They remark how traditional PINNs only enforce the strong form of the PDE on the collocation points, resulting in a lack of global smoothness, while a variational approach ensures this implicitly.
Other semi-intrusive strategies have been proposed that embed reduced-order residual information into neural networks to enhance generalization and enforce physical consistency in parametric regimes. We refer to these as semi-intrusive methods, since they require partial access to governing equations or their projections during training—such as reduced residuals—but retain a decoupled, non-intrusive structure at inference time. In [
48], a Physics-Reinforced Neural Network (PRNN) was introduced, which minimizes a hybrid loss composed of reduced residuals and projection data in the latent space. Subsequently, Ref. [
49] combined POD-Galerkin ROMs with a neural network trained on both data and the residual of the reduced Navier–Stokes equations, enabling the same architecture to address forward prediction and inverse parameter-identification tasks. Moreover, Ref. [
50] enhanced POD–DL-ROMs by incorporating a strong-form PDE residual into the training process and adopting a pre-train plus fine-tune strategy that significantly reduces computational cost in nonlinear flow problems.
Beyond reduced-order modeling, broader physics-informed machine learning frameworks such as the Deep Galerkin Method for high-dimensional free-boundary PDEs [
51] and PINN-based RANS modeling for turbulent incompressible flows [
52] further demonstrate the growing applicability of physics-aware neural architectures to complex nonlinear systems. Related efforts have explored manifold-learning and structure-preserving neural architectures outside traditional ROM contexts, including shallow masked autoencoders for nonlinear mechanical simulations [
53], mechanics-informed neural networks for robust constitutive modeling [
54], physics-informed architectures for modeling mistuned integrally bladed rotors [
55], FE-ROM-informed neural operators for structural dynamics [
56], and two-tier deep neural architectures for multiscale nonlinear mechanics [
57]. Although these methods primarily remain data-driven, their built-in physics constraints substantially enhance predictive capability. Despite these promising developments, a gap remains in fully leveraging the discrete physics of the HFM directly during the training of projection-based ROMs, particularly within nonlinear manifold approximations.
In this work, we propose a method to incorporate physics information into the ROM nonlinear approximation manifold by using the FEM residual as the training loss. This requires two key components: (1) a flexible ROM architecture capable of accommodating custom loss functions for the definition of the projection operators, and (2) a framework to integrate FEM residuals into the training process. For the architecture, we adapt the PROM-ANN framework from [
32,
33], which uses neural networks in a scalable manner. We modify this architecture to suit our needs and develop a framework to integrate FEM residuals into a neural network’s loss, along with their Jacobians for the backpropagation. Our approach assumes that the user has access to a fully functional FEM software capable of providing these quantities—a reasonable requirement given the need for an HFM to generate training data and perform intrusive ROM.
Our residual-based loss function differs from previous studies in its generality and flexibility. Instead of minimizing the FEM residual norm directly, we compute the difference between the obtained residual and ground truth, thereby learning the behavior of the residual in non-converged conditions. We also provide an optimized implementation for computing the gradient of the residual loss, enabling efficient backpropagation.
To validate our methodology, we apply it to a steady-state structural mechanics problem involving a cantilever modeled by an unstructured mesh. The FEM software of choice is KratosMultiphysics [
58], which we adapted for this purpose. Our results show that the modified PROM-ANN architecture, combined with the residual-based loss, achieves slightly but consistently improved accuracy in ROM simulations. We acknowledge that training with the residual loss is computationally expensive compared to the traditional snapshot-based loss. To address this, we propose using residual training only as a fine-tuning step after initial snapshot-based training, significantly reducing overall training time.
While adapting the architecture of PROM-ANN to suit our specific needs, we also identified opportunities to enhance the original design, enabling it to learn effectively across a broader range of scenarios, even without incorporating the residual-based loss. These improvements are presented as additional contributions in this paper.
It should be noted that, although projection-based ROMs have also been employed to accelerate inverse problems [
59,
60], the present work exclusively addresses forward parametric simulations. Extensions to inverse tasks—such as parameter estimation—would require further developments, such as involving adjoint-based gradients or parameter-to-output mappings, which lie beyond the scope of this study.
In summary, our contributions are threefold:
Physics-Informed Residual-Based Loss: A residual-based loss function is introduced for training ROMs using discrete FEM residuals. While generally applicable to nonlinear problems and ROM architectures, it is demonstrated here within the PROM-ANN framework. The loss is parameter-agnostic and integrated through a general backpropagation strategy compatible with existing FEM infrastructure.
Enhanced PROM-ANN Architecture: Modifications are proposed to improve the original PROM-ANN framework, enabling it to handle problems with fast-decaying singular-value spectra. These include scaling strategies that enhance training stability and general applicability.
Quantitative Evaluation of Residual Training: A comprehensive study is conducted to assess the impact of residual-informed training on both snapshot reconstruction and ROM simulation, demonstrating modest but consistent improvements and laying the groundwork for future refinements.
The application of the physics-informed training in this specific architecture does not yield enough enhancement in terms of accuracy to justify the increase in training time. However, our findings suggest that focusing on residual behavior could unlock further potential in nonlinear ROMs, particularly when combined with architectures specifically designed for this purpose. Possible directions to make the training process faster and to make the effect of the physics-based training more impactful are proposed within this paper.
The rest of the paper is organized as follows.
Section 2 provides a review of the main methods that form the basis for this work, i.e., PINNs and projection-based ROM with an emphasis on the original PROM-ANN architecture. In
Section 3, we propose a discrete, FEM-based residual loss and develop an adequate implementation strategy for it. Then,
Section 4 provides a series of modifications to the original PROM-ANN architecture and loss that make it compatible with problems with fast-decaying singular values.
Section 5 effectively merges the developments presented in the two previous sections to enable physics-informed nonlinear ROM. Following this,
Section 6 explains the specific FEM problem in which the developments will be tested, as well as the software of choice and the neural network training strategy.
Section 7 shows the results of applying the methods developed throughout the paper onto our specific use case.
Section 8 further discusses the implications of the results from the previous section and proposes further research directions for future improvements. Finally,
Section 9 closes the paper with the most significant conclusions.
3. Discrete PINN-like Loss
Our nonlinear ROM architecture aims to incorporate the physics of the problem into the approximation manifold construction. The equivalent effect is accomplished in traditional PINNs by auto-differentiating the neural network’s output with regard to a given point in continuous space and time, using the strong form of the PDE system. In contrast, a discrete approach like ours requires a numerical approximation through the discretization of the PDE, which can be performed via a variety of techniques such as the finite element or finite volume methods. The integration of these discretized residuals into neural networks places our approach within the category of informed machine learning, as detailed by [
64].
The proposal to use discrete approximation for substituting the auto-differentiation in PINNs for residual minimization is introduced almost simultaneously in [
44,
45]. Both of these approaches introduce NN architectures for solving forward problems of linear, steady-state simulation and [
44] additionally presents a model for backwards problems of the same nature. Their conceptualization does not differ too much from classical PINNs in terms of inputs, outputs, and loss definition: they take the parameters vector for the desired simulation as input, and return the results of the nodal variables of the system as output. The spatial information that is typically an input in PINNs is intrinsically defined in the FEM solver at the time of the residual computation.
In terms of the training loss, both approaches aim to minimize the mean squared L2-norm of the residual, as determined by the FEM solver. This minimization considers the predicted snapshot (nodal variables) and the relevant simulation parameters:
where
are the trainable parameters of the neural network conforming the PINN, index
j specifies the different samples to be used within the batch,
m is the number of samples in the batch, and
N is the number of degrees of freedom in our system (and therefore the size of the residual). An important remark about this loss is that it requires the removal of contributions in the residual
at the degrees of freedom with Dirichlet conditions; otherwise, the norm will not approach zero.
The exact implementation of this loss differs in both approaches. The one in [
45] is limited to static linear cases of structural mechanics and proposes a specific loss scaling strategy for these cases. They also propose an implementation strategy to perform the loss computation in batches. Meanwhile, the approach in [
44] is more general, but still only applicable to linear PDEs. This limitation to linear cases significantly simplifies the loss implementation, as the residual becomes of the form
. So, both the stiffness matrix
and the vector of external contributions
are independent of the current snapshot. Accordingly, the loss becomes the following:
where one could have pre-computed all
and
, thus allowing the whole optimization to be performed via auto-differentiation, without calling the FEM software.
Even the approaches in more recent papers like [
65,
66] are still designed only for linear problems, with the difference being their specific use cases, the architectures they use for the surrogate model, and the loss being just the norm of the residual, instead of the square of it.
In contrast, our approach differs in two key aspects: (1) the loss function is formulated in a parameter-agnostic manner, and (2) it is designed to handle both linear and nonlinear cases, thereby enabling a much broader range of applications. As with PINNs, our method also allows for a combination of physics-based and data-driven losses. The following subsections discuss these three developments.
3.1. Parameter-Agnostic Loss
One aspect in which our methodology diverges significantly from the original idea of PINNs is that we are not training a self-contained surrogate model (typically in the form of a single neural network ), but instead, the approximation manifold is defined by a trainable encoder–decoder pair . As we can see, the latter case does not take the simulation parameters as an input, so it is agnostic to them. This is because the FEM-based ROM software itself will be in charge of conditioning the simulation with those parameters and then finding the most appropriate solution within our latent space.
This is not the only difference in our methodology. Traditionally, for a loss like the one in Equation (
20), the exact parameters
for the solution need to be specified, as these are what will yield a residual of zero and therefore enable the learning by minimization. Instead, we design a loss function in which the parameters applied in the FEM software can be arbitrary. In this new loss, we are not merely minimizing the properly parameterized residual of the predicted quantity
, but the difference between this quantity and the residual of the target solution
, both with constant parameter
:
In this case, the trainable parameters are contained within the encoder and/or decoder of our ROM, and their specific form depends on the chosen architecture. Strictly speaking, we should write . However, for clarity and conciseness, we will omit from the notation in what follows.
Our approach aims to minimize the discrepancy in residual behavior when it is non-zero, ensuring that the ROM approximation manifold captures not only the converged solution but also the behavior of the residual outside of convergence situations. In our approach, the decoder will be readily integrated into the Newton iterative procedure. Thus, we aim for it to enhance its residual representation near the convergence space, aiding in achieving an optimal converged solution. On the same line, we no longer have the restriction that we mentioned for Equation (
20) on the components of the residual associated with the Dirichlet conditions. This means that we can leave those components in order to learn them too. The main caveat of using this approach is that it still requires the original HFM’s snapshots samples
, even when training via the residual. In our specific case, the encoder–decoder architecture of choice will need these snapshots regardless, so it is not a major inconvenient.
Regarding boundary conditions, it is important to consider that Dirichlet conditions must be imposed strongly in the solutions vector whenever we compute the residual. That means that whatever architecture we use as the encoder–decoder pair, it needs to operate on and predict only the degrees of freedom unaffected by Dirichlet conditions. Then, the fixed ones are given their corresponding value forcefully before computing the residual and Jacobian matrix.
3.2. In-Training Integration of FEM Software
The obstacle impeding the transition from linear to nonlinear cases in other FEM-based residual losses [
44,
45] is not a theoretical or mathematical difficulty from generating the residuals themselves or their derivatives. We have extensive FEM software at our disposal that already does precisely this. The difficulty is in dynamically integrating this information in an effective way during the training of the decoder.
Let us study the loss we proposed in Equation (
22) in more detail to identify our needs during training. The loss itself needs the values for two residuals:
and
. The latter can be pre-computed, as it will be constant for sample
j during the whole training. The first one, however, has to be computed within the FEM software with an updated snapshot value at each training step.
The actual training of the model happens during the backpropagation of the loss, which necessitates calculating the gradient of the loss with respect to
. This is typically carried out automatically thanks to the auto-differentiation capabilities of deep learning frameworks. However, as we take part of the loss computation onto external software, we are unable to do this and we have to code the gradient manually. The derivative of the loss function
can be decomposed using the chain rule:
where
is the current prediction for the nodal values of the solution.
The factor
is the Jacobian matrix of the residual function with respect to the predicted solution vector
. This Jacobian is computed and assembled entirely in the FEM software, given the current snapshot and arbitrary simulation parameter. Within the context of FEM, it is expressed as follows:
The final factor
represents another Jacobian, this time of the predicted snapshot with respect to the trainable parameters. We can express it as follows:
This latter derivative is applied only on the computations performed in the trainable encoder–decoder pair . As such, this factor is self-contained within the deep learning framework and does not require additional external data. Such a Jacobian could be obtained by using the tf.GradientTape.batch_jacobian() method in TensorFlow, or equivalent methodologies in other deep learning frameworks.
To compute the loss gradient as it is defined explicitly in Equation (
23), we just need to collect the factors coming from the FEM software into the deep learning framework. However, this computation would be unnecessarily inefficient because of the two main reasons described next. For each of these, we propose a corresponding implementation strategy:
In our case in particular, we take KratosMultiphysics as our choice of FEM software. As it is open-source, it enables us to develop all the custom functionalities needed to take a given set of snapshots (those of the current batch), and for each one apply it as the current solution to then output and .
3.3. Data-Based Loss Term
Even when training with the residual loss, it might be beneficial to introduce a data-related loss simultaneously. This is common in traditional PINNs in two instances: It is used specifically on the boundary and initial conditions to try to enforce Dirichlet conditions [
37] (unless a special approach is used to establish them strongly [
63]), and it is also used on collocation points sampled inside the simulation space as a regularization that can help the overall loss converge faster [
38].
In our case, the Dirichlet conditions are enforced strongly and managed by the FEM software for their effect on the residual. However, we could still introduce such a loss term for regularization purposes. Thus, the total loss function is defined by two components:
where
and
are tunable hyper-parameters to balance both terms as needed, and the data-related loss
is defined simply as the mean squared error between the currently predicted snapshot
and the ground truth one
:
Then, the implementation of the total loss
and its gradient starts by defining the following vectors as constants:
and then using these to compute the loss as
Finally, its gradient via auto-differentiation is as follows:
4. Modifications to the PROM-ANN Architecture
We adopt the PROM-ANN architecture from [
32] as the foundation for developing our physics-informed ROM model, which introduces the use of neural networks while ensuring scalability and avoiding the requirement of a structured mesh for the underlying simulation. The architecture was introduced in
Section 2.4, where we noted that it can be interpreted as a nonlinear extension of classical POD that introduces additional effective modes without increasing the size of the latent space.
However, we find that the architecture, as originally proposed, is difficult to train—at least in our case, where the underlying problem exhibits a rapidly decaying singular value spectrum. To address this, we first revise both the architecture and the data-driven loss formulation to improve training capability. Later, in the following section, we will incorporate our residual-based loss into the framework.
The modifications we propose in this section are as follows: (1) scaling of reduced coefficients, (2) changing the data-based loss for one that takes the full snapshot into account, and (3) properly scaling the loss.
4.1. Scaling of Reduced Coefficients
The main concern for us from the original architecture is that there is no normalization or scaling of the reduced coefficients prior to using them in the neural network. Ideally, neural networks are designed to operate on inputs that are approximately independent and identically distributed (i.i.d.), as this assumption facilitates more effective learning and optimization [
67,
68]. This can rarely be guaranteed, but it is still common practice to perform some sort of normalization or scaling on the inputs so that they all operate in a similar range of values. Otherwise, serious issues may arise during training, mainly because of some of the inputs are ignored.
In the case of PROM-ANN, the inputs and outputs of the neural network are the coefficients for a given snapshot (remember from
Section 2.4 that we train a network such that
). These coefficients,
and
, will scale similarly to the singular value decay observed when performing SVD on the training data. Essentially, for a fast-decaying singular value profile, each coefficient will result in a considerably smaller range of coefficients than the previous one, causing the neural network to learn only from a few of the first ones.
In order to correct this issue, we modify the architecture of the encoder and the decoder themselves to include a pair of scaling matrices:
where both the projection matrices
,
and the scaling matrices
,
come from the SVD decomposition of the snapshots matrix:
and
represents the singular values found in the diagonal of the
matrix. Finally,
M is the total number of samples in
.
This procedure effectively rescales each coefficient to have a roughly equivalent range. In the ideal case where all rows of the training snapshot matrix have zero mean, multiplying by the matrix scales the quantity such that the covariance matrix between its rows becomes the identity. In other words, the modes in are uncorrelated—already ensured by the projection onto —and have unit variance.
In our case, the condition that all row means in
are exactly zero does not hold. Nevertheless, as we will show in
Section 6, the resulting scaling still leads to reduced coefficients with similar magnitudes in our particular use case.
We intentionally avoid enforcing zero-mean values, as we do not wish to apply any offset to the projected values. This design choice is crucial because it enables a neural network architecture without biases, thereby ensuring that holds. Additionally, the proposed scaling procedure preserves the orthogonality of the projection matrices, so we still have .
Finally, no additional computation is required to obtain the scaling factors, since the SVD is already performed as part of the original methodology. In this sense, the approach is highly efficient.
Note that this formulation makes the assumption that the problem is homogenous, which is true for our particular use case. Still, it can be applied to non-homogenous cases. In such cases, the user should remove the components affected by Dirichlet conditions from all snapshots and proceed as stated. Then, at the time of running the online simulation, the fixed components of the solution can be imposed strongly, as they are known.
4.2. Corrected Data-Based Loss
Now we have an architecture that provides appropriately scaled features for the neural network. But at the same time, this scaling may not be the best if we want to apply the training loss as in the original paper [
32]; that is, measuring the error on the predicted
coefficients themselves. This loss would translate like this to our architecture:
The rationale behind dividing by
N is to ensure consistency with the loss formulations introduced in
Section 3.
Such a loss will give the same importance to all of the output features, or reduced coefficients in this case. We know from the nature of POD that this is not desirable, as lower modes should be given more importance than higher ones. In fact, we now must reverse, within the loss, the scaling that we applied to the reduced coefficients. We can do so by applying
on the contents of the norm in Equation (
35):
But we could also achieve the same effect by just enforcing the whole reconstructed full-order snapshot to approximate the ground truth one; that is, using exactly the same data-based loss that we had defined in
Section 3.3:
This second loss is more intuitive, as we make it explicit to achieve the final goal for our ROM approximation manifold: learning the full snapshot itself. However, it is not difficult to prove that both Equations (
36) and (
37) are equivalent up to a constant offset; that is, assuming that all snapshots
were included in the set
to which we performed the SVD.
Proof. By developing from
, we obtain the following:
By developing
. Where
is the orthonormal basis containing the singular vectors from
that were not included in neither
or
, and
is analog but for the singular values matrix. Then, applying this obtains the following:
By acknowledging that
and
are orthogonal to each other, we obtain the following:
By acknowledging that the
norm is invariant to the right-multiplication of an orthonormal matrix and that the terms
do not depend on trainable parameters
, we obtain the following:
□
If the user does not intend on applying physics-informed training, then choosing would make the most sense because of its reduced complexity. However, the fact that takes the snapshots to the full space within the computation makes it most appropriate to be paired with a physics-based loss, which will require the full vector of nodal solutions anyway. In any of the two cases, the ideal method would be to pre-compute for all samples to improve efficiency.
4.3. Scaling of the Data-Based Loss
As written in Equation (
37),
would exhibit high variability depending on the number of modes included in the primary ROB. This is because, by including more modes in
while following their importance order, we are heavily limiting the possible error
that we can have (this is true for snapshots within the set
, and should reflect in new samples if they are properly represented by the POD).
In order to correct this issue, we propose to use a pre-computed scaling factor that will be applied globally to the loss:
With the new factor
defined as follows:
This quantity corresponds to the mean squared reconstruction error of the standard POD approach when only the primary modes are retained. This is averaged over all the samples in the training set, not only those in the batch, in order to make it representative for any choice of samples during the training, and thus means that it only has to be computed once at the beginning.
This choice of scaling acts as a safeguard preventing the gradients from becoming too low, which could induce numerical instabilities during training, and prevents the weight updates from varying wildly in scale based on the chosen numbers of primary modes for the same learning rate. Apart from this, it also gives a much more interpretable value to the loss, as it will become an indicator to how much better the current model is compared to just using POD for the same size of latent space. In this sense, it is helpful when troubleshooting, as a value over 1 would clearly indicate that we are losing accuracy compared to POD.
4.4. Online Phase of Nonlinear ROM
In order to perform the online ROM simulation, we need to adapt the nonlinear iteration problem to the new architecture. Essentially, we substitute our decoder into the Galerkin-based nonlinear iteration formulation for nonlinear manifolds (as seen in Equation (14)). The result would be as follows:
meaning that at each nonlinear iteration, we have to recompute
.
The online ROM simulation is performed entirely within the FEM software, KratosMultiphysics, as going back between this and the deep learning software would be unnecessarily expensive. Therefore, we made custom methods within KratosMultiphysics to compute both the forward pass of the neural network, , and the Jacobian of its outputs with respect to the inputs, . The other quantities are defined at initialization from the training results and are kept constant.
6. Use Case and Evaluation Methodology
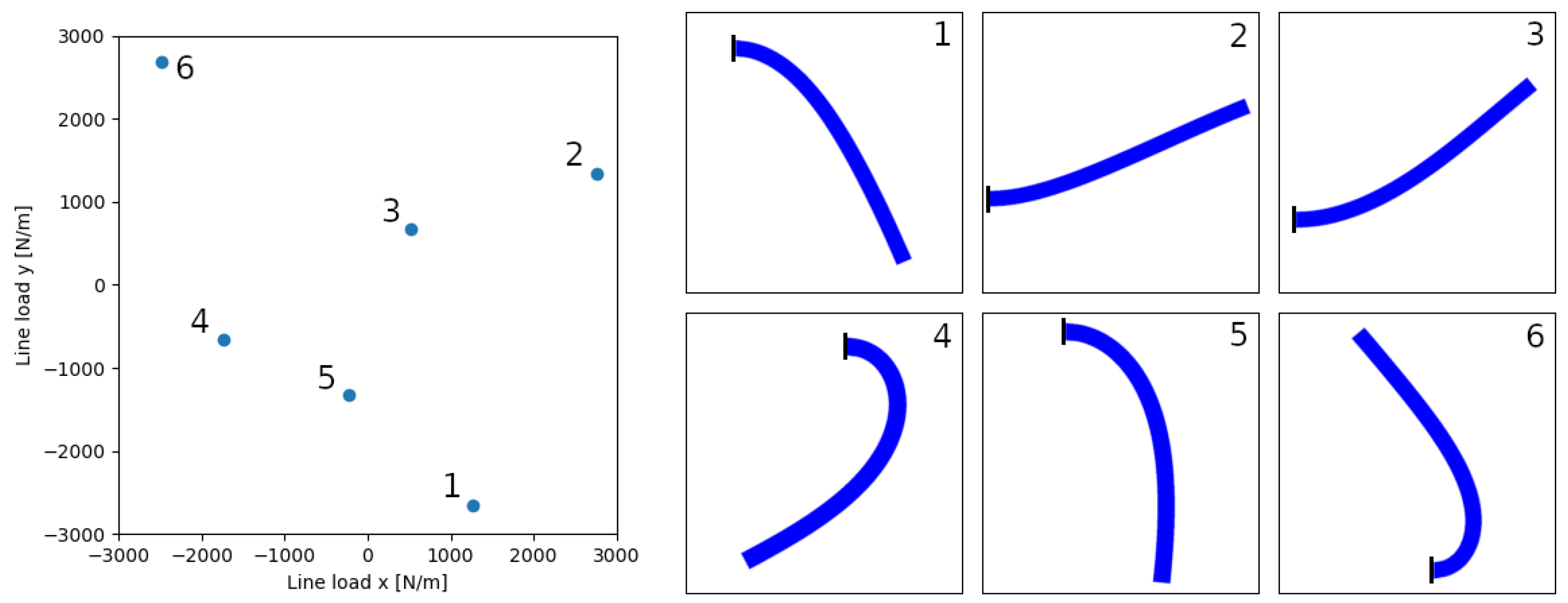
The evaluation of our method is performed on a quasi-static structural mechanics case, specifically a nonlinear case of hyperelasticity. It simulates the deformation in a 2D rubber cantilever that is fixed at its left wall which has two different and perpendicularly oriented line loads,
and
, applied to its right end. The cantilever is defined by an unstructured mesh with 797 nodes, and the nodal variables to compute are the displacements in components X and Y. Therefore, our FOM system is of dimension
.
Figure 1 shows a schematic of the described setup.
We define the parametric space as the range of loads that can be applied in each direction:
N/m. And the displacements are computed in reference to the unperturbed position of each node
.
Figure 2 shows the deformation on the cantilever for a random set of lineload combinations within the parametric space.
In order to build the snapshot matrix for the training, we perform the ROM simulations of 5000 different cases with parameters defined by a 2D Halton pseudo-random number generator. From each of these simulations, we store both the full snapshot and the corresponding residual . For the validation set, we generate 1250 different samples using the same strategy, and we generate 300 more for the test set. We perform all evaluations over the test dataset; the training and the validation ones are used exclusively during the training process.
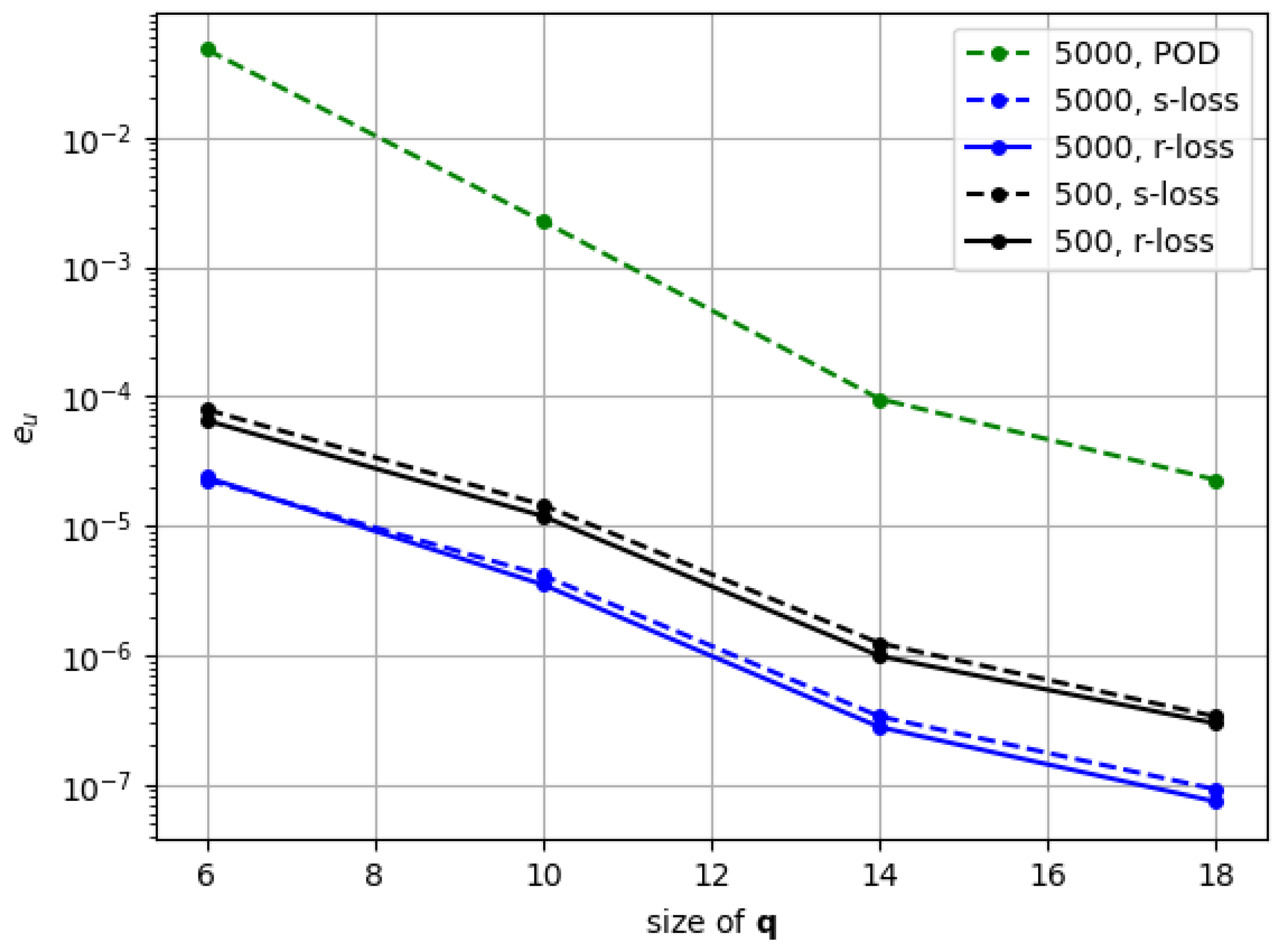
A reduced dataset with one order of magnitude fewer FOM simulations (i.e., 500 samples) was also evaluated (see
Appendix A). While this resulted in a moderate decrease in accuracy, the PROM-ANN approach remained consistently more accurate than POD. Reducing the dataset by yet another order of magnitude introduces significant challenges—particularly for training the neural network—since learning a reliable nonlinear mapping (e.g., from 10 to 40 latent coordinates) from only 50 samples is a highly underdetermined task. The choice of 5000 samples was motivated by the low cost of the benchmark and the data demands of neural network training [
68]. Adaptive sampling techniques (e.g., [
69]) could be explored in future work to reduce offline cost.
,
,
, and
are obtained from the SVD of the snapshots dataset for training.
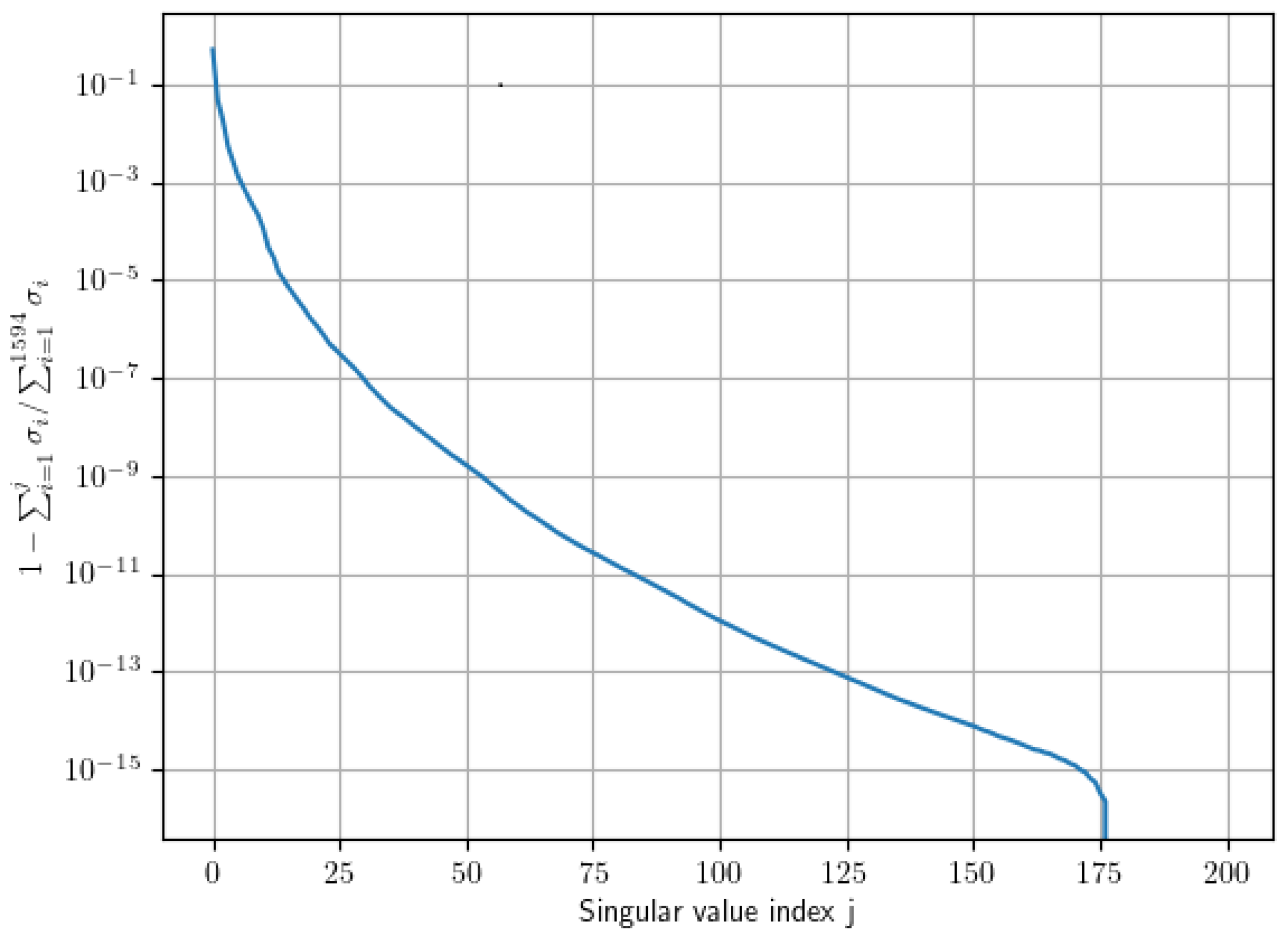
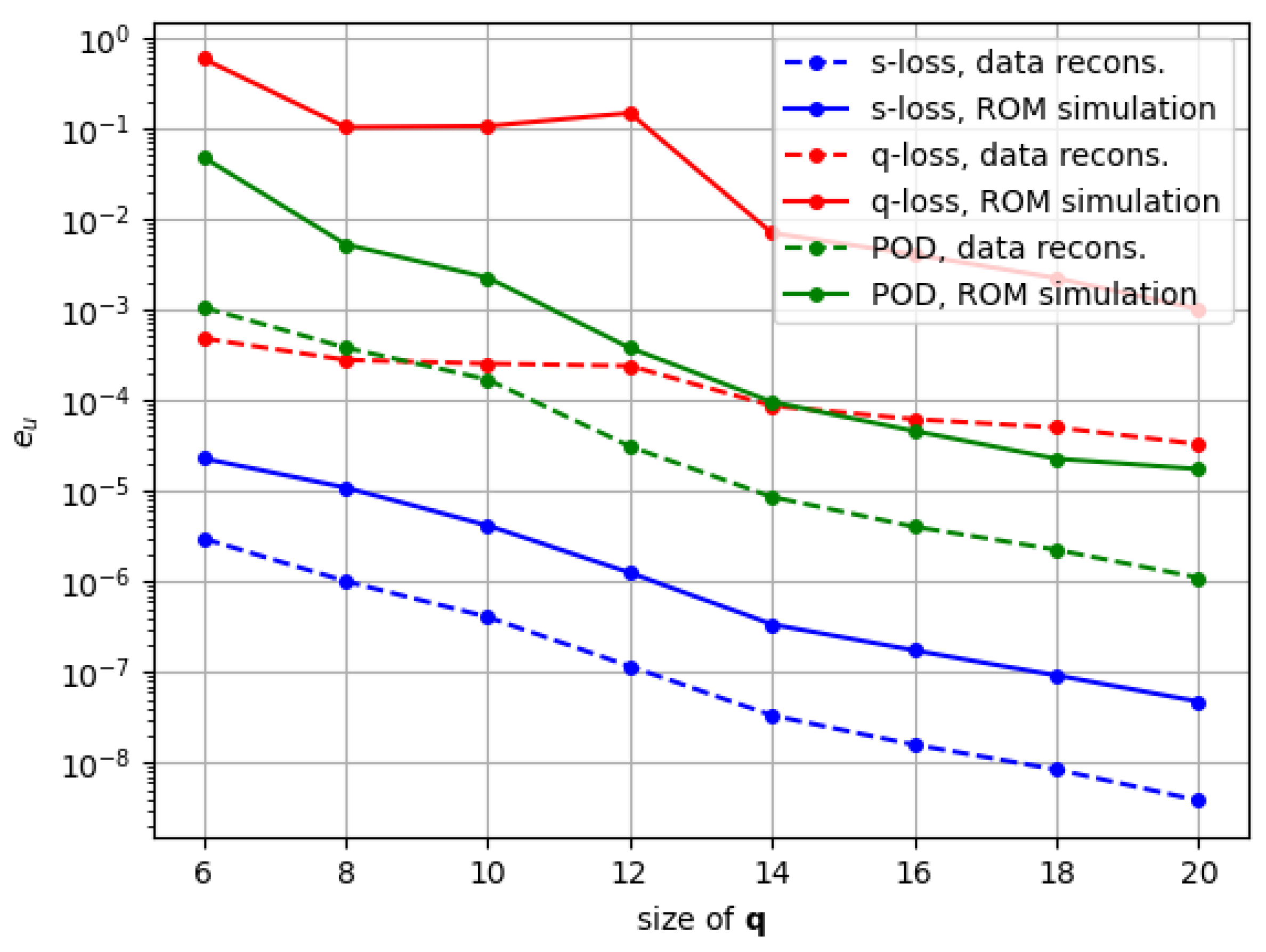
Figure 3 shows the decay of the singular values’ energy for the first 200 modes of the SVD. The number of modes in each projection matrix is chosen by taking into account the accuracy obtained via traditional POD-based ROM using the same amount of modes. We establish two limit cases: one in which we select a value of
, which would lead to a
error on the displacements snapshot using POD, and one with
, which would achieve a relative error of
. We then take a series of
n values in between these to compare in our experiments. The secondary ROM basis contains a variable amount of modes so that
always.
Two different error metrics are defined:
Relative error on snapshot:
This is the geometric mean of the relative errors of each ROM sample compared to the FOM one .
Relative error on residual:
Again, this is the geometric mean of the samples’ relative errors, but this time comparing the residual.
We will use these metrics in the next section in order to compare the behavior of our models both in reconstruction and online ROM.
In terms of software, we use KratosMultiphysics [
58] as our FEM framework as it is open-source and lets us implement the required methods and interfaces in Python. For the neural network framework, we choose TensorFlow.
All neural networks presented contain two hidden layers of 200 neurons each with no bias. The architecture was selected based on empirical tuning through several trials using the snapshot-based loss. For the residual-based loss, the only hyper-parameter modification was a reduction in the initial learning rate to prevent overwriting previously learned weights, as this stage is intended as a fine-tuning pass. We use the Exponential Linear Unit (ELU) as the activation function following its successful application in the related literature [
28,
32]. ELU is continuously differentiable, being twice differentiable almost everywhere, and avoids vanishing gradients by allowing small negative outputs, addressing the known limitations of ReLU [
70]. While no explicit comparison with other activations was conducted, we believe that functions with similar smoothness and gradient-preserving properties—such as Swish [
71]—would behave similarly in this context. We implemented ELU directly within our FEM software to allow for ANN-PROM online simulation without the need for external software. A sinusoidal learning rate scheduling strategy is applied, reducing the learning rate down to
, and the AdamW optimizer is used with TensorFlow’s default parameters. All trainings are performed with batches of size
.
We emphasize that the proposed methodology is designed and validated exclusively for forward parametric simulations.
8. Discussion and Future Work
Once we have assessed the performance of our proposed architecture and losses, we will further discuss the implications of these results and the impact of our contributions.
We comment first on the discrete FEM residual-based loss that we developed throughout
Section 3, and its proposed implementation strategy. These developments pose a step-up from recent initiatives to design discrete PINN-like losses [
44,
45,
65,
66] that limit themselves to linear problems of different natures. By taking advantage of open-source FEM software like KratosMultiphysics [
58], we can access all the FEM methodology needed to obtain residuals and Jacobians for nonlinear cases in a wide range of state-of-the-art FEM formulations. The cost for this is a loss in time efficiency during training compared to the classic data-based approach, because of the required dynamic interaction between the FEM software and the neural network framework during training and also the manual computation of the gradient loss. It is in this sense that our implementation proposal makes a huge difference, taking the training time from being prohibitive to being just an order of magnitude higher than the data-based one. These comparisons are shown in
Section 7.3. We believe that the main computational bottleneck after our proposed methodology is the fact that the FEM software currently runs the computations in series for each sample in the batch. Some future work on parallelizing these procedures could potentially unlock training times much closer to the data-based ones. In addition, the current formulation introduces a fundamental architectural shift compared to the original PROM-ANN framework [
32], which operated entirely in the reduced-order space, learning a map from
to
. In contrast, our physics-aware variant requires training in the high-dimensional physical space of the full-order model, since the FEM residual and its Jacobian must be evaluated in that space. This change increases training cost considerably, both due to the FEM evaluations and the need to retrieve full Jacobians for backpropagation. While this enables the integration of high-fidelity physics, it does not scale well for large-scale problems. Future work could address this by coupling the current approach with scalable network architectures—e.g., convolutional or graph-based neural networks—and by projecting the residual into an intermediate reduced-order space before backpropagation. Related ideas have emerged in the recent literature, notably in the form of semi-intrusive training strategies such as the one proposed by Halder et al. [
72], where residuals are used only in projected form during training, avoiding full-order evaluations. However, these approaches preserve non-intrusiveness. We believe such hybrid strategies are promising and plan to explore them in future developments. Another key characteristic of the proposed loss is being parameter-agnostic. This makes it more versatile in various ways: in terms of efficiency, the FEM software does not need to re-configure the simulation for each specific sample, and in terms of use case, it can be applied to cases in which not only the minimization of the residual itself is important, but also its behavior while being non-zero. This latter aspect is key in using this loss for our particular setting of intrusive ROM. One unexplored advantage of this loss formulation would be the possibility to perform partial physics-based learning, where only specific components of the total residual are used for the training. For example, one could train only on the steady-state component of the residual of a dynamic case in order to avoid the inconveniences from the dependency on previous time-steps. This is not addressed in this paper, but left as possible future contributions. There are further options that the residual loss could open up and that we have not fully explored, e.g., the possibility of training on the residual with noisy data in order to achieve data augmentation. Next, we comment on the modification to the PROM-ANN architecture itself and the data-based loss
with the scaling matrices
,
, and the global scaling
. The scaling matrices are an inexpensive way to normalize the input ranges for the neural network with the direct results from the SVD so that we avoid extra statistical studies of the dataset. The global scaling is a single scalar computed inexpensively via POD, only once for the whole training. The effect of these modifications is apparent in the results in
Section 7.1, where both the reconstruction and ROM results from our architecture are several orders of magnitude better than the simpler, original approach described in [
32]. Now there is a very plausible explanation for the lack of performance of the original PROM-ANN, mostly when comparing with the good results that they obtain in their paper. The use case that they use for evaluation is a 2D inviscid Burgers problem, which has a much flatter decay in the SVD’s singular values compared to ours. Thus, the range of their inputs to the neural network should naturally be more uniform. Another possibility is that they apply some normalization routine prior to the neural network without mentioning it explicitly. In any case, we can say that our modification makes the architecture generalizable to any kind of problem in terms of their singular value decay. Additionally, the global scaling
is key in order to stabilize the scale of the loss and the backpropagation gradients, making the neural network optimizer perform equally whatever the choice of latent size. It also has an interpretational purpose, which is to make the loss a direct indicator of how much better the results are relative to the simple POD version. Something to explore in the future would be better methodologies to choose the modes included in the primary and secondary ROBs. Right now, this is performed in a greedy way, selecting as many modes that are needed to achieve a certain accuracy in POD, but it is not clear how different modes are related to one another (especially since they are uncorrelated in the linear sense). The implementation of our version of ANN-PROM (only with the data-based loss) is readily available within the ROM application of KratosMultiphysics [
58]. The framework to train via residual has not yet been implemented in the master branch of the KratosMultiphysics software at the time of publication. Until it is fully implemented, interested users can check out the branch at
https://github.com/KratosMultiphysics/Kratos/tree/RomApp_RomManager_ResidualTrainingStructural (accessed on 15 May 2025) which handles the residual usage for the StructuralMechanicsApplication. Once using that branch, the user may run the example in
https://github.com/KratosMultiphysics/Examples/tree/master/rom_application/RomManager_cantilever_NN_residual (accessed on 15 May 2025) which implements this cantilever use case (with a reduced number of samples by default).
Finally, we discuss the effect of training our modified ANN-PROM architecture on the residual loss. Other than the increased duration of the training routine, it was also difficult for us to prevent the model from falling in non-optimal local minima during training with the residual loss. This is why the chosen approach was to train first with the data-based approach and only then fine-tune with a purely physics-based loss. The intuition for proposing this physics-based training comes from the fact that the intrusive ROM accuracy is not only given by the snapshot-reconstruction capabilities of the approximation manifold (which would work more like a lower limit in terms of error), but should also be dependant on how well the residuals are represented within these solutions in the manifold. This is essentially because the residual is the quantity being optimized during the intrusive ROM simulation. The general discrepancy between ROM and reconstruction is clearly demonstrated within our use case in
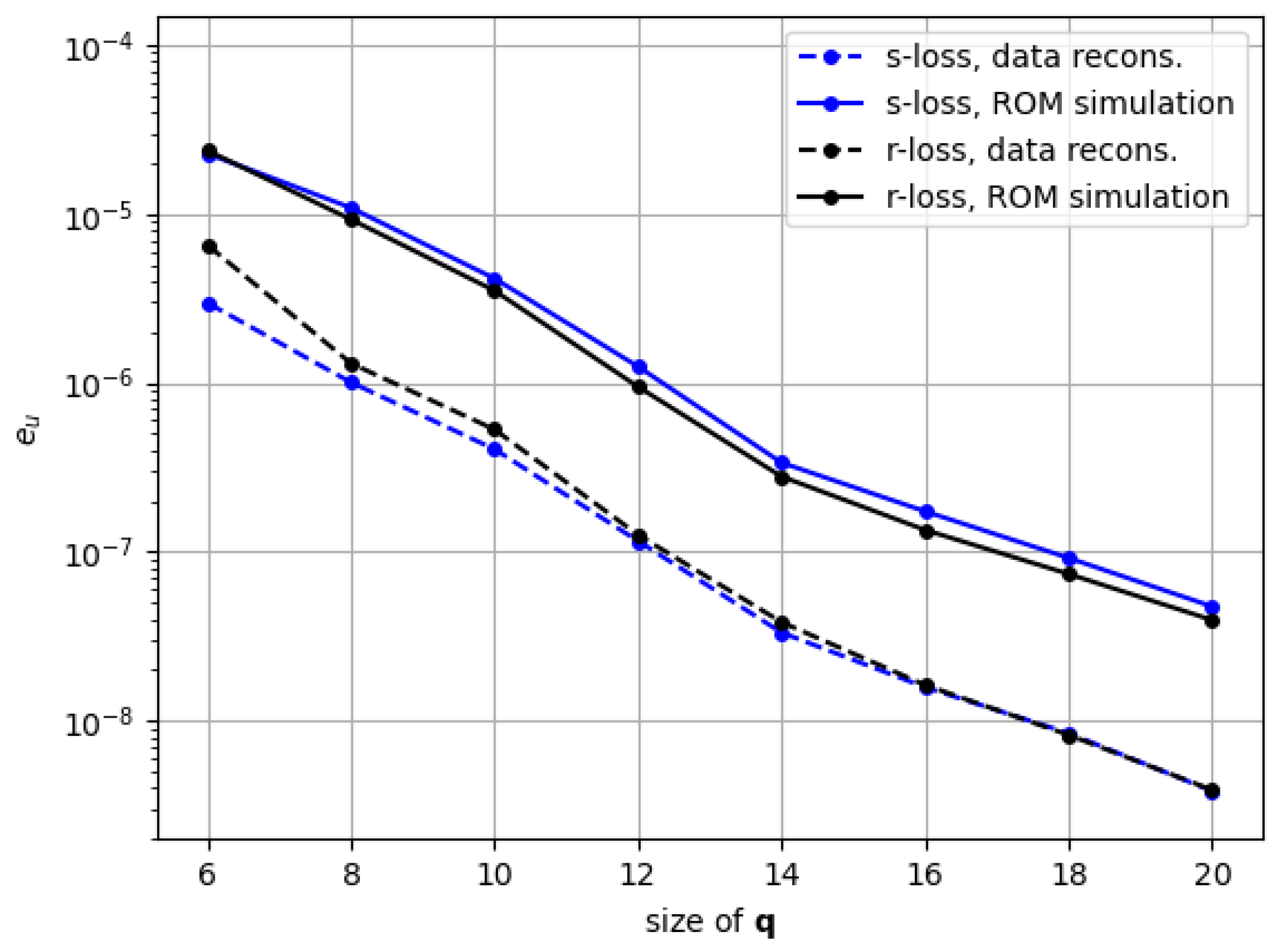
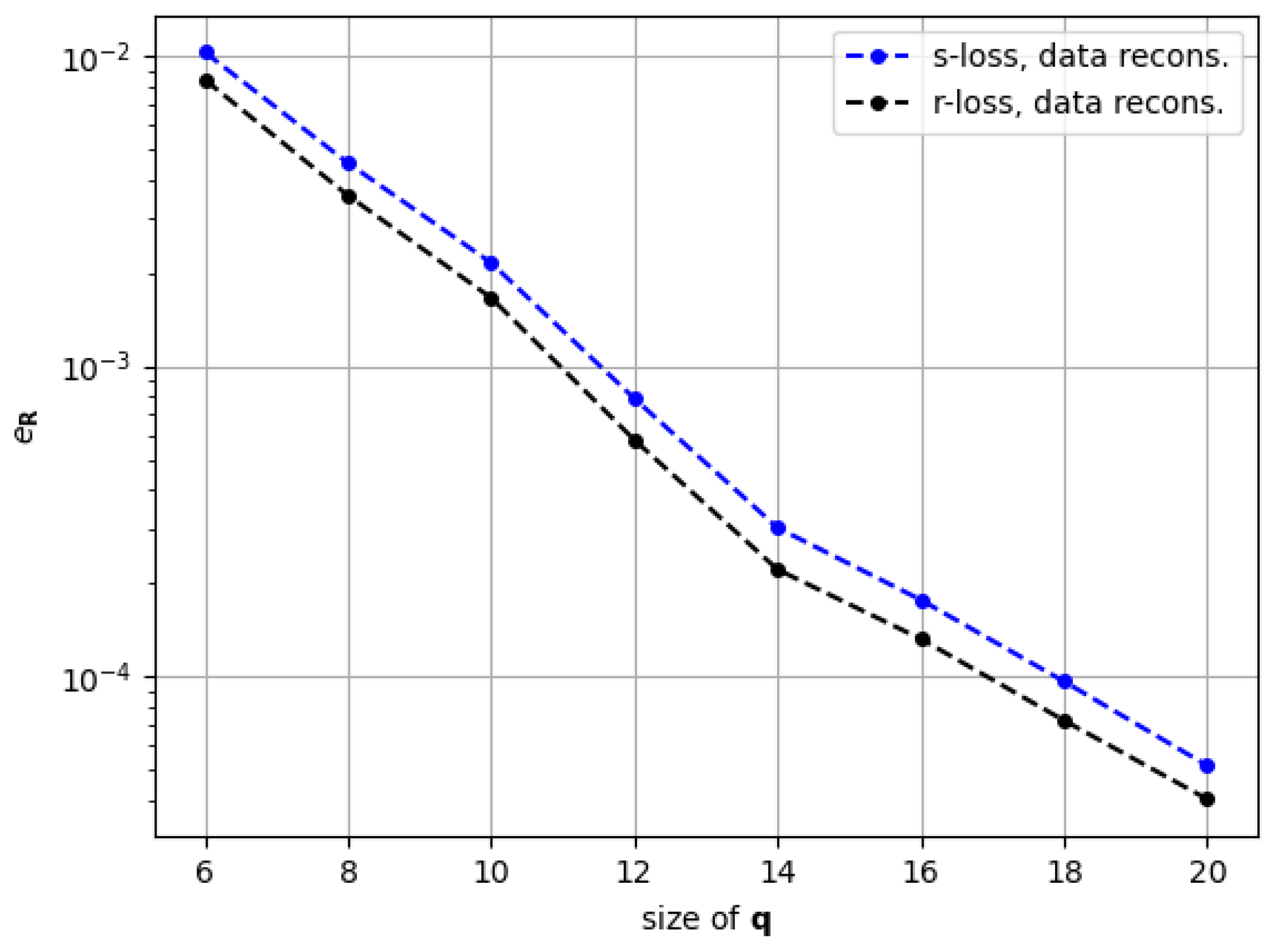
Section 7.1, with the error in ROM simulation being approximately one order of magnitude higher than the reconstruction one for both our proposed architecture with the data-based loss and traditional POD. Further on, we look at the results in
Section 7.2 to specifically understand the effect of the residual-based training. The observations are encouraging, even if not spectacular. We say this in the sense that performing ROM with the model trained on the residual provided slightly but consistently better results than the one trained with the snapshot. It can also be interpreted as achieving a slightly lower discrepancy between reconstruction and ROM simulation, which is what we were aiming for. But the most important insight is that this phenomenon coincides with a consistently lower error in the representation of the residual by the models trained on physics. We are aware that, as it is right now, the significantly higher training time with the residual loss renders the proposed method unattractive, taking into account the marginal increase in ROM accuracy, but we are optimistic that future research can enable more meaningful improvements.
We make the observation, in retrospective, that choosing the ANN-PROM architecture for implementing the residual loss limited the achievable accuracy. That is because, even if the neural network allows us to introduce the loss of our choosing, we still depend entirely on the modes that we gathered via SVD on our snapshots dataset, without any regard for the residual accuracy. The fact that even with this caveat we were able to achieve slightly better results makes us very optimistic for the future where we could explore new architectures (or variants of this one) that put the residual in the focus point from the beginning, or that allow more freedom to correct the residual on top of the modes for the snapshot. This restriction of ANN-PROM towards the flexibility of the residual also hinders the potential ability of the residual training to enhance the model’s behavior outside the training parameter space, which is a topic worthy of studying in detail in further work (see
Appendix B).
Although the present work focuses solely on augmenting the PROM-ANN framework with a discrete residual loss to enhance physics-awareness, it is useful to briefly comment on its positioning within the broader landscape of nonlinear ROMs. In this paper, comparisons were limited to traditional linear subspace PROMs, as our contribution centers specifically on the integration of the high-fidelity residual in the PROM-ANN training. Broader comparisons with alternative nonlinear ROM techniques—such as quadratic ROMs or kriging-based interpolation—relate more directly to the PROM-ANN methodology itself, independently of the residual loss term. In this context, recent studies such as [
33] have benchmarked PROM-ANN against several nonlinear ROM strategies. Furthermore, the residual-based loss proposed in this work is not restricted to PROM-ANN and can be readily integrated into other neural network-based ROM architectures, such as convolutional autoencoder ROMs [
28]. It is also fair to note that, within the broader family of nonlinear PROMs, our formulation remains fully compatible with local or piecewise PROM-ANN variants—whether using a single ANN that adapts to the active local basis, or multiple models trained for different regions in parameter space. These broader methodological directions are considered valuable future extensions.
All in all, the three main contributions of the paper work together to complement each other and obtain a physics-informed intrusive ROM framework, but also hold value by themselves: the residual loss could be applied for other purposes like non-intrusive ROM, the modifications to the ANN-PROM architecture make it more versatile in terms of the types of problems it can handle, and the study of the effect of the residual in intrusive ROM provides a seed for a new path of research in this discipline for us and for the rest of the community in numerical methods.
9. Conclusions
In this paper, we extend the PROM-ANN architecture proposed in [
32] by incorporating a training approach based on the finite element method (FEM) residual, rather than relying solely on snapshot data. This establishes a connection between nonlinear reduced-order models (ROMs) and physics-informed neural networks (PINNs). While traditional PINNs use analytical partial differential equations (PDEs) to train continuous, non-intrusive models, our approach leverages discrete FEM residuals as the loss function for backpropagation, guiding the learning of the ROM approximation manifold. This development allows us to investigate the impact of improving the residual of the snapshots on the overall performance of projection-based ROMs.
The path to achieve this final goal enables us to present three independently significant contributions: (1) a loss based on the FEM residual and which is parameter-agnostic and, most importantly, applicable to nonlinear problems; (2) a modification on the original PROM-ANN architecture in [
32] that makes it applicable to cases with fast-decaying singular values, and (3) a study on the effect of the residual-based training on ROM simulation. We demonstrate our approach in the context of static structural mechanics with nonlinear hyperelasticity, specifically in the deformation of a rubber cantilever subjected to two orthogonal variable loads.
In terms of the residual loss, the fact that it is based on existing FEM software makes it applicable to a high range of problems. The proposed implementation strategy makes the interaction between the neural network and the FEM software viable in reasonable training time, around 40ms per batch. Finally, the enhancement of the resulting residuals via this loss is demonstrated by applying it to our proposed PROM-ANN-based architecture and performing data reconstruction. This results in a consistently lower residual representation compared to the cases trained on snapshot data alone.
In terms of the modifications to the original ANN-PROM architecture, we observe how our method lowers the snapshot error by several orders of magnitude compared to POD in both the data reconstruction and the ROM simulation results. This improvement is consistent for latent space sizes ranging from to . In contrast, the original PROM-ANN formulation struggles to train the neural network, resulting in errors higher than POD in most cases. This enhancement from our methodology comes from a proper scaling strategy on both the architecture itself and the loss that is used.
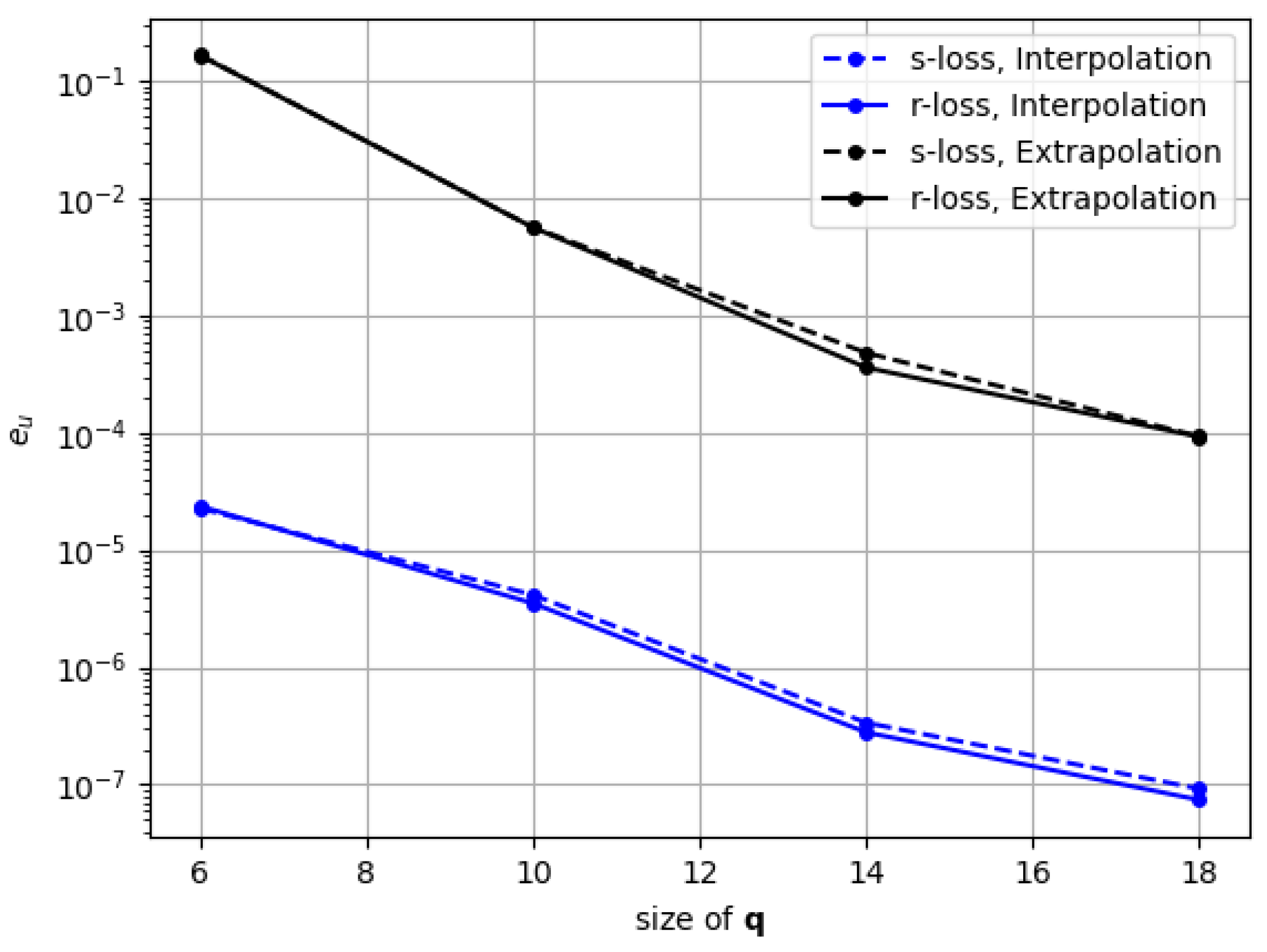
Finally, regarding the effect of applying the FEM residual loss on the approximation manifold for projection-based ROM, our results show a modest but consistent reduction of the gap between the accuracy for snapshot reconstruction and the accuracy for projection-based ROM. While not being useful in practice as of now, this observation makes us optimistic that better results for projection-based ROM could be unlocked in the future by taking care of the residual representations within the approximation manifold. In the future, alternative nonlinear ROM architectures that enable more control over the resulting solutions’ residuals can greatly improve the results presented in this work.
As a corollary to the discussion and to provide a roadmap for future work, we summarize below, in
Table 3, the main current limitations of the proposed approach and potential directions to address them:




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}