

Ensuring Topological Data-Structure Preservation under Autoencoder Compression Due to Latent Space Regularization in Gauss–Legendre Nodes

 , , , and
, , , and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. The Inherent Instability of Inverse Problems
1.2. Contribution
- (C1)
- For realising a latent space regularized AE (AE-REG) we introduce the -regularization lossand mathematically prove the AE-REG to satisfy condition Equation (1), Theorem 1, when being trained due to this additional regularization.
- (C2)
- To approximate we revisit the classic Gauss–Legendre quadratures (cubatures) [30,31,32,33,34], only requiring sub-sampling of , on a Legendre grid of sufficient high resolution in order to execute the regularization. While the data-independent latent Legendre nodes are contained in the smaller dimensional latent space, regularization of high resolution can be efficiently realised.
- (C3)
- Based on our prior work [35,36,37], and [38,39,40,41], we complement the regularization through a hybridisation approach combining autoencoders with multivariate Chebyshev-polynomial-regression. The resulting Hybrid AE is acting on the polynomial coefficient space, given by pre-encoding the training data due to high-quality regression.
1.3. Related Work—Regularization of Autoencoders
- (R1)
- Contractive AEs (ContraAE) [48,49] are based on an ambient Jacobian regularization lossformulated in the ambient domain. This makes contraAEs arbitrarily contractive in perpendicular directions of . However, this is insufficient to guarantee Equation (1). In addition, the regularization is data dependent, resting on the training dataset, and is computationally costly due to the large Jacobian , . Several experiments in Section 5 demonstrate contraAE failing to deliver topologically preserved representations.
- (R2)
- Variational AEs (VAE), along with extensions like -VAE, consist of stochastic encoders and decoders and are commonly used for density estimation and generative modelling of complex distributions based on minimisation of the Evidence Lower Bound (ELBO) [50,51]. The variational latent space distribution induces an implicit regularization, which is complemented by [52,53] due to a -sparsity constraint of the decoder Jacobian.However, as the contraAE-constraint, this regularization is computationally costly and insufficient for guaranteeing a one-to-one encoding, which is reflected in the degenerated representations appearing in Section 5.
- (R3)
- Convolutional AEs (CNN-AE) are known to deliver one-to-one representations for a generic setup theoretically [54]. However, the implicit convolutions seems to prevent clear separation of tangent and perpendicular direction of the data manifold , resulting in topological defects already for simple examples, see Section 5.
2. Mathematical Concepts
2.1. Notation
2.2. Orthogonal Polynomials and Gauss–Legendre Cubatures
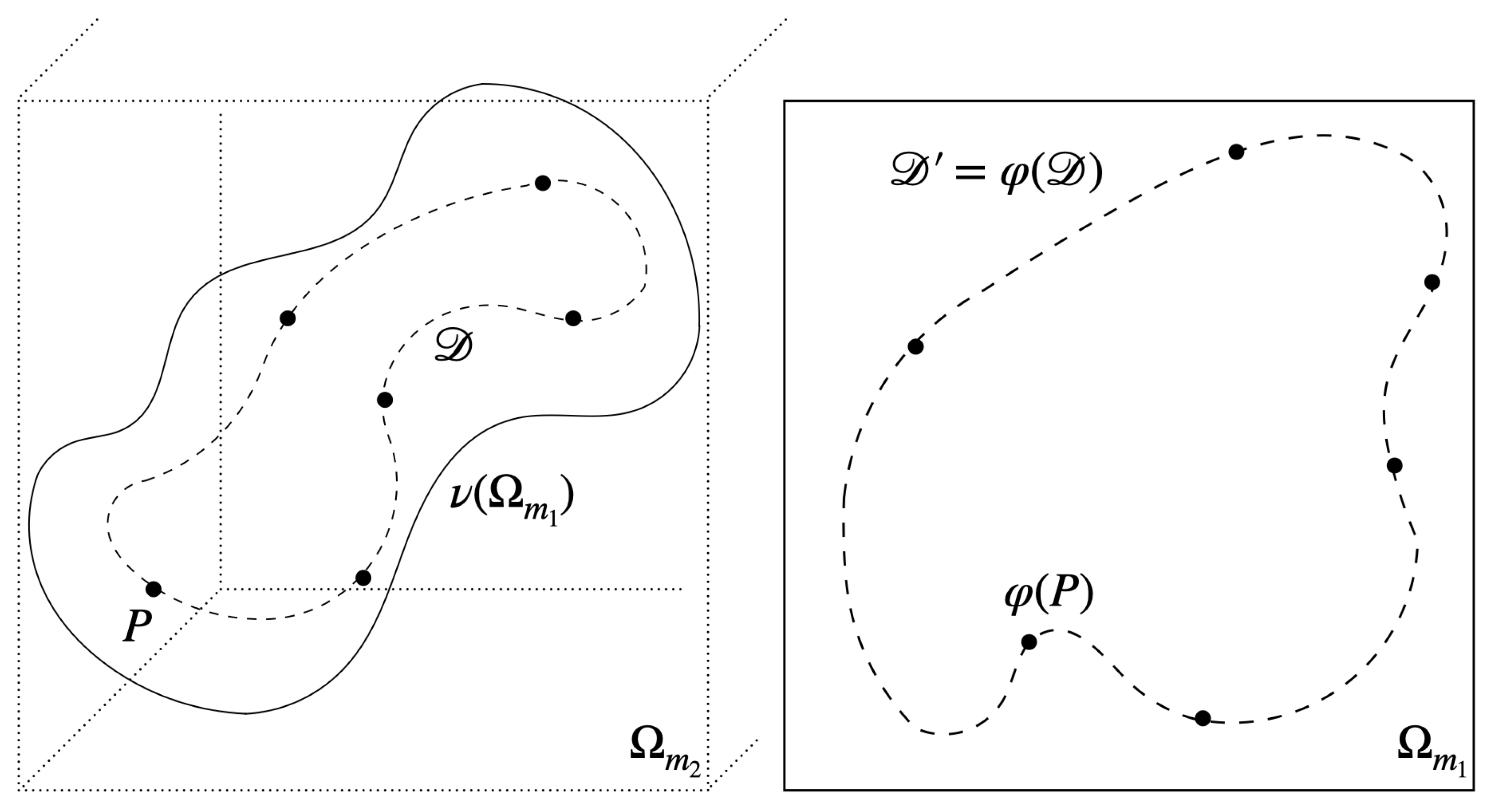
3. Legendre-Latent-Space Regularization for Autoencoders
- (i)
- ν is a right-inverse of φ on , i.e, for all .
- (ii)
- φ is a left-inverse of ν, i.e, for all
- (i)
- The loss converges .
- (ii)
- The weight sequences converge
- (iii)
- The decoder satisfies , for some .
4. Hybridization of Autoencoders Due to Polynomial Regression
5. Numerical Experiments
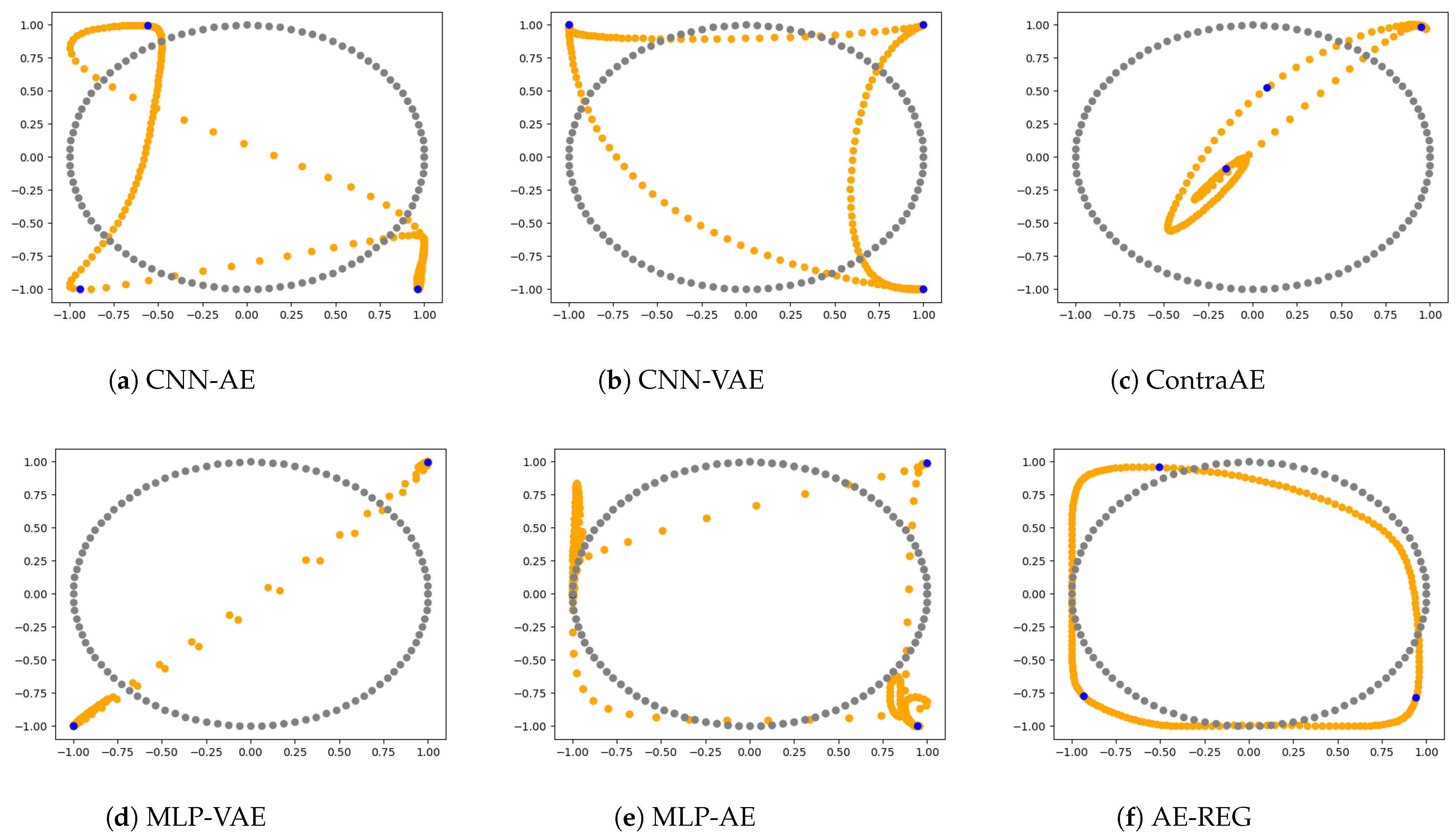
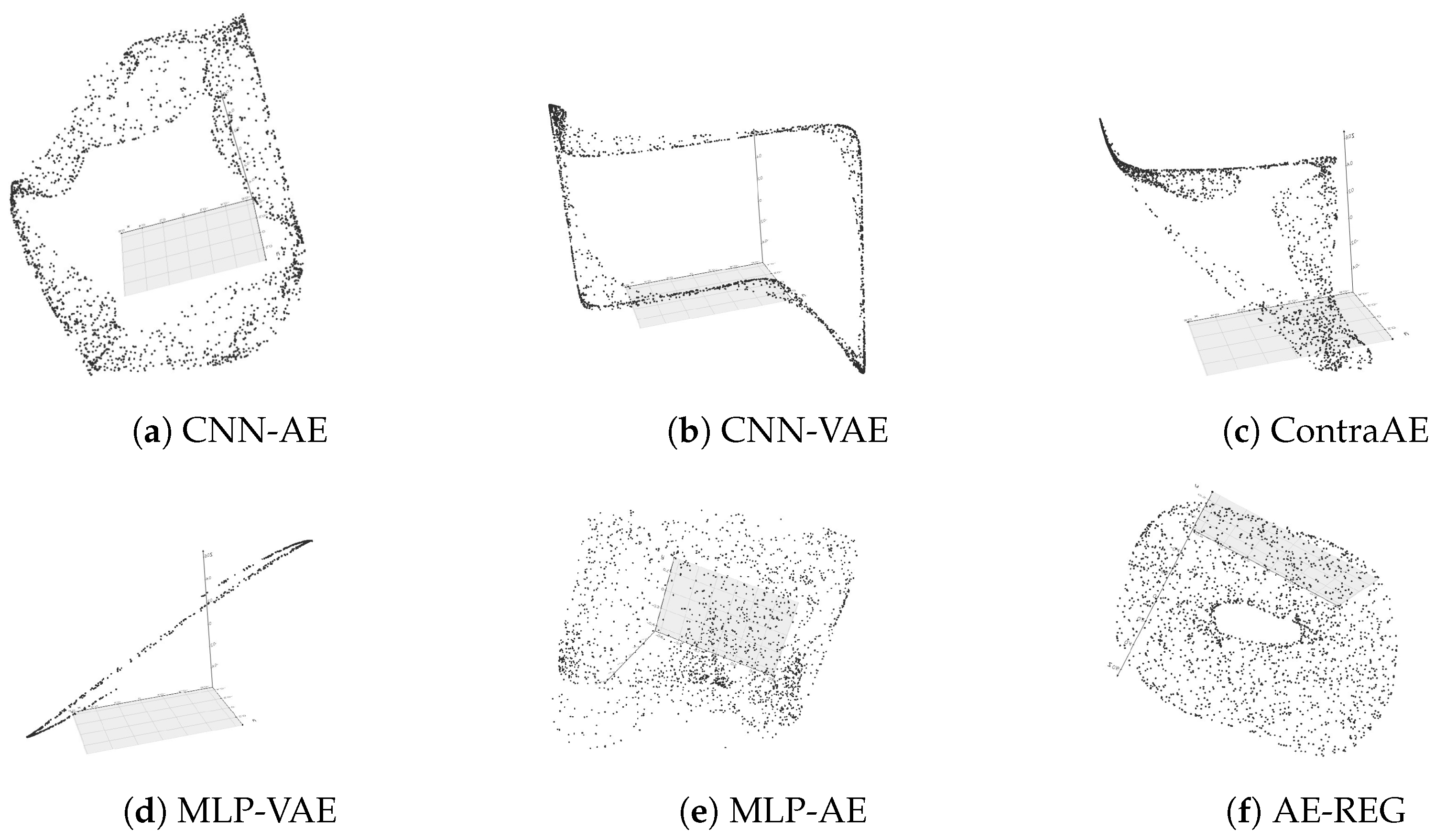
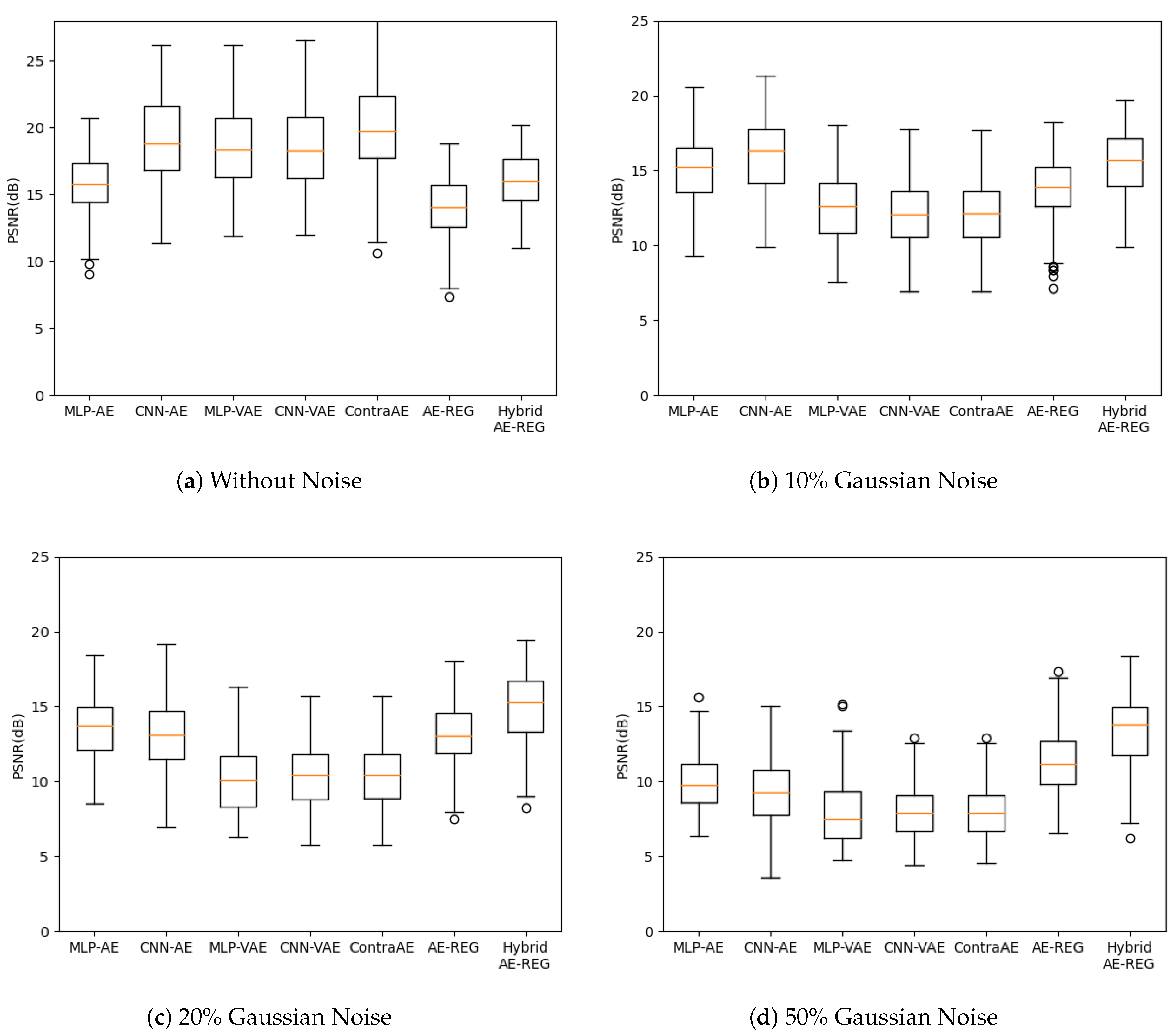
- (B1)
- Multilayer perceptron autoencoder (MLP-AE): Feed forward NNs with activation functions .
- (B2)
- Convolutional autoencoder (CNN-AE): Standard convolutional neural networks (CNNs) with activation functions , as discussed in (R3).
- (B3)
- (B4)
- (B5)
- regularized autoencoder (AE-REG): MLP based, as in (B1), trained with respect to the regularization loss from Definition 2.
- (B6)
- Hybridised AE (Hybrid AE-REG): MLP based, as in (B1), trained with respect to the modified loss in Definition 2 due to Equation (15).
5.1. Topological Data-Structure Preservation
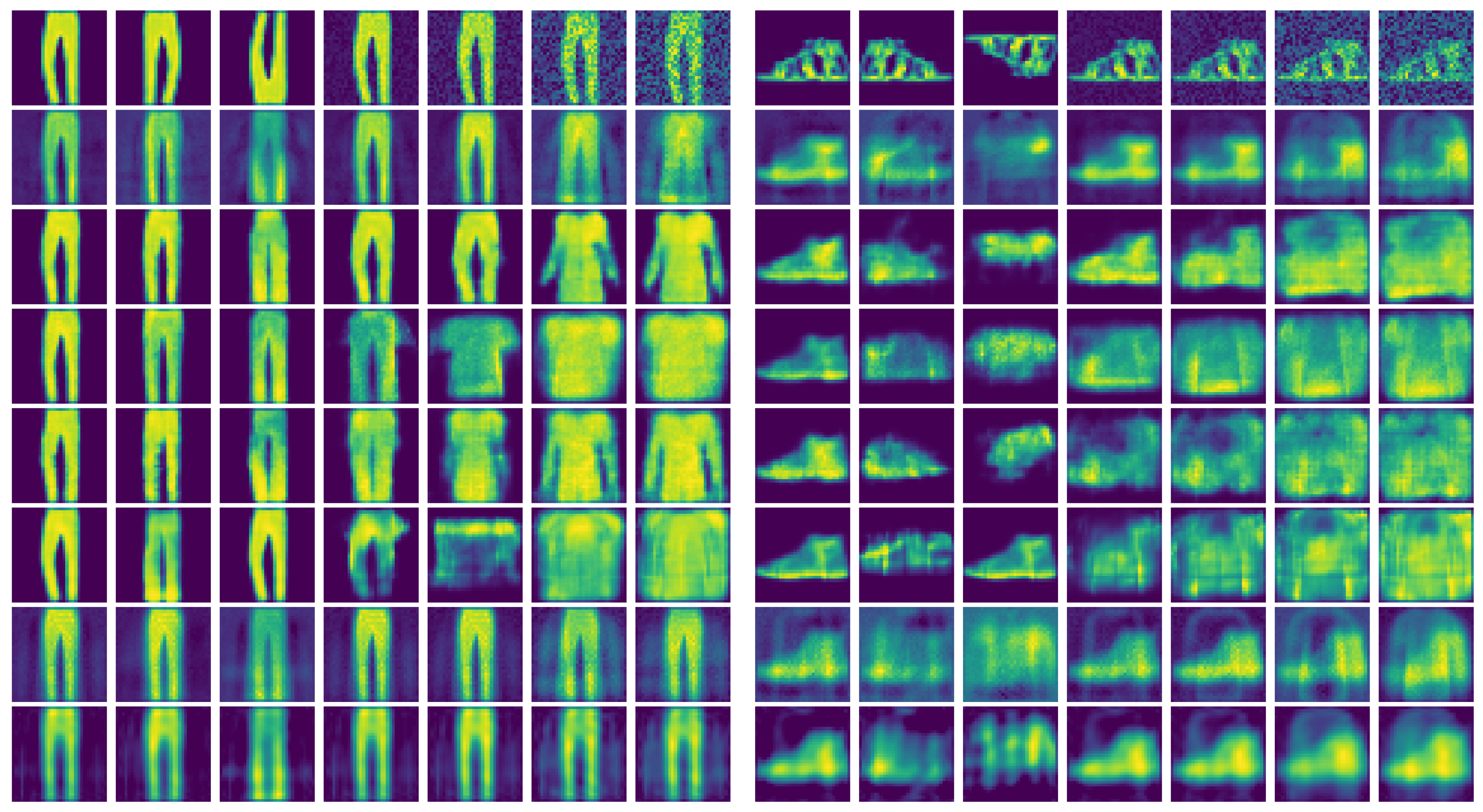
5.2. Autoencoder Compression for FashionMNIST
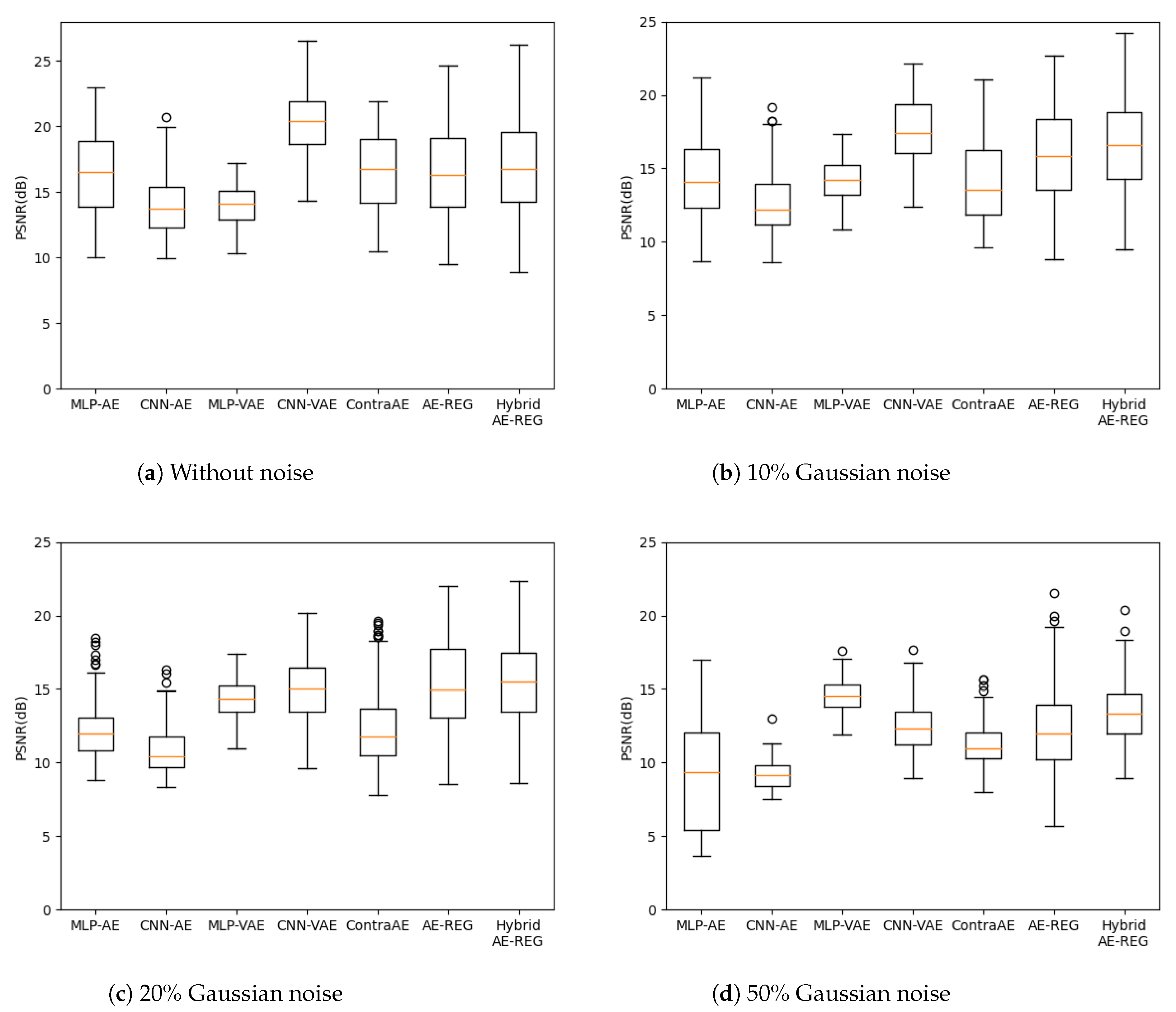
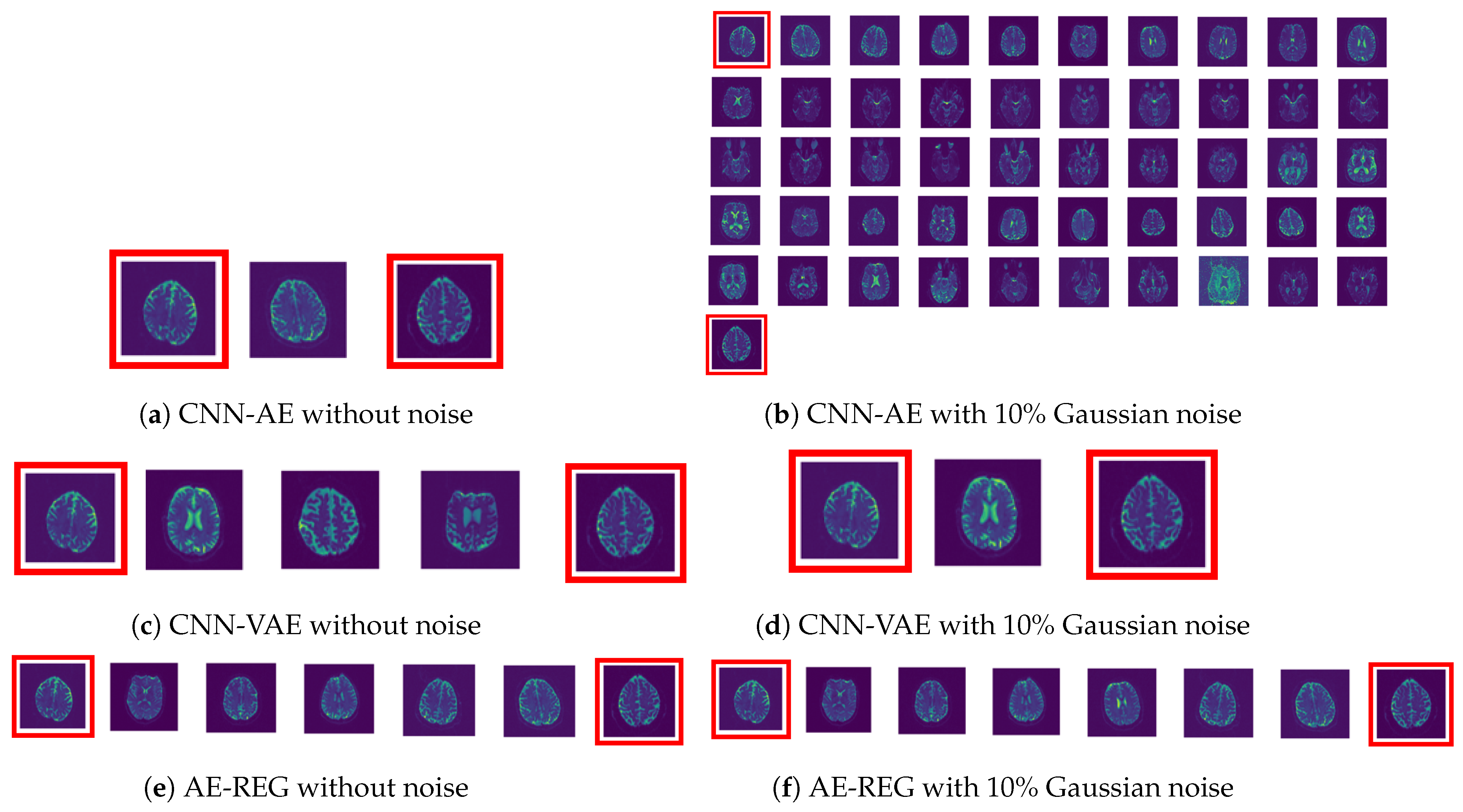
5.3. Autoencoder Compression for Low-Resolution MRI Brain Scans
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pepperkok, R.; Ellenberg, J. High-throughput fluorescence microscopy for systems biology. Nat. Rev. Mol. Cell Biol. 2006, 7, 690–696. [Google Scholar] [CrossRef] [PubMed]
- Perlman, Z.E.; Slack, M.D.; Feng, Y.; Mitchison, T.J.; Wu, L.F.; Altschuler, S.J. Multidimensional drug profiling by automated microscopy. Science 2004, 306, 1194–1198. [Google Scholar] [CrossRef] [PubMed]
- Vogt, N. Machine learning in neuroscience. Nat. Methods 2018, 15, 33. [Google Scholar] [CrossRef]
- Carlson, T.; Goddard, E.; Kaplan, D.M.; Klein, C.; Ritchie, J.B. Ghosts in machine learning for cognitive neuroscience: Moving from data to theory. NeuroImage 2018, 180, 88–100. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Cetin Karayumak, S.; Hoffmann, N.; Rathi, Y.; Golby, A.J.; O’Donnell, L.J. Deep white matter analysis (DeepWMA): Fast and consistent tractography segmentation. Med. Image Anal. 2020, 65, 101761. [Google Scholar] [CrossRef] [PubMed]
- Karniadakis, G.E.; Kevrekidis, I.G.; Lu, L.; Perdikaris, P.; Wang, S.; Yang, L. Physics-informed machine learning. Nat. Rev. Phys. 2021, 3, 422–440. [Google Scholar] [CrossRef]
- Rodriguez-Nieva, J.F.; Scheurer, M.S. Identifying topological order through unsupervised machine learning. Nat. Phys. 2019, 15, 790–795. [Google Scholar] [CrossRef]
- Willmann, A.; Stiller, P.; Debus, A.; Irman, A.; Pausch, R.; Chang, Y.Y.; Bussmann, M.; Hoffmann, N. Data-Driven Shadowgraph Simulation of a 3D Object. arXiv 2021, arXiv:2106.00317. [Google Scholar]
- Kobayashi, H.; Cheveralls, K.C.; Leonetti, M.D.; Royer, L.A. Self-supervised deep learning encodes high-resolution features of protein subcellular localization. Nat. Methods 2022, 19, 995–1003. [Google Scholar] [CrossRef]
- Chandrasekaran, S.N.; Ceulemans, H.; Boyd, J.D.; Carpenter, A.E. Image-based profiling for drug discovery: Due for a machine-learning upgrade? Nat. Rev. Drug Discov. 2021, 20, 145–159. [Google Scholar] [CrossRef]
- Anitei, M.; Chenna, R.; Czupalla, C.; Esner, M.; Christ, S.; Lenhard, S.; Korn, K.; Meyenhofer, F.; Bickle, M.; Zerial, M.; et al. A high-throughput siRNA screen identifies genes that regulate mannose 6-phosphate receptor trafficking. J. Cell Sci. 2014, 127, 5079–5092. [Google Scholar] [CrossRef]
- Nikitina, K.; Segeletz, S.; Kuhn, M.; Kalaidzidis, Y.; Zerial, M. Basic Phenotypes of Endocytic System Recognized by Independent Phenotypes Analysis of a High-throughput Genomic Screen. In Proceedings of the 2019 3rd International Conference on Computational Biology and Bioinformatics, Nagoya, Japan, 17–19 October 2019; pp. 69–75. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Galimov, E.; Yakimovich, A. A tandem segmentation-classification approach for the localization of morphological predictors of C. elegans lifespan and motility. Aging 2022, 14, 1665. [Google Scholar] [CrossRef]
- Yakimovich, A.; Huttunen, M.; Samolej, J.; Clough, B.; Yoshida, N.; Mostowy, S.; Frickel, E.M.; Mercer, J. Mimicry embedding facilitates advanced neural network training for image-based pathogen detection. Msphere 2020, 5, e00836-20. [Google Scholar] [CrossRef] [PubMed]
- Fisch, D.; Yakimovich, A.; Clough, B.; Mercer, J.; Frickel, E.M. Image-Based Quantitation of Host Cell–Toxoplasma gondii Interplay Using HRMAn: A Host Response to Microbe Analysis Pipeline. In Toxoplasma gondii: Methods and Protocols; Humana: New York, NY, USA, 2020; pp. 411–433. [Google Scholar]
- Andriasyan, V.; Yakimovich, A.; Petkidis, A.; Georgi, F.; Witte, R.; Puntener, D.; Greber, U.F. Microscopy deep learning predicts virus infections and reveals mechanics of lytic-infected cells. Iscience 2021, 24, 102543. [Google Scholar] [CrossRef] [PubMed]
- Sánchez, J.; Mardia, K.; Kent, J.; Bibby, J. Multivariate Analysis; Academic Press: London, UK; New York, NY, USA; Toronto, ON, Canada; Sydney, Australia; San Francisco, CA, USA, 1979. [Google Scholar]
- Dunteman, G.H. Basic concepts of principal components analysis. In Principal Components Analysis; SAGE Publications Ltd.: London, UK, 1989; pp. 15–22. [Google Scholar]
- Krzanowski, W. Principles of Multivariate Analysis; OUP Oxford: Oxford, UK, 2000; Volume 23. [Google Scholar]
- Rolinek, M.; Zietlow, D.; Martius, G. Variational Autoencoders Pursue PCA Directions (by Accident). In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; Volume 2019, pp. 12398–12407. [Google Scholar] [CrossRef]
- Antun, V.; Gottschling, N.M.; Hansen, A.C.; Adcock, B. Deep learning in scientific computing: Understanding the instability mystery. SIAM News 2021, 54, 3–5. [Google Scholar]
- Gottschling, N.M.; Antun, V.; Adcock, B.; Hansen, A.C. The troublesome kernel: Why deep learning for inverse problems is typically unstable. arXiv 2020, arXiv:2001.01258. [Google Scholar]
- Antun, V.; Renna, F.; Poon, C.; Adcock, B.; Hansen, A.C. On instabilities of deep learning in image reconstruction and the potential costs of AI. Proc. Natl. Acad. Sci. USA 2020, 117, 30088–30095. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, H.; Si, S.; Li, Y.; Boning, D.; Hsieh, C.J. Robustness Verification of Tree-based Models. In Proceedings of the Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Galhotra, S.; Brun, Y.; Meliou, A. Fairness testing: Testing software for discrimination. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, Paderborn, Germany, 4–8 September 2017; pp. 498–510. [Google Scholar]
- Mazzucato, D.; Urban, C. Reduced products of abstract domains for fairness certification of neural networks. In Proceedings of the Static Analysis: 28th International Symposium, SAS 2021, Chicago, IL, USA, 17–19 October 2021; Proceedings 28; Springer: Berlin/Heidelberg, Germany, 2021; pp. 308–322. [Google Scholar]
- Lang, S. Differential Manifolds; Springer: Berlin/Heidelberg, Germany, 1985. [Google Scholar]
- Krantz, S.G.; Parks, H.R. The implicit function theorem. Modern Birkhäuser Classics. In History, Theory, and Applications, 2003rd ed.; Birkhäuser/Springer: New York, NY, USA, 2013; Volume 163, p. xiv. [Google Scholar]
- Stroud, A. Approximate Calculation of Multiple Integrals: Prentice-Hall Series in Automatic Computation; Prentice-Hall: Englewood, NJ, USA, 1971. [Google Scholar]
- Stroud, A.; Secrest, D. Gaussian Quadrature Formulas; Prentice-Hall: Englewood, NJ, USA, 2011. [Google Scholar]
- Trefethen, L.N. Multivariate polynomial approximation in the hypercube. Proc. Am. Math. Soc. 2017, 145, 4837–4844. [Google Scholar] [CrossRef]
- Trefethen, L.N. Approximation Theory and Approximation Practice; SIAM: Philadelphia, PA, USA, 2019; Volume 164. [Google Scholar]
- Sobolev, S.L.; Vaskevich, V. The Theory of Cubature Formulas; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1997; Volume 415. [Google Scholar]
- Veettil, S.K.T.; Zheng, Y.; Acosta, U.H.; Wicaksono, D.; Hecht, M. Multivariate Polynomial Regression of Euclidean Degree Extends the Stability for Fast Approximations of Trefethen Functions. arXiv 2022, arXiv:2212.11706. [Google Scholar]
- Suarez Cardona, J.E.; Hofmann, P.A.; Hecht, M. Learning Partial Differential Equations by Spectral Approximates of General Sobolev Spaces. arXiv 2023, arXiv:2301.04887. [Google Scholar]
- Suarez Cardona, J.E.; Hecht, M. Replacing Automatic Differentiation by Sobolev Cubatures fastens Physics Informed Neural Nets and strengthens their Approximation Power. arXiv 2022, arXiv:2211.15443. [Google Scholar]
- Hecht, M.; Cheeseman, B.L.; Hoffmann, K.B.; Sbalzarini, I.F. A Quadratic-Time Algorithm for General Multivariate Polynomial Interpolation. arXiv 2017, arXiv:1710.10846. [Google Scholar]
- Hecht, M.; Hoffmann, K.B.; Cheeseman, B.L.; Sbalzarini, I.F. Multivariate Newton Interpolation. arXiv 2018, arXiv:1812.04256. [Google Scholar]
- Hecht, M.; Gonciarz, K.; Michelfeit, J.; Sivkin, V.; Sbalzarini, I.F. Multivariate Interpolation in Unisolvent Nodes–Lifting the Curse of Dimensionality. arXiv 2020, arXiv:2010.10824. [Google Scholar]
- Hecht, M.; Sbalzarini, I.F. Fast Interpolation and Fourier Transform in High-Dimensional Spaces. In Proceedings of the Intelligent Computing; Arai, K., Kapoor, S., Bhatia, R., Eds.; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2018; Volume 857, pp. 53–75. [Google Scholar]
- Sindhu Meena, K.; Suriya, S. A Survey on Supervised and Unsupervised Learning Techniques. In Proceedings of the International Conference on Artificial Intelligence, Smart Grid and Smart City Applications; Kumar, L.A., Jayashree, L.S., Manimegalai, R., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 627–644. [Google Scholar]
- Chao, G.; Luo, Y.; Ding, W. Recent Advances in Supervised Dimension Reduction: A Survey. Mach. Learn. Knowl. Extr. 2019, 1, 341–358. [Google Scholar] [CrossRef]
- Mitchell, T.M. The Need for Biases in Learning Generalizations; Citeseer: Berkeley, CA, USA, 1980. [Google Scholar]
- Gordon, D.F.; Desjardins, M. Evaluation and selection of biases in machine learning. Mach. Learn. 1995, 20, 5–22. [Google Scholar] [CrossRef]
- Wu, H.; Flierl, M. Vector quantization-based regularization for autoencoders. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6380–6387. [Google Scholar]
- Van Den Oord, A.; Vinyals, O.; Kavukcuoglu, K. Neural discrete representation learning. Adv. Neural Inf. Process. Syst. 2017, 30, 6306–6315. [Google Scholar]
- Rifai, S.; Mesnil, G.; Vincent, P.; Muller, X.; Bengio, Y.; Dauphin, Y.; Glorot, X. Higher order contractive auto-encoder. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Athens, Greece, 5–9 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 645–660. [Google Scholar]
- Rifai, S.; Vincent, P.; Muller, X.; Glorot, X.; Bengio, Y. Contractive auto-encoders: Explicit invariance during feature extraction. In Proceedings of the 28th International Conference on International Conference on Machine Learning (ICML), Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Burgess, C.P.; Higgins, I.; Pal, A.; Matthey, L.; Watters, N.; Desjardins, G.; Lerchner, A. Understanding disentangling in β-VAE. arXiv 2018, arXiv:1804.03599. [Google Scholar]
- Kumar, A.; Poole, B. On implicit regularization in β-VAEs. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020), Vienna, Austria, 12–18 July 2020; pp. 5436–5446. [Google Scholar]
- Rhodes, T.; Lee, D. Local Disentanglement in Variational Auto-Encoders Using Jacobian L_1 Regularization. Adv. Neural Inf. Process. Syst. 2021, 34, 22708–22719. [Google Scholar]
- Gilbert, A.C.; Zhang, Y.; Lee, K.; Zhang, Y.; Lee, H. Towards understanding the invertibility of convolutional neural networks. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 1703–1710. [Google Scholar]
- Anthony, M.; Bartlett, P.L. Neural Network Learning: Theoretical Foundations; Cambridge University Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Adams, R.A.; Fournier, J.J. Sobolev Spaces; Academic Press: Cambridge, MA, USA, 2003; Volume 140. [Google Scholar]
- Brezis, H. Functional Analysis, Sobolev Spaces and Partial Differential Equations; Springer: Berlin/Heidelberg, Germany, 2011; Volume 2. [Google Scholar]
- Pedersen, M. Functional Analysis in Applied Mathematics and Engineering; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Gautschi, W. Numerical Analysis; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Chen, W.; Chern, S.S.; Lam, K.S. Lectures on Differential Geometry; World Scientific Publishing Company: Singapore, 1999; Volume 1. [Google Scholar]
- Taubes, C.H. Differential Geometry: Bundles, Connections, Metrics and Curvature; OUP Oxford: Oxford, UK, 2011; Volume 23. [Google Scholar]
- Do Carmo, M.P. Differential Geometry of Curves and Surfaces: Revised and Updated, 2nd ed.; Courier Dover Publications: Mineola, NY, USA, 2016. [Google Scholar]
- Weierstrass, K. Über die analytische Darstellbarkeit sogenannter willkürlicher Funktionen einer reellen Veränderlichen. Sitzungsberichte K. Preußischen Akad. Wiss. Berl. 1885, 2, 633–639. [Google Scholar]
- De Branges, L. The Stone-Weierstrass Theorem. Proc. Am. Math. Soc. 1959, 10, 822–824. [Google Scholar] [CrossRef]
- Baydin, A.G.; Pearlmutter, B.A.; Radul, A.A.; Siskind, J.M. Automatic differentiation in machine learning: A survey. J. Mach. Learn. Res. 2018, 18, 1–43. [Google Scholar]
- Bézout, E. Théorie Générale des Équations Algébriques; de l’imprimerie de Ph.-D. Pierres: Paris, France, 1779. [Google Scholar]
- Fulton, W. Algebraic Curves (Mathematics Lecture Note Series); The Benjamin/Cummings Publishing Co., Inc.: Menlo Park, CA, USA, 1974. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Moor, M.; Horn, M.; Rieck, B.; Borgwardt, K. Topological autoencoders. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 7045–7054. [Google Scholar]
- Marcus, D.S.; Wang, T.H.; Parker, J.; Csernansky, J.G.; Morris, J.C.; Buckner, R.L. Open Access Series of Imaging Studies (OASIS): Cross-sectional MRI data in young, middle aged, nondemented, and demented older adults. J. Cogn. Neurosci. 2007, 19, 1498–1507. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramanaik, C.K.; Willmann, A.; Suarez Cardona, J.-E.; Hanfeld, P.; Hoffmann, N.; Hecht, M. Ensuring Topological Data-Structure Preservation under Autoencoder Compression Due to Latent Space Regularization in Gauss–Legendre Nodes. Axioms 2024, 13, 535. https://doi.org/10.3390/axioms13080535
Ramanaik CK, Willmann A, Suarez Cardona J-E, Hanfeld P, Hoffmann N, Hecht M. Ensuring Topological Data-Structure Preservation under Autoencoder Compression Due to Latent Space Regularization in Gauss–Legendre Nodes. Axioms. 2024; 13(8):535. https://doi.org/10.3390/axioms13080535
Chicago/Turabian StyleRamanaik, Chethan Krishnamurthy, Anna Willmann, Juan-Esteban Suarez Cardona, Pia Hanfeld, Nico Hoffmann, and Michael Hecht. 2024. "Ensuring Topological Data-Structure Preservation under Autoencoder Compression Due to Latent Space Regularization in Gauss–Legendre Nodes" Axioms 13, no. 8: 535. https://doi.org/10.3390/axioms13080535
APA StyleRamanaik, C. K., Willmann, A., Suarez Cardona, J.-E., Hanfeld, P., Hoffmann, N., & Hecht, M. (2024). Ensuring Topological Data-Structure Preservation under Autoencoder Compression Due to Latent Space Regularization in Gauss–Legendre Nodes. Axioms, 13(8), 535. https://doi.org/10.3390/axioms13080535