Abstract
With the rapid development of the economy, data have become a new production factor and strategic asset, enhancing efficiency and energy for technological innovation and industrial upgrading in enterprises. The evaluation of enterprise digital asset value (EDAV) is a typical multi-attribute decision-making (MADM) problem. Generalized hesitant fuzzy numbers (GHFNs) can better express the uncertainty and fuzziness of evaluation indexes, thus finding wide applications in MADM problems. In this paper, we first propose the Kullback–Leibler (K-L) divergence distance of GHFNs and prove its mathematical properties. Second, recognizing that decision-makers often have finite rationality in practical problems, we combine the cumulative prospect theory (CPT) with the Complex Proportional Assessment (COPRAS) method to propose the GHF-CPT-COPRAS model for solving MADM problems. Simultaneously, we extend the distance correlation-based Criteria Importance Through Intercriteria Correlation (D-CRITIC) method to the GHF environment to rationally calculate the weights of attributes in the EDAV evaluation problem. Finally, we apply the proposed GHF-CPT-COPRAS model to the EDAV evaluation problem and compare it with existing GHF decision-making methods to verify its effectiveness and feasibility. This study provides an important reference for addressing the EDAV assessment problem within an uncertain fuzzy environment and extends its application methods in the decision-making field.
Keywords:
generalized hesitant fuzzy numbers; complex proportional assessment; cumulative prospect theory; D-CRITIC method; Kullback–Leibler (K-L) divergence measure; enterprise data asset valuation MSC:
90B50; 91B06
1. Introduction
Data are often referred to as the ‘oil’ of the 21st century, as it has become a new factor of production and strategic asset, contributing significantly to technological innovation and industrial upgrading. At the enterprise level, data play an increasingly important role as a key element in enhancing the core competitiveness of enterprises. Therefore, a scientific assessment of the value of enterprise data assets is crucial for enterprise development. Feng [1] investigated data asset value and impact factors, suggesting a valuation model that is adaptable across societal sectors. Brennan, Attard, Petkov, Nagle and Helfert [2] pointed out that there is a lack of research on data valuation techniques and observed that data value perceptions differ among organizations. Li and Alotaibi [3] utilized nonparametric estimation methods and nonlinear expectations to build various risk metric models for the asset pricing and financing risk assessments of small businesses. Harish, Liu, Zhong and Huang [4] studied digital asset valuation and risk assessment of logistics companies and utilized digital assets of letters of credit to help finance logistics. However, the data model in these studies is quantitative data [5,6,7].
The EDAV evaluation is a complex issue involving multiple variables and factors, with some factors possibly being difficult to express in clear numerical terms. Zadeh [8] believed that traditional set theory is too precise and difficult to handle the uncertainty and fuzziness present in the real world. Therefore, he introduced the concept of Fuzzy sets (FSs) in 1965. In the last few decades, the application of FSs has driven the development of various fields and has given rise to numerous new variations and extensions (IFS [9], HFS [10], PHFS [11], PDHFS [12], HFNs [13], GHFNs [14], etc. [15,16,17]). However, we found that GHFNs can comprehensively describe the potential information of variables and enable the representation of multiple possible degrees of membership. In MADM problems, they excel at handling complex uncertainty and fuzziness scenarios. Keikha [14] proposed GHFNs based on HFNs and introduced their definition, operation laws, aggregation operators, and so on. Keikha [18] gave some useful distance measures for GHFNs and proposed updating the TOPSIS method, which is applied to the selection of energy projects. Based on the general forms of t-norm and t-conorm functions, Garg and Keikha [19] introduced several aggregation operators for GHFNs, thereby expanding the aggregation theory of GHFNs. Liu, Wang, Ning and Wei [20] extended the CPT-TODIM method to GHFNs and used it for researcher selection. Liu, Wang and Wei [21] proposed a new score function and entropy measure for GHFNs to select energy projects using the GHF-EDAS method. GHFNs have been widely used in MADM problems, but there are currently no relevant applications for EDAV evaluation.
The problem with MADM is how to fuse and rank the evaluative information being processed. The COPRAS method is capable of considering the importance and validity of various alternatives in the process of evaluating and ranking them, and its calculation process is simple and transparent. Therefore, this method is widely used in MADM problems. Seker, Baglan, Aydin, Deveci and Ding [22] used the IVq-ROF-COPRAS method to evaluate COVID-19 social risk factors. Mishra, Rani, Saha, Senapati, Hezam and Yager [23] proposed the COPRAS method for Fermatean FSs and applied the method to the selection of renewable energy sources. Naz, Akram and Muzammal [24] extended the COPRAS method to the 2-tuple linguistic T-spherical fuzzy MAGDM problem. Dang, Nguyen, Nguyen and Dang [25] proposed SFs Gray COPRAS (G-COPRAS) and applied it to the SSS problem. Buyukozkan and Gocer [26] proposed the PFS-COPRAS method and applied it to the MADM problem of partner selection. Yuan, Xu and Zhang [27] proposed a hybrid DEMATEL-COPRAS approach for probabilistic linguistic term sets and applied it to third-party supplier selection. Song and Chen [28] proposed the COPRAS method for the MADM problem in PHFS. The application of the COPRAS method in some other fuzzy environments is not listed [29,30,31]. However, until now, the application of the COPRAS method within the context of GHFNs has remained unexplored.
It is noteworthy that in real-world scenarios, decision-makers frequently exhibit bounded rationality, not always aiming to maximize utility. Instead, they tend to opt for choices that best align with their preferences. For this reason, Tversky and Kahneman [32] proposed a CPT for decision analysis under uncertainty and risk conditions. Currently, CPT has been successfully applied to a wide range of fuzzy information risk-based MADM problems. Zhang, Wei, Guo and Wei [33] developed the CPT-TODIM model, which is the MADM for 2TLPFSs, and applied it to company credit risk assessment. Zhang, Wei, Lin and Chen [34] proposed an intuitionistic fuzzy TOPSIS method (IF-CPT-TOPSIS) based on CPT and applied it to the MAGDM problem. Liao, Gao, Lin, Wei and Chen [35] proposed the PHF-CPT-EDAS method by combining CPT and information entropy theory and used it to solve the MAGDM. Zhang and Wei [36] established the SF-CPT-CoCoSo model based on CPT in a spherical fuzzy environment and used this method for the location of electric vehicle charging stations. Mao, Chen, Lv, Guo and Xie [37] proposed a MADM method based on the CPT and DEMATEL methods and applied it to the problem of municipal plastic solid waste disposal. Han, Zhang and Deng [38] proposed IF-CPT-VIKOR in an intuitionistic fuzzy environment based on the CPT and VIKOR decision-making methods and applied it to commercial concrete supplier selection. However, research on CPT-based generalized hesitant fuzzy MADM methods is still relatively limited to date. It is interesting to note that the CPT-COPRAS method has not yet been proposed to cope with the uncertainty problem in GHFNs.
Another problem with MADM is how to identify the weights of the criteria. In the MADM problem, the objective weights method is based on the available data and information to determine the weights, which can better reflect the relationship and importance between the decision criteria and reduce the subjective bias and subjective judgment of the DMs, thus making the decision-making process more objective and scientific. The objective weight method mainly includes the entropy weight method [39], MEREC method [40], CRITIC method [41], etc. The CRITIC method comprehensively determines the weights through the intensity of comparison within the indexes and the degree of conflict between the indexes. Therefore, the CRITIC method is widely used to determine attribute weights in MADM problems [42,43,44,45]. As research into the CRITIC method deepens, we have identified distinct limitations in its approach to determining attribute weights: (1) The conflict ability of the indices should only be associated with the degree of relevance, independent of positive or negative correlations. Hence, it is necessary to eliminate the positive and negative signs of the correlation coefficients. (2) The CRITIC method tends to assign higher weights to attributes of indices that are directly assigned or less relevant, thereby requiring a reduction in conflict ability. Recently, Krishnan, Kasim, Hamid and Ghazali [46] proposed the D-CRITIC method, which integrates distance correlation into the CRITIC method to capture linear and nonlinear relationships between criteria and overcomes the inadequacy of conflicting relationships between Pearson’s correlation coefficients to obtain attribute weights efficiently. Zhang and Wei [36] extended the D-CRITIC method to Spherical fuzzy sets to compute attribute weights and apply it to uncertain fuzzy decision problems. Maneengam [47] used the weights of the D-CRITIC method objective function and then used the modified TOPSIS method to study the MRP problem with multiple objective functions. Wu, Yan, Wang, Chen, Jin and Shen [48] used the modified CRITIC to calculate attribute weights, then simulated a multidimensional connectivity cloud, and calculated the connectivity relative to the evaluation criteria to evaluate eutrophication water quality. However, there are fewer applications of the D-CRITIC method in other fuzzy environments. In the D-CRITIC method, one of the key factors is the distance measure. Kullback–Leibler (K-L) divergence is an evolved form of Jensen–Shannon divergence [49], and K-L divergence is an effective method for data fusion that distinguishes between two probability distributions on the same variable, reflecting the distance of one probability distribution from the other. Kumar, Patel and Mahanta [50] proposed PFSs new distance measure using K-L divergence, which proves its mathematical properties, and conducted a comparative study with existing distance measures to verify the superiority of K-L divergence measures. Moreno, Ho and Vasconcelos [51] derived the kernel function distance of the probabilistic models between the generating models based on the K-L divergence. However, there are no relevant works on the K-L divergence measure under GHFNs.
Therefore, it is clear from the study of the literature that the EDAV evaluation problem is a typical MADM problem. In this paper, we first propose the CPT-based COPRAS decision-making method given the DMs’ limited rational behavior and establish the GHF-CPT-COPRAS model of MADM. Second, we propose the K-L divergence measures for GHFNs and extend the D-CRITIC method to GHFNs to obtain the weights of MADM criteria. Finally, we illustrate the applicability of the GHF-CPT-COPRAS model through an EDAV evaluation examples analysis and conduct a comparative study to verify the validity and feasibility of the model.
The primary motivations of this paper are as follows: (1) In the era of big data, EDAV evaluation holds significant practical importance. However, there is a scarcity of related studies. Therefore, this paper aims to establish an EDAV evaluation index system and translate decision-making information into GHFNs to facilitate better decision-making on EDAV evaluation problems. (2) The K-L divergence measure distinguishes between two probability distributions on the same variable, indicating the distance between them. This measure has been extended to the GHF environment to reflect the distance measure of two GHFNs. (3) The COPRAS method has been widely utilized due to its capability to consider the importance and validity of different alternatives in the evaluation and ranking process, along with its simple and transparent calculation process. Decision-makers exhibit various psychological preferences when facing losses and gains, and CPT effectively simulates these preferences. By integrating CPT with COPRAS, the CPT-COPRAS model can fully capture DMs’ psychological preferences and provide effective and rational rankings. (4) The D-CRITIC method combines distance correlation with the CRITIC method to capture linear and nonlinear relationships between criteria, which overcomes the inadequacy of conflicting relationships between Pearson’s correlation coefficients and minimizes the possible deviation of the final weights. However, so far, the D-CRITIC method has rarely been applied in GHFNs. (5) It is important to apply the proposed GHF-CPT-COPRAS model to the EDAV evaluation problem for decision-making. For the reasons stated above, this paper first proposes the K-L divergence measure for GHFNs. Second, the GHF-CPT-COPRAS model is established to be applied to uncertain fuzzy decision-making problems, and the D-CRITIC method is extended to obtain the criteria weights in the MADM problem. Finally, the developed model is applied to the EDAV evaluation problem to verify its effectiveness. In addition, it further demonstrated the effectiveness and feasibility of the GHF-CPT-COPRAS model through a comparative discussion with existing decision-making methods for GHFNs.
The main contributions are as follows: (1) established the EDAV evaluation index system and transformed the EDAV evaluation information into GHFNs; (2) proposed the K-L divergence measure for GHFNs, which enriched the distance measure theory of GHFNs; (3) extended the D-CRITIC method to assign the weights of unknown attributes in the GHF environment decision-making; (4) established the GHF-CPT-COPRAS model to solve the MADM problem, integrating decision-making habits of DMs and risk preferences and integrating CPT theory into the COPRAS method for effective evaluation of the scheme; (5) the proposed model was used for the EDAV evaluation problem to evaluate the value of the data assets of five Internet financial enterprises, and the results of the study can provide a reference to the managers; (6) further comparative analyses to validate the GHF-CPT-COPRAS model’s validity and feasibility, which provides a reference for expanding the CPT-COPRAS method to other decision-making environments and also providing some ideas for expanding the established model to other MADM problems.
In addition to the above, this paper consists of the following sections: In Section 2, we review the definition and operator laws of GHFNs, CPT theory, COPRAS method, and D-CRITIC method. Section 3 proposes a distance measure of GHFNs based on the K-L divergence measure. Section 4 introduces the GHF-CPT-COPRAS model, incorporating the D-CRITIC method. In Section 5, we establish the EDAV evaluation system, apply the proposed method to practical EDAV evaluation problems, and compare GHFN operators and decision-making methods to illustrate the effectiveness and feasibility of the EDAV evaluation method. Finally, Section 6 provides a summary of the paper and suggests interesting directions for future research.
2. Preliminaries
2.1. GHFNs and Their Operational Laws
Definition 1
([14]). Let be the universal set; a GHFN is shown as
In which are positive values, and are membership/doubtless degrees. To make it easier in the use and calculation process, is recorded as .
To make GHFNs work efficiently, it is necessary for us to adjust GHFNs (AGHFNs). If and , then and are two AGHFNs. If this is not the case, let and , then must be extended.
For the pessimistic DMs, we put repeated times in the real number part of , and repeated times in the membership degree part of .
For the optimistic DMs, we put repeated times in the real number part of , and repeated times in the membership degree part of .
For the indifference DMs, we put repeated times in the real number part of , and repeated times in the membership degree part of .
Next, some operation laws for GHFNs are given.
Let and and be two AGHFNs, then operation laws for GHFNs are defined as [14]:
- (1)
- ;
- (2)
- ;
- (3)
- ;
- (4)
- ;
where is a substitution of for any with , and is a substitution of for any with .
Keikha [14] defined the score function and variance of GHFNs to compare the sizes of two GHFNs.
Definition 2
([14]). is a GHFN; the GHFN mean, score, and variance functions are recorded as:
and are two AGHFNs, and the method of comparing the size of two AGHFNs was recorded as:
- (1)
- If , that is , then , denoted is strongly superior to .
- (2)
- If , that is (), then , denoted is superior to .
- (3)
- If , that is () or and , then , denoted is weakly superior to .
- (4)
- If and , then , denoted is almost equal to .
Next, we introduce the aggregation operator of GHFNs in detail.
Definition 3
([14]). GHFNs arithmetic averaging operator (GHWAA). Let be AGHFNs, where . The weight vector is denoted as and , . Then,
If , the GHWAA operator is called the GHAA operator.
Definition 4
([14]). GHFN geometric averaging operator (GHWGA). Let be AGHFNs, where . The weight vector is denoted as and , . Then,
where . If , the GHWGA operator is called the GHGA operator.
Definition 5
([14]). GHFNs order weighted arithmetic and geometric averaging operator (GHOWA/GHOWG). Let be AGHFNs, where , and . The weight vector is denoted as and , . Then, the GHOWA operator and GHOWG operator are recorded as:
where .
2.2. Cumulative Prospect Theory (CPT)
CPT was proposed by Tversky and Kahneman [32] based on PT, which is different from the traditional expected utility theory. CPT consists of a reference point, value function, and weighting function, which is based on the precondition of finite rationality, and can reflect the psychological preference of DMs, which can effectively overcome the phenomenon that PT contradicts with the advantage of randomness. The formula for the total prospective value is as follows:
where , with as the value of the difference between the decision alternatives relative to the reference point, when , is the gain; when , is the value of the loss.
The value function and the probability weight function are obtained as follows:
where and denote the concavity of the power functions of gain and loss, respectively, and both are less than 1; denotes the characteristic that loss is steeper than gain, and when the value is greater than 1, it denotes the rejection of loss. Tversky and Kahneman [32] utilized the method of linear regression to obtain cumulative prospect theory when the parameters in the value function and weight function were , , and the parameters , , which was more consistent with the empirical data.
2.3. D-CRITIC Method
The CRITIC method is an objective weighting approach that hinges on data volatility and conflict. Volatility is denoted by the standard deviation; a larger standard deviation signifies greater volatility, which in turn corresponds to a higher weight. On the other hand, conflict is represented by the correlation coefficient. A higher correlation coefficient value between criteria suggests reduced conflict, leading to diminished weight. Based on the existing research [52,53,54], there are the following shortcomings in using the CRITIC method to assign the weights of criteria: (1) the conflict ability of criteria should only be related to the degree of correlation of the criteria and has nothing to do with the positive or negative, so it is necessary to eliminate the positive and negative signs of the correlation coefficient; (2) If there are attributes of direct assignment type or low relevance, the CRITIC method assigns higher weights to such attributes, so the conflictive ness needs to be weakened. As an improved form of the original CRITIC method, D-CRITIC was proposed by Krishnan, Kasim, Hamid and Ghazali [46]. This method integrates distance correlation into the CRITIC method to capture linear and nonlinear relationships between attributes, which overcomes the inadequacy of conflicting relationships between Pearson’s correlation coefficients. It can more reliably model the conflicting relationships between attributes and thus obtain attribute weights efficiently. The computational steps of the D-CRITIC method are as follows:
Assume that in the MADM problem under uncertainty, is the set of alternatives, is the set of attributes to evaluate the alternatives. Determining the decision matrix based on the DMs is given as follows:
Step 1. The decision matrix is normalized by Equation (13):
Step 2. The standard deviation for each attribute is calculated using Equation (14):
where and denote the standard deviation and mean of attribute , respectively.
Step 3. The distance correlation is calculated for each pair of attributes. The main difference between the traditional CRITIC method and the D-CRITIC method is in this step. The former calculates the Pearson correlation between attributes; when the Pearson correlation coefficient is zero, it may not be completely independent. The CRITIC method associates a higher weight to such attributes, so it needs to be weakly conflicting. Therefore, Szekely and Rizzo [55] presented a new measure of correlation called distance correlation, which is effective in capturing the nonlinear relationship between variables. In the D-CRITIC approach, distance correlation is used as an alternative way of modeling relationships to minimize possible errors in the final weights. The distance correlation coefficient between attributes and is calculated as follows:
where is the distance covariance between attributes and , is the distance covariance of the attribute , , and are interpreted in the same way. The detailed calculation procedure is listed below:
- (1)
- In all alternatives, the distance matrix is constructed for each attribute based on Equation (16).
- (2)
- The double-centered matrix for attributes is obtained based on Equation (17).
- (3)
- The distance covariance of attributes and is determined through Equation (18).
- (4)
- The distance variance of the attribute is determined through Equation (19).
- (5)
- Using the covariance and variance of the attribute distances, a distance correlation between the attributes is obtained.
Step 4. The information content of each attribute is determined through Equation (20):
Step 5. The weights are calculated through Equation (21).
2.4. COPRAS Method
The COPRAS method [56] is a tool to efficiently deal with the MCDM problem, which is used to evaluate the values of the maximization and minimization indexes and to separately consider the influence of the attribute maximization and minimization indexes on the evaluation of the results. The advantages of this method are its simplicity of calculation, its ability to clearly reflect the degree of improvement and deterioration of the alternatives compared to other alternatives, ensuring that the ranking results are reasonable and reliable. The initial decision matrix is assumed to be given in Equation (12), where the weights of the attributes form a set that satisfies and . The COPRAS method is calculated as follows:
Step 1. The decision matrix is normalized by Equation (22):
Step 2. The weighted normalization is performed by Equation (23):
Step 3. To obtain the maximizing and minimizing indexes for each attribute for the given attribute type, Equations (24) and (25) can be used:
Here, represents the number of positive attributes, represents the number of negative attributes, and the maximizing and minimizing indexes of the attributes are defined according to the type of attributes.
Step 4. The relative significance value is calculated by Equation (26):
Step 5. The relative significance values are ranked in descending order.
3. GHFNs K–L Divergence Measure
In this section, we propose a new distance measure for GHFNs based on K-L divergence measures. It is an effective data fusion method that quantifies the proximity of two probability distributions for highly precise estimations. The K-L divergence distinguishes between two probability distributions on the same variable, reflecting the distance of one probability distribution from the other.
For any discrete random variable , suppose and are two probability distributions. Then, define the K-L divergence between and as:
To avoid the situation where , can be modified as follows:
where is a value with .
This is because the K-L divergence does not satisfy the symmetric property. Therefore, we obtain the following result by transforming it into a symmetric divergence:
Since all possibilities are less than 1, which is the case, we set .
Divergence is used to measure the difference or dissimilarity between two probability distributions. Therefore, we can construct a distance measure to measure the difference between information using K-L divergence. Next, we define the K-L divergence measure for two GHFNs.
Let and be two GHFNs, then the new distance measures of GHFNs are recorded as:
Since and when , and , the distance measure takes the maximum value , which is more than 1. Consequently is not limited to the interval [0, 1]. Therefore, we normalize the distance measure by dividing it by its maximum value.
Theorem 1.
Let , and be three AGHFNs, and if satisfies the three properties of distance, then is the distance measure between two AGHFNs.
- (A1)
- ;
- (A2)
- if and only if ;
- (A3)
- ;
Proof.
The GHFNs K-L divergence measure Equation (32) can be reformulated as follows:
To expedite the proof of the distance properties, we exploit the following function
- (A1)
- Obtained the partial derivatives of with respect to and as
Assuming has no loss of normality, we have . In addition, we also obtain and . This shows that the monotonicity of with respect to is the exact opposite of that with respect to . That is, the largest value of occurs at (1,0), and the largest value is . Furthermore, since , then there is , so we have .
Since , then, we get , so .
- (A2)
- If , then and , therefore, and , we obtain
- (A3)
- Since
Therefore, the equation holds. □
4. COPRAS Method Based on CPT and D-CRITIC Weights for MADM under GHFNs
Assume that in the multi-attribute EDAV evaluation decision problem under uncertainty, is the set of alternatives, use attributes to evaluate the alternatives, where the weights of the attributes form a set that satisfies and . To address the problems, this paper proposes a fresh CPT-COPRAS method with a D-CRITIC method for GHFNs with the following steps:
4.1. Phase 1: Construct Evaluation Information for GHFNs
Step 1. The evaluation expert team evaluated the alternatives based on all attributes and allowed the evaluation values to be shown as uncertainty values represented in decision matrix . Then, decision matrix is converted to the generalized hesitant fuzzy decision matrix .
Step 2. Since the real and membership degree parts of each GHFN are not of the same length, the generalized hesitant fuzzy decision matrix should be adjusted, as in , where and are the largest values in their corresponding set.
4.2. Phase 2: Calculation of Weights Using the D-CRITIC Method
Step 3. GHF decision matrix must be free of scales. Normalized GHF decision matrix , in which , results in:
Step 4. The expected mean of the attributes of the decision matrix is obtained, which is used as a reference point for the loss of gain.
Step 5. The standard deviation for each attribute was calculated using Equation (38):
where denotes the GHFN K-L divergence measure computed by Equation (32).
Step 6. The distance correlation is calculated for each pair of attributes.
- (1)
- In all alternatives, distance matrix is constructed for each attribute using Equation (39).
Here, stands for the distance matrix about attribute , and denotes the K-L divergence measure between and computed by Equation (32).
- (2)
- The double-centered matrix for attribute is obtained based on Equation (40).
- (3)
- The distance covariance of attributes and is determined through Equation (41).
- (4)
- The distance variance of attribute is determined through Equation (42).
- (5)
- The distance correlation coefficient between attributes and is calculated as follows:
Step 7. The information content of each attribute is calculated through Equation (44).
Step 8. The weights are calculated through Equation (45).
4.3. Phase 3: GHF-CPT-COPRAS
Step 9. Decision matrix is normalized using Equation (46), obtaining the normalized matrix, in which .
Step 10. The expected mean of the attributes of decision matrix is obtained.
Step 11. The distance matrix between each GHFN and the expected value of the corresponding attribute is calculated according to Equation (48):
where denotes the GHFN K-L divergence measure computed by Equation (32).
Step 12. The transformed probability weight of each alternative is calculated through Equation (49):
Tversky and Kahneman [32] utilized the method of linear regression to obtain the cumulative prospect theory, when parameters and , which is more consistent with the empirical data.
Step 13. The comprehensive prospect value matrix is computed from Equation (50):
Tversky and Kahneman [32] utilized the method of linear regression to obtain cumulative prospect theory when the parameters in the value function and weight function were and .
Step 14. To obtain the maximizing and minimizing indexes for each attribute for the given attribute type, Equations (51) and (52) can be used:
Here, represents the number of positive attributes, represents the number of negative attributes, and the maximizing and minimizing indexes of the attributes are defined according to the type of attributes.
Step 15. The relative significance value is calculated by Equation (53):
Step 16. Relative significance values are ranked in descending order.
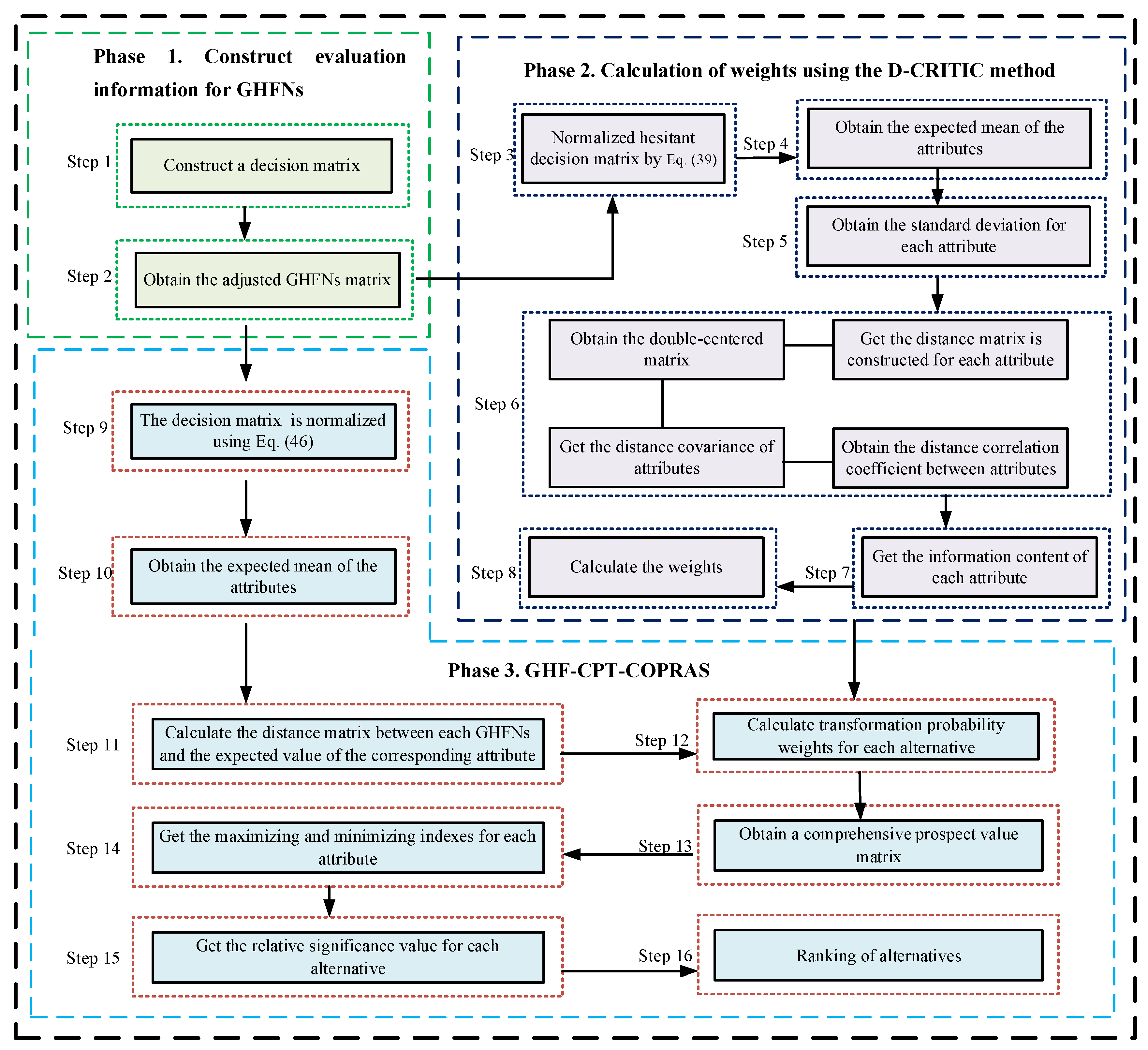
The flowchart of the proposed GHF-CPT-COPRAS method is shown in Figure 1.
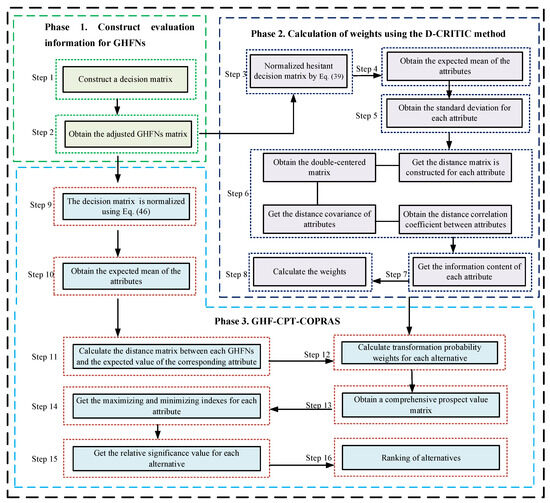
Figure 1.
Flowchart of the proposed GHF-CPT-COPRAS method.
5. An Illustrative Example
One company plans to carry out data business cooperation with Internet financial enterprises and now evaluates the data asset value of five Internet financial enterprises; the five enterprises are . The GHF-CPT-COPRAS method is applied to the EDAV evaluation problem in the following sections.
5.1. Background
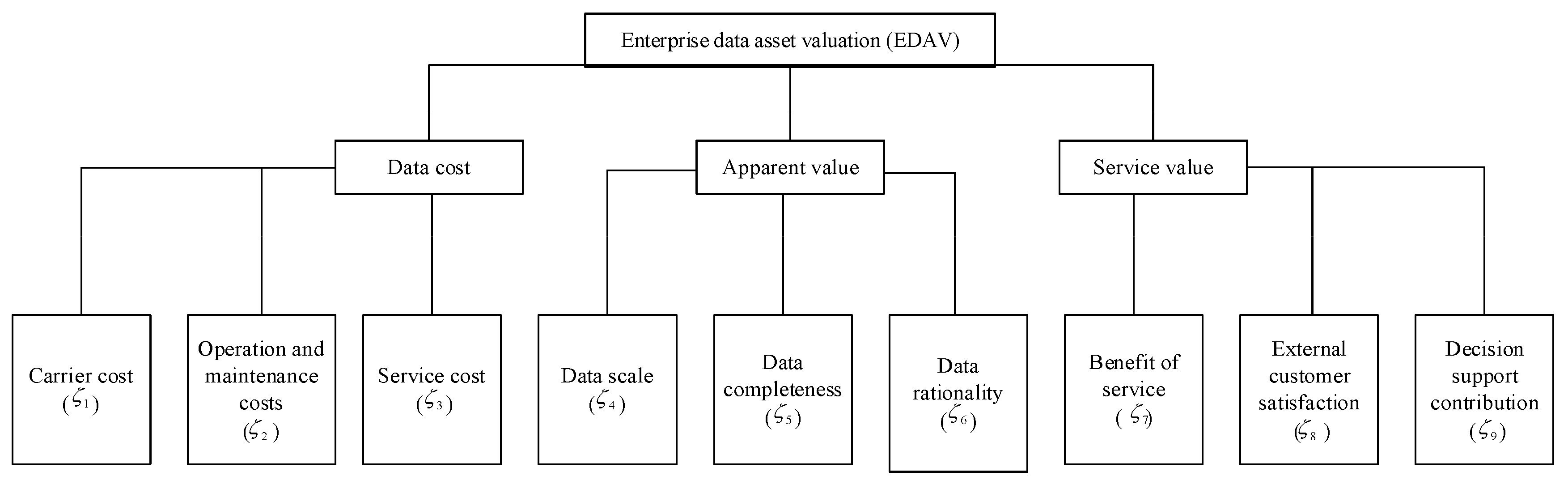
Data assets encompass the data that an enterprise owns and manages, which, in turn, can generate value for the enterprise. Examining the EDAV evaluation’s inputs, they primarily comprise labor, equipment, material, power and related expenses associated with data collection, storage, analysis and business applications. These can be further categorized into costs for data carriers, operations and maintenance, and services. From an output perspective, value manifests in two main ways. First, there is the directly tangible value from external services, evident in the amount of processed and analyzed data provided to external customers, its quality, and the resulting gains. Second, it is the value derived from the internally processed data used as an enterprise resource, influencing quality and contributing to decision-making support. Guided by the principles of being systematic, hierarchical, objective and comparable, we structure the EDAV evaluation index system as illustrated in Figure 2.
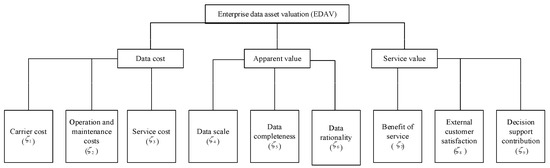
Figure 2.
The EDAV evaluation index system.
Data cost reflects the value of various types of cost inputs. It mainly includes the following indexes: Carrier cost, the construction and transformation cost of creating various types of business data systems and convergent data systems (such as data warehouses, data marts) and other data carriers; Operation and maintenance cost, the cost of daily data collection, cleaning, loading, storage, dynamic monitoring, and integration, as well as the cost of security and maintenance, fault detection, etc.; Service cost, the cost to meet the needs of the enterprise’s internal business scenarios and customer customization needs, the cost of data computation, analysis, mining, delivery of products and outputs.
The apparent value reflects the quantity and quality of data assets, which are the source of current service value and its future value added. It mainly includes the following indexes: Data scale, the amount of data owned and controlled by the enterprise; Data completeness, the completeness of the coverage of the delivered data to support internal decision-making in the business area and external services; and Data rationality, the degree of accuracy and reasonableness of the delivered data.
Service value includes both external and internal services and reflects the application value of EDAV. It mainly includes the following indexes: Service revenue, the amount of revenue gained from the delivery of data products to external customers; External customer satisfaction, the degree of satisfaction of external customers with the quality and delivery time of data deliverables; and Decision support contribution, the level of contribution of the data deliverables or data sources to the enterprise’s decision support in terms of strategy, operation and so on.
In practice, EDAV evaluation indexes have both quantitative and qualitative indexes. When dealing with decision-making problems containing uncertainty and ambiguity, the unified conversion to the form of GHFNs has certain advantages and can avoid the problem of more information distortion caused by converting uncertain variables to deterministic variables. According to this EDAV evaluation system: , , , and are quantitative indexes, the real part of GHFNs is composed of experts according to the actual survey data, and the membership degree part expresses the degree of the hesitancy of the experts to the survey data, and the assessment includes a set of a finite number of values ranging from 0 to 1. , , , , and are qualitative indexes, and the real part of GHFNs is composed of experts according to the interviews and surveys, the quantitative assessment includes a finite set of values from 0 to 10, the membership degree part expresses the degree of hesitation of experts in evaluating the data, and the assessment includes a finite set of values from 0 to 1.
5.2. Decision Process
Step 1: The EDAV evaluation results are obtained through the research and organized into a data matrix expressed by GHFNs. The evaluation results are displayed in Table 1, Table 2 and Table 3.

Table 1.
The GHF decision information matrix .
Table 2.
The GHF decision information matrix .
Table 3.
The GHF decision information matrix .
Next, we select the optimal cooperative enterprise using the new GHF-CPT-COPRAS method and the D-CRITIC method.
Step 2: Since GHF decision matrix of GHFNs is not of equal length, we need to adjust GHFNs, and in this paper, we use an optimistic way to adjust it and obtain the adjusted matrix , which is exhibited in Table 4, Table 5 and Table 6.
Table 4.
The adjusted GHF decision information matrix .
Table 5.
The adjusted GHF decision information matrix .
Table 6.
The adjusted GHF decision information matrix .
Step 3: In the EDAV evaluation decision problem, attributes , and are cost attributes and attributes , , , , and are benefit attributes. The matrix is normalized according to Equation (36) and the results are displayed in Table 7, Table 8 and Table 9.
Table 7.
The normalized matrix .
Table 8.
The normalized matrix .
Table 9.
The normalized matrix .
Step 4. The decision reference point for the loss of gain for each attribute is calculated by Equation (37), and the results are displayed in Table 10, Table 11 and Table 12.
Table 10.
The decision reference point for each attribute.
Table 11.
The decision reference point for each attribute.
Table 12.
The decision reference point for each attribute.
Step 5. The standard deviation of each attribute is calculated through Equation (38), and the results are displayed in Table 13.
Table 13.
The standard deviation.
Step 6. The distance correlation matrix for each pair of attributes is calculated through Equations (39)–(43), and the results are displayed in Table 14.
Table 14.
Distance correlation matrix.
Step 7. The information content of each attribute is calculated through Equation (44), and the results are displayed in Table 15.
Table 15.
The information content of each attribute.
Step 8. The D-CRITIC method weights are calculated through Equation (45), and the results are displayed in Table 16.
Table 16.
The D-CRITIC method weights .
Step 9. Using Equation (46), we obtain the normalized matrix, and the results are displayed in Table 17, Table 18 and Table 19.
Table 17.
The normalized matrix .
Table 18.
The normalized matrix .
Table 19.
The normalized matrix .
Step 10. The expected mean of the attributes is obtained by Equation (47), and the results are displayed in Table 20, Table 21 and Table 22.
Table 20.
The expected mean for each attribute.
Table 21.
The expected mean for each attribute.
Table 22.
The expected mean for each attribute.
Step 11. The distance matrix between each GHFN and the expected value of the corresponding attribute is computed according to Equation (48), and the results are displayed in Table 23.
Table 23.
The distance matrix .
Step 12. The transformed probability weight of each alternative is computed through Equation (49), and the results are displayed in Table 24.
Table 24.
The transformed probability weight.
Step 13. The comprehensive prospect value matrix is computed from Equation (50), and the results are displayed in Table 25.
Table 25.
The comprehensive prospect value matrix .
Step 14. Given that the negative attributes are , and , and the positive attributes are , , , , and . The maximizing and minimizing indexes of each attribute are obtained by Equations (51) and (52), and the results are displayed in Table 26.
Table 26.
The results of the GHF-CPT-COPRAS method.
Step 15. The relative significance value is calculated through Equation (53), and the results are displayed in Table 26.
Step 16. Relative significance values were ranked in descending order, and the optimal cooperative enterprise is .
5.3. Comparative Analysis
In this subsection, we compare and rank the proposed model with the GHWAA operator [14], the GHWGA operator [14], the A-GHWAA operator [19], the A-GHWGA operator [19], the GHF-TOPSIS method [18] and the GHF-CPT-TODIM method (, , and ) [20]. The results are shown in Table 27 and Table 28, and the is the preferable alternative.
Table 27.
Calculations for different GHFNs decision-making methods.
Table 28.
Ranking results of different methods.
From Table 28, it can be seen that the results of the GHF-CPT-COPRAS method are almost the same as those of the other methods, except that the ordering of the individual solutions is not consistent. The GHWAA operator and the A-GHWAA operator emphasize the overall impact, while the GHWGA operator and the A-GHWGA operator emphasize the impact of the extremes. The GHF-TOPSIS method measures the distance from the ideal solution to evaluate each solution. The GHF-CPT-TODIM method describes the decision-making process by taking into account the limited rational behavior of the DMs and using the overall value to measure the degree of dominance of the alternatives. However, our proposed method in this paper not only utilizes the advantages of the COPRAS method but also integrates CPT into the decision-making process, which fully simulates the psycho-behavioral characteristics of DMs facing risks. In addition, we use the proposed K-L divergence distance measure to effectively extend the D-CRITIC method to assign attribute objective weights under GHFNs. Therefore, the proposed D-CRITIC-based method and GHF-CPT-COPRAS technique make the EDAV evaluation results more scientific. In addition, Table 29 shows further details of the advantages of the various methods.
Table 29.
Comparison of the characteristics of different methods.
6. Conclusions
In this paper, we propose a MADM method based on CPT and COPRAS in a GHF environment. Considering the advantages of the D-CRITIC method in obtaining nonlinear relationships between attributes using distance correlation, we develop a K-L divergence distance measure for GHFNs and apply this distance to the D-CRITIC method to compute attribute weights. Subsequently, we propose the GHF-CPT-COPRAS model by integrating the CPT method into the COPRAS method by considering the decision maker’s psycho-behavioral factors, i.e., risk preference and loss aversion. Finally, the GHF-CPT-COPRAS model proposed in this paper is applied to the evaluation problem of EDAV. Therefore, the research results of this paper are summarized as follows: (1) we propose a new GHFNs K-L divergence measure, which enriches the theory of GHFNs and provides more choices for calculating the differences between GHFNs; (2) a new GHF-CPT-COPRAS model is developed to solve the uncertainty fuzzy decision-making problem; (3) the D-CRITIC method is applied for the first time to assign the unknown attribute weights under GHFNs; (4) the developed GHF-CPT-COPRAS model is applied to the EDAV evaluation, and the example analysis shows that the constructed EDAV evaluation index system and model system are feasible and effective, which enriches the theory of EDAV evaluation to some extent and also provides inspiration and references for the actual EDAV evaluation. In addition, further comparisons prove the validity and feasibility of the GHF-CPT-COPRAS model; (5) the established model provides more choices for solving the MADM problem and also provides some references for the extension of the CPT-COPRAS method in other decision-making environments.
In the future, we will focus on the following research. First, the D-CRITIC method determines the weights more objectively and ignores the subjective weights of the experts. Therefore, in the future, we will consider integrating the D-CRITIC method with other objective weights, such as AHP [57], BWM [58] and KEMIRA [59]. Second, because of the complexity of decision information and the diversity of decision attributes, in the future, we will consider integrating the CPT-COPRAS model with other FSs, such as Z-numbers [60], q-Rung Orthopair Probabilistic Hesitant Fuzzy [61], etc. Finally, the model can also be applied to other decision problems, such as green supplier selection [62], stock investment [63], investment decision-making [64], sustainable circular supplier selection [65], etc. [66,67].
Author Contributions
Conceptualization, P.L. and J.S.; methodology, P.L. and J.S.; writing—original draft, P.L.; writing—review and editing, J.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Science Foundation of China [Nos. 71964018], the Yunnan Province Applied Basic Research Key Program [Nos. 202401AS070112], and the Kunming University of Science and Technology Humanities and Social Sciences Cultivation Key Program [Nos. SKPY2D01].
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Feng, B. Enterprise Data Asset Value Evaluation with Model Building and Case Study. Int. J. Adv. Eng. Manag. 2023, 5, 857–863. [Google Scholar]
- Brennan, R.; Attard, J.; Petkov, P.; Nagle, T.; Helfert, M. Exploring data value assessment: A survey method and investigation of the perceived relative importance of data value dimensions. In Proceedings of the ICEIS 2019-21st International Conference on Enterprise Information Systems, Heraklion, Greece, 3–5 May 2019; SciTePress: Setúbal, Portugal, 2019; pp. 200–207. [Google Scholar]
- Li, X.M.; Alotaibi, R. Application of nonlinear dynamic expectation and stochastic differential equation in valuation and financing risk measurement of technology-based small and medium-sized enterprises. Fractals-Complex Geom. Patterns Scaling Nat. Soc. 2022, 30, 2240057. [Google Scholar] [CrossRef]
- Harish, A.R.; Liu, X.; Zhong, R.Y.; Huang, G.Q. Log-flock: A blockchain-enabled platform for digital asset valuation and risk assessment in E-commerce logistics financing. Comput. Ind. Eng. 2021, 151, 107001. [Google Scholar] [CrossRef]
- Amekudzi-Kennedy, A.; Labi, S.; Singh, P. Transportation Asset Valuation: Pre-, Peri- and Post-Fourth Industrial Revolution. Transp. Res. Rec. 2019, 2673, 163–172. [Google Scholar] [CrossRef]
- Birch, K.; Cochrane, D.T.; Ward, C. Data as asset? The measurement, governance, and valuation of digital personal data by Big Tech. Big Data Soc. 2021, 8, 20539517211017308. [Google Scholar] [CrossRef]
- Skalicky, R.; Meluzin, T.; Zinecker, M. Brand valuation: An innovative approach based on the risk difference. Oeconomia Copernic. 2021, 12, 159–191. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Atanassov, K.; Pasi, G.; Yager, R. Intuitionistic fuzzy interpretations of multi-criteria multi-person and multi-measurement tool decision making. Int. J. Syst. Sci. 2005, 36, 859–868. [Google Scholar] [CrossRef]
- Torra, V. Hesitant Fuzzy Sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Zhang, S.; Xu, Z.; He, Y. Operations and integrations of probabilistic hesitant fuzzy information in decision making. Inf. Fusion 2017, 38, 1–11. [Google Scholar] [CrossRef]
- Ning, B.Q.; Wang, H.J.; Wei, G.W.; Wei, C. Probabilistic dual hesitant fuzzy MAGDM method based on generalized extended power average operator and its application to online teaching platform supplier selection. Eng. Appl. Artif. Intell. 2023, 125, 106667. [Google Scholar] [CrossRef]
- Ranjbar, M.; Miri, S.M.; Effati, S. Arithmetic operations and ranking of hesitant fuzzy numbers by extension principle. Iran. J. Fuzzy Syst. 2022, 19, 97–114. [Google Scholar]
- Keikha, A. Generalized hesitant fuzzy numbers: Introducing, arithmetic operations, aggregation operators, and an application. Int. J. Intell. Syst. 2021, 36, 7709–7730. [Google Scholar] [CrossRef]
- Yiarayong, P. On interval-valued fuzzy soft set theory applied to semigroups. Soft Comput. 2020, 24, 3113–3123. [Google Scholar] [CrossRef]
- Ye, J.; Du, S.; Yong, R. Multi-criteria decision-making model using trigonometric aggregation operators of single-valued neutrosophic credibility numbers. Inf. Sci. 2023, 644, 118968. [Google Scholar] [CrossRef]
- Yu, Q.; Cao, J.; Tan, L.; Liao, Y.; Liu, J. Multiple attribute decision-making based on maclaurin symmetric mean operators on q-rung orthopair cubic fuzzy sets. Soft Comput. 2022, 26, 9953–9977. [Google Scholar] [CrossRef]
- Keikha, A. Generalized hesitant fuzzy numbers and their application in solving MADM problems based on TOPSIS method. Soft Comput. 2022, 26, 4673–4683. [Google Scholar] [CrossRef]
- Garg, H.; Keikha, A. Various aggregation operators of the generalized hesitant fuzzy numbers based on Archimedean t-norm and t-conorm functions. Soft Comput. 2022, 26, 13263–13276. [Google Scholar] [CrossRef] [PubMed]
- Liu, P.; Wang, H.; Ning, B.; Wei, G. MAGDM method based on generalized hesitant fuzzy TODIM and cumulative prospect theory and application to recruitment of university researchers. J. Intell. Fuzzy Syst. 2023, 45, 1863–1880. [Google Scholar] [CrossRef]
- Liu, P.; Wang, H.; Wei, G. EDAS method for multi-attribute decision-making with generalized hesitant fuzzy numbers and its application to energy projects selection. J. Intell. Fuzzy Syst. 2023, 45, 2763–2779. [Google Scholar] [CrossRef]
- Seker, S.; Baglan, F.B.; Aydin, N.; Deveci, M.; Ding, W.P. Risk assessment approach for analyzing risk factors to overcome pandemic using interval-valued q-rung orthopair fuzzy decision making method. Appl. Soft Comput. 2023, 132, 109891. [Google Scholar] [CrossRef] [PubMed]
- Mishra, A.R.; Rani, P.; Saha, A.; Senapati, T.; Hezam, I.M.; Yager, R.R. Fermatean fuzzy copula aggregation operators and similarity measures-based complex proportional assessment approach for renewable energy source selection. Complex Intell. Syst. 2022, 8, 5223–5248. [Google Scholar] [CrossRef] [PubMed]
- Naz, S.; Akram, M.; Muzammal, M. Group decision-making based on 2-tuple linguistic T-spherical fuzzy COPRAS method. Soft Comput. 2023, 27, 2873–2902. [Google Scholar] [CrossRef]
- Dang, T.T.; Nguyen, N.A.T.; Nguyen, V.T.T.; Dang, L.T.H. A Two-Stage Multi-Criteria Supplier Selection Model for Sustainable Automotive Supply Chain under Uncertainty. Axioms 2022, 11, 228. [Google Scholar] [CrossRef]
- Buyukozkan, G.; Gocer, F. A Novel Approach Integrating AHP and COPRAS Under Pythagorean Fuzzy Sets for Digital Supply Chain Partner Selection. IEEE Trans. Eng. Manag. 2021, 68, 1486–1503. [Google Scholar] [CrossRef]
- Yuan, Y.Y.; Xu, Z.S.; Zhang, Y.X. The DEMATEL-COPRAS hybrid method under probabilistic linguistic environment and its application in Third Party Logistics provider selection. Fuzzy Optim. Decis. Mak. 2022, 21, 137–156. [Google Scholar] [CrossRef]
- Song, H.F.; Chen, Z.C. Multi-Attribute Decision-Making Method Based Distance and COPRAS Method with Probabilistic Hesitant Fuzzy Environment. Int. J. Comput. Intell. Syst. 2021, 14, 1229–1241. [Google Scholar] [CrossRef]
- Ashraf, S.; Abdullah, S.; Almagrabi, A.O. A new emergency response of spherical intelligent fuzzy decision process to diagnose of COVID19. Soft Comput. 2023, 27, 1809–1825. [Google Scholar] [CrossRef]
- Rani, P.; Mishra, A.R.; Mardani, A. An extended Pythagorean fuzzy complex proportional assessment approach with new entropy and score function: Application in pharmacological therapy selection for type 2 diabetes. Appl. Soft Comput. 2020, 94, 106441. [Google Scholar] [CrossRef]
- Shen, M.; Liu, P. Risk Assessment of Logistics Enterprises Using FMEA Under Free Double Hierarchy Hesitant Fuzzy Linguistic Environments. Int. J. Inf. Technol. Decis. Mak. 2021, 20, 1221–1259. [Google Scholar] [CrossRef]
- Tversky, A.; Kahneman, D. Advances in prospect theory: Cumulative representation of uncertainty. J. Risk. Uncertain. 1992, 5, 297–323. [Google Scholar] [CrossRef]
- Zhang, Y.J.; Wei, G.W.; Guo, Y.F.; Wei, C. TODIM method based on cumulative prospect theory for multiple attribute group decision-making under 2-tuple linguistic Pythagorean fuzzy environment. Int. J. Intell. Syst. 2021, 36, 2548–2571. [Google Scholar] [CrossRef]
- Zhang, S.S.; Wei, G.W.; Lin, R.; Chen, X.D. Cumulative prospect theory integrated CRITIC and TOPSIS methods for intuitionistic fuzzy multiple attribute group decision making. J. Intell. Fuzzy Syst. 2022, 43, 7793–7806. [Google Scholar] [CrossRef]
- Liao, N.N.; Gao, H.; Lin, R.; Wei, G.W.; Chen, X.D. An extended EDAS approach based on cumulative prospect theory for multiple attributes group decision making with probabilistic hesitant fuzzy information. Artif. Intell. Rev. 2023, 56, 2971–3003. [Google Scholar] [CrossRef]
- Zhang, H.; Wei, G. Location selection of electric vehicles charging stations by using the spherical fuzzy CPT-CoCoSo and D-CRITIC method. Comput. Appl. Math. 2023, 42, 60. [Google Scholar] [CrossRef]
- Mao, Q.; Chen, J.; Lv, J.; Guo, M.; Xie, P. Selection of plastic solid waste treatment technology based on cumulative prospect theory and fuzzy DEMATEL. Environ. Sci. Pollut. Res. 2023, 30, 41505–41536. [Google Scholar] [CrossRef]
- Han, Y.G.; Zhang, S.S.; Deng, D.X. An integrated methodology for commercial concrete supplier selection with intuitionistic fuzzy CPT-VIKOR. J. Intell. Fuzzy Syst. 2023, 44, 2643–2654. [Google Scholar] [CrossRef]
- Wu, J.-Z.; Zhang, Q. Multicriteria decision making method based on intuitionistic fuzzy weighted entropy. Expert Syst. Appl. 2011, 38, 916–922. [Google Scholar] [CrossRef]
- Saidin, M.S.; Lee, L.S.; Marjugi, S.M.; Ahmad, M.Z.; Seow, H.-V. Fuzzy Method Based on the Removal Effects of Criteria (MEREC) for Determining Objective Weights in Multi-Criteria Decision-Making Problems. Mathematics 2023, 11, 1544. [Google Scholar] [CrossRef]
- Bilisik, O.N.; Duman, N.H.; Tas, E. A novel interval-valued intuitionistic fuzzy CRITIC-TOPSIS methodology: An application for transportation mode selection problem for a glass production company. Expert Syst. Appl. 2024, 235, 121134. [Google Scholar] [CrossRef]
- Aro, J.L.; Selerio, E.; Evangelista, S.S.; Maturan, F.; Atibing, N.M.; Ocampo, L. Fermatean fuzzy CRITIC-CODAS-SORT for characterizing the challenges of circular public sector supply chains. Oper. Res. Perspect. 2022, 9, 100246. [Google Scholar] [CrossRef]
- Gou, C. An Integrated CoCoSo-CRITIC-Based Decision-Making Framework for Quality Evaluation of Innovation and Entrepreneurship Education in Vocational Colleges with Intuitionistic Fuzzy Information. Math. Probl. Eng. 2022, 2022, 6071276. [Google Scholar] [CrossRef]
- Kahraman, C.; Onar, S.C.; Oztaysi, B. A Novel spherical fuzzy CRITIC method and its application to prioritization of supplier selection criteria. J. Intell. Fuzzy Syst. 2022, 42, 29–36. [Google Scholar] [CrossRef]
- Trivedi, P.; Vansjalia, R.; Erra, S.; Narayanan, S.; Nagaraju, D. A Fuzzy CRITIC and Fuzzy WASPAS-Based Integrated Approach for Wire Arc Additive Manufacturing (WAAM) Technique Selection. Arab. J. Sci. Eng. 2022, 48, 3269–3288. [Google Scholar] [CrossRef]
- Krishnan, A.R.; Kasim, M.M.; Hamid, R.; Ghazali, M.F. A modified critic method to estimate the objective weights of decision criteria. Symmetry 2021, 13, 973. [Google Scholar] [CrossRef]
- Maneengam, A. Multi-Objective Optimization of the Multimodal Routing Problem Using the Adaptive & epsilon;-Constraint Method and Modified TOPSIS with the D-CRITIC Method. Sustainability 2023, 15, 12066. [Google Scholar]
- Wu, D.G.; Yan, J.H.; Wang, M.W.; Chen, G.Y.; Jin, J.L.; Shen, F.Q. Multidimensional Connection Cloud Model Coupled with Improved CRITIC Method for Evaluation of Eutrophic Water. Math. Probl. Eng. 2022, 2022, 4753261. [Google Scholar] [CrossRef]
- Xiao, F.Y.; Ding, W.P. Divergence measure of Pythagorean fuzzy sets and its application in medical diagnosis. Appl. Soft Comput. 2019, 79, 254–267. [Google Scholar] [CrossRef]
- Kumar, N.; Patel, A.; Mahanta, J. K-L divergence-based distance measure for Pythagorean fuzzy sets with various applications. J. Exp. Theor. Artif. Intell. 2023. [Google Scholar] [CrossRef]
- Moreno, P.; Ho, P.; Vasconcelos, N. A Kullback-Leibler divergence based kernel for SVM classification in multimedia applications. Adv. Neural Inf. Process. Syst. 2004, 16, 1385–1392. [Google Scholar]
- Mahmood, T.; Ali, Z.; Naeem, M. Aggregation operators and CRITIC-VIKOR method for confidence complex q-rung orthopair normal fuzzy information and their applications. Caai Trans. Intell. Technol. 2023, 8, 40–63. [Google Scholar] [CrossRef]
- Wang, G.; Wang, J.-S.; Wang, H.-Y.; Liu, J.-X. Component-wise design method of fuzzy C-means clustering validity function based on CRITIC combination weighting. J. Supercomput. 2023, 79, 14571–14601. [Google Scholar] [CrossRef]
- Zhang, H.; Bai, X.; Hong, X. Site selection of nursing homes based on interval type-2 fuzzy AHP, CRITIC and improved TOPSIS methods. J. Intell. Fuzzy Syst. 2022, 42, 3789–3804. [Google Scholar] [CrossRef]
- Szekely, G.J.; Rizzo, M.L. Partial distance correlation with methods for dissimilarities. Ann. Stat. 2014, 42, 2382–2412. [Google Scholar] [CrossRef]
- Hajiagha, S.H.R.; Hashemi, S.S.; Zavadskas, E.K. A complex proportional assessment method for group decision making in an interval-valued intuitionistic fuzzy environment. Technol. Econ. Dev. Econ. 2013, 19, 22–37. [Google Scholar] [CrossRef]
- Ekmekcioglu, O.; Koc, K.; Ozger, M. Stakeholder perceptions in flood risk assessment: A hybrid fuzzy AHP-TOPSIS approach for Istanbul, Turkey. Int. J. Disaster Risk Reduct. 2021, 60, 102327. [Google Scholar] [CrossRef]
- Guo, S.; Zhao, H. Fuzzy best-worst multi-criteria decision-making method and its applications. Knowl.-Based Syst. 2017, 121, 23–31. [Google Scholar] [CrossRef]
- Onar, S.C.; Kahraman, C.; Oztaysi, B. A new hesitant fuzzy KEMIRA approach: An application to adoption of autonomous vehicles. J. Intell. Fuzzy Syst. 2022, 42, 109–120. [Google Scholar] [CrossRef]
- Li, Y.; Herrera-Viedma, E.; Perez, I.J.; Xing, W.; Morente-Molinera, J.A. The arithmetic of triangular Z-numbers with reduced calculation complexity using an extension of triangular distribution. Inf. Sci. 2023, 647, 119477. [Google Scholar] [CrossRef]
- Ghailani, H.; Zaidan, A.A.; Qahtan, S.; Alsattar, H.A.; Al-Emran, M.; Deveci, M.; Delen, D. Developing sustainable management strategies in construction and demolition wastes using a q-rung orthopair probabilistic hesitant fuzzy set-based decision modelling approach. Appl. Soft Comput. 2023, 145, 110606. [Google Scholar] [CrossRef]
- Wei, G.W.; Wei, C.; Guo, Y.F. EDAS method for probabilistic linguistic multiple attribute group decision making and their application to green supplier selection. Soft Comput. 2021, 25, 9045–9053. [Google Scholar] [CrossRef]
- Zhao, M.W.; Wei, G.W.; Wei, C.; Wu, J. Improved TODIM method for intuitionistic fuzzy MAGDM based on cumulative prospect theory and its application on stock investment selection. Int. J. Mach. Learn. Cybern. 2021, 12, 891–901. [Google Scholar] [CrossRef]
- Yu, W.Y.; Zhang, Z.; Zhong, Q.Y. Consensus reaching for MAGDM with multi-granular hesitant fuzzy linguistic term sets: A minimum adjustment-based approach. Ann. Oper. Res. 2021, 300, 443–466. [Google Scholar] [CrossRef]
- Mishra, A.R.; Rani, P.; Pamucar, D.; Saha, A. An integrated Pythagorean fuzzy fairly operator-based MARCOS method for solving the sustainable circular supplier selection problem. Ann. Oper. Res. 2023. [Google Scholar] [CrossRef]
- Dursun, M.; Arslan, O. A combined fuzzy multi-criteria group decision making framework for material selection procedure: Integration of fuzzy qfd with fuzzy topsis. Int. J. Ind. Eng.-Theory Appl. Pract. 2020, 27, 585–601. [Google Scholar]
- Zhao, M.; Wei, G.; Wei, C.; Guo, Y. CPT-TODIM method for bipolar fuzzy multi-attribute group decision making and its application to network security service provider selection. Int. J. Intell. Syst. 2021, 36, 1943–1969. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).