Abstract
The choice of an appropriate regression model for econometric modeling minimizes information loss and also leads to sound inferences. In this study, we develop four quantile regression models based on trigonometric extensions of the unit generalized half-normal distributions for the modeling of a bounded response variable defined on the unit interval. The desirable shapes of these distributions, such as left-skewed, right-skewed, reversed-J, approximately symmetric, and bathtub shapes, make them competitive models for bounded responses with such traits. The maximum likelihood method is used to estimate the parameters of the regression models, and Monte Carlo simulation results confirm the efficiency of the method. We demonstrate the utility of our models by investigating the relationship between OECD countries’ educational attainment levels, labor market insecurity, and homicide rates. The diagnostics reveal that all our models provide a good fit to the data because the residuals are well behaved. A comparative analysis of the trigonometric quantile regression models with the unit generalized half-normal quantile regression model shows that the trigonometric models are the best. However, the sine unit generalized half-normal (SUGHN) quantile regression model is the best overall. It is observed that labor market insecurity and the homicide rate have significant negative effects on the educational attainment values of the OECD countries.
1. Introduction
Regression analyses are very instrumental in the econometric modeling of the relationship between a response variable and a set of covariates or exogenous variables. The regression models adopted for such analysis can either be parametric or non-parametric in nature. However, when we are certain about the distribution of the response variable, the parametric regression model is preferred over the non-parametric model. Due to this, the development of parametric regression models using (statistical or probability) distributions is on the rise.
Due to their applicability in the fields of psychology, environment, epidemiology, finance, education, and economics, among others, numerous regression models for examining relationships between an endogenous variable defined on the unit interval and exogenous variables have been developed more recently. Basically, they aim to model the conditional mean of the response variable. Among them, the beta regression model developed in [1] is the most utilized because of the easy interpretation of the estimated coefficients. Despite the flexibility of the beta regression model, the literature has been flooded with other regression models using distributions defined on the unit interval. They include the Vasicek regression model [2], log-weighted exponential regression model [3], log-Bilal regression model [4], unit improved second-degree Lindley regression model [5], and the unit Lindley regression model [6], among others.
When the bounded response variable is non-symmetric or contaminated with outliers, the appropriateness of the regression model based on the conditional mean becomes questionable. This is because the mean is not a robust measure of central tendency due to its susceptibility to outliers. Thus, quantile regression models have been proposed as alternatives; thanks to their robustness, they are suitable when the response variable is skewed or contaminated by outliers. In light of this, many quantile regression models for modeling the conditional quantile of the response variable defined on the unit interval have been developed using bounded distributions. Examples include the Vasicek quantile regression model [2], unit generalized half-normal (UGHN) quantile regression model [7], unit exponentiated Fréchet quantile regression model [8], unit gamma/Gompertz quantile regression model [9], generalized Topp-Leone median regression model [10], unit log-log quantile regression model [11], and the new unit Burr XII quantile regression model [12].
Although several bounded quantile regression models exist in the literature, none can be said to handle all the complex characteristics of data generated on a daily basis. As a result, the ongoing creation of new models facilitates data analysis with little information loss. In this study, we propose four new quantile regression models for the modeling of a bounded response variable using trigonometric classes of distributions and the UGHN distribution. The choice of trigonometric classes for modifying the UGHN distribution before developing the quantile regression model comes from the fact that they are parsimonious, simple to handle, and provide excellent parametric fit (see [13,14]). On the other hand, the UGHN distribution has proved itself as a flexible and adaptive distribution that can serve to construct efficient fit and regression models (see [7,15]). The motivations behind combining the functionalities of trigonometric classes with the UGHN distribution are thus to provide parsimonious quantile regression models capable of modeling a bounded response variable that exhibits left-skewed, right-skewed, approximately symmetric, reversed-J, J, and bathtub probability density shapes, and also to offer a heavy-tailed quantile regression model for modeling a bounded response.
The article is structured into eight sections. Section 2 describes the preliminary knowledge. The trigonometric forms of the UGHN distribution are indicated in Section 3. Section 4 develops the quantile densities of the trigonometric forms of the UGHN distribution. Section 5 presents the proposed quantile regression models, parameter estimation method and residual analysis. Section 6 is devoted to the Monte Carlo simulations. An empirical illustration of the developed models is given in Section 7. The conclusion is finally presented in Section 8.
2. Preliminary Knowledge
2.1. Trigonometric Classes of Distributions
Trigonometric classes of distributions have been useful in recent times for modifying existing classical distributions. In a Ph.D. thesis in 2015, Souza [14] derived some simple and novel trigonometric classes for changing the functional structure of standard distributions, which were later refined in [16,17,18,19]. These include the sin-G, cos-G, tan-G, and sec-G classes. For the purposes of this study, a mathematical presentation of these classes is now presented. Let and denote the cumulative distribution function (CDF) and probability density function (PDF) of a continuous distribution, respectively, and denotes a vector of parameters. According to [16], the CDF and PDF of the sin-G class are, respectively, given by
and
According to [17], the CDF and PDF of the cos-G class are, respectively, defined as
and
With reference to [18] (or [20]), the CDF and PDF of the tan-G class are, respectively, given by
and
Finally, Souza et al. [19] defined the CDF and PDF of the sec-G class as, respectively,
and
The merits of these trigonometric classes are that there is no addition of parameters to the baseline distribution; the trigonometric function confers an original oscillating feature to the probability functions, mainly the PDF and hazard rate function; these functions are quite simple from a mathematical viewpoint; and it projects a different modeling target than the baseline distribution. To illustrate this last point, the sin-G class and its baseline distribution have the following comprehensive first-order stochastic ordering: for any . Further developments on trigonometric classes can be found in the survey of [21]. Some specific lifetime distributions based on these classes have been the subject of full publications. See, for example, the sin-exponential distribution in [22], sin-Weibull, cos-Weibull, and tan-Weibull distributions in [13], sin-Fréchet distribution in [23], sin-inverse Rayleigh distribution in [24], and the sin-Nadarajah-Haghighi distribution in [25]. To the best of our knowledge, in the context of these trigonometric classes, the consideration of bounded baseline distributions and the construction of efficient quantile regression models based on them have been unexplored.
2.2. UGHN Distribution
The mathematical foundations of the UGHN distribution, which were sketched in the introduction, are presented in this section. To begin, the UGHN distribution is a unit distribution created in [15]. In the functional aspect, it depends on two parameters, and , and corresponds to the distribution of , where X denotes a random variable following the classical generalized half-normal distribution with parameters and (introduced in [26]). The CDF and PDF of Y are, respectively, given by
and
where is the CDF of the standard normal distribution. The UGHN distribution is a flexible distribution with a thicker left tail than the Weibull, gamma, and lognormal distributions. In addition, it can exhibit both left and right-skewness for given parameter values. The UGHN distribution’s desirable properties have made it a viable candidate for modeling lifetime data (see [15]). It is also desirable in the applied context of quantile regression modeling (see [7]).
3. Trigonometric UGHN Distributions
In this section, based on the material presented in the above sections, we propose four trigonometric distributions. These are the sin-UGHN (SUGHN), cos-UGHN (CUGHN), tan-UGHN (TUGHN), and sec-UGHN (SCUGHN) distributions.
3.1. SUGHN Distribution
Combining Equations (1), (2), (9), and (10), the CDF and PDF of the SUGHN distribution are, respectively, given by
and
The PDF plots of the SUGHN distribution for some selected values of the parameters are shown in Figure 1. These plots display left-skewed, right-skewed, approximately symmetric, reversed-J, and bathtub shapes. This makes the SUGHN distribution suitable for modeling data with these traits.
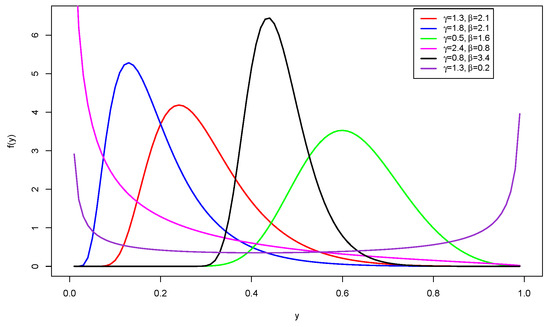
Figure 1.
PDF plots of the SUGHN distribution.
The quantile function (QF) (or the inverse CDF) is very useful when generating random observations from the distribution and also for computing measures of shape and dispersion. The QF of the SUGHN distribution is
3.2. CUGHN Distribution
The CDF and PDF of the CUGHN distribution are obtained by combining Equations (3), (4), (9), and (10). Thus, the CDF is given by
The corresponding PDF is given by
The PDF plots of the CUGHN distribution displayed in Figure 2 exhibit left-skewed, right-skewed, reversed-J, and bathtub shapes. However, they do not display the approximately symmetric shape shown by the SUGHN distribution. Hence, this distribution is capable of modeling data with such characteristics.
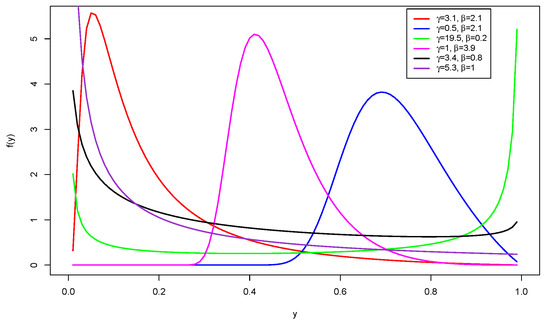
Figure 2.
PDF plots of the CUGHN distribution.
The corresponding QF is
3.3. TUGHN Distribution
The TUGHN distribution is developed using Equations (5), (6), (9), and (10). Hence, the corresponding CDF and PDF are, respectively, given by
and
respectively. The PDF plots of the TUGHN distribution in Figure 3 show left-skewed, right-skewed, reversed-J, J, and bathtub shapes. Although the TUGHN distribution does not show the approximate symmetric shape displayed by the SUGHN, it has an increasing or J shape that is not exhibited by the SUGHN and CUGHN distributions. Hence, the TUGHN distribution is a candidate for modeling bounded data with such characteristics.
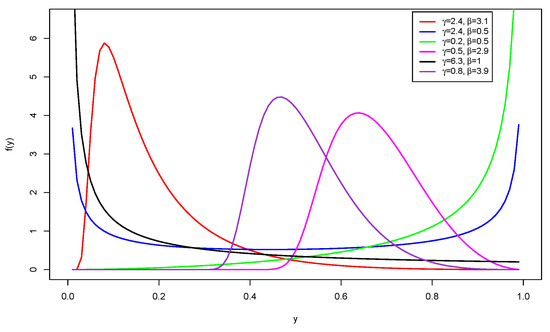
Figure 3.
PDF plots of the TUGHN distribution.
The corresponding QF is
3.4. SCUGHN Distribution
The CDF and PDF of the SCUGHN distribution are developed by substituting Equation (9) into (7) and, Equations (10) and (9) into (8). Therefore, the corresponding CDF is given by
The associated PDF is
Figure 4 shows that the SCUGHN distribution can exhibit left-skewed, right-skewed, reversed-J, and bathtub shapes for some given parameter values. The SCUGHN distribution shows similar shapes to the CUGHN distribution.
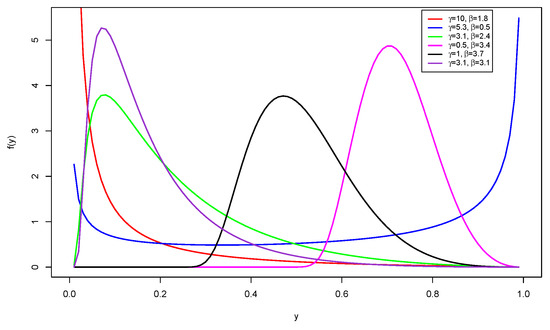
Figure 4.
PDF plots of the SCUGHN distribution.
The corresponding QF is
4. Quantile PDFs of the Trigonometric Forms of the UGHN Distribution
In order to develop the quantile regression models for the SUGHN, CUGHN, TUGHN, and SCUGHN distributions, it is essential to parametrize their PDF in terms of the quantile, . To do this, we make the subject in the QFs of the SUGHN, CUGHN, TUGHN, and SCUGHN distributions and substitute them in their corresponding PDFs. To get the quantile PDF of the SUGHN distribution, we substitute into Equation (12). The quantile PDF is calculated as follows:
where is the shape parameter, is the quantile parameter, and p satisfies .
Similarly, the quantile PDF of the CUGHN distribution is obtained by substituting into Equation (15). It is thus given by
To obtain the quantile PDF of the TUGHN distribution, we substitute
into Equation (18). This PDF is thus given by
Substituting into Equation (21) yields the quantile PDF of the SCUGHN distribution, which is given by
The quantile PDFs given in Equations (23)–(26) form the basis of our quantile regression models. Indeed, the SUGHN quantile regression model is obtained using Equation (23), the CUGHN quantile regression model is obtained using Equation (24), the TUGHN quantile regression model is obtained using Equation (25), and the SCUGHN quantile regression model is obtained using Equation (26).
5. Quantile Regression Model, Estimation and Residual Analysis
5.1. Quantile Regression Model
This section presents the quantile regression model for the proposed trigonometric distributions. Consider n independent realizations of a random variable Y that follows the SUGHN, CUGHN, TUGHN, or SCUGHN distributions (depending on the context), denoted by . The quantile regression models are developed using the logit link function. Thus, for any , we set
where is the logit link function used to link the conditional quantile of the dependent variable to the independent variables, is the vector of unknown parameters, and are the known i-th vector of independent variables. Although several link functions exist, we adopt the logit link function because of its simplicity when interpreting the coefficients of the independent variables. As a result, the model can be written as
It is important to note that, for , when is continuous, a unit increase causes change in the conditional quantile of the dependent variable, while the other independent variables remain constant. When is a categorical variable, a unit increase results in a change in the conditional quantile of the dependent variable from to , while the other independent variables remain constant. Setting yields the median regression. See [2,7,8,9] and [11] for more information on the formulation of quantile regression models with bounded distributions.
5.2. Parameter Estimation
This section describes the parameter estimation method and inference conducted using the classical maximum likelihood estimation approach. Consider n independent realizations of a random variable Y that follows the SUGHN, CUGHN, TUGHN, or SCUGHN distributions (depending on the context), denoted by and the vector of the involved parameters, denoted by . Then, the log-likelihood function is given by
where is the corresponding quantile PDF and . The maximum likelihood estimates are obtained by maximizing the function
where is the parameter space of . For the models in Equations (23)–(26), it is not possible to obtain closed form solutions for the maximum likelihood estimates of parameters. Thus, numerical solutions are employed using the BFGS algorithm in the R software [27]. The standard errors of the estimates of the parameters are determined using the large sample property of the maximum likelihood method (see [28]). The observed Fisher information matrix used to estimate standard errors for the parameters is given by
5.3. Residual Analysis
To examine the adequacy of a fitted quantile regression model, it is important to investigate the behavior of its residuals. In this study, we adopt the randomized quantile residuals developed in [29]. They are defined as
where is the corresponding estimated quantile CDF and is the quantile of the standard normal distribution. If the model fits the data well, then it is expected that the randomized quantile residuals will follow the standard normal distribution.
6. Monte Carlo Simulations
In this section, Monte Carlo simulation experiments are performed to investigate the properties of the maximum likelihood estimates. We take and the experiments are repeated times using sample sizes of , and 200. The following two parameter combinations are used in the experiment: and . For each parameter combination, the following regression structure is employed during the simulation:
where is a realization from a standard uniform distribution and is a realization from a four-degree-of-freedom student distribution. The independent variables remain fixed throughout the simulations. The observations for the response variable for a given quantile regression model are obtained using its corresponding distribution. Hence, for the various quantile regression models proposed, the response variable observations are generated using the following:
- For the SUGHN distribution, for any , we considerwhere and is an observation from the standard uniform distribution.
- For the CUGHN distribution, we considerwhere .
- For the TUGHN distribution, we considerwhere .
- For the SCUGHN distribution, we considerwhere .
The simulation is carried out using the median regression by setting . The performance of the estimates is examined using the absolute bias (AB) and root mean square error (RMSE), which are, respectively, given by
and
where or . We also compute the average estimates (AEs) of the parameters. According to Table 1 and Table 2, the AEs approach the true parameter values as the sample size increases. The ABs and RMSEs decrease as the sample size increases. The results from our Monte Carlo simulation agree with the large sample property of the maximum likelihood method. Thus, the estimates of the parameters are consistent.

Table 1.
Simulations results for .
Table 2.
Simulations results for .
7. Empirical Application
Educational attainment value is essential in the formulation of national policy. Hence, empirical application of the proposed models is illustrated in this section by investigating the effect of labour market insecurity (LMI) and homicide rate (HR) on educational attainment value (EAV) in OECD countries. The EAV is measured in percentages. These data were investigated in [3,7], and they are available in [7]. In this study, a regression structure of the form
is utilized to assess the impact of LMI and HR on EAV. We fit the SUGHN, CUGHN, TUGHN, and SCUGHN quantile regression models using the conditional quantiles and . The performances of the models are compared using the , Akaike information criterion (AIC), and Bayesian information criterion (BIC). The model with the lowest values of the , AIC, and BIC is the best. It is worth noting that, in [3], the beta regression model is fitted with the results and , and the log-weighted exponential mean regression model is fitted with the results and . Before fitting our regression models, we perform an exploratory analysis of the EAV. As seen in Figure 5, the variable is left-skewed and contains some extreme data points. This is an indication that a mean regression model may not be appropriate. However, after fitting the UGHN quantile regression model to the data, the study in [7] discovered that the conditional quantile provided the best fit, with and .
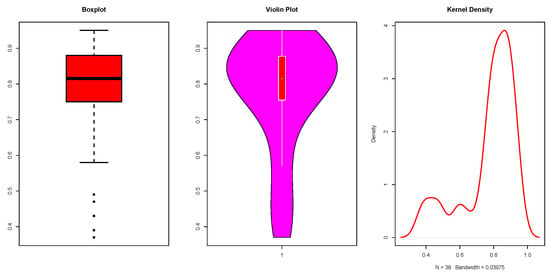
Figure 5.
Boxplot, violin, and kernel density plots.
Table 3 provides the estimates, standard errors, and p-values of the parameters of our fitted models for the various conditional quantiles. The estimated parameters were all significant at the level of significance. This is an indication that the LMI and HR have a significant impact on the EAV for all the conditional quantiles. Looking at the signs of the LMI and HR, it is observed that they have a negative impact on the EAV.
Table 3.
Estimates of parameters, standard errors, and p-values for some quantiles.
Table 4 presents the model selection criteria for our fitted models, and it can be seen that for all the models, the conditional quantile provided the best fit to the data. As the difference between their AICs and ours is greater than 2, all of our fitted models outperformed the models proposed in [3,7] at the conditional quantile. In addition, comparing the various quantiles, our models outperform the UGHN quantile regression model. The SUGHN quantile regression model is the best for all the conditional quantiles.
Table 4.
Statistical criteria.
We perform diagnostic checks on the model residuals to examine how adequate the fitted models are. The probability–probability (P–P) plots of the randomized quantile residuals shown in Figure 6 and Figure 7 suggest that the residuals of the SUGHN, CUGHN, TUGHN, and SCUGHN quantile regression models follow the standard normal distribution as the plots cluster along the diagonal.
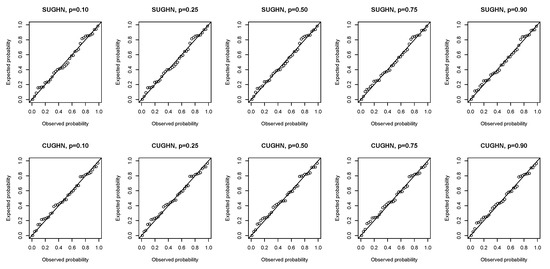
Figure 6.
P–P plots of randomized quantile residuals of the SUGHN and CUGHN regression models.
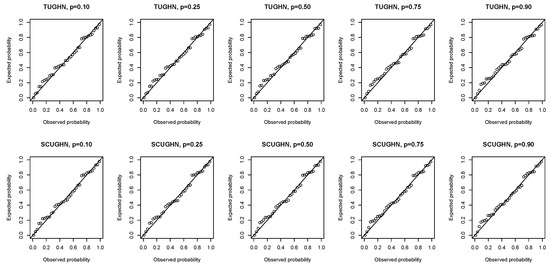
Figure 7.
P–P plots of randomized quantile residuals of the TUGHN and SCUGHN regression models.
Further, the randomized quantile residuals are examined using the half-normal plots with the simulated envelope proposed in [30]. Figure 8 and Figure 9 clearly show that the fitted models are adequate since all the observations are inside the simulated envelope.
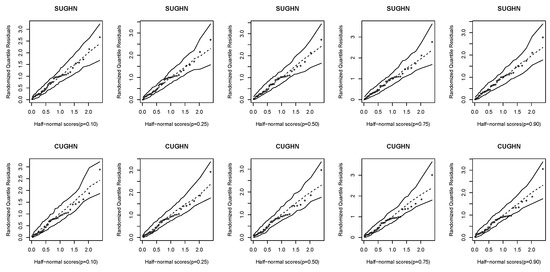
Figure 8.
Half-normal plots of randomized quantile residuals of the SUGHN and CUGHN regression models.
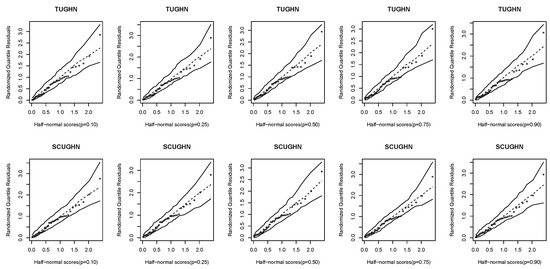
Figure 9.
Half-normal plots of randomized quantile residuals of the TUGHN and SCUGHN regression models.
8. Conclusions
In this study, we developed four trigonometric extensions of the UGHN distribution. These are the SUGHN, CUGHN, TUGHN, and SCUGHN distributions. Their PDFs exhibit desirable shapes, such as left-skewed, right-skewed, approximately symmetric, reversed-J, J, and bathtub shapes, making the new distributions suitable candidate models for data with these characteristics. Given the flexibility of the proposed distributions, we developed four quantile regression models for studying the relationship between a response variable and a set of independent variables. The maximum likelihood method was used to estimate the parameters of the regression model, and the Monte Carlo simulation performed showed that the method is able to estimate the parameters well. An empirical illustration of the model using educational data from OECD countries demonstrated that the models provided a good fit, as evidenced by the residual diagnostics. From the application of the model, we observed that the LMI and HR have significant negative effects on the EAV. Thus, to ensure good EAV, issues of LMI and HR need to be addressed with all seriousness.
Author Contributions
Conceptualization, S.N., C.C.; Data curation, S.N., C.C.; Methodology, S.N., C.C.; Supervision, S.N., C.C.; Validation, S.N., C.C.; Visualization, S.N., C.C.; Writing, S.N., C.C.; Review and editing, S.N., C.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare that they have no conflicts of interest.
References
- Ferrari, S.; Cribari-Neto, F. Beta regression for modelling rates and proportions. J. Appl. Stat. 2004, 31, 799–815. [Google Scholar] [CrossRef]
- Mazucheli, J.; Alves, B.; Korkmaz, M.Ç; Leiva, V. Vasicek quantile and mean regression models for bounded data: New formulations, mathematical derivations and numerical applications. Mathematics 2022, 10, 1389. [Google Scholar] [CrossRef]
- Altun, E. The log-weighted exponential regression model: Alternative to the beta regression model. Commun. Stat. Theory Methods 2021, 50, 2306–2321. [Google Scholar] [CrossRef]
- Altun, E.; El-Morshedy, M.; Eliwa, M.S. A new regression model for bounded response variable: An alternative to the beta and unit-Lindley regression models. PLoS ONE 2021, 16, e0245627. [Google Scholar] [CrossRef] [PubMed]
- Altun, E.; Cordeiro, G.M. The unit-improved second-degree Lindley distribution: Inference and regression modeling. Comput. Stat. 2020, 35, 259–279. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Chakraborty, S. On the one parameter unit-Lindley distribution and its associated regression model for proportion data. J. Appl. Stat. 2019, 46, 700–714. [Google Scholar] [CrossRef]
- Mazucheli, J.; Korkmaz, M.Ç.; Menezes, A.F.B.; Leiva, V. The unit generalized half-normal quantile regression model: Formulation, estimation, diagnostics and numerical applications. Soft Comput. 2023, 27, 279–295. [Google Scholar] [CrossRef]
- Abubakari, A.G.; Luguterah, A.; Nasiru, S. Unit exponentiated Fréchet distribution: Actuarial measures, quantile regression and applications. J. Indian Soc. Probab. Stat. 2022, 23, 387–424. [Google Scholar] [CrossRef]
- Mustapha, M.H.B.; Nasiru, S. Unit gamma/Gompertz quantile regression with applications to skewed data. Sri Lankan J. Appl. Stat. 2022, 23, 49–73. [Google Scholar] [CrossRef]
- Shekhawat, K.; Sharma, V.K. An extension of J-shaped distribution with application to tissue damage proportions in blood. Sankhya B Indian J. Stat. 2020, 83, 548–574. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç.; Korkmaz, Z.S. The unit log-log distribution: A new unit distribution with alternative quantile regression modeling and educational measurements applications. J. Appl. Stat. 2023, 50, 889–908. [Google Scholar] [CrossRef]
- Ribeiro, T.F.; Pena-Ramírez, F.A.; Guerra, R.R.; Cordeiro, G.M. Another unit Burr XII quantile regression model based on the different reparameterization applied to dropout in Brazilian undergraduate courses. PLoS ONE 2022, 17, e0276695. [Google Scholar] [CrossRef]
- Chesneau, C.; Artault, A. On a comparative study on some trigonometric classes of distributions by the analysis of practical datasets. J. Nonlinear Model. Anal. 2021, 3, 225–262. [Google Scholar]
- Souza, L. New Trigonometric Classes of Probabilistic Distributions. Ph.D. Thesis, Universidade Federal Rural de Pernambuco, Recife, Brazil, 2015. [Google Scholar]
- Korkmaz, M.M.Ç. The unit generalized half normal distribution: A new bounded distribution with inference and application. Sci. Bull.-Univ. Politeh. Bucharest Ser. A 2020, 82, 133–140. [Google Scholar]
- Souza, L.; Junior, W.R.O.; de Brito, C.C.R.; Chesneau, C.; Ferreira, T.A.E.; Soares, L. On the Sin-G class of distributions: Theory, model and application. J. Math. Model. 2019, 7, 357–379. [Google Scholar]
- Souza, L.; Junior, W.R.O.; de Brito, C.C.R.; Chesneau, C.; Ferreira, T.A.E.; Soares, L. General properties for the Cos-G class of distributions with applications. Eurasian Bull. Math. 2019, 2, 63–79. [Google Scholar]
- Souza, L.; Junior, W.R.O.; de Brito, C.C.R.; Chesneau, C.; Ferreira, T.A.E. Tan-G class of trigonometric distributions and its applications. Cubo 2019, 23, 1–20. [Google Scholar] [CrossRef]
- Souza, L.; de Oliveira, W.R.; de Brito, C.C.R.; Chesneau, C.; Fernandes, R.; Ferreira, T.A. Sec-G class of distributions: Properties and applications. Symmetry 2022, 14, 299. [Google Scholar] [CrossRef]
- Ampadu, C.B. The Tan-G family of distributions with illustration to data in the health sciences. Phys. Sci. Biophys. J. 2019, 3, 000125. [Google Scholar]
- Tomy, L.; Satish, G. A review study on trigonometric transformations of statistical distributions. Biom. Biostat. Int. J. 2021, 10, 130–136. [Google Scholar]
- Kumar, D.; Singh, U.; Singh, S.K. A new distribution using sine function—Its application to bladder cancer patients data. J. Stat. Appl. Probab. 2015, 4, 417–427. [Google Scholar]
- Aldahlan, M.A. Sine Fréchet model: Modeling of COVID-19 death cases in Kingdom of Saudi Arabia. Math. Probl. Eng. 2022, 2022, 2039076. [Google Scholar] [CrossRef]
- Ahmadini, A.A.H. Statistical inference of sine inverse Rayleigh distribution. Comput. Syst. Sci. Eng. 2022, 41, 405–414. [Google Scholar]
- Almetwally, E.M.; Meraou, M.A. Application of environmental data with new extension of Nadarajah-Haghighi distribution. Comput. J. Math. Stat. Sci. 2022, 1, 26–41. [Google Scholar] [CrossRef]
- Cooray, K.; Ananda, M. A generalization of the half-normal distribution with applications to lifetime data. Commun. Stat.—Theory Methods 2008, 37, 1323–1337. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: https://www.R-project.org/ (accessed on 5 October 2022).
- Cox, D.R.; Hinkley, D.V. Theoretical Statistics; Chapman and Hall/CRC: London, UK, 1974. [Google Scholar]
- Dunn, P.K.; Smyth, G.K. Randomized quantile residuals. J. Comput. Graph. Stat. 1996, 5, 236–244. [Google Scholar]
- Atkinson, A.C. Two graphical displays of outlying and influential observations in regression. Biometrika 1981, 68, 13–20. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).