
Change Point Detection Using Penalized Multidegree Splines


Abstract
:1. Introduction
2. Model and Estimator
3. Implementation
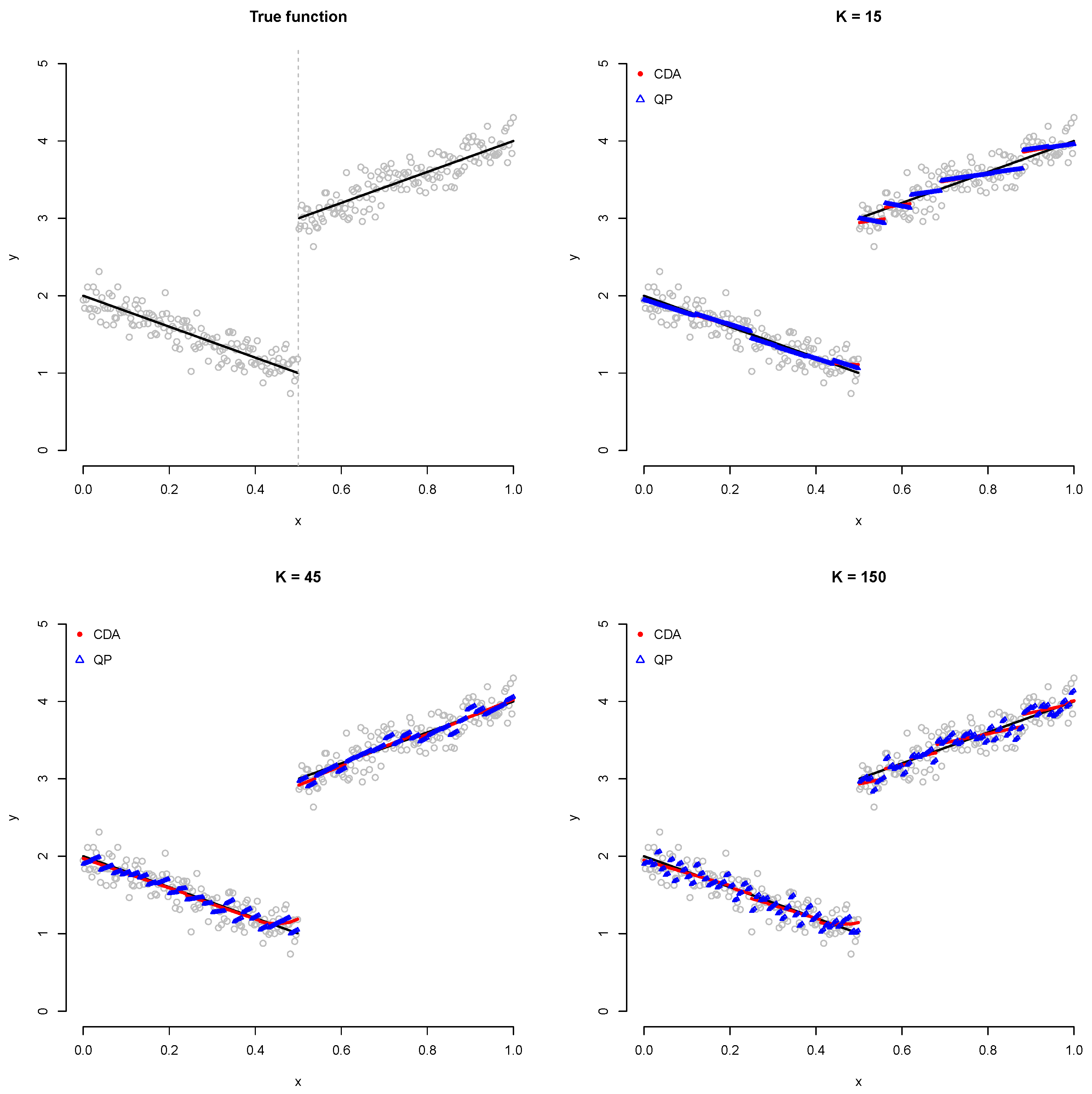
3.1. CDA
3.1.1. Updating
3.1.2. Updating and
3.1.3. Algorithm Details
| Algorithm 1: Coordinate descent algorithm (CDA). |
 |
3.2. Quadratic Programming
3.3. Comparison between CDA and QP
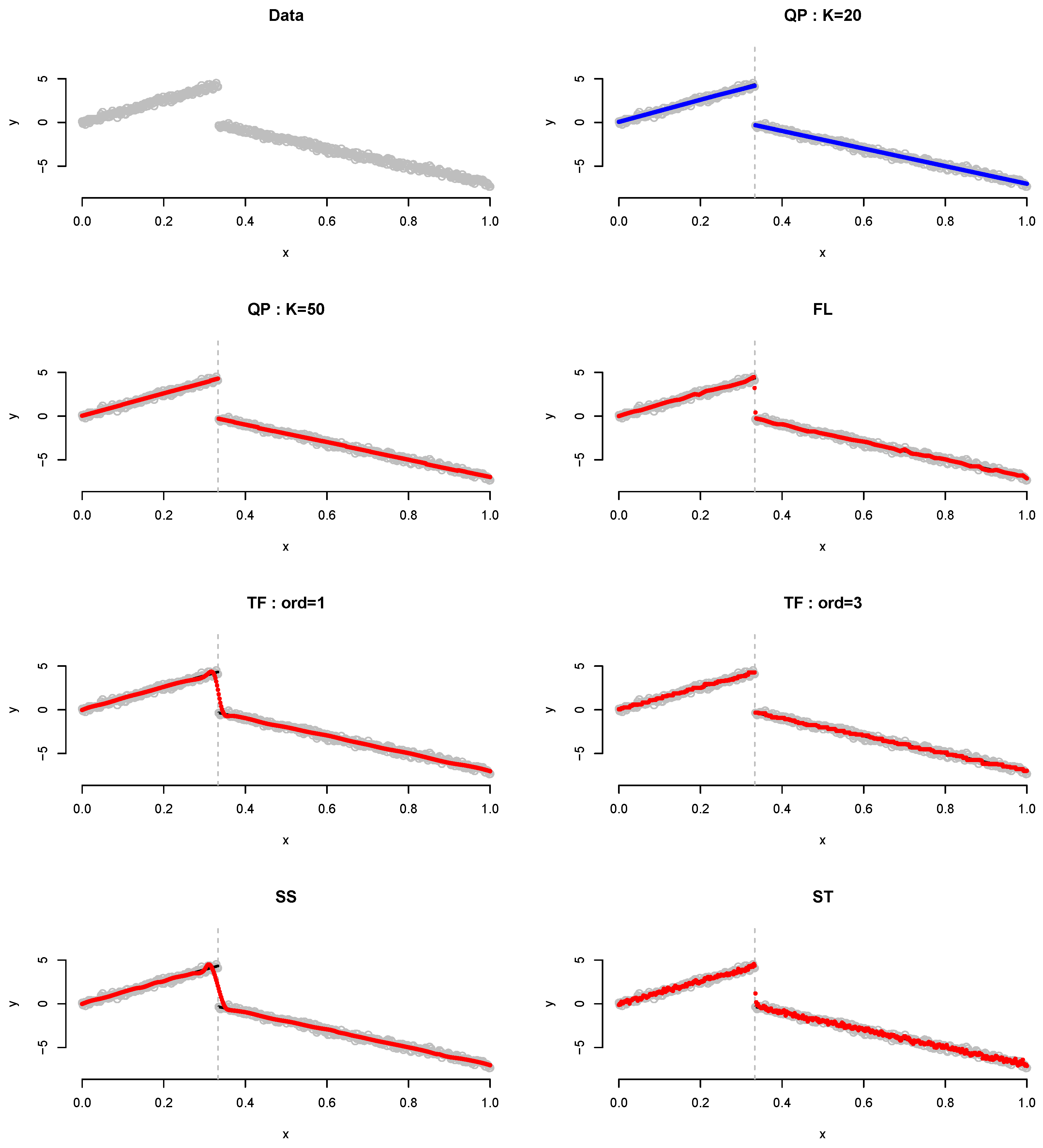
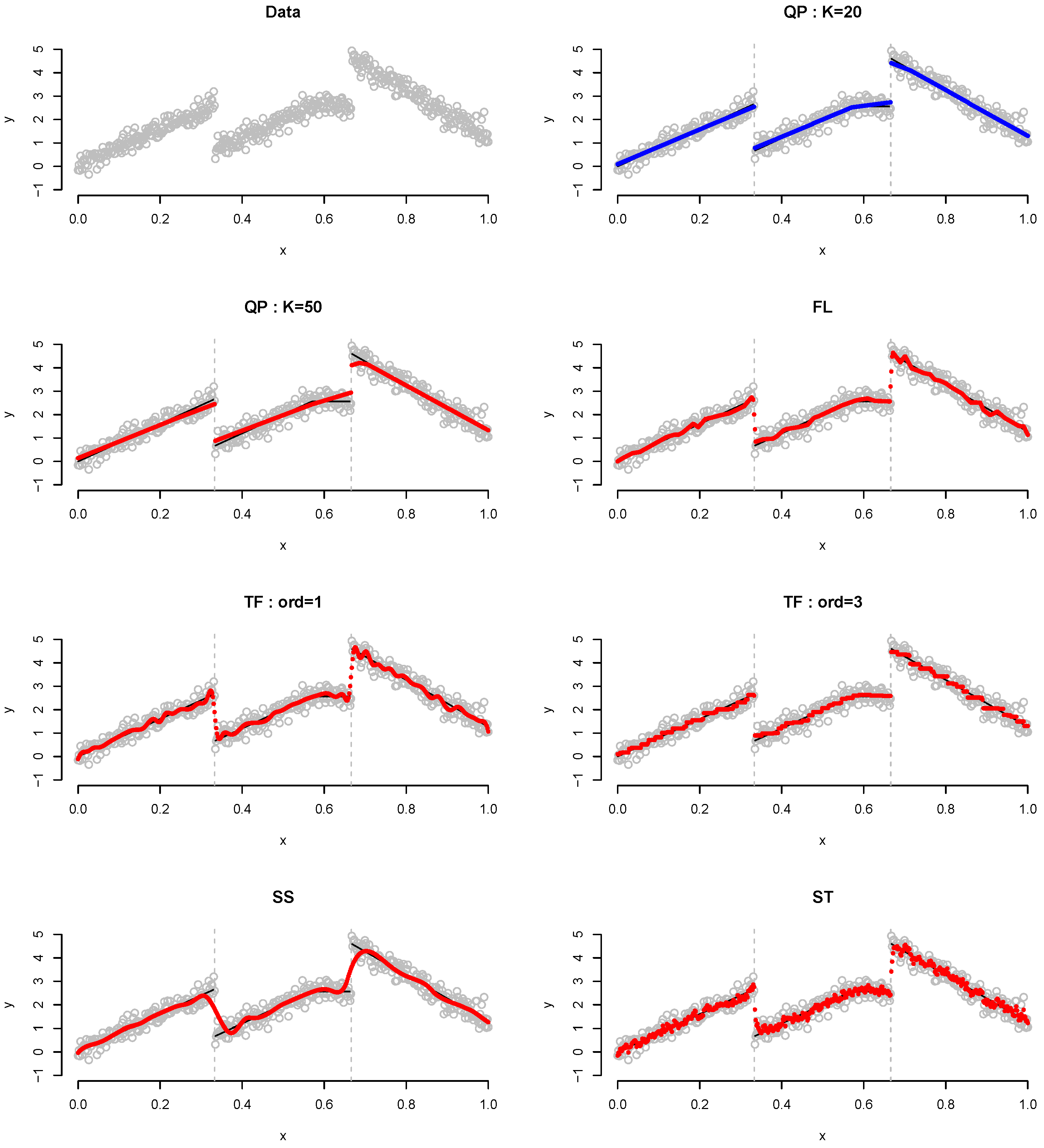
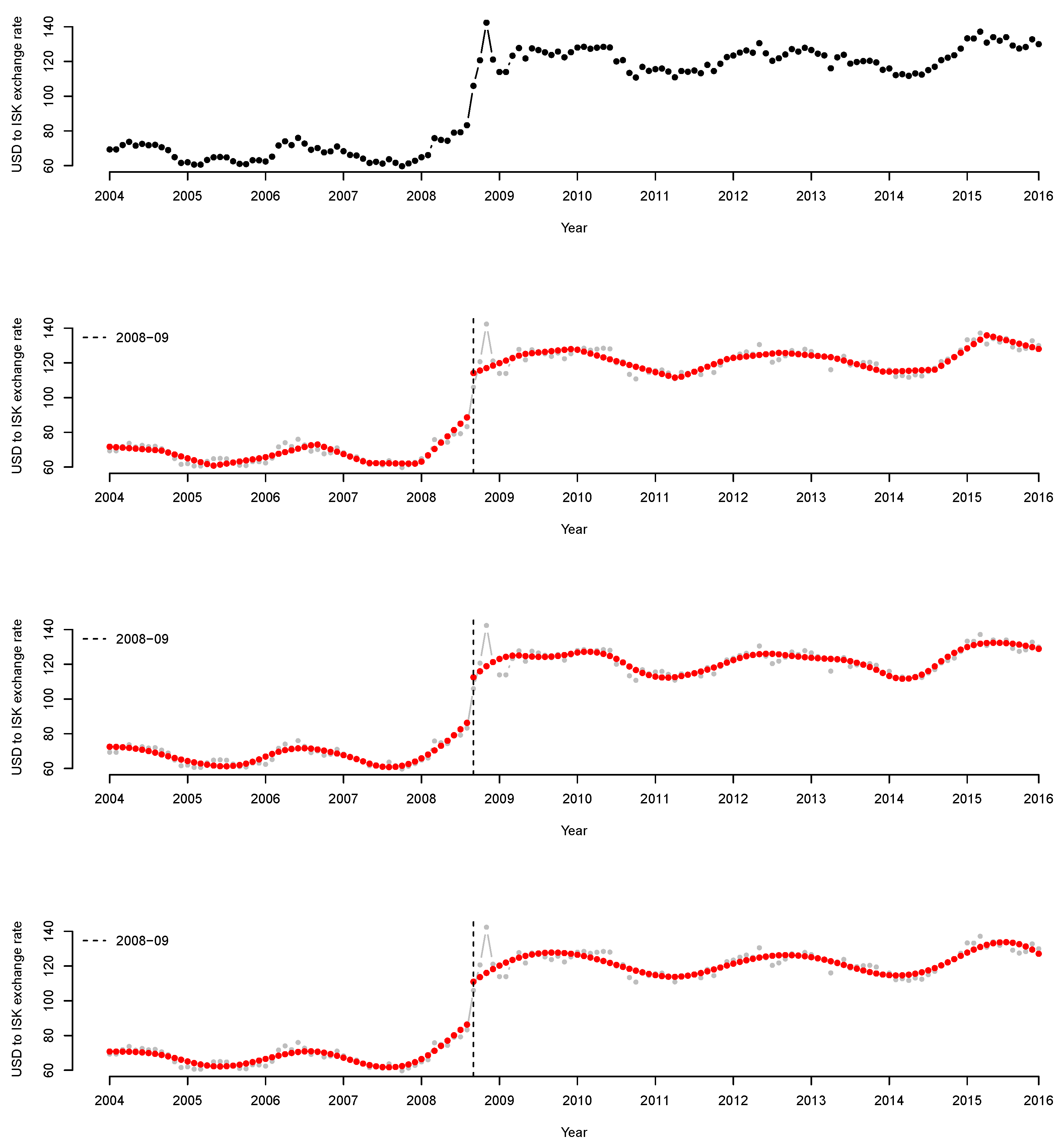
4. Numerical Analysis
4.1. Simulation
4.2. Real Data Analysis
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tsybakov, A.B. Introduction to Nonparametric Estimation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Fan, J.; Gijbels, I.; Hu, T.C.; Huang, L.S. A study of variable bandwidth selection for local polynomial regression. Stat. Sin. 1996, 6, 113–127. [Google Scholar]
- Efromovich, S. Nonparametric Curve Estimation: Methods, Theory, and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Green, P.J.; Silverman, B.W. Nonparametric Regression and Generalized Linear Models: A Roughness Penalty Approach; CRC Press: Boca Raton, FL, USA, 1993. [Google Scholar]
- Massopust, P. Interpolation and Approximation with Splines and Fractals; Oxford University Press, Inc.: Oxford, UK, 2010. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; Volume 112. [Google Scholar]
- Wright, S.J. Coordinate descent algorithms. Math. Program. 2015, 151, 3–34. [Google Scholar] [CrossRef]
- Tseng, P. Convergence of a block coordinate descent method for nondifferentiable minimization. J. Optim. Theory Appl. 2001, 109, 475–494. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Meier, L.; Van De Geer, S.; Bühlmann, P. The group lasso for logistic regression. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2008, 70, 53–71. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Goldfarb, D.; Idnani, A. A numerically stable dual method for solving strictly convex quadratic programs. Math. Program. 1983, 27, 1–33. [Google Scholar] [CrossRef]
- Osborne, M.; Presnell, B.; Turlach, B. Knot selection for regression splines via the lasso. Comput. Sci. Stat. 1998, 30, 44–49. [Google Scholar]
- Leitenstorfer, F.; Tutz, G. Knot selection by boosting techniques. Comput. Stat. Data Anal. 2007, 51, 4605–4621. [Google Scholar] [CrossRef]
- Garton, N.; Niemi, J.; Carriquiry, A. Knot selection in sparse Gaussian processes. arXiv 2020, arXiv:2002.09538. [Google Scholar]
- Aminikhanghahi, S.; Cook, D.J. A survey of methods for time series change point detection. Knowl. Inf. Syst. 2017, 51, 339–367. [Google Scholar] [CrossRef] [PubMed]
- Tibshirani, R.; Saunders, M.; Rosset, S.; Zhu, J.; Knight, K. Sparsity and smoothness via the fused lasso. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2005, 67, 91–108. [Google Scholar] [CrossRef]
- Turlach, B.A.; Weingessel, A. Quadprog: Functions to Solve Quadratic Programming Problems; R Package Version 1.5-8. 2019. Available online: https://cran.r-project.org/package=quadprog (accessed on 15 July 2021).
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization paths for generalized linear models via coordinate descent. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Jhong, J.H.; Koo, J.Y.; Lee, S.W. Penalized B-spline estimator for regression functions using total variation penalty. J. Stat. Plan. Inference 2017, 184, 77–93. [Google Scholar] [CrossRef]
- Bozdogan, H. Model selection and Akaike’s information criterion (AIC): The general theory and its analytical extensions. Psychometrika 1987, 52, 345–370. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Luenberger, D.G.; Ye, Y. Linear and Nonlinear Programming; Springer: Berlin/Heidelberg, Germany, 1984; Volume 2. [Google Scholar]
- Rockafellar, R.T. Convex Analysis; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Kim, S.J.; Koh, K.; Boyd, S.; Gorinevsky, D. ℓ1 trend filtering. SIAM Rev. 2009, 51, 339–360. [Google Scholar] [CrossRef]
- Kim, Y.J.; Gu, C. Smoothing spline Gaussian regression: More scalable computation via efficient approximation. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2004, 66, 337–356. [Google Scholar] [CrossRef]
- Harvey, A.C. Forecasting, Structural Time Series Models and the Kalman Filter; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Arnold, T.B.; Tibshirani, R.J. Efficient implementations of the generalized lasso dual path algorithm. J. Comput. Graph. Stat. 2016, 25, 1–27. [Google Scholar] [CrossRef]
- Gu, C. Smoothing spline ANOVA models: R package gss. J. Stat. Softw. 2014, 58, 1–25. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2021. [Google Scholar]
- De Boor, C.; De Boor, C. A Practical Guide to Splines; Springer: New York, NY, USA, 1978; Volume 27. [Google Scholar] [CrossRef]
- Roth, V. The generalized LASSO. IEEE Trans. Neural Netw. 2004, 15, 16–28. [Google Scholar] [CrossRef] [PubMed]
- Tibshirani, R.J.; Taylor, J. The solution path of the generalized lasso. Ann. Stat. 2011, 39, 1335–1371. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | QP (K = 20) | QP (K = 50) | FL | TF (ord = 1) | TF (ord = 3) | SS | ST | |
|---|---|---|---|---|---|---|---|---|
| 200 | MSE | 0.52 | 0.80 | 1.72 | 1.96 | 3.54 | 9.47 | 4.55 |
| () | () | () | () | () | () | () | ||
| MAE | 4.27 | 5.35 | 10.41 | 8.45 | 11.77 | 13.16 | 16.18 | |
| () | () | () | () | () | () | () | ||
| MXDV | 37.70 | 49.67 | 39.71 | 102.70 | 133.93 | 217.82 | 117.69 | |
| () | () | () | () | () | () | () | ||
| 300 | MSE | 0.22 | 0.40 | 0.94 | 1.11 | 2.11 | 7.85 | 2.91 |
| () | () | () | () | () | () | () | ||
| MAE | 2.74 | 3.78 | 7.72 | 6.15 | 8.66 | 10.70 | 12.76 | |
| () | () | () | () | () | ( | () | ||
| MXDV | 25.84 | 37.02 | 29.90 | 95.21 | 133.34 | 222.44 | 120.09 | |
| () | () | () | () | () | () | () | ||
| 500 | MSE | 0.13 | 0.22 | 0.65 | 0.92 | 4.57 | 7.07 | 2.55 |
| () | () | () | () | () | () | () | ||
| MAE | 2.01 | 2.70 | 6.44 | 5.43 | 6.91 | 9.43 | 11.62 | |
| () | () | () | () | () | () | () | ||
| MXDV | 19.84 | 28.95 | 26.03 | 113.64 | 218.35 | 232.12 | 159.22 | |
| () | () | () | () | () | () | () |
| n | QP (K = 20) | QP (K = 50) | FL | TF (ord = 1) | TF (ord = 3) | SS | ST | |
|---|---|---|---|---|---|---|---|---|
| 200 | MSE | 0.62 | 1.39 | 1.51 | 2.10 | 2.89 | 4.44 | 3.51 |
| () | () | () | () | () | () | () | ||
| MAE | 5.65 | 8.32 | 9.65 | 9.20 | 11.46 | 11.93 | 13.96 | |
| () | () | () | () | () | () | () | ||
| MXDV | 28.50 | 39.88 | 38.92 | 83.52 | 86.71 | 100.90 | 93.29 | |
| () | () | () | () | () | () | () | ||
| 300 | MSE | 0.43 | 0.58 | 1.13 | 1.64 | 2.19 | 3.82 | 3.05 |
| () | () | () | () | () | () | () | ||
| MAE | 4.72 | 5.50 | 8.37 | 7.87 | 9.72 | 10.53 | 12.67 | |
| () | () | () | () | () | () | () | ||
| MXDV | 25.33 | 29.66 | 36.30 | 86.71 | 89.47 | 103.02 | 107.01 | |
| () | () | () | () | () | () | () | ||
| 500 | MSE | 0.25 | 0.63 | 0.76 | 1.20 | 1.66 | 3.21 | 2.49 |
| () | () | () | () | () | () | () | ||
| MAE | 3.52 | 5.21 | 6.87 | 6.54 | 7.76 | 9.09 | 11.23 | |
| () | () | () | () | () | () | () | ||
| MXDV | 20.33 | 32.89 | 32.42 | 91.12 | 96.79 | 105.51 | 122.67 | |
| () | () | () | () | () | () | () |
| n | QP (K = 20) | QP (K = 50) | FL | TF (ord = 1) | TF (ord = 3) | SS | ST | |
|---|---|---|---|---|---|---|---|---|
| 200 | MSE | 0.95 | 1.97 | 2.30 | 1.77 | 4.81 | 26.96 | 5.53 |
| () | () | () | () | () | () | () | ||
| MAE | 6.73 | 11.11 | 11.90 | 8.62 | 12.59 | 18.83 | 18.58 | |
| () | () | () | () | () | () | () | ||
| MXDV | 50.06 | 41.95 | 46.85 | 91.63 | 165.54 | 382.14 | 81.19 | |
| () | () | () | () | () | () | () | ||
| 300 | MSE | 0.63 | 1.46 | 1.65 | 1.57 | 3.97 | 23.48 | 5.20 |
| () | () | () | () | () | () | () | ||
| MAE | 5.46 | 9.52 | 10.10 | 7.69 | 11.20 | 16.70 | 17.69 | |
| () | () | () | () | () | () | () | ||
| MXDV | 47.32 | 38.72 | 42.29 | 113.08 | 191.36 | 395.16 | 119.95 | |
| () | () | () | () | () | () | () | ||
| 500 | MSE | 0.50 | 1.02 | 1.17 | 1.50 | 15.90 | 21.60 | 4.79 |
| () | () | () | () | () | () | () | ||
| MAE | 4.56 | 7.79 | 8.50 | 6.96 | 11.23 | 15.17 | 16.37 | |
| () | () | () | () | () | () | () | ||
| MXDV | 47.87 | 38.85 | 39.65 | 146.05 | 390.08 | 407.96 | 193.31 | |
| () | () | () | () | () | () | () |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, E.-J.; Jhong, J.-H. Change Point Detection Using Penalized Multidegree Splines. Axioms 2021, 10, 331. https://doi.org/10.3390/axioms10040331
Lee E-J, Jhong J-H. Change Point Detection Using Penalized Multidegree Splines. Axioms. 2021; 10(4):331. https://doi.org/10.3390/axioms10040331
Chicago/Turabian StyleLee, Eun-Ji, and Jae-Hwan Jhong. 2021. "Change Point Detection Using Penalized Multidegree Splines" Axioms 10, no. 4: 331. https://doi.org/10.3390/axioms10040331
APA StyleLee, E.-J., & Jhong, J.-H. (2021). Change Point Detection Using Penalized Multidegree Splines. Axioms, 10(4), 331. https://doi.org/10.3390/axioms10040331