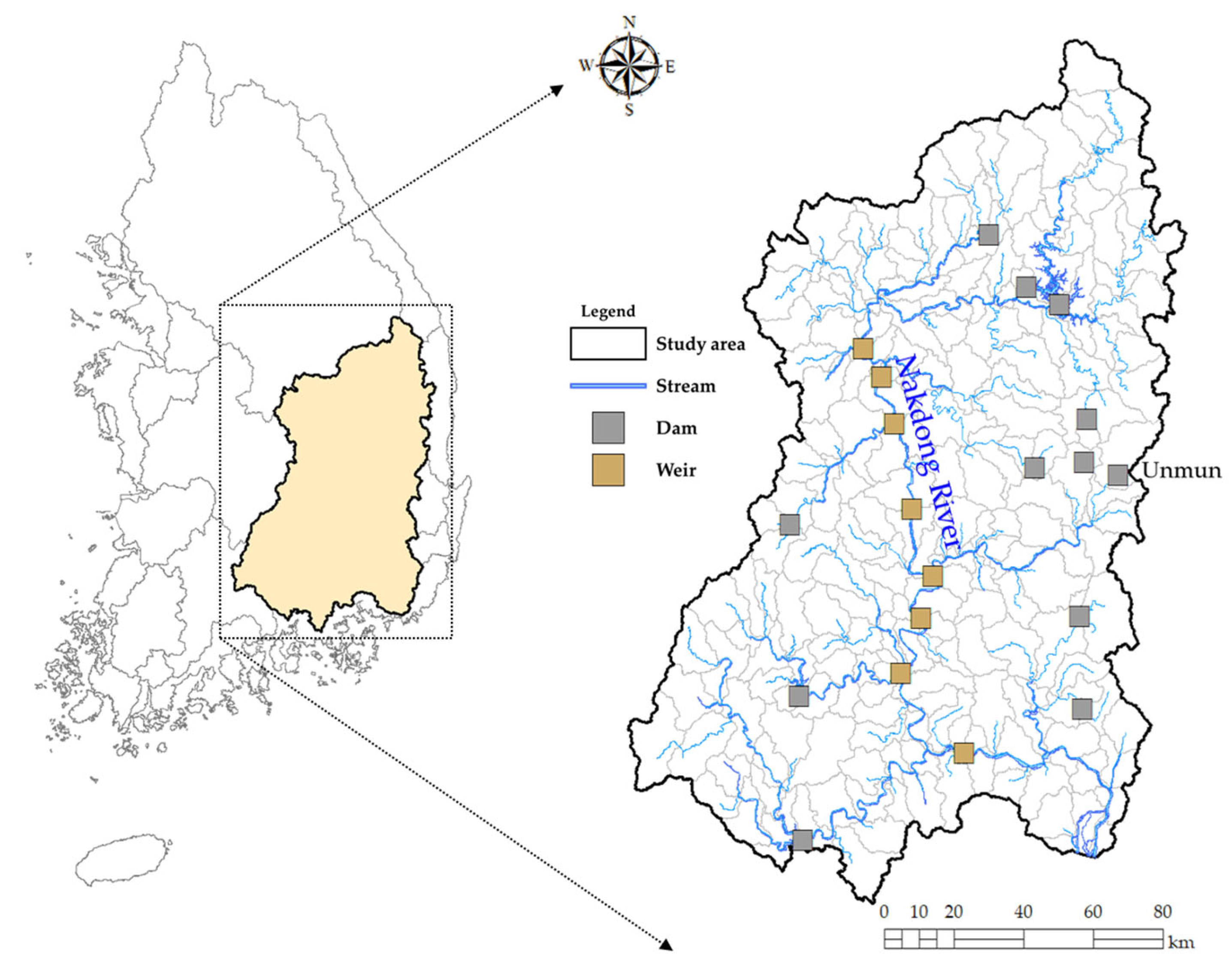
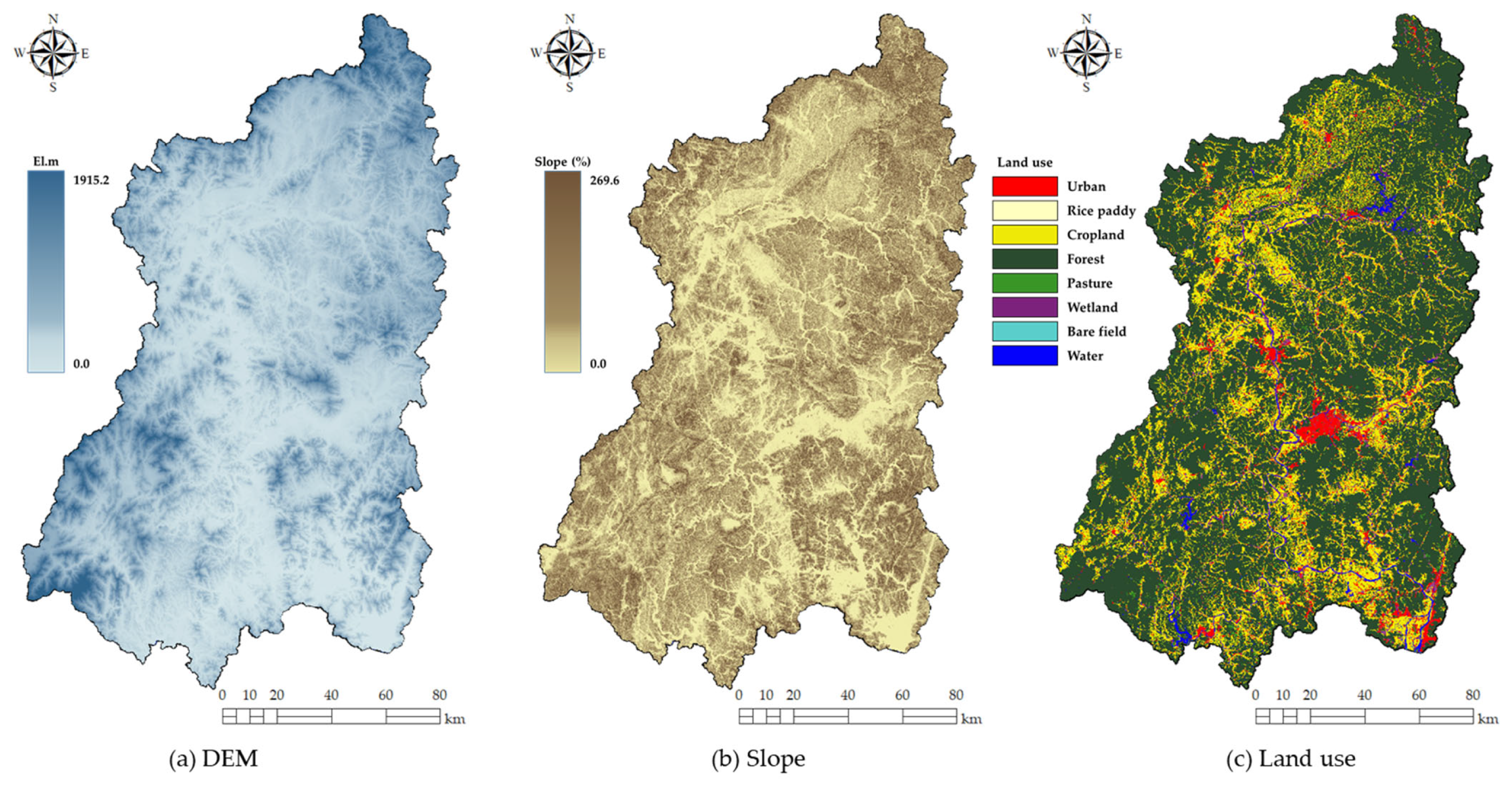
3.1. Delineation of Homogeneous Regions
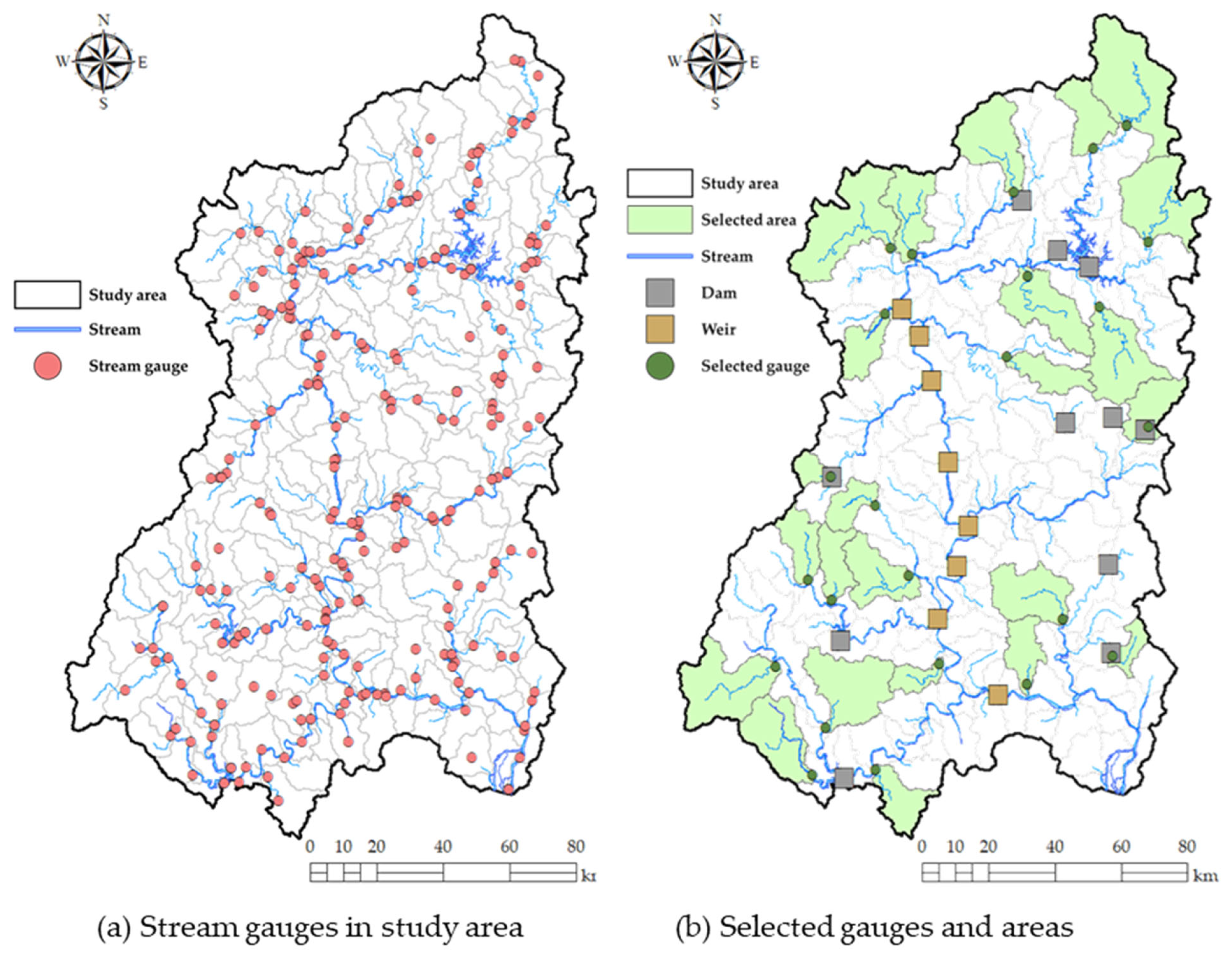
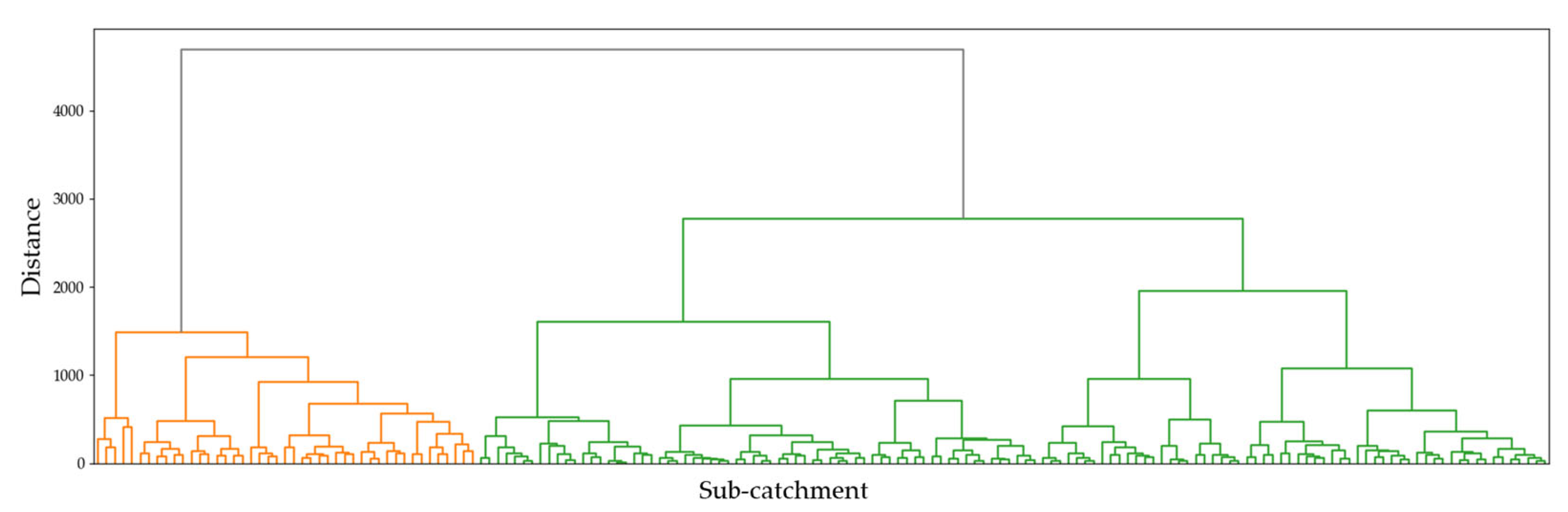
Cluster analysis was performed on a total of 171 sub-catchments, including 24 selected areas to delineate the hydrologically homogeneous regions. The process of determining the optimal number of cluster for two different methods is displayed in
Figure 4 and
Figure 5. The dendrograms in
Figure 4 provide a visual representation of the hierarchical clustering process, where the vertical axis indicates the distance or dissimilarity between clusters. The dendrograms suggest the presence of two primary clusters, as indicated by the significant vertical distance at which the branches merge. The classification into two clusters reflects distinct hydrological or climatological characteristics among the sub-catchments. The selection of the optimal number of clusters was further validated using additional clustering evaluation metrics, ensuring that the chosen clustering structure provides meaningful differentiation in the regionalization of low-flow characteristics. This classification served as the basis for the development of regional regression models tailored to each group.
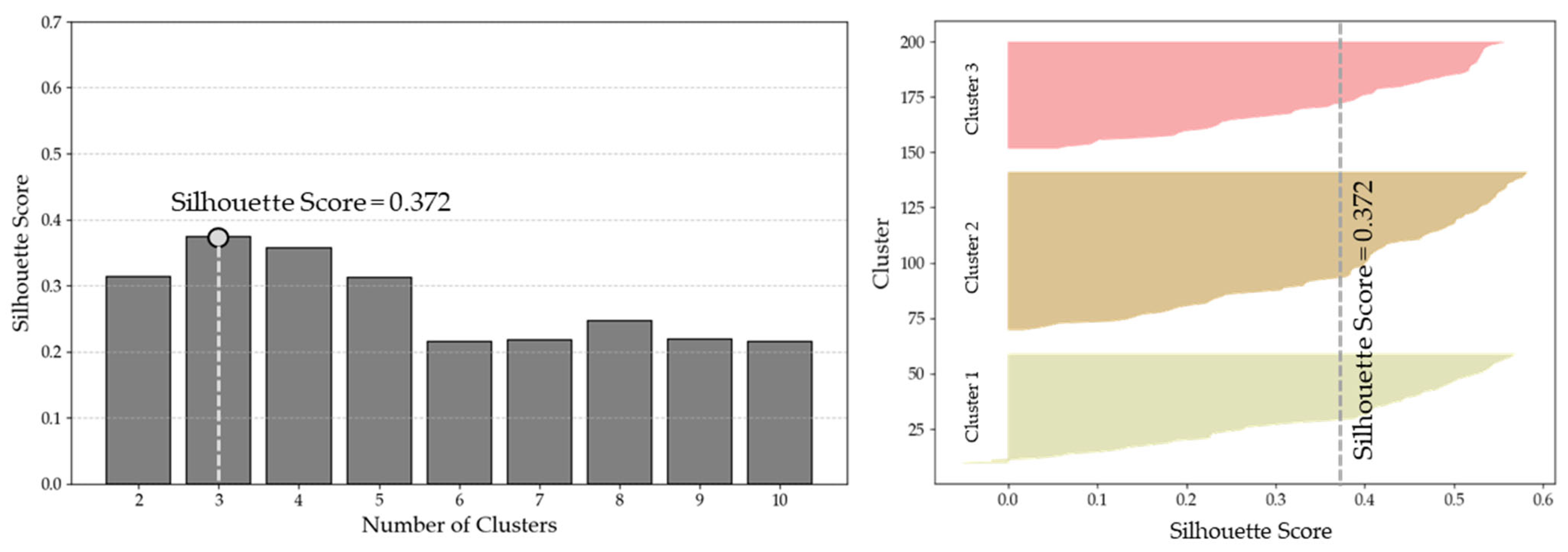
In case of K-means clustering, the optimal number of clusters was determined using the Silhouette score. The left panel of
Figure 5 presents the Silhouette scores for different numbers of clusters, indicating that the highest score was observed at three clusters. This suggests that partitioning the dataset into three groups provides the best balance between cohesion and separation. The right panel of
Figure 5 displays the Silhouette coefficient distribution for each cluster. The majority of sub-catchments within each cluster exhibit positive silhouette coefficients, confirming that the chosen clustering structure effectively differentiates between groups while maintaining internal consistency. These results support the classification of sub-catchments into three homogeneous regions based on climatological and hydrological characteristics.
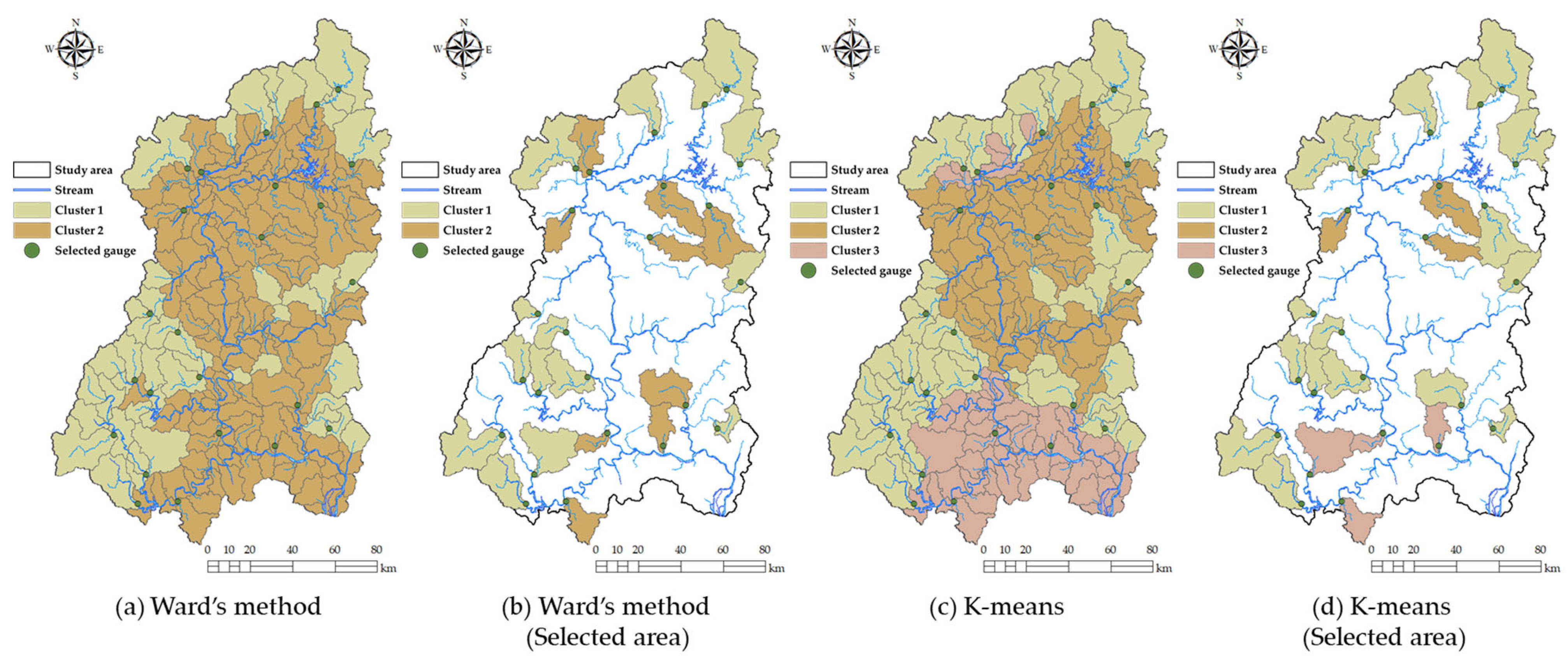
The spatial distribution of homogeneous regions, derived from both Ward’s method and the K-means algorithm, is presented in
Figure 6. Panels (a) and (b) illustrate the clustering results for the entire watershed and the selected area (gauged basins) using Ward’s method, while panels (c) and (d) show the corresponding results obtained through K-means clustering. The classification results show the distinct spatial characteristics of sub-catchments based on climatological and hydrological similarities.
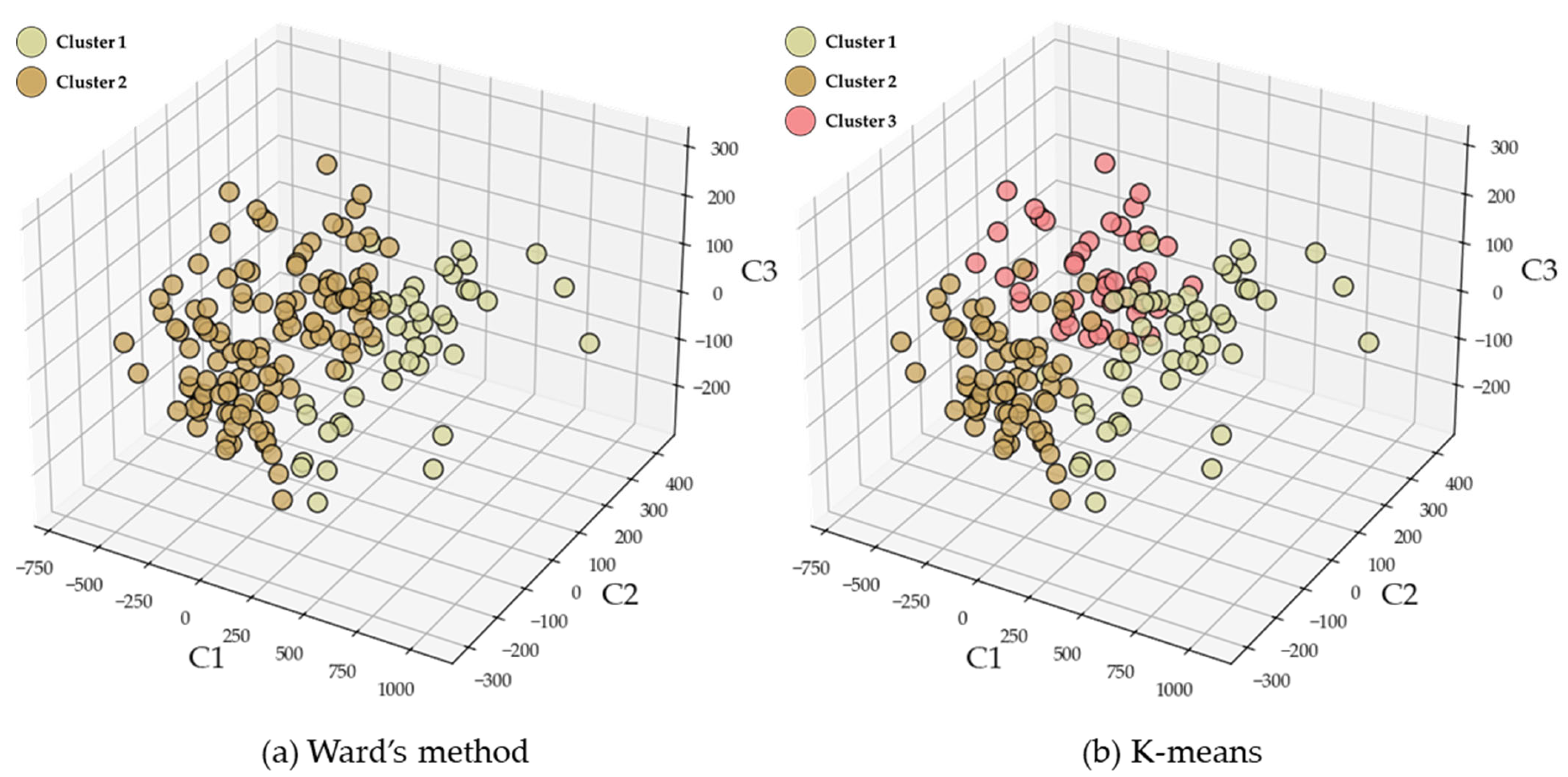
Figure 7 presents a three-dimensional visualization of the classified sub-catchments based on the three components derived from principal component analysis (PCA), which account for the largest variance. Panels (a) and (b) illustrate the clustering results obtained using Ward’s method and the K-means algorithm, respectively. In both methods, a clear separation between clusters is observed, although K-means exhibits a more evenly distributed clustering pattern compared to Ward’s method. The clustering patterns suggest that the identified homogeneous regions effectively capture the underlying climatological and hydrological characteristics of the study area. The PCA-based visualization confirms that the clusters exhibit distinct spatial structures, supporting the reliability of the classification approach. The consistency between the two methods further enhances the robustness of the delineated homogeneous regions.
3.2. Determination of Regression Model
3.2.1. Global Regression Model
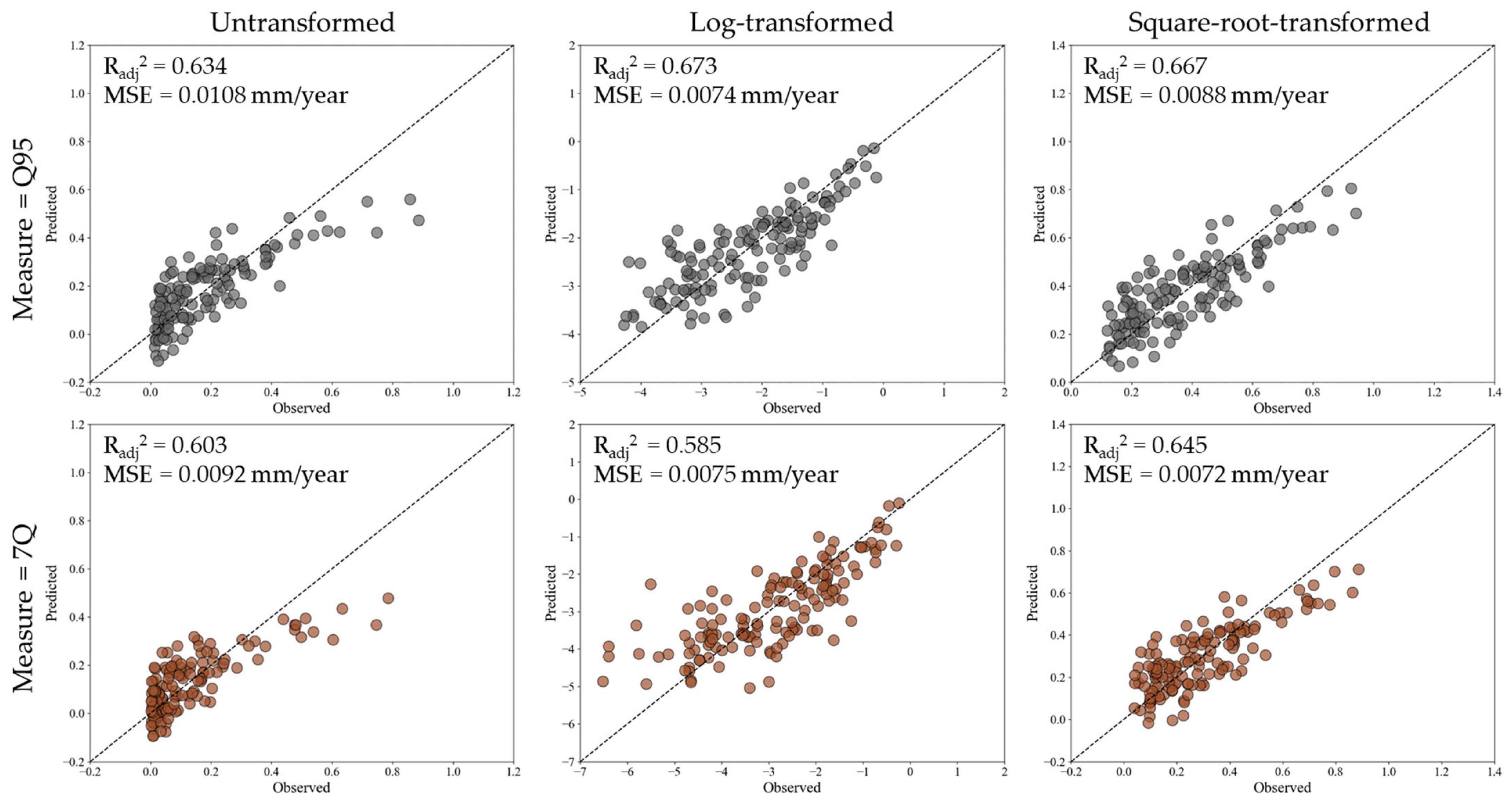
A global regression model was developed to estimate low-flow metrics (Q95 and 7Q) using climatological variables across the study area (
Figure 8). For Q95, the log-transformed model exhibited the highest predictive accuracy (
Radj2 = 0.673,
MSE = 0.0074 mm/year), followed by the square-root-transformed model (
Radj2 = 0.667,
MSE = 0.0088 mm/year). The untransformed model had the lowest performance (
Radj2 = 0.634,
MSE = 0.0108 mm/year), suggesting that transformation enhances the performance of the regression model to capture the skewed distribution of Q95 values. For 7Q, the square-root-transformed model performed best (
Radj2 = 0.645,
MSE = 0.0072 mm/year), slightly outperforming the log-transformed model (
Radj2 = 0.585,
MSE = 0.0075 mm/year) and the untransformed model (
Radj2 = 0.603,
MSE = 0.0092 mm/year). These results indicate that log transformation enhances Q95 prediction, whereas square-root transformation better represents 7Q variations by balancing interpretability and predictive accuracy.
The results indicate that data transformation significantly improves regression model performance, particularly for Q95. The log transformation led to a noticeable improvement in Radj2 and a reduction in the MSE, demonstrating that Q95 exhibits a skewed distribution that benefits from logarithmic scaling. For 7Q, the best performance was observed with the square-root transformation, which suggests that this measure follows a moderately skewed distribution rather than a log-normal pattern. The 7-day minimum flow represents a more stable low-flow condition influenced by base-flow contributions, leading to fewer extreme values compared to Q95. Consequently, a square-root transformation appears more suitable for preserving hydrological relationships while enhancing predictive accuracy. Despite the improvements gained through transformation, the global regression model still demonstrates limitations in capturing local variations in low flow. The moderate values of Radj2 suggest that, while the selected climatological and geomorphological predictors explain a portion of low-flow variability, spatial heterogeneity remains a key challenge. This limitation underlines the need for regional regression models, which will be explored in the next section to address spatial variability more effectively.
3.2.2. Regional Regression Model
Based on Ward’s method, regional regression models were developed for Q95 (
Figure 9). For Cluster 1, the square-root-transformed model exhibited the highest predictive accuracy (
Radj2 = 0.723,
MSE = 0.0077 mm/year), followed by the log-transformed model (
Radj2 = 0.712,
MSE = 0.0084 mm/year). The untransformed model had the lowest performance (
Radj2 = 0.634,
MSE = 0.0131 mm/year), indicating that transformation effectively improves the ability of the model to capture the distribution of Q95. For Cluster 2, the log-transformed model performed best (
Radj2 = 0.655,
MSE = 0.0017 mm/year), slightly outperforming the square-root-transformed model (
Radj2 = 0.642,
MSE = 0.0014 mm/year). The untransformed model (
Radj2 = 0.615,
MSE = 0.0014 mm/year) showed the lowest predictive accuracy. These results suggest that log and square-root transformations enhance Q95 prediction, with the square-root transformation particularly effective in Cluster 1 and log transformation balancing accuracy and interpretability in Cluster 2.
The regional regression models developed using Ward’s method show clear improvements over the global model, confirming the effectiveness of hydrologically homogeneous clustering in enhancing low-flow predictions. The higher Radj2 values and lower MSEs indicate that regionally calibrated models better capture spatial variations in Q95 compared to a single global model. The superior performance of transformation techniques reinforces the right-skewed nature of Q95. The log transformation showed the best performance in Cluster 1, suggesting that hydrological conditions in this cluster exhibit a stronger skewed distribution. In contrast, Cluster 2 showed similar performance between log and square-root transformations, implying a more stable low-flow regime that benefits from moderate normalization rather than extreme scaling.
The effectiveness of regional regression models in predicting 7Q was evaluated using clusters derived from Ward’s method (
Figure 10). For Cluster 1, the log-transformed model exhibited the highest predictive capability (
Radj2 = 0.710,
MSE = 0.0083 mm/year), followed closely by the square-root-transformed model (
Radj2 = 0.695,
MSE = 0.0084 mm/year). The untransformed model lagged behind, with the lowest predictive accuracy (
Radj2 = 0.668,
MSE = 0.0101 mm/year), suggesting that applying transformations enhances model performance by normalizing the skewed distribution of 7Q. In Cluster 2, a similar pattern emerged. The log-transformed model demonstrated the best predictive performance (
Radj2 = 0.626,
MSE = 0.0010 mm/year), followed by the square-root-transformed model (
Radj2 = 0.606,
MSE = 0.0009 mm/year). The untransformed model produced the lowest accuracy (
Radj2 = 0.493,
MSE = 0.0011 mm/year), indicating that a lack of transformation may hinder the performance of the model to capture low-flow variability.
The findings reaffirm that regional regression models developed using Ward’s method improve the predictive accuracy of 7Q estimates. The higher values of Radj2 and reduced MSEs across both clusters demonstrate that spatially calibrated models offer superior performance compared to a single global model. One notable insight from this analysis is the effectiveness of log transformation in enhancing model performance. In Cluster 1, where low-flow characteristics are likely influenced by highly seasonal flow regimes or intermittent base-flow contributions, the log transformation resulted in the best predictive performance. This suggests that 7Q in this cluster exhibits a heavily skewed distribution, where extreme low-flow values require a logarithmic scale for accurate representation. Meanwhile, in Cluster 2, the log and square-root transformations both significantly improved model accuracy, though the log transformation outperformed the others. This result indicates that, while 7Q in this cluster is also right-skewed, it has a more stable base-flow component compared to Cluster 1.
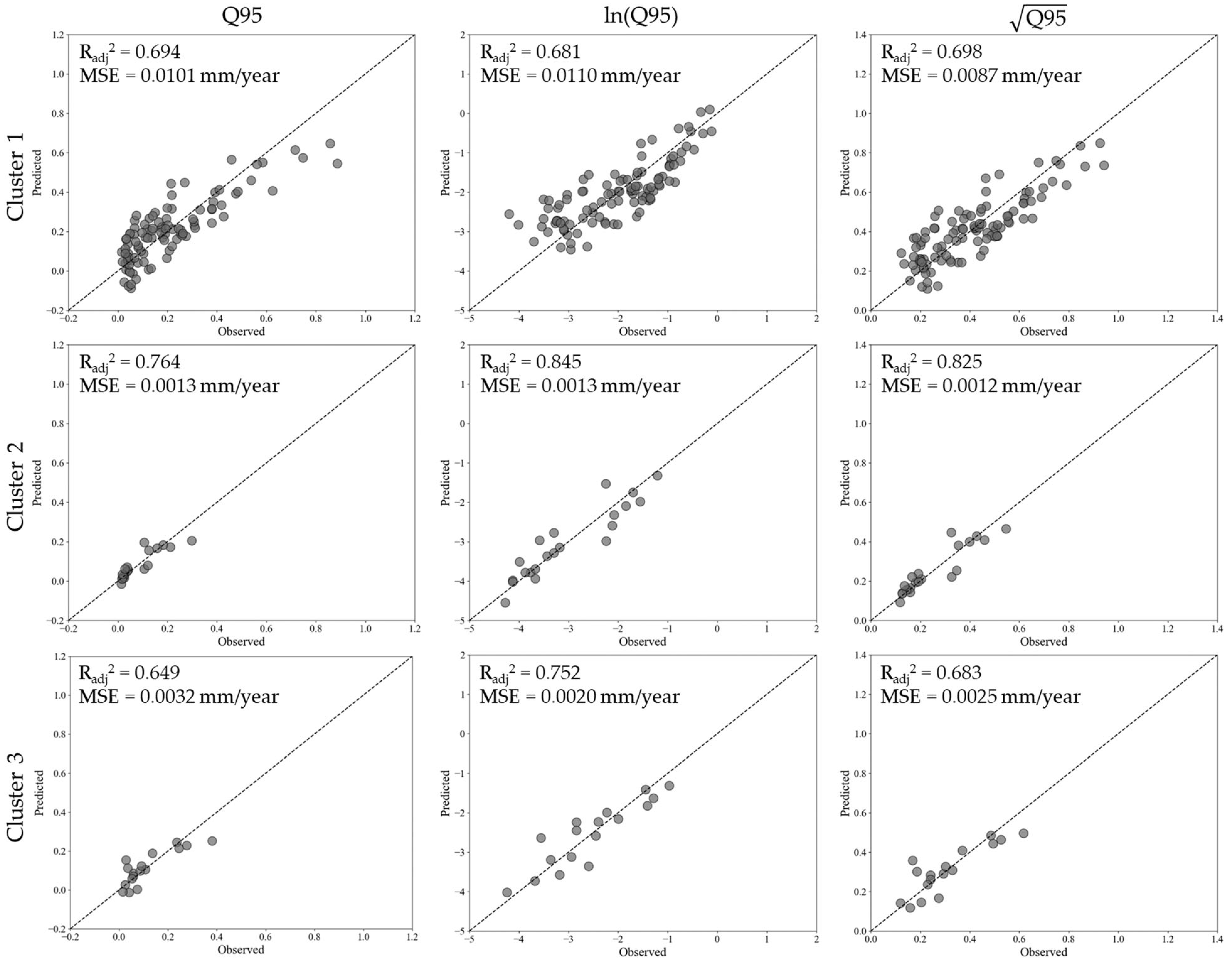
Regional regression models with K-means clustering are constructed for Q95 estimation (
Figure 11). In the case of Cluster 1, the square-root-transformed model demonstrated the highest predictive accuracy (
Radj2 = 0.698,
MSE = 0.0087 mm/year), performing slightly better than the untransformed model (
Radj2 = 0.694,
MSE = 0.0101 mm/year) and the log-transformed model (
Radj2 = 0.681,
MSE = 0.0110 mm/year). The relatively minor variations in performance suggest that Q95 in this cluster follows a less skewed distribution, resulting in limited benefits from transformation. For Cluster 2, the log-transformed model achieved the best results (
Radj2 = 0.845,
MSE = 0.0013 mm/year), surpassing both the square-root-transformed model (
Radj2 = 0.825,
MSE = 0.0012 mm/year) and the untransformed model (
Radj2 = 0.764,
MSE = 0.0013 mm/year). In Cluster 3, the log-transformed model again provided the most accurate predictions (
Radj2 = 0.752,
MSE = 0.0020 mm/year), followed by the square-root-transformed model (
Radj2 = 0.683,
MSE = 0.0025 mm/year) and the untransformed model (
Radj2 = 0.649,
MSE = 0.0032 mm/year).
The analysis showed the strong influence of transformation on model accuracy, particularly in Clusters 2 and 3. The log-transformed model consistently provided the best performance. Notably, minimal differences in transformation performance for Cluster 1 suggest that low flows in this region are more stable and require less extreme normalization. The comparable accuracy of the untransformed model implies that Q95 in this cluster may be governed by relatively uniform hydrological processes. On the other hand, the effectiveness of K-means clustering in delineating hydrologically distinct regions is evident in the clear differences in model behavior across clusters. Unlike Ward’s method, which produces hierarchical clusters, K-means allows for greater flexibility in identifying statistically similar sub-catchments, leading to robust regression models.
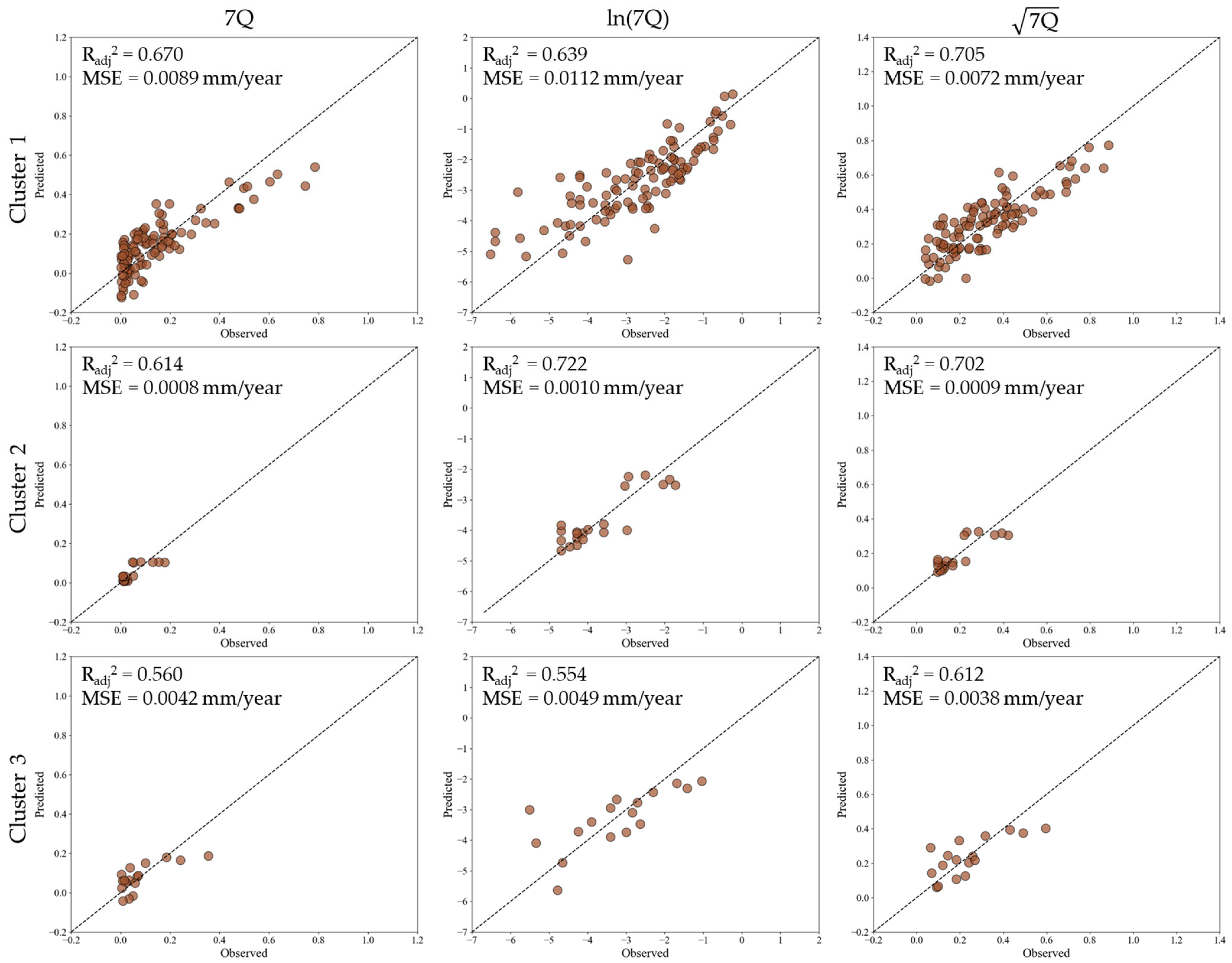
Regional regression models for 7Q under K-mean clustering conditions were also developed to allow for low-flow variability (
Figure 12). As a result, in Cluster 1, the square-root-transformed model delivered the best performance (
Radj2 = 0.705,
MSE = 0.0072 mm/year), slightly outperforming the untransformed model (
Radj2 = 0.670,
MSE = 0.0089 mm/year) and the log-transformed model (
Radj2 = 0.639,
MSE = 0.0112 mm/year). The relatively minor differences in transformation effects suggest that 7Q in this cluster follows a moderately skewed distribution, with square-root transformation providing an optimal balance between interpretability and predictive power. For Cluster 2, the log-transformed model achieved the highest accuracy (
Radj2 = 0.722,
MSE = 0.0010 mm/year), followed closely by the square-root transformation (
Radj2 = 0.702,
MSE = 0.0009 mm/year). The untransformed model lagged behind (
Radj2 = 0.614,
MSE = 0.0008 mm/year), demonstrating that transformation substantially enhances predictive accuracy in this region. For Cluster 3, all models performed relatively poorly compared to other clusters, but the square-root transformation provided the highest accuracy (
Radj2 = 0.612,
MSE = 0.0038 mm/year), surpassing both the untransformed model (
Radj2 = 0.560,
MSE = 0.0042 mm/year) and the log-transformed model (
Radj2 = 0.554,
MSE = 0.0049 mm/year). These results indicate that 7Q in this cluster may be influenced by localized hydrological controls that are not fully captured by the regression models.
3.3. Low-Flow Regionalization
Both Q95 and 7Q demonstrated better explanatory power in regression models under K-means clustering, and the regression model of Q95 showed improved accuracy with log transformation, while that of 7Q performed better with square-root transformation. Based on these findings, low-flow regionalization was conducted using these two specific models with the global regression model for each measure as a comparison target.
The analysis of the ln(Q95) model revealed that key factors influencing hydrology varied across clusters. In Cluster 1, precipitation, maximum elevation, runoff curve number, mean slope, and area size were identified as the primary variables, indicating that complex processes including climate, runoff generation, and topographic structure influence low-flow formation. In Cluster 2, precipitation in wet period and mean elevation emerged as the significant variables, highlighting the importance of seasonal precipitation variability and topography. In Cluster 3, precipitation, runoff curve number, and area size were identified as key factors. The analysis of the model also revealed distinct regional differences in low-flow formation processes. Cluster 1 exhibited key influencing variables similar to those of Q95. In contrast, Clusters 2 and 3 showed different patterns. In Cluster 2, mean precipitation and mean slope were identified as the primary factors, whereas, in Cluster 3, the mean precipitation and runoff curve number were determined to be the major variables for low-flow estimation.
These model selection results emphasize the significance of regional hydrological characteristics in low-flow estimation. The variation in predictor variables across clusters proves the necessity of regionalization, demonstrating that a single global model fails to adequately capture the variability of climatic and topographic factors. Furthermore, the findings provide strong evidence that regional regression models outperform global models. While global models offer a broad-scale understanding of low-flow characteristics, they fail to account for local hydrological processes, resulting in limitations in predictive accuracy. In contrast, regional models derived through clustering techniques incorporate spatial heterogeneity, enabling more precise and reliable low-flow predictions. The key hydrological factors identified in each cluster further reinforce the necessity of a regionalized modeling approach, indicating that precipitation patterns, topography, and watershed characteristics influence base-flow formation in region-specific ways.
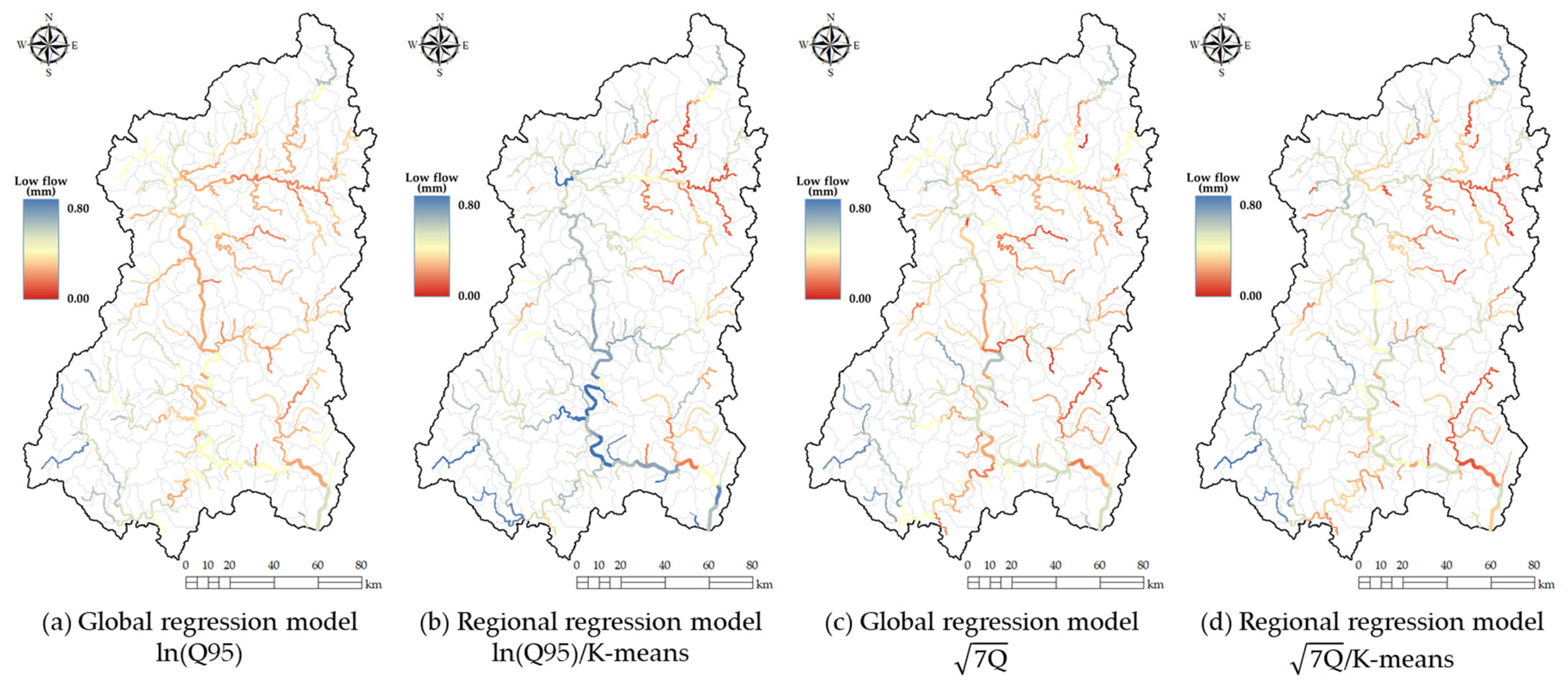
The spatial distribution of low-flow estimates was derived using both global and regional regression models for ln(Q95) and
.
Figure 13 presents the predicted low-flow conditions along the river network, comparing results from the global regression model and the regional regression model developed using K-means clustering.
When ln(Q95) is considered a low-flow measure, the global regression model (
Figure 13a) provides a broad-scale estimation of low flow across the watershed. However, the regional model (
Figure 13b) shows a more detailed spatial differentiation, capturing localized variations in hydrological response. The regional regression model produces more distinct spatial contrasts, particularly in areas where elevation, slope, and seasonal precipitation effects are more pronounced. The ability to account for regional hydrological characteristics enhances the accuracy of low-flow predictions, reducing the overgeneralization observed in the global model.
In case of the
, a similar pattern is observed. The global regression model (
Figure 13c) provides a general trend of low-flow distribution but lacks finer spatial differentiation. The regional model (
Figure 13d) improves the representation of spatial variability by incorporating cluster-specific hydrological controls. Notably, the regional model highlights localized variations in base-flow conditions, which are less apparent in the global approach. These differences suggest that regional models may be more effective in capturing hydrologically distinct sub-regions, leading to a better representation of low-flow spatial distribution.
These results explain the importance of using a regional approach for low-flow estimation, particularly in large-scale watersheds where climatic and geomorphological heterogeneity influences hydrological response. The regional regression model not only improves prediction accuracy but also provides a spatially refined representation of low-flow patterns, making it a more suitable tool for watershed-scale water resource management.
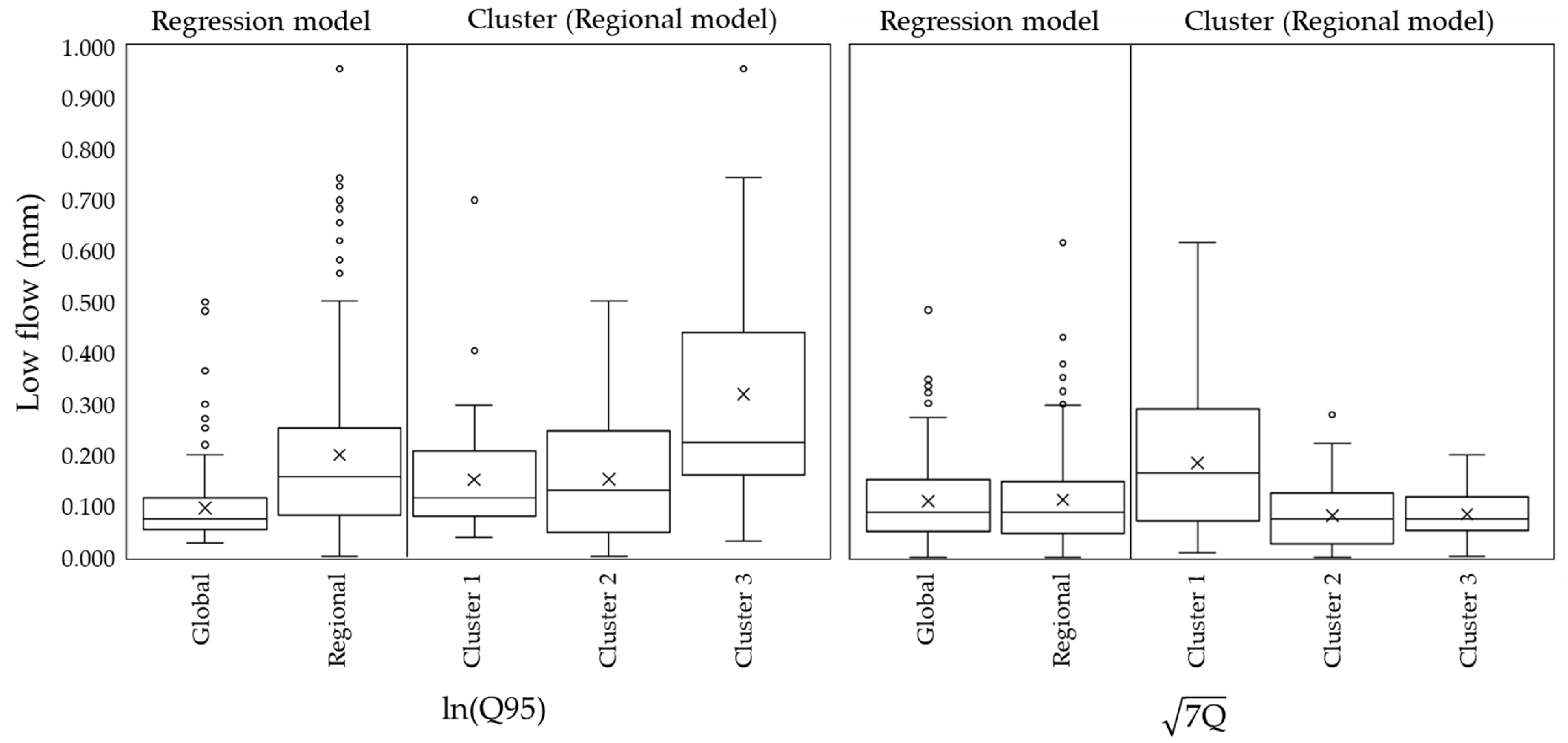
A box plot analysis was conducted to further evaluate the performance of the global and regional regression models.
Figure 14 presents the distribution of low-flow estimates derived from the global and regional regression models for ln(Q95) and
. The boxplots illustrate the variability in low-flow predictions across different modeling approaches. The “Global” and “Regional” categories represent the outcomes of global and regional regression models, respectively, while “Cluster 1”, “Cluster 2”, and “Cluster 3” correspond to the results of the regional regression model, stratified by clusters.
For ln(Q95), the global regression model exhibited a relatively narrow interquartile range, indicating constrained predictions with limited responsiveness to local variability. In contrast, the regional regression model demonstrated a wider range and a higher median value, suggesting the improved representation of hydrological differences within the watershed. Among the cluster-based models, Cluster 3 exhibited the highest median value and the widest distribution range, showing its distinct hydrological characteristics compared to Clusters 1 and 2. These results demonstrate the effectiveness of the regionalization approach in identifying hydrologically distinct sub-watersheds and enhancing predictive accuracy. A similar trend was observed for . The global regression model produced predictions with low variability and a more restricted distribution, whereas the regional regression model exhibited improved variability and accuracy in low-flow predictions. Further analysis of cluster-based models revealed that Cluster 3 displayed the widest distribution range of predicted low-flow values. This finding suggests that certain regions are more strongly influenced by localized climatic and topographic factors, reinforcing the necessity of regional models in capturing these characteristics.
A comparative analysis of ln(Q95) and
within the same clusters provided further insights into the effectiveness of regional regression models. The regression equations for each model indicated that the coefficients of key explanatory variables varied depending on the selected low-flow index, reflecting differences in their relative importance. The ln(Q95) model exhibited a large absolute value for the intercept, along with high coefficients for precipitation, runoff-generation, and topographic factors, indicating that variations in climatological variables have a significant impact on low-flow characteristics. In contrast, the
regression model showed a smaller absolute intercept value and relatively lower coefficients for climatological variables, suggesting lower sensitivity to these factors. Furthermore, an analysis of variable changes across indices revealed that the decline rate of precipitation coefficients was more pronounced than that of the runoff curve number or topographic variables. This finding suggests that, compared to ln(Q95), the
model became more dependent on geomorphological factors and less dependent on climatic variables (
Table 2). These findings are consistent with those of Smakhtin [
3], Vogel and Kroll [
7], and Fenicia et al. [
29], who reported a strong linkage between base-flow characteristics, watershed runoff, and precipitation patterns, emphasized the significant role of topographic factors in base-flow processes and the persistence of low flows, and argued that topographic and soil properties may exert a more critical influence on low-flow characteristics than long-term climatic factors, respectively. These studies may help explain the varying dependence of climatological variables on the two different measures of low flow.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}