
A Bayesian Ensemble Learning-Based Scheme for Real-Time Error Correction of Flood Forecasting

Abstract
1. Introduction
- i.
- To develop a new error correction scheme based on the Bayesian ensemble learning framework by integrating the XAJ model and four base learners, and to evaluate its suitability for application in the Hengshan Reservoir basin;
- ii.
- To evaluate the characteristics of the proposed scheme by comparing it with baseline schemes, and to provide data support for research on ensemble learning frameworks in flood forecasting;
- iii.
- To investigate the potential of the K-means clustering technique under the Bayesian ensemble learning framework.
2. Materials and Methods
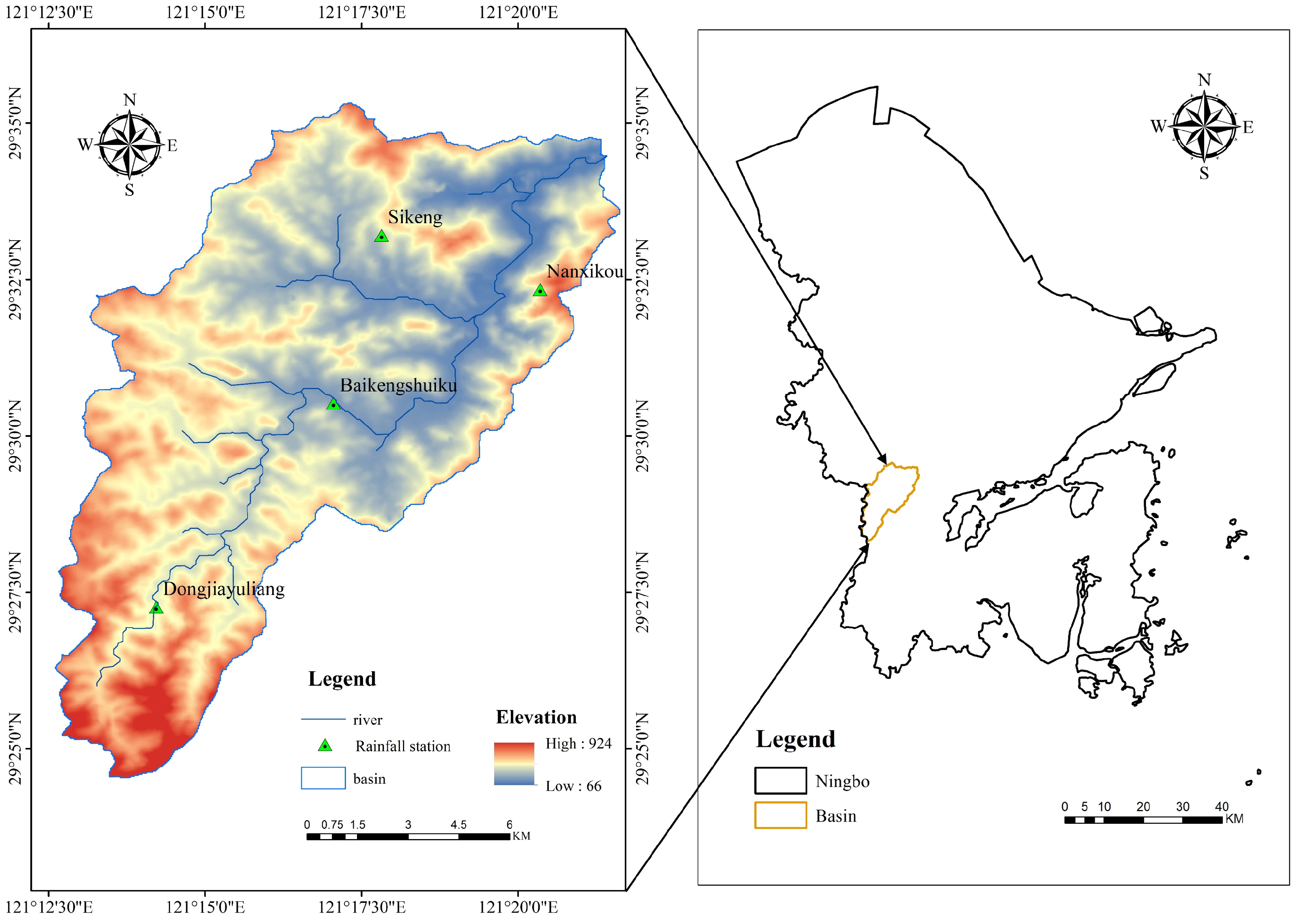
2.1. Study Area and Data Sources
2.2. Hydrological Model
2.3. Machine Learning Methods
2.3.1. Long Short-Term Memory (LSTM) Networks
2.3.2. Light Gradient-Boosting Machine (LGBM)
2.3.3. Temporal Convolutional Networks (TCNs)
2.3.4. Random Forest (RF)
2.4. Bayesian Ensemble Learning-Based Correction Scheme
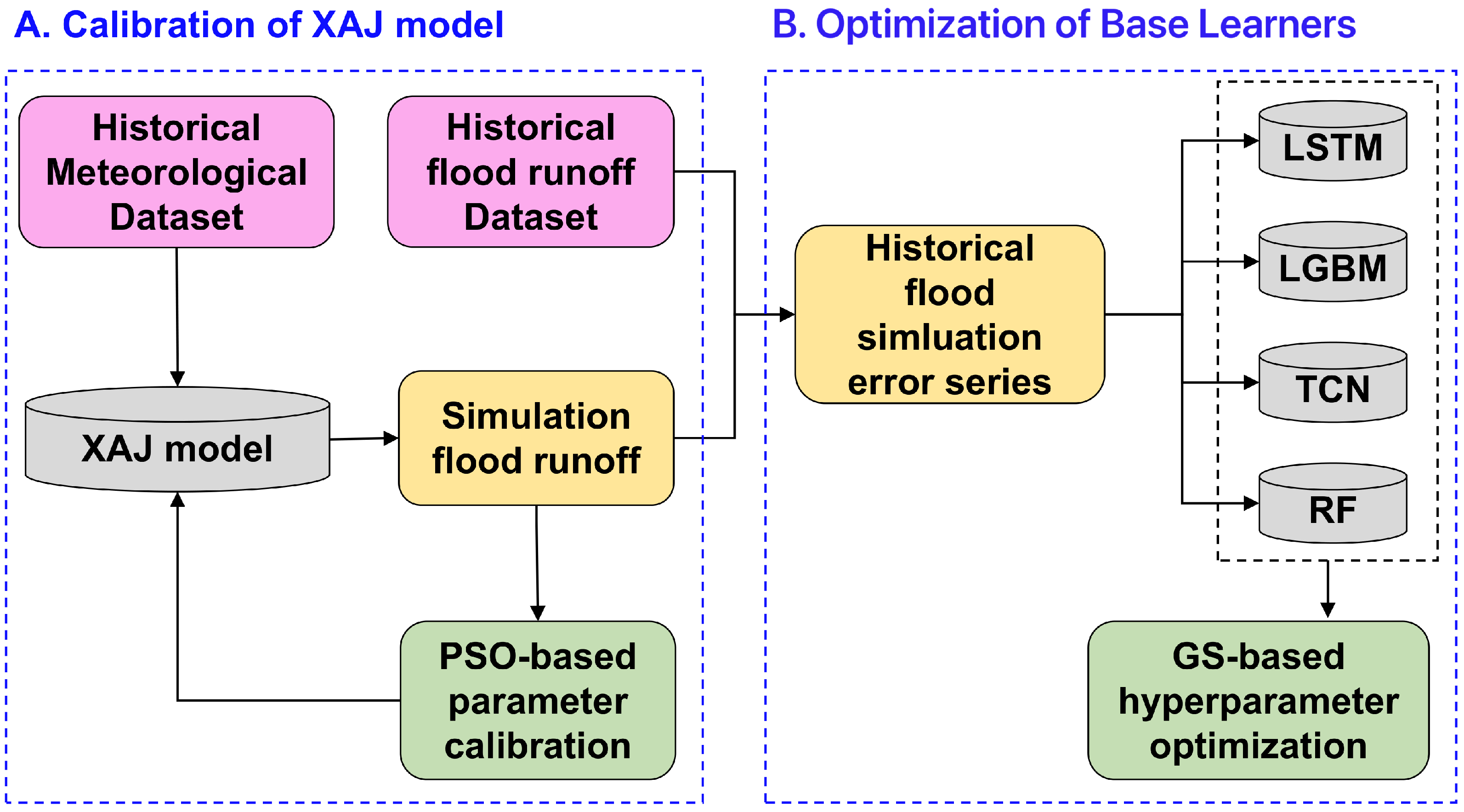
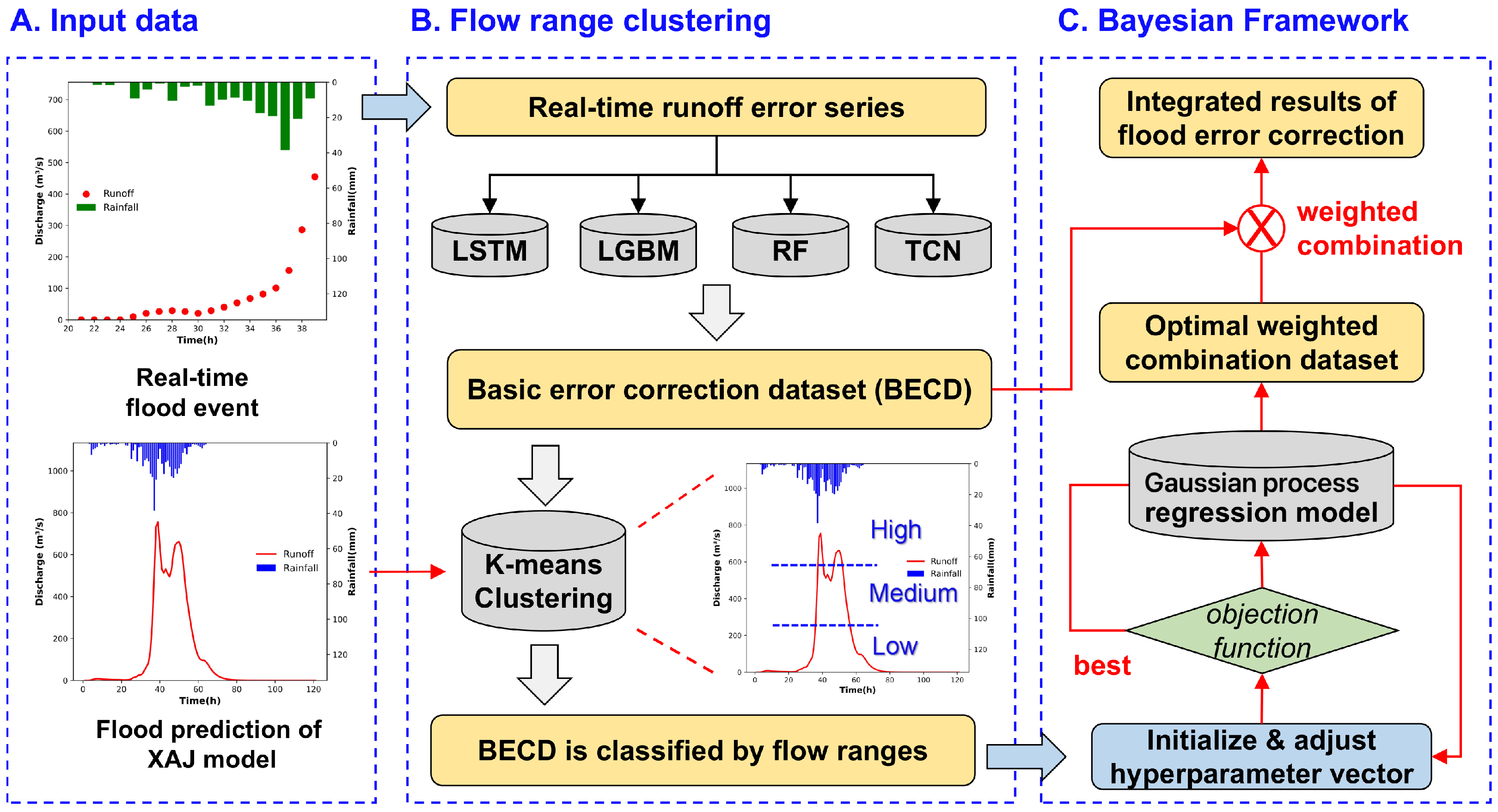
2.4.1. Preprocessing
2.4.2. Generation of Basic Error Correction Dataset (BECD)
2.4.3. Classification of BECD Based on Flow Range Clustering
- i.
- Randomly selecting three initial cluster centers from the simulation flood flow discharge dataset, calculating the Euclidean distance (Equation (3)) between the remaining data objects and the cluster center , finding the cluster center closest to the target data object, and assigning the data object to the cluster corresponding to the cluster center .
- ii.
- Updating cluster centers by calculating the average value of the data objects in each cluster. The iteration process terminates when either the Sum of Squared Errors(SSE) (Equation (4)) of all clusters converges or the predefined maximum number of iterations is reached.
2.4.4. Optimization Under Bayesian Ensemble Learning Framework
2.4.5. Evaluation Metrics of Flood Correction
- i.
- NSE > 0.7;
- ii.
- RMSE < 15% of observed peak discharge ();
- iii.
- PTE must be positive and within 3 h;
- iv.
- RPE < 20%.
3. Results and Discussion
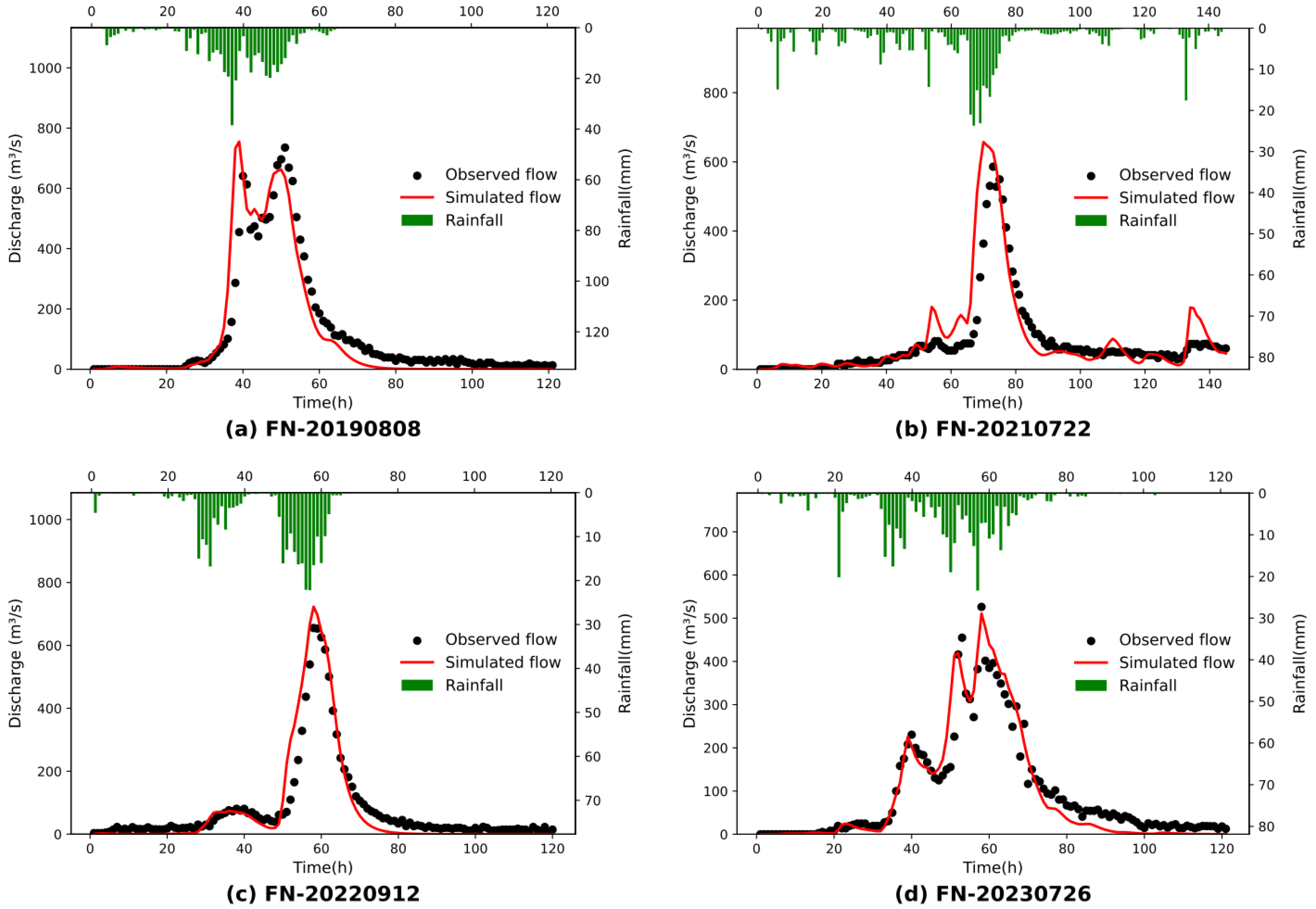
3.1. Results of the Calibrated and Validated Simulations
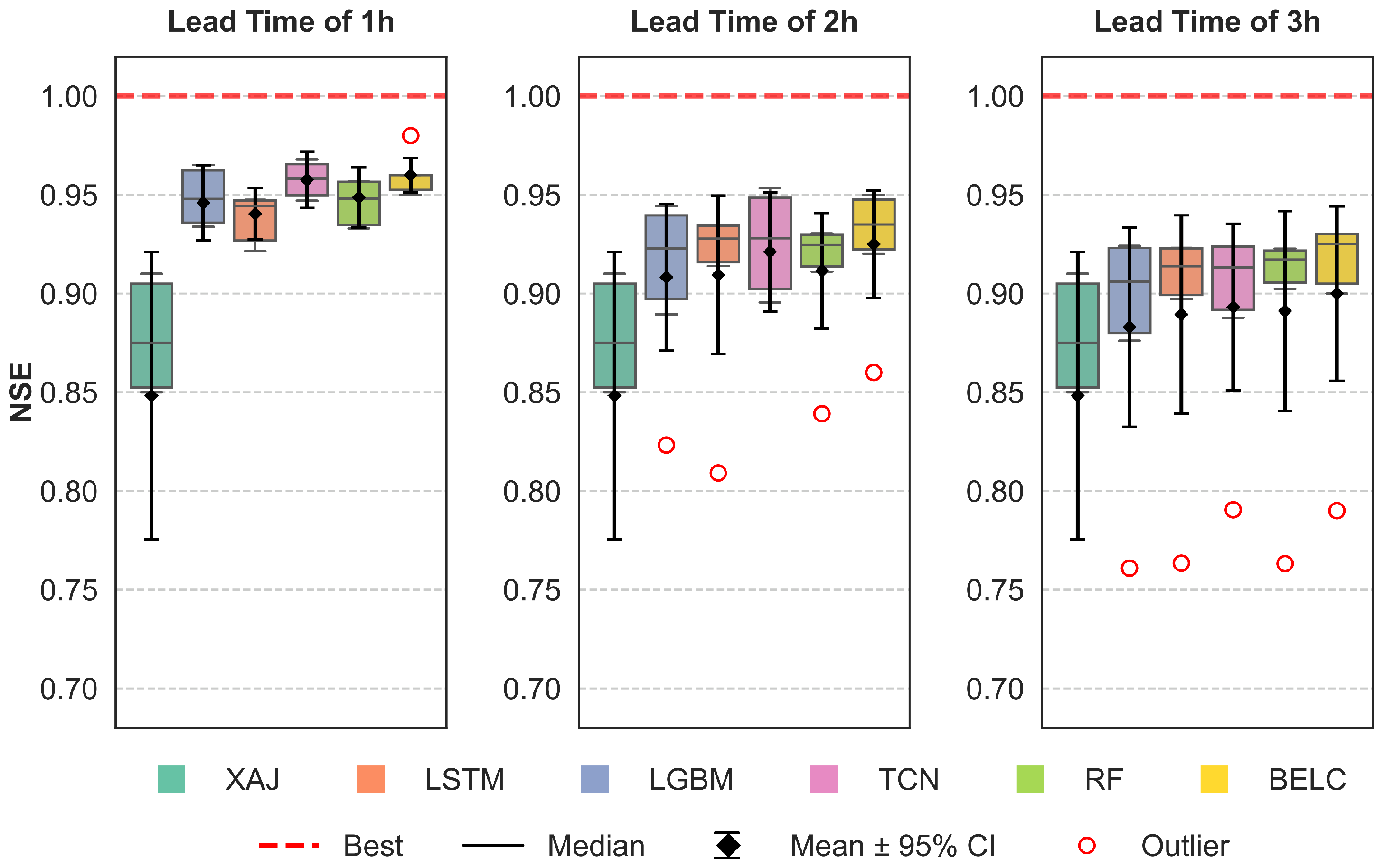
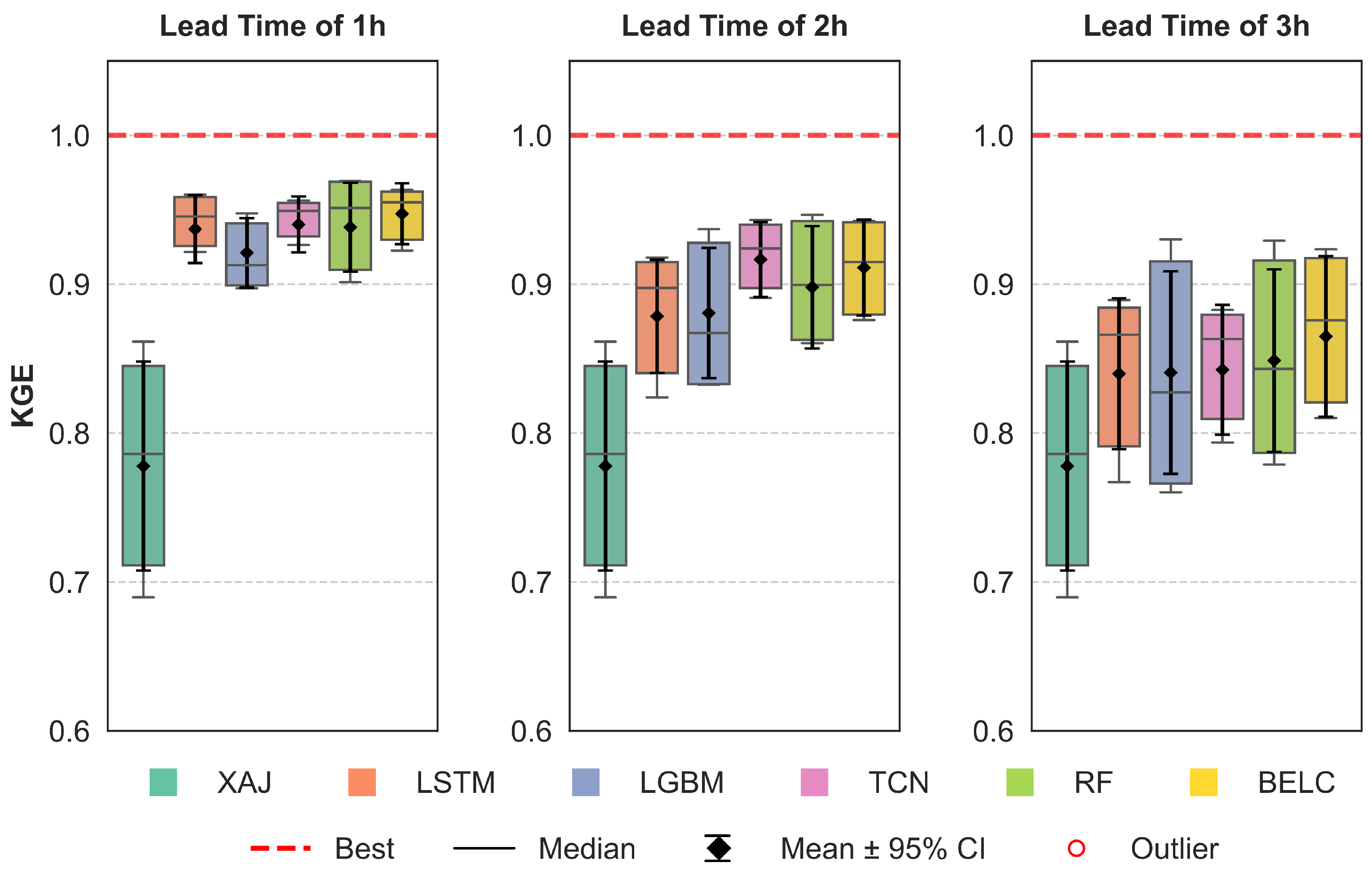
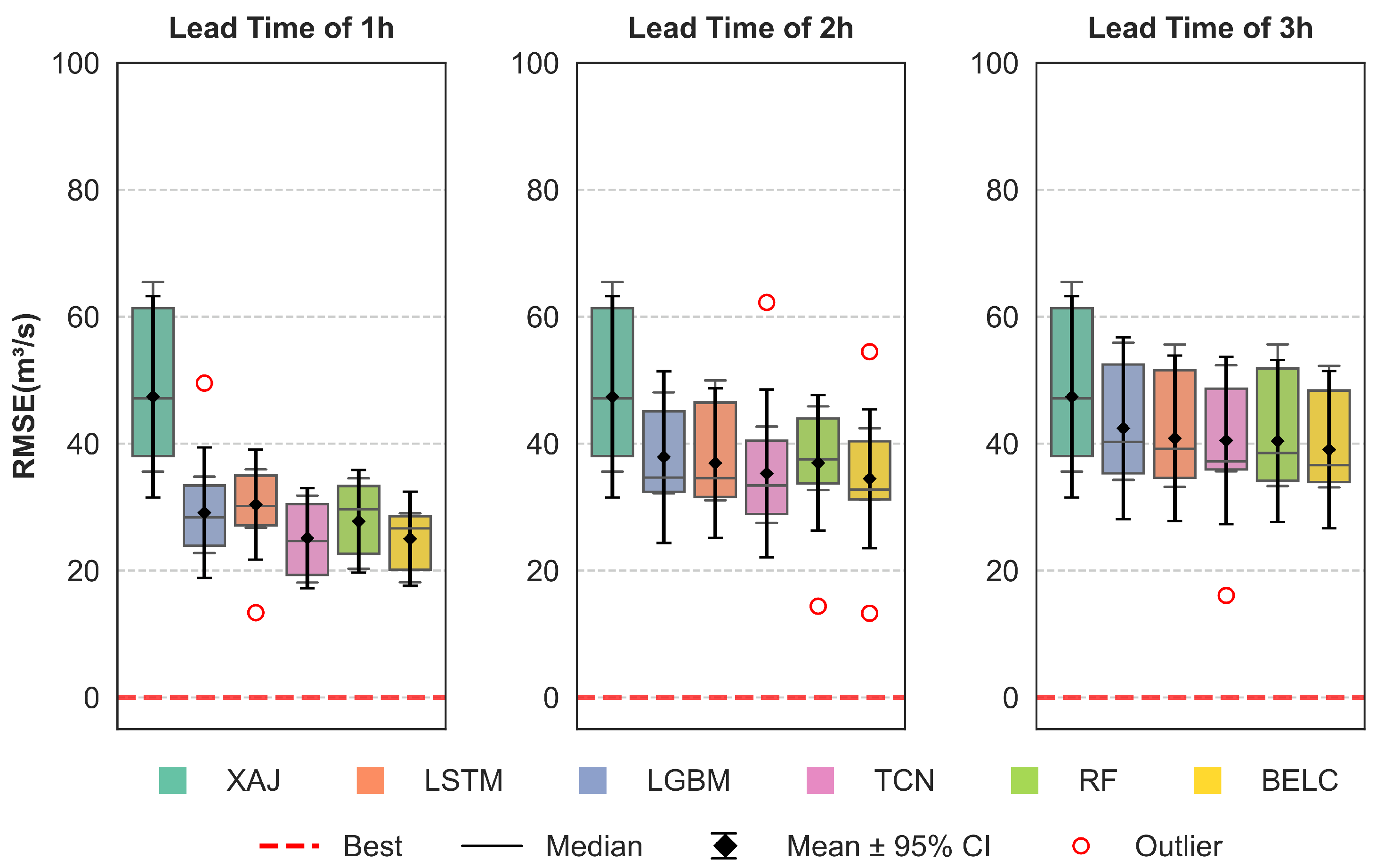
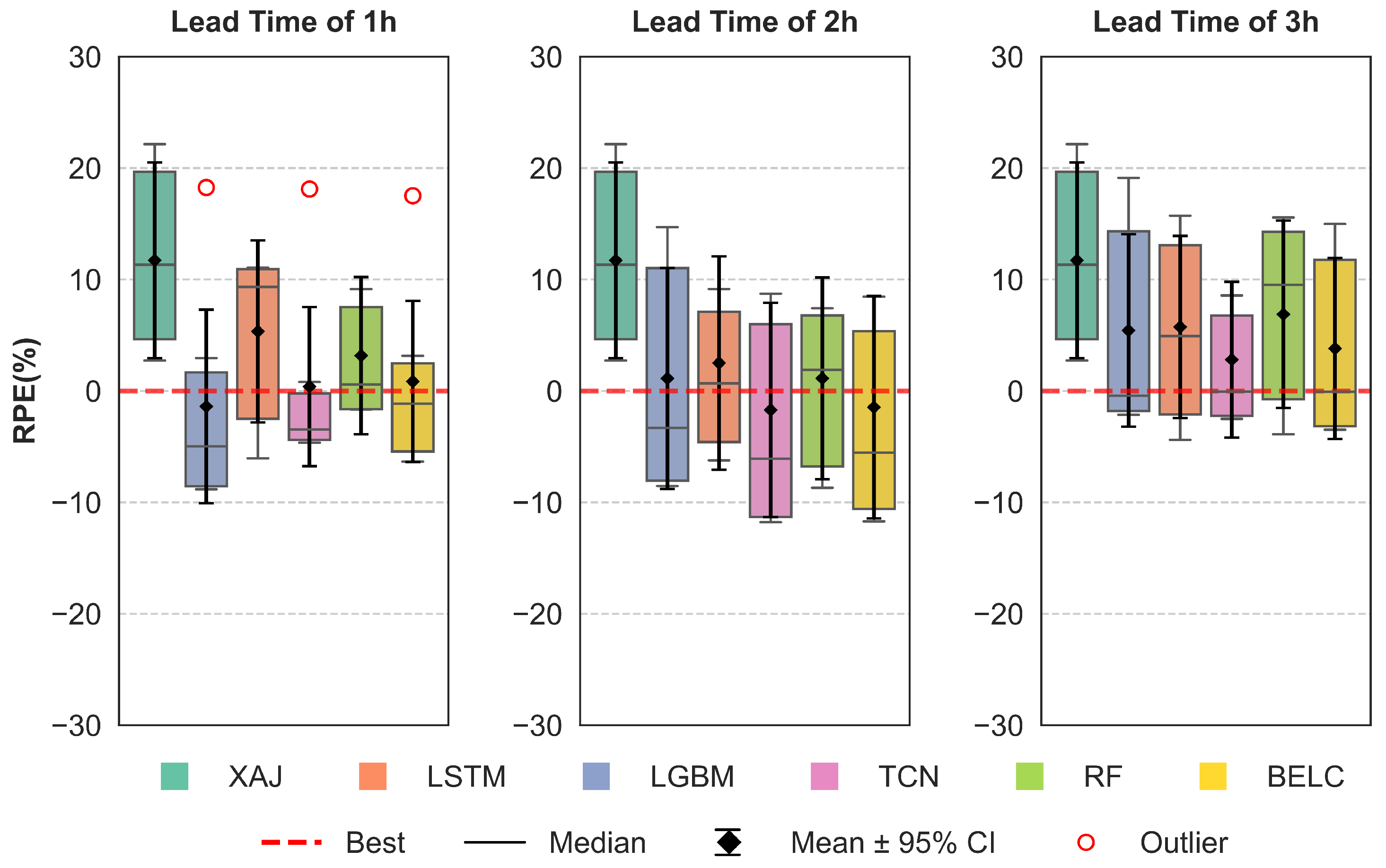
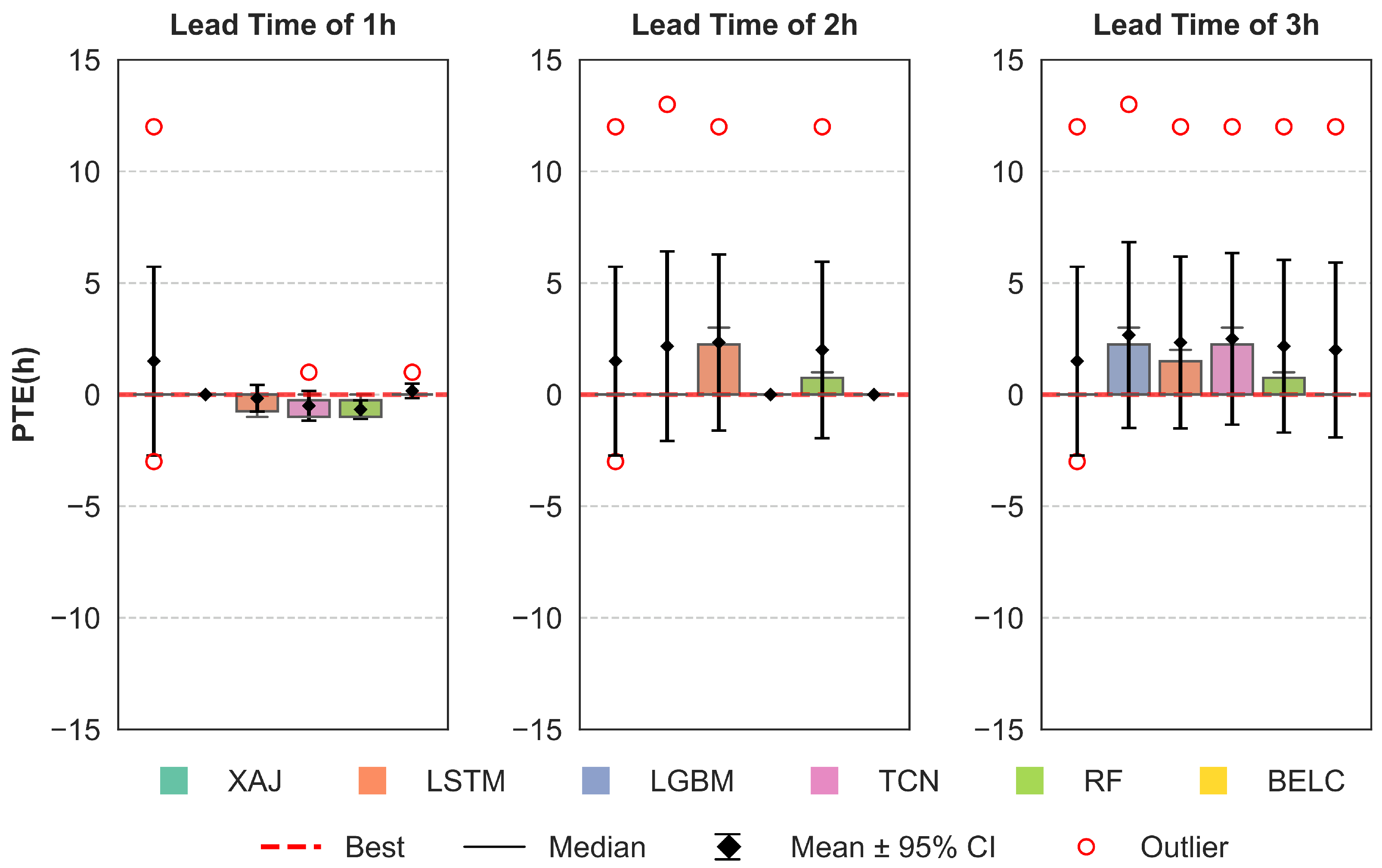
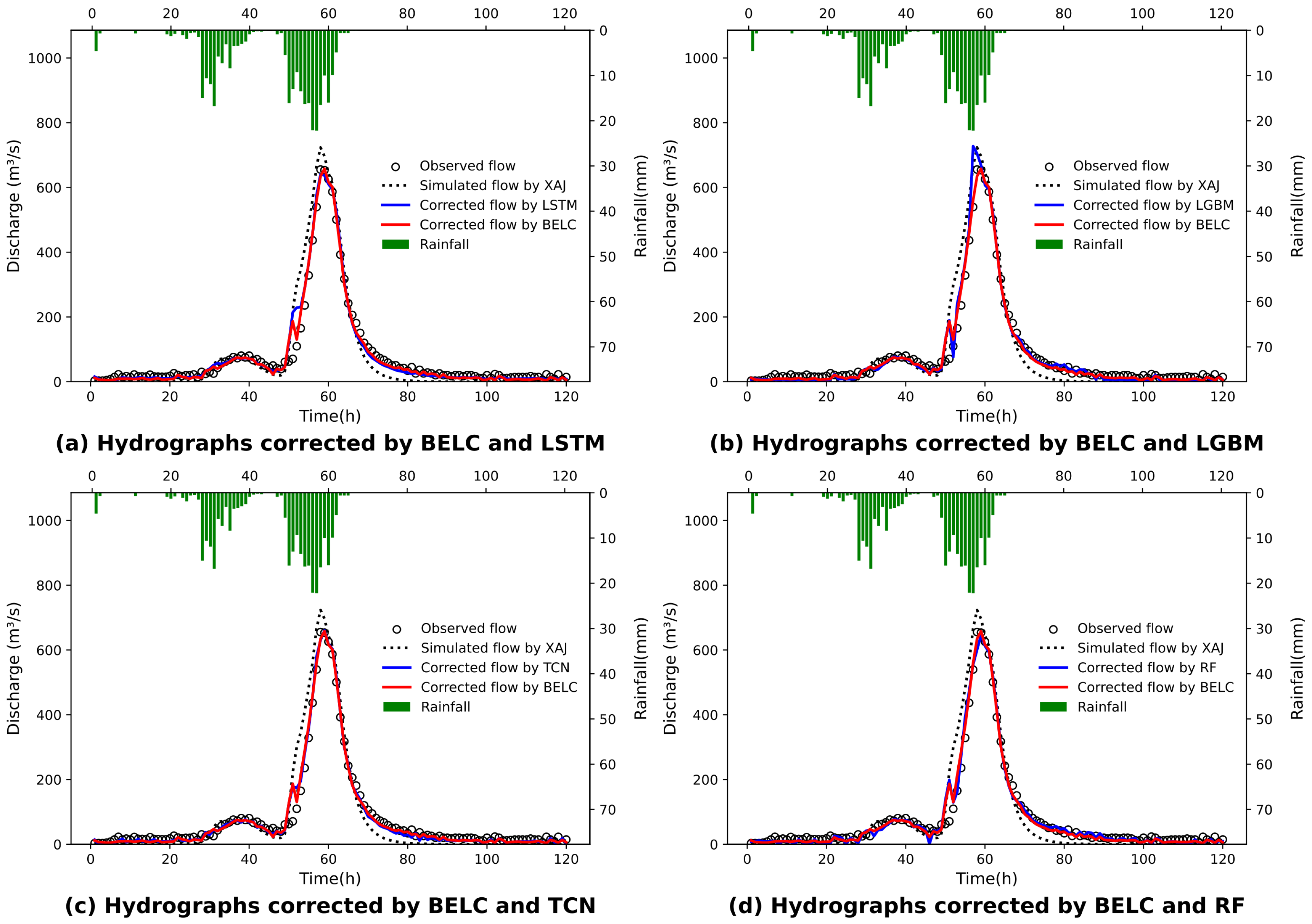
3.2. Correction Performance Comparisons of Different Schemes
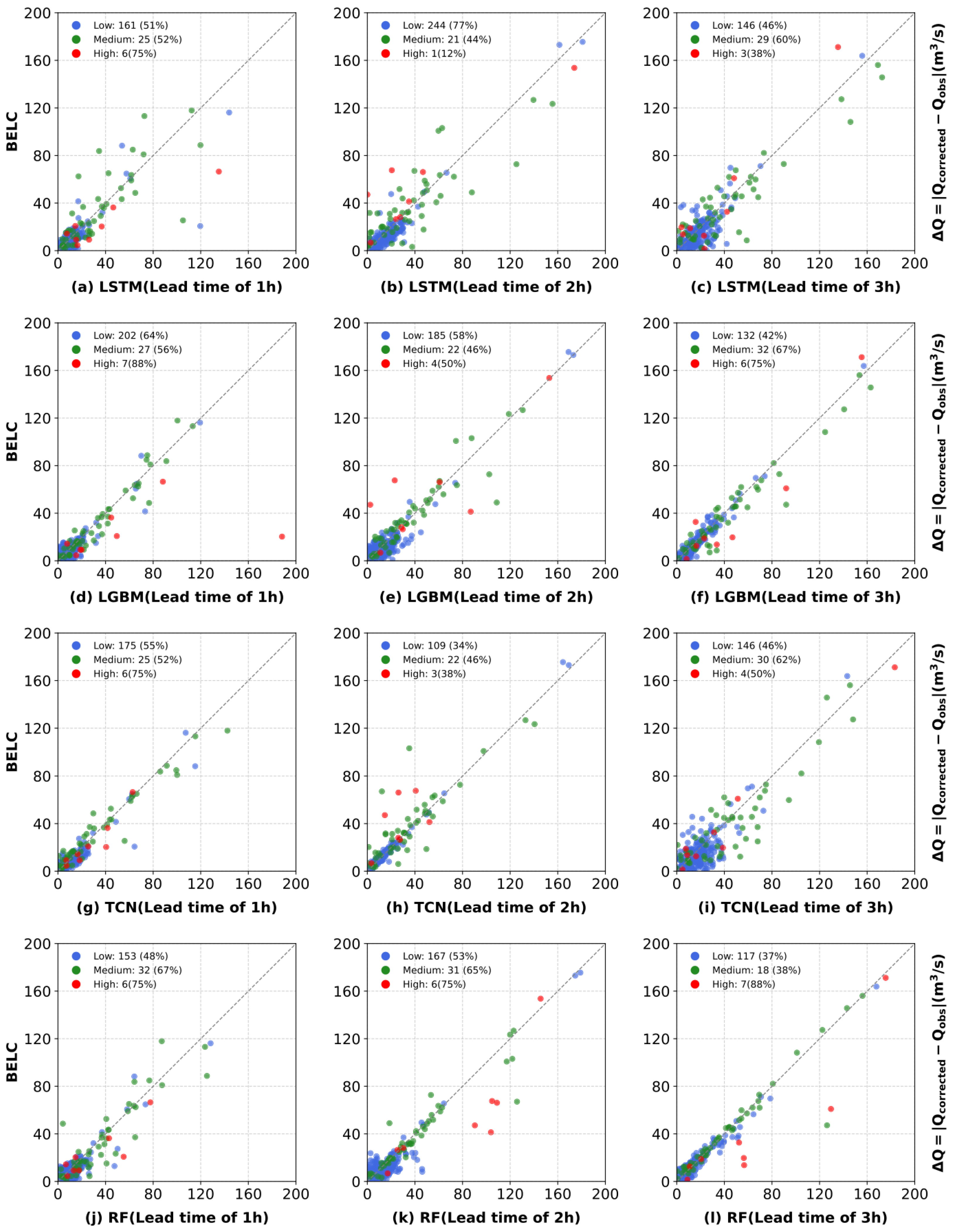
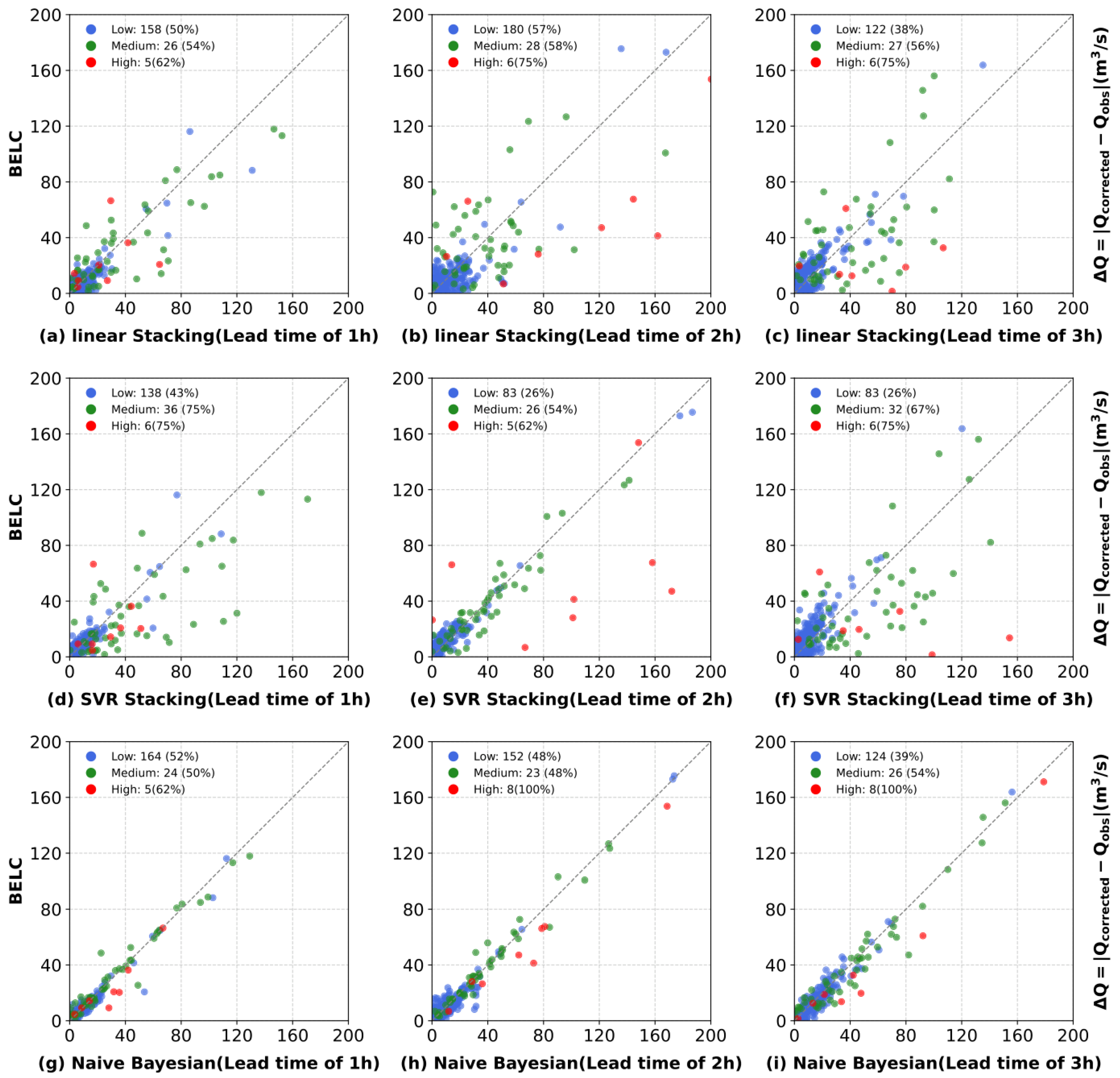
3.3. Comparative Performance of Ensemble Learning Frameworks
4. Conclusions
- i.
- All four baseline schemes can effectively correct flood errors and improve forecasting performance for all lead times, but their performance varies across different lead times and specific flood events. No single machine learning method can maintain optimal robustness and correction effectiveness for all lead time scenarios.
- ii.
- The BELC scheme exhibited superior error correction capability and demonstrated robust performance across 1–3 h lead times, outperforming both baseline schemes and conventional ensemble learning approaches. Evaluated across five metrics (NSE, KGE, RMSE, RPE, and PTE), the BELC outperformed other models in most scenarios. The average performance metrics of the validation period were 0.95 (NSE), 0.92 (KGE), 24.25 /s (RMSE), and 8.71% (RPE), with a PTE consistently below 1 h in advance. Meanwhile, BELC maintained stable correction performance across varying flow ranges, delivering reliable flood flow forecasts with outstanding comprehensive performance.
- iii.
- The K-means flow range clustering significantly enhanced the BELC model’s adaptability to various types of flood, substantially improving flood flow correction accuracy for high flow ranges. The correction performance surpassed that of the Naive Bayesian scheme by 62%, 100%, and 100% for a lead time of 1, 2, and 3 h, respectively.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Peredo, D.; Ramos, M.H.; Andréassian, V.; Oudin, L. Investigating hydrological model versatility to simulate extreme flood events. Hydrol. Sci. J. 2022, 67, 628–645. [Google Scholar] [CrossRef]
- Xin, Z.; Shi, K.; Wu, C.; Wang, L.; Ye, L. Applicability of Hydrological Models for Flash Flood Simulation in Small Catchments of Hilly Area in China. Open Geosci. 2019, 11, 1168–1181. [Google Scholar] [CrossRef]
- Ren-Jun, Z. The Xinanjiang model applied in China. J. Hydrol. 1992, 135, 371–381. [Google Scholar] [CrossRef]
- Zotz, G.; Thomas, V. How Much Water is in the Tank? Model Calculations for Two Epiphytic Bromeliads. Ann. Bot. 1999, 83, 183–192. [Google Scholar] [CrossRef]
- Beven, K. TOPMODEL: A critique. Hydrol. Processes 1997, 11, 1069–1085. [Google Scholar] [CrossRef]
- Abbott, M.; Bathurst, J.; Cunge, J.; O’Connell, P.; Rasmussen, J. An introduction to the European Hydrological System—Systeme Hydrologique Europeen, “SHE”, 1: History and philosophy of a physically-based, distributed modelling system. J. Hydrol. 1986, 87, 45–59. [Google Scholar] [CrossRef]
- Liang, X.; Lettenmaier, D.P.; Wood, E.F. One-dimensional statistical dynamic representation of subgrid spatial variability of precipitation in the two-layer variable infiltration capacity model. J. Geophys. Res. Atmos. 1996, 101, 21403–21422. [Google Scholar] [CrossRef]
- Arnold, J.G.; Srinivasan, R.; Muttiah, R.S.; Williams, J.R. Large Area Hydrologic Modeling and Assessment Part I: Model Development. JAWRA J. Am. Water Resour. Assoc. 1998, 34, 73–89. [Google Scholar] [CrossRef]
- Ko, D.; Lee, T.; Lee, D. Spatio-temporal-dependent errors of radar rainfall estimates in flood forecasting for the Nam River Dam basin. Meteorol. Appl. 2018, 25, 322–336. [Google Scholar] [CrossRef]
- Shen, Y.; Ruijsch, J.; Lu, M.; Sutanudjaja, E.H.; Karssenberg, D. Random forests-based error-correction of streamflow from a large-scale hydrological model: Using model state variables to estimate error terms. Comput. Geosci. 2022, 159, 105019. [Google Scholar] [CrossRef]
- Shi, P.; Wu, H.; Qu, S.; Yang, X.; Lin, Z.; Ding, S.; Si, W. Advancing real-time error correction of flood forecasting based on the hydrologic similarity theory and machine learning techniques. Environ. Res. 2024, 246, 118533. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Wang, Q.; Liang, Z.; Deng, X. Research advances on real-time correction methods for flood forecasting. South-North Water Transf. Water Sci. Technol. 2021, 19, 12–35. [Google Scholar] [CrossRef]
- Zhang, T.; Liang, Z.; Bi, C.; Wang, J.; Hu, Y.; Li, B. Statistical Post-Processing for Precipitation Forecast Through Deep Learning Coupling Large-Scale and Local-Scale Spatiotemporal Information. Water Resour. Manag. 2025, 39, 145–160. [Google Scholar] [CrossRef]
- Yang, S.; Cheng, R.; Yan, W.; Zhang, Q. Application of Ridge Estimation Method of Rainfall Error BasedDifferential Response in Flood Forecasting of Jianyang Basin. Water Resour. Power 2023, 41, 1–3+58. [Google Scholar] [CrossRef]
- Guo, W.D.; Chen, W.B.; Chang, C.H. Error-correction-based data-driven models for multiple-hour-ahead river stage predictions: A case study of the upstream region of the Cho-Shui River, Taiwan. J. Hydrol. Reg. Stud. 2023, 47, 101378. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, Y.; Xu, D.; Hong, Y. Error correction method based on deep learning for improving the accuracy of conceptual rainfall-runoff model. J. Hydrol. 2024, 643, 131992. [Google Scholar] [CrossRef]
- Zounemat-Kermani, M.; Batelaan, O.; Fadaee, M.; Hinkelmann, R. Ensemble machine learning paradigms in hydrology: A review. J. Hydrol. 2021, 598, 126266. [Google Scholar] [CrossRef]
- Duan, Y.; Liang, Z.; Zhao, J.; Qiu, Z.; Li, B. Combined Forecasting of Hydrological Model Based on Stacking Integrated Framework. Water Resour. Power 2022, 40, 27–30+39. [Google Scholar] [CrossRef]
- Lin, Y.; Du, Y.; Meng, Y.; Xie, H.; Wang, D. The Influence of Different Integrated Models on Short-term Runoff Forecast in Small Watershed. China Rural. Water Hydropower 2021, 11, 97–102. [Google Scholar]
- Shin, S.; Her, Y.; Muñoz-Carpena, R.; Khare, Y.P. Multi-parameter approaches for improved ensemble prediction accuracy in hydrology and water quality modeling. J. Hydrol. 2023, 622, 129458. [Google Scholar] [CrossRef]
- Mohammed, A.; Kora, R. A comprehensive review on ensemble deep learning: Opportunities and challenges. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 757–774. [Google Scholar] [CrossRef]
- Xu, C.; Zhong, P.A.; Zhu, F.; Yang, L.; Wang, S.; Wang, Y. Real-time error correction for flood forecasting based on machine learning ensemble method and its uncertainty assessment. Stoch. Environ. Res. Risk Assess. 2022, 37, 1557–1577. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Lange, H.; Sippel, S. Machine Learning Applications in Hydrology. In Forest-Water Interactions; Springer International Publishing: Cham, Switzerland, 2020; pp. 233–257. [Google Scholar] [CrossRef]
- Lu, M. Recent and future studies of the Xinanjiang Model. J. Hydraul. Eng. 2021, 52, 432–441. [Google Scholar] [CrossRef]
- Qiao, X.; Peng, T.; Sun, N.; Zhang, C.; Liu, Q.; Zhang, Y.; Wang, Y.; Nazir, M.S. Metaheuristic evolutionary deep learning model based on temporal convolutional network, improved aquila optimizer and random forest for rainfall-runoff simulation and multi-step runoff prediction. Expert Syst. Appl. 2023, 229, 120616. [Google Scholar] [CrossRef]
- Kedam, N.; Tiwari, D.K.; Kumar, V.; Khedher, K.M.; Salem, M.A. River stream flow prediction through advanced machine learning models for enhanced accuracy. Results Eng. 2024, 22, 102215. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Li, B.; Li, R.; Sun, T.; Gong, A.; Tian, F.; Khan, M.Y.A.; Ni, G. Improving LSTM hydrological modeling with spatiotemporal deep learning and multi-task learning: A case study of three mountainous areas on the Tibetan Plateau. J. Hydrol. 2023, 620, 129401. [Google Scholar] [CrossRef]
- Zhang, Y.; Gu, Z.; Thé, J.; Yang, S.; Gharabaghi, B. The Discharge Forecasting of Multiple Monitoring Station for Humber River by Hybrid LSTM Models. Water 2022, 14, 1794. [Google Scholar] [CrossRef]
- Meng, Q. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Bian, L.; Qin, X.; Zhang, C.; Guo, P.; Wu, H. Application, interpretability and prediction of machine learning method combined with LSTM and LightGBM-a case study for runoff simulation in an arid area. J. Hydrol. 2023, 625, 130091. [Google Scholar] [CrossRef]
- Gan, M.; Pan, S.; Chen, Y.; Cheng, C.; Pan, H.; Zhu, X. Application of the Machine Learning LightGBM Model to the Prediction of the Water Levels of the Lower Columbia River. J. Mar. Sci. Eng. 2021, 9, 496. [Google Scholar] [CrossRef]
- Xu, Y.; Hu, C.; Wu, Q.; Li, Z.; Jian, S.; Chen, Y. Application of temporal convolutional network for flood forecasting. Hydrol. Res. 2021, 52, 1455–1468. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Singh, A.K.; Kumar, P.; Ali, R.; Al-Ansari, N.; Vishwakarma, D.K.; Kushwaha, K.S.; Panda, K.C.; Sagar, A.; Mirzania, E.; Elbeltagi, A.; et al. An Integrated Statistical-Machine Learning Approach for Runoff Prediction. Sustainability 2022, 14, 8209. [Google Scholar] [CrossRef]
- Zhou, P.; Xu, Y.; Zhou, X.; Liu, L.; Liang, X.; Guo, Y. Seasonal Streamflow Ensemble Forecasting Based on Multi-Model Fusion. Adv. Sci. Technol. Water Resour. 2025, 45, 62–69. [Google Scholar]
- Liu, L.; Liang, X.; Wang, Q.; Xu, Y. Justified ERRlS Real-time Correction Method for Streamflow Forecasting Based on Deep Learning. Water Resour. Prot. 2024, 40, 155–164. [Google Scholar]
- Wu, H.; Shi, P.; Qu, S.; Yang, X.; Zhang, H.; Wang, L.; Ding, S.; Li, H.; Lu, M.; Qiu, C. A hydrologic similarity-based parameters dynamic matching framework: Application to enhance the real-time flood forecasting. Sci. Total Environ. 2024, 907, 167767. [Google Scholar] [CrossRef]
- McMillan, H.K. A review of hydrologic signatures and their applications. WIREs Water 2021, 8, e1499. [Google Scholar] [CrossRef]
- Zhang, X.; Song, S.; Guo, T. Nonlinear Segmental Runoff Ensemble Prediction Model Using BMA. Water Resour. Manag. 2024, 38, 3429–3446. [Google Scholar] [CrossRef]
- Gui, Z.; Zhang, F.; Yue, K.; Lu, X.; Chen, L.; Wang, H. Identifying and Interpreting Hydrological Model Structural Nonstationarity Using the Bayesian Model Averaging Method. Water 2024, 16, 1126. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian optimization of machine learning algorithms. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NU, USA, 3–6 December 2012; NIPS’12. Volume 2, pp. 2951–2959. [Google Scholar]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling. J. Hydrol. 2009, 377, 80–91. [Google Scholar] [CrossRef]
- GB/T 22482-2008; Standard for Hydrological Information and Forecasting. Standards Press of China: Beijing, China, 2008.
- Asurza Véliz, F.; Lavado, W. Regional Parameter Estimation of the SWAT Model: Methodology and Application to River Basins in the Peruvian Pacific Drainage. Water 2020, 12, 3198. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Description | Value |
|---|---|---|
| KC | Ratio of potential evapotranspiration to pan evaporation | 0.667 |
| WUM | Tension water capacity of upper layer, mm | 32.84 |
| WLM | Tension water capacity of lower layer, mm | 89 |
| SM | Free water storage capacity, mm | 9.71 |
| KG | Outflow coefficient of free water storage to groundwater flow | 0.01 |
| KI | Outflow coefficient of free water storage to interflow | 0.7 |
| CS | Recession coefficient of surface runoff | 0.632 |
| CI | Recession coefficient of interflow | 0.769 |
| CG | Recession coefficient of groundwater | 0.999 |
| XE | Muskingum weighting factor | 0.1 |
| Models | Description and Value Range | Value |
|---|---|---|
| Number of estimators: 100–1000 | 200 | |
| LGBM | Learning rate: 0.001–0.3 | 0.1 |
| Max. depth: 3–20 | 3 | |
| Number of epochs: 10–200 | 50 | |
| LSTM | Learning rate: 0.0001–0.1 | 0.01 |
| Batch size: 8–128 | 16 | |
| Number of epochs: 10–200 | 50 | |
| TCN | Learning rate: 0.0001–0.1 | 0.01 |
| Batch size: 32–512 | 128 | |
| Number of estimators: 100–1000 | 200 | |
| RF | Max. depth: 3–50 | 10 |
| Minimum samples per node: 2–20 | 5 |
| Flood Events | RPE (%) | PTE (h) | NSE | RMSE (/s) | |
|---|---|---|---|---|---|
| Calibration | 19970818 | 24.35 | 1 | 0.70 | 169.60 |
| 20050910 | 18.19 | 0 | 0.96 | 68.06 | |
| 20071005 | 11.83 | 0 | 0.97 | 34.95 | |
| 20090006 | 22.40 | 0 | 0.92 | 70.70 | |
| 20120807 | −9.99 | −2 | 0.86 | 83.35 | |
| 20150710 | −9.63 | 0 | 0.80 | 75.97 | |
| 20150928 | −8.59 | −1 | 0.77 | 84.46 | |
| 20160914 | −2.09 | −1 | 0.84 | 90.36 | |
| Validation | 20200008 | 82.3 | 12 | 0.86 | 116.04 |
| 20200102 | 122.3 | 8 | 0.88 | 65.47 | |
| 20210912 | 22.15 | 0 | 0.85 | 48.91 | |
| 20220912 | 103.2 | 8 | 0.89 | 45.56 | |
| 20230726 | 139.4 | 8 | 0.91 | 55.50 | |
| 20240724 | 25.74 | 0 | 0.91 | 17.28 |
| Models | Optimal Parameters | Training Time (s) | Prediction Time (s) |
|---|---|---|---|
| Linear Stacking | Linear model: Lasso | 0.06 | 0.0075 |
| Maximum iterations: 5000 | |||
| Regularization coefficient: 1 | |||
| Fit interception: True | |||
| SVR Stacking | Linear model: Lasso | 1.42 | 0.0021 |
| Maximum iterations: 5000 | |||
| Regularization coefficient: 1 | |||
| Naive Bayesian | Optimization iterations: 7 | 0.01 | |
| Acquisition function: EI | |||
| Exploration parameter: 0.01 | |||
| Number of initial DOE points: 10 | |||
| BELC | Optimization iterations: 7 | 0.02 | |
| Acquisition function: EI | |||
| Exploration parameter: 0.01 | |||
| Number of initial DOE points: 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, L.; Fu, J.; Yuan, Y.; Wang, X.; Zhao, Y.; Tong, J. A Bayesian Ensemble Learning-Based Scheme for Real-Time Error Correction of Flood Forecasting. Water 2025, 17, 2048. https://doi.org/10.3390/w17142048
Peng L, Fu J, Yuan Y, Wang X, Zhao Y, Tong J. A Bayesian Ensemble Learning-Based Scheme for Real-Time Error Correction of Flood Forecasting. Water. 2025; 17(14):2048. https://doi.org/10.3390/w17142048
Chicago/Turabian StylePeng, Liyao, Jiemin Fu, Yanbin Yuan, Xiang Wang, Yangyong Zhao, and Jian Tong. 2025. "A Bayesian Ensemble Learning-Based Scheme for Real-Time Error Correction of Flood Forecasting" Water 17, no. 14: 2048. https://doi.org/10.3390/w17142048
APA StylePeng, L., Fu, J., Yuan, Y., Wang, X., Zhao, Y., & Tong, J. (2025). A Bayesian Ensemble Learning-Based Scheme for Real-Time Error Correction of Flood Forecasting. Water, 17(14), 2048. https://doi.org/10.3390/w17142048