
Spatial Interpolation of Soil Temperature and Water Content in the Land-Water Interface Using Artificial Intelligence

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
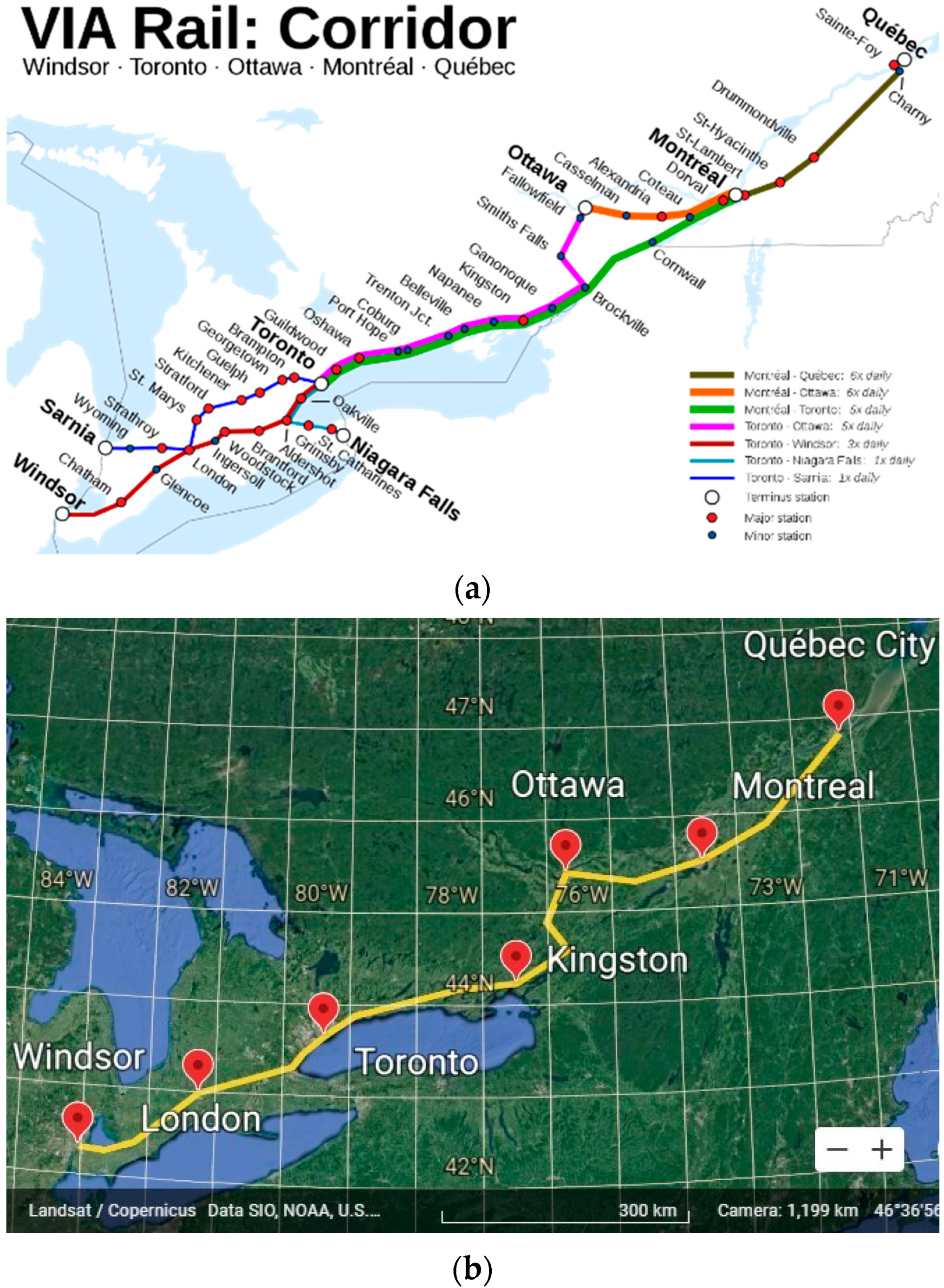
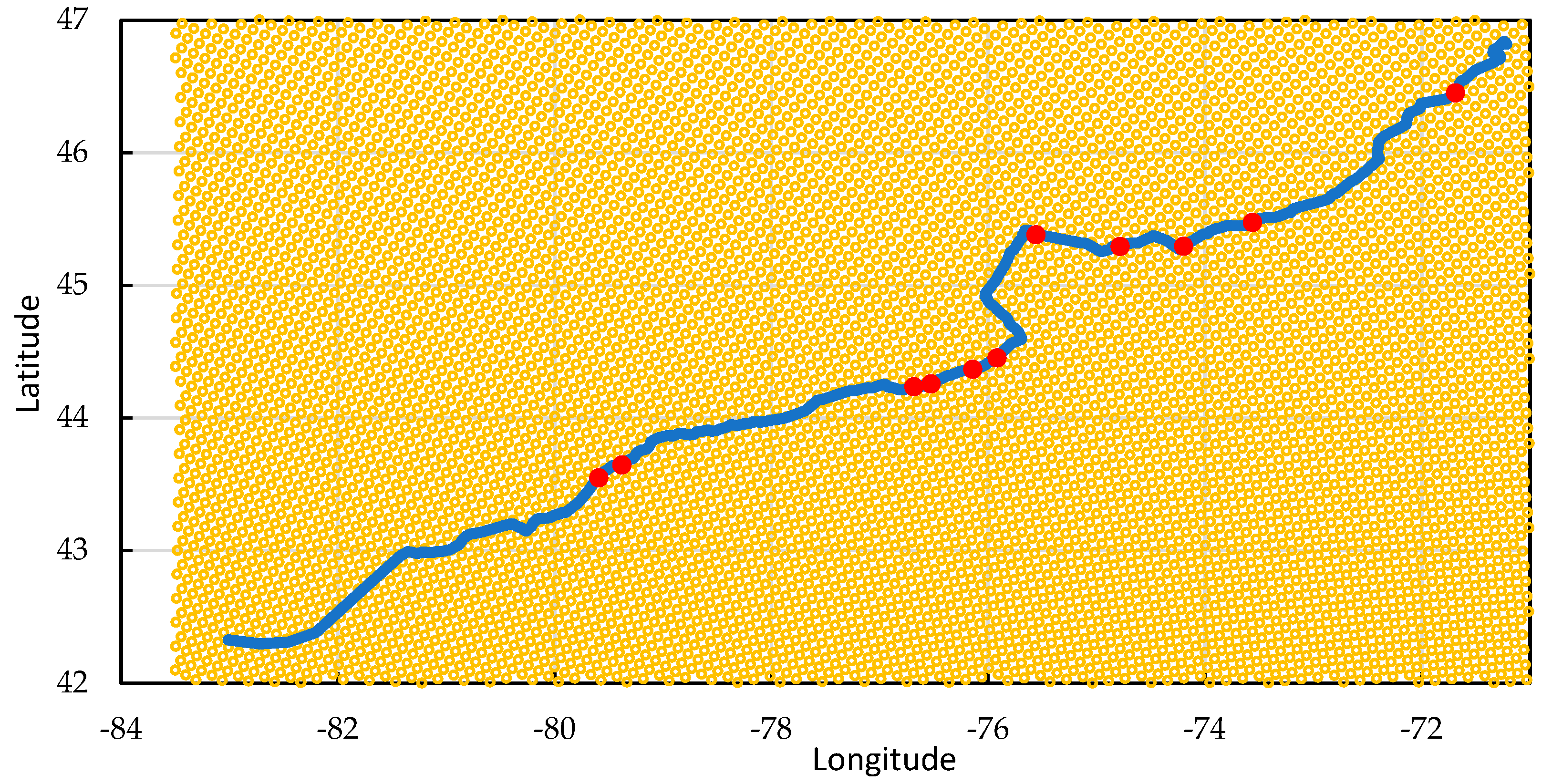
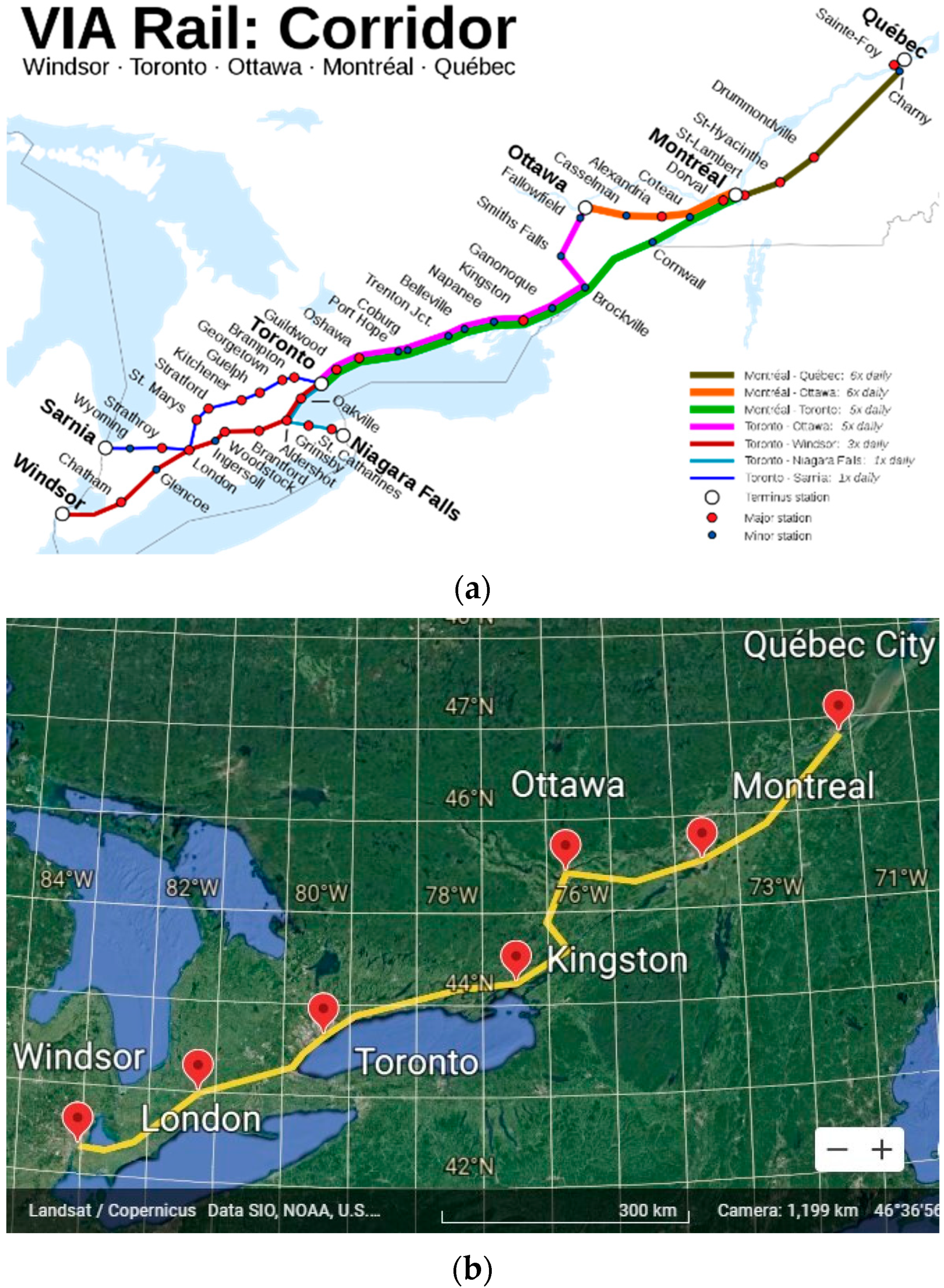
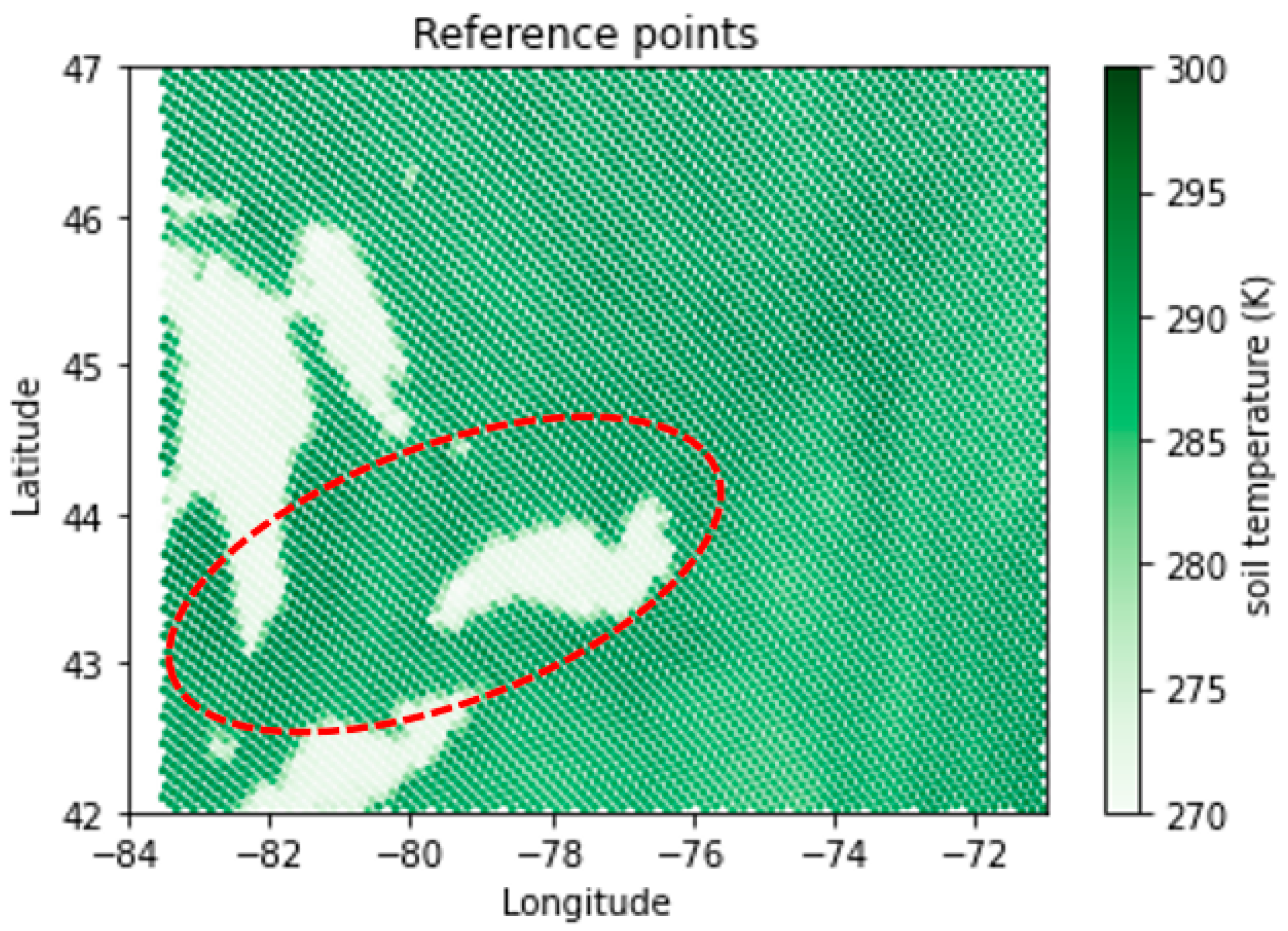
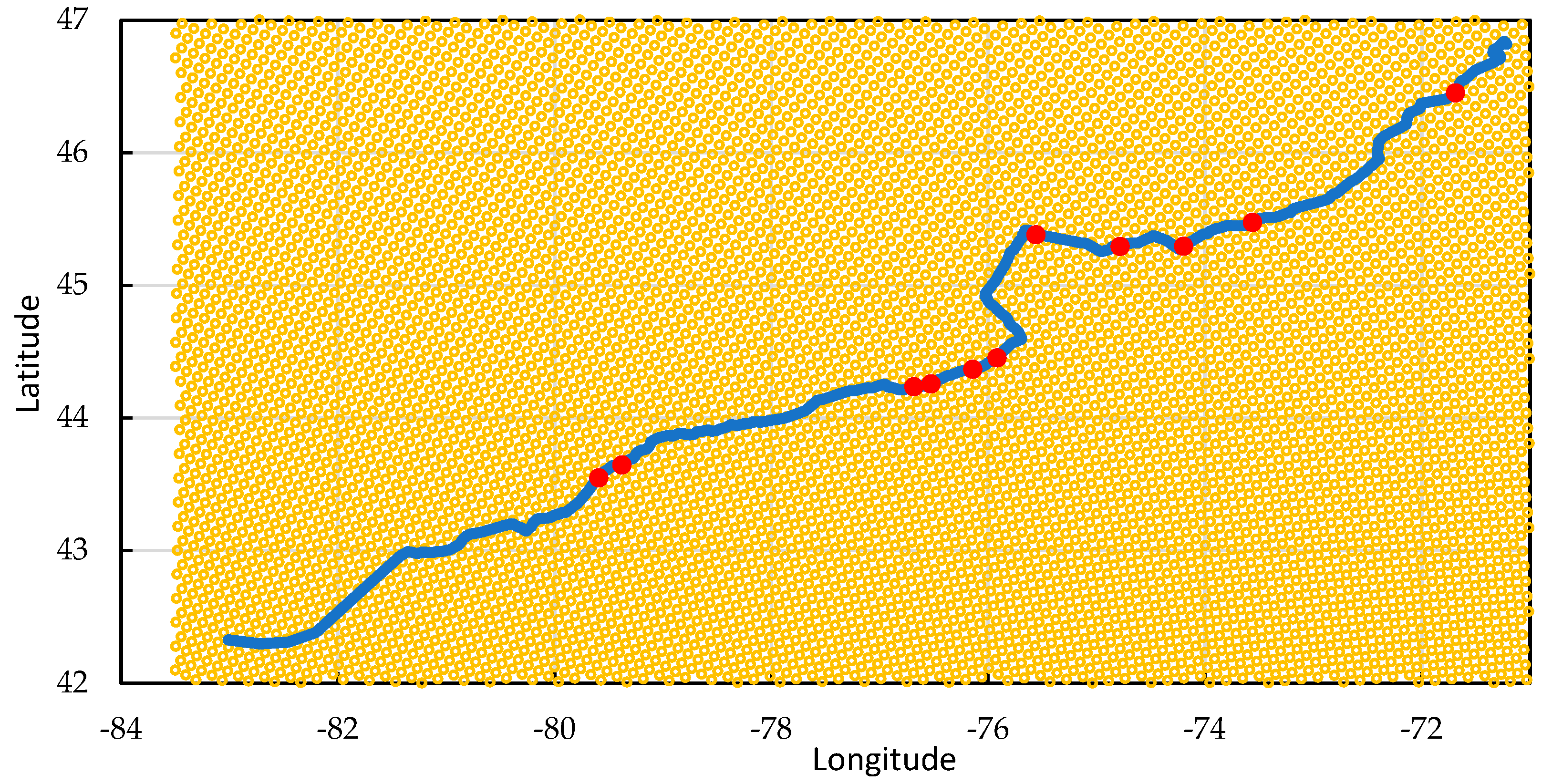
2.1. Study Area and Dataset
2.2. Description of Applied Methods
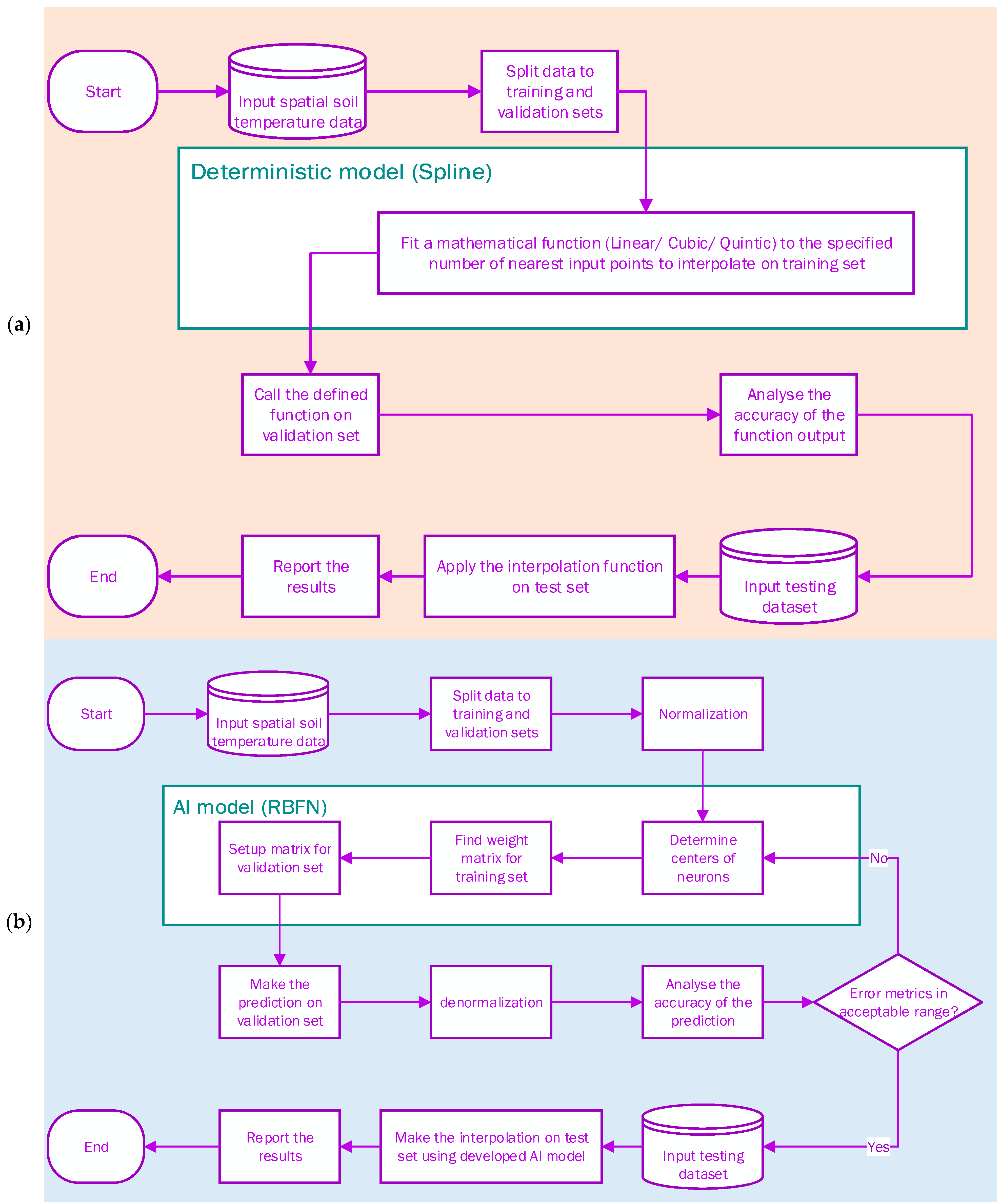
2.2.1. Deterministic Interpolation
2.2.2. Radial Basis Function Neural Networks
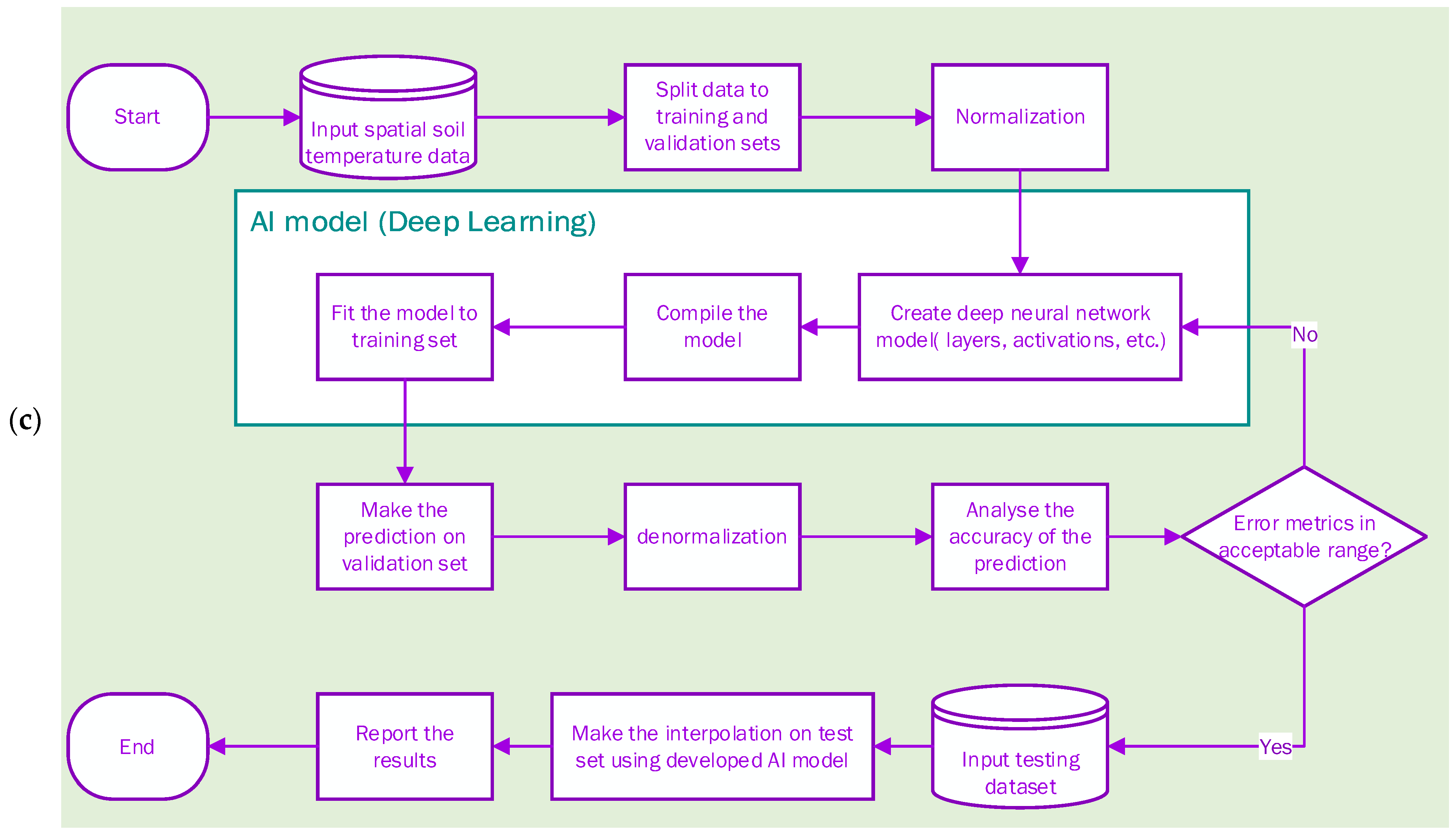
2.2.3. Deep Learning
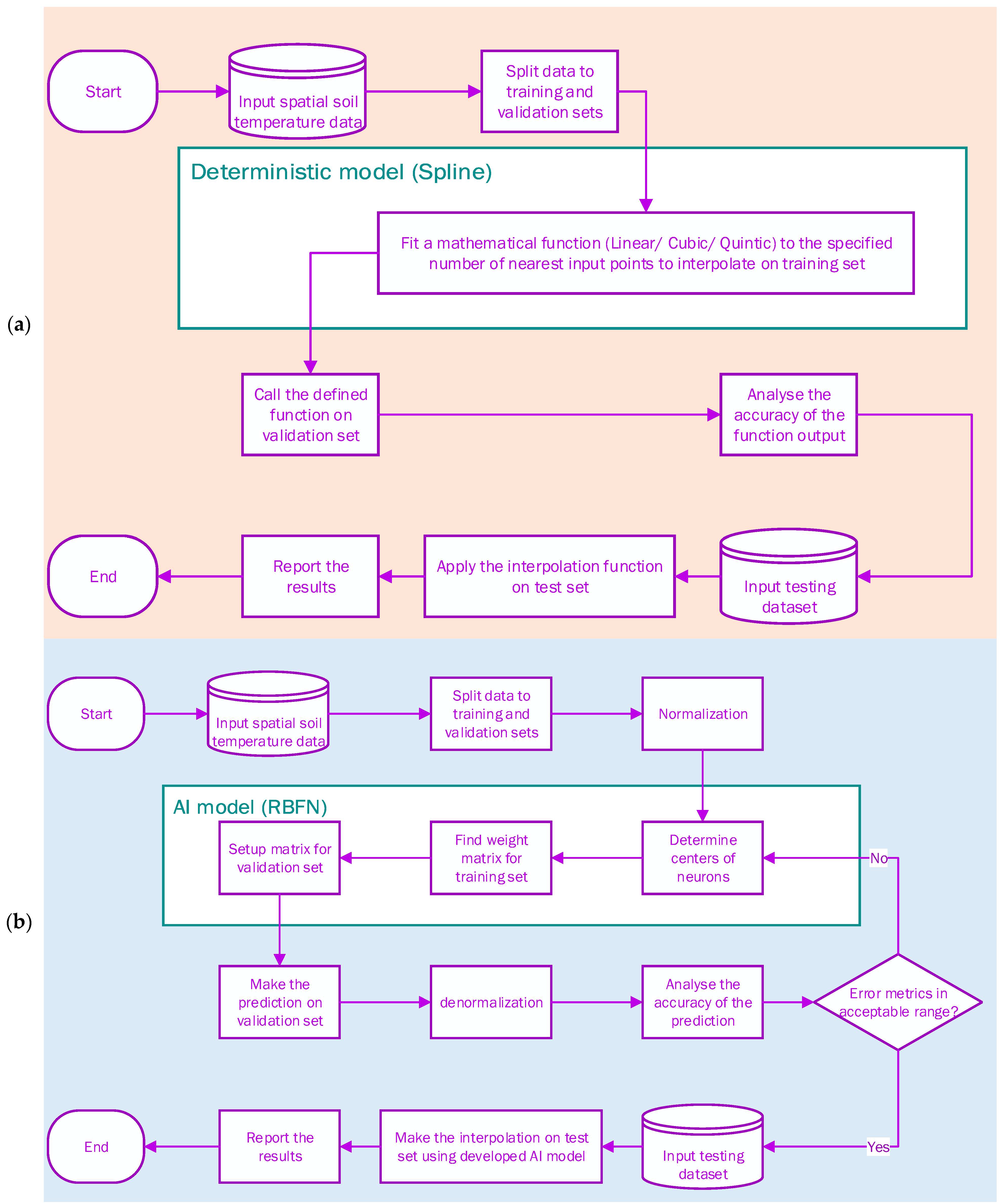
2.3. Methodological Overview
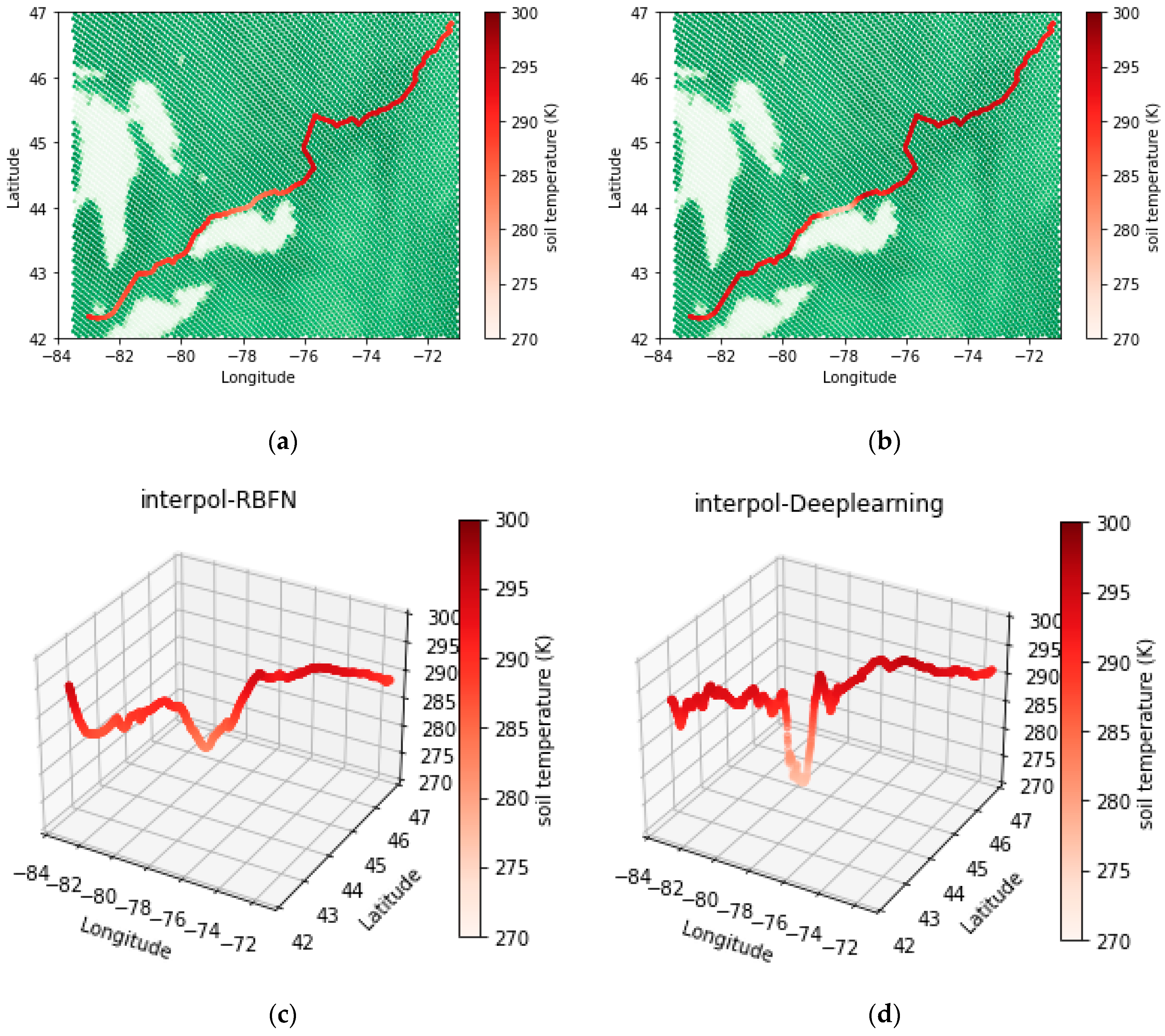
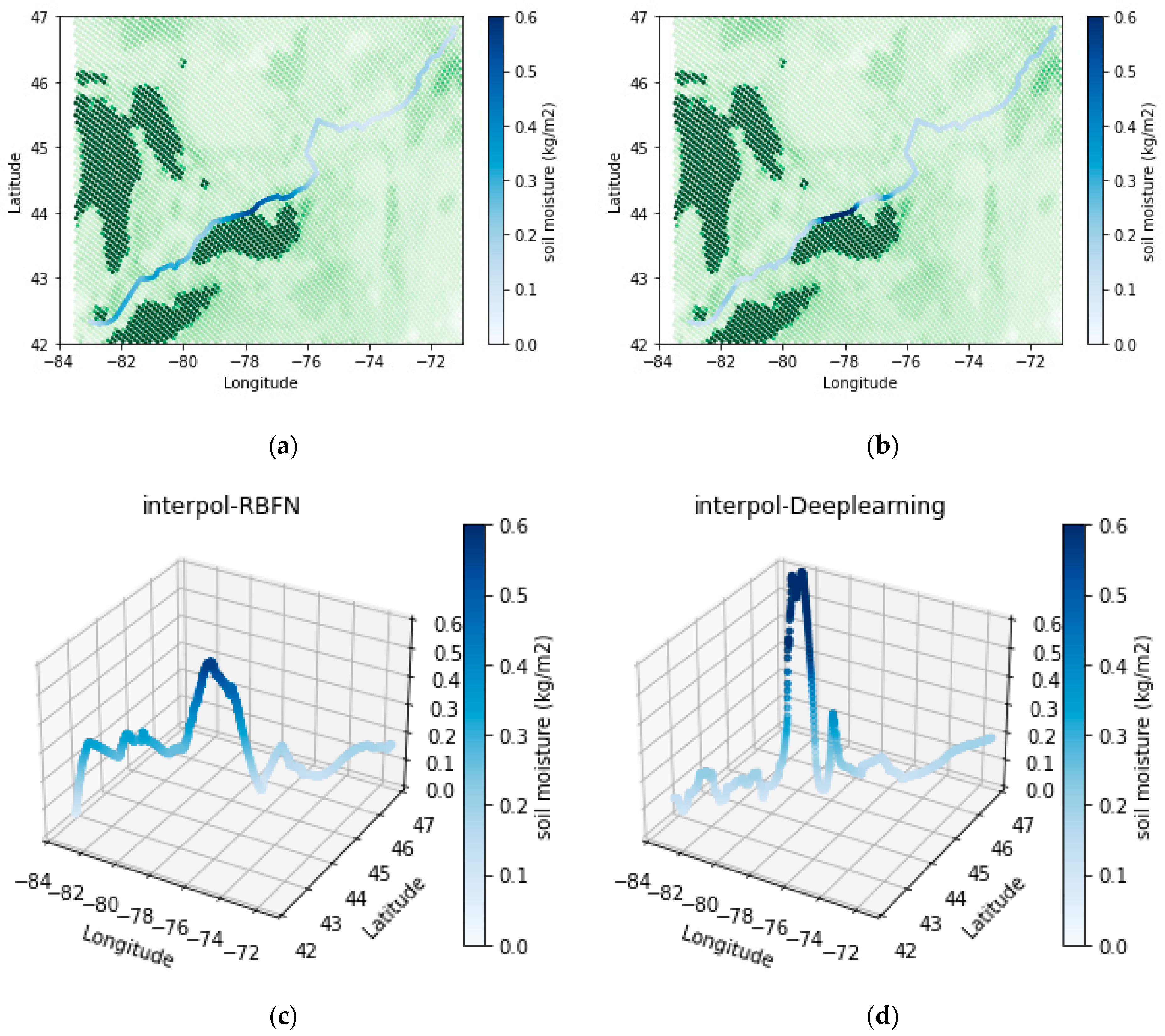
3. Results
4. Discussions
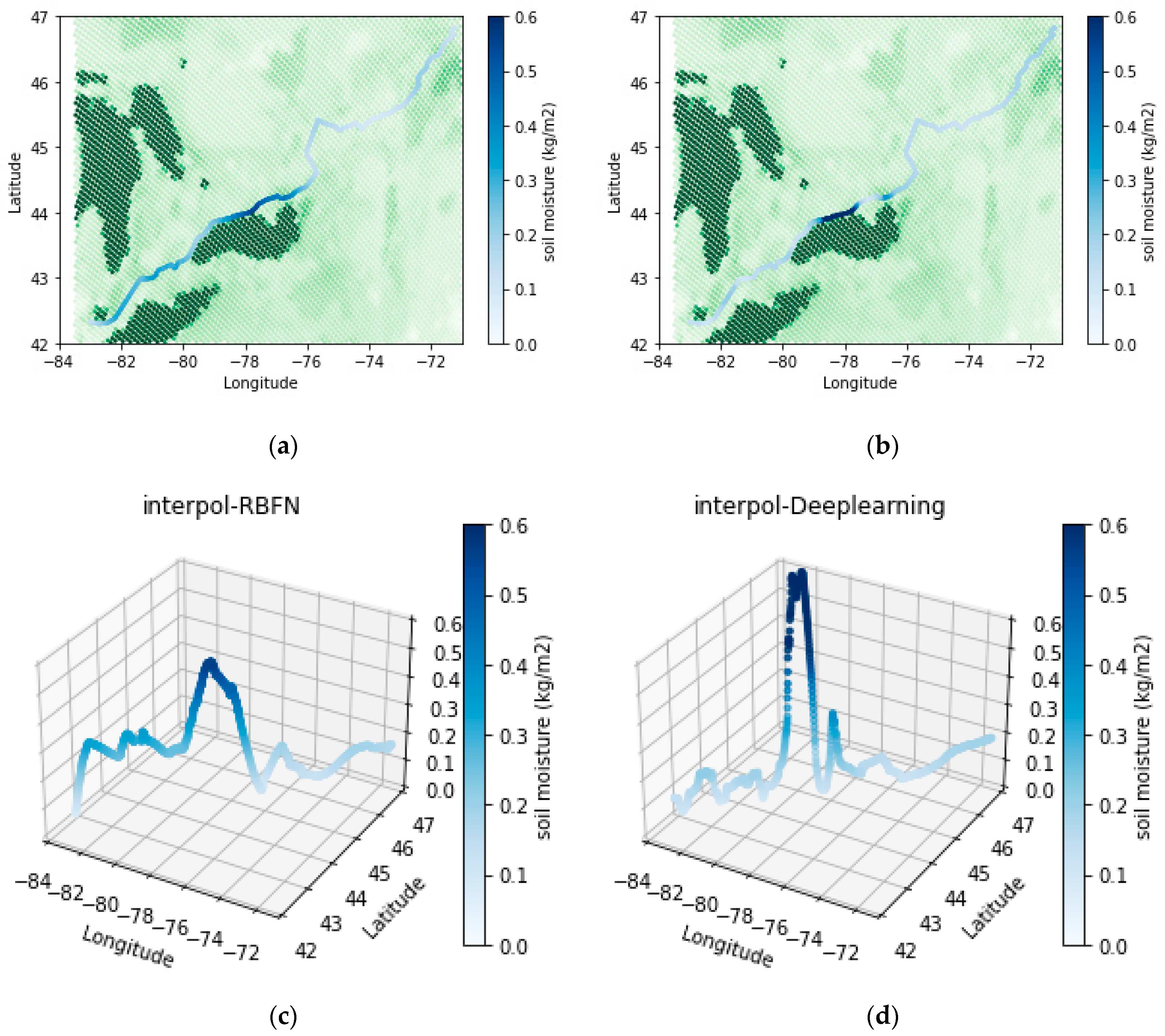
4.1. Interpolation of the Water Content of the Soil
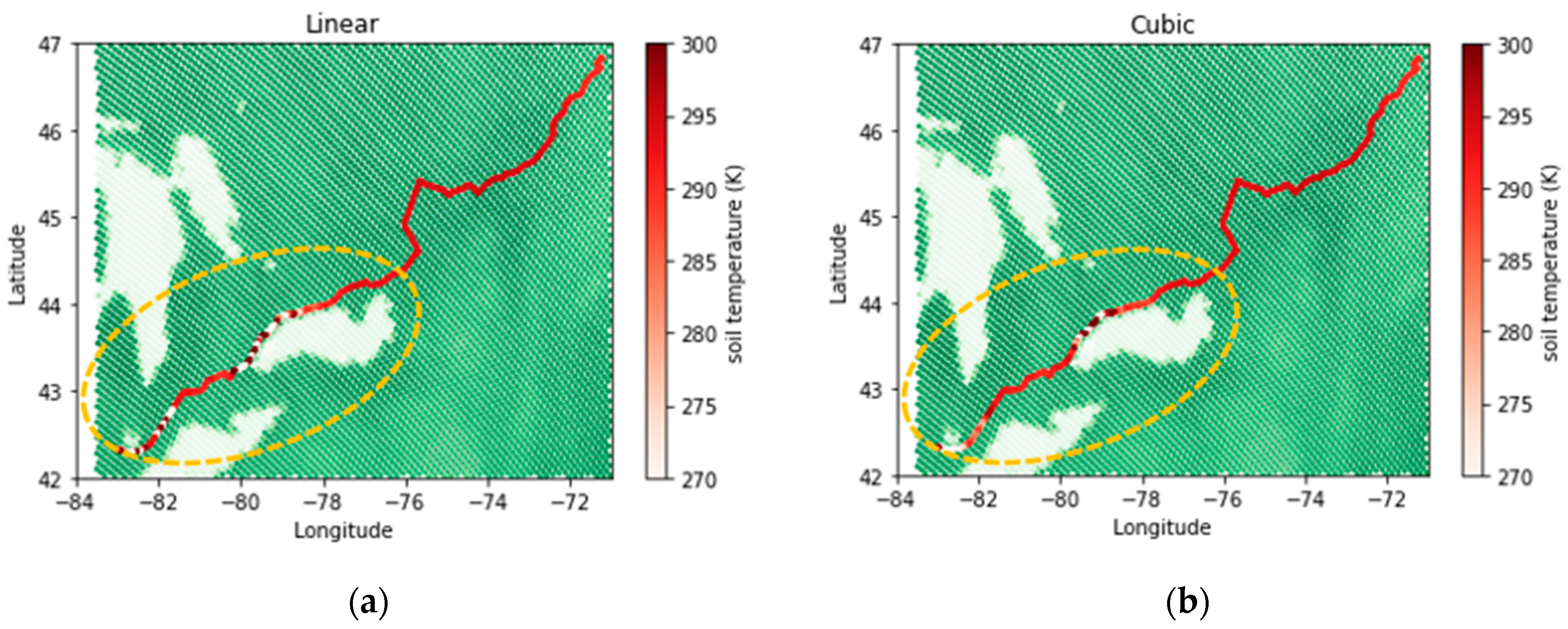
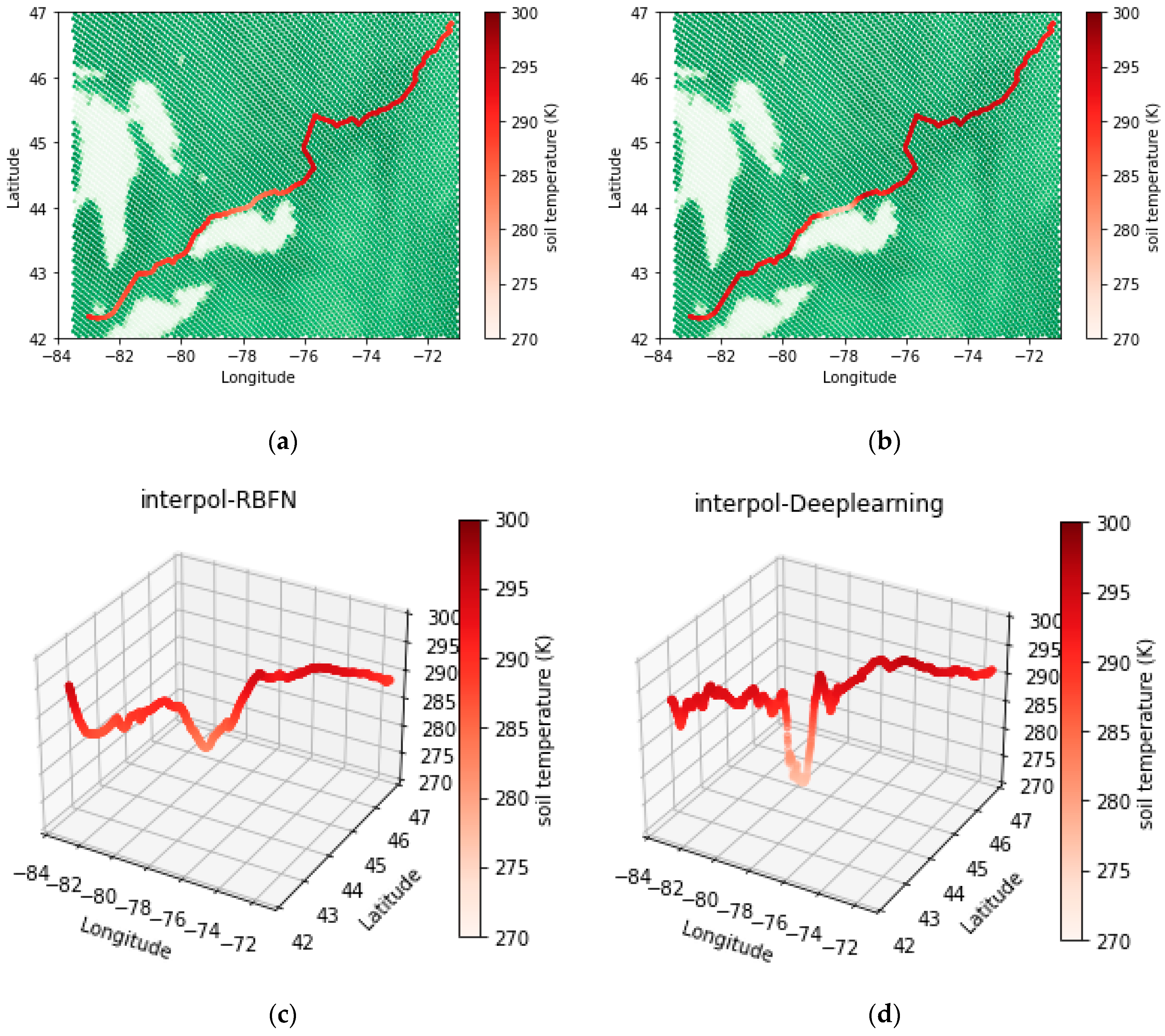
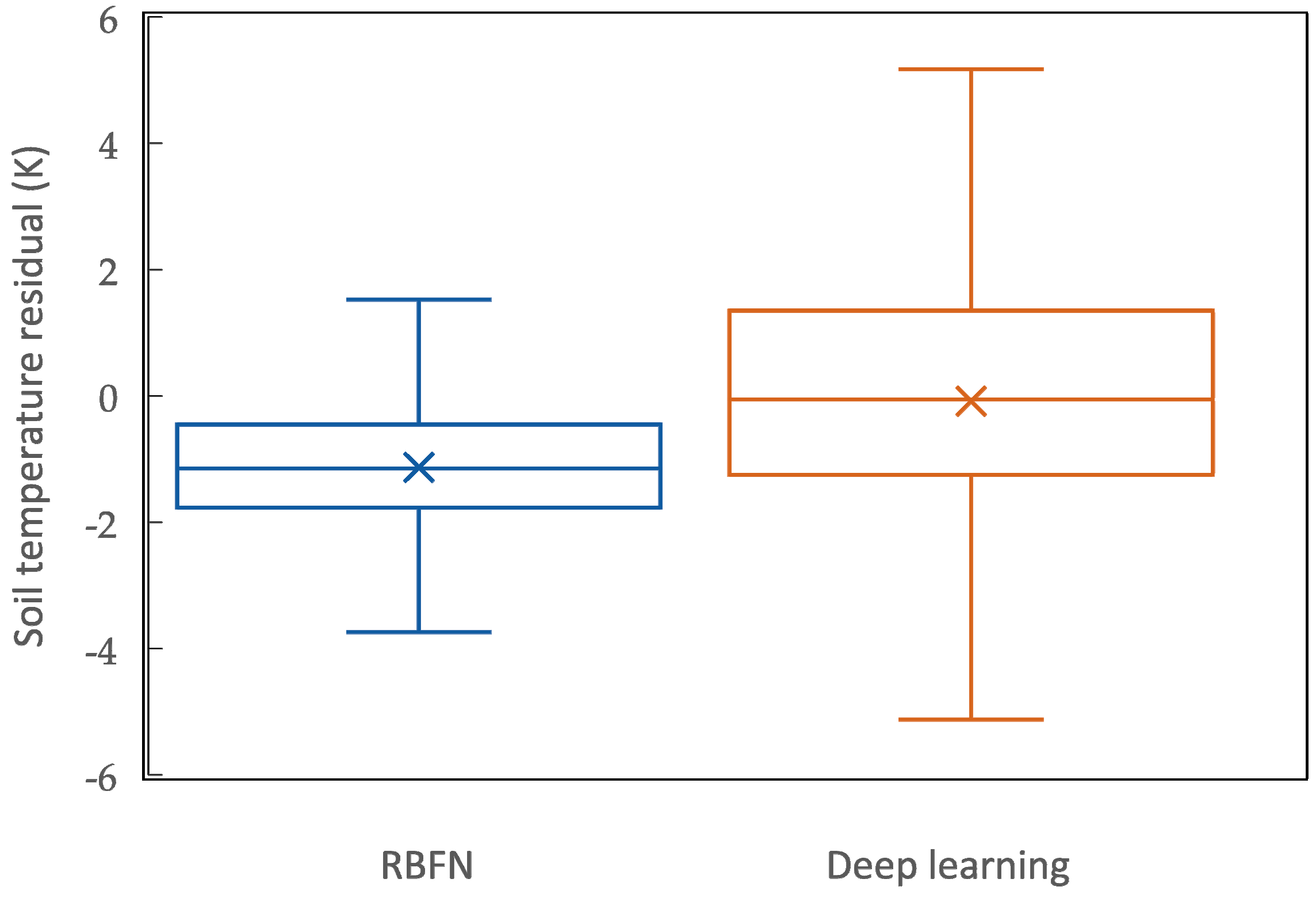
4.2. Evaluation of Methods’ Performance along the Railroad
5. Conclusions
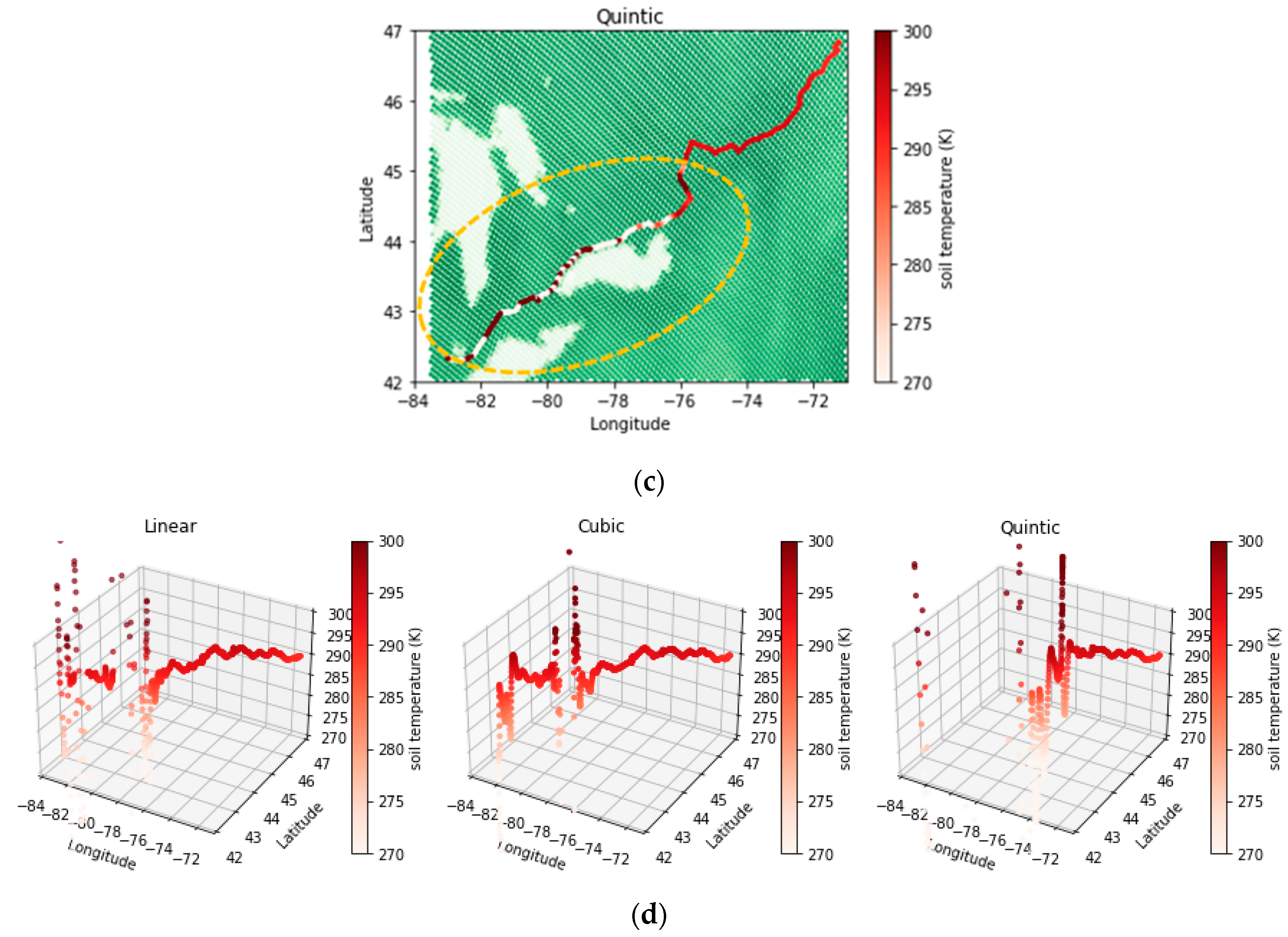
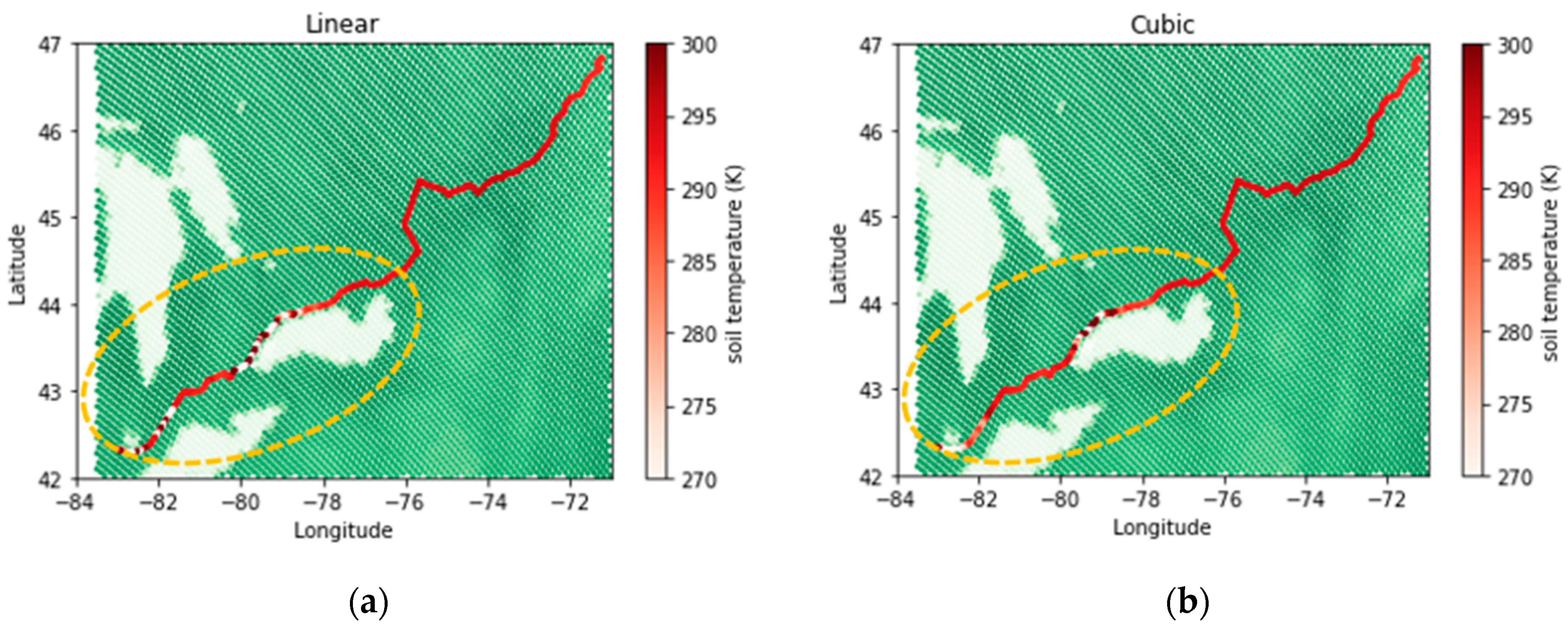
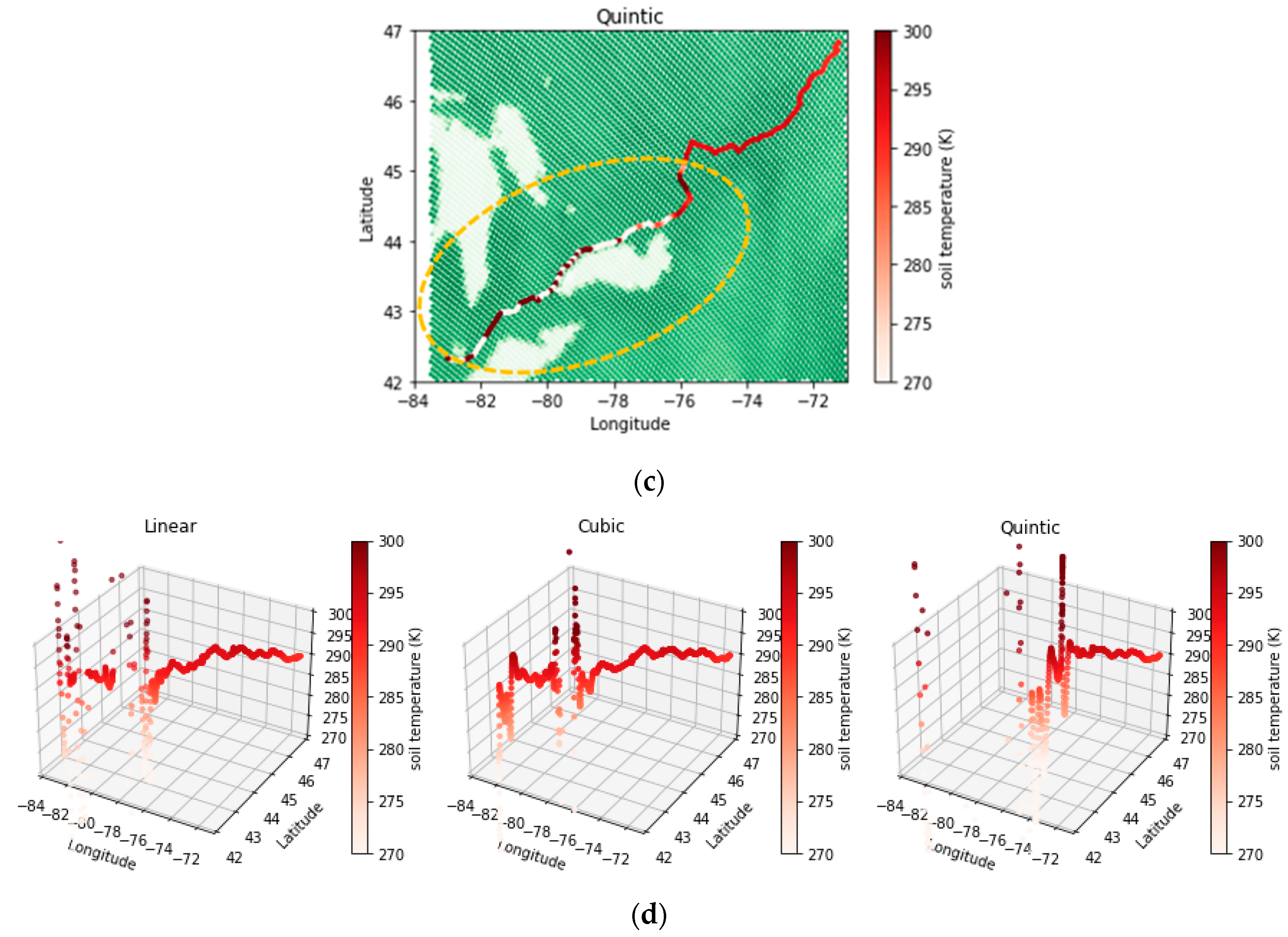
- The spline interpolation method, which belongs to the deterministic category, showed weaknesses in calculating interpolated values in areas with sudden variations due to its inherent property of fitting a minimum curvature surface. This limitation did not improve relatively by increasing the nonlinearity of the fitted function.
- AI methods used in this study were able to demonstrate a confident and stable performance in zones with sudden changes and can provide an alternative for deterministic interpolation methods.
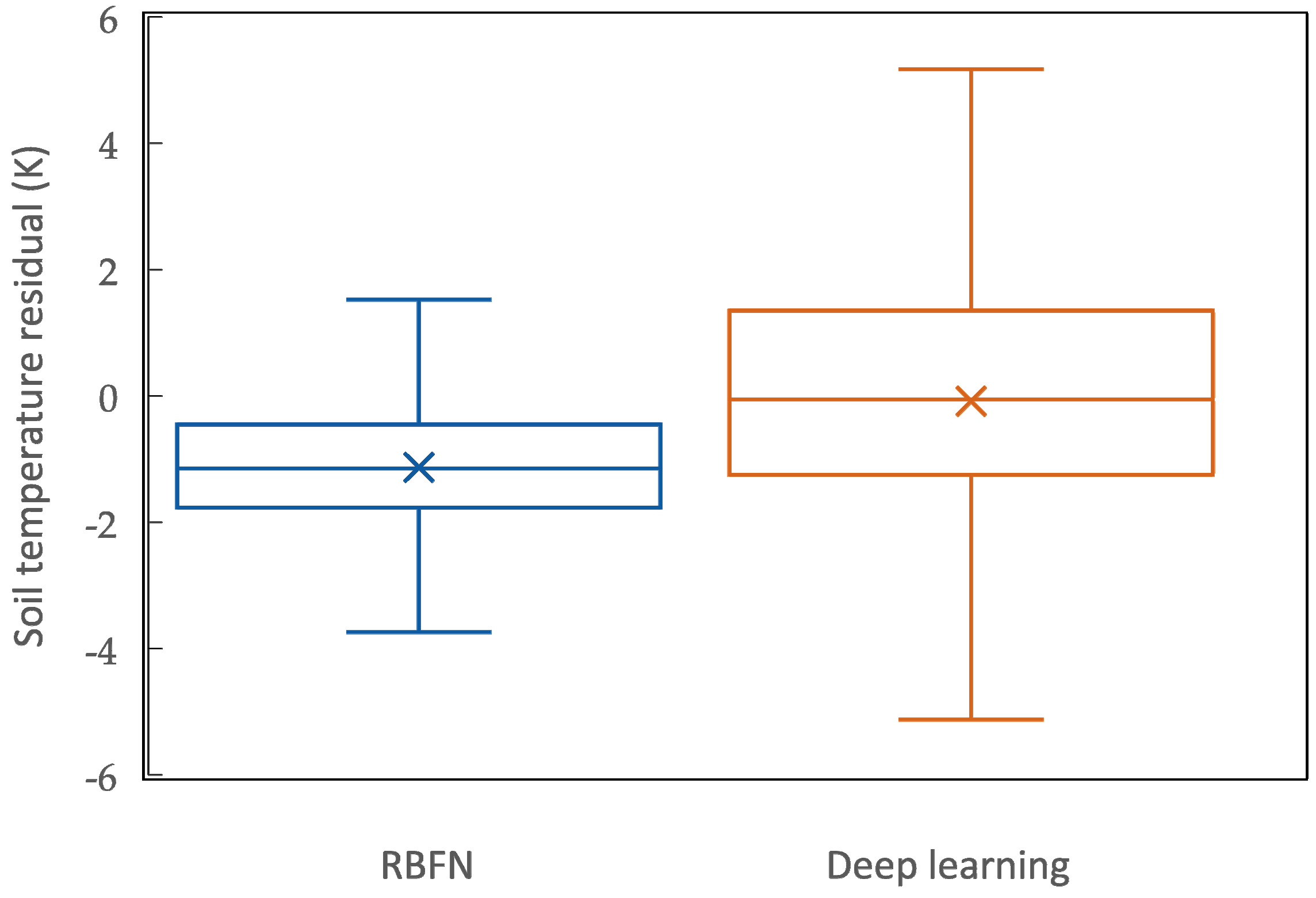
- Although both RBF and deep neural networks showed successful performance in interpolating data even over sharp change areas, deep learning demonstrated overall better accuracy in validation. Therefore, interpolated temperatures estimated along the railroad, calculated with a deep neural network model, were more reliable.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Buchanan, S.; Triantafilis, J. Mapping water table depth using geophysical and environmental variables. Ground Water 2009, 47, 80–96. [Google Scholar] [CrossRef] [PubMed]
- Adhikary, P.P.; Dash, C.J. Comparison of deterministic and stochastic methods to predict spatial variation of groundwater depth. Appl. Water Sci. 2017, 7, 339–348. [Google Scholar] [CrossRef] [Green Version]
- Wu, W.; Tang, X.P.; Ma, X.Q.; Liu, H.B. A comparison of spatial interpolation methods for soil temperature over a complex topographical region. Theor. Appl. Climatol. 2016, 125, 657–667. [Google Scholar] [CrossRef]
- Mohammadi, S.A.; Azadi, M.; Rahmani, M. Comparison of spatial interpolation methods for gridded bias removal in surface temperature forecasts. J. Meteorol. Res. 2017, 31, 791–799. [Google Scholar] [CrossRef]
- Wang, M.; He, G.; Zhang, Z.; Wang, G.; Zhang, Z.; Cao, X.; Wu, Z.; Liu, X. Comparison of spatial interpolation and regression analysis models for an estimation of monthly near surface air temperature in China. Remote Sens. 2017, 9, 1278. [Google Scholar] [CrossRef] [Green Version]
- Rufo, M.; Antolín, A.; Paniagua, J.M.; Jiménez, A. Optimization and comparison of three spatial interpolation methods for electromagnetic levels in the AM band within an urban area. Environ. Res. 2018, 162, 219–225. [Google Scholar] [CrossRef]
- Amini, M.A.; Torkan, G.; Eslamian, S.; Zareian, M.J.; Adamowski, J.F. Analysis of deterministic and geostatistical interpolation techniques for mapping meteorological variables at large watershed scales. Acta Geophys. 2019, 67, 191–203. [Google Scholar] [CrossRef]
- Kisi, O.; Mohsenzadeh Karimi, S.; Shiri, J.; Keshavarzi, A. Modelling long term monthly rainfall using geographical inputs: Assessing heuristic and geostatistical models. Meteorol. Appl. 2019, 26, 698–710. [Google Scholar] [CrossRef] [Green Version]
- Ahmadi, H.; Ahmadi, F. Evaluation of sunshine duration and temporal–spatial distribution based on geostatistical methods in Iran. Int. J. Environ. Sci. Technol. 2019, 16, 1589–1602. [Google Scholar] [CrossRef]
- Zhu, G.; Li, Q.; Pan, H.; Huang, M.; Zhou, J. Variation of the relative soil moisture of farmland in a continental river basin in China. Water 2019, 11, 1974. [Google Scholar] [CrossRef] [Green Version]
- Yang, R.; Xing, B. A comparison of the performance of different interpolation methods in replicating rainfall magnitudes under different climatic conditions in chongqing province (China). Atmosphere 2021, 12, 1318. [Google Scholar] [CrossRef]
- Sekulić, A.; Kilibarda, M.; Heuvelink, G.B.M.; Nikolić, M.; Bajat, B. Random forest spatial interpolation. Remote Sens. 2020, 12, 1687. [Google Scholar] [CrossRef]
- Appelhans, T.; Mwangomo, E.; Hardy, D.R.; Hemp, A.; Nauss, T. Evaluating machine learning approaches for the interpolation of monthly air temperature at Mt. Kilimanjaro, Tanzania. Spat. Stat. 2015, 14, 91–113. [Google Scholar] [CrossRef] [Green Version]
- Hengl, T.; Nussbaum, M.; Wright, M.N.; Heuvelink, G.B.M.; Gräler, B. Random forest as a generic framework for predictive modeling of spatial and spatio-temporal variables. PeerJ 2018, 2018, e5518. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- da Silva Júnior, J.C.; Medeiros, V.; Garrozi, C.; Montenegro, A.; Gonçalves, G.E. Random forest techniques for spatial interpolation of evapotranspiration data from Brazilian’s Northeast. Comput. Electron. Agric. 2019, 166, 105017. [Google Scholar] [CrossRef]
- Guevara, M.; Vargas, R. Downscaling satellite soil moisture using geomorphometry and machine learning. PLoS ONE 2019, 14, e0219639. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mohsenzadeh Karimi, S.; Kisi, O.; Porrajabali, M.; Rouhani-Nia, F.; Shiri, J. Evaluation of the support vector machine, random forest and geo-statistical methodologies for predicting long-term air temperature. ISH J. Hydraul. Eng. 2020, 26, 376–386. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, F.; Jiang, H.; Hu, H.; Zhong, K.; Jing, W.; Yang, J.; Jia, B. Downscaling ASTER land surface temperature over urban areas with machine learning-based area-to-point regression kriging. Remote Sens. 2020, 12, 1082. [Google Scholar] [CrossRef] [Green Version]
- Cho, D.; Yoo, C.; Im, J.; Lee, Y.; Lee, J. Improvement of spatial interpolation accuracy of daily maximum air temperature in urban areas using a stacking ensemble technique. GIScience Remote Sens. 2020, 57, 633–649. [Google Scholar] [CrossRef]
- Chen, C.; Hu, B.; Li, Y. Easy-to-use spatial random-forest-based downscaling-calibration method for producing precipitation data with high resolution and high accuracy. Hydrol. Earth Syst. Sci. 2021, 25, 5667–5682. [Google Scholar] [CrossRef]
- Leirvik, T.; Yuan, M. A Machine Learning Technique for Spatial Interpolation of Solar Radiation Observations. Earth Space Sci. 2021, 8, e2020EA001527. [Google Scholar] [CrossRef]
- Wikipedia. Available online: https://en.wikipedia.org/wiki/Quebec_City%E2%80%93Windsor_Corridor_%28Via_Rail%29 (accessed on 20 November 2022).
- Google Earth. Available online: https://earth.google.com/web/search/Smiths+Falls,+ON/@44.6989271,-75.59612627,309.29280915a,1176575.24702311d,35y,0h,0t,0r/data=CigiJgokCVEopqyx30ZAEc1G9KXwK0ZAGQK18wChXlLAIVN0rLhielPA (accessed on 14 December 2022).
- Imanian, H.; Hiedra Cobo, J.; Payeur, P.; Shirkhani, H.; Mohammadian, A.A. Comprehensive study of artificial intelligence applications for soil temperature prediction in ordinary climate conditions and extremely hot events. Sustainability 2022, 14, 8065. [Google Scholar] [CrossRef]
- Fletcher, S.J. Introduction to Semi-Lagrangian Advection Methods. In Data Assimilation for the Geosciences; Elsevier: Amsterdam, The Netherlands, 2017; pp. 361–441. [Google Scholar] [CrossRef]
- Araghinejad, S. Data-driven modeling: Using MATLAB® in water resources and environmental engineering. In Water Science and Technology Library; Springer: Berlin/Heidelberg, Germany, 2014; Volume 67, p. 292. [Google Scholar]
- Pantazi, X.E.; Moshou, D.; Bochtis, D. Artificial intelligence in agriculture. In Intelligent Data Mining and Fusion Systems in Agriculture; Elsevier: Amsterdam, The Netherlands, 2020; pp. 17–101. [Google Scholar] [CrossRef]
- Dubuisson, B. Neural networks, general principles. In Encyclopedia of Vibration; Elsevier: Amsterdam, The Netherlands, 2001; pp. 869–877. [Google Scholar] [CrossRef]
- Faris, H.; Aljarah, I.; Mirjalili, S. Evolving Radial Basis Function Networks Using Moth-Flame Optimizer. In Handbook of Neural Computation; Elsevier Inc.: Amsterdam, The Netherlands, 2017; pp. 537–550. [Google Scholar] [CrossRef]
- Montavon, G.; Samek, W.; Müller, K.R. Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 2018, 73, 1–15. [Google Scholar] [CrossRef]
- Kim, J.; Lee, Y.; Lee, M.H.; Hong, S.Y. A Comparative Study of Machine Learning and Spatial Interpolation Methods for Predicting House Prices. Sustainability 2022, 14, 9056. [Google Scholar] [CrossRef]
- Wang, X.; Li, W.; Li, Q. A New Embedded Estimation Model for Soil Temperature Prediction. Sci. Program. 2021, 2021, 5881018. [Google Scholar] [CrossRef]
- Li, C.; Zhang, Y.; Ren, X. Modeling Hourly Soil Temperature Using Deep BiLSTM Neural Network. Algorithms 2020, 13, 173. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maximum iteration (RBFN) | 100 | 500 | 700 | 1000 | ||||
| R-squared | 0.54655 | 0.54378 | 0.54957 | 0.54641 | ||||
| Neurons in hidden layer (Deep learning) | 300 | 500 | 300, 30 | 300, 100 | 500, 30 | 500, 100 | ||
| R-squared | 0.83668 | 0.84645 | 0.85651 | 0.87846 | 0.88696 | 0.89011 | ||
| Error index | MaxE (K) | MAE (K) | MSE (K2) | RMSE (K) | NRMSE (-) | RRMSE (-) |
| Method | ||||||
| RBFN | 14.89 | 2.58 | 16.50 | 4.06 | 16.25% | 1.41% |
| Deep Learning | 8.13 | 1.63 | 5.12 | 2.26 | 9.05% | 0.78% |
| Error index | MAPE (-) | Bias (K) | R2 (-) | NSE (-) | VAF (-) | AIC |
| Method | ||||||
| RBFN | 0.90% | 0.08 | 53.81% | 53.78% | 53.80% | 23100 |
| Deep Learning | 0.57% | 1.13 | 89.24% | 85.65% | 89.22% | 20800 |
| Error index | MaxE (kg/m2) | MAE (kg/m2) | MSE (kg2/m4) | RMSE (kg/m2) | NRMSE (-) | RRMSE (-) |
| Method | ||||||
| RBFN | 0.76 | 0.10 | 0.03 | 0.17 | 17.54% | 69.55% |
| Deep Learning | 0.66 | 0.04 | 0.01 | 0.08 | 7.92% | 31.39% |
| Error index | MAPE (-) | Bias (kg/m2) | R2 (-) | NSE (-) | VAF (-) | AIC |
| Method | ||||||
| RBFN | 48.00% | 0.00 | 56.91% | 56.88% | 56.91% | 8600 |
| Deep Learning | 20.69% | 0.01 | 91.32% | 91.21% | 91.32% | 5900 |
| Variable | Soil Temperature | Water Content | ||
|---|---|---|---|---|
| Interpolation Method | RBFN | Deep Learning | RBFN | Deep Learning |
| RMSE | 2.26 | 1.30 | 0.09 | 0.06 |
| R2 | 26% | 67% | 39% | 34% |
| Bias | −1.34 | 0.32 | 0.05 | 0.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Imanian, H.; Shirkhani, H.; Mohammadian, A.; Hiedra Cobo, J.; Payeur, P. Spatial Interpolation of Soil Temperature and Water Content in the Land-Water Interface Using Artificial Intelligence. Water 2023, 15, 473. https://doi.org/10.3390/w15030473
Imanian H, Shirkhani H, Mohammadian A, Hiedra Cobo J, Payeur P. Spatial Interpolation of Soil Temperature and Water Content in the Land-Water Interface Using Artificial Intelligence. Water. 2023; 15(3):473. https://doi.org/10.3390/w15030473
Chicago/Turabian StyleImanian, Hanifeh, Hamidreza Shirkhani, Abdolmajid Mohammadian, Juan Hiedra Cobo, and Pierre Payeur. 2023. "Spatial Interpolation of Soil Temperature and Water Content in the Land-Water Interface Using Artificial Intelligence" Water 15, no. 3: 473. https://doi.org/10.3390/w15030473