1. Introduction
Runoff volume, a significant source of water resource management, has been studied for over half a century [
1]. Accurate prediction of runoff is crucial for effective water resources management, agricultural irrigation, flood warning systems, and hydropower generation. The intricate interplay between vegetation and precipitation has gained widespread recognition. Considering the limitations imposed by water availability on ecosystem functioning, precise runoff prediction can facilitate optimal ecological restoration under limited water conditions and serve as a decision-making basis for vegetation restoration in diverse regions [
2,
3]. During the melting process, substantial amounts of snow-melt runoff enter rivers, potentially leading to flooding. Shigemi Hatta proposed the use of weekly weather forecast data in snowmelt runoff prediction, which was calculated based on sunshine percentage at that time when solar activity was not well understood [
4]. Subsequently, researchers have explored more variables such as topography, geology, air temperature, precipitation, and watershed area to improve the accuracy of flood damage avoidance predictions [
5]. In recent years, with richer meteorological and surface parameter data as well as remote sensing technology available, progress has also been made in data quality control and preprocessing techniques for research purposes. H.V. Trivedi pioneered the application of grey system theory in hydrology to model runoff prediction with good practical effects using only a small set of hydrological data required for flow prediction [
6].
Due to the complex characteristics of the runoff process, such as time-varying and non-stationary behavior, the selection of a leading predictor plays a crucial role in accurately predicting runoff. The prediction of runoff performance can potentially be influenced by the addition of rainfall factors and underlying surface [
7,
8]. Rai’s study on overland roughness found that hydrological curves with different land roughness were consistent with observed runoff hydrological curves [
9]. Samantaray discovered that predicting runoff always relies on five data items, including rainfall, temperature, stage, specific humidity, and relative humidity to evaluate models [
10]. In the ensemble streamflow prediction (ESP) modelranspiration, temperature, soil moisture, groundwater level, and snow are allowed to be incorporated into modeling to enhance flow rate predictions’ reliability [
11]. Given the wide availability of models, selecting the most appropriate predictive model for a particular problem depends on available data quality as well as system complexity and desired accuracy levels. Therefore, when studying runoff prediction, valuable data include rainfall data, runoff data, groundwater level data, land cover map and soil map from 1980 to 2010, which includes 88 monthly general circulation indices, 26 monthly SST indices, and 16 monthly other indices [
12]. The primary purpose of this study is to investigate whether these factors can aid in proposing a model for predicting and evaluating empirical results. Three feature-selection methods have been applied to determine if these features are effective predictors.
The methods for medium and long-term runoff forecasting can be categorized into two groups: process-driven methods, which are based on hydrological mechanisms, and data-driven methods guided by probability, statistics, and other mathematical tools [
13]. The process-driven approach can be categorized into a conceptual model and a distributed model. The conceptual representative models encompass the Xinanjiang model and GR4J, while the distributed representative models include VIC and SWAT. The former is relatively straightforward to construct. Louise et al. employed the GR6J model to assess the performance of original (uncorrected) and deviation-corrected ensemble forecasts for precipitation and discharge in 16 river basins in France [
14]. The latter is comparatively intricate to build. Yuan et al. utilized real-time seasonal climate predictions from the North American multi-model Ensemble (NMME) climate model and developed a seasonal runoff forecast model for the Yellow River Basin using statistical downscaling methods [
15]. The construction process of process-driven methods is more complex than that of data-driven methods, hence these approaches are less commonly used for medium- and long-term runoff forecasting. On the other hand, data-driven methods involve a more complex construction process but rely on multidisciplinary knowledge such as probability, statistics, and optimization to establish a mapping relationship from forecast factors to runoff processes by uncovering potential physical laws behind hydro-meteorological data [
16]. These models are often referred to as “black box models” due to their reduced interpretability. Data-driven methods can be further classified into three categories: traditional statistical methods, machine learning techniques, and deep learning techniques. The traditional statistical method is a kind of method used earlier in the medium- and long-term runoff forecast, among which the more commonly used are the periodic analysis extrapolation method, historical evolution method, time series method, and regression analysis method. Compared with traditional statistical methods, machine learning methods have stronger nonlinear mapping ability and can better describe the complex nonlinear laws behind hydrometeorological data. Previous studies have demonstrated that neural networks offer higher accuracy predictions in this domain—Sofia’s experiment successfully predicted Tupungato River’s monthly flow one month in advance using optimized mathematical relationships with variable representation. Therefore, these research methodologies and ideas serve as valuable references.
In order to achieve higher prediction accuracy, most research employs and trains various machine learning and deep learning prediction models. These include artificial neural network (ANN), support vector machine (SVM), decision tree (DT), convolutional neural network (CNN), long short-term memory network (LSTM), grey system method, wavelet analysis method, chaos theory method, optimal combination prediction method, and other medium- and long-term runoff prediction methods. These models possess the capability to handle nonlinear relationships and adapt to changing hydrological environments, yielding promising results in previous hydrological modeling studies. The SVM model is particularly effective in handling high-dimensional data and capturing complex correlations within hydrological processes [
17]. Runoff prediction also uses decision trees and their integration methods, such as XGBoost and LGBM, which are also widely used to predict runoff discharge [
18]. Maurus Borne emphasized the significance of accurate forecasting in addressing water resource management issues in semi-arid regions where reliable scheduling decisions heavily rely on forecasted data from water resources ministries [
19]. Timely mid- and long-term forecasting incorporating rainfall factors and underlying surface characteristics into theoretical models has become increasingly crucial for flood control and drought resistance in river basins. Sofia conducted an experiment using samples to indicate monthly discharges with a 1-month lead-time in the Tupungato River basin located in the Central Andes of Argentina. They recommended combining support vector regression (SVR) with artificial neural networks (ANN) as a promising model compared to classification and regression trees [
1]. Eui Hoon Lee’s case study demonstrated that an ANN model based on optimization algorithms is effective for predicting runoff [
20]. Short-term components neural network was used to predict runoff for the Brosna catchment located in Ireland [
21], while pre-processed evolutionary Levenberg–Marquardt neural networks (PELMNN) model and feed-forward neural networks were employed for streamflow runoff prediction at the Aghchai watershed [
22].
Junguo proposes a model selection and combination strategy that integrates 16 different physical models with LSTM technology. Additionally, an extensive performance index is proposed to consider the characteristics of model groups by analyzing their respective performances [
23]. The Granata study compares the application of four distinct types of neural networks (MLP, RBF-NN, LSTM, and Bi-LSTM) for short-to-medium-term flow forecasts (up to 15 days) across six rivers in the United States. It concludes that the RBF-neural network exhibits significant potential in achieving accurate short-to-medium-term forecasts with minimal parameter optimizations [
24]. The NARX-MLP-RF model established by Di Nunno et al. has been demonstrated to be particularly suitable for accurate prediction of rainfall and flow distribution changes in small river basins [
25]. These techniques effectively consider temporal dependence and capture complex relationships through nonlinear modeling, enabling precise runoff prediction. Artificial neural network methods, among them, are well-suited for simulating nonlinear relationships between random variables in medium- to long-term runoff prediction. They possess advantages such as self-learning, self-organizing, strong adaptability, and simplicity that have been widely applied with favorable outcomes [
26,
27,
28,
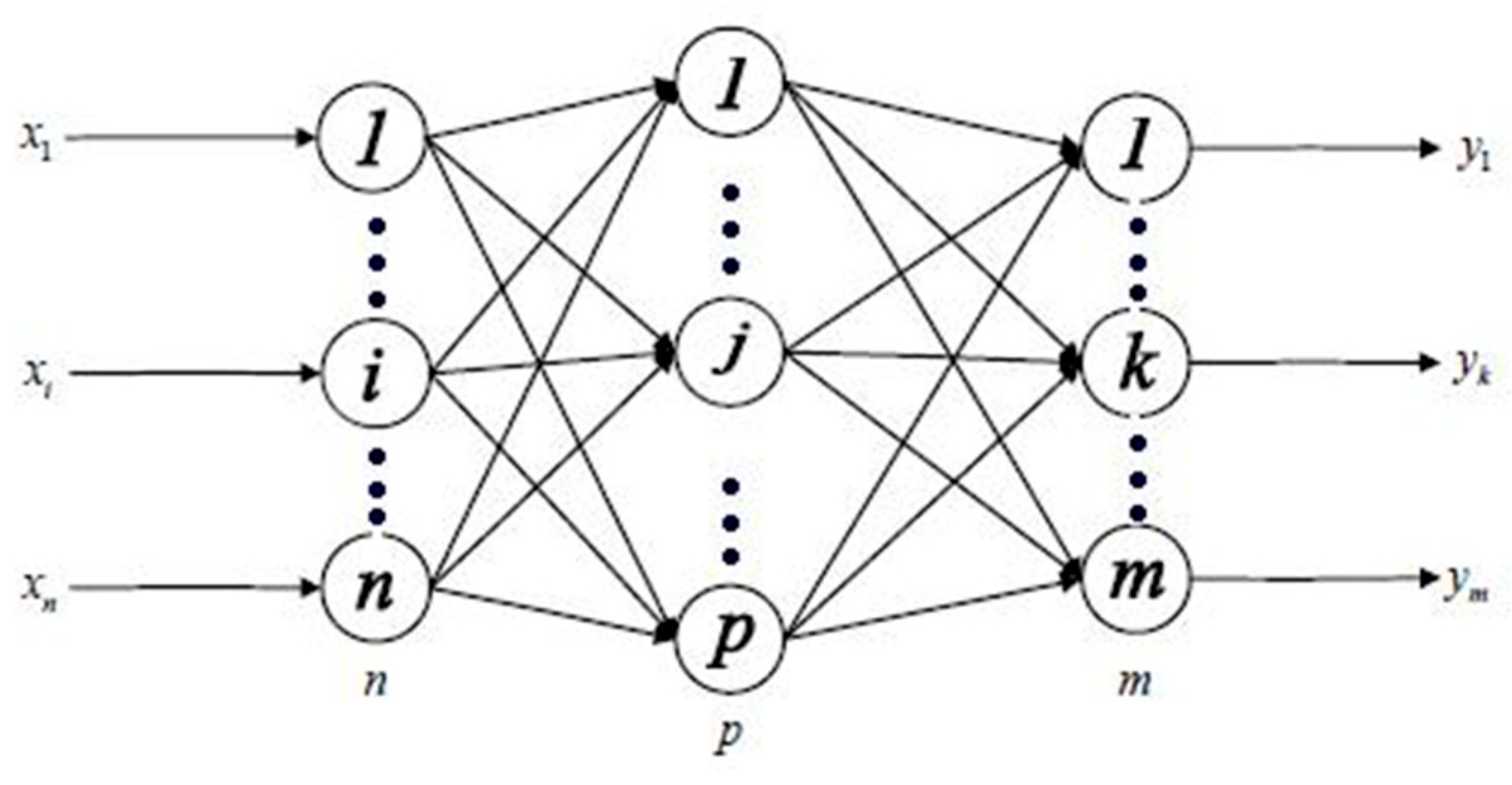
29]. Furthermore, this study aims to select a model exhibiting stable performance as well as verify whether it can achieve improved prediction accuracy through factor screening. Therefore, this paper selects the widely recognized backpropagation neural network but enhances its optimization algorithm by constructing an adaptive learning rate while investigating the influence of influential factors on prediction effectiveness.
To address the gaps in previous studies, this paper also provides several innovative points and contributions. On one hand, prior researchers have dedicated their efforts to studying model precision comparison and combination models [
30,
31]. However, there is limited research exploring the optimization of the back propagation algorithm. In this study, the author constructs a self-adaptive learning rate to enhance neural network performance. Additionally, an excellent model is employed for runoff forecasting with its prediction accuracy serving as a benchmark for subsequent model studies. On the other hand, selecting appropriate meteorological factors under different lag times in the early stage plays a crucial role in forecasting accuracy. While previous studies have examined astronomical factors, atmospheric circulation, ocean thermal conditions, underlying surface conditions, and basin water conditions [
12], investigations into influential features remain insufficiently explored. As previous studies primarily focused on prediction model selection, it is imperative to analyze more representative factors for a comprehensive understanding of runoff volume changes. Representative impact factors can also be recommended for areas with limited hydrological data. Therefore, this paper effectively improves the overall forecasting performance of a single forecasting model through optimal factor selection and provides valuable references for future research.
The following are the remaining sections of this paper.
Section 2 represents data collection and then discusses experiment methodology. All models’ reliability and validity were also measured to compare their performance. The empirical findings and result assessment related to existing literature are outlined in
Section 3. Study insights and conclusions are provided at the end of this paper.
5. Conclusions
The prediction of medium and long-term runoff holds significant importance for the coordinated management of water resources. This study focuses on evaluating the impact of different multi-factor combinations, selected through various methods, on the prediction accuracy of medium and long-term runoff in a specific coastal area of Jiangsu. The analysis is based on the latest monthly index set comprising 130 climate systems released by the National Climate Center. Consequently, this research has yielded the following outcomes:
(1) Using the Spearman rank correlation coefficient, 29, 11, 16, 28, 36, and 33 dominant climate factors were identified for medium to long-term runoff prediction in the coastal area of Jiangsu over a period of one to six months.
(2) Through stepwise regression analysis, a set of 20 significant climate factors with good independence at different lag times was selected for further analysis.
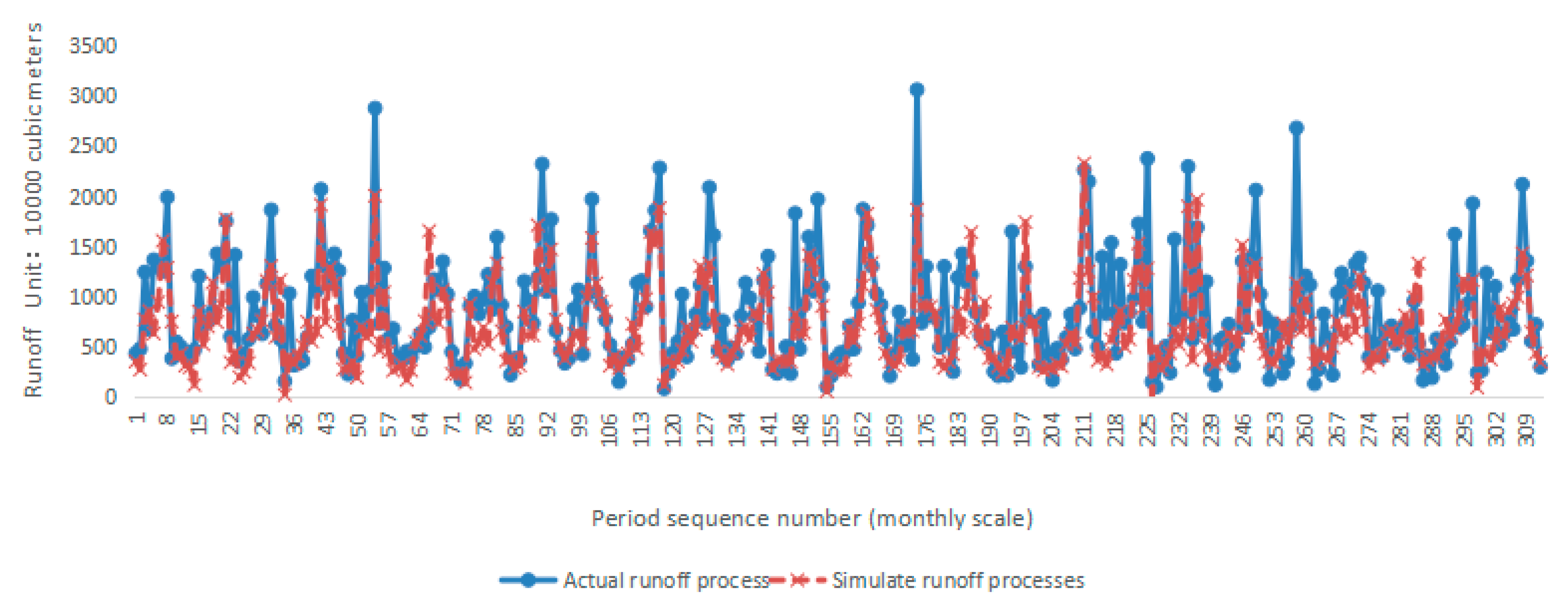
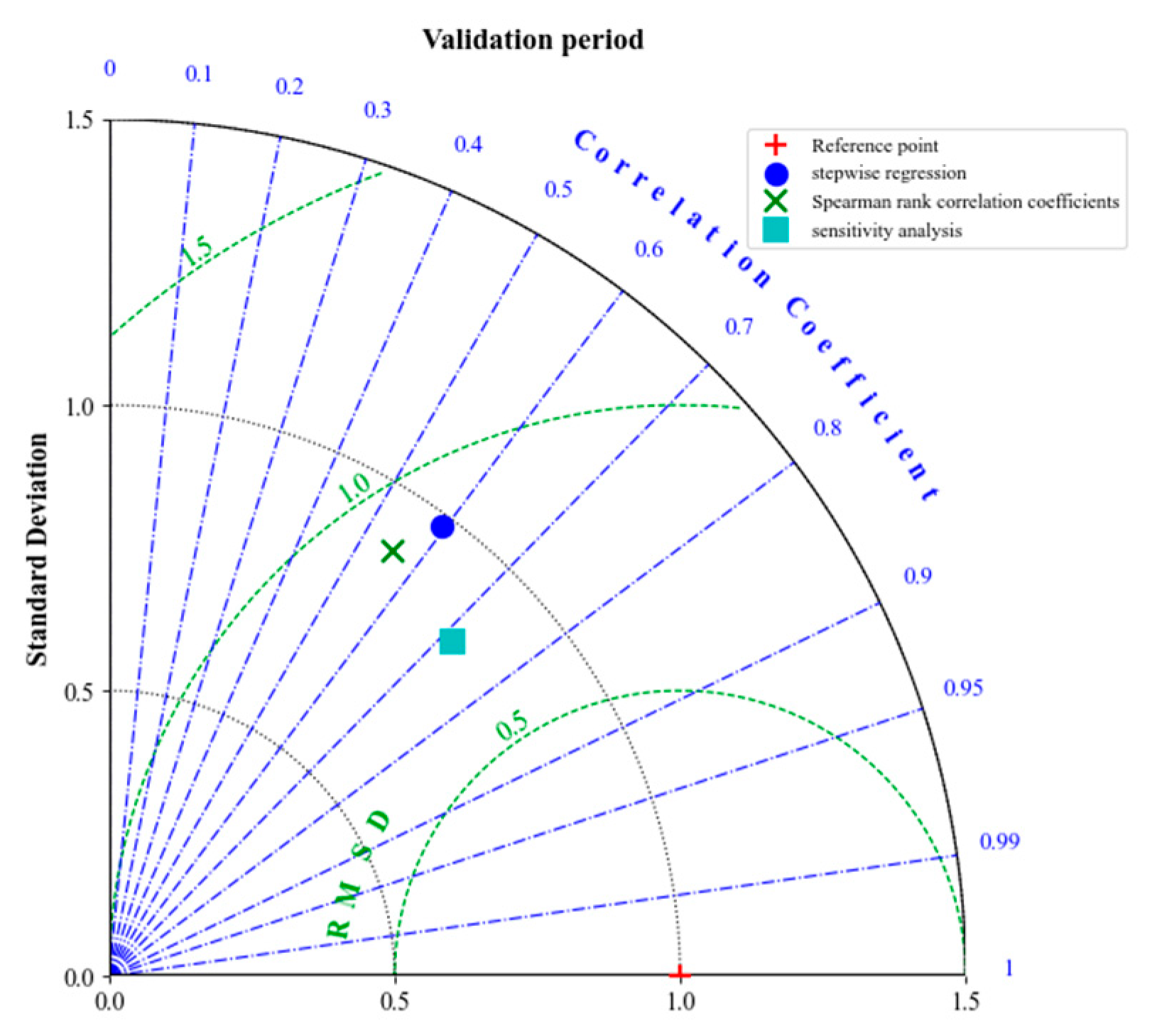
(3) According to the stepwise regression, Spearman rank correlation, and sensitivity analysis methods, a total of eight factors were selected from the significant factor set individually, resulting in three distinct multi-factor combination schemes. Utilizing an improved BP artificial neural network for simulating medium and long-term runoff in the research area, a comparison of comprehensive evaluation index values between the three schemes during both the rating period and verification period revealed that the sensitivity analysis method yielded the most effective simulation results. The comprehensive index values for this scheme were 0.636 and 0.482, respectively, during the training period and verification period. Furthermore, it was observed that these selected eight factors exhibited relatively stable sensitivities over time. Therefore, this particular multi-factor combination is chosen for predicting medium and long-term runoff in coastal areas of Jiangsu province.
The eight climate factors include the Indian Ocean Warm Pool Intensity Index, the Northern Hemisphere Vortex Area Index, and the Western Pacific Subtropical High Intensity Index from the previous month. Additionally, it comprises the Indian Ocean Warm Pool Area Index from the previous two months, the Indian Subtropical High Ridge Line Position Index, and the Indian Ocean Warm Pool Area Index from the previous three months. Furthermore, it incorporates the Indian Ocean Warm Pool Area Index from the previous five months and finally concludes with the Northern Hemisphere Vortex Intensity Index from the previous six months.
(4) The method optimizes eight pre-climate indexes suitable for the coastal area of Jiangsu Province. In the future, these optimized pre-significant factors can be directly utilized for regional runoff prediction, providing a valuable reference for formulating flood control and relief strategies, farmland irrigation management, hydropower station operations, and other disaster relief scheduling plans in the region. Moreover, this approach introduces novel perspectives for medium and long-term runoff forecasting in the region.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}