


Salinity Modeling Using Deep Learning with Data Augmentation and Transfer Learning

 ,
,  , and
, and
Abstract
1. Introduction
1.1. Background
1.2. Literature Review
1.3. Scope of the Current Work
2. Methodology
2.1. Study Location and Datasets
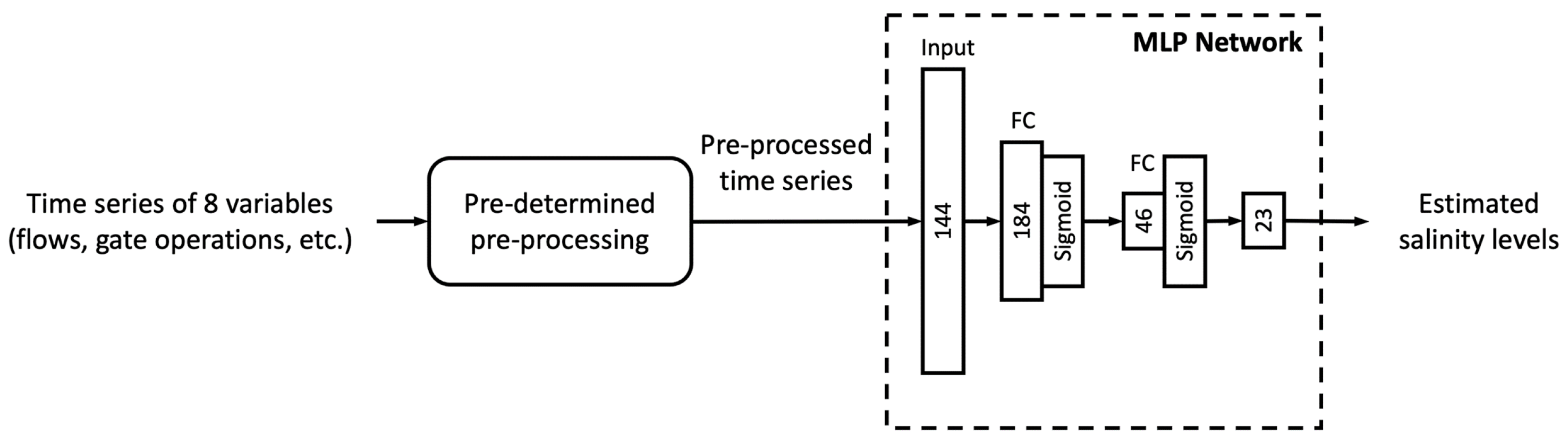
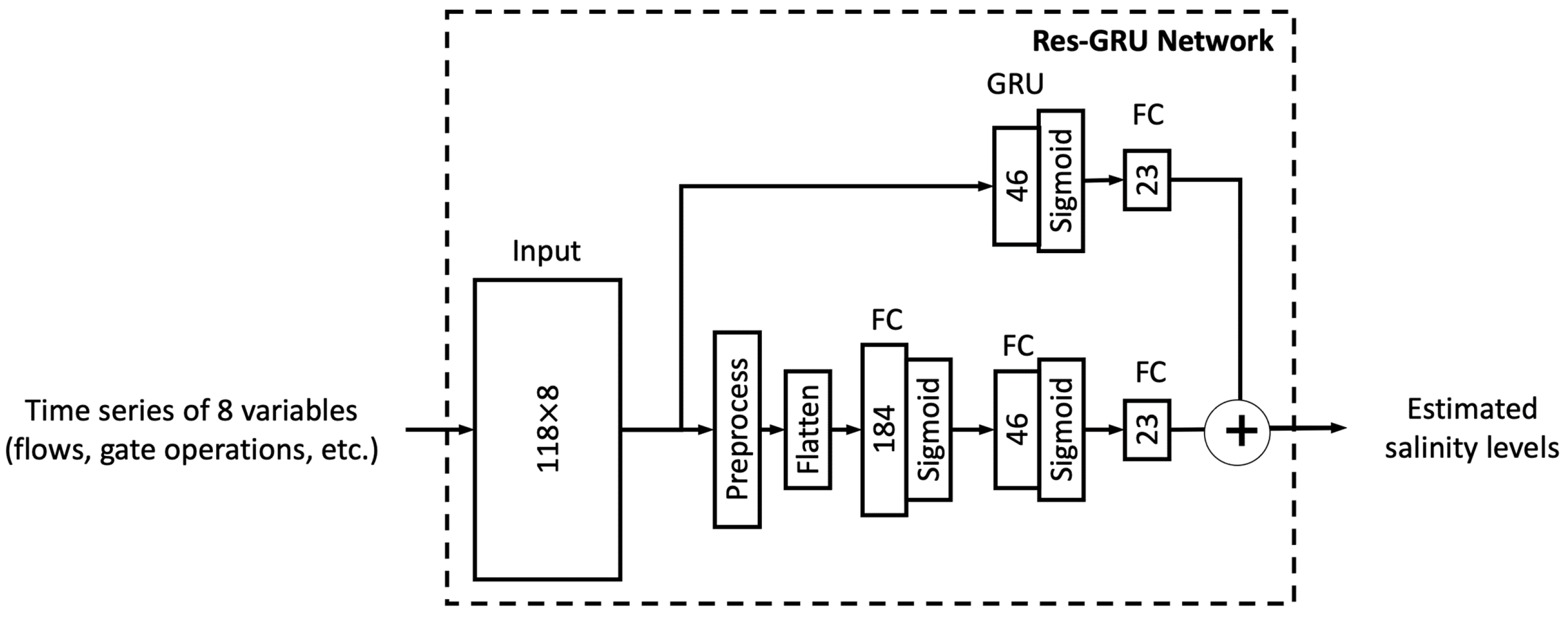
2.2. Machine Learning (ML) Models
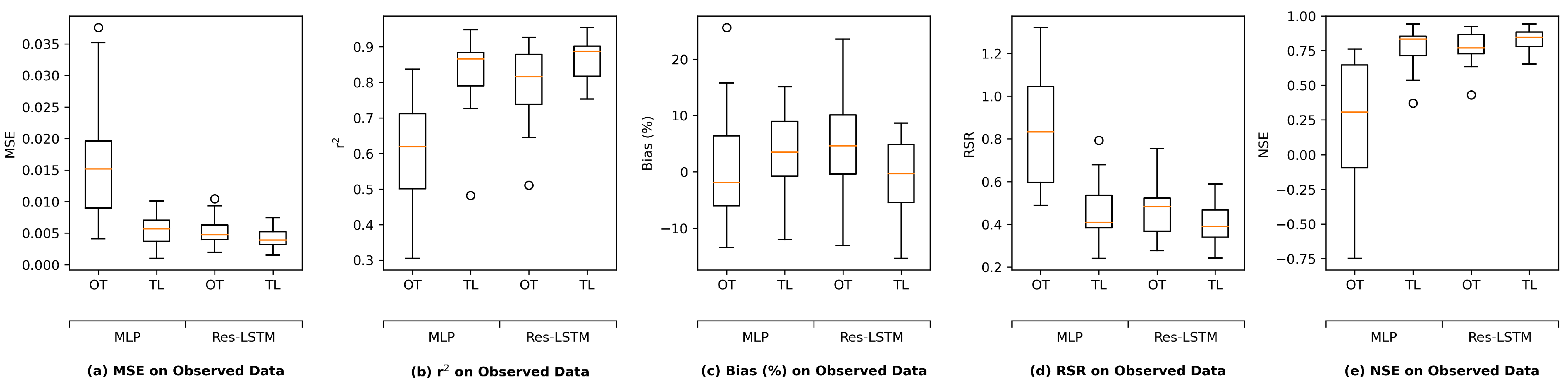
2.3. Study Metrics
2.4. Model Training and Test
2.5. Transfer Learning to Observed Data
2.6. Dashboard
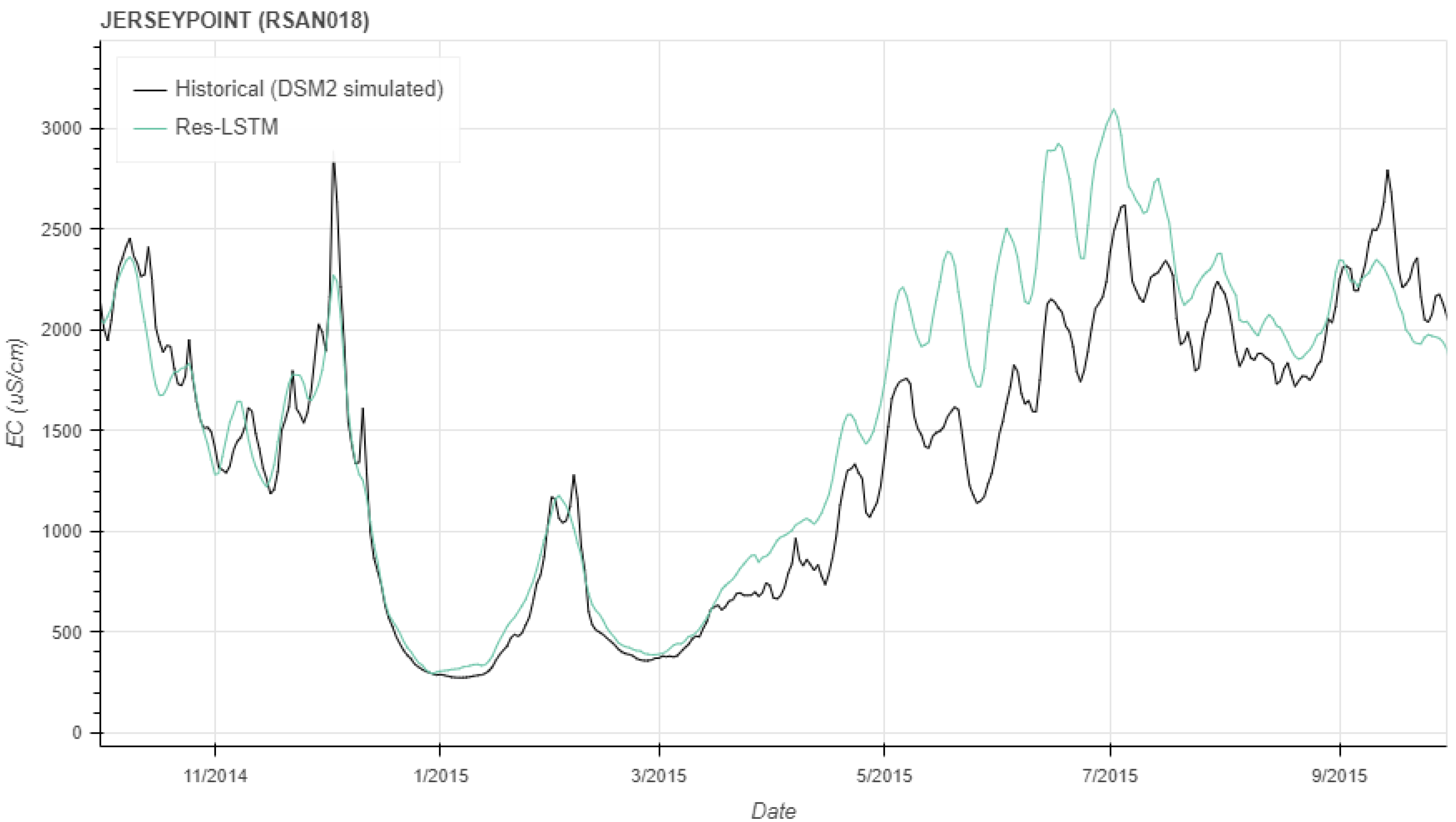
3. Results
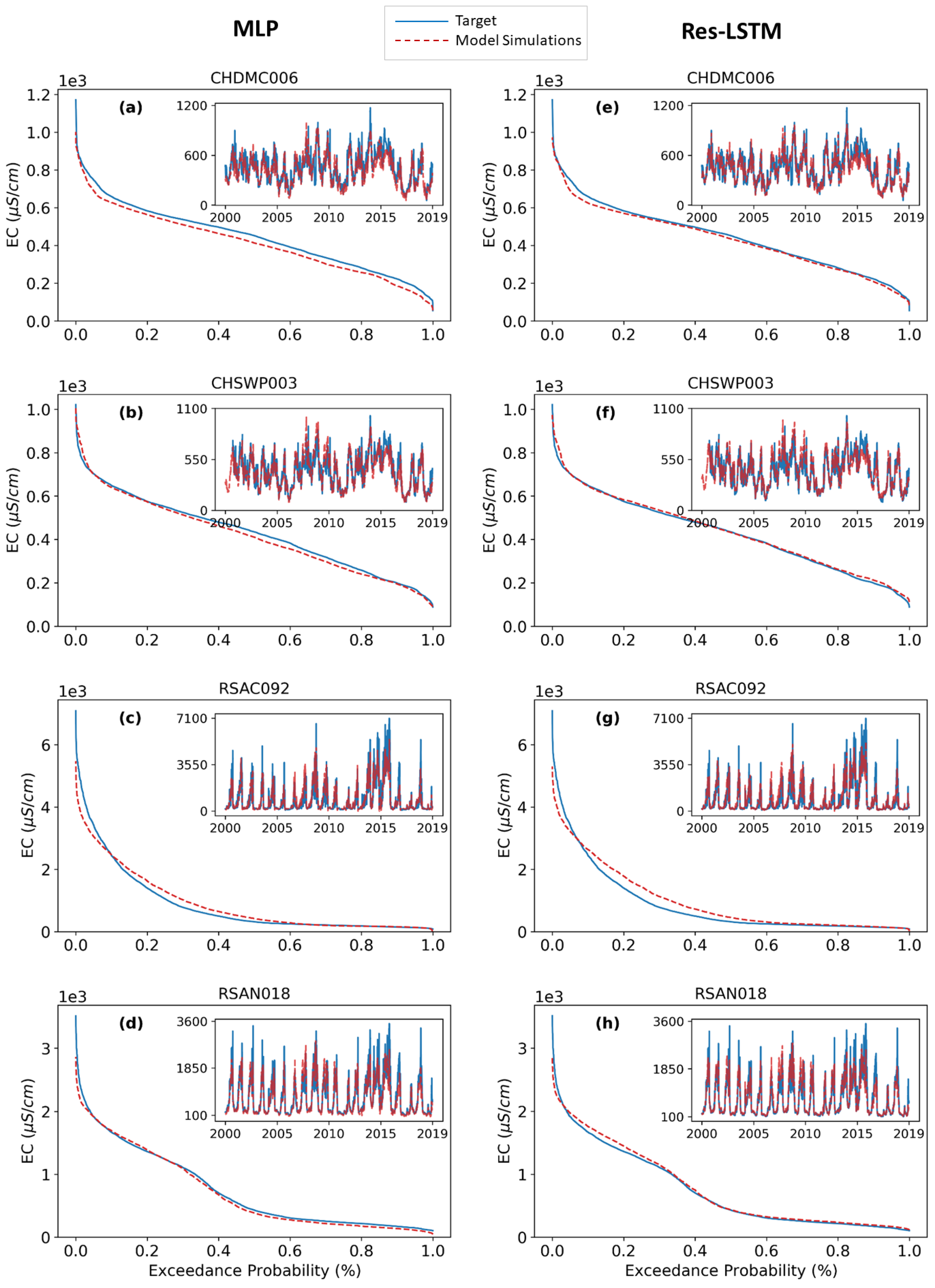
3.1. ANNs with Augmented Data
3.2. Transfer Learning
3.3. Dashboard
3.3.1. Dashboard Architecture
3.3.2. Dashboard Elements
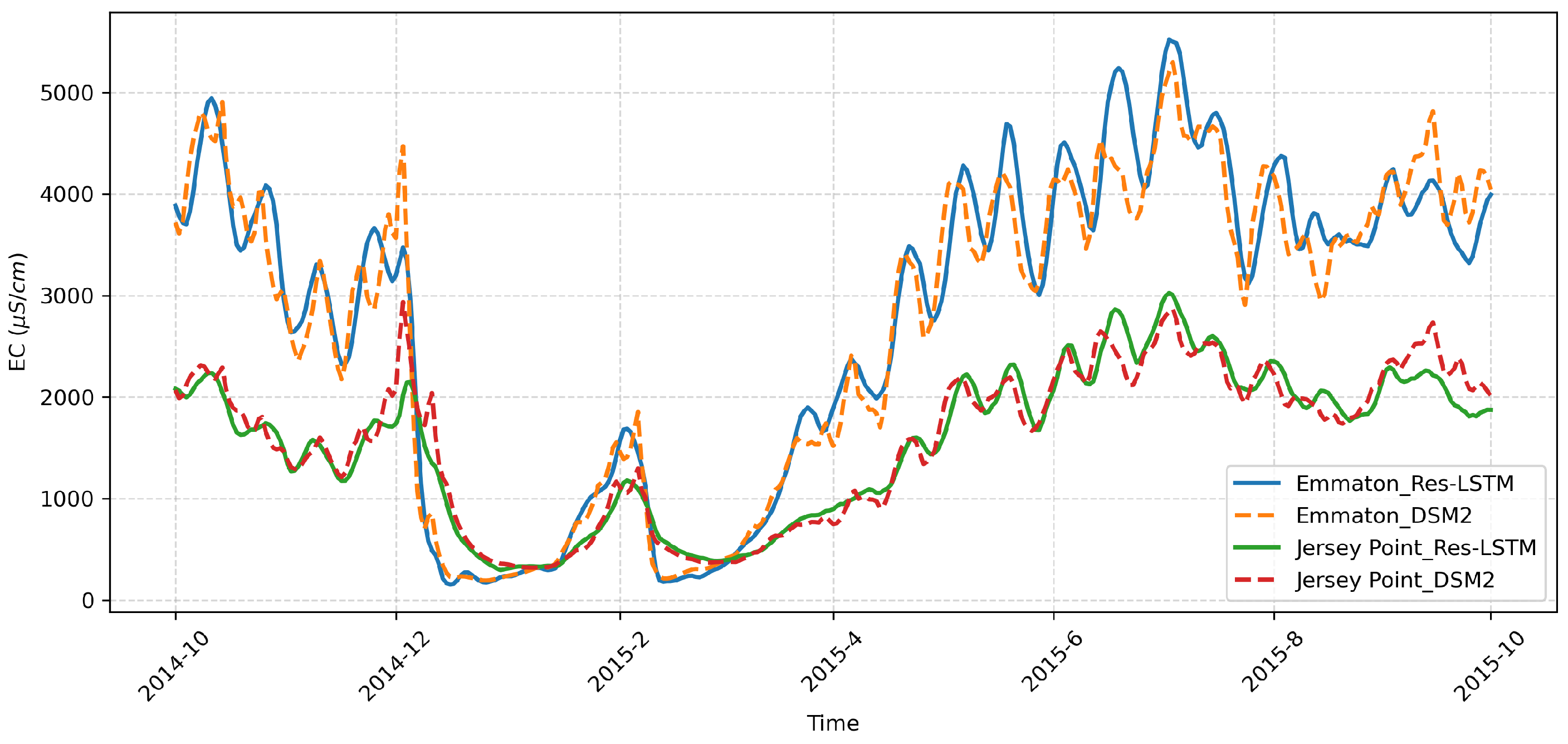
3.3.3. Dashboard Example Use Case
4. Discussions
4.1. Implications
- (a)
- Data augmentation: The study demonstrates the effectiveness of data augmentation in addressing the challenge of limited historical measurements for data-driven deep learning models. This approach enhances the performance and versatility of machine learning models by providing a more diverse and representative dataset. In practical terms, the data-augmentation method can be applied to various scientific explorations, allowing researchers to tackle complex problems with limited data.
- (b)
- Transfer learning: The introduction of transfer learning allows knowledge gained from one problem to be applied to solve a related problem. This methodology can be adapted to simulate numerous other variables relevant to water resource management (e.g., water temperature, dissolved oxygen, turbidity, and ion constituents) and the same variables for other estuarine environments.
- (c)
- Continuous model evolution: Both the data augmentation and transfer learning methods aim to incorporate augmented data into the training process, achieving improvements over the baseline model trained using observed data alone. As hydrodynamic models, salinity observations, and regulatory constraints are constantly evolving, the ability to build upon previous knowledge through transfer learning allows machine learning models to continuously adapt to the changing state of science in the Delta.
- (d)
- Machine learning-based Salinity Dashboard: The Salinity Dashboard is capable of estimating salinity data comparable to a full-featured DSM2 model. It has practical applications in real-time operations. By incorporating the Salinity Dashboard with real-time data, it can inform decision-making and improve water-management strategies. Furthermore, the efficient emulation facilitates sensitivity analyses in long-term planning studies, enabling researchers to conduct a higher number of scenario permutations.
4.2. Future Work
- (a)
- Improved utilities to modify the inputs: The Dashboard’s input modification utilities will be expanded beyond the current pre-set range. Future iterations will enable users to upload their own input datasets in various formats (e.g., text files) to provide more customized simulation scenarios.
- (b)
- Additional post-processing options: In addition to the current time series plots, the Dashboard’s outputs will be post-processed to include other useful formats such as exceedance plots and monthly averages.
- (c)
- Multi-year simulation: Instead of limiting the simulation to one year, future iterations of the Dashboard will allow for multiple years of simulation to facilitate the simulation of, for example, multi-year droughts.
- (d)
- Spatial output viewer: Incorporate a map view to show key metrics of all locations simultaneously.
- (e)
- Report renerator: Include an option to generate a template-based report with key indicators of Delta water quality.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Machine Learning Architectures






Appendix B. Additional Results




References
- Alber, M. A conceptual model of estuarine freshwater inflow management. Estuaries 2002, 25, 1246–1261. [Google Scholar] [CrossRef]
- Water Resilience Portfolio; California Natural Resources Agency: Sacramento, CA, USA, 2020; p. 141.
- Moyle, P.B.; Brown, L.R.; Durand, J.R.; Hobbs, J.A. Delta smelt: Life history and decline of a once-abundant species in the San Francisco Estuary. San Fr. Estuary Watershed Sci. 2016, 14. [Google Scholar] [CrossRef]
- Rath, J.S.; Hutton, P.H.; Chen, L.; Roy, S.B. A hybrid empirical-Bayesian artificial neural network model of salinity in the San Francisco Bay-Delta estuary. Environ. Model. Softw. 2017, 93, 193–208. [Google Scholar] [CrossRef]
- Gude, V.G. Desalination of deep groundwater aquifers for freshwater supplies–Challenges and strategies. Groundw. Sustain. Dev. 2018, 6, 87–92. [Google Scholar] [CrossRef]
- Dhakal, N.; Salinas-Rodriguez, S.G.; Hamdani, J.; Abushaban, A.; Sawalha, H.; Schippers, J.C.; Kennedy, M.D. Is desalination a solution to freshwater scarcity in developing countries? Membranes 2022, 12, 381. [Google Scholar] [CrossRef] [PubMed]
- Abdelfattah, M.; Abu-Bakr, H.A.A.; Mewafy, F.M.; Hassan, T.M.; Geriesh, M.H.; Saber, M.; Gaber, A. Hydrogeophysical and hydrochemical assessment of the northeastern coastal aquifer of Egypt for desalination suitability. Water 2023, 15, 423. [Google Scholar] [CrossRef]
- Cooley, H.; Ajami, N. Key Issues for Seawater Desalination in California: Cost and Financing; Pacific Institute: Oakland, CA, USA, 2012; pp. 1–48. [Google Scholar]
- Meng, M.; Chen, M.; Sanders, K.T. Evaluating the feasibility of using produced water from oil and natural gas production to address water scarcity in California’s Central Valley. Sustainability 2016, 8, 1318. [Google Scholar] [CrossRef]
- Badiuzzaman, P.; McLaughlin, E.; McCauley, D. Substituting freshwater: Can ocean desalination and water recycling capacities substitute for groundwater depletion in California? J. Environ. Manag. 2017, 203, 123–135. [Google Scholar] [CrossRef]
- He, M.; Zhong, L.; Sandhu, P.; Zhou, Y. Emulation of a process-based salinity generator for the sacramento–San Joaquin Delta of california via deep learning. Water 2020, 12, 2088. [Google Scholar] [CrossRef]
- CDWR. Minimum Delta Outflow Program. In Methodology for Flow and Salinity Estimates in the Sacramento–San Joaquin Delta and Suisun Marsh: 11th Annual Progress Report; CDWR: Sacramento, CA, USA, 1990. [Google Scholar]
- Denton, R.A. Accounting for antecedent conditions in seawater intrusion modeling—Applications for the San Francisco Bay-Delta. Hydraul. Eng. 1993, 1, 448–453. [Google Scholar]
- Hutton, P.H.; Rath, J.S.; Chen, L.; Ungs, M.J.; Roy, S.B. Nine decades of salinity observations in the San Francisco Bay and Delta: Modeling and trend evaluations. J. Water Resour. Plan. Manag. 2016, 142, 04015069. [Google Scholar] [CrossRef]
- CDWR. Calibration and verification of DWRDSM. In Methodology for Flow and Salinity Estimates in the Sacramento–San Joaquin Delta and Suisun Marsh: 12th Annual Progress Report; CDWR: Sacramento, CA, USA, 1991. [Google Scholar]
- Cheng, R.T.; Casulli, V.; Gartner, J.W. Tidal, residual, intertidal mudflat (TRIM) model and its applications to San Francisco Bay, California. Estuarine Coast. Shelf Sci. 1993, 36, 235–280. [Google Scholar] [CrossRef]
- DeGeorge, J.F. A Multi-Dimensional Finite Element Transport Model Utilizing a Characteristic-Galerkin Algorithm; University of California: Davis, CA, USA, 1996. [Google Scholar]
- Casulli, V.; Zanolli, P. Semi-implicit numerical modeling of nonhydrostatic free-surface flows for environmental problems. Math. Comput. Model. 2002, 36, 1131–1149. [Google Scholar] [CrossRef]
- MacWilliams, M.; Bever, A.J.; Foresman, E. 3-D simulations of the San Francisco Estuary with subgrid bathymetry to explore long-term trends in salinity distribution and fish abundance. San Franc. Estuary Watershed Sci. 2016, 14. [Google Scholar] [CrossRef]
- CDWR. Bay-Delta SCHISM: A Framework for Decision Support in the Sacramento San Joaquin Delta. In Methodology for Flow and Salinity Estimates in the Sacramento–San Joaquin Delta and Suisun Marsh: 36th Annual Progress Report; CDWR: Sacramento, CA, USA, 2015. [Google Scholar]
- Chao, Y.; Farrara, J.D.; Zhang, H.; Zhang, Y.J.; Ateljevich, E.; Chai, F.; Davis, C.O.; Dugdale, R.; Wilkerson, F. Development, implementation, and validation of a modeling system for the San Francisco Bay and Estuary. Estuarine Coast. Shelf Sci. 2017, 194, 40–56. [Google Scholar] [CrossRef]
- Gaagai, A.; Aouissi, H.A.; Bencedira, S.; Hinge, G.; Athamena, A.; Heddam, S.; Gad, M.; Elsherbiny, O.; Elsayed, S.; Eid, M.H.; et al. Application of water quality indices, machine learning approaches, and GIS to identify groundwater quality for irrigation purposes: A case study of Sahara Aquifer, Doucen Plain, Algeria. Water 2023, 15, 289. [Google Scholar] [CrossRef]
- Gad, M.; Saleh, A.H.; Hussein, H.; Elsayed, S.; Farouk, M. Water Quality Evaluation and Prediction Using Irrigation Indices, Artificial Neural Networks, and Partial Least Square Regression Models for the Nile River, Egypt. Water 2023, 15, 2244. [Google Scholar] [CrossRef]
- Gad, M.; Gaagai, A.; Eid, M.H.; Szucs, P.; Hussein, H.; Elsherbiny, O.; Elsayed, S.; Khalifa, M.M.; Moghanm, F.S.; Moustapha, M.E.; et al. Groundwater Quality and Health Risk Assessment Using Indexing Approaches, Multivariate Statistical Analysis, Artificial Neural Networks, and GIS Techniques in El Kharga Oasis, Egypt. Water 2023, 15, 1216. [Google Scholar] [CrossRef]
- Sandhu, N.; Finch, R. Application of artificial neural networks to the Sacramento-San Joaquin Delta. In Estuarine and Coastal Modeling; ASCE: Reston, FL, USA, 1995; pp. 490–504. [Google Scholar]
- Wilbur, R.; Munevar, A. Integration of CALSIM and Artificial Neural Networks Models for Sacramento–San Joaquin Delta Flow-Salinity Relationships. In Methodology for Flow and Salinity Estimates in the Sacramento–San Joaquin Delta and Suisun Marsh: 22nd Annual Progress Report; CDWR: Sacramento, CA, USA, 2001. [Google Scholar]
- Mierzwa, M. CALSIM versus DSM2 ANN and G-model Comparisons. In Methodology for Flow and Salinity Estimates in the Sacramento–San Joaquin Delta and Suisun Marsh: 23rd Annual Progress Report; CDWR: Sacramento, CA, USA, 2002. [Google Scholar]
- Seneviratne, S.; Wu, S. Enhanced Development of Flow-Salinity Relationships in the Delta Using Artificial Neural Networks: Incorporating Tidal Influence. In Methodology for Flow and Salinity Estimates in the Sacramento–San Joaquin Delta and Suisun Marsh: 28th Annual Progress Report; CDWR: Sacramento, CA, USA, 2007. [Google Scholar]
- Jayasundara, N.C.; Seneviratne, S.A.; Reyes, E.; Chung, F.I. Artificial neural network for Sacramento–San Joaquin Delta flow–salinity relationship for CalSim 3.0. J. Water Resour. Plan. Manag. 2020, 146, 04020015. [Google Scholar] [CrossRef]
- Chen, L.; Roy, S.B.; Hutton, P.H. Emulation of a process-based estuarine hydrodynamic model. Hydrol. Sci. J. 2018, 63, 783–802. [Google Scholar] [CrossRef]
- Qi, S.; Bai, Z.; Ding, Z.; Jayasundara, N.; He, M.; Sandhu, P.; Seneviratne, S.; Kadir, T. Enhanced Artificial Neural Networks for Salinity Estimation and Forecasting in the Sacramento–San Joaquin Delta of California. J. Water Resour. Plan. Manag. 2021, 147, 04021069. [Google Scholar] [CrossRef]
- Qi, S.; He, M.; Bai, Z.; Ding, Z.; Sandhu, P.; Zhou, Y.; Namadi, P.; Tom, B.; Hoang, R.; Anderson, J. Multi-Location Emulation of a Process-Based Salinity Model Using Machine Learning. Water 2022, 14, 2030. [Google Scholar] [CrossRef]
- Qi, S.; He, M.; Bai, Z.; Ding, Z.; Sandhu, P.; Chung, F.; Namadi, P.; Zhou, Y.; Hoang, R.; Tom, B.; et al. Novel Salinity Modeling Using Deep Learning for the Sacramento–San Joaquin Delta of California. Water 2022, 14, 3628. [Google Scholar] [CrossRef]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time series data augmentation for deep learning: A survey. arXiv 2020, arXiv:2002.12478. [Google Scholar]
- Bandara, K.; Hewamalage, H.; Liu, Y.H.; Kang, Y.; Bergmeir, C. Improving the accuracy of global forecasting models using time series data augmentation. Pattern Recognit. 2021, 120, 108148. [Google Scholar] [CrossRef]
- Wang, F.; Tian, D.; Lowe, L.; Kalin, L.; Lehrter, J. Deep learning for daily precipitation and temperature downscaling. Water Resour. Res. 2021, 57, e2020WR029308. [Google Scholar] [CrossRef]
- Kim, H.I.; Han, K.Y. Urban flood prediction using deep neural network with data augmentation. Water 2020, 12, 899. [Google Scholar] [CrossRef]
- Li, X.; Grandvalet, Y.; Davoine, F.; Cheng, J.; Cui, Y.; Zhang, H.; Belongie, S.; Tsai, Y.H.; Yang, M.H. Transfer learning in computer vision tasks: Remember where you come from. Image Vis. Comput. 2020, 93, 103853. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Brodzicki, A.; Piekarski, M.; Kucharski, D.; Jaworek-Korjakowska, J.; Gorgon, M. Transfer learning methods as a new approach in computer vision tasks with small datasets. Found. Comput. Decis. Sci. 2020, 45, 179–193. [Google Scholar] [CrossRef]
- Ruder, S.; Peters, M.E.; Swayamdipta, S.; Wolf, T. Transfer learning in natural language processing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Tutorials; 2019; pp. 15–18. Available online: https://www.ruder.io/state-of-transfer-learning-in-nlp/ (accessed on 1 May 2023).
- Sullivan, P.; Shibano, T.; Abdul-Mageed, M. Improving automatic speech recognition for non-native english with transfer learning and language model decoding. arXiv 2022, arXiv:2202.05209. [Google Scholar]
- Mamyrbayev, O.; Alimhan, K.; Oralbekova, D.; Bekarystankyzy, A.; Zhumazhanov, B. Identifying the influence of transfer learning method in developing an end-to-end automatic speech recognition system with a low data level. East.-Eur. J. Enterp. Technol. 2022, 1, 84–92. [Google Scholar] [CrossRef]
- Willard, J.D.; Read, J.S.; Appling, A.P.; Oliver, S.K.; Jia, X.; Kumar, V. Predicting water temperature dynamics of unmonitored lakes with meta-transfer learning. Water Resour. Res. 2021, 57, e2021WR029579. [Google Scholar] [CrossRef]
- Zhao, X.; Luo, T.; Jin, H. Predicting diffusion coefficients of binary and ternary supercritical water mixtures via machine and transfer learning with deep neural network. Ind. Eng. Chem. Res. 2022, 61, 8542–8550. [Google Scholar] [CrossRef]
- Kimura, N.; Yoshinaga, I.; Sekijima, K.; Azechi, I.; Baba, D. Convolutional neural network coupled with a transfer-learning approach for time-series flood predictions. Water 2019, 12, 96. [Google Scholar] [CrossRef]
- Prechelt, L. Automatic early stopping using cross validation: Quantifying the criteria. Neural Netw. 1998, 11, 761–767. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Yao, Y.; Rosasco, L.; Caponnetto, A. On early stopping in gradient descent learning. Constr. Approx. 2007, 26, 289–315. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In International Conference on Machine Learning; PMLR: Sydney, Australia, 2017; pp. 3145–3153. [Google Scholar]
- Ancona, M.; Ceolini, E.; Öztireli, C.; Gross, M. Towards better understanding of gradient-based attribution methods for deep neural networks. arXiv 2017, arXiv:1711.06104. [Google Scholar]
- Lu, L.; Meng, X.; Mao, Z.; Karniadakis, G.E. DeepXDE: A deep learning library for solving differential equations. SIAM Rev. 2021, 63, 208–228. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Roh, D.M.; He, M.; Bai, Z.; Sandhu, P.; Chung, F.; Ding, Z.; Qi, S.; Zhou, Y.; Hoang, R.; Namadi, P.; et al. Physics-Informed Neural Networks-Based Salinity Modeling in the Sacramento–San Joaquin Delta of California. Water 2023, 15, 2320. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario Index | Scenario Description |
|---|---|
| Baseline | Historical DSM2 run from 1990 to 2019 |
| 1 | Historical DSM2 run with Sacramento River inflows shifted forward by 15 days |
| 2 | Historical DSM2 run with Sacramento River inflows shifted backward by 15 days |
| 3 | Historical DSM2 run with Sacramento River inflows scaled down by 20% |
| 4 | Historical DSM2 run with Sacramento River inflows scaled up by 20% |
| 5 | Historical DSM2 run with San Joaquin River inflows shifted forward by 15 days |
| 6 | Historical DSM2 run with San Joaquin River inflows shifted backward by 15 days |
| 7 | Historical DSM2 run with San Joaquin River inflows scaled down by 20% |
| 8 | Historical DSM2 run with San Joaquin River inflows scaled up by 20% |
| 9 | Historical DSM2 run with Delta Cross Channel Gates closed all the time |
| 10 | Historical DSM2 run with Delta Cross Channel Gates open all the time |
| 11 | Historical DSM2 run with Suisun Marsh Salinity Control Gates closed all the time |
| 12 | Historical DSM2 run with Suisun Marsh Salinity Control Gates open all the time |
| Dashboard Element | Description |
|---|---|
| 1. Water Year Selector | Select the water year for simulation. This tool simulates one water year at a time, where antecedent inputs are assumed to be historical conditions. Note: the modified inputs are not saved in memory. For example, if a user modifies the inputs for 2014, and then changes the simulation to 2015, the scaling factors for 2014 are reverted to historical conditions and 2015 inputs will be modified to reflect the scaling configurations shown on the Dashboard. |
| 2. Input Location Selector | Select the boundary input to modify. This dashboard supports the modification of major Delta boundary conditions, including Northern Flows, Pumping, San Joquin River Flow, and EC boundaries for the San Joaquin River and Sacramento River. Refer to Table 1 in [33] for descriptions of the input features. |
| 3. Input Scaler | Sliders to scale the selected Delta boundary condition from the baseline (historical) values. The values shown next to the slider for each month indicate the scale factor. The scale factor uniformly scales the daily values of the boundary condition for a given month. The default scale factor of 1 sets the inputs equal to historical conditions for that month. A scale factor of 1.2 uniformly scales the daily values of that month to 120% of historical values and a scale factor of 0.8 uniformly scales the daily values of that month to 80% of historical values. |
| 4. Input Data Plot | Plot of the input features. The blue line indicates the user-modified (i.e., scaled) input feature and the light grey line shows the historical value. |
| 5. Output Location Selector | Select the output location for which to display outputs. Key water quality locations (including compliance locations) are included. See Figure 1 for details of the available output locations. |
| 6. Output Location Salinity Plot | Plot of the output locations. The black line represents the historical DSM2 simulation, and the various colored lines represent the outcomes from the salinity emulator, based on the user-modified inputs. |
| 7. Machine Learning Architecture Selection | Select the architectures to use in the emulator. See Section 2.2 for details. |
| 8. Data Export Options | Options to export the inputs and outputs of the simulation in .csv format for the selected water year. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, S.; He, M.; Hoang, R.; Zhou, Y.; Namadi, P.; Tom, B.; Sandhu, P.; Bai, Z.; Chung, F.; Ding, Z.; et al. Salinity Modeling Using Deep Learning with Data Augmentation and Transfer Learning. Water 2023, 15, 2482. https://doi.org/10.3390/w15132482
Qi S, He M, Hoang R, Zhou Y, Namadi P, Tom B, Sandhu P, Bai Z, Chung F, Ding Z, et al. Salinity Modeling Using Deep Learning with Data Augmentation and Transfer Learning. Water. 2023; 15(13):2482. https://doi.org/10.3390/w15132482
Chicago/Turabian StyleQi, Siyu, Minxue He, Raymond Hoang, Yu Zhou, Peyman Namadi, Bradley Tom, Prabhjot Sandhu, Zhaojun Bai, Francis Chung, Zhi Ding, and et al. 2023. "Salinity Modeling Using Deep Learning with Data Augmentation and Transfer Learning" Water 15, no. 13: 2482. https://doi.org/10.3390/w15132482
APA StyleQi, S., He, M., Hoang, R., Zhou, Y., Namadi, P., Tom, B., Sandhu, P., Bai, Z., Chung, F., Ding, Z., Anderson, J., Roh, D. M., & Huynh, V. (2023). Salinity Modeling Using Deep Learning with Data Augmentation and Transfer Learning. Water, 15(13), 2482. https://doi.org/10.3390/w15132482