1. Introduction
A sewer network is one of the most important components of the urban water infrastructure [
1]. This network plays a vital role in the collection and transport of wastewater and stormwater from the urban landscape to reduce the incidence of flooding, mitigate environmental pollution and protect public health [
2,
3]. However, sewer networks in operation are subjected to different intrinsic and extrinsic factors that contribute to their deterioration and failures [
4], thereby preventing the network from realizing its intended objectives. Failures in the sewer system often result in debilitating impacts on infrastructure, the environment, and public health with a significant economic burden on society [
5]. Therefore, investments in maintenance programs that reduce the incidence of sewer pipe failure are a priority in many countries [
6,
7].
Maintenance management approaches can be generally categorized into
Reactive Maintenance (RaM),
Preventive Maintenance (PvM), and
Predictive Maintenance (PdM) [
8]. The RaM, or run-to-failure, is the simplest approach that is only implemented when break(s) in sewer pipes occur. This reactive maintenance approach is also the least effective one. The PvM, or proactive maintenance, is implemented based on predetermined intervals (usually time or event-based triggers). This approach is more effective than the RaM method because many failures can be prevented. However, several unnecessary corrective actions are usually implemented [
8]. The PdM approach mainly focuses on assessing sewer pipes based on condition assessment. In this way historical data are combined with analytic and prediction tools to predict the condition of sewer pipes, and maintenance strategies are scheduled.
A predictive maintenance strategy cannot be implemented effectively without a deep understanding of the system, and an efficient water management strategy requires a proper condition assessment framework [
9]. Many condition assessment models have been developed in literature and they can be divided into three main groups:
physical,
statistical, and
machine learning models [
10]. The physical models assess the deterioration process based on the influence of the physical properties and the mechanical processes in the sewer pipes [
11,
12]. However, these types of models are suitable for the construction period and initial operation, and data for the simulation of the deterioration mechanism are not always available [
13]. The statistical models (e.g., linear regression, cohort survival model, or Markov chains) can produce good accuracy but they are limited in revealing the physical relationship between limited physical factors and the target [
14]. In recent times, machine learning (ML) algorithms have been widely used to model sewer pipe deterioration because they are capable of handling the complex non-linear interlinked processes involved in the deterioration of sewer pipes [
15]. However, a large number of input factors and observations are needed to improve the accuracy of these models [
6].
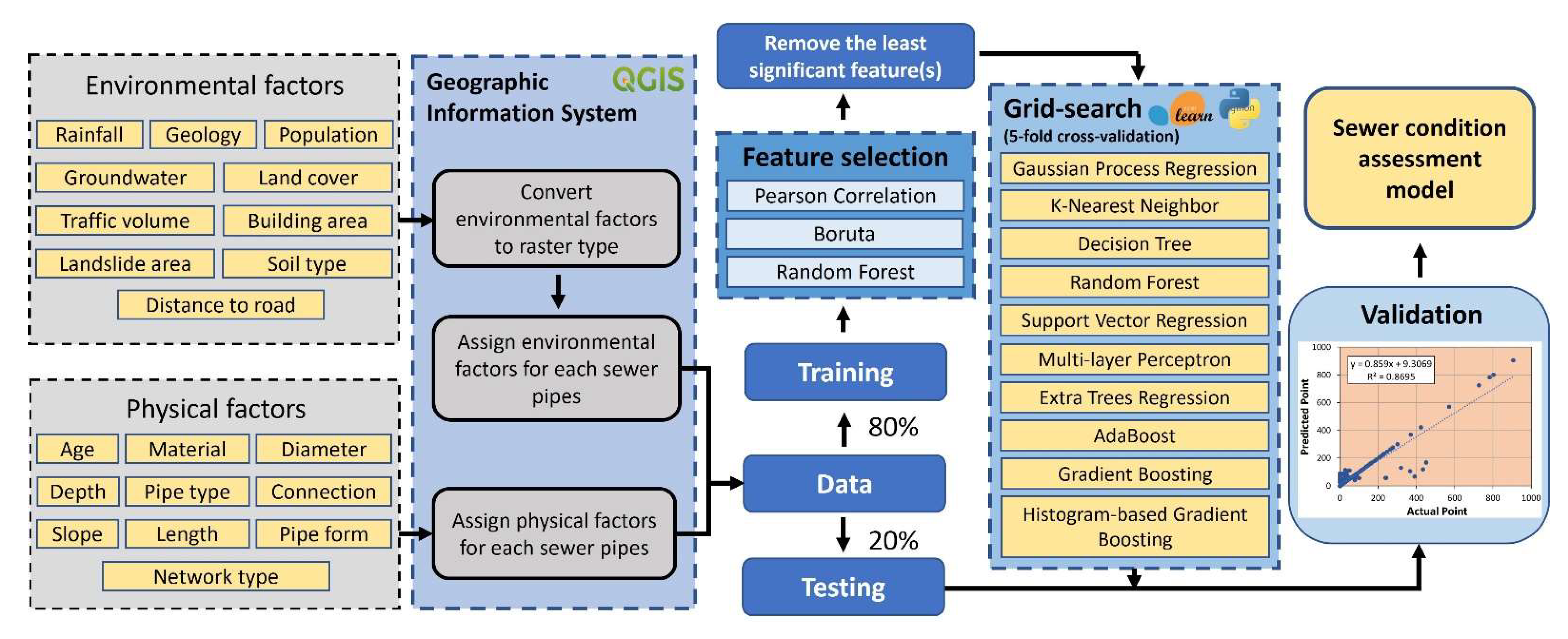
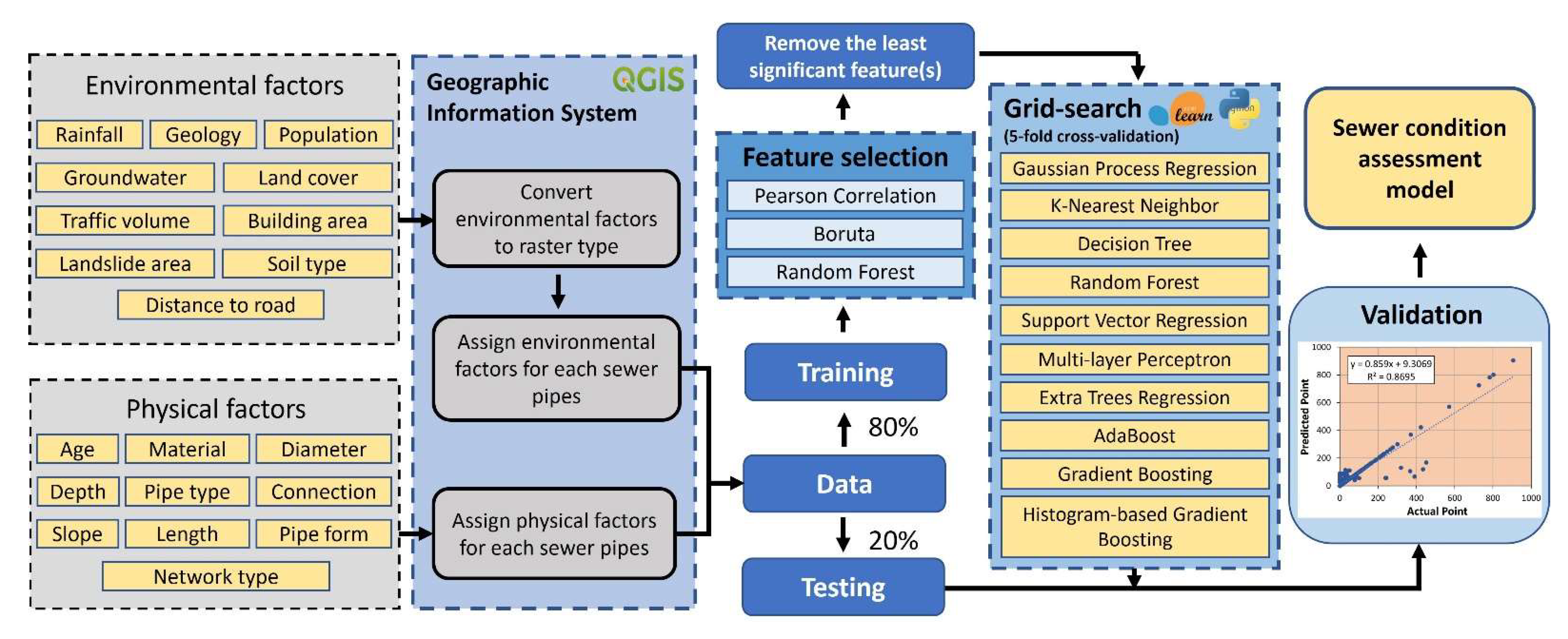
The output of a mathematical model in general, and an ML model in particular, significantly depends on the quality of input data. Factors considered for building condition assessment models can be divided into three groups:
physical,
operational, and
environmental factors [
16]. In general, physical data on most sewer networks are readily available. The same can be said about data on environmental factors. However, when it comes to operational data, it is most often scarce [
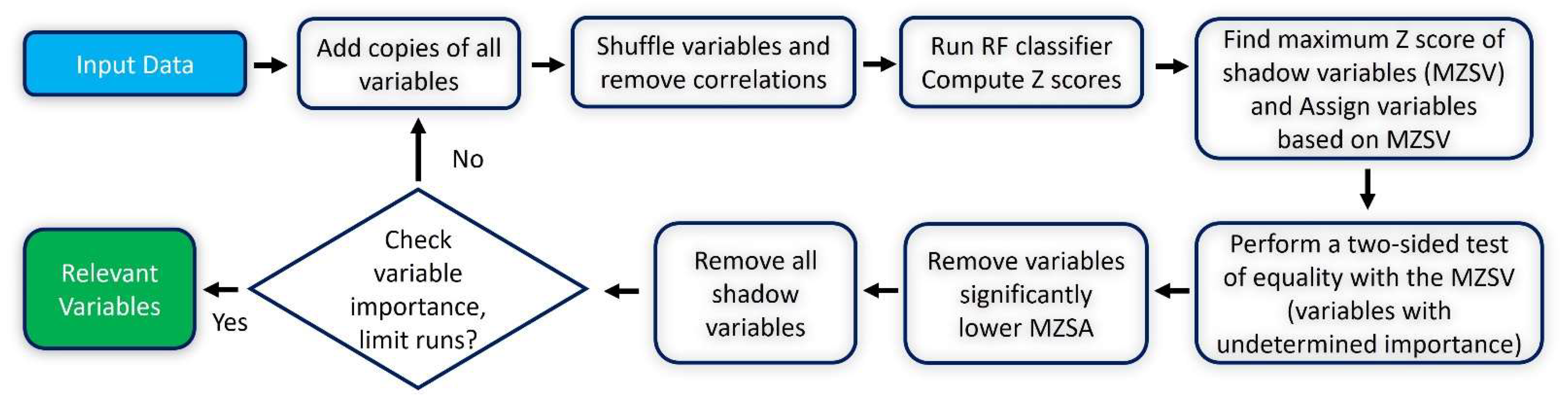
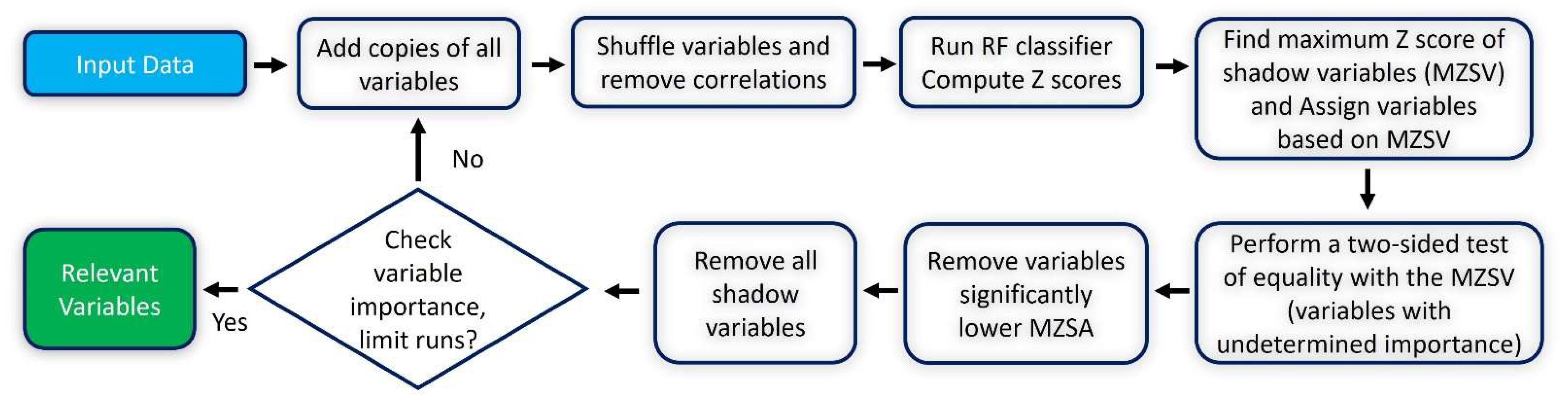
9]. Therefore, considering the quality of input data plays a vital role in improving the ML models’ predictive performance. The importance of the input data should be assessed to prioritize inputs while collecting and preparing data before building condition assessment models. Therefore, defining significant factors for building condition assessment models is a key task to improve the efficiency of the predictive models. This task is accomplished via feature selection methods that can be grouped into
filter,
wrapper, and
embedded methods [
17]. The filter methods assess the importance of input variables, mainly based on their statistical properties and relationship with the output variable. The wrapper methods select a sensitive subset of features by adding and removing subsets based on the performance of the model. In the embedded methods, the effectiveness of input variables is assessed by tuning predictive models [
17]. The important degree of different feature selection methods may be incompatible due to randomness in selecting and combining subsets [
18]. In this study, all three types of feature selection are investigated, and the insignificant features are eliminated based on a consensus of the three methods used.
Closed-circuit television (CCTV) is the most widely used method for assessing the condition of the sewer network because it can directly provide sewer pipes statements with very high accuracy [
19]. To inspect the sewer pipes’ status, a camera is put inside pipelines or drains without needing to conduct more invasive methods like digging, removing walls, or flooring to gain access to plumbing. Based on the recovered CCTV videos, the trained inspectors can monitor the status of sewers in real-time (while controlling the camera inside pipes) or offline (after finishing the inspection). Depending on the status (e.g., roots, sediments, cracks, deformations), the local and global damaged score can be assigned for the particular sewer pipe and rehabilitation schedules and be prioritized [
20]. However, this method is time-consuming and expensive because workers need to inspect sewer pipes individually. As a result, only a small fraction of all sewer pipes, depending on their role and importance, are inspected during a specific period [
21]. This data can be used to construct sewer condition models using ML algorithms, and derived ML models can be used to predict the sewer’s status for the entire network.
Although ML models used for regression problems have been successfully applied in many fields [
22,
23], their application in sewer status prediction is still limited. Moreover, no ML model is the best in all cases for modeling sewer deterioration and a comprehensive comparison of prediction performance between these models needs to be investigated. In the literature the influence of factors on sewer condition is still controversial, and the determination of the significance of these factors is valuable for local water utilities to prioritize their maintenance and rehabilitation activities. This work is an attempt to partly fill these gaps by developing ML models for sewer condition status prediction and assessing the importance of factors affecting sewer condition. In this study, ten state-of-the-art ML algorithms are explored to predict the damage score of the sewer network in Ålesund city, Norway. Ten physical factors (i.e., age, diameter, depth, slope, length, pipe type, material, network type, pipe form, and connection type) and ten environmental factors (i.e., rainfall, geology, landslide area, population, land use, building area, groundwater level, traffic volume, distance to road, and soil type) were used for training ML models. The best model is selected to predict the sewer’s damage score and it can help water engineers/workers predict sewer status on the large scale in a short time. Consequently, the model effectively supports water network management and maintenance. The final condition assessment model can help local water utilities/managers to have an overview of the status of the sewer network and support maintenance strategies in the future.
The rest of the paper is organized as follows:
Section 2 describes the study area and data used. The overview of the feature selection techniques, the basic theory of used algorithms, the criteria for evaluating the developed models, and the framework for modeling the condition of sewer pipes are also discussed in this section.
Section 3 presents and discusses the results. Finally,
Section 4 presents the conclusions of the work.
3. Results and Discussions
3.1. Feature Selection
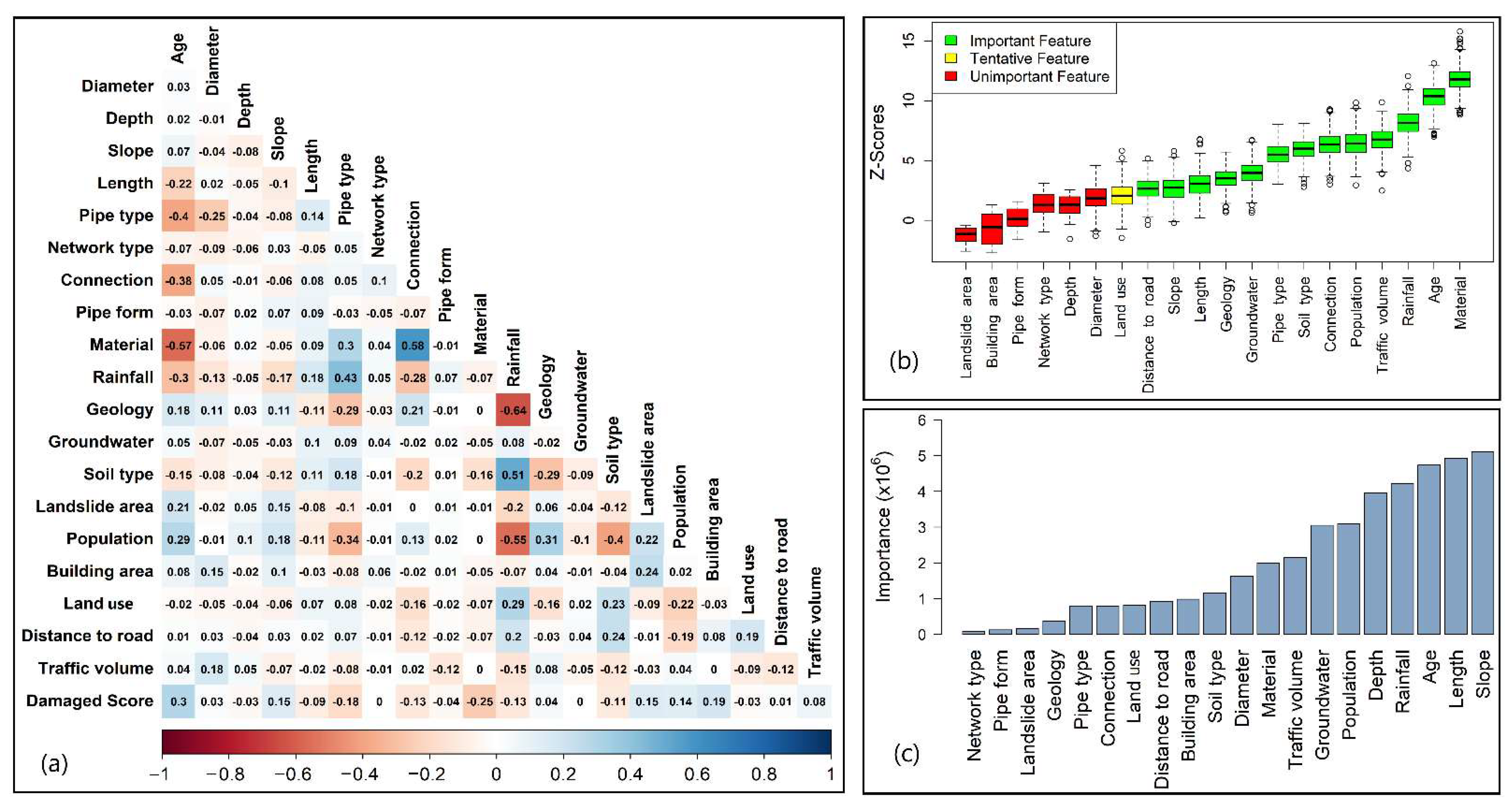
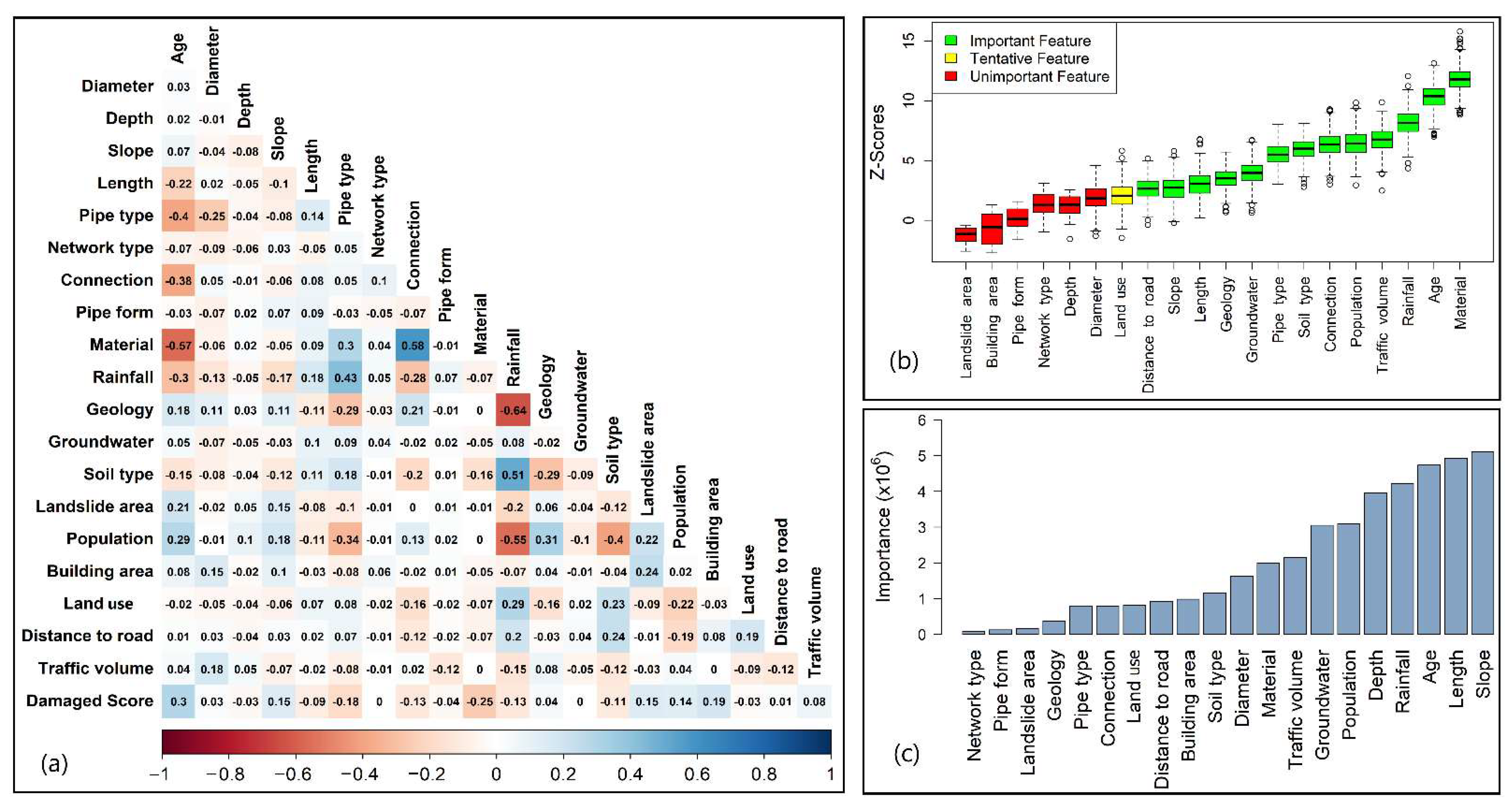
Results of feature selection using the filter, wrapper, and embedded methods are shown in
Figure A2. The results revealed slight differences in determining the most significant factors by each feature selection method. For instance, while the RF feature selection method identifies slope as the most significant factor, followed by length, both the Pearson correlation and the Boruta methods identify age (PR = 0.30) and material (PR = −0.25) as the most significant factors. The Boruta method also identifies age (Z-score = 12) and material (Z-score = 10) as the most significant factors for sewer damage. In
Figure A2a, the negative values represent the inverse relationships between physical/environmental variables and a sewer’s damaged scores, and vice versa. A positive correlation between a continuous input variable and the output shows that when the values of the input increase, the value of the output increase as well [
66]. For example, the sewer’s age has a positive correlation (PR = 0.30) with the sewer’s damaged score, showing that when the age of the sewer pipe increases (old pipes) the damaged score of the sewer pipe will rises (worse condition). Material has a negative correlation (PR = −0.25) with the damaged score indicating that sewer pipes in concrete material are more durable than sewer pipes in polypropylene and PVC materials.
In contrast, there is a less significant difference between the feature selection methods in terms of the least important determinations of sewer condition. For example, the Pearson correlation coefficients revealed network type and groundwater do not affect the sewer pipe condition (PRs = 0.00). Two factors associated with distance to road (PR = 0.01), land use and depth (PRs = −0.03), and diameter (PRs = 0.03) are the six lowest significant factors (
Figure A2a). For the Boruta method, landslide area, building area, pipe form, network type, depth, and diameter were assessed as insignificant factors (
Figure A2b). Network type, pipe form, landslide area, geology, pipe type, and connection were identified as the least significant factors in the RF feature selection method (
Figure A2c).
Table 3 summarizes the importance of the factors from each feature selection method, where the number represents the important degree (1: the highest importance, 20: the lowest importance). The same important factors, which have similar PR values, are denoted by the slash. For example, the rainfall factor and connection factor have the same importance. In conclusion, all feature selection methods show that network type is the least significant factor. Therefore, this factor was eliminated from the dataset before building the condition assessment models.
3.2. Model Comparison
The optimal hyperparameters used for tuning the ML models are shown in
Table A2. The performance of ten ML models was compared based on the training and validation phases as presented in
Table 4.
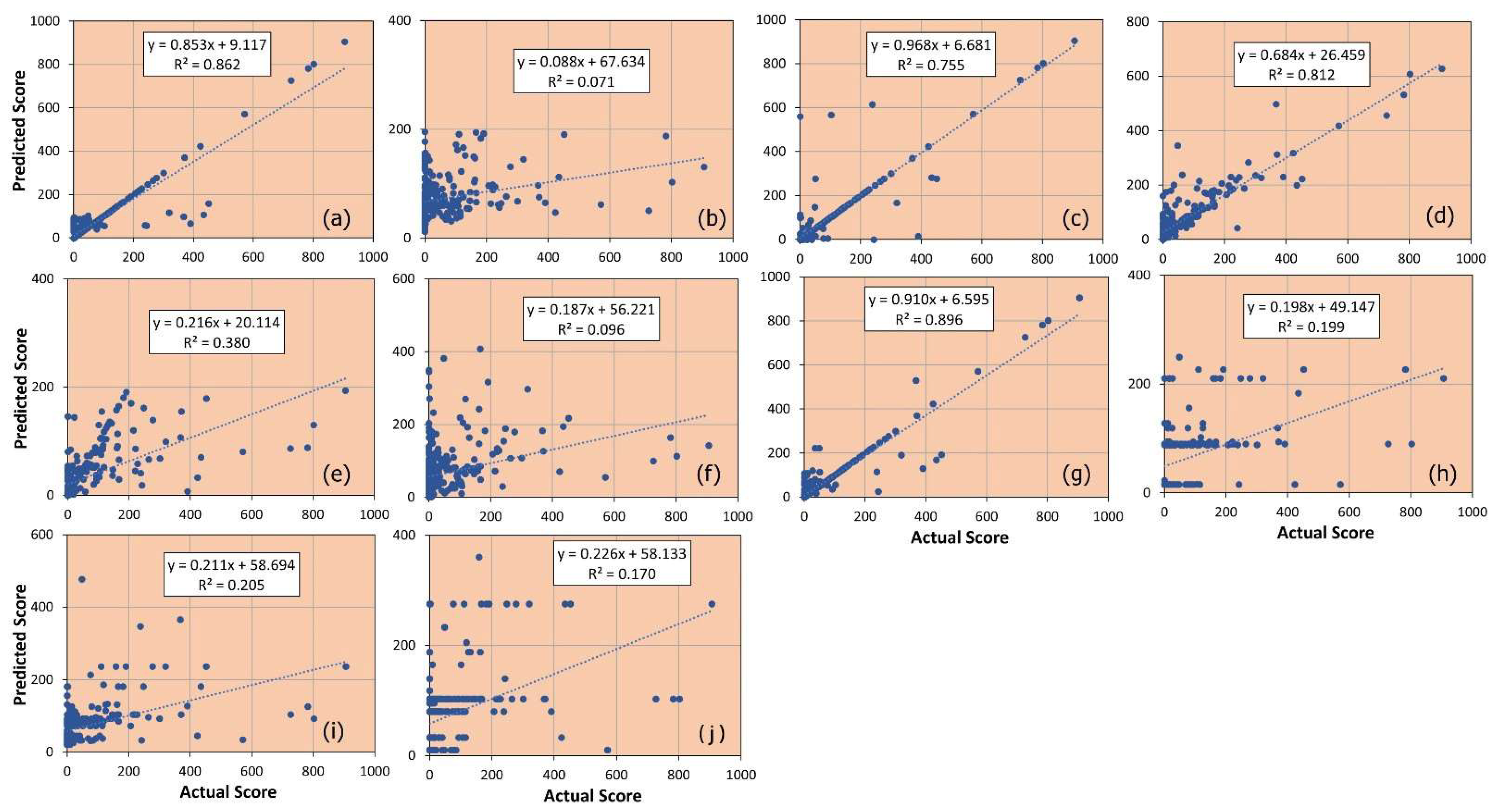
The results in
Table 4 show that the GPR, DT, and ETR models fit very well with the training dataset (the values of R
2 and errors are equal to 1.0 and 0.0, respectively). In contrast, the KNN model performed poorly in predicting the sewers’ damage scores (R
2 is almost equal to zero) indicating the worst ML model. The predictive capability of the ML models on the testing dataset is presented in
Figure A3.
In general, predictive models have been assessed as effective tools if they can effectively predict unseen data that are not used for model construction. Therefore, the validation data are used to assess the constructed ML models. In the validation phase, the ETR has the best performance (R2 = 0.90, MAE = 11.37, RMSE = 40.75), followed by the GPR (R2 = 0.86, MAE = 14.36, RMSE = 46.95) and the RF model (R2 = 0.81, MAE = 30.59, RMSE = 58.19). The KNN (R2 = 0.07, MAE = 76.07, RMSE = 122.96) and MLP (R2 = 0.10, MAE = 73.93, RMSE = 126.07) performed poorly in predicting the condition status of the sewer pipes.
Even though all ensembles ETR, RF, HGB, AdaBoost, and GB use the DT as the base learner, their predictive performance is significantly different. For instance, the ETR and RF remarkably improve the predictive performance of the original DT algorithm (R2 = 0.76, MAE = 15.19, RMSE = 69.96). In contrast, the HGB (R2 = 0.17, MAE = 64.18, RMSE = 117.10), AdaBoost (R2 = 0.20, MAE = 58.86, RMSE = 113.15), and GB (R2 = 0.20, MAE = 63.20, and RMSE = 113.45) significantly reduce the predictive capability of the DT algorithm. These results show that the adaptive boosting and gradient boosting techniques are unsuitable approaches for the dataset in the study area; in contrast, the randomly generated threshold method (in the ETR algorithm) or the bootstrap aggregation method (in the RF algorithm) is a more suitable option.
The prediction performance of the KNN model mainly depends on the number of neighbors that were obtained based on similar characteristics [
44]; limited data in the study area may not provide enough information for the KNN algorithm to effectively distinguish clusters resulting in the low prediction performance. The GPR model with high interpolating ability can deal with high-dimensional input for the complex process of sewer deterioration in the study area [
38].
In this study, the MLP algorithm has a low prediction capability in modeling sewer pipes’ damage scores. This agrees with a previous study in which the neural network-based models have lower performance in regression problems [
67]. Similarly, the prediction capabilities of KNN, SVM, AdaBoost, GB, and HGB models were low in both training and validation datasets. The reason is that there are several sewer pipes that have excessive damage score values (over 1000); meanwhile, the majority of sewer pipes (approximately 90%) have damage score values below 1000. To test the prediction ability of ML algorithms in distinguishing these values, we prioritized using the original dataset. The results showed that the overmentioned models did not effectively distinguish the excessive values of sewer pipes, indicating they are unsuitable for the study area. In conclusion, among the constructed models, the ETR is the most suitable ML algorithm for modeling the sewer conditions in the study area.
The constructed ML algorithms have been ranked using the TOPSIS method and the results are shown in
Table 5. According to these results, the ETR is the most suitable ML algorithm and the KNN is the worst ML algorithm for modeling the sewer’s condition in Ålesund city.
Although sewer damage scores can be used to predict sewer status using regression-based ML models they present varied levels of accuracy (
Table 4). This can be attributed to the skewness of damage score data, which affects the predictive performance of the models due to the large variability [
68,
69]. To address this problem, sewer damage scores are aggregated into classes and the regression problem is converted into a classification problem. It is therefore recommended that future studies consider the classification-based approach to ML models for sewer condition assessment.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}