


Flood Susceptibility Mapping Using Remote Sensing and Integration of Decision Table Classifier and Metaheuristic Algorithms

 , ,
, ,
Abstract
1. Introduction
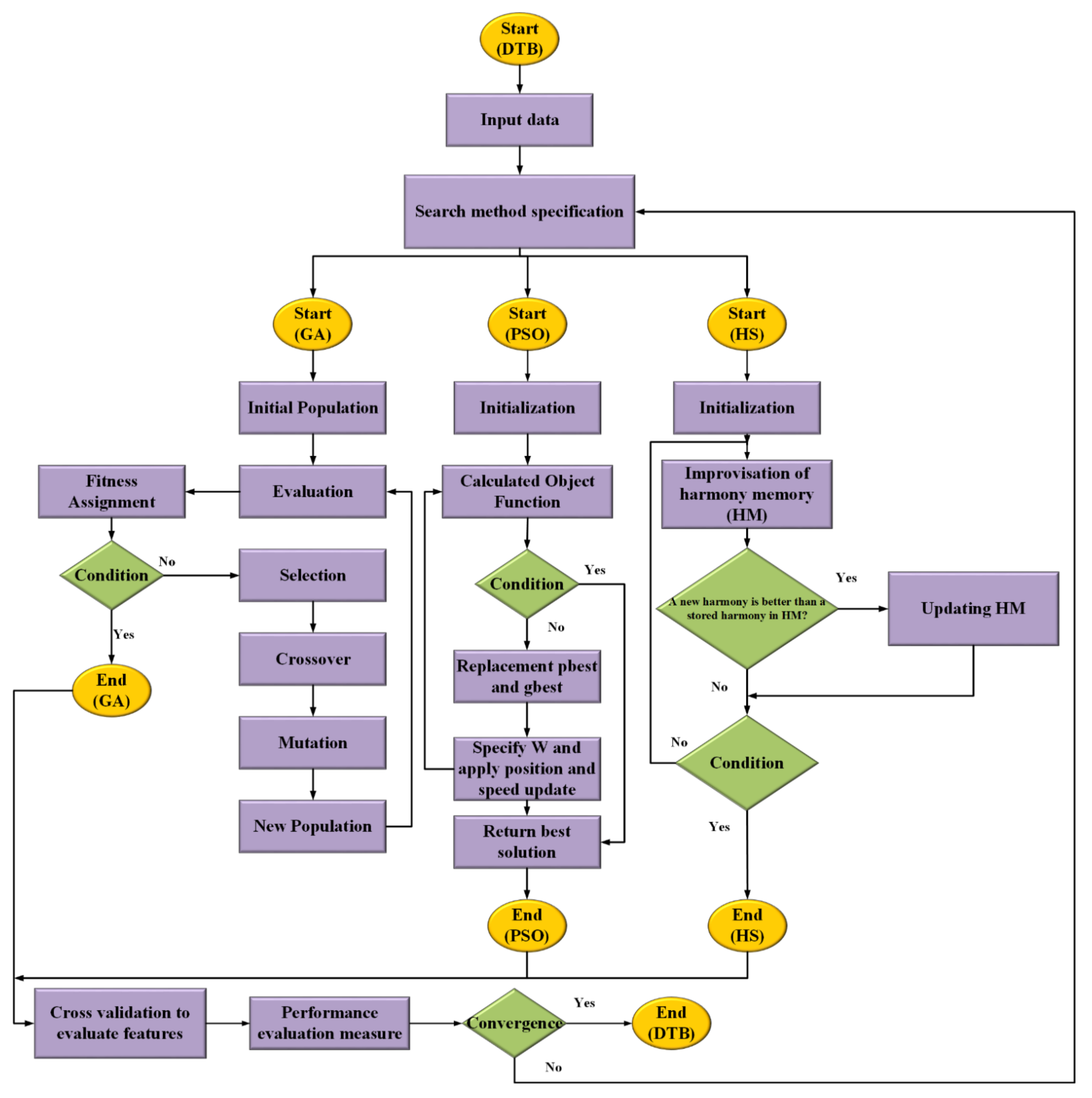
2. Methodology

3. Material and Methods
3.1. Materials
3.1.1. Study Area
3.1.2. Flood Detection and Inventory
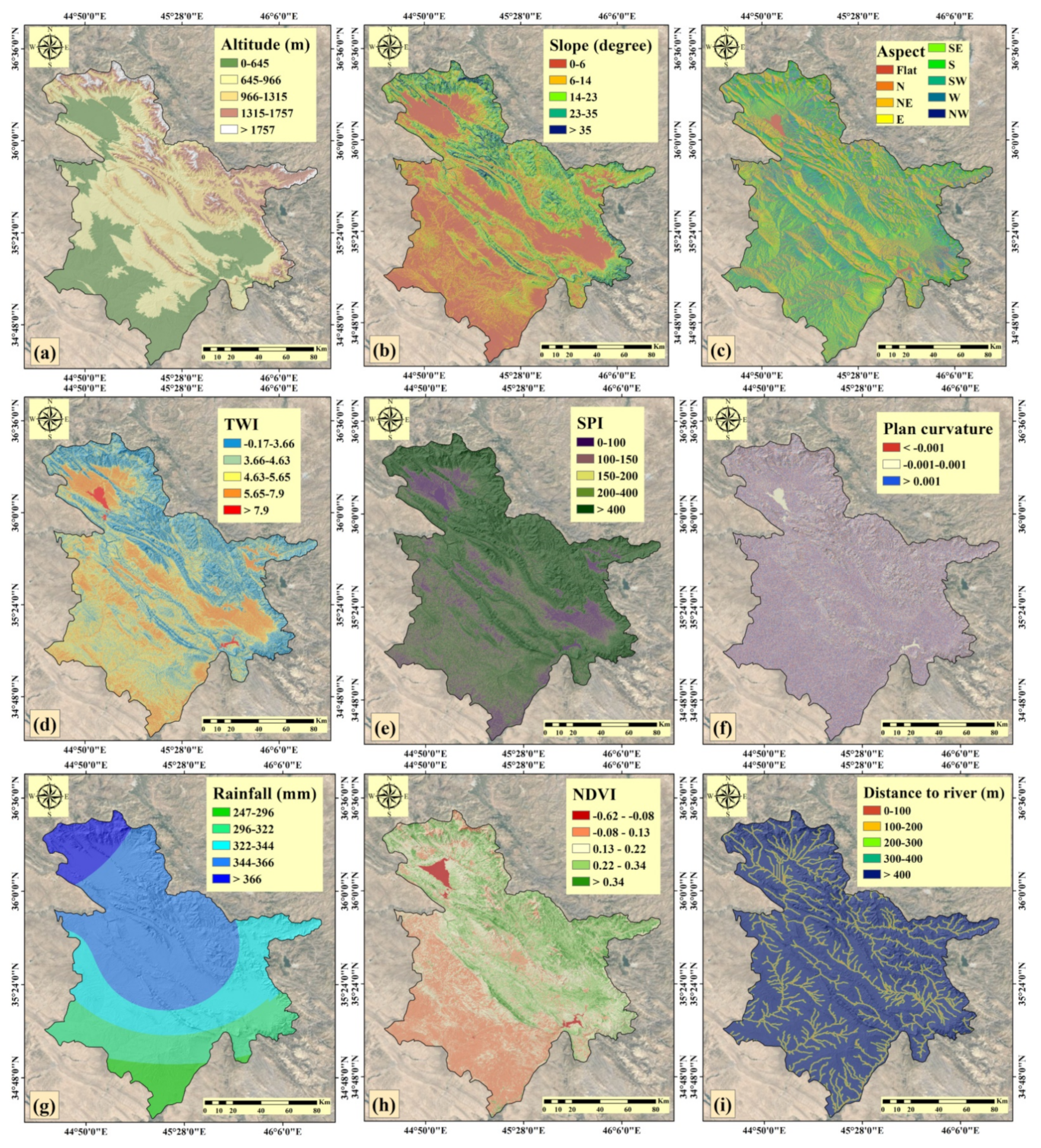
3.1.3. Conditioning Factors
- Altitude
- Slope
- Slope aspect
- Topographic wetness index (TWI)
- Stream power index (SPI)
- Plan curvature
- Rainfall
- Normalized difference vegetation index (NDVI)
- Distance from the river
- Land cover
- Geology
3.2. Methods
3.2.1. Certainty Factor (CF) Method
3.2.2. Pairwise Consistency Method
3.2.3. Decision Table (DTB) Classifier
3.2.4. Genetic Algorithm (GA)
3.2.5. Particle Swarm Optimization (PSO) Algorithm
3.2.6. Harmony Search (HS) Algorithm
3.2.7. Hybrid Algorithms
3.2.8. Validation Methods
4. Results
4.1. Results of Pairwise Consistency
4.2. Results of CF Method
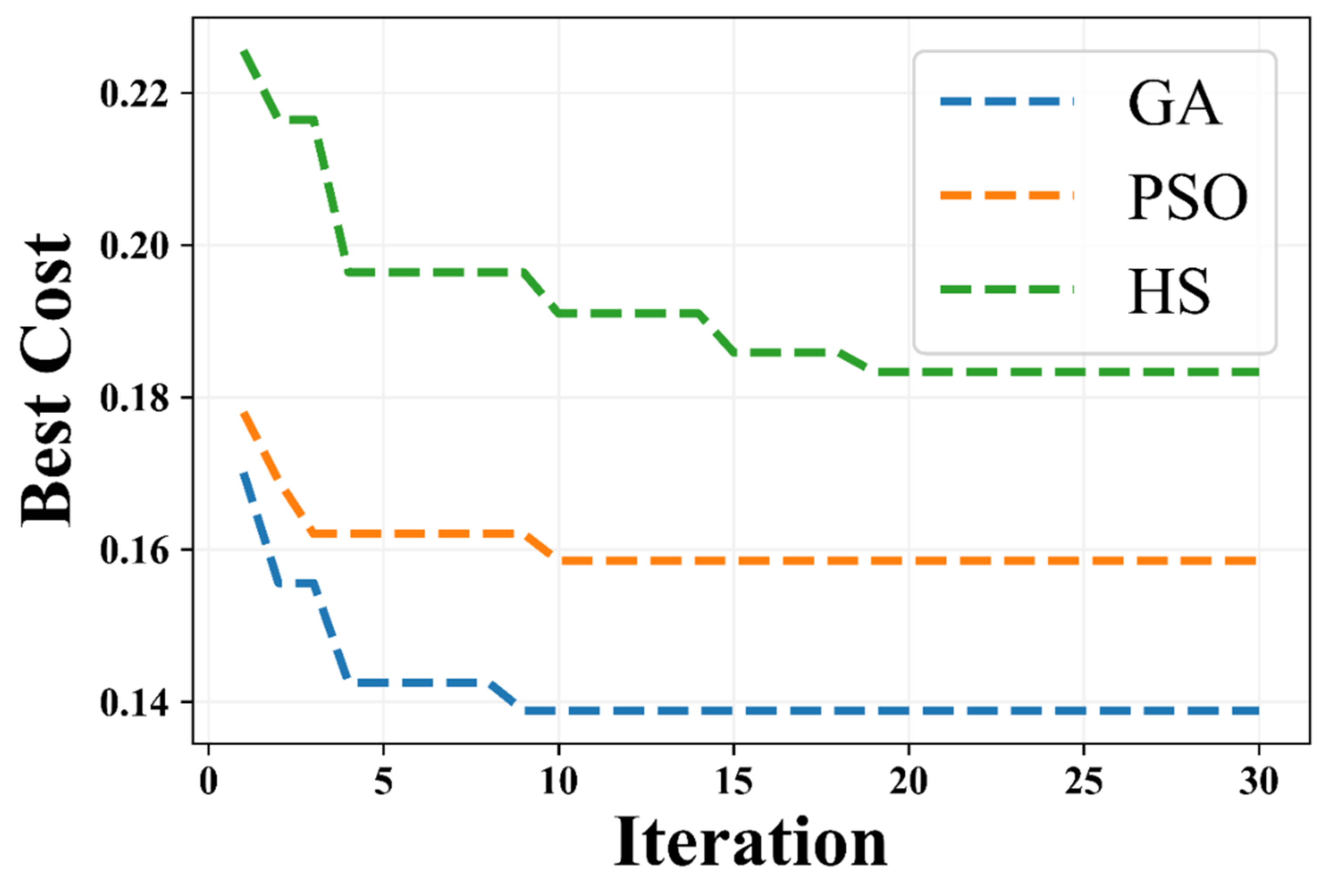
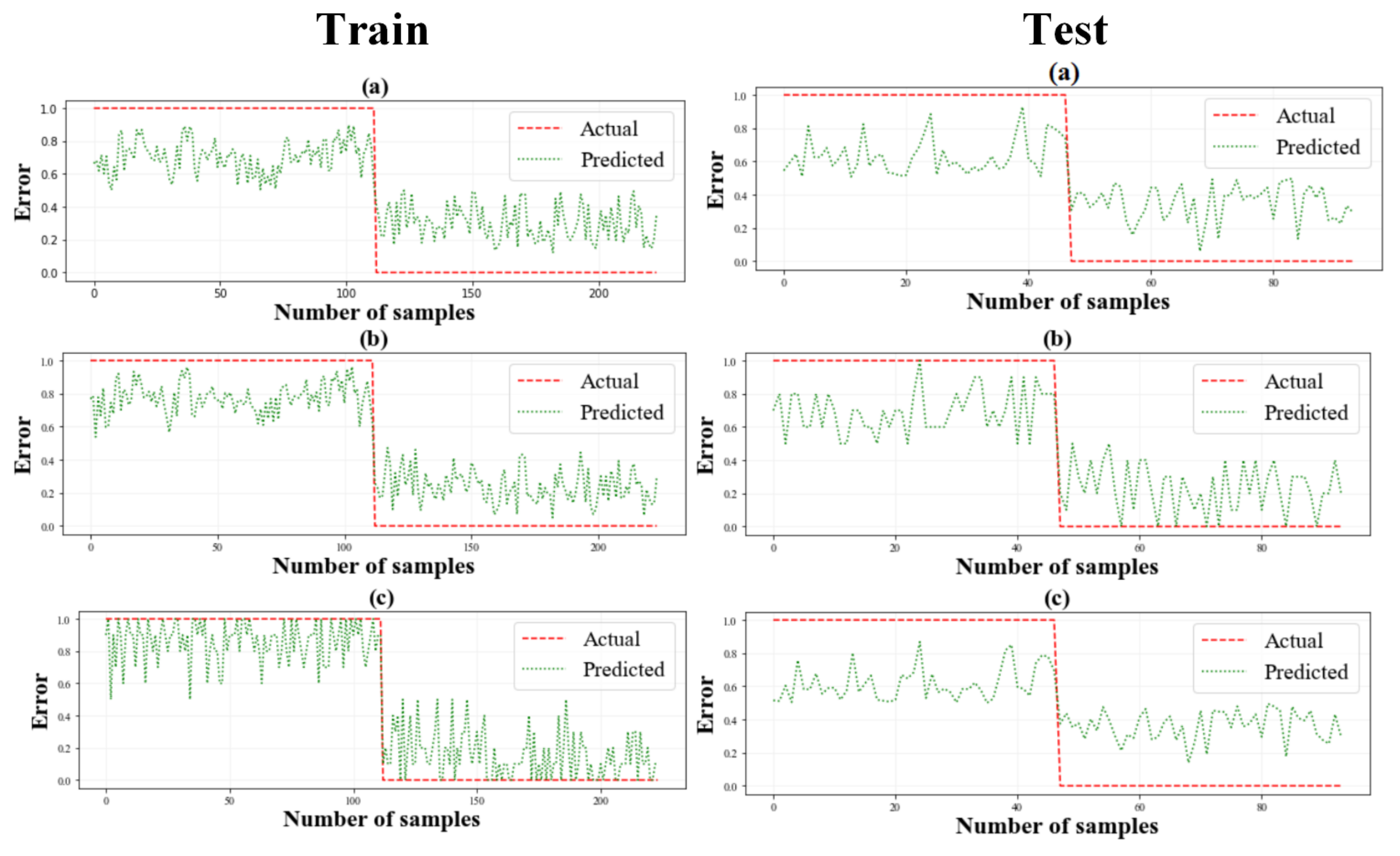
4.3. Results of Hybrid Modeling
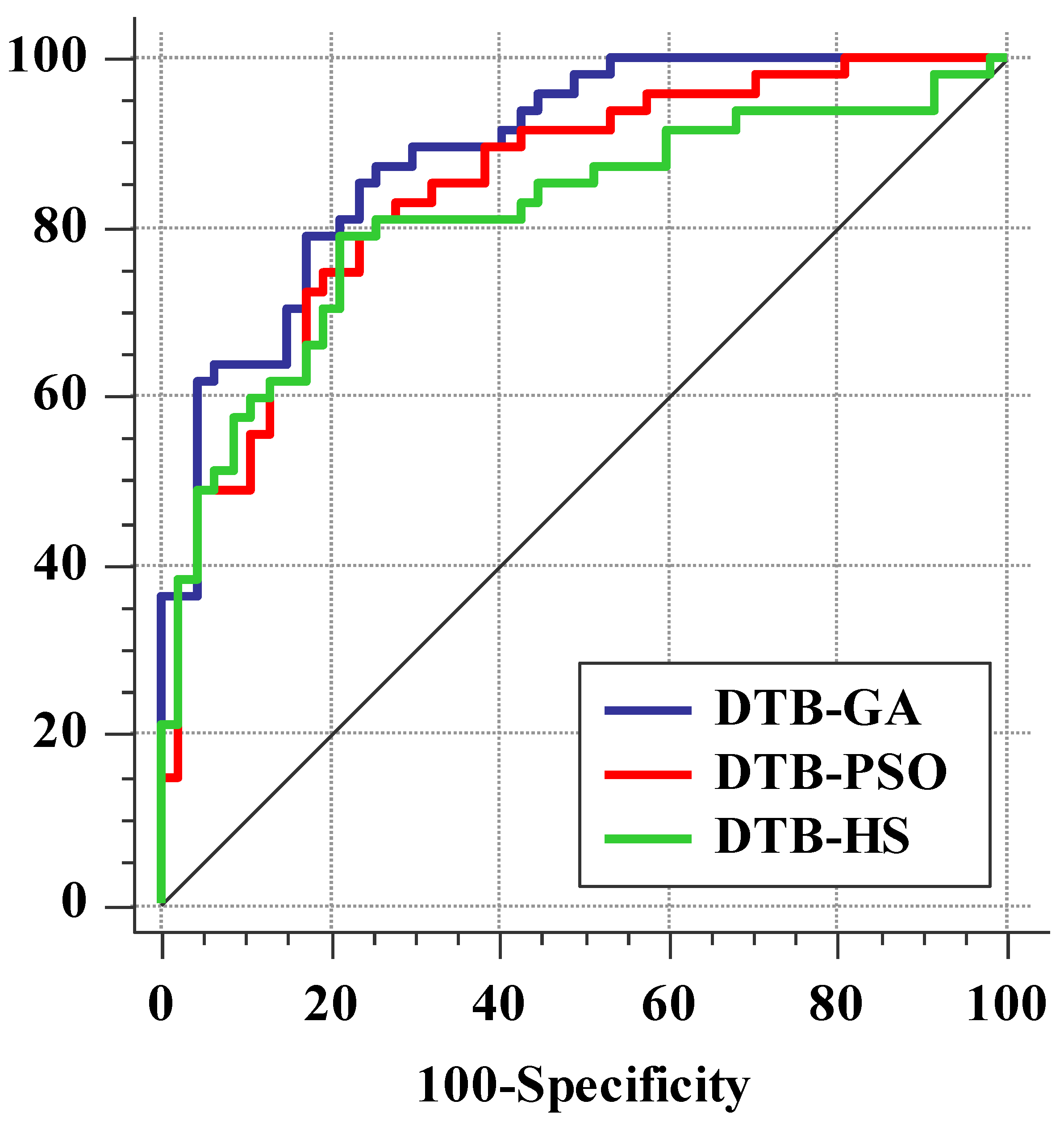
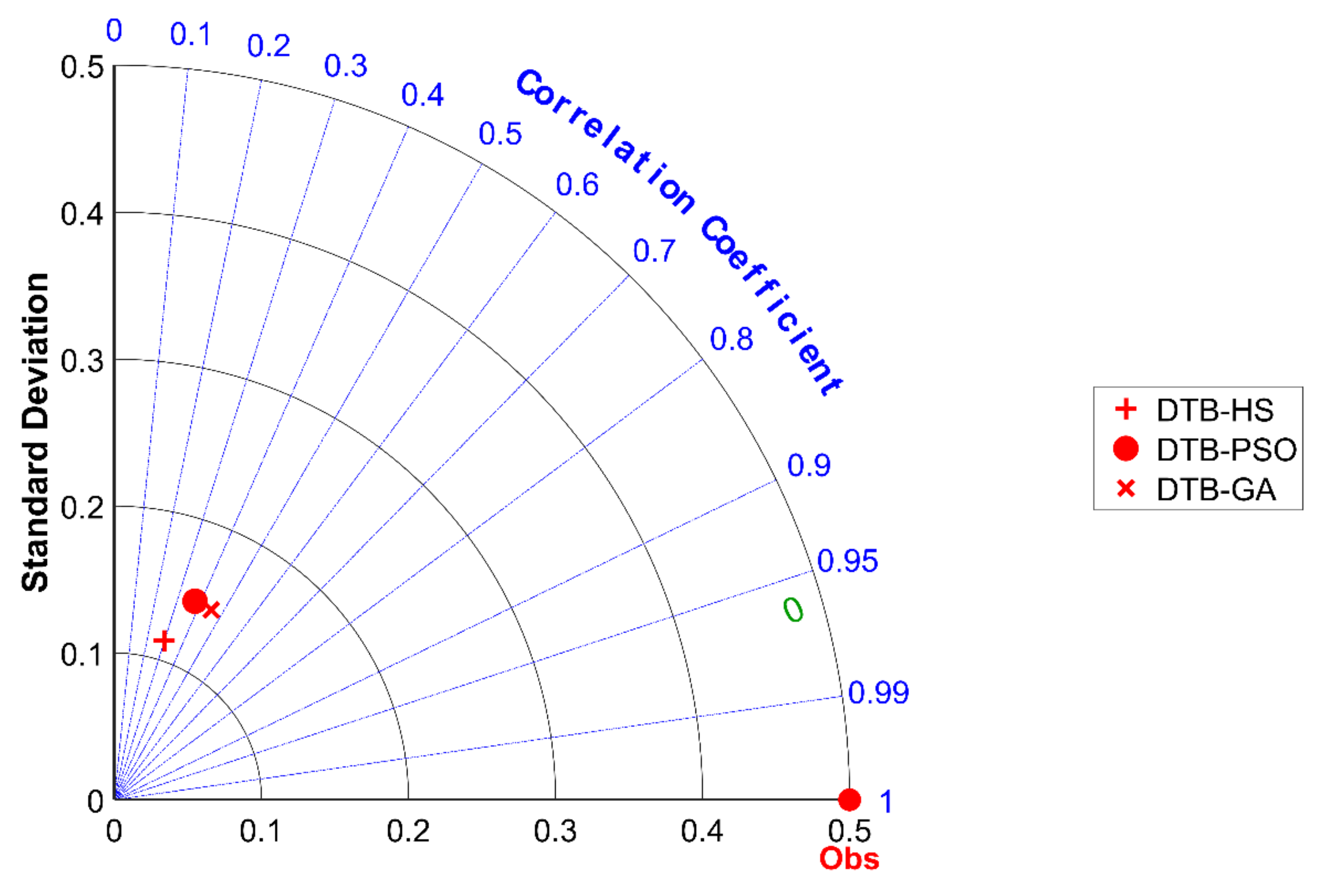
4.4. Flood Susceptibility Mapping (FSM) and Validation
5. Discussion
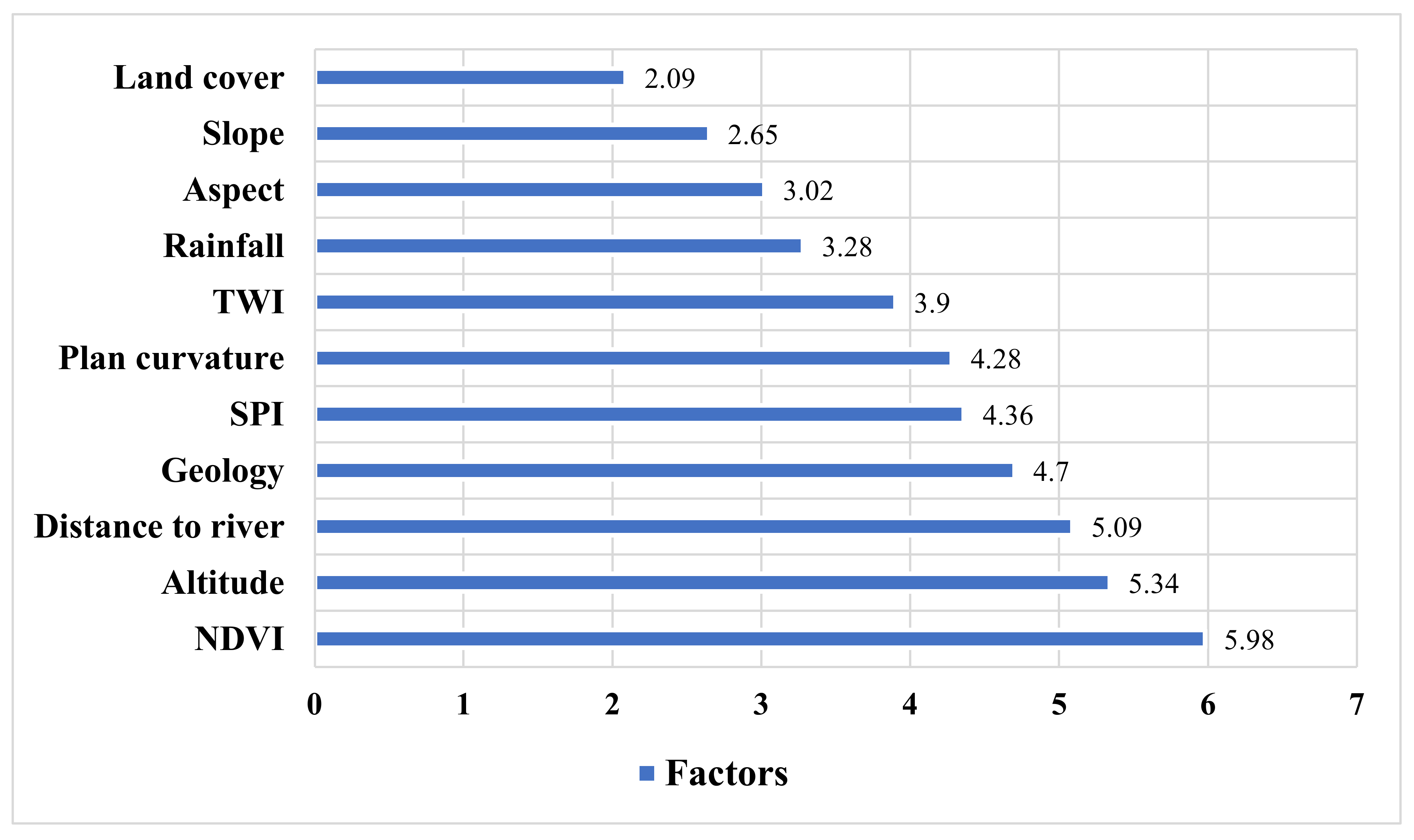
5.1. Examining the Role of Factors in Flood Prediction
5.2. Evaluation and Comparison of Algorithms
5.3. Strengths of the Research
6. Conclusions and Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nachappa, T.G.; Piralilou, S.T.; Gholamnia, K.; Ghorbanzadeh, O.; Rahmati, O.; Blaschke, T. Flood susceptibility mapping with machine learning, multi-criteria decision analysis and ensemble using dempster shafer theory. J. Hydrol. 2020, 590, 125275. [Google Scholar] [CrossRef]
- Bui, D.T.; Ngo, P.-T.T.; Pham, T.D.; Jaafari, A.; Minh, N.Q.; Hoa, P.V.; Samui, P. A novel hybrid approach based on a swarm intelligence optimized extreme learning machine for flash flood susceptibility mapping. Catena 2019, 179, 184–196. [Google Scholar] [CrossRef]
- Costache, R.; Pham, Q.B.; Sharifi, E.; Linh, N.T.T.; Abba, S.I.; Vojtek, M.; Vojteková, J.; Nhi, P.T.T.; Khoi, D.N. Flash-flood susceptibility assessment using multi-criteria decision making and machine learning supported by remote sensing and gis techniques. Remote Sens. 2019, 12, 106. [Google Scholar] [CrossRef]
- Islam, A.; Sarkar, B. Analysing flood history and simulating the nature of future floods using gumbel method and log-pearson type iii: The case of the mayurakshi river basin, india. Bull. Geogr. Phys. Geogr. Ser. 2020, 19, 43–69. [Google Scholar] [CrossRef]
- Dodangeh, E.; Panahi, M.; Rezaie, F.; Lee, S.; Bui, D.T.; Lee, C.-W.; Pradhan, B. Novel hybrid intelligence models for flood-susceptibility prediction: Meta optimization of the gmdh and svr models with the genetic algorithm and harmony search. J. Hydrol. 2020, 590, 125423. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Jones, S.; Shabani, F. Identifying the essential flood conditioning factors for flood prone area mapping using machine learning techniques. Catena 2019, 175, 174–192. [Google Scholar] [CrossRef]
- Al-Abadi, A.M. Mapping flood susceptibility in an arid region of southern iraq using ensemble machine learning classifiers: A comparative study. Arab. J. Geosci. 2018, 11, 218. [Google Scholar] [CrossRef]
- Termeh, S.V.R.; Kornejady, A.; Pourghasemi, H.R.; Keesstra, S. Flood susceptibility mapping using novel ensembles of adaptive neuro fuzzy inference system and metaheuristic algorithms. Sci. Total Environ. 2018, 615, 438–451. [Google Scholar] [CrossRef]
- Wang, Y.; Hong, H.; Chen, W.; Li, S.; Panahi, M.; Khosravi, K.; Shirzadi, A.; Shahabi, H.; Panahi, S.; Costache, R. Flood susceptibility mapping in dingnan county (China) using adaptive neuro-fuzzy inference system with biogeography based optimization and imperialistic competitive algorithm. J. Environ. Manag. 2019, 247, 712–729. [Google Scholar] [CrossRef]
- Samanta, R.K.; Bhunia, G.S.; Shit, P.K.; Pourghasemi, H.R. Flood susceptibility mapping using geospatial frequency ratio technique: A case study of subarnarekha river basin, india. Model. Earth Syst. Environ. 2018, 4, 395–408. [Google Scholar] [CrossRef]
- Kumar, P.; Debele, S.E.; Sahani, J.; Rawat, N.; Marti-Cardona, B.; Alfieri, S.M.; Basu, B.; Basu, A.S.; Bowyer, P.; Charizopoulos, N. An overview of monitoring methods for assessing the performance of nature-based solutions against natural hazards. Earth Sci. Rev. 2021, 217, 103603. [Google Scholar] [CrossRef]
- Watts, A.C.; Ambrosia, V.G.; Hinkley, E.A. Unmanned aircraft systems in remote sensing and scientific research: Classification and considerations of use. Remote Sens. 2012, 4, 1671–1692. [Google Scholar] [CrossRef]
- Mojaddadi Rizeei, H. Flood Risk Assessment Using Multi-Sensor Remote Sensing, Geographic Information System, 2D Hydraulic and Machine Learning Based Models. Ph.D. Thesis, University of Technology Sydney (UTS), Sydney, NSW, Australia, 2018. [Google Scholar]
- Yang, Y.; Zhang, M.; Sun, Z.; Han, J.; Wang, J. The relationship between water level change and river channel geometry adjustment in the downstream of the three gorges dam. J. Geogr. Sci. 2018, 28, 1975–1993. [Google Scholar]
- Chai, Y.; Yang, Y.; Deng, J.; Sun, Z.; Li, Y.; Zhu, L. Evolution characteristics and drivers of the water level at an identical discharge in the jingjiang reaches of the yangtze river. J. Geogr. Sci. 2020, 30, 1633–1648. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Razavi-Termeh, S.V.; Kariminejad, N.; Hong, H.; Chen, W. An assessment of metaheuristic approaches for flood assessment. J. Hydrol. 2020, 582, 124536. [Google Scholar] [CrossRef]
- Bui, D.T.; Pradhan, B.; Nampak, H.; Bui, Q.-T.; Tran, Q.-A.; Nguyen, Q.-P. Hybrid artificial intelligence approach based on neural fuzzy inference model and metaheuristic optimization for flood susceptibilitgy modeling in a high-frequency tropical cyclone area using gis. J. Hydrol. 2016, 540, 317–330. [Google Scholar]
- Mousavi, S.M.; Ataie-Ashtiani, B.; Hosseini, S.M. Comparison of statistical and mcdm approaches for flood susceptibility mapping in northern iran. J. Hydrol. 2022, 612, 128072. [Google Scholar] [CrossRef]
- Wang, Z.; Lai, C.; Chen, X.; Yang, B.; Zhao, S.; Bai, X. Flood hazard risk assessment model based on random forest. J. Hydrol. 2015, 527, 1130–1141. [Google Scholar] [CrossRef]
- Hong, H.; Tsangaratos, P.; Ilia, I.; Liu, J.; Zhu, A.-X.; Chen, W. Application of fuzzy weight of evidence and data mining techniques in construction of flood susceptibility map of poyang county, china. Sci. Total Environ. 2018, 625, 575–588. [Google Scholar] [CrossRef]
- Hoang, N.-D.; Tran, X.-L. Remote sensing–based urban green space detection using marine predators algorithm optimized machine learning approach. Math. Probl. Eng. 2021, 2021, 5586913. [Google Scholar] [CrossRef]
- Bui, D.T.; Panahi, M.; Shahabi, H.; Singh, V.P.; Shirzadi, A.; Chapi, K.; Khosravi, K.; Chen, W.; Panahi, S.; Li, S. Novel hybrid evolutionary algorithms for spatial prediction of floods. Sci. Rep. 2018, 8, 15364. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H.; Peng, L. Flood susceptibility mapping using convolutional neural network frameworks. J. Hydrol. 2020, 582, 124482. [Google Scholar] [CrossRef]
- Arora, A.; Arabameri, A.; Pandey, M.; Siddiqui, M.A.; Shukla, U.; Bui, D.T.; Mishra, V.N.; Bhardwaj, A. Optimization of state-of-the-art fuzzy-metaheuristic anfis-based machine learning models for flood susceptibility prediction mapping in the middle ganga plain, india. Sci. Total Environ. 2021, 750, 141565. [Google Scholar] [CrossRef]
- Rahmati, O.; Darabi, H.; Panahi, M.; Kalantari, Z.; Naghibi, S.A.; Ferreira, C.S.S.; Kornejady, A.; Karimidastenaei, Z.; Mohammadi, F.; Stefanidis, S. Development of novel hybridized models for urban flood susceptibility mapping. Sci. Rep. 2020, 10, 12937. [Google Scholar] [CrossRef]
- Rezaie, F.; Panahi, M.; Bateni, S.M.; Jun, C.; Neale, C.M.; Lee, S. Novel hybrid models by coupling support vector regression (svr) with meta-heuristic algorithms (woa and gwo) for flood susceptibility mapping. Nat. Hazards 2022, 1–37. [Google Scholar] [CrossRef]
- Panahi, M.; Dodangeh, E.; Rezaie, F.; Khosravi, K.; Van Le, H.; Lee, M.-J.; Lee, S.; Pham, B.T. Flood spatial prediction modeling using a hybrid of meta-optimization and support vector regression modeling. Catena 2021, 199, 105114. [Google Scholar] [CrossRef]
- Rezaie, F.; Bateni, S.M.; Heggy, E.; Lee, S. Utilizing the sar, gis, and novel hybrid metaheuristic-gmdh algorithm for flood susceptibility mapping. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 8612–8615. [Google Scholar]
- Khosravi, K.; Nohani, E.; Maroufinia, E.; Pourghasemi, H.R. A gis-based flood susceptibility assessment and its mapping in iran: A comparison between frequency ratio and weights-of-evidence bivariate statistical models with multi-criteria decision-making technique. Nat. Hazards 2016, 83, 947–987. [Google Scholar] [CrossRef]
- Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Bui, D.T.; Pham, B.T.; Khosravi, K. A novel hybrid artificial intelligence approach for flood susceptibility assessment. Environ. Model. Softw. 2017, 95, 229–245. [Google Scholar] [CrossRef]
- Cao, C.; Xu, P.; Wang, Y.; Chen, J.; Zheng, L.; Niu, C. Flash flood hazard susceptibility mapping using frequency ratio and statistical index methods in coalmine subsidence areas. Sustainability 2016, 8, 948. [Google Scholar] [CrossRef]
- Fernández, D.; Lutz, M.A. Urban flood hazard zoning in tucumán province, argentina, using gis and multicriteria decision analysis. Eng. Geol. 2010, 111, 90–98. [Google Scholar] [CrossRef]
- Al-Juaidi, A.E.; Nassar, A.M.; Al-Juaidi, O.E. Evaluation of flood susceptibility mapping using logistic regression and gis conditioning factors. Arab. J. Geosci. 2018, 11, 765. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Mansor, S.; Ahmad, N. Flood susceptibility assessment using gis-based support vector machine model with different kernel types. Catena 2015, 125, 91–101. [Google Scholar] [CrossRef]
- Abdel Hamid, H.; Wenlong, W.; Qiaomin, L. Environmental sensitivity of flash flood hazard using geospatial techniques. Glob. J. Environ. Sci. Manag. 2020, 6, 31–46. [Google Scholar]
- Segond, M.-L.; Wheater, H.S.; Onof, C. The significance of spatial rainfall representation for flood runoff estimation: A numerical evaluation based on the lee catchment, UK. J. Hydrol. 2007, 347, 116–131. [Google Scholar] [CrossRef]
- Ali, S.A.; Parvin, F.; Pham, Q.B.; Vojtek, M.; Vojteková, J.; Costache, R.; Linh, N.T.T.; Nguyen, H.Q.; Ahmad, A.; Ghorbani, M.A. Gis-based comparative assessment of flood susceptibility mapping using hybrid multi-criteria decision-making approach, naïve bayes tree, bivariate statistics and logistic regression: A case of topľa basin, slovakia. Ecol. Indic. 2020, 117, 106620. [Google Scholar] [CrossRef]
- Shrestha, R.; Di, L.; Eugene, G.Y.; Kang, L.; Shao, Y.-Z.; Bai, Y.-Q. Regression model to estimate flood impact on corn yield using modis ndvi and usda cropland data layer. J. Integr. Agric. 2017, 16, 398–407. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Lee, M.-J.; Pradhan, B.; Jebur, M.N.; Lee, S. Flood susceptibility mapping using integrated bivariate and multivariate statistical models. Environ. Earth Sci. 2014, 72, 4001–4015. [Google Scholar] [CrossRef]
- Shahabi, H.; Shirzadi, A.; Ghaderi, K.; Omidvar, E.; Al-Ansari, N.; Clague, J.J.; Geertsema, M.; Khosravi, K.; Amini, A.; Bahrami, S. Flood detection and susceptibility mapping using sentinel-1 remote sensing data and a machine learning approach: Hybrid intelligence of bagging ensemble based on k-nearest neighbor classifier. Remote Sens. 2020, 12, 266. [Google Scholar] [CrossRef]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with sentinel 2 and deep learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4704–4707. [Google Scholar]
- Razavi-Termeh, S.V.; Sadeghi-Niaraki, A.; Choi, S.-M. Spatio-temporal modelling of asthma-prone areas using a machine learning optimized with metaheuristic algorithms. Geocarto Int. 2022, 1–26. [Google Scholar] [CrossRef]
- Cao, Y.; Jia, H.; Xiong, J.; Cheng, W.; Li, K.; Pang, Q.; Yong, Z. Flash flood susceptibility assessment based on geodetector, certainty factor, and logistic regression analyses in fujian province, China. ISPRS Int. J. Geo Inf. 2020, 9, 748. [Google Scholar] [CrossRef]
- Liu, H.; Setiono, R. A probabilistic approach to feature selection-a filter solution. In ICML; Citeseer: Princeton, NJ, USA; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1996; pp. 319–327. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.294.9980&rep=rep1&type=pdf (accessed on 20 January 2022).
- Jiménez, F.; Palma, G.S.J.; Miralles-Pechuán, L.; Botía, J. Multivariate feature ranking of gene expression data. arXiv 2021, arXiv:2111.02357. [Google Scholar]
- Jiménez, F.; Sánchez, G.; Palma, J.; Miralles-Pechuán, L.; Botía, J.A. Multivariate feature ranking with high-dimensional data for classification tasks. IEEE Access 2022, 10, 60421–60437. [Google Scholar] [CrossRef]
- Nilsen, P. Making sense of implementation theories, models, and frameworks. In Implementation Science 3.0; Springer: Cham, Switzerland, 2020; pp. 53–79. [Google Scholar]
- Chen, C.; Zhang, G.; Yang, J.; Milton, J.C. An explanatory analysis of driver injury severity in rear-end crashes using a decision table/naïve bayes (dtnb) hybrid classifier. Accid. Anal. Prev. 2016, 90, 95–107. [Google Scholar] [CrossRef]
- Kalmegh, S.R. Comparative analysis of the weka classifiers rules conjunctiverule & decisiontable on indian news dataset by using different test mode. Int. J. Eng. Sci. Invent. (IJESI) 2018, 7, 2319–6734. [Google Scholar]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–73. [Google Scholar] [CrossRef]
- Mirjalili, S. Evolutionary algorithms and neural networks. In Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2019; Volume 780. [Google Scholar]
- Maleki, N.; Zeinali, Y.; Niaki, S.T.A. A k-nn method for lung cancer prognosis with the use of a genetic algorithm for feature selection. Expert Syst. Appl. 2021, 164, 113981. [Google Scholar] [CrossRef]
- Reddy, G.T.; Reddy, M.; Lakshmanna, K.; Rajput, D.S.; Kaluri, R.; Srivastava, G. Hybrid genetic algorithm and a fuzzy logic classifier for heart disease diagnosis. Evol. Intell. 2020, 13, 185–196. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; IEEE: Piscataway, NJ, USA, 1995; pp. 1942–1948. [Google Scholar]
- Roy, C.; Das, D.K. A hybrid genetic algorithm (ga)–particle swarm optimization (pso) algorithm for demand side management in smart grid considering wind power for cost optimization. Sādhanā 2021, 46, 101. [Google Scholar] [CrossRef]
- Ramdania, D.; Irfan, M.; Alfarisi, F.; Nuraiman, D. Comparison of genetic algorithms and particle swarm optimization (pso) algorithms in course scheduling. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2019; p. 022079. [Google Scholar]
- Geem, Z.W.; Kim, J.H.; Loganathan, G.V. A new heuristic optimization algorithm: Harmony search. Simulation 2001, 76, 60–68. [Google Scholar] [CrossRef]
- Gholami, J.; Pourpanah, F.; Wang, X. Feature selection based on improved binary global harmony search for data classification. Appl. Soft Comput. 2020, 93, 106402. [Google Scholar] [CrossRef]
- Razavi-Termeh, S.V.; Sadeghi-Niaraki, A.; Choi, S.-M. Effects of air pollution in spatio-temporal modeling of asthma-prone areas using a machine learning model. Environ. Res. 2021, 200, 111344. [Google Scholar] [CrossRef] [PubMed]
- Razavi-Termeh, S.V.; Khosravi, K.; Sadeghi-Niaraki, A.; Choi, S.-M.; Singh, V.P. Improving groundwater potential mapping using metaheuristic approaches. Hydrol. Sci. J. 2020, 65, 2729–2749. [Google Scholar] [CrossRef]
- Bui, Q.-T.; Nguyen, Q.-H.; Nguyen, X.L.; Pham, V.D.; Nguyen, H.D.; Pham, V.-M. Verification of novel integrations of swarm intelligence algorithms into deep learning neural network for flood susceptibility mapping. J. Hydrol. 2020, 581, 124379. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Valavi, R.; Shahabi, H.; Chapi, K.; Shirzadi, A. Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J. Environ. Manag. 2018, 217, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Rahmati, O.; Pourghasemi, H.R. Identification of critical flood prone areas in data-scarce and ungauged regions: A comparison of three data mining models. Water Resour. Manag. 2017, 31, 1473–1487. [Google Scholar] [CrossRef]
- Lookingbill, T.; Urban, D. An empirical approach towards improved spatial estimates of soil moisture for vegetation analysis. Landsc. Ecol. 2004, 19, 417–433. [Google Scholar] [CrossRef]
- Shahabi, H.; Shirzadi, A.; Ronoud, S.; Asadi, S.; Pham, B.T.; Mansouripour, F.; Geertsema, M.; Clague, J.J.; Bui, D.T. Flash flood susceptibility mapping using a novel deep learning model based on deep belief network, back propagation and genetic algorithm. Geosci. Front. 2021, 12, 101100. [Google Scholar] [CrossRef]
- Yariyan, P.; Avand, M.; Abbaspour, R.A.; Torabi Haghighi, A.; Costache, R.; Ghorbanzadeh, O.; Janizadeh, S.; Blaschke, T. Flood susceptibility mapping using an improved analytic network process with statistical models. Geomat. Nat. Hazards Risk 2020, 11, 2282–2314. [Google Scholar] [CrossRef]
- Yıldız, N.; Şişman, A. Investigation of flood risk areas in ünye district with best-worst method using geographic information systems. Adv. Land Manag. 2022, 2, 21–28. [Google Scholar]
- Tien Bui, D.; Khosravi, K.; Li, S.; Shahabi, H.; Panahi, M.; Singh, V.P.; Chapi, K.; Shirzadi, A.; Panahi, S.; Chen, W. New hybrids of anfis with several optimization algorithms for flood susceptibility modeling. Water 2018, 10, 1210. [Google Scholar] [CrossRef]
- Turoğlu, H.; Dölek, İ. Floods and their likely impacts on ecological environment in Bolaman River basin (Ordu, Turkey). Res. J. Agric. Sci. 2011, 43, 167–173. [Google Scholar]
- Pham, B.T.; Luu, C.; Van Phong, T.; Nguyen, H.D.; Van Le, H.; Tran, T.Q.; Ta, H.T.; Prakash, I. Flood risk assessment using hybrid artificial intelligence models integrated with multi-criteria decision analysis in quang nam province, vietnam. J. Hydrol. 2021, 592, 125815. [Google Scholar] [CrossRef]
- Mahdi, J.M.; Lohrasbi, S.; Nsofor, E.C. Hybrid heat transfer enhancement for latent-heat thermal energy storage systems: A review. Int. J. Heat Mass Transf. 2019, 137, 630–649. [Google Scholar] [CrossRef]
- Nguyen, H.; Mehrabi, M.; Kalantar, B.; Moayedi, H.; Abdullahi, M.a.M. Potential of hybrid evolutionary approaches for assessment of geo-hazard landslide susceptibility mapping. Geomat. Nat. Hazards Risk 2019, 10, 1667–1693. [Google Scholar] [CrossRef]
- Harifi, S.; Mohammadzadeh, J.; Khalilian, M.; Ebrahimnejad, S. Hybrid-epc: An emperor penguins colony algorithm with crossover and mutation operators and its application in community detection. Prog. Artif. Intell. 2021, 10, 181–193. [Google Scholar] [CrossRef]
- Martinez, C.M.; Hu, X.; Cao, D.; Velenis, E.; Gao, B.; Wellers, M. Energy management in plug-in hybrid electric vehicles: Recent progress and a connected vehicles perspective. IEEE Trans. Veh. Technol. 2016, 66, 4534–4549. [Google Scholar] [CrossRef]
- Janiga, D.; Czarnota, R.; Stopa, J.; Wojnarowski, P. Self-adapt reservoir clusterization method to enhance robustness of well placement optimization. J. Pet. Sci. Eng. 2019, 173, 37–52. [Google Scholar] [CrossRef]
- Chen, F.; Sun, X.; Wei, D.; Tang, Y. Tradeoff strategy between exploration and exploitation for pso. In Proceedings of the 2011 Seventh International Conference on Natural Computation, Shanghai, China, 26–28 July 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1216–1222. [Google Scholar]
- Yang, X.-S. Harmony search as a metaheuristic algorithm. In Music-Inspired Harmony Search Algorithm; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–14. [Google Scholar]
- Moayedi, H.; Mehrabi, M.; Bui, D.T.; Pradhan, B.; Foong, L.K. Fuzzy-metaheuristic ensembles for spatial assessment of forest fire susceptibility. J. Environ. Manag. 2020, 260, 109867. [Google Scholar] [CrossRef]
- Mehrabi, M.; Pradhan, B.; Moayedi, H.; Alamri, A. Optimizing an adaptive neuro-fuzzy inference system for spatial prediction of landslide susceptibility using four state-of-the-art metaheuristic techniques. Sensors 2020, 20, 1723. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensors | Sensor Mode | Polarization | Path | Dates |
|---|---|---|---|---|
| Sentinel-1A | Interferometry wide swath (IW) | VV, VH | Ascending | 27 December 2018 27 January 2019 |
| Class | No. of Pixels in Domain | No. of Floods | CF | Class | No. of Pixels in Domain | No. of Floods | CF |
|---|---|---|---|---|---|---|---|
| Altitude (m) | Distance to river (m) | ||||||
| 0–645 | 6,462,394 | 37 | −0.002 | 0–100 | 1,089,056 | 9 | 0.305 |
| 645–966 | 6,334,216 | 49 | 0.25 | 100–200 | 927,573 | 8 | 0.334 |
| 966–1315 | 3,744,146 | 11 | −0.48 | 200–300 | 982,420 | 6 | 0.06 |
| 1315–1757 | 224,136 | 11 | −0.14 | 300–400 | 821,497 | 5 | 0.057 |
| >1757 | 733,452 | 4 | −0.049 | >400 | 1,569,502 | 84 | −0.06 |
| Slope | SPI | ||||||
| 0–6 | 8,391,442 | 64 | 0.24 | 0–100 | 3,408,492 | 30 | 0.34 |
| 6–14 | 4,852,114 | 20 | −0.281 | 100–150 | 1,163,948 | 8 | 0.16 |
| 14–23 | 3,413,191 | 14 | −0.285 | 150–200 | 940,593 | 10 | 0.46 |
| 23–35 | 214,618 | 12 | −0.026 | 200–400 | 2,584,906 | 14 | −0.05 |
| >35 | 712,641 | 2 | −0.51 | >400 | 1,141,762 | 50 | −0.23 |
| TWI | NDVI | ||||||
| −0.17–3.66 | 4,749,037 | 25 | −0.082 | −0.62–−0.08 | 237,367 | 0 | −1 |
| 3.66–4.63 | 5,674,969 | 23 | −0.293 | −0.08–0.13 | 5,926,676 | 45 | 0.24 |
| 4.63–5.65 | 4,988,295 | 26 | −0.091 | 0.13–0.22 | 6,876,000 | 43 | 0.08 |
| 5.65–7.9 | 385,582 | 36 | 0.38 | 0.22–0.34 | 498,872 | 17 | −0.4 |
| >7.9 | 247,441 | 2 | 0.28 | >0.34 | 148,036 | 7 | −0.17 |
| Land cover | Rainfall (mm) | ||||||
| Water body | 347,922 | 4 | 0.5 | 247–296 | 1,203,193 | 1 | −0.85 |
| Forest | 94,861 | 0 | −1 | 296–322 | 3,444,360 | 13 | −0.34 |
| Agriculture | 4,167,971 | 33 | 0.27 | 322–344 | 4,516,856 | 41 | 0.36 |
| Pasture | 1,3496,784 | 67 | −0.13 | 344–366 | 874,886 | 48 | −0.044 |
| Residential areas | 731,632 | 3 | −0.28 | >366 | 160,229 | 9 | −0.021 |
| Bare land | 671,524 | 5 | 0.22 | ||||
| Slope aspect | Geology | ||||||
| F | 174,452 | 0 | −1 | Tertiary | 1,0294,396 | 47 | −0.2 |
| N | 2,101,154 | 16 | 0.24 | Cretaceous | 5,260,569 | 20 | −0.33 |
| NE | 2,342,310 | 10 | −0.25 | Mesozoic | 1,292,709 | 14 | 0.47 |
| E | 2,369,979 | 11 | −0.19 | Quaternary | 1,890,736 | 30 | 0.63 |
| SE | 2,086,778 | 11 | −0.081 | Jurassic | 245,395 | 0 | −1 |
| S | 2,712,349 | 19 | 0.18 | Triassic | 39,804 | 0 | −1 |
| SW | 3,103,277 | 17 | −0.045 | Cenozoic | 266,473 | 1 | −0.34 |
| W | 274,472 | 17 | 0.073 | Cretaceous volcanoes | 225,608 | 0 | −1 |
| NW | 188,054 | 11 | 0.018 | ||||
| Plan curvature | |||||||
| <−0.001 | 5,462,084 | 25 | −0.2 | ||||
| −0.001–0.001 | 8,406,182 | 47 | −0.02 | ||||
| >0.001 | 5,647,302 | 40 | 0.19 |
| Algorithm | Parameters |
|---|---|
| GA | Iteration = 30 Population size = 100 Crossover rate = 0.7 Mutation rate = 0.5 |
| PSO | Iteration = 30 Population size = 100 Inertia weight = 1 Personal learning coefficient = 1 Global learning coefficient = 2 |
| HS | Iteration = 30 Harmony memory size = 20 Number of new harmonies = 20 Harmony memory consideration rate = 0.5 Pitch adjustment rate = 0.1 |
| Algorithm | Number of Features | Features | Objective Function Value |
|---|---|---|---|
| GA | 7 | Slope, rainfall, geology, distance to river, ndvi, altitude, land cover | 0.138 |
| PSO | 6 | SPI, NDVI, rainfall, geology, land cover, plan curvature | 0.158 |
| HS | 4 | Geology, land cover, rainfall, altitude | 0.183 |
| Algorithm | Training | Validation |
|---|---|---|
| DTB-GA | 0.2029 | 0.4524 |
| DTB-PSO | 0.2507 | 0.4571 |
| DTB-HS | 0.3232 | 0.459 |
| Models | AUC | SE | 95% CI |
|---|---|---|---|
| DTB-GA | 0.889 | 0.0322 | 0.807 to 0.944 |
| DTB-PSO | 0.844 | 0.0399 | 0.755 to 0.911 |
| DTB-HS | 0.812 | 0.0456 | 0.718 to 0.885 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Askar, S.; Zeraat Peyma, S.; Yousef, M.M.; Prodanova, N.A.; Muda, I.; Elsahabi, M.; Hatamiafkoueieh, J. Flood Susceptibility Mapping Using Remote Sensing and Integration of Decision Table Classifier and Metaheuristic Algorithms. Water 2022, 14, 3062. https://doi.org/10.3390/w14193062
Askar S, Zeraat Peyma S, Yousef MM, Prodanova NA, Muda I, Elsahabi M, Hatamiafkoueieh J. Flood Susceptibility Mapping Using Remote Sensing and Integration of Decision Table Classifier and Metaheuristic Algorithms. Water. 2022; 14(19):3062. https://doi.org/10.3390/w14193062
Chicago/Turabian StyleAskar, Shavan, Sajjad Zeraat Peyma, Mohanad Mohsen Yousef, Natalia Alekseevna Prodanova, Iskandar Muda, Mohamed Elsahabi, and Javad Hatamiafkoueieh. 2022. "Flood Susceptibility Mapping Using Remote Sensing and Integration of Decision Table Classifier and Metaheuristic Algorithms" Water 14, no. 19: 3062. https://doi.org/10.3390/w14193062
APA StyleAskar, S., Zeraat Peyma, S., Yousef, M. M., Prodanova, N. A., Muda, I., Elsahabi, M., & Hatamiafkoueieh, J. (2022). Flood Susceptibility Mapping Using Remote Sensing and Integration of Decision Table Classifier and Metaheuristic Algorithms. Water, 14(19), 3062. https://doi.org/10.3390/w14193062