1. Introduction
In recent years, there has been a growing demand for oceanographic forecast data [
1,
2], which comes from different public and private subjects for operational oceanography purposes. This request stimulates the production of reliable predictions of physical and biogeochemical ocean variables to support activities such as search and rescue operations, ocean energy, fisheries, and environmental monitoring and pollution control. Observations play an essential role in operational systems as they also allow evaluating the reliability of predictions. The most important initiative in this context is the Global Ocean Observation System (GOOS), which includes several regional observation components providing data to global and basin-scale operational services, as well as to regional downstream services [
3].
Operational oceanographic services both at the basin and regional scales improve their forecast reliability when the model forecast is properly initialized with fields obtained through a data assimilation procedure. Data assimilation (DA) combines observations and models first-guess-weighted by their respective accuracies to obtain the best unbiased estimation of the ocean state. In a DA scheme, the observations correct the trajectory (first guess) according to their influence, which mainly depends on the observation and model error covariance matrices. As a consequence, DA can be useful to better control the error growth of the state trajectory with respect to the real evolution. Furthermore, in the operational practice, a common procedure of initializing a simulation starting with external data (e.g., climatology, objective analysis, model analysis, etc.) requires a spin-up interval during which the solution is not usable. DA schemes as 4D-Var reduce the spin-up effects (keeping a dynamical consistency between analysis and model equations) and also reduce model uncertainties.
Large amounts of data come from satellite observations (mainly Sea Surface Temperature and Sea Surface Height), which have some intrinsic limitations (surface-limited observations, revisiting times). Many parameters are only observable by collecting in situ observations through specific sensor networks that integrate satellite observations with data along the water column and at higher frequencies. The main limitation of in situ observation networks is their high cost for installation and maintenance over time; it is very important, therefore, to design an in situ observing system that maximizes the impact of the observations in the forecast, minimizing the cost.
Ocean models can also be used to evaluate both existing and new observing networks through different methodologies [
4]. Observing System Experiments (OSEs) compare analysis obtained by eliminating only a part of the observations with the analysis obtained by assimilating the entire dataset to understand the impact of the omitted observations. Observation System Simulation Experiments (OSSEs) use “synthetic” observations to evaluate the benefit of assimilating observations from instruments/networks not yet installed. Adjoint-based techniques and ensemble-based methods can be used to study observation sensitivities and the impact on assimilated systems, contributing to the design of observing systems [
4,
5,
6].
As different observations have different impacts when they are assimilated in an ocean model, a major problem is designing an observation network that provides data giving the best results (i.e., fewer errors) when they are assimilated. The positioning of the observing system is indeed somehow related to the unstable modes, which deserve more than others to be corrected. Since the fundamental milestone made by Lorenz in 1965 [
7], it is well known how the divergence in chaotic systems rises from the unstable directions of the state trajectory where small errors in initial conditions significantly grow, leading to very different final states. This places a time limit to the predictability of the system state, which is usually evaluated by the largest Lyapunov exponents. The assimilation of observations attempts to prolong that time limit [
8]. Some significant errors could decay over time, whereas smaller errors could intensely grow and produce a heavy impact on forecast reliability. The growth of the divergence between model evolution and the real state of the system is driven by these unstable directions, rather than by the largest components of the error embedded in the predicting system [
9,
10]. Indeed, the structure of the fast-growing perturbations is a dynamically evolving field and depends on the flow regime, as it derives from the position of the current state on the attractor and varies over time [
7,
11,
12].
For what concerns observation strategies, we can expect that a suitable positioning of observation devices in areas in which error in the initial condition is fast-growing may better control this growth. Such a choice can be performed on the basis of the study of perturbation growth. Hansen and Smith [
13] showed that for sufficiently small errors, observation strategies based on system dynamics produce better results than strategies based on error estimates.
A notable contribution to this field was made by Farrell and Joannou [
14,
15] in their General Stability Theory (GST) of a dynamical system, in which they extended the traditional modal stability theory to include transient growth processes. The authors identified the decomposition to singular values (SVD) as a suitable tool for treating perturbation growths in geophysical fluid systems. A variation of this method considers the calculation of Hessian singular vectors, which identify the errors in initial conditions that evolve into the largest forecast errors [
6].
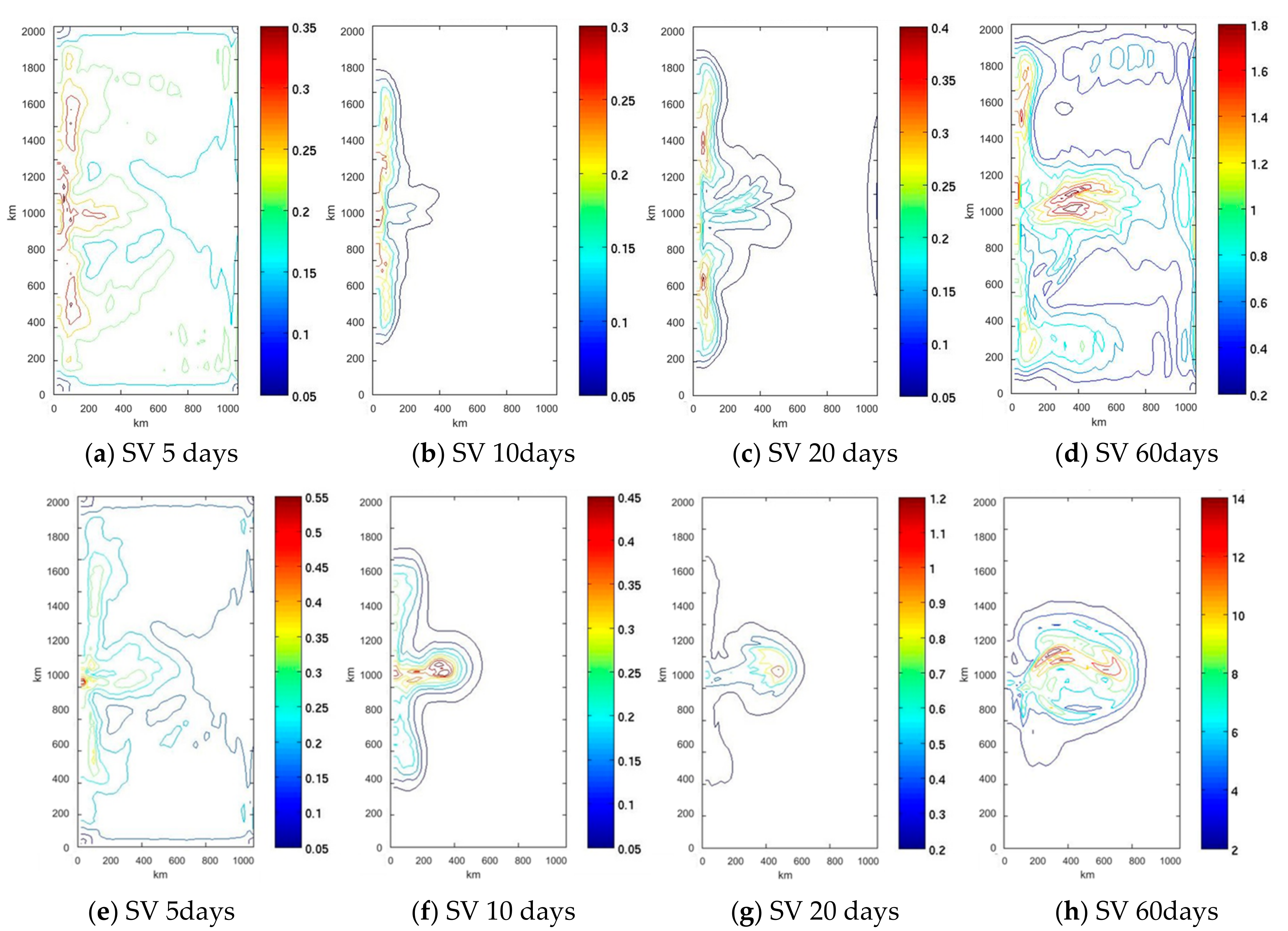
The existence of large singular values indicates that small errors in the initial background state can grow very rapidly, reducing the system predictability, and the respective singular vectors indicate the areas where disturbances grow faster. Analyzing Singular Vectors (SVs) appears strategic to increase model predictability by giving an indication of where it is more important to reduce errors in initial conditions [
6,
16].
The application of SVD to select observations has been already tested in a number of studies, mostly related to operational aspects of atmospheric forecasting systems [
5,
17,
18,
19,
20,
21]. A review of observation strategies [
22] confirmed the utility of SVD information in choosing the observations to be assimilated. Bergot et al. [
23] considered the SVD as a useful tool to identify areas where assimilating even a few observations is able to significantly reduce forecast errors. An important portion of literature about the topic of adaptive observations was originated by the first experimental reference, the so-called Fronts and Atlantic Storm Track Experiment (FASTEX) [
24,
25,
26]. Other experiments were carried out by assimilating additional observations from aircraft in regions characterized by rapidly growing SVs [
19,
27,
28].
In this work, we test some possible observation strategies of a simplified ocean system with the aim of establishing an optimal configuration of an in situ observing network able to reduce forecasting uncertainties through DA. For simplicity, we limit this study to velocity observations. In particular, our goal is to achieve such an optimal configuration using a limited number of observation points, as these may have a significant cost, in order to ensure the greatest possible benefit to an integrated assimilation/forecasting system. The benefit is measured with respect to the short-/medium-range forecast (analysis and forecast cycles of a few days), as required in the operational practice. In order to select the possible observation points, the proposed strategy is based on the SVD and on a maximum correlation among the horizontal velocities, which is traduced into a minimum distance, variable over the model domain. Indeed, we verify that an observation strategy based on SVD may fail if it is not accompanied by other considerations linked to the flow structure, and such a combination of SVD analysis with a correlation analysis can be used to limit redundant observations.
The experiments are carried out by using the ocean model ROMS (Regional Ocean Modelling System,
www.myroms.org) [
29], which already includes suitable routines for the SVD computation [
30]. We perform a set of numerical experiments assimilating different datasets and investigate the effects on model results.
In
Section 2, the configuration of the experiment is presented, and in particular, the description of the model, the DA scheme, and the proposed strategy to place in situ observation points.
In
Section 3, the results of all experiments are reported; our best strategy is compared to a random localization strategy and also to a selection procedure based on SVD and on a minimum fixed distance among observations.
3. Results
As described in the previous sections, we test three different observation strategies applied to an idealized ocean model (DG) to identify the observation network configuration, which gives rise to the best analysis and forecast.
To compare each test, we adopt the Taylor diagram representation [
36], which is often used in the operational field and allows collecting the same graph three of the most used statistical indices: the correlation, the centered root-mean-square error, and the standard deviations between two series (considering the Nature Run as the target). As in this study, we compare the maps of values at the same time, and correlation must be understood as a spatial correlation. These statistics are computed on the surface velocity components at the final time of the assimilation window, which is the initial condition for the five-day forecast run.
In the first experiment, we test the assimilation of an increasing number of velocity profiles, randomly located using the criteria described in the previous section. We start with 20 observation instruments (i.e., velocity profilers or ADCPs). As randomness can produce datasets more or less impactful for DA, the test is repeated considering different positions.
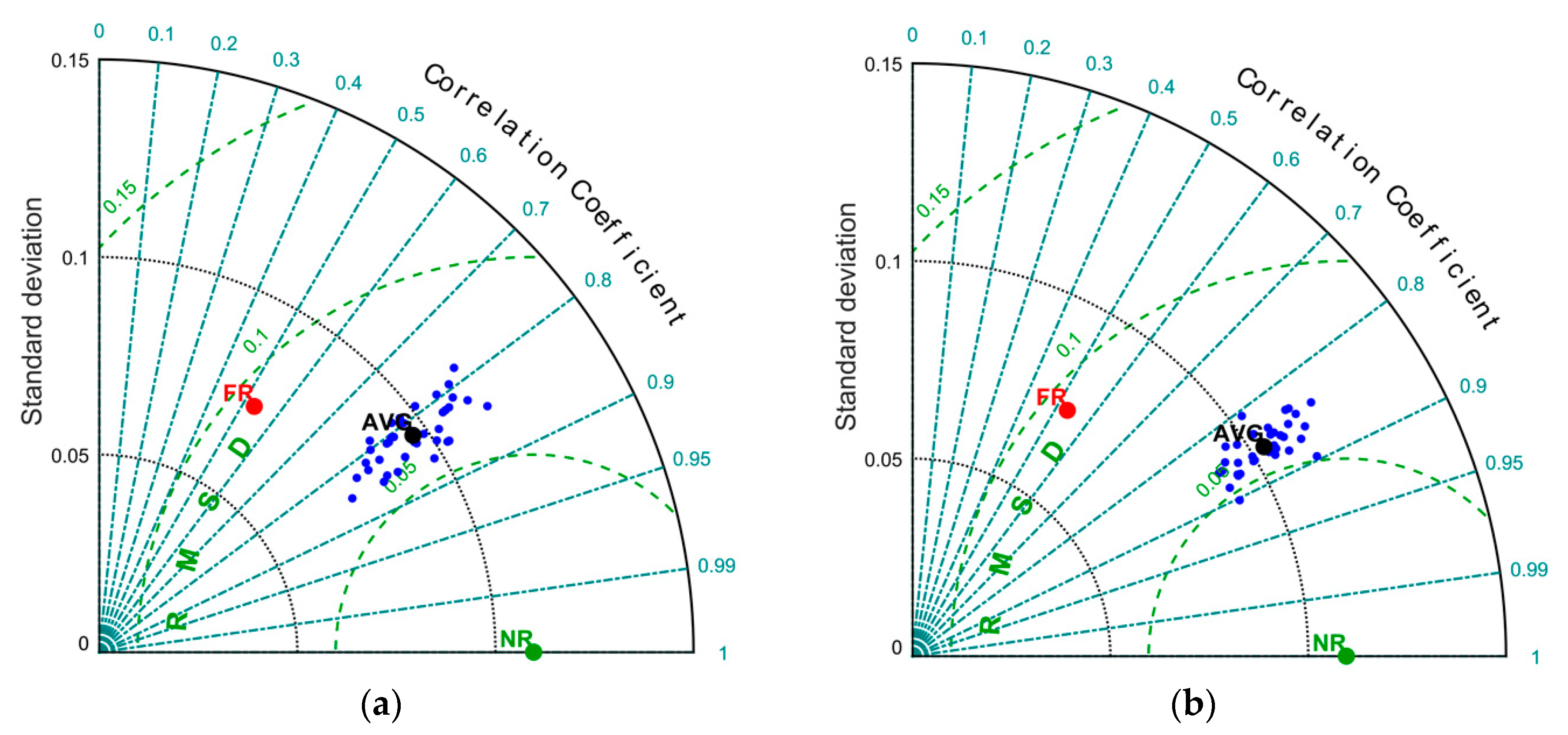
For the five-day assimilation window, two points are highlighted in
Figure 5:
- 1.
The Nature Run (NR), that we assume as the true state of the system;
- 2.
The Free Run (FR), starting from the climatological state, which is poorly correlated with the NR (around 50%).
We find an excellent capability of the DA algorithm (ROMS-IS4DVar) to adjust the initial condition and bring the evolution of the state of the system closer to the truth.
Figure 5 shows a wide spread between the analyses produced by assimilating different datasets, each corresponding to a different network configuration. We observe a significant spread of the results around such average, as analysis data can have a stronger (around 0.8 for Dataset M) or weaker correlation (around 0.6 for Dataset U). Some analyses although characterized by a high correlation to the NR have lower standard deviations than the NR, hence they poorly represent the true circulation structures.
As an example, in
Figure 6, we report the snapshots of the circulation of both the worst and the best analysis obtained, respectively, from the synthetic datasets corresponding to the configuration networks “M” and “U.”
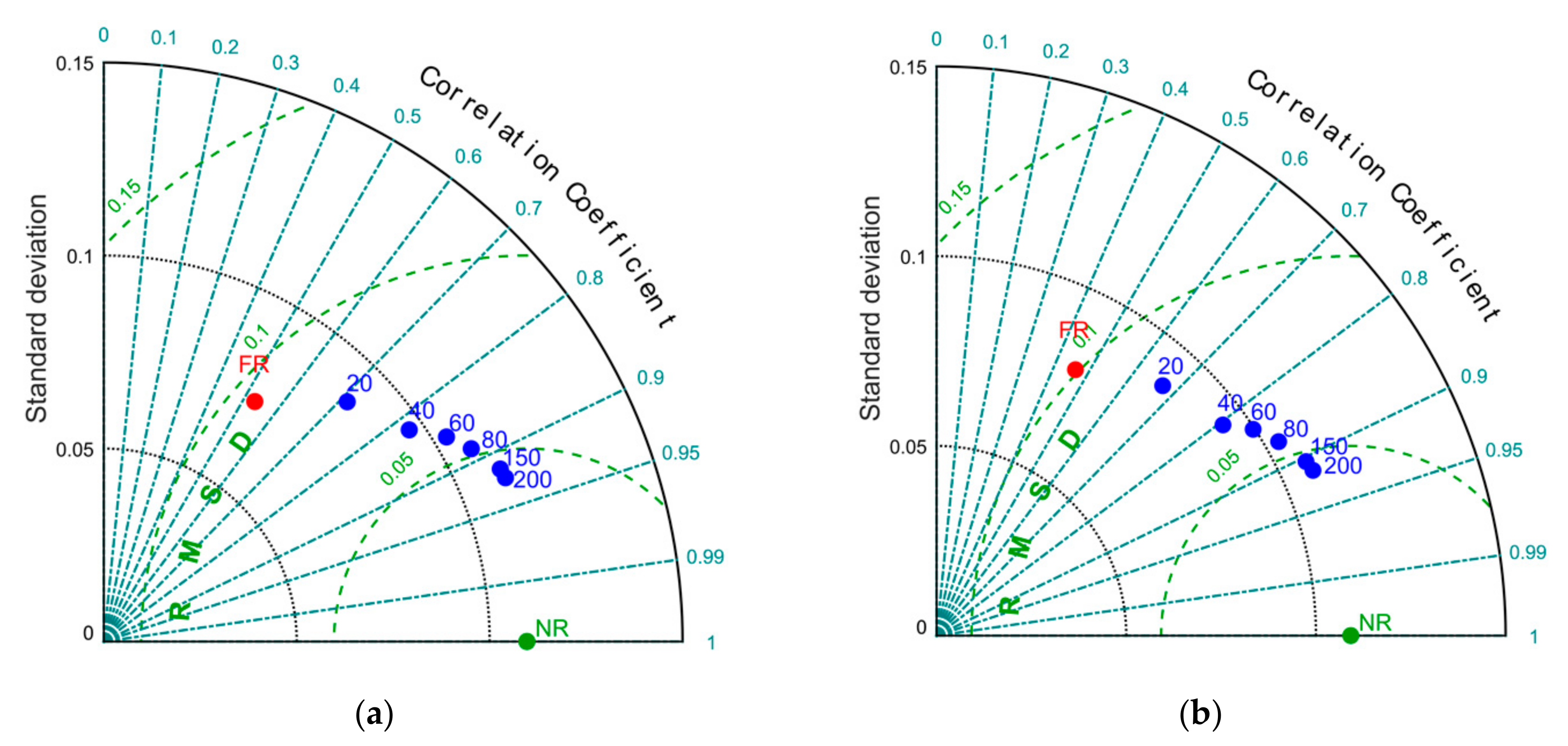
This first set of experiments is extended through the assimilation of a growing number of randomly positioned ADCPs (40, 60, 80, 100, 150, and 200).
Looking at the averaged statistics of analyses (named AVG in
Figure 7), we have a positive effect of DA in improving the estimation of the model state as the number of observation points increases. At the same time, the statistical indices within each ensemble are increasingly closer to each other.
The results of all tests with the same number of observation points are summarized by means of a number of average points, each representing the averaged statistics of the related ensemble in
Figure 8. We observe a progressively better quality of analyses in terms of all statistical indices (correlation, RMSE, and standard deviation) and a progressively lower benefit in the assimilation of additional observations. Indeed, as the number of observations increases, the marginal improvement of the analyses decreases. Therefore, a suitable strategy to localize measuring tools is especially impactful in observation networks characterized by a few instruments, which is the case of most in situ observation networks used in operational oceanography.
Figure 9 shows the improvement of the quality of analysis and forecast for an increasing number of observations. Forecast reliability, in terms of correlation and error, is strictly dependent on the quality of initial conditions; therefore, it is quite proportioned to the analysis.
By considering individually each analysis, some overlapping areas between the statistical scores of different ensembles are also shown in
Figure 7 and
Figure 9. This means that, in some cases, a significantly different number of assimilated data can approximately lead to the same improvement. Therefore, a relatively small number of well-positioned instruments can produce an analysis almost equivalent to that produced by a network of poorly located instruments, albeit larger. In fact, some analyses obtained with only 20 ADCPs have produced results equivalent to networks with 40 or even 60 ADCPs (
Figure 7 and
Figure 9).
In the second set of experiments, the positions of in situ observation instruments are identified by two elements: (1) the highest values of the projection on the velocity components of the dominant singular vectors, and (2) a fixed minimum distance among the instruments. As we mentioned in
Section 2.2, the need to impose a minimum distance among instruments arises from the typical structure of the dominant singular vectors concentrated in relatively small areas.
In some experiments, not reported in this paper, we sample our DG system by extracting most measurements in the area of highly dominant SVs, but the results are even worse than those obtained with randomly positioned observations.
Distances are provided in dimensionless units, as they are divided by the barotropic Rossby deformation radius LR = (gh)1/2/f ≈ 900 km. We repeat the ensemble for testing different minimum distances from 0.04xLR to 0.28xLR.
Following the present observation strategy, the first observation point is located where the projection of the dominant SV on the velocity is maximum, and the following observation points lie farther than the chosen minimum distance.
The results of this set of experiments are shown in
Figure 10 and
Figure 11, in which we compare the analyses obtained in the first assimilation window (
Figure 10) and, on average, for all the assimilation windows (
Figure 11).
Looking at the first assimilation window (0−5 days), the worse dataset corresponds to an imposed minimum distance of the order of the spatial resolution, which is 0.04xLR. By increasing this minimum distance, we progressively obtained better correlation up to a value approaching 0.8, in turn corresponding to a minimum separation of about 0.25xLR. The observation positions of both the worst and the best dataset are reported in
Figure 12. Considering other assimilation windows, the results are quite similar: the worst correlations are usually obtained for short minimum distances, and the correlation tends to increase when we separate the observation positions. The maximum correlation is found in the range of 0.15−0.25xLR (
Figure 13).
Taking the average of all curves referred to the whole set of assimilation windows, the best correlations are obtained by imposing a minimum distance of about 0.2 xLR (
Figure 13).
Datasets selected by imposing a distance up to 0.08−0.1 xLR produce worse analyses than randomly selected observations; the same occurs with minimum distances larger than 0.3 xLR. Conversely, in the range between 0.1 xLR and 0.25−0.3 xLR, this selection procedure produces, on average, analyses more reliable than that corresponding to random positioning.
Finally, as a third set of experiments, we test a procedure, still based on SVD, in which we impose a maximum correlation between the time series of the observed variables at the observation positions, instead of a fixed minimum distance. Such a limitation on the correlation between the time series of model velocities at observation points is introduced by imposing a minimum distance variable over the domain, and it is computed as explained in
Section 2.2.
The selection procedure for this set of experiments is based on the map in
Figure 4. Starting from the observation point in which we compute the maximum value of the projection of the SV onto the velocity, we identify the minimum distance to place additional observations through such a map derived from the correlation analysis.
It is important to underline that, in this procedure, the position of observation points are uniquely determined once a correlation threshold is defined. Such a threshold should be itself a calibration parameter of the sampling strategy to be selected on the basis of the correlation value that may guarantee the best comparison between analysis and the (virtual) truth. Although the correlation threshold is not calibrated in this study, such a unique configuration of the observation points is found to be the one that gives rise, on average, to the best analysis.
The average value of such a variable correlation distance is around 300 km, which is about 0.3xLR, slightly outside the “best” minimum distance found for the second set of experiments in which a fixed separation among observations is set. However, this distance, on the map in
Figure 4, varies between lower values (around 150−200 km), near the convergence area, and higher values (>600 km) near the northern, southern, and eastern edges. The highest SVs are located within the area of lower correlation distances that fall within the range of 0.15−0.20 LR that we find, empirically, as an optimal distance interval using the fixed distance criterion.
The third procedure is able, on average, to improve the quality of the analysis model with respect to both the random procedure, and to the SVD-based procedure with a fixed distance among observations.
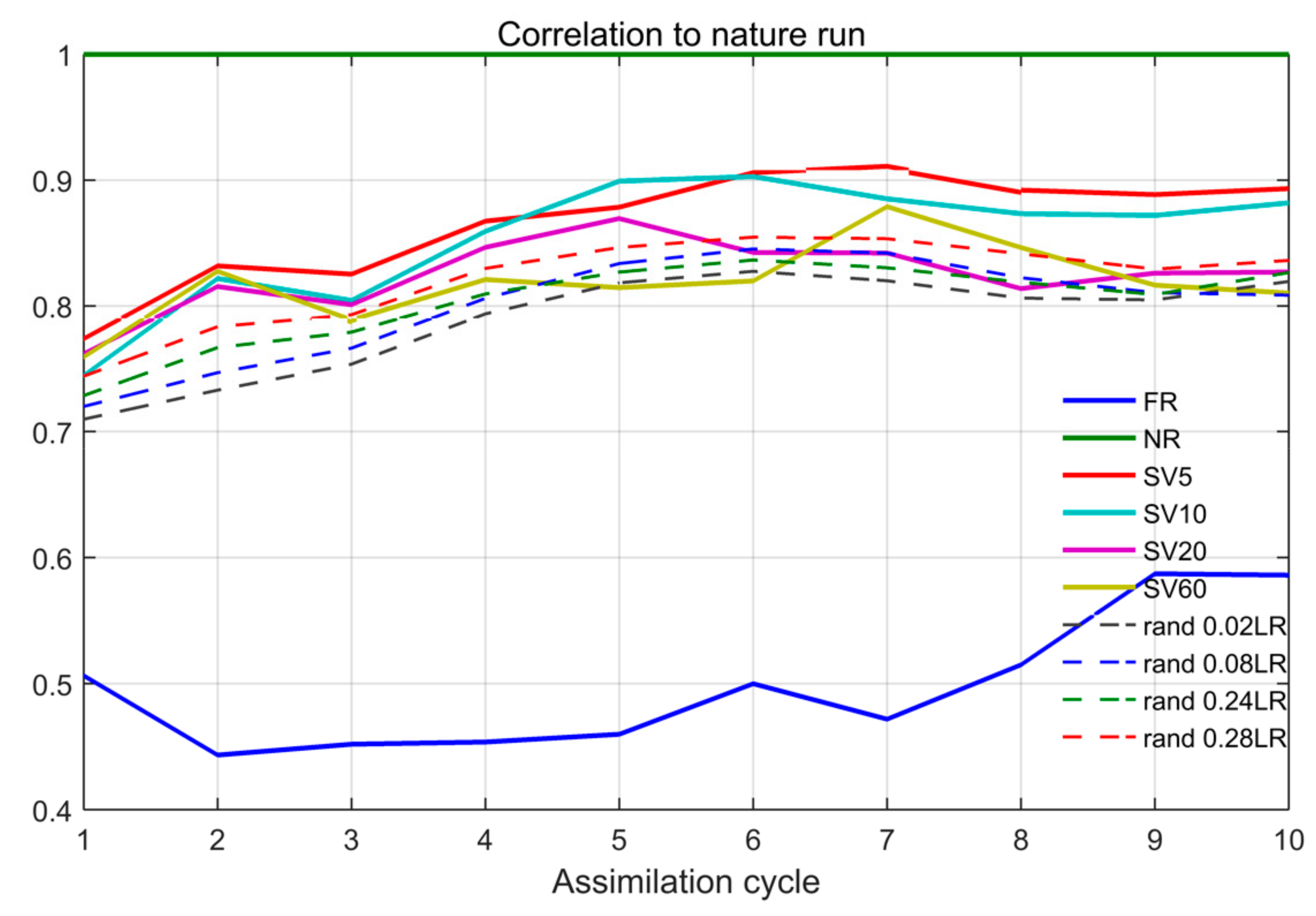
The observation strategy is tested for repeated assimilation cycles, as in the normal procedures adopted in the operational practice. A summary representation of results is shown in
Figure 13. The observation strategy based on the combination of SVD and correlation analysis (solid lines) in most cases gives the best performances with respect to any random positioning procedure (dashed lines).
We also assess the sensitivity of the results to the optimization time for the SVD computation. In this case, the difference among the datasets, in terms of correlation with respect to the NR, is not so relevant, but we find that the configuration of observation points obtained by the SVD on a shorter optimization period (5−10 days) gives the best results. In particular, the analysis corresponding to the SVD with an optimization time of five days (SV5 in
Figure 13) always yields significantly better analyses than any other tested strategy.
4. Discussion and Conclusions
The marginal improvement of the reliability of an ocean forecasting system can be obtained by a proper design of the ocean-observing component.
The Singular Value Decomposition was already used by various authors in the field of Geophysical Fluid Dynamics (mainly in the atmosphere) for several purposes, including the identification of possible adaptive observation strategies. However, the analysis of the potential of this method is still rather lacking to provide effective and functional indications for the design of in situ observation networks.
In this work, we evaluate some possible SVD-based strategies to determine an optimal set of in situ observation points in the case only a limited number of observation tools are available. This situation is common in reality, given the high cost of installing and managing in situ observation networks, especially in the oceanographic field.
We compare three observation strategies aimed at reducing the forecast uncertainty obtained through an idealized Double-Gyre ocean model, with repeated analysis and forecast cycles, using the variational assimilation scheme ROMS-IS4DVar.
We first proceed to evaluate the benefit linked to the assimilation of randomly positioned observations. The assimilation algorithm in use always produces a positive improvement in the estimation of the state of the system. The effectiveness of this improvement is not straightforward, as it depends in a complex way on the number of observation points and also on the location of these points in the model domain. This is especially evident in case only a limited number of observations is available.
Having a limited number of observation tools, and looking for the combination of positions that gives maximum benefit to DA, we assume that a fundamental indication for selecting observation points can be provided by the study of the areas in which the maximum error growth occurs. SVD is an excellent method for identifying these areas. The computation of the dominant Singular Vectors (SVs), and in particular of its projection on the physical components of interest, i.e., the velocity field, can give important information about error dynamics in the limit of validity of the linear tangent model. However, as the highest values of such SVs components can be concentrated in small areas, information obtained from points too close to each other is likely to be too correlated. To avoid this effect, we test two criteria:
A first criterion, based on a rigid distance, is able to identify an optimal separation distance, which, in this case, is equal to about one-fifth of the Barotropic Rossby Deformation Radius. Around this value we have, on average, the best skills for the analysis model compared to the Nature Run assumed as truth;
A second criterion, based on the maximum correlation between points, adopts a variable minimum distance among observation points. This criterion defines uniquely the position of observation points and provides better results both with respect to random simulations and with respect to the former optimization criterion.
Further improvements of the last criterion can be achieved through an accurate calibration of the threshold correlation parameter. However, even when adopting a threshold parameter of the first attempt, the obtained results are, on average, better than any formerly adopted strategy.
The extension of this method to real applications must take into account other factors, such as the presence of other variables of interest or a more accurate characterization of the observation error. In cases of ocean models more complex than the ocean DG, when baroclinic effects and density variations are more important, an SVD-based observation strategy should also evaluate the projection of the dominant SV on other variables, such as temperature and salinity, as any observation strategy cannot disregard the acquisition of density profiles. The application of this method to real ocean systems will also require a careful characterization of measurement errors, estimated from the performances of real observation instruments.
Testing such criteria to the design of observation networks, as in the standard Observing System Simulation Experiments (OSSEs) used for simulating the possible benefits of observing systems, could be of great interest. Indeed, most existing ocean observation networks are not designed from the very beginning using objective criteria to optimally support analysis/forecast models. Suitable design strategies are therefore needed for both making up new observation systems and expanding the capabilities of existing observation networks in order to improve their efficiency for data assimilation.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













