
Population Pharmacogenomics for Health Equity

{kind=link}
Abstract
:1. Introduction
Population Pharmacogenomics Can and Should Be Leveraged for Health Equity—Improved Health Outcomes for All People Everywhere
2. Race, Ethnicity, and Pharmacogenomic Variation
Socially Defined Racial and Ethnic Groups Exhibit Differences in the Frequencies of Pharmacogenomic Variants, with Direct Implications for Health Equity
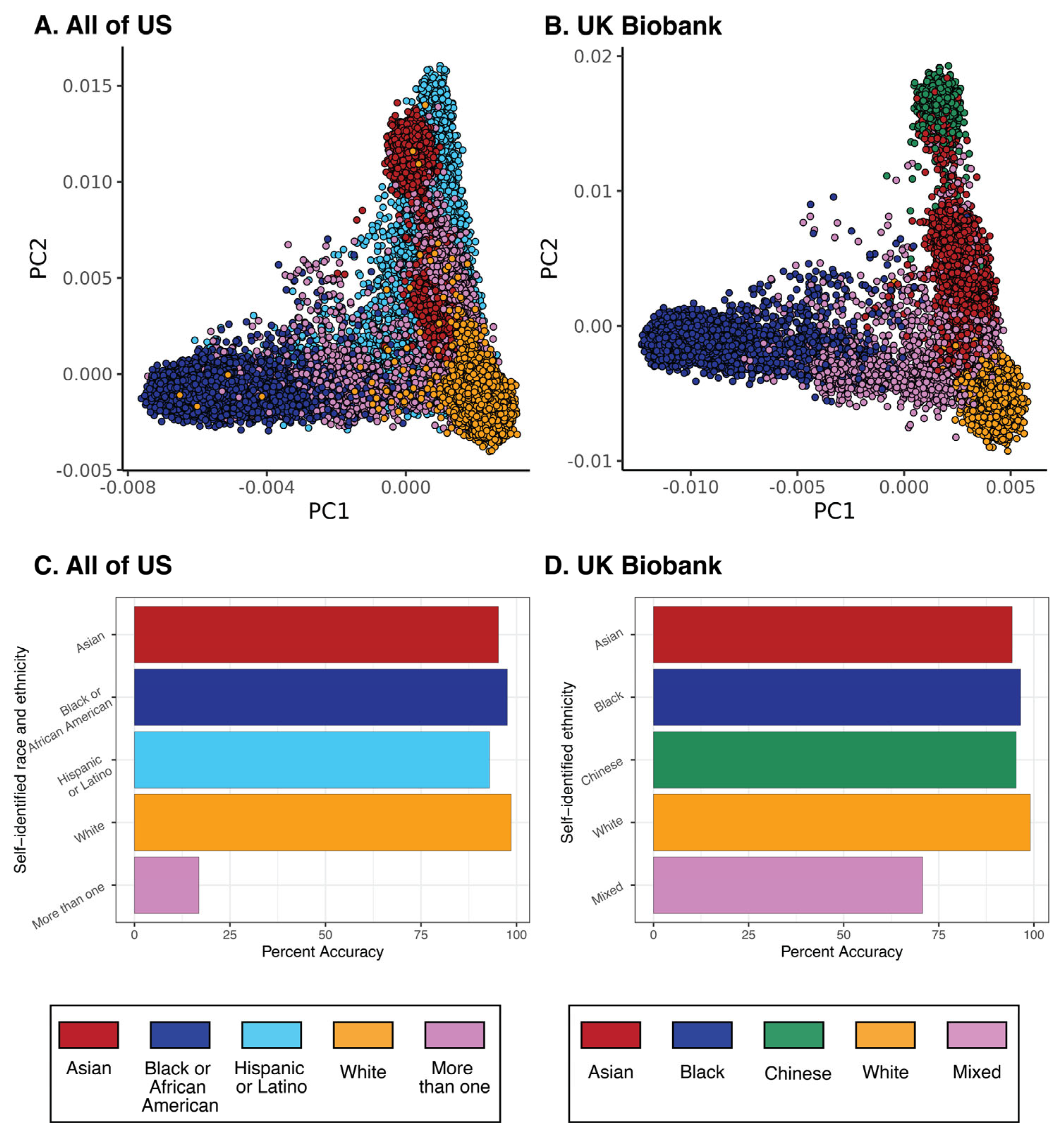
3. Global and Local Views on Race, Ethnicity, and Genetics
Race and Ethnicity Stratify Pharmacogenomic Variation at the Local Level but Do Not Represent Natural Groups That Correspond to Global Patterns of Human Genetic Variation
4. Pharmacogenomics and Modifiable Risk Factors
The Characterization of Pharmacogenomic Variants Provides a Means to Elucidate Modifiable Risk Factors in Support of Health Equity
5. Precision Medicine Versus Precision Public Health
Population Pharmacogenomics Is an Essential Component of Precision Public Health, Where the Focus Is on Population-Level Variation as Opposed to Individual-Level Differences
6. Adverse Drug Reactions
The Mitigation of Adverse Drug Reactions Is an Area Where Population Pharmacogenomics Can Have a Direct and Immediate Impact on Public Health
7. Conclusions: Embrace Genomic Diversity for Health Equity
A Reckoning with the Implications of Population Pharmacogenomic Diversity Is a Prerequisite for Health Equity
Author Contributions
Funding
Conflicts of Interest
References
- National Insititute on Minority Health and Health Disparities. What is Health Equity? Available online: https://www.nimhd.nih.gov/resources/understanding-health-disparities/health-equity.html (accessed on 15 July 2023).
- National Insititute on Minority Health and Health Disparities. Minority Health and Health Disparities: Definitions and Parameters. Available online: https://www.nimhd.nih.gov/about/strategic-plan/nih-strategic-plan-definitions-and-parameters.html (accessed on 15 July 2023).
- National Academies of Sciences Engineering and Medicine. Using Population Descriptors in Genetics and Genomics Research: A New Framework for an Evolving Field; The National Academies Press: Washington, DC, USA, 2023. [Google Scholar]
- Colombian Government. Population and Demography: Ethnic Groups. Available online: http://www.dane.gov.co/index.php/en/statistics-by-topic-1/population-and-demography/ethnic-groups (accessed on 15 July 2023).
- Unite Kingdom Government. List of Ethnic Groups. Available online: https://www.ethnicity-facts-figures.service.gov.uk/style-guide/ethnic-groups (accessed on 15 July 2023).
- United States Census Bureau. About the Topic of Race. Available online: https://www.census.gov/topics/population/race/about.html (accessed on 15 July 2023).
- United States Census Bureau. About the Hispanic Population and Its Origin. Available online: https://www.census.gov/topics/population/hispanic-origin/about.html (accessed on 15 July 2023).
- Pew Research Center. Race and Multiracial Americans in the US Census. In Multiracial in America: Proud, Diverse and Growing in Numbers; Pew Research Center: Washington, DC, USA, 2015; pp. 19–31. [Google Scholar]
- Yuan, J.; Hu, Z.; Mahal, B.A.; Zhao, S.D.; Kensler, K.H.; Pi, J.; Hu, X.; Zhang, Y.; Wang, Y.; Jiang, J.; et al. Integrated Analysis of Genetic Ancestry and Genomic Alterations across Cancers. Cancer Cell 2018, 34, 549–560. [Google Scholar] [CrossRef]
- Witherspoon, D.J.; Wooding, S.; Rogers, A.R.; Marchani, E.E.; Watkins, W.S.; Batzer, M.A.; Jorde, L.B. Genetic similarities within and between human populations. Genetics 2007, 176, 351–359. [Google Scholar] [CrossRef] [PubMed]
- Tang, H.; Quertermous, T.; Rodriguez, B.; Kardia, S.L.; Zhu, X.; Brown, A.; Pankow, J.S.; Province, M.A.; Hunt, S.C.; Boerwinkle, E.; et al. Genetic structure, self-identified race/ethnicity, and confounding in case-control association studies. Am. J. Hum. Genet. 2005, 76, 268–275. [Google Scholar] [CrossRef]
- Paschou, P.; Lewis, J.; Javed, A.; Drineas, P. Ancestry informative markers for fine-scale individual assignment to worldwide populations. J. Med. Genet. 2010, 47, 835–847. [Google Scholar] [CrossRef] [PubMed]
- Jin, Y.; Schaffer, A.A.; Feolo, M.; Holmes, J.B.; Kattman, B.L. GRAF-pop: A Fast Distance-Based Method to Infer Subject Ancestry from Multiple Genotype Datasets Without Principal Components Analysis. G3 Genes Genomes Genet. 2019, 9, 2447–2461. [Google Scholar] [CrossRef] [PubMed]
- Fang, H.; Hui, Q.; Lynch, J.; Honerlaw, J.; Assimes, T.L.; Huang, J.; Vujkovic, M.; Damrauer, S.M.; Pyarajan, S.; Gaziano, J.M.; et al. Harmonizing Genetic Ancestry and Self-identified Race/Ethnicity in Genome-wide Association Studies. Am. J. Hum. Genet. 2019, 105, 763–772. [Google Scholar] [CrossRef] [PubMed]
- Rosenberg, N.A.; Li, L.M.; Ward, R.; Pritchard, J.K. Informativeness of genetic markers for inference of ancestry. Am. J. Hum. Genet. 2003, 73, 1402–1422. [Google Scholar] [CrossRef] [PubMed]
- Rosenberg, N.A. A population-genetic perspective on the similarities and differences among worldwide human populations. Hum. Biol. 2011, 83, 659–684. [Google Scholar] [CrossRef]
- Ding, L.; Wiener, H.; Abebe, T.; Altaye, M.; Go, R.C.; Kercsmar, C.; Grabowski, G.; Martin, L.J.; Khurana Hershey, G.K.; Chakorborty, R.; et al. Comparison of measures of marker informativeness for ancestry and admixture mapping. BMC Genom. 2011, 12, 622. [Google Scholar] [CrossRef]
- Genomes Project Consortium; Auton, A.; Brooks, L.D.; Durbin, R.M.; Garrison, E.P.; Kang, H.M.; Korbel, J.O.; Marchini, J.L.; McCarthy, S.; McVean, G.A.; et al. A global reference for human genetic variation. Nature 2015, 526, 68–74. [Google Scholar] [CrossRef]
- Cavalli-Sforza, L.L.; Menozzi, P.; Piazza, A. The History and Geography of Human Genes; Princeton University Press: Princeton, NJ, USA, 1994. [Google Scholar]
- Bergstrom, A.; McCarthy, S.A.; Hui, R.; Almarri, M.A.; Ayub, Q.; Danecek, P.; Chen, Y.; Felkel, S.; Hallast, P.; Kamm, J.; et al. Insights into human genetic variation and population history from 929 diverse genomes. Science 2020, 367, eaay5012. [Google Scholar] [CrossRef] [PubMed]
- Nagar, S.D.; Moreno, A.M.; Norris, E.T.; Rishishwar, L.; Conley, A.B.; O’Neal, K.L.; Velez-Gomez, S.; Montes-Rodriguez, C.; Jaraba-Alvarez, W.V.; Torres, I.; et al. Population Pharmacogenomics for Precision Public Health in Colombia. Front. Genet. 2019, 10, 241. [Google Scholar] [CrossRef] [PubMed]
- Nagar, S.D.; Conley, A.B.; Jordan, I.K. Population structure and pharmacogenomic risk stratification in the United States. BMC Biol. 2020, 18, 140. [Google Scholar] [CrossRef] [PubMed]
- Jordan, I.K.; Sharma, S.; Nagar, S.D.; Valderrama-Aguirre, A.; Marino-Ramirez, L. Genetic Ancestry Inference for Pharmacogenomics. Methods Mol. Biol. 2022, 2547, 595–609. [Google Scholar] [CrossRef] [PubMed]
- Jordan, I.K.; Sharma, S.; Nagar, S.D.; Marino-Ramirez, L. The Apportionment of Pharmacogenomic Variation: Race, Ethnicity, and Adverse Drug Reactions. Med. Res. Arch. 2022, 10. [Google Scholar] [CrossRef]
- Sharma, S.; Mariño-Ramírez, L.; Jordan, I.K. Race, Ethnicity, and Pharmacogenomic Variation in the United States and the United Kingdom. Pharmaceutics 2023, 15, 1923. [Google Scholar] [CrossRef] [PubMed]
- Peter, B.M.; Petkova, D.; Novembre, J. Genetic Landscapes Reveal How Human Genetic Diversity Aligns with Geography. Mol. Biol. Evol. 2020, 37, 943–951. [Google Scholar] [CrossRef]
- Schlebusch, C.M.; Malmstrom, H.; Gunther, T.; Sjodin, P.; Coutinho, A.; Edlund, H.; Munters, A.R.; Vicente, M.; Steyn, M.; Soodyall, H.; et al. Southern African ancient genomes estimate modern human divergence to 350,000 to 260,000 years ago. Science 2017, 358, 652–655. [Google Scholar] [CrossRef]
- Ragsdale, A.P.; Weaver, T.D.; Atkinson, E.G.; Hoal, E.G.; Moller, M.; Henn, B.M.; Gravel, S. A weakly structured stem for human origins in Africa. Nature 2023, 617, 755–763. [Google Scholar] [CrossRef]
- Choudhury, A.; Aron, S.; Botigue, L.R.; Sengupta, D.; Botha, G.; Bensellak, T.; Wells, G.; Kumuthini, J.; Shriner, D.; Fakim, Y.J.; et al. High-depth African genomes inform human migration and health. Nature 2020, 586, 741–748. [Google Scholar] [CrossRef]
- Rodriguez, C.E. Changing Race: Latinos, the Census, and the History of Ethnicity in the United States; NYU Press: New York, NY, USA, 2000. [Google Scholar]
- Graves, J.L. Biological Theories of Race beyond the Millennium. In Reconsidering Race: Social Science Perspectives on Racial Categories in the Age of Genomics; Suzuki, K., Von Vacano, D.A., Eds.; Oxford University Press: Oxford, UK, 2018; pp. 21–31. [Google Scholar]
- Jameson, J.L.; Longo, D.L. Precision medicine—Personalized, problematic, and promising. N. Engl. J. Med. 2015, 372, 2229–2234. [Google Scholar] [CrossRef] [PubMed]
- Collins, F.S.; Varmus, H. A new initiative on precision medicine. N. Engl. J. Med. 2015, 372, 793–795. [Google Scholar] [CrossRef] [PubMed]
- Weeramanthri, T.S.; Dawkins, H.J.S.; Baynam, G.; Bellgard, M.; Gudes, O.; Semmens, J.B. Editorial: Precision Public Health. Front. Public Health 2018, 6, 121. [Google Scholar] [CrossRef] [PubMed]
- Khoury, M.J.; Iademarco, M.F.; Riley, W.T. Precision Public Health for the Era of Precision Medicine. Am. J. Prev. Med. 2016, 50, 398–401. [Google Scholar] [CrossRef] [PubMed]
- Khoury, M.J.; Bowen, M.S.; Clyne, M.; Dotson, W.D.; Gwinn, M.L.; Green, R.F.; Kolor, K.; Rodriguez, J.L.; Wulf, A.; Yu, W. From public health genomics to precision public health: A 20-year journey. Genet. Med. 2018, 20, 574–582. [Google Scholar] [CrossRef] [PubMed]
- Nordling, L. How the genomics revolution could finally help Africa. Nature 2017, 544, 20–22. [Google Scholar] [CrossRef]
- Nyakutira, C.; Roshammar, D.; Chigutsa, E.; Chonzi, P.; Ashton, M.; Nhachi, C.; Masimirembwa, C. High prevalence of the CYP2B6 516G-->T(*6) variant and effect on the population pharmacokinetics of efavirenz in HIV/AIDS outpatients in Zimbabwe. Eur. J. Clin. Pharmacol. 2008, 64, 357–365. [Google Scholar] [CrossRef]
- Lewontin, R.C. The apportionment of human diversity. In Evolutionary Biology; Springer: Berlin/Heidelberg, Germany, 1972; pp. 381–398. [Google Scholar]
- Novembre, J. The background and legacy of Lewontin’s apportionment of human genetic diversity. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2022, 377, 20200406. [Google Scholar] [CrossRef]
- Edge, M.D.; Ramachandran, S.; Rosenberg, N.A. Celebrating 50 years since Lewontin’s apportionment of human diversity. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2022, 377, 20200405. [Google Scholar] [CrossRef]
- Flanagin, A.; Frey, T.; Christiansen, S.L.; AMA Manual of Style Committee. Updated Guidance on the Reporting of Race and Ethnicity in Medical and Science Journals. JAMA 2021, 326, 621–627. [Google Scholar] [CrossRef]
- Oni-Orisan, A.; Mavura, Y.; Banda, Y.; Thornton, T.A.; Sebro, R. Embracing Genetic Diversity to Improve Black Health. N. Engl. J. Med. 2021, 384, 1163–1167. [Google Scholar] [CrossRef] [PubMed]
- Marino-Ramirez, L.; Perez-Stable, E.J.; Jordan, I.K. Honour genetic diversity to realize health equity. Nature 2023, 613, 243. [Google Scholar] [CrossRef] [PubMed]
- Sirugo, G.; Williams, S.M.; Tishkoff, S.A. The Missing Diversity in Human Genetic Studies. Cell 2019, 177, 1080. [Google Scholar] [CrossRef] [PubMed]
- Bustamante, C.D.; Burchard, E.G.; De la Vega, F.M. Genomics for the world. Nature 2011, 475, 163–165. [Google Scholar] [CrossRef] [PubMed]
- Popejoy, A.B.; Fullerton, S.M. Genomics is failing on diversity. Nature 2016, 538, 161–164. [Google Scholar] [CrossRef] [PubMed]
- Petrovski, S.; Goldstein, D.B. Unequal representation of genetic variation across ancestry groups creates healthcare inequality in the application of precision medicine. Genome Biol. 2016, 17, 157. [Google Scholar] [CrossRef] [PubMed]
- Liao, W.W.; Asri, M.; Ebler, J.; Doerr, D.; Haukness, M.; Hickey, G.; Lu, S.; Lucas, J.K.; Monlong, J.; Abel, H.J.; et al. A draft human pangenome reference. Nature 2023, 617, 312–324. [Google Scholar] [CrossRef]
- Lewis, A.C.F.; Molina, S.J.; Appelbaum, P.S.; Dauda, B.; Di Rienzo, A.; Fuentes, A.; Fullerton, S.M.; Garrison, N.A.; Ghosh, N.; Hammonds, E.M.; et al. Getting genetic ancestry right for science and society. Science 2022, 376, 250–252. [Google Scholar] [CrossRef]
- Carlson, J.; Henn, B.M.; Al-Hindi, D.R.; Ramachandran, S. Counter the weaponization of genetics research by extremists. Nature 2022, 610, 444–447. [Google Scholar] [CrossRef]
- Biddanda, A.; Rice, D.P.; Novembre, J. A variant-centric perspective on geographic patterns of human allele frequency variation. Elife 2020, 9, e60107. [Google Scholar] [CrossRef]
- Yudell, M.; Roberts, D.; DeSalle, R.; Tishkoff, S. NIH must confront the use of race in science. Science 2020, 369, 1313–1314. [Google Scholar] [CrossRef]
- Yudell, M.; Roberts, D.; DeSalle, R.; Tishkoff, S. Taking race out of human genetics. Science 2016, 351, 564–565. [Google Scholar] [CrossRef]
- Kampourakis, K.; Peterson, E.L. The racist origins, racialist connotations, and purity assumptions of the concept of “admixture” in human evolutionary genetics. Genetics 2023, 223, iyad002. [Google Scholar] [CrossRef]
- Coop, G. Genetic similarity versus genetic ancestry groups as sample descriptors in human genetics. arXiv 2022, arXiv:2207.11595. [Google Scholar]
- Coyne, J.A.; Maroja, L.S. The Ideological Subversion of Biology. Skept. Inq. 2023, 47. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jordan, I.K.; Sharma, S.; Mariño-Ramírez, L. Population Pharmacogenomics for Health Equity. Genes 2023, 14, 1840. https://doi.org/10.3390/genes14101840
Jordan IK, Sharma S, Mariño-Ramírez L. Population Pharmacogenomics for Health Equity. Genes. 2023; 14(10):1840. https://doi.org/10.3390/genes14101840
Chicago/Turabian StyleJordan, I. King, Shivam Sharma, and Leonardo Mariño-Ramírez. 2023. "Population Pharmacogenomics for Health Equity" Genes 14, no. 10: 1840. https://doi.org/10.3390/genes14101840
APA StyleJordan, I. K., Sharma, S., & Mariño-Ramírez, L. (2023). Population Pharmacogenomics for Health Equity. Genes, 14(10), 1840. https://doi.org/10.3390/genes14101840