
Breeding Tomato Hybrids for Flavour: Comparison of GWAS Results Obtained on Lines and F1 Hybrids

 , and
, and
Abstract
:1. Introduction
2. Materials and Methods
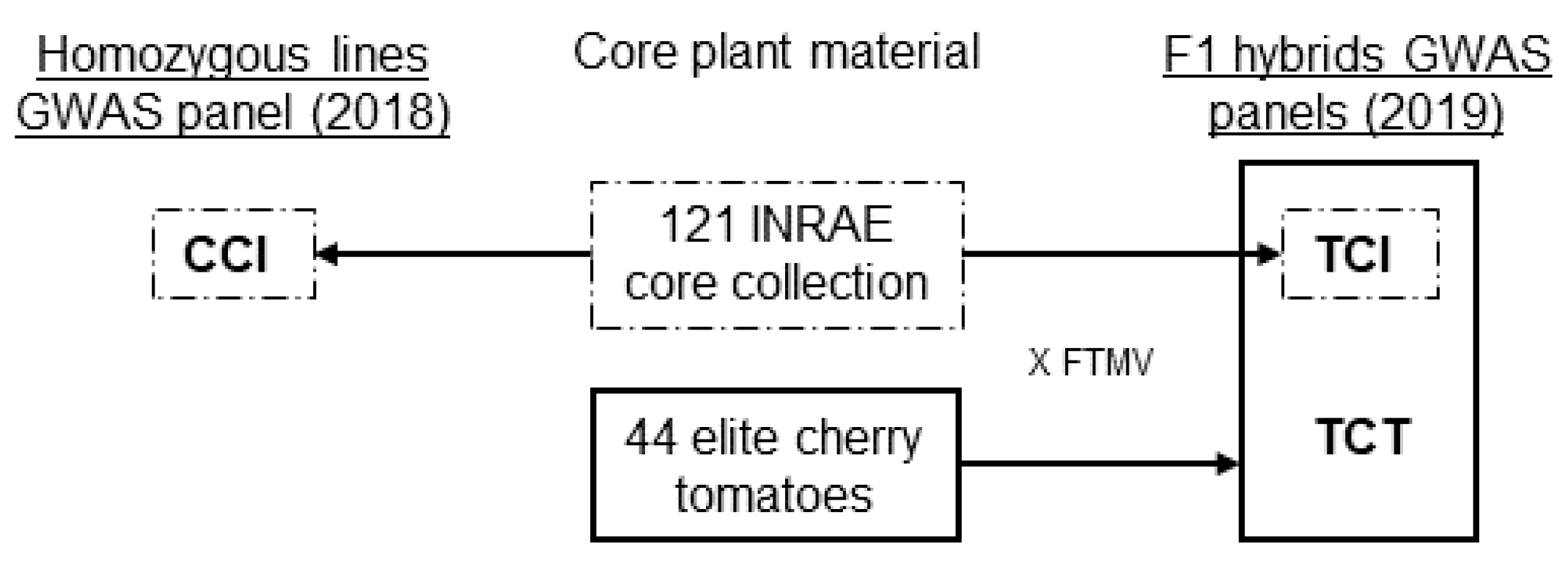
2.1. Plant Material
2.2. Growth Conditions
2.3. Fruit Samples
2.4. VOC Profiling by Gas Chromatography/Mass Spectrometry
2.5. Data Processing and Statistics
2.6. GWAS Analysis
2.7. QTL Compilation
2.8. Putative Effect of Polymorphisms in Candidate Genes
3. Results
3.1. Panel Structure
3.2. Variability of VOCs in the GWAS Panels
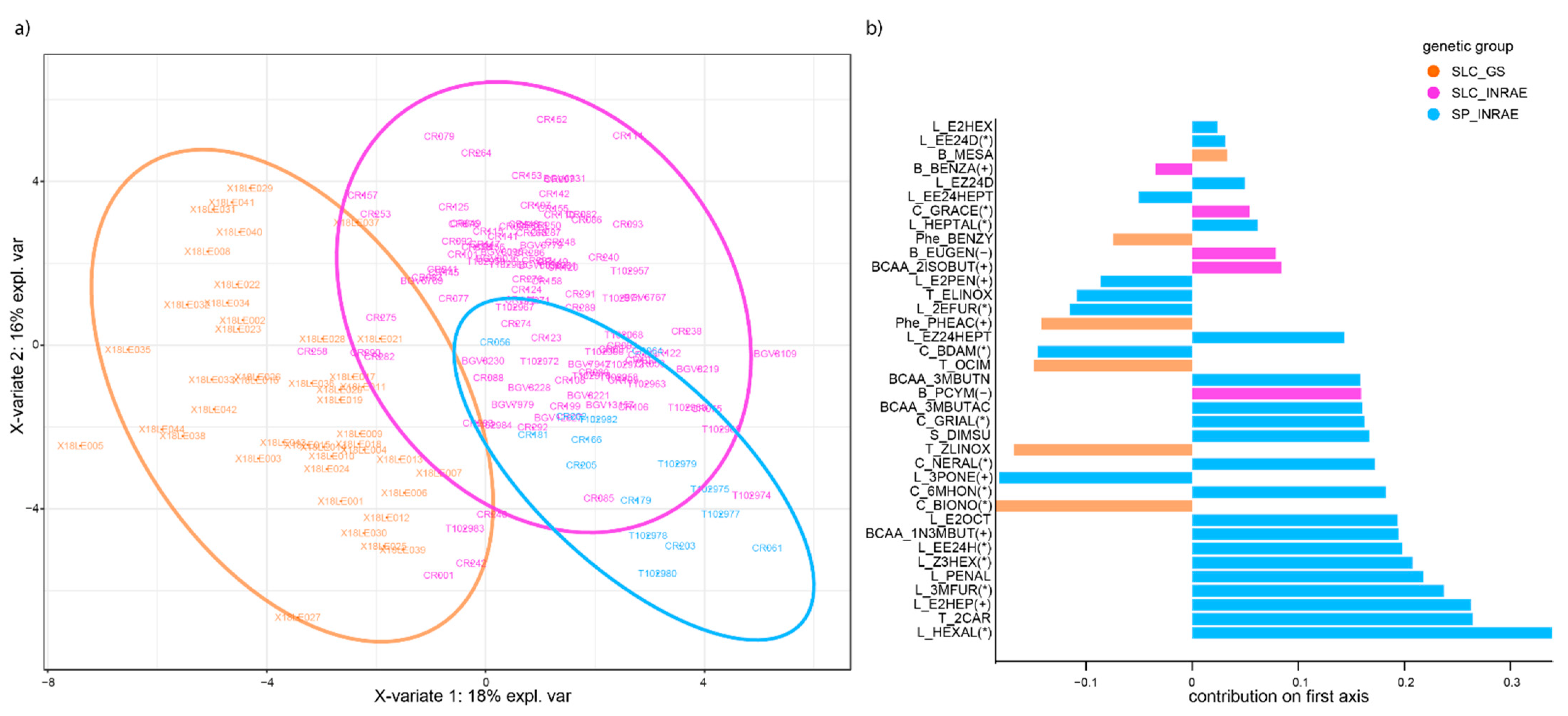
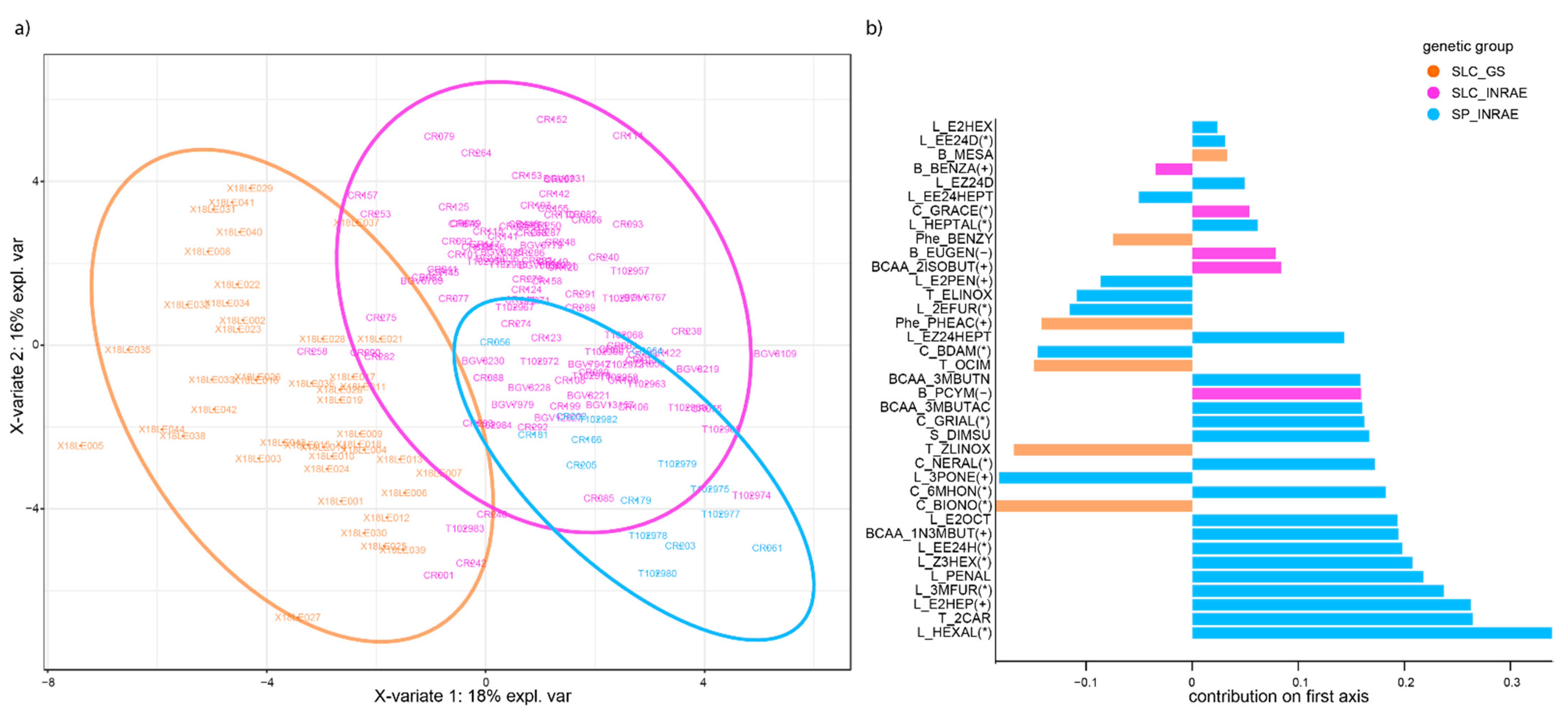
3.3. Cluster Analysis and Metabolic Signatures Per Genetic Group
3.3.1. Metabolite Clusters Are Consistent at the Line and F1 Hybrid Levels
3.3.2. Genetic Groups Display Characteristic VOC Signatures
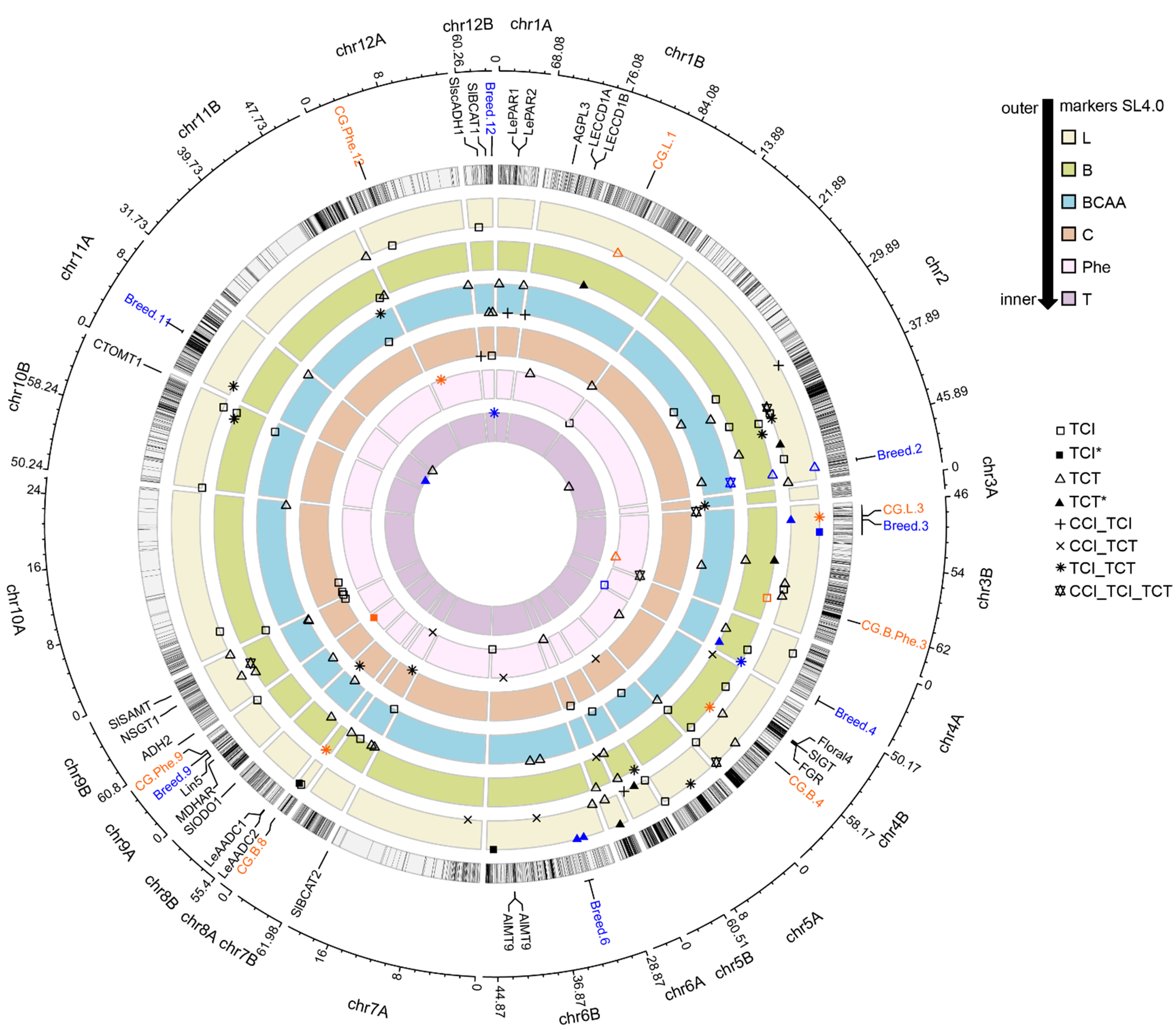
3.4. GWAS Analysis
3.5. Candidate Genes for F1 Hybrid Quality
3.5.1. Lipid-Derived VOCs
3.5.2. Phenylalanine and Benzenoid-Derived VOCs
3.6. Breeding for F1 Hybrid Quality
4. Discussion
4.1. Targeting Appropriate Plant Material to Better Elucidate VOC Genetic Control
4.2. Strategy for F1 Hybrids Quality Improvement
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- FAOSTAT. Available online: http://www.fao.org/faostat/en/#data/QC (accessed on 16 January 2020).
- Decoene, C. Tomates, qu’en pensent les consommateurs. Infos.-Ctifl. 1995, 112, 8–11. [Google Scholar]
- Fernqvist, F.; Hunter, E. Who’s to blame for tasteless tomatoes? The effect of tomato chilling on consumers’ taste perceptions. Eur. J. Hortic. Sci. 2012, 77, 193–198. [Google Scholar]
- Laing, D.G.; Jinks, A. Flavour perception mechanisms. Trends Food Sci. Technol. 1996, 7, 387–389. [Google Scholar] [CrossRef]
- Baldwin, E.A.; Scott, J.; Shewmaker, C.K.; Schuch, W. Flavor trivia and tomato aroma: Biochemistry and possible mechanisms for control of important aroma components. HortScience 2000, 35, 1013–1022. [Google Scholar] [CrossRef] [Green Version]
- Granell, A.; Rambla, J.L. Biosynthesis of volatile compounds. In The Molecular Biology and Biochemistry of Fruit Ripening; John Wiley & Sons, Ltd.: New York, NY, USA, 2013; pp. 135–161. [Google Scholar]
- Pott, D.M.; Osorio, S.; Vallarino, J.G. From central to specialized metabolism: An overview of some secondary compounds derived from the primary metabolism for their role in conferring nutritional and organoleptic characteristics to fruit. Front. Plant Sci. 2019, 10, 835. [Google Scholar] [CrossRef] [Green Version]
- Klee, H.J.; Tieman, D.M. The genetics of fruit flavour preferences. Nat. Rev. Genet. 2018, 19, 347–356. [Google Scholar] [CrossRef] [PubMed]
- Mainland, J.D.; Keller, A.; Li, Y.R.; Zhou, T.; Trimmer, C.; Snyder, L.L.; Moberly, A.H.; Adipietro, K.A.; Liu, W.L.L.; Zhuang, H.; et al. The missense of smell: Functional variability in the human odorant receptor repertoire. Nat. Neurosci. 2014, 17, 114–120. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Togari, N.; Kobayashi, A.; Aishima, T. Relating sensory properties of tea aroma to gas chromatographic data by chemometric calibration methods. Food Res. Int. 1995, 28, 485–493. [Google Scholar] [CrossRef]
- Baldwin, E.A.; Scott, J.W.; Einstein, M.A.; Malundo, T.M.M.; Carr, B.T.; Shewfelt, R.L.; Tandon, K.S. Relationship between sensory and instrumental analysis for tomato flavor. J. Am. Soc. Hortic. Sci. 1998, 123, 906–915. [Google Scholar] [CrossRef] [Green Version]
- Bezman, Y.; Mayer, F.; Takeoka, G.R.; Buttery, R.G.; Ben-Oliel, G.; Rabinowitch, H.D.; Naim, M. Differential effects of tomato (Lycopersicon Esculentum Mill) matrix on the volatility of important aroma compounds. J. Agric. Food Chem. 2003, 51, 722–726. [Google Scholar] [CrossRef]
- Birtić, S.; Ginies, C.; Causse, M.; Renard, C.M.G.C.; Page, D. Changes in volatiles and glycosides during fruit maturation of two contrasted tomato (Solanum Lycopersicum) lines. J. Agric. Food Chem. 2009, 57, 591–598. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Baldwin, E.A.; Bai, J. Recent advance in aromatic volatile research in tomato fruit: The metabolisms and regulations. Food Bioprocess Technol. 2016, 9, 203–216. [Google Scholar] [CrossRef]
- Baldwin, E.A.; Goodner, K.; Plotto, A.; Pritchett, K.; Einstein, M. Effect of volatiles and their concentration on perception of tomato descriptors. J. Food Sci. 2004, 69, S310–S318. [Google Scholar] [CrossRef]
- Tikunov, Y.M.; Roohanitaziani, R.; Meijer-Dekens, F.; Molthoff, J.; Paulo, J.; Finkers, R.; Capel, I.; Moreno, F.C.; Maliepaard, C.; Vries, M.N.; et al. The genetic and functional analysis of flavor in commercial tomato: The FLORAL4 gene underlies a QTL for floral aroma volatiles in tomato fruit. Plant J. 2020, 103, 1189–1204. [Google Scholar] [CrossRef] [PubMed]
- Causse, M.; Saliba-Colombani, V.; LeComte, L.; Duffé, P.; Rousselle, P.; Buret, M. QTL analysis of fruit quality in fresh market tomato: A few chromosome regions control the variation of sensory and instrumental traits. J. Exp. Bot. 2002, 53, 2089–2098. [Google Scholar] [CrossRef] [PubMed]
- Tieman, D.; Taylor, M.; Schauer, N.; Fernie, A.R.; Hanson, A.D.; Klee, H.J. Tomato aromatic amino acid decarboxylases participate in synthesis of the flavor volatiles 2-phenylethanol and 2-phenylacetaldehyde. Proc. Natl. Acad. Sci. USA 2006, 103, 8287–8292. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mageroy, M.H.; Tieman, D.M.; Floystad, A.; Taylor, M.G.; Klee, H.J. A solanum lycopersicum catechol-o-methyltransferase involved in synthesis of the flavor molecule guaiacol: Synthesis of guaiacol by catechol-o-methyltransferase. Plant J. 2012, 69, 1043–1051. [Google Scholar] [CrossRef]
- Martina, M.; Tikunov, Y.; Portis, E.; Bovy, A.G. The genetic basis of tomato aroma. Genes 2021, 12, 226. [Google Scholar] [CrossRef] [PubMed]
- Tieman, D.; Zhu, G.; Resende, M.F.R.; Lin, T.; Nguyen, C.; Bies, D.; Rambla, J.L.; Beltran, K.S.O.; Taylor, M.; Zhang, B.; et al. A chemical genetic roadmap to improved tomato flavor. Science 2017, 355, 391–394. [Google Scholar] [CrossRef]
- Bauchet, G.; Grenier, S.; Samson, N.; Segura, V.; Kende, A.; Beekwilder, J.; Cankar, K.; Gallois, J.-L.; Gricourt, J.; Bonnet, J.; et al. Identification of major loci and genomic regions controlling acid and volatile content in tomato fruit: Implications for flavor improvement. New Phytol. 2017, 215, 624–641. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, J.; Sauvage, C.; Zhao, J.; Bitton, F.; Bauchet, G.; Liu, D.; Huang, S.; Tieman, D.M.; Klee, H.J.; Causse, M. Meta-analysis of genome-wide association studies provides insights into genetic control of tomato flavor. Nat. Commun. 2019, 10, 1534. [Google Scholar] [CrossRef] [Green Version]
- Santamaria, P.; Signore, A. How has the consistency of the common catalogue of varieties of vegetable species changed in the last ten years? Sci. Hortic. 2021, 277, 109805. [Google Scholar] [CrossRef]
- Lecomte, L.; Duffé, P.; Buret, M.; Servin, B.; Hospital, F.; Causse, M. Marker-assisted introgression of five QTLs controlling fruit quality traits into three tomato lines revealed interactions between QTLS and genetic backgrounds. Theor. Appl. Genet. 2004, 109, 658–668. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Lindhout, P. Domestication and breeding of tomatoes: What have we gained and what can we gain in the future? Ann. Bot. 2007, 100, 1085–1094. [Google Scholar] [CrossRef] [PubMed]
- Semel, Y.; Nissenbaum, J.; Menda, N.; Zinder, M.; Krieger, U.; Issman, N.; Pleban, T.; Lippman, Z.; Gur, A.; Zamir, D. Overdominant quantitative trait loci for yield and fitness in tomato. Proc. Natl. Acad. Sci. USA 2006, 103, 12981–12986. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.; Zhu, G.; Zhang, J.; Xu, X.; Yu, Q.; Zheng, Z.; Zhang, Z.; Lun, Y.; Li, S.; Wang, X.; et al. Genomic analyses provide insights into the history of tomato breeding. Nat. Genet. 2014, 46, 1220–1226. [Google Scholar] [CrossRef]
- Blanca, J.; Montero-Pau, J.; Sauvage, C.; Bauchet, G.; Illa, E.; Díez, M.J.; Francis, D.; Causse, M.; van der Knaap, E.; Cañizares, J. Genomic variation in tomato, from wild ancestors to contemporary breeding accessions. BMC Genom. 2015, 16, 257. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sauvage, C.; Segura, V.; Bauchet, G.; Stevens, R.; Do, P.T.; Nikoloski, Z.; Fernie, A.R.; Causse, M. Genome-wide association in tomato reveals 44 candidate loci for fruit metabolic traits. Plant Physiol. 2014, 165, 1120–1132. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Albert, E.; Segura, V.; Gricourt, J.; Bonnefoi, J.; Derivot, L.; Causse, M. Association mapping reveals the genetic architecture of tomato response to water deficit: Focus on major fruit quality traits. J. Exp. Bot. 2016, 67, 6413–6430. [Google Scholar] [CrossRef] [PubMed]
- Rambla, J.L.; Alfaro, C.; Medina, A.; Zarzo, M.; Primo, J.; Granell, A. tomato fruit volatile profiles are highly dependent on sample processing and capturing methods. Metabolomics 2015, 11, 1708–1720. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. 2020. Available online: https://www.r-project.org/ (accessed on 19 July 2021).
- Hamilton, J.P.; Sim, S.-C.; Stoffel, K.; Van Deynze, A.; Buell, C.R.; Francis, D.M. Single nucleotide polymorphism discovery in cultivated tomato via sequencing by synthesis. Plant Genome 2012, 5, 17–29. [Google Scholar] [CrossRef]
- Sim, S.-C.; Durstewitz, G.; Plieske, J.; Wieseke, R.; Ganal, M.W.; Van Deynze, A.; Hamilton, J.P.; Buell, C.R.; Causse, M.; Wijeratne, S.; et al. Development of a large SNP genotyping array and generation of high-density genetic maps in tomato. PLoS ONE 2012, 7, e40563. [Google Scholar] [CrossRef] [PubMed]
- Purcell, S.; Neale, B.; Todd-Brown, K.; Thomas, L.; Ferreira, M.A.R.; Bender, D.; Maller, J.; Sklar, P.; de Bakker, P.I.W.; Daly, M.J.; et al. PLINK: A tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 2007, 81, 559–575. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Segura, V.; Vilhjálmsson, B.J.; Platt, A.; Korte, A.; Seren, Ü.; Long, Q.; Nordborg, M. An efficient multi-locus mixed-model approach for genome-wide association studies in structured populations. Nat. Genet. 2012, 44, 825–830. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lê, S.; Josse, J.; Husson, F. FactoMineR: An R package for multivariate analysis. J. Stat. Softw. 2008, 25, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Kang, H.M.; Zaitlen, N.A.; Wade, C.M.; Kirby, A.; Heckerman, D.; Daly, M.J.; Eskin, E. Efficient control of population structure in model organism association mapping. Genetics 2008, 178, 1709–1723. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mangin, B.; Siberchicot, A.; Nicolas, S.; Doligez, A.; This, P.; Cierco-Ayrolles, C. Novel measures of linkage disequilibrium that correct the bias due to population structure and relatedness. Heredity 2012, 108, 285–291. [Google Scholar] [CrossRef] [Green Version]
- Diouf, I.; Albert, E.; Duboscq, R.; Santoni, S.; Bitton, F.; Gricourt, J.; Causse, M. Integration of QTL, transcriptome and polymorphism studies reveals candidate genes for water stress response in tomato. Genes 2020, 11, 900. [Google Scholar] [CrossRef]
- Andrews, S. FastQC: A Quality Control Tool for High Throughput Sequence Data. Available online: https://www.bioinformatics.babraham.ac.uk/projects/fastqc/ (accessed on 17 June 2021).
- Ewels, P.; Magnusson, M.; Lundin, S.; Käller, M. MultiQC: Summarize analysis results for multiple tools and samples in a single report. Bioinformatics 2016, 32, 3047–3048. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Zhou, Y.; Chen, Y.; Gu, J. Fastp: An ultra-fast all-in-one FASTQ preprocessor. Bioinformatics 2018, 34, i884–i890. [Google Scholar] [CrossRef]
- Li, H.; Handsaker, B.; Wysoker, A.; Fennell, T.; Ruan, J.; Homer, N.; Marth, G.; Abecasis, G.; Durbin, R.; 1000 Genome Project Data Processing Subgroup. The sequence alignment/map format and SAMtools. Bioinformatics 2009, 25, 2078–2079. [Google Scholar] [CrossRef] [Green Version]
- Der Auwera, G.A.V.; O’Connor, B.D. Genomics in the Cloud: Using Docker, GATK, and WDL in Terra, 1st ed.; O’Reilly Media: Newton, MA, USA, 2020. [Google Scholar]
- Köster, J.; Rahmann, S. Snakemake—A scalable bioinformatics workflow engine. Bioinformatics 2012, 28, 2520–2522. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kurtzer, G.M.; Sochat, V.; Bauer, M.W. Singularity: Scientific containers for mobility of compute. PLoS ONE 2017, 12, e0177459. [Google Scholar] [CrossRef] [PubMed]
- Rambla, J.L.; Medina, A.; Fernández-Del-Carmen, A.; Barrantes, W.; Grandillo, S.; Cammareri, M.; López-Casado, G.; Rodrigo, G.; Alonso, A.; García-Martínez, S.; et al. Identification, introgression, and validation of fruit volatile QTLs from a red-fruited wild tomato species. J. Exp. Bot. 2017, 68, 429–442. [Google Scholar] [CrossRef]
- Francini, A.; Pintado, M.M.; Manganaris, G.A.; Ferrante, A. Bioactive compounds biosynthesis and metabolism in fruit and vegetables. Front. Plant Sci. 2020, 11, 129. [Google Scholar] [CrossRef] [Green Version]
- Zhu, G.; Wang, S.; Huang, Z.; Zhang, S.; Liao, Q.; Zhang, C.; Lin, T.; Qin, M.; Peng, M.; Yang, C.; et al. Rewiring of the fruit metabolome in tomato breeding. Cell 2018, 172, 249–261.e12. [Google Scholar] [CrossRef] [Green Version]
- Tikunov, Y.M.; Molthoff, J.; de Vos, R.C.H.; Beekwilder, J.; van Houwelingen, A.; van der Hooft, J.; Nijenhuis-de Vries, M.; Labrie, C.W.; Verkerke, W.; van de Geest, H.; et al. Non-smoky glycosyltransferase1 prevents the release of smoky aroma from tomato fruit. Plant Cell 2013, 25, 3067–3078. [Google Scholar] [CrossRef] [Green Version]
- Speirs, J.; Lee, E.; Holt, K.; Yong-Duk, K.; Scott, N.S.; Loveys, B.; Schuch, W. Genetic manipulation of alcohol dehydrogenase levels in ripening tomato fruit affects the balance of some flavor aldehydes and alcohols. Plant Physiol. 1998, 117, 1047–1058. [Google Scholar] [CrossRef] [Green Version]
- Fridman, E.; Carrari, F.; Liu, Y.-S.; Fernie, A.R.; Zamir, D. Zooming in on a quantitative trait for tomato yield using interspecific introgressions. Science 2004, 305, 1786–1789. [Google Scholar] [CrossRef]
- Chen, G.; Hackett, R.; Walker, D.; Taylor, A.; Lin, Z.; Grierson, D. Identification of a specific isoform of tomato lipoxygenase (TomloxC) involved in the generation of fatty acid-derived flavor compounds. Plant Physiol. 2004, 136, 2641–2651. [Google Scholar] [CrossRef] [Green Version]
- Tandon, K.S.; Baldwin, E.A.; Shewfelt, R.L. Aroma perception of individual volatile compounds in fresh tomatoes (Lycopersicon Esculentum, Mill.) as affected by the medium of evaluation. Postharvest Biol. Technol. 2000, 20, 261–268. [Google Scholar] [CrossRef]
- Tzin, V.; Rogachev, I.; Meir, S.; Ben Zvi, M.M.; Masci, T.; Vainstein, A.; Aharoni, A.; Galili, G. Tomato fruits expressing a bacterial feedback-insensitive 3-deoxy-d-arabino-heptulosonate 7-phosphate synthase of the shikimate pathway possess enhanced levels of multiple specialized metabolites and upgraded aroma. J. Exp. Bot. 2013, 64, 4441–4452. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schouten, H.J.; Tikunov, Y.; Verkerke, W.; Finkers, R.; Bovy, A.; Bai, Y.; Visser, R.G.F. Breeding has increased the diversity of cultivated tomato in The Netherlands. Front. Plant Sci. 2019, 10, 1606. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
| Full Name | VOC ID | Met. Path | Aroma. Impact | Aroma. Descriptors |
|---|---|---|---|---|
| Benzaldehyde | BENZA | B | + | Almond, burnt sugar, peaches, fruity |
| Eugenol | EUGEN | B | − | Sweet, spicy, clove, woody, pharmaceutical |
| Guaiacol | GUAIA | B | * | Phenolic, smoke, spice, vanilla, woody |
| p-cymene | PCYM | B | * | Solvent, gasoline, citrus |
| Salicylaldehyde | SALI | B | − | NA |
| 1-nitro-3-methylbutane | 1N3MBUT | BCAA | + | NA |
| 2-isobutylthiazole | 2ISOBUT | BCAA | + | Tomato, leafy, green, pungent, medicinal |
| 3-methylbutanal | 3MBUT | BCAA | * | Ethereal, aldehydic, chocolate, peach, fatty, malt |
| β-damascenone | BDAM | C | * | Apple, rose, honey, tobacco, sweet |
| β-ionone | BIONO | C | * | Floral, sweet |
| Geranylacetone | GRACE | C | * | Sweet, floral, estery, citrus |
| Geranial | GRIAL | C | * | Sharp, lemon, sweet |
| Neral | NERAL | C | * | Lemon |
| 6-methyl-5-hepten-2-one | 6MHON | C | + | Fruity, floral, sweet |
| (E)-2-heptenal | E2HEP | L | + | Dried fruits |
| (E)-2-pentenal | E2PEN | L | + | NA |
| (E,E)-2,4-decadienal | EE24D | L | * | Earthy, musty |
| (E,E)-2,4-hexadienal | EE24H | L | * | Green |
| Heptanal | HEPTAL | L | * | Fat, citrus, rancid |
| Hexanal | HEXAL | L | * | Grass, tallow, fat |
| 1-penten-3-one | 1P3ON | L | + | Fruity, floral, green, fresh, sweet |
| 2-ethylfuran | 2EFUR | L | * | Rum, coffee, chocolate |
| 3-methylfuran | 3MFUR | L | * | NA |
| 3-pentanone | 3PONE | L | + | NA |
| (Z)-3-hexenal | Z3HEX | L | * | Leafy, green, grass, tomato |
| Phenylacetaldehyde | PHEAC | Phe | + | Hawthorne, honey, sweet |
| 2-phenylethanol | PHENE | Phe | + | Honey, spice, rose, lilac |
| 1-nitro-2-phenylethane | 1N2PHENE | Phe | + | Flower, spice |
| Linalool | LIN | T | * | Citrusy, fruity, sweet taste |
| Met. ID | Met. Path | Aroma | Mean | h2 | Nb. Assoc | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| FTMV | TCT | CCI | TCI | TCT | CCI | TCI | TCT | |||
| BENZA | B | + | 1.91 | 1.21 | 0.63 | 0.36 | 0.32 | 1 | 1 | 4 |
| EUGEN | B | − | 1.33 | 1.18 | 0.63 | 0.75 | 0.76 | 8 | 9 | 11 |
| GUAIA | B | * | 1.60 | 0.68 | 0.86 | 0.76 | 0.74 | 7 | 3 | 3 |
| PCYM | B | * | 0.82 | 1.07 | 0.72 | 0.48 | 0.44 | 4 | 6 | 3 |
| SALI | B | − | 1.44 | 0.98 | 0.77 | 0.67 | 0.66 | 11 | 2 | 6 |
| 1N3MBUT | BCAA | + | 1.49 | 1.55 | 0.55 | 0.30 | 0.37 | 2 | 5 | 10 |
| 2ISOBUT | BCAA | + | 1.36 | 1.12 | 0.68 | 0.43 | 0.45 | 1 | 2 | 1 |
| 3MBUT | BCAA | * | 1.94 | 1.22 | 0.51 | 0.16 | 0.08 | 4 | 3 | 10 |
| 6MHON | C | + | 1.04 | 1.15 | 0.62 | 0.32 | 0.47 | 4 | 1 | 0 |
| BDAM | C | * | 0.64 | 0.99 | 0.75 | 0.53 | 0.55 | 0 | 6 | 2 |
| BIONO | C | * | 0.91 | 1.18 | 0.41 | 0.18 | 0.35 | 8 | 0 | 2 |
| GRACE | C | * | 1.15 | 1.48 | 0.40 | 0.34 | 0.30 | 4 | 1 | 0 |
| GRIAL | C | * | 1.02 | 1.16 | 0.60 | 0.32 | 0.43 | 6 | 1 | 0 |
| NERAL | C | * | 1.14 | 1.13 | 0.60 | 0.22 | 0.36 | 3 | 0 | 0 |
| 1P3ON | L | + | 0.90 | 1.03 | 0.77 | 0.52 | 0.55 | 4 | 4 | 7 |
| 2EFUR | L | * | 0.99 | 1.04 | 0.32 | 0.38 | 0.46 | 1 | 5 | 0 |
| 3MFUR | L | * | 0.84 | 1.22 | 0.40 | 0.25 | 0.36 | 3 | 4 | 1 |
| 3PONE | L | + | 1.14 | 1.17 | 0.49 | 0.28 | 0.22 | 1 | 3 | 3 |
| E2HEP | L | + | 0.84 | 1.05 | 0.33 | 0.19 | 0.36 | 1 | 1 | 3 |
| E2PEN | L | + | 0.88 | 1.12 | 0.65 | 0.45 | 0.56 | 2 | 3 | 5 |
| EE24D | L | * | 0.86 | 1.13 | 0.61 | 0.35 | 0.33 | 4 | 0 | 0 |
| EE24H | L | * | 1.13 | 0.94 | 0.65 | 0.41 | 0.51 | 0 | 2 | 3 |
| EZ24D | L | * | 0.77 | 1.02 | 0.65 | 0.25 | 0.31 | 3 | 0 | 4 |
| HEPTAL | L | * | 0.97 | 1.10 | 0.30 | 0.19 | 0.02 | 5 | 1 | 5 |
| HEXAL | L | * | 0.92 | 0.96 | 0.51 | 0.25 | 0.56 | 3 | 1 | 3 |
| Z3HEX | L | * | 1.04 | 0.99 | 0.53 | 0.29 | 0.41 | 3 | 2 | 4 |
| 1N2PHENE | Phe | + | 0.97 | 1.31 | 0.71 | 0.48 | 0.52 | 9 | 4 | 0 |
| BENZY | Phe | * | 1.99 | 1.12 | 0.85 | 0.61 | 0.58 | 9 | 4 | 0 |
| PHEAC | Phe | + | 1.97 | 1.22 | 0.71 | 0.35 | 0.33 | 4 | 3 | 11 |
| PHENE | Phe | + | 1.40 | 1.29 | 0.71 | 0.55 | 0.59 | 4 | 1 | 2 |
| ELINOX | T | * | 0.66 | 1.12 | 0.80 | 0.62 | 0.59 | 5 | 2 | 4 |
| LIN | T | * | 0.94 | 0.99 | 0.03 | 0.32 | 0.30 | 1 | 1 | 4 |
| ZLINOX | T | * | 0.62 | 1.13 | 0.81 | 0.67 | 0.65 | 3 | 5 | 4 |
| SSC | SUGAR | + | 4.70 | 5.88 | 0.82 | 0.77 | 0.73 | 6 | 3 | 2 |
| ID | VOCs | Solyc. ID | Function | Exp | eQTL | Low | Mod | High |
|---|---|---|---|---|---|---|---|---|
| CG.L.1 | 1P3ON | Solyc01g099160 | Lipoxygenase | + | − | 7 | 19 | 0 |
| CG.L.1 | 1P3ON | Solyc01g099170 | Lipoxygenase | + | − | 1 | 5 | 1 |
| CG.L.1 | 1P3ON | Solyc01g099190 | Lipoxygenase B | + | − | 6 | 7 | 0 |
| CG.L.1 | 1P3ON | Solyc01g099200 | Lipoxygenase | + | − | 3 | 2 | 0 |
| CG.L.1 | 1P3ON | Solyc01g099210 | Lipoxygenase | + | − | 3 | 5 | 1 |
| CG.L.3 | 3PONE-E2HEX-E2PEN-EE24H-EE24HEPT-EZ24HEPT-Z3HEX | Solyc03g083370 | GDSL esterase/lipase | + | − | 8 | 10 | 0 |
| CG.B.Phe.3 | EUGEN-PHEAC | Solyc03g118120 | Glycosyltransferase | + | + | 3 | 4 | 0 |
| CG.B.Phe.3 | EUGEN-PHEAC | Solyc03g118190 | Transcription factor | + | + | 0 | 0 | 0 |
| CG.B.Phe.3 | EUGEN-PHEAC | Solyc03g118230 | Transcription factor | + | − | 0 | 0 | 0 |
| CG.B.Phe.3 | EUGEN-PHEAC | Solyc03g118310 | Transcription factor | + | − | 0 | 0 | 0 |
| CG.B.4 | EUGEN-GUAIA | Solyc04g074480 | DAHP synthase 2 | + | + | 2 | 1 | 0 |
| CG.B.8 | BENZA | Solyc08g006110 | Transcription factor | + | − | 0 | 0 | 0 |
| CG.B.8 | BENZA | Solyc08g006190 | Transcription factor | + | − | 0 | 0 | 0 |
| CG.B.8 | BENZA | Solyc08g006200 | Transcription factor | + | − | 0 | 0 | 0 |
| CG.B.8 | BENZA | Solyc08g006210 | Transcription factor | + | − | 0 | 0 | 0 |
| CG.B.8 | BENZA | Solyc08g006220 | Transcription factor | + | + | 0 | 0 | 0 |
| CG.B.8 | BENZA | Solyc08g006230 | Transcription factor | + | − | 0 | 0 | 0 |
| CG.B.8 | BENZA | Solyc08g006240 | Transcription factor | + | − | 0 | 0 | 0 |
| CG.B.8 | BENZA | Solyc08g006270 | Transcription factor | + | − | 0 | 0 | 0 |
| CG.B.8 | BENZA | Solyc08g006280 | Transcription factor | + | − | 0 | 0 | 0 |
| CG.B.8 | BENZA | Solyc08g006320 | Transcription factor | + | − | 0 | 0 | 0 |
| CG.B.8 | BENZA | Solyc08g006330 | Glycosyltransferase | + | + | 14 | 14 | 1 |
| CG.B.8 | BENZA | Solyc08g006350 | Glycosyltransferase | + | + | 10 | 15 | 1 |
| CG.B.8 | BENZA | Solyc08g006360 | Glycosyltransferase | + | + | 7 | 4 | 0 |
| CG.B.8 | BENZA | Solyc08g006370 | Glycosyltransferase | + | + | 1 | 9 | 1 |
| CG.B.8 | BENZA | Solyc08g006390 | Glycosyltransferase | − | − | 2 | 6 | 1 |
| CG.B.8 | BENZA | Solyc08g006400 | Glycosyltransferase | − | − | 0 | 0 | 0 |
| CG.B.8 | BENZA | Solyc08g006410 | Glycosyltransferase | + | − | 5 | 4 | 0 |
| CG.B.8 | BENZA | Solyc08g006483 | Transcription factor | − | − | 0 | 0 | 0 |
| CG.Phe.9 | PHEAC-1N2PHENE-PHENE | Solyc09g011090 | Glycosyltransferase | − | − | 4 | 5 | 0 |
| CG.Phe.9 | PHEAC-1N2PHENE-PHENE | Solyc09g011110 | Transcription factor | + | − | 0 | 0 | 0 |
| CG.Phe.12 | PHEAC | Solyc12g010170 | Transcription factor | + | − | 0 | 0 | 0 |
| CG.Phe.12 | PHEAC | Solyc12g010200 | Hexosyltransferase | + | − | 3 | 2 | 0 |
| ID | Met. Path | Flav. Geno | Position | FTMV.Effect | ||
|---|---|---|---|---|---|---|
| Chr | Start–End | Increases | Decreases | |||
| Breed.2 | B-BCAA-L | F/C | 2 | 50.05–50.46 | EUGEN(−) | 1N3MBUT(+) HEPTAL(*) |
| Breed.3 | L | F/C | 3 | 46.44–50.25 | / | HEPTAL(*) 1P3ON(+) 3PONE(+) E2PEN(+) EE24H(*) Z3HEX(*) E2HEP(+) 2EFUR(*) |
| Breed.4 | Phe-B | F/F | 4 | 5.79–7.23 | 1N2PHENE(+) | EUGEN(−) GUAIA (*) |
| Breed.6 | L | F/F | 6 | 31.61–33.17 | E2PEN(+) 1P3ON(+) 3PONE(+) EE24H (*) | / |
| Breed.9 | Phe | F/C | 9 | 3.51–4.90 | / | 1N2PHENE(+) PHENE(+) |
| Breed.11 | T | F/C | 11 | 4.58–4.97 | / | LIN(*) |
| Breed.12 | T | F/F | 12 | 63.98–64.08 | LIN(*) | / |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bineau, E.; Rambla, J.L.; Priego-Cubero, S.; Hereil, A.; Bitton, F.; Plissonneau, C.; Granell, A.; Causse, M. Breeding Tomato Hybrids for Flavour: Comparison of GWAS Results Obtained on Lines and F1 Hybrids. Genes 2021, 12, 1443. https://doi.org/10.3390/genes12091443
Bineau E, Rambla JL, Priego-Cubero S, Hereil A, Bitton F, Plissonneau C, Granell A, Causse M. Breeding Tomato Hybrids for Flavour: Comparison of GWAS Results Obtained on Lines and F1 Hybrids. Genes. 2021; 12(9):1443. https://doi.org/10.3390/genes12091443
Chicago/Turabian StyleBineau, Estelle, José Luis Rambla, Santiago Priego-Cubero, Alexandre Hereil, Frédérique Bitton, Clémence Plissonneau, Antonio Granell, and Mathilde Causse. 2021. "Breeding Tomato Hybrids for Flavour: Comparison of GWAS Results Obtained on Lines and F1 Hybrids" Genes 12, no. 9: 1443. https://doi.org/10.3390/genes12091443
APA StyleBineau, E., Rambla, J. L., Priego-Cubero, S., Hereil, A., Bitton, F., Plissonneau, C., Granell, A., & Causse, M. (2021). Breeding Tomato Hybrids for Flavour: Comparison of GWAS Results Obtained on Lines and F1 Hybrids. Genes, 12(9), 1443. https://doi.org/10.3390/genes12091443