
Molecular Classification and Interpretation of Amyotrophic Lateral Sclerosis Using Deep Convolution Neural Networks and Shapley Values


Abstract
:1. Introduction
2. Materials and Methods
2.1. Datasets
2.2. Evaluation Criteria
- Area under curve of receiver operating curve (AUC-ROC): AUC-ROC takes into account all the threshold. The higher the value of AUC-ROC, the better the model is at distinguishing between classes. It can be computed by taking area under the curve for true-positive rate (TPR) on the y-axis and false-positive rate (FPR) on the x-axis for a given dataset. TPR which is also called sensitivity (SEN) describes how good the model is at classifying a sample as ALS when the actual outcome is also ALS. FPR describes how often a ALS class is predicted when the actual outcome is control.where TP = True Positives, TN = True Negatives, FP = False Positives, FN = False Negatives, and SEN = Sensitivity.
- Specificity (SPE): SPE is the total number of true negatives divided by the sum of the number of true negatives and false positives. Specificity would describe what proportion of the negative class were correctly classified by our model.
- Negative predictive value (NPV): NPV describes the probability of a sample predicted as negative class to be actually as negative class.
- Positive predictive value (PPV): PPV describes the probability of a sample predicted as positive class to be actually as positive class.
- Accuracy (ACC): ACC is the fraction of prediction our model was correct about, i.e., it predicted positive class and negative class correctly.
- Matthews correlation coefficient (MCC): MCC has a range from −1 to 1 where −1 indicates a completely wrong binary classifier while 1 indicates a completely correct binary classifier.
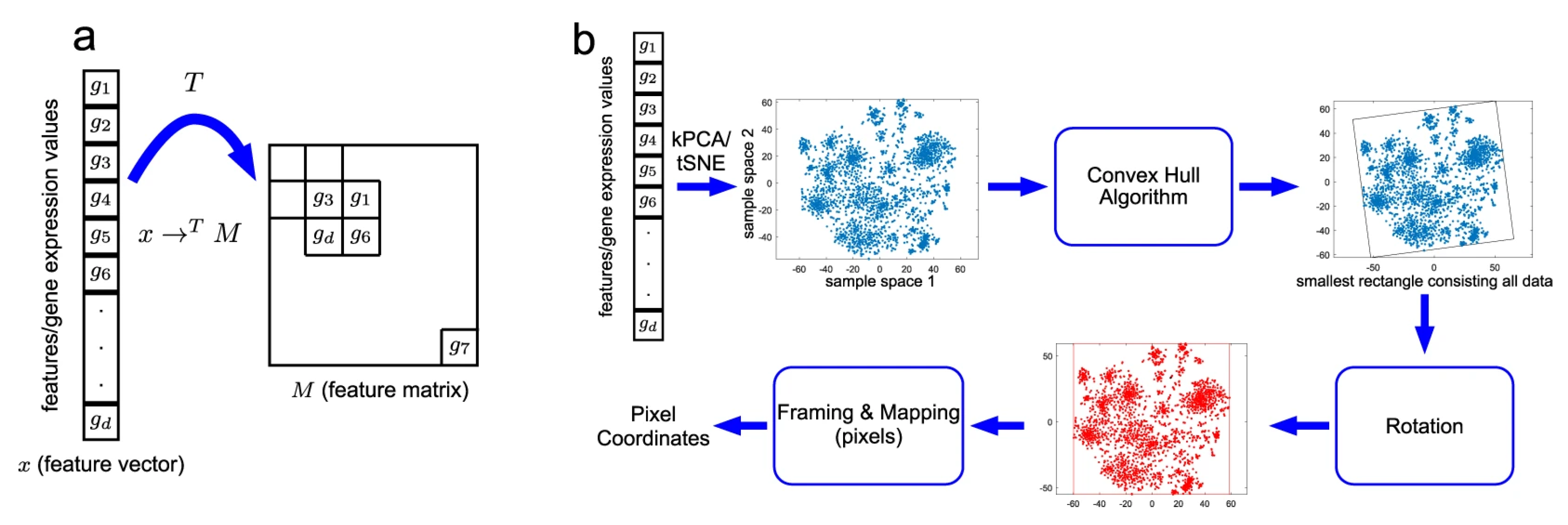
2.3. Image Creation Module
2.4. Classification Module
CNN Training
2.5. Classical Machine Learning Methods
2.5.1. Random Forest (RF)
2.5.2. Support Vector Machines (SVM)
2.5.3. Fully Connected Neural Networks (FCNN)
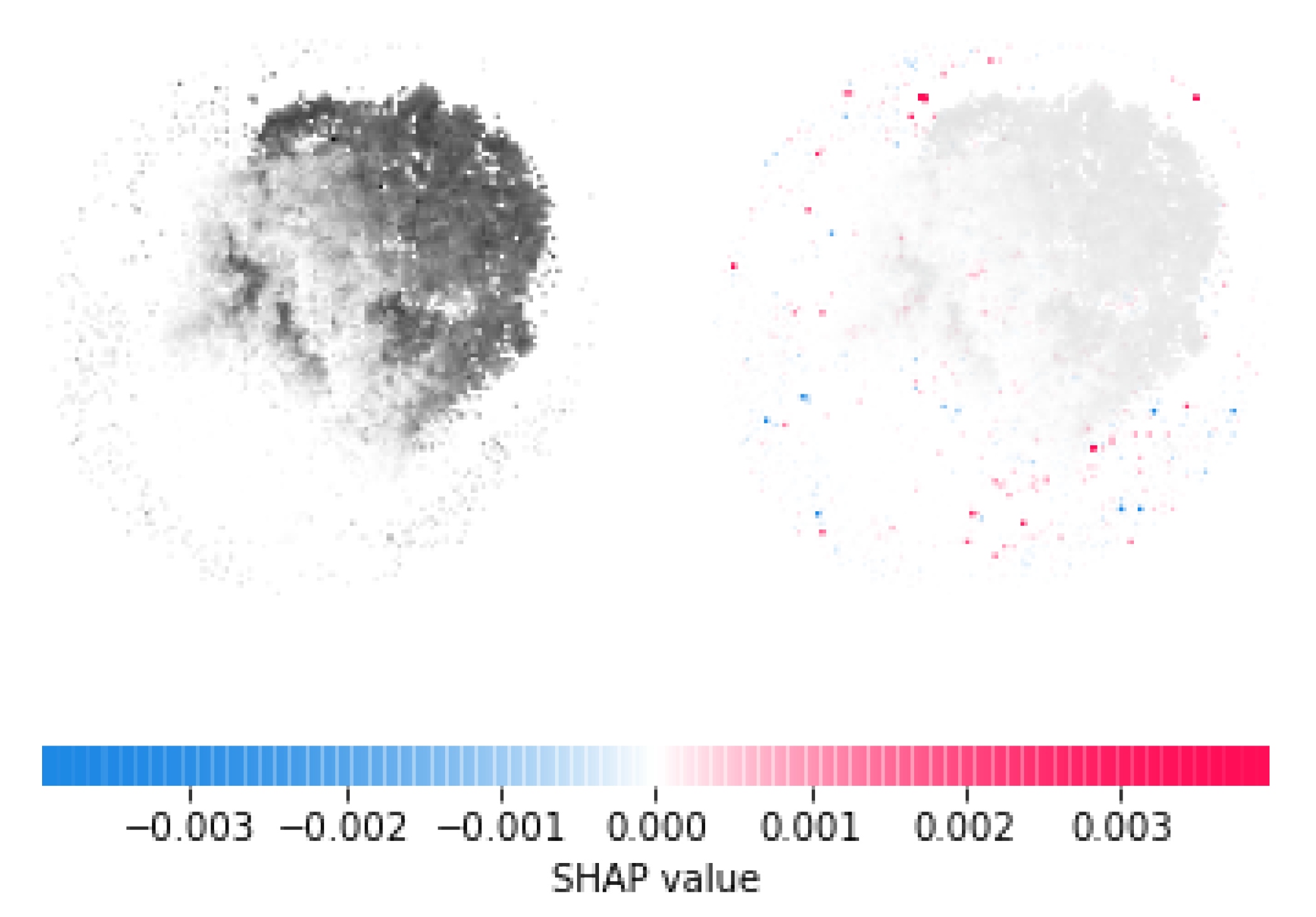
2.6. Post Hoc Interpretation Module
3. Results and Discussion
3.1. Samples and Quality Controls
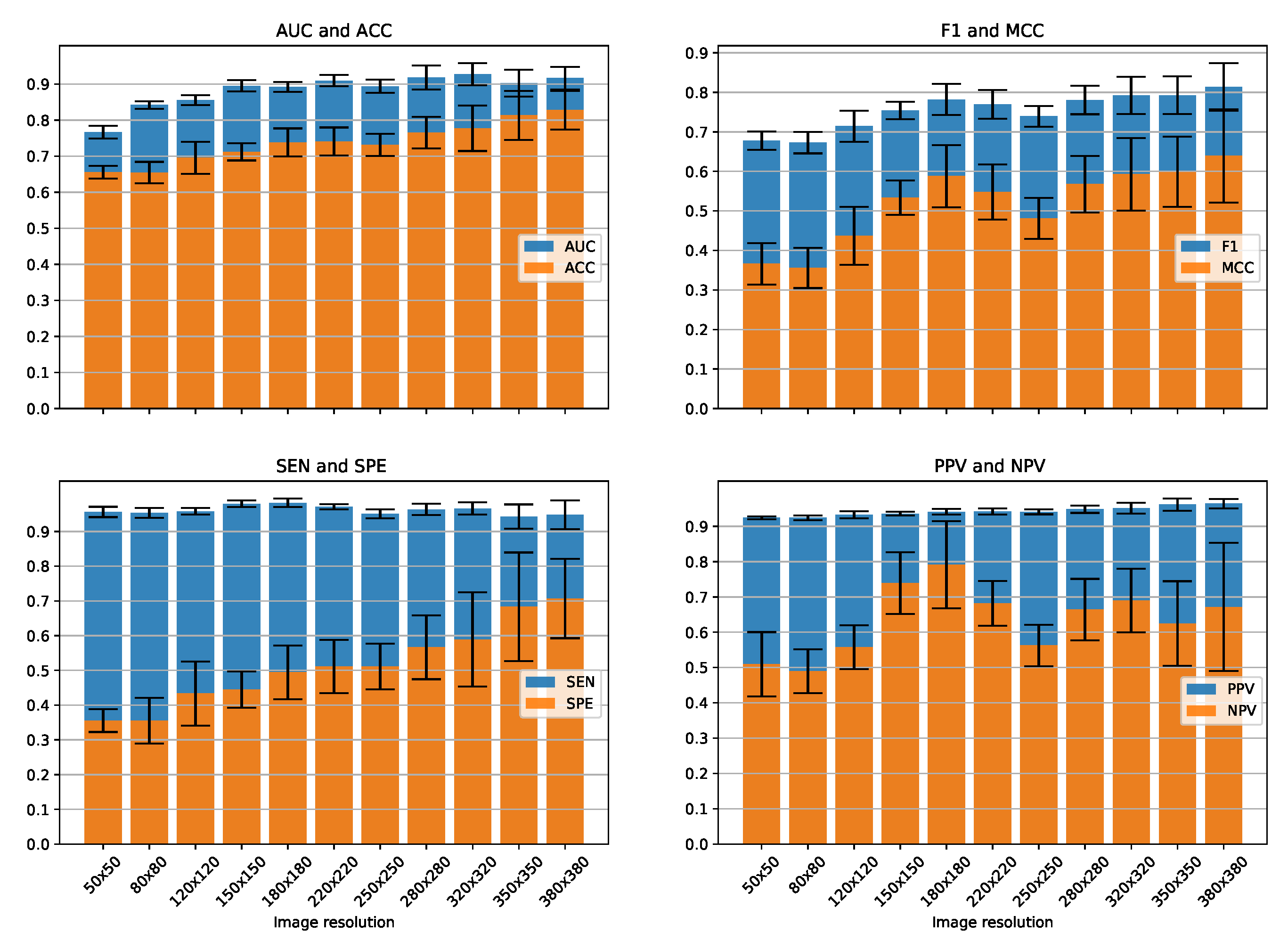
3.2. Classification Performance for Various Image Resolutions
3.3. Comparison with Classical Models
3.4. Case Study of Classification Performance with High Count and Protein-Coding Genes
- High-expression genes: Many of the 33,153 autosomal genes only express in very few samples and carry little information; thus, we filtered out those genes with low expression and only included genes with a high read count in a certain number of samples. For that purpose, we used a threshold of 10, i.e., at least 10 samples across our training data have a read count of 10 or higher. Through this filtering strategy, we obtained a total of 18,194 high expression genes. The RNA expression values of these high read count genes were converted into 350 × 350 images and subsequently used in CNN training for classification.
- Protein-coding genes: As including non-protein-coding genes in the training data may only increase the model complexity but bring little benefit to the model, thus in the second case study, we also selected RNA expression data of 19,724 protein-coding genes, converted them into images with resolution of 350 × 350 and evaluated the performance of CNN model trained with those images.
3.5. SHAP Interpretation
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ALS | Amyotrophic Lateral Sclerosis |
| FUS | Fused In Sarcoma |
| MND | Motor Neuron Disease |
| SMN | Survival of Motor Neuron |
| SOD1 | Superoxide Dismutase 1 |
| TDP-43 | TAR DNA-binding protein 43 |
References
- Phukan, J.; Pender, N.P.; Hardiman, O. Cognitive impairment in amyotrophic lateral sclerosis. Lancet Neurol. 2007, 6, 994–1003. [Google Scholar] [CrossRef]
- Yin, B.; Balvert, M.; van der Spek, R.A.; Dutilh, B.E.; Bohté, S.; Veldink, J.; Schönhuth, A. Using the structure of genome data in the design of deep neural networks for predicting amyotrophic lateral sclerosis from genotype. Bioinformatics 2019, 35, i538–i547. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amyotrophic Lateral Sclerosis (ALS) Fact Sheet | National Institute of Neurological Disorders and Stroke. Available online: https://www.ninds.nih.gov/Disorders/Patient-Caregiver-Education/Fact-Sheets/Amyotrophic-Lateral-Sclerosis-ALS-Fact-Sheet (accessed on 15 February 2021).
- Van Rheenen, W.; Shatunov, A.; Dekker, A.M.; McLaughlin, R.L.; Diekstra, F.P.; Pulit, S.L.; Van Der Spek, R.A.; Võsa, U.; De Jong, S.; Robinson, M.R.; et al. Genome-wide association analyses identify new risk variants and the genetic architecture of amyotrophic lateral sclerosis. Nat. Genet. 2016, 48, 1043–1048. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arloth, J.; Eraslan, G.; Andlauer, T.F.; Martins, J.; Iurato, S.; Kühnel, B.; Waldenberger, M.; Frank, J.; Gold, R.; Hemmer, B.; et al. DeepWAS: Multivariate genotype-phenotype associations by directly integrating regulatory information using deep learning. PLoS Comput. Biol. 2020, 16, e1007616. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Y.; Wang, D.; He, F.; Wang, J.; Joshi, T.; Xu, D. Phenotype prediction and genome-wide association study using deep convolutional neural network of soybean. Front. Genet. 2019, 10, 1091. [Google Scholar] [CrossRef]
- Drouin, A.; Letarte, G.; Raymond, F.; Marchand, M.; Corbeil, J.; Laviolette, F. Interpretable genotype-to-phenotype classifiers with performance guarantees. Sci. Rep. 2019, 9, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aronica, E.; Baas, F.; Iyer, A.; ten Asbroek, A.L.; Morello, G.; Cavallaro, S. Molecular classification of amyotrophic lateral sclerosis by unsupervised clustering of gene expression in motor cortex. Neurobiol. Dis. 2015, 74, 359–376. [Google Scholar] [CrossRef] [Green Version]
- Baloch, Z.Q.; Raza, S.A.; Pathak, R.; Marone, L.; Ali, A. Machine Learning Confirms Nonlinear Relationship between Severity of Peripheral Arterial Disease, Functional Limitation and Symptom Severity. Diagnostics 2020, 10, 515. [Google Scholar] [CrossRef] [PubMed]
- Nicholls, H.L.; John, C.R.; Watson, D.S.; Munroe, P.B.; Barnes, M.R.; Cabrera, C.P. Reaching the end-game for GWAS: Machine learning approaches for the prioritization of complex disease loci. Front. Genet. 2020, 11, 350. [Google Scholar] [CrossRef] [PubMed]
- Zarei, S.; Carr, K.; Reiley, L.; Diaz, K.; Guerra, O.; Altamirano, P.F.; Pagani, W.; Lodin, D.; Orozco, G.; Chinea, A. A comprehensive review of amyotrophic lateral sclerosis. Surg. Neurol. Int. 2015, 6. [Google Scholar] [CrossRef]
- Grollemund, V.; Pradat, P.F.; Querin, G.; Delbot, F.; Le Chat, G.; Pradat-Peyre, J.F.; Bede, P. Machine learning in amyotrophic lateral sclerosis: Achievements, pitfalls, and future directions. Front. Neurosci. 2019, 13, 135. [Google Scholar] [CrossRef] [Green Version]
- Mitani, A.A.; Haneuse, S. Small data challenges of studying rare diseases. JAMA Netw. Open 2020, 3, e201965. [Google Scholar] [CrossRef] [Green Version]
- Rowland, L.P.; Shneider, N.A. Amyotrophic lateral sclerosis. N. Engl. J. Med. 2001, 344, 1688–1700. [Google Scholar] [CrossRef]
- Agah, E.; Saleh, F.; Moghaddam, H.S.; Saghazadeh, A.; Tafakhori, A.; Rezaei, N. CSF and blood biomarkers in amyotrophic lateral sclerosis: Protocol for a systematic review and meta-analysis. Syst. Rev. 2018, 7, 1–5. [Google Scholar] [CrossRef] [Green Version]
- Barbour, D.L. Precision medicine and the cursed dimensions. NPJ Digit. Med. 2019, 2, 1–2. [Google Scholar] [CrossRef] [Green Version]
- Chattopadhyay, A.; Lu, T.P. Gene-gene interaction: The curse of dimensionality. Ann. Transl. Med. 2019, 7, 24. [Google Scholar] [CrossRef]
- Köppen, M. The curse of dimensionality. In Proceedings of the 5th Online World Conference on Soft Computing in Industrial Applications (WSC5), Online, 4–8 September 2000; Volume 1, pp. 4–8. [Google Scholar]
- Consortium, G.T. The Genotype-Tissue Expression (GTEx) pilot analysis: Multitissue gene regulation in humans. Science 2015, 348, 648–660. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dols-Icardo, O.; Montal, V.; Sirisi, S.; López-Pernas, G.; Cervera-Carles, L.; Querol-Vilaseca, M.; Muñoz, L.; Belbin, O.; Alcolea, D.; Molina-Porcel, L.; et al. Motor cortex transcriptome reveals microglial key events in amyotrophic lateral sclerosis. Neurol.-Neuroimmunol. Neuroinflamm. 2020, 7. [Google Scholar] [CrossRef] [PubMed]
- Li, D.C.; Liu, C.W.; Hu, S.C. A learning method for the class imbalance problem with medical data sets. Comput. Biol. Med. 2010, 40, 509–518. [Google Scholar] [CrossRef] [PubMed]
- Haque, M.M.; Skinner, M.K.; Holder, L.B. Imbalanced class learning in epigenetics. J. Comput. Biol. 2014, 21, 492–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sharma, A.; Vans, E.; Shigemizu, D.; Boroevich, K.A.; Tsunoda, T. DeepInsight: A methodology to transform a non-image data to an image for convolution neural network architecture. Sci. Rep. 2019, 9, 1–7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lundberg, S.; Lee, S.I. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Andrews, S. FastQC: A Quality Control Tool for High throughput Sequence Data. Available online: http://www.bioinformatics.babraham.ac.uk/projects/fastqc (accessed on 27 September 2021).
- Yates, A.D.; Achuthan, P.; Akanni, W.; Allen, J.; Allen, J.; Alvarez-Jarreta, J.; Amode, M.R.; Armean, I.M.; Azov, A.G.; Bennett, R. Ensembl 2020. Nucleic Acids Res. 2020, 48, D682–D688. [Google Scholar] [CrossRef]
- Bray, N.L.; Pimentel, H.; Melsted, P.; Pachter, L. Near-optimal probabilistic RNA-seq quantification. Nat. Biotechnol. 2016, 34, 525–527. [Google Scholar] [CrossRef] [PubMed]
- Frankish, A.; Diekhans, M.; Ferreira, A.M.; Johnson, R.; Jungreis, I.; Loveland, J.; Mudge, J.M.; Sisu, C.; Wright, J.; Armstrong, J.; et al. GENCODE reference annotation for the human and mouse genomes. Nucleic Acids Res. 2019, 47, D766–D773. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sharma, A. GitHub-alok-ai-lab/DeepInsight: A Methodology to Transform a Non-Image Data to an Image for Convolution Neural Network Architecture. Available online: https://github.com/alok-ai-lab/DeepInsight (accessed on 25 February 2021).
- Karim, A.; Singh, J.; Mishra, A.; Dehzangi, A.; Newton, M.H.; Sattar, A. Toxicity prediction by multimodal deep learning. In Pacific Rim Knowledge Acquisition Workshop; Springer: Berlin/Heidelberg, Germany, 2019; pp. 142–152. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 15 February 2021).
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. arXiv 2013, arXiv:1309.0238. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Andrews, S.; Tsochantaridis, I.; Hofmann, T. Support vector machines for multiple-instance learning. Adv. Neural Inf. Process. Syst. 2003, 15, 577–584. [Google Scholar]
- Platt, J. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Adv. Large Margin Classif. 1999, 10, 61–74. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Neurocomputing: Foundations of Research; MIT Press: Cambridge, MA, USA, 1988. [Google Scholar]
- Karim, A.; Mishra, A.; Newton, M.H.; Sattar, A. Efficient toxicity prediction via simple features using shallow neural networks and decision trees. ACS Omega 2019, 4, 1874–1888. [Google Scholar] [CrossRef]
- Karim, A.; Mishra, A.; Newton, M.; Sattar, A. Machine Learning Interpretability: A Science rather than a tool. arXiv 2018, arXiv:1807.06722. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Štrumbelj, E.; Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 2014, 41, 647–665. [Google Scholar] [CrossRef]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In International Conference on Machine Learning; PMLR: Sydney, Australia, 2017; pp. 3145–3153. [Google Scholar]
- Datta, A.; Sen, S.; Zick, Y. Algorithmic transparency via quantitative input influence: Theory and experiments with learning systems. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 598–617. [Google Scholar]
- GitHub—Shaoshanglqy/Shap-Shapley. Available online: https://github.com/shaoshanglqy/shap-shapley (accessed on 28 February 2021).
- Romero, I.G.; Pai, A.A.; Tung, J.; Gilad, Y. RNA-seq: Impact of RNA degradation on transcript quantification. BMC Biol. 2014, 12, 1–13. [Google Scholar]
- Imbeaud, S.; Graudens, E.; Boulanger, V.; Barlet, X.; Zaborski, P.; Eveno, E.; Mueller, O.; Schroeder, A.; Auffray, C. Towards standardization of RNA quality assessment using user-independent classifiers of microcapillary electrophoresis traces. Nucleic Acids Res. 2005, 33, e56. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weis, S.; Llenos, I.C.; Dulay, J.R.; Elashoff, M.; Martinez-Murillo, F.; Miller, C.L. Quality control for microarray analysis of human brain samples: The impact of postmortem factors, RNA characteristics, and histopathology. J. Neurosci. Methods 2007, 165, 198–209. [Google Scholar] [CrossRef] [PubMed]
- Abel, O.; Powell, J.F.; Andersen, P.M.; Al-Chalabi, A. ALSoD: A user-friendly online bioinformatics tool for amyotrophic lateral sclerosis genetics. Hum. Mutat. 2012, 33, 1345–1351. [Google Scholar] [CrossRef]
- Miccio, A.; Antoniou, P.; Ciura, S.; Kabashi, E. Novel genome-editing-based approaches to treat motor neuron diseases: Promises and challenges. Mol. Ther. 2021, in press. [Google Scholar] [CrossRef] [PubMed]
- Chaytow, H.; Huang, Y.T.; Gillingwater, T.H.; Faller, K.M.E. The role of survival motor neuron protein (SMN) in protein homeostasis. Cell Mol. Life Sci. 2018, 75, 3877–3894. [Google Scholar] [CrossRef] [Green Version]
- Bowerman, M.; Murray, L.M.; Scamps, F.; Schneider, B.L.; Kothary, R.; Raoul, C. Pathogenic commonalities between spinal muscular atrophy and amyotrophic lateral sclerosis: Converging roads to therapeutic development. Eur. J. Med. Genet. 2018, 61, 685–698. [Google Scholar] [CrossRef] [PubMed]
- Groen, E.J.; Fumoto, K.; Blokhuis, A.M.; Engelen-Lee, J.; Zhou, Y.; van den Heuvel, D.M.; Koppers, M.; van Diggelen, F.; van Heest, J.; Demmers, J.A.; et al. ALS-associated mutations in FUS disrupt the axonal distribution and function of SMN. Hum. Mol. Genet. 2013, 22, 3690–3704. [Google Scholar] [CrossRef] [Green Version]
- Sun, S.; Ling, S.C.; Qiu, J.; Albuquerque, C.P.; Zhou, Y.; Tokunaga, S.; Li, H.; Qiu, H.; Bui, A.; Yeo, G.W.; et al. ALS-causative mutations in FUS/TLS confer gain and loss of function by altered association with SMN and U1-snRNP. Nat. Commun. 2015, 6, 6171. [Google Scholar] [CrossRef]
- Yamazaki, T.; Chen, S.; Yu, Y.; Yan, B.; Haertlein, T.C.; Carrasco, M.A.; Tapia, J.C.; Zhai, B.; Das, R.; Lalancette-Hebert, M.; et al. FUS-SMN protein interactions link the motor neuron diseases ALS and SMA. Cell Rep. 2012, 2, 799–806. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gertz, B.; Wong, M.; Martin, L.J. Nuclear localization of human SOD1 and mutant SOD1-specific disruption of survival motor neuron protein complex in transgenic amyotrophic lateral sclerosis mice. J. Neuropathol. Exp. Neurol. 2012, 71, 162–177. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kariya, S.; Re, D.B.; Jacquier, A.; Nelson, K.; Przedborski, S.; Monani, U.R. Mutant superoxide dismutase 1 (SOD1), a cause of amyotrophic lateral sclerosis, disrupts the recruitment of SMN, the spinal muscular atrophy protein to nuclear Cajal bodies. Hum. Mol. Genet. 2012, 21, 3421–3434. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zou, T.; Ilangovan, R.; Yu, F.; Xu, Z.; Zhou, J. SMN protects cells against mutant SOD1 toxicity by increasing chaperone activity. Biochem. Biophys. Res. Commun. 2007, 364, 850–855. [Google Scholar] [CrossRef] [Green Version]
- Perera, N.D.; Sheean, R.K.; Crouch, P.J.; White, A.R.; Horne, M.K.; Turner, B.J. Enhancing survival motor neuron expression extends lifespan and attenuates neurodegeneration in mutant TDP-43 mice. Hum. Mol. Genet. 2016, 25, 4080–4093. [Google Scholar] [CrossRef] [Green Version]
- Turner, B.J.; Alfazema, N.; Sheean, R.K.; Sleigh, J.N.; Davies, K.E.; Horne, M.K.; Talbot, K. Overexpression of survival motor neuron improves neuromuscular function and motor neuron survival in mutant SOD1 mice. Neurobiol. Aging 2014, 35, 906–915. [Google Scholar] [CrossRef] [Green Version]
- Turner, B.J.; Parkinson, N.J.; Davies, K.E.; Talbot, K. Survival motor neuron deficiency enhances progression in an amyotrophic lateral sclerosis mouse model. Neurobiol. Dis. 2009, 34, 511–517. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Venugopal, S.; Majid, S.; Ahn, I.S.; Diamante, G.; Hong, J.; Yang, X.; Chandler, S.H. Single-cell RNA-seq analysis of the brainstem of mutant SOD1 mice reveals perturbed cell types and pathways of amyotrophic lateral sclerosis. Neurobiol. Dis. 2020, 141, 104877. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AUC | SPE | SEN | NPV | PPV | ACC | MCC | F1 |
|---|---|---|---|---|---|---|---|---|
| Our method | 0.917 ± 0.03 | 0.707 ± 0.11 | 0.947 ± 0.04 | 0.671 ± 0.18 | 0.963 ± 0.01 | 0.827 ± 0.05 | 0.639 ± 0.11 | 0.813 ± 0.06 |
| RF | 0.831 ± 0.04 | 0.155 ± 0.05 | 0.994 ± 0.00 | 0.798 ± 0.19 | 0.906 ± 0.00 | 0.575 ± 0.02 | 0.319 ± 0.09 | 0.602 ± 0.04 |
| SVM | 0.866 ± 0.05 | 0.083 ± 0.03 | 1 ± 0 | 1 ± 0 | 0.899 ± 0.00 | 0.541 ± 0.01 | 0.270 ± 0.04 | 0.549 ± 0.02 |
| FCNN | 0.805 ± 0.04 | 0.4 ± 0.12 | 0.974 ± 0.02 | 0.692 ± 0.20 | 0.930 ± 0.01 | 0.687 ± 0.06 | 0.478 ± 0.15 | 0.723 ± 0.07 |
| RNA Features | AUC | SPE | SEN | NPV | PPV | ACC | MCC | F1 |
|---|---|---|---|---|---|---|---|---|
| High count genes | 0.964 ± 0.04 | 0.776 ± 0.12 | 0.978 ± 0.00 | 0.809 ± 0.00 | 0.973 ± 0.01 | 0.877 ± 0.06 | 0.767 ± 0.10 | 0.882 ± 0.05 |
| Protein-coding genes | 0.910 ± 0.04 | 0.646 ± 0.13 | 0.968 ± 0.02 | 0.720 ± 0.12 | 0.957 ± 0.01 | 0.807 ± 0.07 | 0.643 ± 0.13 | 0.819 ± 0.06 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karim, A.; Su, Z.; West, P.K.; Keon, M.; The NYGC ALS Consortium; Shamsani, J.; Brennan, S.; Wong, T.; Milicevic, O.; Teunisse, G.; et al. Molecular Classification and Interpretation of Amyotrophic Lateral Sclerosis Using Deep Convolution Neural Networks and Shapley Values. Genes 2021, 12, 1754. https://doi.org/10.3390/genes12111754
Karim A, Su Z, West PK, Keon M, The NYGC ALS Consortium, Shamsani J, Brennan S, Wong T, Milicevic O, Teunisse G, et al. Molecular Classification and Interpretation of Amyotrophic Lateral Sclerosis Using Deep Convolution Neural Networks and Shapley Values. Genes. 2021; 12(11):1754. https://doi.org/10.3390/genes12111754
Chicago/Turabian StyleKarim, Abdul, Zheng Su, Phillip K. West, Matthew Keon, The NYGC ALS Consortium, Jannah Shamsani, Samuel Brennan, Ted Wong, Ognjen Milicevic, Guus Teunisse, and et al. 2021. "Molecular Classification and Interpretation of Amyotrophic Lateral Sclerosis Using Deep Convolution Neural Networks and Shapley Values" Genes 12, no. 11: 1754. https://doi.org/10.3390/genes12111754
APA StyleKarim, A., Su, Z., West, P. K., Keon, M., The NYGC ALS Consortium, Shamsani, J., Brennan, S., Wong, T., Milicevic, O., Teunisse, G., Rad, H. N., & Sattar, A. (2021). Molecular Classification and Interpretation of Amyotrophic Lateral Sclerosis Using Deep Convolution Neural Networks and Shapley Values. Genes, 12(11), 1754. https://doi.org/10.3390/genes12111754