
Genome-Wide Identification, Characterization and Expression Pattern Analysis of the γ-Gliadin Gene Family in the Durum Wheat (Triticum durum Desf.) Cultivar Svevo

 ,
,  ,
,  and
and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Plant Material and Growth Conditions
2.2. Sequence Analysis of the Genomic Region Harboring the γ-Gliadin Genes in the Durum Wheat cv. Svevo
2.3. Sequence Alignment and Phylogenetic Analysis
2.4. qRT-PCR
2.5. Gliadin Protein Extraction
2.6. A-PAGE
2.7. RP-HPLC Analysis
2.8. Statistical Analysis
3. Results
3.1. Identification and Characterization of the γ-Gliadin Genes in the Genome of the Durum Wheat cv. Svevo
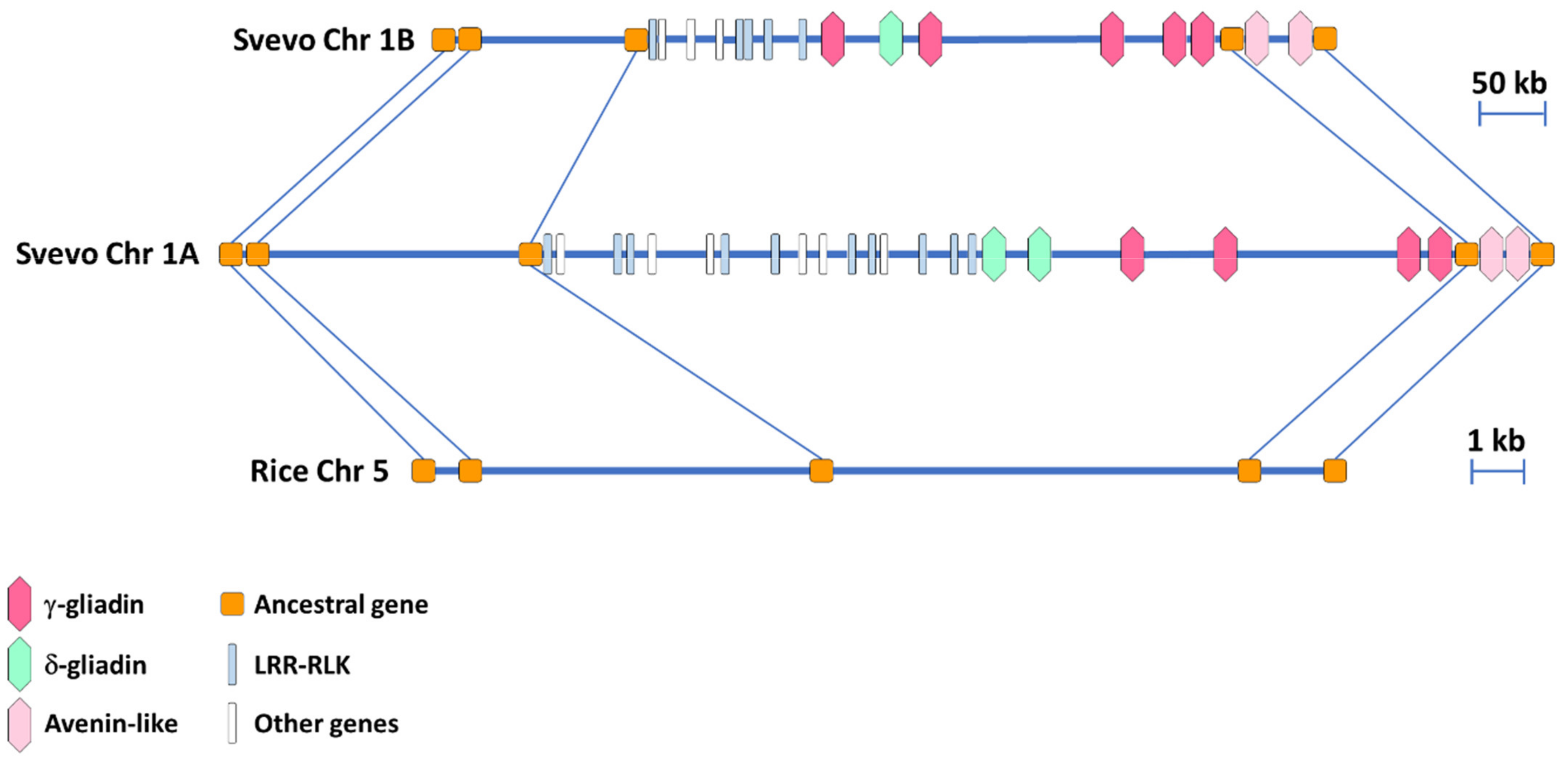
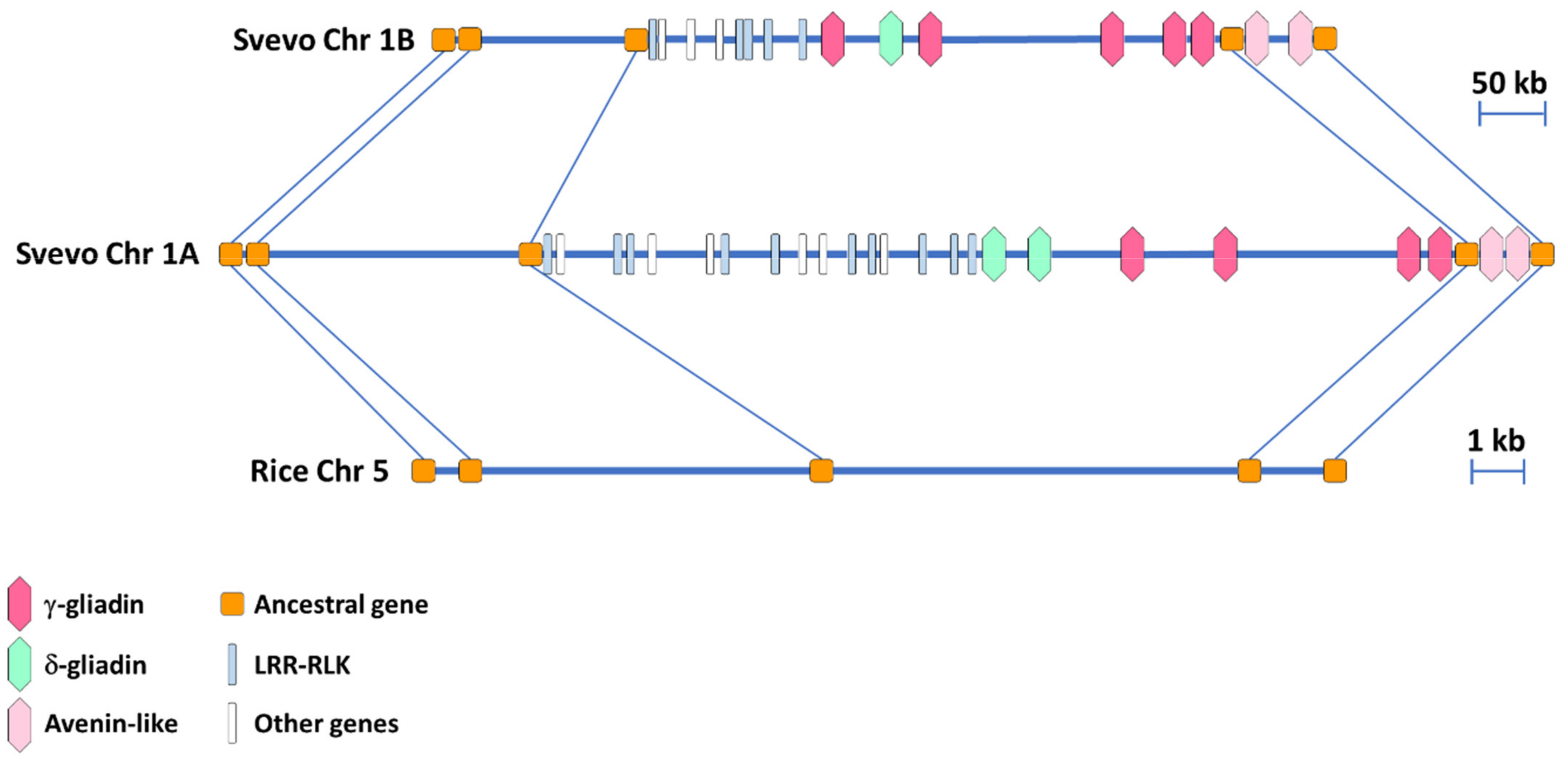
3.2. Synteny Comparison of the Homeologous Regions in the A and B Genome of the Durum Wheat cv. Svevo Harboring the γ-Gliadin Genes
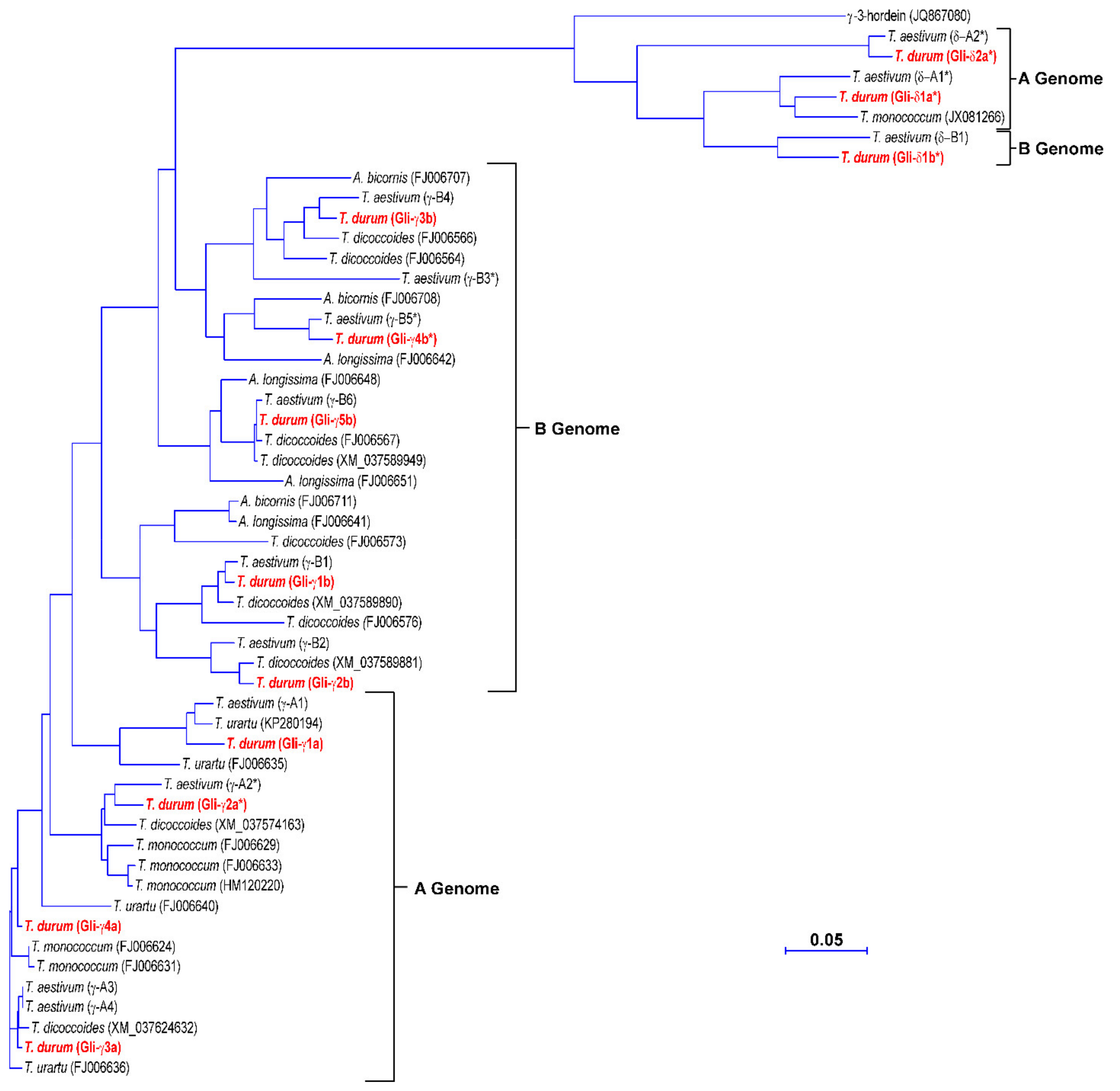
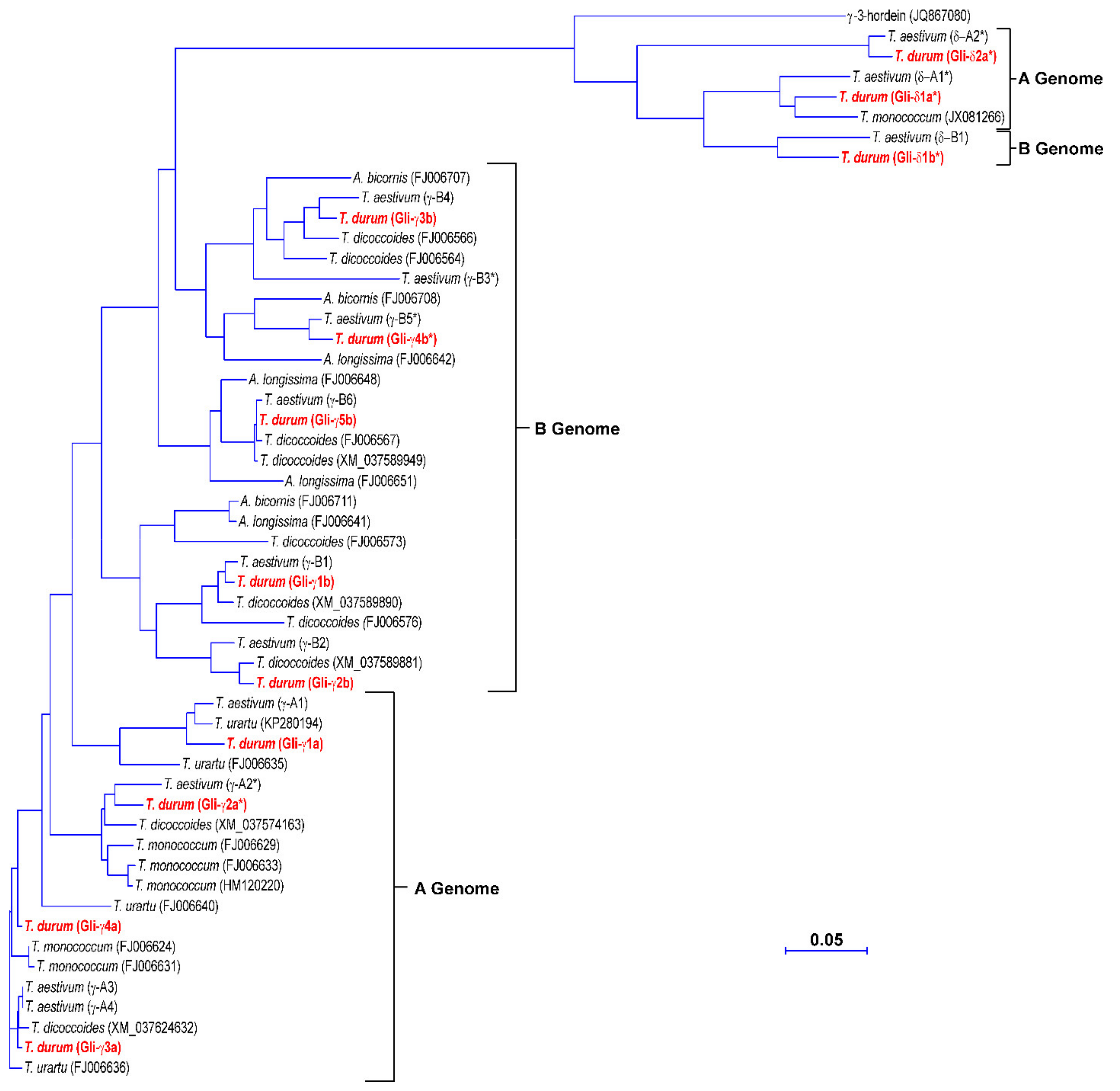
3.3. Phylogenetic Analysis of the γ-Gliadin Genes
3.4. Analysis of Deduced Amino Acid Sequences of γ-Gliadins
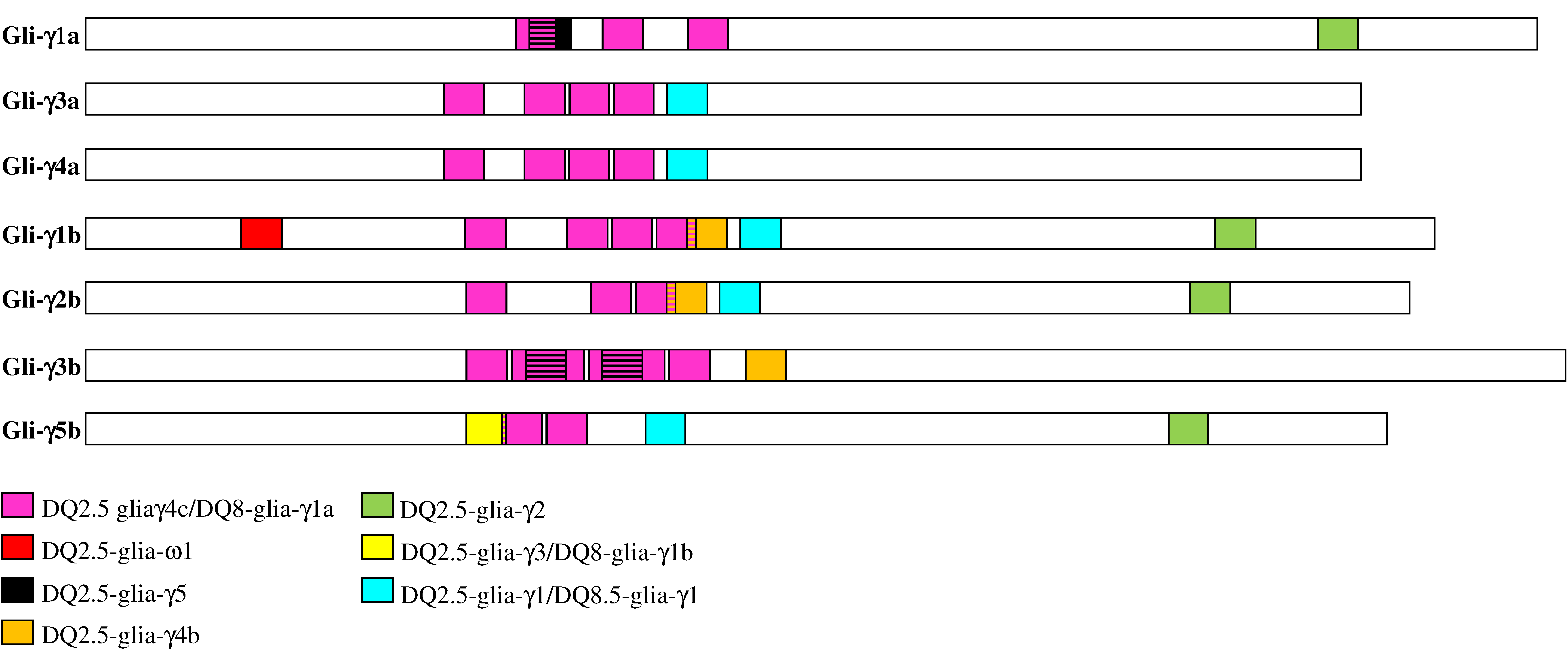
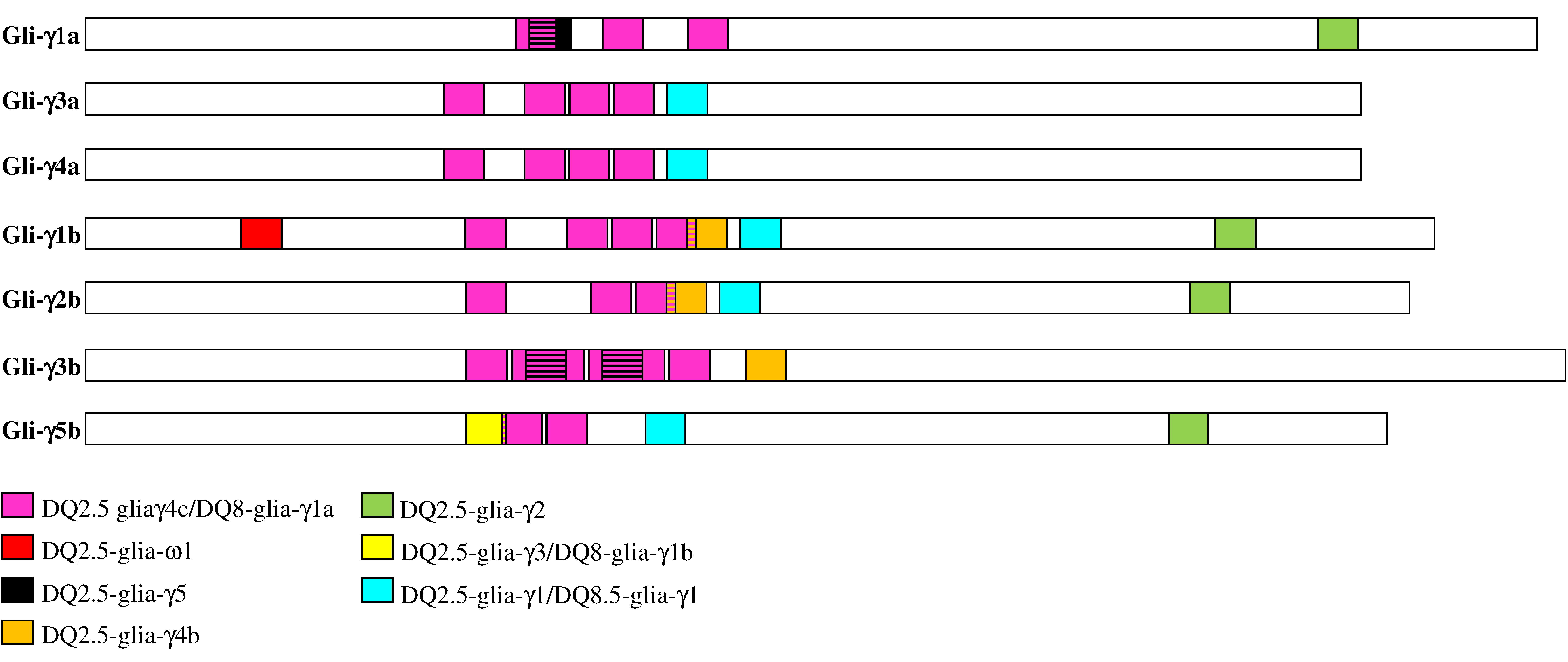
3.5. Differences in CD Epitopes among γ-Gliadins
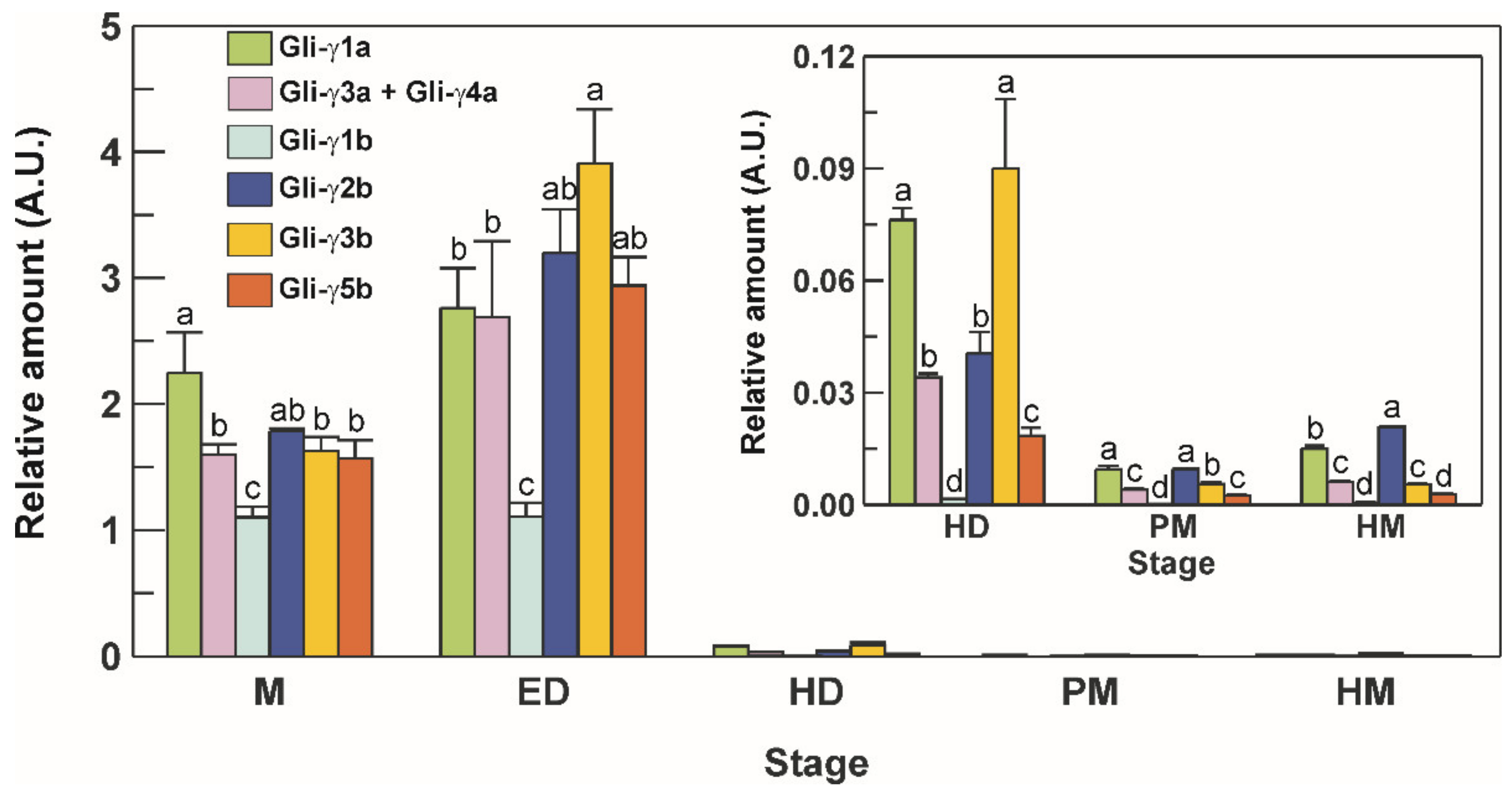
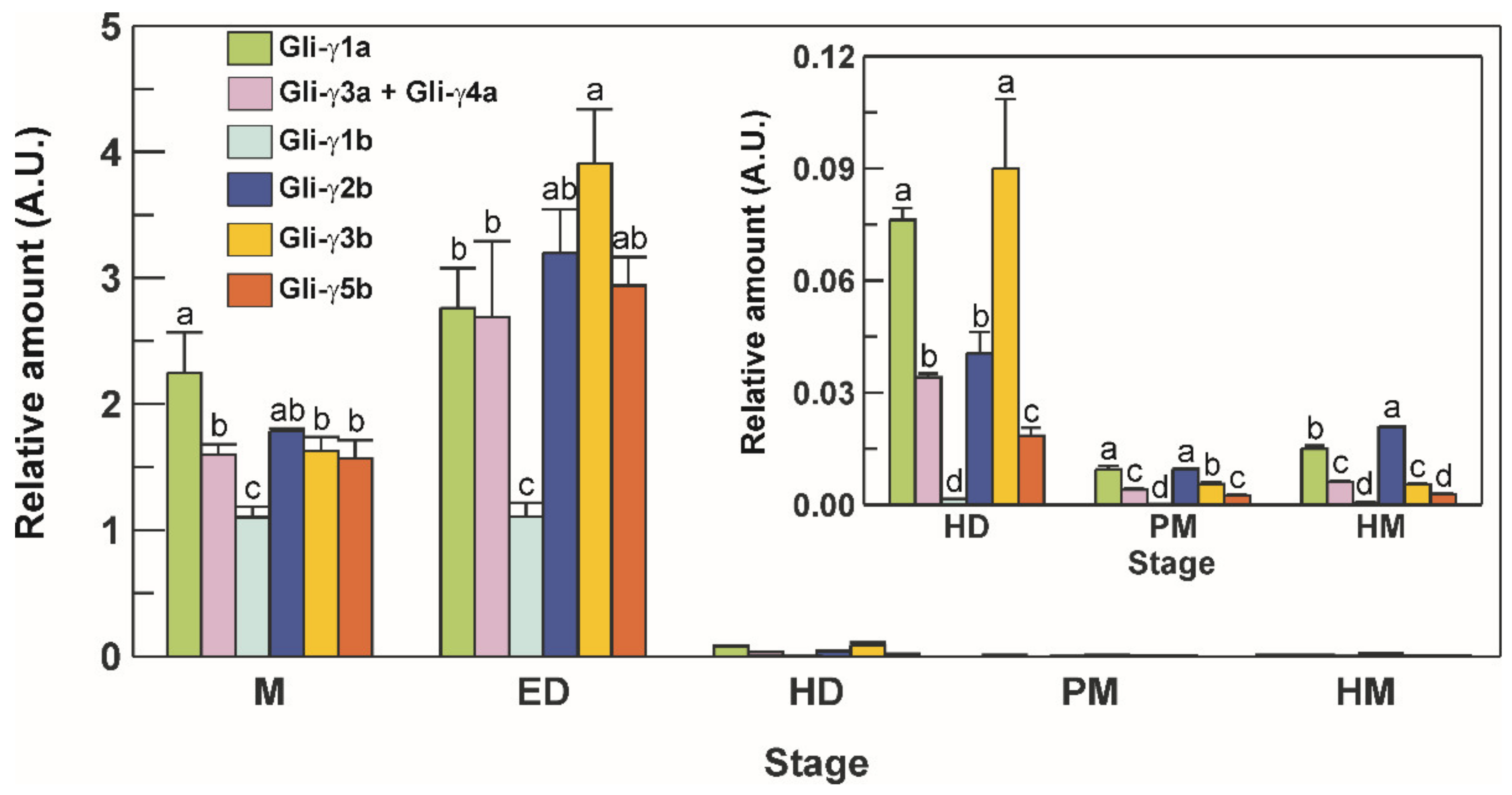
3.6. Transcriptional Profile of γ-Gliadins during Grain Development
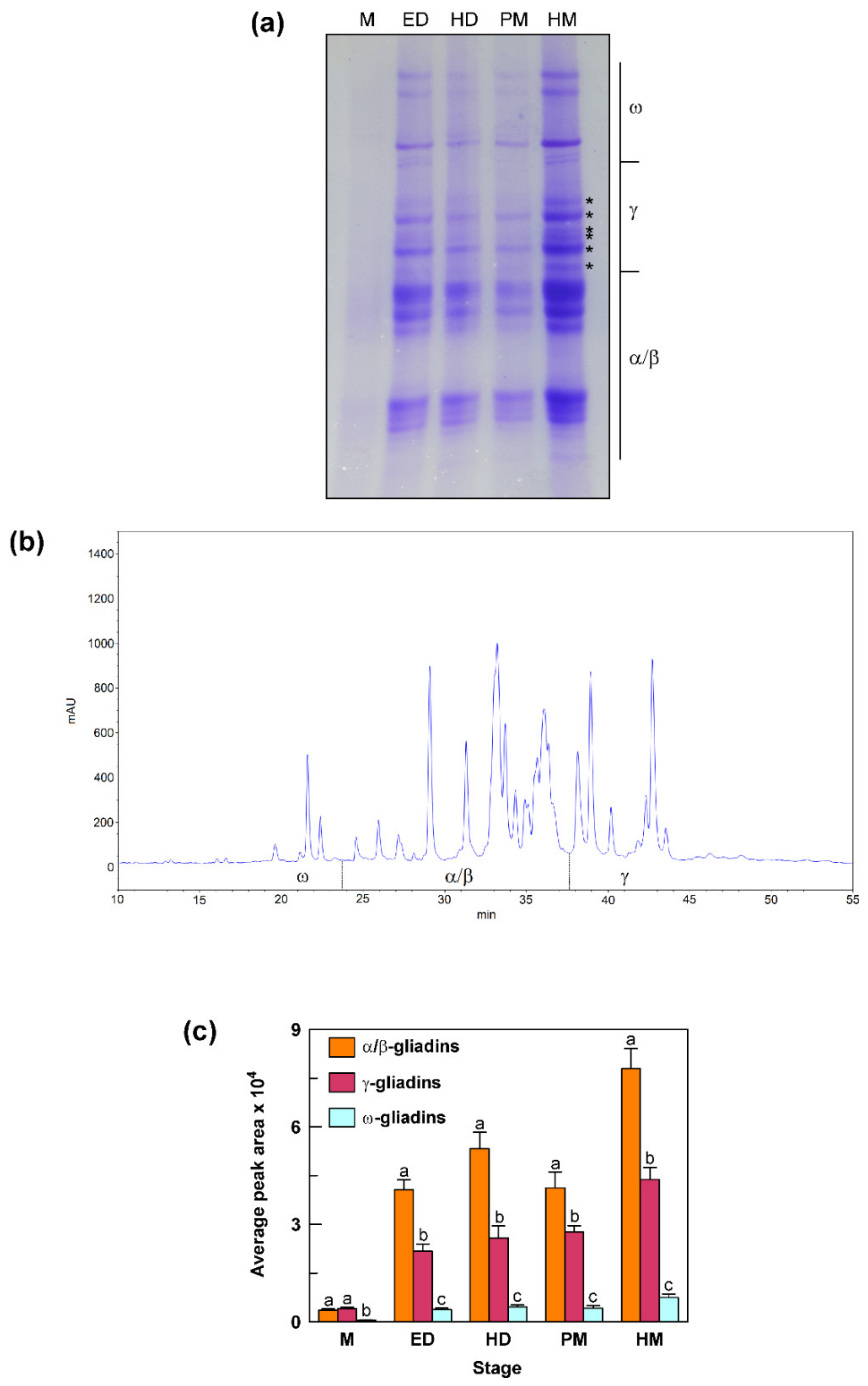
3.7. Accumulation Pattern of Gliadin Proteins during Grain Development
4. Discussion
4.1. The γ-Gliadin Gene Family in the Durum Wheat cv. Svevo
4.2. Characteristics of the Svevo γ-Gliadins
4.3. Expression of Durum Wheat γ-Gliadins during Grain Development
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shewry, P.R.; Halford, N.G. Cereal seed storage proteins: Structures, properties and role in grain utilization. J. Exp. Bot. 2002, 53, 947–958. [Google Scholar] [CrossRef] [Green Version]
- Hausch, F.; Shan, L.; Santiago, N.A.; Gray, G.M.; Khosla, C. Intestinal digestive resistance of immunodominant gliadin peptides. Am. J. Physiol. Liver Physiol. 2002, 283, G996–G1003. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shewry, P.R.; Tatham, A.S. Improving wheat to remove celiac epitopes but retain functionality. J. Cereal Sci. 2016, 67, 12–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stepniak, D.; Wiesner, M.; De Ru, A.H.; Moustakas, A.K.; Drijfhout, J.W.; Papadopoulos, G.K.; Van Veelen, P.A.; Koning, F. Large-scale characterization of natural ligands explains the unique gluten-binding properties of HLA-DQ2. J. Immunol. 2008, 180, 3268–3278. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adelman, D.C.; Murray, J.; Wu, T.-T.; Mäki, M.; Green, P.H.; Kelly, C.P. Measuring Change in Small Intestinal Histology in Patients With Celiac Disease. Am. J. Gastroenterol. 2018, 113, 339–347. [Google Scholar] [CrossRef]
- Sollid, L.M.; Qiao, S.-W.; Anderson, R.P.; Gianfrani, C.; Koning, F. Nomenclature and listing of celiac disease relevant gluten T-cell epitopes restricted by HLA-DQ molecules. Immunogenetics 2012, 64, 455–460. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Iversen, R.; Roy, B.; Stamnæs, J.; Høydahl, L.S.; Hnida, K.; Neumann, R.S.; Korponay-Szabó, I.R.; Lundin, K.E.A.; Sollid, L.M. Efficient T cell–B cell collaboration guides autoantibody epitope bias and onset of celiac disease. Proc. Natl. Acad. Sci. USA 2019, 116, 15134–15139. [Google Scholar] [CrossRef] [Green Version]
- Dørum, S.; Steinsbø, Ø.; Bergseng, E.; Arntzen, M.Ø.; de Souza, G.A.; Sollid, L.M. Gluten-specific antibodies of celiac disease gut plasma cells recognize long proteolytic fragments that typically harbor T-cell epitopes. Sci. Rep. 2016, 6, 25565. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shewry, P.R.; Halford, N.G.; Lafiandra, D. Genetics of Wheat Gluten Proteins. Adv. Genet. 2003, 49, 111–184. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.W.; Li, D.; Wang, J.; Zhao, Y.; Wang, Z.; Yue, G.; Liu, X.; Qin, H.; Zhang, K.; Dong, L.; et al. Genome-wide analysis of complex wheat gliadins; the dominant carriers of celi-ac disease epitopes. Sci. Rep. 2017, 7, 44609. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qiao, S.-W.; Bergseng, E.; Molberg, Ø.; Xia, J.; Fleckenstein, B.; Khosla, C.; Sollid, L.M. Antigen Presentation to Celiac Lesion-Derived T Cells of a 33-Mer Gliadin Peptide Naturally Formed by Gastrointestinal Digestion. J. Immunol. 2004, 173, 1757–1762. [Google Scholar] [CrossRef] [Green Version]
- Qi, P.-F.; Wei, Y.-M.; Ouellet, T.; Chen, Q.; Tan, X.; Zheng, Y.-L. The γ-gliadin multigene family in common wheat (Triticum aestivum) and its closely related species. BMC Genom. 2009, 10, 168. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vader, W.; Kooy, Y.; van Veelen, P.; de Ru, A.; Harris, D.; Benckhuijsen, W.; Peña, S.; Mearin, L.; Drijfhout, J.W.; Koning, F. The gluten response in children with celiac disease is directed toward multiple gliadin and glutenin peptides. Gastroenterology 2002, 122, 1729–1737. [Google Scholar] [CrossRef] [Green Version]
- Camarca, A.; Anderson, R.P.; Mamone, G.; Fierro, O.; Facchiano, A.; Costantini, S.; Zanzi, D.; Sidney, J.; Auricchio, S.; Sette, A.; et al. Intestinal T Cell Responses to Gluten Peptides Are Largely Heterogeneous: Implications for a Peptide-Based Therapy in Celiac Disease. J. Immunol. 2009, 182, 4158–4166. [Google Scholar] [CrossRef]
- Kumar, B.V.M.; Rao, U.J.S.P.; Prabhasankar, P. Immunogenicity characterization of hexaploid and tetraploid wheat varieties related to celiac disease and wheat allergy. Food Agric. Immunol. 2017, 28, 888–903. [Google Scholar] [CrossRef]
- Molberg, Ø.; Uhlen, A.K.; Jensen, T.; Flæte, N.S.; Fleckenstein, B.; Arentz–Hansen, H.; Raki, M.; Lundin, K.E.; Sollid, L.M. Mapping of gluten T-cell epitopes in the bread wheat ancestors: Implications for celiac disease. Gastroenterology 2005, 128, 393–401. [Google Scholar] [CrossRef] [Green Version]
- Maccaferri, M.; Harris, N.S.; Twardziok, S.O.; Pasam, R.K.; Gundlach, H.; Spannagl, M.; Ormanbekova, D.; Lux, T.; Prade, V.M.; Milner, S.G.; et al. Durum wheat genome highlights past domestication signatures and future improvement targets. Nat. Genet. 2019, 51, 885–895. [Google Scholar] [CrossRef] [Green Version]
- Intranet of Durum Wheat Genome Data. Available online: https://www.interomics.eu/durum-wheat-genome-intranet (accessed on 2 September 2021).
- FGENESH. Available online: http://www.softberry.com/berry.phtml?topic=fgenesh&group=programs&subgroup=gfind (accessed on 10 September 2021).
- WHEAT URGI. Available online: https://wheat-urgi.versailles.inra.fr/ (accessed on 25 August 2021).
- ExPASy Bioinformatics Resource Portal. Available online: http://www.expasy.org (accessed on 6 November 2012).
- Gimenez, M.J.; Pistón, F.; Atienza, S.G. Identification of suitable reference genes for normalization of qPCR data in comparative transcriptomics analyses in the Triticeae. Planta 2010, 233, 163–173. [Google Scholar] [CrossRef] [PubMed]
- Marcotuli, I.; Colasuonno, P.; Blanco, A.; Gadaleta, A.; Ilaria, M.; Pasqualina, C.; Antonio, B.; Agata, G. Expression analysis of cellulose synthase-like genes in durum wheat. Sci. Rep. 2018, 8, 15675. [Google Scholar] [CrossRef]
- Bustin, S.A.; Benes, V.; Garson, J.A.; Hellemans, J.; Huggett, J.; Kubista, M.; Mueller, R.; Nolan, T.; Pfaffl, M.W.; Shipley, G.L.; et al. The MIQE guidelines: Min-imum information for publication of quantitative real-time PCR experiments. Clin. Chem. 2009, 55, 611–622. [Google Scholar] [CrossRef] [Green Version]
- Lafiandra, D.; Kasarda, D.D. One- and two-dimensional (Two-pH) polyacrilamide gel electrophoresis in a single gel: Separation of wheat proteins. Cereal Chem. 1985, 62, 314–319. [Google Scholar]
- Mejías, J.; Lu, X.; Osorio, C.E.; Ullman, J.L.; Von Wettstein, D.; Rustgi, S. Analysis of Wheat Prolamins, the Causative Agents of Celiac Sprue, Using Reversed Phase High Performance Liquid Chromatography (RP-HPLC) and Matrix-Assisted Laser Desorption Ionization Time of Flight Mass Spectrometry (MALDI-TOF-MS). Nutrients 2014, 6, 1578–1597. [Google Scholar] [CrossRef] [Green Version]
- Anderson, O.D.; Dong, L.; Huo, N.; Gu, Y.Q. A New Class of Wheat Gliadin Genes and Proteins. PLoS ONE 2012, 7, e52139. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wan, Y.; Shewry, P.R.; Hawkesford, M. A novel family of γ-gliadin genes are highly regulated by nitrogen supply in developing wheat grain. J. Exp. Bot. 2012, 64, 161–168. [Google Scholar] [CrossRef] [PubMed]
- Dong, L.; Huo, N.; Wang, Y.; Deal, K.; Wang, D.; Hu, T.; Dvorak, J.; Anderson, O.D.; Luo, M.C.; Gu, Y.Q. Rapid evolutionary dynamics in a 2.8-Mb chromosomal region containing mul-tiple prolamin and resistance gene families in Aegilops tauschii. Plant J. 2016, 87, 495–506. [Google Scholar] [CrossRef] [PubMed]
- Huo, N.; Zhang, S.; Zhu, T.; Dong, L.; Wang, Y.; Mohr, T.; Hu, T.; Liu, Z.; Dvorak, J.; Luo, M.-C.; et al. Gene Duplication and Evolution Dynamics in the Homeologous Regions Harboring Multiple Prolamin and Resistance Gene Families in Hexaploid Wheat. Front. Plant Sci. 2018, 9, 673. [Google Scholar] [CrossRef] [Green Version]
- Anderson, O.D.; Torres, V.; Hsia, C.C. The wheat γ-gliadin genes: Characterization of ten new sequences and further understanding of γ-gliadin gene family structure. Theor. Appl. Genet. 2001, 103, 323–330. [Google Scholar] [CrossRef]
- Scheets, K.; Rafalski, J.; Hedgcoth, C.; Söll, D.G. Heptapeptide repeat structure of a wheat γ-gliadin. Plant Sci. Lett. 1985, 37, 221–225. [Google Scholar] [CrossRef]
- Jang, Y.-R.; Cho, K.; Kim, S.; Sim, J.-R.; Lee, S.-B.; Kim, B.-G.; Gu, Y.Q.; Altenbach, S.B.; Lim, S.-H.; Goo, T.-W.; et al. Comparison of MALDI-TOF-MS and RP-HPLC as Rapid Screening Methods for Wheat Lines with Altered Gliadin Compositions. Front. Plant Sci. 2020, 11, 1936. [Google Scholar] [CrossRef]
- Wang, S.; Shen, X.; Ge, P.; Li, J.; Subburaj, S.; Li, X.; Zeller, F.J.; Hsam, S.L.; Yan, Y. Molecular characterization and dynamic expression patterns of two types of γ-gliadin genes from Ae-gilops and Triticum species. Theor. Appl. Genet. 2012, 125, 1371–1384. [Google Scholar] [CrossRef]
- Anderson, O.D.; Huo, N.; Gu, Y.Q. The gene space in wheat: The complete γ-gliadin gene family from the wheat cultivar Chinese Spring. Funct. Integr. Genom. 2013, 13, 261–273. [Google Scholar] [CrossRef] [PubMed]
- Goryunova, S.V.; Salentijn, E.M.; Chikida, N.N.; Kochieva, E.Z.; van der Meer, I.M.; Gilissen, L.J.; Smulders, M.J. Expansion of the Gamma-gliadin gene family in Aegilops and Triticum. BMC Evol. Biol. 2012, 12, 215. [Google Scholar] [CrossRef] [Green Version]
- De Santis, M.A.; Cunsolo, V.; Giuliani, M.M.; Di Francesco, A.; Saletti, R.; Foti, S.; Flagella, Z. Gluten proteome comparison among durum wheat genotypes with different release date. J. Cereal Sci. 2020, 96, 103092. [Google Scholar] [CrossRef]
- Huo, N.; Zhu, T.; Altenbach, S.; Dong, L.; Wang, Y.; Mohr, T.; Liu, Z.; Dvorak, J.; Luo, M.-C.; Gu, Y.Q. Dynamic Evolution of α-Gliadin Prolamin Gene Family in Homeologous Genomes of Hexaploid Wheat. Sci. Rep. 2018, 8, 5181. [Google Scholar] [CrossRef] [PubMed]
- Hamer, R.J.; van Vliet, T. Understanding the structure and properties of gluten: An overview. In Wheat Gluten, Proceedings of the 7th International Workshop Gluten 2000, Bristol, UK, 2–6 April 2000; Shewry, P.R., Tatham, A.S., Eds.; Royal Society of Chemistry: Cambridge, UK, 2000; pp. 125–131. [Google Scholar]
- Shewry, P.; Tatham, A. Disulphide Bonds in Wheat Gluten Proteins. J. Cereal Sci. 1997, 25, 207–227. [Google Scholar] [CrossRef]
- Köhler, P.; Belitz, H.D.; Wieser, H. Disulphide bonds in wheat gluten: Further cystine peptides from high molecular weight (HMW) and low molecular weight (LMW) subunits of glutenin and from γ-gliadins. Eur. Food Res. Technol. 1993, 196, 239–247. [Google Scholar] [CrossRef]
- Lutz, E.; Wieser, H.; Koehler, P. Identification of Disulfide Bonds in Wheat Gluten Proteins by Means of Mass Spectrometry/Electron Transfer Dissociation. J. Agric. Food Chem. 2012, 60, 3708–3716. [Google Scholar] [CrossRef]
- Ferrante, P.; Masci, S.; D’Ovidio, R.; Lafiandra, D.; Volpi, C.; Mattei, B. A proteomic approach to verify in vivo expression of a novel γ-gliadin containing an extra cysteine residue. Proteomics 2006, 6, 1908–1914. [Google Scholar] [CrossRef]
- Gil-Humanes, J.; Pistón, F.; Giménez, M.J.; Martín, A.; Barro, F. The introgression of RNAi silencing of γ-gliadins into commercial lines of bread wheat changes the mixing and technological properties of the dough. PLoS ONE 2012, 7, e45937. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jouanin, A.; Schaart, J.G.; Boyd, L.A.; Cockram, J.; Leigh, F.; Bates, R.; Wallington, E.J.; Visser, R.G.F.; Smulders, M.J.M. Outlook for coeliac disease patients: Towards bread wheat with hypoimmunogenic gluten by gene editing of α- and γ-gliadin gene families. BMC Plant Biol. 2019, 19, 333. [Google Scholar] [CrossRef] [Green Version]
- Laudencia-Chingcuanco, D.L.; Stamova, B.S.; You, F.M.; Lazo, G.R.; Beckles, D.M.; Anderson, O.D. Transcriptional profiling of wheat caryopsis development using cDNA microarrays. Plant Mol. Biol. 2007, 63, 651–668. [Google Scholar] [CrossRef] [PubMed]
- Pistón, F.; Dorado, G.; Martin, A.; Barro, F. Cloning of nine γ-gliadin mRNAs (cDNAs) from wheat and the molecular characterization of comparative transcript levels of γ-gliadin sub-classes. J. Cereal Sci. 2006, 43, 120–128. [Google Scholar] [CrossRef]
- Miclaus, M.; Xu, J.-H.; Messing, J. Differential gene expression and epiregulation of Alpha zein gene copies in maize haplotypes. PLoS Genet. 2011, 7, e1002131. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Li, F.; Cao, S.; Zhang, K. Genomic and functional genomics analyses of gluten proteins and prospect for simultaneous improvement of end-use and health-related traits in wheat. Theor. Appl. Genet. 2020, 133, 1521–1539. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aussenac, T.; Rhazi, L. Storage proteins accumulation and aggregation in developing wheat grains. In Global Wheat Production; Fahad, S., Basir, A., Eds.; IntechOpen: London, UK, 2018; pp. 133–163. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Automatic Annotation | Manual Annotation | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Chr | Gene ID | Start | Stop | Size (bp) | Annotation | Start | Stop | Size (bp) | Annotation | Gene/ Pseudogene | Note |
| 1A | TRITD1Av1G002070 | 4,613,285 | 4,614,202 | 918 | γ-gliadin | 4,613,285 | 4,614,202 | 918 | δ-gliadin (Gli-δ1a*) | pseudogene | TAG at bp 247 |
| 1A | N.A. a | — | — | — | — | 4,631,881 | 4,632,772 | 892 | δ-gliadin (Gli-δ2a*) | pseudogene | TAA at bp 163 |
| 1A | TRITD1Av1G002120 | 4,687,840 | 4,688,874 | 1035 | γ-gliadin | 4,687,840 | 4,688,874 | 966 b | γ-gliadin (Gli-γ1a) | full-length gene | |
| 1A | N.A. | — | — | — | — | 4,744,130 | 4,7449,69 | 840 | γ-gliadin (Gli-γ2a*) | pseudogene | TAG at bp 115 |
| 1A | TRITD1Av1G002200 | 4,871,918 | 4,880,492 | 8575 | γ-gliadin | 4,871,918 | 4,872,775 | 858 | γ-gliadin (Gli-γ3a) | full-length gene | |
| 1A | 4,879,635 | 4,880,492 | 858 | γ-gliadin (Gli-γ4a) | full-length gene | ||||||
| 1A | N.A. | — | — | — | — | 4,887,801 | 4,888,553 | 753 | avenin-like (Av-1a*) | pseudogene | TAG at bp 169 |
| 1A | TRITD1Av1G002230 | 4,891,405 | 4,892,007 | 603 | γ-gliadin | 4,891,405 | 4,892,007 | 603 | avenin-like (Av-2a) | full-length gene | |
| 1B | TRITD1Bv1G001870 | 4,313,476 | 4,519,819 | 206,344 | γ-gliadin | 4,313,476 | 4,314,384 | 909 | γ-gliadin (Gli-γ1b) | full-length gene | |
| 4,341,737 | 4,342,690 | 954 | δ-gliadin (Gli-δ1b*) | pseudogene | TAG at bp 277 | ||||||
| 4,355,195 | 4,356,088 | 894 | γ-gliadin (Gli-γ2b) | full-length gene | |||||||
| 4,481,997 | 4,482,992 | 996 | γ-gliadin (Gli-γ3b) | full-length gene | |||||||
| 4,514,026 | 4,515,024 | 999 | γ-gliadin (Gli-γ4b*) | pseudogene | TAA at bp 196 | ||||||
| 4,518,944 | 4,519,819 | 876 | γ-gliadin (Gli-γ5b) | full-length gene | |||||||
| 1B | N.A. | — | — | — | — | 4,528,580 | 4,529,044 | 465 | avenin-like (Av-1b*) | pseudogene | TAG at bp 79 Truncated at bp 465 |
| 1B | TRITD1Bv1G001950 | 4,543,310 | 4,543,921 | 612 | γ-gliadin | 4,543,310 | 4,543,921 | 612 | avenin-like (Av-2b) | full-length gene | |
| Gli-γ1a | Gli-γ2a* | Gli-γ3a | Gli-γ4a | Gli-γ1b | Gli-γ2b | Gli-γ3b | Gli-γ4b* | Gli-γ5b | Gli-δ1a* | Gli-δ2a* | Gli-δ1b* | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gli-γ1a | 100 | 79.6 | 82.4 | 82.2 | 83.7 | 83.2 | 80.1 | 79.6 | 77.5 | 57.8 | 59.6 | 59.6 |
| Gli-γ2a* | 76.4 | 100 | 89.5 | 89.6 | 83.7 | 85.5 | 74.6 | 73.6 | 80.9 | 59.0 | 59.8 | 60.0 |
| Gli-γ3a | 78.2 | 88.5 | 100 | 99.3 | 86.5 | 87.9 | 76.3 | 76.4 | 85.4 | 60.4 | 59.6 | 61.4 |
| Gli-γ4a | 77.9 | 88.9 | 98.9 | 100 | 86.6 | 87.9 | 76.5 | 76.5 | 85.5 | 60.4 | 59.7 | 61.1 |
| Gli-γ1b | 76.4 | 78.9 | 82.5 | 82.5 | 100 | 93.2 | 80.2 | 76.7 | 80.0 | 57.1 | 57.4 | 60.0 |
| Gli-γ2b | 76.9 | 80.5 | 83.2 | 82.5 | 88.4 | 100 | 78.6 | 75.9 | 81.4 | 57.2 | 57.7 | 51.6 |
| Gli-γ3b | 72.2 | 69.0 | 71.0 | 71.3 | 73.2 | 71.3 | 100 | 86.5 | 80.1 | 59.4 | 59.2 | 59.7 |
| Gli-γ4b* | 73.3 | 67.9 | 70.9 | 70.9 | 68.7 | 67.5 | 81.9 | 100 | 80.6 | 58.6 | 57.5 | 59.0 |
| Gli-γ5b | 73.0 | 78.4 | 81.8 | 82.1 | 75.5 | 76.3 | 75.5 | 76.6 | 100 | 62.2 | 60.9 | 61.8 |
| Gli-δ1a* | 42.9 | 43.3 | 43.9 | 45.4 | 42.4 | 42.1 | 43.9 | 43.5 | 47.0 | 100 | 82.9 | 84.7 |
| Gli-δ2a* | 40.1 | 40.7 | 40.7 | 41.0 | 41.0 | 41.1 | 41.6 | 39.2 | 43.7 | 74.4 | 100 | 78.5 |
| Gli-δ1b* | 45.7 | 45.6 | 46.6 | 46.3 | 42.2 | 44.0 | 45.2 | 44.1 | 46.3 | 80.7 | 69.8 | 100 |
| Protein | Length (aa) | Number of Cysteines | Predicted MW (Da) | Predicted Pi |
|---|---|---|---|---|
| Gli-γ1a | 321 | 8 | 36607 | 8.16 |
| Gli-γ3a | 285 | 8 | 32666 | 8.70 |
| Gli-γ4a | 285 | 8 | 32678 | 8.70 |
| Gli-γ1b | 302 | 9 | 34302 | 6.62 |
| Gli-γ2b | 296 | 8 | 33652 | 8.16 |
| Gli-γ3b | 328 | 8 | 37446 | 8.17 |
| Gli-γ5b | 291 | 8 | 32994 | 8.48 |
| HLA | Epitope | Sequence * | Gli-γ1a | Gli-γ3a | Gli-γ4a | Gli-γ1b | Gli-γ2b | Gli-γ3b | Gli-γ5b |
|---|---|---|---|---|---|---|---|---|---|
| DQ2.5 | DQ2.5-glia-γ1 | PQQSFPQQQ | 1 | 1 | 1 | 1 | 1 | ||
| DQ2.5-glia-γ2 | IQPQQPAQL | 1 | 1 | 1 | 1 | ||||
| DQ2.5-glia-γ3 | QQPQQPYPQ | 1 | |||||||
| DQ2.5-glia-γ4b | PQPQQQFPQ | 1 | 1 | 1 | |||||
| DQ2.5 glia-γ4c | QQPQQPFPQ | 3 | 4 | 4 | 4 | 3 | 6 | 2 | |
| DQ2.5-glia-γ5 | QQPFPQQPQ | 1 | 2 | ||||||
| DQ2.5-glia-ω1 | PFPQPQQPF | 1 | |||||||
| DQ8 | DQ8-glia-γ1a | QQPQQPFPQ | 3 | 4 | 4 | 4 | 3 | 6 | 2 |
| DQ8-glia-γ1b | QQPQQPYPQ | 1 | |||||||
| DQ8.5 | DQ8.5-glia-γ1 | PQQSFPQQQ | 1 | 1 | 1 | 1 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paris, R.; Petruzzino, G.; Savino, M.; De Simone, V.; Ficco, D.B.M.; Trono, D. Genome-Wide Identification, Characterization and Expression Pattern Analysis of the γ-Gliadin Gene Family in the Durum Wheat (Triticum durum Desf.) Cultivar Svevo. Genes 2021, 12, 1743. https://doi.org/10.3390/genes12111743
Paris R, Petruzzino G, Savino M, De Simone V, Ficco DBM, Trono D. Genome-Wide Identification, Characterization and Expression Pattern Analysis of the γ-Gliadin Gene Family in the Durum Wheat (Triticum durum Desf.) Cultivar Svevo. Genes. 2021; 12(11):1743. https://doi.org/10.3390/genes12111743
Chicago/Turabian StyleParis, Roberta, Giuseppe Petruzzino, Michele Savino, Vanessa De Simone, Donatella B. M. Ficco, and Daniela Trono. 2021. "Genome-Wide Identification, Characterization and Expression Pattern Analysis of the γ-Gliadin Gene Family in the Durum Wheat (Triticum durum Desf.) Cultivar Svevo" Genes 12, no. 11: 1743. https://doi.org/10.3390/genes12111743
APA StyleParis, R., Petruzzino, G., Savino, M., De Simone, V., Ficco, D. B. M., & Trono, D. (2021). Genome-Wide Identification, Characterization and Expression Pattern Analysis of the γ-Gliadin Gene Family in the Durum Wheat (Triticum durum Desf.) Cultivar Svevo. Genes, 12(11), 1743. https://doi.org/10.3390/genes12111743