
Intelligent Modelling of the Real Dynamic Viscosity of Rubber Blends Using Parallel Computing

 , , ,
, , ,  ,
, 

Abstract
:
1. Introduction
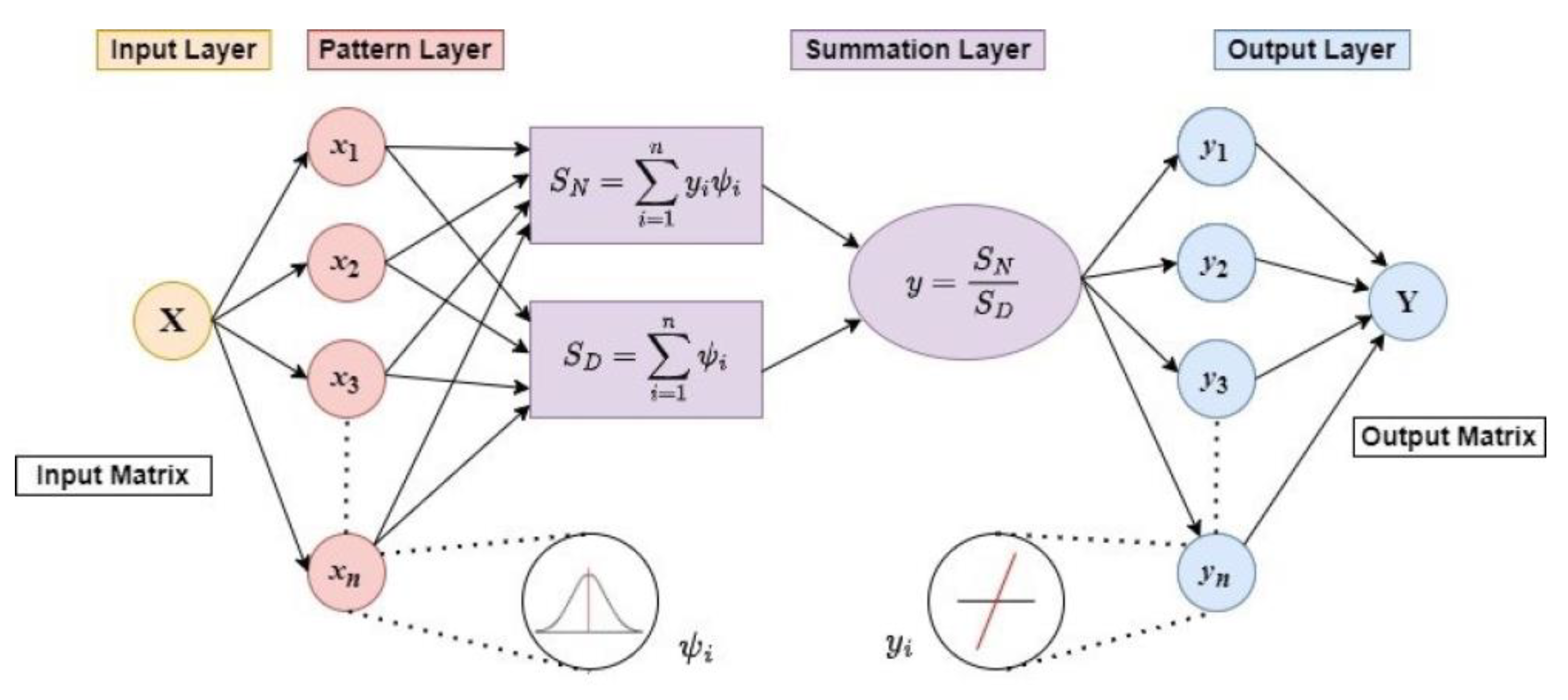
Generalised Regression Neural Network Theory
2. Materials and Methods
2.1. Materials
2.2. Samples Preparation
2.3. Rheological Analysis
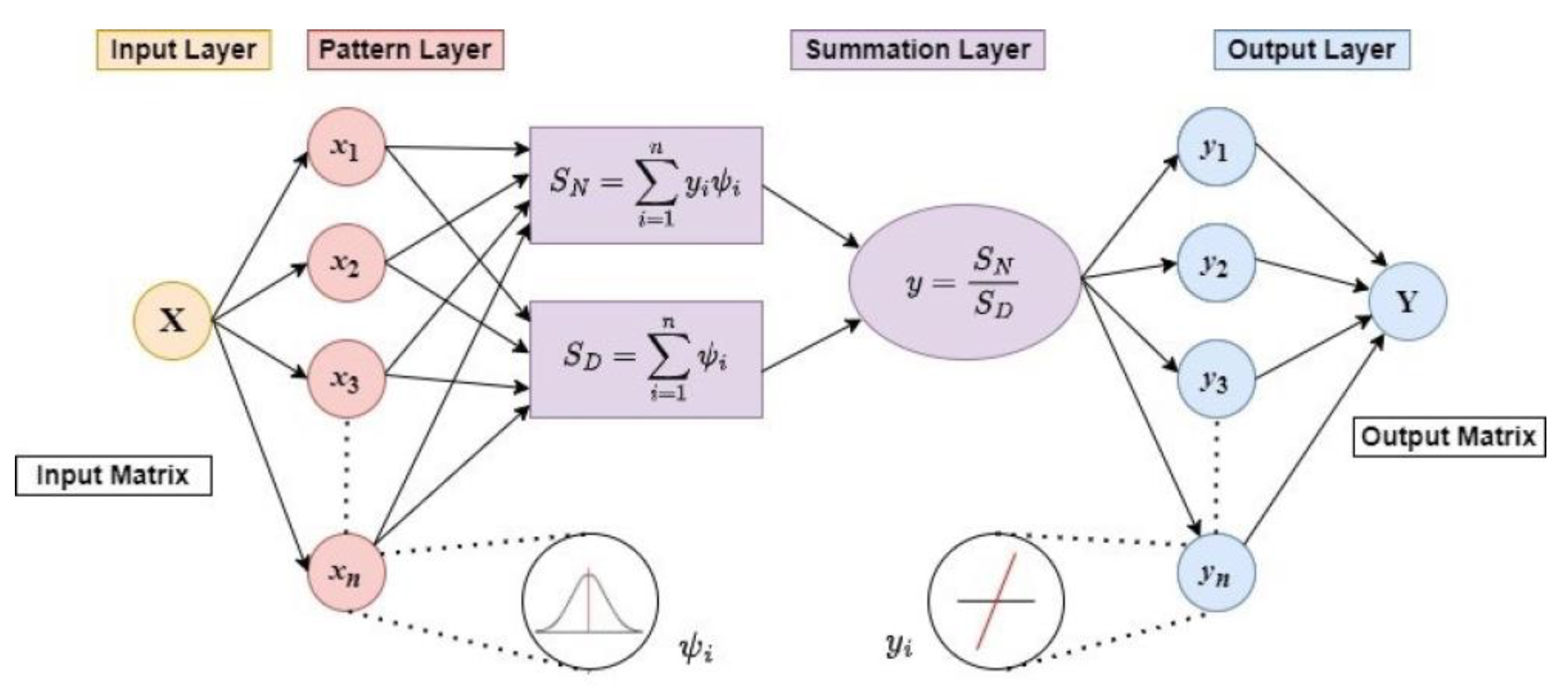
2.4. Artificial Neural Network Modelling
3. Results and Discussion
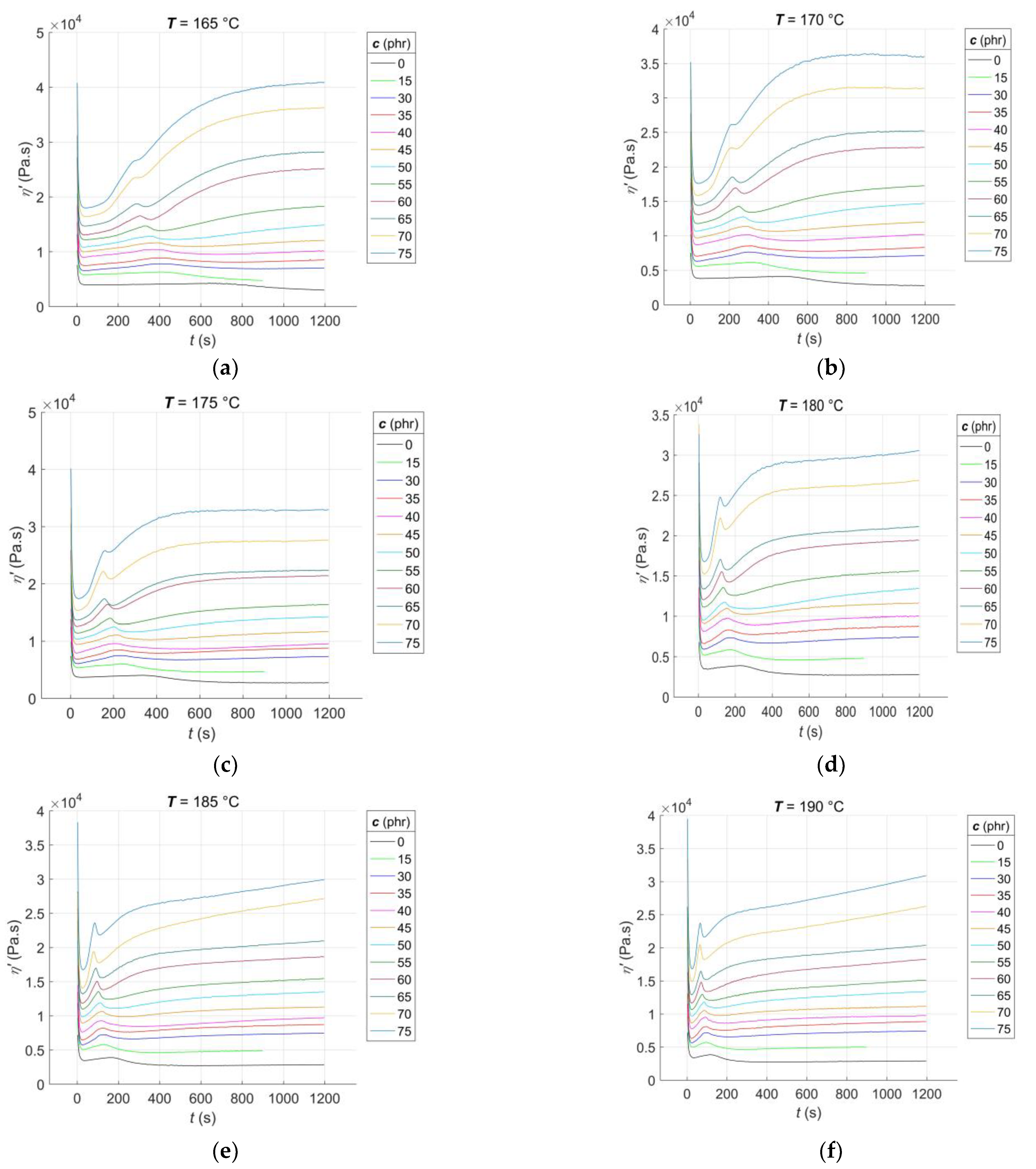
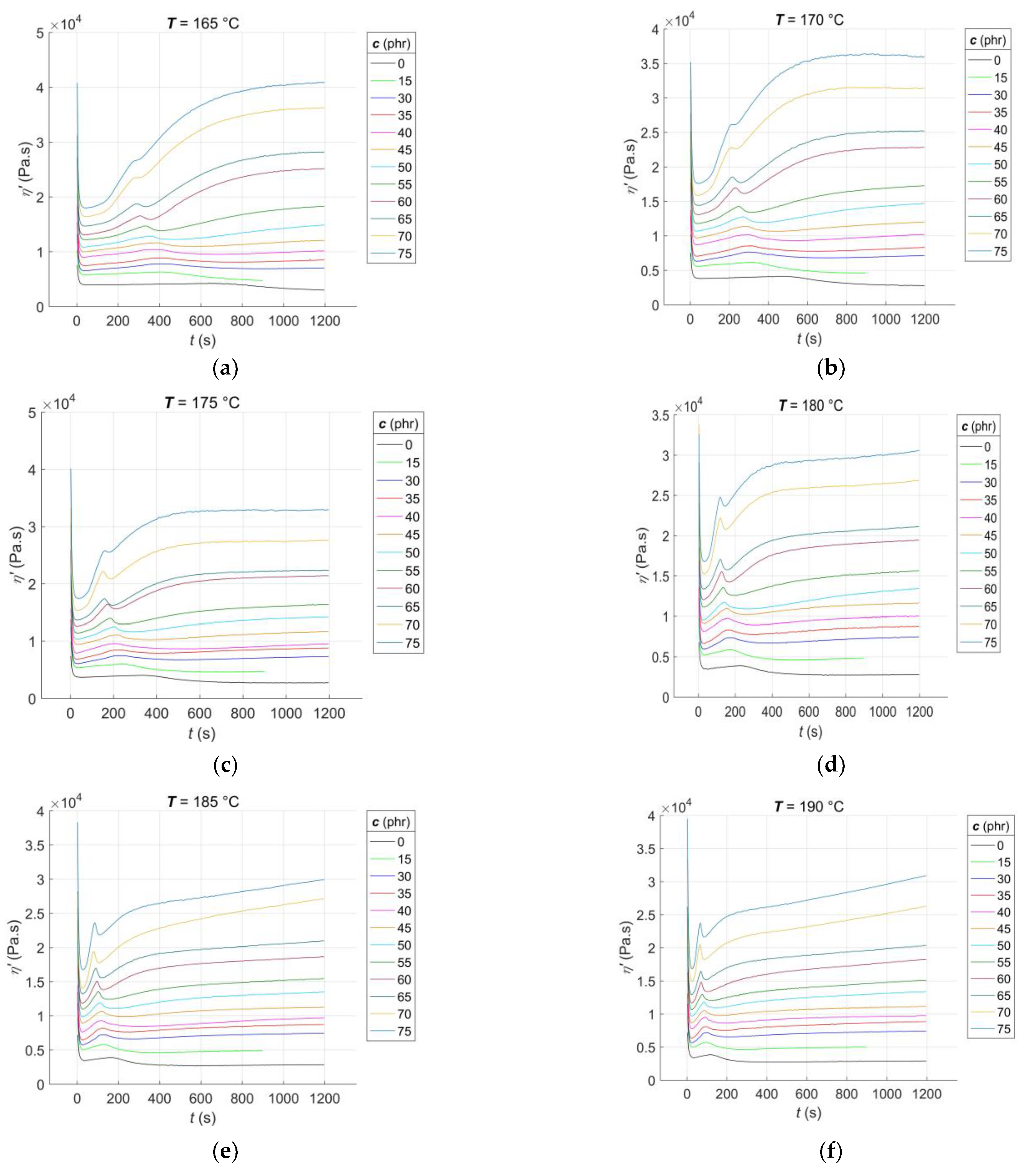
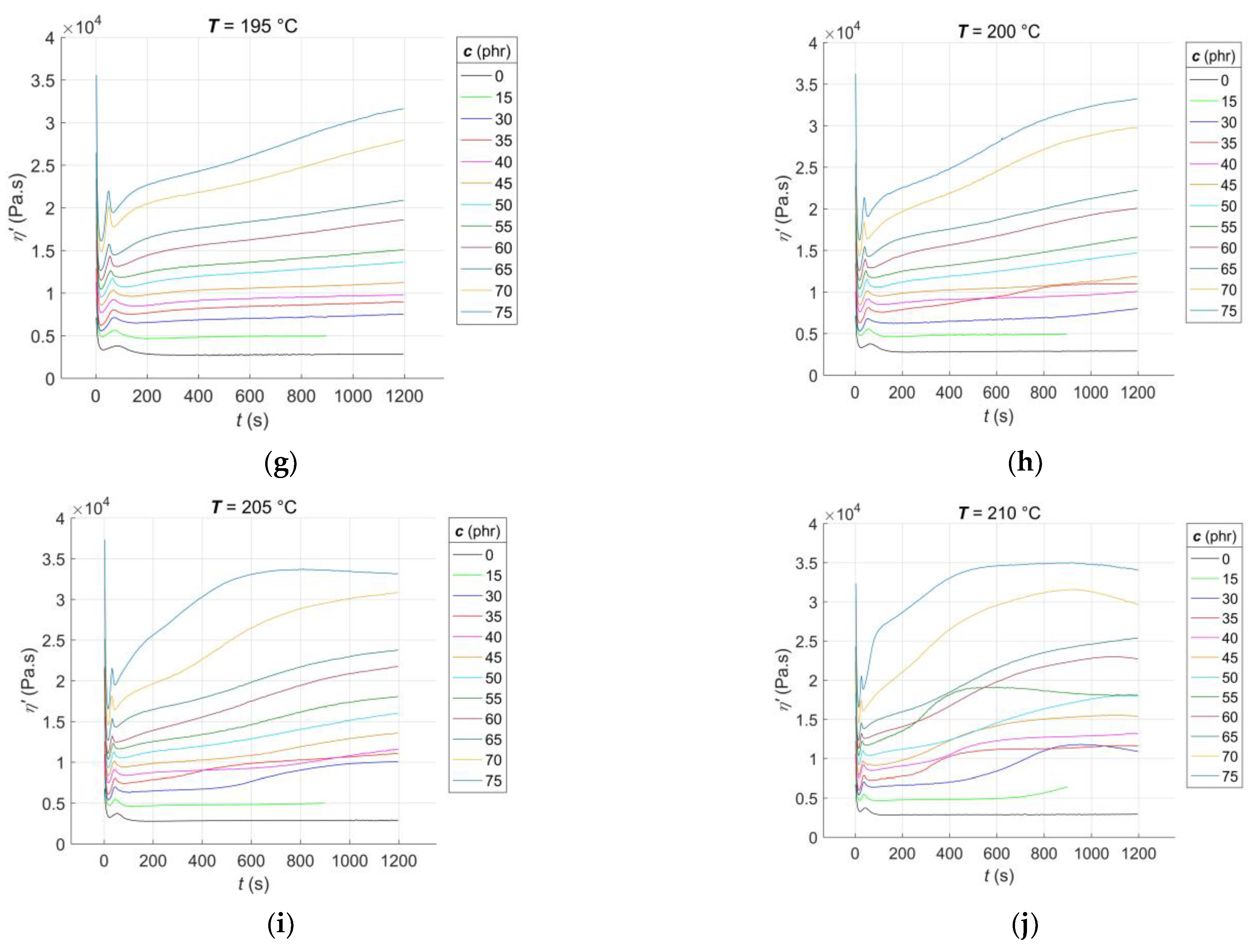
3.1. Experimental Results
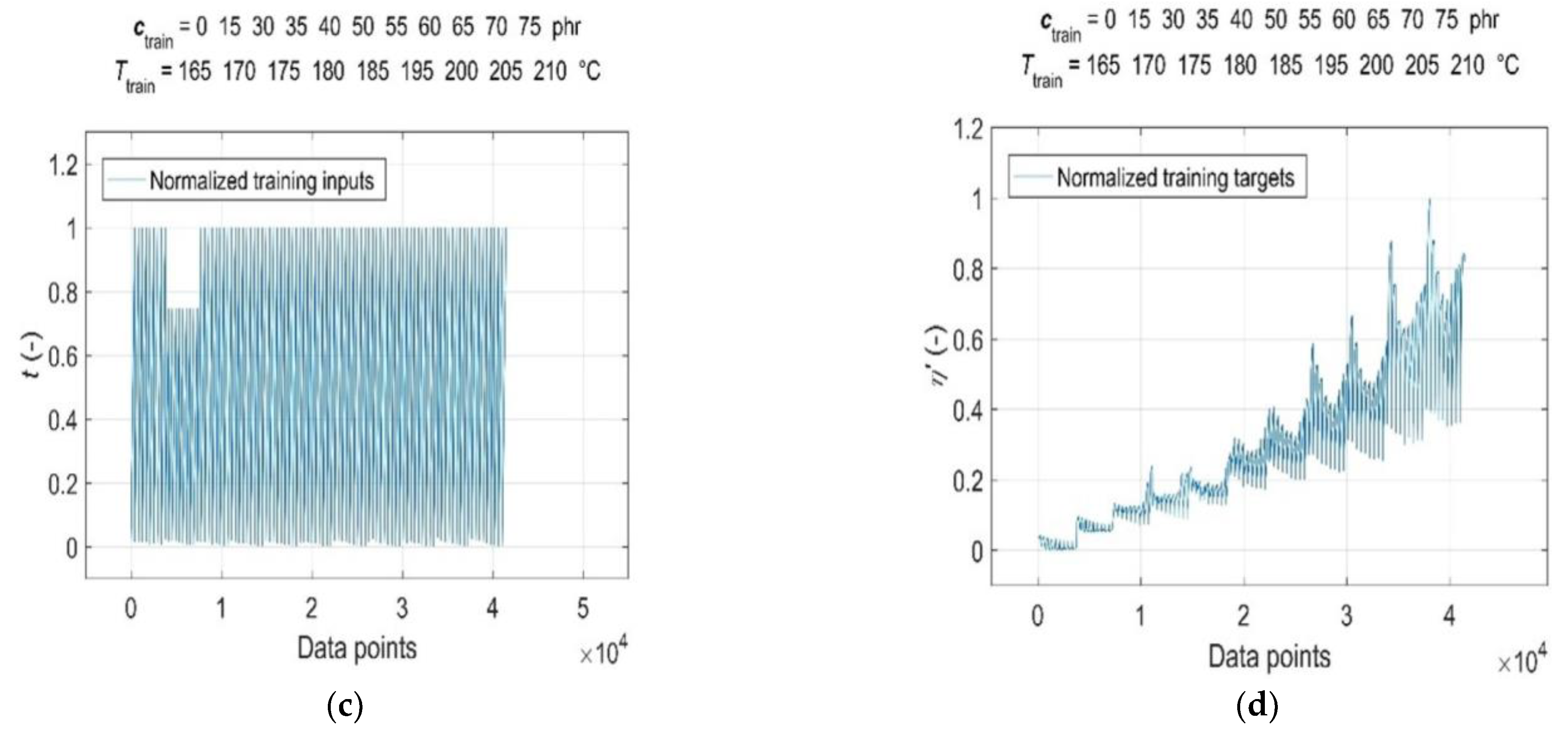
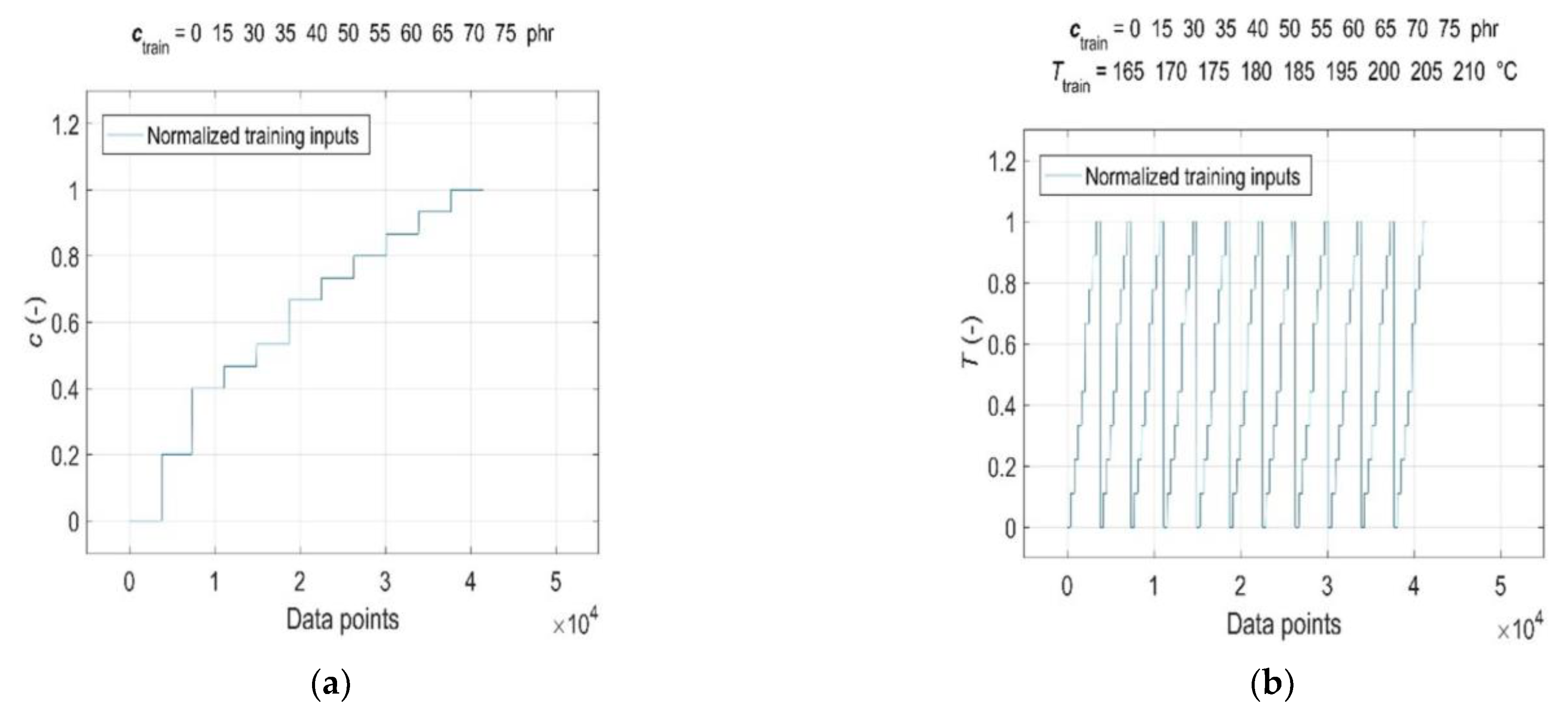
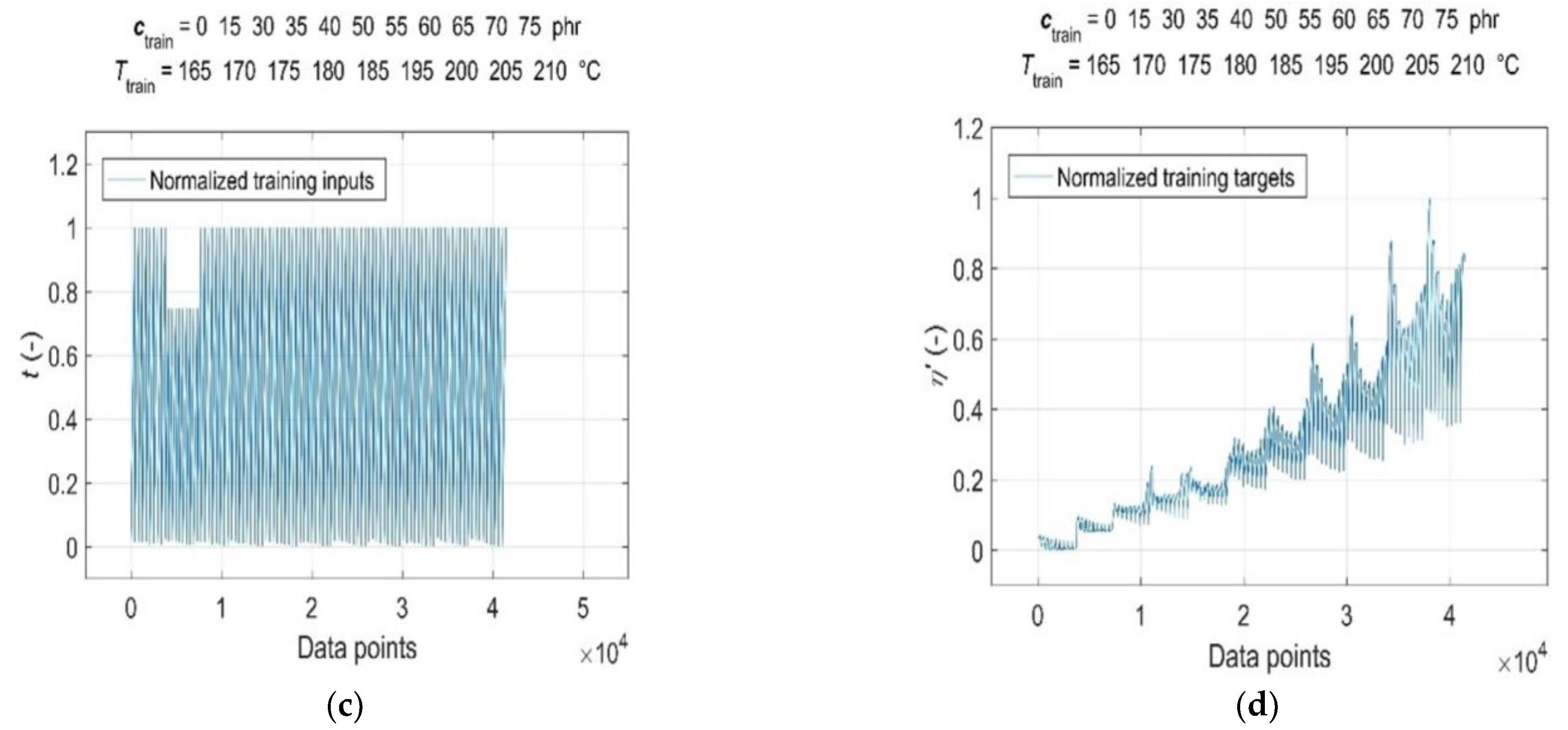
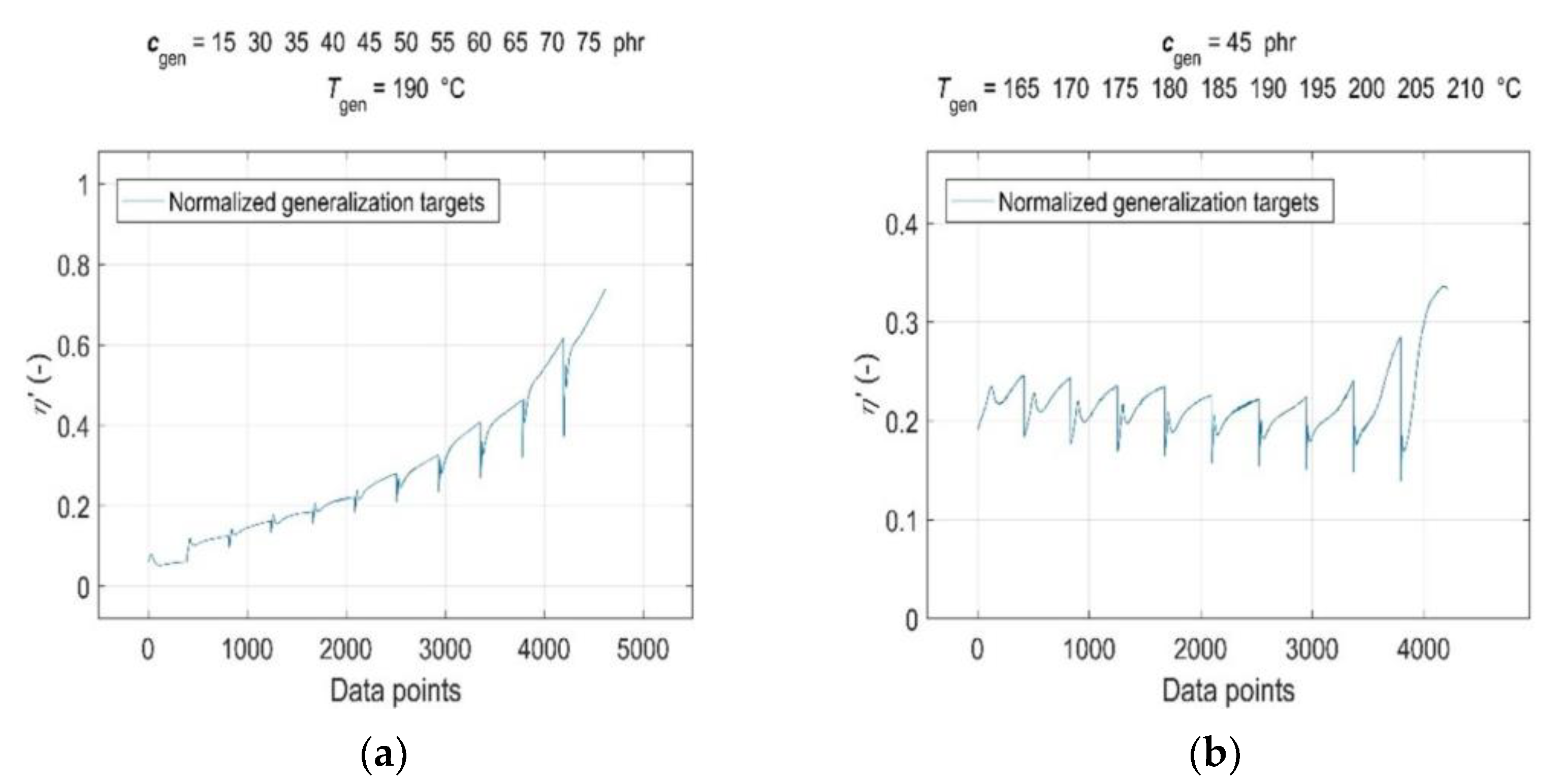
3.2. Data Pre-Processing for Neural Network Computations
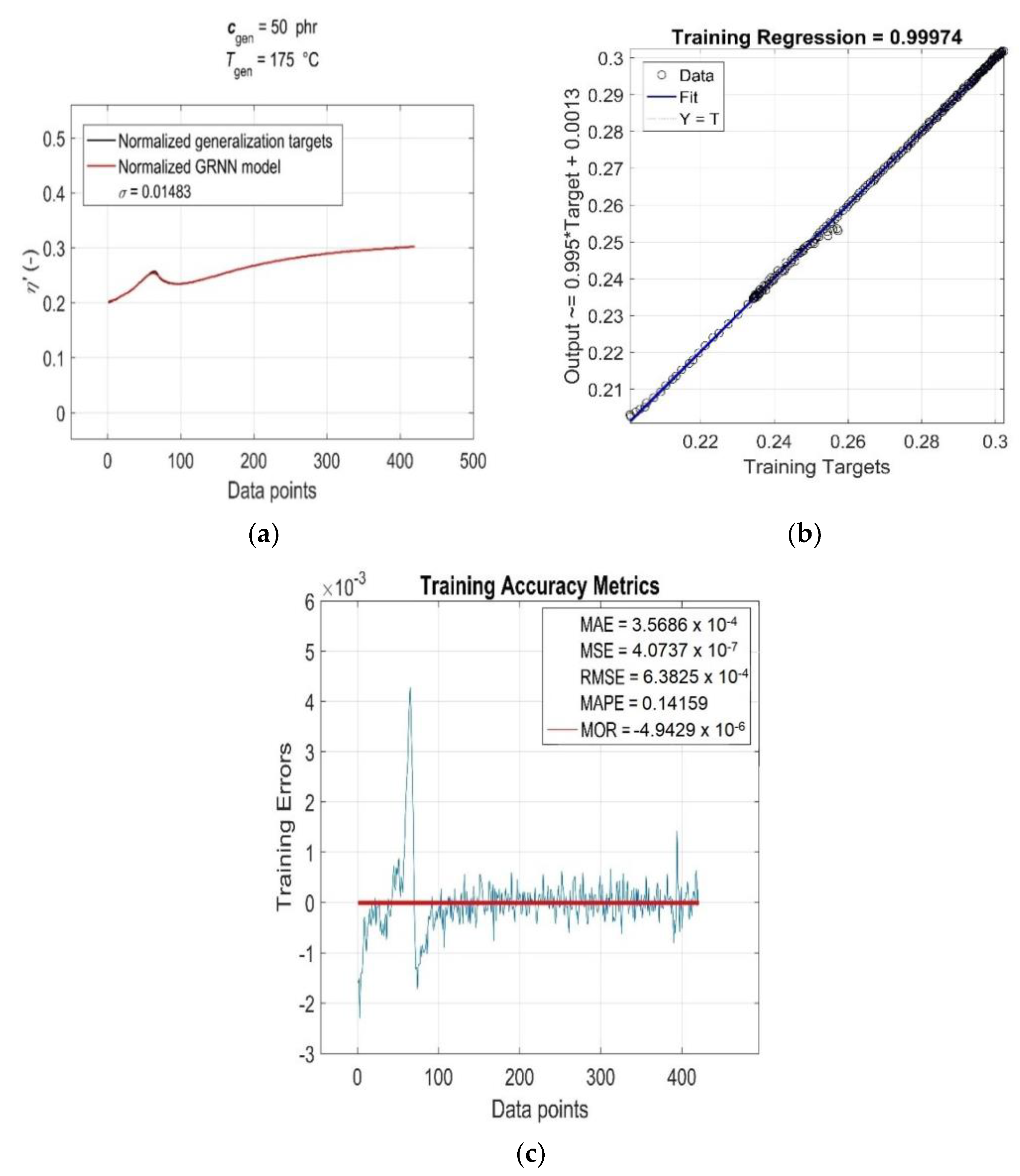
3.3. GRNN Training Algorithm for Parallel Computing
| Algorithm 1. MATLAB® code for GRNN parallel training algorithm |
| % Setting the spread constant population vector with step s Spread = [Spread_min:s:Spread_max]; % Parallel computing loop for calling the built-in GRNN training function parfor ii = 1:length(Spread) pop_GRNN(ii).net = newgrnn(Inputs_train,Targets_train,Spread(ii)); end % Calling the built-in simulation function of the trained GRNN with % training inputs in parallel computing mode for ii = 1:length(Spread) Outputs_train = sim(pop_GRNN(ii).net,Inputs_train,... ‘useParallel’,’yes’); % Calculation of the absolute error of the trained network Err = Targets_train − Outputs_train; % Calculation of the average absolute percentage error of the trained % network pre_MAPE = abs(Err./Targets_train); mean_MAPE = mean(pre_MAPE(isfinite(pre_MAPE))) * 100; % Conditional storage of the corresponding variables in the pop_GRNN % structure if mean_MAPE < max_MAPE pop_GRNN(ii).Spread = Spread(ii); pop_GRNN(ii).Outputs = Outputs_train; pop_GRNN(ii).MAPE = mean_MAPE; else % Premature termination of the cycle break end end % Identification of the MAPE maximum value index in the pop_GRNN % structure [~,k] = max([pop_GRNN.MAPE]); % Setting the variables of the found values of the corresponding % parameters if ~isempty([pop_GRNN(k).Spread]) spread = pop_GRNN(k).Spread; net_GRNN = pop_GRNN(k).net; Outputs_GRNN_train = pop_GRNN(k).Outputs; % Removing empty fields from the pop_GRNN structure pop_GRNN = pop_GRNN(1:length([pop_GRNN.Spread]),:); else % Terminate execution return end |
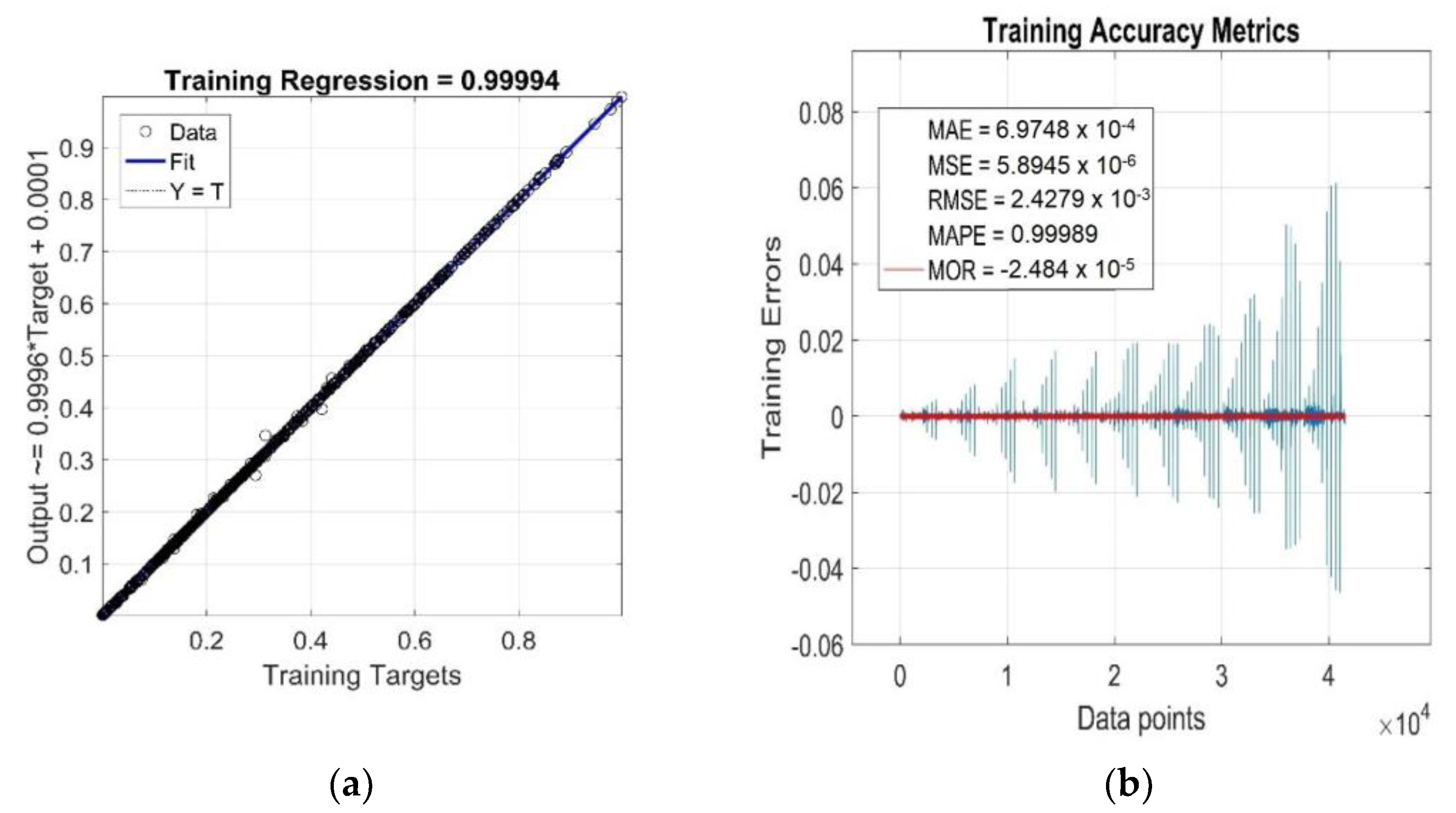
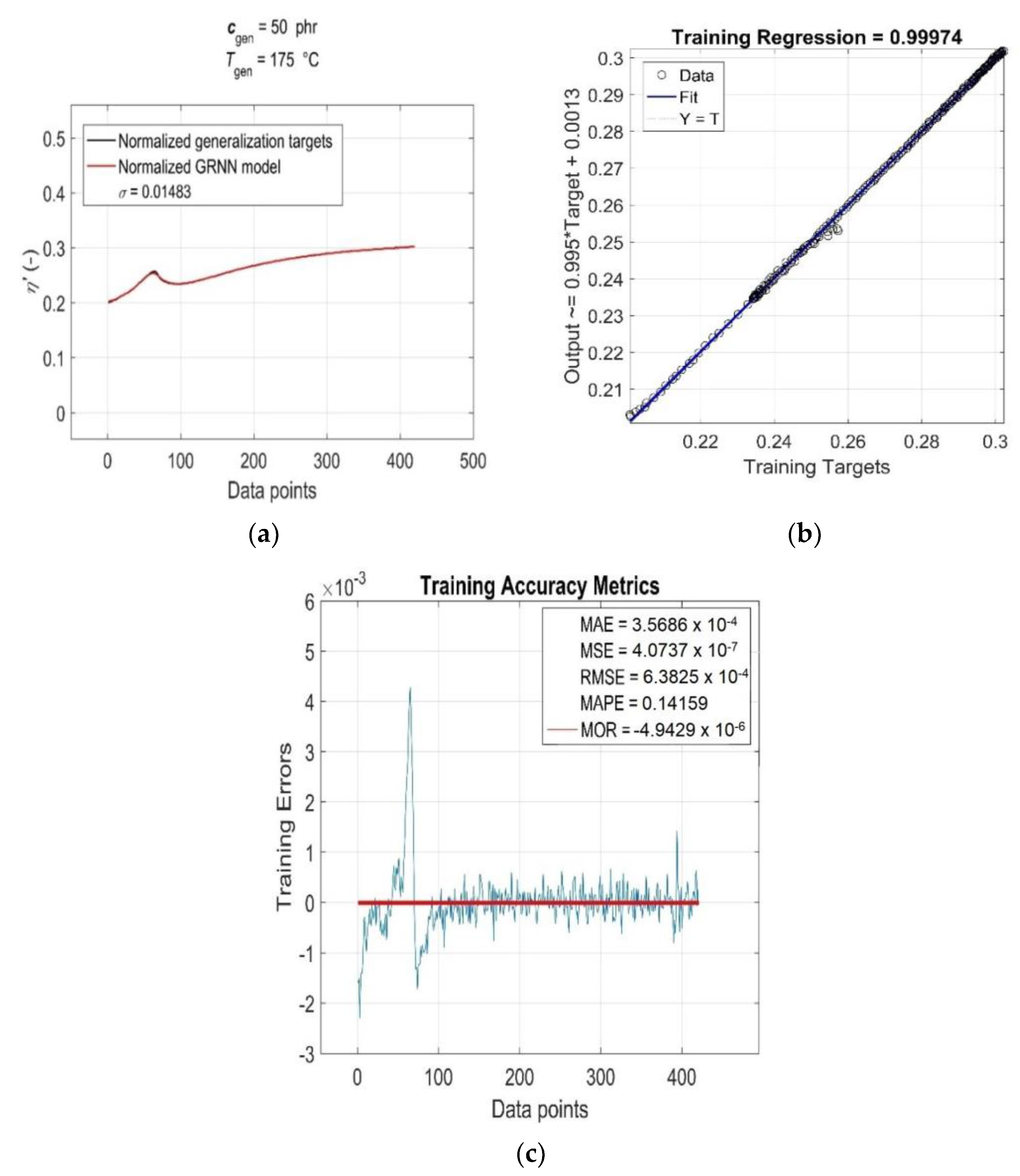
3.4. Goodness-of-Fit Model Evaluation
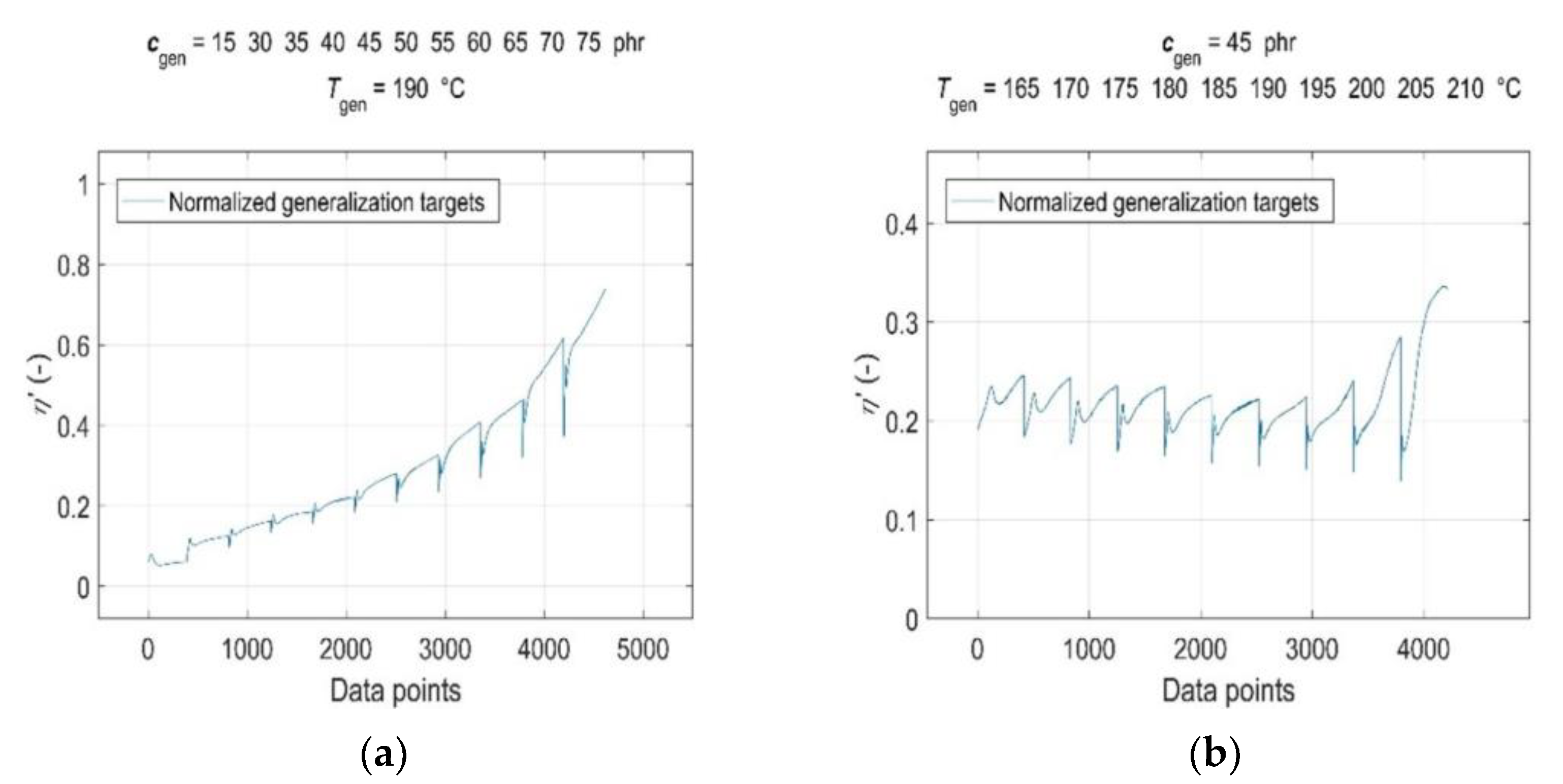
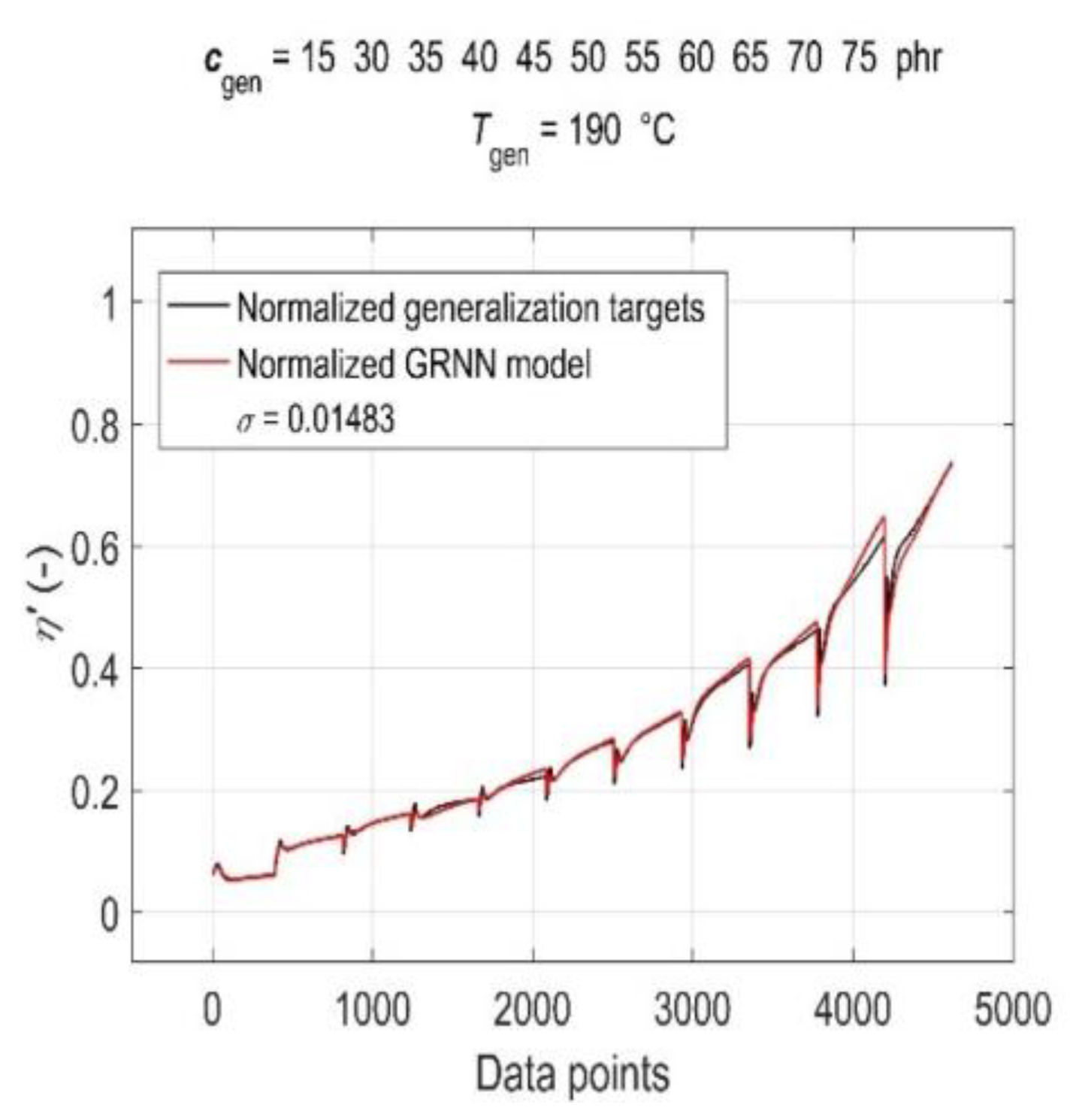
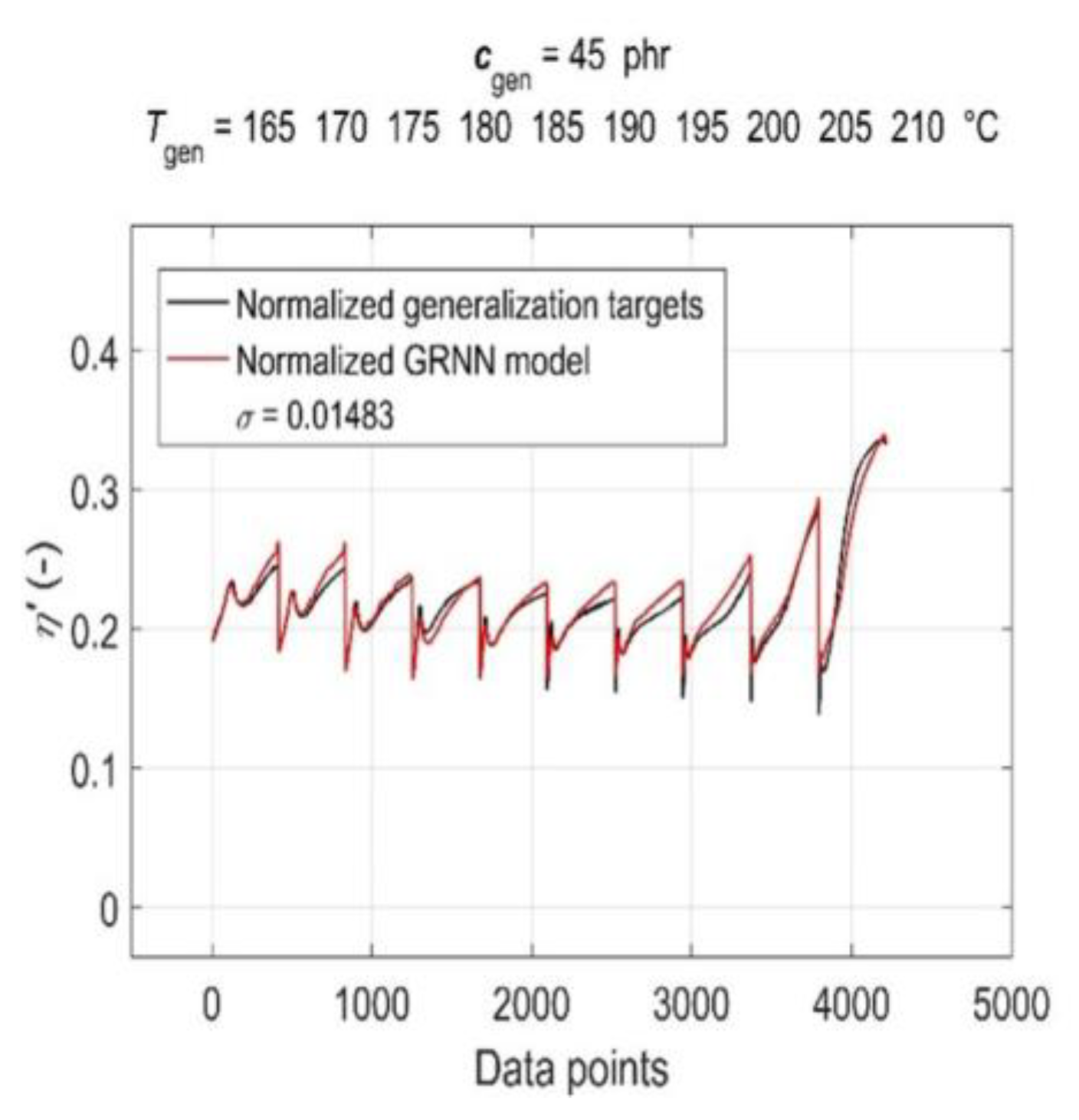
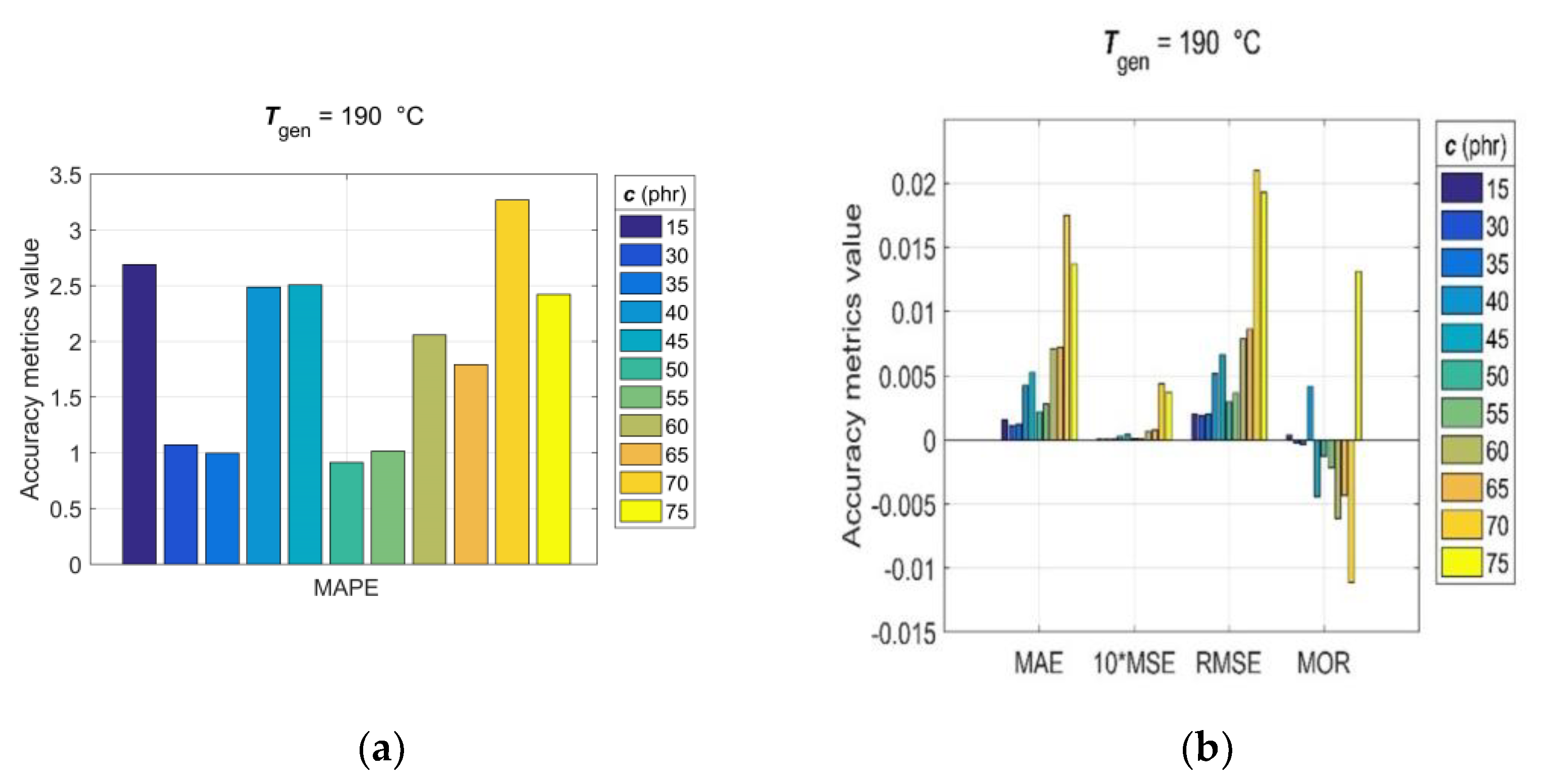
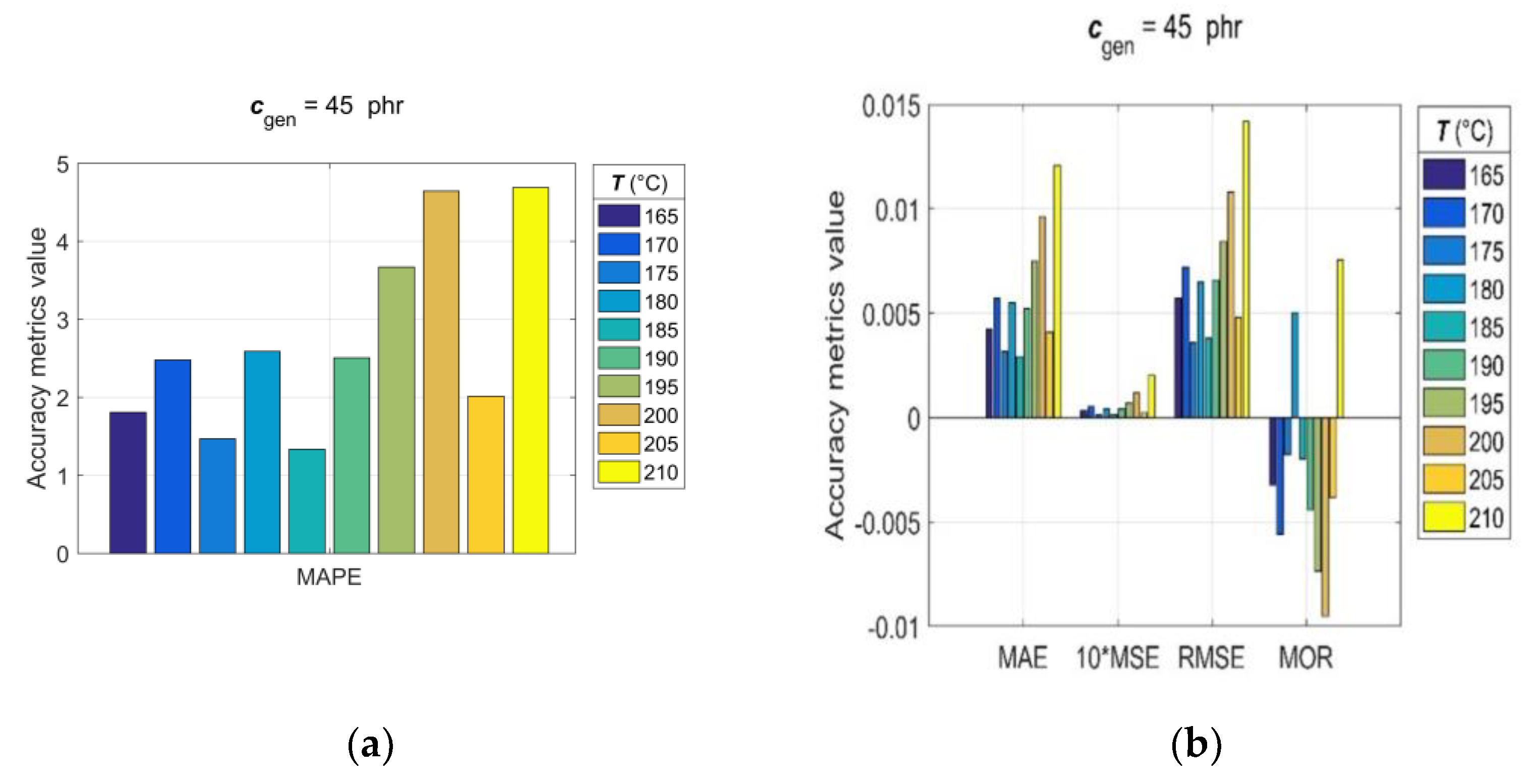
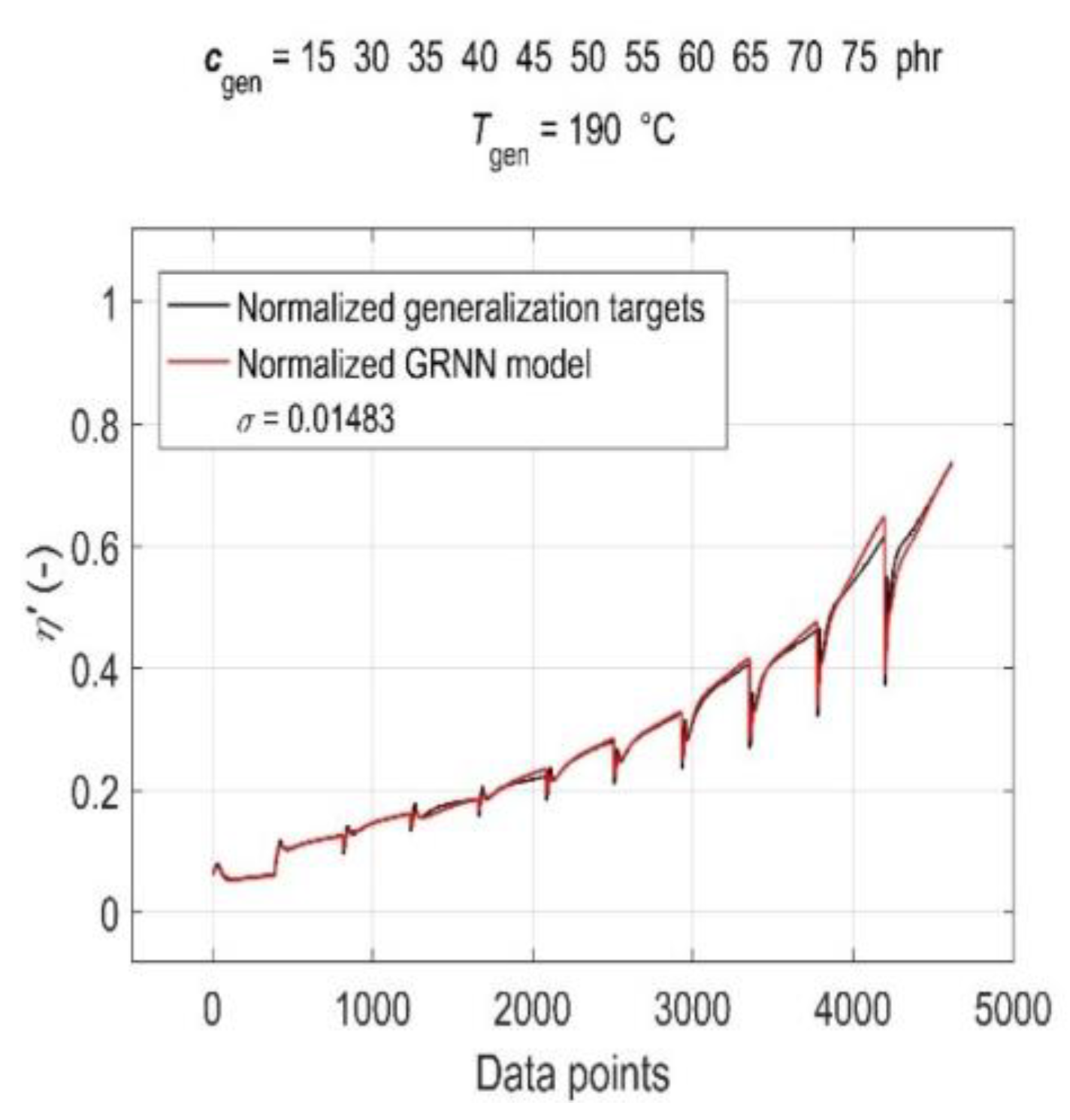
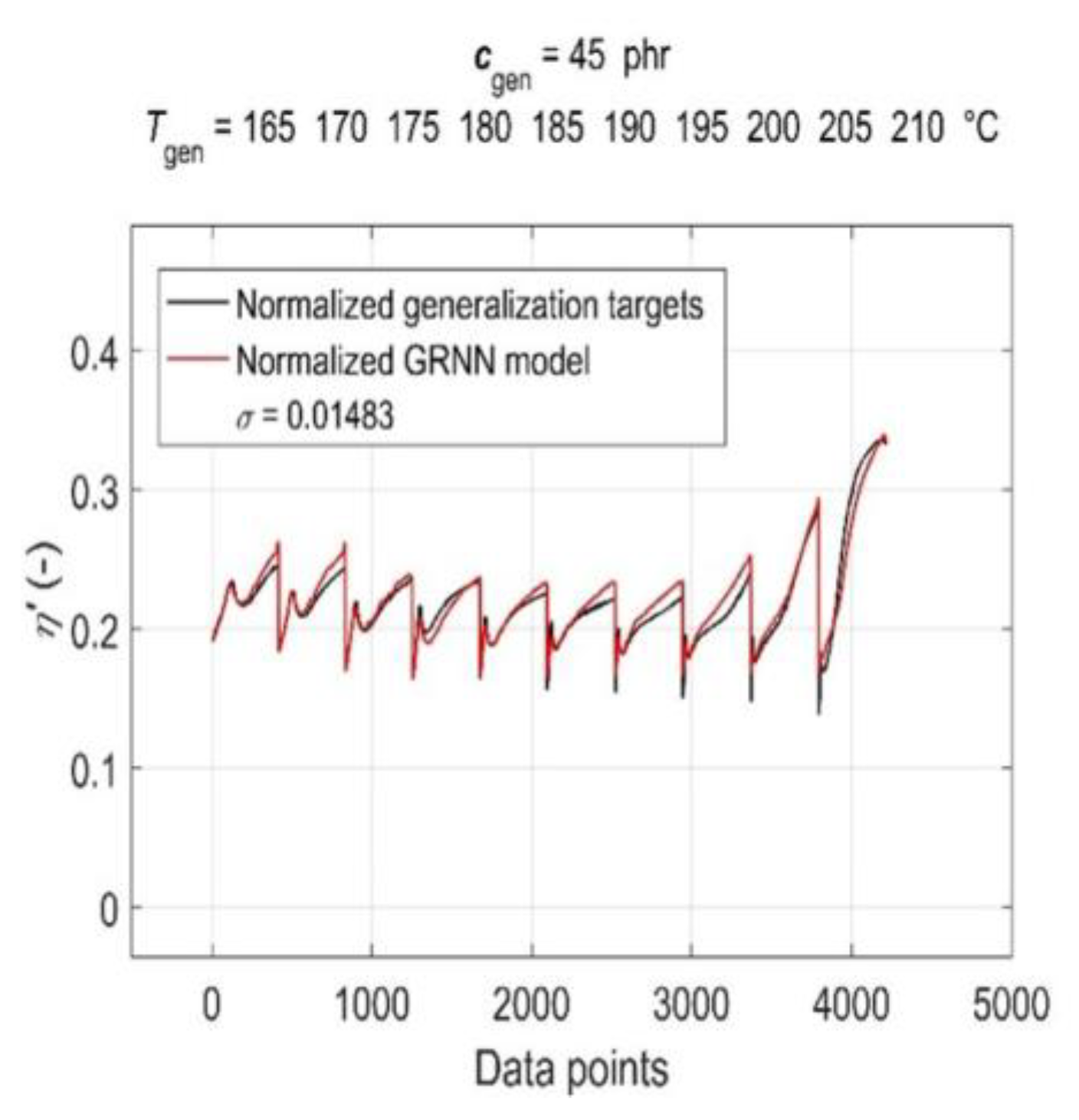
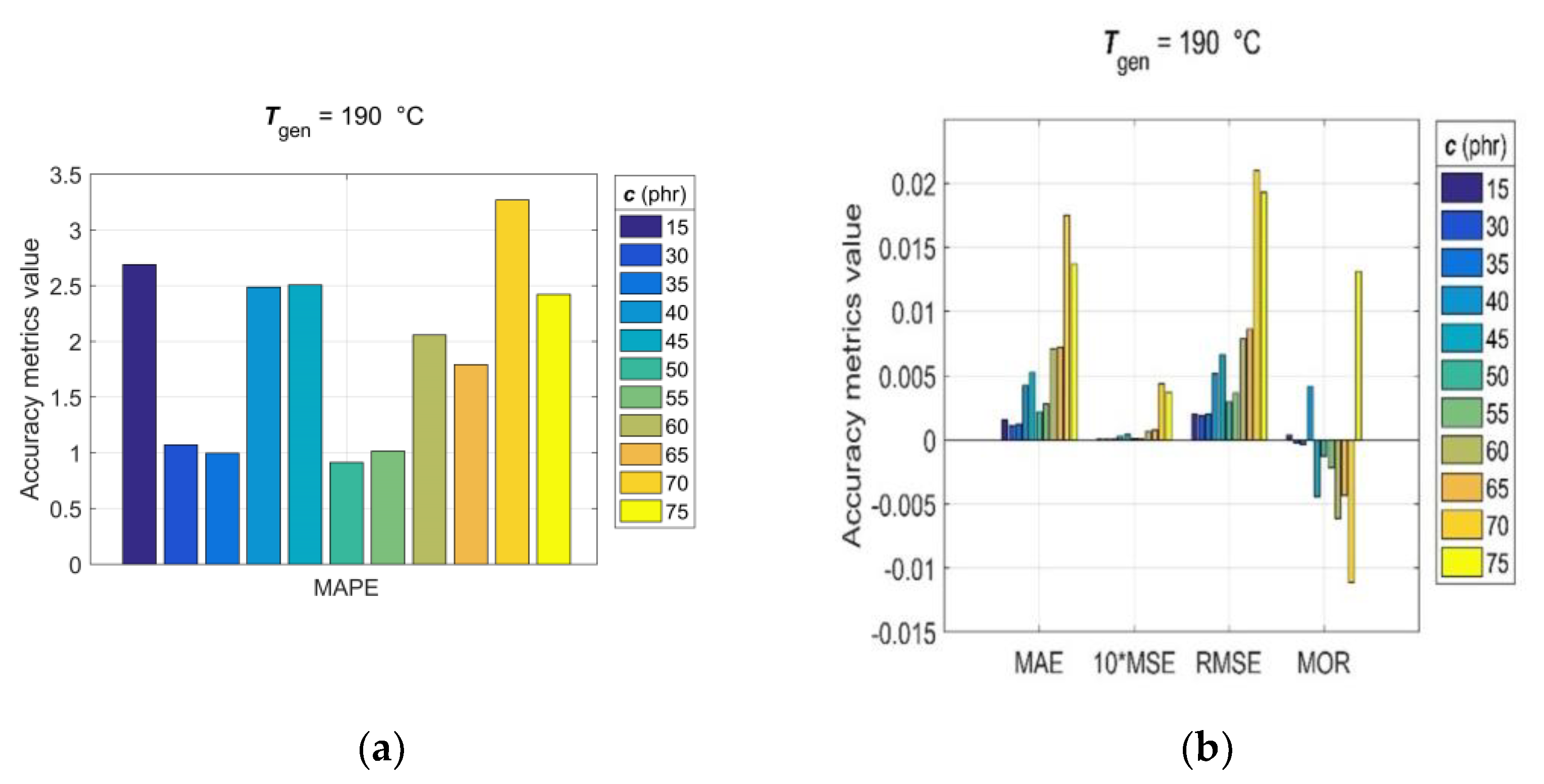
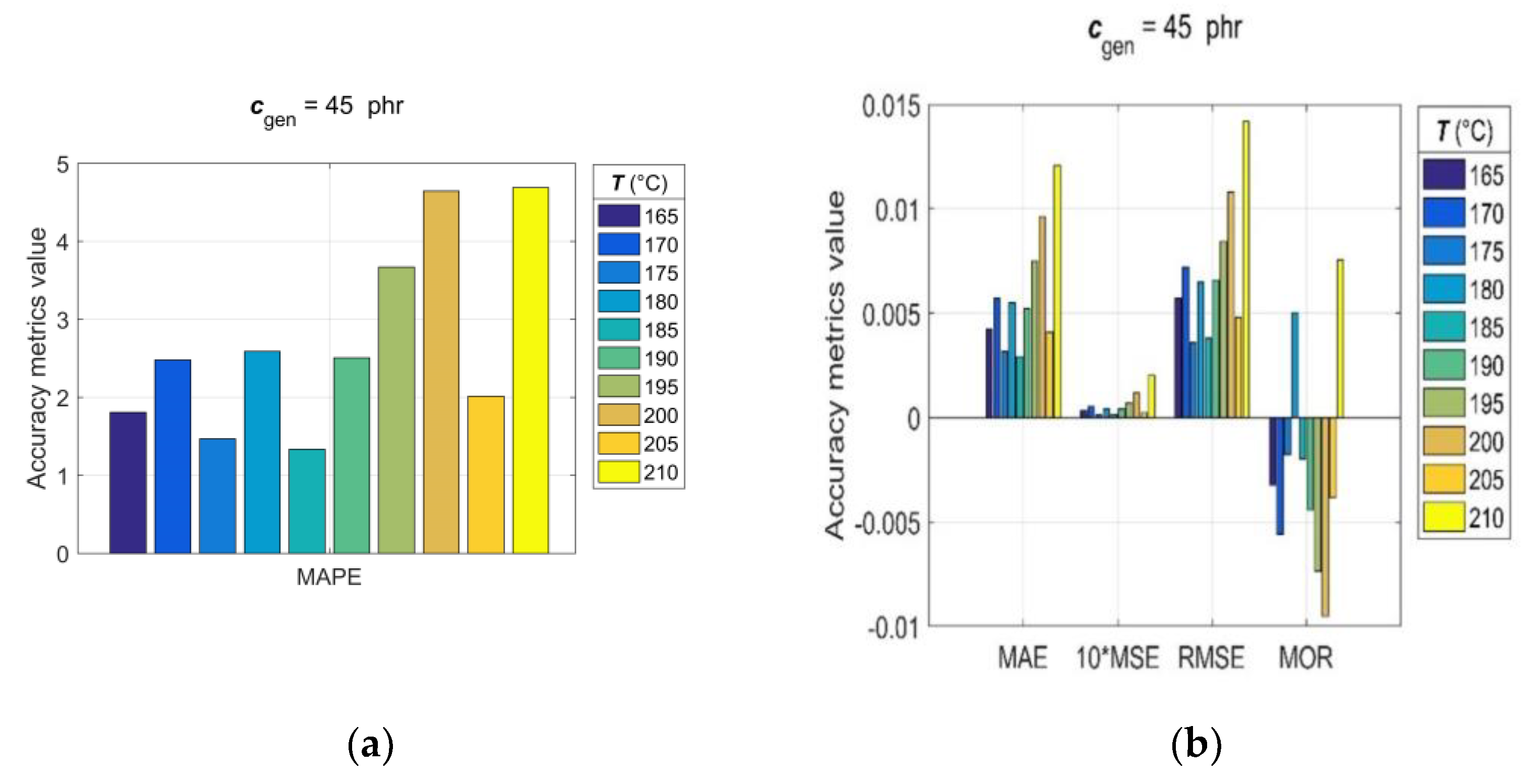
3.5. Model Generalisation Capability and Forecasting Accuracy Evaluation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Mark, J.E.; Erman, B.; Roland, C.M. The Science and Technology of Rubber, 4th ed.; Elsevier: Alpharetta, GA, USA, 2013. [Google Scholar]
- Dick, J.S. Basic Rubber Testing: Selecting Methods for a Rubber Test Program, 1st ed.; ASTM International: West Conshohocken, PA, USA, 2003. [Google Scholar]
- Gupta, B.R. Rheology Applied in Polymer Processing, 1st ed.; CRC Press: Boca Raton, FL, USA, 2022. [Google Scholar]
- Wilczynski, K. Rheology in Polymer Processing: Modeling and Simulation, 1st ed.; Hanser Publishers: Cincinnati, OH, USA, 2020. [Google Scholar]
- ASTM D6204−15; Standard Test Method for Rubber—Measurement of Unvulcanized Rheological Properties Using Rotorless Shear Rheometers. ASTM International: West Conshohocken, PA, USA, 2019.
- Forrest, M.J. Rubber Analysis—Polymers, Compounds and Products, 1st ed.; Smithers Rapra Technology: Shewsbury Shropshire, UK, 2001. [Google Scholar]
- Kopal, I.; Labaj, I.; Vršková, J.; Harničárová, M.; Valíček, J.; Ondrušová, D.; Krmela, J.; Palková, Z. A Generalized Regression Neural Network Model for Predicting the Curing Characteristics of Carbon Black-Filled Rubber Blends. Polymers 2022, 14, 653. [Google Scholar] [CrossRef] [PubMed]
- Strobl, G. The Physics of Polymers: Concepts for Understanding Their Structures and Behavior, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Liptáková, T.; Alexy, P.; Gondár, E.; Khunová, V. Polymérne Konštrukčné Materiály, 1st ed.; EDIS: Žilina, Slovakia, 2012. [Google Scholar]
- Ghoreishy, M.H.R. A State of the Art Review on the Mathematical Modeling and Computer Simulation of Rubber Vulcanization Process. Iran. Polym. J. 2016, 25, 89–109. [Google Scholar] [CrossRef]
- Hossain, M. Modelling and Computation of Polymer Curing. Ph.D. Thesis, Universität Erlangen-Nürnberg, Erlangen-Nürnberg, Germany, 7 July 2009. [Google Scholar]
- Krmela, J.; Artyukhov, A.; Krmelová, V.; Pozovnyi, O. Determination of Material Parameters of Rubber and Composites for Computational Modeling Based on Experiment Data. J. Phys. Conf. Ser. 2021, 1741, 012047. [Google Scholar] [CrossRef]
- Hagan, M.T.; Demuth, H.B.; Beale, M.H.; De Jesús, O. Neural Network Design, 2nd ed.; Martin Hagan: Stillwater, OK, USA, 2014. [Google Scholar]
- Lubura, J.; Kojić, P.; Pavličević, J.; Ikonić, B.; Omorjan, R.; Bera, O. Prediction of rubber vulcanisation using an artificial neural network. Hem. Ind. 2021, 75, 277–283. [Google Scholar] [CrossRef]
- Schwartz, G.A. Prediction of Rheometric Properties of Compounds by Using Artificial Neural Networks. Rubber Chem. Technol. 2001, 74, 116–123. [Google Scholar] [CrossRef]
- Karaağaç, B.; İnal, M.; Deniz, V. Artificial neural network approach for predicting optimum cure time of rubber compounds. Mater. Des. 2009, 30, 1685–1690. [Google Scholar] [CrossRef]
- Uruk, Z.; Kiraz, A.; Deniz, V. A comparison of machine learning methods to predict rheometric properties of rubber compounds. J. Rubber Res. 2022, 25, 265–277. [Google Scholar] [CrossRef]
- Uruk, Z.; Kiraz, A. Artificial intelligence based prediction models for rubber compounds. J. Polym. Eng. 2023, 43, 113–124. [Google Scholar] [CrossRef]
- Mehlig, B. Machine Learning with Neural Networks: An Introduction for Scientists and Engineers; CUP: Cambridge, UK, 2021. [Google Scholar]
- Deepa, A.; Thasliya, F.P.A. Back propagation. Int. J. Res. Appl. Sci. Eng. Technol. 2023, 11, 334–339. [Google Scholar]
- Seidl, D.; Ružiak, I.; Koštialová Jančíková, Z.; Koštial, P. Sensitivity Analysis: A Tool for Tailoring Environmentally Friendly Materials. Expert Syst. Appl. 2022, 208, 118039. [Google Scholar] [CrossRef]
- Specht, D.F. A general regression neural network. IEEE Trans. Neural Netw. 1991, 2, 568–576. [Google Scholar] [CrossRef] [PubMed]
- Al-Mahasneh, A.J.; Anavatti, S.; Garratt, M.; Pratama, M. Applications of General Regression Neural Networks in Dynamic Systems. In Digital Systems, 1st ed.; Asadpour, V., Ed.; IntechOpen: Rijeka, Croatia, 2018; Volume 1, pp. 133–154. [Google Scholar]
- Bontempi, G.; Birattari, M.; Bersini, H. Lazy Learning: A Logical Method for Supervised Learning. In New Learning Paradigms in Soft Computing; Kacprzyk, J., Ed.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 97–149. [Google Scholar]
- Ghosh, S. Kernel Smoothing: Principles, Methods and Applications, 2nd ed.; Wiley: Hoboken, NJ, USA, 2018. [Google Scholar]
- Mohebali, B.; Tahmassebi, A.; Meyer-Baese, A.; Gandomi, A.H. Probabilistic Neural Networks: A Brief Overview of Theory, Implementation, and Application. In Handbook of Probabilistic Models, 1st ed.; Samui, P., Bui, D.T., Chakraborty, S., Deo, R.C., Eds.; Butterworth-Heinemann Elsevier Ltd.: Oxford, UK, 2020; pp. 347–367. [Google Scholar]
- Bates, D.M.; Watts, D.G. Nonlinear Regression Analysis and Its Applications, 1st ed.; Wiley: Hoboken, NJ, USA, 2007. [Google Scholar]
- Shwechuk, J.R. Concise Machine Learning. Ph.D. Thesis, University of California, Berkeley, CA, USA, 6 May 2023. [Google Scholar]
- Martínez, F.; Charte, F.; Frías, M.P.; Martínez-Rodríguez, A.M. Strategies for time series forecasting with generalized regression neural networks. Neurocomputing 2022, 491, 509–521. [Google Scholar] [CrossRef]
- López, C.P. Deep Learning Techniques: Cluster Analysis and Pattern Recognition with Neural Networks. Examples with MATLAB, 1st ed.; Lulu Press Inc.: Morrisville, NC, USA, 2021. [Google Scholar]
- Hou, J.; Lu, X.; Zhang, K.; Jing, Y.; Zhang, Z.; You, J.; Li, Q. Parameters Identification of Rubber-like Hyperelastic Material Based on General Regression Neural Network. Materials 2022, 15, 3776. [Google Scholar] [CrossRef] [PubMed]
- Kowalski, P.A.; Kusy, M. Algorithms for Triggering General Regression Neural Network. In Computational Intelligence and Mathematics for Tackling Complex Problems 3, 3rd ed.; Harmati, I.Á., Kóczy, L.T., Medina, J., Ramírez-Poussa, E., Eds.; Springer: Cham, Switzerland, 2022; pp. 177–182. [Google Scholar]
- Chiroma, H.; Noor, A.S.M.; Abdulkareem, S.; Abubakar, A.I.; Hermawan, A.; Qin, H.; Hamza, M.F.; Herawan, T. Neural Networks Optimization through Genetic Algorithm Searches: A Review. Appl. Math. Inf. Sci. 2017, 11, 1543–1564. [Google Scholar] [CrossRef]
- Matlab. Parallel Computing Toolbox™ User’s Guide R2013b; Matlab: Natick, MA, USA, 2013. [Google Scholar]
- Xu, S. An Introduction to Scientific Computing with Matlab® and Python Tutorials, 1st ed.; Chapman & Hall/CRC: London, OH, USA, 2022. [Google Scholar]
- ISO 2393; Rubber Test Mixes—Preparation, Mixing and Vulcanisation—Equipment and Procedures. International Organization for Standardization: Geneva, Switzerland, 2011.
- Labban, A.; Mousseau, P.; Bailleul, J.L.; Deterre, R. Optimization of Thick Rubber Part Curing Cycles. Inverse Probl. Sci. Eng. 2010, 18, 313–340. [Google Scholar] [CrossRef]
- Nakajima, N. The Science and Practice of Rubber Mixing, 1st ed.; Technomic Publishing Company, Rapra Technology: Shropshire, UK, 2000. [Google Scholar]
- Lipińska, M.; Soszka, K. Viscoelastic Behavior, Curing and Reinforcement Mechanism of Various Silica and POSS Filled Methyl-Vinyl Polysiloxane MVQ Rubber. Silicon 2019, 11, 2293–2305. [Google Scholar] [CrossRef]
- Noordermeer, J.W.M. Vulcanization. In Encyclopedia of Polymeric Nanomaterial, 2015th ed.; Springer: Berlin/Heidelberg, Germany, 2014; Volume 3, pp. 1–16. [Google Scholar]
- Zhang, H.; Li, Y.; Shou, J.Q.; Zhang, Z.Y. Effect of Curing Temperature on Properties of Semi-Efficient Vulcanized Natural Rubber. J. Elastomers Plast. 2015, 48, 331–339. [Google Scholar] [CrossRef]
- Saito, T.; Yamano, M.; Nakayama, K.; Kawahara, S. Quantitative Analysis of Crosslinking Junctions of Vulcanized Natural Rubber through Rubber-State NMR Spectroscopy. Polym. Test. 2019, 96, 107130. [Google Scholar] [CrossRef]
- Han, I.S.; Chung, C.B.; Lee, J.W. Optimal Curing of Rubber Compounds with Reversion Type Cure Behavior. Rubber Chem. Technol. 2000, 73, 101–113. [Google Scholar] [CrossRef]
- Liu, X.; Tian, S.; Tao, F.; Yu, W. A Review of Artificial Neural Networks in the Constitutive Modeling of Composite Materials. Compos. Part B Eng. 2021, 224, 109152. [Google Scholar] [CrossRef]
- Kanwar, H. Mathematical Statistics, 1st ed.; Mohindra Capital Publishers: Chandigarh, India, 2022. [Google Scholar]
- Kopal, I.; Labaj, I.; Vršková, J.; Harničárová, M.; Valíček, J.; Tozan, H. Research Data for the Study Titled Intelligent Modelling of the Real Dynamic Viscosity of Rubber Blends Using Parallel Computing; Mendeley Data: London, UK, 2023. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Material | Contents (phr) | Producer | Function |
|---|---|---|---|
| Styrene–butadiene rubber grade 1500 | 100 | Synthos Kralupy a.s., Kralupy nad Vltavou, Czech Republic | Matrix |
| Carbon black type N550 (CB) | 0, 15, 30–75 * | Makrochem Sp. z o.o., Lublin, Poland | Filler |
| Zinc oxide (ZnO) | 3 | SlovZink a.s., Koseca, Slovakia | Vulcanisation activator |
| Stearic acid | 1 | Setuza a.s., Ústí nad Labem, Czech Republic | Vulcanisation activator |
| Sulfur Crystex OT33 (S) | 1.75 | Eastman Chemical Company, Kingsport, TN, USA | Vulcanising agent |
| TBBS ** | 1 | Duslo a.s., Šaľa, Slovakia | Vulcanisation accelerator |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kopal, I.; Labaj, I.; Vršková, J.; Harničárová, M.; Valíček, J.; Tozan, H. Intelligent Modelling of the Real Dynamic Viscosity of Rubber Blends Using Parallel Computing. Polymers 2023, 15, 3636. https://doi.org/10.3390/polym15173636
Kopal I, Labaj I, Vršková J, Harničárová M, Valíček J, Tozan H. Intelligent Modelling of the Real Dynamic Viscosity of Rubber Blends Using Parallel Computing. Polymers. 2023; 15(17):3636. https://doi.org/10.3390/polym15173636
Chicago/Turabian StyleKopal, Ivan, Ivan Labaj, Juliána Vršková, Marta Harničárová, Jan Valíček, and Hakan Tozan. 2023. "Intelligent Modelling of the Real Dynamic Viscosity of Rubber Blends Using Parallel Computing" Polymers 15, no. 17: 3636. https://doi.org/10.3390/polym15173636
APA StyleKopal, I., Labaj, I., Vršková, J., Harničárová, M., Valíček, J., & Tozan, H. (2023). Intelligent Modelling of the Real Dynamic Viscosity of Rubber Blends Using Parallel Computing. Polymers, 15(17), 3636. https://doi.org/10.3390/polym15173636