1. Introduction
Successful algorithms have been developed for computing approximate Nash equilibrium strategies in a variety of finite game classes, even classes that are challenging from a computational complexity perspective. For example, an algorithm that was recently applied for approximating Nash equilibrium strategies in six-player no-limit Texas hold’em poker defeated strong human professional players [
1]. This is an extremely large extensive-form game of imperfect information. Even solving three-player perfect-information strategic-form games is challenging from a theoretical complexity perspective; it is PPAD-hard
1 to compute a Nash equilibrium in two-player general-sum and multiplayer games, and it is widely believed that no efficient algorithms exist [
2,
3,
4]. Strong algorithms have also been developed for stochastic games, even with multiple players and imperfect information [
5]. Stochastic games have potentially infinite duration but a finite number of states and actions.
Continuous games are fundamentally different from finite games in several important ways. The first is that they are not guaranteed to have a Nash equilibrium; Nash’s theorem only proved the existence of a Nash equilibrium in finite games [
6]. A second challenge is that we may not even be able to represent mixed strategies in continuous games, as they correspond to probability distributions over a potentially (uncountably) infinite pure strategy space. So even if a game has a Nash equilibrium, we may not even be able to represent it, let alone compute it. Equilibrium existence results and algorithms have been developed for certain specialized classes; however, there are still many important game classes for which these results do not hold. Even two-player zero-sum games remain a challenge. For example, the fictitious play algorithm has been proven to converge to Nash equilibrium for finite two-player zero-sum games (and certain classes of multiplayer and nonzero-sum games), but this result does not extend to continuous games [
7].
A strategic-form game consists of a finite set of players , a finite set of pure strategies for each player i, and a real-valued utility for each player for each strategy vector (aka strategy profile), . A two-player game is called zero sum if the sum of the payoffs for all strategy profiles equals zero, i.e., for all .
A
mixed strategy for player
i is a probability distribution over pure strategies, where
is the probability that player
i plays
under
. Let
denote the full set of mixed strategies for player
i. A strategy profile
is a
Nash equilibrium if
for all
for all
, where
denotes the vector of the components of strategy
for all players excluding
i. It is well known that a Nash equilibrium exists in all finite games [
6]. In practice, all that we can hope for in many games is the convergence of iterative algorithms to an approximation of Nash equilibrium. For a given candidate strategy profile
, define
. The goal is to compute a strategy profile
with as small a value of
as possible (i.e.,
indicates that
comprises an exact Nash equilibrium). We say that a strategy profile
with value
constitutes an
ϵ-equilibrium. For two-player zero-sum games, there are algorithms with bounds on the value of
as a function of the number of iterations and game size, and for different variations
is proven to approach zero in the limit at different worst-case rates (e.g., [
8]).
If and are two mixed strategies for player i and , then we can consider mixed strategy in two different ways. The first interpretation, which is the traditional one, is that is the mixed strategy that plays pure strategy with probability . Thus, can be represented as a single mixed strategy vector of length . A second interpretation is that is the mixed strategy that with probability p selects an action by randomizing according to the probability distribution , and with probability selects an action by randomizing according to . Using this interpretation implementing requires storing full strategy vectors for both and , though clearly the result would be the same as in the first case.
In extensive-form imperfect-information games, play proceeds down nodes in a game tree. At each node x, the player function denotes the player to act at x. This player can be from the finite set N or an additional new player called Chance or Nature. Each player’s nodes are partitioned into information sets, where the player cannot distinguish between the nodes at a given information set. Each player has a finite set of available actions at each of the player’s nodes (note that the action sets must be identical at all nodes in the same information set because the player cannot distinguish the nodes). When play arrives at a leaf node in the game tree, a terminal real-valued payoff is obtained for each player according to utility function . Nash equilibrium existence and computational complexity results from strategic-form games hold similarly for imperfect-information extensive-form games; e.g., all finite games are guaranteed to have a Nash equilibrium, two-player zero-sum games can be solved in polynomial time, and equilibrium computation for other game classes is PPAD-hard.
Randomized strategies can have two different interpretations in extensive-form games. Note that a
pure strategy for a player corresponds to a selection of an action for each of that player’s information sets. The classic definition of a
mixed strategy in an extensive-form game is the same as for strategic-form games: a probability distribution over pure strategies. However, in general the number of pure strategies is exponential in the size of the game tree, so a mixed strategy corresponds to a probability vector of exponential size. By contrast, the concept of a
behavioral strategy in an extensive-form game corresponds to a strategy that assigns a probability distribution over the set of possible actions at each of the player’s information sets. Since the number of information sets is linear in the size of the game tree, representing a behavioral strategy requires only storing a probability vector of size that is linear in the size of the game tree. Therefore, it is much preferable to work with behavioral strategies than mixed strategies, and algorithms for extensive-form games generally operate on behavioral strategies. Kuhn’s theorem states that in any finite extensive-form game with perfect recall, for any player and any mixed strategy, there exists a behavioral strategy that induces the same distribution over terminal nodes as the mixed strategy against all opponent strategy profiles [
9]. The converse is also true. Thus, mixed strategies are still functionally equivalent to behavioral strategies, despite the increased complexity of representing them.
Continuous games generalize finite strategic-form games to the case of (uncountably) infinite strategy spaces. Many natural games have an uncountable number of actions; for example, games in which strategies correspond to an amount of time, money, or space. One example of a game that has recently been modeled as a continuous game in the AI literature is computational billiards, in which the strategies are vectors of real numbers corresponding to the orientation, location, and velocity at which to hit the ball [
10].
Definition 1. A continuous game is a tuplewhere
is the set of players
, where eachis a (compact) metric space corresponding to the set of strategies of player i
, whereis the utility function of player i
Mixed strategies are the space of Borel probability measures on
. The existence of a Nash equilibrium for any continuous game with continuous utility functions can be proven using Glicksberg’s generalization of the Kakutani fixed point theorem [
11]. The result is stated formally in Theorem 1 [
12]. In general, there may not be a solution if we allow non-compact strategy spaces or discontinuous utility functions. We can define extensive-form imperfect-information continuous games similarly to that for finite games, with analogous definitions of mixed and behavioral strategies.
Theorem 1. Consider a strategic-form game in which the strategy spacesare nonempty compact subsets of a metric space. If the payoff functionsare continuous, there exists a (mixed strategy) Nash equilibrium.
While this existence result has been around for a long time, there has been very little work on practical algorithms for computing equilibria in continuous games. One interesting class of continuous games for which algorithms have been developed is
separable games [
13]; however, this imposes a significant restriction on the utility functions, and many interesting continuous games are not separable. Additionally, algorithms for computing approximate equilibria have been developed for several other classes of continuous games, including simulation-based games [
14], graphical tree-games [
15], and continuous poker models [
16]. The continuous Blotto game that we consider does not fit in any of these classes, and in fact has discontinuous utility functions, so we cannot apply Theorem 1 or these algorithms.
2. Continuous Blotto Game
The Blotto game is a type of two-player zero-sum game in which the players are tasked to simultaneously distribute limited resources over several objects (or battlefields). In the classic version of the game, the player devoting the most resources to a battlefield wins that battlefield and the gain (or payoff) is then equal to the total number of battlefields won. The Blotto game was first proposed and solved by Borel in 1921 [
17] and has been frequently applied to national security scenarios. It has also been applied as a metaphor for electoral competition, with two political parties devoting money or resources to attract the support of a fixed number of voters: each voter is a “battlefield” that can be won by one party. The game also finds application in auction theory where bidders must make simultaneous bids [
18].
Initial approaches derived analytical solutions for special cases of the general problem. Borel and Ville proposed the first solution for three battlefields [
19], and Gross and Wagner generalized this result for any number of battlefields [
20]. However, they assumed that colonels have the same number of troops. Roberson computed optimal strategies of the Blotto games in the continuous version of the problem where all of the battlefields have the same weight, for models with both symmetric and asymmetric budgets [
21]. Hart considered the discrete version, again when all battlefields have equal weight, and solved it for certain special cases [
22]. It was not until 2016 that the first algorithm was provided to solve the general version of the game. Initially a polynomial-time algorithm that involved solving exponential-sized linear programs was presented [
23], which was later improved to a linear program of polynomial size [
24]. These polynomial-time algorithms are for the discrete version of the game; however, no general algorithm has been devised for the original continuous Blotto game. As described earlier, there are many challenges present for solving continuous games that do not exist for finite games, even for two-player zero-sum games.
Most of the prior approaches solve perfect-information versions of the game in which all players have public knowledge of the values of the battlefields. Adamo and Matros studied a Blotto game in which players have incomplete information about the other player’s resource budgets [
25]. Kovenock and Roberson studied a model where the players are subject to incomplete information about the battlefield valuations [
26]. In both of these works, all players are equally uninformed about the parameters. Recently some work has provided analytical solutions for certain settings with asymmetric information, in which both players know the values of the battlefields but one player knows their order while the other player only knows a distribution over the possible orders [
27,
28]. This model is an imperfect-information game in which player 1 must select a strategy without knowing the order, while player 2 can select a different mixed strategy conditional on the actual order. We study and present an algorithm for the asymmetric imperfect-information continuous version of the Blotto game, which is perhaps the most challenging variant. Note that our approach also applies to the perfect information version as well.
A continuous Blotto game is a tuple :
Set of players
Set of battlefields
Set of slots
Set O of outcomes, which is a subset of the set of permutations of elements of F, where denotes the battlefield in slot q for , . Let
Probability mass function p with for each
Positive real value for each battlefield
Positive real-valued budget for each player
Pure strategy space of player 1 is . Let denote the probability of selecting slot q for
Pure strategy space of player 2 is . Let denote the probability of selecting slot q under outcome o for
Utility function for , where
if ,
if ,
otherwise
Utility function for , where
if ,
if ,
otherwise
Each player must select a real-valued amount of resources to put on the battlefield in slot , subject to the constraint that the total does not exceed the player’s budget . Player 1 does not know the outcome o, which defines the order of the battlefields; they only know that the outcome is with probability . Player 2 knows the order and is able to condition their strategy on this additional information. For each slot q, if player 1 uses an amount of resources that exceeds player 2’s amount by at least , then player 1 “wins” the battlefield in slot q and receives its value (and player 2 receives ); if then player 2 wins and player 1 loses ; otherwise, both players get zero. This game is clearly zero sum because player 1 and player 2’s payoff sum to zero for each situation.
Note that the utility function is discontinuous: payoffs for a given slot can shift abruptly between , 0, and with arbitrarily small changes in the strategies. This means that Theorem 1 does not apply, and the game is not necessarily guaranteed to have a Nash equilibrium. The game does also not fall into the specialized classes of games such as separable games for which prior algorithms have been developed. Note that often the Blotto game is presented without the term; typically player 1 wins the battlefield if , and player 2 wins if . We add in the term because our algorithm involves the invocation of an optimization solver, and optimization algorithms typically cannot handle strict inequalities. We can set to a value very close to zero.
3. Algorithm
Fictitious play is an iterative algorithm that is proven to converge to Nash equilibrium in two-player zero-sum games (and in certain other game classes), though not in general for multiplayer or non-zero-sum games [
7,
29]. While it is not guaranteed to converge in multiplayer games, it has been proven that if it does converge, then the average of the strategies played throughout the iterations constitute an equilibrium [
30]. Fictitious play has been successfully applied to approximate Nash equilibrium strategies in a three-player poker tournament to a small degree of approximation error [
5,
31]. More recently, fictitious play has also been used to approximate equilibrium strategies in multiplayer auction [
32,
33] and national security [
34] scenarios. Fictitious play has been demonstrated to outperform another popular iterative algorithm, counterfactual regret minimization, in convergence to equilibrium in a range of multiplayer game classes [
35].
In classical fictitious play, each player plays a best response to the average strategies of his opponents thus far. Strategies are initialized arbitrarily (typically they are initialized to be uniformly random). Then each player uses the following rule to obtain the average strategy at time
t:
where
is a best response of player
i to the profile
of the other players played at time
. The final strategy output after
T iterations
is the average of the strategies played in the individual iterations (while the best response
is the strategy actually played at iteration
t).
The classical version of fictitious play involves representing two strategies per player; the current strategy and the current best response . Note that once we compute the next round strategy from and , we no longer need to maintain either or in memory. We interpret as a single mixed strategy that selects action with probability
An alternative, and seemingly nonsensical, way to implement fictitious play would be to separately store each of the pure strategies that are played
, rather than to explicitly average them at each step. Using this representation, the best response can be computed by selecting the pure strategy that maximizes the average (or sum) of the utilities against
. This method of implementing fictitious play seems nonsensical for several reasons. First, it involves picking a strategy that maximizes the sum of utilities against
t different opponent strategies as opposed to maximizing the utility against a single strategy. And second, it involves storing
t pure strategies for each player, which would require using significantly more memory than the original approach when
t exceeds
. Despite these clear drawbacks, nonetheless it is apparent that this approach is still equivalent to the original approach and results in the same sequence of strategies being played. When the algorithm is applied to an imperfect-information game, we can view it as operating with mixed as opposed to behavioral strategies (in contrast to prior algorithms for solving imperfect-information games). We refer to this new approach as “Redundant fictitious play” due to the fact that it “redundantly” stores all of the strategies played individually instead of storing them as a single mixed strategy. Redundant fictitious play is depicted in Algorithm 1.
| Algorithm 1 Redundant fictitious play for two-player games |
Inputs: Number of iterations T Initialize strategy arrays , InitialValues() for to T do |
In Algorithm 1, we store
T strategies for each player, where
T is the total number of iterations. We can initialize strategies arbitrarily for the first iteration (e.g., to uniform random). For all subsequent iterations the strategy
is a pure strategy best response to a strategy of the opponent.
2 The notation
refers to the mixed strategy for player
i that plays strategy
with probability
, for
; that is, it mixes uniformly over the strategies
. The algorithm then computes the game value to player
i under the current iteration strategies as well as the
exploitability of each player (difference between best response payoff and game value). This determines the maximum amount that each player can gain by deviating from the strategies; we can then say that the strategies computed at iteration
constitute an
-equilibrium, where
.
Now, suppose that G is a continuous game and no longer a finite game. Assuming that we initialize the strategies to be pure strategies, all of the strategies are now pure strategies and the algorithm does not need to represent any mixed strategies. This is very useful, since for continuous games a mixed strategy may be a probability distribution that puts weight on infinitely many pure strategies and cannot be compactly represented. However, pure strategies can typically be represented compactly in continuous games. For example, if the strategy spaces are compact subsets of , then each pure strategy corresponds to a vector of n real numbers, which can be easily represented assuming that n is not too large. For example in continuous Blotto player 1 must select an amount of resource to use for each of battlefields, and therefore storing a pure strategy requires storing real numbers, which is easy to do. Thus, Redundant Fictitious Play can be feasibly applied to continuous games, while the classical version cannot.
The only remaining challenge for continuous games is the best response computation, which may be challenging for certain complex utility functions. However, for the common assumptions that the pure strategy spaces are compact and the utility functions are continuous, this optimization is typically feasible to compute.
For the continuous Blotto game, we present optimization formulations for computing player 1 and 2’s best response below. Both of these are mixed integer linear programs (with a polynomial number of variables and constraints). Note that we are able to construct efficient best response procedures for this game despite the fact that the utility function is discontinuous.
Player 1’s best response function is the following, where is a variable denoting the amount of resources put on slot q, and is the amount of resources put on slot q under outcome o by player 2’s fixed strategy at iteration t:
Maximize
subject to:
The constraints in Equation (
1) are called indicator constraints and state that if the binary variable
has value equal to 1, then the linear constraint
must hold. Indicator constraints are supported by many integer-linear program optimization solvers, such as CPLEX and Gurobi. We could additionally impose indicator constraints
; however, these are unnecessary and would significantly increase the size of the problem. To see the correctness of the procedure, suppose that
and
but that
. Then the objective clearly increases by setting
instead to include the additional term
. So there cannot exist another solution satisfying the budget and indicator constraints with higher objective value.
While player 1 must assume that the outcome is distributed according to p, player 2 is aware of the outcome and therefore can condition their strategy on it. Therefore, player 2 solves a separate optimization for each value of to compute the best response to the strategy of player 1.
Player 2’s best response function given outcome is the following, where is a variable denoting the amount of resources put on slot q and is the amount of resources put on slot q according to player 1’s fixed strategy at iteration t:
Maximize
subject to:
Correctness of player 2’s best response function follows by similar reasoning to that of player 1’s. Player 1’s best response optimization has binary variables , where is the current algorithm iteration and denotes the number of outcomes, and continuous variables . Since the number of indicator constraints is also , the size of the formulation is , which is polynomial in all of the input parameters. Similarly, player 2 must solve M optimizations, each one with size . Note that in practice this algorithm could be parallelized by solving each of these optimizations simultaneously on separate cores as opposed to solving them sequentially (in our implementation we solve them sequentially). However, since player 1’s optimization is much larger than each of player 2’s, the bottleneck step is player 1’s optimization, and such a parallelization may not provide a significant reduction in the runtime.
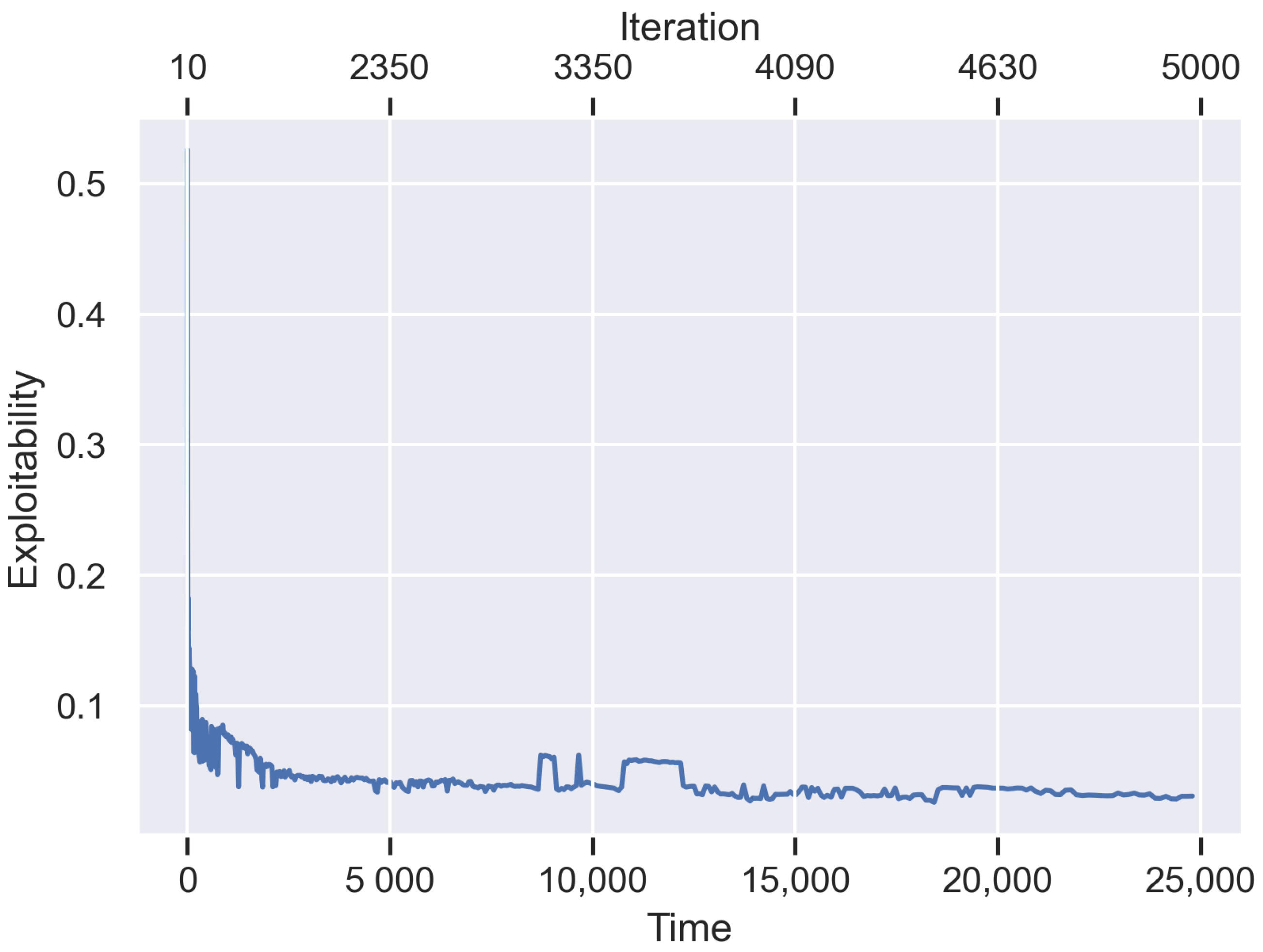
Note that as we run successive iterations of Algorithm 1, the size of these optimization problems becomes larger, since the opponent’s strategy is a mixture over
t pure strategies, where
t is the current algorithm iteration. We have seen that the number of variables and constraints scales linearly in
t. Therefore, we expect earlier iterations of the algorithm to run significantly faster than later iterations. We will see the exact magnitude of this disparity in the experiments in
Section 4. A potential solution to this issue would be to include an additional parameter
K in Algorithm 1. Instead of computing a best response to the mixture over all
t of the opponent’s pure strategies, a subset of
K of them is selected by sampling and a best response is computed just to a uniform mixture over the pure strategies in the sampled subset. This sampling would occur for each iteration, so a potentially different subset of size
K would be selected at each iteration. This would ensure that the complexity of the best response computations remains constant over all iterations and does not become intractable for later iterations. This approach would be unbiased and produces the same result in expectation over the sampling outcomes. However, it may lead to high variance in results and lead to poor convergence in practice. Perhaps this could be mitigated by performing multiple runs of the sampling algorithm in parallel and selecting the run with lowest value of
.
Note that Algorithm 1 can be applied to extensive-form imperfect-information games in addition to simultaneous strategic-form games (in fact the continuous Blotto game that we apply it to has imperfect information for player 1, since player 1 does not know the value of
o while player 2 does). As long as pure strategies can be represented and best responses can be computed efficiently (which are both the case for imperfect-information games), the algorithm can be applied. Also note that while we presented the algorithm just for a two-player game, it can also be run on multiplayer games (just as for standard fictitious play). The best response computations are still just a single agent optimization problem given fixed strategies for the opposing players. In fact, fictitious play has been demonstrated to obtain successful convergence to Nash equilibrium in a variety of multiplayer settings [
35], despite the fact that it is not guaranteed to converge to Nash equilibrium in general for games that are not two-player zero-sum.
We can compute
and
for Algorithm 1 in the continuous Blotto game using the procedures depicted in Algorithms 2 and 3 (and analogously for
and
).
| Algorithm 2 Procedure to compute in continuous Blotto |
for to t do for to t do for do for do if then else if then return |
| Algorithm 3 Procedure to compute in continuous Blotto |
for to do for do for do if then else if then return |


{kind=link}
