2. Materials and Methods
The process of the development and validation of this test was conducted in three main steps (
Figure 1). The first step was the development of the materials; followed by the assessment and refinement of the test; and finally, the evaluation of the developed test.
2.1. Materials
To develop the A-CAPT, we established an inventory of 120 monosyllabic words found in Arabic children’s books and commonly used in everyday life that are familiar to Arabic-speaking children aged five years and older. We arranged the words in groups of four Arabic meaningful monosyllabic CVC or CVCC words that differ only in one phoneme. Words were grouped based on their consonant environments, where each selected word was in a group with three other confusable words. These confusion groups (CGs) containing the four similar words differed only in the first or final phoneme. The test therefore used a closed-set four-alternative-forced-choice test paradigm. Since not all the words in the inventory could fit into groups of four minimally contrastive words with similar phonemes, only 77 words were used and we produced 20 CGs consisting of 80 words, three words (/batˤ/, /tˤiːn/, /bar/, were presented in two CGs). Each CG contained four similar words that differed in either the initial (e.g., /jad/, /sad/, /yad/, /xad/) or final phoneme (e.g., /xatˤ/, /xas/, /xal/, /xad/). The groups were divided equally into two subgroups (ten CGs, i.e., 40 words each), one of which assessed the first phoneme and the other assessed the third or final phoneme. The subgroups were also divided equally into two subgroups for vowel length (five CGs). In total, there were two groups of words, first phoneme contrast and final phoneme contrast. Both groups contained forty words divided into twenty long vowel words and twenty short vowel words.
Familiarity and intelligibility of words within CGs was assessed by a simple binary forced response survey that was used with the three native Arabic audiologists (Saudi Arabian, Egyptian, and Libyan) who volunteered to assess the appropriateness of the materials for the target group of children. In a group setting, the clinicians listened to each stimulus and matched it to the corresponding picture then decided whether it was appropriate or inappropriate. The group agreed that the word /ɣaːb/, which refers to a verb form of the word ‘absent’, was rather abstract and the illustration may cause confusion to the children. Accordingly, the CG that contained this word was marked for elimination in the final version of the word lists. To keep an even number of CGs for the purpose of creating equal word lists, we opted to eliminate three more CGs that was determined to be least familiar to children and use it instead for a practice run. Otherwise, the expert panel agreed that the words selected were appropriate and matched the illustrations.
2.1.1. Recording Words
Three native Arabic-speaking adults volunteered to record the words in Modern Standard Arabic, two females and one male (age range 35–46 year old); each word was recorded twice. The female speakers were both originally from the central region of Saudi Arabia (Al-Qassim), the first speaker was a post-graduate student while the other speaker was an elementary-school teacher. The male speaker was from the western region of Saudi Arabia (Makkah) and was a university lecturer. The speakers were seated a meter away from the microphone. The stimuli were recorded in an Anechoic Chamber (AC) at University College London with a Bruel and Kjaer 2231 Sound Level Meter fitted with a type 4190 condenser microphone. The signal was digitised with a Focusrite 2i2 USB sound card at a sample rate of 44,100 Hz. Six continuous wav files were recorded using ProRec 2.4 [
26], recording software developed at UCL. Automatic separation before and after utterances and labelling for each word was achieved through ProRec after filtering the .wav files with a high pass filter to reduce gross fluctuations (using a MatLab script). Finally, the RMS values for all words was equated.
Three Arabic native speakers critically listened to the recorded words and gave their feedback on pronunciation, clarity of the recordings, accuracy of utterances in the Modern Standard Arabic and their preferred speaker out of the three. Using google forms, the evaluators individually listened and rated each word as clear or not clear. One of the evaluators who completed the forms was a post-graduate student in linguistics and her Ph.D. project involved investigation of dialects in Saudi Arabia, the other two evaluators were highly educated clinical audiologists in Saudi Arabia. The three evaluators voted for the same female speaker, and thus her voice was selected for the A-CAPT.
2.1.2. Handling Test Materials and Illustrations
The pictures were all drawn by a 14-year-old child to ensure that they were relevant for younger children. Although there is no evidence that children’s drawings are necessarily more relevant to other children than professional illustrators, we chose to do this because in the original implementation of the CAPT some of the figures had to be altered to make them more meaningful for children. For example, the word peg was originally a picture of a clothes peg to be used on a washing line but had to be replaced with a clothes peg for hanging up coats. The pictures were then made into jpegs and a caption of the word written in Arabic was added to each figure (See
Figure 2). After recording the words and matching them to corresponding pictures, the familiarity and appropriateness of the words and their corresponding pictures were assessed by an expert review panel, three Arabic-speaking audiologists, who listened and evaluated all the words and their corresponding pictures.
2.2. Methods
2.2.1. Phase I: Assessment of Speech Materials and Development and Refinement of Word Lists
In this phase, we evaluated whether or not the selected words in Modern Standard Arabic language were appropriate and intelligible for the targeted age group of children.
Participants
Adverts were sent to the King Fahad Academy (KFA) in London, United Kingdom (UK) to recruit children for this experiment. The KFA is an independent school that follows the UK national curriculum and is funded by the Saudi Arabian Embassy in the UK. Twenty-eight children aged between six and eleven years (mean age = 8.94 years) were randomly selected from families that responded to adverts. All children were screened at 20 dBHL using pure-tone audiometry at frequencies 0.5, 1.0, 2.0 and 4.0 kHz. Transient evoked otoacoustic emission (TEOAE) was also performed on each child. All children passed the hearing screening and have no known learning disabilities.
Evaluation of the Test Material
Test materials, 80 monosyllabic words, were delivered via a computer using Prezi presentation slides on a screen through an EB-X62 EPSON projector. The words were presented at a soft presentation level calibrated to be 50 dBA at the centre of where the children were sitting for the testing to avoid ceiling effects. Words were delivered via a wall speaker Model NV-WA40W-SP to a group of normal hearing children. Tests were conducted in a classroom where the average background noise level of the room ranged 40–45 dB SPL; the noise level was measured three times within each session, before conducting the test, during the test and at the end of the test session. Each test was run twice with a ten-minute break between each session; the order of words was the same in test and retest sessions.
The classroom windows were shut to minimize external background noise. The classroom was allocated for non-English speaking children who receive extra language sessions and was located in the administration area which was generally the quietest in the school. No incidents of sudden background noise were observed during testing. The dimensions of the classroom were: 800 cm long, 704 cm wide, and 250 cm high. The children sat on the carpet in the middle of the room with the first row two meters from the loudspeaker. There were five rows of children in total and the calibration was conducted at the midpoint of these rows.
The children were instructed to select one out of four pictures that visually and orthographically represented the presented word. Children had a practice run that consisted of 4 words to familiarize them with the process. Following Vickers’ speech test procedure [
27], each child was assigned a hand-held infrared transmitter to record her or his response to each trial. Turning point software and a USB receiver were used to capture the children’s responses. A rule from Vickers’ study was also followed, this was to exclude participants if they missed four or more items to rule out technical issues such as malfunction of transmitters, accordingly two children were excluded.
2.2.2. Phase II: Evaluation of the Developed Lists
In this phase, data were collected to evaluate the developed lists from phase I, of which there were four (two easy and two hard lists). The level of difficulty of the lists was determined based on the average scores for each CG (
Figure 3 and
Figure 4). Data were analyzed for individual lists and also by combining the two easier lists and combining the two harder lists producing a total of two lists, an easy list and a hard list. Each list can be used repeatedly by merely changing the order of the words within the list because all words are represented on each run (See
Table 2).
Participants
Children were recruited via advert at King Abdul-Aziz University in Jeddah, Saudi Arabia. Sixteen children aged between five and eleven years (mean age = 8.33 years) participated in the validation of this phase, nine males and seven females. All children were screened at 20 dB HL using pure-tone audiometry at frequencies 0.5, 1.0, 2.0 and 4.0 kHz. All children passed hearing screening and none were reported to have learning disabilities.
Technical Delivery
Experiments were conducted in a quiet room in King Abdul-Aziz University or at the participant’s home. The noise floor was measured using a sound level meter to be equal or less than 40 dBA. The test materials were delivered via a computer running a MatLab script to present stimuli, show response options and record responses. The participants were instructed to select one out of four pictures that visually and orthographically represent the presented word. Each participant was tested individually; the child listened to the stimuli over Sennheiser HD 650 headphones and selected the corresponding picture out of four choices shown on the computer’s screen that visually and orthographically represented the presented word. The lists were presented at four different levels starting at soft level 40 dB SPL, then increasing the volume by 10 dB SPL increments (50, 60, and 70 dB SPL) until the child reached the maximum score. The four different presentation levels were used to map out the psychometric function (performance by level) so that the most appropriate presentation level for future test presentation could be established. This psychometric function could also be used to find a presentation level for test re-test reliability and critical difference calculations for a performance level that was not at the floor or ceiling of the performance range. Each test was run twice before increasing the volume to the next level with a ten-minutes break in between; order of words was altered to minimize learning effect.
3. Results
3.1. Phase I: Assessment of Speech Materials and Development of Lists
In this phase, the speech materials were designed to assess two distinct skills, discrimination of initial consonant and final consonant of monosyllabic words. Therefore, the test and analysis were conducted in two parts that assessed each skill separately. Three measures were utilized to evaluate the appropriateness and intelligibility of the developed materials. The first measure was the scores of participants in each CG, where scoring was calculated by adding the number of correct words within a CG, then dividing it by the total number of words within a CG producing an average score for each CG. Even though the test was presented at a soft level (50 dB SPL), participants’ scores were overall high with an average of 3.4 points out of 4 for initial phoneme CGs and 2.8 points out of 4 for final phonemes CGs. Scores in the final phoneme component were consistently lower, with the lowest score for the word /bar/. The word /bar/, which means land (particularly referring to desert in Saudi Arabic) is pronounced the same in the colloquial and Modern Standard Arabic and is a very familiar word to children in Saudi Arabia. It is worth noting that such a low score was not caused by the use of Modern Standard Arabic language but potentially due to the difficulty of perception of the acoustic cues for /bar/ when presented at a low level.
The second measure was intraclass correlation coefficient (ICC) to assess the agreement between the participants’ scores within each CG, where responses of all participants for each CG were assessed to evaluate the degree of agreement between participants. We used two-way mixed-effects ICC model with type consistency to assess agreement between subjects’ averaged scores at each CG in the test and retest runs. The ICC showed excellent agreement of 0.94 between the participants in both the initial and final phoneme components, suggesting a significant correlation between participants’ responses in each CGs.
The third measure was the comparison of the average scores of each CG. Two ANOVAs were conducted, one for initial phoneme and one for final phoneme. For both, a repeated measures ANOVA with within-subject factors of Test session (one and two) and Word group (10 CGs) were used. If the Mauchley’s test of Sphericity was significant we used Greenhouse-Geisser corrections. For the initial phoneme, there was no significant effect of Test session, F (1, 22) = 0.04, p = 0.84 s, but a significant main effect of Word group, F (4.371, 96.168) = 14.589, p < 0.001. The results also show significant interactions between Test session and Word group, F (5.056, 111.233) = 2.981, p = 0.014, where participants’ scores for CG2 were significantly higher by an average increase of 0.4 points in the retest session. For the final phoneme contrast there was no significant main effect of Test session F (1, 18) = 0.945, p = 0.344 but there was a significant main effect of Word group, F (9, 162) = 14.608, p < 0.001. Pairwise comparison generally showed that the mean scores for the CGs for the long vowel words were significantly different from mean scores for the CGs for the short vowel words, for both initial and final phonemes tests. The results also show significant interactions between Test session and Word Group, F (9, 96.966) = 7.580, p < 0.001, where participants’ scores at CG2, CG4 in the long vowel CGs and CG2 in the short vowel CGs were significantly different in the retest session by an average change of −1.2, 0.85, and 0.6 points, respectively.
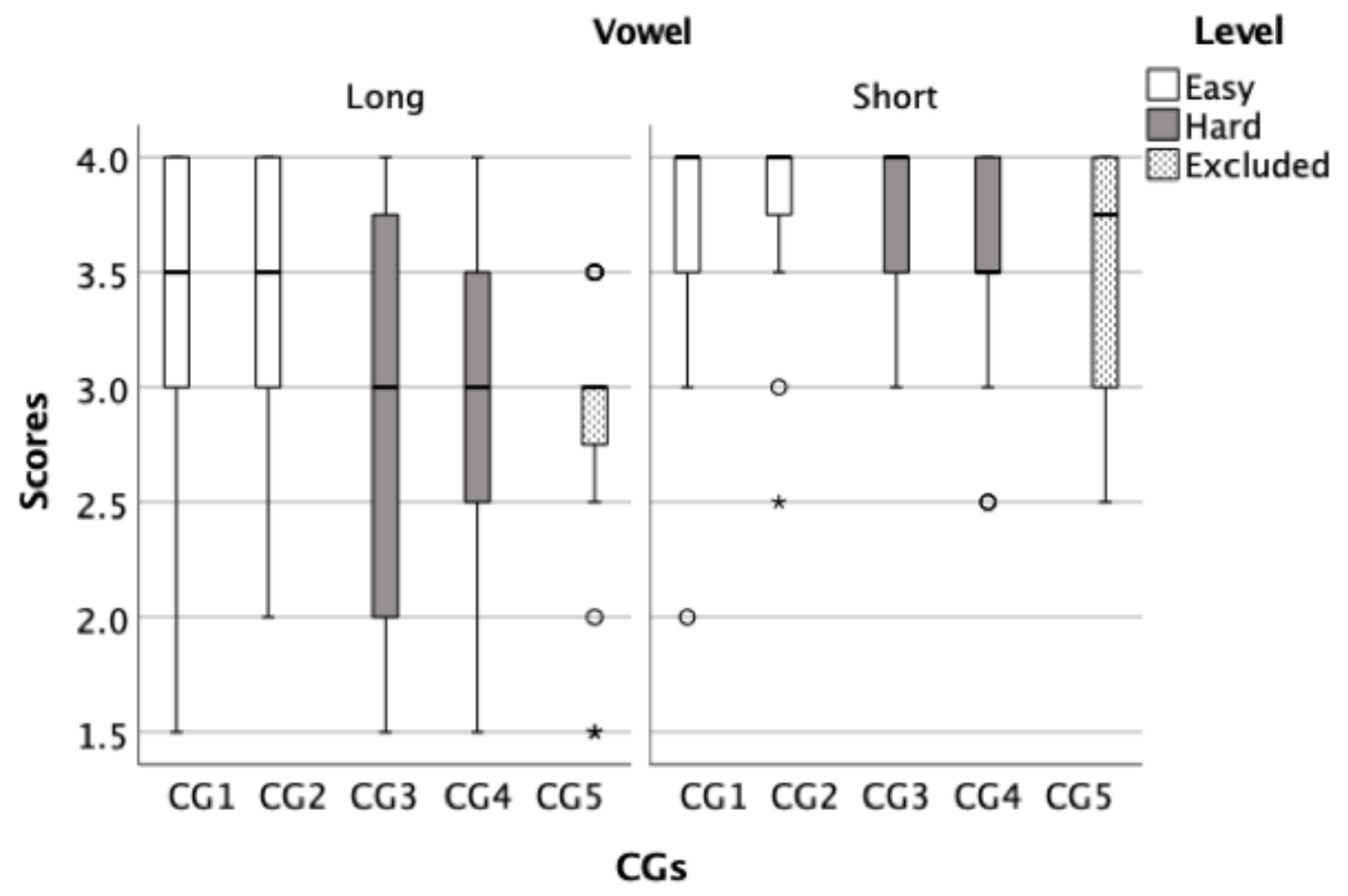
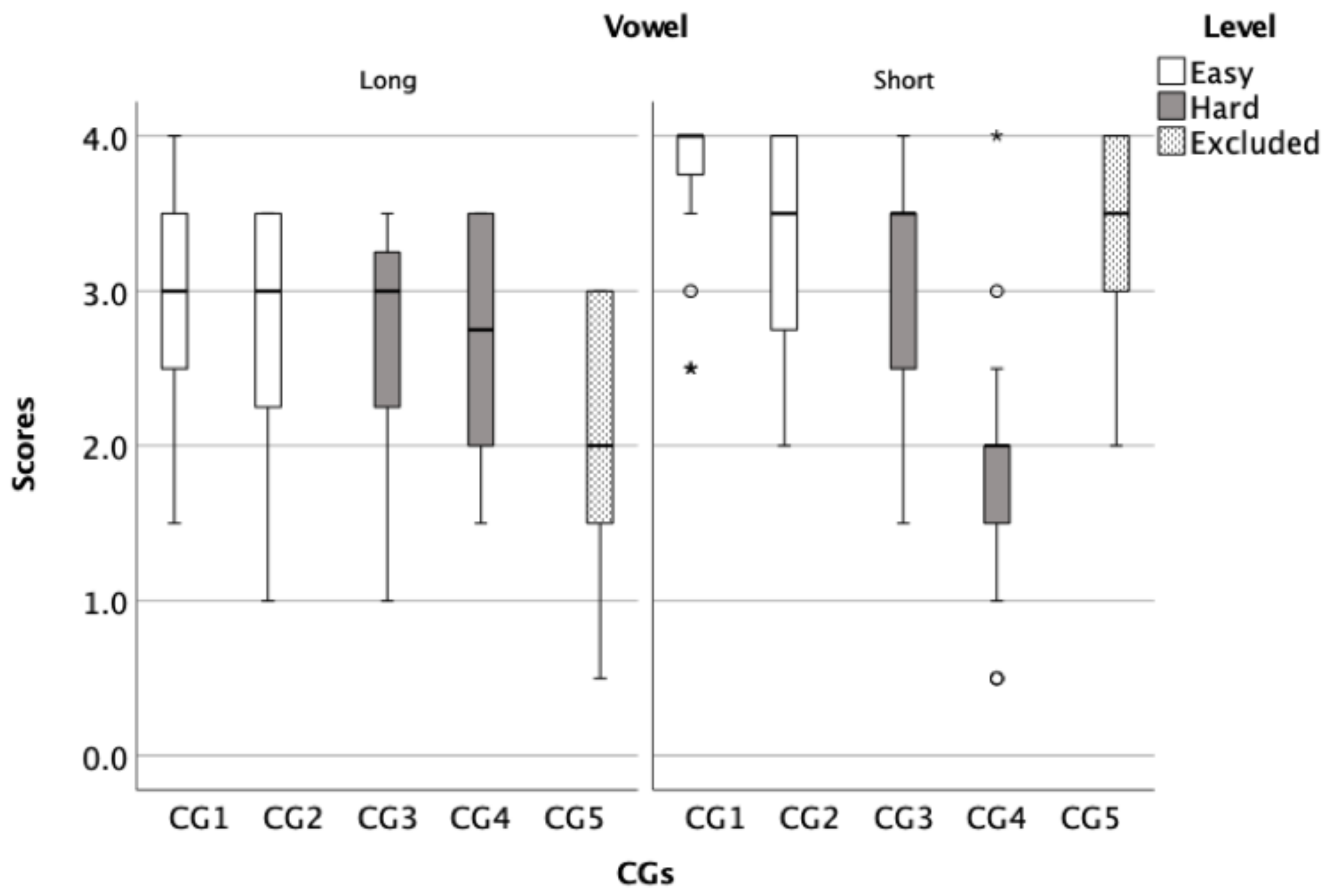
To show the average score of CGs, box plots for both the initial (
Figure 3) and final phoneme components (
Figure 4) were created to illustrate the overall performance of the children. These figures were used to analyse the similarities and differences between CGs within each test to inform the development of the final word lists. After analysing the CGs, the CGs that had lower average scores were considered difficult and were selected for a harder list. Then, CGs were sorted based on its level of difficulty from least confusing to most confusing, subsequently four lists were developed, two of which were easy and two were hard. For example, CG1 in
Figure 3 consisted of the words /naːr/, /daːr/, / tˤaːr/, and /ħaːr/ had an average score of 3.38 (out of 4) while CG5 in the same panel consisted of /baːb/, /ðaːb/, /ʃaːb/, and /ɣaːb/ had and average score of 2.85 (out of 4), indicating that the CG1 is easier (less confusing) than the CG5.
3.2. Phase II: Validation of the Developed Lists: Lists Equivalency Analysis
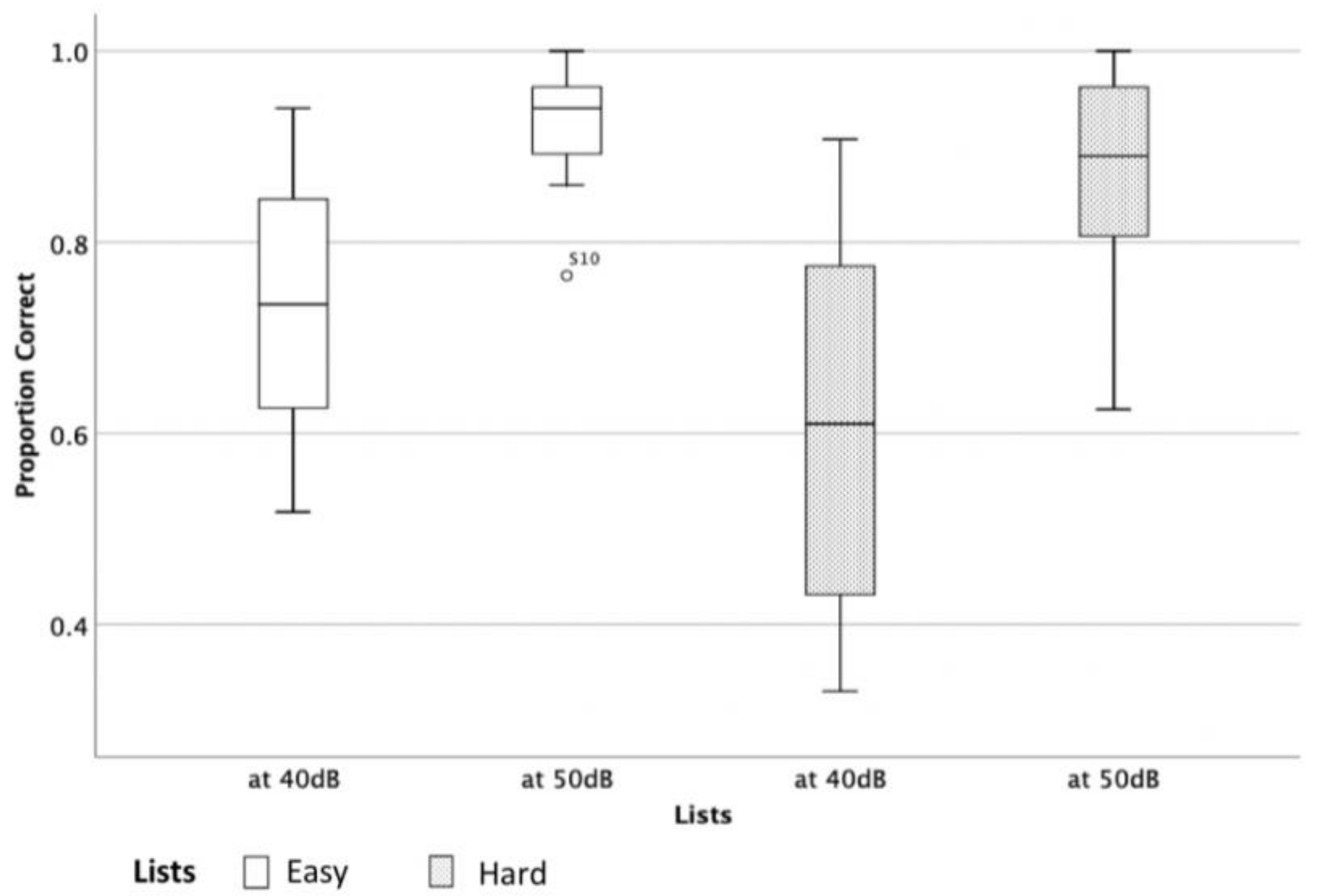
Using the lists (two easy and two hard) that were developed in phase I, an experiment was conducted to evaluate the difficulty and equivalency across lists. Since the difference between the lists was most apparent at lower presentation levels and ceiling effects were observed in the higher presentation levels (
Table 3), only the data that were collected at 40 dB SPL were used to evaluate the list equivalency and produce the final form of the lists. A repeated-measure ANOVA was performed with a within-subject factor Test Sessions (test and re-test) and Lists (four lists) and Sphericity was assumed.
The results indicate a significant main effect of List, F (3, 13) = 12.1,
p < 0.001 and a significant main effect of Test Sessions, F (1, 15) = 5.54,
p = 0.03, suggesting the existence of different level of difficulty within lists and performance in retest session. The results show no significant interaction between the effects of Lists and Test Sessions on scores, F (3, 13) = 0.96,
p = 0.44. Post hoc comparisons using the Tukey HSD test indicated that the mean scores for List 4 was significantly lower than the mean scores of List 1 (
p < 0.001) and List 2 (
p < 0.001). In addition, the mean score of List 3 was significantly lower than the mean scores of List 2 (
p = 0.03) and (
p = 0.05) List 1 (
Figure 5). The results indicate that List 1 and List 2 were easier than List 3 List 4. In addition, participants’ scores increased by an average of 0.05 points in retest session.
3.3. Critical Difference
When the initial critical difference calculations were conducted with the four lists, reliability was not satisfactory. To address this, lists were combined to increase the number of items in a list. The two easy lists were merged into one list of 32 items and the two hard lists were also merged into one list of 32 items. This improved reliability of the test by increasing the number of items within lists.
A within-subject sω was calculated (as calculated in the original CAPT) to derive the 95% confidence interval of the score for an individual [
28]. The quantity sω is the square root of the mean group variance (mean across individuals of the variance calculated for each individual). An individual’s observed score is expected to lie within ±1.96 sω of their true score (for 95% of observations; the CI). The critical difference is calculated as √2 × 1.96 sω. If scores obtained on two different occasions differ by √2 × 1.96 sω or more, then they differ significantly at
p < 0.05.
The critical difference was calculated for both levels 40- and 50-dB SPL. However, it was decided to present the 50 dB SPL calculations as 50 dB SPL was determined to be the preferred presentation level since 40 dB SPL is considered soft speech and could be affected by variation of hearing thresholds and noise floor as observed by the participants’ performance (see
Figure 6).
The mean critical difference at 50 dB SPL for the easy list was 18% and the hard list was 12%.
Table 4 shows how the critical difference varies across the performance range at 50 dB SPL and what the critical difference is for an individual score out of 32. For example, a child scored 88% on the easy list one occasion and 77% in the second. This would not be considered as a significant change in performance since the score falls between 69% and 100%. However, if the child scored 66% on the second occasion, this would be viewed as a significant decrease in performance.
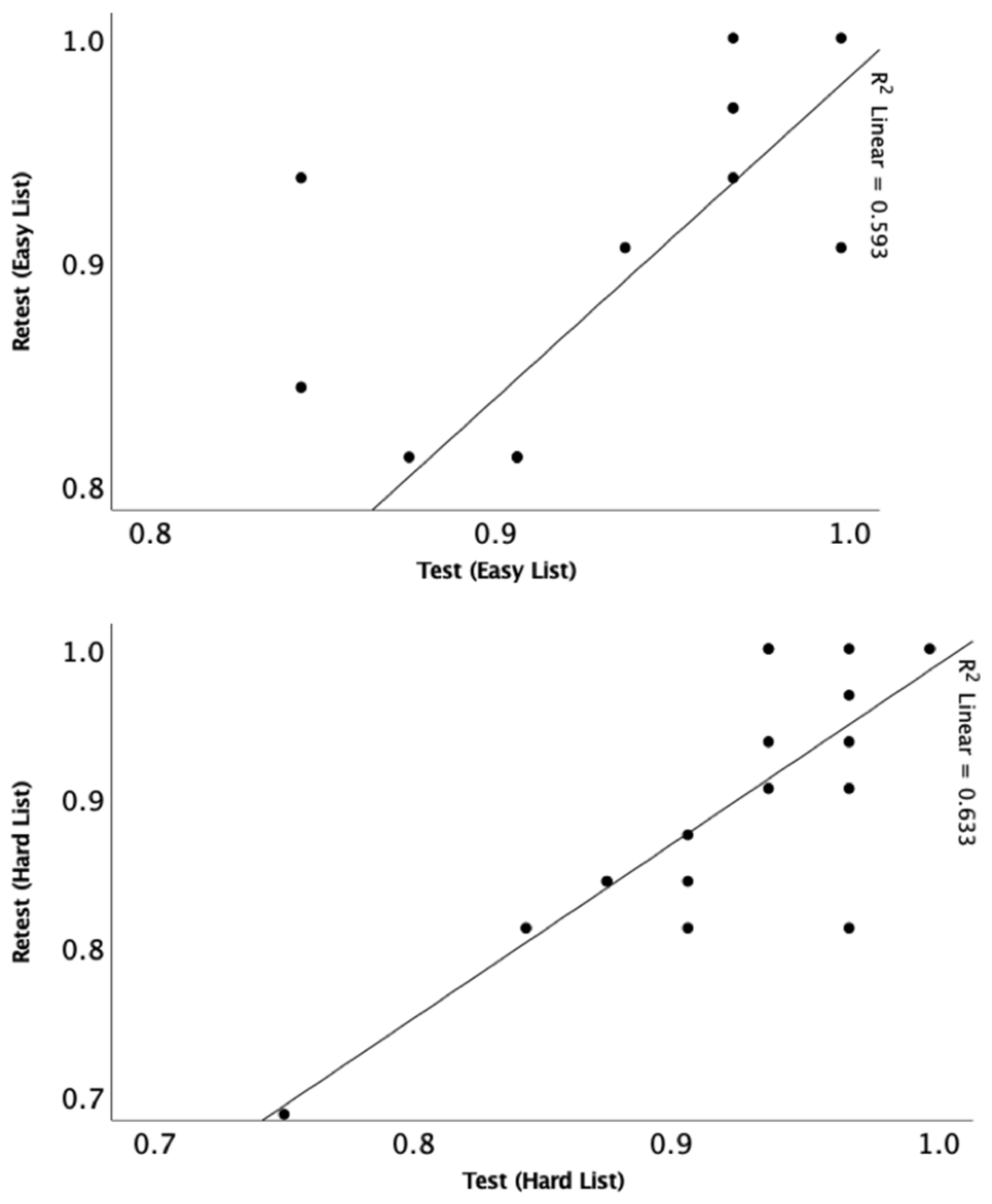
3.4. Test–Retest Reliability and Age Effect
Pearson correlation was conducted to assess test–retest reliability and showed significant correlations at 50-dB SPL for easy (r = 0.77,
p < 0.001) and hard (r = 0.79,
p < 0.001) lists (
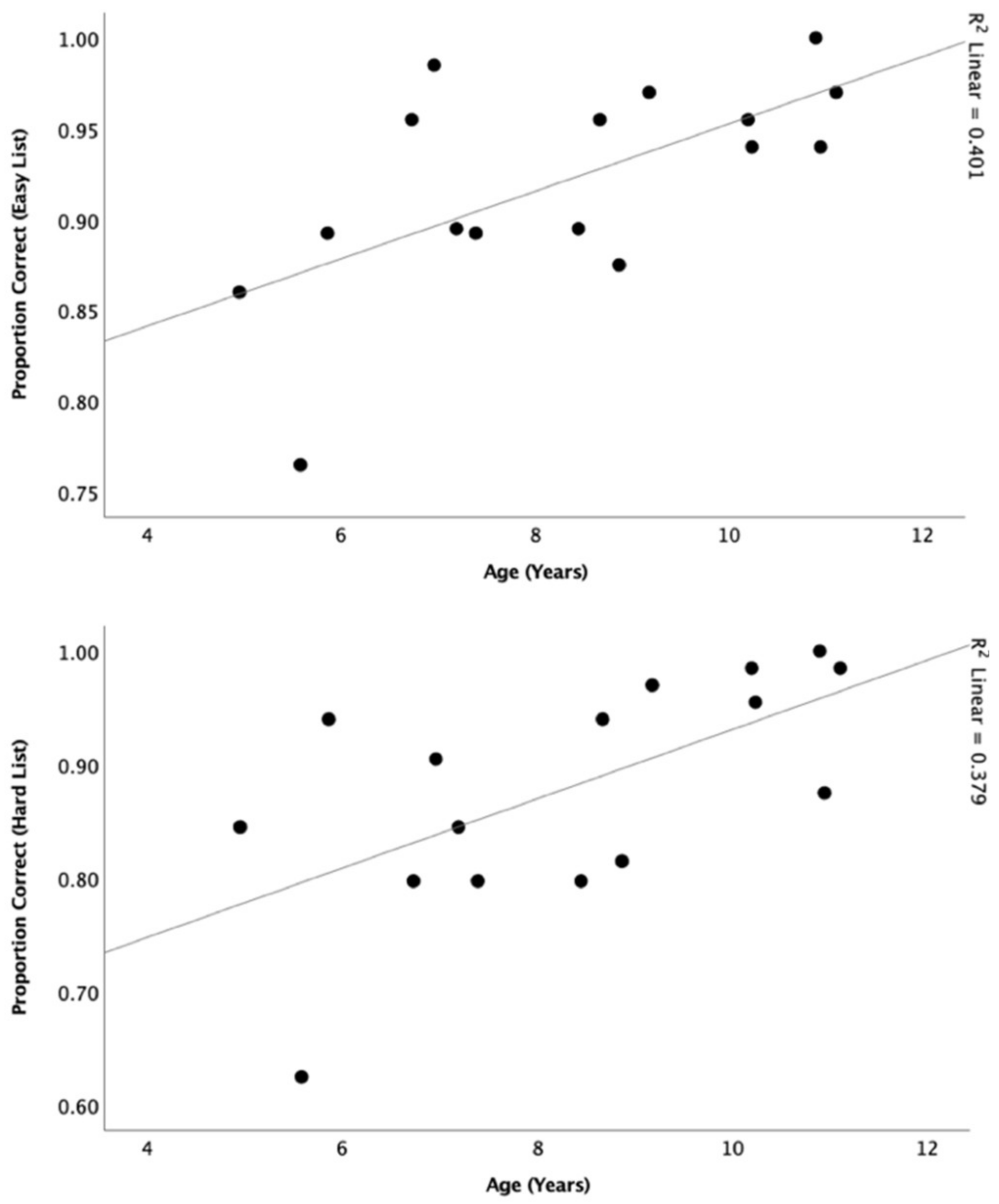
Figure 7). Pearson correlations were also conducted to determine the relationship between participants’ performance and age at 50 dB SPL (
n = 16) (
Figure 8). There was a significant relationship for both the easy list (r = 0.63,
p = 0.01) and hard list (r = 0.62,
p = 0.01).
4. Discussion
A new Arabic monosyllabic closed-set consonant-discrimination test, for use with Arabic-speaking children over the ages of five years has been developed. The main motivation for this research was the lack of materials that can be used with this population to assess their consonant perception skills and monitor changes over time or after an intervention. The new test is an adaptation of the CAPT into Modern Standard Arabic.
Selecting the format of the speech test is key to ensure that the measurement is assessing the desired function in a reliable way [
29,
30]. We therefore decided to use a closed-set format because this makes the task a discrimination task, which is easier for younger children, not reliant upon a child’s ability to produce sounds, and shows how different phonemes are confused. This analytical information can be used to guide fitting to optimise delivery of speech information. The mode of delivery of this test was auditory-only in a quiet environment following the standard approach used for the CAPT [
21]. We chose to adapt the CAPT because it has been shown to be a reliable outcome measure for assessing speech perception in young children and is sensitive to hearing aid gain settings [
22] and differences in the audiogram [
24].
To develop this word discrimination test, the word familiarity and language level was determined to be aligned with recommendations from other authors [
29,
30]. This was done by presenting the selected Arabic words in Modern Standard Arabic to a group of primary-school Saudi Arabian children to assess the familiarity and appropriateness of the words and the clarity of the corresponding pictures. The scores of the children in the development stage were generally very high suggesting that the pictures and words were intelligible for the majority of normal hearing participants. This part of the study was conducted in the UK at the KFA, a Saudi-funded primary school. The children at this school who partook in this experiment were from Saudi Arabia and were exposed to the same type of Modern Standard Arabic as those children who participated in the final phase of the study that was conducted in Saudi Arabia. The only difference between these two groups was the fact that most of the children who participated in the study that was conducted in the UK were bilingual while most of the children who participated in the study conducted in Saudi Arabia were monolingual. Such a difference is not expected to be an issue since all the children were native Arabic speakers who were equally exposed to Modern Standard Arabic.
The above scenario illustrates the benefits of using the formal form of the language with school-aged children when dealing with diglossic languages such as Arabic, Modern Greek, Swiss German, and Haitian Creole. This study showed that despite the existence of various number of dialects within the Saudi-Arabic language, children with different backgrounds were familiar with the materials that were presented in a closed-set format in the formal form of the language and achieved high scores in this test. This may also indicate that the test can be used with Arabic-speaking children in non-Arabic-speaking countries. For example, it has been reported that Arabic is the fastest growing language in the United States [
31]. In addition, providing such tests can minimize the reported lack of materials for assessing speech in children who lives in the UK but speaks languages other than English [
32]. In large cities, it has been reported that the proportion of children who have English as not their first language can be higher than those who have English as the family language [
33].
The final version of the A-CAPT differs slightly from the original CAPT [
21]. The A-CAPT consisted of two lists, one was considered ‘easy’ and one ‘hard’, where each list consisted of eight CGs producing a total of sixteen CGs. The original CAPT [
21] has only one stimulus set consisting of twelve CGs (48 items) which are presented in multiple lists comprised of different presentation orders of the items. For each of list in the A-CAPT the measures were shown to have strong agreement between the test and retest sessions with Pearson correlation values of 0.77 and 0.95 for the easy and hard lists, respectively; these values were similar to the reported value (0.83) in the original CAPT.
The effect of age is a critical element to evaluate when validating a speech perception measure [
29,
30]. There was a significant correlation between the scores on the test and the age of the participants, with older children performing better than younger children. Such trend was expected as older children with normal hearing are reported to have better speech discrimination skills and advanced spectral resolution maturity compared to younger children [
34,
35]. Age accounted for approximately 40% of the variance for both the easy and hard lists. The relationship did not reach a stronger level possibly due to the small sample size (
n = 16) used in this experiment. However, this relationship was stronger than the reported in the original CAPT [
21], which only accounted for 15% of the variance, which was explained by the limited spread of ages of participants used in the CAPT validation [
21].
The critical differences for the two lists can be used to determine whether or not changes in performance of an individual child are significant. The critical difference values reported for the CAPT was 13.7%, which is similar to the critical values that we calculated for the hard list (12%). For the easy list, the average critical difference was larger (18%). These critical difference values indicate that the harder list is a better discriminator when comparing an individual child’s performance in two different conditions
Finally, limitations of the test and study should be noted. Firstly, the sample size in the development of material phase (
n = 26) and lists’ evaluation phase (
n = 16) of this study was smaller than the original CAPT (
n = 55). In addition, the range of ages was wider, where the range of ages in the CAPT was 4–8 years and in the A-CAPT it was 5–11 years. Further work to determine the age ranges for the final version of the A-CAPT needs to be conducted with a larger number of participants at each year. Secondly, the critical differences are larger than would be desired but in a similar region to the CAPT [
21]. This is typical for measures used with young children. It does mean that in an ideal clinical situation that two lists would be conducted to improve the confidence in the scores or at least a short practice list is needed prior to running the actual test. As with all speech measures for children, it means that on the individual level small changes in performance will not be detected. The critical differences were larger at the lower level (40 dB SPL compared to 50 dB SPL), and this is again as expected because the children were being tested at a lower point on the psychometric function closer to their hearing threshold, where greater variability is typically observed. Third, this test is conducted in Modern Standard Arabic, which is not the everyday mother-tongue spoken language by Arabic-speaking children, but rather a formal form used in media and at school. It was selected because the variation in dialects for Saudi Arabic is vast and the Modern Standard Arabic can be considered as a common ground that everyone is exposed to on daily basis, including the selected age group of children.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}