Towards Auditory Profile-Based Hearing-Aid Fitting: Fitting Rationale and Pilot Evaluation

 ,
,  , , and
, , and 
Abstract

1. Introduction
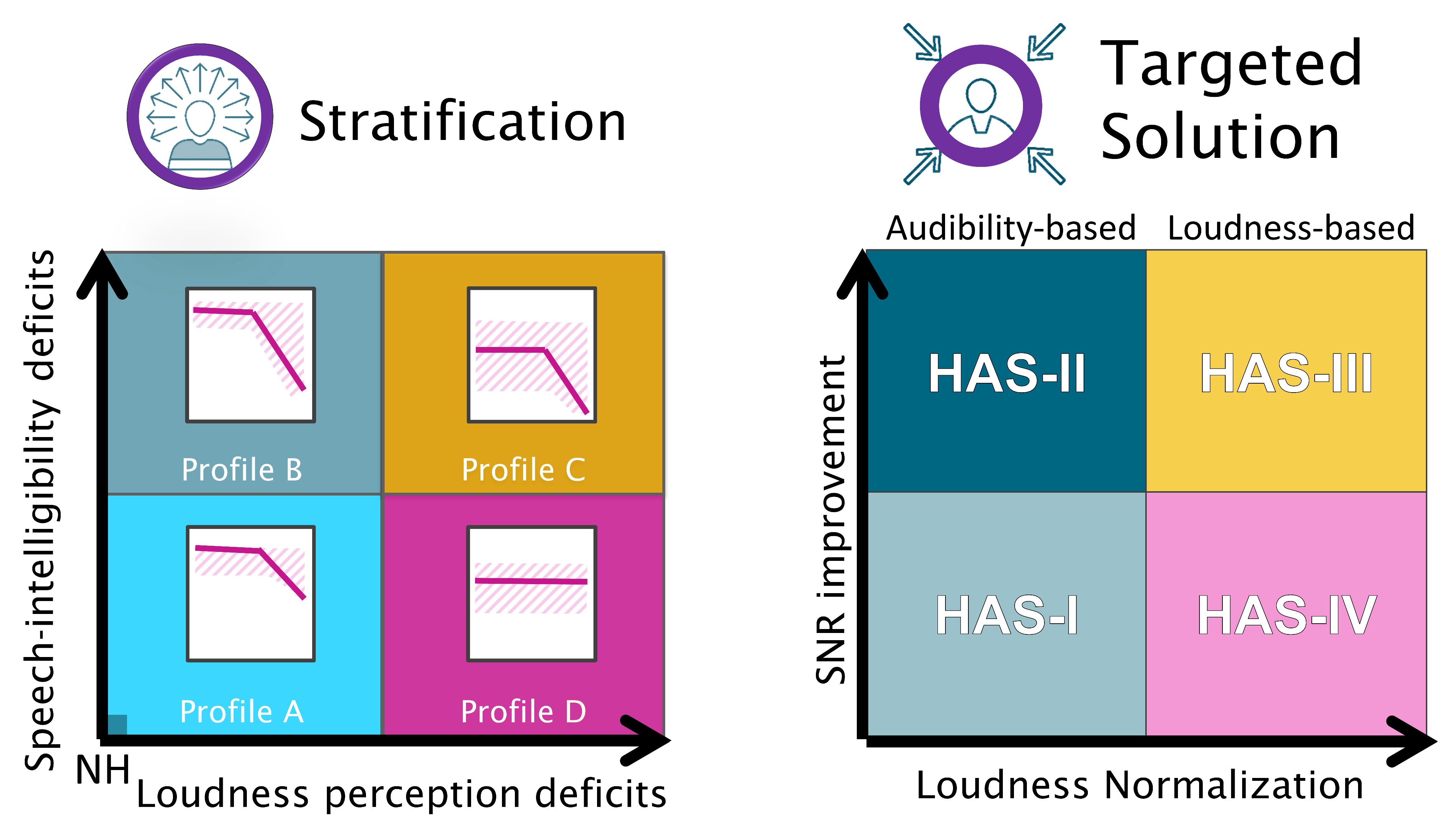
2. Auditory Profile-Based Fitting Rationale
3. Pilot Evaluation
3.1. Candidate Hearing-Aid Settings
3.2. Participants
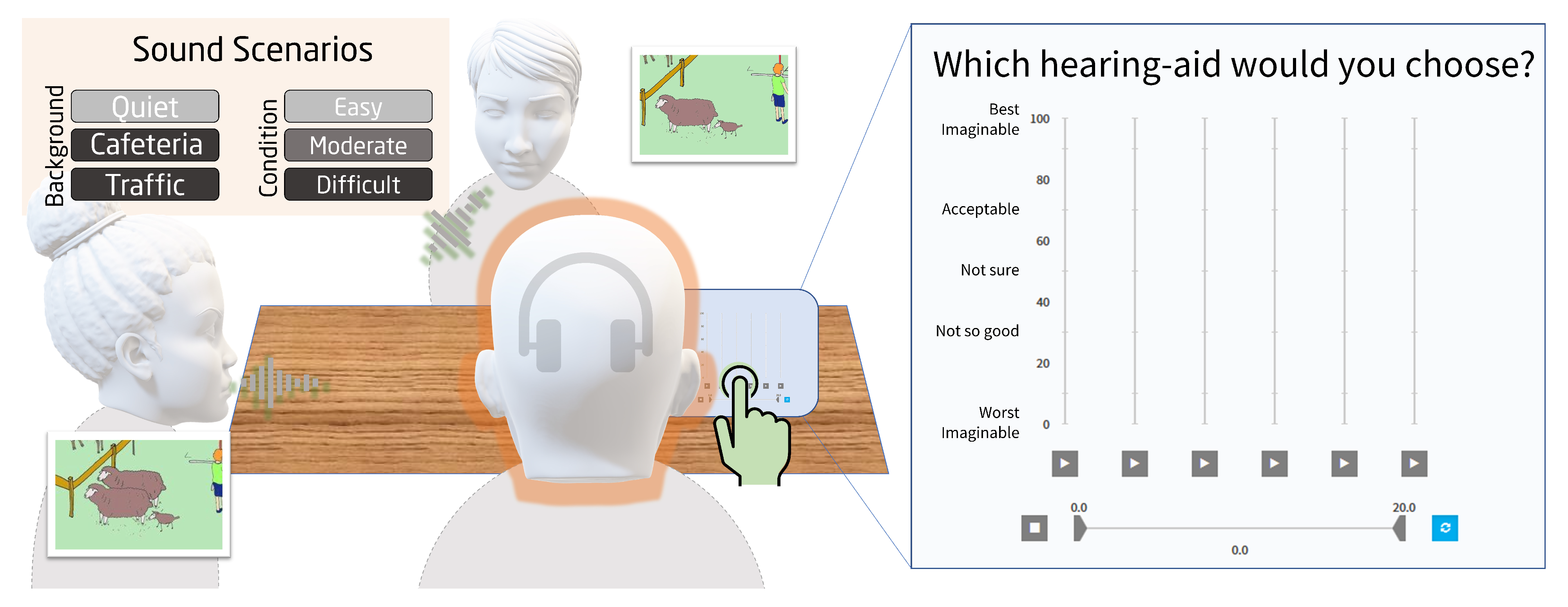
3.3. Experimental Setup and Procedure
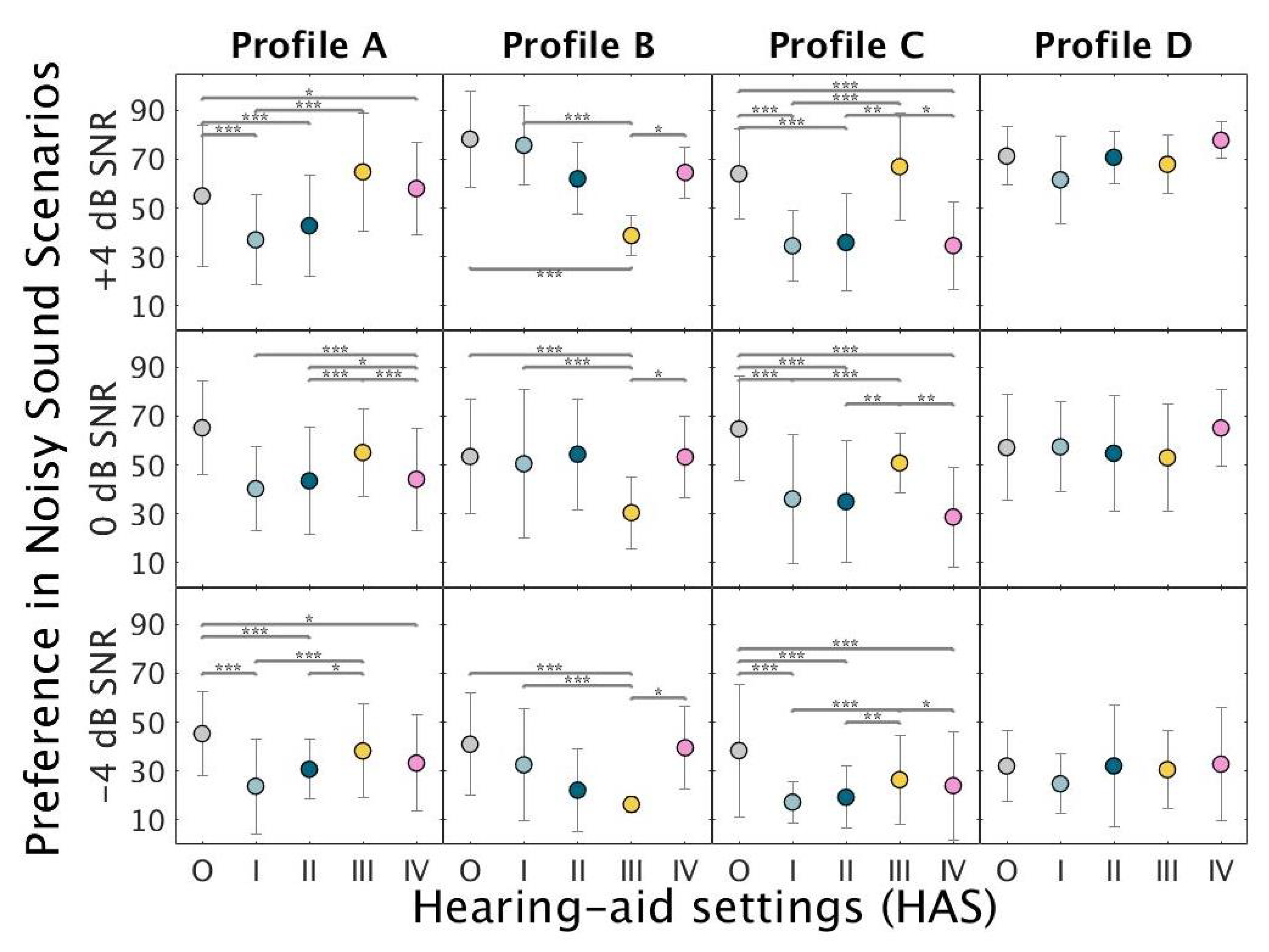
4. Experimental Results
5. Discussion
5.1. Gain Prescription
5.2. Advanced Features
5.3. Acoustic Coupling
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BEAR-LFP | Better hEAring Rehabilitation - Level-Frequency-Profile fitting rule |
| DIR | Directionality |
| HA | Hearing aid |
| HAS | Hearing-aid settings |
| HASIM | Hearing-aid simulator |
| HL | Hearing Level |
| HTL | Hearing thresholds |
| LP | Loudness perception |
| NAL-NL2 | National Acoustic Laboratories—Nonlinear version 2 |
| NR | Noise reduction |
| SI | Speech intelligibility |
| SNR | Signal-to-noise ratio |
| SPL | Sound pressure level |
Appendix A. Linear Mixed Model

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fixed effects | Sum Sq | Mean Sq | NumDF | DenDF | F Value | Pr (>F) |
| Profile | 444.71 | 148.24 | 3.00 | 3.00 | 0.50 | 0.7102 |
| Condition | 112,063.98 | 56,031.99 | 2.00 | 910.00 | 187.55 | <0.0001 |
| Background | 165,740.77 | 82,870.38 | 2.00 | 910.00 | 277.39 | <0.0001 |
| HAS | 24,207.18 | 6051.79 | 4.00 | 910.00 | 20.26 | <0.0001 |
| Profile:HAS | 31,595.01 | 2632.92 | 12.00 | 910.00 | 8.81 | <0.0001 |
| Background:HAS | 11,113.38 | 1389.17 | 8.00 | 910.00 | 4.65 | <0.0001 |
| Random effects | npar | logLik | AIC | LRT | Df | Pr (>Chisq) |
| 33.00 | −4033.15 | 8132.30 | 136.89 | 1 | <0.0001 |
References
- Chung, K. Challenges and recent developments in hearing aids. Part I. Speech understanding in noise, microphone technologies and noise reduction algorithms. Trends Amplif. 2004, 8, 83–124. [Google Scholar] [CrossRef] [PubMed]
- Keidser, G.; Dillon, H.; Flax, M.; Ching, T.; Brewer, S. The NAL-NL2 prescription procedure. Audiol. Res. 2011, 1, 1–3. [Google Scholar] [CrossRef] [PubMed]
- Keidser, G.; Grant, F. Comparing Loudness Normalization (IHAFF) with Speech Intelligibility Maximization (NAL-NL1) when Implemented in a Two-Channel Device. Ear Hear. 2001, 22, 501–515. [Google Scholar] [CrossRef] [PubMed]
- Oetting, D.; Hohmann, V.; Appell, J.E.; Kollmeier, B.; Ewert, S.D. Restoring Perceived Loudness for Listeners With Hearing Loss. Ear Hear. 2018. [Google Scholar] [CrossRef]
- Henry, K.S.; Sayles, M.; Hickox, A.E.; Heinz, M.G. Divergent Auditory Nerve Encoding Deficits Between Two Common Etiologies of Sensorineural Hearing Loss. J. Neurosci. 2019, 39, 6879–6887. [Google Scholar] [CrossRef]
- Neher, T.; Wagener, K.C.; Fischer, R.L. Directional Processing and Noise Reduction in Hearing Aids: Individual and Situational Influences on Preferred Setting. J. Am. Acad. Audiol. 2016, 27, 628–646. [Google Scholar] [CrossRef]
- Sanchez-Lopez, R.; Fereczkowski, M.; Neher, T.; Santurette, S.; Dau, T. Robust Data-driven Auditory Profiling Towards Precision Audiology. Trends Hear. 2020, 24. [Google Scholar] [CrossRef]
- Sanchez-Lopez, R.; Nielsen, S.; El-Haj-Ali, M.; Bianchi, F.; Fereckzowski, M.; Cañete, O.; Wu, M.; Neher, T.; Dau, T.; Santurette, S. Auditory tests for characterizing hearing deficits: The BEAR test battery. medRxiv 2020. [Google Scholar] [CrossRef]
- Trusheim, M.R.; Berndt, E.R.; Douglas, F.L. Stratified medicine: Strategic and economic implications of combining drugs and clinical biomarkers. Nat. Rev. Drug Discov. 2007, 6, 287–293. [Google Scholar] [CrossRef]
- Ching, T.Y.C.; Dillon, H.; Katsch, R.; Byrne, D. Maximizing Effective Audibility in Hearing Aid Fitting. Ear Hear. 2001, 22, 212–224. [Google Scholar] [CrossRef]
- Kowalewski, B.; Zaar, J.; Fereczkowski, M.; MacDonald, E.N.; Strelcyk, O.; May, T.; Dau, T. Effects of Slow- and Fast-Acting Compression on Hearing-Impaired Listeners’ Consonant—Vowel Identification in Interrupted Noise. Trends Hear. 2018, 22. [Google Scholar] [CrossRef] [PubMed]
- Sanchez-Lopez, R.; Fereczkowski, M.; Bianchi, F.; Piechowiak, T.; Hau, O.; Pedersen, M.S.; Behrens, T.; Neher, T.; Dau, T.; Santurette, S. Technical evaluation of hearing-aid fitting parameters for different auditory profiles. In Proceedings of the Euronoise 2018, 11th European Congress and Exposition on Noise Control Engineering, Heraklion, Greece, 27–31 May 2018; pp. 381–388. [Google Scholar]
- Sørensen, A.J.; Fereczkowski, M.; MacDonald, E.N. Task Dialog by Native-Danish Talkers in Danish and English in Both Quiet and Noise. 2018. Available online: https://doi.org/10.5281/zenodo.1204951 (accessed on 15 January 2021).
- Baker, R.; Hazan, V. DiapixUK: Task materials for the elicitation of multiple spontaneous speech dialogs. Behav. Res. Methods 2011, 43, 761–770. [Google Scholar] [CrossRef] [PubMed]
- SenseLab. SenseLabOnline: Listening Test Software (Version 4.0.2). Listening Test Software; Browser-Based Software; Force Technology: Hørsholm, Denmark, 2017. [Google Scholar]
- Zacharov, N. Sensory Evaluation of Sound; CRC Press LLC: Boca Raton, FL, USA, 2018. [Google Scholar] [CrossRef]
- Gatehouse, S.; Naylor, G.; Elberling, C. Linear and nonlinear hearing aid fittings—1. Patterns of benefit. Int. J. Audiol. 2006, 45, 130–152. [Google Scholar] [CrossRef] [PubMed]
- Gatehouse, S.; Naylor, G.; Elberling, C. Linear and nonlinear hearing aid fittings—2. Patterns of candidature. Int. J. Audiol. 2006, 45, 153–171. [Google Scholar] [CrossRef]
- Keidser, G.; Brew, C.; Brewer, S.; Dillon, H.; Grant, F.; Storey, L. The preferred response slopes and two-channel compression ratios in twenty listening conditions by hearing-impaired and normal-hearing listeners and their relationship to the acoustic input. Int. J. Audiol. 2005, 44, 656–670. [Google Scholar] [CrossRef]
- Neher, T.; Wagener, K.C. Investigating Differences in Preferred Noise Reduction Strength Among Hearing Aid Users. Trends Hear. 2016, 20. [Google Scholar] [CrossRef]
- Kates, J.M. Modeling the effects of single-microphone noise-suppression. Speech Commun. 2017, 90, 15–25. [Google Scholar] [CrossRef]
- Wu, M.; Sanchez-Lopez, R.; El-Haj-Ali, M.; Nielsen, S.G.; Fereczkowski, M.; Dau, T.; Santurette, S.; Neher, T. Investigating the Effects of Four Auditory Profiles on Speech Recognition, Overall Quality, and Noise Annoyance with Simulated Hearing-Aid Processing Strategies. Trends Hear. 2020, 24. [Google Scholar] [CrossRef]
- Keidser, G.; Carter, L.; Chalupper, J.; Dillon, H. Effect of low-frequency gain and venting effects on the benefit derived from directionality and noise reduction in hearing aids. Int. J. Audiol. 2007, 46, 554–568. [Google Scholar] [CrossRef]
- Agnew, J. Acoustic Feedback and Other Audible Artifacts in Hearing Aids. Trends Amplif. 1996, 1, 45–82. [Google Scholar] [CrossRef] [PubMed]
- Winkler, A.; Latzel, M.; Holube, I. Open Versus Closed Hearing-Aid Fittings: A Literature Review of Both Fitting Approaches. Trends Hear. 2016, 20. [Google Scholar] [CrossRef] [PubMed]




| Insertion Gain | ||||||
|---|---|---|---|---|---|---|
| HAS-I | 250 Hz | 500 Hz | 1 kHz | 2 kHz | 4 kHz | >6 kHz |
| Target 50 | - | - | + 3 | + 7 | + 7 | + 5 |
| Target 65 | - | - | −2 | 0 | 0 | 0 |
| Target 80 | - | - | −5 | −5 | −5 | −5 |
| HAS-II | 250 Hz | 500 Hz | 1 kHz | 2 kHz | 4 kHz | >6 kHz |
| Target 50 | −3 | −3 | + 3 | + 7 | + 7 | + 10 |
| Target 65 | −3 | −3 | −2 | 0 | 0 | 0 |
| Target 80 | −6 | −6 | −9 | −9 | −9 | −9 |
| HAS-III | 250 Hz | 500 Hz | 1 kHz | 2 kHz | 4 kHz | >6 kHz |
| Target 50 | + 2 | + 3 | + 4 | + 6 | + 10 | + 10 |
| Target 65 | −10 | −10 | −5 | 0 | 0 | 0 |
| Target 80 | −14 | −14 | −14 | −14 | −14 | −14 |
| HAS-IV | 250 Hz | 500 Hz | 1 kHz | 2 kHz | 4 kHz | >6 kHz |
| Target 50 | + 2 | + 3 | + 4 | + 6 | + 5 | + 5 |
| Target 65 | −6 | −6 | −6 | −3 | −3 | −3 |
| Target 80 | −10 | −10 | −10 | −10 | −14 | −14 |
| HAS | Anchor | HAS-O | HAS-I | HAS-II | HAS-III | HAS-IV |
|---|---|---|---|---|---|---|
| DIR setting | Omni | Cardioid | Omni | Cardioid | Cardioid | Omni |
| NR (dB) | 15 * | 5 | Off | 9 | 9 | Off |
| Attack time (ms) | 5 | 250 | 5 | 5 | 5 | 5 |
| Release time (ms) | 10 | 1250 | 40 | 40 | 1250 | 1250 |
| SNR improvement (dB) | 0 | 2 | 0 | 2.5 | 2.5 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sanchez-Lopez, R.; Fereczkowski, M.; Santurette, S.; Dau, T.; Neher, T. Towards Auditory Profile-Based Hearing-Aid Fitting: Fitting Rationale and Pilot Evaluation. Audiol. Res. 2021, 11, 10-21. https://doi.org/10.3390/audiolres11010002
Sanchez-Lopez R, Fereczkowski M, Santurette S, Dau T, Neher T. Towards Auditory Profile-Based Hearing-Aid Fitting: Fitting Rationale and Pilot Evaluation. Audiology Research. 2021; 11(1):10-21. https://doi.org/10.3390/audiolres11010002
Chicago/Turabian StyleSanchez-Lopez, Raul, Michal Fereczkowski, Sébastien Santurette, Torsten Dau, and Tobias Neher. 2021. "Towards Auditory Profile-Based Hearing-Aid Fitting: Fitting Rationale and Pilot Evaluation" Audiology Research 11, no. 1: 10-21. https://doi.org/10.3390/audiolres11010002
APA StyleSanchez-Lopez, R., Fereczkowski, M., Santurette, S., Dau, T., & Neher, T. (2021). Towards Auditory Profile-Based Hearing-Aid Fitting: Fitting Rationale and Pilot Evaluation. Audiology Research, 11(1), 10-21. https://doi.org/10.3390/audiolres11010002