A Flexible Object-of-Interest Annotation Framework for Online Video Portals

Abstract
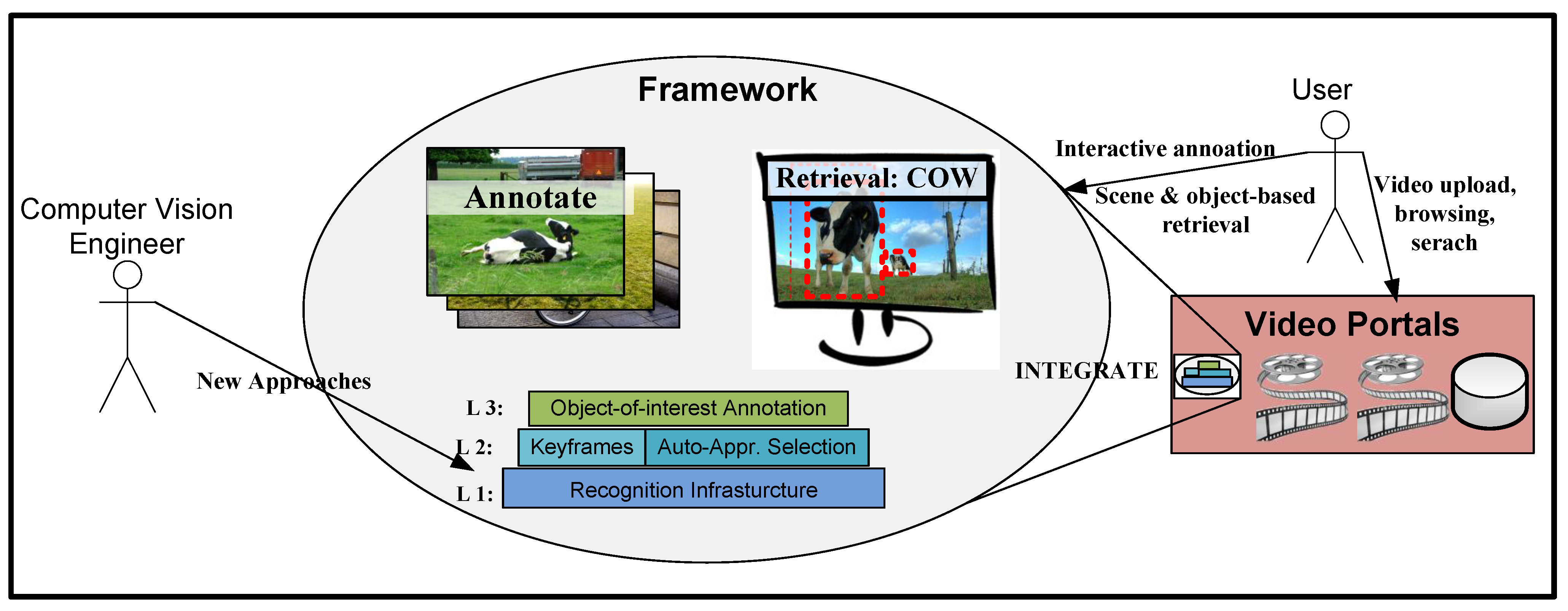
:1. Introduction
2. Related Work
2.1. Content-Based Annotation and Retrieval
2.2. Object Recognition
2.3. Recognition Infrastructures
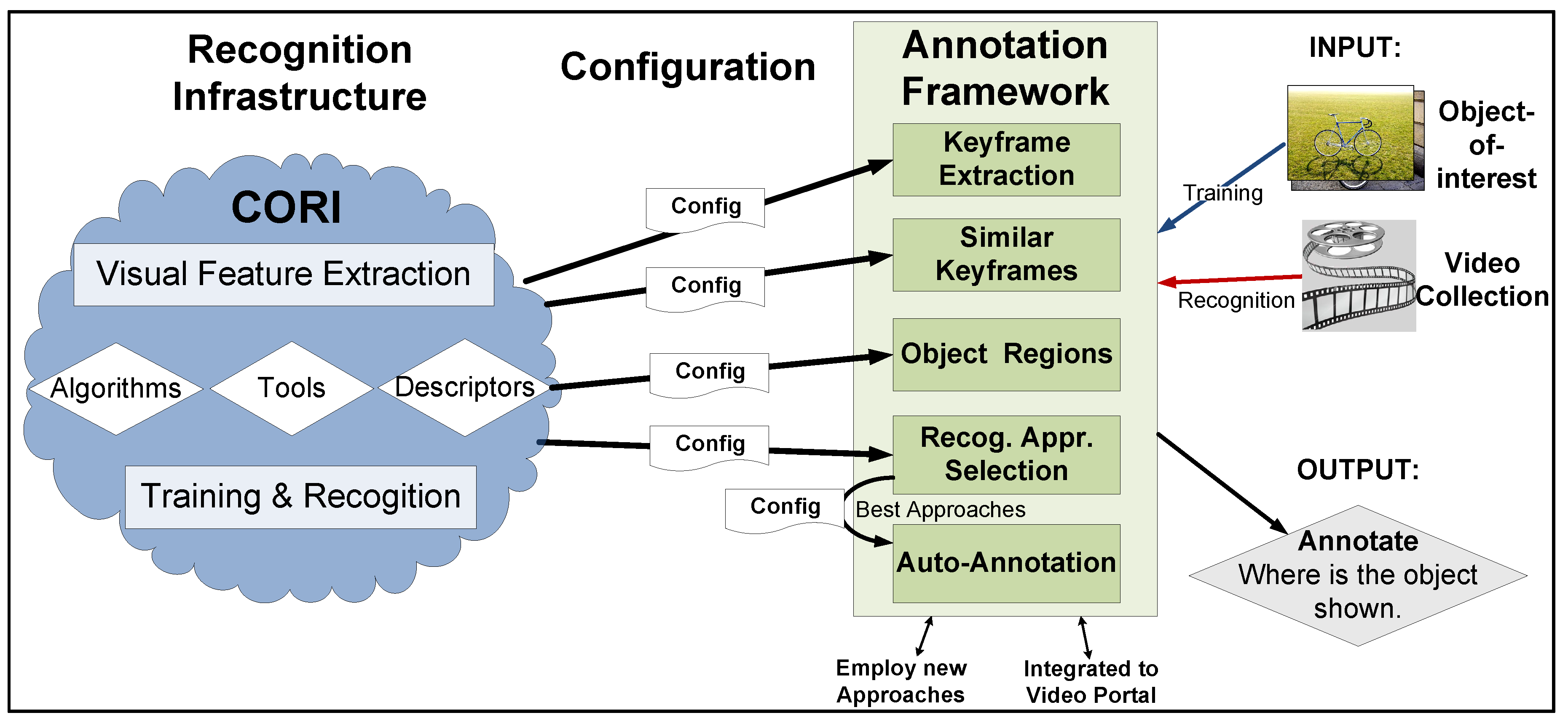
3. Object-of-Interest Annotation
3.1. Video Pre-Processing
| Algorithm 1 Keyframe Selection |
| Input: |
| vector<keyframe> = every 10th frame of the shot |
| float = threshold of last shot |
| Output: |
| vector<keyframe> |
| repeat |
| .clear() |
| for all f in do |
| boolean = false |
| for all k in do |
| if EuclidianDistance( globalSIFT(f), globalSIFT(k) ) then |
| = true |
| end if |
| end for |
| if == false then |
| .add(f) |
| end if |
| end for |
| if .size() then |
| = * 1.25 |
| else |
| = * 0.95 |
| end if |
| until .size() |
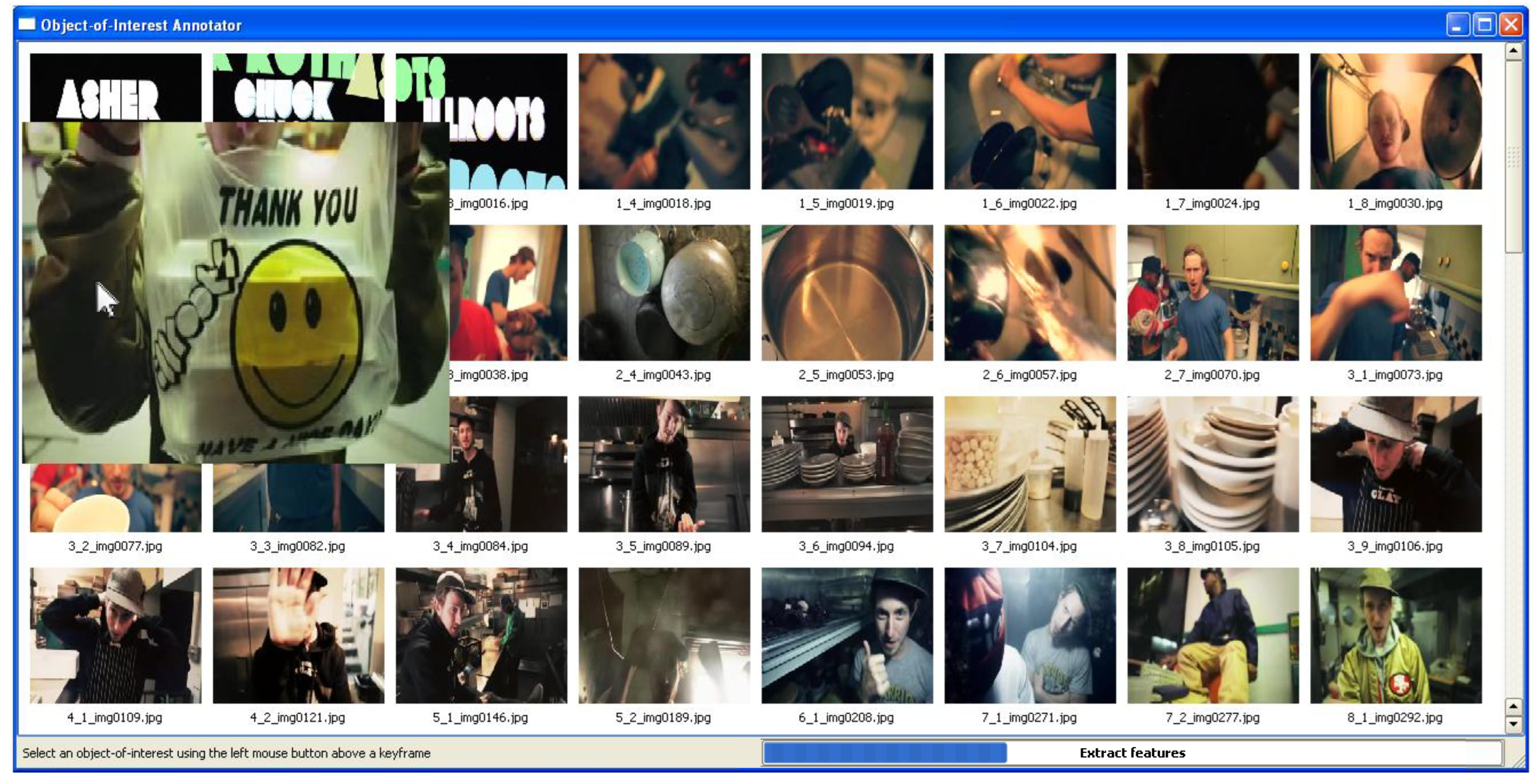
3.2. Object Specification
| Algorithm 2 Suggest similar keyframes |
| Input: |
| vector<features> = features of the selected keyframe |
| vector<features> = features from keyframes without the object |
| integer = video id of the selected keyframe |
| integer = id of the selected keyframe |
| Output: |
| vector<keyframe> |
| for to numberOfKeyframes( ) do |
| = loadFeatures( + i ) |
| = nearestNeighbour( , ) |
| = nearestNeighbour( , ) |
| if and then |
| .add( + i ) |
| end if |
| if then |
| end if |
| end for |
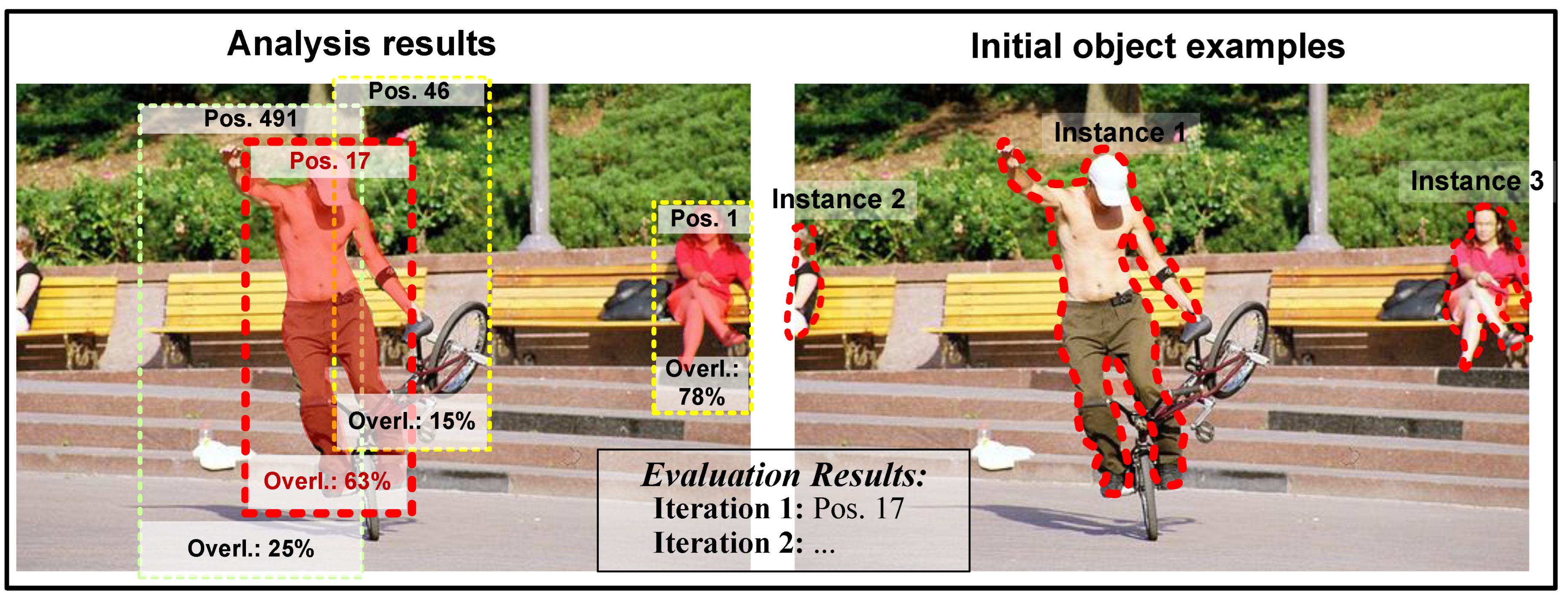
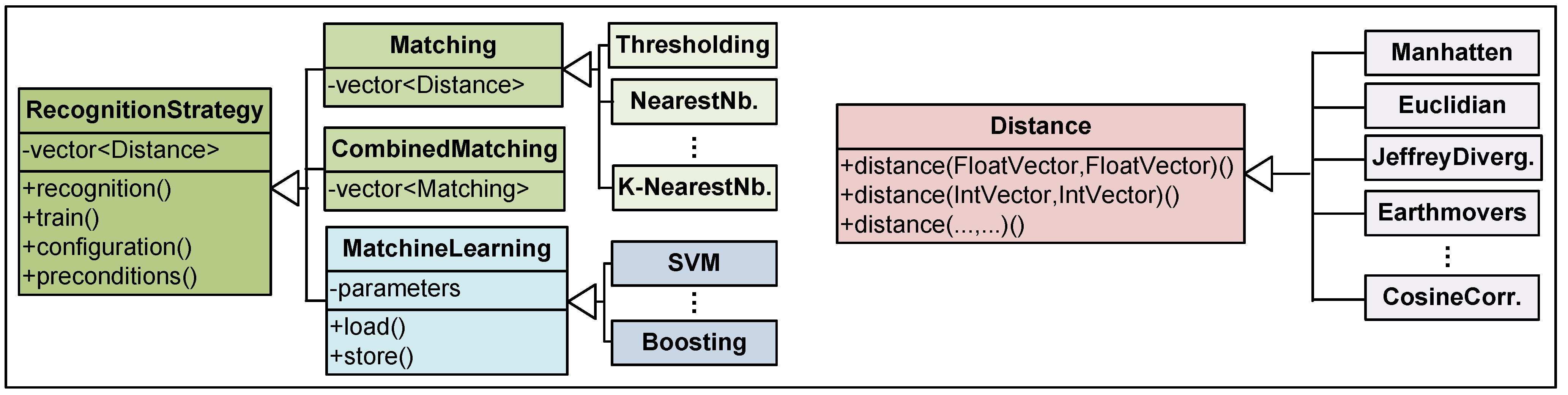
3.3. Recognition Approach Selection
| Algorithm 3 Recognition Approach Selection |
| Input: |
| vector<recognition approach> = recognition approaches to investigate |
| vector<instance> = the initially selected object instances |
| vector<keyframe> = videos to annotate |
| Output: |
| vector<instance> |
| for all a in do |
| vector<features> |
| for all in do |
| if .positiveExample() is false then |
| continue |
| end if |
| = - |
| = + |
| = analysis( , ) |
| = evaluate( , ) |
| .add( ) |
| .add( ) |
| end for |
| .add( fusion( ) ) |
| end for |
| vector<setup> = selectBest( ) |
| = fusion( , ) |
3.4. Automatic Annotation
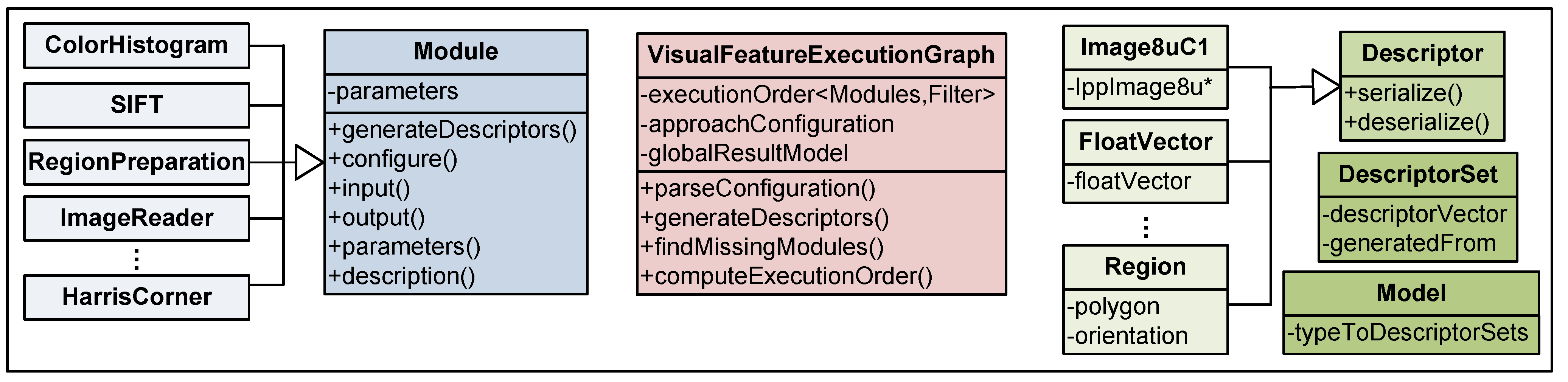
4. Recognition Infrastructure
| Listing 1. Configuration of visual feature extraction (left) and recognition (right). |
 |
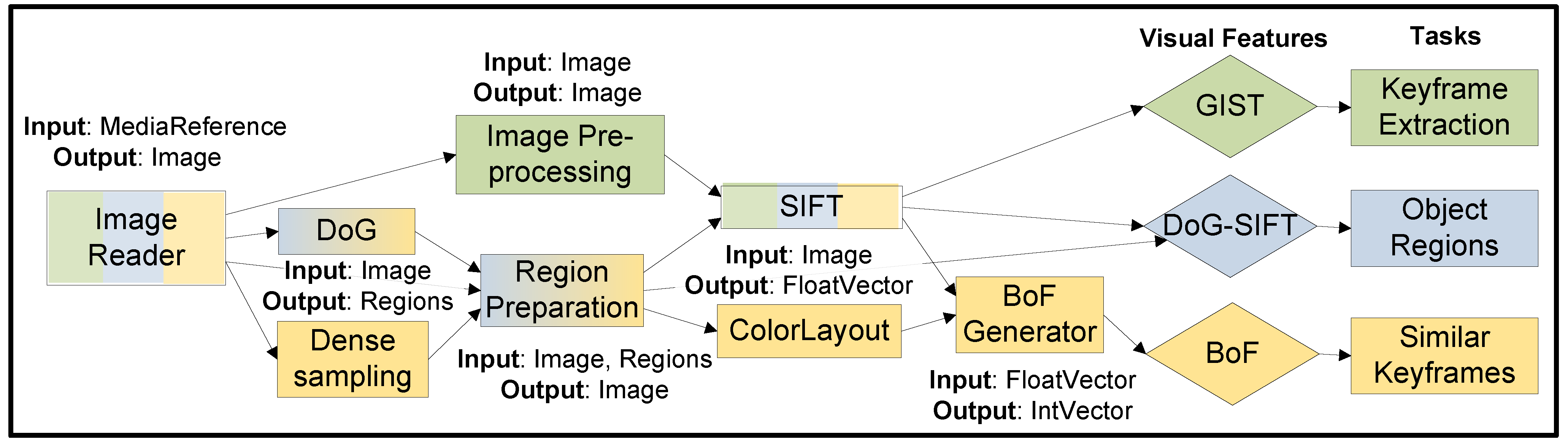
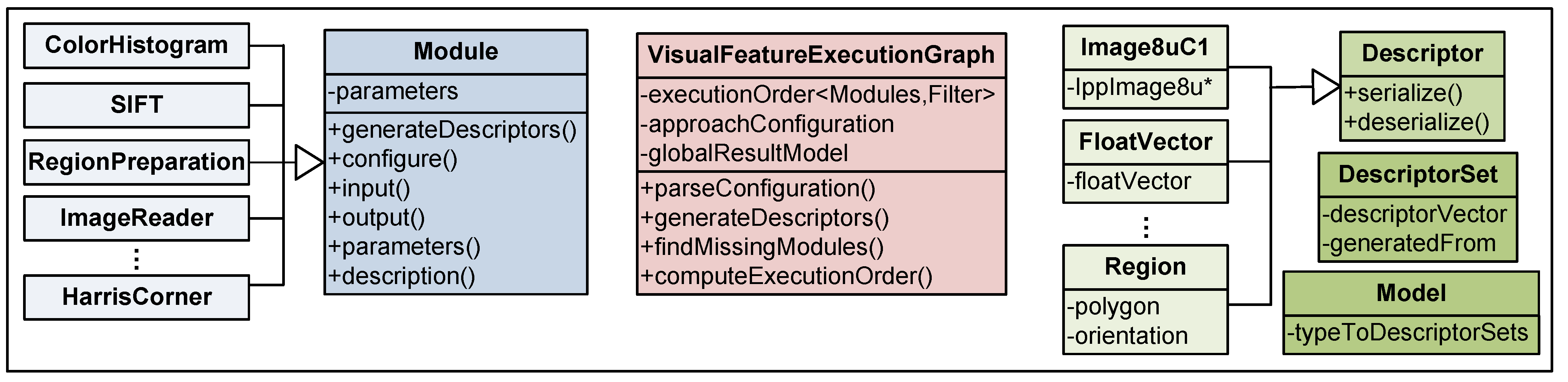
4.1. Visual Feature Extraction
4.2. Training and Recognition
4.3. Integration in Video Portals
5. Experiments
5.1. Annotation Prototype
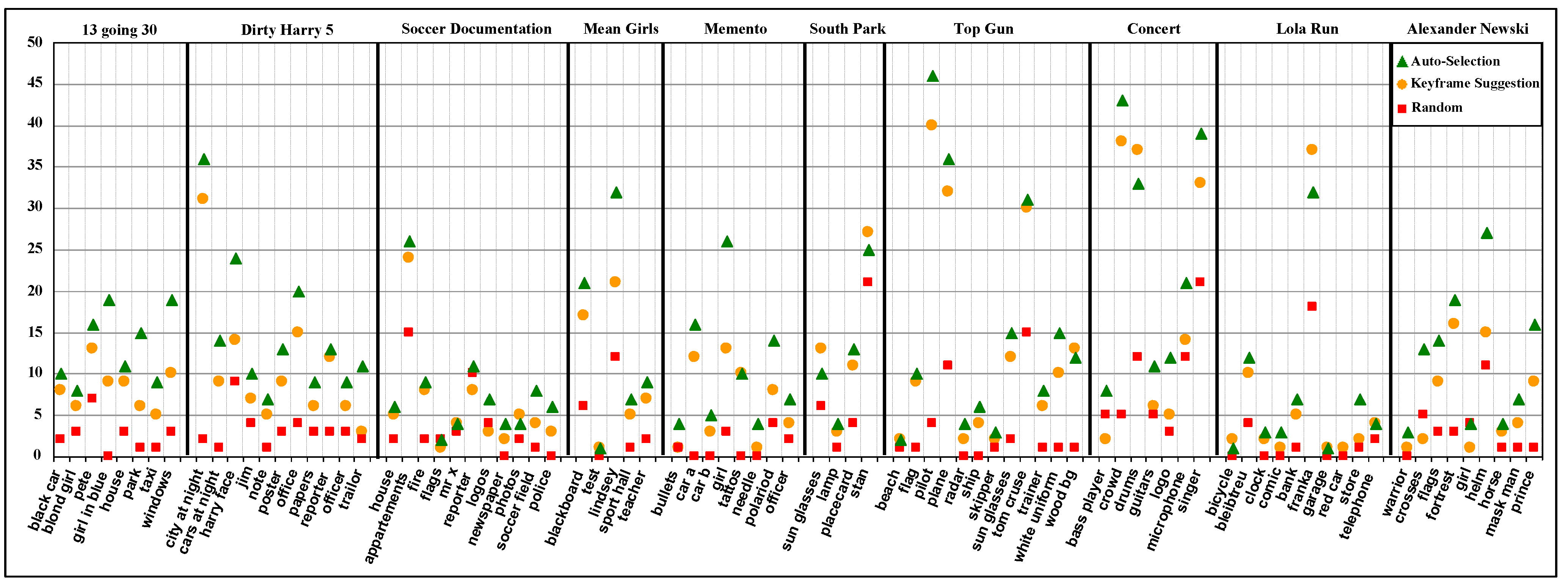
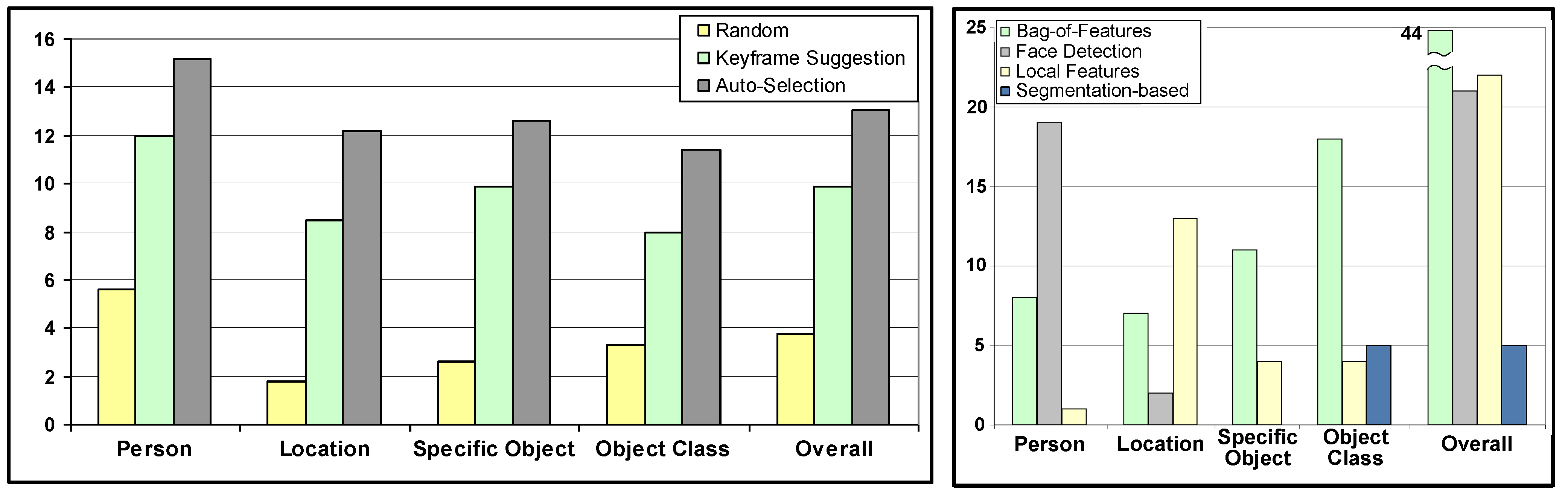
5.2. Case Study
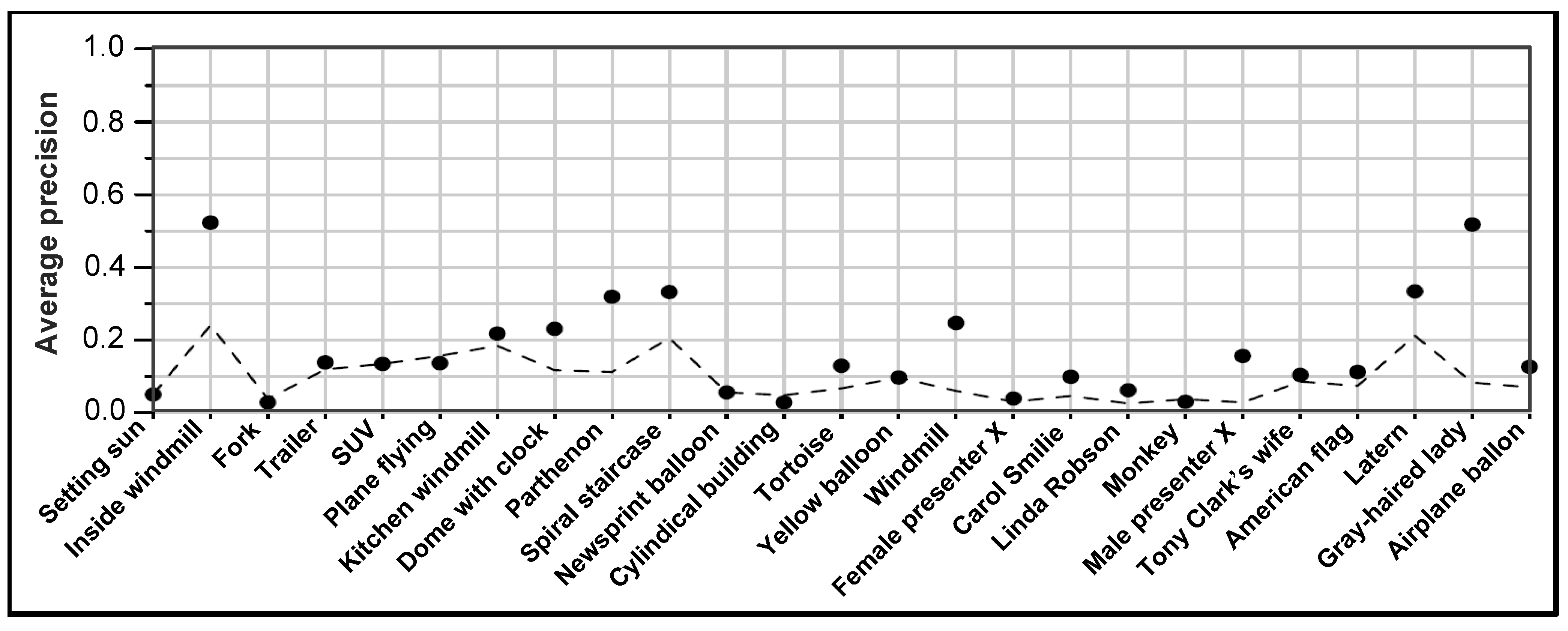
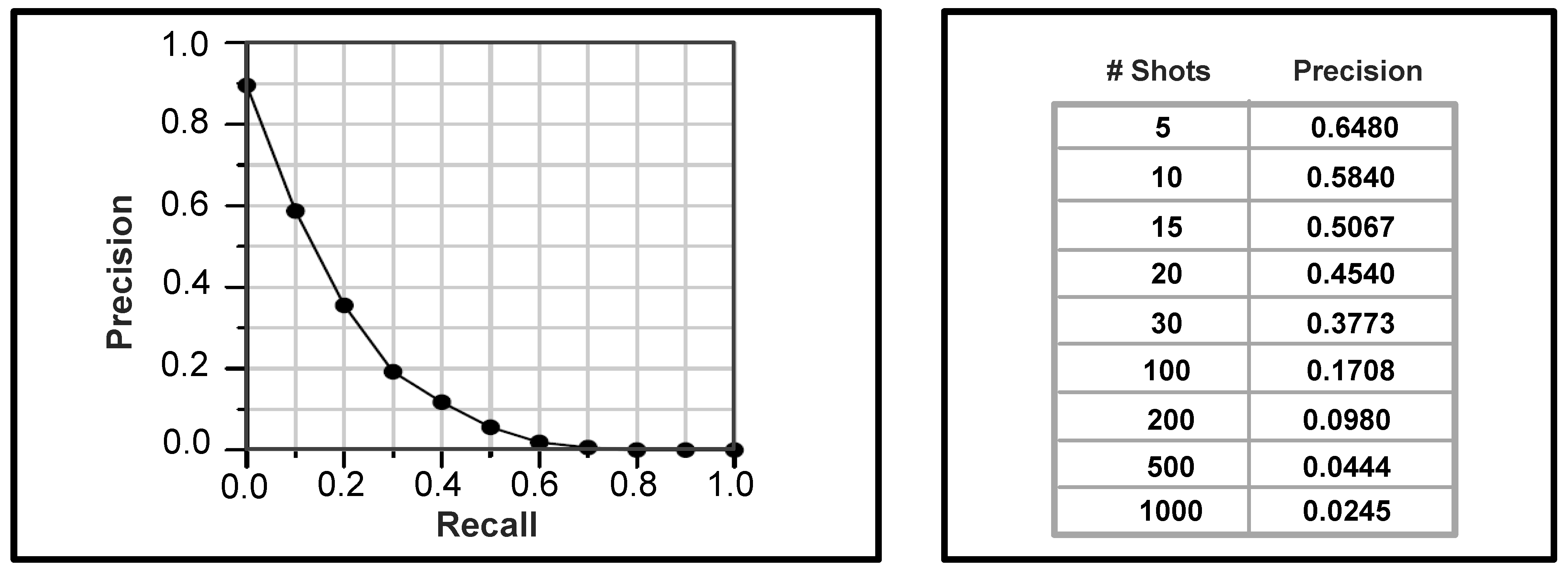
5.3. TRECVID
5.4. Discussion
6. Conclusions and Future Work
Acknowledgments
References
- Cheng, X.; Lai, K.; Wang, D.; Liu, J. UGC video sharing: Measurement and analysis. Intell. Multimed. Commmun. Tech. Appl. 2010, 280/2010, 367–402. [Google Scholar]
- YouTube. Available online: www.youtube.com (accessed on 21 February 2012).
- YouKo. Available online: www.youku.com (accessed on 21 February 2012).
- Vimeo. Available online: www.vimeo.com (accessed on 21 February 2012).
- Hulu. Available online: www.hulu.com (accessed on 21 February 2012).
- Metacafe. Available online: www.metacafe.com (accessed on 21 February 2012).
- Alexia. Available online: http://www.alexa.com (accessed on 21 February 2012).
- Snoek, C.; Worring, M. A State-of-the-Art Review on Multimodal Video Indexing. In Proceedings of the Conference of the Advanced School for Computing and Imaging, Heijen, The Netherlands, 30 May–1 June 2001; Volume 24. [Google Scholar]
- Rowe, L.; Boreczky, J.; Eads, C. Indexes for user access to large video databases. Storage Retr. Image Video Database II 1994, 2185, 150–161. [Google Scholar]
- Weber, J.; Lefevre, S.; Gancarski, P. Video Object Mining: Issues and Perspectives. In Proceedings of the International Conference on Semantic Computing, Pittsburgh, PA, USA, 22–24 September 2010; pp. 85–90. [Google Scholar]
- Bolle, R.; Yeo, B.; Yeung, M. Video query: Research directions. IBM J. Res. Dev. 1998, 42, 233–252. [Google Scholar] [CrossRef]
- Netflix. Available online: www.netflix.com (accessed on 21 February 2012).
- Yamamoto, D.; Masuda, T.; Ohira, S.; Nagao, K. Collaborative Video Scene Annotation Based on Tag Cloud. In Proceedings of the Advances in Multimedia Information Processing (PCM ’08), Tainan, Taiwan, December 2008; pp. 397–406. [Google Scholar]
- Wakamiya, S.; Kitayama, D.; Sumiya, K. Scene extraction system for video clips using attached comment interval and pointing region. Multimed. Tools Appl. 2011, 54, 7–25. [Google Scholar] [CrossRef]
- Ulges, A.; Schulze, C.; Keysers, D.; Breuel, T. Identifying Relevant Frames in Weakly Labeled Videos for Training Concept Detectors. In Proceedings of the International Conference on Content-Based Image and Video Retrieval, Niagara Falls, Canada, 7–9 July 2008; pp. 9–16. [Google Scholar]
- Davidson, J.; Liebald, B.; Liu, J.; Nandy, P.; Van Vleet, T.; Gargi, U.; Gupta, S.; He, Y.; Lambert, M.; Livingston, B. The YouTube Video Recommendation System. In Proceedings of the Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 293–296. [Google Scholar]
- Li, Z.; Gu, R.; Xie, G. Measuring and Enhancing the Social Connectivity of UGC Video Systems: A Case Study of YouKu. In Proceedings of the 19th International Workshop on Quality of Service, San Jose, CA, USA, 6–7 June 2011; pp. 1–9. [Google Scholar]
- Cheng, X.; Dale, C.; Liu, J. Statistics and Social Network of Youtube Videos. In Proceedings of the 16th International Workshop on Quality of Service (IWQoS ’08), Enskede, The Netherlands, 2–4 June 2008; pp. 229–238. [Google Scholar]
- Lai, K.; Wang, D. Towards Understanding the External Links of Video Sharing Sites: Measurement and Analysis. In Proceedings of the 20th International Workshop on Network and Operating Systems Support for Digital Audio and Video, Amsterdam, The Netherlands, 2–4 June 2010; pp. 69–74. [Google Scholar]
- Hu, W.; Xie, N.; Li, L.; Zeng, X.; Maybank, S. A survey on visual content-based video indexing and retrieval. Trans. Syst. Man Cybern. Part C Appl. Rev. 2011, 41, 797–819. [Google Scholar]
- Gupta, S.; Gupta, N.; Sahu, S. Object based video retrieval using SIFT. Int. J. Electron. Commun. Comput. Eng. 2011, 1, 1–4. [Google Scholar]
- Zavřel, V.; Batko, M.; Zezula, P. Visual Video Retrieval System Using MPEG-7 Descriptors. In Proceedings of the International Conference on SImilarity Search and Applications, Istanbul, Turkey, 18–19 September 2010; pp. 125–126. [Google Scholar]
- Sekura, A.; Toda, M. Video Retrieval System Using Handwriting Sketch. In Proceedings of the Conference on Machine Vision Applications, Yokohama, Japan, 20–22 May 2009. [Google Scholar]
- Zha, Z.; Yang, L.; Mei, T.; Wang, M.; Wang, Z. Visual Query Suggestion. In Proceedings of the ACM Multimedia, Vancouver, Canada, 19–24 October 2009; pp. 15–24. [Google Scholar]
- Datta, R.; Joshi, D.; Li, J.; Wang, J. Image retrieval: Ideas, influences, and trends of the New Age. ACM Comput. Surv. 2008, 40, 1–60. [Google Scholar] [CrossRef]
- Geisler, G.; Burns, S. Tagging video: Conventions and strategies of the YouTube community. In Proceedings of the Conference on Digital Libraries, Vancouver, Canada, 18–23 June 2007; pp. 480–480. [Google Scholar]
- Ames, M.; Naaman, M. Why We Tag: Motivations for Annotation in Mobile and Online Media. In Proceedings of the Conference on Human Factors in Computing Systems, San Jose, CA, USA, 28 April–3 May 2007; pp. 971–980. [Google Scholar]
- Marlow, C.; Naaman, M.; Boyd, D.; Davis, M. HT06, Tagging Paper, Taxonomy, Flickr, Academic Article, to Read. In Proceedings of the Conference on Hypertext and Hypermedia, Odense, Denmark, 22–25 August 2006; pp. 31–40. [Google Scholar]
- Flickr. Available online: www.flickr.com (accessed on 21 February 2012).
- Delicious. Available online: delicious.com (accessed on 21 February 2012).
- Thaler, S.; Siorpaes, K.; Simperl, E.; Hofer, C. A Survey on Games for Knowledge Acquisition. Available online: http://www.sti-innsbruck.at/fileadmin/documents/technical_report/A-survey-on-games-for-knowledge-acquisition.pdf (accessed on 21 February 2012).
- Eidenberger, H. The Common Methods of Audio Retrieval, Biosignal processing, Content-Based Image Retrieval, Face recognition, Genome Analysis, Music Genre Classification, Speech Recognition, Technical Stock Analysis, Text Retrieval and Video Surveillance. In Fundamental Media Understanding; atpress: Vienna, VA, USA, 2011. [Google Scholar]
- Flickner, M.; Sawhney, H.; Niblack, W.; Ashley, J.; Huang, Q.; Dom, B.; Gorkani, M.; Hafner, J.; Lee, D.; Petkovic, D.; Steele, D.; Yanker, P. Query by image and video content: The QBIC system. IEEE Comput. 1995, 28, 23–32. [Google Scholar] [CrossRef]
- Dyana, A.; Das, S. MST-CSS (Multi-Spectro-Temporal Curvature Scale Space), a novel spatio-temporal representation for content-based video retrieval. Trans. Circuits Syst. Video Technol. 2010, 20, 1080–1094. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Lu, J.; Lim, R.; Wang, J. Video Analysis and Trajectory Based Video Annotation System. In Proceedings of the 2010 Asia-Pacific Conference on Wearable Computing Systems, Shenzhen, China, 17–18 April 2010; pp. 307–310. [Google Scholar]
- Assfalg, J.; Bertini, M.; Colombo, C.; Bimbo, A. Semantic annotation of sports videos. IEEE Multimed. 2002, 9, 52–60. [Google Scholar] [CrossRef]
- Hauptmann, A.; Yan, R.; Lin, W.; Christel, M.; Wactlar, H. Can high-level concepts fill the semantic gap in video retrieval? A case study with broadcast news. Trans. Multimed. 2007, 9, 958–966. [Google Scholar] [CrossRef]
- Wyl, M.; Mohamed, H.; Bruno, E.; Marchand-Maillet, S. A Parallel Cross-Modal Search Engine over Large-Scale Multimedia Collections with Interactive Relevance Feedback. In Proceedings of the ACM International Conference on Multimedia Retrieval (ICMR ’11), Trento, Italy, 17–20 April 2011. [Google Scholar]
- Paredes, R.; Ulges, A.; Breuel, T. Fast Discriminative Linear Models for Scalable Video Tagging. In Proceedings of the International Conference on Machine Learning and Applications, Miami Beach, FL, USA, 13–15 December 2009; pp. 571–576. [Google Scholar]
- Morsillo, N.; Mann, G.; Pal, C. YouTube Scale, Large Vocabulary Video Annotation. In Video Search and Mining; Springer: Heidelberg, Germany, 2010; pp. 357–386. [Google Scholar]
- Brezeale, D.; Cook, D. Automatic video classification: A survey of the literature. Trans. Syst. Man Cybern. Part C Appl. Rev. 2008, 38, 416–430. [Google Scholar] [CrossRef]
- Wang, M.; Hua, X.; Tang, J.; Hong, R. Beyond distance measurement: Constructing neighborhood similarity for video annotation. IEEE Trans. Multimed. 2009, 11, 465–476. [Google Scholar] [CrossRef]
- Naphade, M.; Smith, J. On the Detection of Semantic Concepts at TRECVID. In Proceedings of the 12th annual ACM international conference on Multimedia, New York, NY, USA, 10–16 October 2004; pp. 660–667. [Google Scholar]
- Lampert, C.; Nickisch, H.; Harmeling, S. Learning to Detect Unseen Object Classes by Between-Class Attribute Transfer. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR ’09), Miami, FL, USA, 20–26 June 2009; pp. 951–958. [Google Scholar]
- Wang, X.; Zhang, L.; Jing, F.; Ma, W. Annosearch: Image auto-annotation by search. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR ’06), New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Ballan, L.; Bertini, M.; Del Bimbo, A.; Serra, G. Enriching and Localizing Semantic Tags in Internet Videos. In Proceedings of the ACM Multimedia, Scottsdale, AZ, USA, 28 November 2011. [Google Scholar]
- Kennedy, L.; Chang, S.; Kozintsev, I. To Search or to Label? Predicting the Performance of Search-Based Automatic Image Classifiers. In Proceedings of the International Workshop on Multimedia Information Retrieval, Santa Barbara, CA, USA, 26–27 October 2006; pp. 249–258. [Google Scholar]
- Ulges, A.; Schulze, C.; Koch, M.; Breuel, T. Learning automatic concept detectors from online video. Comput. Vis. Image Underst. 2010, 114, 429–438. [Google Scholar] [CrossRef]
- Siersdorfer, S.; San Pedro, J.; Sanderson, M. Automatic Video Tagging Using Content Redundancy. In Proceedings of the International Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009; pp. 395–402. [Google Scholar]
- Wang, M.; Li, G.; Zheng, Y.T.; Chua, T.S. ShotTagger: Tag Location for Internet Videos. In Proceedings of the the 1st International Conference on Multimedia Retrieval (ICMR ’11), Trento, Italy, 18–20 April 2011. [Google Scholar]
- Halvey, M.; Vallet, D.; Hannah, D.; Jose, J. ViGOR: A Grouping Oriented Interface for Search and Retrieval. In Video Libraries. In Proceedings of the Conference on Digital Libraries, Austin, TX, USA, June 2009; pp. 87–96. [Google Scholar]
- Tahara, Y.; Tago, A.; Nakagawa, H.; Ohsuga, A. NicoScene: Video scene search by keywords based on social annotation. Active Media Technol. 2010, 6335/2010, 461–474. [Google Scholar]
- Wattamwar, S.; Mishra, S.; Ghosh, H. Multimedia Explorer: Content Based Multimedia Exploration. In Proceedings of the TENCON Region 10 Conference, Hyderabad, India, 19–21 November 2008; pp. 1–6. [Google Scholar]
- Weber, J.; Lefevre, S.; Gancarski, P. Interactive Video Segmentation Based on Quasi-Flat Zones. In Proceedings of the International Symposium on Image and Signal Processing and Analysis, Dubrovnik, Croatia, 4–6 September 2011; pp. 265–270. [Google Scholar]
- Sivic, J.; Zisserman, A. Efficient visual search for objects in videos. Proc. IEEE 2008, 96, 548–566. [Google Scholar] [CrossRef]
- Everingham, M.; Sivic, J.; Zisserman, A. Hello! My Name is… Buffy—Automatic Naming of Characters in TV Video. In Proceedings of the British Machine Vision Conference, Edinburgh, UK, 4–7 September 2006; Volume 2. [Google Scholar]
- Alexe, B.; Deselaers, T.; Ferrari, V. What is An Object? In Proceedings of the 23rd IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’10), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Hu, Y.; Rajan, D.; Chia, L. Attention-from-motion: A factorization approach for detecting attention objects in motion. Comput. Vis. Image Underst. 2009, 113, 319–331. [Google Scholar] [CrossRef]
- Liu, D.; Chen, T. Video retrieval based on object discovery. Comput. Vis. Image Underst. 2009, 113, 397–404. [Google Scholar] [CrossRef]
- Suna, S.; Wanga, Y.; Hunga, Y.; Changb, C.; Chenb, K.; Chenga, S.; Wanga, H.; Liaoa, H. Automatic Annotation of Web Videos. In Proceedings of the International Conference on Multimedia and Expo (ICME ’11), Barcelona, Spain, 11–15 July 2011. [Google Scholar]
- Jain, M.; Jawahar, C. Characteristic Pattern Discovery in Videos. In Proceedings of the Indian Conference on Computer Vision, Graphics and Image Processing, Chennai, India, 12–15 December 2010; pp. 306–313. [Google Scholar]
- Quack, T.; Ferrari, V.; Van Gool, L. Video Mining with Frequent Itemset Configurations. In Proceedings of the International Conference on Image and Video Retrieval, Tempe, AZ, USA, 13–15 July 2006; pp. 360–369. [Google Scholar]
- Over, P.; Awad, G.; Fiscus, J.; Antonishek, B.; Michel, M.; Smeaton, A.; Kraaij, W.; Quénot, G. TRECVID 2010–An overview of the goals, tasks, data, evaluation mechanisms, and metrics. Available online: http://www-nlpir.nist.gov/projects/tvpubs/tv10.papers/tv10overview.pdf (accessed on 21 February 2012).
- Volkmer, T.; Smith, J.; Natsev, A. A Web-Based System for Collaborative Annotation of Large Image and Video Collections: An Evaluation and User Study. In Proceedings of the ACM Multimedia, Singapore, Singapore, 6–11 November 2005; pp. 892–901. [Google Scholar]
- Larson, M.; Soleymani, M.; Serdyukov, P.; Rudinac, S.; Wartena, C.; Murdock, V.; Friedland, G.; Ordelman, R.; Jones, G.J.F. Automatic Tagging and Geotagging in Video Collections And Communities. In Proceedings of the International Conference on Multimedia Retrieval, Trento, Italy, April 2011; Volume 51, pp. 1–8. [Google Scholar]
- Wu, X.; Zhao, W.L.; Ngo, C.W. Towards Google Challenge: Combining Contextual and Social Information for Web Video Categorization. In Proceedings of the ACM Multimedia, Vancouver, Canada, 19–24 October 2009. [Google Scholar]
- Lowe, D. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Mikolajczyk, K.; Schmid, C. A performance evaluation of local descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.; Winn, J.; Zisserman, A. The pascal Visual Object Classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Tuytelaars, T.; Mikolajczyk, K. Local invariant feature detectors: A survey. Found. Trends Comput. Graph. Vis. 2008, 3, 177–280. [Google Scholar] [CrossRef]
- Hsu, C.; Chang, C.; Lin, D. A Practical Guide to Support Vector Classification. Available online: http://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf (accessed on 21 February 2012).
- Varma, M.; Ray, D. Learning the Discriminative Power-Invariance Trade-Off. In Proceedings of the 8th IEEE International Conference on Computer Vision (ICCV ’07), Rio de Janeiro, Brazil, 14–20 October 2007. [Google Scholar]
- Jiang, Y.; Ngo, C.; Yang, J. Towards Optimal Bag-of-Features for Object Categorization and Semantic Video Retrieval. In Proceedings of the 6th ACM International Conference on Image and Video Retrieval, Amsterdam, The Netherlands, 9–11 July 2007. [Google Scholar]
- Mikolajczyk, K.; Tuytelaars, T.; Schmid, C.; Zisserman, A.; Matas, J.; Schaffalitzky, F.; Kadir, T.; Van Gool, L. A Comparison of Affine Region Detectors. In Proceedings of the 10th IEEE International Conference on Computer Vision (IJCV ’05), Beijing, China, 17–20 October 2005; pp. 43–72. [Google Scholar]
- Carreira, J.; Sminchisescu, C. Constrained Parametric Min-Cuts for Automatic Object Segmentation. In Proceedings of the 23rd IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’10), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Van de Sande, K.E.A.; Gevers, T.; Snoek, C.G.M. Evaluating color descriptors for object and scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1582–1596. [Google Scholar] [CrossRef] [PubMed]
- Oliva, A.; Torralba, A. Building the gist of a scene: The role of global image features in recognition. Prog. Brain Res. 2006, 155, 23–36. [Google Scholar] [PubMed]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognitio (CVPR ’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR ’06), New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G. Online learning for matrix factorization and sparse coding. J. Mach. Learn. Res. 2010, 11, 19–60. [Google Scholar]
- Babenko, B.; Dollar, P.; Belongie, S. Task Specific Local Region Matching. In Proceedings of the IEEE 11th International Conference on Computer Vision (ICCV ’07), Rio de Janeiro, Brazil, 14–20, October 2007. [Google Scholar]
- Stavens, D.; Thrun, S. Learning of Invariant Features using Video. In Proceedings of the 23rd IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’10), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Winder, S.; Hua, G.; M.B. Picking the Best DAISY. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR ’09), Miami, FL, USA, 20–26 June 2009. [Google Scholar]
- Winder, S.; Brown, M. Learning Local Image Descriptors. In Proceedings of the 2007 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR ’07), Minneapolis, MI, USA, 18–23 June 2007. [Google Scholar]
- Jahrer, M.; Grabner, M.; Bischof, H. Learned Local Descriptors for Recognition and Matching. In Proceedings of the Computer Vision Winter Workshop, Ljubljana, Slovenia, February 2008. [Google Scholar]
- Torralba, A.; Russell, B.; Yeun, J. LabelMe: Online image annotation and applications. Proc. IEEE 2010, 98, 1467–1484. [Google Scholar] [CrossRef]
- Doermann, D.; Mihalcik, D. Tools and Techniques for Video Performance Evaluation. In Proceedings of the 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2000; Volume 4, pp. 167–170. [Google Scholar]
- Muja, M.; Rusu, R.; Bradski, G.; Lowe, D. REIN—A Fast, Robust, Scalable REcognition INfrastructure. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Forsyth, D.; Malik, J.; Fleck, M.; Greenspan, H.; Leung, T.; Belongie, S.; Carson, C.; Bregler, C. Finding Pictures of Objects in Large Collections of Images. In Proceedings of the Object Representation in Computer Vision, New York, NY, USA, April 1996. [Google Scholar]
- Wong, G.; Frei, H. Object Recognition: The Utopian Method is Dead; the Time for Combining Simple Methods Has Come. In Proceedings of the International Conference on Pattern Recognition, The Hague, The Netherlands, August 30–September 3 1992. [Google Scholar]
- Bradski, G.; Kaehler, A. Learning OpenCV: Computer vision with the OpenCV library. Available online: http://www.vision.ee.ethz.ch/~tquack/quack_fimi_videomining.pdf (accessed on 21 February 2012).
- Vedaldi, A.; Fulkerson, B. VLfeat: An Open and Portable Library of Computer Vision Algorithms. In Proceedings of the ACM Multimedia, Florence, Italy, 25–29 October 2008. [Google Scholar]
- Matlab: Computer Vision System Toolbox. 2012. Available online: www.mathworks.com/products/computer-vision (accessed on 15 February 2012).
- Oerlemans, A.; Lew, M. RetreivalLab—A Programming Tool for Content-Based Retrieval. In Proceedings of the International Conference on Multimedia Retrieval, Trento, Italy, 17–20 April 2011. [Google Scholar]
- Lienhart, R. Reliable transition detection in videos: A survey and practitioner’s guide. Int. J. Image Graph. 2001, 1, 469–486. [Google Scholar] [CrossRef]
- Frigo, M.; Johnson, S. The design and implementation of FFTW3. Proc. IEEE 2005, 93, 216–231. [Google Scholar] [CrossRef]
- Manjunath, B.; Ohm, J.R.; Vasudevan, V.; Yamada, A. Color and texture descriptors. Trans. Circuits Syst. Video Technol. 2001, 11, 703–715. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Robust Real-Time Face Detection. In Proceedings of the 8th International Conference on Computer Vision (ICCV ’01), Vancouver, Canada, 7–14 July 2001. [Google Scholar]
- Liu, H.; Song, D.; Ruger, S.; Hu, R.; Uren, V. Comparing Dissimilarity Measures for Content-Based Image Retrieval. In Proceedings of the 4th Aisa Information Retrieval Symposium (AIRS ’08), Harbin, China, 15–18 January 2008; pp. 44–50. [Google Scholar]
- Sorschag, R.; Morzinger, R.; Thallinger, G. Automatic Region of Interest Detection in Tagged Images. In Proceedings of the International Conference on Multimedia and Expo (ICME ’09), New York, NY, USA, 28 June–3 July 2009; pp. 1612–1615. [Google Scholar]
- Sorschag, R. CORI: A Configurable Object Recognition Infrastructure. In Proceedings of the International Conference on Signal and Image Processing Applications, Kuala Lumpur, Malaysia, 16–18 November 2011. [Google Scholar]
- Video Annotation Prototype. Available online: http://www.ims.tuwien.ac.at/sor/VAP.zip (accessed on 21 February 2012).
- Shotdetect. Available online: http://shotdetect.nonutc.fr/ (accessed on 21 February 2012).
- FFmpeg. Available online: http://ffmpeg.org (accessed on 21 February 2012).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # | Duration (min) | Clustered Keyframes | Number of Annotations | Categories | Annotation Time (secs) | Annotated Example | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Avg | Min | Max | Avg | Min | Max | # | Avg | Min | Max | Persons | Locations | Specific Object | Object class | Avg | Min | Max | Positive | Negative | ||
| Short videos | 20 | 5.02 | 0.52 | 22.00 | 68.5 | 13 | 177 | 55 | 2.75 | 1 | 6 | 15 | 10 | 17 | 13 | 32.56 | 9 | 60 | 5.02 | 1.8 |
| Long videos | 10 | 77.13 | 27.85 | 108.73 | 606.1 | 234 | 889 | 98 | 9.8 | 5 | 15 | 31 | 15 | 22 | 28 | 47.23 | 21 | 146 | 5.35 | 2.62 |
| Measurement Units | Keyframe Clustering | Keyframe Suggestion | Region Detection | Auto-Selection | |||||
|---|---|---|---|---|---|---|---|---|---|
| 320 × 240 | 640 × 480 | 1280 × 720 | BoF | Face Det. | Local Feature | Seg.-based | |||
| Feature Extraction (seconds) | 242 | 1,315 | 4,050 | 31 | 0.75 /kf | 20 | 125 | 50 | 135 |
| Matching (seconds) | 0.25 | 0.2 | 8 | 87.5 | 0.15 | ||||
| Storage (KB) | 19,000 | 19,000 | 19,000 | 620 | 40 | 445 | 3,500 | 15,000 | 185 |
© 2012 by the author. licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/.)
Share and Cite
Sorschag, R. A Flexible Object-of-Interest Annotation Framework for Online Video Portals. Future Internet 2012, 4, 179-215. https://doi.org/10.3390/fi4010179
Sorschag R. A Flexible Object-of-Interest Annotation Framework for Online Video Portals. Future Internet. 2012; 4(1):179-215. https://doi.org/10.3390/fi4010179
Chicago/Turabian StyleSorschag, Robert. 2012. "A Flexible Object-of-Interest Annotation Framework for Online Video Portals" Future Internet 4, no. 1: 179-215. https://doi.org/10.3390/fi4010179
APA StyleSorschag, R. (2012). A Flexible Object-of-Interest Annotation Framework for Online Video Portals. Future Internet, 4(1), 179-215. https://doi.org/10.3390/fi4010179