Abstract
The increasing elderly population presents major challenges to traditional healthcare due to the need for continuous care, a shortage of skilled professionals, and increasing medical costs. To address this, smart elderly care homes where multiple residents live with the support of caregivers and IoT-based assistive technologies have emerged as a promising solution. For their effective operation, a reliable high speed network like 5G is essential, along with intelligent resource allocation to ensure efficient service delivery. This study proposes a deep reinforcement learning (DRL)-based resource management framework for smart elderly homes, formulated as a Markov decision process. The framework dynamically allocates computing and network resources in response to real-time application demands and system constraints. We implement and compare two DRL algorithms, emphasizing their strengths in optimizing edge utilization and throughput. System performance is evaluated across balanced, high-demand, and resource-constrained scenarios. The results demonstrate that the proposed DRL approach effectively learns adaptive resource management policies, making it a promising solution for next-generation intelligent elderly care environments.
1. Introduction
The rapidly growing global elderly population presents significant challenges to traditional health and care systems [1,2,3]. Many elderly people live alone or require specialized attention that demands continuous health monitoring, timely medical intervention, and improved safety measures. The increasing shortage of trained healthcare professionals, along with rising medical costs, has led to a growing demand for smart elderly care systems [4,5,6,7,8]. These systems contribute to the UN Sustainable Development Goal 3 by promoting healthy lives and well-being for elderly populations through continuous health monitoring in community care settings, where multiple seniors reside under caregiver supervision supported by technologies enabled by IoT [9,10]. Smart homes for the elderly offer a variety of services to improve the quality of life of elderly residents [11,12]. Wearable sensors enable real-time health monitoring, continuously tracking vital signs such as heart rate, blood pressure, oxygen levels, and glucose, transmitting the data to caregivers for early detection and timely intervention [13]. In addition, AI-powered cameras and motion sensors can automatically detect falls or abnormal movements, alerting caregivers to emergency responses. To achieve these objectives of a smart elderly home, a robust backbone network such as 5G is highly recommended [14].
Beyond monitoring and safety, 5G can also support seamless remote consultations, remote diagnostics, and real-time communication with the family [15,16]. By allowing voice or sensor triggered automation, it creates a comfortable and secure living environment. Continuous connectivity for devices such as smart wheelchairs improves mobility support. With its ultra-low latency, high reliability, and massive connectivity to devices, 5G offers significant advantages over Wi-Fi or previous-generation cellular technologies in ensuring the continuity and responsiveness of elderly care systems [17,18]. However, delivering these capabilities in a scalable and efficient manner requires intelligent resource allocation within the 5G infrastructure [16,19,20,21]. The increasing number of connected devices and diverse applications in smart environments introduces complexity, as each service may have distinct requirements in terms of bandwidth, latency, and reliability. Traditional static or rule-based resource allocation approaches are inadequate to handle such dynamic demands. Therefore, intelligent and adaptive resource management mechanisms are required.
Deep reinforcement learning (DRL) has emerged as a powerful and promising approach for dynamic and intelligent resource allocation in 5G-enabled smart environments [22,23,24]. These environments are characterized by dynamic traffic loads and strict quality of service (QoS) requirements, making traditional static or rule-based resource management techniques inadequate [25,26]. DRL addresses these challenges by enabling agents to autonomously learn optimal resource allocation strategies through continuous interaction with the network environment. By observing state transitions and receiving feedback in the form of rewards, the agent improves its policy to adapt to real-time variations and uncertainties. However, the effectiveness of DRL is highly dependent on the design of the reward function. A poorly designed reward function can mislead the agent, resulting in suboptimal or inefficient policies. In the context of resource allocation, the reward function must be carefully designed to balance multiple objectives such as minimizing latency, maximizing throughput, and ensuring fairness across users.
In this study, we propose a Markov decision process (MDP) framework, specifically designed for resource allocation in smart elderly care systems. The MDP captures the characteristics and constraints of smart care home environments for the elderly, including latency sensitivity. A reward function is formulated to minimize packet loss while maximizing the throughput, aligning with the quality and reliability demands of elderly care networks. To solve the MDP, we implement and evaluate two DRL algorithms: Deep Q-Network (DQN) and Deep Deterministic Policy Gradient (DDPG). We compare their performance in optimizing resource allocation and identify the most effective strategy to improve the responsiveness of 5G-enabled smart elderly care systems.
The main contributions of this paper are as follows:
- Design of an MDP framework for dynamic resource allocation in 5G-enabled smart elderly care systems, with a customized reward function aimed at improving the packet delivery rate and the reducing loss rate.
- Implementation of two DRL algorithms, DQN and DDPG, to solve the MDP formulation for adaptive resource management.
- Evaluation of the customized DQN and DDPG algorithms to determine the most effective DRL-based strategy.
The remainder of this paper is structured as follows. Section 2 provides a review of the existing research on resource allocation for smart environments. Section 3 details the architecture design, including the specific MDP formulation used for the DRL solution. Section 4 details the experimental setup and analyzes the obtained results. Finally, Section 5 summarizes the findings of the study and presents concluding remarks.
2. Related Work
Recent advances in machine learning and wireless communication have accelerated the adoption of artificial intelligence for intelligent resource and service management across next-generation networks. As communication technologies evolve into 5G and Beyond 5G systems, researchers have increasingly explored the integration of AI and DRL to handle complex and dynamic resource allocation challenges. Xiong et al. conducted a survey on DRL applications for dynamic service and resource management in dense 5G networks and validated their efficiency through a case study of network slice optimization [27]. Building on this, Rafique et al. provided a comprehensive review of network slicing in B5G networks, emphasizing smart city use cases [28].
The application of DRL has been extended to mobile edge computing (MEC). Jiang et al. [29] explored the evolution of 6G systems towards pervasive intelligence by 2030. Sami et al. [30] introduced IScaler, a DRL-based framework for resource scaling and service placement in MEC environments. Similarly, Wei et al. reviewed the role of DRL in MEC-based 6G systems, especially where conventional machine learning fails [31]. A DQN-based migration approach by Zhang et al. [32] and a dynamic placement strategy by Lu et al. [33] both addressed delay-sensitive services. Rui et al. [34] developed an RL-based migration model that is resilient to network failures, while Chen et al. [35] and Liu et al. [36] proposed DRL models to reduce workload and latency in edge–cloud systems.
DRL has also proven impactful in offloading optimization and ultra-reliable low-latency communication. Chen et al. introduced DRL-based strategies for offloading and resource allocation without prior transition knowledge [37,38]. Hortelano et al. [39] and Chen et al. [40] focused on edge-device offloading using decentralized DRL for real-time adaptability. Liu et al. [41] emphasized the broader role of ML in enabling URLLC in 6G networks. Further, many DRL contributions have focused on system-wide optimization. Doke et al. [42] demonstrated DRL’s utility in data center load balancing, while Chen et al. [35] and Ihsan et al. [43] addressed task migration and real-time optimization in edge-cloud infrastructures.
Beyond network infrastructure, DRL has been adopted in healthcare-centric MEC systems. The resource management challenges in IoT-based healthcare monitoring systems are discussed in [44,45]. Lv et al. proposed a DQN-based resource allocation strategy for healthcare systems in dense 6G networks [46]. Su et al. contributed to an offloading DRL method adapted to smart healthcare networks, minimizing energy and latency for sensitive devices [47]. In the context of intelligent home care, Naseer et al. proposed an IoT-enabled elderly care system that integrates adversarial generative networks. This framework generated synthetic health data and performed privacy-preserving prediction [48]. Although DRL has shown significant promise in diverse domains, including MEC, IoT, and healthcare, each application requires fine-tuning the algorithmic models to domain-specific needs. In the case of smart elderly care homes, constraints such as critical care quality and responsiveness require a customized approach. This paper addresses this gap by designing an MDP that reflects the requirements of elderly care and solves it using customized DDPG and DQN algorithms, providing an intelligent resource management framework.
3. DRL Based Resource Allocation in 5G-Enabled Elderly Care Home Network
The elderly require immediate medical attention in case of emergency where multiple senior residents live in a shared environment supported by caregivers and digital technologies. These care settings require seamless connectivity, emergency response, and personalized care, for which an intelligent communication backbone is necessary. This creates a challenge of managing heterogeneous service demands and resource constraints in real time. In this context, DRL offers a powerful mechanism to dynamically allocate network and computational resources. The subsequent subsections describe the architecture of the intelligent care home network for the elderly, the MDP design, and the DRL algorithm used to achieve optimal resource allocation.
3.1. Architecture of Smart Elderly Care Home Network
The network architecture of the elderly home care network, as shown in Figure 1, comprises the following components: intelligent IoT devices, a local 5G gateway or Customer Premises Equipment (CPE), the 5G infrastructure (gNodeB base station and 5G Core), edge computing servers, and cloud computing services. At the device level, smart elderly homes are equipped with wearable health monitors, telemedicine interfaces, entertainment systems, emergency support and response units, IoT-based home automation devices, and general information services. These devices continuously collect data on vital signs and movements. Data are transmitted to a local 5G CPE, which acts as a gateway that ensures fast, secure, and reliable connectivity to the 5G network. The 5G infrastructure includes the gNodeB base station alongside the 5G Core network. This setup utilizes smart algorithms to enable functionalities like network slicing and QoS management, ensuring that critical healthcare data are prioritized and enabling low-latency and high-throughput communication.
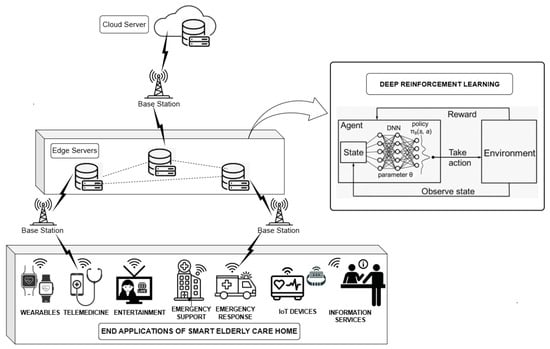
Figure 1.
5G Enabled smart elderly care home network architecture.
To ensure high-speed data transfer and low-latency responses, the architecture employs 5G base stations that connect the end devices to nearby edge servers. Edge computing is integrated into the network to perform local data processing and AI inference close to the source of data generation. Edge servers can handle tasks such as fall detection, health anomaly prediction, and basic decision making without having to interact with the cloud for every operation. When more complex analytics, long-term data storage, or electronic health record integration are required, the data are synchronized with cloud servers. These servers provide computational and storage capabilities and are accessible to healthcare professionals. The flow of data begins with IoT devices that capture health or environmental data, which are transmitted through 5G CPE to the gNodeB base station. From there, data are routed to the closest edge server, where a DRL algorithm dynamically allocates bandwidth and processing power. If the edge server experiences high load or limitations, the system automatically redirects traffic to the cloud server through the 5G core. The bandwidth and latency requirements for the elderly home services are given in Table 1. The priorities of the services are statically defined according to their criticality levels. These predefined priorities are utilized in the reward function and governing state transitions within the MDP. The user demands are synthetically generated based on the requirements summarized in Table 1. These synthetic profiles closely reflect realistic data rates and latency constraints commonly encountered in smart elderly care environments.

Table 1.
Bandwidth and latency requirements for services in smart elderly home.
3.2. MDP Model for Resource Allocation in Smart Elderly Home Network
In a smart elderly care home powered by 5G, the network needs to meet some essential demands. For example, in situations like a fall or a sudden health emergency, the system must respond in real time, with less than one millisecond of delay. The network must ensure uninterrupted data delivery so that health information consistently reaches caregivers. With numerous connected devices, such as wearables monitoring heart rate and smart wheelchairs operating simultaneously, the network must support a large number of simultaneous connections. Additionally, the network must be intelligent enough to allocate bandwidth, for example, prioritizing a live video consultation with a doctor over background music streaming. Since service requirements vary, prioritizing according to activity type ensures that critical tasks operate seamlessly. To maintain efficiency, the system should distribute the workload between edge devices and cloud servers based on load and the speed at which data processing is required.
An MDP is characterized by , where S is the set of states, A is the set of actions, R is the reward function, P is the state transition probability matrix, and is the discount factor. The goal of this MDP is to enhance the efficient distribution of resources among users and edge servers. This MDP is formulated as follows.
State Space: To enable effective and intelligent decision making in a 5G-enabled smart elderly care home network, the state space must represent the operational status and demands of the system. The state is defined as a six-tuple , where each variable is selected to reflect a specific dimension for optimal resource allocation and task offloading.
CPU utilization denotes the utilization of each edge server, indicating the percentage of processing power currently used providing information on the processing efficiency of computational tasks. This metric helps in resource allocation and workload distribution management. , representing the available computational resources, is vital to evaluate the feasibility of hosting new tasks without degrading the system performance. The available bandwidth of each connection between edge servers indicates the data transfer capacity for task offloading or resource sharing. , the available bandwidth determines the ability to offload tasks and share data between network elements. The volume of data transmitted provides information on the ongoing data exchange, influencing the need for bandwidth and server buffering. The number of users is an important factor in assessing overall network load, as higher user counts generally correlate with increased competition for limited resources. The current network load, in terms of connected user count, indicates the level of activity and resource demand. Finally, , the offloading target, specifies where computational tasks or data processing of a mobile user should occur, typically referring to a specific edge server.
Action Space: The action space represents the decisions the system can make. In this case, it involves the allocation of computing resources, migration bandwidth, and determining the offload target for each mobile user. The action space is represented as a three-tuple where represents the bandwidth allocation for each user, represents the computing resource allocation for each user, and represents the offload target of each user. Allocating computing resources for each mobile user’s task refers to the process of assigning or dedicating computational capacity to the execution of tasks associated with a specific mobile user. Allocating bandwidth for each mobile user’s task involves deciding how much network bandwidth should be allocated to facilitate the transfer of data between the mobile user’s device and the edge server. The offload target of each mobile user determines where the user’s computational task should be processed.
Reward Function: A reward function in RL acts as a guide for an agent, assigning numerical values to its actions or state transitions to encourage the desired behavior. To optimize throughput, the function assesses the efficiency of data delivery by analyzing the difference between the requested data and the amount that was not transmitted successfully. Equations (1) and (2) define the amount of data transmitted and the average throughput.
where represents the amount of data transmitted, denotes the total amount of data requested, and denotes the amount of data that could not be transmitted.
where represents the average throughput, providing a measure of the overall efficiency or success of the data transmission process, and n denotes the total number of episodes. The reward function in terms of the average throughput and edge capability is defined in Equation (1).
where R represents the overall reward function, and denotes the edge capability, referring to the capacity of the edge server available to users. Edge capability is the normalized proportion of computational resources at the edge server that remain available to serve incoming user demands. It is a dimensionless quantity computed by evaluating the ratio of unallocated resources to the total server capacity at a given time. This abstraction enables the model to generalize across different hardware configurations while focusing on efficient resource utilization patterns rather than hardware-specific values.
The reward function is a combination of two components: the average throughput, which emphasizes the system’s efficiency in handling data transmission, and the edge capability, which accounts for the server’s capacity. The weighting parameter allows for the adjustment of the influence of each component. When is closer to 1, the reward is more influenced by the average throughput, emphasizing the importance of efficient data transmission. Conversely, when is closer to 0, the reward is more influenced by the edge capability, prioritizing the capacity of the edge server.
DRL Algorithms for Resource Management
To solve the aforementioned MDP, there are two customized DRL-based resource allocation (DRA) algorithms: DQN and DDPG. The DQN algorithm is a value-based method to handle discrete action spaces effectively. The pipeline is structured to continuously adapt to dynamic service demands and network conditions. The environment consists of user equipment, edge servers, and cloud servers. The DRL agent receives the state parameters discussed in Section 3.1 and, based on its policy network, selects an optimal resource allocation action. This action determines how computing and network resources are distributed across services. Once the action is executed, the environment transitions to a new state, and a reward is computed based on the average throughput and edge capability. This feedback is then used to update the DRL agent policy using the learning algorithms DQN or DDPG. The cycle continues, allowing the agent to learn and improve over time. The DQN utilizes a Q-learning approach with deep neural networks. On the other hand, the DDPG is an actor–critic algorithm outside the policy that extends the capabilities of the DQN to continuous action spaces by incorporating the principles of the deterministic policy gradient [32,37].
The DDPG-based algorithm begins by initializing the state space S, encompassing various state components and the action space A representing the allocation decisions. In addition, hyperparameters are identified, including the learning rates for both the actor and critic networks, the discount factor, the target network’s update rate, the replay buffer’s memory capacity, the batch size, and the maximum episode count. During each episode, the DRA interacts with the environment and selects an action based on the current state using the actor network policy. The chosen action is then executed, and the observed reward and the next state are recorded. This experience is stored in a replay buffer for future learning. Periodically, the algorithm samples a minibatch of experiences from the replay buffer. The critic network is then updated by comparing the actual reward with the expected future reward based on the evaluation of the target critic network of the next state . This process minimizes the temporal difference error and refines the critic’s ability to assess the effectiveness of actions. Subsequently, the actor network is updated using the sampled policy gradient. This encourages the actor to prioritize actions that lead to higher long-term rewards. To ensure the agent focuses on long-term rewards and avoids overfitting, the target networks are slowly updated toward the main networks using a soft replacement parameter . Through repetition of these actions, the DRA in Algorithm 1 gradually learns how to distribute bandwidth, processing power, and task offloading to optimize resource usage and service provision.
The DQN algorithm presented in Algorithm 2 initializes the state S, action A, learning rate , discount factor , exploration rate , decay rate for , the memory capacity of the replay buffer B, batch size N, and the maximum number of episodes M. During each episode, the algorithm interacts with the environment by selecting actions based on an -greedy policy. This policy balances exploration and exploitation, allowing the algorithm to explore new actions while also exploiting learned knowledge. Learning stores experiences, which include states, actions, consequences, and subsequent ones, in a replay buffer. The Q-network is updated using periodic sampling of small sets of experiences from the replay buffer. This update step involves minimizing the discrepancy between the predicted Q-values and target Q-values derived from the Bellman equation. Hence, this update process helps to improve the estimate of the Q-Network of the future anticipated rewards for different actions in different states.
| Algorithm 1: DRA: DDPG-based Resource Allocation |
 |
| Algorithm 2: DRA: DQN-based Resource Allocation |
 |
4. Performance Evaluation
To evaluate the proposed DRL-based resource allocation scheme, a simulation environment was set up using the Python-based SimPy 4.0.2 library. The environment models interactions between mobile users and edge servers through two core object-oriented classes: User and EdgeServer. The User class encapsulates user-related behaviors such as task generation, mobility, and offloading decisions, while the EdgeServer class manages server-side operations including resource allocation, processing, and bandwidth management. User mobility is simulated using real-world location data from the KAIST mobility dataset [49]. Based on the geographical distances computed from this dataset, each user dynamically selects the most appropriate edge server for offloading their computational tasks. The DRL agent determines the optimal actions within the action space at each decision epoch.
During each episode, metrics including cumulative rewards, throughput, edge server capacity utilization, number of offloading operations, and migration size are analyzed. Multiple configurations with varying numbers of edge servers and users are used to test the robustness of the algorithms under different load and mobility conditions. The DDPG and DQN algorithms are also evaluated in relation to the environment, and this comparison is carried out. The evaluation criteria concentrated on reward analysis to comprehend the algorithm’s learning dynamics, investigation of performance regarding resource usage, and edge capacity to accommodate varying edge server capabilities. The experimental objective was to compare how variations in user and edge server configurations impact the algorithm’s learning process and the agent’s performance. Table 2 outlines the test cases considered during the evaluation of the experiment.
Table 2.
Experimental design and evaluation criteria.
4.1. Analysis 1: Evaluation of User and Edge Server Configurations on Model Learning
Three experiments were set up to analyze the effect of user and edge server configuration on model learning. In one instance, we have a case with balanced resources with a matching number of users and edge servers. The second scenario looks at a situation of excess resources characterized by more edge servers than users. Finally, the third scenario deals with high-traffic cases, in which the number of users is higher than that of accessible edge servers. By studying these different scenarios, we will be able to know how this system operates under different resource limitations, as well as the algorithms’ performance in various situations. In order for the algorithm to be adaptable and also perform well in different resource availability and demand scenarios, the DDPG-based DRA algorithm was evaluated in three cases. The principal objective was to see how efficiently a DDPG-based algorithm can distribute resources while maintaining system stability, maximizing throughput, and edge server utilization.
4.1.1. DDPG-Based DRA Algorithm
Case 1: Balanced Resource Distribution with an Equal Number of Users and Edge Servers: The system had the same distribution of resources with as many users as edge servers.
Figure 2 presents the simulation results for a scenario that involves 10 users and 10 edge servers. In Figure 2a, the cumulative reward earned by the agent in the training episodes is depicted. The reward curve demonstrates convergence around episode 20, indicating that the agent has successfully learned an effective policy for resource allocation. Figure 2b,c display the corresponding throughput and edge server capabilities, respectively, during the training phase. Both metrics exhibit stable trends, highlighting consistent system performance in terms of network efficiency and optimal utilization of edge server resources.
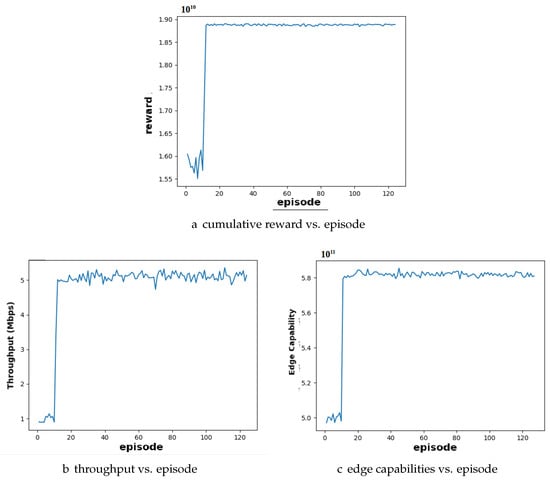
Figure 2.
Performance analysis of user- and edge server-balanced configuration for DDPG algorithm: (a) cumulative reward converges around episode 20; (b) throughput increases as episode increases and gradually converges; (c) edge capabilities increase as episode increases and converges.
Case 2: Excess Resource Distribution with More Servers than Users: In the second case, we explore a scenario with more edge servers than users, representing an excess resource situation. Here, the system has more computational power available than users currently demand. Figure 3 shows the performance of the DRA algorithm with 10 users and 15 edge servers. Similarly to Case 1, the cumulative reward graph in Figure 3a exhibits convergence around episode 20, indicating that the agent effectively learns a resource allocation policy. Unlike Case 1, the edge capability graph in Figure 3c converges at a significantly higher value. This is expected behavior, as there are more servers available to handle tasks. With increased server capacity, the system can process more data and provide better service to users. In particular, the throughput graph shown in Figure 3b maintains stability throughout the training process. This shows that the system does not compromise on data transmission even with excess resources.
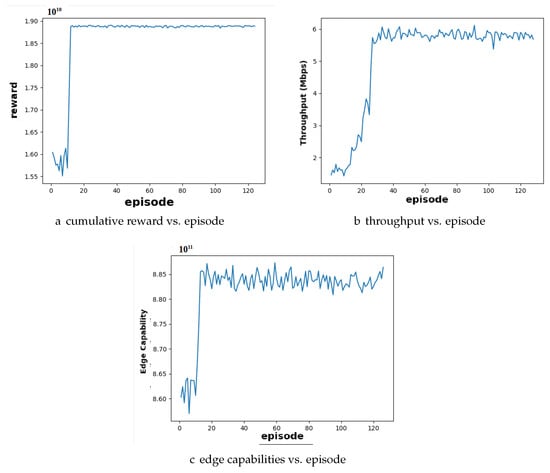
Figure 3.
Performance analysis of user and edge server configuration under surplus resource conditions for DDPG algorithm: (a) the cumulative reward converges approximately by episode 20; (b) throughput shows a progressive increase with each episode and eventually stabilizes; (c) edge capabilities show a steady rise with each episode until converging.
Case 3: Higher User Demand with More Users than Servers: The third case investigates a scenario where there are more users than edge servers, representing a situation with a higher computational demand than available resources.
Figure 4 illustrates a sample simulation result for a scenario involving 15 users and 10 edge servers. Compared to Case 1, the cumulative reward curve in Figure 4a converges to a slightly lower value, indicating that although the agent successfully adapts to the increased user demand, overall performance experiences a modest decline. As shown in Figure 4c, the edge capability stabilizes once the servers reach full utilization, reflecting the system’s ability to effectively manage limited computational resources. Meanwhile, the performance depicted in Figure 4b shows a slight reduction compared to more balanced setups, suggesting that under higher demand conditions, the model emphasizes optimal resource distribution rather than maximizing performance. The observations from the above analysis show that the DRL model demonstrates a strong ability to learn effective resource allocation policies, as evidenced by the convergence of cumulative reward graphs in all cases. Additionally, Cases 1 (balanced) and 2 (excess resources) demonstrate stable performance in terms of throughput and utilization of edge capability.
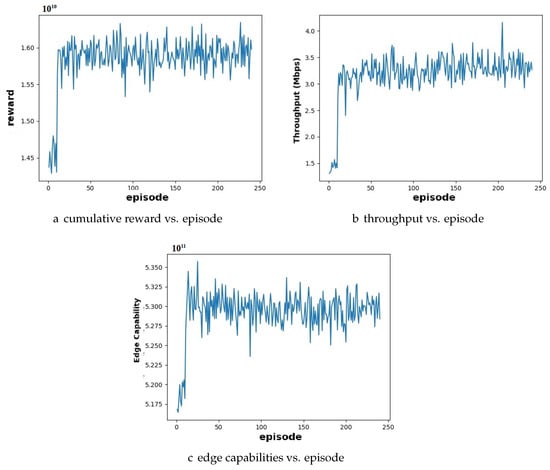
Figure 4.
Performance analysis of user and edge server configuration under high user demand conditions for DDPG algorithm: (a) cumulative reward reaches convergence; (b) throughput demonstrates an increase in growth with each episode, eventually converging; (c) edge capabilities show continuous enhancement per episode until converging at episode 25.
4.1.2. DQN-Based DRA Algorithm
The DQN-based DRA algorithm was evaluated using the same three scenarios to evaluate its performance under different resource conditions. The focus was on evaluating the effectiveness of the DQN-based algorithm in managing resource allocation efficiently and maintaining system stability while optimizing throughput and edge server utilization.
Case 1: Balanced Resource Distribution with an Equal Number of Users and Edge Servers: In this scenario, where the number of users and the number of edge servers are equal, the system demonstrated a balanced resource distribution. Figure 5 presents a sample simulation result for a scenario involving 10 users and 10 edge servers utilizing the DQN algorithm. Figure 5a illustrates DQN’s reward graph. Here, we observe a convergence around episode 10, suggesting that the agent has learned an effective resource allocation policy. This convergence signifies a stable and efficient learning process. Figure 5b, showing DQN’s throughput graph, shows a relatively stable throughput value. This indicates that the DQN can handle user requests while maintaining a balance with resource utilization. Figure 5c illustrates the stability of edge capability throughout the training process, convergent around 6.0. This demonstrates the DQN’s ability to distribute tasks effectively and prevent resource exhaustion.
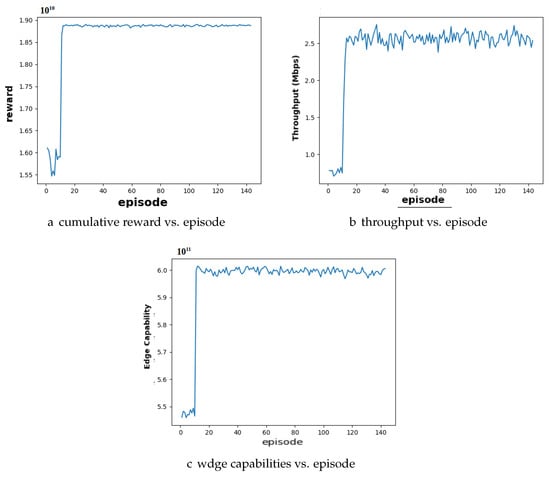
Figure 5.
Performance analysis of user- and edge server-balanced configuration for DQN algorithm: (a) cumulative reward converges around episode 10; (b) throughout stabilizes; (c) edge capabilities show steady growth until convergence.
Case 2: Excess Resource Distribution with More Servers than Users: Case 2 presents a scenario with more edge servers than users. Figure 6 shows the performance of the DQN algorithm in this case, with 10 users and 15 edge servers. The cumulative reward graph in Figure 6a shows convergence around episode 60, suggesting that the agent has learned a resource allocation policy after 60 episodes that takes advantage of the available resources. The throughput graph in Figure 6b has a slightly higher throughput compared to Case 1. This indicates that the model prioritizes efficient resource utilization even with excess capacity. The model did not increase throughput beyond what was necessary to serve all users efficiently. The edge capability graph in Figure 6c converges at a significantly higher value compared to Case 1, due to the greater number of edge servers available to handle more requests in this scenario. This signifies that the system can use the additional edge servers to handle more requests efficiently, resulting in improved overall performance and increased resource utilization.
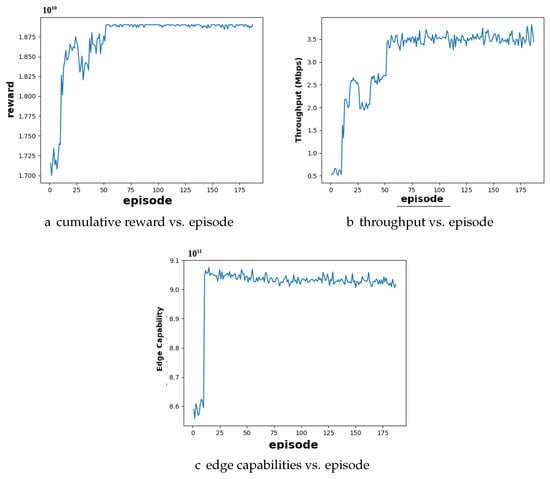
Figure 6.
Performance analysis of user and edge server configuration under excess resource conditions for DQN algorithm: (a) he cumulative reward graph converges around episode 60; (b) throughput shows a progressive increase with each episode and eventually stabilizes at 3.5; (c) edge capabilities show a steady rise with each episode until converging around episode 15.
Case 3: Higher User Demand with More Users than Servers: In the third case, we explore a scenario in which computational demand exceeds available resources. Figure 7 presents a sample simulation result for this scenario. Compared to Case 1, the cumulative reward graph in Figure 7a exhibits convergence around episode 20, but at a slightly lower value due to resource limitations. The throughput graph in Figure 7b also shows a slight decrease in its value compared to the balanced scenario. The edge capability graph in Figure 7c shows a stable value after convergence, potentially lower than the maximum capability observed in balanced cases. This signifies that the servers are fully utilized due to high demand.
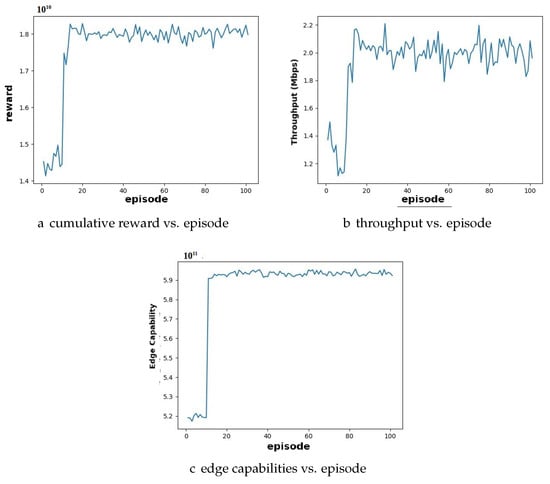
Figure 7.
Performance analysis of user and edge server configuration under high user demand conditions for DQN algorithm: (a) the reward graph converges around episode 20; (b) throughput increases with each episode until convergence; (c) edge capabilities converge.
The analysis of DQN’s performance across different user and edge server configurations reveals its capability to learn effective resource allocation strategies. The convergence of the cumulative reward graphs in all cases demonstrates the learning ability of the model. DQN adapts its strategy on the basis of resource availability. Cases 1 (balanced) and 2 (excess resources) show stable performance in terms of throughput and edge capability, and Case 2 highlights the efficient utilization of excess resources. In Case 3 (high user demand), DQN prioritized efficient resource allocation, potentially leading to a slight decrease in throughput compared to balanced scenarios.
4.2. Analysis 2: Evaluation of Throughput and Edge Capability Considering Varying User Demands and Resource Capacity
Here, we examine the adaptability of DDPG- and DQN-based DRA models in dynamic environments by fluctuating user demands and resource availability. To understand how the models handle these variations, we investigate two key scenarios, varying the number of edge servers with a constant number of users (Scenario 1) and vice versa (Scenario 2). In Scenario 1, we hold the user base fixed and observe the influence of increasing the number of edge servers on the throughput and edge capacity. We do this to determine how effectively the model can use additional resources to deal with a steady workload. In contrast, in Scenario 2, we maintain a constant edge server number and see what happens as more users sign up. This provides insight into whether or not this model can handle the rising demand among its users without an increase in the size of the server pool. DDPG is an algorithm effective at managing continuous action spaces, enabling accurate resource allocation and enhanced throughput. The actor–critic architecture promotes rapid adaptation to network changes, whereas DQN’s slower adaptation requires a combinatorial explosion of action options. The high-dimensional state spaces of the DDPG offer better decision making.
Scenario 1: Varying Number of Edges with Constant Users: This scenario examines how the system’s performance is influenced by varying edge server availability while the number of users stays the same. We investigated the impact of increasing the number of edge servers on both throughput and edge capability, going from 5 to 20 servers. The findings show a noticeable pattern in both algorithms: When the number of edges increases, both throughput and edge capability improve. As Figure 8a suggests, the DDPG throughput graph shows a gradual increase. For example, increasing the number of edges from 5 to 10 leads to a 25% increase in throughput. This trend continues, reaching a throughput of 6 Mbps with 20 available edges. Similarly, DQN shows an increase in throughput from 1.3 to 2.5 Mbps. Having additional edge servers increases the system’s processing capacity. This enables better allocation of user requests among the resources on hand, resulting in better resource utilization. The graph in Figure 8a shows that the DDPG-based model can process more tasks compared to DQN, leading to an overall increase in throughput. Additionally, the graph depicting the edge capability against the number of edges displays a similar consistent upward trend for both models. In Figure 8b, as the number of edges increases from 5 to 20, the edge capacity of the DDPG model increases. This emphasizes the benefit of having more available edge servers. As a baseline for comparison, we implement a static resource allocation algorithm, which operates without adaptive learning or dynamic optimization. In this approach, each service is assigned fixed resources based on its priority level. The allocation is performed in a round-robin manner. It is noted that both DRL algorithms perform better than the static allocation scheme.
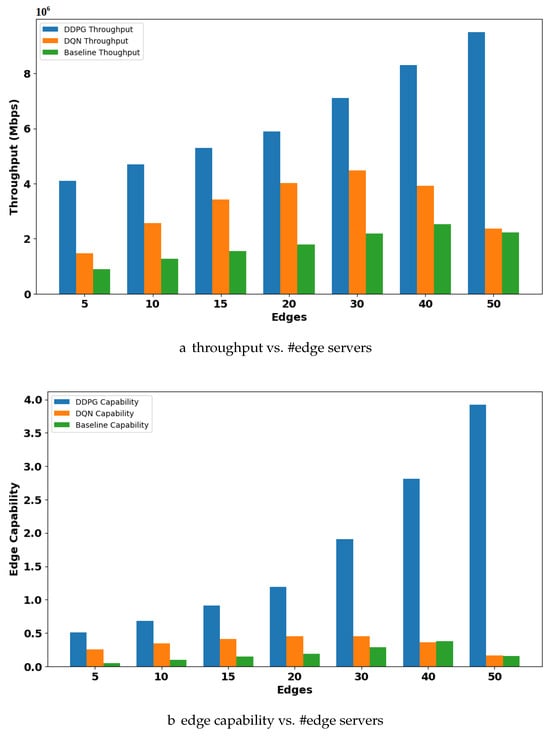
Figure 8.
Analysis of throughput and edge capability with varying resource capacity and constant user demands: (a) throughput increases with increased number of edge servers; (b) edge capability increases with increased number of edge servers.
Case 2: Varying Number of Users with Constant Edges: In Figure 9a, the DDPG’s throughput increases with a growing user base (from 10 to 25 users). However, the rate of increase is much lower compared to Case 1, where the number of users remained constant. The DQN throughput graph also showed an increasing trend with a growing user base. However, the increase is minimal compared to the DDPG. The observed increase in throughput with the DDPG and DQN shows that the algorithms are effectively distributing data and available resources within the constant number of edges. This suggests that both models can handle larger volumes of data even if the number of users increases. Furthermore, examining edge capability under this scenario provides the system’s capacity to handle user demands. The graph showing the edge capability against the number of users reveals a consistent downward trend for both models. As the user load increases, the edge capability decreases. With more users submitting requests, the available processing power is stretched thin. In this case, the DRL methods outperform the static baseline methods.
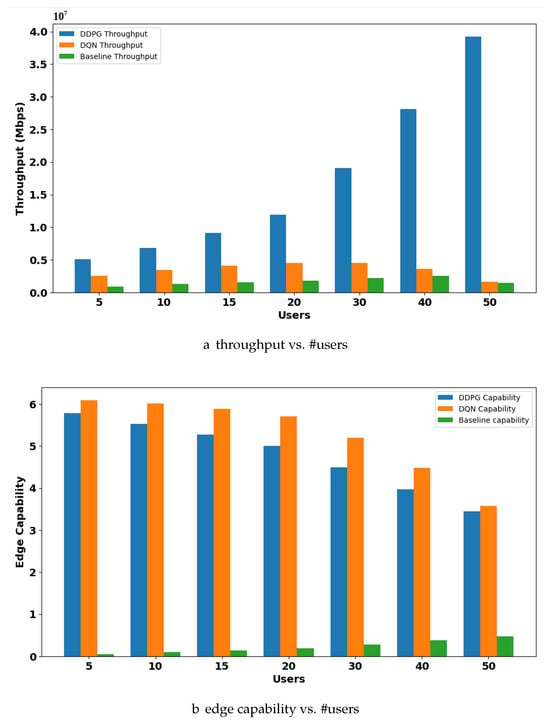
Figure 9.
Analysis of throughput and edge capability with varying user demands and fixed resource capacity: (a) throughput gradually decreases with increased number of users; (b) edge capability gradually decreases with increased number of users.
The experimental findings emphasize the correlation between resource allocation, particularly the number of edges and users, and its effect on both throughput and edge capability. Scenario 1 demonstrates the model’s strength in resource allocation. Increased edge servers with a constant user base lead to significant improvements in throughput and edge capability. While scenario 1 demonstrated the model’s ability to leverage increased edge servers for improved throughput and edge capability, scenario 2 revealed a trade-off between these metrics when user demands rise with a fixed number of edge servers.
4.3. Discussion
In this study, we employ DQN and DDPG algorithms to solve the MDP formulated for resource management in the 5G-enabled elderly home network. The primary objective was to evaluate how well these algorithms learn resource allocation policies and how they respond under varying user and edge server configurations. The action space in this environment includes the bandwidth allocation for each user, the computing resource allocation, and the offload target, which decides whether a user’s task should be processed at a particular edge. The DQN is a value-based method that excels in discrete action spaces, making it ideal when action components are quantized into fixed levels or categories. In contrast, the DDPG is a policy-based actor–critic algorithm designed for continuous action spaces, which provides precise control over resource parameters. DDPG enables continuous-valued decisions and learns deterministic policies that can directly map states to continuous actions. Our experimental findings reveal that DDPG performs better than DQN in continuous resource allocation scenarios. The DQN is constrained by its discrete action representations.
Across the three scenarios, balanced resources (case 1), excess resources (case 2), and high user demand (case 3), both algorithms demonstrated a strong learning capability, as shown by the convergence of the cumulative reward graphs. This convergence indicates that the DRL agents successfully adapted their policies to different environmental conditions, finding effective strategies for allocating edge server resources in response to changing user demands. In Case 1, where the number of users and edge servers was the same, both DDPG and DQN achieved stable throughput and edge utilization early in the training process. This highlights the strength of the DRL model in efficiently balancing loads under ideal resource conditions. The agent could fully utilize the available edge capacity, resulting in optimal performance with minimal overhead. In Case 2, the scenario with more edge servers than users, the system showed a steady increase in throughput and edge capability allowing for better distribution of computational loads and improved quality of service. In contrast, Case 3 introduced a higher user demand relative to the number of edge servers. Although the overall performance experienced a slight reduction, the DRL models still maintained reasonably stable throughput and edge capability.
When the number of edge servers increased with a constant number of users, both performance metrics improved significantly, supporting the idea that resource abundance benefits task offloading and data delivery. However, when the user demand increased while the edge capacity remained fixed, both throughput and edge capability declined. This behavior suggests that the DRL models can effectively manage resource constraints up to a point, after which performance degradation becomes unavoidable unless more servers are provisioned. These observations demonstrate the adaptability of DRL-based models in real-time resource management for elderly home networks. As the user base grows or changes dynamically, DRL agents can respond intelligently to maintain service quality. However, achieving consistently high performance under extreme demand conditions requires scaling of infrastructure.
5. Conclusions
This paper presented a dynamic resource allocation strategy for 5G-enabled smart elderly care homes, where both computing and network resources must be intelligently managed to support the growing and evolving demands of healthcare applications. Due to the essential nature of these services, static allocation methods are inadequate in maintaining consistent performance across different scenarios. To address this challenge, we introduced a DRL-based solution and designed an MDP, specifically to optimize resource allocation in smart elderly care settings. The proposed DRA model adapts to dynamic user demands and varying resource availability. To evaluate the adaptability of our model, we evaluated it through test scenarios such as balanced resource distribution, increased computing demands, and resource shortage conditions. Our results show that the DRA approach is capable of learning optimal allocation strategies and adapting to changes in demand. Furthermore, the comparison between the DQN and DDPG algorithms highlights their unique advantages: the DQN proves effective in managing edge resources efficiently in environments with high user density, with slightly lower throughput, while the DDPG performs exceptionally in maximizing throughput even under heavy loads, although it may compromise on edge resource optimization.
Author Contributions
Conceptualization, S.S. and K.V.S.; methodology, K.V.S.; validation, S.S.R., N.S. and H.D.; formal analysis, S.S.; investigation, L.G.; resources, S.S.; data curation, L.G.; writing—original draft preparation, K.V.S.; writing—review and editing, S.S.; visualization, L.G.; supervision, S.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- World Population Ageing 2020: Highlights: Living Arrangements of Older Persons; UN: New York, NY, USA, 2021.
- Mayhew, L.D. Health and Elderly Care Expenditure in an Aging World; IIASA Research Report; IIASA: Laxenburg, Austria, 2000. [Google Scholar]
- Ogura, S.; Jakovljevic, M.M. Global population aging-health care, social and economic consequences. Front. Public Health 2018, 6, 335. [Google Scholar] [CrossRef]
- Ahmed, S.; Irfan, S.; Kiran, N.; Masood, N.; Anjum, N.; Ramzan, N. Remote health monitoring systems for elderly people: A survey. Sensors 2023, 23, 7095. [Google Scholar] [CrossRef]
- Majumder, S.; Aghayi, E.; Noferesti, M.; Memarzadeh-Tehran, H.; Mondal, T.; Pang, Z.; Deen, M.J. Smart homes for elderly healthcare—Recent advances and research challenges. Sensors 2017, 17, 2496. [Google Scholar] [CrossRef]
- Hung, J. Smart elderly care services in China: Challenges, progress, and policy development. Sustainability 2022, 15, 178. [Google Scholar] [CrossRef]
- Kulurkar, P.; kumar Dixit, C.; Bharathi, V.; Monikavishnuvarthini, A.; Dhakne, A.; Preethi, P. AI based elderly fall prediction system using wearable sensors: A smart home-care technology with IOT. Meas. Sens. 2023, 25, 100614. [Google Scholar] [CrossRef]
- Shi, J.; Zhang, N.; Wu, K.; Wang, Z. Application Status, Challenges, and Development Prospects of Smart Technologies in Home-Based Elder Care. Electronics 2025, 14, 2463. [Google Scholar] [CrossRef]
- Ji, Y.A.; Kim, H.S. Scoping review of the literature on smart healthcare for older adults. Yonsei Med. J. 2022, 63, S14. [Google Scholar] [CrossRef]
- Nedungadi, P.; Surendran, S.; Tang, K.Y.; Raman, R. Big data and AI algorithms for sustainable development goals: A topic modeling analysis. IEEE Access 2024, 12, 188519–188541. [Google Scholar] [CrossRef]
- Choukou, M.A.; Syed-Abdul, S. Smart Home Technologies and Services for Geriatric Rehabilitation; Academic Press: Cambridge, MA, USA, 2021. [Google Scholar]
- Hoque, K.; Hossain, M.B.; Sami, A.; Das, D.; Kadir, A.; Rahman, M.A. Technological trends in 5G networks for IoT-enabled smart healthcare: A review. Int. J. Sci. Res. Arch. 2024, 12, 1399–1410. [Google Scholar] [CrossRef]
- Peralta-Ochoa, A.M.; Chaca-Asmal, P.A.; Guerrero-Vásquez, L.F.; Ordoñez-Ordoñez, J.O.; Coronel-González, E.J. Smart healthcare applications over 5G networks: A systematic review. Appl. Sci. 2023, 13, 1469. [Google Scholar] [CrossRef]
- Reddy, A.P.K.; Kumari, M.S.; Dhanwani, V.; Bachkaniwala, A.K.; Kumar, N.; Vasudevan, K.; Selvaganapathy, S.; Devar, S.K.; Rathod, P.; James, V.B. 5G new radio key performance indicators evaluation for IMT-2020 radio interface technology. IEEE Access 2021, 9, 112290–112311. [Google Scholar] [CrossRef]
- Li, C.; Zheng, J.; Zhang, X.; Luo, L.; Chu, G.; Zhao, J.; Zhang, Z.; Wang, H.; Qin, F.; Zhou, G.; et al. Telemedicine network latency management system in 5G telesurgery: A feasibility and effectiveness study. Surg. Endosc. 2024, 38, 1592–1599. [Google Scholar] [CrossRef]
- Aswanth, A.; Manoj, E.; Rajendran, K.; EM, S.K.; Duttagupta, S. Meeting Delay guarantee in Telemedicine service using SDN framework. In Proceedings of the 2021 IEEE 9th Region 10 Humanitarian Technology Conference (R10-HTC), Bangalore, India, 30 September–2 October 2021; IEEE: New York, NY, USA, 2021; pp. 1–5. [Google Scholar]
- Nayak, S.; Patgiri, R. 6G communication technology: A vision on intelligent healthcare. In Health Informatics: A Computational Perspective in Healthcare; Springer: Singapore, 2021; pp. 1–18. [Google Scholar]
- Ahad, A.; Tahir, M.; Aman Sheikh, M.; Ahmed, K.I.; Mughees, A.; Numani, A. Technologies trend towards 5G network for smart health-care using IoT: A review. Sensors 2020, 20, 4047. [Google Scholar] [CrossRef]
- Mamdiwar, S.D.; Shakruwala, Z.; Chadha, U.; Srinivasan, K.; Chang, C.Y. Recent advances on IoT-assisted wearable sensor systems for healthcare monitoring. Biosensors 2021, 11, 372. [Google Scholar] [CrossRef]
- Abdulmalek, S.; Nasir, A.; Jabbar, W.A.; Almuhaya, M.A.; Bairagi, A.K.; Khan, M.A.M.; Kee, S.H. IoT-based healthcare-monitoring system towards improving quality of life: A review. Healthcare 2022, 10, 1993. [Google Scholar] [CrossRef]
- Bisht, N.S.; Duttagupta, S. Deploying a Federated Learning Based AI Solution in a Hierarchical Edge Architecture. In Proceedings of the 2022 IEEE 10th Region 10 Humanitarian Technology Conference (R10-HTC), Hyderabad, India, 16–18 September 2022; IEEE: New York, NY, USA, 2022; pp. 247–252. [Google Scholar]
- Surendran, S.; Montresor, A.; Vinodini Ramesh, M. A Reinforcement Learning Approach for Routing in Marine Communication Network of Fishing Vessels. SN Comput. Sci. 2025, 6, 62. [Google Scholar] [CrossRef]
- Surendran, S.; Montresor, A.; Ramesh, M.V.; Casari, P. Reinforcement Learning-Based Connectivity Restoration in an Ocean Network of Fishing Vessels. In Proceedings of the 2022 IEEE International Conference on Advanced Networks and Telecommunications Systems (ANTS), Gandhinagar, India, 18–21 December 2022; IEEE: New York, NY, USA, 2022; pp. 1–6. [Google Scholar]
- Gopalakrishnan, A.; Duttagupta, S. Scheduling in time-sensitive networks using deep reinforcement learning. In Proceedings of the International Conference on Applied Soft Computing and Communication Networks, Chennai, India, 14–17 October 2020; Springer: Berlin/Heidelberg, Germany, 2023; pp. 193–207. [Google Scholar]
- Khani, M.; Jamali, S.; Sohrabi, M.K.; Sadr, M.M.; Ghaffari, A. Resource allocation in 5G cloud-RAN using deep reinforcement learning algorithms: A review. Trans. Emerg. Telecommun. Technol. 2024, 35, e4929. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, Z.; Yuan, Y.; Guan, X. Distributed Real-Time and Fair Resource Allocation for 5G Dense Cellular Networks Based on Deep Reinforcement Learning. IEEE Internet Things J. 2025. [Google Scholar] [CrossRef]
- Xiong, Z.; Zhang, Y.; Niyato, D.; Deng, R.; Wang, P.; Wang, L.C. Deep reinforcement learning for mobile 5G and beyond: Fundamentals, applications, and challenges. IEEE Veh. Technol. Mag. 2019, 14, 44–52. [Google Scholar] [CrossRef]
- Rafique, W.; Barai, J.R.; Fapojuwo, A.O.; Krishnamurthy, D. A survey on beyond 5g network slicing for smart cities applications. IEEE Commun. Surv. Tutor. 2024, 27, 595–628. [Google Scholar] [CrossRef]
- Jiang, W.; Han, B.; Habibi, M.A.; Schotten, H.D. The road towards 6G: A comprehensive survey. IEEE Open J. Commun. Soc. 2021, 2, 334–366. [Google Scholar] [CrossRef]
- Sami, H.; Otrok, H.; Bentahar, J.; Mourad, A. AI-based resource provisioning of IoE services in 6G: A deep reinforcement learning approach. IEEE Trans. Netw. Serv. Manag. 2021, 18, 3527–3540. [Google Scholar] [CrossRef]
- Wei, P.; Guo, K.; Li, Y.; Wang, J.; Feng, W.; Jin, S.; Ge, N.; Liang, Y.C. Reinforcement learning-empowered mobile edge computing for 6G edge intelligence. IEEE Access 2022, 10, 65156–65192. [Google Scholar] [CrossRef]
- Zhang, C.; Zheng, Z. Task migration for mobile edge computing using deep reinforcement learning. Future Gener. Comput. Syst. 2019, 96, 111–118. [Google Scholar] [CrossRef]
- Lu, S.; Wu, J.; Shi, J.; Lu, P.; Fang, J.; Liu, H. A dynamic service placement based on deep reinforcement learning in mobile edge computing. Network 2022, 2, 106–122. [Google Scholar] [CrossRef]
- Rui, L.; Zhang, M.; Gao, Z.; Qiu, X.; Wang, Z.; Xiong, A. Service migration in multi-access edge computing: A joint state adaptation and reinforcement learning mechanism. J. Netw. Comput. Appl. 2021, 183, 103058. [Google Scholar] [CrossRef]
- Chen, Y.; Sun, Y.; Wang, C.; Taleb, T. Dynamic task allocation and service migration in edge-cloud iot system based on deep reinforcement learning. IEEE Internet Things J. 2022, 9, 16742–16757. [Google Scholar] [CrossRef]
- Liu, F.; Yu, H.; Huang, J.; Taleb, T. Joint service migration and resource allocation in edge IoT system based on deep reinforcement learning. IEEE Internet Things J. 2023, 11, 11341–11352. [Google Scholar] [CrossRef]
- Chen, M.; Wang, T.; Zhang, S.; Liu, A. Deep reinforcement learning for computation offloading in mobile edge computing environment. Comput. Commun. 2021, 175, 1–12. [Google Scholar] [CrossRef]
- Chen, J.; Xing, H.; Xiao, Z.; Xu, L.; Tao, T. A DRL agent for jointly optimizing computation offloading and resource allocation in MEC. IEEE Internet Things J. 2021, 8, 17508–17524. [Google Scholar] [CrossRef]
- Hortelano, D.; de Miguel, I.; Barroso, R.J.D.; Aguado, J.C.; Merayo, N.; Ruiz, L.; Asensio, A.; Masip-Bruin, X.; Fernández, P.; Lorenzo, R.M.; et al. A comprehensive survey on reinforcement-learning-based computation offloading techniques in Edge Computing Systems. J. Netw. Comput. Appl. 2023, 216, 103669. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, X. Decentralized computation offloading for multi-user mobile edge computing: A deep reinforcement learning approach. Eurasip J. Wirel. Commun. Netw. 2020, 2020, 188. [Google Scholar] [CrossRef]
- Liu, Y.; Deng, Y.; Nallanathan, A.; Yuan, J. Machine learning for 6G enhanced ultra-reliable and low-latency services. IEEE Wirel. Commun. 2023, 30, 48–54. [Google Scholar] [CrossRef]
- Doke, A.R.; Sangeeta, K. Deep reinforcement learning based load balancing policy for balancing network traffic in datacenter environment. In Proceedings of the 2018 Second International Conference on Green Computing and Internet of Things (ICGCIoT), Bangalore, India, 16–18 August 2018; IEEE: New York, NY, USA, 2018; pp. 1–5. [Google Scholar]
- Ullah, I.; Lim, H.K.; Seok, Y.J.; Han, Y.H. Optimizing task offloading and resource allocation in edge-cloud networks: A DRL approach. J. Cloud Comput. 2023, 12, 112. [Google Scholar] [CrossRef]
- Pradhan, R.; Dash, A.K.; Jena, B. Resource management challenges in IoT based healthcare system. In Smart Healthcare Analytics: State of the Art; Springer: Berlin/Heidelberg, Germany, 2021; pp. 31–41. [Google Scholar]
- Mutlag, A.A.; Ghani, M.K.A.; Mohammed, M.A. A healthcare resource management optimization framework for ECG biomedical sensors. In Efficient Data Handling for Massive Internet of Medical Things: Healthcare Data Analytics; Springer: Berlin/Heidelberg, Germany, 2021; pp. 229–244. [Google Scholar]
- Lv, J.; Chen, C.M.; Kumari, S.; Li, K. Resource allocation for AI-native healthcare systems in 6G dense networks using deep reinforcement learning. Digit. Commun. Netw. 2025; in press. [Google Scholar] [CrossRef]
- Su, X.; Fang, X.; Cheng, Z.; Gong, Z.; Choi, C. Deep reinforcement learning based latency-energy minimization in smart healthcare network. Digit. Commun. Netw. 2025, 11, 795–805. [Google Scholar] [CrossRef]
- Naseer, F.; Addas, A.; Tahir, M.; Khan, M.N.; Sattar, N. Integrating generative adversarial networks with IoT for adaptive AI-powered personalized elderly care in smart homes. Front. Artif. Intell. 2025, 8, 1520592. [Google Scholar] [CrossRef]
- Rhee, I.; Shin, M.; Hong, S.; Lee, K.; Kim, S.; Chong, S. CRAWDAD ncsu/mobilitymodels. IEEE Dataport. 2022. Available online: https://ieee-dataport.org/open-access/crawdad-ncsumobilitymodels (accessed on 29 July 2025). [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).