
Exact and Approximation Algorithms for Task Offloading with Service Caching and Dependency in Mobile Edge Computing


Abstract
1. Introduction
- We define the delay-minimization problem under task dependency, service caching, and the maximum completion cost constraint, and prove its NP-hardness. Due to dependency, the delay and cost of task offloading are related to all the predecessor nodes. However, many existing studies fail to take this into account, which is of practical importance for delay-sensitive applications.
- We then propose a -approximation algorithm to solve the aforementioned problem, and derive its time complexity as , where L denotes the depth of the task graph, denotes the maximum indegree of the task graph, is the number of execution devices, is the number of tasks, and and represent the lower and upper bounds of the delay, respectively. In this paper, our approximation algorithm enables each task to make its offloading decision based on local information during execution, without the need to consider global decisions. Moreover, it provides worst-case performance guarantees, which aligns well with the characteristics of the distributed structure of MEC.
- We propose an exact algorithm that can obtain the optimal solution to the aforementioned problem. Although its time complexity is theoretically exponential, in practice, the running time is much smaller than the theoretical value when solving real-world problems.
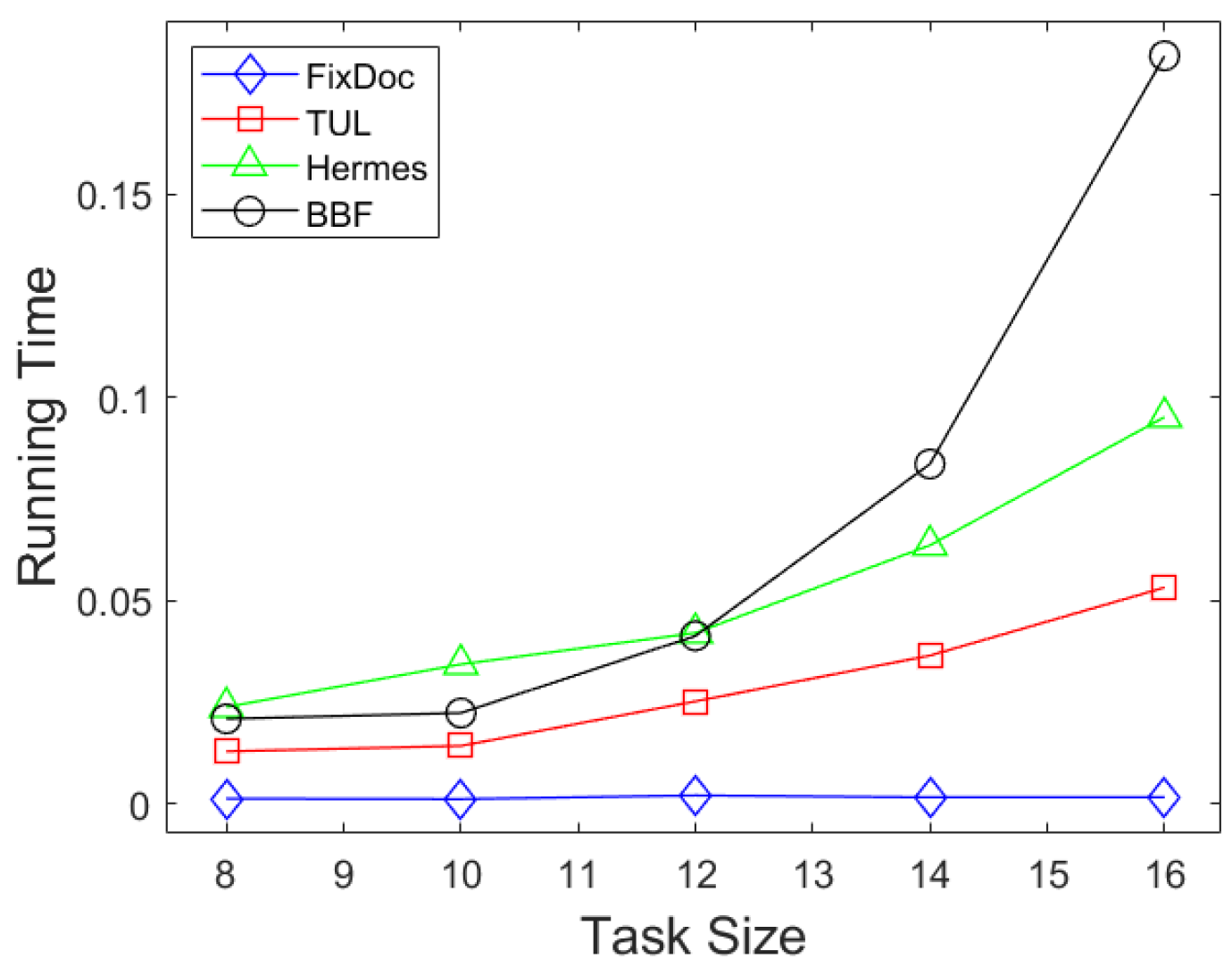
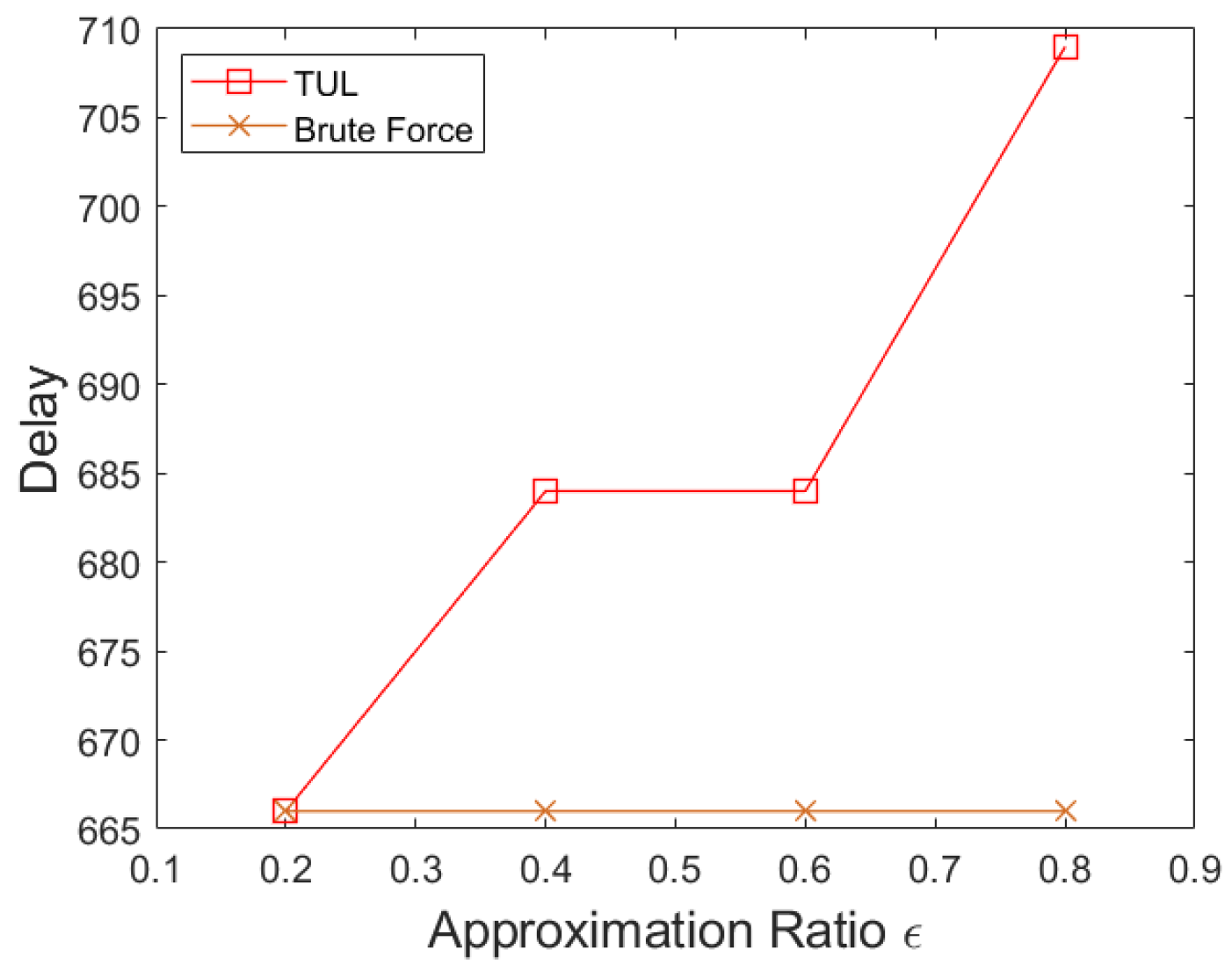
- We finally evaluate the proposed algorithm using a random task model and a real task model, then compare it with the FixDoc algorithm [19], the Hermes algorithm [32], and a brute force algorithm. The simulation results validate the approximation ratio and the superiority of the obtained offloading scheme of our algorithm over the other algorithms.
2. Related Works
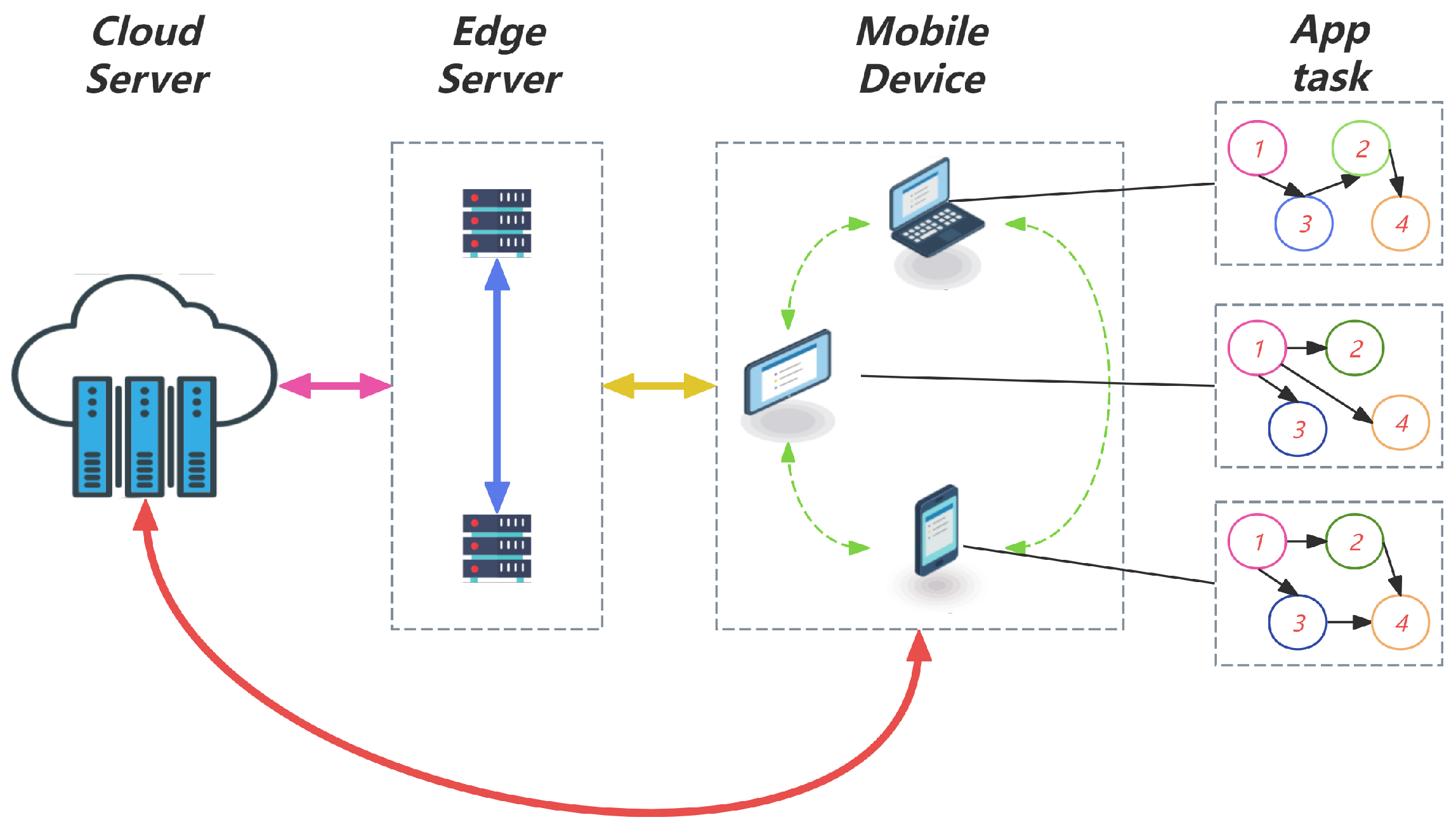
3. System Model and Problem Formulation
3.1. System Model
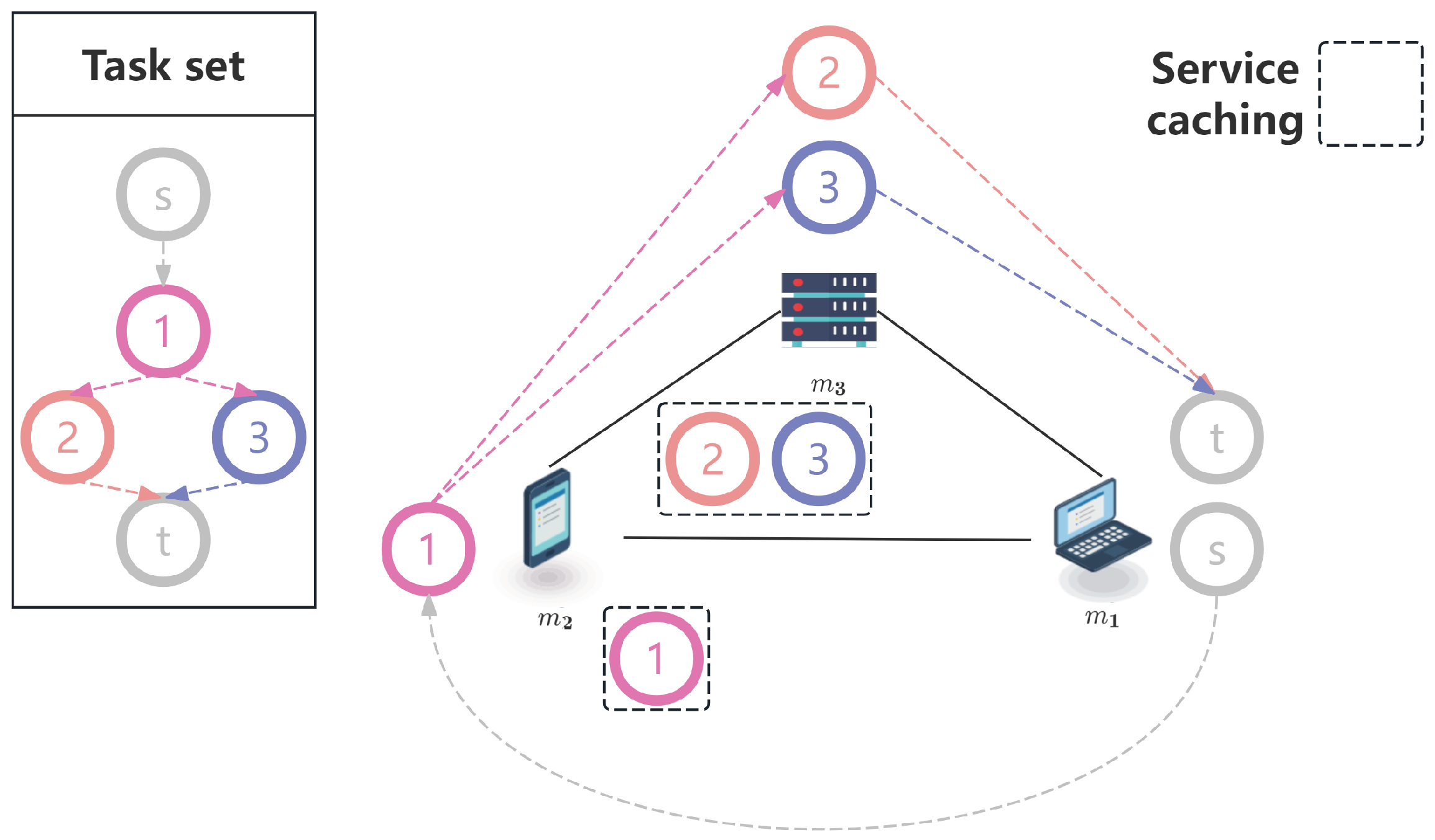
3.2. Problem Formulation
4. Approximation Algorithm
4.1. Upper and Lower Bounds of Delay
| Algorithm 1 FULC(, List I) |
|
4.2. Polynomial-Time Approximation Algorithm
| Algorithm 2 PTA(, , , , T, , List I) |
|
| Algorithm 3 TUL(, , , T, , List I) |
|
5. Exact Algorithm
5.1. Label Structure
5.2. Dominance Test
5.3. Exact Algorithm
| Algorithm 4 BFF(, , T, List I) |
|
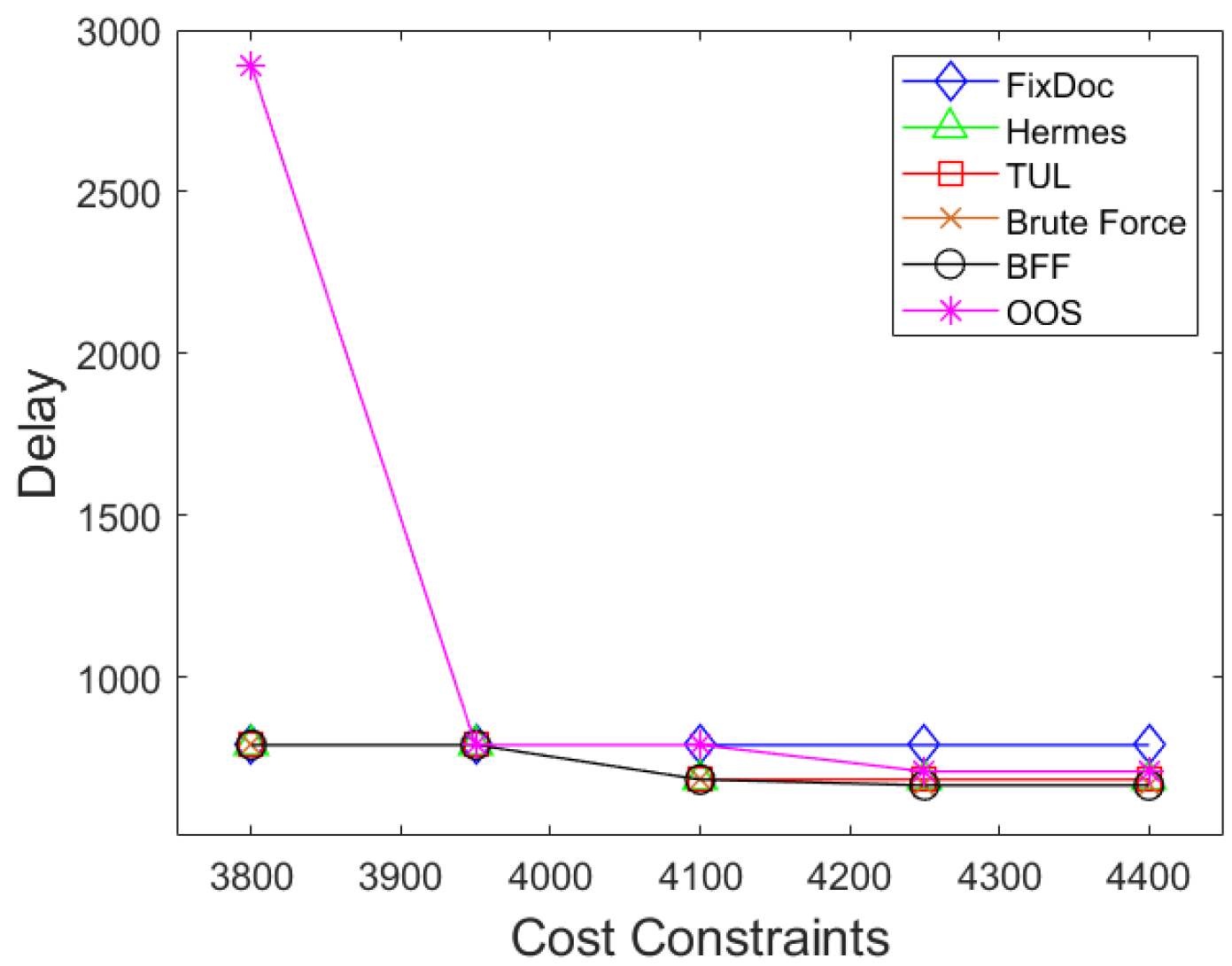
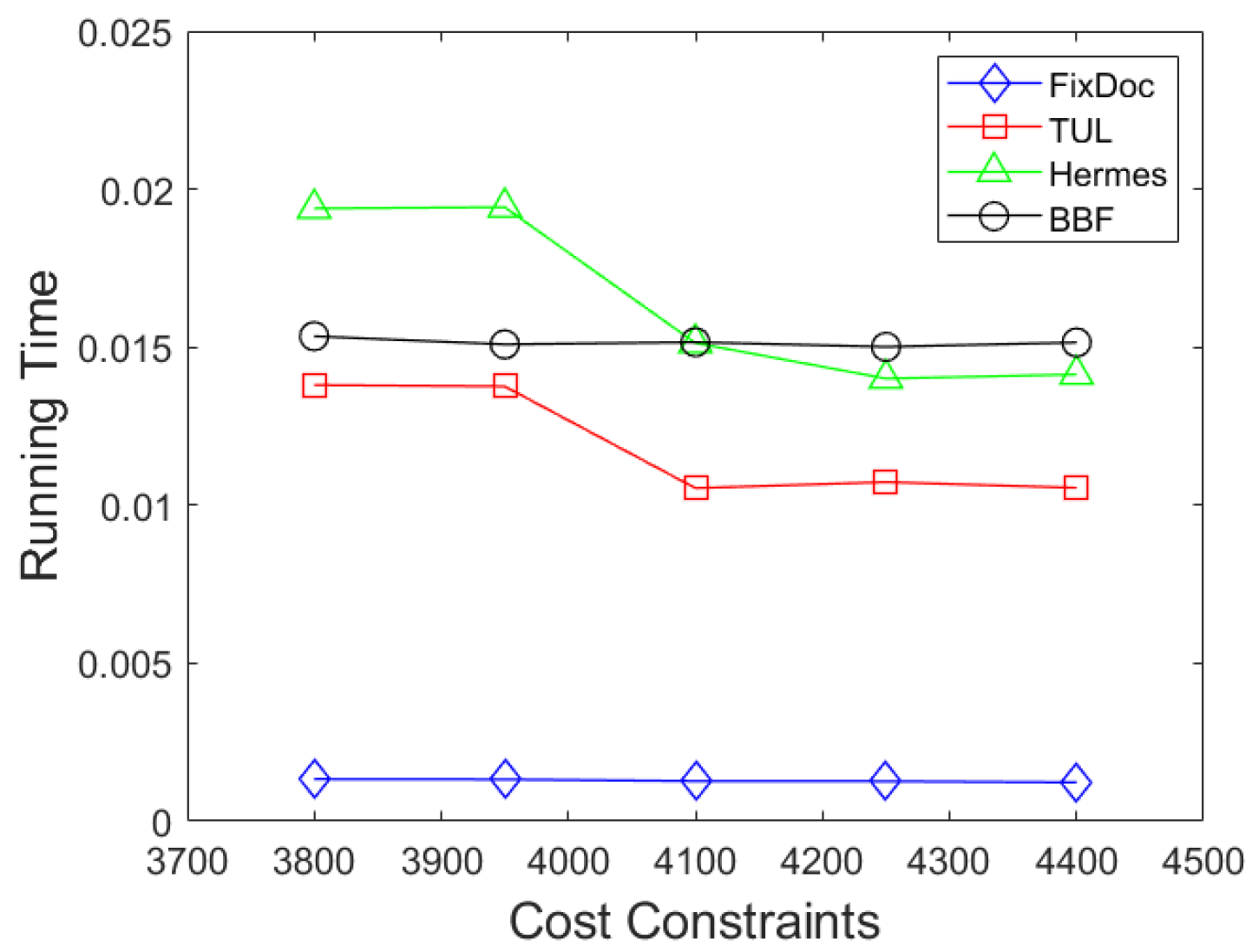
6. Simulation Results
6.1. Simulation Environment and Settings
- Offloading only to servers (OOS): The BFF algorithm offloads tasks only to edge and cloud servers. If the final offloading scheme fails to meet the cost constraints, a significant amount of time will need to be spent on the local device to cache the services required to execute these tasks. Note that the BFF algorithm in this paper is primarily used for comparison with approximation algorithms, and it also performs well in certain scenarios.
- FixDoc [19]: The algorithm is presented as Algorithm 1 in [19]. It is a task offloading method based on DP, which is the earliest proposed method in the problem we are considering. We use this algorithm to derive the task offloading strategy that minimizes the cost while satisfying the cost constraint.
- Hermes [32]: A polynomial-time approximation algorithm used to solve the delay-minimization problem under the cost constraint. To ensure fairness, we impose a constraint of service caching on the original algorithm.
- Brute force: This algorithm enumerates all possible offloading strategies to obtain the optimal solution.
6.2. Simulation Results
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Proof of Lemma 1
Appendix B. Proof of Lemma 2
References
- Mach, P.; Becvar, Z. Mobile edge computing: A survey on architecture and computation offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Xu, J.; Chen, L.; Zhou, P. Joint service caching and task offloading for mobile edge computing in dense networks. In Proceedings of the IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 207–215. [Google Scholar]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Chen, M.H.; Liang, B.; Dong, M. Joint offloading and resource allocation for computation and communication in mobile cloud with computing access point. In Proceedings of the IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Bozorgchenani, A.; Mashhadi, F.; Tarchi, D.; Monroy, S.A.S. Multi-objective computation sharing in energy and delay constrained mobile edge computing environments. IEEE Trans. Mob. Comput. 2020, 20, 2992–3005. [Google Scholar] [CrossRef]
- Chen, M.; Hao, Y. Task offloading for mobile edge computing in software defined ultra-dense network. IEEE J. Sel. Areas Commun. 2018, 36, 587–597. [Google Scholar] [CrossRef]
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile edge computing: A survey. IEEE Internet Things J. 2017, 5, 450–465. [Google Scholar] [CrossRef]
- Mao, Y.; Zhang, J.; Letaief, K.B. Joint task offloading scheduling and transmit power allocation for mobile edge computing systems. In Proceedings of the IEEE Wireless Communications and Networking Conference, San Francisco, CA, USA, 19–22 March 2017; pp. 1–6. [Google Scholar]
- Bi, S.; Huang, L.; Zhang, Y.J.A. Joint optimization of service caching placement and computation offloading in mobile edge computing systems. IEEE Trans. Wirel. Commun. 2020, 19, 4947–4963. [Google Scholar] [CrossRef]
- Zhao, G.; Xu, H.; Zhao, Y.; Qiao, C.; Huang, L. Offloading tasks with dependency and service caching in mobile edge computing. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 2777–2792. [Google Scholar] [CrossRef]
- Yang, Y.; Gong, Y.; Wu, Y.C. Intelligent-reflecting-surface-aided mobile edge computing with binary offloading: Energy minimization for IoT devices. IEEE Internet Things J. 2022, 9, 12973–12983. [Google Scholar] [CrossRef]
- Liu, Z.; Li, Z.; Wen, M.; Gong, Y.; Wu, Y.-C. STAR-RIS-aided mobile edge computing: Computation rate maximization with binary amplitude coefficients. IEEE Trans. Commun. 2023, 71, 4313–4327. [Google Scholar] [CrossRef]
- Chen, Y.; Li, K.; Wu, Y.; Huang, J.; Zhao, L. Energy efficient task offloading and resource allocation in air-ground integrated MEC systems: A distributed online approach. IEEE Trans. Mob. Comput. 2024, 23, 8129–8142. [Google Scholar] [CrossRef]
- Qin, L.; Lu, H.; Chen, Y.; Chong, B.; Wu, F. Towards decentralized task offloading and resource allocation in user-centric MEC. IEEE Trans. Mob. Comput. 2024, 23, 11807–11823. [Google Scholar] [CrossRef]
- Ra, M.R.; Sheth, A.; Mummert, L.; Pillai, P.; Wetherall, D.; Govindan, R. Odessa: Enabling interactive perception applications on mobile devices. In Proceedings of the 9th International Conference on Mobile Systems, Applications, and Services, Bethesda, MD, USA, 28 June–1 July 2011. [Google Scholar]
- Zhou, Y.; Liu, L.; Wang, L.; Hui, N.; Cui, X.; Wu, J.; Peng, Y.; Qi, Y.; Xing, C. Service-aware 6G: An intelligent and open network based on the con-vergence of communication, computing and cachin. Digit. Commun. Netw. 2020, 6, 253–260. [Google Scholar] [CrossRef]
- Cheng, G.; Jiang, C.; Yue, B.; Wang, R.; Alzahrani, B.; Zhang, Y. AI-driven proactive content caching for 6G. IEEE Wirel. Commun. 2023, 30, 180–188. [Google Scholar] [CrossRef]
- Kuo, T.Y.; Lee, M.C.; Kim, J.H.; Lee, T.S. Quality-aware joint caching, computing and communication optimization for video delivery in vehicular networks. IEEE Trans. Veh. Technol. 2023, 72, 5240–5256. [Google Scholar] [CrossRef]
- Liu, L.; Tan, H.; Jiang, S.H.C.; Han, Z.; Li, X.Y.; Huang, H. Dependent task placement and scheduling with function configuration in edge computing. In Proceedings of the IEEE International Symposium on Quality of Service, Phoenix, AZ, USA, 24–25 June 2019; pp. 1–10. [Google Scholar]
- Farhadi, V.; Mehmeti, F.; He, T.; La Porta, T.F.; Khamfroush, H.; Wang, S.; Chan, K.S.; Poularakis, K. Service placement and request scheduling for data-intensive applications in edge clouds. IEEE Trans. Netw. 2021, 29, 779–792. [Google Scholar] [CrossRef]
- Lv, X.; Du, H.; Ye, Q. TBTOA: A DAG-based task offloading scheme for mobile edge computing. In Proceedings of the IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 4607–4612. [Google Scholar]
- Arabnejad, V.; Bubendorfer, K.; Ng, B. Budget and deadline aware e-science workflow scheduling in clouds. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 29–44. [Google Scholar] [CrossRef]
- Lou, J.; Tang, Z.; Zhang, S.; Jia, W.; Zhao, W.; Li, J. Cost-effective scheduling for dependent tasks with tight deadline constraints in mobile edge computing. IEEE Trans. Mob. Comput. 2023, 22, 5829–5845. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, J.; Zhou, Y.; Yang, L.; He, B.; Yang, Y. Dependent task offloading with energy-latency tradeoff in mobile edge computing. IET Commun. 2022, 16, 1993–2001. [Google Scholar] [CrossRef]
- Wu, Q.; Ishikawa, F.; Zhu, Q.; Xia, Y.; Wen, J. Deadline-constrained cost optimization approaches for workflow scheduling in clouds. IEEE Trans. Parallel Distribut. Syst. 2017, 28, 3401–3412. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, Y.; He, X.; Yu, S. Joint scheduling and offloading of computational tasks with time dependency under edge computing networks. Simul. Model. Pract. Theory 2023, 129, 102824. [Google Scholar] [CrossRef]
- Hosny, K.M.; Awad, A.I.; Khashaba, M.M.; Fouda, M.M.; Guizani, M.; Mohamed, E.R. Enhanced multi-objective gorilla troops optimizer for real-time multi-user dependent tasks offloading in edge-cloud computing. J. Netw. Comput. Appl. 2023, 218, 103702. [Google Scholar] [CrossRef]
- Cai, Q.; Zhou, Y.; Liu, L.; Qi, Y.; Shi, J. Prioritized assignment with task dependency in collaborative mobile edge computing. IEEE Trans. Mob. Comput. 2024, 23, 13505–13521. [Google Scholar] [CrossRef]
- Zhao, M.; Zhang, X.; He, Z.; Chen, Y.; Zhang, Y. Dependency-aware task scheduling and layer loading for mobile edge computing networks. IEEE Internet Things J. 2024, 11, 34364–34381. [Google Scholar] [CrossRef]
- Zhao, L.; Zhao, Z.; Hawbani, A.; Liu, Z.; Tan, Z.; Yu, K. Dynamic caching dependency-aware task offloading in mobile edge computing. IEEE Trans. Comput. 2025, 74, 1510–1523. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, X.; Li, N.; Wang, L.; Chen, Y.; Yang, F.; Zhai, L. Collaborative content caching and task offloading in multi-access edge computing. IEEE Trans. Veh. Technol. 2023, 72, 5367–5372. [Google Scholar] [CrossRef]
- Kao, Y.H.; Krishnamachari, B.; Ra, M.R.; Bai, F. Hermes: Latency optimal task assignment for resource-constrained mobile computing. IEEE Trans. Mob. Comput. 2017, 16, 3056–3069. [Google Scholar] [CrossRef]
- Eshraghi, N.; Liang, B. Joint offloading decision and resource allocation with uncertain task computing requirement. In Proceedings of the IEEE INFOCOM, Paris, France, 29 April–2 May 2019; pp. 1414–1422. [Google Scholar]
- Tan, C.W.; Chiang, M.; Srikant, R. Fast algorithms and performance bounds for sum rate maximization in wireless networks. IEEE Trans. Netw. 2013, 21, 706–719. [Google Scholar] [CrossRef]
- Tan, C.W. Wireless network optimization by Perron-Frobenius theory. Found. Trends® Netw. 2015, 9, 107–218. [Google Scholar] [CrossRef]
- Zhang, W.; Wen, Y.; Wu, D.O. Collaborative task execution in mobile cloud computing under a stochastic wireless channel. IEEE Trans. Wirel. Commun. 2015, 14, 81–93. [Google Scholar] [CrossRef]
- Zhou, W.; Fang, W.; Li, Y.; Yuan, B.; Li, Y.; Wang, T. Markov approximation for task offloading and computation scaling in mobile edge computing. Mob. Inf. Syst. 2019, 2019, 8172698. [Google Scholar] [CrossRef]
- Younis, A.; Tran, T.X.; Pompili, D. Energy-latency-aware task offloading and approximate computing at the mobile edge. In Proceedings of the 2019 IEEE 16th International Conference on Mobile Ad Hoc and Sensor Systems, Monterey, CA, USA, 4–7 November 2019; pp. 299–307. [Google Scholar]
- Sundar, S.; Liang, B. Offloading dependent tasks with communication delay and deadline constraint. In Proceedings of the IEEE INFOCOM, Honolulu, HI, USA, 16–19 April 2018; pp. 37–45. [Google Scholar]
- Flipsen, B.; Geraedts, J.; Reinders, A.; Bakker, C.; Dafnomilis, I.; Gudadhe, A. Environmental sizing of smartphone batteries. In Proceedings of the IEEE 2012 Electronics Goes Green 2012+, Berlin, Germany, 9–12 September 2012; pp. 1–9. [Google Scholar]
- Hassin, R. Approximation schemes for the restricted shortest path problem. Math. Oper. Res. 1992, 17, 36–42. [Google Scholar] [CrossRef]
- Paixão, J.M.; Santos, J.L. Labeling methods for the general case of the multi-objective shortest path problem—A computational study. In Computational Intelligence and Decision Making: Trends and Applications; Springer: Berlin/Heidelberg, Germany, 2012; pp. 489–502. [Google Scholar]
- Gandibleux, X.; Beugnies, F.; Randriamasy, S. Martins’ algorithm revisited for multi-objective shortest path problems with a MaxMin cost function. 4OR 2006, 4, 47–59. [Google Scholar] [CrossRef]
- Topcuoglu, H.; Hariri, S.; Wu, M.Y. Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEE Trans. Parallel Distribut. Syst. 2002, 13, 260–274. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ⊙ | |||
| BFF | 763 | 335 | 1345 | 510 | 1326 | 765 |
| TUL() | 763 | 335 | 1345 | 510 | 1326 | 765 |
| TUL() | 763 | 367 | 1345 | 510 | 1326 | 813 |
| TUL() | 763 | 335 | 1533 | 591 | 1326 | 861 |
| BFF | 0.02 | 53.73 | 0.05 | 94.42 | 0.12 | 140.48 |
| TUL() | 0.07 | 4.13 | 0.14 | 6.08 | 0.29 | 17.54 |
| TUL() | 0.02 | 1.03 | 0.02 | 1.39 | 0.07 | 2.84 |
| TUL() | 0.007 | 0.51 | 0.01 | 0.79 | 0.04 | 1.58 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, B.; Zhang, J. Exact and Approximation Algorithms for Task Offloading with Service Caching and Dependency in Mobile Edge Computing. Future Internet 2025, 17, 255. https://doi.org/10.3390/fi17060255
Cui B, Zhang J. Exact and Approximation Algorithms for Task Offloading with Service Caching and Dependency in Mobile Edge Computing. Future Internet. 2025; 17(6):255. https://doi.org/10.3390/fi17060255
Chicago/Turabian StyleCui, Bowen, and Jianwei Zhang. 2025. "Exact and Approximation Algorithms for Task Offloading with Service Caching and Dependency in Mobile Edge Computing" Future Internet 17, no. 6: 255. https://doi.org/10.3390/fi17060255
APA StyleCui, B., & Zhang, J. (2025). Exact and Approximation Algorithms for Task Offloading with Service Caching and Dependency in Mobile Edge Computing. Future Internet, 17(6), 255. https://doi.org/10.3390/fi17060255