1. Introduction
Botnets persist as a significant threat to computing resources worldwide. They are one of the most hazardous types of malware, efficiently used by cyber criminals as a platform to launch various malicious activities such as distributed denial of service (DDoS) attacks, identity theft, sending spam, phishing attacks, etc. [
1]. The term “botnet” came from a combination of the two words “robot network” [
2]. It is a large network of compromised computers which are interconnected via the internet and controlled by one attacker known as the botmaster [
3]. Since the botmaster has large computing resources at their disposal, botnet attacks can be massive. In fact, cybersecurity threats are one of the major challenges for countries worldwide after digitization. According to a report [
4], over 3800 major corporations worldwide encountered data breaches in 2019, leading to significant repercussions. Another study [
5] reveals a sharp surge in botnet attacks during the first half of 2021, with their frequency increasing by 41%. Concurrently, a separate report [
5] highlights a substantial rise in the percentage of organizations detecting botnet activity, increasing from 35% to 51% during a similar time frame. Since organizations worldwide are negatively influenced by botnet attacks, there is a vital need to detect such activities. Hence, there is a necessity to develop an enhanced botnet detection framework.
Botnets are classified as centralized and decentralized botnets [
6]. Centralized botnets operate through a specific Command and Control (C&C) server. The botmaster utilizes this centralized hub to communicate with all the bots under their influence. Centralized botnets basically use IRC and HTTP protocols for communication. This architecture offers many advantages to the botmaster. It offers consistent control and coordination between the botmaster and the bots, simplifying monitoring for the botmaster. Nevertheless, it comes with a vulnerability—a single point of failure. Detecting and blocking the C&C server exposes a critical weakness. With the server blocked, the botmaster loses communication with the other bots, leading to the collapse of the entire botnet. On the other hand, decentralized botnets, also known as peer-to-peer (P2P), do not have a designated C&C server. Initially, a single bot receives the message from the C&C server. This bot then takes on the responsibility of relaying the message to peer bots, creating a chain of transmission across the network. Various communication protocols, such as Overnet, Kademlia, etc., are employed for this purpose [
6,
7].
For botnet detection, researchers are mainly focusing on machine-learning-based botnet detection models because of their high effectiveness [
8,
9]. Most of these detection models rely on feature selection, where distinct feature sets are derived from the existing high-dimensional dataset. A high-dimensional real-world dataset consists of a large number of features. But all of the features may not be essential or beneficial. Some features might be redundant and irrelevant. Feature selection removes redundant, irrelevant, and misleading features in order to obtain the most critical subset representing the best solution, thereby increasing the overall performance, accuracy, and learning speed of any machine-learning model [
10]. Hence, feature selection becomes crucial. The underlying concept of feature selection is to thoughtfully choose a relevant subset of features from the initial dataset. This reduces the dimensionality of the dataset, enhancing the overall efficiency of the learning model.
Feature selection is a combinatorial optimization problem. Combinatorial optimization problems involve a finite set of potential solutions. An optimal solution to such problems is typically found by examining all feasible solutions within the search space. However, this exhaustive approach is often impractical, particularly when dealing with a vast search space. Consequently, numerous metaheuristic algorithms have been developed and adapted to address these challenges [
11]. Metaheuristic algorithms are stochastic optimization methods designed to enhance the effectiveness of underlying heuristic techniques. These approaches effectively address the challenge of local optima and have proven successful in solving a diverse range of optimization problems [
11,
12]. While metaheuristic-based feature selection plays a crucial role in the development of various machine-learning models, it has received comparatively less attention in the literature on botnet detection.
This paper introduces an enhanced P2P botnet detection model using differential evolution-based feature selection and supervised machine-learning algorithms including ensemble learning, which can efficiently identify P2P bot communications by considering the following key questions:
- (1)
How to enhance feature selection using evolutionary metaheuristic algorithm such as differential evolution.
- (2)
How to design an enhanced learning model for P2P botnet detection using various supervised machine-learning algorithms.
- (3)
How to enhance the performance of the proposed model by using the majority voting ensemble learning algorithm.
- (4)
How to validate the proposed model in a dataset containing real-world botnet flows.
- (5)
How to evaluate the performance of the proposed model using metrics such as accuracy, precision, recall, F1-score, and confusion matrix.
The rest of this paper is arranged as follows:
Section 2 covers the related work,
Section 3 covers the proposed approach,
Section 4 contains the experiment discussions,
Section 5 contains results,
Section 6 contains comparison, and
Section 7 contains conclusions and scope for future research.
2. Related Work
Some related works that have used metaheuristic-based techniques for feature selection (FS) and machine-learning-based botnet detection are presented in this section. Based on the category of feature selection algorithms applied, we group all the state-of -the-art research works into four categories. In the first group, we discuss research works that have used swarm- and evolution-based metaheuristics for FS. In the second group, we discuss those research works that have used evolution-based metaheuristics for FS. In the third group, we discuss research works that have used human-behavior-based metaheuristics for FS. In the fourth group, we discuss those research works that have used filter methods for FS.
Lin et al. [
13] proposed a botnet detection method combining the Artificial Fish Swarm Algorithm (AFSA) for feature selection and Support Vector Machine (SVM) for classification. They compared this model with a GA-SVM system and found that AFSA yielded a superior performance, achieving 100% detection under a 10-fold cross-validation scheme. However, their experiments were conducted in a simulated LAN environment, which limits applicability to real-world, diverse network conditions. Moreover, their work does not target P2P botnets specifically, nor does it incorporate ensemble learning, which can enhance generalization. In contrast, our work focuses on detecting P2P botnets using differential evolution for feature selection and a majority voting ensemble of classifiers, applied on a real-world botnet dataset (CTU-13). Liao et al. [
14] investigated botnet detection using two metaheuristic algorithms—Particle Swarm Optimization (PSO) and Genetic Algorithm (GA)—for feature selection, combined with a backpropagation neural network for classification. Their model achieved an average detection accuracy of 95.09%. The authors also introduced a custom feature based on packet transmission regularity. While the work highlights the effectiveness of metaheuristic-driven feature selection, it lacks clarity on the dataset used and does not target P2P botnets, which are harder to detect due to their decentralized architecture. Additionally, the use of a single neural network classifier may limit generalization. In contrast, our approach employs differential evolution for feature selection and integrates six supervised classifiers in a majority voting ensemble, evaluated on a real-world P2P botnet dataset, thereby offering improved robustness and relevance. Asadi et al. [
15] proposed a hybrid botnet detection system, BD-PSO-V, that integrates Particle Swarm Optimization (PSO) for feature selection with an ensemble voting-based classification system comprising a Deep Neural Network (DNN), Support Vector Machine (SVM), and decision tree. Their model was evaluated on the ISOT and Bot-IoT datasets and achieved a high accuracy (up to 99.63%). While their work effectively demonstrates the advantage of hybrid ensemble approaches, it focuses primarily on IoT botnets and does not specifically address the detection of P2P botnets, which have more complex and decentralized architectures. Moreover, the computational demands of PSO and the limited scope of classifier diversity may constrain generalizability. In contrast, our proposed method used differential evolution (DE) for efficient feature selection and employed a broader ensemble of six classifiers under a majority voting system, specifically targeting P2P botnet detection using a real-world dataset (CTU-13 Scenario 12).
Alejandre et al. [
16] proposed a botnet detection framework focused on identifying connections during the Command and Control (C&C) phase of botnet activity. They employed a Genetic Algorithm (GA) for selecting optimal features and used a C4.5 decision tree classifier to distinguish botnet traffic. Their model achieved a high detection rate (up to 99.46%) using datasets from ISOT and ISCX. While their focus on C&C traffic is important, the work does not address P2P botnets, which do not have centralized control structure and are inherently more difficult to detect. Additionally, the use of a single classifier may limit adaptability to varying network patterns. In contrast, our work focuses on detecting P2P botnets using differential evolution (DE) for efficient feature selection and a diverse ensemble of classifiers under a majority voting strategy, validated on real-world botnet data (CTU-13 Scenario 12). Alhijaj et al. [
8] proposed a botnet detection model that integrates the Genetic Algorithm (GA) for feature selection with a decision tree classifier for traffic classification. Their approach aimed to find the optimal feature subset that enhances classification performance. Using the UNSW-NB15 and CICIDS2017 datasets, they demonstrated improved results over standard decision tree models across metrics such as precision, F1-score, and detection rate. However, their study does not address the detection of P2P botnets, which are decentralized and more elusive than conventional botnets or intrusions. Furthermore, the use of only one classifier may limit adaptability in real-world environments. In contrast, our work uses differential evolution for more efficient feature selection and applies a majority voting ensemble with six diverse classifiers, evaluated on a real-world P2P botnet dataset (CTU-13) to improve both accuracy and robustness.
Nejad et al. [
17] presented a real-time botnet detection model that utilizes the World Competitive Contests (WCC) algorithm for feature selection and Support Vector Machine (SVM) for classification. Their approach achieved an accuracy of 95%, outperforming other comparative methods. While the focus on real-time detection is commendable, the study does not specify the type of botnet traffic, and it relies on a single classifier, which may limit robustness. Additionally, the novel WCC algorithm is not extensively benchmarked against more established metaheuristics. In contrast, our work focuses on the detection of P2P botnets, a more evasive and challenging class, using differential evolution (DE) for efficient feature selection and a majority voting ensemble of six classifiers, which collectively improve accuracy and resilience under real-world conditions.
Yallamanda et al. [
18] proposed a machine-learning-based model for detecting both botnet and DDoS attacks using Support Vector Machine (SVM) and Naïve Bayes (NB) classifiers. Evaluated on the CICIDS2017 dataset, the results indicated that SVM performed better than NB. However, their approach lacks a feature selection component and focuses solely on traditional classifiers, which may limit performance on more complex and stealthy threats. Additionally, their study does not address P2P botnets, nor does it explore ensemble learning or comprehensive performance metrics. In contrast, our work focuses on P2P botnet detection using differential evolution for feature selection and a diverse ensemble of classifiers, validated with detailed performance analysis on real-world traffic. Joshi et al. [
19] conducted an empirical study using five filter-based feature selection techniques—Univariate Selection, RFE, PCA, Correlation Matrix, and Feature Importance—combined with four classifiers including SVM, Logistic Regression, KNN, and decision trees. Their experiments, conducted on the CTU-13 dataset, found that KNN consistently outperformed other classifiers across different FS techniques. While their work offers useful insights into the interaction between feature selection and classifier performance, it is limited to filter methods, which do not consider feature interdependencies. The study does not explore metaheuristic or optimization-based FS techniques, nor does it address P2P botnet detection, which presents more complex detection challenges. Our work addresses these gaps by using differential evolution (DE) for feature selection and a majority voting ensemble of six classifiers, specifically tailored for P2P botnet detection on CTU-13 Scenario 12. Ismail et al. [
20] proposed the BADS framework for botnet detection over encrypted channels using a structured six-phase methodology. They employed Information Gain as a filter-based feature selection method and used the NIMS and MCFP datasets for experimentation. While the study is notable for addressing encrypted traffic and presenting a modular detection pipeline, it relies on a single FS approach and classifier, limiting its adaptability to more dynamic and evasive botnets such as those with P2P architectures. In contrast, our work focuses on P2P botnet detection using a differential evolution-based feature selection strategy and a majority voting ensemble of six classifiers, enhancing detection performance and robustness in decentralized botnet scenarios. Muhammad et al. [
21] proposed an early-stage botnet detection model that utilizes filter-based feature selection methods (such as PCA and Information Gain) and evaluates the classification performance using Logistic Regression, Multilayer Perceptron, Support Vector Machine, and Random Forest. Using the Cyber Clean Centre (CCC) dataset, which contains IRC and HTTP-based botnet traces, their model achieved a detection accuracy of 99%. While the focus on early detection is valuable, the approach does not address the challenges posed by P2P botnets, which lack centralized control and are harder to detect. Moreover, the use of filter-based FS methods may overlook critical feature dependencies. In contrast, our study targets P2P botnet detection using differential evolution (DE) for feature selection and a majority voting ensemble of six classifiers, tested on real-world decentralized botnet traffic (CTU-13 Scenario 12) for enhanced robustness and relevance. Joshi et al. [
22] proposed a multiclass botnet detection framework using Artificial Neural Networks (ANNs), trained on a dataset comprising seven different botnet classes. Their study employed various filter-based feature selection techniques and evaluated the model on the MCFP dataset, achieving a classification accuracy of 99.04%. While the shift toward multiclass detection is noteworthy, this study does not clearly address P2P botnets, which are more difficult to detect due to their decentralized nature. Additionally, the exclusive reliance on ANN and filter-based FS methods may limit adaptability to unseen or complex attack patterns. In contrast, our study specifically targets P2P botnets using a differential evolution-based feature selection strategy and a majority voting ensemble of six classifiers, evaluated on the real-world CTU-13 Scenario 12 dataset, offering both higher robustness and practical relevance.
To summarize, while prior works have contributed significantly to botnet detection using various filter-based and metaheuristic feature selection techniques alongside diverse classifiers, several critical gaps remain unaddressed. The comprehensive summary of existing work on machine learning based botnet detection with their advantages and disadvantages are presented in
Table 1. Most studies focus on centralized botnet types and rely on limited classifier diversity or simulated environments. Moreover, filter-based feature selection dominates the landscape, often overlooking feature interdependencies and the adaptability required for detecting more elusive peer-to-peer (P2P) botnets. In contrast, our proposed approach introduces differential evolution (DE) as an efficient evolutionary strategy for feature selection, which better captures complex feature interactions. Furthermore, we enhance robustness by employing a majority voting ensemble of six diverse supervised classifiers. Most importantly, our method is specifically tailored for P2P botnet detection and is rigorously evaluated using the real-world CTU-13 Scenario 12 dataset, thereby offering a novel, scalable, and practical solution that addresses the limitations found in the existing literature.
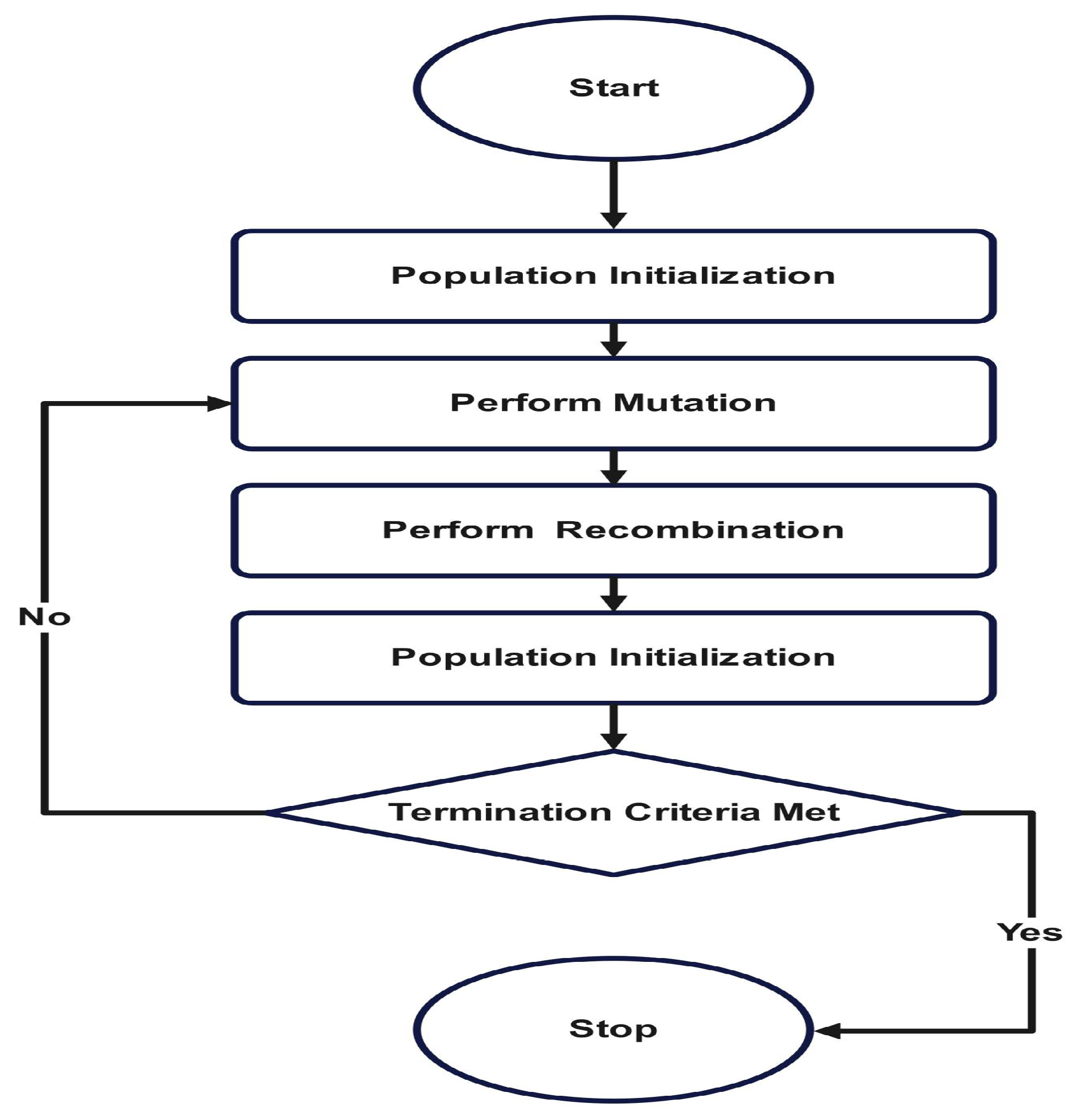
4. Experiments
This section describes the dataset used, parameter tuning of DE, all classification algorithms, and the majority voting algorithm. This section also explains all of the the evaluation matrices used in this work.
4.1. Dataset
Our experiments utilized the CTU-13 botnet dataset, which is a collection of botnet traffic that was assembled by CTU University, Czech Republic, in 2011. This is a publicly available dataset which contains 13 botnet scenarios or captures of different botnet samples summarized in 13 bidirectional NetFlow files, which comprises actual botnet traffic, offering a valuable resource for scrutinizing real botnet behavior and gaining insights into the diverse strategies employed by botnet operators [
39]. Out of these 13 bidirectional NetFlow files, we have selected the 12th scenario for our experiments because only the 12th scenario contains P2P bot nodes’ communication as well as benign nodes’ communication. The first reason for selecting this dataset is that it is publicly available, whereas there are some datasets which are not publicly accessible. Another reason is that there are certain datasets that comprise bot flows originating from a single bot node, while others feature multiple bot nodes without inter-node communication. However, the CTU-13 (Scenario 12) dataset contains three P2P bot nodes along with benign nodes and also incorporates the communication flow among bot nodes.
While the CTU-13 Scenario 12 dataset originates from 2011, it continues to serve as a valuable benchmark for botnet research—particularly in the context of P2P botnet detection. This scenario is among the few publicly available datasets that include real-world P2P botnet communication with multiple infected hosts and inter-bot interactions. These characteristics are essential for studying decentralized botnet behavior. Nevertheless, we acknowledge that botnet communication patterns evolve, and future work will involve validating the proposed feature selection and classification framework on newer datasets or real-time traffic to further assess generalizability and resilience to emerging threats.
The features related to the network traffic for Scenario 12 are shown in
Table 2.
Table 2 represents information like size, duration, number of packets, number of flows, number of bots, and bot family [
35].
This dataset is labelled and comprises bidirectional NetFlows. NetFlow is a network protocol developed by Cisco that facilitates the collection and monitoring of IP traffic information. The CTU-13 (Scenario 12) dataset is specifically a bidirectional NetFlow file and is characterized by 15 features [
6].
Table 3 describes various features of the dataset used in our experiments.
4.2. Parameter Tuning
This section discusses the experiments performed for parameter tuning of all of the algorithms used.
4.2.1. Parameter Tuning of Differential Evolution Algorithm
DE is an evolutionary metaheuristic optimization algorithm, with multiple parameters that influence its performance. The selection of these parameters plays a crucial role in determining the algorithm’s efficiency and convergence speed. These parameters can be optimized using methodologies such as grid search, random search, or by using some advanced optimization techniques to discover values that effectively address the specifics of the optimization problem at hand. Python (version 3.12) offers a range of libraries for implementing evolutionary algorithms such as SciPy, DEAP, etc. In our experiments, we have used python’s DEAP (Distributed Evolutionary Algorithms in Python) library. DEAP is a multi-purpose library for evolution strategies, and it has a number of modules adapted to various kinds of evolutionary strategies including DE. This library offers a high degree of customization and flexibility, making it a preferred choice if we wish to tailor our evolutionary algorithms to specific needs or experiment with different aspects of the algorithm’s behavior [
40]. DEAP is a powerful library for building custom evolutionary strategies for specific purposes. In our studies, however, the DE parameters [
41] that were used according to DEAP’s Simple function are as follows: “ngen”, “popsize”, “cxpb”, and “mutpb”.
Number of generations (“ngen”) is a controlling factor used to determine how many generations or iterations to carry out within the algorithm.
Population size (“popsize”) is a controlling factor used to control the number of the candidate solutions that are maintained in each generation.
Crossover probability (“cxpb”) is a control parameter that determines the likelihood of performing crossover (recombination) operations on the individuals in the population.
Mutation probability (“mutpb”) is also a control parameter that governs the chances of mutations happening in individual candidate solutions within the population.
In order to find the best value for these parameters, we have experimented with a random search algorithm. We have taken 10 values (V1 to V10) for each parameter as shown in
Table 4.
To make a selection for the most optimal values of the DE parameters, a random search algorithm was run 50 times.
Table 5 shows the fluctuations of “ngen” selected values during 50 runs.
Table 5 reveals that V8 (90) is the value that was mostly selected for the parameter “ngen”.
Table 6 shows the fluctuations of “popsize” values selected during 50 runs.
Table 6 reveals that V9 (100) is the value that was mostly selected for the parameter “popsize”.
Table 7 shows the fluctuations of “cxpb” values selected during 50 runs.
Table 7 reveals that V1 (0.1) is the value that was mostly selected for the parameter “cxpb”.
Table 8 shows the fluctuations of selected “mutpb” value.
Table 8 reveals that V10 (0.3) is the value that was mostly selected for the parameter “mutpb”.
The selected parameters of DE that are used for feature selection are given in
Table 9.
4.2.2. Parameter Tuning of Classification Algorithms
For our experiments, we have used six classification algorithms, namely NB, LDA, SVM, KNN, DT, and RF. To implement these algorithms, we used the Scikit-learn python library. To select the best values for the parameters of these algorithms, we used the randomSearchCV algorithm.
Table 10,
Table 11,
Table 12,
Table 13,
Table 14 and
Table 15 present the key parameters along with their optimal values for various classification algorithms. Specifically,
Table 10 details the parameters for the Gaussian Naïve Bayes algorithm [
42],
Table 11 for the K-Nearest Neighbors (KNN) algorithm [
43],
Table 12 for the Linear Discriminant Analysis (LDA) algorithm [
44],
Table 13 for the decision tree (DT) algorithm [
45],
Table 14 for the Random Forest (RF) algorithm [
46], and
Table 15 for the Support Vector Machine (SVM) algorithm [
47].
4.2.3. Parameter Tuning of Majority Voting Ensemble Learning Algorithm
Table 16 presents the key parameters and their optimal values for the majority voting ensemble algorithm [
48], which combines multiple base classifiers to improve the overall predictive performance. The algorithm utilizes six individual estimators—LDA, KNN, DT, RF, NB, and SVM—as the constituent models. The voting strategy employed is soft voting, which considers the predicted class probabilities from each model rather than just the final class labels. Additionally, the weights assigned to each estimator are specified as [1, 2, 2, 2, 1, 1], indicating a higher influence of KNN, DT, and RF in the final ensemble decision, thereby reflecting their stronger individual performance or contribution in the ensemble framework.
The weights [1, 2, 2, 2, 1, 1] assigned to LDA, KNN, DT, RF, NB, and SVM, respectively, were obtained using RandomizedSearchCV, which explored multiple combinations of weights across five-fold cross-validation to identify the configuration with the best predictive performance. This ensures a systematic, data-driven approach to weighting rather than relying on heuristic assumptions.
4.3. Evaluation Metrics
The following evaluation matrices have been used in our experiments:
Confusion Matrix: A confusion matrix is a very useful tool for evaluating classification models. It is particularly beneficial for handling imbalanced datasets and provides a more comprehensive evaluation than accuracy alone. It offers a comprehensive analysis of a classification algorithm’s performance by presenting a detailed summary of true positive, true negative, false positive, and false negative predictions. The key components of a confusion matrix are as follows:
True Positive (TP): TPs are occurrences that are correctly predicted as positive by the classification model.
True Negative (TN): TNs are occurrences that are correctly predicted as negative by the classification model.
False Positive (FP): FPs are occurrences that are incorrectly predicted as positive by the classification model.
False Negative (FN): FNs are occurrences that are incorrectly predicted as negative by the classification model.
Accuracy: Accuracy is a fundamental performance metric that measures the overall correctness of predictions made by a classification model. It is the ratio of correctly classified instances, both positive and negative, to the total number of instances in the dataset. It is calculated as Equation (5):
Precision: Precision is a performance metric that measures the accuracy of the positive predictions made by a classification model. In other words, it is the ratio of true positive instances, among all instances predicted as positive. It is calculated as Equation (6):
Recall (Sensitivity): Recall is also known as sensitivity or the true positive rate. This performance metric measures the ability of a classification model to correctly identify all relevant instances from a dataset. In other words, it is the ratio of true positive instances among all actual positive instances. It is calculated as Equation (7):
F1-Score: The F1-score is a performance metric that combines both precision and recall into a single value. It is the harmonic mean of precision and recall and provides a balanced measure of performance of a classification model. It is particularly useful when there is an uneven class distribution or when the cost of false positives and false negatives needs to be balanced. It is calculated as Equation (8):
5. Results
To reduce the dimensionality of the dataset, one of the state-of-the-art evolutionary algorithms known as differential evolution (DE) is used. Due to the inherent nature of stochastic optimization algorithms like DE, it produces different results each time it is run. This algorithm involves an element of randomness, and this stochastic nature can yield diverse outcomes in separate runs, even under optimal functioning conditions. The factors given below describes variations observed in the results of stochastic optimization algorithms like DE.
DE starts with a randomly generated initial population of candidate solutions. The variations among these initial solutions can influence diverse paths in the optimization process.
DE involves stochastic operations such as mutation and crossover. These stochastic processes can result in different offspring or solutions at each generation.
With each generation, the mutation operation introduces random perturbations to the solutions. The unpredictability in these perturbations can lead the optimization process to explore diverse regions of the search space in each iteration.
DE employs heuristics to direct the search, and the interaction of these heuristics with randomness can result in varied decisions across different runs.
Therefore, to mitigate the effects of randomness and to determine the most optimal features, we run the algorithm 50 times. In each run, the DE algorithm produces a diverse set of optimal features. If the number of times a feature is selected is high, that means the particular feature is very important and very relevant for classification. Thus, those features with high counts are deemed critical for effective botnet detection. The 12th scenario of the CTU-13 dataset consists of 14 features (F1 to F14), excluding the target or label, as described in
Table 3.
Table 17 shows the count of all of the features that were selected during 50 runs, where it is possible that more than one feature is selected in each run.
Table 17 reveals that feature 4 (SrcAddr) was the mostly selected feature.
The repeated use of SrcAddr (source IP address) shows how useful it is in classifying P2P botnet traffic. In networks infected with botnets, compromised hosts (bots) participate in recurrent and decentralized peer-to-peer communication. This leads to anomalous behavior where specific source IPs initiate an excessive number of connections, sometimes to different destinations or within very short intervals. These patterns can significantly differ from typical host behavior in legitimate traffic, making SrcAddr a valuable feature for distinguishing infected nodes.
Sport (source port) was the second most frequently selected feature in DE runs due to its operational significance. Botnet communications may involve the use of non-standard or fixed source ports for consistent peer discovery or command exchange. The appearance of uncommon or repetitive source ports across different flows can signal the presence of malware or automated behavior. From a domain perspective, both SrcAddr and Sport provide granular, connection-level insights that are highly effective for detecting distributed and stealthy P2P botnet activities.
In the experiments, it has been found that all of the classifiers and the ensemble learning algorithm exhibit different levels of performance when different feature subsets are applied. In order to find out the optimal result, the proposed approach was tested with different feature subsets. The initial subset encompasses the two most optimal features, followed by the gradual creation of subsequent subsets through the incremental addition of less significant features, up to the incorporation of the least significant one.
Table 18 demonstrates the results of the majority voting ensemble algorithm using all of the feature subsets.
By analyzing the table above, we can draw the following conclusions:
Accuracy is consistently high across all feature sets, ranging between 99.97% and 99.99%. The accuracy remains nearly unchanged, even as the number of features increases.
Precision is a key metric that measures the proportion of true positives out of all positive predictions. A feature set with two features gives the highest precision at 99.49, which decreases slightly as more features are included but generally remains high.
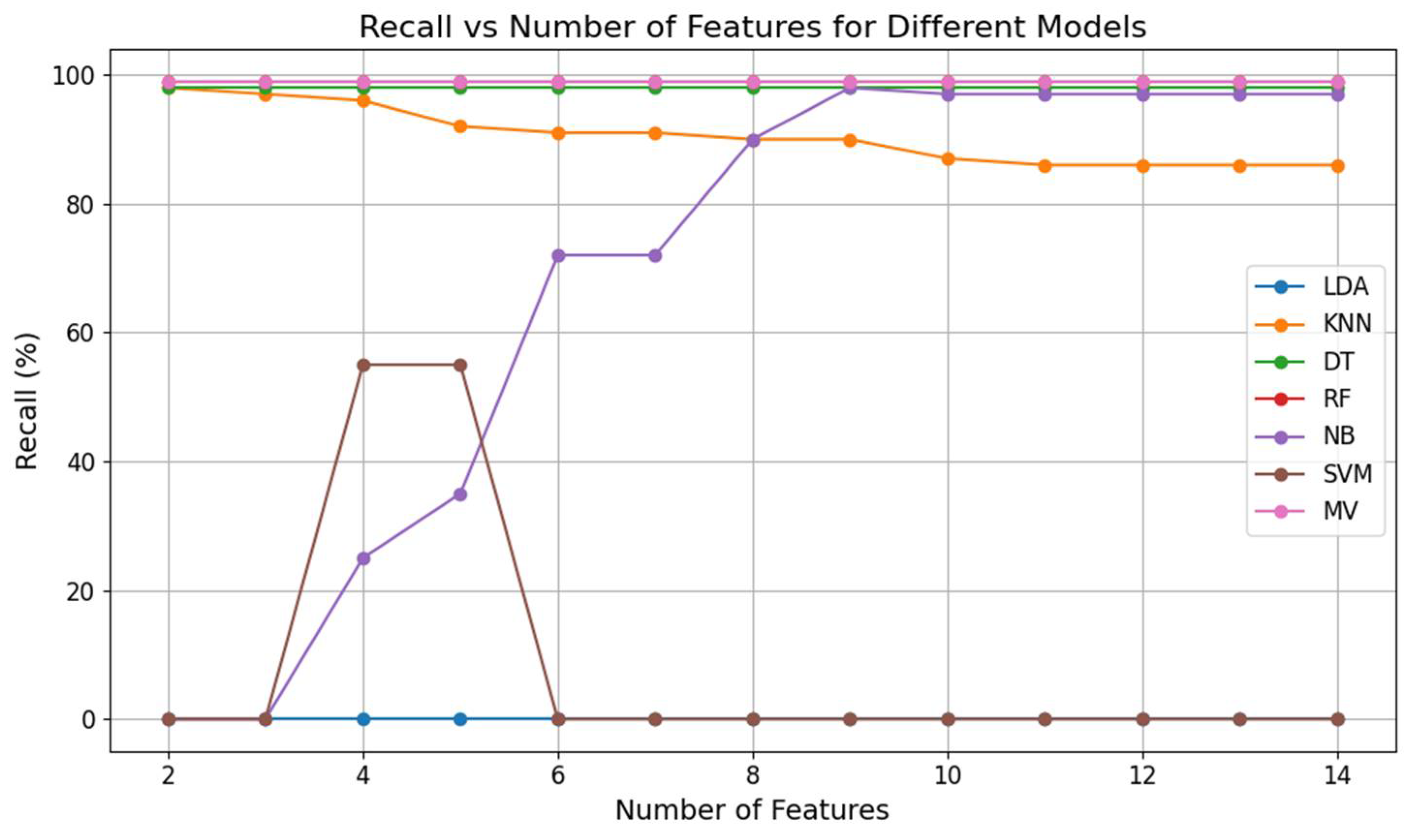
Recall measures how well the model identifies true positives out of all actual positives. The recall is highest with the two-feature set (98.98%) and tends to decrease as more features are added, bottoming out at 95.54% with seven features.
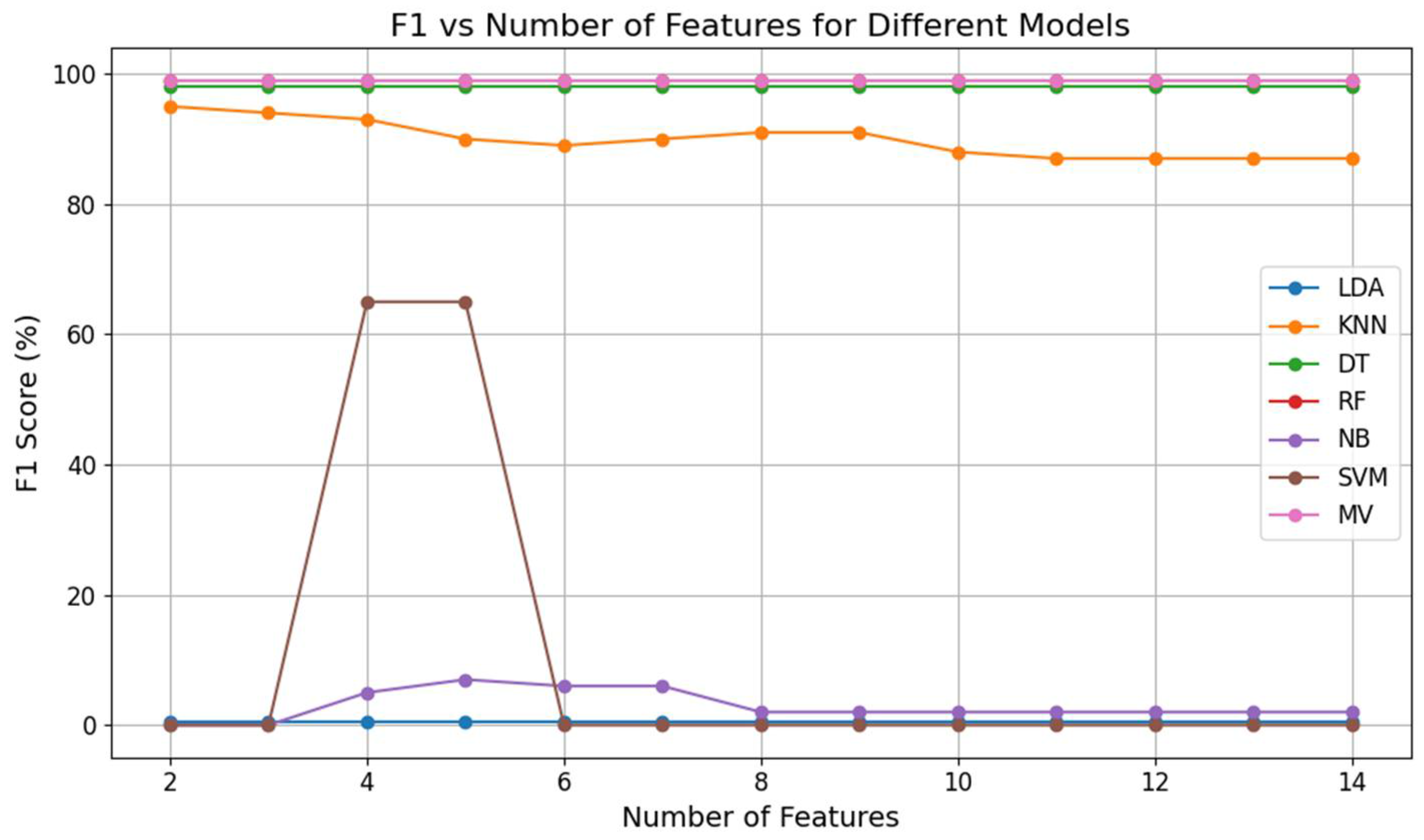
The F1-score balances precision and recall, and its values are high across all feature sets. The highest F1-score (99.23%) is observed with two features, which balances both precision and recall well.
The true positives are highest with feature sets ranging from 9 to 10 features (2086 TPs).
The false negatives (missed detections) are lowest when using two features (22 FNs), which is desirable as it indicates fewer missed detections of positive cases.
The false positives (incorrect positive classifications) are slightly higher with feature sets that have fewer features (such as 2 features with 11 FPs) but remain very close across most feature sets.
Based on the F1-score (which balances precision and recall), two features appear to represent the optimal feature set, as this provides the highest F1-score (99.23%); the highest recall (98.98%), which means the model identifies more true positives; the highest precision (99.49%), reducing the number of false positives; and the lowest number of false negatives (22 FNs). Thus, using two features gives the best balance between precision and recall, making it the most efficient feature set for this task.
The following table (
Table 19) demonstrates the accuracy matrix of the model using all of the feature subsets.
The below figures (
Figure 3 and
Figure 4) display the accuracy and precision of the six classification algorithms and majority voting ensemble learning algorithm. The following table (
Table 20) demonstrates the precision matrix of the model using all of the feature subsets.
The following table (
Table 21) demonstrates the recall matrix of the model using all of the feature subsets.
Figure 5 shows the recall vs. number of features for different models for a peer-to-peer botnet detection system.
The following table (
Table 22) demonstrates the F1-score matrix of the model using all of the feature subsets.
The figures above (
Figure 3,
Figure 4,
Figure 5 and
Figure 6) illustrate the performance of six classification algorithms (NB, KNN, DT, LDA, RF, and SVM) and the ensemble learning algorithm (mv) across all of the feature subsets.
In order to enhance the performance of the proposed method, we employed the majority voting algorithm. This involved taking the results obtained from the base classifiers mentioned earlier (as detailed in
Table 18) and utilizing them as input for the majority voting algorithm. The output of this ensemble approach, depicted in
Table 18, represents the final result of our methodology.
Our method attained an accuracy of 99.99% (
Table 23), indicating that the overall predictions made by the classification model are highly accurate. While accuracy is crucial, especially in balanced datasets, it may not fully represent model performance in imbalanced class distributions. Therefore, we also evaluated our model using precision, recall, and F1-score metrics and we generated a confusion matrix as well. Our method achieved a precision of 99.49%, ensuring that a large proportion of instances predicted as positive are indeed relevant. With a recall value of 98.98%, our model effectively minimizes false negatives, correctly identifying a significant portion of positive instances. Furthermore, the F1-score, at 99.23%, signifies a strong balance between precision and recall, highlighting the robustness of our model’s performance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}