
Optimizing Internet of Things Services Placement in Fog Computing Using Hybrid Recommendation System

Abstract

1. Introduction
2. Related Work
2.1. Fog Computing Architecture
Fog Computing Features
- Proximity to end users and low latency: FC offers the advantage of being close to end users and having low latency. This is because Fog nodes are located close to end devices or data sources, allowing them to collect and process service requests, store the results at the Edge of the network, and send the responses to the service requester. As a result, Fog nodes (FNs) can reduce the amount of data transmitted across the network, minimizing the risk of data loss, thus minimizing the average response time. This feature renders FC well suited for delay-sensitive applications, such as live gaming traffic monitoring, among others.
- Greater data control and privacy: Users have greater control over their data, thanks to the proximity of end devices with Fog nodes, rather than outsourcing them to distant Cloud data centers. In fact, FC enables data to be processed locally before transferring delay-tolerant data to remote servers [11].
- Heterogeneity: Fog nodes are available in a variety of form factors and will be deployed in a wide variety of environments [12]. In fact, the heterogeneity of FNs refers to the diversity of devices and configurations in which these nodes are deployed. That is, they exist in a multitude of sizes, shapes, and hardware capabilities. These nodes can be complete servers dedicated to gateways, specialized IoT devices, etc. What is more, these nodes are deployed in a wide variety of environments, ranging from dense urban to remote rural areas, from industrial plants to transportation infrastructures, etc.
- Support for real-time applications: FC can support real-time applications thanks to its ability to have close proximity to end devices, enabling faster data analysis and response times than conventional centralized data centers. These include applications such as virtual reality, augmented reality, traffic monitoring, telesurgery, etc. [11].
- Decentralization and geo-distribution: Unlike the centralized architecture of Cloud computing, FC is a distributed architecture comprising huge, geographically distributed heterogeneous nodes covering numerous domains. This property enables location-based services and guarantees the provision of very low-latency services [11].
- Autonomy and programmability: Fog infrastructures are characterized by autonomous decision making for the management of the applications deployed on it. In fact, the simplicity of programming and reconfiguration, made possible by virtualization, simplifies management and ensures the infrastructure’s ability to adapt to the changing dynamics of the environment.
- Energy efficiency: It remains a challenge in the IoT environment, particularly regarding the energy consumption of large IoT devices. FC addresses this issue by empowering these devices to make intelligent decisions, such as toggling between on/off/hibernate states, ultimately leading to a reduction in overall energy consumption [13].
- Cost: In the context of Cloud computing, where resources are generally billed according to usage (pay-per-use model), some applications may find it more advantageous to invest once in the acquisition of private Fog resources (a form of decentralized processing closer to users) rather than pay regularly for instances in the Cloud. This highlights an alternative economic consideration for specific applications.
- Management of services: FC operates as an intermediary layer to furnish computational capabilities. This not only facilitates device control but also permits the customization of services tailored to the specific environment [14].
2.2. Overview of Existing Solutions
3. Hybrid Service Placement Based on a Recommender System
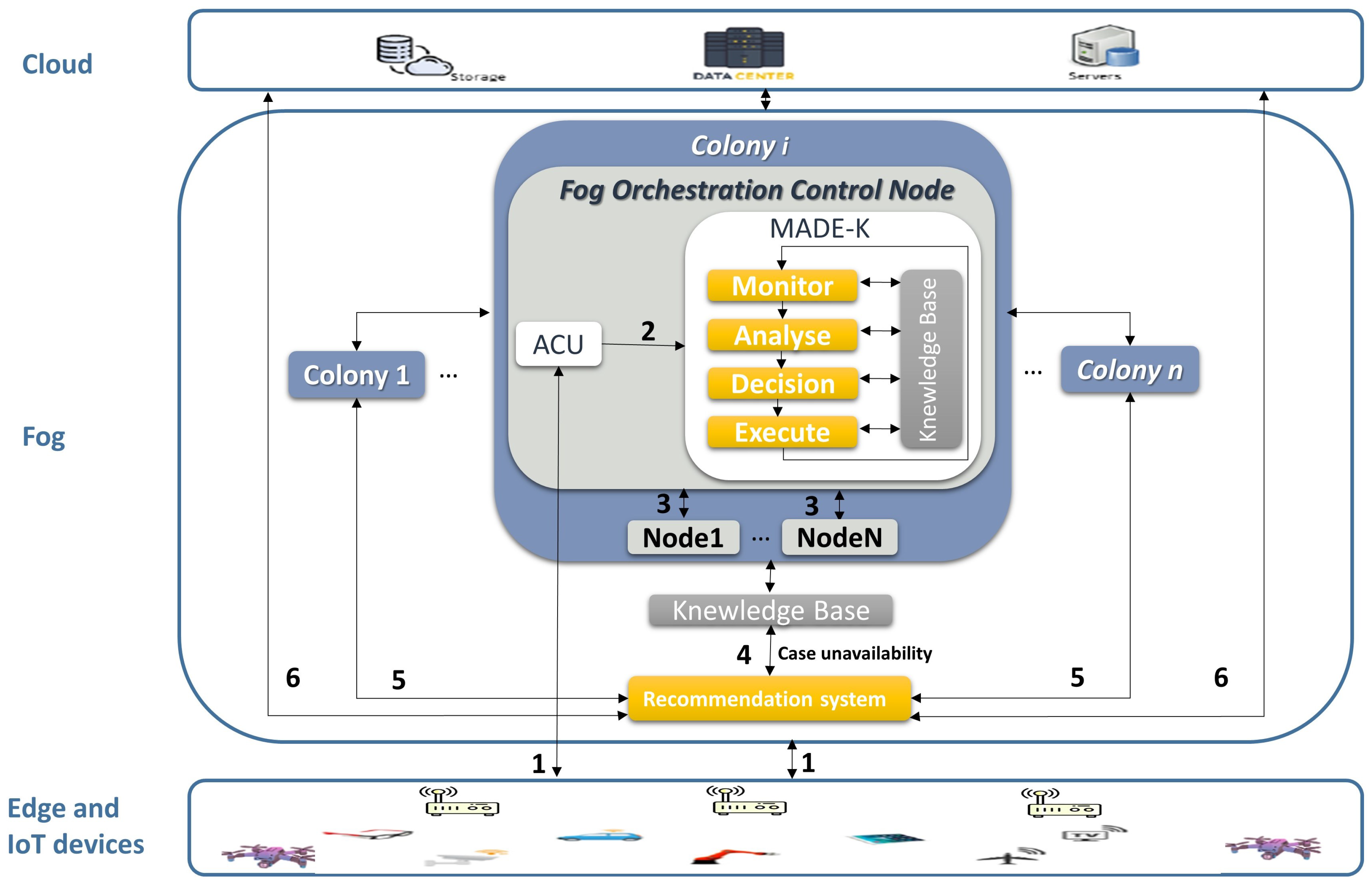
3.1. Proposed Architecture (System Model)
3.1.1. Colony
3.1.2. Fog Nodes
3.1.3. Fog Orchestrator Control Node
3.1.4. Recommendation System
4. Proposed Methodology
4.1. Solution Based on the FOCN
4.2. Solution Based on the Recommendation System
4.2.1. Data Collection
4.2.2. Data Processing
| Algorithm 1 Data Processing |
|
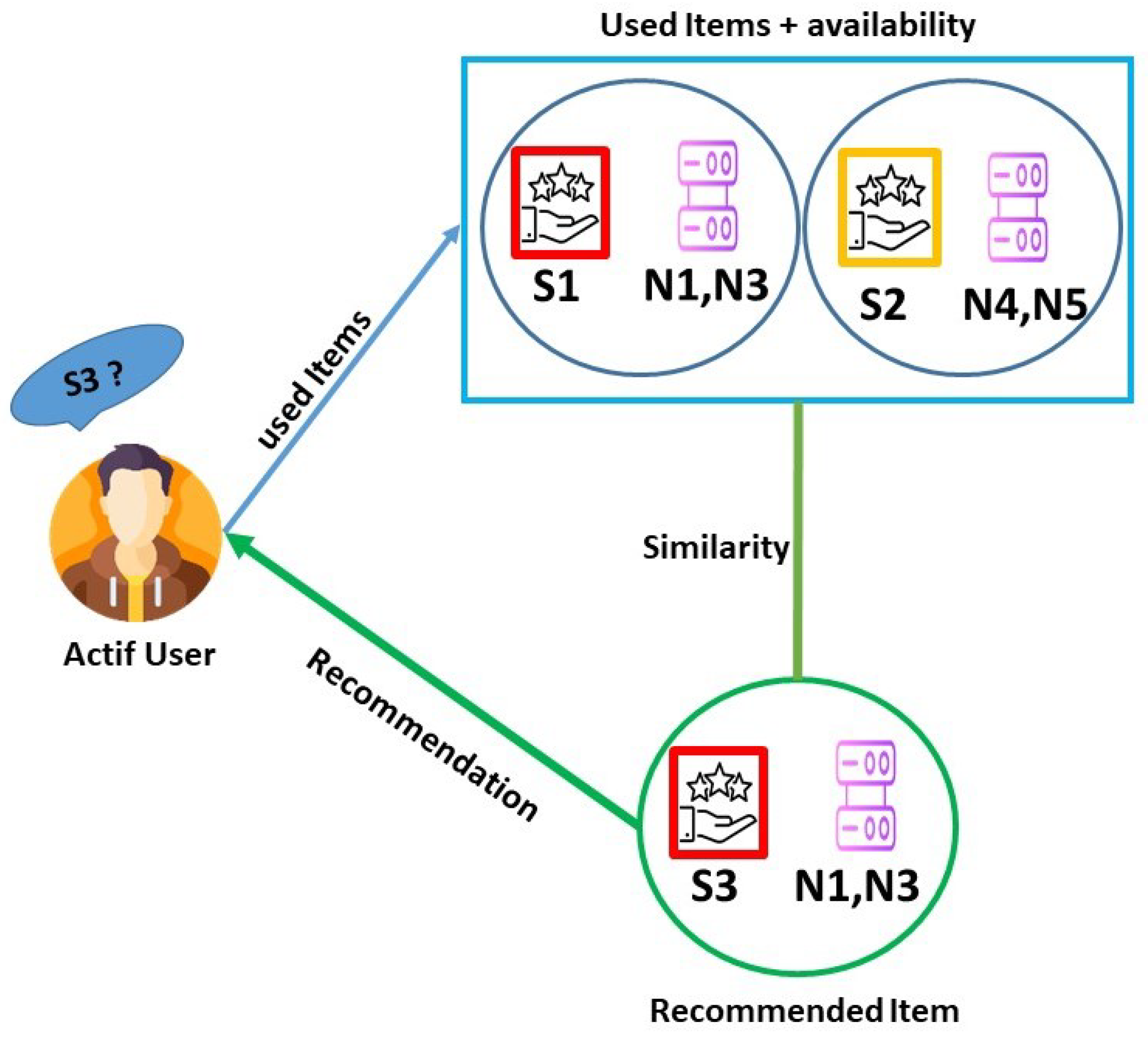
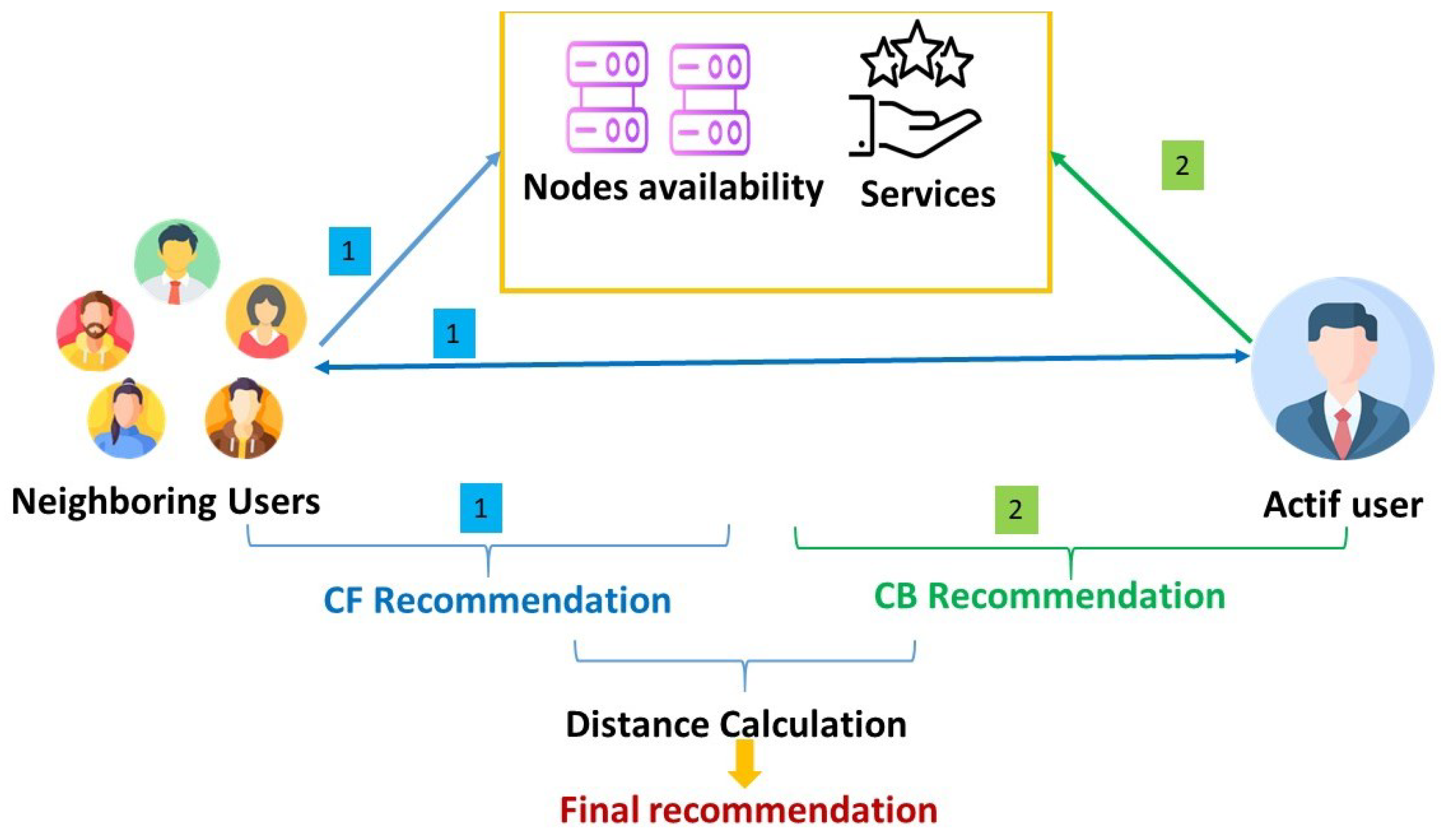
4.2.3. Collaborative Filtering
- be the requirement vector of the target user .
- be the requirement vector of another user .
- n be the number of considered features.
- For each of the top K users, the system retrieves the node they previously used to deploy the same or a similar service.
- If the node is still available (i.e., it satisfies the current resource constraints), it is immediately selected.
- If not, the system proceeds to the next most similar user, continuing this process until a suitable node is found or the K-list is exhausted.
| Algorithm 2 Collaborative Filtering |
|
4.2.4. Content-Based Filtering
- is the value of feature i (e.g., CPU, RAM, storage, and delay) in the requirement vector of the target service .
- is the value of feature i (e.g., CPU, RAM, storage, and delay) in the feature vector of colony node .
- n is the number of features considered (e.g., 4 features: CPU, RAM, storage, and delay).
| Algorithm 3 Content-Based Filtering |
|
4.2.5. Combining Results
- be the 3D coordinates of the user.
- be the coordinates of the node recommended by collaborative filtering.
- be the coordinates of the node recommended by content-based filtering.
| Algorithm 4 Combining Results |
|
4.2.6. Implementation
| Algorithm 5 Implementation |
|
- Use of Fog: our solution maximizes the use of Fog. Indeed, we aim to place the maximum number of services in the Fog layer instead of transferring them to the Cloud, since in the event of the unavailability of the current colony, instead of sending the request to the Cloud layer, the RS looks for a location in the other Fog colonies to increase the chance of placement in Fog.
- Dynamism: Our solution takes dynamism into account. If the RS detects the unavailability of the Fog node, it looks for another available node, then retransmits and reallocates the service to the most suitable node.
- Mobility: Our proposal takes mobility into account. Indeed, if the RS detects the mobility of the end user, then it looks for another node that is closer to this customer, then retransmits and re-routes the service to the most suitable node.
- Latency: Placing the service in the Fog layer reduces latency since it is closer to the user. What is more, in the event of the unavailability of a node in the current colony, the RS can search faster than moving from one colony to another.
- Response time: fog placement is faster than Cloud placement.
- SLA: service placement considers service delay and prioritizes the service with the closest delay.
- QOS: SLA criteria, latency, etc., are QOS criteria that help satisfy the customer.
5. Experimental Results and Discussion
5.1. Simulation and Technical Development Framework
5.2. Case Study: Drones
- Functional modules: The drone is equipped with functional modules, including sensor and actuator modules. These modules enable the drone to collect sensor data from its environment and perform actions based on the processed data.
- Client module: likely can be located on the IoT device itself, preprocesses the data and sends it to the processing module.
- Processing/main module: this module includes Fog devices and Cloud data centers.
- Storage module: after processing, making the decision, etc., the results will be stored in this module which can be in Fog or Cloud.
5.3. Performance Metrics, Results, and Discussion
- Number of services performed: this metric represents the number of services executed successfully within defined time periods, which directly reflects the system’s effectiveness in meeting time constraints and user expectations [7].
- Number of failed services: This measures how many services were not executed before their deadlines. A lower number indicates better placement decisions that respect time-critical requirements.
- Number of remaining services: Some services may not be successfully allocated due to a limited number of time periods. Services that meet the deadline but remain unallocated are eligible for placement in the next time period.
- Fog resource utilization: Reflects deploying the highest possible number of services on Fog nodes. A higher Fog utilization means more services are executed closer to end users, reducing reliance on remote Cloud resources. Since Cloud offloading often introduces additional delay, improving Fog usage directly contributes to reducing overall service latency.
- Improve the results found in our system evaluation concerning waiting time, Fog utilization, etc.
- The treatment of other SPP-related objectives in Fog such as cost of service and energy consumption.
- Testing our work in the real world with large amounts of data.
- Ensuring QOS becomes an important issue in the event of faulty Fog nodes. Indeed, a faulty node means, for example, a node that gives false information about its state or has not processed the services received after a certain time, so that if the number of services received is small, it will be considered available and can receive other services. Therefore, it is necessary to address the issue of the fault tolerance of service placement in Fog.
- Security is also very important, and we have to consider it. Indeed, for solutions based on user history and information (like our solution), it is crucial to protect these data.
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| FC | Fog Computing |
| SPP | Service placement problem |
| IoT | Internet of Things |
| IoD | Internet of Drones |
| HRS | Hybrid recommendation system |
| RS | Recommendation system |
| S | Second |
| QOS | Quality of Service |
| SLA | Service-level agreement |
| GA | Genetic algorithm |
| ICA | Imperialist Competitive Algorithm |
| HAPs | High-Altitude Platforms |
| LAPs | Low-Altitude Platforms |
| CSA | Cuckoo search algorithm |
| ACU | Admission control unit |
References
- Zorgati, H.; Djemaa, R.; Amor, I. Finding Internet of Things resources: A state-of-the-art study. Data Knowl. Eng. 2022, 140, 102025. [Google Scholar] [CrossRef]
- Burke, R. Hybrid recommender systems: Survey and experiments. User Model. User Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Mior, I.; Sicari, S.; De Pellegrini, F.; Chlamtac, I. Internet of things: Vision, applications and research challenges. Ad Hoc Netw. 2012, 10, 1497–1516. [Google Scholar] [CrossRef]
- Tan, L.; Wang, N. Future internet: The internet of things. In Proceedings of the 2010 3rd International Conference on Advanced Computer Theory and Engineering (ICACTE), Chengdu, China, 20–22 August 2010; Volume 5, p. V5-376. [Google Scholar] [CrossRef]
- Lopez, P.; Montresor, A.; Epema, D.; Datta, A.; Higashino, T.; Iamnitchi, A.; Barcellos, M.; Felber, P.; Riviere, E. Edge-centric computing: Vision and challenges. ACM SIGCOMM Comput. Commun. Rev. 2015, 45, 37–42. [Google Scholar] [CrossRef]
- Sabireen, H.; Neelanarayanan, V. A review on fog computing: Architecture, fog with IoT, algorithms and research challenges. ICT Express 2021, 7, 162–176. [Google Scholar] [CrossRef]
- Zhao, D.; Zou, Q.; Boshkani Zadeh, M. A QoS-aware IoT service placement mechanism in fog computing based on open-source development model. J. Grid Comput. 2022, 20, 12. [Google Scholar] [CrossRef]
- Sarrafzade, N.; Entezari-Maleki, R.; Sousa, L. A genetic-based approach for service placement in fog computing. J. Supercomput. 2022, 78, 10854–10875. [Google Scholar] [CrossRef]
- Gasmi, K.; Dilek, S.; Tosun, S.; Ozdemir, S. A survey on computation offloading and service placement in fog computing-based IoT. J. Supercomput. 2022, 78, 1983–2014. [Google Scholar] [CrossRef]
- Mell, P.; Grance, T. The NIST Definition of Cloud Computing; Technical report; Computer Security Division, Information Technology Laboratory, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2011. [Google Scholar]
- Raghavendra, M.; Chawla, P.; Rana, A. A survey of optimization algorithms for fog computing service placement. In Proceedings of the 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 4–5 June 2020; pp. 259–262. [Google Scholar]
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog computing and its role in the internet of things. In Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing, Helsinki, Finland, 17 August 2012; pp. 13–16. [Google Scholar]
- Jalali, F.; Vishwanath, A.; De Hoog, J.; Suits, F. Interconnecting Fog computing and microgrids for greening IoT. In Proceedings of the 2016 IEEE Innovative Smart Grid Technologies-Asia (ISGT-Asia), Melbourne, Australia, 28 November–1 December 2016; pp. 693–698. [Google Scholar]
- Taneja, M.; Davy, A. Resource aware placement of IoT application modules in Fog-Cloud Computing Paradigm. In Proceedings of the 2017 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Lisbon, Portugal, 8–12 May 2017; pp. 1222–1228. [Google Scholar] [CrossRef]
- Srichan, S.; Majhi, S.; Jena, S.; Mishra, K.; Bhat, R. A Secure and Distributed Placement for Quality of Service-Aware IoT Requests in Fog-Cloud of Things: A Novel Joint Algorithmic Approach. IEEE Access 2024, 12, 56730–56748. [Google Scholar] [CrossRef]
- Wei, Z.; Mao, J.; Li, B.; Zhang, R. Privacy-Preserving Hierarchical Reinforcement Learning Framework for Task Offloading in Low-Altitude Vehicular Fog Computing. IEEE Open J. Commun. Soc. 2024, 6, 3389–3403. [Google Scholar] [CrossRef]
- Liu, C.; Wang, J.; Zhou, L.; Rezaeipanah, A. Solving the multi-objective problem of IoT service placement in fog computing using cuckoo search algorithm. Neural Process. Lett. 2022, 54, 1823–1854. [Google Scholar] [CrossRef]
- Ayoubi, M.; Ramezanpour, M.; Khors, R. An autonomous IoT service placement methodology in fog computing. Softw. Pract. Exp. 2021, 51, 1097–1120. [Google Scholar] [CrossRef]
- Skarlat, O.; Nardelli, M.; Schulte, S.; Borkowski, M.; Leitner, P. Optimized IoT service placement in the fog. Serv. Oriented Comput. Appl. 2017, 11, 427–443. [Google Scholar] [CrossRef]
- Canali, C.; Lancellotti, R. Gasp: Genetic algorithms for service placement in fog computing systems. Algorithms 2019, 12, 201. [Google Scholar] [CrossRef]
- Al Masarweh, M.; Alwada’n, T.; Afandi, W. Fog computing, cloud computing and IoT environment: Advanced broker management system. J. Sens. Actuator Netw. 2022, 11, 84. [Google Scholar] [CrossRef]
- Proietti, M.G.; Magnani, M.; Beraldi, R. A Latency-levelling Load Balancing Algorithm for Fog and Edge Computing. In Proceedings of the 25th International ACM Conference on Modeling Analysis and Simulation of Wireless and Mobile Systems, Montreal, QC, Canada, 24–28 October 2022; pp. 5–14. [Google Scholar]
- Khosroabadi, F.; Fotouhi-Ghazvini, F.; Fotouhi, H. Scatter: Service placement in real-time fog-assisted IoT networks. J. Sens. Actuator Netw. 2021, 10, 26. [Google Scholar] [CrossRef]
- Maiti, P.; Sahoo, B.; Turuk, A.K.; Kumar, A.; Choi, B.J. Internet of Things applications placement to minimize latency in multi-tier fog computing framework. ICT Express 2022, 8, 166–173. [Google Scholar] [CrossRef]
- Kopras, B.; Bossy, B.; Idzikowski, F.; Kryszkiewicz, P.; Bogucka, H. Task allocation for energy optimization in fog computing networks with latency constraints. IEEE Trans. Commun. 2022, 70, 8229–8243. [Google Scholar] [CrossRef]
- Shi, C.; Ren, Z.; Yang, K.; Chen, C.; Zhang, H.; Xiao, Y.; Hou, X. Ultra-low latency cloud-fog computing for industrial internet of things. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar]
- Skarlat, O.; Nardelli, M.; Schulte, S.; Dustdar, S. Towards QoS-aware Fog Service Placement. In Proceedings of the 2017 IEEE 1st International Conference on Fog and Edge Computing (ICFEC), Madrid, Spain, 14–15 May 2017; pp. 89–96. [Google Scholar]
- Natesha, B.; Guddeti, R. Meta-heuristic based hybrid service placement strategies for two-level fog computing architecture. J. Netw. Syst. Manag. 2022, 30, 47. [Google Scholar] [CrossRef]
- Zhang, Z.; Sun, H.; Abutuqayqah, H. An efficient and autonomous scheme for solving IoT service placement problem using the improved Archimedes optimization algorithm. J. King Saud Univ. Comput. Inf. Sci. 2023, 35, 157–175. [Google Scholar] [CrossRef]
- Zare, M.; Sola, Y.; Hasanpour, H. Towards distributed and autonomous IoT service placement in fog computing using asynchronous advantage actor-critic algorithm. J. King Saud Univ. Comput. Inf. Sci. 2023, 35, 368–381. [Google Scholar] [CrossRef]
- Zare, M.; Sola, Y.; Hasanpour, H. Imperialist competitive based approach for efficient deployment of IoT services in fog computing. Clust. Comput. 2023, 7, 1–4. [Google Scholar] [CrossRef]
- Yang, X.; Deb, S. Cuckoo search via Lévy flights. In Proceedings of the 2009 World Congress on Nature Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar]
- Wang, R.F.; Su, W.H. The Application of Deep Learning in the Whole Potato Production Chain: A Comprehensive Review. Agriculture 2024, 14, 1225. [Google Scholar] [CrossRef]
- Ghobaei-Arani, M.; Souri, A.; Rahmanian, A. Resource management approaches in fog computing: A comprehensive review. J. Grid Comput. 2020, 18, 1–42. [Google Scholar] [CrossRef]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl. Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Lops, P.; De Gemmis, M.; Semeraro, G. Content-based recommender systems: State of the art and trends. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2011; pp. 73–105. [Google Scholar] [CrossRef]
- Schafer, J.; Frankowski, D.; Herlocker, J.; Sen, S. Collaborative filtering recommender systems. In The Adaptive Web: Methods and Strategies of Web Personalization; Springer: Berlin/Heidelberg, Germany, 2007; pp. 291–324. [Google Scholar] [CrossRef]
- Burke, R. Hybrid web recommender systems. In The Adaptive Web: Methods and Strategies of Web Personalization; Springer: Berlin/Heidelberg, Germany, 2007; pp. 377–408. [Google Scholar] [CrossRef]
- Mahmud, R.; Buyya, R. Modelling and simulation of fog and edge computing environments using iFogSim toolkit. In Fog and Edge Computing: Principles and Paradigms; Wiley: Hoboken, NJ, USA, 2019; Volume 1. [Google Scholar] [CrossRef]
- Calheiros, R.; Ranjan, R.; Beloglazov, A.; De Rose, C.; Buyya, R. CloudSim: A toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms. Softw. Pract. Exp. 2011, 41, 23–50. [Google Scholar] [CrossRef]
- Gupta, H.; Dastjerdi, A.; Ghosh, S.; Buyya, R. iFogSim: A toolkit for modeling and simulation of resource management techniques in the Internet of Things, Edge and Fog computing environments. Softw. Pract. Exp. 2017, 47, 1275–1296. [Google Scholar] [CrossRef]
- Mahmud, R.; Pallewatta, S.; Goudarzi, M.; Buyya, R. Ifogsim2: An extended ifogsim simulator for mobility, clustering, and microservice management in edge and fog computing environments. J. Syst. Softw. 2022, 190, 111351. [Google Scholar] [CrossRef]
- Qayyum, T.; Malik, A.; Khattak, M.; Khalid, O.; Khan, S. FogNetSim++: A toolkit for modeling and simulation of distributed fog environment. IEEE Access 2018, 6, 63570–63583. [Google Scholar] [CrossRef]
- Puliafito, C.; Goncalves, D.; Lopes, M.; Martins, L.; Madeira, E.; Mingozzi, E.; Rana, O.; Bittencourt, L. MobFogSim: Simulation of mobility and migration for fog computing. Simul. Model. Pract. Theory 2020, 101, 102062. [Google Scholar] [CrossRef]
- Lera, I.; Guerrero, C.; Juiz, C. YAFS: A simulator for IoT scenarios in fog computing. IEEE Access 2019, 7, 91745–91758. [Google Scholar] [CrossRef]
- Salama, M.; Elkhatib, Y.; Blair, G. IoTNetSim: A modelling and simulation platform for end-to-end IoT services and networking. In Proceedings of the 12th IEEE/ACM International Conference on Utility and Cloud Computing (UCC’19), Auckland, New Zealand, 2–5 December 2019; pp. 251–261. [Google Scholar]
- Mass, J.; Srirama, S.; Chang, C. STEP-ONE: Simulated testbed for edge-fog processes based on the opportunistic network environment simulator. J. Syst. Softw. 2020, 166, 110587. [Google Scholar] [CrossRef]
- Piorkowski, M.; Sarafijanovic-Djukic, N.; Grossglauser, M. CRAWDAD epfl/mobility. IEEE Dataport 2022. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect: | Cloud | Fog | Edge |
|---|---|---|---|
| Operator: | Cloud Providers | Cloud and Network Access Providers | Edge Providers |
| Architecture: | Centralized | Distributed | Distributed |
| Basic equipment | Powerful servers | Network equipment, dedicated computing nodes | Network equipment, Edge devices |
| Energy consumption: | High | Moderate | Low |
| Latency: | High | Moderate | Low |
| User distance: | Large | Relatively small | Very small |
| Number of nodes: | Small | Large | Very large |
| Mobility support: | Limited | Yes | Yes |
| Security: | Less (non-local) | High (local) | High (local) |
| Response time: | High | Low | Very low |
| Computing power: | High | Less power | Moderate |
| Fog Feature | References |
|---|---|
| Reduce latency | [7,8,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31] |
| Data privacy and security | [15,16] |
| Energy efficiency | [7,17,23,28,29,31] |
| Cost | [7,17,21,23,28,29,30,31] |
| Method | Ref | Techniques | Performance Metrics | Domain | Evaluation Tool |
|---|---|---|---|---|---|
| Heuristic | [19] | GA | Latency, throughput | Smart city | iFogSim |
| [20] | GA | Latency | Smart city | Testbed | |
| [22] | Load balancing | Latency | General | Simpy | |
| [23] | SCATTER | Cost, EC, RT, latency, and FU | Smart Home | iFogSim | |
| [7] | ODMA | Cost, EC, RT, latency, and FU | Healthcare | iFogSim | |
| [8] | GA | Application delay and network usage | General | iFogSim | |
| Exact solvers | [25] | CPLEX solver | Latency, cost | General | Matlab |
| [27] | ILP solver | Latency, cost | General | iFogSim | |
| Meta-Heuristic | [29] | SPP-AOA | FU, service cost, EC, delay cost, and throughput | General | Matlab |
| [17] | CSA | FU, delay, RT, SLA, EC, and cost | Industry | Matlab | |
| [31] | ICA | FU, service cost, EC, delay, and throughput | General | Matlab | |
| Evolutionary | [18] | SPEA-II | FU, service latency, and cost | General | iFogSim |
| scheduling | [21] | Round robin + Weighted fair queuing | QOS (SLA) | General | iFogSim + CloudSim |
| [24] | Scheduling algorithms | Latency | General | Matlab | |
| Machine learning | [30] | DRL + A3C-SPP | Latency, cost | General | Matlab |
| [16] | AFedPPO and CCP FL | Privacy preservation, latency | Vehicular Fog Computing | AirFogSim | |
| Hybrid | [15] | ANFIS, CHBA, and OBL | Makespan, delay violation, cost, FU, and EC | General | Matlab |
| [28] | MGAPSO + EGAPSO | QOS, service cost, EC, and the service time | Industry | Testbed | |
| HRS | Content + collaborative filtering | FU, delay, and RT | IoD | iFogSim2 |
| Ref. | Use of Fog | Dynamic | Mobility | Latency | Recommendation System | History and Preferences | Simulation |
|---|---|---|---|---|---|---|---|
| [17] | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [18] | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [19] | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [20] | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| [21] | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [22] | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [23] | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [24] | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [25] | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| [26] | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [27] | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [7] | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ |
| [8] | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ |
| [28] | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ |
| [29] | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [30] | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [31] | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [15] | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ |
| [16] | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ |
| HRS | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Matlab | iFogSim |
|---|---|
| Created in 1984 | Created in 2012 |
| Used in various fields of science | Specific: specifically designed for engineering fields |
| Uses its own Matlab | Used in conjunction with Java |
| Language for scripting and Simulink for graphical modeling |
| Simulators Dataset | Real Mobility | Custumized Formation | Cluster |
|---|---|---|---|
| FogNetSim++ [44] | ✗ | ✓ | ✗ |
| MobFogSim [45] | ✓ | ✓ | ✗ |
| YAFS [46] | ✗ | ✗ | ✓ |
| IoTNetSim [47] | ✓ | ✓ | ✗ |
| STEP-ONE [48] | ✓ | ✓ | ✗ |
| iFogSim2 [45] | ✓ | ✓ | ✓ |
| Device Type | CPU (MIPS) | RAM (MB) | Uplink Bandwidth (Mbps) | Downlink Bandwidth (Mbps) |
|---|---|---|---|---|
| Cloud data center | 44,800 | 40,000 | 100 | 10,000 |
| Proxy server | 2800 | 4000 | 10,000 | 10,000 |
| Fog device | 2800 | 4000 | 10,000 | 10,000 |
| End device | 1000 | 1000 | 10,000 | 270 |
| Source | Destination | Latency |
|---|---|---|
| Sensor | Final device | 0.6 |
| Actuator | Final device | 0.1 |
| Final device | Fog device | 2.0 |
| Fog device | Proxy server | 4.0 |
| Proxy server | Cloud datacenter | 100.0 |
| Time Period (T) | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Time (S) | 8 | 16 | 24 | 32 | 40 |
| Number of services | 71 | 48 | 48 | 46 | 97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ben Rjeb, H.; Sliman, L.; Zorgati, H.; Ben Djemaa, R.; Dhraief, A. Optimizing Internet of Things Services Placement in Fog Computing Using Hybrid Recommendation System. Future Internet 2025, 17, 201. https://doi.org/10.3390/fi17050201
Ben Rjeb H, Sliman L, Zorgati H, Ben Djemaa R, Dhraief A. Optimizing Internet of Things Services Placement in Fog Computing Using Hybrid Recommendation System. Future Internet. 2025; 17(5):201. https://doi.org/10.3390/fi17050201
Chicago/Turabian StyleBen Rjeb, Hanen, Layth Sliman, Hela Zorgati, Raoudha Ben Djemaa, and Amine Dhraief. 2025. "Optimizing Internet of Things Services Placement in Fog Computing Using Hybrid Recommendation System" Future Internet 17, no. 5: 201. https://doi.org/10.3390/fi17050201
APA StyleBen Rjeb, H., Sliman, L., Zorgati, H., Ben Djemaa, R., & Dhraief, A. (2025). Optimizing Internet of Things Services Placement in Fog Computing Using Hybrid Recommendation System. Future Internet, 17(5), 201. https://doi.org/10.3390/fi17050201