

Railway Cloud Resource Management as a Service


Abstract
1. Introduction
- The requirements for fault and performance management of the railway cloud resource are identified based on an analysis of different use cases;
- The communication between railway cloud management applications and the railway cloud management services for fault and performance management is designed as RESTful Application Programming Interfaces (APIs);
- Models, representing the views on the alarm status of a fault management application and a fault management service, are developed, and formally described. Using the concept of synchronization between the states of two state machines, it is proved that the models maintain synchronized-in-time views on the alarm status;
- Models, representing the views on the performance management job status and on the process of subscription to and notification of performance data of an application and a service, are developed, and formally described. It is proved that the models maintain synchronized-in-time views.
2. Related Works
- Automated deployment of services and applications across multiple environments. This ensures consistent configurations and reduces human errors through automation. In [24], the authors present a survey on edge clouds that use automated deployment mechanisms, namely Infrastructure as Code tools. In [25], the authors describe a framework for managing edge computing and heterogenous high performance computing clusters. A framework that facilitates the development and deployment of AI services at the network edge is proposed in [26].
- Resource management. This enables management and scaling infrastructure resources based on demands. Automatic allocation and deallocation of infrastructure resources optimizes the costs. In [27], the authors present a literature survey of cloud computing algorithms and provide a comparative study of various resource management. In [28], the authors propose a strategy for cloud resource management based on an auction mechanism which improves the resource allocation rate. In [29], the authors present a collaborative cloud resource management approach based on a job scheduling algorithm, which is an improved version of a swarm intelligence algorithm that reduces the convergence speed for optimal results. In [30], the authors demonstrated the advantages and significance of the workload pattern for learning-based cloud resource management.
- Management of multi-cloud or hybrid cloud environments. Coordinating resources across multiple cloud providers needs to ensure the seamless integration and management of diverse environments. A discussion on management of computing in the era of the hybrid cloud is presented in [31]. In [32], the authors provide a review of the research on multi-cloud management platforms.
- Continuous integration/continuous deployment (CI/CD). This includes automation of the testing and deployment process to ensure rapid and reliable software delivery. In [33], the authors present an implementation of a cybersecurity approach to the CI/CD pipeline that automates the installation and deployment of its various components in cloud-based systems. An entire automated pipeline, starting with detecting changes in the application source code, creating new resources in the Kubernetes cluster to host this new version, and finally deploying the containerized application is presented in [34]. Based on a discussion of use cases and current challenges, the authors of [35] describe a framework for managing cloud-based AI application lifecycles and its key components. Research on configuration management of cloud-based applications is presented in [36].
- Disaster recovery. The creation of automated disaster recovery plans can quickly restore services after an outage or failure. This includes testing and validating backup procedures in a streamlined manner. A discussion on the role of cloud computing in preparation of disaster management and how an organization can use the latest technology to minimize the consequences on it is presented in [37]. A cloud platform disaster recovery model based on the characteristics of the cloud platform, data replication, and load balancing technologies described in [38].
- Security and Compliance. Implementing security policies across all cloud resources is important to maintain compliance with industry standards. This includes automation of security measures enforcement, such as access controls, encryption, and logging. In [39], the authors outline the security issues that cloud computing raises, and suggest solutions that safeguard private information and systems in cloud-based environments for businesses. In [40], the author provides general guidelines on auditing standards by referring to threats and vulnerabilities, and suggests a unified approach toward audit considerations in cloud computing environment.
- Monitoring and analytics. Integration of cloud orchestration with monitoring and analytics platforms provides real-time insights into the performance of the cloud infrastructure. It is aimed at automatic resource adjustment based on usage patterns and alerts from monitoring tools. The tutorial presented in [41] discusses the AI techniques that can help in fault and performance management in multi-cloud virtual network. In [42], the authors present an application anomaly detection and bottleneck identification system based on cloud platform service components, that can monitor and analyze applications on multi-layered cloud platforms with customized index values. Studies on the platform design of distributed cloud monitoring and the key technologies of big data storage can be found in [43]. The survey presented in [44] provides an overview and analysis of advanced techniques for anomaly detection and localization of cloudified multi-service applications.
- Container management. Orchestration tools, like Kubernetes, can manage containerized applications, ensuring high availability and efficient resource utilization. It is also referred to as automatically scaling of container instances based on application demand. The authors of [45] discuss and compare emerging container platforms and cloud-centric orchestration frameworks, highlighting the challenges involved.
- Microservices architecture. Microservices are a powerful architectural paradigm for creating and deploying contemporary applications in the cloud computing environment. They can be managed and scaled independently. Microservices management must ensure service discovery and load balancing across distributed systems. In [46], the authors compare the features and constraints of several cloud platforms and tools for deploying and orchestrating microservices. A comprehensive overview of microservices as a suitable complementation of cloud computing is provided in [47], where the authors outline their technical challenges, such as performance, debugging, and data consistency.
- Cloud resource management (CRM) services that orchestrate railway cloud lifecycle processes, and are responsible for the allocation and delivery of cloud resources and resource management software, including cloud deployment services, cloud infrastructure catalogue services, railway cloud monitoring services, railway cloud provisioning services, etc.
- Cloudified function management (CFM) services that are responsible for the management of the lifecycles of the cloudified railway functions deployed on the railway cloud.
- Verification of API: Synchronization between the states is used to verify that an API (as a way of communication in distributed system) behaves correctly under various conditions.
- Concurrency verification: Synchronization between the states is used to verify whether the models maintained by a managing application and respective models maintained by a service, which communicate with each other, are synchronized in time. This is important for ensuring that systems behave correctly when they run concurrently.
- Model checking: Synchronization between the states is used in model checking, which is a method of verifying the correctness of a system by constructing mathematical models of the application logic and service logic, and then checking them against the desired behavior. The concept is used to verify whether the models behave as expected.
3. Fault Management of Railway Cloud Resources
3.1. Fault Management Use Cases
3.2. Fault Management as a Service
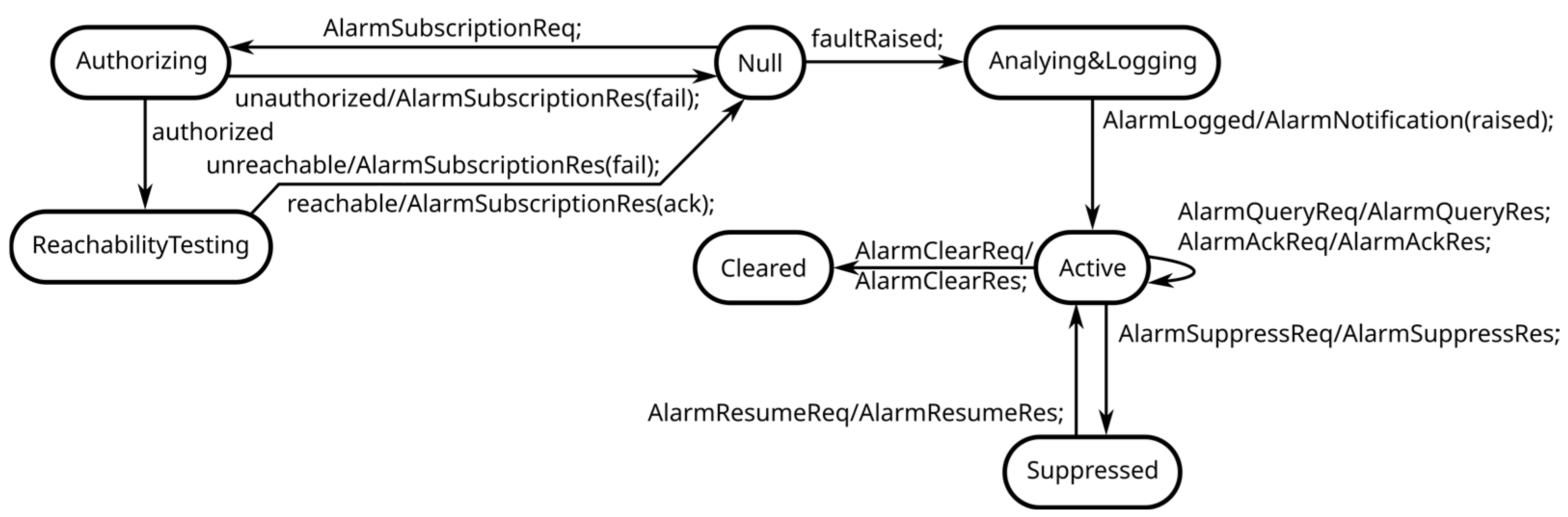
- create a new alarm definition and its criteria and actions, and to update the criteria and actions for an existing alarm;
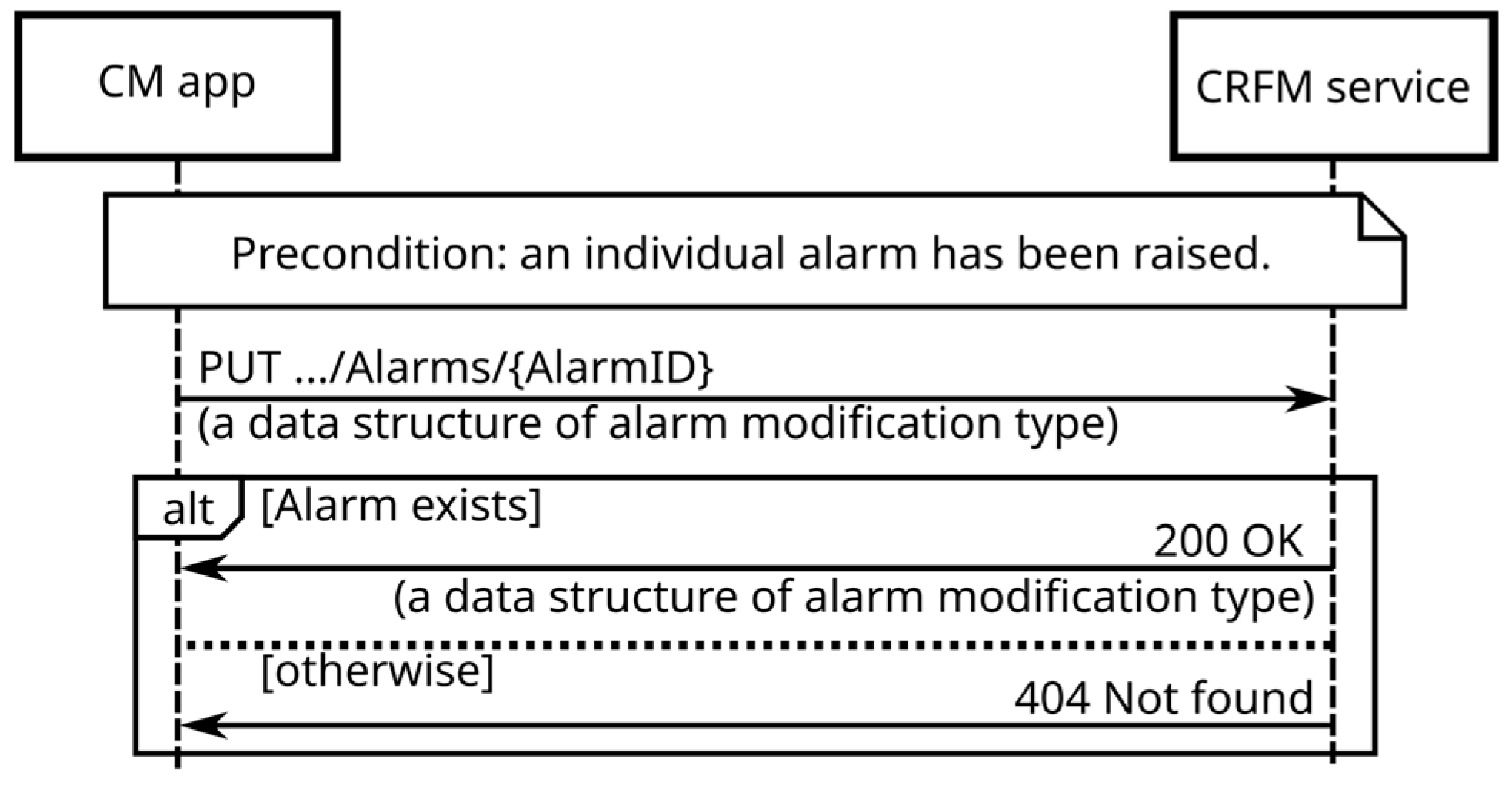
- retrieve information about an existing alarm;
- acknowledge/clear an existing alarm;
- activate/deactivate the alarm suppression;
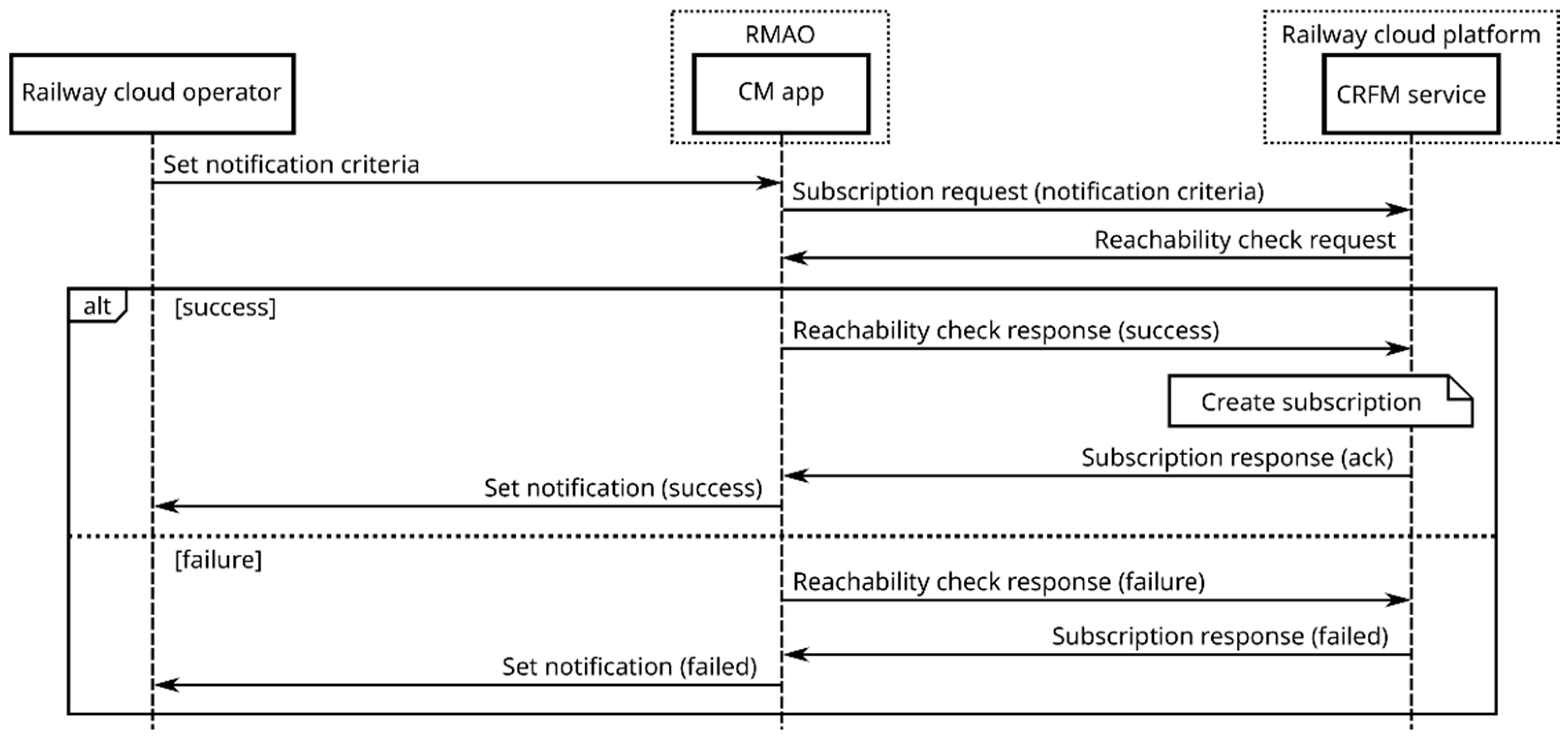
- subscribe to alarm events by providing notification criteria, such as the alarm type and severity, and the address where the notifications have to be sent to;
- be notified of an alarm occurrence that attracts the subscriber attention.
3.3. Formal Verification of CRFM API
4. Performance Management of Railway Cloud Resources
4.1. Performance Management Use Cases
4.2. Performance Management as a Service
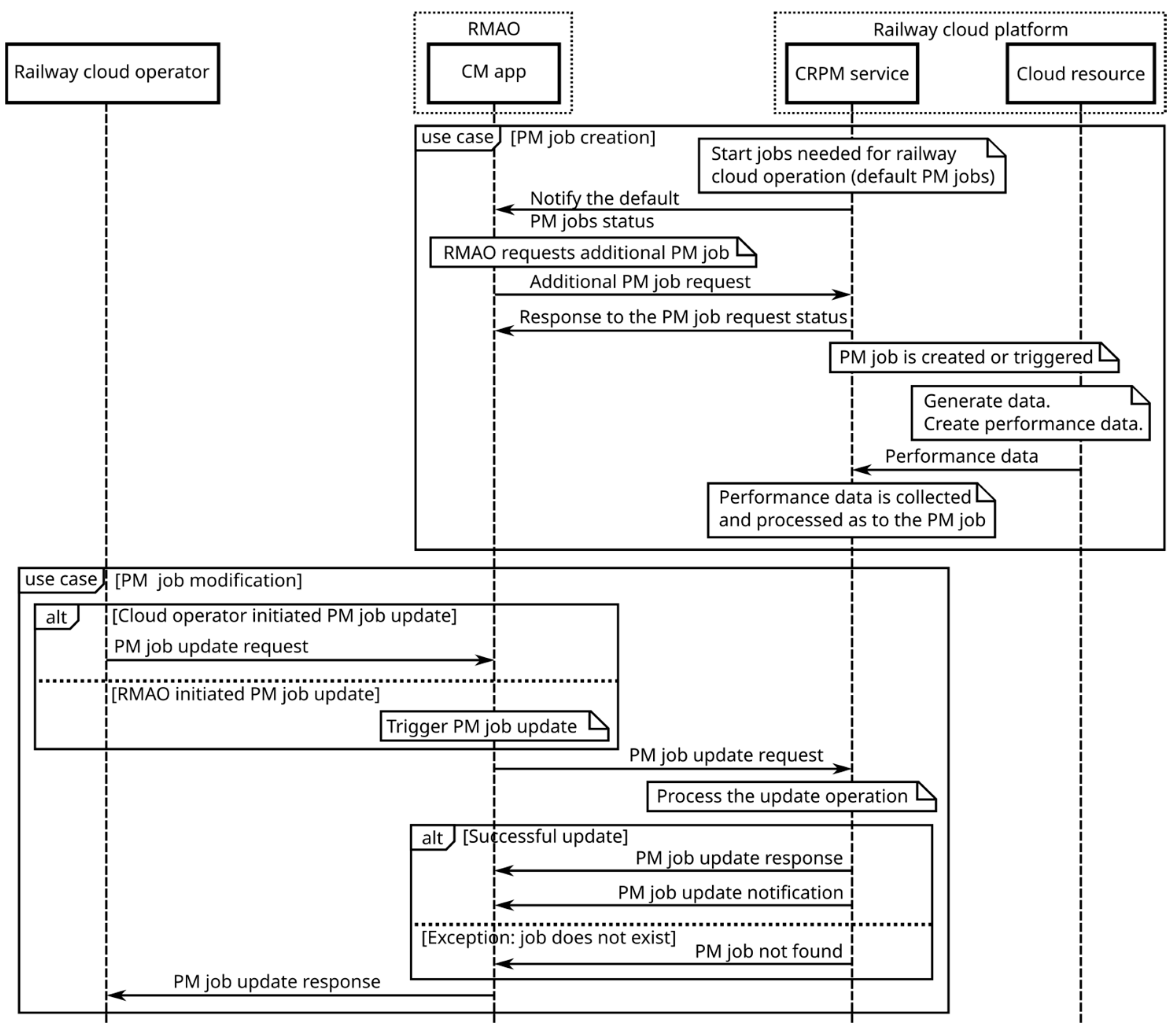
- create a PM job;
- subscribe to reporting of the PM data;
- be notified of the PM data;
- query, delete, suspend, and resume an existing PM job.
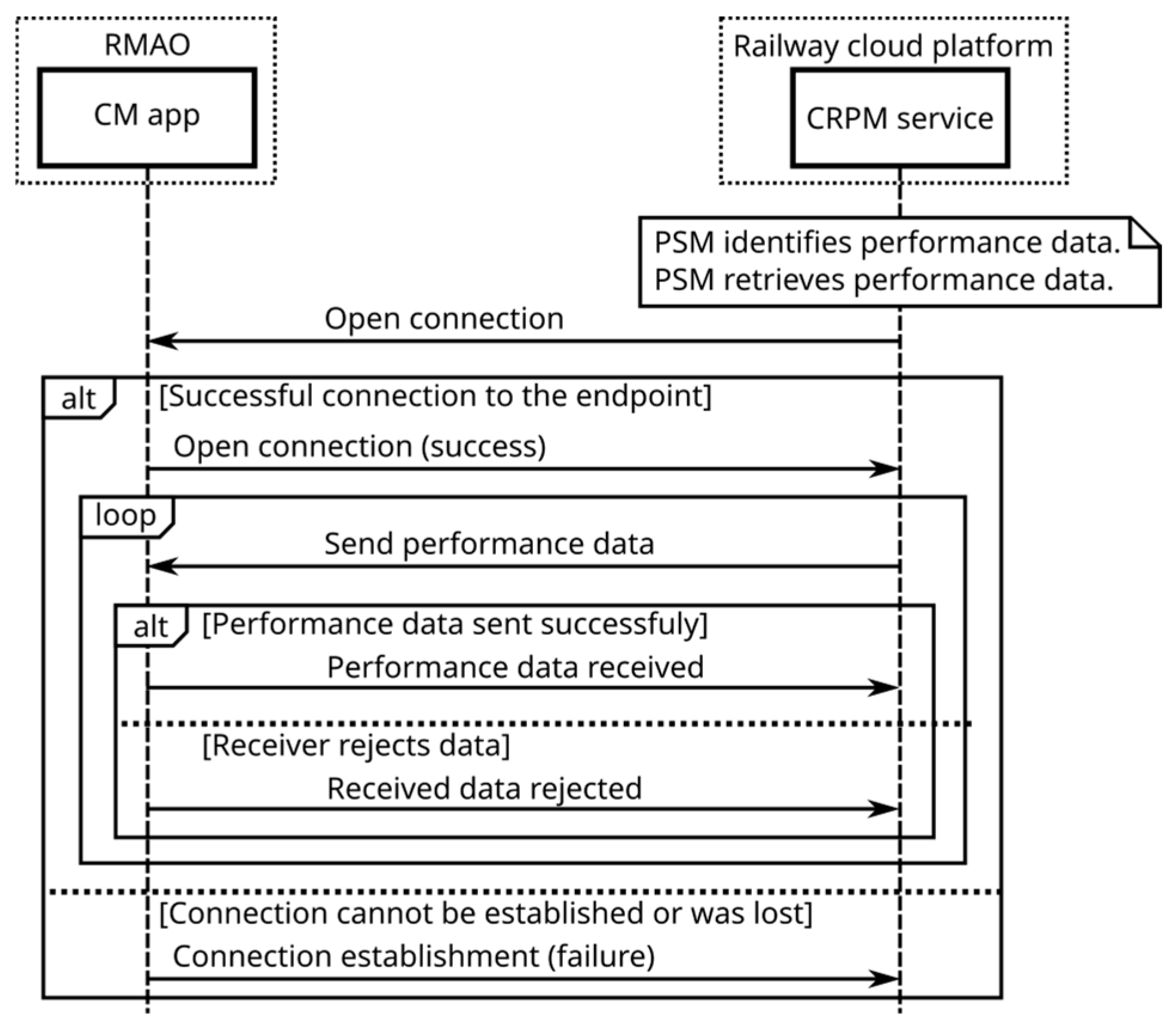
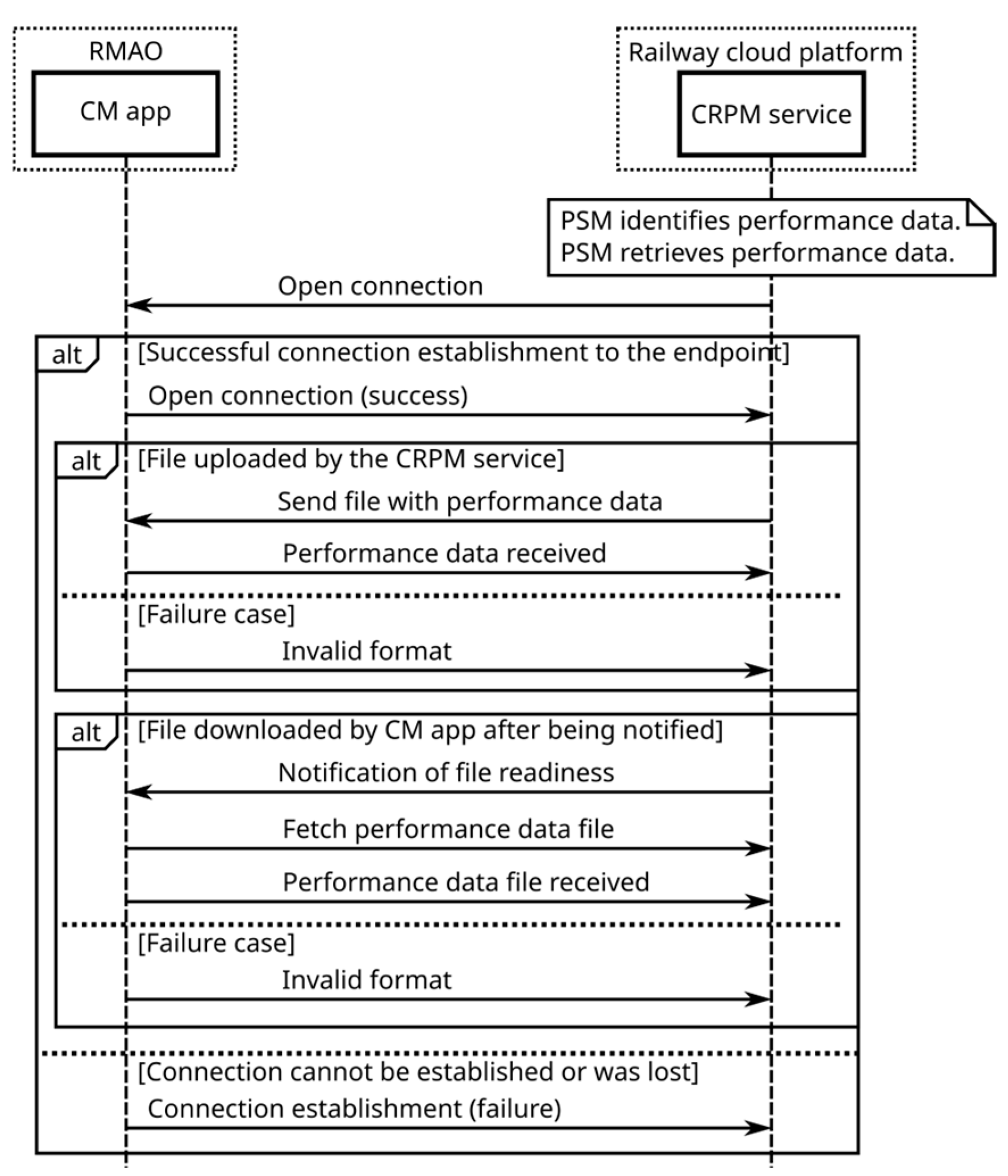
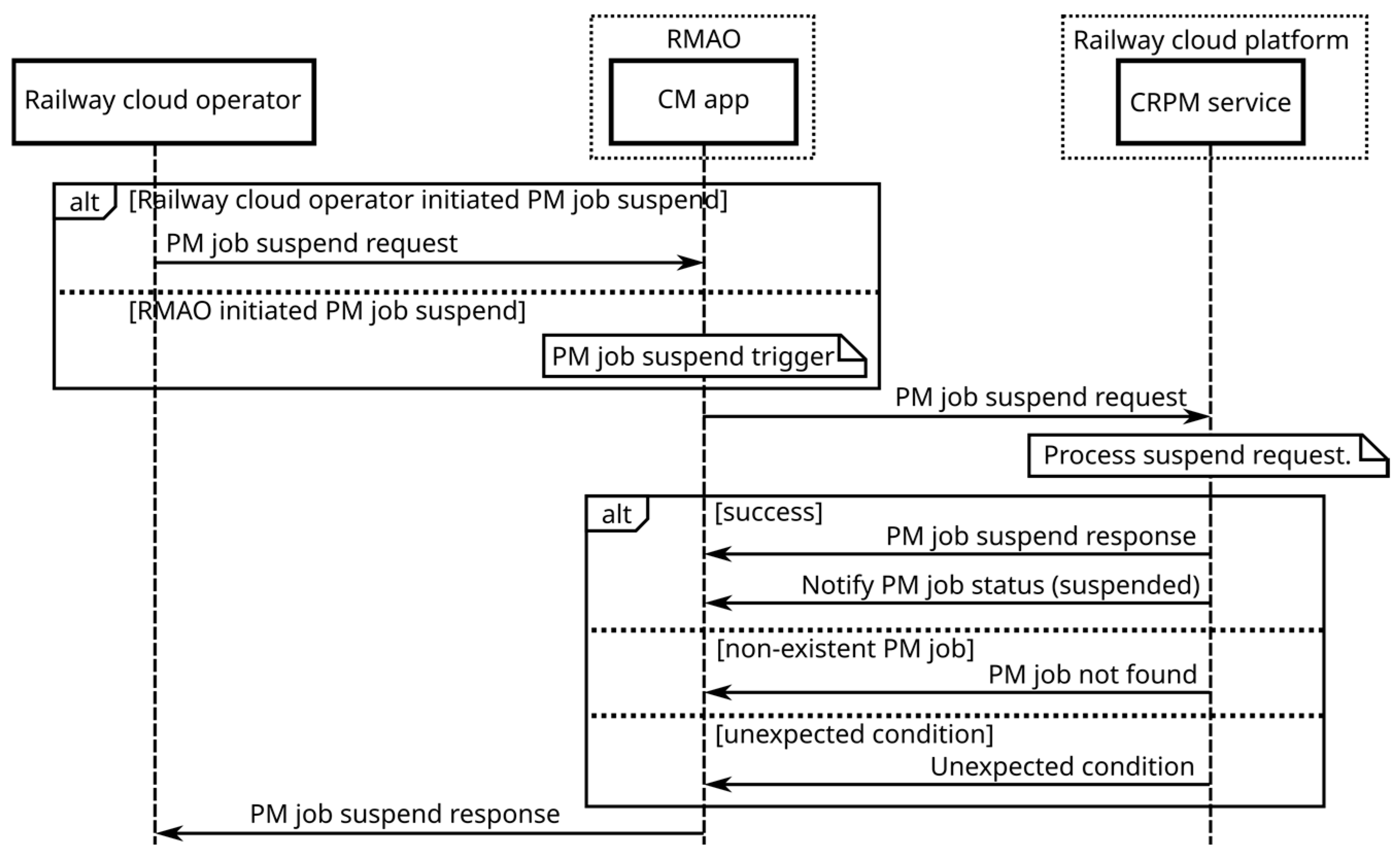
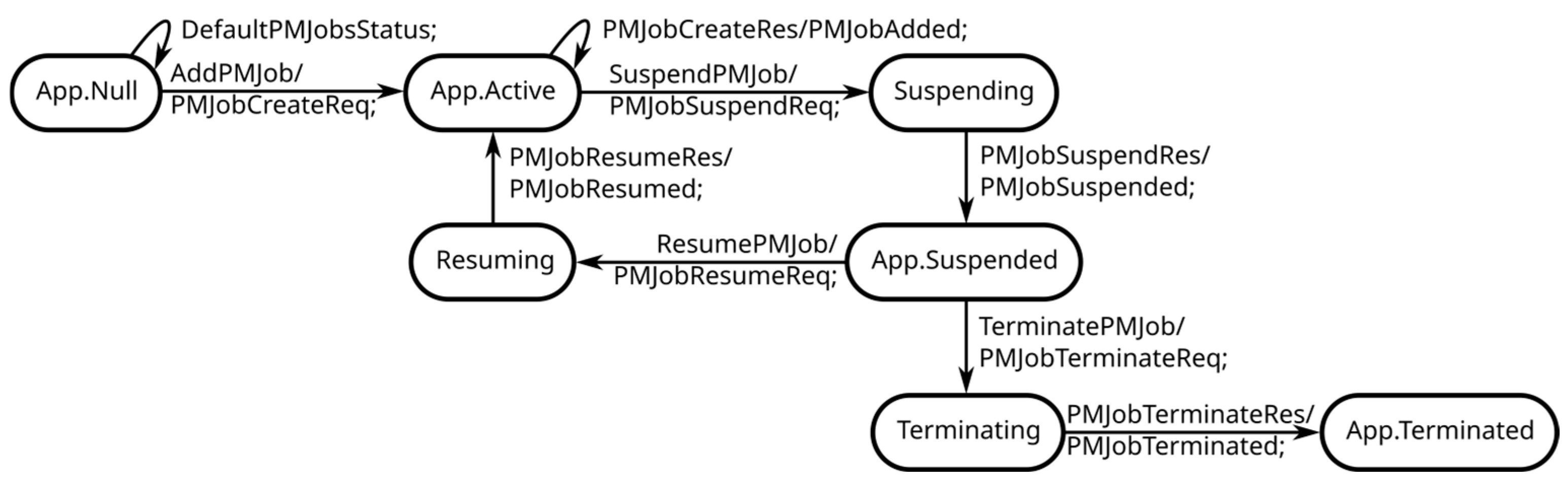
4.3. Formal Verification of the CRPM API
5. Discussion and Conclusions
- Security risks: Exposing parts of a railway cloud system can lead to vulnerabilities if not secured properly.
- Complexity: APIs can be complex to design and maintain, especially for large systems, such as a railway cloud.
- Rate limiting: Many APIs have rate limits, restricting how often they can be called.
- Third-party dependency: Relying on railway cloud management APIs can be risky if the cloud provider changes or discontinues a given service.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| API | Application Programming Interface |
| CI/CD | Continuous integration/continuous deployment |
| CFM | Cloudified function management |
| CM | Cloud Management |
| CPU | Central Processing Unit |
| CRFM | Cloud Resource Fault Management |
| CRM | Cloud Resource Management |
| CRPM | Cloud Resource Performance Management |
| FM | Fault Management |
| HTTP | Hypertext Transfer Protocol |
| ID | Identifier |
| KPI | Key Performance Indicator |
| LTS | Labeled Transition System |
| PM | Performance Management |
| QoS | Quality of Service |
| RCP | Railway Cloud Platform |
| REST | Representational State Transfer |
| RMAO | Railway Management Automation and Orchestration |
| UML | Unified Modeling Language |
| URI | Uniform Resource Identifier |
References
- Dekker, B.; Ton, B.; Meijer, J.; Bouali, N.; Linssen, J.; Ahmed, F. Point Cloud Analysis of Railway Infrastructure: A Systematic Literature Review. IEEE Access 2023, 11, 134355–134373. [Google Scholar] [CrossRef]
- Binder, M.; Mezhuyev, V.; Tschandl, M. Predictive Maintenance for Railway Domain: A Systematic Literature Review. IEEE Eng. Manag. Rev. 2023, 51, 120–140. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, R.; Dong, R.; Qiu, Z.; Bai, H. Point Cloud and Visible Light Fusion Detection System. In Proceedings of the IEEE 17th International Conference on Signal Processing (ICSP), Suzhou, China, 28–31 October 2024; pp. 136–140. [Google Scholar] [CrossRef]
- Ksica, F.; Rubes, O.; Kovar, J.; Chalupa, J.; Hadas, Z. Smart Sensing System for Railway Monitoring. In Proceedings of the 20th International Conference on Mechatronics—Mechatronika (ME), Pilsen, Czech Republic, 7–9 December 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Liang, H.; Zhu, L.; Yu, F.R.; Yuen, C. Cloud-Edge-End Collaboration for Intelligent Train Regulation Optimization in TACS. TVT 2025, 74, 454–465. [Google Scholar] [CrossRef]
- Memon, T.R.; Memon, T.D.; Chowdhry, B.S.; Kalwar, I.H.; Mal, K. Development of Specialized IoT Cloud Platform for Railway Track Condition Monitoring. In Proceedings of the International Conference on Robotics and Automation in Industry (ICRAI), Rawalpindi, Pakistan, 26–27 October 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Singh, P.; Zeinab, V.; Meriga, K.; Pasha, J.; Dulebenets, M.A. Internet of Things for sustainable railway transportation: Past, present, and future. Clean. Logist. Supply Chain. 2022, 4, 100065. [Google Scholar] [CrossRef]
- Yan, Z.; Zhang, W.; Wang, X.; Khan, M.K. Multidimensional Data Integrity Checking Scheme for IoT-Edge Computing-Assisted Intelligent Railway Systems. IEEE Trans. Veh. Technol. 2025. [Google Scholar] [CrossRef]
- Sobrinho, O.G.; Bernucci, L.L.M.; Pizzigatti, P.L.; Motta, R.D.S.; Nachicao, J.; Sanuel, A. Big data analytics in support of the under-rail maintenance management at Vitória—Minas Railway. In Proceedings of the IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 6026–6028. [Google Scholar] [CrossRef]
- Mcmahon, P.; Zhang, T.; Dwight, R. Requirements for Big Data Adoption for Railway Asset Management. IEEE Access 2020, 8, 15543–15564. [Google Scholar] [CrossRef]
- Li, G.; Or, S.W.; Chan, K.W. Intelligent Energy-Efficient Train Trajectory Optimization Approach Based on Supervised Reinforcement Learning for Urban Rail Transits. IEEE Access 2023, 11, 31508–31521. [Google Scholar] [CrossRef]
- Bešinović, N.; Donato, L.D.; Flammini, F.; Goverde, R.; Lin, Z.; Liu, R. Artificial Intelligence in Railway Transport: Taxonomy, Regulations, and Applications. T-ITS 2022, 23, 14011–14024. [Google Scholar] [CrossRef]
- Vadivel, M.; Marin, V.B.; Balasubramani, S.; Hemalatha, S.; Murugan, S.; Velmurugan, S. Cloud-Based Passenger Experience Management in Bus Fare Ticketing Systems Using Random Forest Algorithm. In Proceedings of the 11th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 14–15 March 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Sathish, M.; Sushmitha, K.; Devannan, V.; Sharan, S.J. Cloud Based Town Bus Ticket Payment System Integrated with Mobile Application. In Proceedings of the 2nd International Conference on Advancements in Electrical, Electronics, Communication, Computing and Automation (ICAECA), Coimbatore, India, 16–17 June 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Zhu, L.; Zhuang, Q.; Jiang, H.; Liang, H.; Gao, X.; Wang, W. Reliability-aware failure recovery for cloud computing based automatic train supervision systems in urban rail transit using deep reinforcement learning. J. Cloud. Comp. 2023, 12, 147. [Google Scholar] [CrossRef]
- Li, G.; Qiu, Y.; Wang, J. Research on Efficient Utilization of Network Resources and Intelligent Operation and Maintenance of Rail Transit Cloud Platform Based on SDN, HP3C ‘24. In Proceedings of the 8th International Conference on High Performance Compilation, Computing and Communications, Guangzhou, China, 7–9 June 2022; pp. 102–107. [Google Scholar] [CrossRef]
- Narouwa, M.; Mendiboure, L.; Badis, H.; Maaloul, S.; Molla, D.M.; Berbineau, M.; Langar, R. Enabling Network Technologies for Flexible Railway Connectivity. IEEE Access 2024, 12, 151532–151553. [Google Scholar] [CrossRef]
- Qlu, Y. Secure Mechanism of Intelligent Urban Railway Cloud Platform Based on Zero-trust Security Architecture, HP3C ‘22. In Proceedings of the 6th International Conference on High Performance Compilation, Computing and Communications, New York, NY, USA, 23–25 June 2022; pp. 99–105. [Google Scholar] [CrossRef]
- Kour, R.; Patwardhan, A.; Krim, R.; Thaduri, A. A review on cybersecurity in railways. Proc. Inst. Mech. Eng. Part F J. Rail. Rapid. Transit. 2022, 237, 3–20. [Google Scholar] [CrossRef]
- Zhu, W. Research on Construction of Cloud Computing Platform for Railway Enterprises. In Proceedings of the International Conference on Artificial Intelligence and Advanced Manufacturing (AIAM), Dublin, Ireland, 16–18 October 2019; pp. 488–492. [Google Scholar] [CrossRef]
- Liu, J.; Song, J.; Wang, H.; Lin, S. Comparative Analysis on Collaborative Cloud-Edge-End Computing Architecture of High-Speed Train. In Proceedings of the IEEE 23rd International Conference on Communication Technology (ICCT), Wuxi, China, 20–22 October 2023; pp. 752–757. [Google Scholar] [CrossRef]
- Zhang, X. Optimization design of railway logistics center layout based on mobile cloud edge computing. PeerJ Comput. Sci. 2023, 9, e1298. [Google Scholar] [CrossRef] [PubMed]
- Saeik, F.; Avgeris, M.; Spatharakis, D.; Santi, N.; Dechouniotis, D.; Violos, J.; Leivadeas, A.; Athanasopoulos, N.; Mitton, N.; Papavassiliou, S. Task offloading in Edge and Cloud Computing: A survey on mathematical, artificial intelligence and control theory solutions. J. Comput. Netw. 2021, 195, 108177. [Google Scholar] [CrossRef]
- Santos, Á.; Bernardino, J.; Correia, N. Automated Application Deployment on Multi-Access Edge Computing: A Survey. IEEE Access 2023, 11, 89393–89408. [Google Scholar] [CrossRef]
- Nitto, E.D.; Gorronogoitia, J.; Kumara, I.; Meditskos, G. An Approach to Support Automated Deployment of Applications on Heterogeneous Cloud-HPC Infrastructures. In Proceedings of the 22nd International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 1–4 September 2020; pp. 133–140. [Google Scholar] [CrossRef]
- Valadares, D.C.G.; Filho, T.B.D.O.; Meneses, T.F.; Santos, D.F.S.; Perkusich, A. Automating the Deployment of Artificial Intelligence Services in Multiaccess Edge Computing Scenarios. IEEE Access 2022, 10, 100736–100745. [Google Scholar] [CrossRef]
- Manchanda, A.; Kaur, A.; Kaur, A. Cloud Computing: Resource Management, Categorization, Scalability and Taxonomy. In Proceedings of the 2nd Edition of IEEE Delhi Section Flagship Conference (DELCON), Rajpura, India, 24–26 February 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Chen, Q.; Wang, X.; Jiang, Z. Efficient Cloud Computing Resource Management Strategy Based on Auction Mechanism. In Proceedings of the 24st Asia-Pacific Network Operations and Management Symposium (APNOMS), Sejong, Republic of Korea, 6–8 September 2023; pp. 286–289. [Google Scholar]
- Mishra, K.; Majhi, S.K.; Sahoo, K.S.; Bhoi, S. Collaborative Cloud Resource Management and Task Consolidation Using JAYA Variants. IEEE TNSM 2024, 21, 6248–6259. [Google Scholar] [CrossRef]
- Saxena, D.; Singh, A.K. Workload Pattern Learning-Based Cloud Resource Management Models: Concepts and Meta-Analysis. IEEE Trans. Sustain. Comput. 2024, 1–20. [Google Scholar] [CrossRef]
- Judith, S.; Hurwitz, D.K. Managing a Hybrid and Multicloud Environment. In Cloud Computing for Dummies; Wiley: Hoboken, NJ, USA, 2020; pp. 43–58. [Google Scholar]
- Xu, D.; Liu, F.; Chen, W.; He, F.; Tang, X.; Zhang, Y.; Wang, B. A review of research on multi-cloud management platforms. In Proceedings of the ISCTT 2022, 7th International Conference on Information Science, Computer Technology and Transportation, Xishuangbanna, China, 27–29 May 2022; pp. 1–16, ISBN 978-3-8007-6006-0. [Google Scholar]
- Bello, Y.; Figetakis, E.; Refaey, A.; Spachos, P. Continuous Integration and Continuous Delivery Framework for SDS. In Proceedings of the IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), Halifax, NS, Canada, 18–20 September 2022; pp. 406–410. [Google Scholar] [CrossRef]
- Cepuc, A.; Botez, R.; Craciun, O.; Ivanciu, I.-A.; Dobrota, V. Implementation of a Continuous Integration and Deployment Pipeline for Containerized Applications in Amazon Web Services Using Jenkins, Ansible and Kubernet. In Proceedings of the 19th RoEduNet Conference: Networking in Education and Research (RoEduNet), Bucharest, Romania, 11–12 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Hummer, W.; Muthusamy, V.; Rausch, T.; Dube, P.; El Maghraoui, K.; Murthi, A.; Oum, P. ModelOps: Cloud-Based Lifecycle Management for Reliable and Trusted AI. In Proceedings of the IEEE International Conference on Cloud Engineering (IC2E), Prague, Czech Republic, 24–27 June 2019; pp. 113–120. [Google Scholar] [CrossRef]
- Wan, R.; Liang, Y.; Wen, Z.; Zhao, L. Research on Application Configuration Management Technology for Cloud Platform. In Proceedings of the IEEE 10th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 17–19 June 2022; pp. 781–784. [Google Scholar] [CrossRef]
- Singhal, S.; Sharma, A.; Gourisaria, M.K.; Sharma, B.; Dhaou, I.B. A Disaster Management System Using Cloud Computing. In Proceedings of the 20th ACS/IEEE International Conference on Computer Systems and Applications (AICCSA), Giza, Egypt, 4–7 December 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Tang, M.; Wang, P.; Cheng, X.; Liu, Z.; Li, Y.; Wang, Z. Cloud Platform Data Disaster Recovery Model. In Proceedings of the IEEE 11th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 8–10 December 2023; pp. 786–790. [Google Scholar] [CrossRef]
- Choudhary, C.; Vyas, N.; Lilhore, U.K. Cloud Security: Challenges and Strategies for Ensuring Data Protection. In Proceedings of the 3rd International Conference on Technological Advancements in Computational Sciences (ICTACS), Tashkent, Uzbekistan, 1–3 November 2023; pp. 669–673. [Google Scholar] [CrossRef]
- Seetharamarao, R.Y. A Unified Approach Towards Security Audit and Compliance in Cloud Computing Environment. In Proceedings of the 16th International Conference on Developments in eSystems Engineering (DeSE), Istanbul, Turkiye, 18–20 December 2023; pp. 623–629. [Google Scholar] [CrossRef]
- Gupta, L.; Salman, T.; Zolanvari, M.; Erbad, A.; Jain, R. Fault and performance management in multi-cloud virtual network services using AI: A tutorial and a case study. Comput. Netw. 2019, 165, 106950. [Google Scholar] [CrossRef]
- Lin, D.; Jiang, M.; Zhang, H.; Xu, Y.; Yan, A. Research on Data Operation Monitoring and Analysis System of Computer Intelligent Cloud Platform. In Proceedings of the IEEE 3rd International Conference on Data Science and Computer Application (ICDSCA), Dalian, China, 27–29 October 2023; pp. 1388–1393. [Google Scholar] [CrossRef]
- Jin, C.; Yao, Z.; Tao, J.; Shao, S. Design and Implementation of Distributed Cloud Monitoring Big Data Storage Based on Zabbix. In Proceedings of the 5th Annual International Conference on Data Science and Business Analytics (ICDSBA), Changsha, China, 24–26 September 2021; pp. 125–130. [Google Scholar] [CrossRef]
- Soldani, J.; Brogi, A. Anomaly Detection and Failure Root Cause Analysis in (Micro)Service-Based Cloud Applications: A Survey. arXiv 2021, arXiv:2105.12378. [Google Scholar] [CrossRef]
- Kumar, E.S.; Ramamoorthy, R.; Kesavan, S.; Shobha, T.; Patil, S.; Vighneshwari, B. Comparative Study and Analysis of Cloud Container Technology. In Proceedings of the 11th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 28 February–1 March 2024; pp. 1681–1686. [Google Scholar] [CrossRef]
- Chhikara, P.; Tekchandani, R.; Kumar, N.; Obaidat, M.S. An Efficient Container Management Scheme for Resource-Constrained Intelligent IoT Devices. IEEE Internet Things J. 2021, 8, 12597–12609. [Google Scholar] [CrossRef]
- Pathak, G.; Singh, M. A Review of Cloud Microservices Architecture for Modern Applications. In Proceedings of the World Conference on Communication & Computing (WCONF), Raipur, India, 12–14 July 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Atanasov, I.; Pencheva, E.; Trifonov, V. Microservices for Cloudification and Orchestration of Railway Operations. In Computer and Communication Engineering. CCCE 2024. Communications in Computer and Information Science; Neri, F., Du, K.L., San-Blas, A.A., Jiang, Z., Eds.; Springer: Cham, Switzerland, 2025; Volume 2192. [Google Scholar] [CrossRef]
- Atanasov, I.; Pencheva, E.; Trifonov, V.; Kassev, K. Railway Cloud: Management and Orchestration Functionality Designed as Microservices. Appl. Sci. 2024, 14, 2368. [Google Scholar] [CrossRef]
- Ramoliya, D.; Patel, A.; Patel, K.; Patel, G.; Vaghela, P.; Budhrani, A. Advanced Techniques to Predict and Detect Cloud System Failure: A Survey. In Proceedings of the 6th International Conference on Electronics, Communication and Aerospace Technology, Coimbatore, India, 1–3 December 2022; pp. 788–793. [Google Scholar] [CrossRef]
- Saleh, L.; al-sitt, W. Cloud Computing Failures, Recovery Approaches and Management Tools. In Proceedings of the 21st International Arab Conference on Information Technology (ACIT), Giza, Egypt, 6 October 2020; pp. 1–10. [Google Scholar] [CrossRef]
- Pandita, A.; Upadhyay, P.K.; Mishra, V.P. Fault-Tolerant Scheduling of Scientific Workflow in Cloud Computing. In Proceedings of the International Conference on Artificial Intelligence and Quantum Computation-Based Sensor Application (ICAIQSA), Nagpur, India, 20–21 December 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Raj, A.; Jadon, S.; Kulshrestha, H.; Rai, V.; Arvindhan, M.; Sinha, A. Cloud Infrastructure Fault Monitoring and Prediction System using LSTM based predictive maintenance. In Proceedings of the 10th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 13–14 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Gorantla, V.A.K.; Sriramulugari, S.K.; Gorantla, B.; Yuvaraj, N.; Singh, K. Optimizing Performance of Cloud Computing Management Algorithm for High-Traffic Networks. In Proceedings of the 2nd International Conference on Disruptive Technologies (ICDT), Greater Noida, India, 15–16 March 2024; pp. 482–487. [Google Scholar] [CrossRef]
- Sawhney, G.; Kaur, G.; Deorari, R. CSPM: A secure Cloud Computing Performance Management Model. In Proceedings of the International Conference on Cyber Resilience (ICCR), Dubai, United Arab Emirates, 6–7 October 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Yezdani, R.; Quadri, S.M.K. Power and Performance Issues and Management Approaches in Cloud Computing. In Proceedings of the 4th International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), Greater Noida, India, 16–17 December 2022; pp. 2112–2120. [Google Scholar] [CrossRef]
- Sandhiya, V.; Suresh, A. Analysis of Performance, Scalability, Availability and Security in Different Cloud Environments for Cloud Computing. In Proceedings of the International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 23–25 January 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Syed, S.B.; Rasul, A.; Javed, T.; Rizwan, M.; Singh, A.; Dev, K. Performance Analysis of Cloud Computing for Distributed Data Center using Cloud-Sim. In Proceedings of the International Conference on Communications Workshops (ICC Workshops), Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Kang, Y.; Bu, B.; Gao, B. Safety Analysis of Rail Transit Redundant Structure in Cloud Computing Environment Based on Graph and Bayesian Theory. In Proceedings of the IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 4284–4289. [Google Scholar] [CrossRef]
- Bolanowski, M.; Żak, K.; Paszkiewicz, A.; Ganzha, M.; Paprzycki, M.; Sowiński, P.; Lacalle, I.; Palau, C.E. Efficiency of REST and gRPC Realizing Communication Tasks in Microservice-Based Ecosystems. In New Trends in Intelligent Software Methodologies, Tools and Techniques; Fujita, H., Watanobe, Y., Azumi, T., Eds.; IOS Press: Amsterdam, The Netherlands, 2022; pp. 97–108. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resource Name | Resource URI | HTTP Method | Description |
|---|---|---|---|
| All alarms | /Alarms | GET | Retrieves the list of all alarms (active or suppressed) |
| Individual alarm | /Alarms/{AlarmID} | GET | Retrieves information about an individual alarm |
| PUT | Used to acknowledge an individual alarm | ||
| DELETE | Used to clear an individual alarm | ||
| Alarm suppression | /Alarms/{AlarmID}/AlarmSuppression | GET | Retrieves the information about the alarm suppression criteria and status |
| PUT | Used to activate or deactivate the alarm suppression, and to query or update alarm suppression criteria | ||
| All alarm subscriptions | /AlarmSubscriptions | GET | Retrieves the list of all alarm subscriptions |
| POST | Creates a new alarm subscription | ||
| Individual alarm subscription | /AlarmSubscriptions/{AlarmSubscriptionID} | GET | Retrieves information about an individual alarm subscription |
| DELETE | Terminates an individual subscription | ||
| All alarm logs | /AlarmLogs | GET | Retrieves the list of all alarm logs |
| Individual alarm log | /AlarmLogs/{AlarmLogID} | GET | Retrieves information about individual alarm log |
| All fault logs | /FaultLogs | GET | Retrieves the list of all fault logs |
| Individual fault log | /FaultLogs/{FaultLogID} | GET | Retrieves information about the individual fault log |
| All debug logs | /DebugLogs | GET | Retrieves the list of all debug logs |
| Individual debug log | /DebugLogs/{DebugLogID} | GET | Retrieves information about the individual debug log |
| Alarm dictionary | /AlarmDictionary | GET | Retrieves the definition of an alarm |
| PUT | Updates an alarm definition | ||
| DELETE | Deletes an alarm definition |
| Transition Abstraction | States Mapping | Transition Sequences in Lapp | Transition Sequences in Lser |
|---|---|---|---|
| Successful creation of subscription to alarm notifications | (sa1, ss1) | sa1sa1sa1 | ss1ss2ss3ss1 |
| Unsuccessful creation of subscription to alarm notifications | (sa1, ss1) | sa1sa1sa1 | ss1ss2ss1 or ss1ss2ss3ss1 |
| A fault rises, is processed, and an alarm notification is sent | (sa2, ss5) | sa1sa2 | ss1ss4ss5 |
| Alarm query | (sa2, ss5) | sa2sa2sa2 | ss5ss5 |
| Alarm acknowledgement | (sa2, ss5) | sa2sa3sa2 | ss5ss5 |
| Alarm suppression | (sa5, ss6) | sa2sa4sa5 | ss5ss6 |
| Alarm retention | (sa2, ss5) | sa5sa6sa2 | ss6ss5 |
| Alarm clearance | (sa8, ss7) | sa2sa7sa8 | ss5ss7 |
| Resource Name | Resource URI | HTTP Method | Meaning |
|---|---|---|---|
| All PM jobs | /pmJobs | POST | Creates a PM job |
| GET | Retrieves the list of PM jobs | ||
| Individual PM job | /pmJobs/{pmJobID} | GET | Queries an individual PM job |
| PUT | Updates a PM job | ||
| PATCH | Suspends or resumes a PM job | ||
| DELETE | Deletes a PM job | ||
| PM subscriptions | /pmSubscriptions | POST | Creates a PM subscription |
| GET | Retrieves the list of PM subscriptions | ||
| Individual PM | /pmSubscriptions/ | GET | Reads a PM subscription |
| Subscription | {pmSubscriptionID} | DELETE | Deletes a PM subscription |
| Transition Abstraction | States Mapping | Transition Sequences in Mapp | Transition Sequences in Mser |
|---|---|---|---|
| Default PM jobs are started | (sa1, ss1) | sa1sa1 | ss1ss1 |
| Creation of an additional PM job | (sa2, ss2) | sa1sa2sa2 | ss1ss2 |
| Suspension of the PM job | (sa4, ss3) | sa2sa3sa4 | ss2ss3 |
| Retention of the PM job | (sa2, ss2) | sa4sa5sa2 | ss3ss2 |
| Termination of the PM job | (sa7, ss4) | sa4sa6sa7 | ss3ss4 |
| Transition Abstraction | State Mapping | Transition Sequences in Napp | Transition Sequences in Nser |
|---|---|---|---|
| Successful creation of subscription to PM data | (sa1, ss1) | sa1sa2sa2sa4sa5 | ss1ss2ss3 |
| Unsuccessful creation of subscription to PM data | (sa1, ss1) | sa1sa2sa2sa3sa1 | ss1ss2ss1 |
| PM data is available for reporting. The connection is established and PM data is sent. | (sa5, ss3) | sa5sa6sa7sa8 | ss3ss4ss5 |
| PM data is available for reporting. The connection setup fails. | (sa5, ss3) | sa5sa6sa5 | ss3ss4ss3 |
| The PM data is received successfully. | (sa8, ss5) | sa8sa5 | ss5ss3 |
| The receiver rejects the PM data. | (sa8, ss5) | sa8sa5 | ss5ss3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Atanasov, I.; Dimitrova, D.; Pencheva, E.; Trifonov, V. Railway Cloud Resource Management as a Service. Future Internet 2025, 17, 192. https://doi.org/10.3390/fi17050192
Atanasov I, Dimitrova D, Pencheva E, Trifonov V. Railway Cloud Resource Management as a Service. Future Internet. 2025; 17(5):192. https://doi.org/10.3390/fi17050192
Chicago/Turabian StyleAtanasov, Ivaylo, Dragomira Dimitrova, Evelina Pencheva, and Ventsislav Trifonov. 2025. "Railway Cloud Resource Management as a Service" Future Internet 17, no. 5: 192. https://doi.org/10.3390/fi17050192
APA StyleAtanasov, I., Dimitrova, D., Pencheva, E., & Trifonov, V. (2025). Railway Cloud Resource Management as a Service. Future Internet, 17(5), 192. https://doi.org/10.3390/fi17050192