Enhancing IoT Scalability and Interoperability Through Ontology Alignment and FedProx

 , ,
, ,  , and
, and
Abstract
1. Introduction
2. Related Works
3. Problem Definition
3.1. Interoperability Challenges
3.2. Decentralized Learning Challenges
- Data heterogeneity: The data distribution across edge servers is often non-independent and non-identically distributed (non-IID), leading to model divergence during training.
- Resource constraints: Edge servers have limited computational and storage capabilities, making traditional centralized training infeasible.
- Communication overhead: Frequent synchronization between the central unit and edge servers increases bandwidth consumption and latency, especially in large- scale deployments.
3.3. Ontology Evolution and Scalability
- —
- C is the set of concepts (or classes) that define the entities in the domain.
- —
- R is the set of relationships between these concepts, specifying how they interact.
- —
- A is the set of axioms and constraints that govern the structure and integrity of the ontology.
3.4. Problem Objective
- Ensure Semantic InteroperabilityUsing one uniform ontology, O will help enable better integration among m edge servers and n IoT devices.
- Enable Scalable and Efficient Machine LearningSupport training for a machine learning model within a decentralized setting to minimize overhead on communications, reducing the value of global loss, .
- Support Dynamic Ontology UpdatesAllow for the incorporation of new IoT devices and metrics through dynamic ontology updates , ensuring smooth operations without disrupting existing processes. In general, there should be provisions to include IoT instruments and new measures that come forth by means of dynamic ontology updating, , ensuring non-interfering, seamless operation with already implemented procedures.
- Achieve System ScalabilityThis would sustain a very high degree of performance with increased numbers of edge servers and IoT devices to cater to expanding demands.
4. Proposed Framework
4.1. Architecture Overview
4.1.1. IoT Device Layer
Composition
- —
- Environmental sensors () designed to measure various parameters, including temperature (T), humidity (H), and CO2 levels ().
- —
- Traffic monitoring devices () tracking vehicle counts (), speeds (S), and congestion levels ().
- —
- Energy meters () recording power consumption () and voltage (V).
- —
- Security devices () such as cameras capturing images or motion data.
Responsibilities
- —
- Data collection: Each IoT device collects raw data over time as follows:Data are either collected continuously or triggered based on specific events or thresholds.
- —
- Communication: IoT devices use lightweight communication protocols (e.g., MQTT, CoAP) to transmit data securely to the nearest edge server .
4.1.2. Edge Server Layer
Composition
Responsibilities
- —
- Data Aggregation: Each edge server aggregates data from its associated IoT devices as follows:
- —
- Preprocessing: The raw aggregated data is cleaned and standardized using the ontology O, as follows:
- –
- Data cleaning: Removes missing values () and outliers.
- –
- Unit conversion: Converts raw data into consistent units, e.g.,
- –
- Ontology mapping: Maps raw data fields to ontology attributes as follows:
- —
- Local model training: Trains the FL model locally on by minimizing the local loss as follows:where is the prediction, y is the true label, and ℓ is the loss function (e.g., mean squared error).
- —
- Communication: Edge servers transmit their model updates to the central unit as follows:where is the global model received from the central unit.
4.1.3. Central Unit Layer
Composition
Responsibilities
- —
- Ontology management: Maintains the ontology O, ensures uniform data representation across edge servers, and distributes updates as needed.
- —
- Model aggregation: Aggregates updates from edge servers to refine the global model:where t denotes the current training round.
- —
- Global coordination: Synchronizes federated learning rounds and ensures edge servers receive the updated model for further training.
4.2. Ontology Design and Deployment
4.2.1. Ontology Selection
- —
- Traffic monitoring: Attributes include VehicleCount (), TrafficFlow (), and CongestionLevel ().
- —
- Environmental sensing: Attributes include CO2Level (), Temperature (T), Humidity (H), and AirQualityIndex.
- —
- Parking management: Attributes include totalspaces, garagecode, etc.
4.2.2. Ontology Customization
Example Schema for Environmental Sensing
4.2.3. Deployment
- —
- Schema mapping: Maps raw data fields to ontology-compliant attributes as follows:
- —
- Data transformation: In this stage, unrefined data are translated into a uniform format according to the ontology, thus providing assurance of uniformity.
- —
- Metadata enrichment: In this stage, contextual information is added to the data, including timestamps, geographical locations, and device IDs.
4.2.4. Local Ontology Alignment
- —
- Schema mapping: Synchronizes local data items with ontology-created attributes, thus providing semantic homogeneity.
- —
- Unit standardization: Converts raw measurement values to uniformly normalized units. For example,
- —
- Data enrichment: Entails adding metadata, and in doing so, enriches semantic data representation and enables uniformity in all edge servers.
4.3. Federated Learning Strategy
4.3.1. FL Algorithm
- is the local loss function at edge server j.
- represents the parameters of the global model.
- is the regularization coefficient that controls the impact of the proximal term.
4.3.2. Local Training
- is the preprocessed and ontology-aligned dataset at edge server j.
- is the local loss function (e.g., mean squared error).
- is the global model at training round t.
- is the prediction function for input x using model parameters w.
4.3.3. Model Updates
4.3.4. Global Aggregation
- m is the number of edge servers.
- is the locally trained model from edge server j at round t.
4.3.5. Communication Optimization
- Gradient compression: Gradients are quantized to minimize their size, enabling more efficient transmission as follows:where g represents the gradient, and Q is the quantization level.
- Sparse upgrades: Only the top-k crucial gradients are transmitted, as follows:Wherein the gradient vector’s k highest values are chosen by .
4.4. Interoperability and Scalability
4.4.1. Interoperability
- Ontology alignment: Links the raw data fields from Internet of Things gadgets to the associated ontology features as follows:
- Unit standardization: Converts a uniform baseline from observations in different units. For example, temperatures are converted from Fahrenheit () to Celsius () as follows:
- Metadata enrichment: Ensures semantic coherence within the system by appending context information to every single information piece, such as timestamps, geolocations, and device identifiers.
4.4.2. Scalability
- Obtains via the central unit the common ontology O.
- The ontology O is aligned alongside its local IoT device data .
- Trains the global model locally and transmits adjustments into the central unit, which helps in the federated learning process.
4.4.3. Dynamic Ontology Updates
5. Implementation and Evaluation
5.1. Experimental Setup
5.2. Results
5.2.1. Model Performance
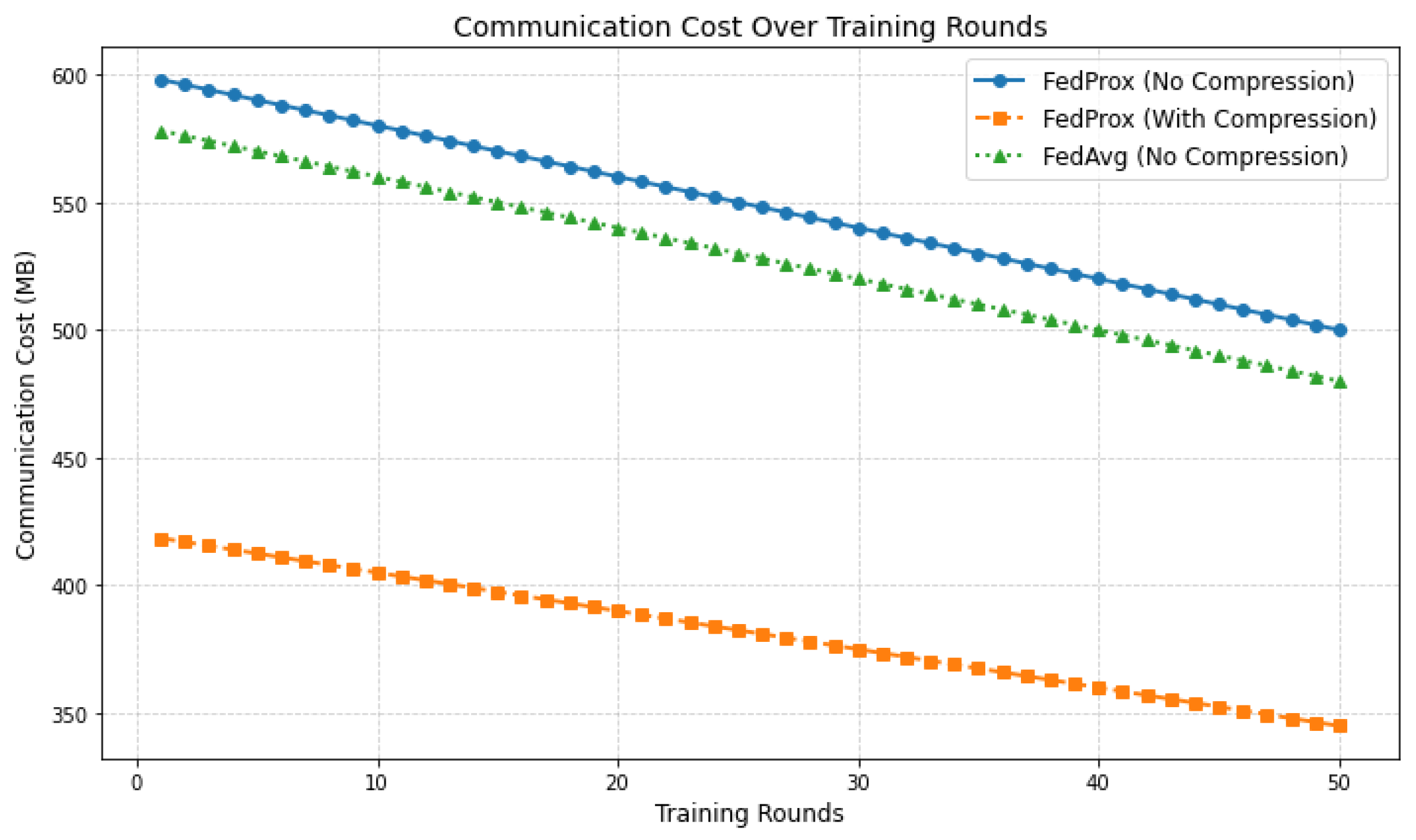
5.2.2. Communication Efficiency
5.2.3. Scalability
5.2.4. Interoperability
5.3. Discussion
- —
- While ontology-based data standardization and federated learning have been explored separately in IoT systems, our work uniquely integrates both to achieve semantic interoperability and decentralized model training.
- —
- Unlike existing ontology frameworks that rely on centralized knowledge repositories, our approach enables dynamic ontology alignment at the edge, ensuring that heterogeneous IoT devices can seamlessly communicate and share knowledge while preserving data privacy.
- —
- We employ FedProx, which mitigates data heterogeneity issues in federated learning, ensuring stable model convergence in IoT-edge environments.
- —
- Our framework outperforms FedAvg in terms of accuracy, convergence speed, and communication efficiency, as demonstrated in our experiments.
- —
- Unlike conventional FL approaches that assume homogeneous datasets, our model adapts to imbalanced and diverse data distributions commonly found in real-world IoT deployments.
- —
- Traditional ontology-based IoT frameworks often lack adaptability, requiring manual intervention to incorporate new devices and data schemas.
- —
- Our framework introduces a dynamic ontology update mechanism, allowing real-time schema evolution without disrupting ongoing federated learning processes.
- —
- This ensures that new IoT devices, sensors, and data formats can be seamlessly integrated, making the framework scalable for long-term IoT deployments.
- —
- We introduce gradient compression and sparse updates to optimize communication efficiency, reducing bandwidth consumption by 30% compared to baseline FL methods.
- —
- This makes our approach particularly suitable for low-bandwidth IoT environments, where communication overhead is a major bottleneck.
- —
- Unlike many existing works that focus on simulated datasets, we evaluate our framework using real-world IoT data (CityPulse dataset), demonstrating its effectiveness in practical applications such as traffic monitoring, environmental sensing, and smart parking.
- —
- Our results highlight significant improvements in model accuracy (+5%), communication efficiency (−30%), and ontology alignment success (95%) compared to existing approaches.
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, P.; Wan, Y.; Wu, Z.; Fang, Z.; Li, Q. A survey on privacy and security issues in IoT-based environments: Technologies, protection measures and future directions. Comput. Secur. 2025, 148, 104097. [Google Scholar] [CrossRef]
- Greengard, S. The Internet of Things; MIT Press: Cambridge, MA, USA, 2021. [Google Scholar]
- Kanzouai, C.; Bouarourou, S.; Zannou, A.; Nfaoui, E.H.; Boulaalam, A. IoT-Powered Big Data Processing for Intelligent Transportation: Enhancing Effectiveness and Forecasting. In Big Data and Internet of Things; Mahboub, O., Haddouch, K., Omara, H., Hefnawi, M., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2024; pp. 913–923. [Google Scholar] [CrossRef]
- Hazra, A.; Adhikari, M.; Amgoth, T.; Srirama, S.N. A Comprehensive Survey on Interoperability for IIoT: Taxonomy, Standards, and Future Directions. ACM Comput. Surv. 2023, 55, 9. [Google Scholar] [CrossRef]
- Ferrer, A.J.; Marquès, J.M.; Jorba, J. Towards the Decentralised Cloud: Survey on Approaches and Challenges for Mobile, Ad hoc, and Edge Computing. ACM Comput. Surv. 2019, 51, 111. [Google Scholar] [CrossRef]
- Shafique, K.; Khawaja, B.A.; Sabir, F.; Qazi, S.; Mustaqim, M. Internet of Things (IoT) for Next-Generation Smart Systems: A Review of Current Challenges, Future Trends and Prospects for Emerging 5G-IoT Scenarios. IEEE Access 2020, 8, 23022–23040. [Google Scholar] [CrossRef]
- Zannou, A.; Nfaoui, E.H.; Boulaalam, A.; Allali, N.E.; Fariss, M. Data Gathering from IoT Networks. In Proceedings of the 2023 7th IEEE Congress on Information Science and Technology (CiSt), Essaouira, Morocco, 16–22 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 361–365. [Google Scholar] [CrossRef]
- Lombardi, M.; Pascale, F.; Santaniello, D. Internet of Things: A General Overview between Architectures, Protocols and Applications. Information 2021, 12, 87. [Google Scholar] [CrossRef]
- Marouan, A.; Badrani, M.; Zannou, A.; Kannouf, N.; Chetouani, A. E-Voting System Based on Blockchain for Enhanced University Elections. SN Comput. Sci. 2025, 6, 204. [Google Scholar] [CrossRef]
- Marouan, A.; Badrani, M.; Kannouf, N.; Zannou, A.; Chetouani, A. Blockchain-based e-voting system in a university. Indones. J. Electr. Eng. Comput. Sci. 2024, 34, 1915–1923. [Google Scholar] [CrossRef]
- Kanellopoulos, D.; Sharma, V.K.; Panagiotakopoulos, T.; Kameas, A. Networking Architectures and Protocols for IoT Applications in Smart Cities: Recent Developments and Perspectives. Electronics 2023, 12, 2490. [Google Scholar] [CrossRef]
- Rahman, Z.; Yi, X.; Mehedi, S.T.; Islam, R.; Kelarev, A. Blockchain Applicability for the Internet of Things: Performance and Scalability Challenges and Solutions. Electronics 2022, 11, 1416. [Google Scholar] [CrossRef]
- Bouarourou, S.; Zannou, A.; Nfaoui, E.H.; Boulaalam, A. An Efficient Model-Based Clustering via Joint Multiple Sink Placement for WSNs. Future Internet 2023, 15, 75. [Google Scholar] [CrossRef]
- Kokila, M.; Reddy, K.S. Authentication, access control and scalability models in Internet of Things Security—A review. Cyber Secur. Appl. 2025, 3, 100057. [Google Scholar] [CrossRef]
- Gilrein, E.J.; Carvalhaes, T.M.; Markolf, S.A.; Chester, M.V.; Allenby, B.R.; Garcia, M. Concepts and practices for transforming infrastructure from rigid to adaptable. Sustain. Resilient Infrastruct. 2021, 6, 213–234. [Google Scholar] [CrossRef]
- Karabulut, E.; Pileggi, S.F.; Groth, P.; Degeler, V. Ontologies in digital twins: A systematic literature review. Future Gener. Comput. Syst. 2024, 153, 442–456. [Google Scholar] [CrossRef]
- Tang, S.; Shelden, D.R.; Eastman, C.M.; Pishdad-Bozorgi, P.; Gao, X. A review of building information modeling (BIM) and the internet of things (IoT) devices integration: Present status and future trends. Autom. Constr. 2019, 101, 127–139. [Google Scholar] [CrossRef]
- Bouarourou, S.; Zannou, A.; Boulaalam, A.; Nfaoui, E.H. IoT Based Smart Agriculture Monitoring System with Predictive Analysis. In Proceedings of the 2022 2nd International Conference on Innovative Research in Applied Science, Engineering and Technology (IRASET), Meknes, Morocco, 3–4 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Allioui, H.; Mourdi, Y. Exploring the Full Potentials of IoT for Better Financial Growth and Stability: A Comprehensive Survey. Sensors 2023, 23, 8015. [Google Scholar] [CrossRef]
- Xu, D.; Li, T.; Li, Y.; Su, X.; Tarkoma, S.; Jiang, T.; Crowcroft, J.; Hui, P. Edge Intelligence: Empowering Intelligence to the Edge of Network. Proc. IEEE 2021, 109, 1778–1837. [Google Scholar] [CrossRef]
- Chen, M.; Gündüz, D.; Huang, K.; Saad, W.; Bennis, M.; Feljan, A.V.; Poor, H.V. Distributed Learning in Wireless Networks: Recent Progress and Future Challenges. IEEE J. Sel. Areas Commun. 2021, 39, 3579–3605. [Google Scholar] [CrossRef]
- Liu, J.; Chen, C.; Li, Y.; Sun, L.; Song, Y.; Zhou, J.; Jing, B.; Dou, D. Enhancing trust and privacy in distributed networks: A comprehensive survey on blockchain-based federated learning. Knowl. Inf. Syst. 2024, 66, 4377–4403. [Google Scholar] [CrossRef]
- Ariza, J.; Garcés, K.; Cardozo, N.; Rodríguez Sánchez, J.P.; Jiménez Vargas, F. IoT architecture for adaptation to transient devices. J. Parallel Distrib. Comput. 2021, 148, 14–30. [Google Scholar] [CrossRef]
- Hofer, M.; Obraczka, D.; Saeedi, A.; Köpcke, H.; Rahm, E. Construction of Knowledge Graphs: Current State and Challenges. Information 2024, 15, 509. [Google Scholar] [CrossRef]
- Pasdar, A.; Koroniotis, N.; Keshk, M.; Moustafa, N.; Tari, Z. Cybersecurity solutions and techniques for Internet of Things integration in combat systems. In IEEE Transactions on Sustainable Computing; IEEE: Piscataway, NJ, USA, 2024; pp. 1–20. [Google Scholar] [CrossRef]
- Rathanasalam, R.; Kanagasabai, K. Data dissemination with interoperability in IoT network. Int. J. Commun. Syst. 2020, 33, e4513. [Google Scholar] [CrossRef]
- Jeong, S.; Kim, S.; Kim, J. City Data Hub: Implementation of Standard-Based Smart City Data Platform for Interoperability. Sensors 2020, 20, 7000. [Google Scholar] [CrossRef] [PubMed]
- Tang, Q.; Xie, R.; Yu, F.R.; Chen, T.; Zhang, R.; Huang, T.; Liu, Y. Distributed Task Scheduling in Serverless Edge Computing Networks for the Internet of Things: A Learning Approach. IEEE Internet Things J. 2022, 9, 19634–19648. [Google Scholar] [CrossRef]
- Tian, H.; Xu, X.; Lin, T.; Cheng, Y.; Qian, C.; Ren, L.; Bilal, M. DIMA: Distributed cooperative microservice caching for internet of things in edge computing by deep reinforcement learning. World Wide Web 2022, 25, 1769–1792. [Google Scholar] [CrossRef]
- Marshoodulla, S.Z.; Saha, G. An approach towards removal of data heterogeneity in SDN-based IoT framework. Internet Things 2023, 22, 100763. [Google Scholar] [CrossRef]
- Sharma, S.; Verma, V.K. An Integrated Exploration on Internet of Things and Wireless Sensor Networks. Wirel. Pers. Commun. 2022, 124, 2735–2770. [Google Scholar] [CrossRef]
- Naidoo, P.; Sibanda, M. Emerging Trends and Future Directions of the Industrial Internet of Things. In From Internet of Things to Internet of Intelligence; Odhiambo, M.O., Mwashita, W., Eds.; Transactions on Computational Science and Computational Intelligence; Springer: Cham, Switzerland, 2024. [Google Scholar] [CrossRef]
- Ali, M.I.; Gao, F.; Mileo, A. CityBench: A Configurable Benchmark to Evaluate RSP Engines Using Smart City Datasets. In The Semantic Web-ISWC 2015; Arenas, M., Corcho, O., Simperl, E., Strohmaier, M., d’Aquin, M., Srinivas, K., Groth, P., Dumontier, M., Heflin, J., Thirunarayan, K., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 374–389. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Edge Server | FedProx Accuracy (%) | FedAvg Accuracy (%) |
|---|---|---|
| 1 | 85.3 | 80.1 |
| 5 | 87.5 | 81.2 |
| 10 | 83.9 | 79.8 |
| 15 | 82.5 | 78.7 |
| 20 | 81.2 | 75.3 |
| Method | Optimization | Total Cost (MB) |
|---|---|---|
| FedProx | Gradient Compression | 420 |
| FedProx | None | 600 |
| FedAvg | None | 580 |
| Domain | Aligned Fields (%) | Unaligned Fields (%) |
|---|---|---|
| Traffic Monitoring | 97 | 3 |
| Environmental Sensing | 94 | 6 |
| Parking Management | 93 | 7 |
| Ontology Version | Global Accuracy (%) | Local Accuracy Range (%) |
|---|---|---|
| Base Ontology | 89.4 | 81.2–87.5 |
| Updated Ontology | 89.1 | 80.9–87.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kanzouai, C.; Bouarourou, S.; Zannou, A.; Boulaalam, A.; Nfaoui, E.H. Enhancing IoT Scalability and Interoperability Through Ontology Alignment and FedProx. Future Internet 2025, 17, 140. https://doi.org/10.3390/fi17040140
Kanzouai C, Bouarourou S, Zannou A, Boulaalam A, Nfaoui EH. Enhancing IoT Scalability and Interoperability Through Ontology Alignment and FedProx. Future Internet. 2025; 17(4):140. https://doi.org/10.3390/fi17040140
Chicago/Turabian StyleKanzouai, Chaimae, Soukaina Bouarourou, Abderrahim Zannou, Abdelhak Boulaalam, and El Habib Nfaoui. 2025. "Enhancing IoT Scalability and Interoperability Through Ontology Alignment and FedProx" Future Internet 17, no. 4: 140. https://doi.org/10.3390/fi17040140
APA StyleKanzouai, C., Bouarourou, S., Zannou, A., Boulaalam, A., & Nfaoui, E. H. (2025). Enhancing IoT Scalability and Interoperability Through Ontology Alignment and FedProx. Future Internet, 17(4), 140. https://doi.org/10.3390/fi17040140