1. Introduction
Online platforms have transformed communication by facilitating the global sharing of personal content, such as photographs, through social networks and cloud storage. Although these platforms offer significant benefits for convenience and connectivity, they also pose substantial privacy risks [
1]. Shared content frequently includes sensitive facial data, exposing individuals to potential privacy threats in the public domain. For instance, facial recognition technologies can exploit this data for biometric-based surveillance [
2].
Biometric surveillance involves the collection and analysis of biometric data, such as facial images, to identify and monitor individuals [
3]. Since facial images inherently carry the risk of unauthorized identification, their widespread availability on online platforms increases privacy concerns, especially when combined with other data sources, such as online activities or location metadata [
4].
In addition, analyzing facial images alongside contextual elements, such as background details, can inadvertently reveal sensitive information, including an individual’s location or daily routines. These vulnerabilities have been exploited in real-world incidents, where perpetrators used facial details from social media to locate and harm individuals [
5].
Furthermore, these concerns have become increasingly urgent due to recent advances in deep-learning generative models, particularly their ability to create and manipulate realistic facial data. For example, Karras et al. [
6] introduced StyleGAN, a model that can generate highly realistic human faces. Similarly, Chen et al. [
7] developed a face-swap technique that can seamlessly replace faces in both images and videos. Xu et al. [
8] further proposed a framework for generating videos of people speaking from a single static image, demonstrating the rapid progression in video synthesis.
Despite their impressive capabilities, these technological advancements pose significant threats to individual privacy and societal integrity due to potential misuse, such as impersonation and misinformation. Although progress has been made in the detection of synthetic content [
9,
10,
11], the rapid advancement of generative models continues to challenge existing detection methods as they generate increasingly realistic images that are often indistinguishable from authentic ones, even by human observers. This ongoing challenge underscores the urgent need for proactive privacy protection strategies that safeguard image data at its source, rather than relying solely on reactive measures to mitigate potential harms.
However, despite these growing concerns, many users continue to underestimate the privacy implications of sharing facial images online [
12]. This lack of awareness is intensified by the ease of capturing and disseminating images on modern online platforms, resulting in a surge of biometric data available for exploitation [
13].
While existing online platforms implement system-level privacy controls to protect biometric data, these measures remain inadequate in addressing facial data privacy challenges. Images shared online are often stored in unencrypted formats and accessible via direct links without authentication, making them vulnerable to unauthorized access and misuse. Furthermore, the persistence of files on online platforms poses another risk, as deleting photos does not guarantee the removal of facial data. Images may still be accessible via their URLs, even after deletion [
14]. These limitations highlight the need for file-level facial privacy protection to ensure that facial data remain secure regardless of the image’s online accessibility.
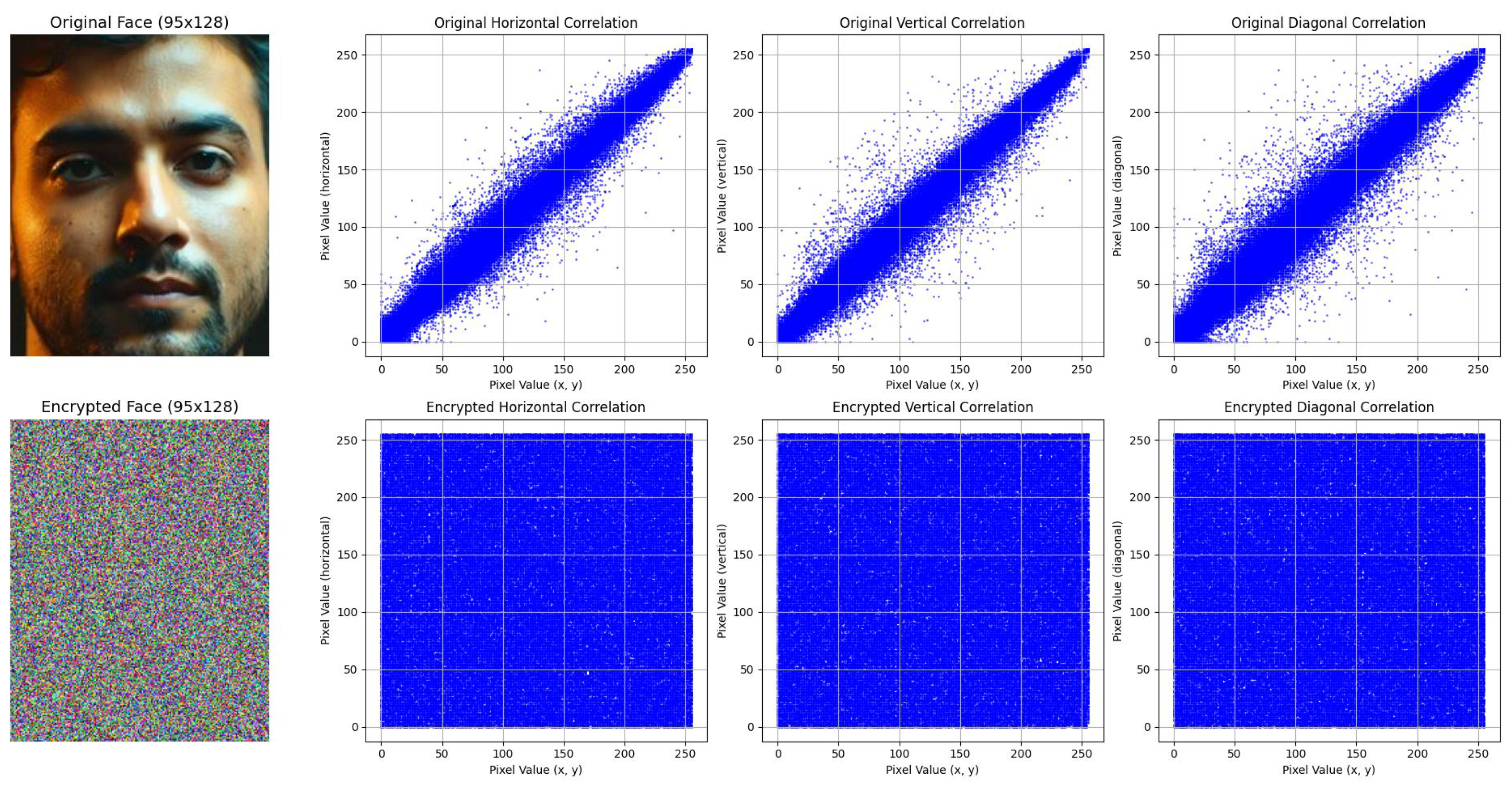
A common approach to file-level privacy in online platforms involves obscuring faces with emoticons or stickers. While this approach may be sufficient for concealing facial features at the file level, it lacks the sophistication of techniques such as image encryption, which enable the restoration of the original face when necessary.
Image encryption provides a robust solution to protect facial data by ensuring that the original face remains hidden until decrypted. Although encryption protects against unauthorized access, it introduces challenges in balancing an image’s security and usability. For instance, encrypting an entire image can render it unusable for general viewing [
15]. This tradeoff is particularly significant on online platforms, where the goal is to share visually meaningful images [
16]. Full-image encryption undermines this usability by obscuring both facial and non-sensitive content, limiting the effectiveness of image sharing.
To address these limitations, our previous work introduced SnapSafe [
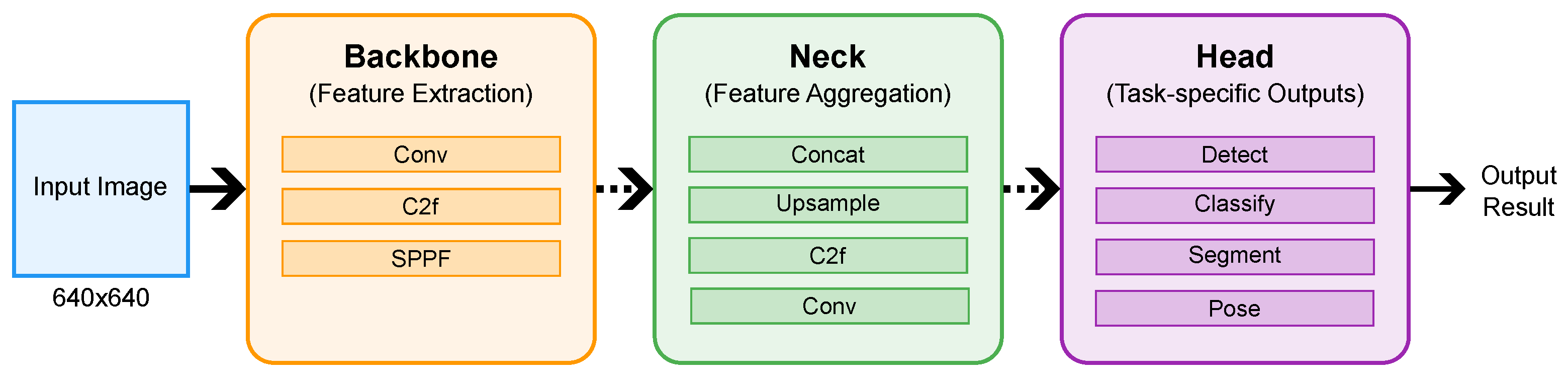
17], a single-party system designed to protect individuals’ privacy by selectively encrypting facial regions in images while preserving the visibility of non-sensitive content. SnapSafe focuses on proactive privacy protection at the source, ensuring that individuals’ privacy is preserved before an image enters the public domain. Using a deep-learning model based on the YOLOv8 architecture [
18] for face detection and an AES algorithm for image encryption, SnapSafe demonstrated the feasibility of safeguarding facial data with minimal impact on image usability. This approach provides a practical solution for protecting facial data in shared images, particularly in the SnapSafe context, i.e., organizational settings where privacy concerns are paramount.
However, in the context of SnapSafe, the original system was designed primarily for organizational use cases, where a single entity—the organization—controlled both encryption and decryption. Consequently, only the organization could reveal faces, as it retained exclusive control over the decryption keys. This centralized model restricted access to the original faces solely to the organization.
Nevertheless, the demand for secure photo sharing extends beyond organizational contexts to online photo platforms, where images are shared among multiple users. Given the limitations of SnapSafe, particularly its single-party design and lack of dynamic access control mechanisms, our current work addresses these gaps by introducing dynamic access control mechanisms that enable controlled sharing of facial data among multiple users while ensuring flexible, user-centered privacy protection.
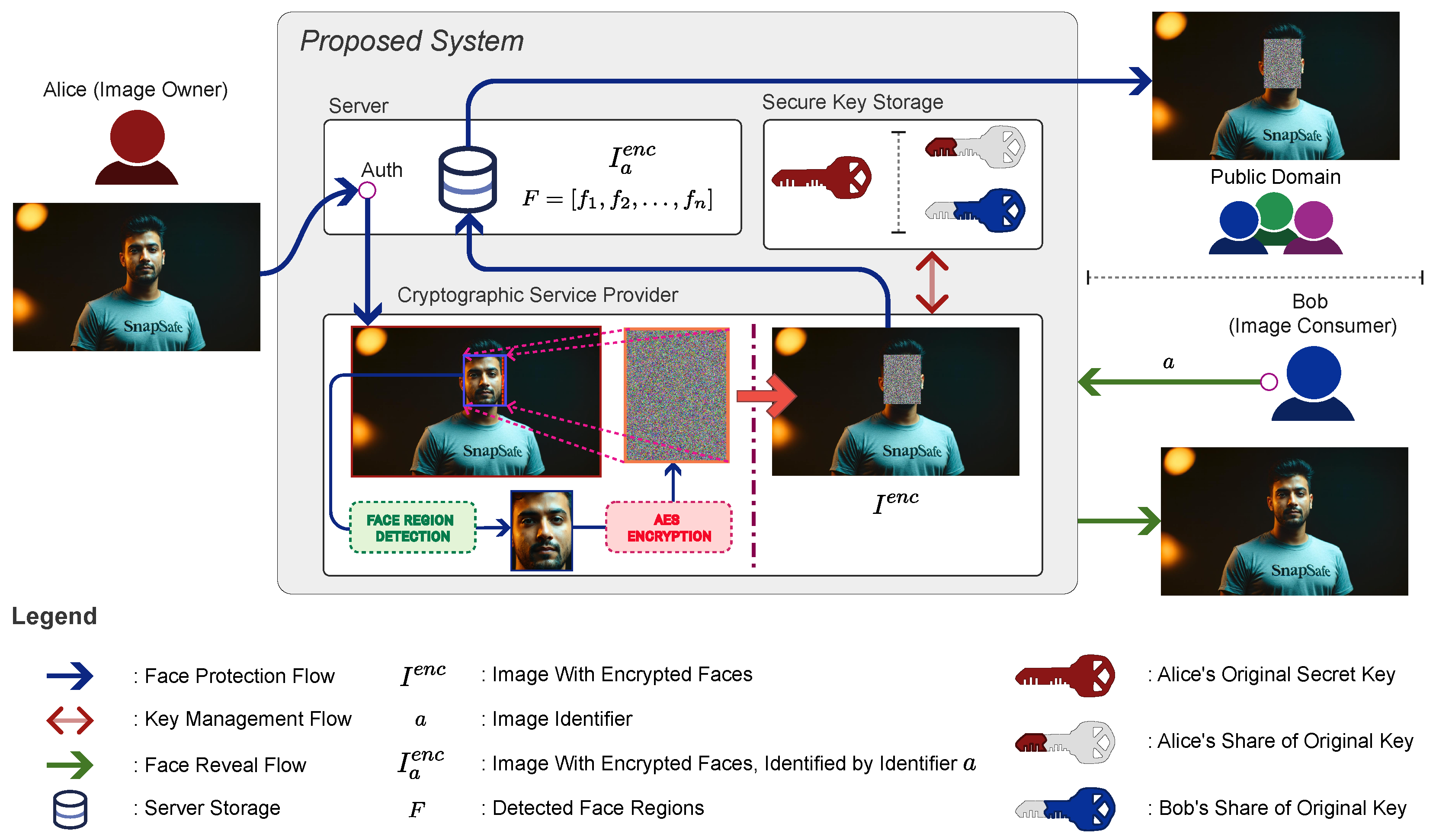
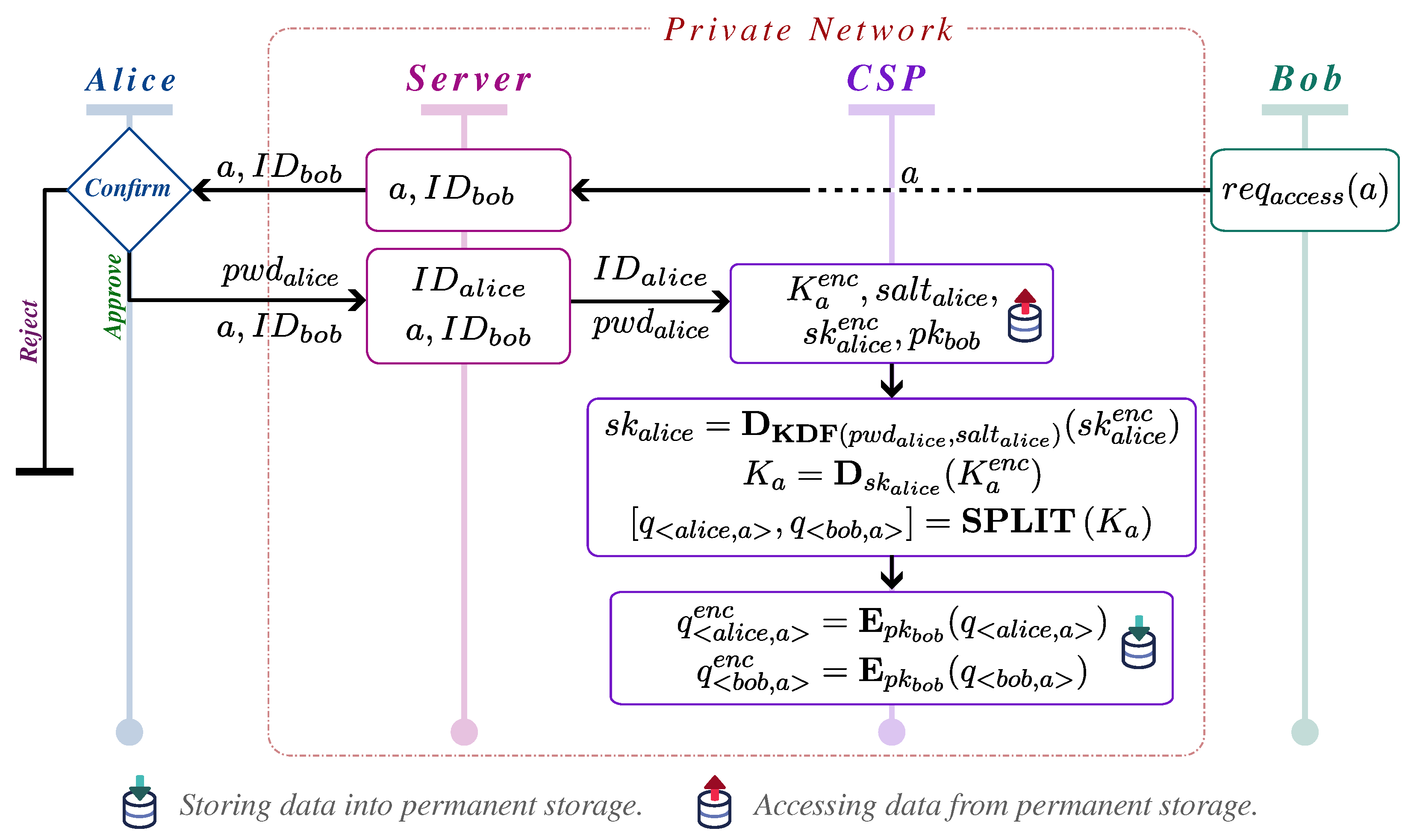
In this study, we classify users into two categories: image owners and image consumers. The interaction between these two groups, including how images are shared and accessed, is illustrated in
Figure 1.
An image owner, referred to as Alice, is an individual who captures and uploads a photograph to the system, rather than the person depicted in it. This classification aligns with U.S. Copyright Office Circular 42 [
19], which states that copyright belongs to the photographer, not the subject, unless transferred to another party. However, this assumption must be applied carefully, as publishing images containing identifiable individuals raises privacy concerns that vary across jurisdictions.
Once an image is uploaded, it may be shared publicly, making it accessible to the public domain, or within a restricted group, where access is limited to specific users. As shown in
Figure 1, people who have permission to view facial data are referred to as image consumers, Bob representing an example. Bob can view the facial data unless his access is revoked, whereas the public domain can only access images with encrypted face regions.
Our proposed system enables image owners to encrypt facial data when necessary. This encryption may be optional for individuals prioritizing privacy or mandatory for organizations (e.g., schools, Non-Governmental Organizations (NGOs), or companies) to comply with regulations such as the General Data Protection Regulation (GDPR) [
20]. For example, a school that shares images of its activities online acts as the image owner and can implement measures to protect students’ privacy before publication. If a parent (acting as an image consumer) wishes to view their child’s face in an image, they must submit a permission request, which the school administrator may approve or deny based on institutional policies and privacy considerations. However, the process of verifying image consumers—such as determining whether or not the requester is the child’s parent in the school use case and whether or not they have the right to view the face—is beyond the scope of this study.
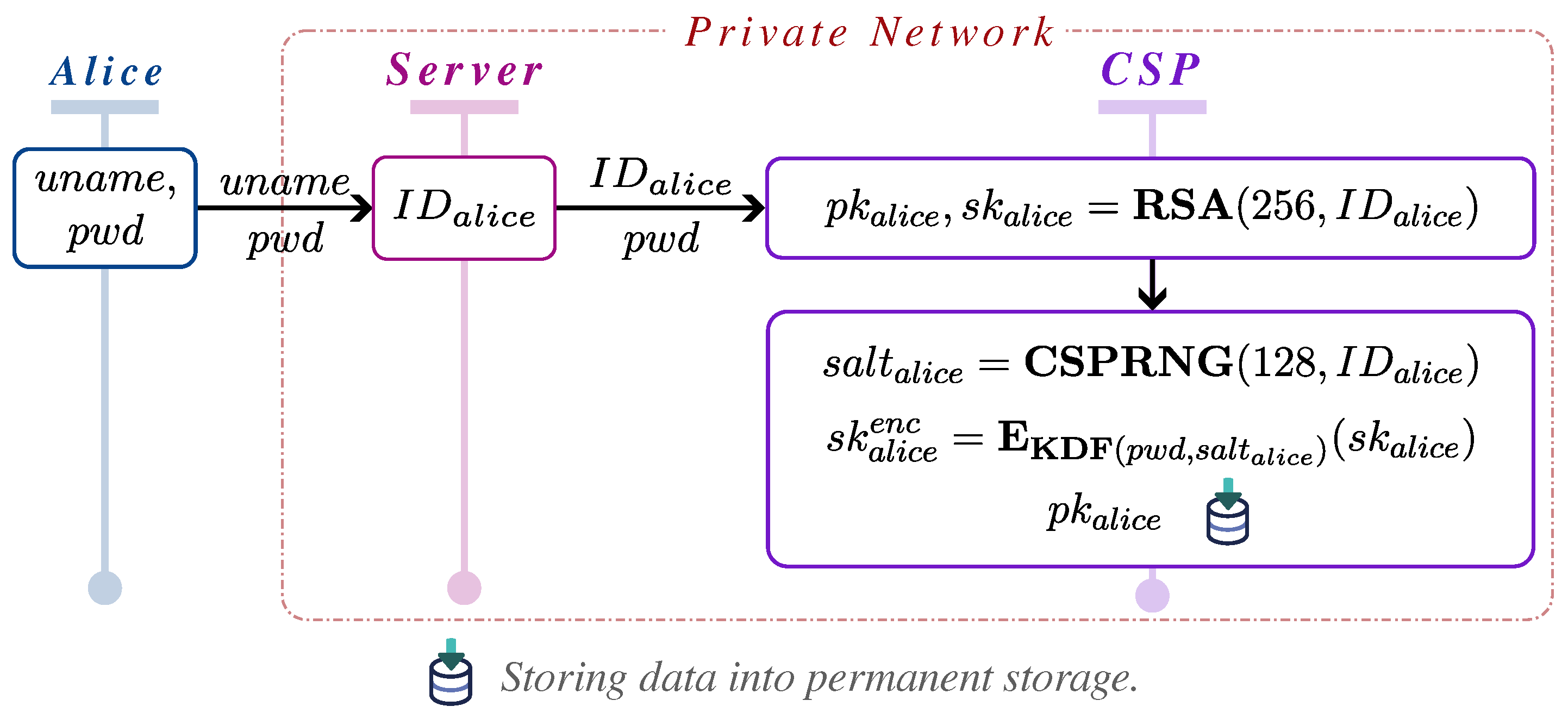
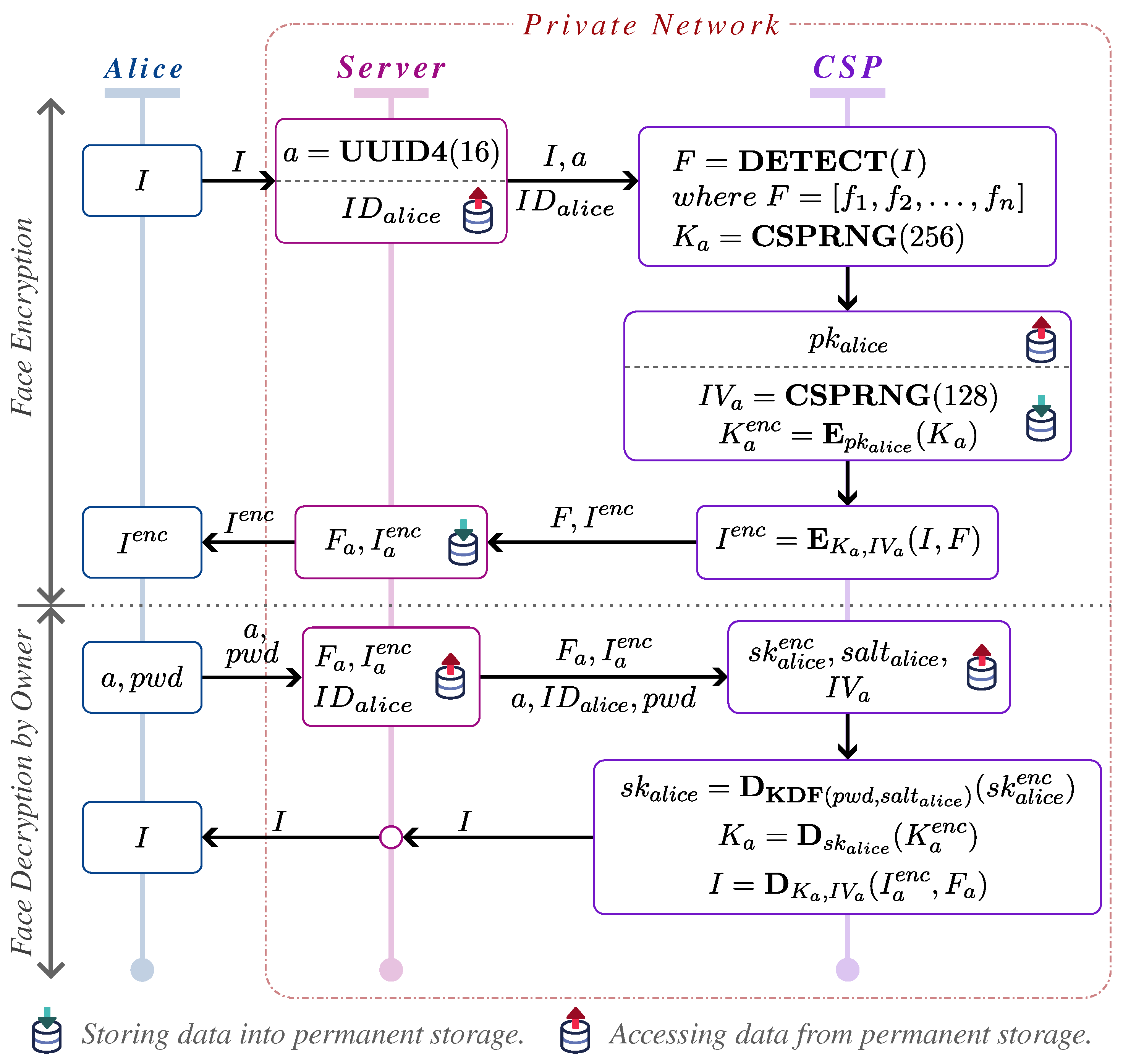
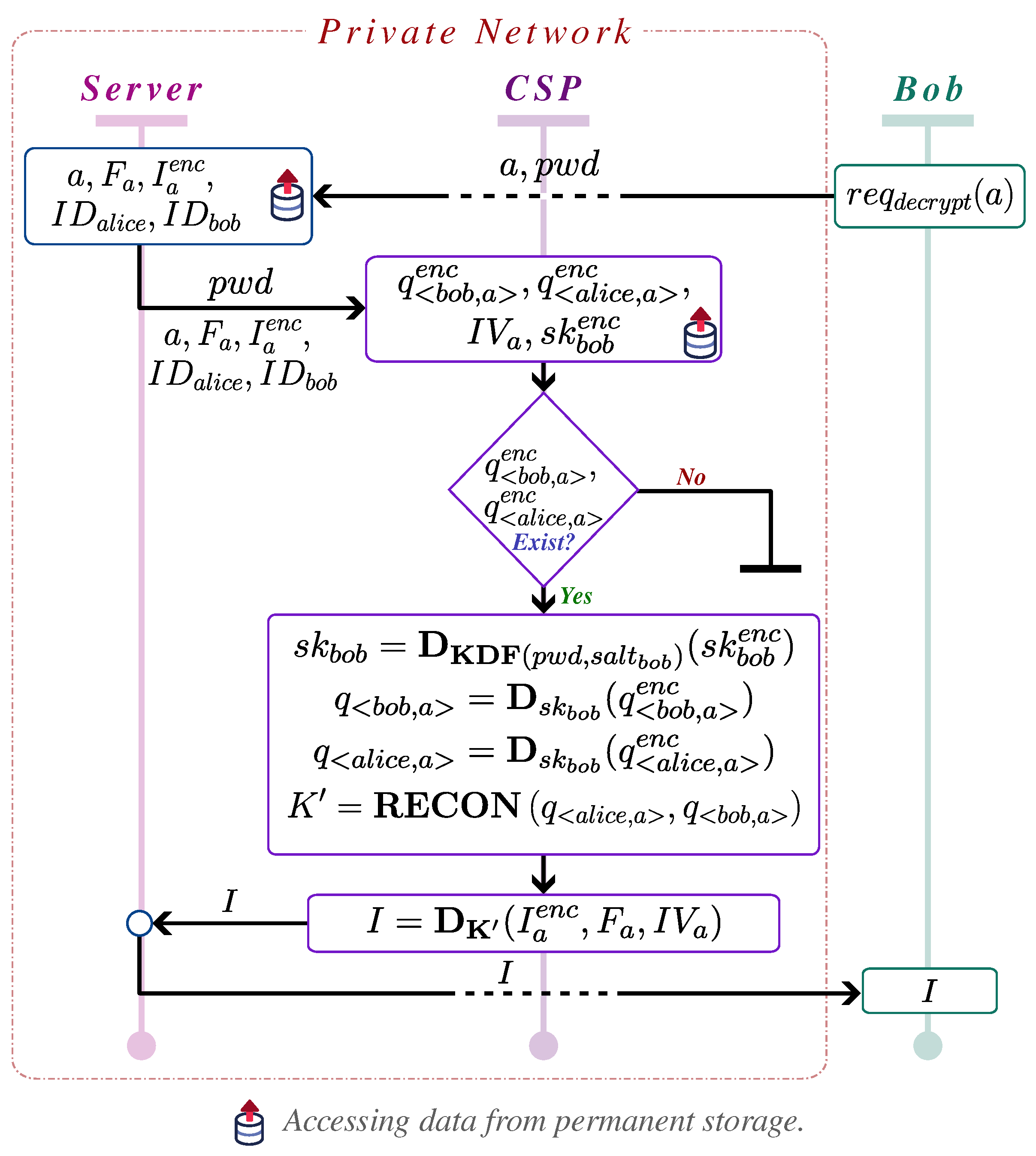
Upon approval, the system splits the original secret key into two shares: one assigned to the owner and the other to the consumer. For decryption, the image consumer must have access to both key shares, ensuring security and restricting access exclusively to authorized users. As part of this process, the image consumer must provide relevant details, such as the image identifier, to initiate the decryption. If all conditions are met, the system decrypts the facial data and displays the original face to the consumer. Although
Figure 1 illustrates the decryption process for the consumer, it does not depict the decryption process by the image owner, which will be detailed in subsequent sections.
Additionally, the system enables the image owner to revoke previously granted access at any time, ensuring that full control over facial data is retained. This owner-centric permission system, combined with the request-based mechanism for initiating permissions, guarantees that non-facial areas of images remain accessible for general viewing, while facial data are protected under strict, dynamic access control policies.
By implementing encryption-based access control, our system ensures file-level security for images, allowing only authorized users to access facial data. This approach is particularly relevant for securely sharing privacy-sensitive images while enforcing strict access control measures. While our discussion primarily focuses on school environments, similar concerns extend to other domains. For instance, companies may need to regulate access to event photos, NGOs might publish images from community projects while safeguarding individuals’ identities, and individuals may wish to share photos from social gatherings while preserving the privacy of those depicted.
Building on this foundation, our approach redefines the role of organizational users in the original single-party SnapSafe system. Instead of a single-user control model, these users now participate equally in sharing protected photos online. This shift to a multi-user access model expands the system’s applicability, supporting a wider range of use cases.
The following sections outline the proposed system in detail and are structured as follows.
Section 2 presents related works on facial privacy protection.
Section 3 provides a preliminary discussion of key concepts and technologies relevant to the proposed system, along with an overview of this work’s contributions.
Section 4 describes the proposed system in detail, covering its components, the workflow for key operations, and security considerations.
Section 5 discusses the experimental setup and analysis. Finally,
Section 6 summarizes the study’s findings and conclusions and outlines potential directions for future research.
2. Related Works
Facial privacy protection has attracted significant attention in recent years due to the proliferation of facial data on online platforms and the increasing risks of misuse. Various techniques have been proposed to address these challenges, each targeting different aspects of facial data protection. Some approaches focus on image modification to protect facial privacy, while others emphasize user consent and access control mechanisms.
In this section, we review several existing works on facial privacy protection, highlighting their key features and limitations.
Table 1 presents a comparative overview of approaches focused on image modification, while
Table 2 provides a comparison of approaches that prioritize user consent and access control.
In the context of image modification to protect facial privacy, You et al. [
21] proposed the Diffusion-Based Facial Privacy Protection Network (DIFP), which employs diffusion models to generate photorealistic and privacy-preserving images. DIFP ensures the reversibility of protected images, enabling the restoration of the original faces when necessary. Similarly, He et al. [
22] introduced Diff-Privacy, which produces visually realistic and diverse anonymized images while maintaining the ability to recover original identities as needed. Although both approaches ensure reversibility, the restored images are not identical to the original images at the pixel level.
Suwala et al. [
23] proposed PluGeN4Faces, a method for decoupling facial attributes from identity in StyleGAN’s latent space, allowing for precise attribute manipulation while maintaining image realism. Although not explicitly designed for privacy protection, this approach could be adapted to anonymize facial images by altering identifiable attributes, such as age, hairstyle, or beard. Yang et al. [
24] introduced the Digital Mask (DM), which uses 3D reconstruction and deep-learning algorithms to irreversibly anonymize facial features while preserving disease-relevant attributes. Unlike DIFP and Diff-Privacy, both PluGeN4Faces and DM lack the capability to reverse to the original image. Nevertheless, these methods offer promising alternatives for generating privacy-preserving facial images.
Another key aspect of facial privacy protection is access control, which involves obtaining user consent and granting users control over the usage of their facial data. Xu et al. [
25] introduced a system where social media users depicted in a photo are notified and allowed to participate in decisions about photo sharing to prevent privacy breaches. Similarly, Tang et al. [
26] proposed an automatic tagging framework that restricts photo access based on the identities of tagged individuals. Although these approaches focus on user consent and access control, they do not address the challenges of file-level protection through the selective encryption of facial data in multi-user scenarios. Moreover, their approaches require users to provide personal photos for face model training, which may raise privacy concerns.
Table 2.
Comparative overview of proposed approaches with some existing works in user consent and access control for facial privacy protection.
Table 2.
Comparative overview of proposed approaches with some existing works in user consent and access control for facial privacy protection.
| Approach | Key Features | Relies on User’s Private Photos | File-Level Protection |
|---|
| Xu et al. [25] | Photo-sharing consent system for privacy protection | Yes | No |
| Tang et al. [26] | Automatic tagging framework for photo access control | Yes | No |
| Proposed System | Dynamic multi-user access control for facial privacy protection | No | Yes |
While the discussed approaches provide valuable insights into facial privacy protection, they do not address the challenges of selective image encryption in multi-user scenarios. Additionally, although methods such as DIFP and Diff-Privacy ensure reversibility, the restored images are not pixel-perfect, which limits their applicability in scenarios requiring precise image restoration. In contrast, our proposed system provides a comprehensive solution for dynamic multi-user access control in online photo platforms. It safeguards facial data through file-level selective image encryption while allowing pixel-perfect restoration when needed. Moreover, it eliminates the need for participating users to submit personal photos for face model training, enhancing both privacy and usability.
6. Conclusions
This paper presents a facial privacy protection system designed as a proactive measure to protect facial data in shared images. The system encrypts facial regions before an image is published, ensuring privacy at the source before others can access it. Building on our previous work on a single-party face protection system, SnapSafe, this study introduces a file-level facial protection mechanism with dynamic multi user access control. The proposed system categorizes users into two roles: image owners, who upload and manage images, and image consumers, who request access to protected facial data. Image owners can grant or revoke access to specific consumers, ensuring controlled facial data sharing through access limitations and an encryption-based permission system.
The system employs key splitting for secure access control, an owner-centric permission model for granting and revoking access, and a request-based mechanism that allows consumers to request facial data access, subject to owner approval.
During the evaluation, the system was tested with varying numbers of faces, categorized into single, small, medium, and large groups. Results demonstrate the system’s efficiency in safeguarding facial data while ensuring seamless access in multi-user environments. The encryption of facial data was completed in an average time of less than , measured from the request to the response of the server, reflecting real-world performance when network variability is excluded. The system maintained a success rate in key-splitting operations across all group sizes, ensuring secure access sharing. Facial data decryption for both image owners and consumers was averaged under , while revocation operations were efficiently processed with average server response times below . These results highlight the system’s ability to balance security and usability for facial data protection.
For future work, we aim to enhance system scalability by optimizing data storage and exploring encryption schemes that are resilient to lossy compression. This will ensure that encrypted images do not occupy excessive storage while still allowing facial data to be decrypted even after image compression. Additionally, we will develop fine-grained access control that enables image owners to grant selective access to specific facial regions. These improvements will improve user control over facial data sharing, ensuring that image owners can grant access to specific facial data rather than revealing all faces to authorized users.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}