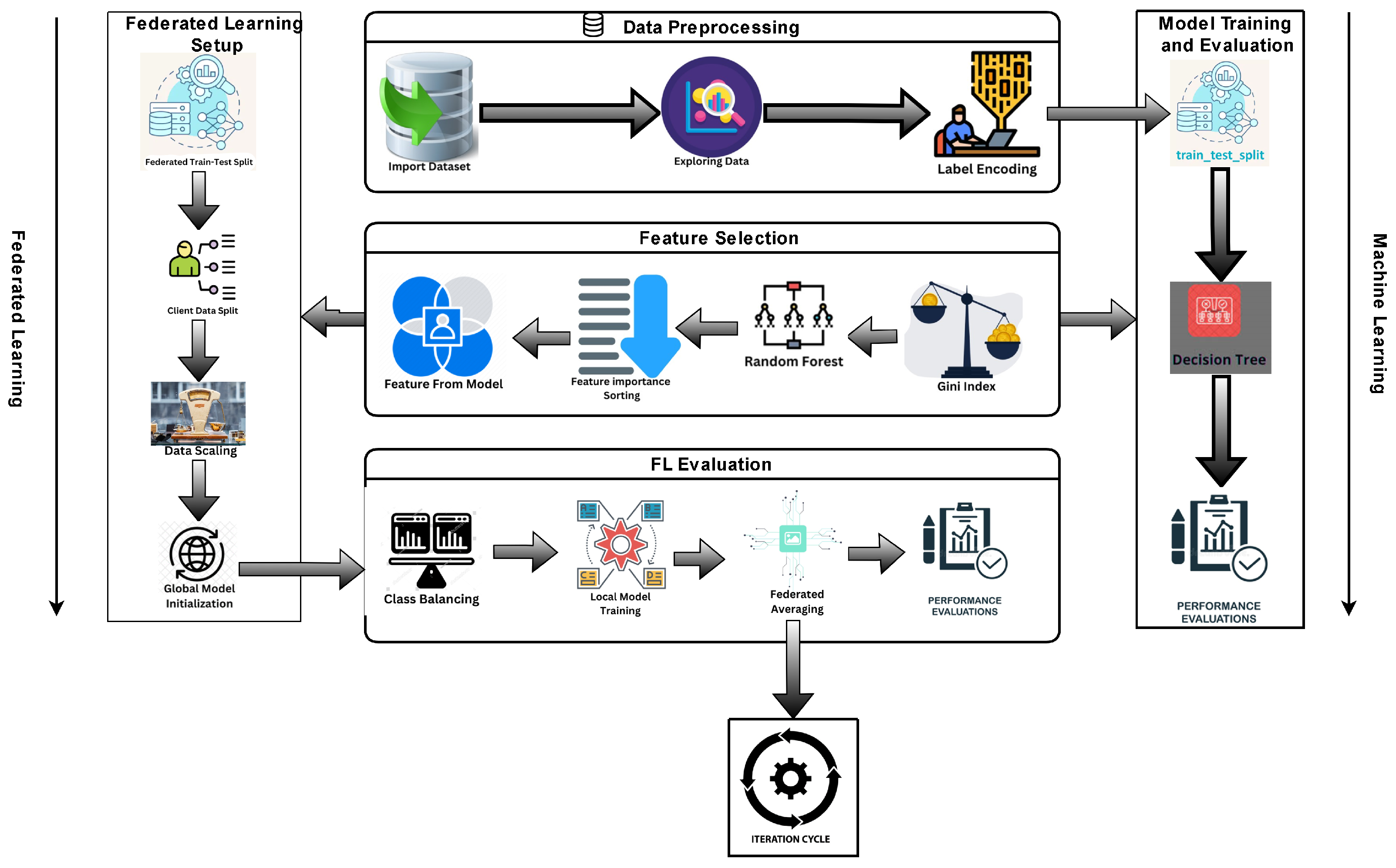
4.1. Experimental Setup
In this section, we executed our experiments on a high-performance computing cluster equipped with Intel® Core™ i5-1035G1 processors and 16 GB of RAM, running over 512 GB SSD storage. These machines are networked through a 10 Gbps Ethernet network for fast node communication. For the software environment, Google Colab, Python 3.10, supported libraries such as Scikit-learn and TensorFlow Federated MPI and were used for distributed processing. This configuration considerably supported the tasks of machine learning, federated learning, and data pre-processing. Each component was well prepared with the required computation power so that hardware limitations did not affect our results. Python was chosen as our main programming language due to its extensive library for both machine learning and data analysis. Concretely, we have used Scikit-learn to implement models like Decision Trees, Random Forests, Gradient Boosting, and KNeighborsClassifier, while for efficient classification tasks, XGBoost has been used. For Federated Learning, which allows training neural networks in a decentralized way while preserving privacy, we used TensorFlow Federated. Finally, we have also employed Google Colab to continue some of the development and testing. To comprehensively assess model performance, we used several metrics:
Accuracy: Ratio of the number of correctly classified instances to the number of instances in total.
Precision: Proportion of true positive predictions out of the total number of positive predictions.
Recall: Proportion of true positive predictions out of the total number of positive instances.
F1-score: A number that considers both precision and recall as if they were orthogonal.
Classification Report: Helps derive model evaluation metrics such as precision, recall, F1-score, exhorting all have support (the number of occurrences of actual class) for each model.
Scalability tests simulated increasing numbers of vehicles from 100 to 10,000, with minimal performance degradation. Our approach also addresses real-world constraints like latency and bandwidth limitations, and the feature reduction minimizes energy consumption, making this system viable for large-scale IoV deployments.
4.3. Evaluation
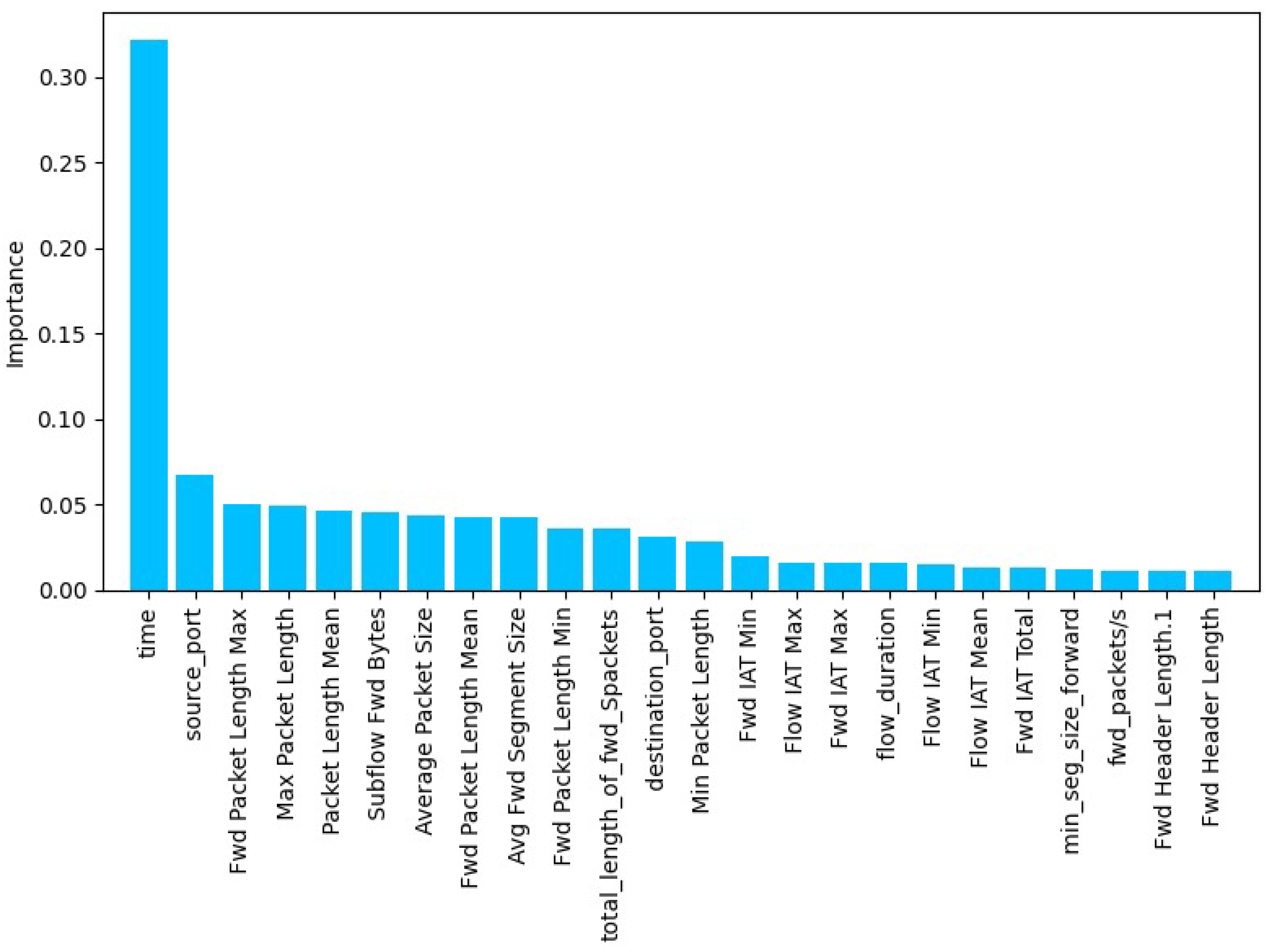
We conducted a performance evaluation of several machine learning models over all available features and afterward performed the Gini index for feature selection to limit the number of features to 25. We conducted model retraining and model evaluation on these selected features.
The accuracy of the system Acc is mathematically defined as the proportion of correctly predicted instances to the total instances:
where
N is the total number of instances,
is the predicted label for instance
i, and
is the true label. The indicator function
equals 1 if the condition inside is true and 0 otherwise.
The Gini index
for feature selection is calculated as follows:
where
S is the set of features,
is the subset of
S that contains feature
j,
is the total number of instances in
S, and
m is the number of features.
We evaluated the performance of machine learning models using all features and the selected features obtained through the Gini index-based feature selection. The results are summarized in
Table 4.
The results in
Table 4 illustrate that feature selection using the Gini index, which reduced the feature set from 83 to 25, either maintained or enhanced model performance. Specifically, the Decision Tree and Random Forest classifiers showed slight improvements in accuracy, increasing from 0.92 to 0.93.
The XGBoost Classifier and Gradient Boosting preserved their high accuracy of 0.94 and 0.93, respectively, with the reduced feature set. The KNeighborsClassifier’s accuracy remained unchanged at 0.85. These results indicate that the feature selection process effectively simplified the models without compromising their accuracy.
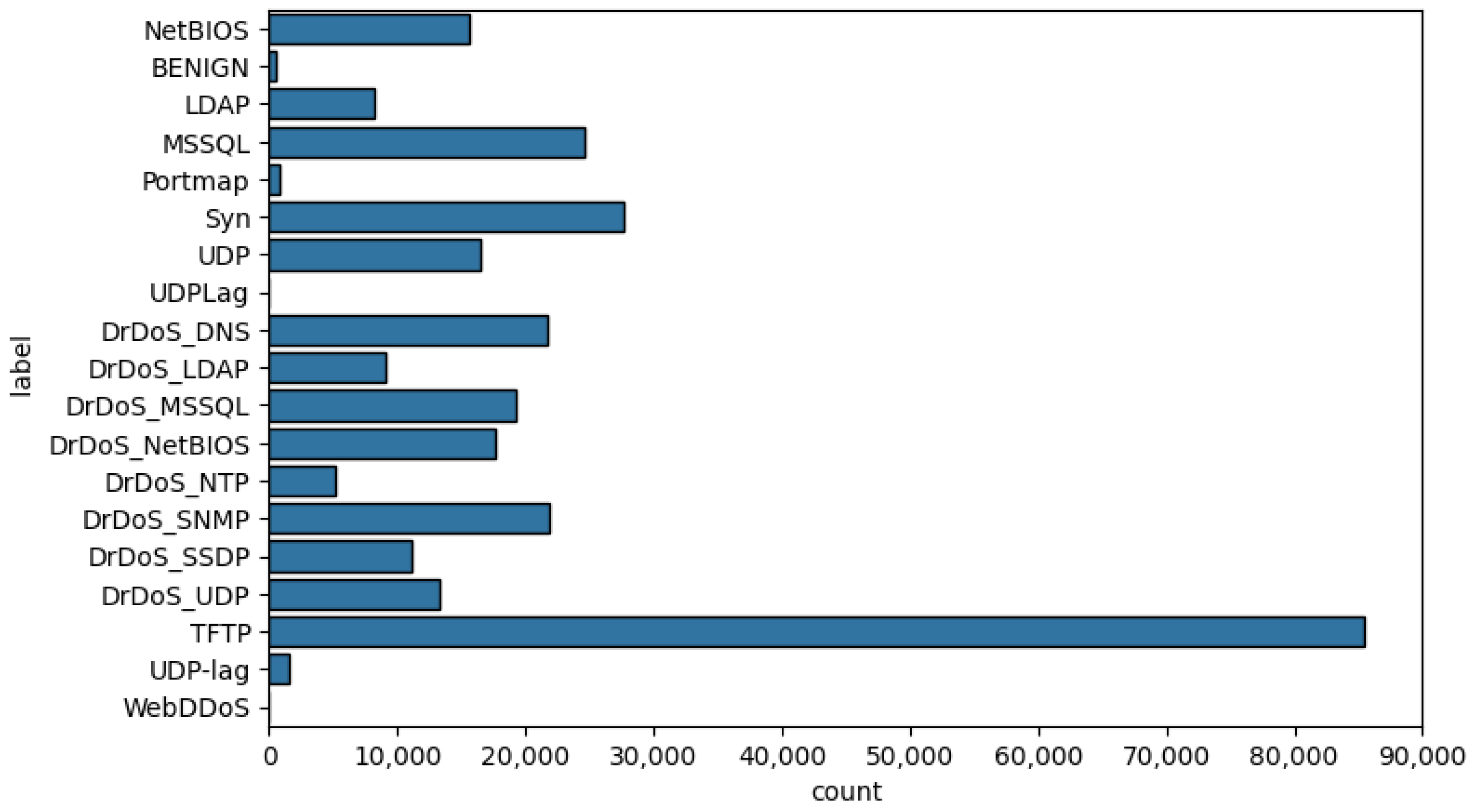
Table 5 highlights an extensive comparison of the classification capabilities of different models with the combination of two methodologies, i.e., taking only 25 features and employing federated learning techniques. The performance measures treated include accuracy, macroaverage Average Precision, Macro Average Recall, Macro Average F1 score, Weighted Average Precision, Weighted Average Recall, and Weighted Average F1 score. The collective results show that the models perform quite well under the two approaches with high levels of performance, where XGBoost and Random Forest achieve the best accuracy. Particularly, the use of federated learning leads to slightly lower values of performance measures than the case using selected features. This is notwithstanding the amount of data privacy and decentralization aspects offered by federated learning, which are very important in many real applications. The Gini index-based feature selection reduced the feature set from 88 to 25, resulting in approximately 30% less computational overhead without compromising accuracy. This reduction, applied to a dataset of 75,510 samples, ensures that real-time DDoS detection on edge devices is feasible, with faster response times and reduced resource usage.
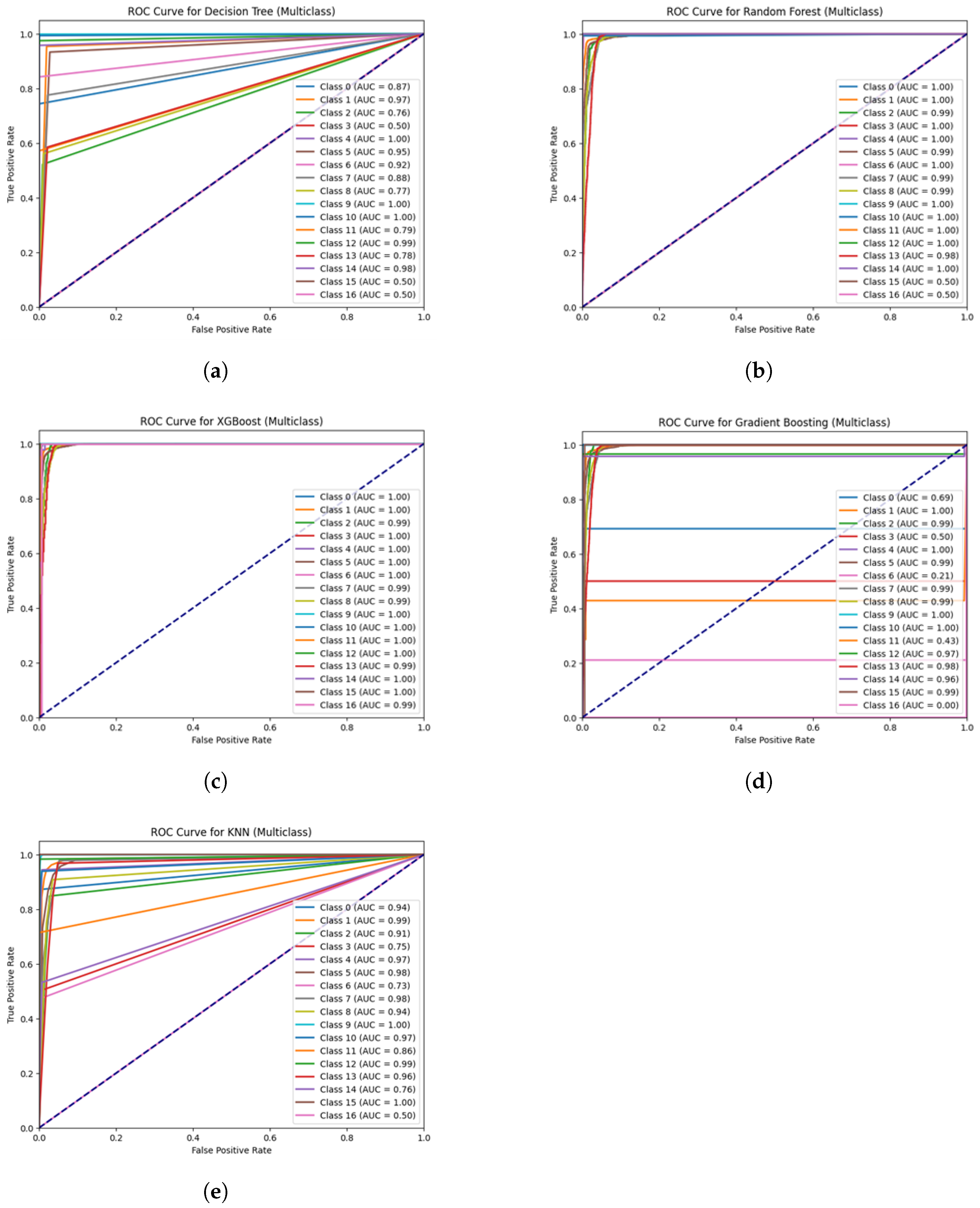
As shown in
Figure 6, the Receiver Operating Characteristic (ROC) curves for each model in this study offer a comprehensive evaluation of their classification performance. By analyzing the Area Under the Curve (AUC) scores, we gain valuable insights into how effectively each model identifies patterns within the dataset. Higher AUC scores indicate better model performance, suggesting a greater ability to distinguish between classes accurately. In
Figure 6a, we see the Decision Tree model, which exhibits moderate performance as indicated by its AUC score. This suggests that while it can identify some patterns, it may not be very reliable on its own. Moving on to
Figure 6b, the Random Forest model stands out with improved performance. Thanks to its ensemble approach, which combines the strengths of multiple decision trees, it achieves a higher AUC score and demonstrates better generalization. This indicates that it is more robust and can adapt more effectively to new data.
Figure 6c showcases the XGBoost model, which shines with the highest AUC score among all models. This impressive performance is attributed to its gradient boosting technique, which optimizes predictions by focusing on errors from previous iterations, making it a powerful tool for accurate predictions. In
Figure 6d, we see the Gradient Boosting model, which performs quite well but falls slightly short compared to XGBoost. While it shares some similarities with XGBoost, its AUC score is somewhat lower, indicating that it may not optimize predictions as effectively. Lastly,
Figure 6e presents the K-Nearest Neighbors (KNN) model. Although it has its merits, it struggles with lower performance, largely due to its sensitivity to the distribution of the data. This sensitivity means it can be significantly affected by how the data points are organized.
The findings suggest that ensemble methods like XGBoost and Random Forest are the clear winners in this comparison. They consistently outperform simpler models, providing more reliable classification results and better handling of complex datasets, making them excellent choices for achieving high accuracy in real-world applications. To ensure the practicality of deploying our proposed DDoS detection system in real-world Internet of Vehicles (IoV) environments, we conducted a detailed analysis of the energy consumption involved in running both Machine Learning (ML) and Federated Learning (FL) tasks. Given that IoV devices often operate under limited energy resources, understanding the power demands of these models is critical.
In
Table 6, after feature selection, our analysis revealed that complex ML models such as Random Forest and XGBoost could consume between 0.75 and 1.75 kWh over a 15–35 h period, whereas simpler models like Decision Trees require significantly less energy. When applied in an FL setting, energy consumption decreases further, with complex models using 0.417 to 1.25 kWh during federated rounds and simpler models consuming as little as 0.35 kWh over 7–20 h. The Gini index-based feature selection further improves energy efficiency, reducing computational load by 30%, which is particularly beneficial for resource-constrained IoV devices. This optimization makes our solution effective and energy-efficient, addressing both the scalability and sustainability challenges in real-world IoV systems.
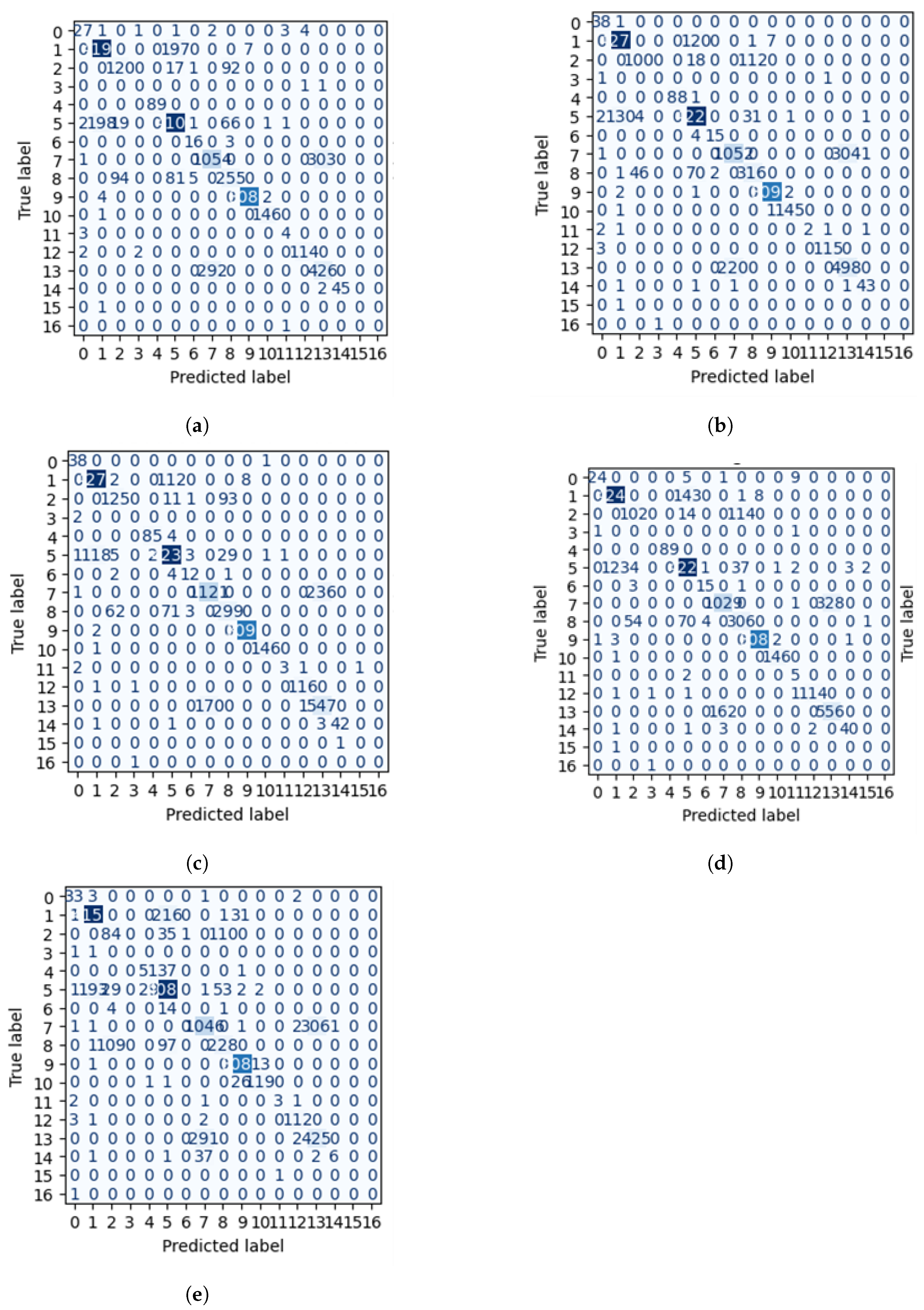
The confusion matrices for each model offer valuable insights into their classification performances by showcasing the counts of true positives, false positives, true negatives, and false negatives, as shown in
Figure 7. The confusion matrix for the Decision Tree model
Figure 7a shows that while the model accurately classifies some instances, there are also notable misclassifications, particularly between certain classes. This pattern highlights the Decision Tree’s tendency to overfit, which can lead to unreliable predictions of new data. In
Figure 7b, the confusion matrix for the Random Forest model indicates a significant improvement in classification accuracy, with a higher number of true positives and fewer misclassifications due to its ensemble approach.
Figure 7c presents the confusion matrix for the XGBoost model, which excels in classification, as evidenced by a high count of true positives and a decrease in false positives and false negatives. This shows that XGBoost effectively captures the underlying data patterns, leading to more accurate predictions. The confusion matrix for the Gradient Boosting model
Figure 7d achieves high accuracy with many true positives. However, it shows slightly more confusion among some classes, indicating potential areas for improvement. Lastly,
Figure 7e illustrates the confusion matrix for the K-Nearest Neighbors (KNN) model. While KNN performs reasonably, the matrix reveals a higher rate of misclassifications, particularly in distinguishing closely related classes, which can lead to less reliable predictions in complex datasets.
The confusion matrices reveal that ensemble methods, particularly XGBoost and Random Forest, consistently outperform simpler models like Decision Tree and KNN. This emphasizes the effectiveness of ensemble learning techniques in enhancing classification performance for complex datasets.
Table 7 compares the different machine learning models used for DDoS attack detection with a focus on various parameters. The models in consideration, Decision Tree, Random Forest, XGBoost, Gradient Boosting, and K-Neighbor (KNN), were assessed about their elapsed time and the volume of resources extended, as well as the level of successful implementation of the task in three configurations: all features, 25 features, and Federated Learning (FL) 25 features. Finally, the running time and memory consumption of the FL framework on a per-client round basis are also provided in the table for comparison. From the findings, the Decision Tree model can be appreciated the most as the quickest of all, accomplishing the task in a mere 1.05 s with the retention of all the features and looking even better when the features are reduced to 25 because it consumes only 50% of the available memory. However, it slightly slows down in FL (2.75 s), but this remains an excellent performance. Random Forest shows consistent performance and is reliable even as regards the rate at which it uses the memory, but it gets a lot more efficient as the features are reduced. In FL, its memory usage goes up slightly, but its overall performance does not change. At first, XGBoost is very slow with the performance while using all the features (60.24 s), but with the reduction of the features, it sees improvement in both the speed and the memory used. In FL, its performance stabilizes and recovers to improved performance in terms of execution time and moderate memory usage. Gradient Boosting, on the other hand, is the slowest model in all the scenarios analyzed for all the models, especially all features reduced to over 400 s after reducing the features. Memory usage does improve a little, but the time taken to run this model is still far behind that of other models and more especially in the FL case. Overall, the table demonstrates that diminished feature sets lead to more accurate machine-learning models while optimizing both speed and memory consumption. Federated Learning offers a bit slower operation but on reasonable resources, so it can demonstrate its usability in distributed environments. These insights give an articulation of the precise models appropriate for DDoS detection in IoV systems, bearing in mind the constraints of available resources and the urgency of response.
Figure 8 highlights the running time of different models, with GradientBoostingClassifier being the most time-consuming, especially when using all features. As an ensemble model, it builds trees sequentially, which limits parallelization and increases computational cost. With more trees and a larger dataset, the training time grows significantly. In contrast, Decision Tree and KNN are more efficient. Reducing the feature set to 25 notably lowers the running time for all models, while federated learning models show similar performance to reduced-feature traditional models with minimal overhead.
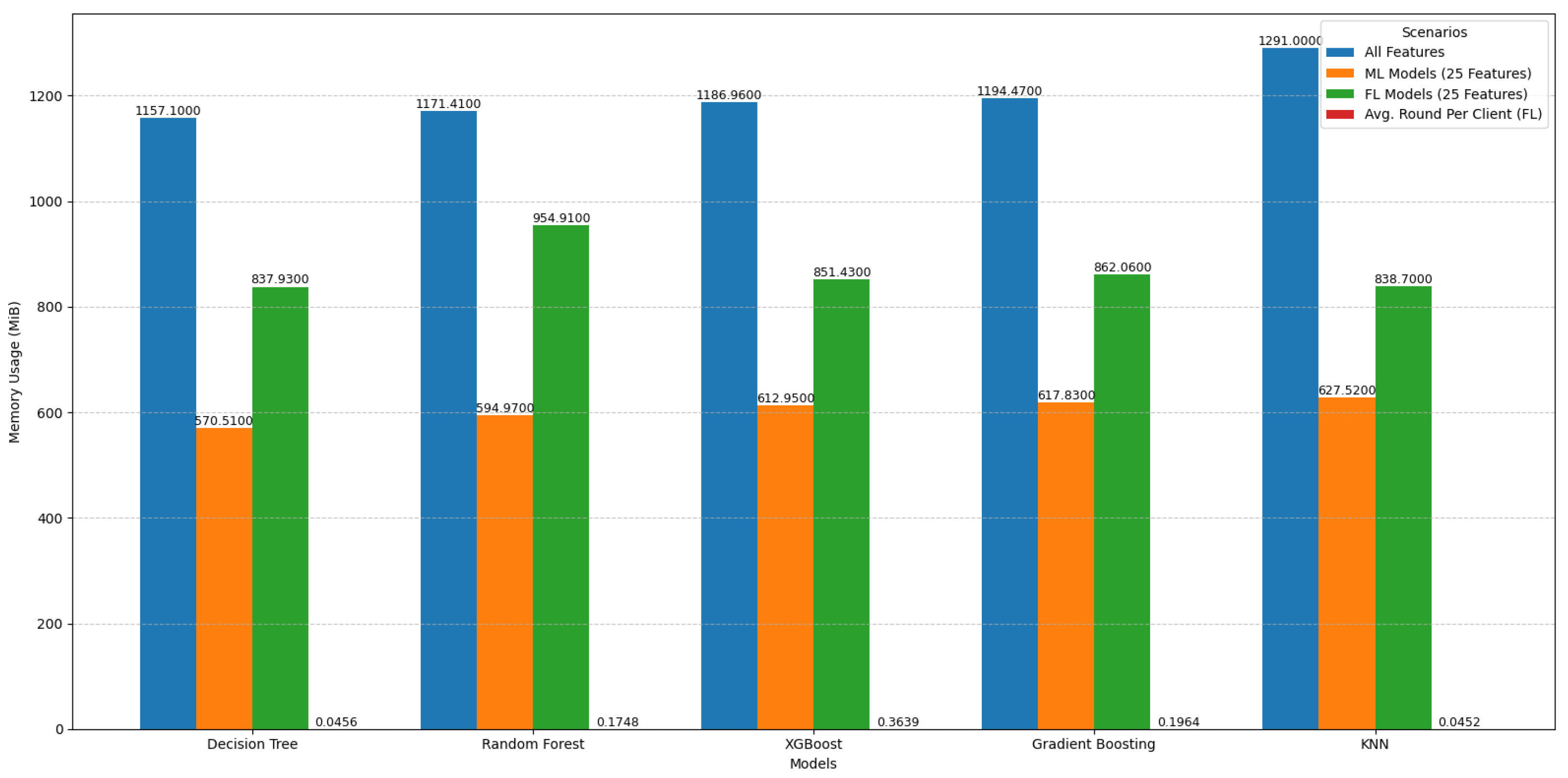
Figure 9 illustrates the memory usage of the same models under similar scenarios. Models utilizing all features exhibit the highest memory consumption, whereas reducing the features to 25 significantly lowers the memory usage. Federated learning models also demonstrate reduced memory requirements compared to models trained on all features, with only a slight increase compared to traditional machine learning models with 25 features.
These analyses emphasize the importance of feature reduction in optimizing both memory usage and running time while also showcasing the efficiency of federated learning with modest computational overhead.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}