

Enhancing Recognition of Human–Object Interaction from Visual Data Using Egocentric Wearable Camera

 ,
, 
Abstract
1. Introduction
List of Contributions
- We propose a novel framework “HP4HOIR” that leverages hand pose information from an egocentric view for the recognition of HOIs.
- We propose a feature extraction and description method for the hand pose data, which captures unique attributes from the hand joints data and represents them as a feature vector for HOIR.
- We conducted a detailed analysis of ODIR and OIIR, which provided insights into the accuracy and computational cost of each approach in recognizing HOI.
2. Related Work
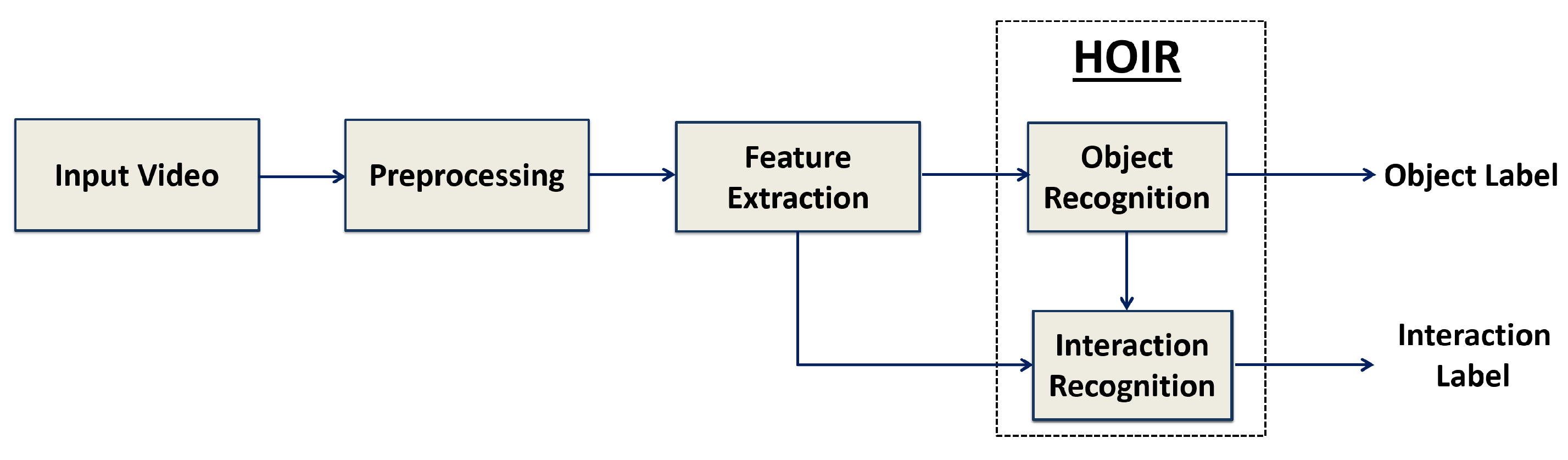
3. Proposed System
3.1. Data Acquisition
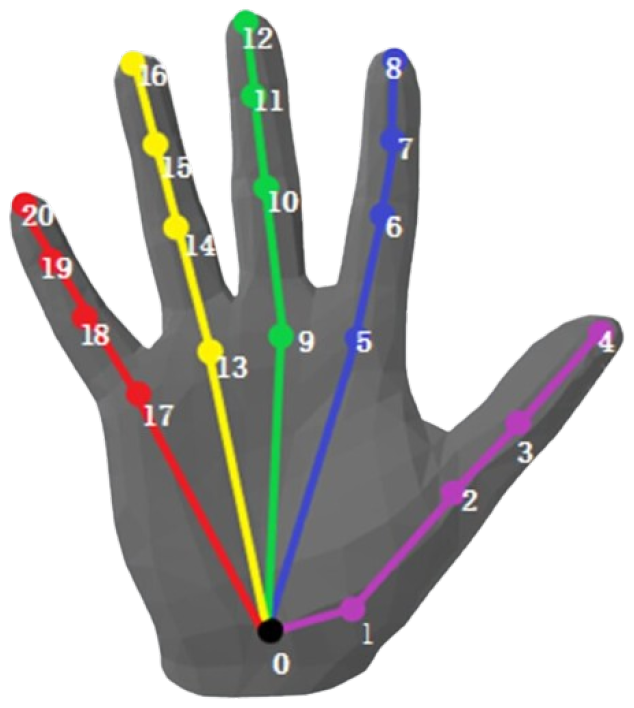
3.2. Segmentation and Hand Joint Extraction
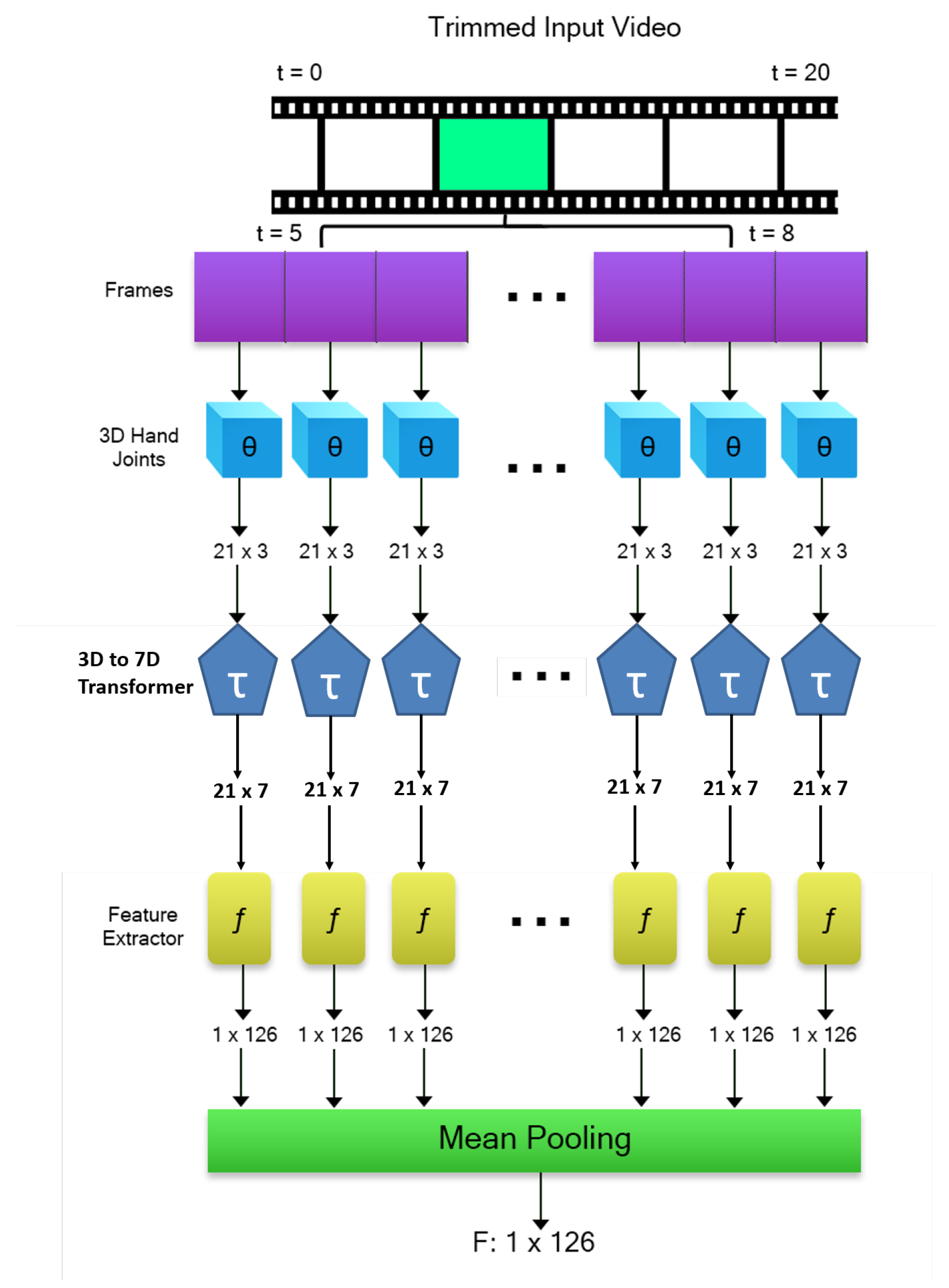
3.3. Hand Joint Transformation: 3D to 7D Space
3.4. Feature Extraction and Description
3.5. Classification
4. Experimental Results and Analysis
4.1. Implementation Details
4.2. Evaluation Metrics and Validation Method
4.3. Analysis of ODIR
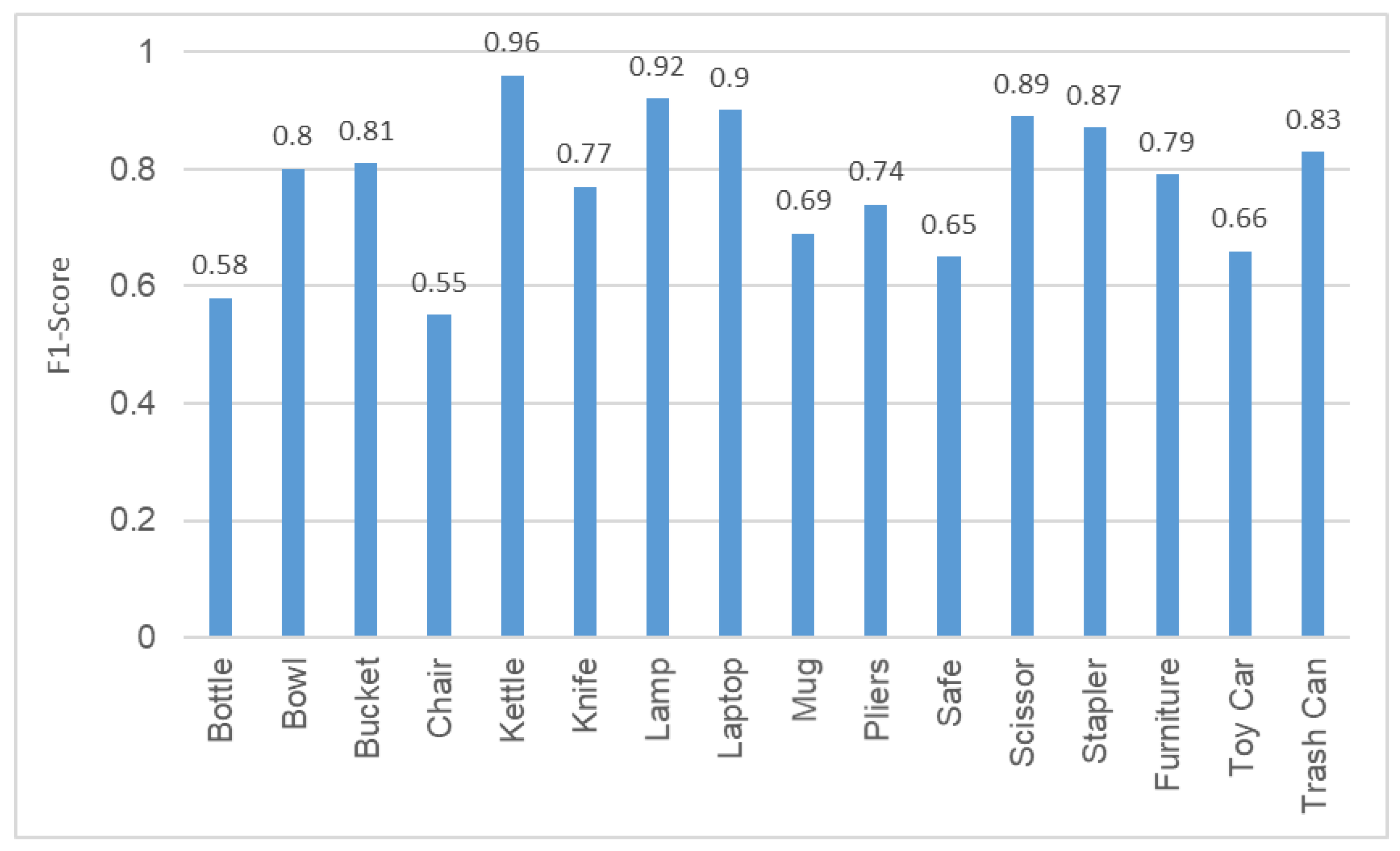
4.3.1. ODIR: Analysis of Object Recognition
4.3.2. ODIR: Analysis of Interaction Recognition
4.4. Analysis of OIIR
4.5. Time and Performance Analysis: ODIR vs. OIIR
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gupta, S.; Malik, J. Visual semantic role labeling. arXiv 2015, arXiv:1505.04474. [Google Scholar]
- Hou, Z.; Yu, B.; Qiao, Y.; Peng, X.; Tao, D. Affordance transfer learning for human-object interaction detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 495–504. [Google Scholar]
- Li, Q.; Xie, X.; Zhang, J.; Shi, G. Few-shot human–object interaction video recognition with transformers. Neural Netw. 2023, 163, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Chao, Y.W.; Wang, Z.; He, Y.; Wang, J.; Deng, J. Hico: A benchmark for recognizing human-object interactions in images. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1017–1025. [Google Scholar]
- Sadhu, A.; Gupta, T.; Yatskar, M.; Nevatia, R.; Kembhavi, A. Visual semantic role labeling for video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5589–5600. [Google Scholar]
- Li, Y.; Ouyang, W.; Zhou, B.; Shi, J.; Zhang, C.; Wang, X. Factorizable net: An efficient subgraph-based framework for scene graph generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 335–351. [Google Scholar]
- Zhou, T.; Wang, W.; Qi, S.; Ling, H.; Shen, J. Cascaded human-object interaction recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4263–4272. [Google Scholar]
- Bansal, S.; Wray, M.; Damen, D. HOI-Ref: Hand-Object Interaction Referral in Egocentric Vision. arXiv 2024, arXiv:2404.09933. [Google Scholar]
- Cai, M.; Kitani, K.; Sato, Y. Understanding hand-object manipulation by modeling the contextual relationship between actions, grasp types and object attributes. arXiv 2018, arXiv:1807.08254. [Google Scholar]
- Chen, L.; Lin, S.Y.; Xie, Y.; Lin, Y.Y.; Xie, X. Mvhm: A large-scale multi-view hand mesh benchmark for accurate 3d hand pose estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 836–845. [Google Scholar]
- Ge, L.; Ren, Z.; Yuan, J. Point-to-point regression pointnet for 3d hand pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 475–491. [Google Scholar]
- Wan, B.; Zhou, D.; Liu, Y.; Li, R.; He, X. Pose-aware multi-level feature network for human object interaction detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9469–9478. [Google Scholar]
- Chu, J.; Jin, L.; Xing, J.; Zhao, J. UniParser: Multi-Human Parsing with Unified Correlation Representation Learning. arXiv 2023, arXiv:2310.08984. [Google Scholar]
- Chu, J.; Jin, L.; Fan, X.; Teng, Y.; Wei, Y.; Fang, Y.; Xing, J.; Zhao, J. Single-Stage Multi-human Parsing via Point Sets and Center-based Offsets. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 1863–1873. [Google Scholar]
- Wang, T.; Yang, T.; Danelljan, M.; Khan, F.S.; Zhang, X.; Sun, J. Learning human-object interaction detection using interaction points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4116–4125. [Google Scholar]
- He, T.; Gao, L.; Song, J.; Li, Y.F. Exploiting scene graphs for human-object interaction detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 15984–15993. [Google Scholar]
- Nagarajan, T.; Feichtenhofer, C.; Grauman, K. Grounded human-object interaction hotspots from video. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8688–8697. [Google Scholar]
- Ehatisham-ul Haq, M.; Azam, M.A.; Loo, J.; Shuang, K.; Islam, S.; Naeem, U.; Amin, Y. Authentication of smartphone users based on activity recognition and mobile sensing. Sensors 2017, 17, 2043. [Google Scholar] [CrossRef] [PubMed]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. A survey of online activity recognition using mobile phones. Sensors 2015, 15, 2059–2085. [Google Scholar] [CrossRef] [PubMed]
- Kanimozhi, S.; Raj Priya, B.; Sandhiya, K.; Sowmya, R.; Mala, T. Human Movement Analysis through Conceptual Human-Object Interaction in Sports Video. 2020. Available online: https://ssrn.com/abstract=4525389 (accessed on 21 July 2024).
- Ye, Q.; Xu, X.; Li, R. Human-object Behavior Analysis Based on Interaction Feature Generation Algorithm. Int. J. Adv. Comput. Sci. Appl. 2023, 14. [Google Scholar] [CrossRef]
- Yang, N.; Zheng, Y.; Guo, X. Efficient transformer for human-object interaction detection. In Proceedings of the Sixth International Conference on Computer Information Science and Application Technology (CISAT 2023), SPIE, Hangzhou, China, 26–28 May 2023; Volume 12800, pp. 536–542. [Google Scholar]
- Zaib, M.H.; Khan, M.J. An HMM-Based Approach for Human Interaction Using Multiple Feature Descriptors. 2023. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4656240 (accessed on 21 July 2024).
- Ozaki, H.; Tran, D.T.; Lee, J.H. Effective human–object interaction recognition for edge devices in intelligent space. SICE J. Control. Meas. Syst. Integr. 2024, 17, 1–9. [Google Scholar] [CrossRef]
- Gkioxari, G.; Girshick, R.; Dollár, P.; He, K. Detecting and recognizing human-object interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8359–8367. [Google Scholar]
- Zhou, P.; Chi, M. Relation parsing neural network for human-object interaction detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 843–851. [Google Scholar]
- Kato, K.; Li, Y.; Gupta, A. Compositional learning for human object interaction. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 234–251. [Google Scholar]
- Xie, X.; Bhatnagar, B.L.; Pons-Moll, G. Visibility aware human-object interaction tracking from single rgb camera. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 4757–4768. [Google Scholar]
- Purwanto, D.; Chen, Y.T.; Fang, W.H. First-person action recognition with temporal pooling and Hilbert–Huang transform. IEEE Trans. Multimed. 2019, 21, 3122–3135. [Google Scholar] [CrossRef]
- Liu, T.; Zhao, R.; Jia, W.; Lam, K.M.; Kong, J. Holistic-guided disentangled learning with cross-video semantics mining for concurrent first-person and third-person activity recognition. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 5211–5225. [Google Scholar] [CrossRef] [PubMed]
- Yao, Y.; Xu, M.; Choi, C.; Crandall, D.J.; Atkins, E.M.; Dariush, B. Egocentric vision-based future vehicle localization for intelligent driving assistance systems. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: New York, NY, USA, 2019; pp. 9711–9717. [Google Scholar]
- Liu, O.; Rakita, D.; Mutlu, B.; Gleicher, M. Understanding human-robot interaction in virtual reality. In Proceedings of the 2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Lisbon, Portugal, 28–31 August 2017; IEEE: New York, NY, USA, 2017; pp. 751–757. [Google Scholar]
- Leonardi, R.; Ragusa, F.; Furnari, A.; Farinella, G.M. Exploiting multimodal synthetic data for egocentric human-object interaction detection in an industrial scenario. Comput. Vis. Image Underst. 2024, 242, 103984. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.; Jiang, C.; Lyu, K.; Wan, W.; Shen, H.; Liang, B.; Fu, Z.; Wang, H.; Yi, L. Hoi4d: A 4d egocentric dataset for category-level human-object interaction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18—24 June 2022; pp. 21013–21022. [Google Scholar]
- Romero, J.; Tzionas, D.; Black, M.J. Embodied hands: Modeling and capturing hands and bodies together. ACM Trans. Graph. 2017, 36, 245. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Objects | Interactions |
|---|---|
| Bottle | Pick and place |
| Pick and place (with water) | |
| Pour all the water into a mug | |
| Put it in the drawer | |
| Reposition the bottle | |
| Take it out of the drawer | |
| Bowl | Pick and place |
| Pick and place (with ball) | |
| Put it in the drawer | |
| Put the ball in the bowl | |
| Take it out of the drawer | |
| Take the ball out of the bowl | |
| Bucket | Pick and place |
| Pour water into another bucket | |
| Chair | Pick and place to a new position |
| Pick and place to the original position | |
| Kettle | Pick and place |
| Pour water into a mug | |
| Knife | Cut apple |
| Pick and place | |
| Put it in the drawer | |
| Take it out of the drawer | |
| Lamp | Pick and place |
| Turn and fold | |
| Turn on and turn off | |
| Laptop | Open and close the display |
| Pick and place | |
| Mug | Fill with water by a kettle |
| Pick and place | |
| Pick and place (with water) | |
| Pour water into another mug | |
| Put it in the drawer | |
| Take it out of the drawer | |
| Pliers | Clamp something |
| Pick and place | |
| Put it in the drawer | |
| Take it out of the drawer | |
| Safe | Open and close the door |
| Put something in it | |
| Take something out of it | |
| Scissors | Cut something |
| Pick and place | |
| Stapler | Bind the paper |
| Pick and place | |
| Furniture | Open and close the door |
| Open and close the drawer | |
| Put the drink in the door | |
| Put the drink in the drawer | |
| Toy car | Pick and place |
| Push toy car | |
| Put it in the drawer | |
| Take it out of the drawer | |
| Trash can | Open and close |
| Throw something in it |
| Feature | Mathematical Description |
|---|---|
| Maximum amplitude | where S can be either accelerometer or gyroscope data, and a represents the axis |
| Minimum amplitude | |
| Arithmetic mean | where N is the total number of samples |
| Standard deviation | where represents the mean value |
| Kurtosis | where E represents the expected value |
| Skewness | |
| Peak-to-peak signal value | , where is the peak-to-peak value of the signal |
| Peak-to-peak time | |
| Peak-to-peak slope | |
| Maximum latency | |
| Minimum latency | |
| Absolute latency-to-amplitude ratio | |
| Mean of absolute values of first difference | , where |
| Mean of absolute values of second difference | |
| Normalized mean of absolute values of first difference | , where n is the normalized signal |
| Normalized mean of absolute values of second difference | , where n is the normalized signal |
| Energy | |
| Normalized energy | |
| Entropy | , where |
| Object Category | Acc. | Pre. | Rec. | F1 |
|---|---|---|---|---|
| Bottle | 0.88 | 0.86 | 0.88 | 0.87 |
| Bowl | 0.78 | 0.77 | 0.78 | 0.77 |
| Bucket | 0.71 | 0.67 | 0.71 | 0.69 |
| Chair | 0.91 | 0.88 | 0.91 | 0.89 |
| Kettle | 0.85 | 0.73 | 0.85 | 0.78 |
| Knife | 0.70 | 0.64 | 0.70 | 0.67 |
| Lamp | 0.61 | 0.77 | 0.61 | 0.68 |
| Laptop | 0.86 | 0.78 | 0.86 | 0.81 |
| Mug | 0.79 | 0.70 | 0.79 | 0.74 |
| Pliers | 0.66 | 0.65 | 0.66 | 0.65 |
| Safe | 0.56 | 0.62 | 0.56 | 0.59 |
| Scissors | 0.81 | 0.82 | 0.81 | 0.81 |
| Stapler | 0.67 | 0.72 | 0.67 | 0.70 |
| Furniture | 0.62 | 0.80 | 0.62 | 0.70 |
| Toy car | 0.57 | 0.65 | 0.57 | 0.60 |
| Trash can | 0.70 | 0.71 | 0.70 | 0.70 |
| Average | 0.73 | 0.74 | 0.73 | 0.73 |
| Object | Interaction | TP | FN | FP | TN | F1 |
|---|---|---|---|---|---|---|
| Bottle | Pick and place | 41 | 12 | 21 | 110 | 0.72 |
| Pick and place (with water) | 11 | 7 | 7 | 157 | 0.61 | |
| Pour all the water into a mug | 12 | 24 | 16 | 130 | 0.37 | |
| Put it in the drawer | 13 | 15 | 16 | 138 | 0.45 | |
| Reposition the bottle | 18 | 7 | 4 | 153 | 0.75 | |
| Take it out of the drawer | 11 | 8 | 9 | 154 | 0.58 | |
| Bowl | Pick and place | 67 | 12 | 11 | 103 | 0.86 |
| Pick and place (with ball) | 7 | 1 | 1 | 184 | 0.83 | |
| Put it in the drawer | 37 | 7 | 9 | 141 | 0.83 | |
| Put the ball in the bowl | 8 | 2 | 2 | 181 | 0.77 | |
| Take it out of the drawer | 21 | 8 | 9 | 155 | 0.71 | |
| Take the ball out of the bowl | 14 | 5 | 3 | 171 | 0.76 | |
| Bucket | Pick and place | 50 | 16 | 13 | 77 | 0.77 |
| Pour water into another bucket | 77 | 13 | 16 | 50 | 0.84 | |
| Chair | Pick and place to a new position | 31 | 25 | 29 | 31 | 0.54 |
| Pick and place to the original position | 31 | 29 | 25 | 31 | 0.54 | |
| Kettle | Pick and place | 84 | 3 | 4 | 79 | 0.96 |
| Pour water into a mug | 79 | 4 | 3 | 84 | 0.95 | |
| Knife | Cut apple | 41 | 6 | 7 | 110 | 0.86 |
| Pick and place | 79 | 5 | 8 | 74 | 0.93 | |
| Put it in the drawer | 11 | 8 | 6 | 139 | 0.62 | |
| Take it out of the drawer | 8 | 5 | 3 | 148 | 0.64 | |
| Lamp | Pick and place | 50 | 5 | 6 | 98 | 0.90 |
| Turn and fold | 54 | 1 | 2 | 103 | 0.97 | |
| Turn on and turn off | 42 | 6 | 4 | 107 | 0.89 | |
| Laptop | Open and close the display | 81 | 7 | 6 | 47 | 0.92 |
| Pick and place | 47 | 6 | 7 | 81 | 0.87 | |
| Mug | Fill with water by a kettle | 6 | 5 | 3 | 206 | 0.60 |
| Pick and place | 76 | 19 | 29 | 96 | 0.76 | |
| Pick and place (with water) | 9 | 4 | 5 | 203 | 0.67 | |
| Pour water into another mug | 19 | 7 | 4 | 190 | 0.75 | |
| Put it in the drawer | 16 | 20 | 12 | 172 | 0.50 | |
| Take it out of the drawer | 30 | 6 | 8 | 176 | 0.82 | |
| Pliers | Clamp something | 30 | 3 | 7 | 114 | 0.85 |
| Pick and place | 49 | 4 | 9 | 92 | 0.88 | |
| Put it in the drawer | 12 | 14 | 8 | 120 | 0.52 | |
| Take it out of the drawer | 27 | 13 | 10 | 104 | 0.70 | |
| Safe | Open and close the door | 44 | 16 | 13 | 72 | 0.75 |
| Put something in it | 42 | 20 | 24 | 60 | 0.66 | |
| Take something out of it | 12 | 10 | 10 | 112 | 0.54 | |
| Scissor | Cut something | 115 | 6 | 8 | 36 | 0.95 |
| Pick and place | 36 | 8 | 6 | 115 | 0.83 | |
| Stapler | Bind the paper | 71 | 8 | 10 | 54 | 0.89 |
| Pick and place | 54 | 10 | 8 | 71 | 0.85 | |
| Storage furniture | Open and close the door | 41 | 10 | 8 | 95 | 0.81 |
| Open and close the drawer | 36 | 6 | 6 | 107 | 0.85 | |
| Put the drink in the door | 24 | 7 | 11 | 114 | 0.73 | |
| Put the drink in the drawer | 22 | 8 | 6 | 118 | 0.76 | |
| Toy car | Pick and place | 79 | 21 | 19 | 116 | 0.80 |
| Push toy car | 44 | 21 | 30 | 140 | 0.63 | |
| Put it in the drawer | 19 | 24 | 19 | 173 | 0.47 | |
| Take it out of the drawer | 18 | 7 | 4 | 206 | 0.74 | |
| Trash can | Open and close | 69 | 14 | 15 | 68 | 0.83 |
| Throw something in it | 68 | 15 | 14 | 69 | 0.83 | |
| Average | 0.75 |
| HOI | Acc | Pre | Rec | F1 |
|---|---|---|---|---|
| Bottle: pick and place | 0.7 | 0.66 | 0.7 | 0.68 |
| Bottle: pick and place (with water) | 0.64 | 0.63 | 0.64 | 0.63 |
| Bottle: pour all the water into a mug | 0.3 | 0.35 | 0.3 | 0.32 |
| Bottle: put it in the drawer | 0.45 | 0.43 | 0.45 | 0.43 |
| Bottle: reposition the bottle | 0.65 | 0.8 | 0.65 | 0.7 |
| Bottle: take it out of the drawer | 0.5 | 0.59 | 0.5 | 0.54 |
| Bowl: pick and place | 0.62 | 0.68 | 0.62 | 0.64 |
| Bowl: put the ball in the bowl | 0.89 | 0.89 | 0.89 | 0.87 |
| Bowl: take it out of the drawer | 0.79 | 0.72 | 0.79 | 0.75 |
| Bowl: take the ball out of the bowl | 0.44 | 0.6 | 0.44 | 0.5 |
| Bowl: take it out of the drawer | 0.68 | 0.65 | 0.68 | 0.66 |
| Bowl: take the ball out of the bowl | 0.72 | 0.72 | 0.72 | 0.72 |
| Bucket: pick and place | 0.65 | 0.57 | 0.65 | 0.6 |
| Bucket: pour water into another bucket | 0.74 | 0.59 | 0.74 | 0.66 |
| Chair: pick and place to a new position | 0.5 | 0.46 | 0.5 | 0.48 |
| Chair: pick and place to the original position | 0.45 | 0.49 | 0.45 | 0.47 |
| Kettle: pick and place | 0.88 | 0.75 | 0.88 | 0.81 |
| Kettle: pour water into a mug | 0.85 | 0.78 | 0.85 | 0.81 |
| Knife: cut apple | 0.68 | 0.66 | 0.68 | 0.67 |
| Knife: pick and place | 0.81 | 0.68 | 0.81 | 0.74 |
| Knife: put it in the drawer | 0.41 | 0.54 | 0.41 | 0.46 |
| Knife: take it out of the drawer | 0.58 | 0.68 | 0.58 | 0.61 |
| Lamp: pick and place | 0.64 | 0.72 | 0.64 | 0.67 |
| Lamp: turn and fold | 0.88 | 0.74 | 0.88 | 0.8 |
| Lamp: turn on and turn off | 0.7 | 0.83 | 0.7 | 0.75 |
| Laptop: open and close the display | 0.8 | 0.67 | 0.8 | 0.73 |
| Laptop: pick and place | 0.84 | 0.78 | 0.84 | 0.81 |
| Mug: fill with water by a kettle | 0.64 | 0.65 | 0.64 | 0.64 |
| Mug: pick and place | 0.65 | 0.61 | 0.65 | 0.62 |
| Mug: pick and place (with water) | 0.67 | 0.59 | 0.67 | 0.62 |
| Mug: pour water into another mug | 0.6 | 0.63 | 0.6 | 0.59 |
| Mug: put it in the drawer | 0.36 | 0.43 | 0.36 | 0.38 |
| Mug: take it out of the drawer | 0.64 | 0.56 | 0.64 | 0.59 |
| Pliers: clamp something | 0.75 | 0.72 | 0.75 | 0.73 |
| Pliers: pick and place | 0.49 | 0.58 | 0.49 | 0.52 |
| Pliers: put it in the drawer | 0.38 | 0.46 | 0.38 | 0.41 |
| Pliers: take it out of the drawer | 0.49 | 0.59 | 0.49 | 0.53 |
| Safe: open and close the door | 0.53 | 0.49 | 0.53 | 0.5 |
| Safe: put something in it | 0.53 | 0.56 | 0.53 | 0.54 |
| Safe: take something out of it | 0.45 | 0.63 | 0.45 | 0.51 |
| Scissors: cut something | 0.84 | 0.77 | 0.84 | 0.41 |
| Scissors: pick and place | 0.68 | 0.73 | 0.68 | 0.53 |
| Stapler: bind the paper | 0.67 | 0.58 | 0.67 | 0.5 |
| Stapler: pick and place | 0.69 | 0.73 | 0.69 | 0.54 |
| Storage furniture: open and close the door | 0.44 | 0.75 | 0.44 | 0.52 |
| Storage furniture: open and close the drawer | 0.72 | 0.88 | 0.72 | 0.79 |
| Storage furniture: put the drink in the door | 0.64 | 0.74 | 0.64 | 0.68 |
| Storage furniture: put the drink in the drawer | 0.61 | 0.76 | 0.61 | 0.67 |
| Toy car: pick and place | 0.52 | 0.66 | 0.52 | 0.58 |
| Toy car: push toy car | 0.41 | 0.54 | 0.41 | 0.46 |
| Toy car: put it in the drawer | 0.3 | 0.46 | 0.3 | 0.36 |
| Toy car: take it out of the drawer | 0.5 | 0.49 | 0.5 | 0.48 |
| Trash can: open and close | 0.65 | 0.68 | 0.65 | 0.66 |
| Trash can: throw something in it | 0.59 | 0.57 | 0.59 | 0.58 |
| Average | 0.62 | 0.64 | 0.61 | 0.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hamid, D.; Haq, M.E.U.; Yasin, A.; Murtaza, F.; Azam, M.A. Enhancing Recognition of Human–Object Interaction from Visual Data Using Egocentric Wearable Camera. Future Internet 2024, 16, 269. https://doi.org/10.3390/fi16080269
Hamid D, Haq MEU, Yasin A, Murtaza F, Azam MA. Enhancing Recognition of Human–Object Interaction from Visual Data Using Egocentric Wearable Camera. Future Internet. 2024; 16(8):269. https://doi.org/10.3390/fi16080269
Chicago/Turabian StyleHamid, Danish, Muhammad Ehatisham Ul Haq, Amanullah Yasin, Fiza Murtaza, and Muhammad Awais Azam. 2024. "Enhancing Recognition of Human–Object Interaction from Visual Data Using Egocentric Wearable Camera" Future Internet 16, no. 8: 269. https://doi.org/10.3390/fi16080269
APA StyleHamid, D., Haq, M. E. U., Yasin, A., Murtaza, F., & Azam, M. A. (2024). Enhancing Recognition of Human–Object Interaction from Visual Data Using Egocentric Wearable Camera. Future Internet, 16(8), 269. https://doi.org/10.3390/fi16080269