

Emotion Recognition from Videos Using Multimodal Large Language Models



Abstract
1. Introduction
2. Related Works
2.1. Emotion Recognition
2.2. Emotional Reaction Intensity Estimation
2.3. Multimodal LLMs
- Vision–language LLMs, which handle combinations of images and text;
- Video–language LLMs, which are capable of automatically recognizing and interpreting video content as a stream of visual and textual sources;
- Audio–visual LLMs, which combine acoustic and visual information together.
- Frame-based methods, which handle each video frame independently using various visual encoders and image resolutions;
- Temporal encoders, which treat videos as cohesive entities, emphasizing the temporal elements of the content [51].
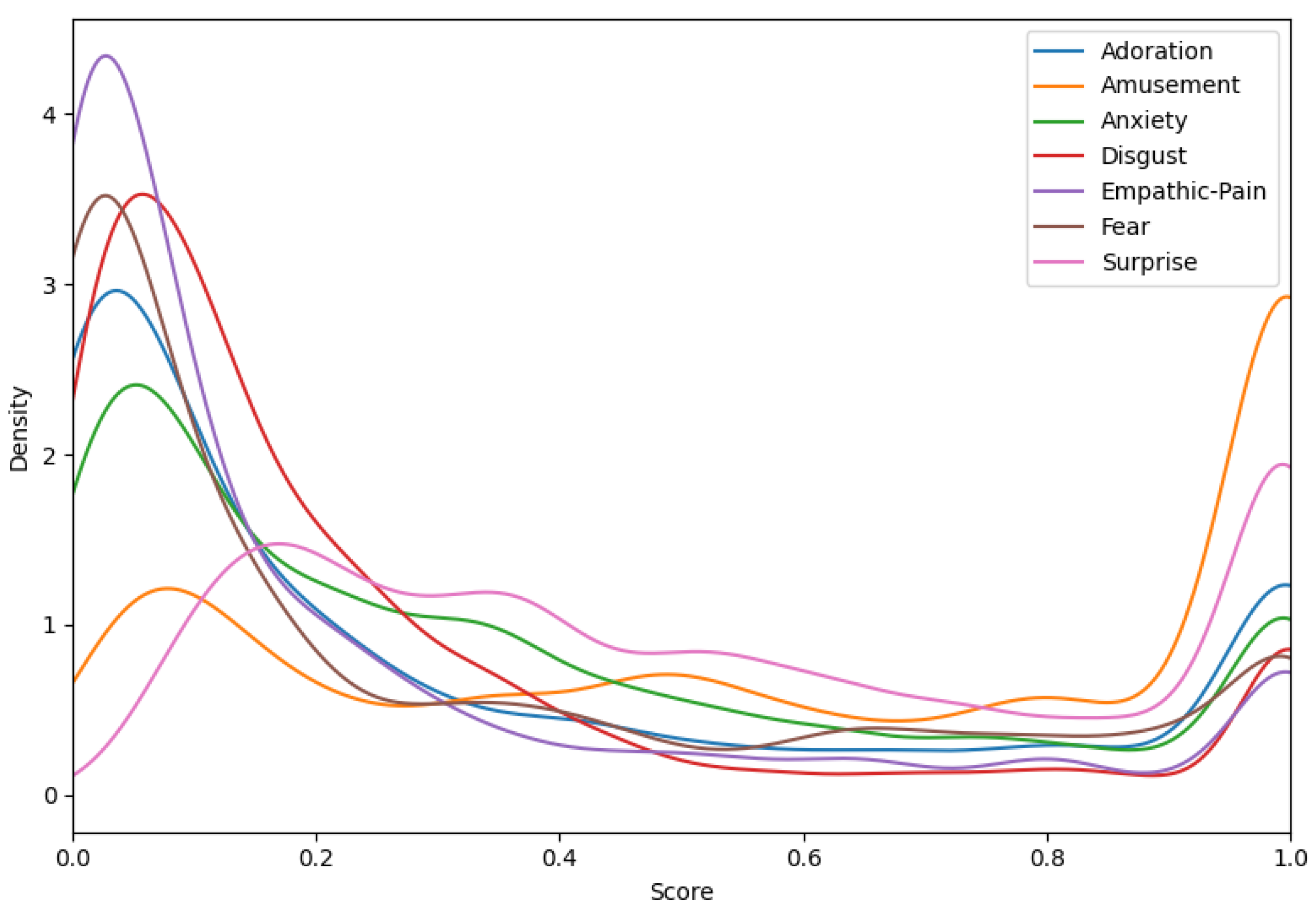
3. Task and Dataset Description
- A training set made of 15,806 samples from 1334 different human subjects, for a total of 51 h of video recordings. This split was employed in our experimentation to train our models.
- A development set made of 4657 samples from 444 different human subjects, for a total of almost 15 h of video recordings. This split was employed in our experimentation to evaluate the proposed approaches.
- A private test set made of 4604 samples from 444 different human subjects, for a total of almost 15 h of video recordings. Labels of this split are not publicly available. Thus, this split was not used in this research.
4. Methods
4.1. Direct Querying of MLLM
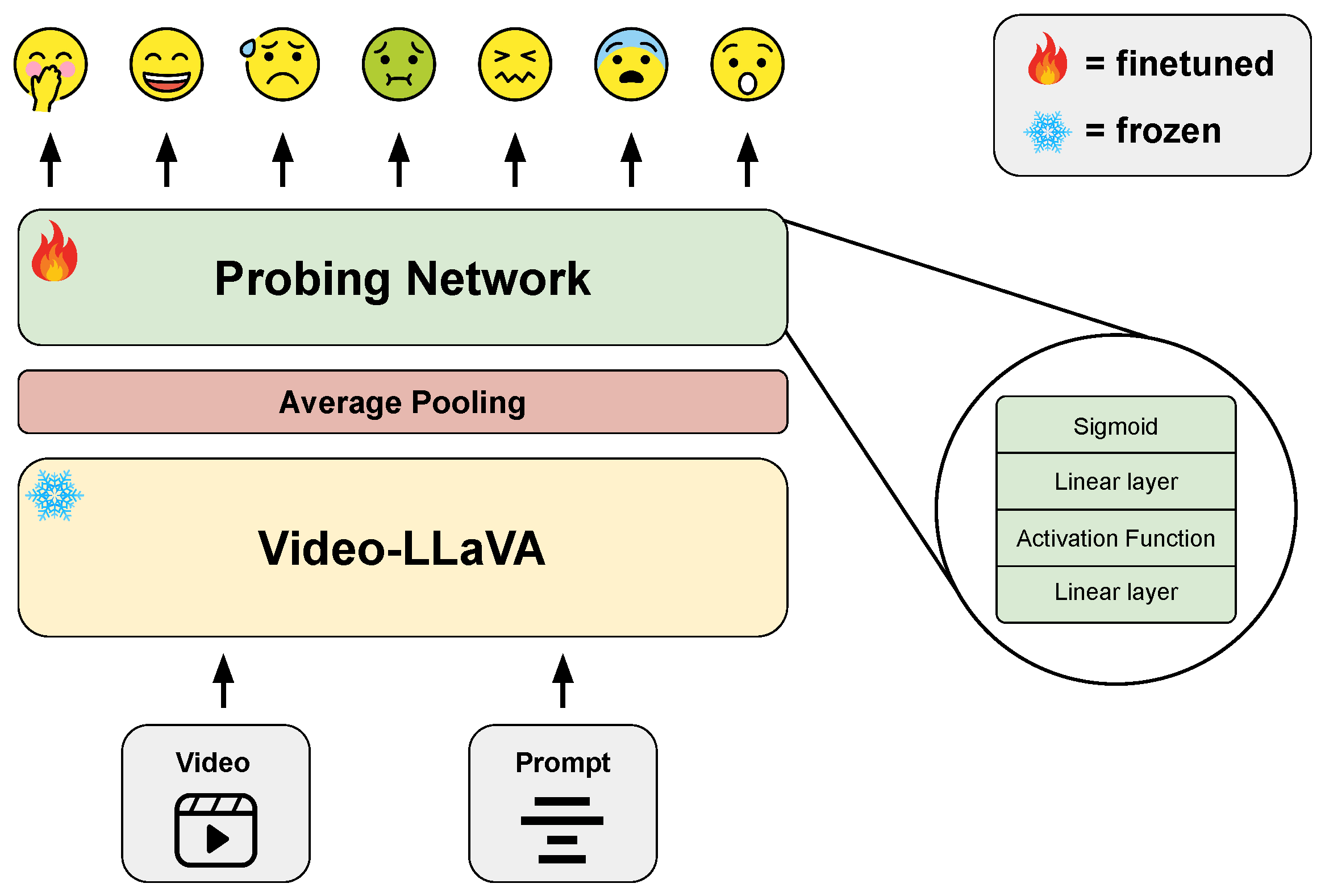
4.2. Probing Network
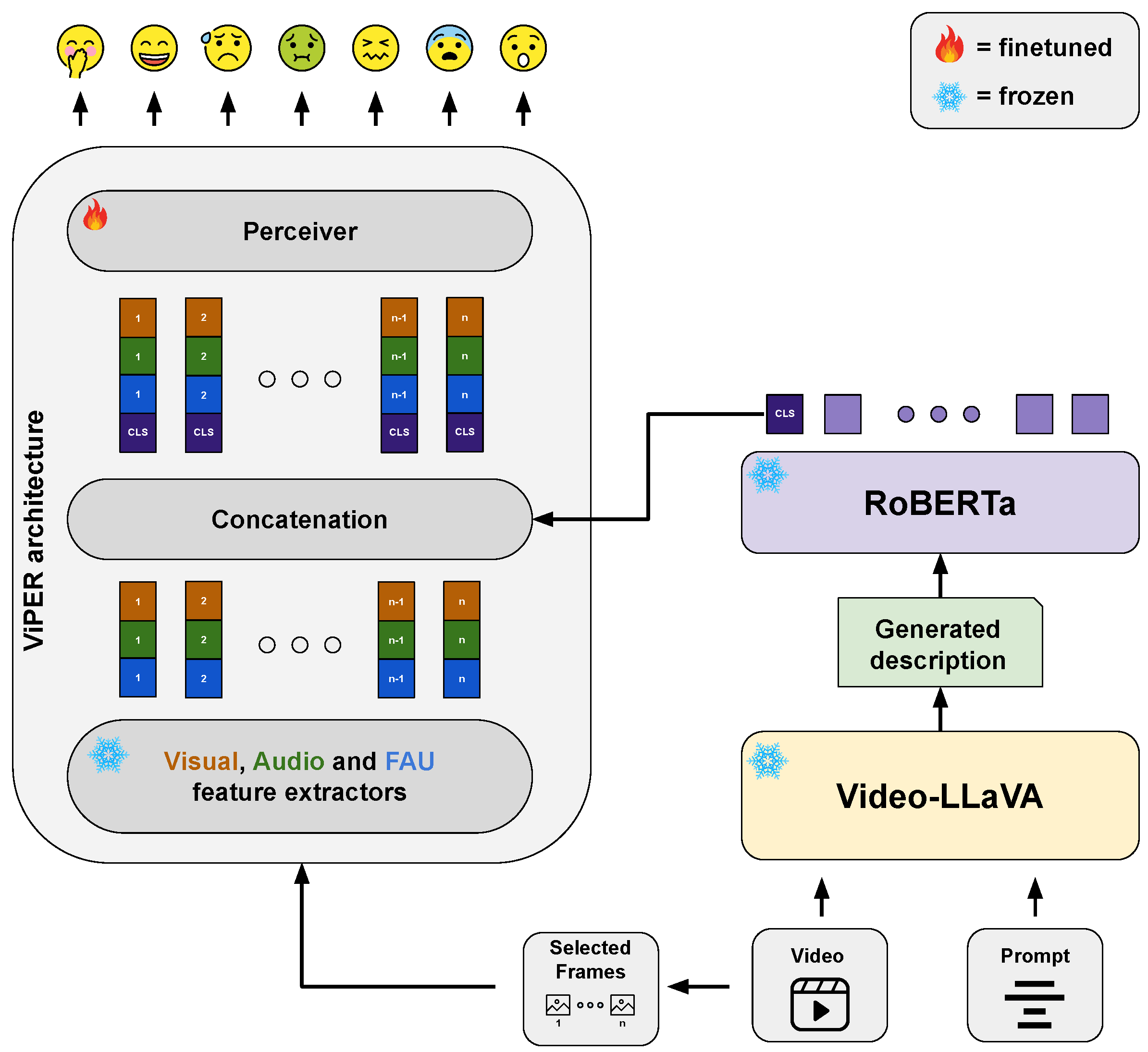
4.3. Integrating MLLM-Generated Description Features into a Transformer-Based Architecture
5. Experimental Results
5.1. Experimental Setup
5.2. Quantitative Results
- Querying Video-LLaVA: Directly querying Video-LLaVA [12] for emotion scores resulted in a mean Pearson correlation of 0.0937, which is lower than all baselines, indicating limited effectiveness for this approach. Additionally, it was observed that the generated text often used the same exact score value or a limited range of values for some emotions, e.g., the score 0.4 appears 2444 times out of 4657 in the Anxiety predictions. This suggests that text generation in a zero-shot fashion may be unsuitable for regression tasks, as it lacks the precision required for accurate scoring across a continuous range.
- Probing Video-LLaVA: Fine-tuning with probing strategies showed improvements, with mean Pearson correlations of 0.2333 for Prompt 1 and 0.2351 for Prompt 2. Although these scores did not surpass the baselines, they highlighted the potential of probing strategies. Additionally, this result indicates that the prompts used, whether general or specific for emotion recognition, do not greatly impact the performance. We also studied the impact of the employed activation function within the probing network. Table 4 reports the results obtained using seven different activation functions while adopting Prompt 2. Noteworthy is that the variation in performance as the activation function varied was very limited, i.e., from 0.2315 to 0.2353. However, the ReLU-based functions achieved a slightly superior result.
- Integrating Video-LLaVA textual features: Integrating Video-LLaVA-generated textual features into the ViPER-VATF [9] framework showed competitive performance, with mean Pearson correlations of 0.3004 for the general prompt and 0.3011 for the specific prompt, closely matching the performance of the original ViPER-VATF [9]. If the results are broken down by observing each emotion separately, these approaches surpassed the classical ViPER-VATF [9] for specific emotions. Specifically, using Prompt 1 yielded better performance for Anxiety and Empathic Pain, while Prompt 2 performed better on Adoration, Anxiety, and Surprise. On the other hand, the CLIP-based approach achieved the highest results in Amusement, Disgust, and Fear. Table 5 reports the breakdown results. Furthermore, we compared the impact that textual, acoustic and FAUs features had when combined with visual ones. The results are reported in Table 6. It is important to note that the textual features extracted from Video-LLaVA [12], although we did not have a contribution at the level of the FAU features, always brought a benefit when injected into the model; this is in contrast to the acoustic ones, which occasionally did not improve or even worsened the performance of the model.
- Integrating LLaVA textual features: Using LLaVA [11] to describe video frames separately and integrating these frame-specific textual features into the ViPER-VATF [9] framework resulted in a mean Pearson correlation of 0.2895, indicating the viability of this alternative approach. However, integrating Video-LLaVA [12] textual was still better (up to 0.3011 vs. 0.2895).
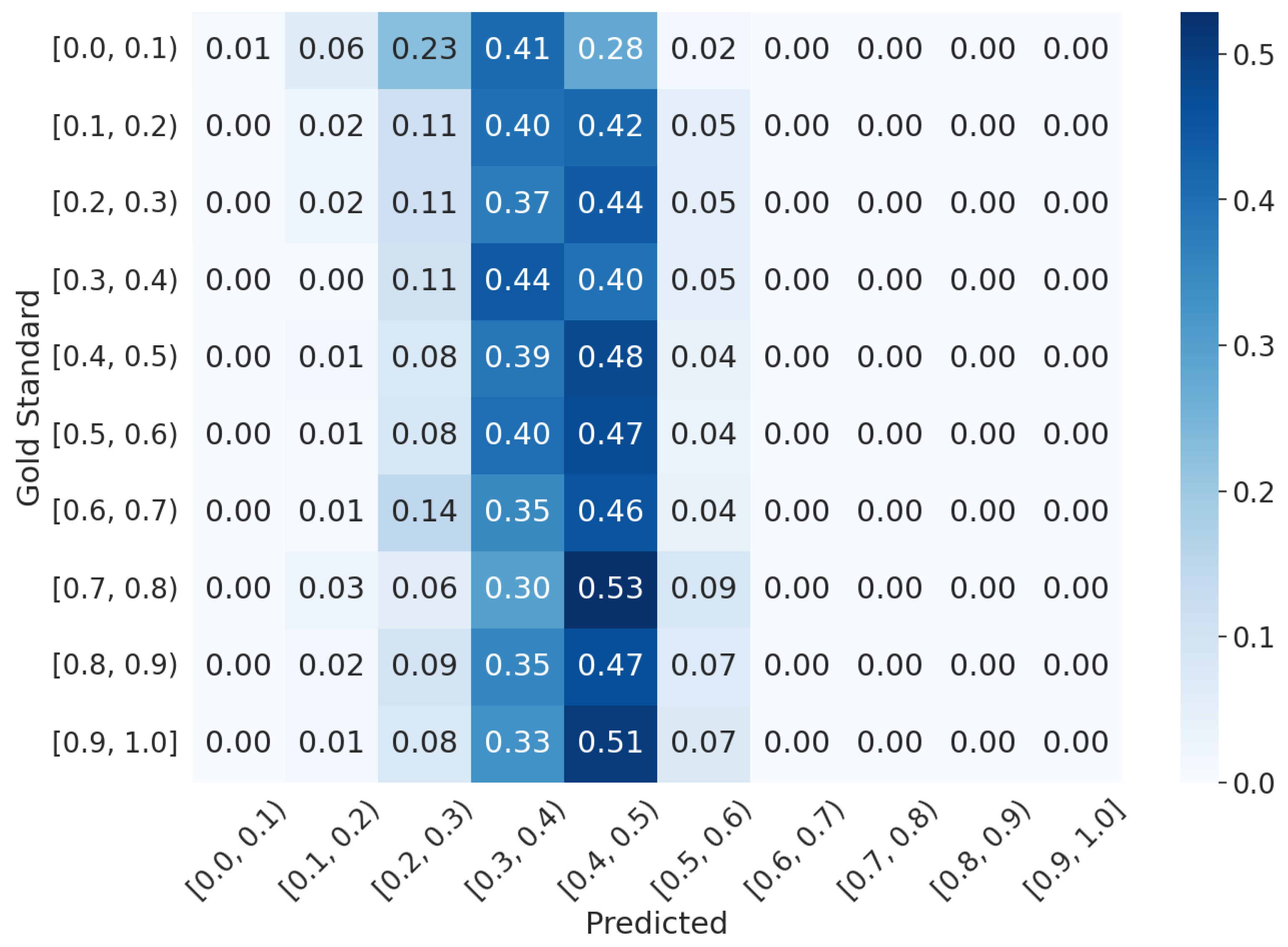
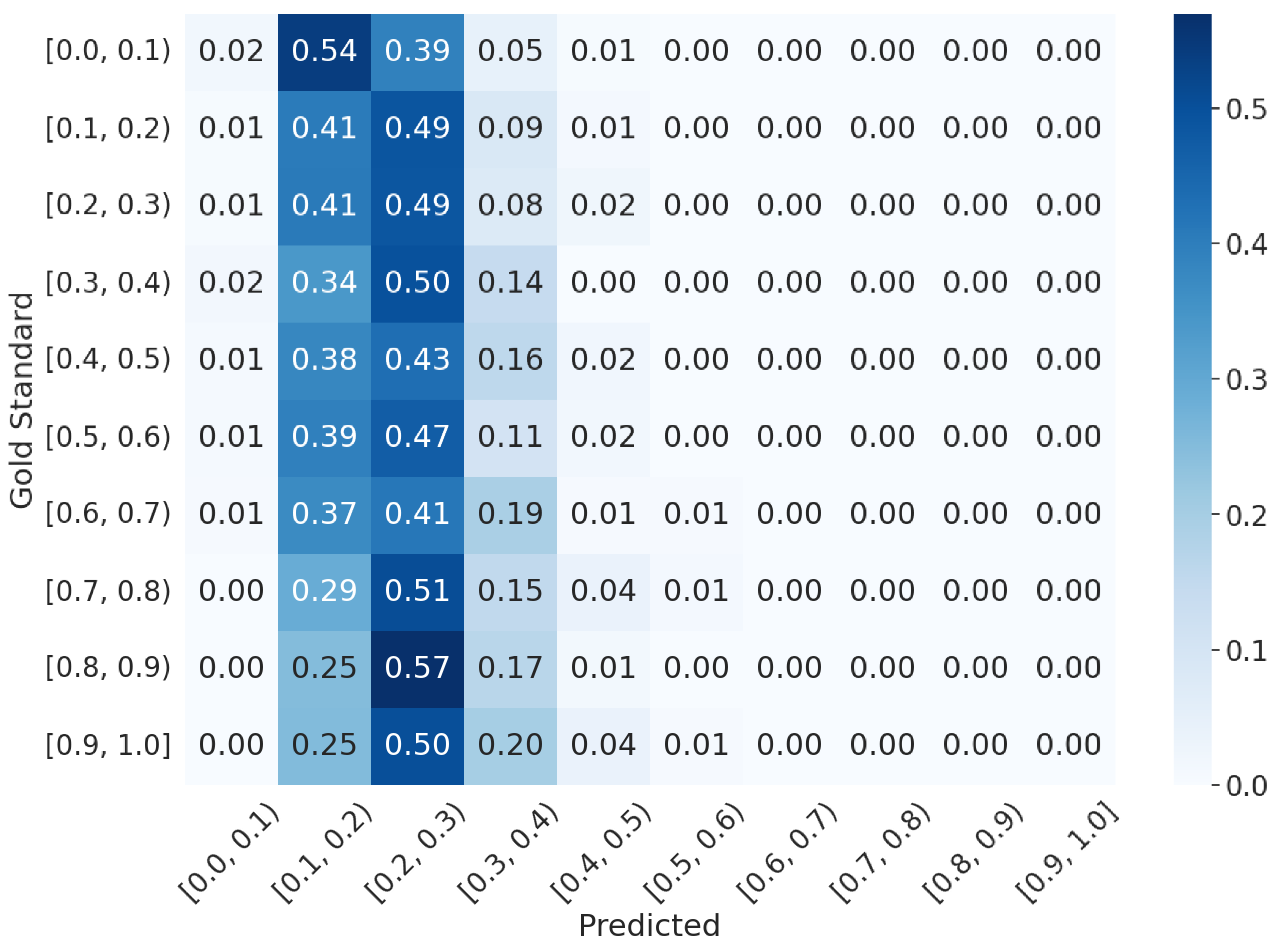
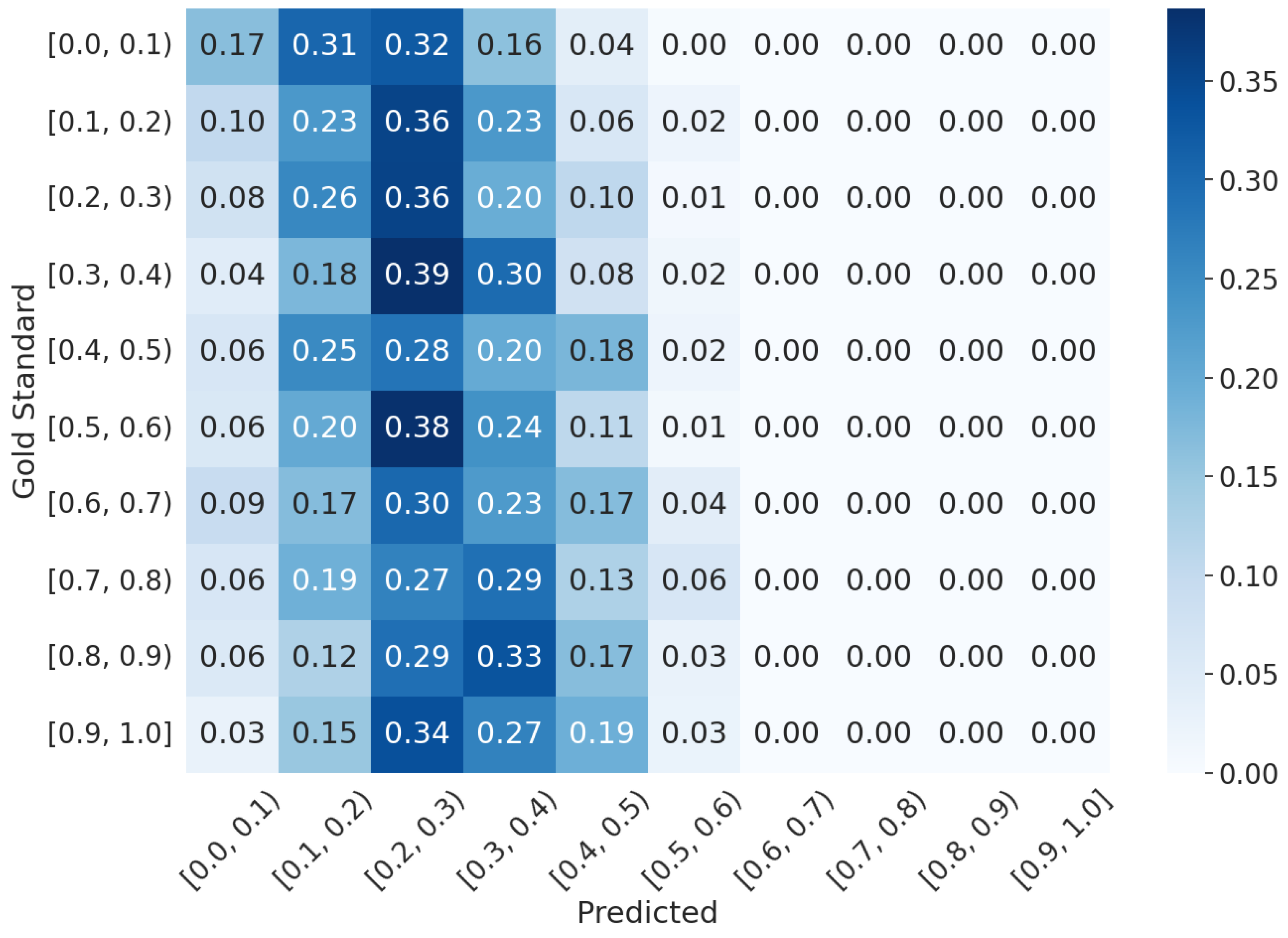
5.3. Qualitative Analysis
- ViPER-VATFCLIP: The predictions are more concentrated near the GT average value. This indicates that the CLIP-based solution is more focused on predicting scores that are close to the average GT value. It suggests a tendency to overfit on the average value, making it more accurate for samples whose scores are near the mean.
- ViPER-VATFVideo−LLaVA: The predictions cover a wider range of values. This means that the LLM-based solution is better at predicting scores that can be considered outliers with respect to the average value. These outliers include cases where an emotion is particularly evident or notably missing.
6. Discussion
6.1. Multimodal LLM vs. Transformers
6.2. Application Scenarios
6.3. Limitations
7. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LLM | Large Language Model |
| MLLM | Multimodal Large Language Model |
| ERI | emotional reaction intensity |
References
- Bartolome, A.; Niu, S. A Literature Review of Video-Sharing Platform Research in HCI. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023. CHI ’23. [Google Scholar] [CrossRef]
- Hossain, M.S.; Muhammad, G. Cloud-Assisted Speech and Face Recognition Framework for Health Monitoring. Mob. Netw. Appl. 2015, 20, 391–399. [Google Scholar] [CrossRef]
- Zhang, Z.; Coutinho, E.; Deng, J.; Schuller, B. Cooperative learning and its application to emotion recognition from speech. IEEE/ACM Trans. Audio, Speech Lang. Proc. 2015, 23, 115–126. [Google Scholar] [CrossRef]
- Szwoch, M. Design Elements of Affect Aware Video Games. In Proceedings of the Mulitimedia, Interaction, Design and Innnovation, Warsaw, Poland, 29–30 June 2015. MIDI ’15. [Google Scholar] [CrossRef]
- Christ, L.; Amiriparian, S.; Baird, A.; Tzirakis, P.; Kathan, A.; Mueller, N.; Stappen, L.; Messner, E.; König, A.; Cowen, A.; et al. The MuSe 2022 Multimodal Sentiment Analysis Challenge: Humor, Emotional Reactions, and Stress. In Proceedings of the 3rd International on Multimodal Sentiment Analysis Workshop and Challenge, Lisboa, Portugal, 10 October 2022. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Sun, L.; Xu, M.; Lian, Z.; Liu, B.; Tao, J.; Wang, M.; Cheng, Y. Multimodal Emotion Recognition and Sentiment Analysis via Attention Enhanced Recurrent Model. In Proceedings of the 2nd on Multimodal Sentiment Analysis Challenge, Virtual Event, 24 October 2021; MuSe ’21. pp. 15–20. [Google Scholar] [CrossRef]
- Sun, L.; Lian, Z.; Tao, J.; Liu, B.; Niu, M. Multi-Modal Continuous Dimensional Emotion Recognition Using Recurrent Neural Network and Self-Attention Mechanism. In Proceedings of the 1st International on Multimodal Sentiment Analysis in Real-Life Media Challenge and Workshop, Seattle, WA, USA, 16 October 2020; MuSe’20. pp. 27–34. [Google Scholar] [CrossRef]
- Vaiani, L.; La Quatra, M.; Cagliero, L.; Garza, P. ViPER: Video-based Perceiver for Emotion Recognition. In Proceedings of the 3rd International on Multimodal Sentiment Analysis Workshop and Challenge, Lisboa, Portugal, 10 October 2022; MuSe’ 22. pp. 67–73. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Technical Report. arXiv 2023. [Google Scholar] [CrossRef]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual Instruction Tuning. arXiv 2023. [Google Scholar] [CrossRef]
- Lin, B.; Ye, Y.; Zhu, B.; Cui, J.; Ning, M.; Jin, P.; Yuan, L. Video-LLaVA: Learning United Visual Representation by Alignment before Projection. arXiv 2023, arXiv:2311.10122. [Google Scholar]
- Zhao, Y.; Misra, I.; Krähenbühl, P.; Girdhar, R. Learning Video Representations From Large Language Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 6586–6597. [Google Scholar]
- Huang, J.; Chang, K.C. Towards Reasoning in Large Language Models: A Survey. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J.L., Okazaki, N., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 1049–1065. [Google Scholar] [CrossRef]
- Hazmoune, S.; Bougamouza, F. Using transformers for multimodal emotion recognition: Taxonomies and state of the art review. Eng. Appl. Artif. Intell. 2024, 133, 108339. [Google Scholar] [CrossRef]
- Zhou, H.; Meng, D.; Zhang, Y.; Peng, X.; Du, J.; Wang, K.; Qiao, Y. Exploring Emotion Features and Fusion Strategies for Audio-Video Emotion Recognition. In Proceedings of the 2019 International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019; ICMI ’19. pp. 562–566. [Google Scholar] [CrossRef]
- Liu, C.; Jiang, W.; Wang, M.; Tang, T. Group Level Audio-Video Emotion Recognition Using Hybrid Networks. In Proceedings of the 2020 International Conference on Multimodal Interaction, Virtual Event, 25–29 October 2020; ICMI ’20. pp. 807–812. [Google Scholar] [CrossRef]
- Qi, F.; Yang, X.; Xu, C. Zero-shot Video Emotion Recognition via Multimodal Protagonist-aware Transformer Network. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; MM ’21. pp. 1074–1083. [Google Scholar] [CrossRef]
- Busso, C.; Deng, Z.; Yildirim, S.; Bulut, M.; Lee, C.M.; Kazemzadeh, A.; Lee, S.; Neumann, U.; Narayanan, S. Analysis of emotion recognition using facial expressions, speech and multimodal information. In Proceedings of the 6th International Conference on Multimodal Interfaces, State College, PA, USA, 13–15 October 2004; ICMI ’04. pp. 205–211. [Google Scholar] [CrossRef]
- Yu, J.; Zhu, J.; Zhu, W.; Cai, Z.; Xie, G.; Li, R.; Zhao, G.; Ling, Q.; Wang, L.; Wang, C.; et al. A dual branch network for emotional reaction intensity estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–23 June 2023; pp. 5810–5817. [Google Scholar]
- Kollias, D.; Tzirakis, P.; Baird, A.; Cowen, A.; Zafeiriou, S. Abaw: Valence-arousal estimation, expression recognition, action unit detection & emotional reaction intensity estimation challenges. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–23 June 2023; pp. 5888–5897. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Chen, S.; Wang, C.; Chen, Z.; Wu, Y.; Liu, S.; Chen, Z.; Li, J.; Kanda, N.; Yoshioka, T.; Xiao, X.; et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. arXiv 2021, arXiv:2110.13900. [Google Scholar] [CrossRef]
- Li, J.; Chen, Y.; Zhang, X.; Nie, J.; Li, Z.; Yu, Y.; Zhang, Y.; Hong, R.; Wang, M. Multimodal feature extraction and fusion for emotional reaction intensity estimation and expression classification in videos with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–23 June 2023; pp. 5837–5843. [Google Scholar]
- Jaegle, A.; Gimeno, F.; Brock, A.; Vinyals, O.; Zisserman, A.; Carreira, J. Perceiver: General perception with iterative attention. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual Event, 18–24 July 2021; pp. 4651–4664. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision— ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Awadalla, A.; Gao, I.; Gardner, J.; Hessel, J.; Hanafy, Y.; Zhu, W.; Marathe, K.; Bitton, Y.; Gadre, S.; Sagawa, S.; et al. OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models. arXiv 2023, arXiv:2308.01390. [Google Scholar]
- Schuhmann, C.; Beaumont, R.; Vencu, R.; Gordon, C.; Wightman, R.; Cherti, M.; Coombes, T.; Katta, A.; Mullis, C.; Wortsman, M.; et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Adv. Neural Inf. Process. Syst. 2022, 35, 25278–25294. [Google Scholar]
- Zhu, D.; Chen, J.; Shen, X.; Li, X.; Elhoseiny, M. MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. arXiv 2023, arXiv:2304.10592. [Google Scholar]
- Zhang, Q.; Zhang, J.; Xu, Y.; Tao, D. Vision Transformer with Quadrangle Attention. arXiv 2023, arXiv:2303.15105. [Google Scholar] [CrossRef]
- Ordonez, V.; Kulkarni, G.; Berg, T. Im2Text: Describing Images Using 1 Million Captioned Photographs. In Advances in Neural Information Processing Systems; Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2011; Volume 24. [Google Scholar]
- Schuhmann, C.; Vencu, R.; Beaumont, R.; Kaczmarczyk, R.; Mullis, C.; Katta, A.; Coombes, T.; Jitsev, J.; Komatsuzaki, A. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv 2021, arXiv:2111.02114. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. arXiv 2023, arXiv:2301.12597. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Sharma, P.; Ding, N.; Goodman, S.; Soricut, R. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2556–2565. [Google Scholar]
- Changpinyo, S.; Sharma, P.; Ding, N.; Soricut, R. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3558–3568. [Google Scholar]
- Bavishi, R.; Elsen, E.; Hawthorne, C.; Nye, M.; Odena, A.; Somani, A.; Taşırlar, S. Introducing our Multimodal Models. 2023. Available online: https://www.adept.ai/blog/fuyu-8b (accessed on 1 June 2024).
- Luo, R.; Zhao, Z.; Yang, M.; Dong, J.; Qiu, M.; Lu, P.; Wang, T.; Wei, Z. Valley: Video assistant with large language model enhanced ability. arXiv 2023, arXiv:2306.07207. [Google Scholar]
- Bain, M.; Nagrani, A.; Varol, G.; Zisserman, A. Frozen in time: A joint video and image encoder for end-to-end retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 1728–1738. [Google Scholar]
- Yu, E.; Zhao, L.; Wei, Y.; Yang, J.; Wu, D.; Kong, L.; Wei, H.; Wang, T.; Ge, Z.; Zhang, X.; et al. Merlin: Empowering Multimodal LLMs with Foresight Minds. arXiv 2023, arXiv:2312.00589. [Google Scholar]
- Huang, B.; Wang, X.; Chen, H.; Song, Z.; Zhu, W. VTimeLLM: Empower LLM to Grasp Video Moments. arXiv 2023, arXiv:2311.18445. [Google Scholar]
- Krishna, R.; Hata, K.; Ren, F.; Fei-Fei, L.; Carlos Niebles, J. Dense-captioning events in videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 706–715. [Google Scholar]
- Gao, J.; Sun, C.; Yang, Z.; Nevatia, R. Tall: Temporal activity localization via language query. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5267–5275. [Google Scholar]
- Maaz, M.; Rasheed, H.; Khan, S.; Khan, F.S. Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. arXiv 2023, arXiv:2306.05424. [Google Scholar]
- Shu, F.; Zhang, L.; Jiang, H.; Xie, C. Audio-Visual LLM for Video Understanding. arXiv 2023, arXiv:2312.06720. [Google Scholar]
- Lyu, C.; Wu, M.; Wang, L.; Huang, X.; Liu, B.; Du, Z.; Shi, S.; Tu, Z. Macaw-LLM: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration. arXiv 2023, arXiv:2306.09093. [Google Scholar]
- Sigurdsson, G.; Russakovsky, O.; Farhadi, A.; Laptev, I.; Gupta, A. Much ado about time: Exhaustive annotation of temporal data. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, Austin, TX, USA, 30 October–3 November 2016; Volume 4, pp. 219–228. [Google Scholar]
- Alamri, H.; Cartillier, V.; Das, A.; Wang, J.; Cherian, A.; Essa, I.; Batra, D.; Marks, T.K.; Hori, C.; Anderson, P.; et al. Audio Visual Scene-Aware Dialog. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Tang, Y.; Bi, J.; Xu, S.; Song, L.; Liang, S.; Wang, T.; Zhang, D.; An, J.; Lin, J.; Zhu, R.; et al. Video Understanding with Large Language Models: A Survey. arXiv 2024, arXiv:2312.17432. [Google Scholar]
- Tan, Q.; Ng, H.T.; Bing, L. Towards Benchmarking and Improving the Temporal Reasoning Capability of Large Language Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, ON, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J.L., Okazaki, N., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 14820–14835. [Google Scholar] [CrossRef]
- Ekman, P. Emotions Revealed: Recognizing Faces and Feelings to Improve Communication and Emotional Life; Henry Holt and Company: New York, NY, USA, 2004. [Google Scholar]
- Tan, P.N.; Steinbach, M.; Karpatne, A.; Kumar, V. Introduction to Data Mining, 2nd ed.; Pearson: London, UK, 2018. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Name | Year | Size | Open | Architectural Details | Downstream Task | Pre-Train |
|---|---|---|---|---|---|---|---|
| Vision–Language | LLaVA [11] | 2023 | 7B, 13B, 34B | Yes | CLIP [26] extracts visual features, which are projected in the word embedding space before feeding the LLM (decoder only) with both visual and textual tokens | Visual Question Answering (in terms of conversation detail, description, complex reasoning) | QA pairs created using ChatGPT and GPT-4 on top of COCO images [27] |
| Open-Flamingo [28] | 2023 | 3B, 4B, 9B | Yes | CLIP [26] extracts visual features; text with interleaved images is passed to the LLM to generate the response | Visual Question Answering | LAION-2B [29], Multimodal C4, ChatGPT-generated data | |
| GPT-4 [10] | 2023 | >70B | No | N/A | N/A | N/A | |
| Mini-GPT-4 [30] | 2023 | 7B, 13B | Yes | ViT [22] backbone plus a Q-Former [31] to extract visual features, used to feed Vicuna model together with textual tokens. Two-stage training: (i) general training to acquire visual knowledge, (ii) high-quality training using a designed conversational template | Visual Question Answering, image captioning, meme interpretation, receipt generation, advertisement creation, and poem composition | SBU [32], LAION [33] | |
| BLIP-2 [34] | 2023 | 3B, 7B | Yes | Q-Former [31] + LLM trained with image–text contrastive learning, Image-grounded Text Generation and image–text matching | Visual Question Answering, image captioning, image–text retrieval | COCO [27], Visual Genome [35], CC3M [36], CC12M [37], SBU [32], LAION400M [33] | |
| Fuyu [38] | 2023 | 8B | Yes | Image patches are instead linearly projected into the first layer of the transformer; there is no image encoder | Visual Question Answering, image captioning | N/A | |
| Video–Language | Video-LLaVA [12] | 2023 | 7B | Yes | United visual representation (video + images) before feeding the LLM | Image Question Answering, video understanding | LAION-CC-SBU, Valley [39], WebVid [40] |
| Merlin [41] | 2023 | 7B | No | Specifically trained to causally model the trajectories interleaved with multi-frame images | Future reasoning, identity association ability, Visual Question Answering | A lot of datasets (captioning + detection + tracking) | |
| VTimeLLM [42] | 2023 | 7B, 13B | Yes | CLIP [26] as visual encoder to feed the LLM, which is trained to be aware of temporal boundaries in videos | Temporal Video Grounding, Video Captioning | ActivityNet Captions [43], CharadesSTA [44] | |
| Video-ChatGPT [45] | 2023 | 7B | Yes | CLIP [26] used to extract frame representations, combined to obtain temporal and spatial video representation, used to feed the LLM | Video-based Generative Performance Benchmarking, Question–Answer Evaluation | Automatically generated data enriched by human annotators | |
| Audio–Visual | Audio–Visual LLM [46] | 2023 | 7B, 13B | Yes | CLIP [26] and CLAP to extract visual and audio features, respectively, projected into the LLM hidden space | Video-QA, Audio–Visual-QA, audio captioning | custom dataset, part of the LLaVA dataset, part of Valley dataset |
| Macaw-LLM [47] | 2023 | 7B | Yes | Unimodal feature extraction, alignment module to align each modality feature before feeding the LLM | Image/video understanding, visual-and-audio question answering | COCO [27], Charades [48], AVSD [49] |
| Emotion | Average Scores ± Std |
|---|---|
| Adoration | 0.3218 ± 0.3612 |
| Amusement | 0.6204 ± 0.3669 |
| Anxiety | 0.3431 ± 0.3245 |
| Disgust | 0.2432 ± 0.2866 |
| Empathic Pain | 0.2152 ± 0.3032 |
| Fear | 0.2824 ± 0.3363 |
| Surprise | 0.5307 ± 0.3219 |
| Model | Mean Pearson Correlation |
|---|---|
| BaselineFAU | 0.2840 |
| BaselineVGGFace2 | 0.2488 |
| ViPER-V | 0.2712 |
| ViPER-VATFCLIP | 0.3025 |
| Video-LLaVAquerying | 0.0937 |
| Video-LLaVAprobing1 | 0.2333 |
| Video-LLaVAprobing2 | 0.2351 |
| 0.3004 | |
| 0.3011 | |
| ViPER-VATFLLaVA | 0.2895 |
| Activation Function | Mean Pearson Correlation |
|---|---|
| Linear | 0.2338 |
| ReLU | 0.2351 |
| Leaky ReLU | 0.2353 |
| Tanh | 0.2332 |
| Sigmoid | 0.2343 |
| GELU | 0.2315 |
| ELU | 0.2326 |
| Textual Features | Mean Pearson Correlation | |||||||
|---|---|---|---|---|---|---|---|---|
| Adoration | Amusement | Anxiety | Disgust | Empathic Pain | Fear | Surprise | Average | |
| CLIP | 0.2575 | 0.3651 | 0.3294 | 0.2755 | 0.2824 | 0.3190 | 0.2890 | 0.3025 |
| Video-LLaVA1 | 0.2575 | 0.3646 | 0.3303 | 0.2632 | 0.2886 | 0.3122 | 0.2865 | 0.3004 |
| Video-LLaVA2 | 0.2624 | 0.3631 | 0.3297 | 0.2708 | 0.2763 | 0.3155 | 0.2918 | 0.3011 |
| Image | Audio | Text | FAU | Mean Pearson Correlation |
|---|---|---|---|---|
| ✓ | - | - | - | 0.2712 |
| ✓ | ✓ | - | - | 0.2748 |
| ✓ | - | ✓ | - | 0.2758 |
| ✓ | - | - | ✓ | 0.2978 |
| ✓ | ✓ | ✓ | - | 0.2758 |
| ✓ | - | ✓ | ✓ | 0.3011 |
| ✓ | ✓ | - | ✓ | 0.2924 |
| ✓ | ✓ | ✓ | ✓ | 0.3011 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vaiani, L.; Cagliero, L.; Garza, P. Emotion Recognition from Videos Using Multimodal Large Language Models. Future Internet 2024, 16, 247. https://doi.org/10.3390/fi16070247
Vaiani L, Cagliero L, Garza P. Emotion Recognition from Videos Using Multimodal Large Language Models. Future Internet. 2024; 16(7):247. https://doi.org/10.3390/fi16070247
Chicago/Turabian StyleVaiani, Lorenzo, Luca Cagliero, and Paolo Garza. 2024. "Emotion Recognition from Videos Using Multimodal Large Language Models" Future Internet 16, no. 7: 247. https://doi.org/10.3390/fi16070247
APA StyleVaiani, L., Cagliero, L., & Garza, P. (2024). Emotion Recognition from Videos Using Multimodal Large Language Models. Future Internet, 16(7), 247. https://doi.org/10.3390/fi16070247