1. Introduction
Communication networks, computers, and artificial intelligence technologies provide a vast array of tools and techniques to improve efficiency. With the development of these technologies and tools, huge amounts of data are generated, stored, and utilized [
1]. For example, a large number of IoT devices monitor, sense, and generate continuous data from the edge [
2]. In addition, operators retain large amounts of historical user data in various transaction and computing platforms. Then again, the generation of rich media data such as short videos and motion pictures also makes the amount of data in the network grow exponentially [
3]. Machine learning can effectively use these data and learn rules and patterns from them to help people make predictions and decisions. Machine learning algorithms have been successfully applied to various fields of life, such as medicine, materials science, and physics. Specifically, machine learning algorithms can extract features from various types of data and use the features to train models for classification, regression, and clustering operations [
4].
Despite the advantages of the mentioned machine learning algorithms in terms of effectiveness, wide application, and malleability, there are still some challenges and urgent issues that machine learning algorithms need to address. First, the training of machine learning algorithms is a time-consuming, computationally intensive, and energy-intensive process, which can lead to limited applications of machine learning algorithms [
5]. Second, the training datasets of machine learning algorithms are derived from the features they extract, which are mostly extracted using automated tools and human experience, and have many repetitive, meaningless, or even misleading features [
6]. These features can slow down the training process of machine learning algorithms even more and reduce the effectiveness of classification, clustering, and regression of machine learning algorithms. Therefore, the elimination of these useless and redundant features is important to improve the performance of machine learning algorithms and reduce their training consumption.
Feature selection is an effective means to solve the above problem. Feature selection can eliminate useless and redundant features in the dataset, thus reducing the number of features and improving the classification accuracy of machine learning algorithms. For a dataset with N features, there are feature selection schemes available, producing a combinatorial explosion. Therefore, selecting a subset of features with high classification accuracy and a low number of features can be regarded as an optimization problem. On the other hand, the feature selection problem is also proved to be an NP-hard problem. It is important to select and propose a suitable algorithm to solve the feature selection problem.
In general, feature selection methods can be classified into three categories, namely filter-based methods, wrapper-based methods, and embedded methods. Specifically, filter-based methods use a statistical measure that gives a score to the relevance of each feature in the dataset, by which the importance of the feature can be quantified. Subsequently, the decision-maker can set a threshold to remove features with scores below the threshold, thus achieving a reduction in the number of features. However, such methods do not consider the complementarity and mutual exclusivity among features, and therefore the classification accuracy obtained by the subset of features selected by such methods is low [
7]. Embedded-based methods are a special kind of wrapper-based method, so they are not discussed in this paper. The wrapper-based methods introduce classifiers and learning algorithms. The learning algorithm continuously generates new feature subsets, while the classifier evaluates the generated feature subsets and selects the optimal one in continuous iterations [
8]. In this type of method, the classification accuracy of feature selection is high but consumes more time due to the introduction of classifiers. On the other hand, this type of method has a great relationship with the performance of the learning algorithm.
Akin to some previous works [
7,
8,
9], we aim to adopt the swarm intelligence algorithm as the learning algorithm in the wrapper-based feature selection method. Specifically, a swarm intelligence algorithm studies the complex behaviors of a swarm consisting of several simple agents. By iteratively updating the swarm, the agents will have a more powerful performance than before, so that the algorithm can provide a sub-optimal solution. Swarm intelligence has the benefits of high convergence and powerful solving ability. Moreover, swarm intelligence can also handle NP-hard problems such as feature selection. Thus, it can be seen as an effective method to overcome the challenges of feature selection. For instance, some well-known swarm intelligence, i.e., genetic algorithm (GA) [
10], particle swarm optimization (PSO) [
11], dragonfly algorithm (DA) [
12], ant-lion optimizer (ALO) [
13], and grey wolf optimizer (GWO) [
14] has been applied in feature selection.
Bat algorithm (BA) and binary BA (BBA) are promising forms of swarm intelligence and have been demonstrated to be better than other algorithms in some applications due to their effectiveness and high performance. However, as suggested in no-free lunch (NFL) theory, there are no algorithms that can suitably solve all optimization problems. In addition, BA also has some shortcomings in solving feature selection problems. Thus, we aim to enhance the performance of BA for solving feature selection. The contributions of this work are summarized as follows:
We show that the feature selection is a multi-objective optimization problem, and we present the decision variables and the optimization goals of the feature selection problem.
We propose an enhanced binary BA (EBBA) for solving the feature selection problem. In EBBA, we propose Lévy flight-based global search method, which enables the algorithm to jump out of the local optimum. Moreover, we propose a population diversity boosting method so that the exploration capability of the algorithm can be further enhanced. In addition, we use a recently proposed chaotic mapping to assign values to the key parameter of the algorithm, thus enhancing the exploitation capability of the algorithm.
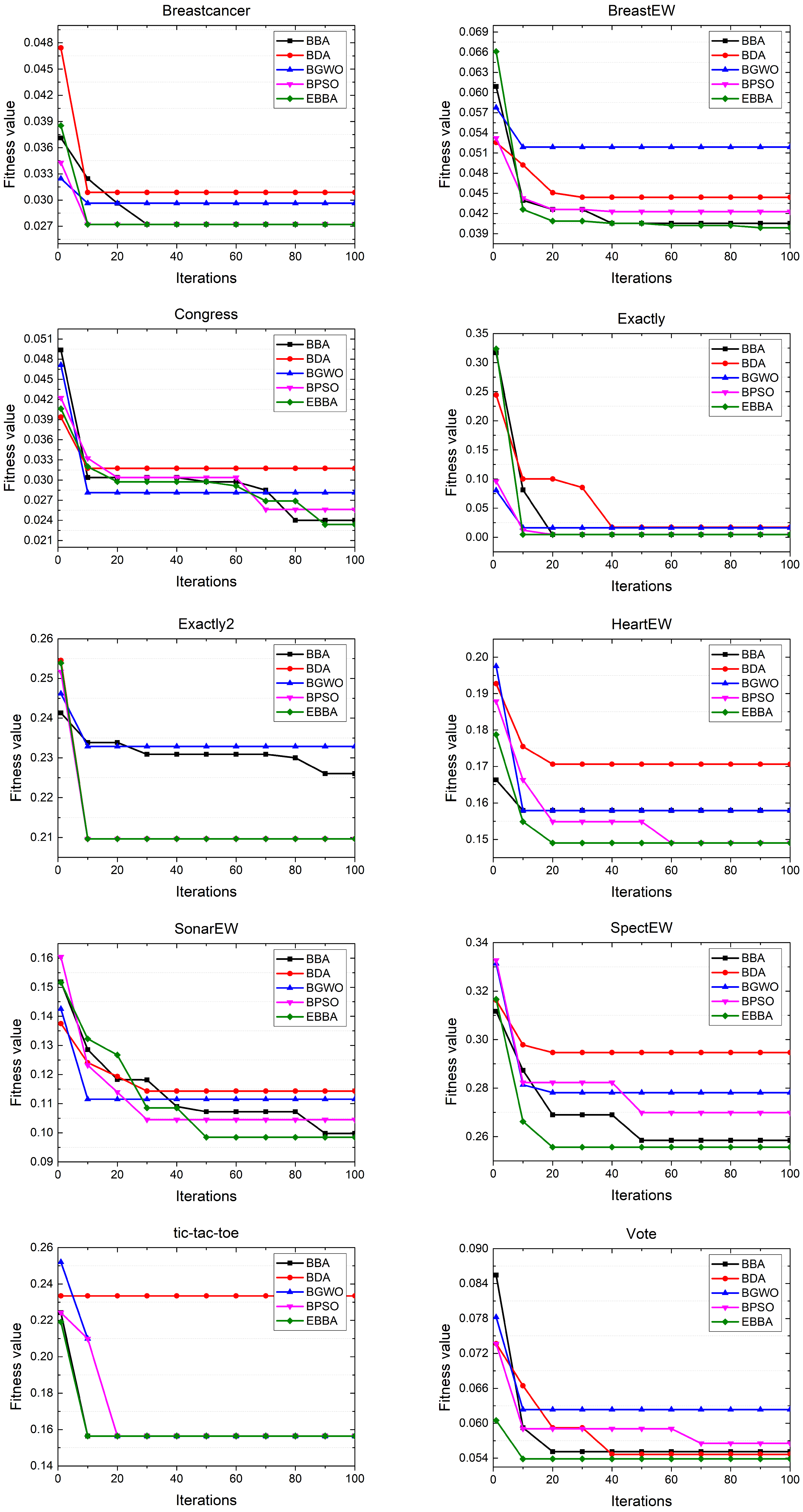
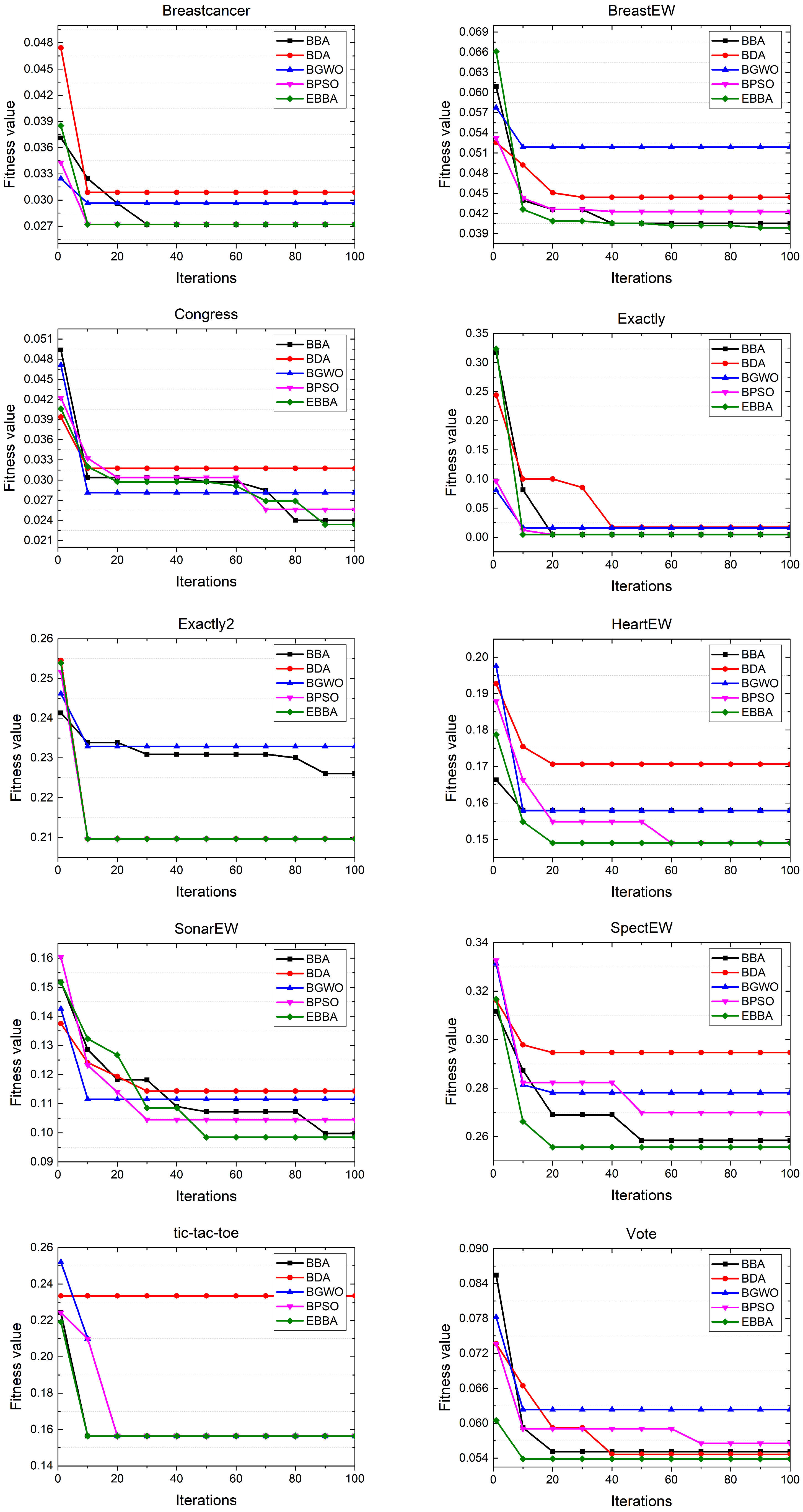
Simulations are conducted based on open datasets of UC Irvine machine learning repository to verify the solving ability of the proposed EBBA. First, we introduce some benchmark algorithms for comparisons. Then, we show the effectiveness of the proposed improved factors.
The rest of this work is arranged as follows.
Section 2 reviews some key related works about swarm intelligence algorithms and feature selection.
Section 3 gives the model of feature selection.
Section 4 proposes the EBBA and details the improved factors.
Section 5 provides simulation results and
Section 6 concludes this work.
2. Related Works
In this work, we aim to use one of the swarm intelligence algorithms, i.e., BA, to solve the feature selection problem, and thus some key related works are briefly introduced in this section.
2.1. Swarm Intelligence Algorithms
Swarm intelligence algorithms refer to evolutionary theory and swarm behavior. In the past few years, a large number of researchers have proposed various types of swarm intelligence algorithms to solve optimization problems in different domains.
First, some representative classical swarm intelligence algorithms are presented as follows. PSO is another representative swarm intelligence algorithm, which is inspired by the behavior of bird/fish populations. Moreover, artificial bee colony (ABC) [
15], ant colony optimization (ACO) [
16], etc., are also well-known swarm intelligence algorithms. Second, swarm intelligence algorithms also contain various types of bio-inspired algorithms. For example, Meng et al. [
17] proposed a chicken swarm optimization (CSO) to solve optimization problems by simulating the rank order and the behavior of chickens (including roosters, hens, and chicks) in a flock. Yang et al. [
18] proposed a BA and validated the performance of BA using eight nonlinear engineering optimization problems. Third, certain swarm intelligence algorithms were proposed inspired by various natural phenomena of the universe. Jiang et al. [
19] proposed a new metaheuristic method, artificial raindrop algorithm (ARA), from natural rainfall phenomena and used it for the identification of unknown parameters of chaotic systems. Kaveh et al. [
20] proposed a ray optimization (RO) based on Snell’s law of light refraction and the phenomenon of light refraction.
In summary, researchers have proposed a large number of effective swarm intelligence algorithms and applied them to various optimization problems. However, these algorithms are not necessarily applicable to all engineering fields. Accordingly, proposing an enhanced swarm intelligence algorithm version according to the characteristics of an optimization problem is a major challenge.
2.2. Ways of Feature Selection
There are several existing methods and ways have been proposed for the purpose of feature selection. First, some filter methods are widely used due to their simplicity and relatively high performance. For instance, some methods based on correlation criteria and mutual information are detailed in reference [
21]. In this case, several effective filter-based algorithms including correlation-based feature selection (CFS) [
22], fast correlation-based filter (FCBF) [
23], wavelet power spectrum (Spectrum) [
24], Information Gain (IG) [
25], ReliefF [
26], etc. Second, wrapper-based approaches are key methods in feature selection. This type of method can be categorized by the type of learning algorithms. For instance, exhaustive, random search and metaheuristic search methods. Due to their effectiveness, the metaheuristic search methods including swarm intelligence algorithms can be seen as the most popular methods [
27]. Finally, there are several embedded methods. The main approach is to incorporate feature selection as part of the training process, e.g., [
21,
28].
2.3. Swarm Intelligence-Based Feature Selection
There are many swarm intelligence algorithms have been adopted or proposed as the learning algorithm in wrapper-based feature selection methods, and we review some key algorithms as follows.
Li et al. [
29] proposed an improved binary GWO (IBGWO) algorithm for solving feature selection problems, in which an enhanced opposition-based learning (E-OBL) initialization and a local search strategy were proposed for improving the performance of the algorithm. Kale et al. [
30] presented four different improved versions of the sine cosine algorithm (SCA), where the updating mechanism of SCA is the improvements and innovations. Ouadfel et al. [
31] proposed a hybrid feature selection approach based on the ReliefF filter method and equilibrium optimizer (EO), which is composed of two phases and tested in some open datasets. Abdel-Basset et al. [
14] proposed three variants of BGWO in addition to the standard variant, applying different transfer functions to tackle the feature selection problem. In [
32], two different wrapper feature selection approaches were proposed based on farmland fertility algorithm (FFA), which denoted as BFFAS and BFFAG, and these methods are effective in solving feature selection problems. On the other hand, BA and some variants have been adopted for solving feature selection problems. Varma et al. [
33] proposed a bat optimization algorithm for wrapper-based feature selection and conducted simulations based on the CICInvesAndMal2019 benchmark dataset. Naik et al. [
34] proposed a feature selection method to identify the relevant subset of features for the machine-learning task using the wrapper approach via BA. Rodrigues et al. [
35] presented a wrapper feature selection approach based on bat algorithm (BA) and optimum-path forest (OPF). In [
36], the authors proposed an improved BPSO algorithm as an essential tool of pre-processing for solving classification problem, in which a new updating mechanism for calculating Pbest and Gbest were proposed. Moreover, the authors in [
37] proposed a binary DA (BDA) and use it to solve the feature selection problems. Likewise, Nakamura et al. [
38] proposed a binary version of the bat algorithm, i.e., BBA, and evaluate its performance in solving the feature selection problems. In addition, in [
39], a new hybrid feature selection method was proposed by using the sine cosine algorithm (SCA) and genetic algorithm (GA), and the algorithm is used for solving feature selection problems. Furthermore, Nagpal et al. [
40] proposed a feature selection method via binary gravitational search algorithms (BGSA) in medical datasets, in which they can reduce the number of features by an average of 66% and enhance the accuracy of prediction.
The aforementioned methods can solve feature selection problems in various applications. However, according to NFL theory, different swarm intelligence algorithms may have different performances in various applications. Therefore, the existing methods are insufficient to solve all feature selection problems, which motivates us to propose an EBBA to handle more feature selection problems in this work.
3. Feature Selection Model
As shown in [
8,
29,
33], the feature selection problem can be seen as a binary optimization model, and in this section, we introduce it in details. Specifically, the main purpose of feature selection is to reduce the data dimension by retaining the most valuable features through feature selection methods. Thus, there are two possibilities for each feature, i.e., to be selected and to be discarded. Therefore, the feature selection problem can be regarded as an optimization problem with a binary solution space.
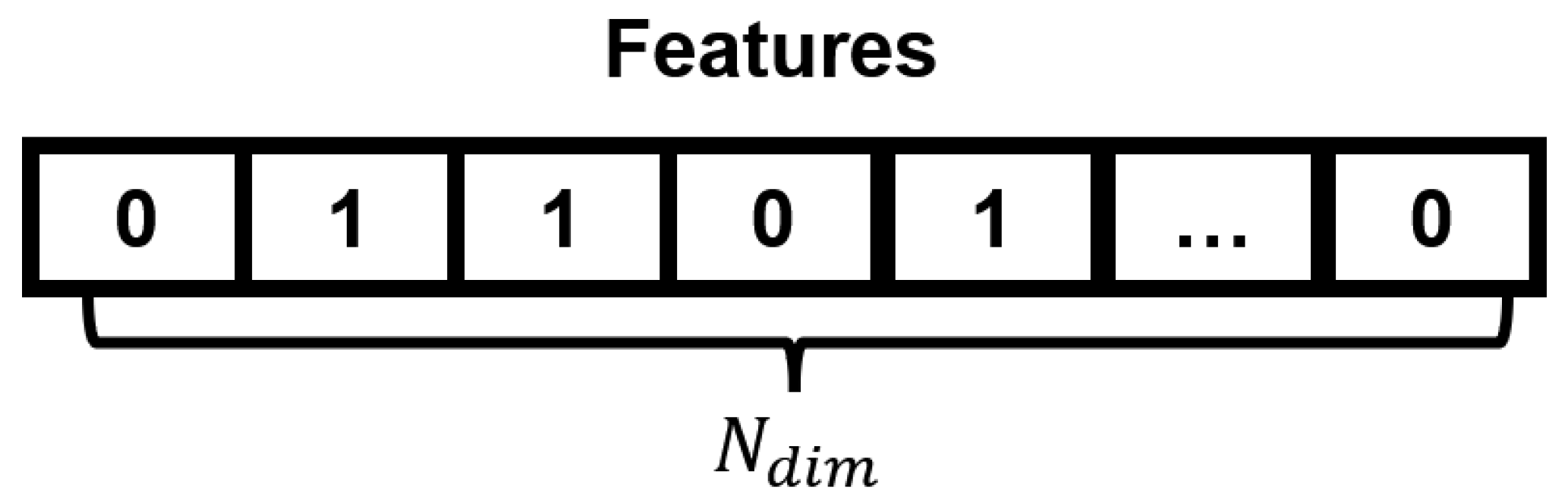
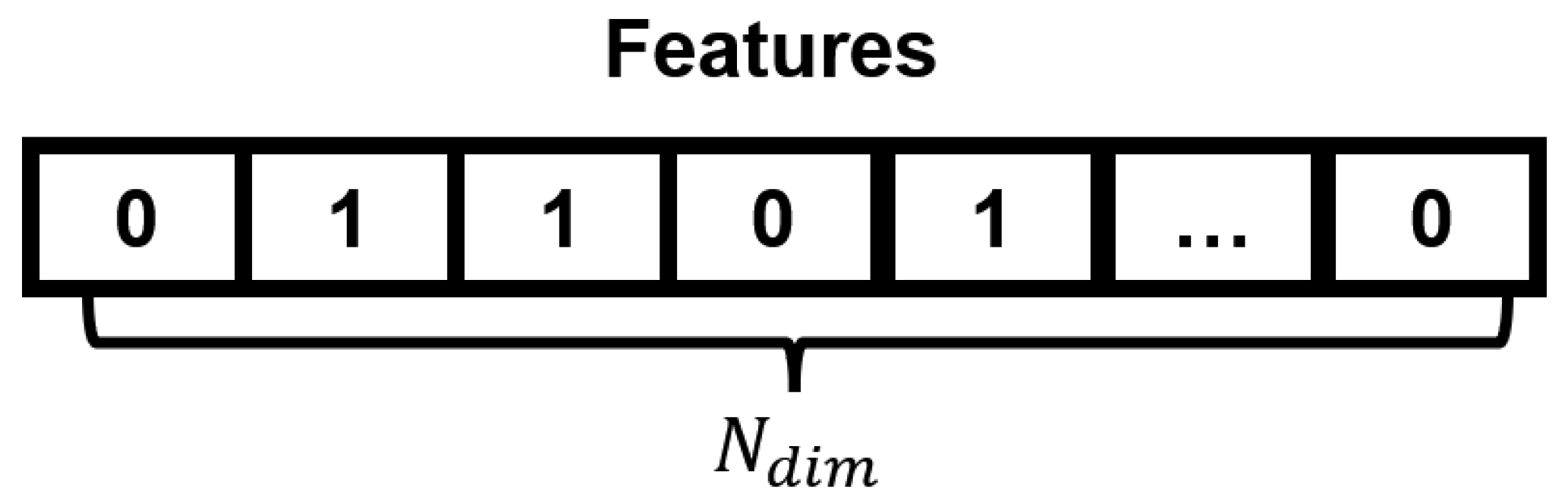
It is can be seen from
Figure 1, the solution space of the considered feature selection problem is a binary. Each feature is represented by a binary number, and if that binary number is 1, it means that the feature is selected, and conversely, if that binary number is 0, it means that the feature is discarded. Thus, the feature selection of a dataset can be represented by a binary array as follow:
where
is the number of features, in other words, the dimension number of the dataset. Under this model, there are two main objectives of the feature selection, i.e., to reduce the classification error rate of the obtained feature subsets, and to reduce the feature number of feature subsets. Thus, the feature selection problem is a multi-objective problem in which the first objective can be expressed as follows:
where
is the classification accuracy of the obtained feature subsets. Note that we introduce the KNN as a classifier to evaluate the feature subsets and the reasons are analyzed in following section. Moreover, the second objective of this work is to reduce the feature number of feature subsets, which can be expressed as follows:
where
is the feature number of the selected feature subsets. To simultaneously the aforementioned objectives, we introduce the fitness function as follows:
where
and
are constants that denote the weights of the two objectives
and
, respectively. Specifically, we can increase
a to obtain a higher classification accuracy or increase
b to obtain a smaller dimensional feature subset.
4. Proposed Algorithm
Based on the aforementioned feature selection model, we can optimize the decision variables shown in Equation (
1) to obtain a better fitness function shown in Equation (
4). Accordingly, we propose an EBBA in this section for solving the feature selection problem.
4.1. Conventional BA
BA is a swarm intelligence algorithm for global optimization, which is inspired by the echolocation behavior of bats. Specifically, bats look for prey by flying at a random velocity
at a random point
with a fixed frequency
, changing wavelength
l, and loudness
. Depending on the proximity of their target, these bats can autonomously modify the wavelength (in other words, frequency) of their generated pulses as well as the rate of pulse emission
r in the range of
. The corresponding mathematical model of BA can be detailed as follows. In the
tth iteration, the frequency
of the the
ith bat is expressed as follows.
where
and
are upper and lower bounds on the frequencies of all bats, respectively, and
is a random number between
.
Moreover, the velocity of the
ith bat
can be modeled as follows:
where
is the bat with the highest fitness function value of the swarm.
In addition, the update method of the
ith bat is shown as follows:
where
is the position of the
ith bat in the
tth iteration.
Furthermore, BA also enhances search ability through local random walks. Specifically, BA asks the best bat in the swarm to conduct a local search with a certain probability, which can be expressed as follows:
where
is the newly generated bat after the random walk,
is the loudness of all bats in the
t iteration, and
is a random variable that ranges
.
Additionally, the loudness
and the rate
of pulse emission are also updated as the iterations proceed, which is shown as follows:
where
is a parameter that ranges from 0 to 1, and
is a parameter.
By using these mathematical models, the main steps of BA can be summarized as follows.
Step 1: Randomly generate population (bat swarm) , where is the population size. Moreover, the velocity, pulse emissivity, and loudness of the bats are randomly generated. Then, the fitness values of all bats are calculated.
Step 2: Update the positions and velocities of bats by using Equations (
5)–(
9).
Step 3: A random number
between 0 and 1 is firstly generated, and then if
, a random walk will be performed by using Equation (
8) to generate a new individual
around the current best individual
.
Step 4: Generate a random number of again. If and , replace with and then update the loudness and pulse firing rate. If , is used to replace .
Step 5: Repeat steps 2–4 until the terminal condition is reached.
Step 6: Return as the final solution to the problem.
4.2. BBA
To make the BA can handle the binary solution space of the feature selection, Mirjalili et al. [
41] introduce a binary operator. Specifically, the authors introduced a v-shape transfer function to map the continuous parameters into binary solution space, which can be expressed as follows:
where
and
indicate the position and velocity of
ith individual at
tth iteration in
jth dimension, and
is the complement of
. As such, the BBA can handle and update the binary decision variable reasonably.
4.3. EBBA
Conventional BA may confront some key challenges in solving the feature selection problems. First, when dealing with the big solution space of feature selection problem, BA may lack exploration ability, which may make the algorithm fall in local optima. Second, the bats of the BA are guided by the best bat of the swarm, i.e.,
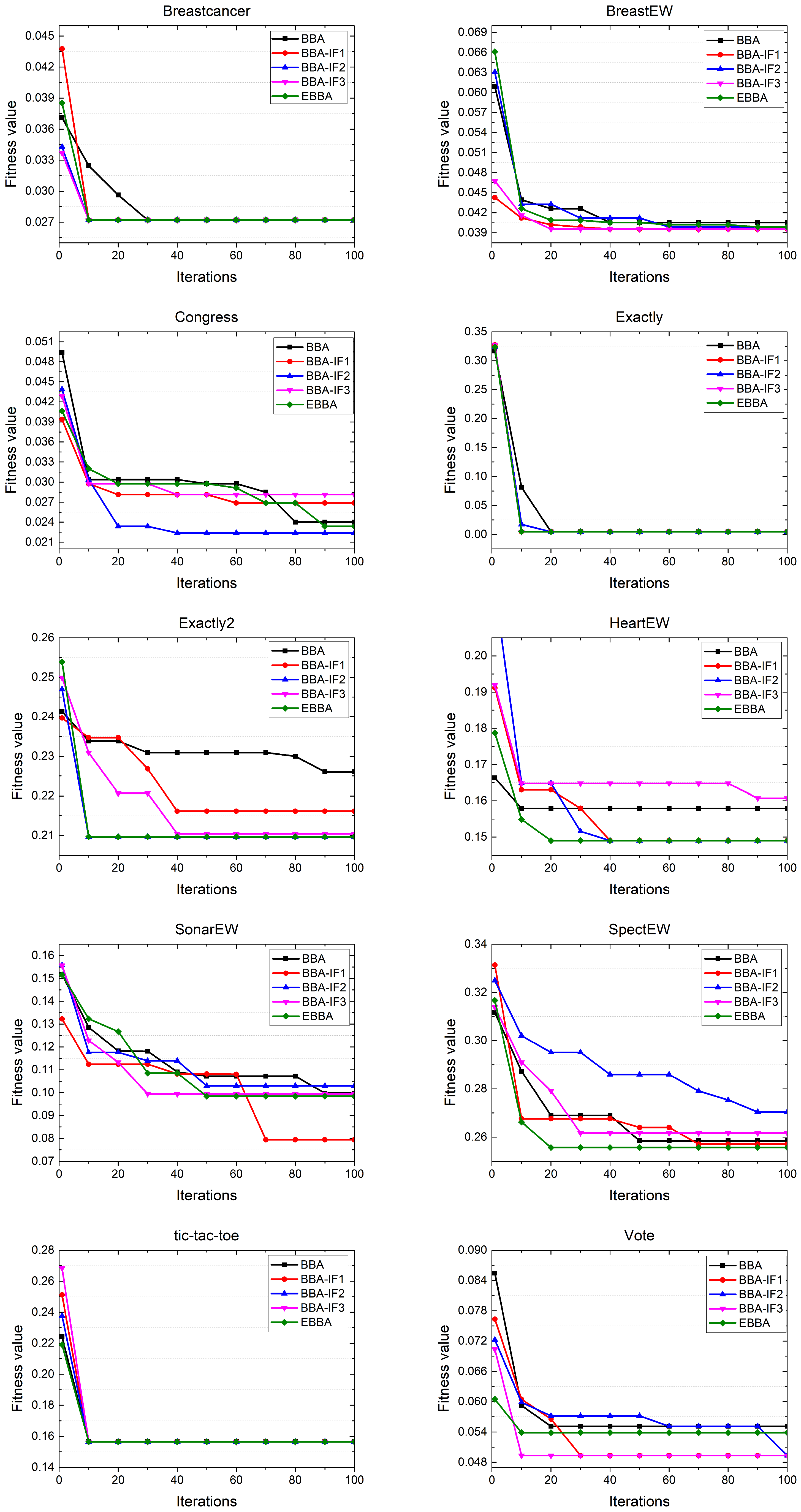
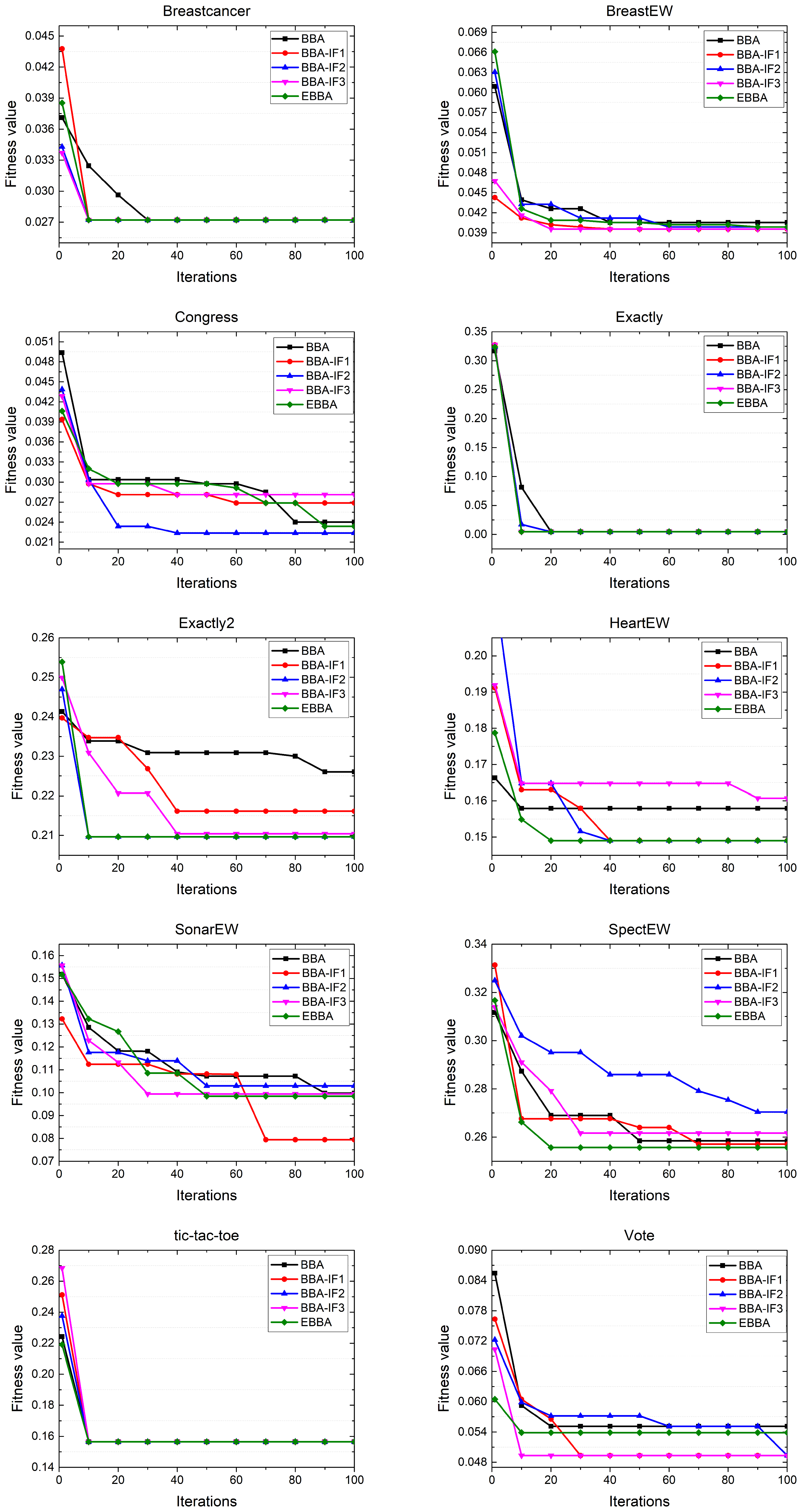
, which means that the population diversity is lower for the large scale datasets. Third, the exploration and exploration abilities of BA should be further balanced. Finally, BA is proposed for continuous problems whereas the feature selection problems are with a binary solution space. Thus, these reasons motivate us to enhance BA for better feature selection performance. The main steps of the proposed EBBA are detailed in Algorithm 1, and the correspondingly improved factors are as follows:
| Algorithm 1 EBBA |
![Futureinternet 14 00178 i001]() |
4.3.1. Lévy Flight-Based Global Search Method
Feature selection problems also are large-scale optimization problems since the dimension of some datasets is relatively large. In this case, the exploration ability of the optimization algorithm should be sufficient. However, the update of other bats in the swarm are determined by the best bat, and this mechanism will undoubtedly decrease the exploration ability of the algorithm. Thus, we introduce the Lévy flight to propose a global search method to improve the exploration ability of the algorithm. Specifically, a Lévy flight is a random walk in which the step-lengths have a Lévy distribution, a probability distribution that is heavy-tailed. By using the short-distance or long-distance searching alternately, the search scope can be extended.
First, mathematically, in each iteration, we generate a new bat according to the best bat
and Lévy flight, which can be expressed as follows:
where
is a parameter and its value is often assigned according to applications. Moreover, Lévy flight is taken from the Lévy distribution, which can be expressed as follows:
Second, the newly generated bat is evaluated to obtain its fitness value, and then we compare the with the best bat based on their fitness function values. If the outmatches , then . By using this method, the best bat of the swarm is easy to jump out of local optima, thereby enhancing the exploration ability of EBBA.
4.3.2. Population Diversity Boosting Method
In BA, all the bats are guided by the best bat of the swarm, which may decrease the population diversity of the algorithm, thereby affecting the solving performance. In this case, we aim to propose a method for boosting population diversity. In bat swarm, the second best bat also is meaningful and with a strong value for guiding other bats. Thus, we use the second best bat
to generate a part of new bats as follows:
where
is the newly generated bat and whether the method used is determined by a parameter
which can be expressed as follows:
By using this method, the bat swarm is simultaneously guided by the best bat and the second-best bat, so that enhancing the population diversity of the algorithm.
4.3.3. Chaos-Based Loudness Method
The loudness in BA can determine the weights of exploitation and exploration abilities of the BA. However, the loudness update method of conventional BA is linear, which may be unsuitable for the feature selection. Thus, we introduce a novel fractional one dimensional chaotic map to update loudness [
42], which can be expressed as follows:
where
is the
tth dimension of the fractional one dimensional chaotic map, which can be expressed as follows:
where
and
are two real parameters, and they are assigned as 0.001 and 0.9 in this work, respectively. By using the high chaotic behavior of the method, the exploitation and exploration abilities of EBBA can be balanced.
4.3.4. Complexity Analysis of EBBA
The complexity of EBBA is analyzed in this part. In the proposed feature selection model, the most time-consuming step is the calculation of fitness function value since we introduce classifier, which is several orders of magnitude complex than other steps. In this case, other steps can be omitted. Accordingly, the complexity of EBBA is when the maximum number of iteration and population size are denoted as and , respectively.




{kind=link}
{kind=link}
{kind=link}