
Deep Regression Neural Networks for Proportion Judgment





Abstract
1. Introduction
2. Materials and Methods
2.1. Datasets
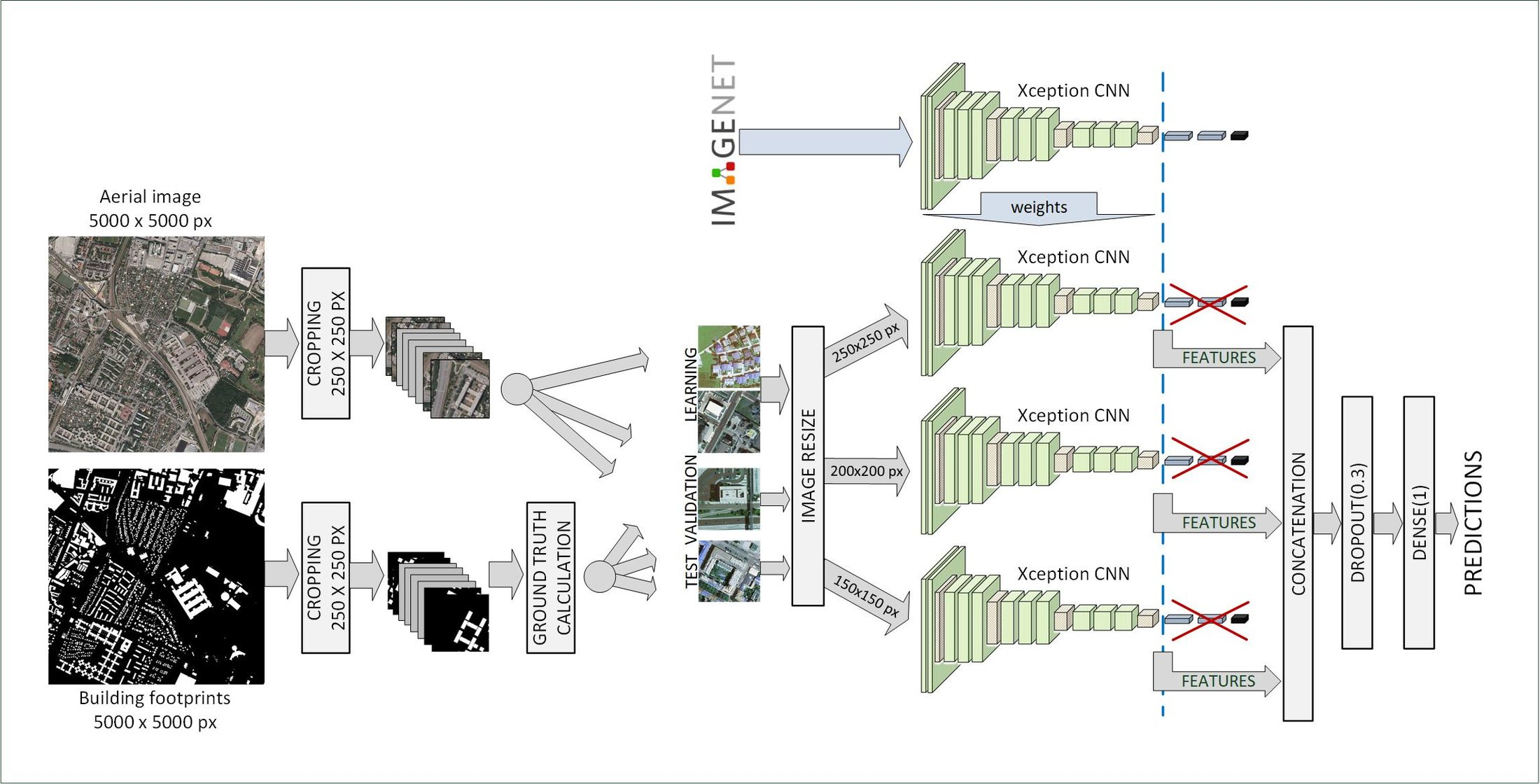
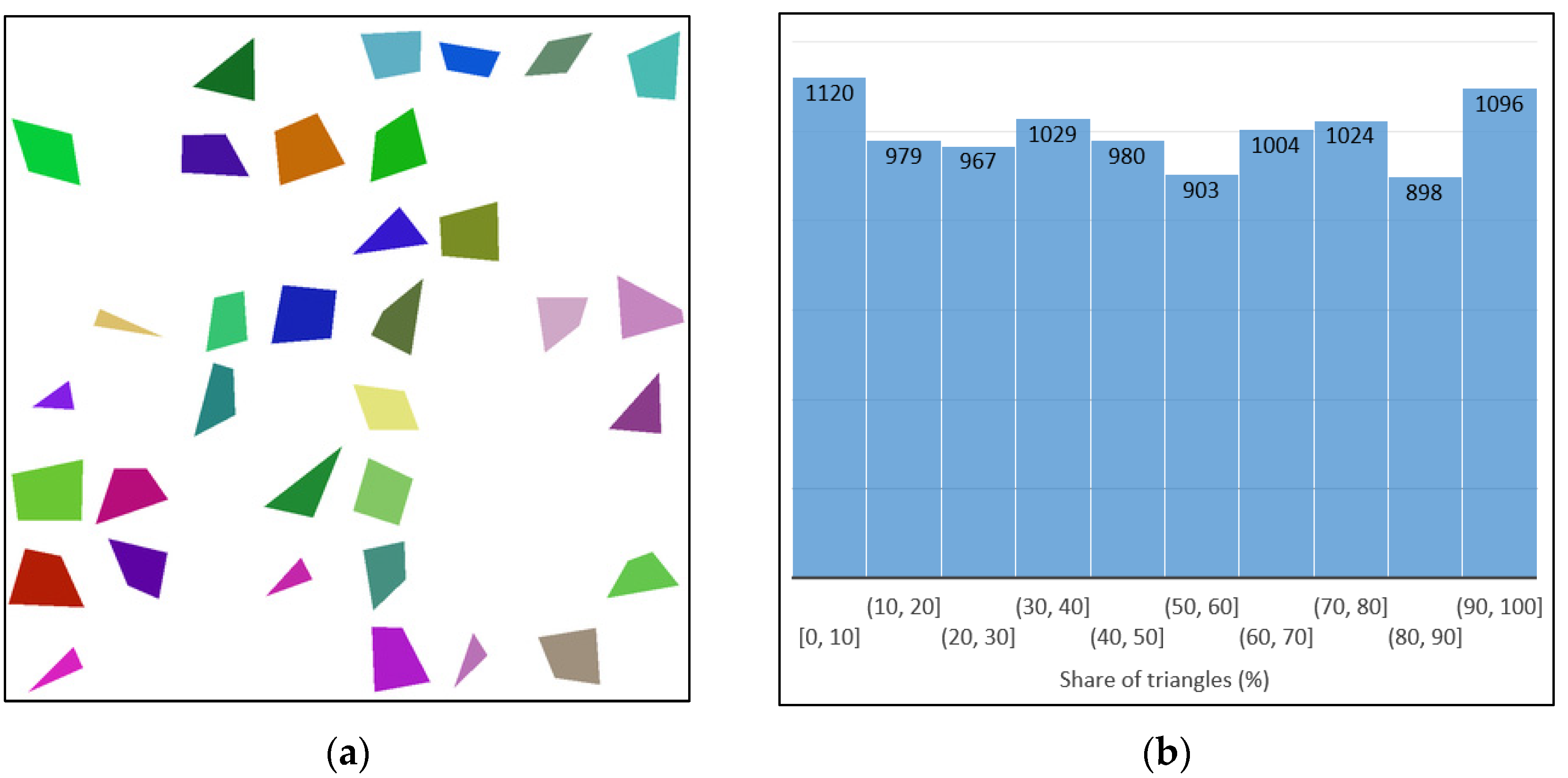
2.1.1. Toy Dataset (TOYds)
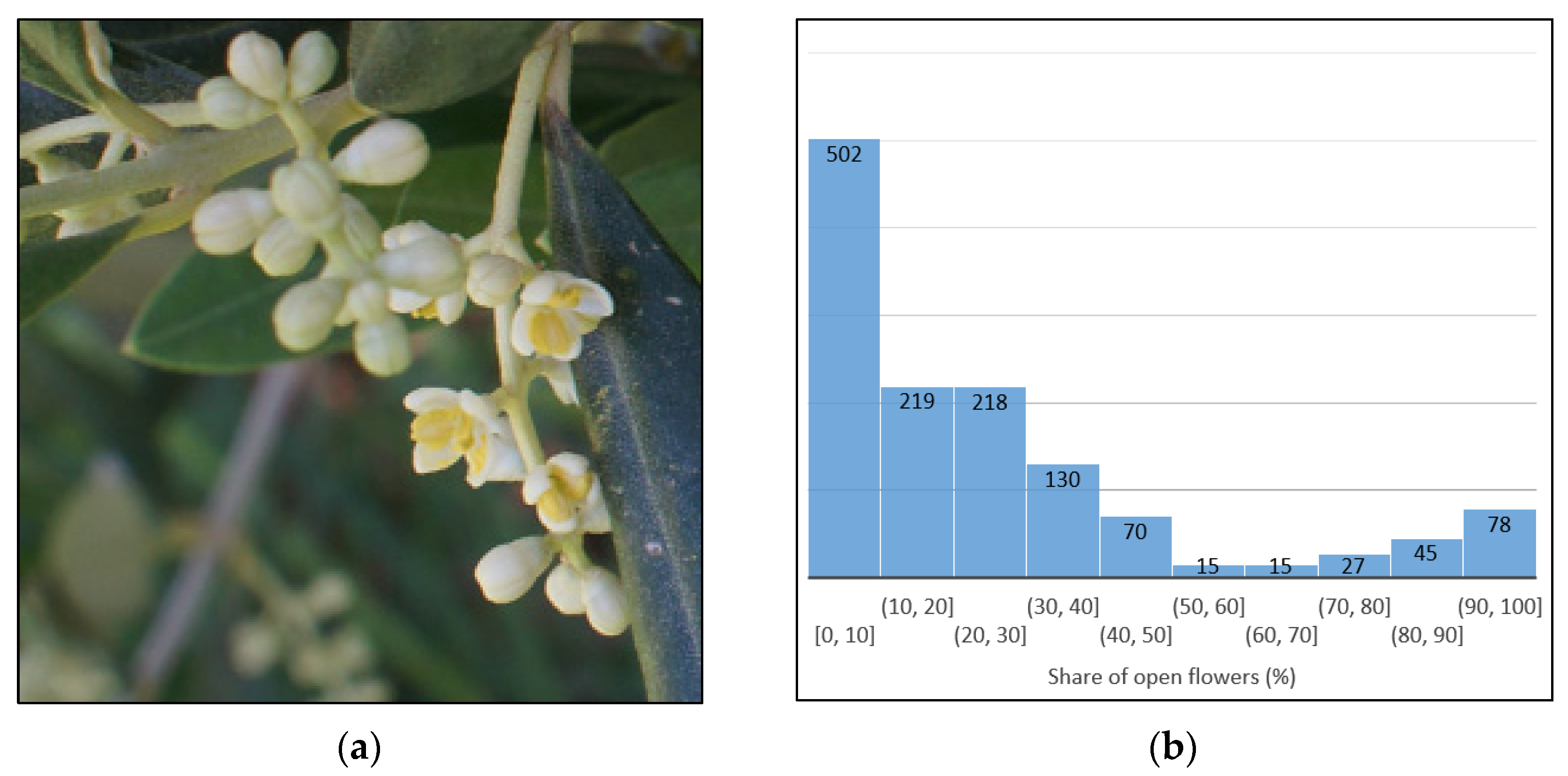
2.1.2. Olive Flowering Phenophases Dataset (OFPds)
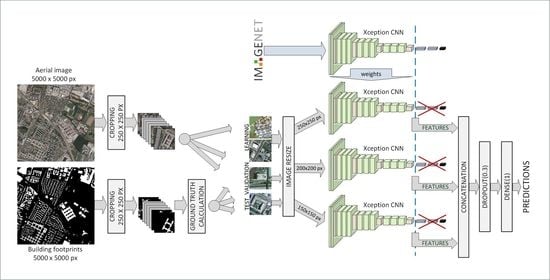
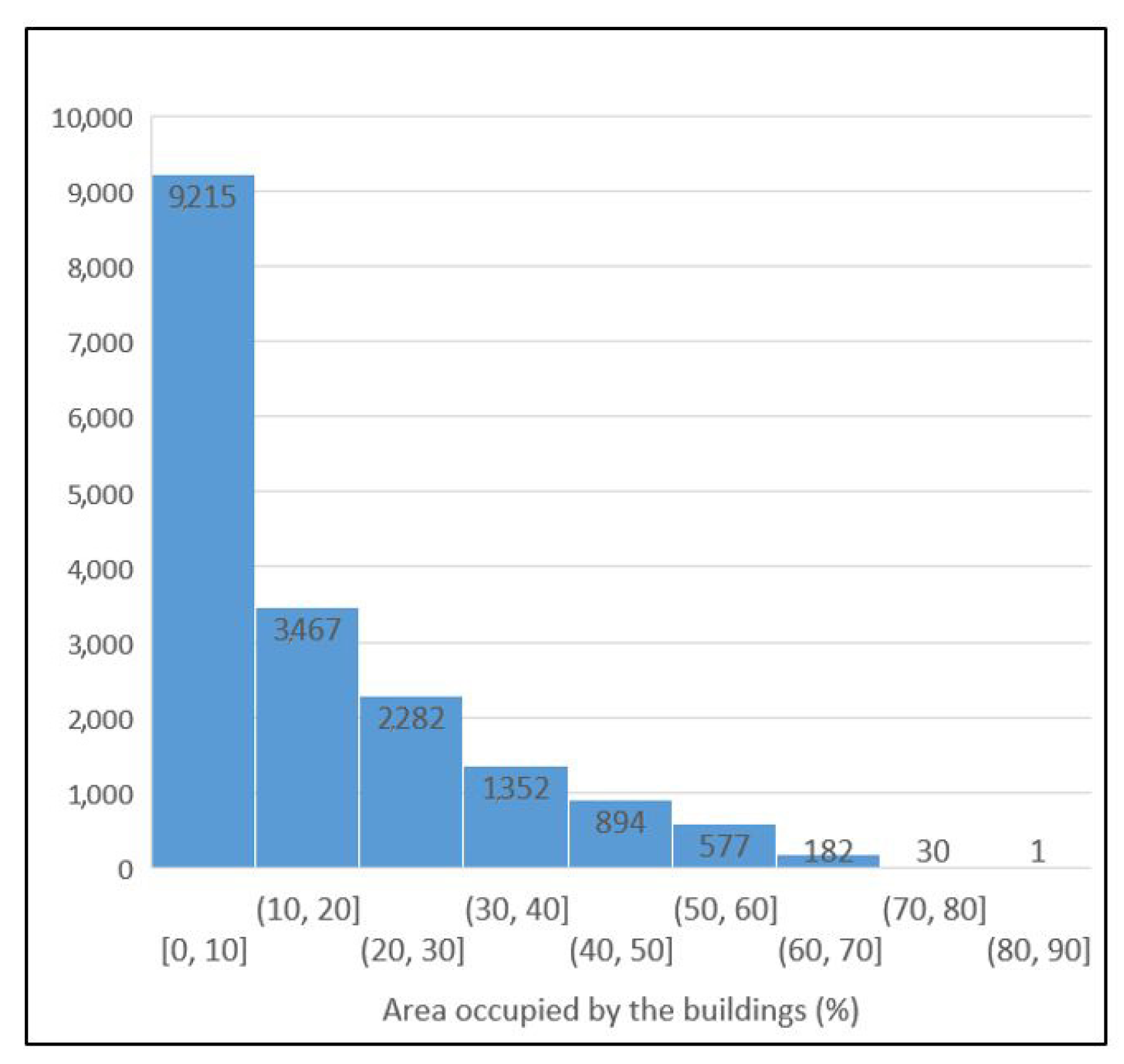
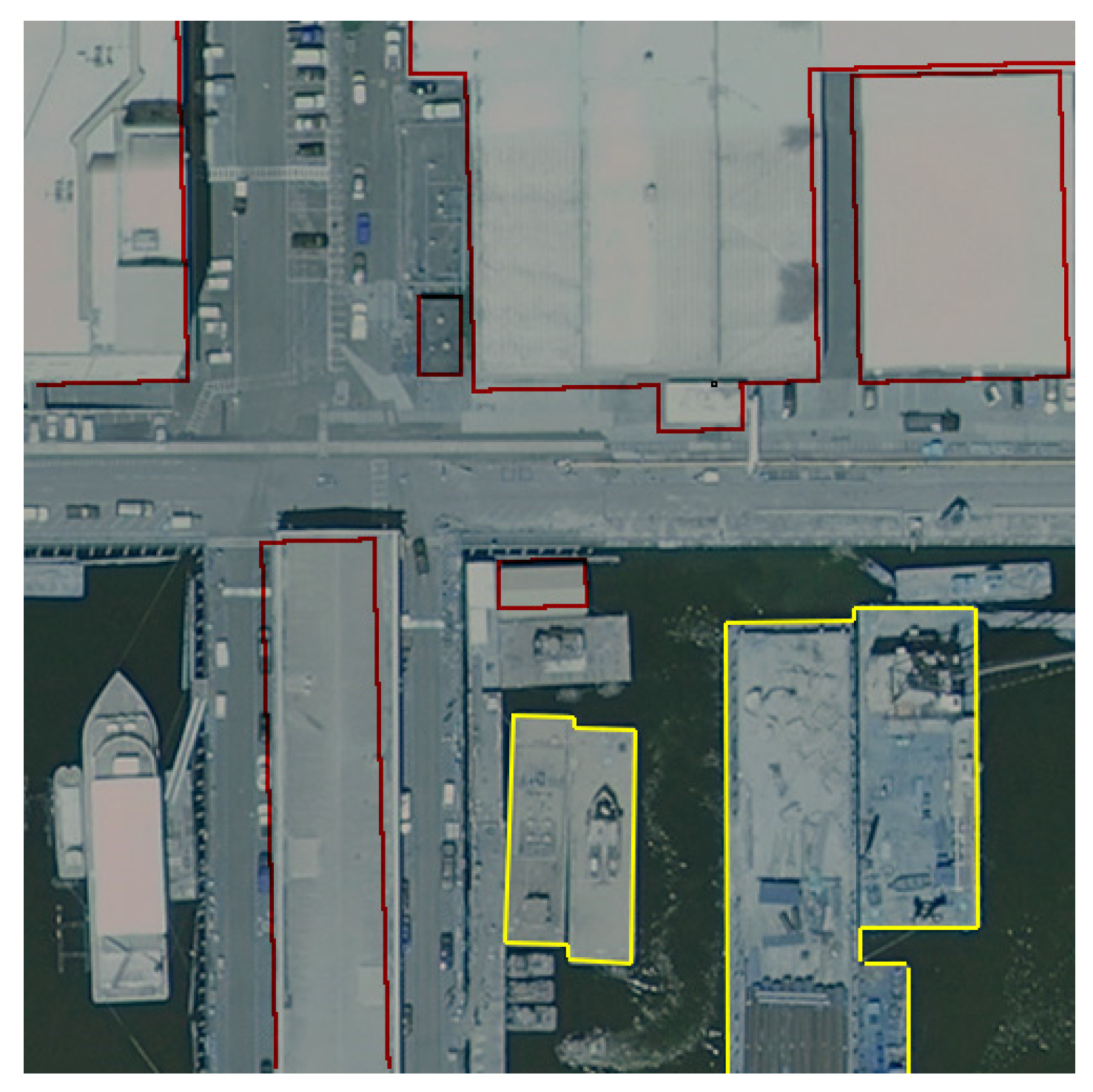
2.1.3. Aerial Image labeling Dataset (AILds)
2.2. Methodology and Architectures
- Vanilla deep regression;
- General-purpose networks (e.g., VGG-19, Xception, InceptionResnetV2, etc.) modified for regression tasks;
- General-purpose networks in transfer learning mode, modified for regression tasks;
- Hybrid architectures (The CNN works as a trainable feature extractor, while the machine learning algorithm (e.g., SVR) performs as a regressor);
- Deep ensemble models for regression.
2.2.1. Vanilla Deep Regression
2.2.2. General-Purpose Networks
- (a)
- GAP() → DR(0.3) → DN(1) → ACT(ReLU_100)
- (b)
- FL → DN(1024)→ BN → DR(0.5) → DN(128) → BN → DR(0.5) → DN(1) → ACT(ReLU_100)
2.2.3. General-Purpose Networks in Transfer Learning Mode
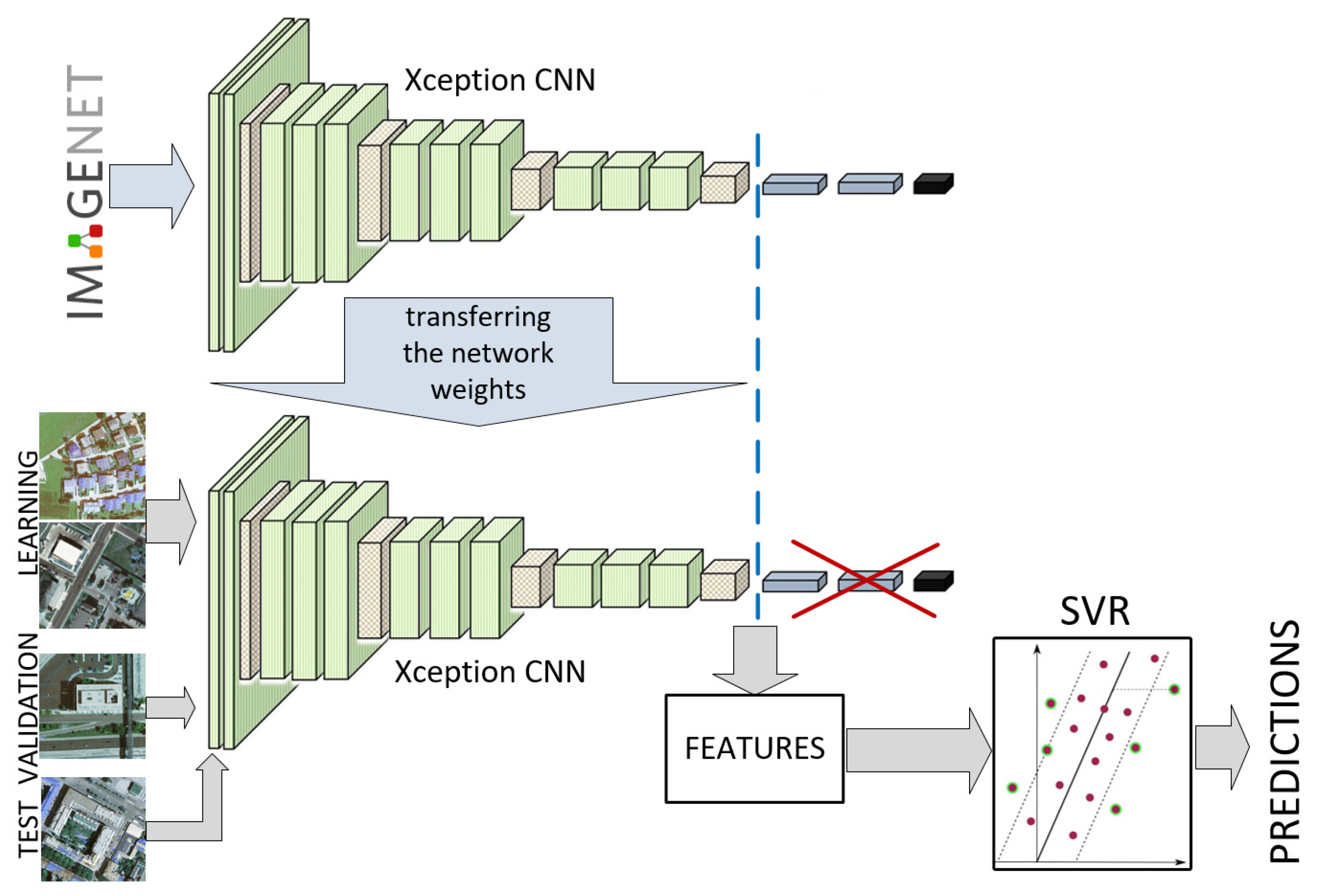
2.2.4. Hybrid Architectures
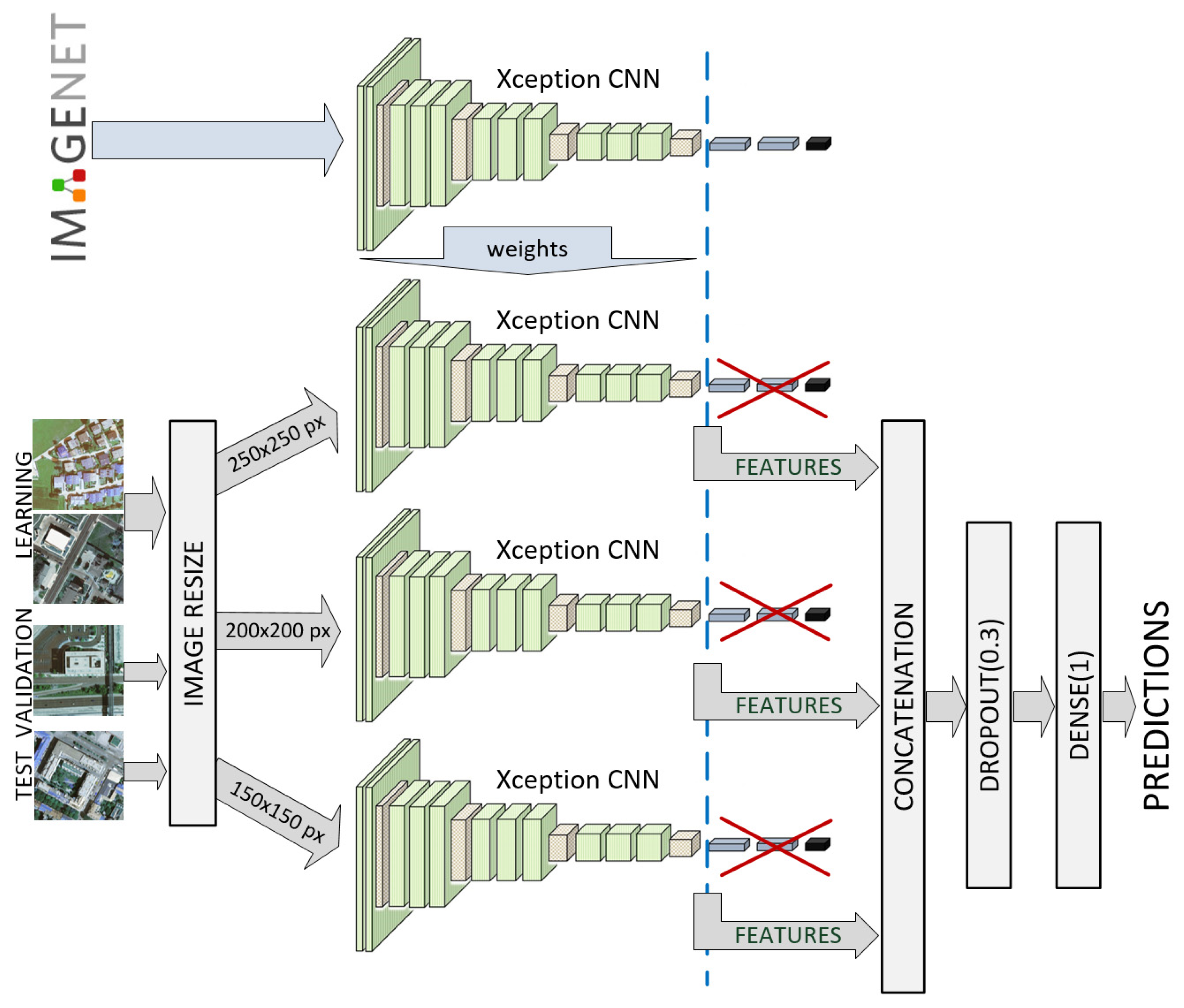
2.2.5. Deep Ensemble Models for Regression
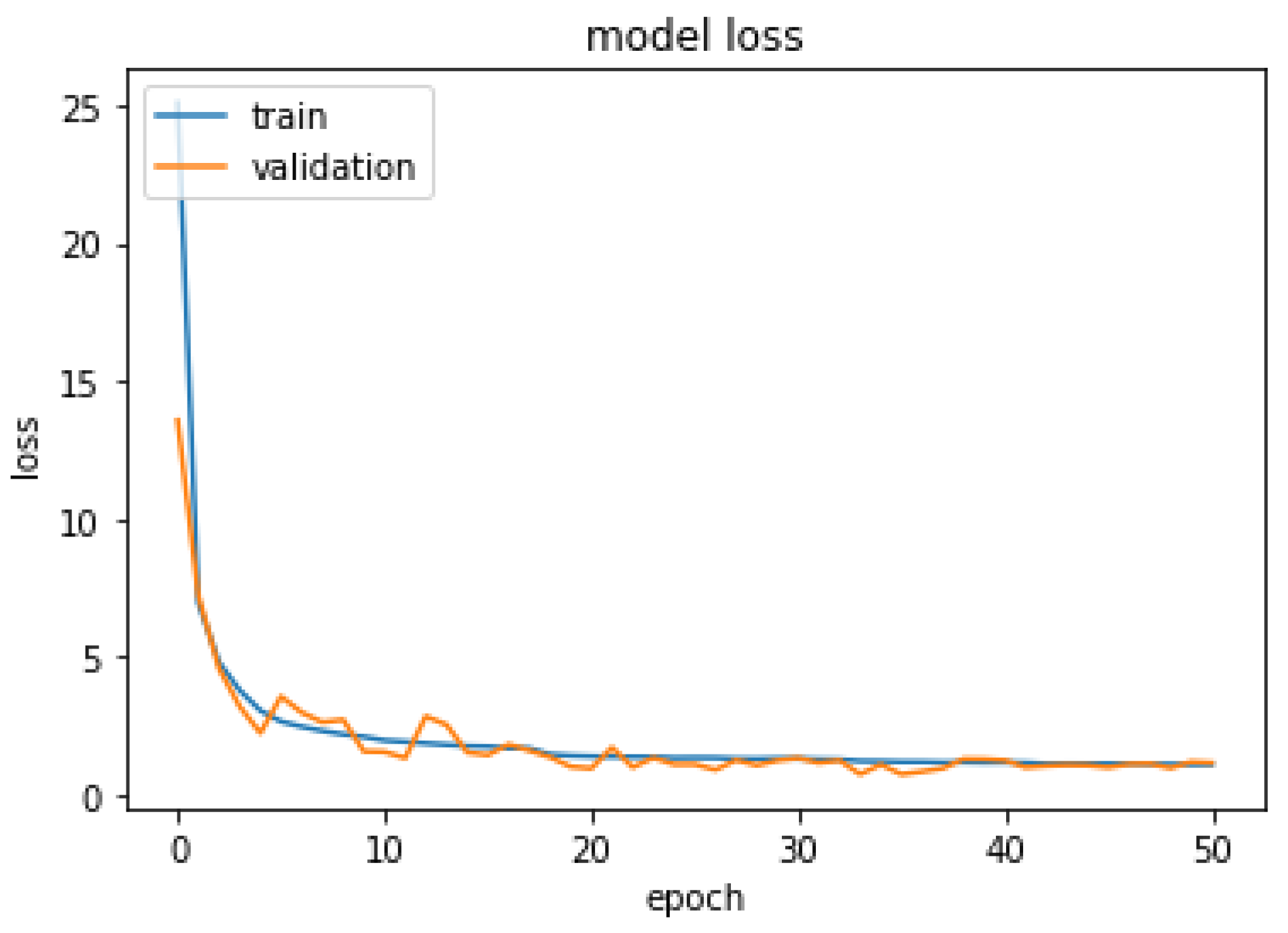
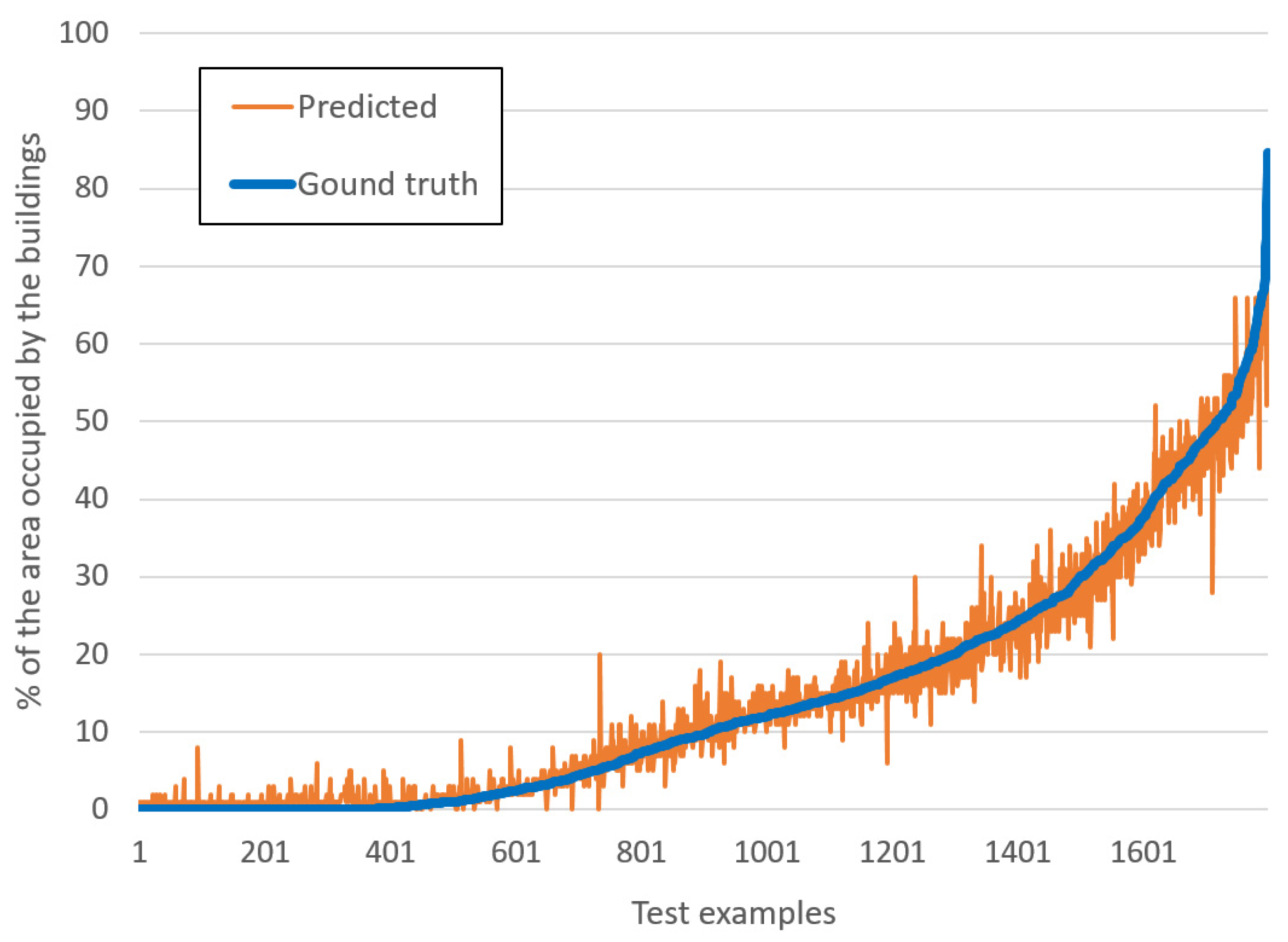
3. Results
4. Summary and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| AILds | Aerial image labeling dataset |
| ANS | Approximate number system |
| CNN | Convolutional neural network |
| MAE | Mean absolute error |
| NMF | Nonnegative matrix factorization |
| OFPds | Olive flowering phenophases dataset |
| ReLU | Rectified Linear Unit |
| RFR | Random Forest Regressor |
| R2 | Coefficient of determination |
| SVR | Support Vector Regression |
| RMSE | Root mean square error |
| TOYds | Toy dataset |
References
- Chesney, D.; Bjalkebring, P.; Peters, E. How to estimate how well people estimate: Evaluating measures of individual differences in the approximate number system. Atten. Percept. Psycho. 2015, 77, 2781–2802. [Google Scholar] [CrossRef] [PubMed]
- Hollands, J.G.; Dyre, B.P. Bias in proportion judgments: The cyclical power model. Psychol. Rev. 2000, 107, 500–524. [Google Scholar] [CrossRef] [PubMed]
- Sheridan, T.B.; Ferrell, W.R. Man-Machine Systems: Information, Control, and Decision Models of Human Performance; The MIT Press: Cambridge, MA, USA, 1974. [Google Scholar]
- Wickens, C.D.; Hollands, J.G.; Banbury, S.; Parasuraman, R. Engineering Psychology and Human Performance, 5th ed.; Routledge: Oxfordshire, UK, 2021. [Google Scholar] [CrossRef]
- Lathuilière, S.; Mesejo, P.; Alameda-Pineda, X.; Horaud, R. A comprehensive analysis of deep regression. IEEE Trans. Pattern Anal. 2019, 42, 2065–2081. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Shen, W.; Guo, Y.; Wang, Y.; Zhao, K.; Wang, B.; Yuille, A.L. Deep regression forests for age estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2304–2313. [Google Scholar]
- Shi, L.; Copot, C.; Vanlanduit, S. A Deep Regression Model for Safety Control in Visual Servoing Applications. In Proceedings of the 2020 Fourth IEEE International Conference on Robotic Computing (IRC), Taichung, Taiwan, 9–11 November 2020; pp. 360–366. [Google Scholar]
- Milicevic, M.; Zubrinic, K.; Grbavac, I.; Keselj, A. Ensemble Transfer Learning Framework for Vessel Size Estimation from 2D Images. In Proceedings of the International Work-Conference on Artificial Neural Networks, Gran Canaria, Spain, 12–14 June 2019; Springer: Cham, Switzerland, 2019; pp. 258–269. [Google Scholar]
- Deng, J.; Bai, Y.; Li, C. A Deep Regression Model with Low-Dimensional Feature Extraction for Multi-Parameter Manufacturing Quality Prediction. Appl. Sci. 2020, 10, 2522. [Google Scholar] [CrossRef]
- Gao, J.; Zhang, T.; Yang, X.; Xu, C. P2T: Part-to-target tracking via deep regression learning. IEEE Trans. Image Process 2018, 27, 3074–3086. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Zhang, Z.; Jiao, Z.; Gao, X. An attention-guided deep regression model for landmark detection in cephalograms. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Cham, Switzerland, 2019; pp. 540–548. [Google Scholar]
- Fang, C.; Huang, J.; Cuan, K.; Zhuang, X.; Zhang, T. Comparative study on poultry target tracking algorithms based on a deep regression network. Biosyst. Eng. 2020, 190, 176–183. [Google Scholar] [CrossRef]
- Wang, Q.; Yang, D.; Li, Z.; Zhang, X.; Liu, C. Deep regression via multi-channel multi-modal learning for pneumonia screening. IEEE Access 2020, 8, 78530–78541. [Google Scholar] [CrossRef]
- Wang, Q.; Wan, J.; Li, X. Robust hierarchical deep learning for vehicular management. IEEE Trans. Veh. Technol. 2018, 68, 4148–4156. [Google Scholar] [CrossRef]
- Salehi, S.S.M.; Khan, S.; Erdogmus, D.; Gholipour, A. Real-time deep pose estimation with geodesic loss for image-to-template rigid registration. IEEE Trans. Med. Imaging 2018, 38, 470–481. [Google Scholar] [CrossRef]
- Abdi, A.M. Land cover and land use classification performance of machine learning algorithms in a boreal landscape using Sentinel-2 data. Gisci. Remote Sens. 2020, 57, 1–20. [Google Scholar] [CrossRef]
- Jia, K.; Liang, S.; Gu, X.; Baret, F.; Wei, X.; Wang, X.; Yao, Y.; Yang, L.; Li, Y. Fractional vegetation cover estimation algorithm for Chinese GF-1 wide field view data. Remote Sens. Environ. 2016, 177, 184–191. [Google Scholar] [CrossRef]
- Yu, R.; Li, S.; Zhang, B.; Zhang, H. A Deep Transfer Learning Method for Estimating Fractional Vegetation Cover of Senti-nel-2 Multispectral Images. IEEE Geosci. Remote Sens. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Carpenter, G.A.; Gopal, S.; Macomber, S.; Martens, S.; Woodcock, C.E. A neural network method for mixture estimation for vegetation mapping. Remote Sens. Environ. 1999, 70, 138–152. [Google Scholar] [CrossRef]
- Mohammed-Aslam, M.A.; Rokhmatloh-Salem, Z.E.; Javzandulam, T.S. Linear mixture model applied to the land-cover classification in an alluvial plain using Landsat TM data. J. Environ. Inform. 2006, 7, 95–101. [Google Scholar] [CrossRef][Green Version]
- Blinn, C.E. Increasing the Precision of Forest Area Estimates through Improved Sampling for Nearest Neighbor Satellite Image Classification. Ph.D. Thesis, Virginia Tech, Blacksburg, VA, USA, 2005. [Google Scholar]
- Wu, B.; Li, Q. Crop planting and type proportion method for crop acreage estimation of complex agricultural landscapes. Int. J. Appl. Earth Obs. 2012, 16, 101–112. [Google Scholar] [CrossRef]
- Drake, N.A.; Mackin, S.; Settle, J.J. Mapping vegetation, soils, and geology in semiarid shrublands using spectral matching and mixture modeling of SWIR AVIRIS imagery. Remote Sens. Environ. 1999, 68, 12–25. [Google Scholar] [CrossRef]
- Gilbert, M.; Grégoire, J.C. Visual, semi-quantitative assessments allow accurate estimates of leafminer population densities: An example comparing image processing and visual evaluation of damage by the horse chestnut leafminer Cameraria ohridella (Lep., Gracillariidae). Jpn. J. Appl. Entomol. Z 2003, 127, 354–359. [Google Scholar] [CrossRef]
- Alaiz-Rodrıguez, R.; Alegre, E.; González-Castro, V.; Sánchez, L. Quantifying the proportion of damaged sperm cells based on image analysis and neural networks. Proc. SMO 2008, 8, 383–388. [Google Scholar]
- Zhu, Q.; Chen, J.; Wang, L.; Guan, Q. Proportion Estimation for Urban Mixed Scenes Based on Nonnegative Matrix Factorization for High-Spatial Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11257–11270. [Google Scholar] [CrossRef]
- Milicevic, M.; Zubrinic, K.; Grbavac, I.; Obradovic, I. Application of deep learning architectures for accurate detection of olive tree flowering phenophase. Remote Sens. 2020, 12, 2120. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Chollet, F. Deep Learning with Python; Simon and Schuster: New York, NY, USA, 2021. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Springer: Cham, Switzerland, 2018; pp. 270–279. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Huh, M.; Agrawal, P.; Efros, A.A. What makes ImageNet good for transfer learning? arXiv 2016, arXiv:1608.08614. [Google Scholar]
- Schölkopf, B.; Smola, A.J.; Williamson, R.C.; Bartlett, P.L. New support vector algorithms. Neural Comput. 2000, 12, 1207–1245. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wires Data Min. Knowl. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Ganaie, M.A.; Hu, M. Ensemble deep learning: A review. arXiv 2021, arXiv:2104.02395. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; PMLR: London, UK, 2015; pp. 448–456. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Garbin, C.; Zhu, X.; Marques, O. Dropout vs. batch normalization: An empirical study of their impact to deep learning. Multimed. Tools Appl. 2020, 79, 12777–12815. [Google Scholar] [CrossRef]
- Krig, S. Ground truth data, content, metrics, and analysis. In Computer Vision Metrics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 247–271. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset (Samples) | Model | MAE | RMSE | R2 |
|---|---|---|---|---|
| TOYds (10,000) | vanilla CNN | 1.26 | 1.84 | 0.983 |
| VGG-19 (scratch) | 3.26 | 4.83 | 0.971 | |
| VGG-19 (transfer) | 2.68 | 3.62 | 0.985 | |
| Xception (scratch) | 0.69 | 0.93 | 0.883 | |
| Xception (transfer) | 0.37 | 0.56 | 0.998 | |
| InceptionResNetV2 (scratch) | 0.90 | 1.29 | 0.997 | |
| InceptionResNetV2 (transfer) | 0.42 | 0.60 | 0.998 | |
| TOY*ds (25,000) | vanilla CNN | 0.23 | 0.29 | 0.998 |
| VGG-19 (scratch) | 1.83 | 3.21 | 0.989 | |
| VGG-19 (transfer) | 1.25 | 2.88 | 0.991 | |
| Xception (scratch) | 0.45 | 1.69 | 0.998 | |
| Xception (transfer) | 0.21 | 0.27 | 0.999 | |
| InceptionResNetV2 (scratch) | 0.37 | 0.53 | 0.999 | |
| InceptionResNetV2 (transfer) | 0.17 | 0.25 | 0.998 | |
| OFPds (1314) | vanilla CNN | 6.95 | 10.87 | 0.817 |
| VGG-19 (scratch) | 8.72 | 12.56 | 0.724 | |
| VGG-19 (transfer) | 5.66 | 8.44 | 0.892 | |
| Xception (scratch) | 7.85 | 8.74 | 0.875 | |
| Xception (transfer) | 5.43 | 8.54 | 0.890 | |
| InceptionResNetV2 (scratch) | 8.78 | 13.12 | 0.711 | |
| InceptionResNetV2 (transfer) | 5.38 | 8.34 | 0.956 | |
| OFPds augmented (8509) | vanilla CNN | 3.45 | 5.68 | 0.954 |
| VGG-19 (scratch) | 3.90 | 6.95 | 0.927 | |
| VGG-19 (transfer) | 3.56 | 5.61 | 0.952 | |
| Xception (scratch) | 6.25 | 9.49 | 0.864 | |
| Xception (transfer) | 3.28 | 5.64 | 0.952 | |
| InceptionResNetV2 (scratch) | 4.03 | 6.62 | 0.933 | |
| InceptionResNetV2 (transfer) | 2.90 | 4.44 | 0.970 | |
| AILds (18,000) | vanilla CNN | 2.13 | 3.98 | 0.939 |
| VGG-19 (scratch) | 2.27 | 4.46 | 0.923 | |
| VGG-19 (transfer) | 1.77 | 3.39 | 0.956 | |
| Xception (scratch) | 2.96 | 5.74 | 0.873 | |
| Xception (transfer) | 1.69 | 3.13 | 0.962 | |
| InceptionResNetV2 (scratch) | 2.50 | 5.06 | 0.901 | |
| InceptionResNetV2 (transfer) | 1.75 | 3.37 | 0.956 |
| Dataset (Samples) | Model | MAE | RMSE | R2 |
|---|---|---|---|---|
| TOYds (10,000) | Xception + SVR | 0.41 | 0.58 | 0.998 |
| Xception + RandomForestRegressor | 0.45 | 0.69 | 0.998 | |
| Xception * 3 | 0.49 | 0.69 | 0.998 | |
| InceptionResNetV2 + SVR | 0.56 | 0.75 | 0.997 | |
| InceptionResNetV2 + RandomForestRegressor | 0.44 | 0.65 | 0.998 | |
| InceptionResNetV2 * 3 | 0.39 | 0.55 | 0.998 | |
| TOY*ds (25,000) | Xception + SVR | 0.33 | 0.45 | 0.999 |
| Xception + RandomForestRegressor | 0.24 | 0.43 | 0.999 | |
| Xception * 3 | 0.21 | 0.33 | 0.999 | |
| InceptionResNetV2 + SVR | 0.32 | 0.47 | 0.999 | |
| InceptionResNetV2 + RandomForestRegressor | 0.27 | 0.46 | 0.999 | |
| InceptionResNetV2 * 3 | 0.29 | 0.47 | 0.999 | |
| OFPds (1314) | Xception + SVR | 5.99 | 8.88 | 0.881 |
| Xception + RandomForestRegressor | 5.61 | 8.75 | 0.883 | |
| Xception * 3 | 5.42 | 8.68 | 0.888 | |
| InceptionResNetV2 + SVR | 5.87 | 8.75 | 0.881 | |
| InceptionResNetV2 + RandomForestRegressor | 5.60 | 8.69 | 0.882 | |
| InceptionResNetV2 * 3 | 5.35 | 8.41 | 0.902 | |
| OFPds augmented (8509) | Xception + SVR | 3.52 | 5.21 | 0.959 |
| Xception + RandomForestRegressor | 2.88 | 4.35 | 0.971 | |
| Xception * 3 | 3.06 | 4.97 | 0.962 | |
| InceptionResNetV2 + SVR | 3.55 | 5.34 | 0.944 | |
| InceptionResNetV2 + RandomForestRegressor | 2.87 | 4.28 | 0.975 | |
| InceptionResNetV2 * 3 | 2.75 | 3.87 | 0.979 | |
| AILds (18,000) | Xception + SVR | 1.93 | 3.71 | 0.947 |
| Xception + RandomForestRegressor | 1.78 | 3.30 | 0.958 | |
| Xception * 3 | 1.62 | 3.12 | 0.982 | |
| InceptionResNetV2 + SVR | 1.96 | 3.85 | 0.940 | |
| InceptionResNetV2 + RandomForestRegressor | 1.79 | 3.45 | 0.954 | |
| InceptionResNetV2 * 3 | 1.73 | 3.32 | 0.961 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Milicevic, M.; Batos, V.; Lipovac, A.; Car, Z. Deep Regression Neural Networks for Proportion Judgment. Future Internet 2022, 14, 100. https://doi.org/10.3390/fi14040100
Milicevic M, Batos V, Lipovac A, Car Z. Deep Regression Neural Networks for Proportion Judgment. Future Internet. 2022; 14(4):100. https://doi.org/10.3390/fi14040100
Chicago/Turabian StyleMilicevic, Mario, Vedran Batos, Adriana Lipovac, and Zeljka Car. 2022. "Deep Regression Neural Networks for Proportion Judgment" Future Internet 14, no. 4: 100. https://doi.org/10.3390/fi14040100
APA StyleMilicevic, M., Batos, V., Lipovac, A., & Car, Z. (2022). Deep Regression Neural Networks for Proportion Judgment. Future Internet, 14(4), 100. https://doi.org/10.3390/fi14040100