
Flow-Based Programming for Machine Learning


Abstract
:1. Introduction
1.1. Contributions
- We take the Java APIs of Spark ML operating on DataFrame [3], a popular ML library of Apache Spark [4,5,6], model them as composable components. Every component abstracts one or more underlying APIs such that they represent one unit of processing step in an ML application. The different parameters accepted by the underlying APIs are made available on the front-end while using a specific component to support easy parametrisation.
- Development of a conceptual approach to parse an ML flow created by connecting several such components from step 1. The parsing ensures that the components are connected in an acceptable positional hierarchy such that it would generate target code which is compilable. The parsed user-flow is used to generate target ML code using principles of Model-Driven Software Development (MDSD). Model to text transformation is used, especially API based code generation techniques [7], to transform the graphical model to target code.
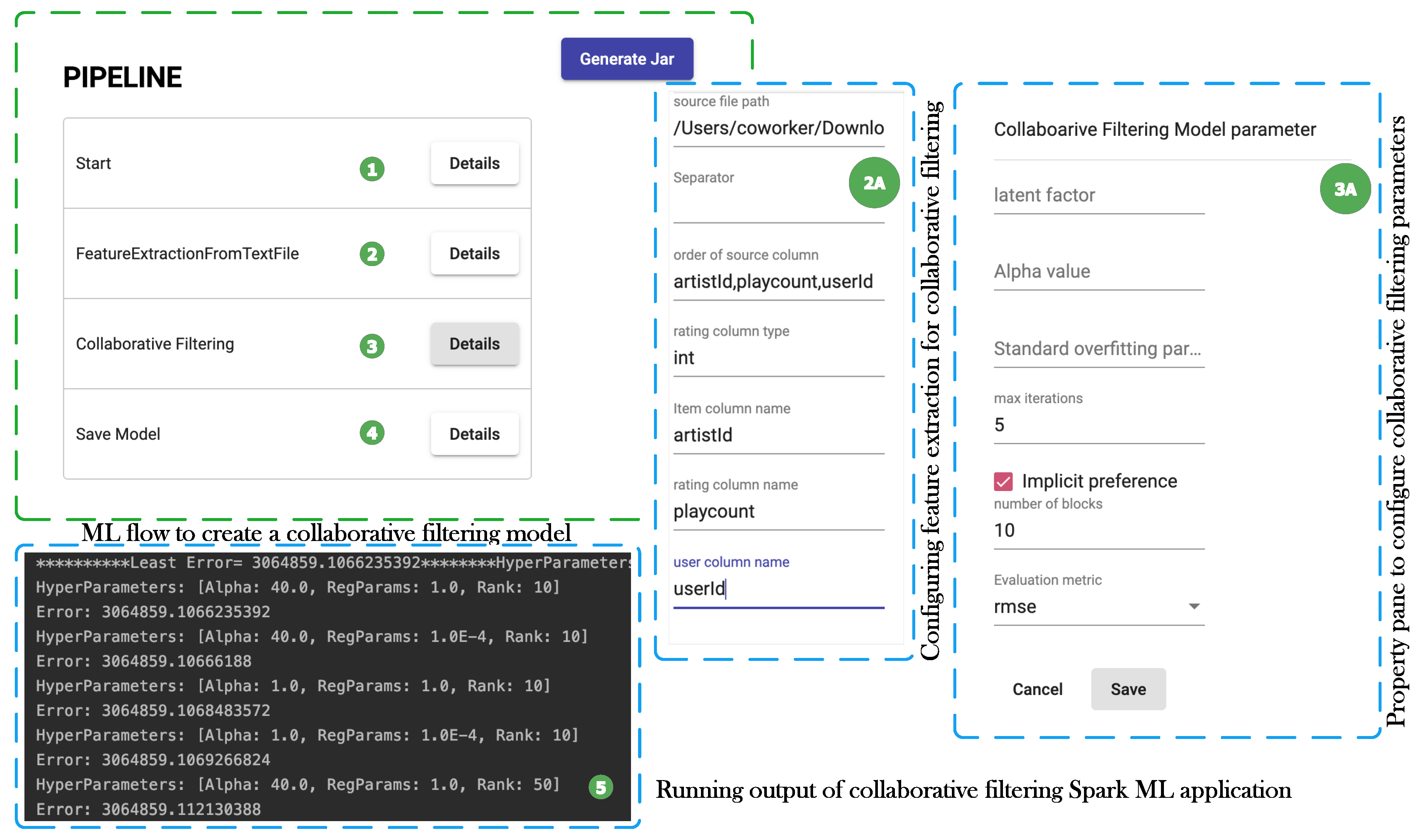
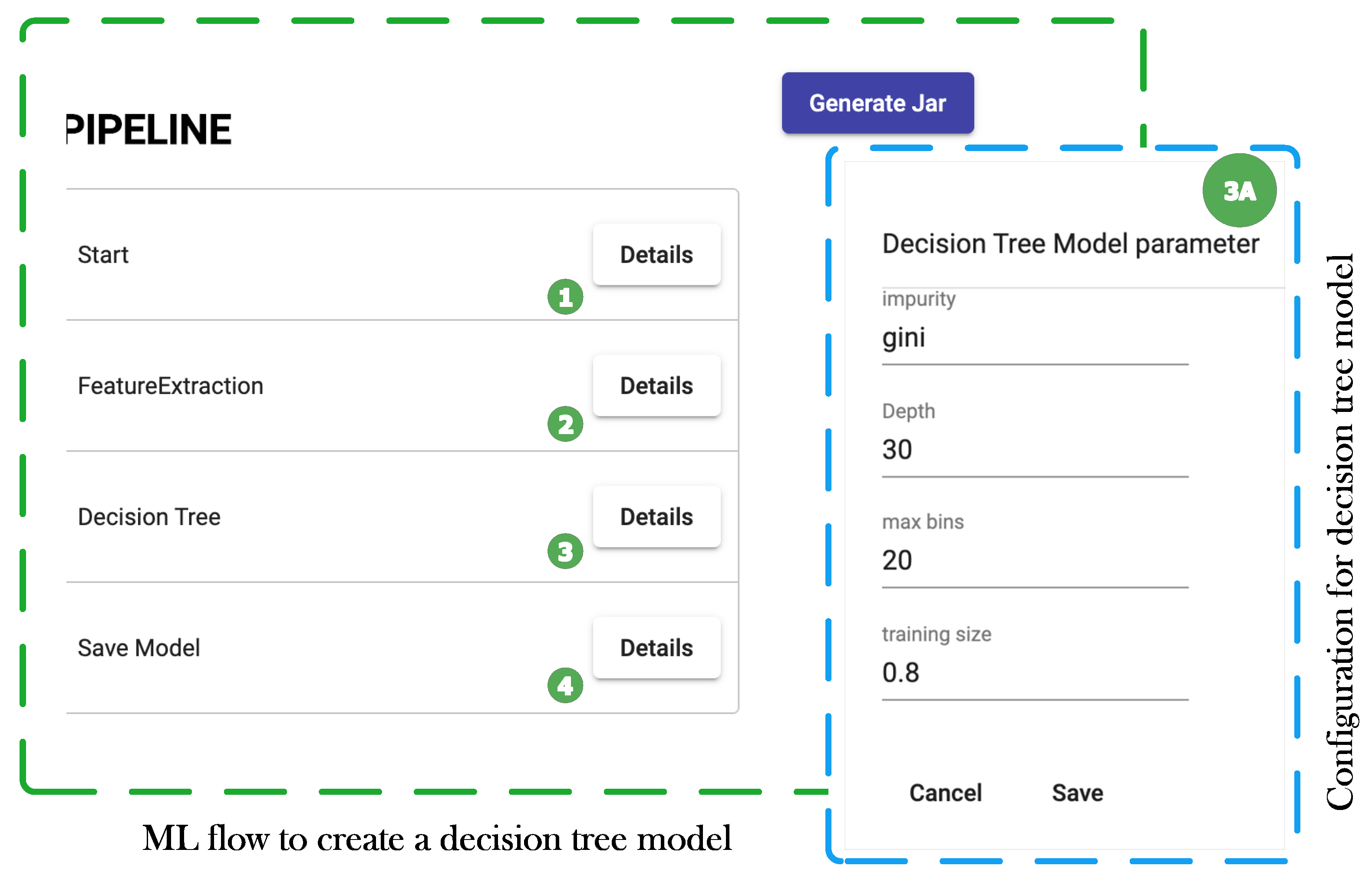
- The conceptual approach is validated by designing three ML use-cases involving prediction using decision trees, anomaly detection with k-means clustering, and collaborative filtering techniques to develop a music recommender application. The use-cases demonstrate how such flows can be created by connecting different components from step 1 at a higher level of abstraction, parameters to various components can be configured with ease, automatic parsing of the user flow to give feedback to the user if a component has been used in a wrong position in a flow and finally automatic generation of ML application without the end-user having to write any code. The user can split the initial dataset into training and testing datasets, specify a range for different model parameters for the system to iteratively generate models and test them till a model is produced with higher prediction accuracy.
1.2. Outline
2. Background
2.1. Machine Learning
2.2. Machine Learning Libraries
2.3. Flow-Based Programming
2.4. Model-Driven Software Development
3. Related Work
4. Apache Spark
4.1. APIs
4.2. ML with Spark
4.3. Design Choice: API Selection
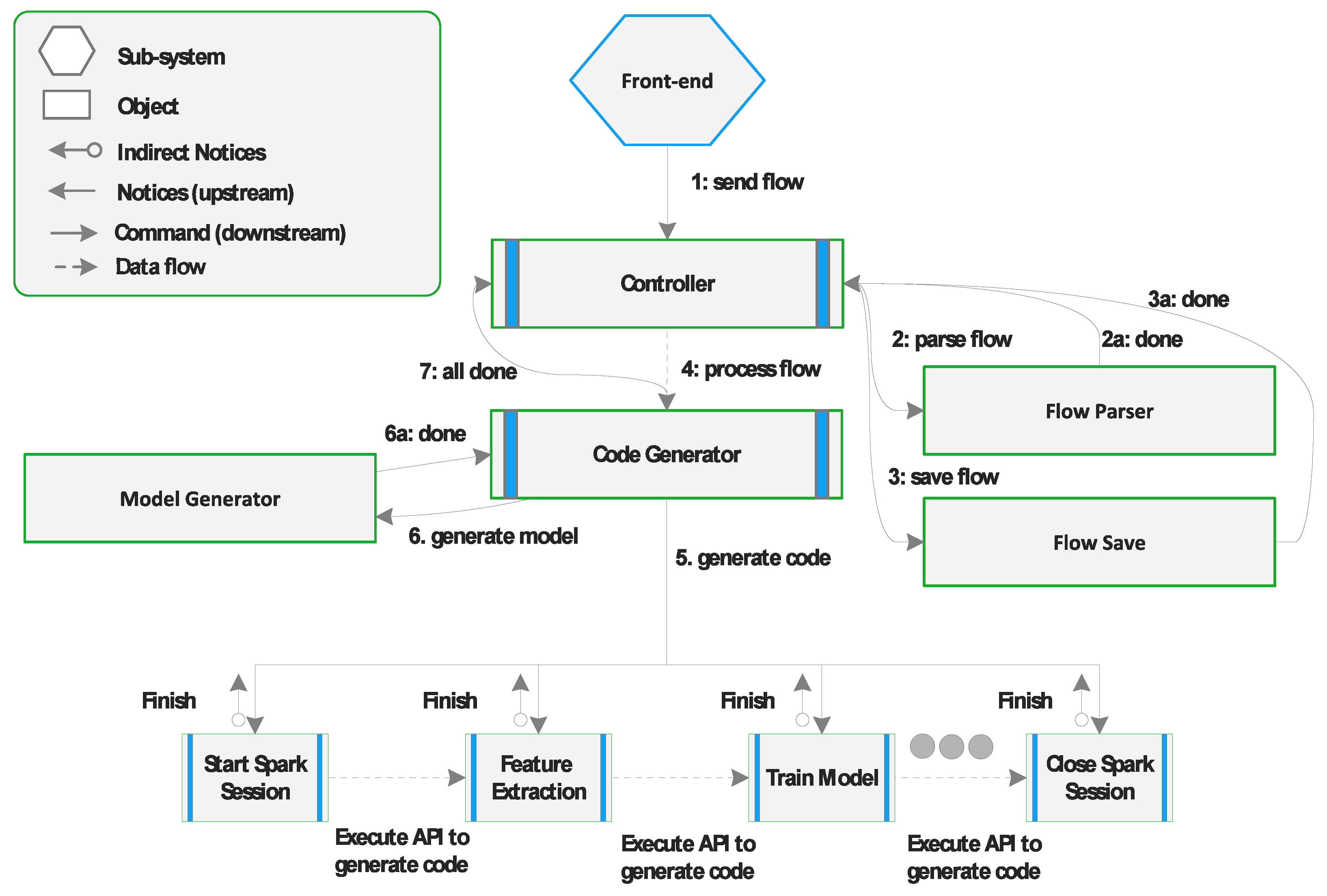
5. Conceptual Approach
5.1. Design of Modular Components
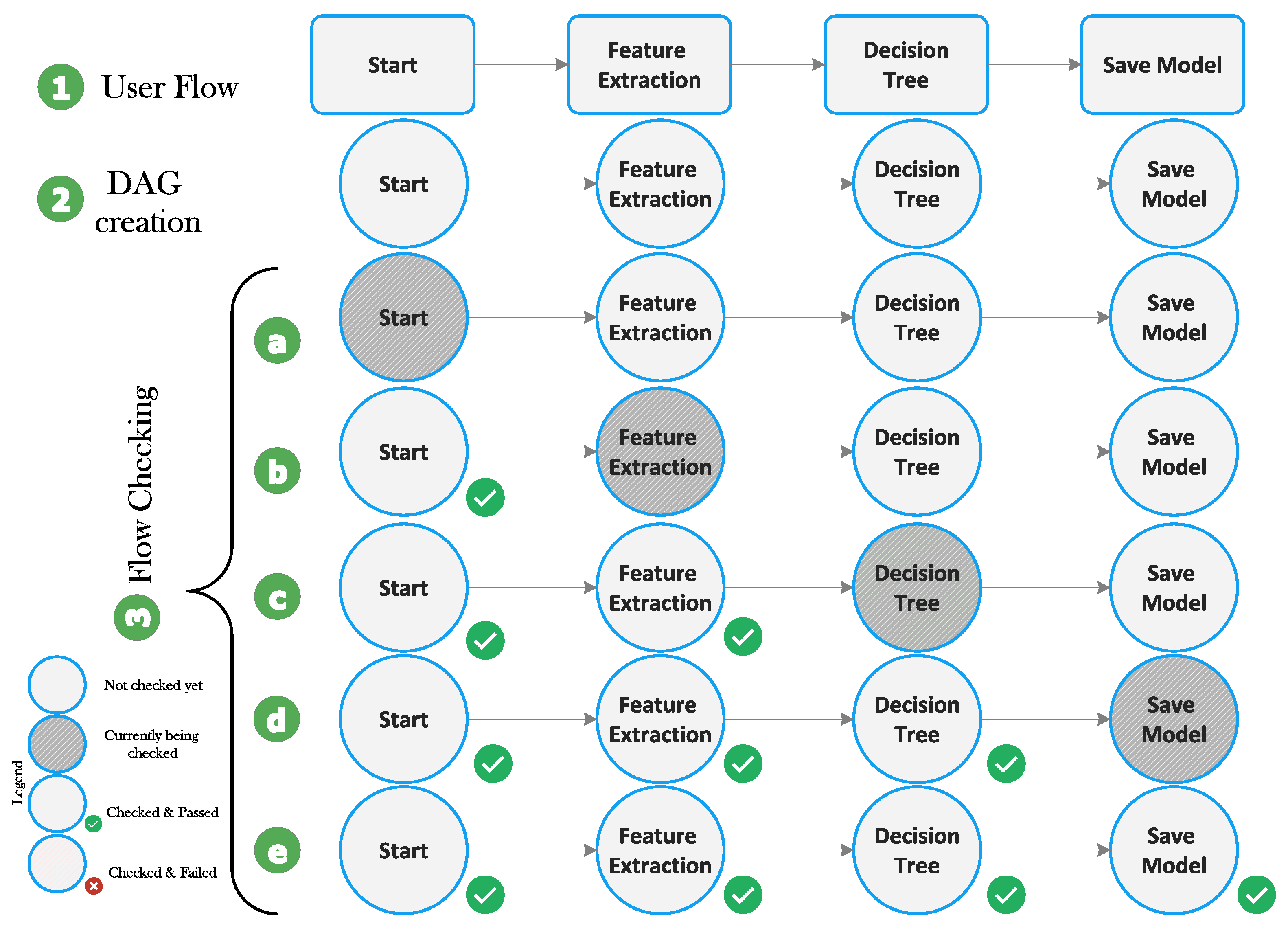
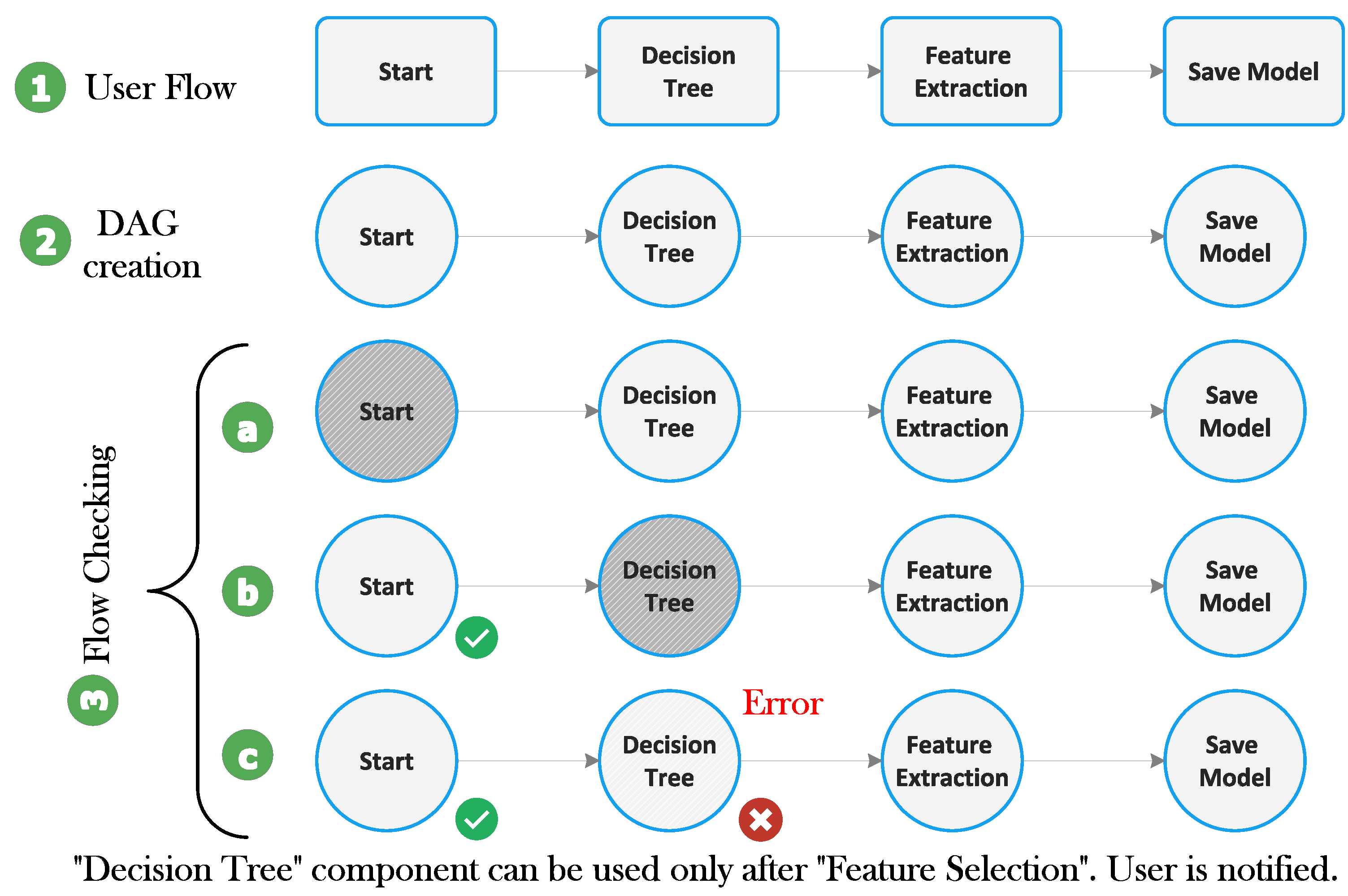
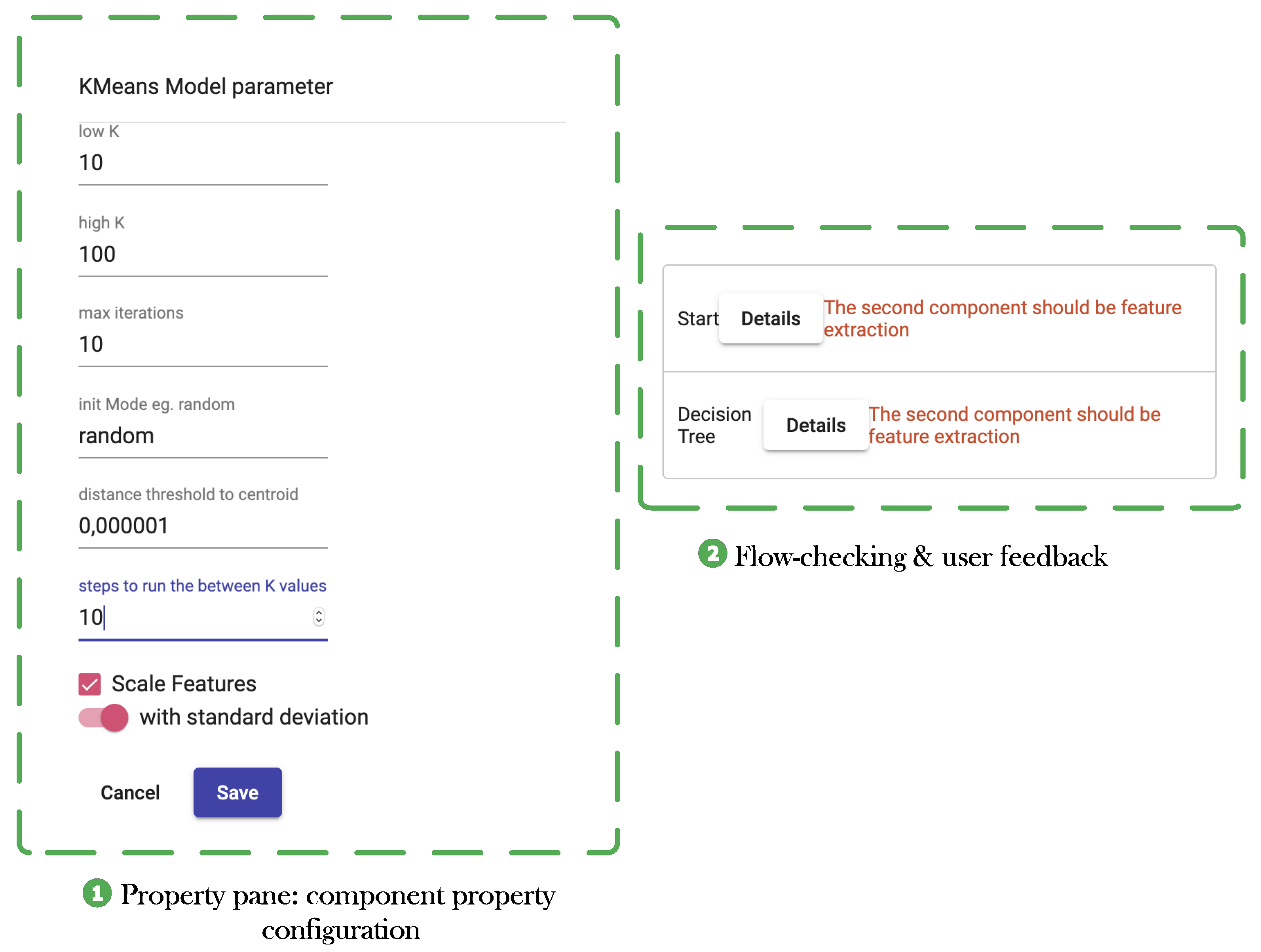
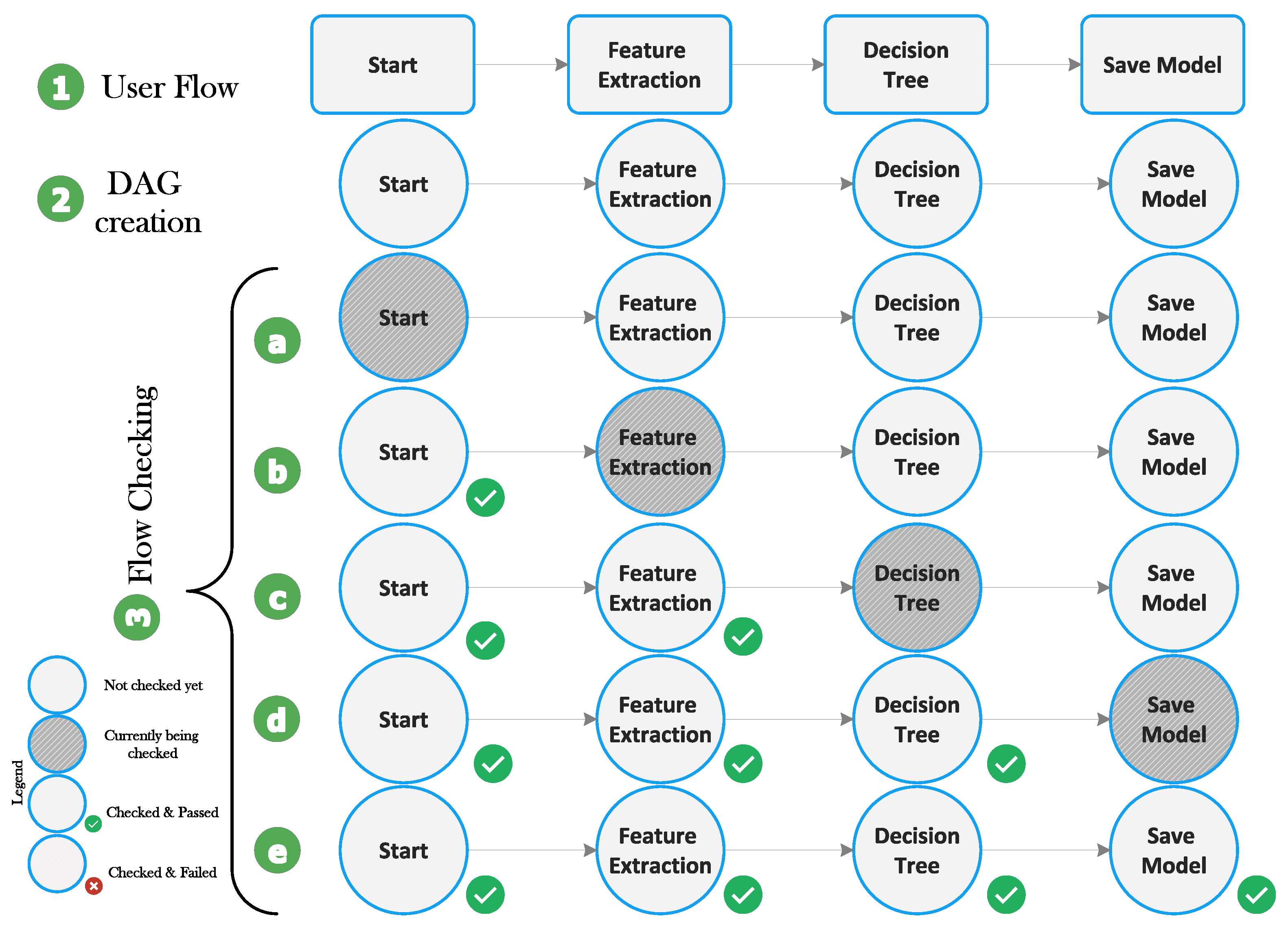
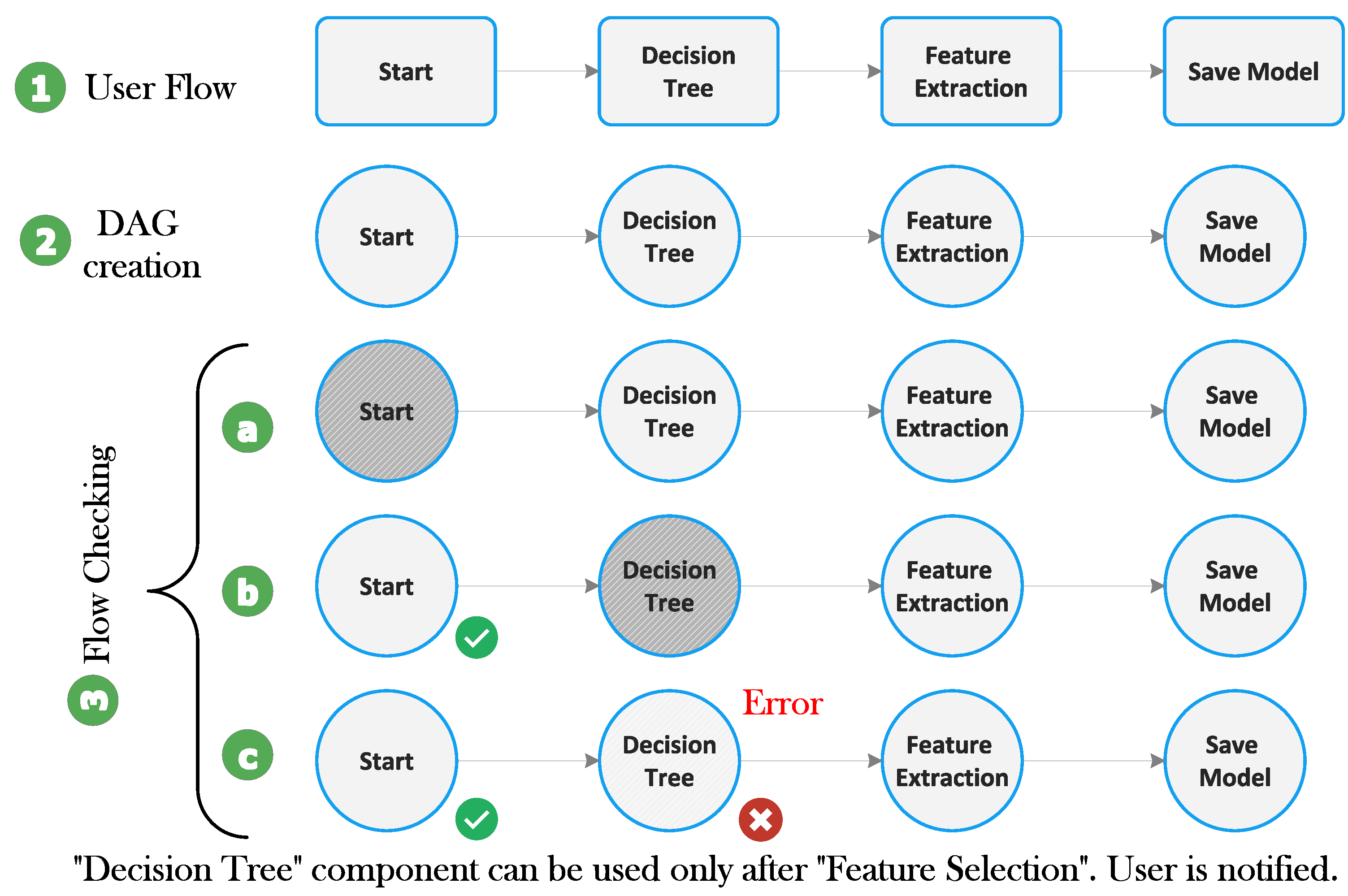
5.2. Flow Specification and Flow-Checking
- A flow is a DAG consisting of a series of connected components.
- It starts with a particular component called the “Start” component and ends with a specific component called the “Save Model” component.
- Every component has its input and output interface adequately defined, and a component can be allowed to be used in a specific position in a flow if it is compatible with the output of its immediate predecessor and if it is permitted at that stage of processing. For example, the application of the ML algorithm is only possible after feature extraction. Hence, the component corresponding to the ML algorithm and evaluation must be connected after the feature extraction component.
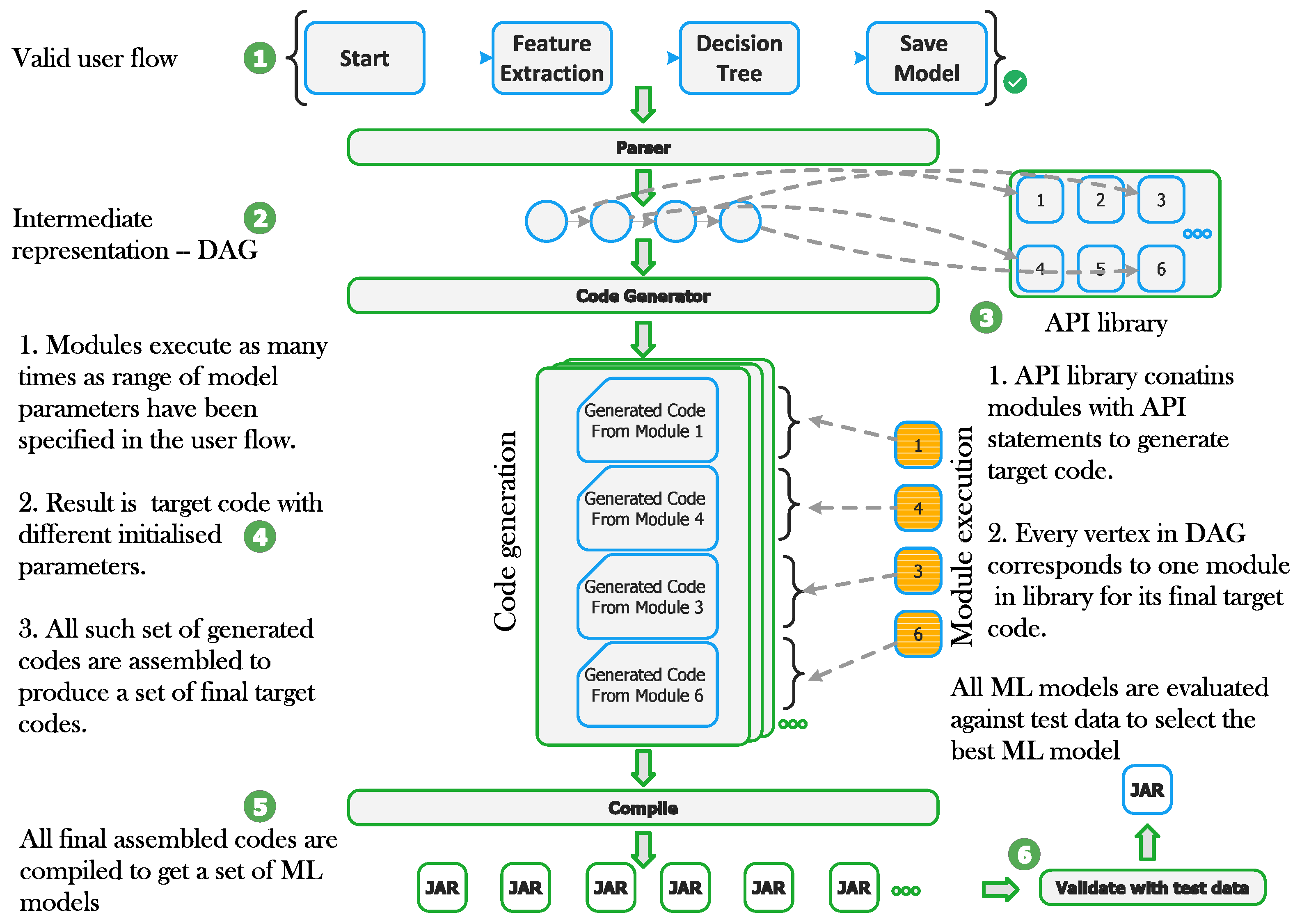
5.3. Model Generation
5.4. Model Evaluation and Hyperparameter Tuning
6. Realisation
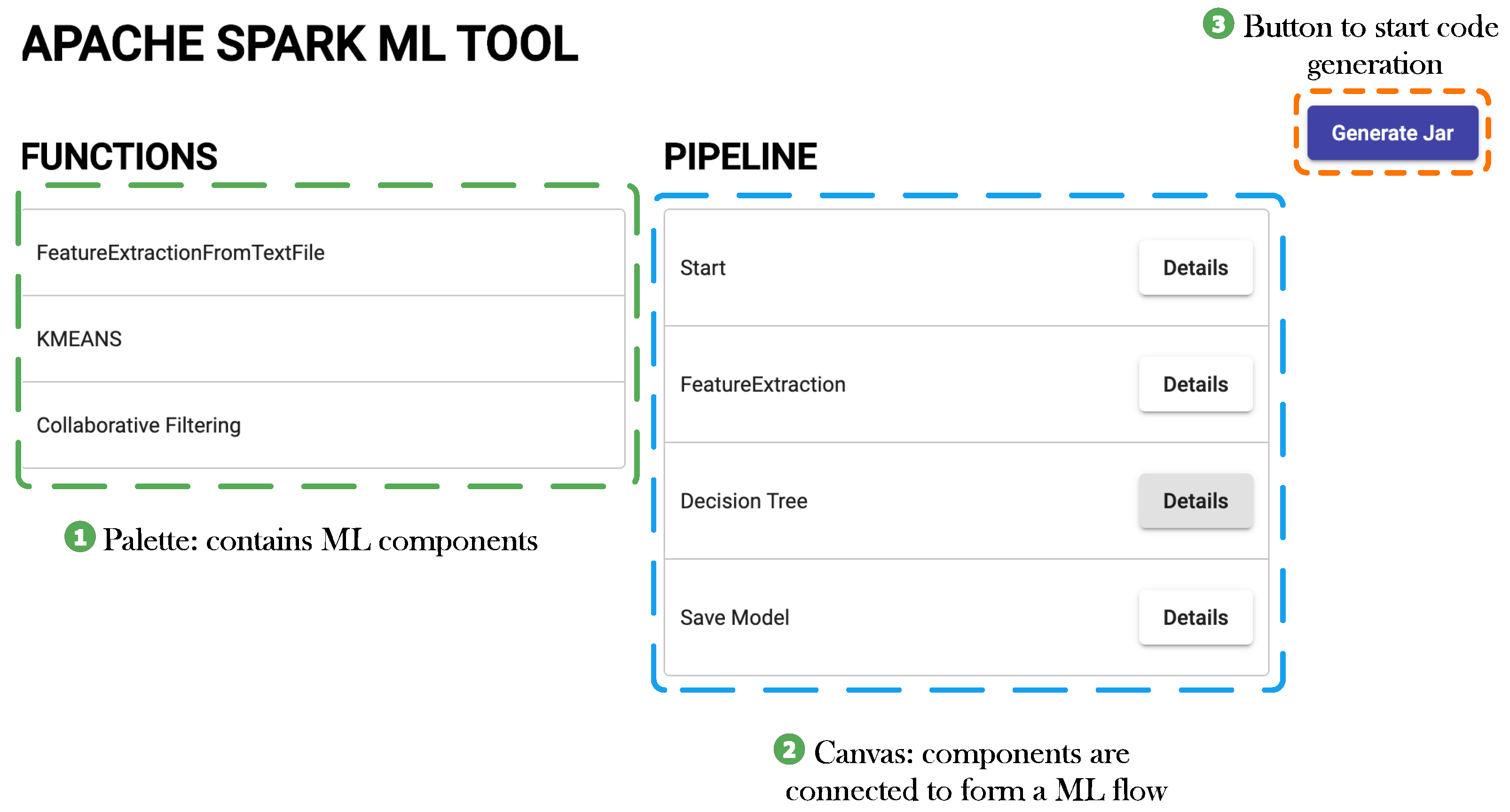
6.1. Prototype Overview
6.2. Components
6.3. Working
7. Running Examples
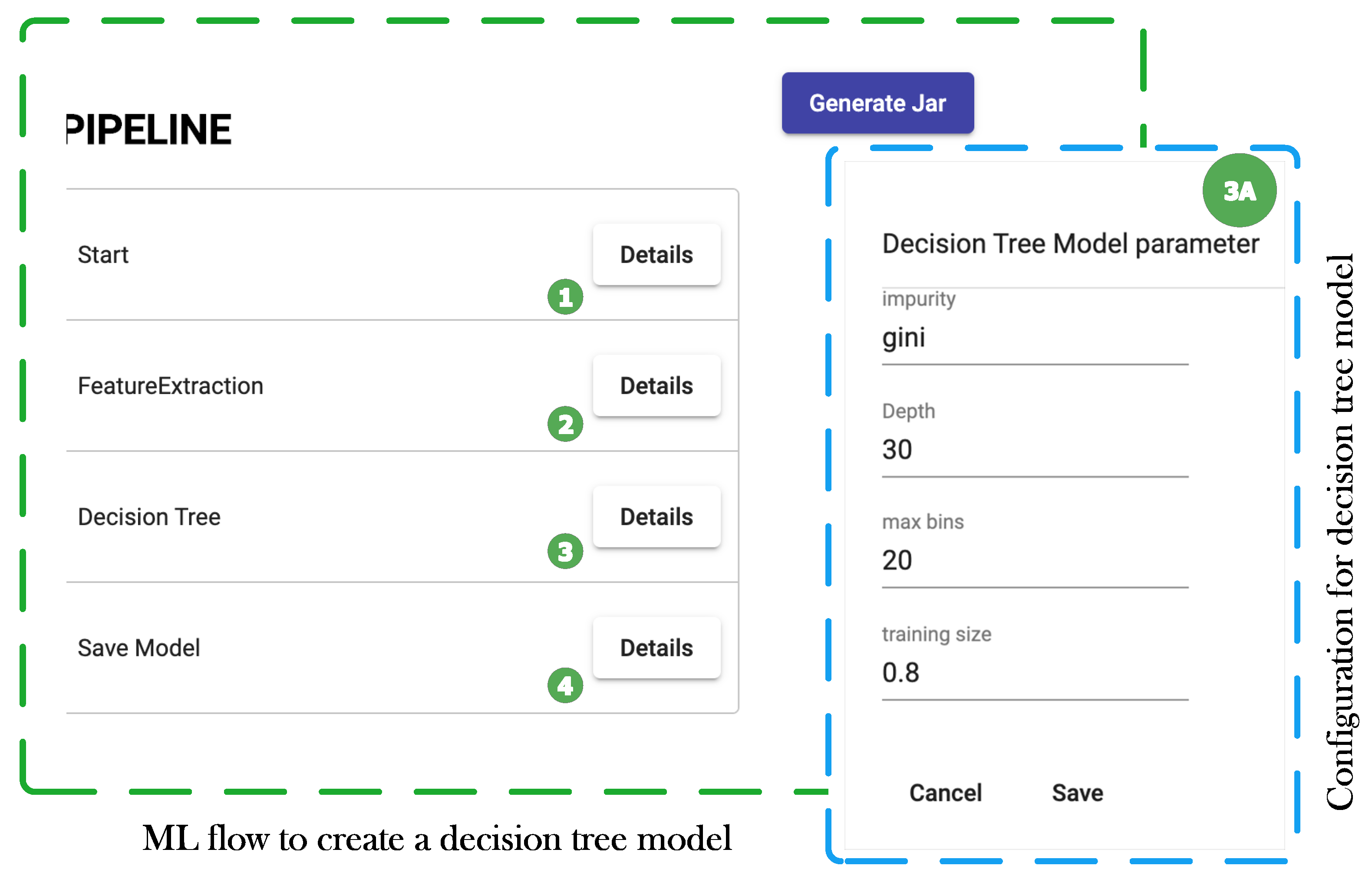
7.1. Use Case 1: Predicting Forest Cover with Decision Trees
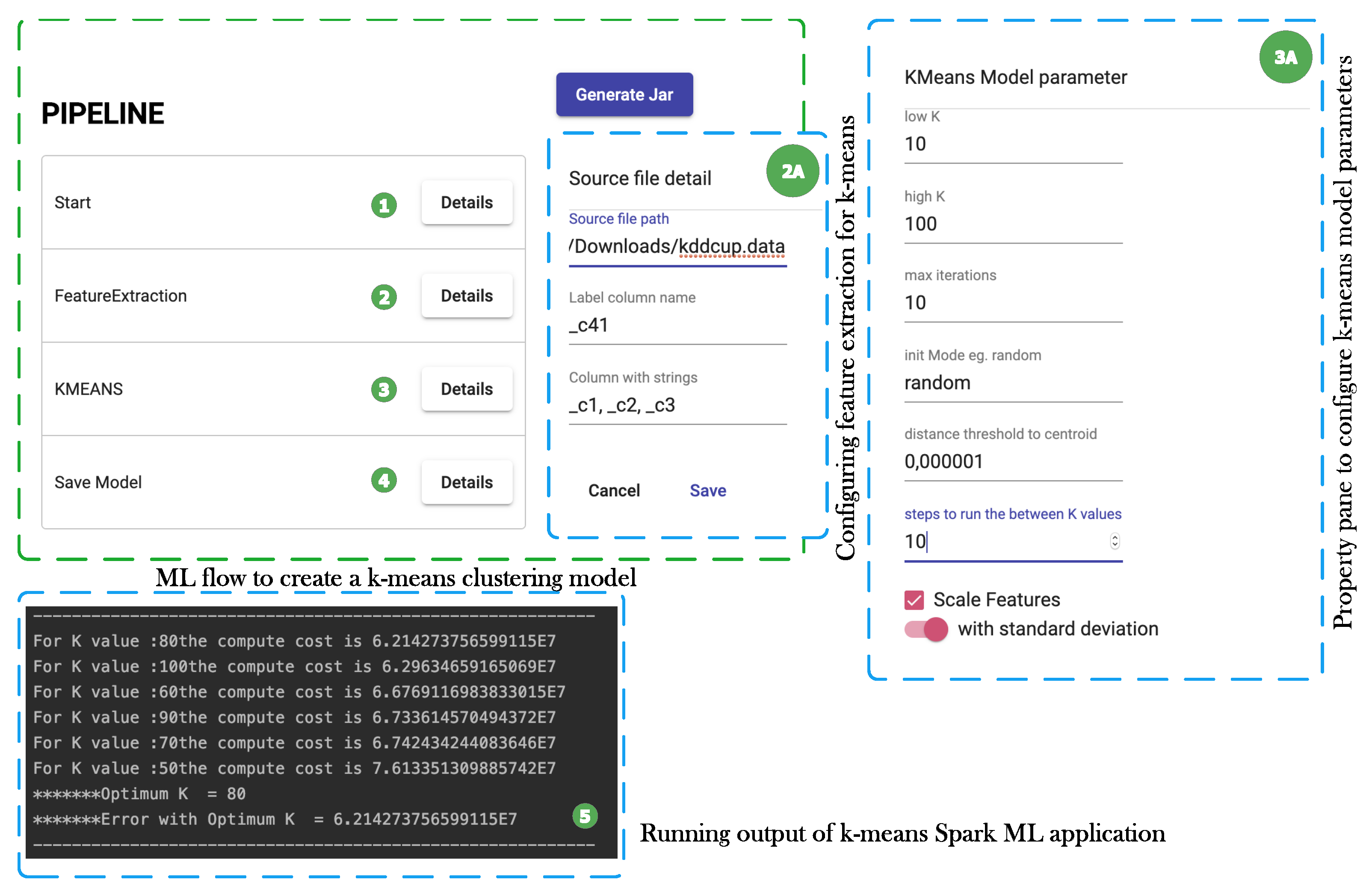
7.2. Use Case 2: Anomaly Detection with k-Means Clustering
7.3. Use Case 3: Music Recommender Application
- The modular approach of the system development helps add new ML functionality without affecting the existing behaviour of the system. The end-user can design applications from the list of the components provided through REST API interfaces. The components are independent of each other, and interaction between the components happen only through the input/output data to and from the components that help the end-user design Spark applications depending on the problem statement.
- The flow-based programming approach hides the underlying Spark implementation from the end-users. The end-users do not have to learn Apache Spark ML library or functionality of Spark Data abstractions to implement an ML application using flow-based ML programming. The end-users can customise the Spark application by providing the specifications through the flow components. The end-users should only have a better understanding of the input dataset used for training a model. The flow-based programming makes it easier for users to customise their ML applications by providing specification through the graphical components.
8. Discussion
- Graphical interface: The graphical interfaces should generally be intuitive and easy to use for the end-users to navigate through a software application. The graphical programming interface with flow-based programming paradigm and options to customise the automatic code generation of ML application makes an ideal choice for users with less knowledge of data science or ML algorithms. As discussed in Section 3, we have seen that almost all existing tools have a flow-based graphical interface implementation for creating an ML model, except Rapidminer. However, Rapidminer provides a graphical wizard to initialise the input parameters. In our approach, we have a list of graphical components representing the steps of ML model creation. The drag and drop feature with feedback on the incorrect assembly of the components guides the user for submitting a logical flow to the back-end system. The graphical interface implemented supports customisation of the components and abstracts the underlying technologies used for automatic Spark application generation for the user.
- Target Frameworks: The second criterion is the target frameworks used by the graphical tools that provide a high-level abstraction. The Deep learning studio offers an interface to implement only deep learning models. Both Microsoft Azure and Rapidminer visual platforms support an end-to-end automated ML application generation, hiding the underlying technology used from the user. However, the Microsoft Azure HDinsight service allows PySpark code snippet to be used through the Jupyter notebook interface of the tool to run the code on a Spark cluster. Lemonade and StreamSets support high-level abstraction of Spark ML to build ML models. Lemonade also uses the Keras platform to generate models for deep learning applications. On the contrary, the Streamanalytix tool uses multiple frameworks to create an ML model, such as Spark MLlib, Spark ML, PMML, TensorFlow, and H2O. In our solution, we support Spark ML as our target framework.
- Code generation: The code generation capability is another exciting feature to compare whether the tool can create a native program in the target framework from the graphical flow created by the end-user or not. StreamSets and Microsoft Azure require customised code snippets from end-users to train the ML model. They do not generate any code, and the models are loaded directly in their environment. Lemonade and Streamanalytix generate a native Apache Spark program, while Deep learning studio generates code in Keras from the graphical flow generated by the user. The user can edit the generated code and re-run the application. Our conceptual approach also generates Java source code for the Apache Spark program from the graphical flow created by the end-user.
- Code snippet input from user: It is desirable to have a graphical tool that can support both experts and non-programmers to create ML applications without having to understand the underlying technology. The fourth criterion is to compare if the tool requires code snippets from the user for ML application creation. Mainly, the code snippet is required for some part of the application generation or the customisation of the program. For example, the StreamSets tool provides an extension to add ML feature by writing customised code in Scala or Python to the pipeline for generating the program. Tools like Rapidminer, Lemonade, Deep learning studio, and Streamanalytix do not require any input code snippet from the user to create the ML application program. While the Microsoft Azure auto ML feature does not require any code-snippet from the user, it explicitly asks for a code snippet to create models to run in the Spark environment. The conceptual approach described in this manuscript does not require the user to write any code for Spark ML application generation.
- Data pre-processing: As we already know, the performance of the ML model hugely depends on the quality of the input data. The collected data are usually not structured, requiring a bit of processing before applying the ML algorithms to the data. The manual preprocessing of these data is time-consuming and prone to errors. Having a visual pre-processing feature to the ML tool saves much time for the users. All the tools except Deep learning studio and Lemonade have a data pre-processing step that supports data cleansing through the graphical interface. Our conceptual approach also helps essential cleansing and feature extraction from the input data.
- Ensemble Learning: The sixth criterion is to compare whether the tools provide the ensemble learning method. Ensemble methods is a machine learning technique that combines several base models to produce one optimal predictive model. The ultimate goal of the machine learning technique is to find the optimum model that best predicts the desired outcome—tools like Streamanalytix, Rapidminer and Microsoft Azure auto ML support the ensemble learning method. This is a limitation in our current approach as it cannot automatically combine several base models to solve a specific use case.
8.1. Comments about Previous Attempts
8.2. Advantages and Limitations
9. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zecevic, P.; Bonaci, M. Spark in Action. 2016. Available online: http://kingcall.oss-cn-hangzhou.aliyuncs.com/blog/pdf/Spark%20in%20Action30101603975704271.pdf (accessed on 12 November 2021).
- Daniel, F.; Matera, M. Mashups: Concepts, Models and Architectures; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Meng, X.; Bradley, J.; Yavuz, B.; Sparks, E.; Venkataraman, S.; Liu, D.; Freeman, J.; Tsai, D.; Amde, M.; Owen, S.; et al. MLlib: Machine Learning in Apache Spark. J. Mach. Learn. Res. 2016, 17, 1235–1241. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster Computing with Working Sets. In Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing (HotCloud’10), Boston, MA, USA, 22–25 June 2010; USENIX Association: Boston, MA, USA, 2010; p. 10. [Google Scholar]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache Spark: A Unified Engine for Big Data Processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A.; Ma, J.; McCauley, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Resilient Distributed Datasets: A Fault-Tolerant Abstraction for in-Memory Cluster Computing. In Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation (NSDI’12), San Jose, CA, USA, 25–27 April 2012; USENIX Association: Berkeley, CA, USA, 2012; p. 2. [Google Scholar]
- Stahl, T.; Völter, M.; Czarnecki, K. Model-Driven Software Development: Technology, Engineering, Management; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2006. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 12 November 2021).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8026–8037. [Google Scholar]
- Carbone, P.; Katsifodimos, A.; Ewen, S.; Markl, V.; Haridi, S.; Tzoumas, K. Apache Flink™: Stream and Batch Processing in a Single Engine. IEEE Data Eng. Bull. 2015, 38, 28–38. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Collobert, R.; Bengio, S.; Mariéthoz, J. Torch: A Modular Machine Learning Software Library; Idiap-RR Idiap-RR-46-2002; IDIAP: Martigny, Switzerland, 2002. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Culjak, I.; Abram, D.; Pribanic, T.; Dzapo, H.; Cifrek, M. A brief introduction to OpenCV. In Proceedings of the 35th International Convention MIPRO, Opatija, Croatia, 21–25 May 2012; pp. 1725–1730. [Google Scholar]
- Nguyen, G.; Dlugolinsky, S.; Bobák, M.; Tran, V.; López García, Á.; Heredia, I.; Malík, P.; Hluchý, L. Machine Learning and Deep Learning frameworks and libraries for large-scale data mining: A survey. Artif. Intell. Rev. 2019, 52, 77–124. [Google Scholar] [CrossRef] [Green Version]
- Morrison, J.P. Flow-Based Programming: A New Approach to Application Development, 2nd ed.; CreateSpace: Paramount, CA, USA, 2010. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Washington, M. Azure Machine Learning Studio for The Non-Data Scientist: Learn How to Create Experiments, Operationalize Them Using Excel and Angular.Net Core …Programs to Improve Predictive Results, 1st ed.; CreateSpace Independent Publishing Platform: North Charleston, SC, USA, 2017. [Google Scholar]
- Berthold, M.R.; Cebron, N.; Dill, F.; Gabriel, T.R.; Kötter, T.; Meinl, T.; Ohl, P.; Thiel, K.; Wiswedel, B. KNIME—The Konstanz Information Miner: Version 2.0 and Beyond. SIGKDD Explor. Newsl. 2009, 11, 26–31. [Google Scholar] [CrossRef] [Green Version]
- Demšar, J.; Curk, T.; Erjavec, A.; Črt Gorup; Hočevar, T.; Milutinovič, M.; Možina, M.; Polajnar, M.; Toplak, M.; Starič, A.; et al. Orange: Data Mining Toolbox in Python. J. Mach. Learn. Res. 2013, 14, 2349–2353. [Google Scholar]
- BigML. Machine Learning That Works. 2020. Available online: https://static.bigml.com/pdf/BigML-Machine-Learning-Platform.pdf?ver=5b569df (accessed on 6 June 2020).
- mljar. Machine Learning for Humans! Automated Machine Learning Platform. 2018. Available online: https://mljar.com (accessed on 18 May 2020).
- Jannach, D.; Jugovac, M.; Lerche, L. Supporting the Design of Machine Learning Workflows with a Recommendation System. ACM Trans. Interact. Intell. Syst. 2016, 6, 1–35. [Google Scholar] [CrossRef]
- StreamAnalytix. Self-Service Data Flow and Analytics For Apache Spark. 2018. Available online: https://www.streamanalytix.com (accessed on 18 May 2020).
- Santos, W.d.; Avelar, G.P.; Ribeiro, M.H.; Guedes, D.; Meira, W., Jr. Scalable and Efficient Data Analytics and Mining with Lemonade. Proc. VLDB Endow. 2018, 11, 2070–2073. [Google Scholar] [CrossRef]
- StreamSets. DataOps for Modern Data Integration. 2018. Available online: https://streamsets.com (accessed on 18 May 2020).
- Armbrust, M.; Xin, R.S.; Lian, C.; Huai, Y.; Liu, D.; Bradley, J.K.; Meng, X.; Kaftan, T.; Franklin, M.J.; Ghodsi, A.; et al. Spark SQL: Relational Data Processing in Spark. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data (SIGMOD’15), Melbourne, Australia, 31 May–4 June 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1383–1394. [Google Scholar] [CrossRef]
- Walls, C. Spring Boot in Action. 2016. Available online: https://doc.lagout.org/programmation/Spring%20Boot%20in%20Action.pdf (accessed on 12 November 2021).
- Freeman, A. Pro Angular 6, 3rd ed.; Apress: New York, NY, USA, 2018; Available online: https://link.springer.com/book/10.1007/978-1-4842-3649-9 (accessed on 12 November 2021).
- Hajian, M. Progressive Web Apps with Angular: Create Responsive, Fast and Reliable PWAs Using Angular, 1st ed.; APress: New York, NY, USA, 2019. [Google Scholar]
- Escott, K.R.; Noble, J. Design Patterns for Angular Hotdraw. In Proceedings of the 24th European Conference on Pattern Languages of Programs (EuroPLop’19), Irsee, Germany, 3–7 July 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Fowler, M. Patterns of Enterprise Application Architecture; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2002. [Google Scholar]
- JavaPoet. Available online: https://github.com/square/javapoet (accessed on 18 May 2020).
- Overton, M.A. The IDAR Graph: An improvement over UML. Queue 2017, 15, 29–48. [Google Scholar] [CrossRef]
- Overton, M.A. The IDAR Graph. Commun. ACM 2017, 60, 40–45. [Google Scholar] [CrossRef]
- University of Irvine. UC Irvine Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/ (accessed on 12 November 2021).
- Mahapatra, T. High-Level Graphical Programming for Big Data Applications. Ph.D. Thesis, Technische Universität München, München, Germany, 2019. [Google Scholar]
- Mahapatra, T.; Gerostathopoulos, I.; Prehofer, C.; Gore, S.G. Graphical Spark Programming in IoT Mashup Tools. In Proceedings of the 2018 Fifth International Conference on Internet of Things: Systems, Management and Security, Valencia, Spain, 15–18 October 2018; pp. 163–170. [Google Scholar] [CrossRef]
- Mahapatra, T.; Prehofer, C. aFlux: Graphical flow-based data analytics. Softw. Impacts 2019, 2, 100007. [Google Scholar] [CrossRef]
- Mahapatra, T.; Prehofer, C. Graphical Flow-based Spark Programming. J. Big Data 2020, 7, 4. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SN. | Component Name | Functionality |
|---|---|---|
| 1. | Start | Marks the start of the flow and help create a Spark session. |
| 2. | Feature Extraction | Creates DataFrame from input data depending on the features selected. |
| 3. | Feature Extraction From Text File | Transforms the input text data to DataFrame(s). |
| 4. | Decision Tree | Processes the DataFrames to train a decision tree model and evaluates it. |
| 5. | KMeans Clustering | Creates a k-means model and evaluates it. It works on given hyperparameters to find the most efficient model with minimum error in prediction. |
| 6. | Collaborative Filtering | Creates a collaborative filtering model and evaluates it. |
| 7. | Save Model | Marks the end of the flow and saves the ML model in a specified file path. |
| SN. | Parameter Name | Purpose |
|---|---|---|
| 1. | numBlocks | parallelizing the computations by partitioning the data. default value is 10. |
| 2. | rank | number of latent factors to be used in the model. default value is 10 |
| 3. | maxIter | maximumn number of iteration to run the train model. default value is 10 |
| 4. | regParam | regularization parameter.default value is 1.0 |
| 5. | implicitPrefs | to specify if the data contain implicit or explicit feedback. default value is false, which means explicit feedback |
| 6. | alpha | Only applicable when implicitPrefs is set to true. default value is 1.0 |
| 7. | userCol | setting of input data user column name in the ALS algorithm |
| 8. | itemCol | setting of input data item col name in the ALS algorithm.in our use case, its artistId |
| 9. | ratingCol | setting of input data rating column name in the ALS algorithm |
| Tools | Graphical Interface | Target Framework | Code-Snippet Not Required as Input | Code Generation for ML Program | Include Data Pre-Processing | Ensemble Method Supported |
|---|---|---|---|---|---|---|
| Deep Learning Studio | Flow-based GUI | Keras | ✓ | ✗ | ✗ | ✗ |
| Microsoft Azure ML | Flow-based GUI | Spark ML (Python, R) | ✓ (✗ for auto ML) | ✗ | ✓ | ✓ (auto ML), ✗ (for Saprk application) |
| Streamanalytix | Graphical wizard-based | Spark ML, H2O, PMML | ✓ | ✗ | ✓ | ✓ |
| StreamSets | Flow-based GUI | Spark ML (Python & Scala) | ✓ | ✗ | ✓ | ✗ |
| Rapidminer | Graphical wizard-based | Unknown | ✓ | ✗ | ✓ | ✓ |
| Lemonade | Flow-based GUI | Spark ML (PySpark) | ✗ | ✓ | ✗ | ✗ |
| Our Solution | Flow-based GUI | Spark ML (Java) | ✓ | ✓ | ✓ | ✗ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahapatra, T.; Banoo, S.N. Flow-Based Programming for Machine Learning. Future Internet 2022, 14, 58. https://doi.org/10.3390/fi14020058
Mahapatra T, Banoo SN. Flow-Based Programming for Machine Learning. Future Internet. 2022; 14(2):58. https://doi.org/10.3390/fi14020058
Chicago/Turabian StyleMahapatra, Tanmaya, and Syeeda Nilofer Banoo. 2022. "Flow-Based Programming for Machine Learning" Future Internet 14, no. 2: 58. https://doi.org/10.3390/fi14020058
APA StyleMahapatra, T., & Banoo, S. N. (2022). Flow-Based Programming for Machine Learning. Future Internet, 14(2), 58. https://doi.org/10.3390/fi14020058