Abstract
Text summarization remains a challenging task in the natural language processing field despite the plethora of applications in enterprises and daily life. One of the common use cases is the summarization of web pages which has the potential to provide an overview of web pages to devices with limited features. In fact, despite the increasing penetration rate of mobile devices in rural areas, the bulk of those devices offer limited features in addition to the fact that these areas are covered with limited connectivity such as the GSM network. Summarizing web pages into SMS becomes, therefore, an important task to provide information to limited devices. This work introduces WATS-SMS, a T5-based French Wikipedia Abstractive Text Summarizer for SMS. It is built through a transfer learning approach. The T5 English pre-trained model is used to generate a French text summarization model by retraining the model on 25,000 Wikipedia pages then compared with different approaches in the literature. The objective is twofold: (1) to check the assumption made in the literature that abstractive models provide better results compared to extractive ones; and (2) to evaluate the performance of our model compared to other existing abstractive models. A score based on ROUGE metrics gave us a value of 52% for articles with length up to 500 characters against 34.2% for transformer-ED and 12.7% for seq-2seq-attention; and a value of 77% for articles with larger size against 37% for transformers-DMCA. Moreover, an architecture including a software SMS-gateway has been developed to allow owners of mobile devices with limited features to send requests and to receive summaries through the GSM network.
1. Introduction
One of the most fascinating advances in the field of artificial intelligence is the ability of computers to understand natural language. Natural language processing (NLP) is an active field of research encompassing text and speech processing. With the huge amount of textual content available on the Internet, the search for relevant information is becoming difficult. Therefore, one tremendous application of NLP remains the text summarization. According to Maybury [1], text summarization aims to distil the most important information from one or several sources to generate an abridged version of the original document(s) for a particular user or task. Text summarization is usually composed of three steps: pre-processing, processing and post-processing [2]. The first step prepares the text to summarize by performing some tasks such as sentence segmentation, word tokenization or stop-words removal. The second step really performs the summarization of the text using a summarization technique based on one of the three approaches: extractive, abstractive and hybrid. Finally, the post-processing aims to address some last issues such as anaphora resolution before generating the final summary [3,4,5].
Text summarization is applied for several purposes including news summarization [6,7], opinion or sentiment summarization [8,9], tweet summarization [10], email summarization [11], scientific papers summarization [12,13] and even web page summarization [14]. The latter offers the potential to provide an overview of web pages to devices with limited features.
However, although the rate of use of mobile devices is increasing in remote and/or rural areas of developing countries, the bulk of those devices offers limited features with no browser and limited connectivity options [15]. The choice of basic phones with limited features is justified by three main reasons. First, it is the cost. Even if the price of smartphone is decreasing, it is still difficult for people living in rural areas with less than USD 1 per day to afford a smartphone [16]. Second is the lack of energy and the need of long-lasting battery. A full battery recharge of a smartphone usually lasts a day, compared to basic phones that can last several days. The third and not the least is the network coverage. Due to the lack of guarantee of return on investment for Telco operators, most part of the rural regions are unconnected and struggle with simple GSM network in the best case. This is justified by the low Internet penetration rate in developing countries, mainly in sub-Saharan Africa, as shown by the Internet World Stats (IWS) (https://www.internetworldstats.com/stats1.htm, accessed on 10 June 2021). According to IWS, the average penetration rate of Internet in Africa in the fourth quarter of 2020 is only 43% compared to 64.2% as the world average.
Despite efforts that have been made to provide Wi-Fi-based wireless connectivity in certain locations [17,18], a large part of those devices is working only with the GSM network. Therefore, the only mean to provide relevant information to those users is through SMS.
An important sector in rural regions, especially in sub-Saharan Africa, remains education that experiences teacher shortage [19,20]. Providing relevant content to sustain the sector has become a priority. Among freely available educational resources, the Wikipedia encyclopedia represents one of the largest and most recognizable reference resources [21]. It is therefore an excellent choice to mitigate teacher shortage by providing relevant information to students. However, due to character limitation when using SMS, a complete Wikipedia page cannot be always sent through SMS, at the risk of losing relevant information. Thus, the summarization of the page is mandatory to provide the quintessence of the page.
Several works have shown potential to summarize Wikipedia pages (e.g., [22,23]). These works are mostly based on extractive techniques that amount to ranking sentences and selecting the best ones. Usually, they produce summaries that are between one quarter to half the length of the original page.
Although some works such as Lin et al. [24] deals with word limitation when generating the summary, it remains very difficult to consider character limitation as imposed by SMS. Indeed, the summary should fit in a maximum of three SMS. Depending on the mobile carrier, the number of characters should not exceed 455, otherwise the message will be transformed into MMS, requiring adapted devices and additional cost compared to SMS. Moreover, due to the unpredictable relationship between the number of words or sentences and the number of characters, summarizing a webpage into SMS is a real challenge.
The first attempt to consider text summarization with character limitation is provided in [25]. The authors used an extractive approach based on the combination of LSA and TextRank algorithms. Although their approach generates summaries with a limitation on the number of characters, the major constraint is the redundancy while producing the summary and the lack of context understanding. In fact, the generated summary is based on the computation of the weight of the words in the sentences, with a complete unawareness of the context. Although some other works try to understand the context during the summarization [26,27,28,29,30,31], they do not take into consideration the limitation in terms of the number of characters.
This paper introduces WATS-SMS, a French Wikipedia Abstractive Text Summarizer that aims to summarize French Wikipedia pages into SMS and to provide summaries directly on the user’s device. It is built by applying a transfer learning technique to fine-tune a pre-trained model on French Wikipedia pages. The length of the summary is checked before producing the final summary. The fine-tuning process quickly becomes the fast approach used to build a custom model due to the huge requirements needed to train a model from scratch and the good performance shown by fine-tuned models [32].
The rest of the paper is organized as follows: Section 2 briefly presents the related works on text summarization. Section 3 explains the general architecture of WATS-SMS, as well as details of its main components. Section 4 presents and discusses the quality of summaries based on comparison with existing approaches. Section 5 presents a demonstration of the solution on a basic phone. This paper ends with conclusions and directions for future works, as discussed in Section 6.
2. Related Works on Text Summarization
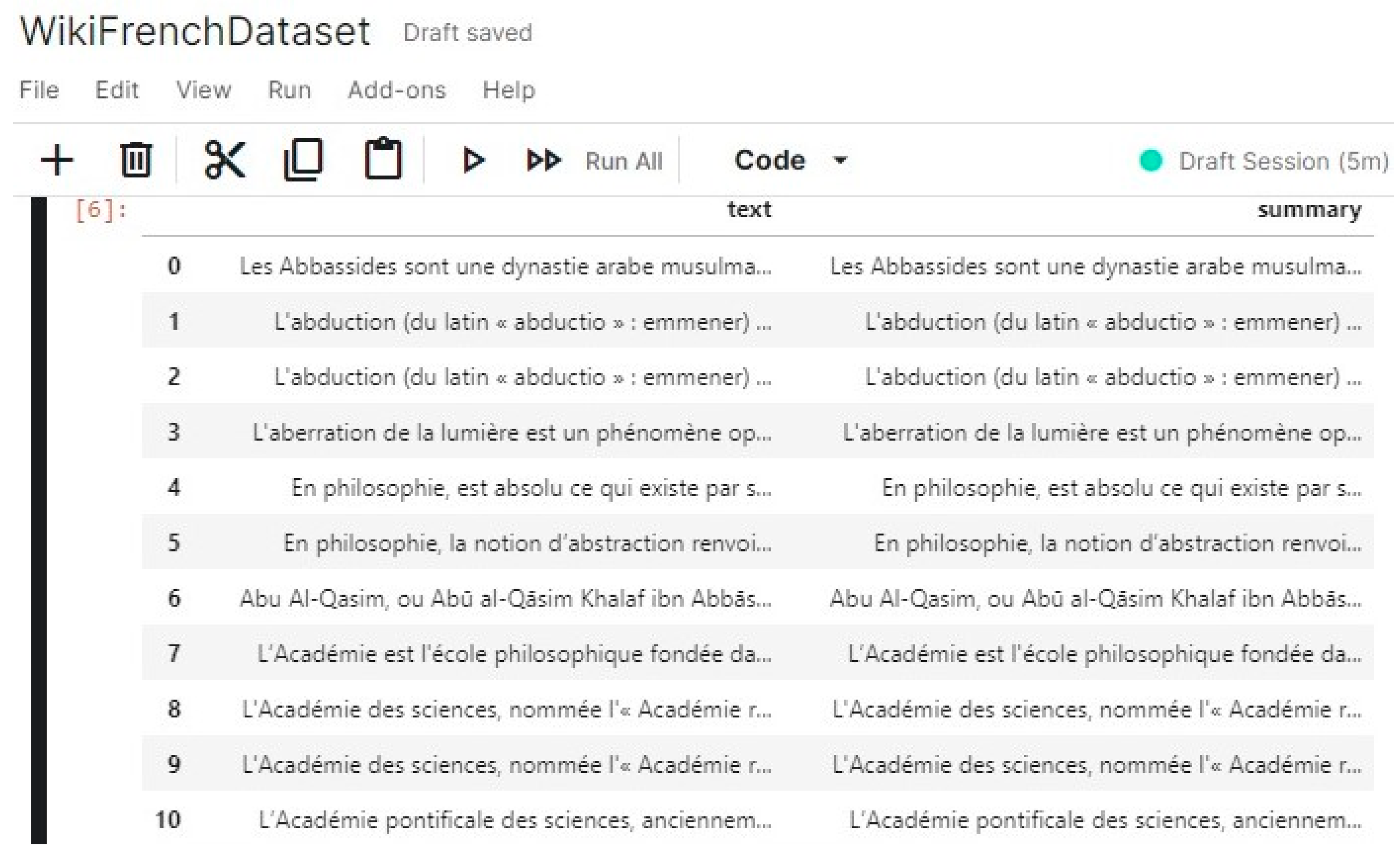
The first significant contributions in text summarization dates back to Luhn [33] in the late 1950s and Edmundson [34] in the early 1960s. The approaches were basic, focusing on the position of sentences and the frequency of words to produce a summary composed of the extracts from the original text. Since then, many efforts have been made to develop new approaches to text summarization. Recent surveys such as [2,35] propose a comprehensive review of the state of art in automatic text summarization techniques and systems. Figure 1, adapted from [2], provides a classification of the automatic text summarization systems.
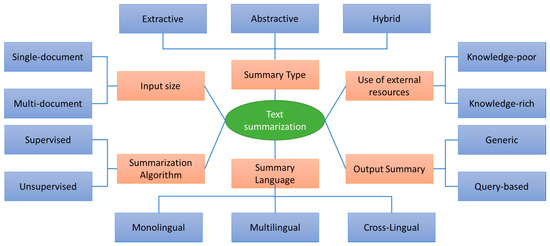
Figure 1.
Classification of text summarization systems adapted from [2].
Text summarization can be classified based on the input size. Some approaches such as [36,37] have been designed for single document while others are targeting multi-document [38,39]. The summary language is another important aspect in text summarization. Although most of the works are focused on English, some have developed multilingual text summarization approaches [8,40,41] and recently cross-lingual approaches have emerged [42,43]. Text summarization can be performed based on the type of summary: Extractive, Abstractive, or Hybrid. The first approach consists in scoring sentences and selecting the subset of high-scored sentences [44]. In the second approach, the input document is represented in an intermediate representation and new sentences are generated to build up the summary [45]. The last approach is just a combination of both previous approaches [5].
Abstractive approaches can generate better summaries using words other than those in the original document [46], with the advantage that they can reduce the length of the summary, compared to extractive approaches [47]. Several methods have been developed for abstractive text summarization including rule-based, graph-based, tree-based, ontology-based, semantic-based, template-based and deep-learning based. The latter was made possible thanks to the success of sequence-to-sequence learning (seq2seq) that uses a set of recurrent neural network (RNN) based on attention encoder-decoder. However, RNN models are slow to train and they cannot deal with long sequences [48]. Long short-term memory (LSTM [49]) draw their potential from the latter, they are capable of learning long sequences. Several works have reported promising results in a wide variety of application where data has long sequences dependencies.
A breakthrough that revolutionized the NLP industry and helped to deal with long term dependencies and parallelization during training is the concept of transformers introduced in [50]. Later, the BERT (Bidirectional Encoder Representations from Transformers) representation model which is a pre-trained model that considers for the first time the context of a word from both sides (left and right) has been developed in [51]. BERT provides a better understanding of the context in which a word has been used, in addition to allow multi-task learning. BERT can be fine-tuned to generate new models for other languages. More recently, models based on BERT such as CamemBERT [52] and FlauBERT [53] have been trained on very large and heterogeneous French corpus. The generated French models have been applied to various NLP tasks including text classification, paraphrasing and word sense disambiguation. However, the application of BERT-based model to summarization is not straightforward. In fact, BERT-based models usually output either a class label or a span of the input.
Text summarization tasks using a BERT-based model are proposed in [54,55]. Generated models have been evaluated on three datasets of news articles: CNN/DailyMail news highlights, the New York Times Annotated Corpus and Xsum. Lately, the Text-to-Text transfer transformer (T5) model and framework that achieve state-of-the-art results on several benchmarks including summarization has been proposed [56]. To the best of our knowledge, no work based on T5 deals with the text summarization using French Wikipedia. In addition, the limitation in terms of number of characters has not yet considered during abstractive summarization process.
Due to the homogeneity of Wikipedia in terms of genre and style and because of the diversity of the domains we are interested in coverage through the WATS-SMS application (news, education, health, etc.), we used the T5 model instead of BERT. T5 works as a ledger of all NLP tasks into a unified format, which is different from BERT-based models that usually generate either a class label or a span of the input [57].
3. WATS-SMS System
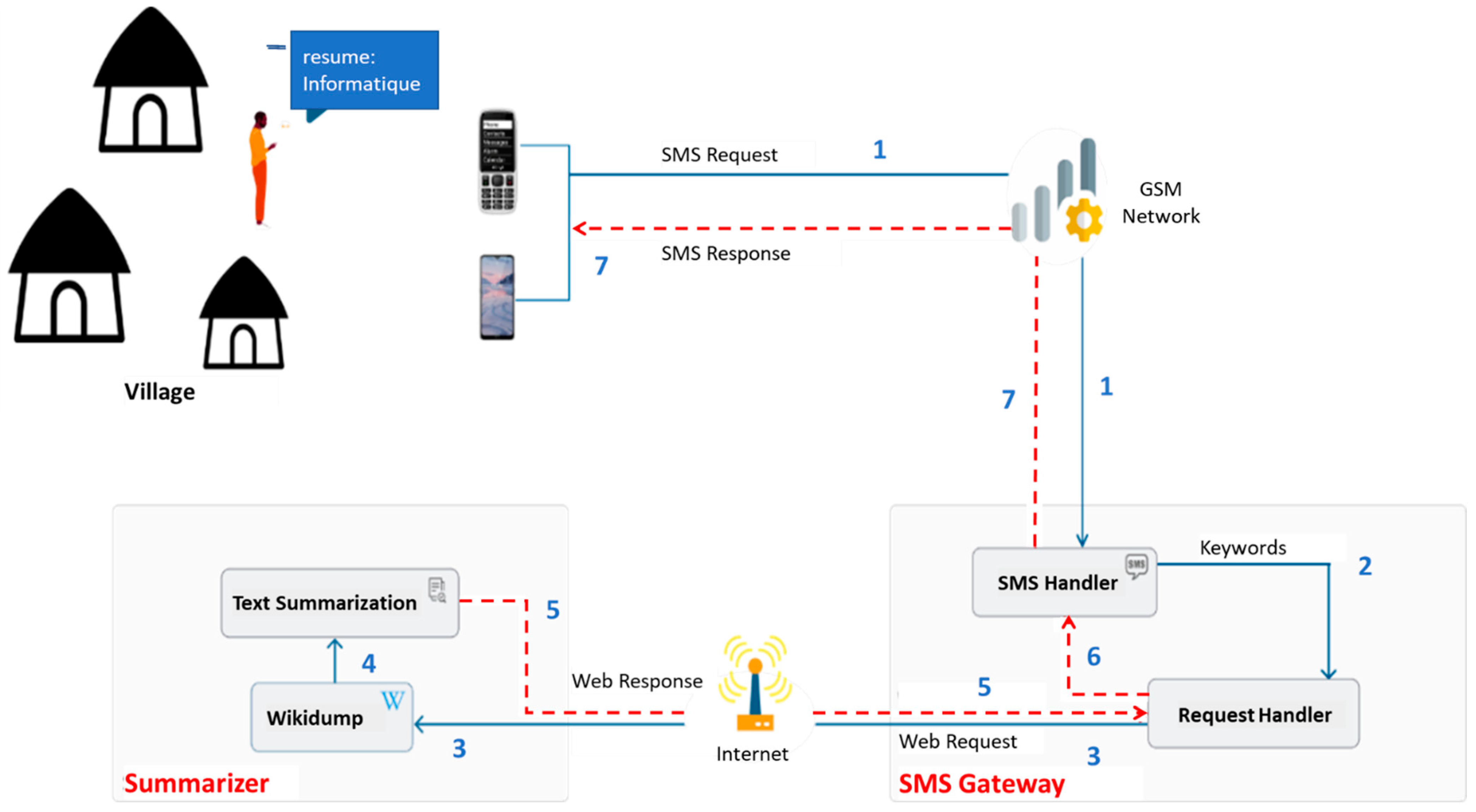
This section presents the proposed WATS-SMS system including the SMS mobile gateway and the summarizer module. The complete working of the system is illustrated in Figure 2, and the links to the GitHub project are provided as Supplementary Materials.
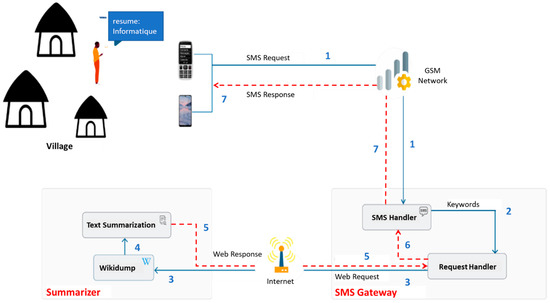
Figure 2.
WATS-SMS Architecture.
In Figure 2, the process starts with the user sending an SMS (through the GSM network) to the SMS gateway (SMS Gateway phone number); this level of communication is indexed by 1 in Figure 2. The first module of the SMS Gateway, namely the SMS Handler, retrieves the keyword and the phone number of the user; this process is indexed by 2 in Figure 2. Then, the second module of the SMS Gateway, namely the Request Handler, will generate the web request to send to the server); this level of communication is indexed by 3 in Figure 2. Once the request is received by the summarizer on the server, the Wikidump module will first retrieve and clean the corresponding Wikipedia page to be sent to the Text Summarization module; see communication indexed by 4 in Figure 2. The latter module generates the summary that takes the reverse path to the user; this is summarized and indexed in Figure 2 by 5, 6 and 7. As mentioned earlier, to prevent the SMS to be transformed into MMS, the number of characters is limited to 455 (the length of three SMS, depending on the Mobile Carrier).
3.1. The SMS Gateway
The SMS Gateway is an application that can be installed on a smartphone to avoid traditional hardware SMS Gateway. It is composed of two modules: The SMS Handler and the Request Handler.
The SMS Handler performs two functions. Firstly, it reads and filters incoming messages to select those containing the keyword “resume”. Since an ordinary smartphone can be used to play this role, not all incoming SMS messages are necessarily requests. Only SMS messages containing the keyword are considered as such. So, the SMS-Reader parses the content and the text next to the keyword “resume” is considered as the title of the requested Wikipedia page. It can be a simple word such as “informatique” or a set of words such as “corona virus”. Two main permissions are required to handle SMS: READ_SMS and SEND_SMS.
The second module of the SMS gateway is the Request Handler which is a JSON parser. It breaks down into words each incoming request to transform it into a JSON format. The result is then sent to the server. This module also works in the reverse way, meaning it converts elements from JSON format into strings. The outgoing JSON file to the server contains the user’s phone number and the title of the page. The incoming JSON file from the server contains the user’s phone number and the summary of the requested page.
3.2. The Summarizer
The proposed summarization approach consists of three main steps:
- Pre-processing of the requested page (Retrieving and cleaning);
- Summarization process;
- Post-processing the summary.
3.2.1. Pre-Processing of French Wikipedia Pages
The pre-processing aims to retrieve and clean the content of a requested page before starting the summarization. It is important to know the structure of a Wikipedia page before starting the retrieval. A typical Wikipedia page is composed of four parts: the top of the page, the stringcourse of the left, the body and the footer. The body contains the main information of the page. It is also divided into four main parts: the title, the introductory summary, the table of contents and the content itself. The page retrieval targets the body part, mainly the content and the introductory summary. This is done by using the Wikidump function, described in Algorithm A1 in Appendix A.
However, we should pay attention during the page retrieval. Some pages do not have a dense introductory summary, while others present relevant information only in the summary and not in the content section. Focusing only on the main content of the requested page may not provide relevant information. It is therefore necessary to combine the introductory summary and the content, to obtain a unique text before starting the summarization process. For instance, the introductory summary section of the page “Eséka” (https://fr.wikipedia.org/wiki/%C3%89s%C3%A9ka, accessed on 10 June 2021) is only one sentence (112 characters with spaces) while the length of the content section of the page is 9762 characters. Another example is the page “Song Bassong” (https://fr.wikipedia.org/wiki/Song_Bassong, accessed on 10 June 2021) that contains relevant information in the introductory summary section that are not present in the content section. In addition, the total number of characters of the latter page is 345 (below the limit 455), meaning that the content of both sections can be sent back to the user, even without a summarization. Even though such situations are quite rare, the content retrieved from the requested page will go through the summarization process.
3.2.2. Summarization Process
- Model
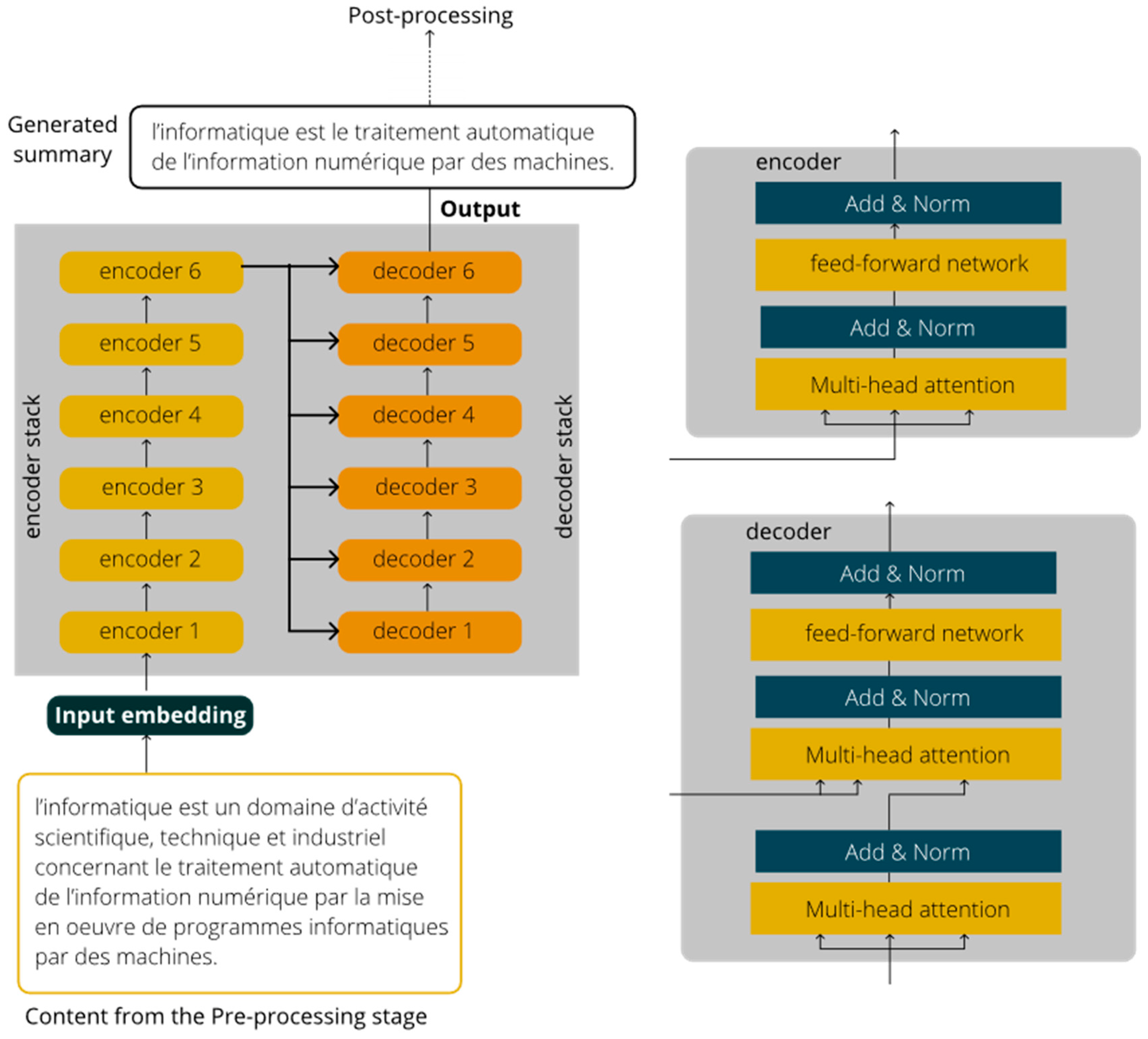
The model used for the summarization is built through a transfer learning process on a T5 model. The choice of T5 is justified by the fact it provides a better generalization compared to BERT, as it is demonstrated in [58]. As an encyclopedia, Wikipedia deals with various topics. Thus, the T5 model is more suitable. In addition, the model can further be used for other aims such as translation and answers to short questions. T5 is based on transformers. A transformer is composed of two types of layers: encoder and decoder layers. A transformer is composed of two types of layers: encoder and decoder layers. An encoder layer aims to encode long sequences input into a numerical form through the attention mechanism, while a decoder layer aims to output a summary by using the encoded information from the encoder layers. Transformers try to solve the parallelization issue by using Convolutional Neural Networks (CNNs) together with attention models. Figure 3 illustrates the data flow in transformer with 6 encoders and 6 decoders. Each encoder has two types of layers: multi-head self-attention layer and position-wise fully connected feed-forward network. In addition to both previous layers, a decoder also includes a masked multi-head self-attention layer [59].
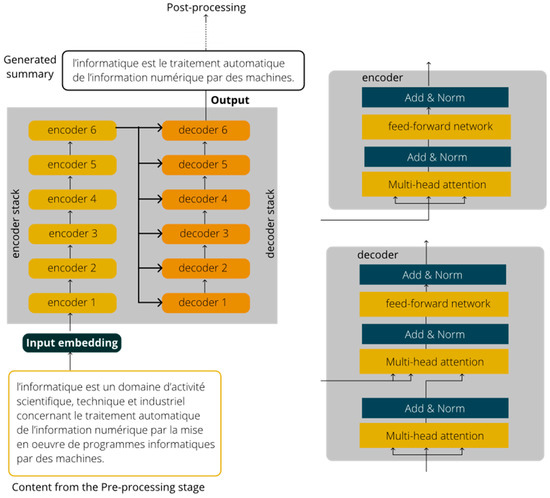
Figure 3.
Data flow in transformer.
We make use of the default T5 model with 12 transformer blocks, 220 million parameters, 768 hidden states, 3072 feed-forward hidden-state, 12 self-attention heads. The model has been originally trained on English text using the Colossal Clean Crawled Corpus (C4) introduced in [56]. We retrain the model using a dataset built with Wikipedia pages.
- Dataset
To ease the access to data, we choose to create a data frame from text files. two steps are important to generate such a dataset: Understanding the structure of the document and defining the output (the structure of the table). Since the structure of the Wikipedia is known, targeted content can be easily retrieved. Only the introductory summary section and content section are retrieved from the body of the page. This is done using the Wikidump function, which also cleans up the text by removing special characters, images, etc. The structure of the dataset, inspired by the structure of OrangeSum dataset (https://huggingface.co/datasets/viewer/?dataset=orange_sum, accessed on 22 August 2021), is composed of two main fields: Text (content section) and Summary (introductory summary section). To build the dataset, a crawler starts from a Wikipedia URL and selects 25,000 pages. An excerpt of the dataset is provided in Figure A1.
- Training and testing
We consider the default architecture of the T5 model and we apply the Adam optimizer proposed in [60] by initializing the learning rate to 0.0001. The input batch size for training and testing is 2 and we use 2 epochs for the training. The training was done using a Tesla T4 from Colab. We split the datasets to 80% for the training set and 20% for the test set. The Wikipedia summary section was used as a reference summary as it is done in [25].
3.2.3. Post-Processing of the Summary
The post-processing is done with the help of the length_Checker function. It checks the length of the summary and eventually modifies it to get an understandable final summary. In fact, the maximal number of characters (455) is given as a parameter to the model. Then, the model outputs the first 455 characters of the generated summary in case the length of the generated summary is greater than 455. After truncation, the last sentence may not be understandable. The easiest way to fix this, is to delete the eventually incomplete last sentence. The length_Checker function is described in Algorithm A2 in Appendix C.
4. Results
The well-known ROUGE (Recall-Oriented Understudy for Gisting Evaluation) metrics are used to evaluate the quality of a summary or machine translation [61]. ROUGE works by comparing an automatically produced summary against a set of typically human-produced reference summaries. The measure is done by counting the number of matching words between a generated summary and the reference summary. In other terms, ROUGE measures the content coverage of an automatic summary over the reference summary. Different variants of ROUGE have been proposed such as ROUGE-N, ROUGE-L and ROUGE-S that count respectively the number of overlapping units of n-gram, word sequences and word pairs between a generated summary and the reference summary [61]. The formula for ROUGE-N is given in Equation (1).
where gram is the choice of n-gram and S is the reference summary.
4.1. Comparison
4.1.1. Comparison with Extractive Approaches
We first compare the results of the proposed summarization model with the results in [25] that defined an approach associating the LSA and Text Rank algorithms for the text summarization of Wikipedia articles. However, the tests carried out in [25] are done on English pages. For a fair comparison, we selected the corresponding French Wikipedia pages of articles in [25]. We focused on the results of articles with a size greater than 2000 characters. This is done for two main reasons. Firstly, most of the French pages in Wikipedia are longer than their English version. For instance, the French version of the page on “Kousseri” is 5797 characters, while the English version is only 1386 characters. Secondly, from the results in [25], the proposed extractive approach struggles to provide a good result when the length of the page is increasing. So, the idea is to also appreciate the quality of results provided by the abstractive approach over extractive approaches when dealing with quite long documents. The results of the comparison are provided in Table 1.

Table 1.
Comparison of Wikipedia article with length over than 2000 characters.
From Table 1, we observe that the summary produced by the proposed abstractive model is most of the time better than the one produced by the extractive approach, even though French pages are longer than their corresponding English pages. A deep observation reveals that the extractive approach struggles to provide a good summary when the reference summary is longer. For instance, on the Wikipedia page “Kousseri”, the reference summary contains 459 characters and the best ROUGE metric equal to 0.57 for LT ROUGE-1. When the length of the reference summary increases like on the page “Bafoussam”, the LT ROUGE-1 drops to 0.52. However, the extractive approach provides better results when the length of the reference summary is very short (up to hundred characters).
Table 2 provides and inspection of some summaries to better appreciate the ability of the proposed abstractive approach to generate new texts. Three cases can be observed. In the first case (“Kousséri”), the summarizer uses partial sentences from both summary and content sections. The generated summary is composed of a first excerpt in the summary section, a second in the content section and a last in the summary section again. In the second case (“Chantal Biya”), the summary is only composed of partial sentences from the summary section. In the last case (“Informatique”), a new text is inserted in the summary.
Table 2.
Excerpt of some Wikipedia pages and their related summaries generated by the proposed approach. Highlighted texts in the “Page Content” and “Generated Summary” columns represent excerpts used to generate the summary and new texts inserted by the summarizer respectively.
WATS-SMS has also been compared to Wikipedia-based summarizer, another extractive-based summarizer system proposed by Sankarasubramaniam et al. [22]. Their approach consists first to construct a bipartite sentence-concept graph and to rank the input sentences using iterative updates on this graph. The work in [22] also makes use of English Wikipedia pages. We used ROUGE metrics for the evaluation and computed the recall scores for 100-word summaries to be able to reproduce the test conditions used by Sankarasubramaniam et al. [22], with the only difference that our proposed model uses French Wikipedia pages.
From Table 3, WATS-SMS provides competitive results, 52% and 41% corresponding respectively to the recall of ROUGE-1 and ROUGE-2. All those results validate the assumption that the abstractive approaches provide better results than extractive approaches.
Table 3.
Comparison with extractive summarizer.
4.1.2. Comparison with Abstractive Models
The proposed approach is compared to other abstractive models defined in [62] and trained using English Wikipedia. We first compared our model to seq2seq-attention and Transformer-ED with an input sequence length up to 500 using the ROUGE-L metric, as it is done in the original paper. The results are given in Table 4.
Table 4.
Comparison with other abstractive models (length up to 500 characters).
For small documents, the proposed model produces a score of 52.3%, thus showing the efficiency of the model for summarizing French Wikipedia pages.
Finally, the proposed model has been compared with Transformer-DMCA using input text between 10,902 and 11,000.
As we observe from Table 5, the proposed model provides a better ROUGE-L value than both Transformer-DMCA without MoE-Layer and Transformer-DMCA with MoE-128. This demonstrates the ability of the proposed model to provide good summary.
Table 5.
Comparison with other abstractive models (length up to 500 characters).
5. Demonstration
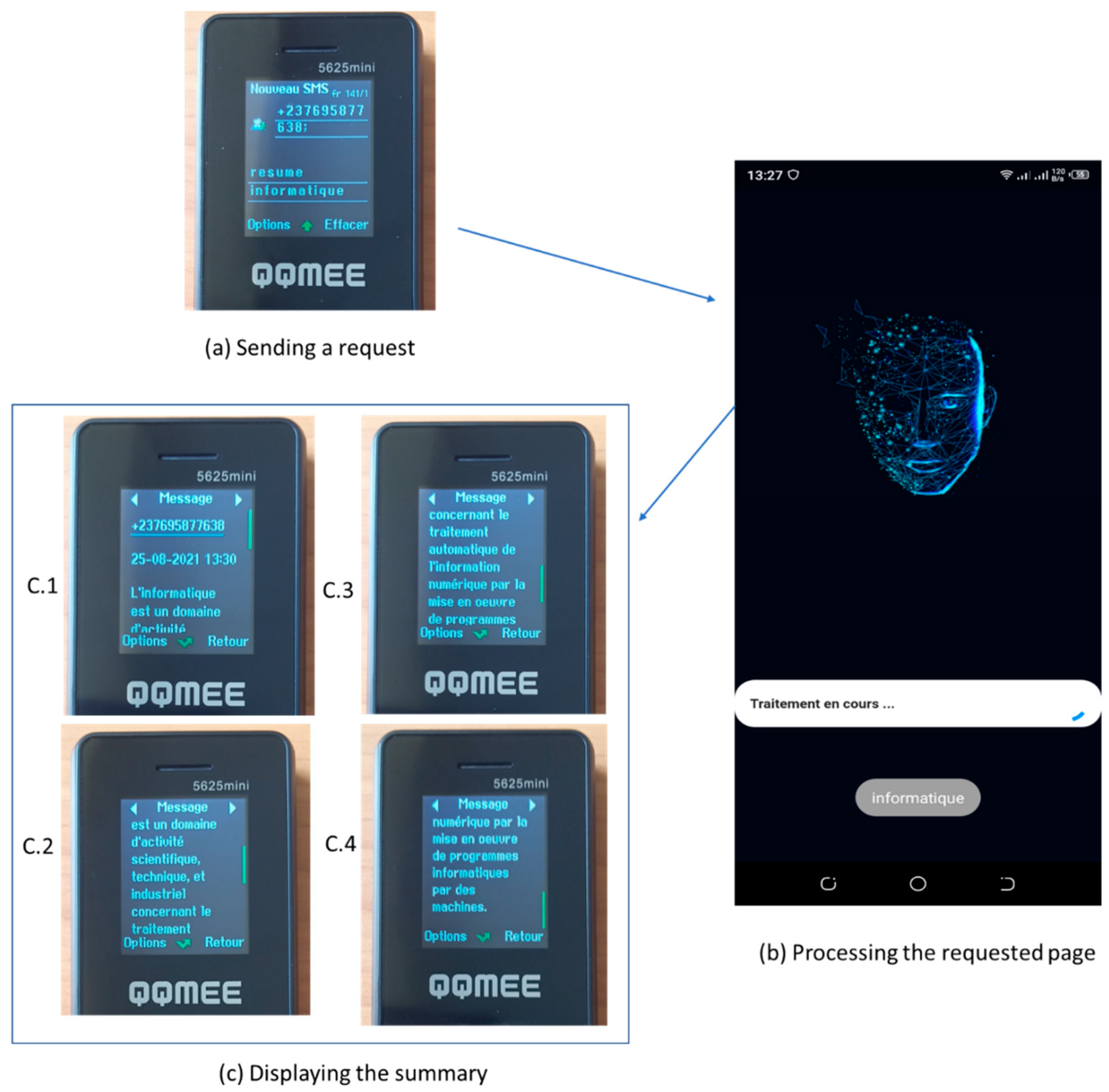
This section shows a demonstration of WATS-SMS on a phone with limited features. In Figure 4 the user starts by sending a request with the keyword “resume”, followed by the title of the requested page: “informatique”. Figure 4b shows the running of the SMS-Gateway application on a smartphone which is used as a gateway, taking the request and sending to the Summarizer. After receiving the summary, the SMS Gateway sends it back to the user. Figure 4c shows the summary on the user’s device. We notice that the SMS containing the summary is complete since its length is less than 455 characters defined as the maximal length.
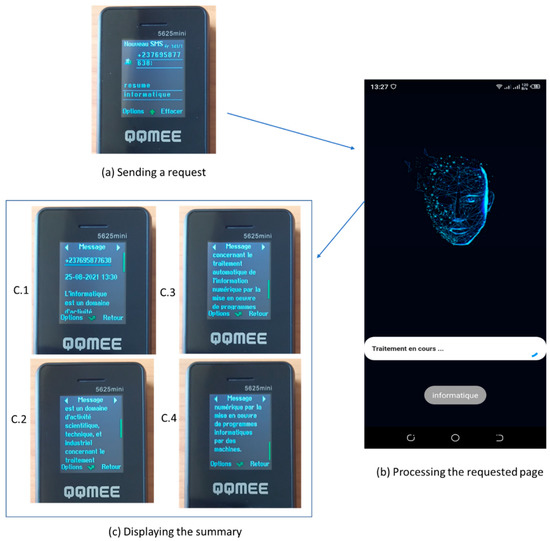
Figure 4.
Demo of using WATS-SMS. (a) A request is sent with the word “Informatique”. (b) The requested page is processed by the SMS Gateway that communicates with the Summarizer. (c) The summary is provided to the user.
6. Conclusions and Future Works
Despite the enormous progress in the field of automatic NLP, text summarization remains a challenging task. This work has highlighted the text summarization issue of French Wikipedia articles with character limitation. This paper introduced WATS-SMS, an abstractive text summarizer for French Wikipedia pages built through a fine-tuning process using T5 model which is based on the Transformer architecture. After training on 25,000 French pages, the generated model outperforms extractive approaches and provides satisfactory results compared to other abstractive models focusing on the English language. Through the SMS-Gateway, users with basic telephones can benefit from the system.
However, even though the limitation of the number of characters in the summary is given as a parameter to the model, the summary requires a post-processing to avoid an uncomplete summary. In fact, the model most of the time produces summaries with an incomplete last sentence which is removed during post-processing. It would be interesting to deal with the number of characters limitation directly during the processing stage rather than counting the number of characters in the generated summary and sending a truncated summary. Another important issue is the case of very long pages. Due to the number of characters limitation (455 characters), the summary can miss relevant information. It would therefore be interesting to design guided summarization process that can consider user preferences.
Supplementary Materials
The SMS-Gateway is accessible at the following address https://github.com/lfendji/WATS-SMS. and the Summarizer at the following address https://github.com/claudelkros/WATS-SMS-Model.git.
Author Contributions
Conceptualization, J.L.E.K.F. and D.M.T.; methodology, J.L.E.K.F. and M.A.; software, A.M.A., D.M.T.; validation, J.L.E.K.F. and M.A.; data curation, D.M.T., A.M.A.; writing—original draft preparation, J.L.E.K.F.; writing—review and editing, M.A.; supervision, J.L.E.K.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not Applicable, the study does not report any data.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Wikidump Function
The Wikidump function uses the wikipedia library (python library) to connect to the wikipedia page and to retrieve the content of the page corresponding to the given title. This content is cleaned up using regular expressions in order to delete unwanted items.
| Algorithm A1. Wikidump. |
| Input: : Title of the requested page Output: : Cleaned Content for summarization process; |
| Begin Import Wikipedia wikipedia.set_lang(“fr”) Connect to fr.wikipedia.org/title wiki = wikipedia.page(title) If a response then Content = wiki.content For every line in the Content text = re.sub(r’==.*?==+’, ‘‘, line) text = text.replace(‘\n’, ‘‘) endFor endIf return End |
Appendix B. Dataset
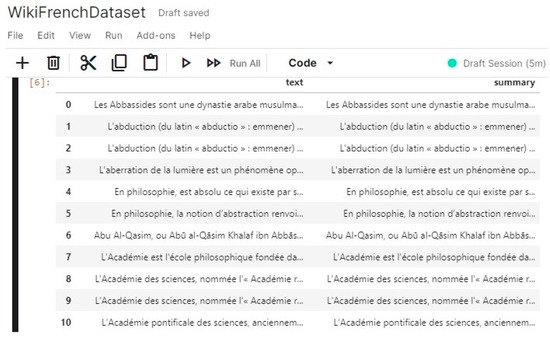
Figure A1.
An excerpt of the dataset.
Figure A1.
An excerpt of the dataset.
Appendix C. Length_Checker Function
The Length_checker algorithm aims to ensure that the length of the generated summary is not exceeding the maximal length. When retrieving only 455 characters, we can obtain an incomplete sentence at the end. The main idea is to retrieve a text longer than 455 characters and to delete last sentence until we get a set of sentences which length is not exceeding 455 characters.
| Algorithm A2. Length_Checker. |
| Input: : The generated summary by the summarizer Output: : The final summary sent to the user; |
| Begin = If length() <= 455 then return Else While > 455 do remove_last_sentence() return End |
References
- Maybury, M.T. Generating summaries from event data. Inf. Process. Manag. 1995, 31, 735–751. [Google Scholar] [CrossRef]
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic text summarization: A comprehensive survey. Expert Syst. Appl. 2021, 165, 113679. [Google Scholar] [CrossRef]
- Antunes, J.; Lins, R.D.; Lima, R.; Oliveira, H.; Riss, M.; Simske, S.J. Automatic cohesive summarization with pronominal anaphora resolution. Comput. Speech Lang. 2018, 52, 141–164. [Google Scholar] [CrossRef]
- Steinberger, J.; Kabadjov, M.; Poesio, M.; Sanchez-Graillet, O. Improving LSA-based summarization with anaphora resolution. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, CB, Canada, 6–8 October 2005; pp. 1–8. [Google Scholar]
- Steinberger, J.; Poesio, M.; Kabadjov, M.A.; Ježek, K. Two uses of anaphora resolution in summarization. Inf. Process. Manag. 2007, 43, 1663–1680. [Google Scholar] [CrossRef]
- Sahni, A.; Palwe, S. Topic Modeling on Online News Extraction. In Intelligent Computing and Information and Communication; Springer: Berlin/Heidelberg, Germany, 2018; pp. 611–622. [Google Scholar]
- Sethi, P.; Sonawane, S.; Khanwalker, S.; Keskar, R.B. Automatic text summarization of news articles. In Proceedings of the 2017 International Conference on Big Data, IoT and Data Science (BID), Pune, India, 20–22 December 2017; pp. 23–29. [Google Scholar]
- Bhargava, R.; Sharma, Y. MSATS: Multilingual sentiment analysis via text summarization. In Proceedings of the 2017 7th International Conference on Cloud Computing, Data Science & Engineering-Confluence, Noida, India, 12–13 January 2017; pp. 71–76. [Google Scholar]
- Mary, A.J.J.; Arockiam, L. ASFuL: Aspect based sentiment summarization using fuzzy logic. In Proceedings of the 2017 International Conference on Algorithms, Methodology, Models and Applications in Emerging Technologies (ICAMMAET), Chennai, India, 16–18 February 2017; pp. 1–5. [Google Scholar]
- Chakraborty, R.; Bhavsar, M.; Dandapat, S.K.; Chandra, J. Tweet summarization of news articles: An objective ordering-based perspective. IEEE Trans. Comput. Soc. Syst. 2019, 6, 761–777. [Google Scholar] [CrossRef]
- Carenini, G.; Ng, R.T.; Zhou, X. Summarizing email conversations with clue words. In Proceedings of the 16th international conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 91–100. [Google Scholar]
- Mohammad, S.; Dorr, B.; Egan, M.; Hassan, A.; Muthukrishnan, P.; Qazvinian, V.; Radev, D.; Zajic, D. Using citations to generate surveys of scientific paradigms. In Proceedings of the Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Boulder, CO, USA, 31 May–5 June 2009; pp. 584–592. [Google Scholar]
- Jiang, X.-J.; Mao, X.-L.; Feng, B.-S.; Wei, X.; Bian, B.-B.; Huang, H. Hsds: An abstractive model for automatic survey generation. In Proceedings of the International Conference on Database Systems for Advanced Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 70–86. [Google Scholar]
- Sun, J.-T.; Shen, D.; Zeng, H.-J.; Yang, Q.; Lu, Y.; Chen, Z. Web-page summarization using clickthrough data. In Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 15–19 August 2005; pp. 194–201. [Google Scholar]
- Ebongue, J.L.F.K. Rethinking Network Connectivity in Rural Communities in Cameroon. arXiv 2015, arXiv:1505.04449. Available online: https://arxiv.org/ftp/arxiv/papers/1505/1505.04449.pdf (accessed on 18 June 2021).
- Pinkovskiy, M.; Sala-i-Martin, X. Africa is on time. J. Econ. Growth 2014, 19, 311–338. [Google Scholar] [CrossRef]
- Ebongue, J.L.F.K.; Thron, C.; Nlong, J.M. Mesh Router Nodes placement in Rural Wireless Mesh Networks. arXiv 2015, arXiv:150503332. [Google Scholar]
- Fendji, J.L.E.K.; Thron, C.; Nlong, J.M. A metropolis approach for mesh router nodes placement in rural wireless mesh networks. arXiv 2015, arXiv:150408212. [Google Scholar] [CrossRef] [Green Version]
- Du Plessis, P.; Mestry, R. Teachers for rural schools—A challenge for South Africa. S. Afr. J. Educ. 2019, 39. [Google Scholar] [CrossRef]
- Mulkeen, A. Teachers for Rural Schools: A Challenge for Africa; FAO: Rome, Italy, 2005. [Google Scholar]
- Selwyn, N.; Gorard, S. Students’ use of Wikipedia as an academic resource—Patterns of use and perceptions of usefulness. Internet High. Educ. 2016, 28, 28–34. [Google Scholar] [CrossRef] [Green Version]
- Sankarasubramaniam, Y.; Ramanathan, K.; Ghosh, S. Text summarization using Wikipedia. Inf. Process. Manag. 2014, 50, 443–461. [Google Scholar] [CrossRef]
- Ramanathan, K.; Sankarasubramaniam, Y.; Mathur, N.; Gupta, A. Document summarization using Wikipedia. In Proceedings of the First International Conference on Intelligent Human Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2009; pp. 254–260. [Google Scholar]
- Lin, C.-Y.; Hovy, E. The potential and limitations of automatic sentence extraction for summarization. In Proceedings of the HLT-NAACL 03 Text Summarization Workshop, Stroudsburg, PA, USA, 31 May 2003; pp. 73–80. [Google Scholar]
- Fendji, J.L.E.K.; Aminatou, B.A.H. From web to SMS: A text summarization of Wikipedia pages with character limitation. EAI Endorsed Trans. Creat. Technol. 2020, 7. [Google Scholar] [CrossRef]
- Banerjee, S.; Mitra, P. WikiWrite: Generating Wikipedia Articles Automatically. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; p. 7. [Google Scholar]
- Paulus, R.; Xiong, C.; Socher, R. A Deep Reinforced Model for Abstractive Summarization. arXiv 2017, arXiv:170504304. Available online: http://arxiv.org/abs/1705.04304 (accessed on 18 June 2021).
- Gehrmann, S.; Deng, Y.; Rush, A.M. Bottom-Up Abstractive Summarization. arXiv 2018, arXiv:180810792. Available online: http://arxiv.org/abs/1808.10792 (accessed on 18 June 2021).
- Liu, F.; Flanigan, J.; Thomson, S.; Sadeh, N.; Smith, N.A. Toward Abstractive Summarization Using Semantic Representations. arXiv 2018, arXiv:180510399. Available online: http://arxiv.org/abs/1805.10399 (accessed on 20 June 2021).
- Chen, Y.-C.; Bansal, M. Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting. arXiv 2018, arXiv:180511080. Available online: http://arxiv.org/abs/1805.11080 (accessed on 20 June 2021).
- Fan, A.; Grangier, D.; Auli, M. Controllable Abstractive Summarization. arXiv 2018, arXiv:171105217. Available online: http://arxiv.org/abs/1711.05217 (accessed on 22 June 2021).
- Wolf, T.; Chaumond, J.; Debut, L.; Sanh, V.; Delangue, C.; Moi, A.; Cistac, P.; Funtowicz, M.; Davison, J.; Shleifer, S. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Luhn, H.P. The automatic creation of literature abstracts. IBM J. Res. Dev. 1958, 2, 159–165. [Google Scholar] [CrossRef] [Green Version]
- Edmundson, H.P. New methods in automatic extracting. J. ACM JACM 1969, 16, 264–285. [Google Scholar] [CrossRef]
- Gambhir, M.; Gupta, V. Recent automatic text summarization techniques: A survey. Artif. Intell. Rev. 2017, 47, 1–66. [Google Scholar] [CrossRef]
- Christian, H.; Agus, M.P.; Suhartono, D. Single document automatic text summarization using term frequency-inverse document frequency (TF-IDF). ComTech Comput. Math. Eng. Appl. 2016, 7, 285–294. [Google Scholar] [CrossRef]
- Sarkar, K. Automatic single document text summarization using key concepts in documents. J. Inf. Process. Syst. 2013, 9, 602–620. [Google Scholar] [CrossRef]
- Erkan, G.; Radev, D. Lexpagerank: Prestige in multi-document text summarization. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 365–371. [Google Scholar]
- Uçkan, T.; Karcı, A. Extractive multi-document text summarization based on graph independent sets. Egypt. Inform. J. 2020, 21, 145–157. [Google Scholar] [CrossRef]
- Patel, A.; Siddiqui, T.; Tiwary, U.S. A language independent approach to multilingual text summarization. Large Scale Semant. Access Content 2007, 123–132. [Google Scholar]
- Radev, D.R.; Allison, T.; Blair-Goldensohn, S.; Blitzer, J.; Celebi, A.; Dimitrov, S.; Drabek, E.; Hakim, A.; Lam, W.; Liu, D.; et al. MEAD-A Platform for Multidocument Multilingual Text Summarization; European Language Resources Association (ELRA): Lisbon, Portugal, 2004. [Google Scholar]
- Pontes, E.L.; González-Gallardo, C.-E.; Torres-Moreno, J.-M.; Huet, S. Cross-lingual speech-to-text summarization. In Proceedings of the International Conference on Multimedia and Network Information System; Springer: Berlin/Heidelberg, Germany, 2018; pp. 385–395. [Google Scholar]
- Zhu, J.; Wang, Q.; Wang, Y.; Zhou, Y.; Zhang, J.; Wang, S.; Zong, C. NCLS: Neural cross-lingual summarization. arXiv 2019, arXiv:190900156. [Google Scholar]
- Moratanch, N.; Chitrakala, S. A survey on extractive text summarization. In Proceedings of the 2017 International Conference on Computer, Communication and Signal Processing (ICCCSP), Chennai, India, 10–11 January 2017; pp. 1–6. [Google Scholar]
- Moratanch, N.; Chitrakala, S. A survey on abstractive text summarization. In Proceedings of the 2016 International Conference on Circuit, Power and Computing Technologies (ICCPCT), Nagercoil, India, 18–19 March 2016; pp. 1–7. [Google Scholar]
- Hou, L.; Hu, P.; Bei, C. Abstractive document summarization via neural model with joint attention. In Proceedings of the National CCF Conference on Natural Language Processing and Chinese Computing; Springer: Berlin/Heidelberg, Germany, 2017; pp. 329–338. [Google Scholar]
- Wang, S.; Zhao, X.; Li, B.; Ge, B.; Tang, D. Integrating extractive and abstractive models for long text summarization. In Proceedings of the 2017 IEEE International Congress on Big Data (BigData Congress), Honolulu, HI, USA, 25–30 June 2017; pp. 305–312. [Google Scholar]
- Liu, P.; Qiu, X.; Chen, X.; Wu, S.; Huang, X.-J. Multi-timescale long short-term memory neural network for modelling sentences and documents. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2326–2335. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; 2017; pp. 5998–6008. Available online: https://arxiv.org/pdf/1706.03762.pdf (accessed on 15 September 2021).
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:181004805. [Google Scholar]
- Martin, L.; Muller, B.; Suárez, P.J.O.; Dupont, Y.; Romary, L.; de La Clergerie, É.V.; Seddah, D.; Sagot, B. Camembert: A tasty french language model. arXiv 2019, arXiv:191103894. [Google Scholar]
- Le, H.; Vial, L.; Frej, J.; Segonne, V.; Coavoux, M.; Lecouteux, B.; Allauzen, A.; Crabbé, B.; Besacier, L.; Schwab, D. Flaubert: Unsupervised language model pre-training for french. arXiv 2019, arXiv:191205372. [Google Scholar]
- Liu, Y.; Lapata, M. Text summarization with pretrained encoders. arXiv 2019, arXiv:190808345. [Google Scholar]
- Liu, Y. Fine-tune BERT for extractive summarization. arXiv 2019, arXiv:190310318. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv 2019, arXiv:191010683. [Google Scholar]
- Google AI Blog: Exploring Transfer Learning with T5: The Text-To-Text Transfer Transformer. Available online: https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html (accessed on 26 August 2021).
- Kale, M. Text-to-text pre-training for data-to-text tasks. arXiv 2020, arXiv:200510433. [Google Scholar]
- Affine. Affine—Bidirectional Encoder Representations for Transformers (BERT) Simplified. 2019. Available online: https://www.affine.ai/bidirectional-encoder-representations-for-transformers-bert-simplified/ (accessed on 26 August 2021).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:14126980. [Google Scholar]
- Lin, C.-Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, July 2004; pp. 74–81. Available online: https://pdfs.semanticscholar.org/60b0/5f32c32519a809f21642ef1eb3eaf3848008.pdf (accessed on 15 September 2021).
- Liu, P.J.; Saleh, M.; Pot, E.; Goodrich, B.; Sepassi, R.; Kaiser, L.; Shazeer, N. Generating wikipedia by summarizing long sequences. arXiv 2018, arXiv:180110198. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).