
Socioeconomic Correlates of Anti-Science Attitudes in the US



Abstract
1. Introduction
- We described an approach to estimate anti-science views from the text of messages posted on social media, enabling the tracking of attitudes toward science at scale.
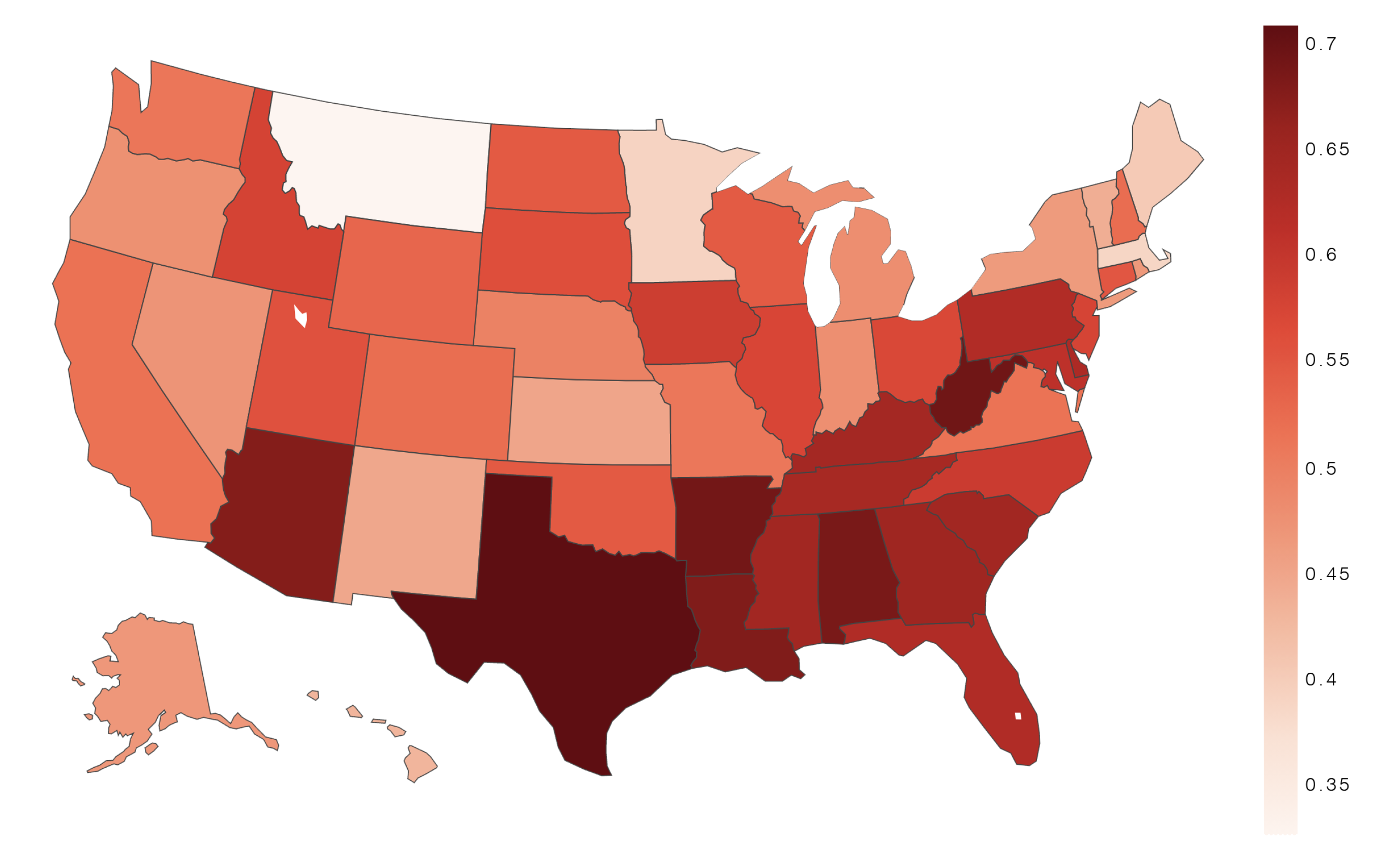
- We studied the geographical variation of anti-science attitudes and found differences across the US.
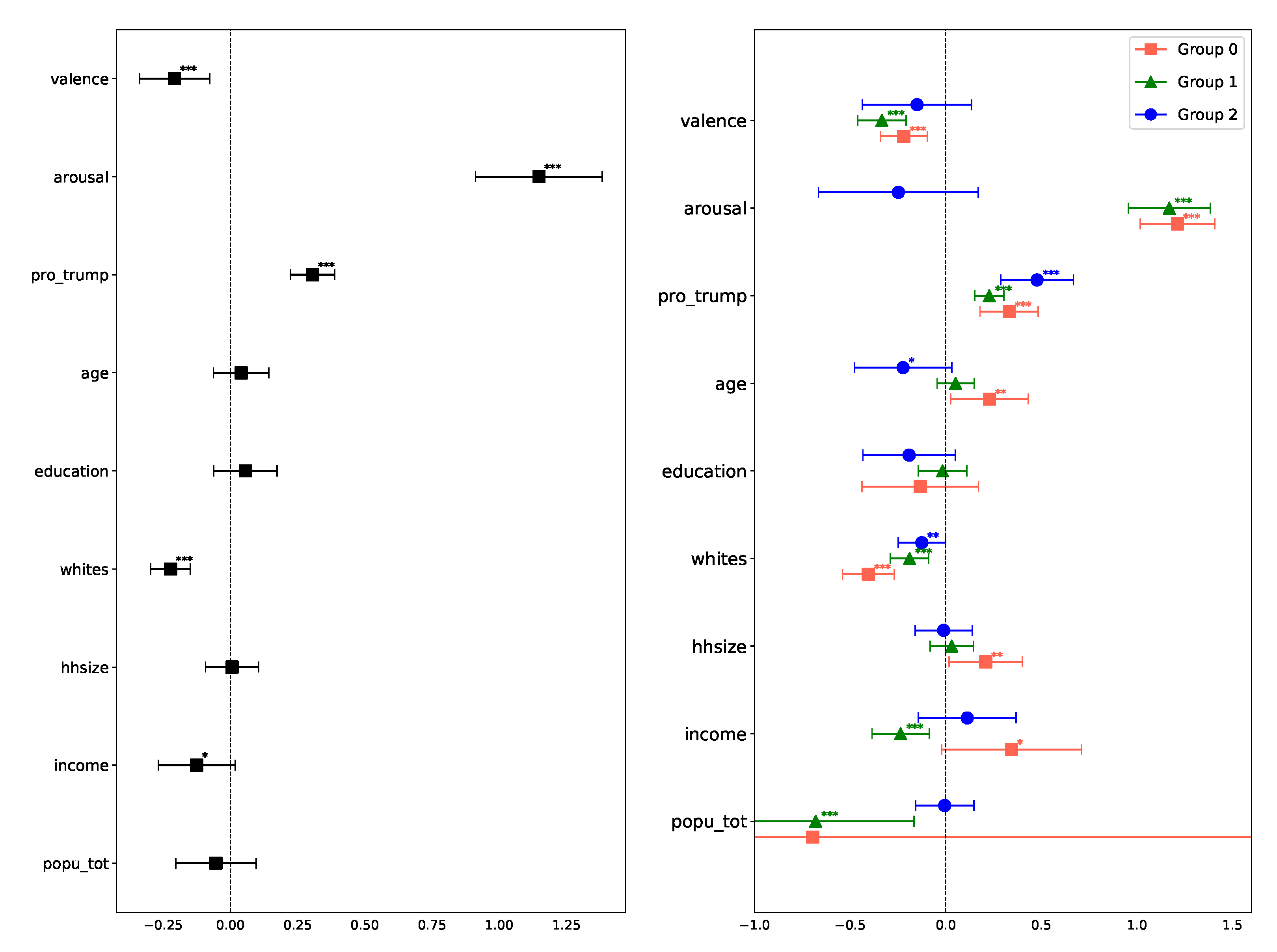
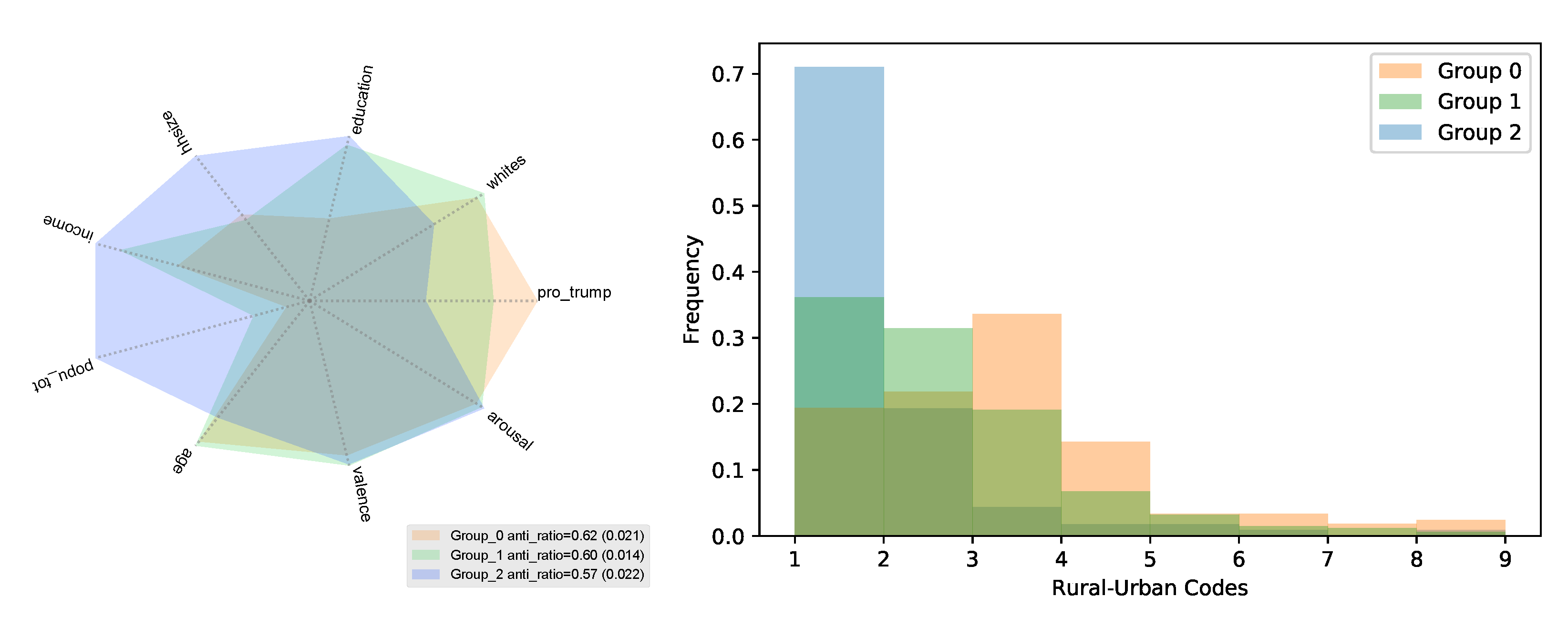
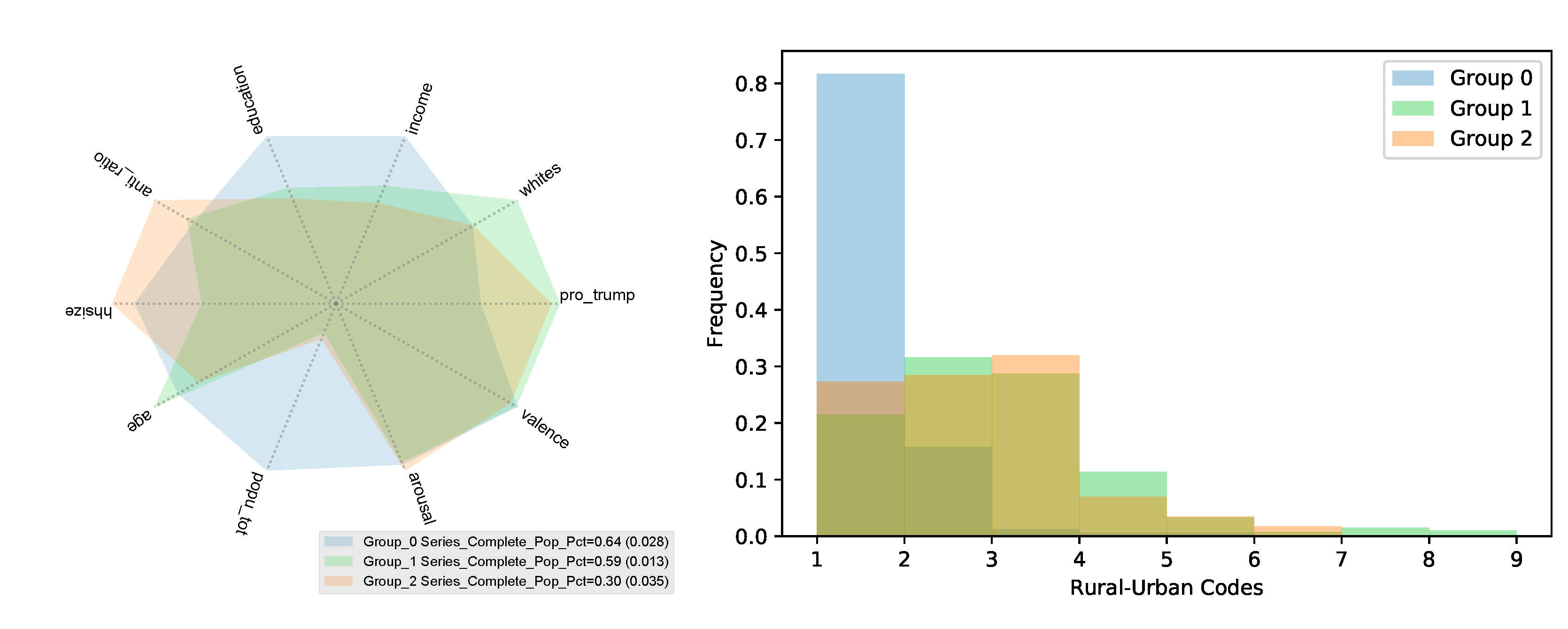
- We identified the latent structure of data using state-of-the-art machine learning methods to demonstrate the importance of stratifying data on latent groups to measure more robust trends. The structure of data suggests that cultural differences are defined by the urban–rural divide.
- We found that anti-science attitudes are associated with lower COVID-19 vaccination rates in urban communities.
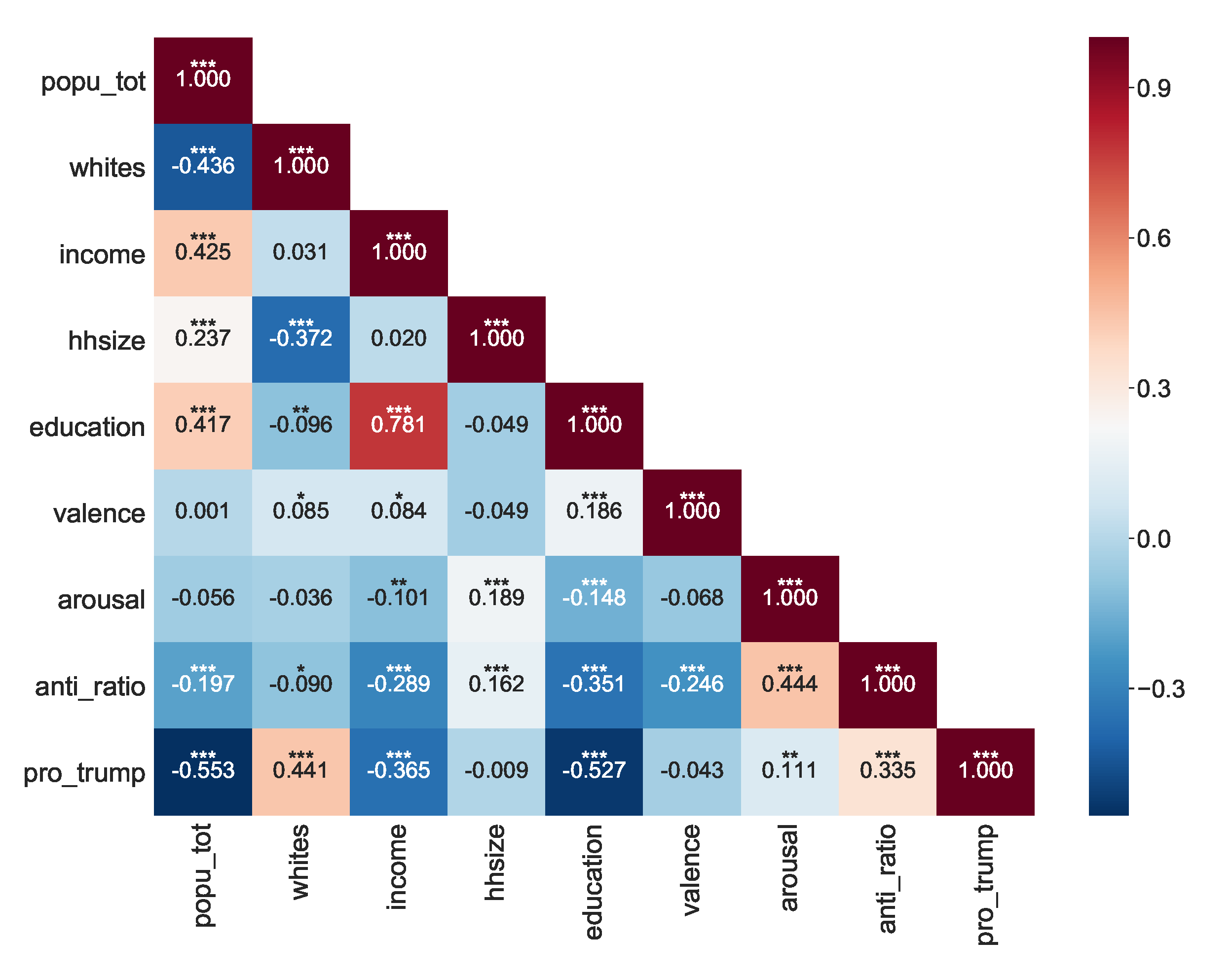
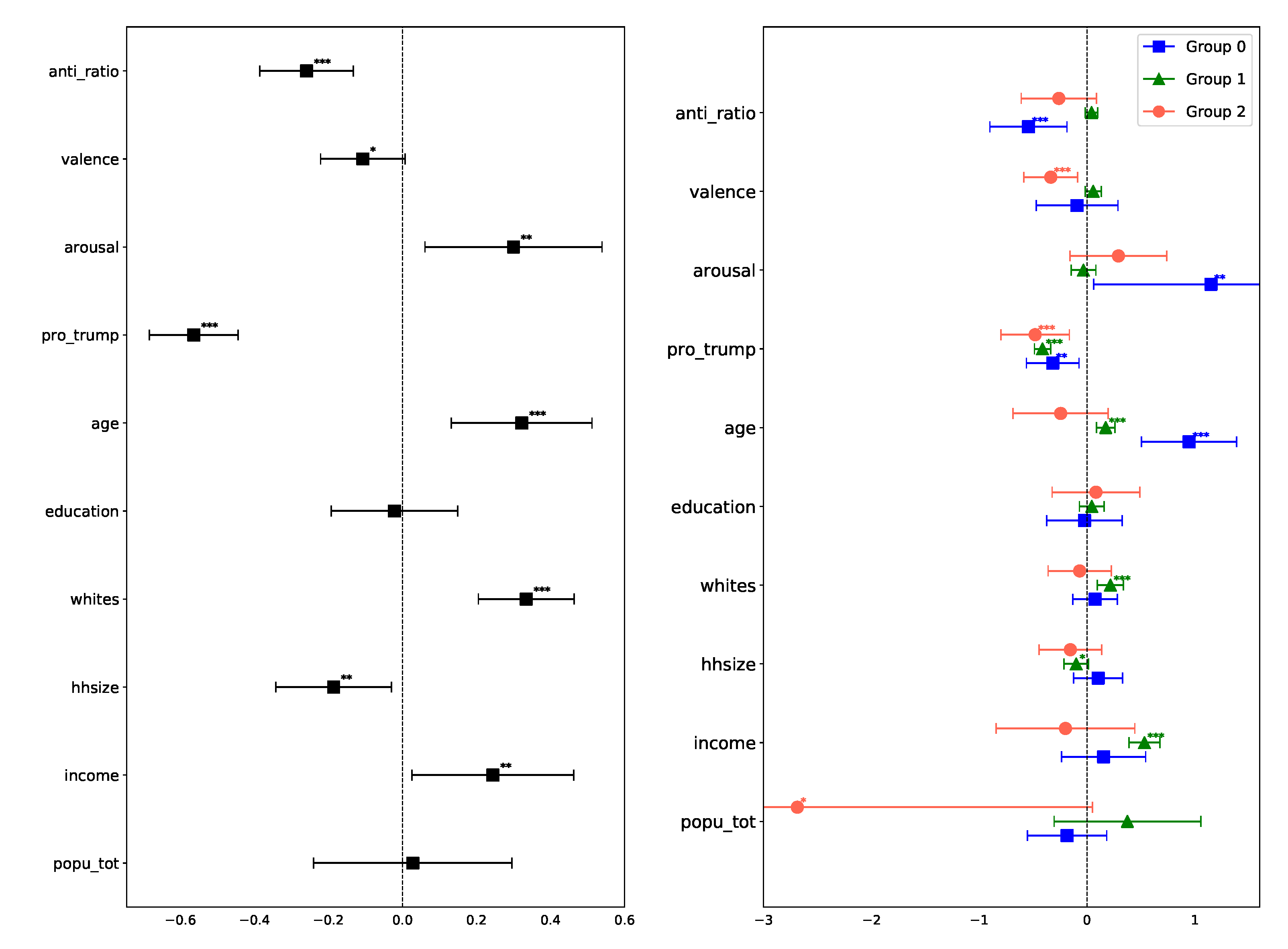
- Our analysis revealed the importance of partisanship, race, and emotions such as anger in explaining anti-science attitudes. However, education is not found to have significant explanatory power and income is only mildly significant.
2. Materials and Methods
2.1. Data
- popu_tot: total county population;
- income: average household income;
- hhsize: average household size;
- whites: share of households who identify as White;
- education: share of adult residents with a college degree or above;
- age: median age of county residents;
- pro_trump: share of voters who voted for Trump in the 2016 presidential election.
2.2. Measuring Anti-Science Attitudes
2.3. Measuring Emotions
2.4. Identifying the Latent Components
3. Results
3.1. Geography of Anti-Science Attitudes
3.2. Correlates of Anti-Science Attitudes
3.3. Latent Structure of Anti-Science Attitudes
3.4. Anti-Science Attitudes in the Age of COVID-19
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Betsch, C. How behavioural science data helps mitigate the COVID-19 crisis. Nat. Hum. Behav. 2020, 4, 438. [Google Scholar] [CrossRef]
- Van Bavel, J.J.; Baicker, K.; Boggio, P.S.; Capraro, V.; Cichocka, A.; Cikara, M.; Crockett, M.J.; Crum, A.J.; Douglas, K.M.; Druckman, J.N.; et al. Using social and behavioural science to support COVID-19 pandemic response. Nat. Hum. Behav. 2020, 4, 460–471. [Google Scholar] [CrossRef]
- Lunn, P.D.; Belton, C.A.; Lavin, C.; McGowan, F.P.; Timmons, S.; Robertson, D.A. Using Behavioral Science to help fight the Coronavirus. J. Behav. Public Adm. 2020, 3, 1–15. [Google Scholar] [CrossRef]
- Gollwitzer, A.; Martel, C.; Brady, W.J.; Pärnamets, P.; Freedman, I.G.; Knowles, E.D.; Van Bavel, J.J. Partisan differences in physical distancing are linked to health outcomes during the COVID-19 pandemic. Nat. Hum. Behav. 2020, 4, 1186–1197. [Google Scholar] [CrossRef]
- Funk, C.; Tyson, A. Partisan Differences over the Pandemic Response Are Growing. Available online: https://blogs.scientificamerican.com/observations/partisan-differences-over-the-pandemic-response-are-growing/ (accessed on 16 June 2021).
- Shear, M.D.; Mervosh, S. Trump Encourages Protest Against Governors Who Have Imposed Virus Restrictions. The New York Times. 29 April 2020. Available online: https://www.nytimes.com/2020/04/17/us/politics/trump-coronavirus-governors.html (accessed on 12 May 2021).
- Rutjens, B.T.; van der Linden, S.; van der Lee, R. Science skepticism in times of COVID-19. Group Process. Intergroup Relat. 2021, 24, 276–283. [Google Scholar] [CrossRef]
- Rutjens, B.T.; Heine, S.J.; Sutton, R.M.; van Harreveld, F. Attitudes towards science. In Advances in Experimental Social Psychology; Academic Press: Cambridge, MA, USA, 2018; Volume 57, pp. 125–165. [Google Scholar]
- van der Linden, S. Countering science denial. Nat. Hum. Behav. 2019, 3, 889–890. [Google Scholar] [CrossRef]
- Rutjens, B.T.; Preston, J.L. Science and religion: A rocky relationship shaped by shared psychological functions. Sci. Relig. Spirit. Existent. 2020, 373–385. [Google Scholar] [CrossRef]
- Bak, H.J. Education and public attitudes toward science: Implications for the “deficit model” of education and support for science and technology. Soc. Sci. Q. 2001, 82, 779–795. [Google Scholar] [CrossRef]
- Miller, J.D. Public understanding of, and attitudes toward, scientific research: What we know and what we need to know. Public Underst. Sci. 2004, 13, 273–294. [Google Scholar] [CrossRef]
- Sturgis, P.; Allum, N. Science in society: Re-evaluating the deficit model of public attitudes. Public Underst. Sci. 2004, 13, 55–74. [Google Scholar] [CrossRef]
- Pennycook, G.; McPhetres, J.; Bago, B.; Rand, D.G. Predictors of attitudes and misperceptions about COVID-19 in Canada, the UK, and the USA. PsyArXiv 2020, 10. [Google Scholar] [CrossRef]
- McPhetres, J.; Pennycook, G. Science Beliefs, Political Ideology, and Cognitive Sophistication. Available online: https://osf.io/ad9v7/download (accessed on 16 June 2021).
- Hornsey, M.J.; Fielding, K.S. Attitude roots and Jiu Jitsu persuasion: Understanding and overcoming the motivated rejection of science. Am. Psychol. 2017, 72, 459. [Google Scholar] [CrossRef] [PubMed]
- Prot, S. Science Denial as Intergroup Conflict: Using Social Identity Theory, Intergroup Emotions Theory and Intergroup Threat Theory to Explain Angry Denial of Science. Available online: https://lib.dr.iastate.edu/cgi/viewcontent.cgi?article=5930&context=etd (accessed on 16 June 2021).
- Ostrom, T.M. The relationship between the affective, behavioral, and cognitive components of attitude. J. Exp. Soc. Psychol. 1969, 5, 12–30. [Google Scholar] [CrossRef]
- Breckler, S.J. Empirical validation of affect, behavior, and cognition as distinct components of attitude. J. Personal. Soc. Psychol. 1984, 47, 1191. [Google Scholar] [CrossRef]
- Forgas, J.P.; Cooper, J.; Crano, W.D. The Psychology of Attitudes and Attitude Change; Psychology Press: London, UK, 2011; Volume 12. [Google Scholar]
- Conover, M.; Ratkiewicz, J.; Francisco, M.; Gonçalves, B.; Menczer, F.; Flammini, A. Political polarization on twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011; Volume 5. [Google Scholar]
- Barberá, P. Birds of the same feather tweet together: Bayesian ideal point estimation using Twitter data. Political Anal. 2015, 23, 76–91. [Google Scholar] [CrossRef]
- Badawy, A.; Ferrara, E.; Lerman, K. Analyzing the digital traces of political manipulation: The 2016 russian interference twitter campaign. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 28–31 August 2018; pp. 258–265. [Google Scholar]
- Cinelli, M.; De Francisci Morales, G.; Galeazzi, A.; Quattrociocchi, W.; Starnini, M. The echo chamber effect on social media. Proc. Natl. Acad. Sci. USA 2021, 118, e2023301118. [Google Scholar] [CrossRef]
- Rao, A.; Morstatter, F.; Hu, M.; Chen, E.; Burghardt, K.; Ferrara, E.; Lerman, K. Political Partisanship and Antiscience Attitudes in Online Discussions About COVID-19: Twitter Content Analysis. J. Med. Internet Res. 2021, 23, e26692. [Google Scholar] [CrossRef]
- Lazer, D.M.; Baum, M.A.; Benkler, Y.; Berinsky, A.J.; Greenhill, K.M.; Menczer, F.; Metzger, M.J.; Nyhan, B.; Pennycook, G.; Rothschild, D.; et al. The science of fake news. Science 2018, 359, 1094–1096. [Google Scholar] [CrossRef]
- Grinberg, N.; Joseph, K.; Friedland, L.; Swire-Thompson, B.; Lazer, D. Fake news on Twitter during the 2016 US presidential election. Science 2019, 363, 374–378. [Google Scholar] [CrossRef]
- Nikolov, D.; Flammini, A.; Menczer, F. Right and Left, Partisanship Predicts (Asymmetric) Vulnerability to Misinformation. Available online: https://misinforeview.hks.harvard.edu/wp-content/uploads/2021/02/nikolov_partisanship_vulnerability_misinformation_20210215.pdf (accessed on 16 June 2021).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Pagliardini, M.; Gupta, P.; Jaggi, M. Unsupervised Learning of Sentence Embeddings Using Compositional n-Gram Features. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers); Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 528–540. [Google Scholar] [CrossRef]
- Warriner, A.B.; Kuperman, V.; Brysbaert, M. Norms of valence, arousal, and dominance for 13,915 English lemmas. Behav. Res. Methods 2013, 45, 1191–1207. [Google Scholar] [CrossRef] [PubMed]
- McLean, R.A.; Sanders, W.L.; Stroup, W.W. A unified approach to mixed linear models. Am. Stat. 1991, 45, 54–64. [Google Scholar]
- Winter, B. A very basic tutorial for performing linear mixed effects analyses. arXiv 2013, arXiv:1308.5499. [Google Scholar]
- Alipourfard, N.; Fennell, P.G.; Lerman, K. Can you Trust the Trend? Discovering Simpson’s Paradoxes in Social Data. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 19–27. [Google Scholar]
- Späth, H. Algorithm 39 clusterwise linear regression. Computing 1979, 22, 367–373. [Google Scholar] [CrossRef]
- da Silva, R.A.; de Carvalho, F.d.A. On Combining Clusterwise Linear Regression and K-Means with Automatic Weighting of the Explanatory Variables. In Proceedings of the International Conference on Artificial Neural Networks, Alghero, Italy, 11–14 September 2017; Springer: Cham, Switzerland, 2017; pp. 402–410. [Google Scholar]
- da Silva, R.A.; de Carvalho, F.d.A. On Combining Fuzzy C-Regression Models and Fuzzy C-Means with Automated Weighting of the Explanatory Variables. In Proceedings of the 2018 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Sung, H.G. Gaussian Mixture Regression and Classification. Ph.D. Thesis, Rice University, Houston, TX, USA, 2004. [Google Scholar]
- Ghahramani, Z.; Jordan, M.I. Supervised Learning from Incomplete Data via an EM Approach. Available online: https://papers.nips.cc/paper/1993/file/f2201f5191c4e92cc5af043eebfd0946-Paper.pdf (accessed on 16 June 2021).
- Alipourfard, N.; Burghardt, K.; Lerman, K. Handbook of Computational Social Science. Volume 2 Data Science, Statistical Modeling, and Machine Learning Methods, Chapter Disaggregation via Gaussian Regression for Robust Analysis of Heterogeneous Data; Taylor & Francis: Abingdon, UK, 2021. [Google Scholar]
- Lerman, K. Computational social scientist beware: Simpson’s paradox in behavioral data. J. Comput. Soc. Sci. 2018, 1, 49–58. [Google Scholar] [CrossRef]
- Ivory, D.; Leatherby, L.; Gebeloff, R. In counties that voted for Trump, fewer people are getting vaccinated. The New York Times. 17 April 2021. Available online: https://www.nytimes.com/2021/04/17/world/in-counties-that-voted-for-trump-fewer-people-are-getting-vaccinated.html (accessed on 22 April 2021).
- Hornsey, M.J.; Harris, E.A.; Fielding, K.S. The psychological roots of anti-vaccination attitudes: A 24-nation investigation. Health Psychol. 2018, 37, 307. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Polarization | PLDs |
|---|---|
| Pro-Science () | cdc.gov, who.int, thelancet.com, mayoclinic.org, nature.com, newscientist.com … (100 + PLDs) |
| Anti-Science () | 911truth.org, althealth-works.com, naturalcures.com, shoebat.com, prison-planet.com … (100 + PLDs) |
| Classifier | Precision | Recall | Micro-F1 | Macro-F1 |
|---|---|---|---|---|
| Pro-Science | 0.90 | 0.89 | 0.89 | 0.89 |
| Anti-Science | 0.89 | 0.90 | 0.89 | 0.90 |
| DogR Result | # of Counties | Adjusted | ||
|---|---|---|---|---|
| Anti-science share | Pooled | 784 | 0.424 | 0.418 |
| Group 0 | 330 | 0.488 | 0.473 | |
| Group 1 | 340 | 0.591 | 0.580 | |
| Group 2 | 114 | 0.357 | 0.302 | |
| Vaccination share | Pooled | 716 | 0.444 | 0.436 |
| Group 0 | 158 | 0.533 | 0.501 | |
| Group 1 | 386 | 0.686 | 0.678 | |
| Group 2 | 172 | 0.311 | 0.268 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, M.; Rao, A.; Kejriwal, M.; Lerman, K. Socioeconomic Correlates of Anti-Science Attitudes in the US. Future Internet 2021, 13, 160. https://doi.org/10.3390/fi13060160
Hu M, Rao A, Kejriwal M, Lerman K. Socioeconomic Correlates of Anti-Science Attitudes in the US. Future Internet. 2021; 13(6):160. https://doi.org/10.3390/fi13060160
Chicago/Turabian StyleHu, Minda, Ashwin Rao, Mayank Kejriwal, and Kristina Lerman. 2021. "Socioeconomic Correlates of Anti-Science Attitudes in the US" Future Internet 13, no. 6: 160. https://doi.org/10.3390/fi13060160
APA StyleHu, M., Rao, A., Kejriwal, M., & Lerman, K. (2021). Socioeconomic Correlates of Anti-Science Attitudes in the US. Future Internet, 13(6), 160. https://doi.org/10.3390/fi13060160