Mitigating phishing, with either prevention or detection, has been well-studied in the academic literature. The following subsections focus on the discussion of software-based approaches, as user awareness is considered out of scope for this work.
2.1. Rule-Based Phishing Detection
Rule-based anti-phishing approaches classify websites as malicious or legitimate based on a set of pre-defined rules. Since the ruleset is the centrepiece of the detection system, its performance is tightly linked to its design. As a consequence, the focus is set on rule selection and conditional relationship setting.
Ye Cao et al. [
13] proposed an automated allowlist capable of updating itself with records of the IP addresses of each website visited that features a login page. If a user attempts to submit data through such a login user interface, they get a warning that they are doing so on a webpage outside of the allowlist. The proposed solution uses the Naive Bayesian as the classifier, which has delivered high effectiveness in previous studies on anti-spam [
14] and junk email filters [
15]. After the decision has been made, the classification is expected to be further confirmed by the user. Although the proposed solution delivered an impressive performance with true positives rate 100% and false negatives rate 0%, this approach relies on the involvement of the users and cannot discover new phishing webpages.
Another allowlist based approach is presented by A. K. Jain and B.B. Gupta [
16], which achieves phishing detection using a two-phase method. The proposed system logically splits webpages into not visited and re-visited. The first module is triggered when a page is re-visited and consists of a domain lookup within the allowlist. If the domain name is found, the system matches the IP address to deliver the decision. When the domain name cannot be found in the allowlist, the system uses statistical analysis of the number of hyperlinks pointing to a foreign domain. After extraction, the system examines the features from the hyperlinks to take the decision. The proposed system covers a variety of phishing attacks (e.g., DNS poisoning, embedded objects, zero-hour attack), and its experimental results report a 86.02% true-positive rate and 1.48% false-negative rate.
Yue Zhang et al. [
17] proposed an adaptation of the term frequency-inverse document frequency (TF-IDF) information retrieval algorithm for detecting phishing webpages in a content-based approach called CANTINA. CANTINA uses the TF-IDF algorithm to extract the most frequently used five words, which are then fed into a search engine. The website’s domain name is then compared with the top
N domain names resulted from the search, and if there is a match, the website is labelled as legitimate. To lower the rate of false-positives, they included a set of heuristics checking the age of the domain, the presence of characters such as @ signs, dashes, dots or IP addresses in the URL. Furthermore, it features some content-based checks such as inconsistent well-known logos, links referenced and forms present. The experimental results show a true positive rate of 97% and a false positive rate of 6%. After the addition of these heuristics, the false positive rate decreased to 1% but so did the true positive rate, which decreased to 89%. Finally, one should note that CANTINA’s effectiveness is tightly linked to the use of the English language.
Rami Mohammad and Lee McCluskey [
18] present an intelligent rule-based phishing detection system, whose ruleset is produced through data mining. The study begins with a proposed list of seventeen phishing features derived from previous work on anti-phishing detection systems. These are then fed into different rule-based classification algorithms, each of which utilises a different methodology in producing knowledge. The conclusion presents C4.5 [
19] as the algorithm that produced the most effective ruleset. The extracted set presents features related to: (a) the request URL, (b) domain age, (c) HTTPS and SSL, (d) website traffic, (e) subdomain and multi subdomain, (f) presence of prefix or suffix separated by “–” in the domain, and (g) IP address usage. The limitation of this work is the reliance on third-party services providing information about the age of the domain, webpage traffic, and DNS record data. Furthermore calibrating the thresholds for each feature requires complex statistical work.
S.C. Jeeva and E.B. Rajsingh [
20] approach phishing detection by firstly focusing on the extraction of quintessential indicators, statistically proven to be found in phishing websites. The work then presents a set of heuristics based on the aforementioned statistical investigations and analysis, which are translated into fourteen rules responsible for URL classification. Similar to the work of Rami Mohammad and Lee McCluskey [
18], the identified rules are fed into two data mining algorithms (Apriori and Predictive Apriori), to discover meaningful associations between them. The work provided two sets resulted from associative rule mining and reported an experimental accuracy of 93% when using the ruleset mined by the apriori algorithm.
2.2. Machine-Learning Based Phishing Detection
Machine learning-based solutions centre around the processes of feature extraction and the training of machine learning models. These features take the shape of information from different parts of the website, such as the URL or the Hypertext Markup Language (HTML) content. This subsection will briefly discuss a variety of machine learning approaches to anti-phishing detection systems, and the essential takeaways from the studies covered.
A. Le et al. [
21] propose PhishDef—a system which performs on-the-fly classification of phishing URLs based on lexical features and adaptive regularisation of weights (AROW [
22]). The AROW algorithm allows the calibration of the classification mechanism upon making a wrong prediction. As a result, the predictions will be of high accuracy even when the trained model is provided with noisy data. Furthermore, PhishDef uses an online classification algorithm, as opposed to a batch-based one. Online classification algorithms continuously retrain their model when encountering new data, instead of just delivering the prediction. PhishDef reports an accuracy of 95% with noise ranging from 5% to 10%, and above 90% when noise is between 10% and 30%. It is worth noting that the aforementioned performance of PhishDef comes with low computational and memory requirements.
Guang Xiang et al. [
23] extend CANTINA ([
17]) by adding a feature-rich machine learning module. The iteration is named CANTINA+ and it aims to address the high false-positive rate of its predecessor. Besides machine learning techniques, this enhanced iteration brings focus on search engines, and the HTML Document Object Model (DOM), adding several checks on brand, domain, hostname search and HTML attributes. Besides the inherited trade-offs of CANTINA, the authors state that one of the limitations of CANTINA+ is the incapability of delivering predictions on phishing websites that are composed of images, thus offering no text which can be analysed. Furthermore, compared to CANTINA, while it manages to provide improved accuracy rate of 92%, it is still prone to considerable false positives rate.
Ling Li et al. [
24] present a multi-stage detection system that aims to both pro-actively and reactively thwart banking botnets. The first module of this model is an early warning detection module which supervises the malicious-looking newly registered domains. The second module does spear phishing detection using a machine learning model trained on different variations of popular domains such as bitsquatting, omission, and other alteration techniques. Although this work is focused more on banking botnets, the approach used in URL variations detection and spear-phishing protection is well designed.
Li Yukun et al. [
25] take a different approach by utilising a stacked machine learning model that surpasses the capability of single model implementations of anti-phishing detection systems. The work provides a thorough comparison of the proposed stack composed of Gradient Boosting Decision trees [
26], XGBoost [
27], and LightGBM [
28] and single models using algorithms such as Support Vector Machine, nearest neighbour classifier, decision trees, and Random Forest. To measure inter-rater reliability for qualitative (categorical) items and select the best candidates for the stacking model the authors used Cohen’s kappa static [
29] and the lower average error. This lowered the false-positive and false-negative rates of the stacking model, when compared to all its components individually, achieving an accuracy rate of 97.3%, false positive rate of 1.61% and a false negative rate of 4.46%.
Similarly, Rendall et al. [
30] implemented and evaluated a two-layered detection framework that identifies phishing domains based on supervised machine learning. The authors considered four supervised machine learning algorithms, i.e., Multilayer Perceptron, Support Vector Machine, Naive Bayes, and Decision Tree, which were trained and evaluated using a dataset consisting of 5995 active phishing and 7053 benign domains. Their detection engine used static and dynamic features derived from domain and DNS packet-level data. Finally, the authors discussed the features’ ability to resist tampering from a threat actor who is trying to circumvent the classifiers, e.g., by typosquatting, as well as their applicability in a production environment.
Sahingoz Koray Ozgur et al. [
31] investigate the possibility of a real-time anti-phishing system by training seven different classification algorithms with natural language processing (NLP), word vector and hybrid features. In doing so, Sahingoz Koray Ozgur et al. [
31] state the lack of a worldwide acceptable test dataset for effectiveness comparison between phishing solutions, and proceeds to construct one containing 73,575 URLs of which 34,600 legitimate and 37,175 malicious. This dataset is used to conduct comparisons between previous work in the field and the selected classification algorithms (Decision Trees, Adaboost, Kstar, K-Nearest Neighbour, Random Forest, Sequential Minimal Optimization and Naive Bayes). The most effective combination discovered is the Random Forest algorithm trained with NLP features. It achieved an experimental accuracy of 97.98% in URL classification, while being language and third-party service independent, and achieving real-time execution and detection of new websites. Finally, the authors’ experiments suggest that the NLP features seem to improve accuracy across the majority of machine learning algorithms covered in their work.
M. A. Adebowale et al. [
10] use an artificial neural network named Adaptive Neuro-Fuzzy Inference System (ANFIS [
32]) which is trained with integrated text, image, and frame features. The work presents a brief comparison between the proposed solution and numerous other anti-phishing detection systems. The works builds a set of 35 features from phishing websites analysis and related work while also comparing their efficiency. These are then bound in sets and fed into ANFIS, SVM, and KNN algorithms to study their performance. The ANFIS-based hybrid solution (including text, image and frame features) delivered an accuracy of 98.30%. Although the work considers the previously mentioned solution as the conclusive, the ANFIS text-based classification records an accuracy of 98.55%. Besides this, throughout the study, there is evidence that text-based detection systems tend to outperform image-based, frame-based and hybrid ones.
Mahmood Moghimi and Ali Yazdian Varjani [
33] present a solution based on a selection of seventeen web content features fed into a Support Vector Machine (SVM) learning algorithm. The most effective features are chosen based on accuracy, error, Cohen’s Kappa Static [
29], sensitivity, and the F-Measure [
29]. Before evaluation, the features are fed into the SVM algorithm to extract knowledge under the shape of rules to increase comprehensibility. By doing this, the importance and effect of each feature can be extracted. The authors benchmark the features and discuss the consequences of omitting different rules, outlining the ones with the biggest contribution in making accurate predictions. The study reports an impressive experimental result of 99.14% accuracy, with only 0.86% false negative. Moreover, the proposed solution achieves zero-day phishing detection and both third party service and language independence. Christou et al. [
34] also used SVM and Random Forest implemented in the Splunk Platform to detect malicious URLs. They reached 85% precision and 87% recall in the case of Random Forests, while SVM achieved up to 90% precision and 88% recall.
Finally, Mouad Zouina and Benaceur Outtaj [
35] examined how similarity indexes influence the accuracy of Support Vector Machine models. The aim of the study is the production of a lightweight anti-phishing detection system, suitable for devices such as smartphones. The work first presents a set of base URL features composed of: (a) the number of hyphens, (b) number of dots, (c) the number of numerical characters, and (d) IP presence. The authors extended this set by adding the: (a) classic Levenshtein distance, (b) normalised Levenshtein distance, (c) Jaro Winkler distance, (d) the longest common subsequence, (e) Q-Gram distance, and (f) the Hamming distance, while measuring their influence on accuracy. Their solution achieves an accuracy of 95% and presents 2000 records (1000 legitimate and 1000 malicious) on which it performs all the calculations mentioned earlier when classifying a URL. The authors conclude that the Hamming distance is the most effective feature from the studied set improving the overall recognition rate by 21.8%.
The literature includes a number of works that facilitate machine learning to mitigate phishing as a threat. From the above works, it is evident that supervised machine learning algorithms, e.g., SVM, Naive Bayes, perform well in a binary classification problem like phishing detection. Nonetheless, contrary to our work, the majority of the literature is using machine learning algorithms that are trained and evaluated in balanced datasets. This means that the evaluation took place using a scenario that is not realistic [
11]. Furthermore, multiple data sources have been used for feature selection. We differentiate from prior works in the literature by proposing a new combination of features, which is evaluated over time. Finally, while the use of Levenshtein distance has been explored in the previous literature, e.g., explored but not used in the SVM classifier of [
35], to the best of our knowledge we are the first to use it as a feature in phishing detection model.








{kind=link}
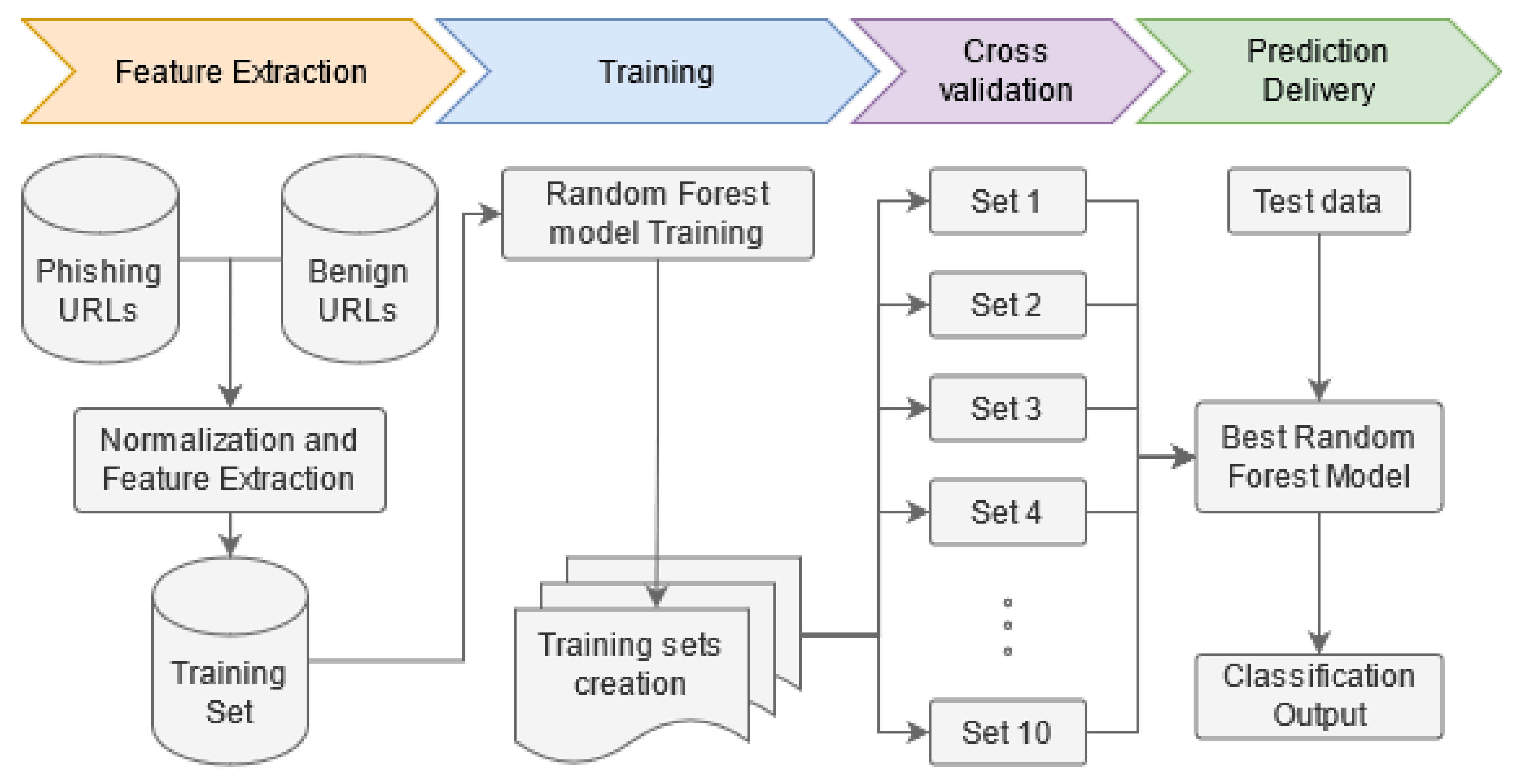{kind=link}