1. Introduction
Many complex systems in real life, such as social networks (e.g., Facebook) and coauthor networks, can be abstracted into graph-structured data for analysis. The analysis results can be leveraged to guide practical applications, such as link prediction and personalized recommendation. The variational graph autoencoder (VGAE) proposed by Kipf and Welling [
1], which extended the variational autoencoder (VAE) [
2] from the field of Euclidean structure data (e.g., image) to that of non-Euclidean data (e.g., graph-structured data), is one of the commonly utilized methods for studying graph-structured data. It could capture the distribution of the samples through a two-layer graph convolutional network (GCN) [
3] and reconstruct the graph structure through a decoder. In recent years, the variations of VAE and VGAE [
4,
5,
6,
7] have emerged in an endless stream, further improving the performance of the variational (graph) autoencoder on traditional machine learning tasks such as link prediction. Although VGAE has been widely applied and promoted, there are two urgent challenges to be solved:
How to set a reasonable prior without additional expert knowledge. VGAE and its variants assumed that the prior distribution of latent variables obeyed a simple standard normal distribution. Under this assumption, the Kullback–Leibler (KL) term in the objective function usually caused the posterior distribution to overfit the shape and parameters of the prior and encouraged samples to focus on the origin. Therefore, the phenomenon of Posterior Collapse [
8] will occur. Two types of methods are proposed to handle the issue. The first is to improve the loss function of the variational (graph) autoencoder [
9,
10,
11,
12]. However, most of the methods were designed for Euclidean structure data based on the variational autoencoder. These methods are difficult to extend to graph-structured data since they are not arranged neatly, making it difficult to define the same convolution operation as image data. The second is to assume the latent variables follow a more complex prior or posterior distribution [
13,
14,
15,
16,
17]. Unfortunately, these methods applied a more complex distribution as the prior for latent variables. In general, a more complex prior means more expert experience is involved. Thus, it is an arduous task to determine a suitable prior when we lack prior knowledge.
How to improve the interpretability of VGAE. Graph neural networks (GNNs) have achieved great success in processing graph-structured data in recent years. However, this type of methods is often a black box, which makes the learned low-dimensional representations unexplainable. For example, we cannot explain the meanings of the neural networks’ parameters when we want to convince people of the prediction results in the neural networks. Existing methods improved the interpretability of GNNs by analyzing and explaining the prediction results of the algorithms [
18] or constructing an interpretable model [
19]. However, the above methods made the node embeddings still black boxes because they did not point out the meanings of embeddings themselves, i.e., they could not explain the meaning of each dimension of the learned representations.
To cope with the above challenges, we propose a noninformative prior [
20] based interpretable variational graph autoencoder called NPIVGAE, which utilizes the noninformative prior distribution as the prior of the latent variables. Such a prior is more reasonable, especially when we lack prior knowledge. It no longer forces the posterior distribution to tend to the standard normal distribution, so that almost all the posterior distribution parameters are learned from the sample data. In addition, we leverage a new perspective to understand the node representations to improve the interpretability of the model. Specifically, each dimension of the latent variables is regarded as the soft assignment probability that the node belongs to each community (also called block in the stochastic blockmodel). Meanwhile, the correlation within and between the blocks to which the nodes belong is described by a block–block correlation matrix. When reconstructing the link between two nodes in the graph, the representations of these two nodes and the correlation between the blocks to which two nodes belong are taken into account.
Our main contributions can be summarized as follows:
We propose a novel noninformative prior-based variational graph autoencoder, giving the prior distribution of latent variables when we lack prior knowledge. Then we analyze the influence of the noninformative prior on the posterior and confirm that the posterior distribution is affected by the data itself instead of the prior knowledge, when we use noninformative prior.
We improve the interpretability of the model by regarding each dimension of the node representations as the probability of which the node belongs to each block. When reconstructing the graph, we also consider the correlation within and between the blocks, which is described by a block–block correlation matrix.
Substantial experiments performed on three real datasets verify the effectiveness of our model. Experimental results show that the proposed model significantly outperforms the graph autoencoder model and its variants.
4. The Proposed NPIVGAE
In this section, we first describe the framework of NPIVGAE and then introduce the model in details. Finally, we analyze the influence of the noninformative prior distribution on the posterior distribution.
4.1. Notations and Problem Formulation
An undirected attribute network with n nodes can be denoted by an adjacency matrix and an attribute matrix . Concerning , if there is an edge (also called a link) between node and node , , otherwise . Set the diagonal elements of to 1, namely, each node has an edge to itself. The attribute information of all nodes is contained in the attribute matrix , of which is the attribute of and m denotes the number of the features observed.
Given an attribute graph , we aim to learn a latent variable for node , and can be explained. Specifically, we define the node representations as an latent variables matrix , where stands for the embedding of node and d is dimensions of latent variables. d is also the number of blocks in the attribute network . Each dimension of the embedding is regarded as the probability that the node belongs to each block. We also introduce a block–block correlation matrix , where affects the link between node and node belonging to block k and block l, respectively.
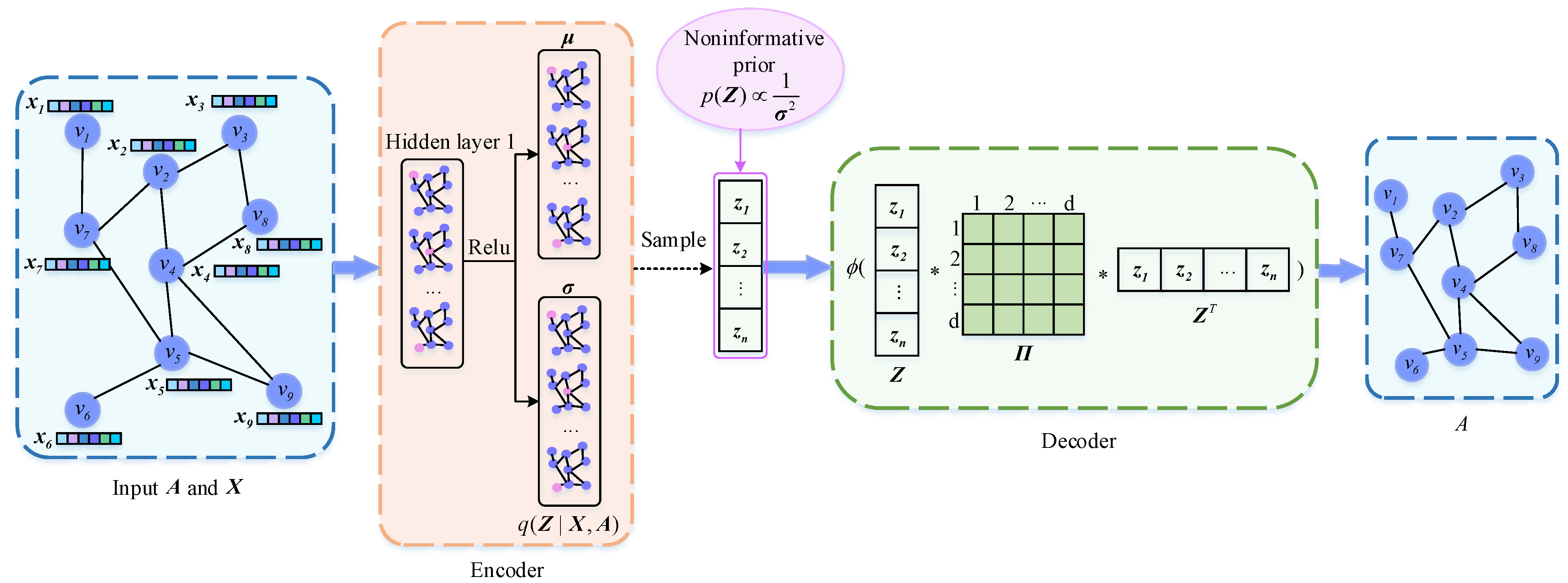
4.2. Framework
Figure 1 shows the overall framework of NPIVGAE, which mainly includes two parts: encoder and decoder. Firstly, we input the adjacency matrix
and the attribute matrix
to the encoder to obtain the mean and variance of the latent variables’ posterior and then sample to get
. Unlike VGAE, we introduce the noninformative prior probability as the prior of
and leverage node embeddings as well as block–block correlation matrix to reconstruct the adjacency matrix. Finally, the loss function is calculated to update the parameters in reverse. Details of each section are described below.
4.3. Encoder
We leverage a two-layer GCN as the encoder to generate the parameters
and
of the normal distribution:
Here
is the matrix corresponding to
(the mean vector of node
’s embedding
), and similarly,
is the matrix corresponding to
(the standard deviation vector of node
’s embedding
). The two-layer GCN is defined as
,
represents the Relu activation function,
is the symmetric normalized matrix of the adjacency matrix
.
and
share the weights
of the first layer. The second layer weights of
and
are
and
respectively. Then the latent variables are obtained by sampling
. The specific process is as follows:
4.4. Decoder
We regard each dimension of the latent representation as the probability that the node belongs to each block. We allow each node to belong to overlapping blocks (communities), making each dimension of interpretable. Then we introduce the block–block correlation matrix to describe the relevance within and between blocks.
We reconstruct the adjacency matrix by considering the node embeddings and the correlation between the block to which node
belongs and the block to which node
belongs by the following equations:
where
represents the activation function. In (
9), each value
in the block–block correlation matrix affects the probability of the link between node
and node
, where node
and node
belong to block
m and block
n, respectively.
4.5. Loss Function
The proposed NPIVGAE takes the noninformative prior as the prior distribution of the latent variables
to minimize the influence of the prior on the posterior. Since we still assume that the variational posterior
is a normal distribution
, the corresponding noninformative prior is
(i.e., uniform distribution, which is regarded as noninformative) according to
Section 3.1.
By minimizing the negative evidence lower bound (ELBO), we define the loss function of the noninformative prior-based interpretable variational graph autoencoder:
After deduction (please refer to
Appendix A for the detailed derivation), we can get the final objective function:
Our model exploits stochastic gradient descent to minimize the objective function and optimize the parameters. Like VGAE, the reparameterization trick is also leveraged for training in this paper to achieve the gradient update of the mean and variance.
4.6. The Influence of the Noninformative Prior on the Posterior
In
Section 3.1, we mentioned that our purpose of designing the noninformative prior was to reduce the influence of the prior on the posterior. We take a single Gaussian variable
as an example to analyze this effect. Assuming that the variance
is known, we desire to get the solution of the mean
based on a set of
t sample data
and set the conjugate prior distribution
. According to [
20], the posterior probability of
is
, of which
and
. The
represents the maximum likelihood estimate of
, and
is given by the sample data.
When in the prior distribution tends to infinity, the prior distribution becomes a uniform distribution, also regarded as a noninformative prior. At this time, the posterior mean is given by the maximum likelihood , and the variance is , i.e., and have nothing to do with the prior parameters and . Thus, we can conclude that when the prior of the Gaussian distribution is selected as the noninformative prior, the prior can have the smallest impact on the posterior distribution, and the posterior parameters can be learned almost all from the sample data.
4.7. Algorithm and Complexity Analysis
The flow of our algorithm is demonstrated in Algorithm 1. First, we initialize the network parameters and the block–block correlation matrix
. For each iteration, the mean and variance of the latent variables
are obtained through step 4, and the noninformative prior of
is obtained according to
. Then sample
according to (
7). Finally, we calculate the objective function and use gradient descent to update the parameters
,
, and
.
In the following, we analyzed the time complexity of our model. In each iteration, it takes
to calculate the
d-dimensional vectors
,
, and
, so the total time complexity is
, where
and
E represents the number of iterations.
| Algorithm 1 NPIVGAE. |
| Input: |
| The adjacency matrix and the attribute matrix . |
| Hyperparameters: Number of iterations E, latent dimension d. |
| Output: |
| Latent variables . |
| 1: Initialize neural networks’ parameters and . |
| 2: for to E do |
| 3: for to n do |
| 4: Obtain the mean and variance according to (4) and (5), respectively. |
| 5: Get the noninformative prior of using . |
| 6: Sample to get the latent variable through (7). |
| 7: end for |
| 8: Calculate the loss function according to (11). |
| 9: Update parameters , , and with back propagation. |
| 10: end for |
| 11: return . |
5. Experimental Results and Analysis
In this section, we assess the effectiveness of our model (NPIVGAE) on two classic downstream tasks: (i) link prediction and (ii) node classification. The processor used in the experiments is Intel(R) Core(TM) i5-9400 CPU @ 2.90 GHZ. The memory is 8G and the Windows version is WIN10. Our experiments are implemented with Python’s Tensorflow, and the version of Tensorflow is 1.12.0. The weights , , and of the two-layer GCN are initialized to be uniform distribution using the random_uniform function in Tensorflow, and the weights are updated in the back propagation process. In order to show the effectiveness of using the noninformative prior, we design a variant of our model, namely NPVGAE. It employs as the noninformative prior of the hidden variables without introducing block–block correlation matrix .
5.1. Datasets
In this paper, we adopt three real datasets—Cora, Citeseer, and Pubmed [
28]—for testing the performance of the proposed NPIVGAE and its variant. They all belong to citation networks. The statistics of the three datasets are depicted in
Table 1. A more detailed description is as follows:
Cora: The nodes in this dataset represent papers in the field of machine learning, the edges are the citation relationships of the papers, and the attributes represent the words contained in the paper. The labels indicate the classification of the papers, such as Neural_Networks and Rule_Learning.
Citeseer: In the Citeseer dataset, the meanings of nodes, edges, and attributes are the same as those in Cora. The labels are also the categories of the papers, such as agents and machine learning.
Pubmed: This dataset is made up of 19,717 papers related to diabetes, all of which are from the Pubmed database. Nodes represent papers, edges denote citation relationships, and attributes are words in the paper. All the papers are divided into 3 categories, namely (1) Diabetes Mellitus, Experimental, (2) Diabetes Mellitus Type I, and (3) Diabetes Mellitus Type II.
5.2. Baselines
We compare NPIVGAE and its variant NPVGAE with several state-of-the-art methods, including using a standard normal distribution as the prior and solving the posterior collapse problem.
GAE [
1] is a non-probabilistic graph autoencoder model, which reconstructs the adjacency matrix through the inner product of the node representations. It minimizes the reconstruction error to learn the parameters in the neural networks.
VGAE [
1] assumes that the latent variables follow a normal distribution. The mean and variance of latent variables are encoded by a two-layer GCN, and the structure is reconstructed by a decoder.
ARGE [
29] introduces an adversarially regularized term into the graph autoencoder. The adversarial module aims to discriminate whether the node embeddings come from the prior distribution or the graph encoder.
ARVGE [
29] realizes regularization and promotion of node embeddings by drawing an adversarial module into the variational graph autoencoder.
EVGAE [
10] divides the dimensions of the latent variables into multiple groups, called epitomes, and only penalizes one group each time. This method alleviates the posterior collapse problem by increasing the activity of the hidden units.
5.3. Link Prediction
5.3.1. Experimental Setup
Link prediction is one of the most common downstream tasks in network representation learning. It can recover missing links or predict possible links in the future by analyzing the given network structure. Consistent with VGAE, we also make use of 5% and 10% links as the validation set and test set, respectively, and randomly generate the same number of non-existent links. The purpose of using the validation set is to adjust the hyperparameters, and the remaining 85% of the links are employed for the training set. In the training process, we add
as a neural network parameter to the objective function and update it through backpropagation. Due to the relatively small scale of Cora and Citeseer datasets, we set weight_decay = 0.01 to prevent overfitting. We iterate 800 times to train sufficiently for the large scale of the Pubmed dataset. The number of hidden layer units and iteration times of three datasets of our model are described in
Table 2. We take advantage of Adam optimizer to optimize the parameters with a learning rate of 0.01.
We take the same experimental setup as our model for GAE and VGAE. As for ARGE, ARVGE, and EVGAE, we adopt the same setting as the original papers. We exploit the area under the ROC curve (AUC) and average precision (AP) to evaluate the performance of our model and other baselines. These are two evaluation indexes commonly employed in the link prediction task. The more the values of AUC and AP approach 1, the better the experimental results are. We ran each dataset five times and reported the average value to ensure the accuracy of the algorithm.
5.3.2. Results and Discussion
The experimental results are illustrated in
Table 3, and the best results are shown in bold. It can be concluded from the experimental results that the proposed NPIVGAE and its variant NPVGAE achieve the best results on almost all datasets. For example, AUC exceeds 93% and AP reaches 94% on the Citeseer dataset, while ARVGE only reaches 92% and 93%, respectively. The reason may be that ARVGE employs a discriminator to make the latent variables more inclined to the prior given manually. This prior may be unreasonable so that ARVGE cannot learn the characteristics of the sample data well. Our variant NPVGAE performs better than other baselines on the Cora’s AP as well as Pubmed’s AUC and AP, proving that the noninformative prior we introduced plays a critical role. We do not give a strong prior assumption to the model so that almost all parameters of the posterior distribution are learned from the sample data. NPIVGAE achieves better results than NPVGAE on the Citeseer dataset. That proves the effectiveness of combining the block–block correlation matrix. To sum up, the two components of the noninformative prior and the block–block correlation matrix can help improve the performance of the model. The noninformative prior module contributes most to the performance of the overall model NPIVGAE.
5.4. Semi-Supervised Node Classification
We evaluate the effectiveness of our model on the semi-supervised node classification task. Let
denote the true label vector of node
, where
l is the number of categories. The learned embeddings are concatenated into a fully connected layer. The outputs of this layer are employed as the predicted label vectors
(the length of the outputs is the number of categories
l). We apply the cross-entropy loss function in (
12) to calculate the loss between the predicted label and the true label of each node and optimize it through the Adam optimizer.
5.4.1. Experimental Setup
Following [
28], we randomly selected 5, 10, and 20 labels per class to train. For the Cora dataset, for example, there are 7 classes, and we select 5 labels randomly for each class. Hence, there are 35 labels for semi-supervised training in all. We randomly divide the dataset into training, validation, and test sets at each iteration. It can provide more robust performance when the dataset is randomly divided. In the experiment, the encoder of our model (NPIVGAE) contains a two-layer GCN with 32 and 16 hidden units in the first and second layers, respectively, and so does that of NPVGAE. The NPIVGAE and NPVGAE, together with other baselines, are trained 50 iterations, and the learning rate is set to 0.01. We took the average results of 10 runs as a report.
5.4.2. Experimental Results and Analysis
The classification results on the Cora, Citeseer, and Pubmed datasets are shown in
Table 4,
Table 5,
Table 6, respectively. When the number of labels applied for training is relatively small (e.g., each class can only obtain 5 or 10 labels), the effect of promotion is particularly obvious. In comparison with the baselines, NPIVGAE and its variant has achieved excellent results on all datasets. The prediction accuracy of NPIVGAE on the Cora dataset has reached more than 81%, as depicted in
Table 4. The indicators of NPIVGAE on the Citeseer dataset also exceed 69%, while the results of other baselines are relatively poor, as displayed in
Table 5. It demonstrates that the NPIVGAE we proposed can learn the information in the graph so effectively that it achieves better performance.
5.5. Efficiency Evaluation
In this section, we analyze the running time of our model to prove the efficiency of the neural network-based model. Then we graphically demonstrated the learning process of NPIVGAE to prove that there is no overfitting.
We selected two methods that did not use neural networks (i.e., LINE (Large-scale Information Network Embedding) [
30] and TADW (text-associated DeepWalk) [
31]) for comparison. LINE embeds a large-scale information network into a low-dimensional vector space while retaining the first-order and second-order similarities. TADW is a matrix factorization method that combines network structure and text features to obtain a better network representation. We conducted experiments on the semi-supervised node classification task with the Cora and Citeseer datasets as examples. To be fair, both TADW and our model NPIVGAE were iterated 50 times. We report the running time in
Figure 2. From
Figure 2, we know that NPIVGAE and TADW are significantly faster than LINE, and NPIVGAE is slightly faster than TADW. In addition, our model was compared with LINE and TADW on time complexity. LINE and TADW have relatively high time complexity, as shown in
Table 7. TADW requires expensive matrix operations, such as SVD decomposition, which limits the ability of TADW to process large-scale data. In contrast, our model NPIVGAE has higher efficiency while guaranteeing accuracy.
Figure 3 shows the learning process of our model in the link prediction task. Our model was iterated 200 times, and the AUC and AP of the training and validation sets are displayed in
Figure 3. The horizontal axis is the number of iterations, and the vertical axis is the accuracy of AUC and AP. We can see that the training and validation accuracy of the model rose sharply in the first 20 iterations, and then gradually slowed down and converged. As mentioned in
Section 5.3.1, we set the weight decay parameter to 0.01 in the experiment since the Cora and Citeseer datasets are relatively small. NPIVGAE performed well on training, validation, and test sets, proving that the strategy we adopted successfully prevented overfitting.
5.6. Visualization
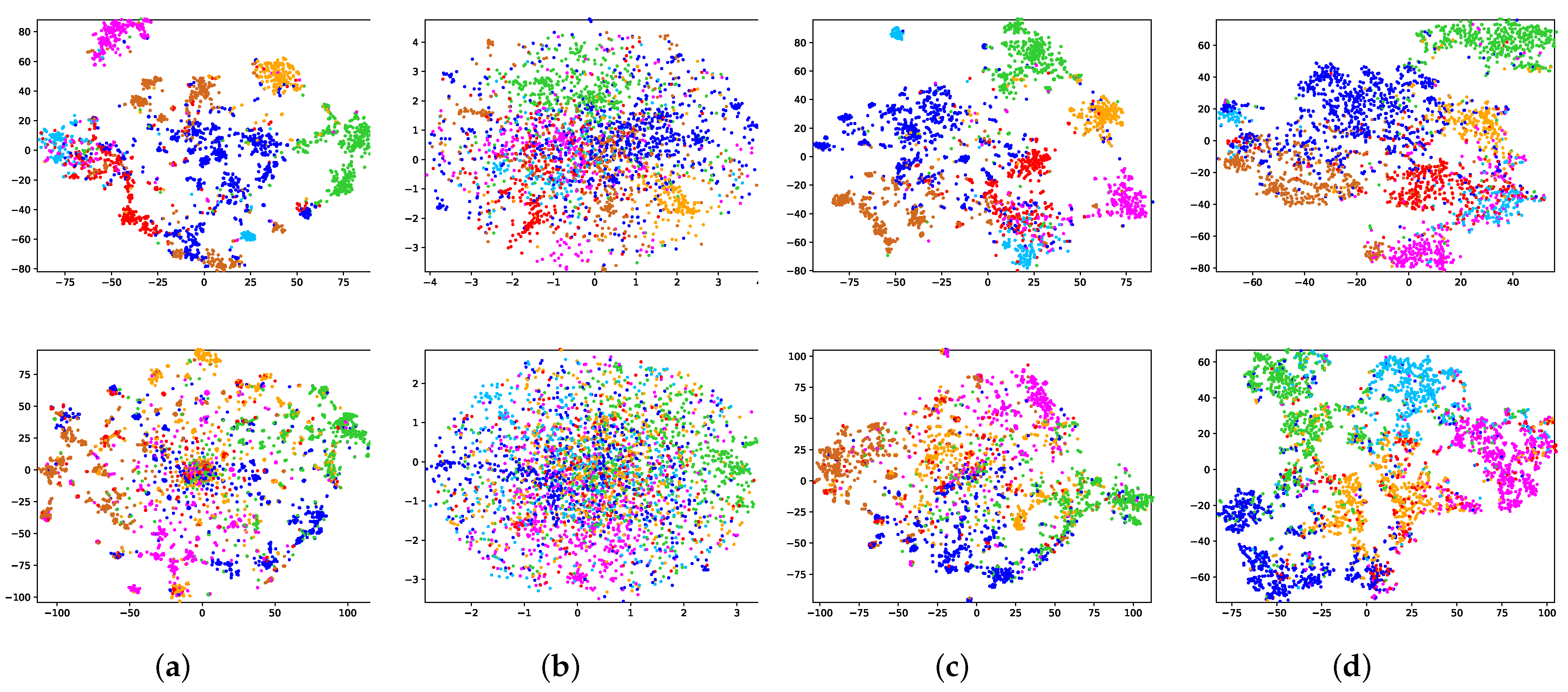
For the purpose of displaying the experimental results more intuitively, t-SNE [
32] is applied to visualize the embeddings of the nodes. We paint nodes according to their true labels, and the nodes belonging to the same category will be painted in the same color. From the second row of
Figure 4a, we can clearly see that the classic VGAE (i.e., assuming that the prior is a standard normal distribution) cannot distinguish different categories of nodes in the latent space. This is because the standard normal distribution prior will encourage the centers of all categories to approach the origin, resulting in the inability to make full use of the latent space. Similar problems also exist in EVGAE and ARVGE, the second row of
Figure 4b,c is more obvious. However, the ideal prior should have as little impact as possible on the posterior distribution and encourage the posterior distribution to learn parameters from the input data. The NPIVGAE we put forward can make full use of the latent space to learn the node representations while distinguishing categories relatively well as shown in
Figure 4d.









{kind=link}
{kind=link}
{kind=link}
{kind=link}