Ensemble Classifiers for Network Intrusion Detection Using a Novel Network Attack Dataset †



Abstract
1. Introduction
- It presents a newly generated IDS dataset called GTCS (Game Theory and Cyber Security) that overcomes most shortcomings of existing datasets and covers most of the necessary criteria for common updated attacks, such as botnet, brute force, distributed denial of service (DDoS), and infiltration attacks. The generated dataset is completely labeled, and about 84 network traffic features have been extracted and calculated for all benign and intrusive flows.
- It analyzes the GTCS dataset using Weka—an open source software which provides tools for data preprocessing and the implementation of several ML algorithms—to select the best feature sets to detect different attacks and provides a comprehensive analysis of six of the most well-known ML classifiers to identify intrusions in network traffic. Specifically, it analyzes the classifiers in terms of accuracy, true positive rates, and false positive rates.
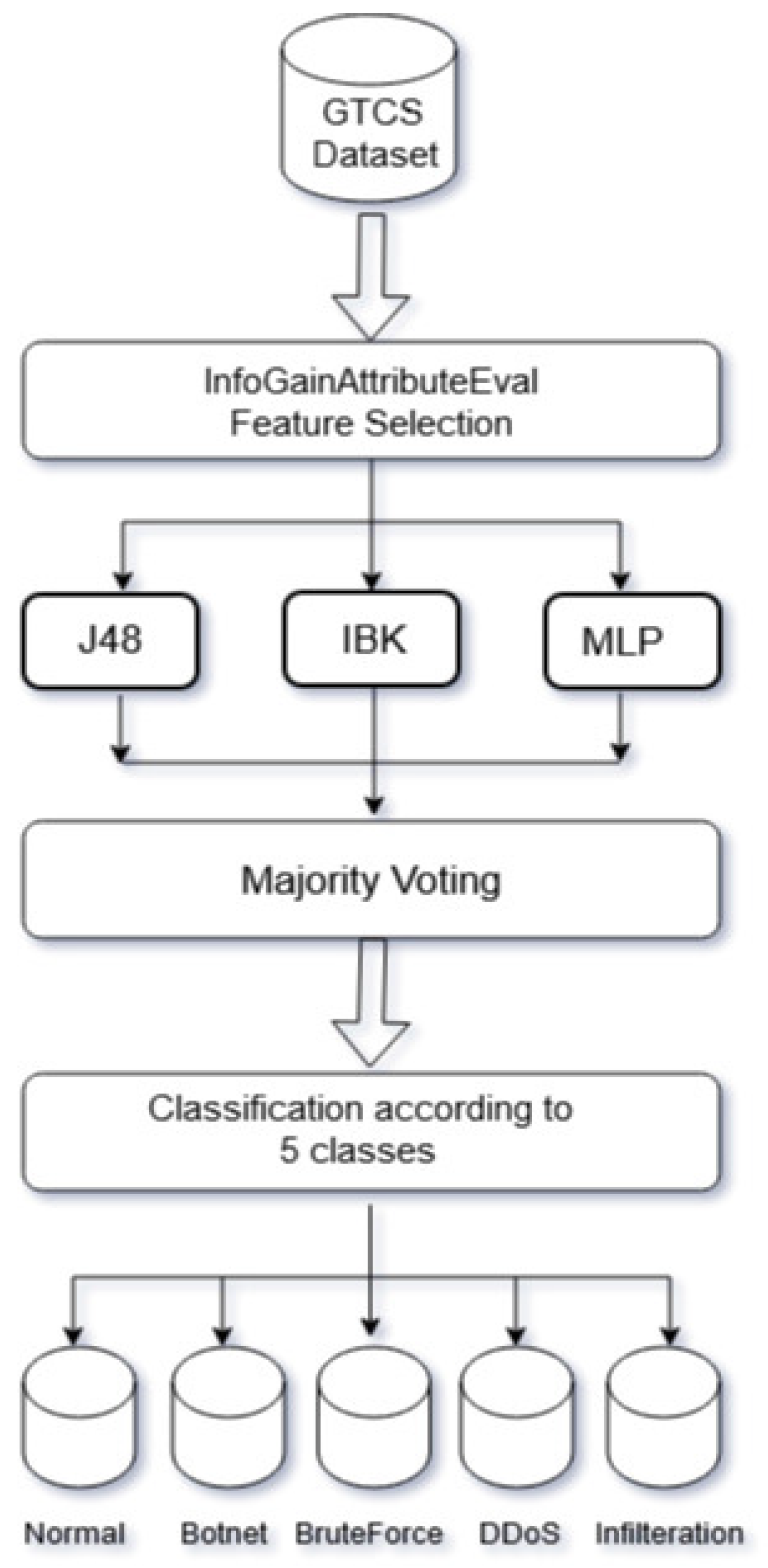
- It proposes an adaptive ensemble learning model that integrates the advantages of different ML classifiers for different types of attacks to achieve optimal results through ensemble learning. The advantage of ensemble learning is its ability to combine the predictions of several base estimators to improve generalizability and robustness over a single estimator.
2. Background
2.1. Intrusion Detection Systems
2.1.1. Limitations of Intrusion Detection Systems
- Most IDSs generate a high false positive rate, which wastes the time of network administrators and in some cases causes damaging automated responses.
- Although most IDSs are marketed as real-time systems, it may in fact take them some time to automatically report an attack.
- IDSs’ automated responses are sometimes inefficient against advanced attacks.
- Many IDSs lack user-friendly interfaces that allow users to operate them.
- To obtain the maximum benefits from the deployed IDS, a skilled IT security staff should exist to monitor IDS operations and respond as needed.
- Numerous IDSs are not failsafe, as they may not be well protected from attacks or destruction.
2.1.2. Why Do We Need Machine Learning?
2.2. Machine Learning
2.2.1. Hyperparameter Optimization
2.2.2. Ensemble Learning
2.3. Datasets
2.3.1. Problems with Evaluative Datasets
- Data privacy issues and security policies may prevent corporate entities from sharing realistic data with users and the research community.
- Getting permission from a dataset’s owner is frequently delayed. Moreover, it usually requires the researcher to agree to an acceptable use policy (AUP) that includes limitations on the time of usage and the data that can be published about the dataset.
- The limited scope of most datasets does not fit various network intrusion detection researchers’ aims and objectives.
- Most of the available datasets in the IDS field suffer from a lack of proper documentation describing the network environment, simulated attacks, and dataset limitations.
- Many of the accessible datasets were labeled manually.
2.3.2. Data Preprocessing
3. Literature Survey and Related Work
4. GTCS Dataset Collection
4.1. Lab Setup
- Botnet attacks [63]: This attack type can be defined as a group of compromised network systems and devices that execute different harmful network attacks, such as sending spam, granting backdoor access to compromised systems, stealing information via keyloggers, performing phishing attacks, and so on.
- Brute force attacks [64]: This refers to a well-known network attack family in which intruders try every key combination in an attempt to guess passwords or use fuzzing methods to obtain unauthorized access to certain hidden webpages (e.g., an admin login page).
- DDoS attacks [65]: DoS attacks are a very popular type of network attack in which an attacker sends an overwhelming number of false requests to a target service or network in order to prevent legitimate users from accessing that service. DDoS attacks are a modern form of DoS attack wherein attackers use thousands of compromised systems to flood the bandwidth or resources of the target system.
- Infiltration attacks [66]: These attacks are usually executed from inside the compromised system by exploiting vulnerabilities in software applications such as Internet browsers, Adobe Acrobat Reader, and the like.
4.2. Data Collection and Feature Extraction
4.3. Statistical Summary of GTCS Dataset
5. Experiments
5.1. Machine Learning Algorithm Performance Comparison
5.2. A Holistic Approach for IDSs Using Ensemble ML Classifiers
Experimental Results
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Singh, R.; Kumar, H.; Singla, R.K.; Ramkumar, K. Internet attacks and intrusion detection system. Online Inf. Rev. 2017, 41, 171–184. [Google Scholar] [CrossRef]
- Kaur, P.; Kumar, M.; Bhandari, A. A review of detection approaches for distributed denial of service attacks. Syst. Sci. Control Eng. 2017, 5, 301–320. [Google Scholar] [CrossRef]
- Davis, J. Machine Learning and Feature Engineering for Computer Network Security; Queensland University of Technology: Brisbane, Australia, 2017. [Google Scholar]
- Pacheco, F.; Exposito, E.; Gineste, M.; Baudoin, C.; Jose, A. Towards the Deployment of Machine Learning Solutions in Network Traffic Classification: A Systematic Survey. IEEE Commun. Surv. Tutor. 2018, 21, 1988–2014. [Google Scholar] [CrossRef]
- Zheng, A.; Casari, A. Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists; O’Reilly Media, Inc.: Newton, MA, USA, 2018. [Google Scholar]
- Bhuyan, M.H.; Bhattacharyya, D.K.; Kalita, J.K.J.I.N.S. Towards Generating Real-life Datasets for Network Intrusion Detection. Int. J. Netw. Secur. 2015, 17, 683–701. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Deshmukh, D.H.; Ghorpade, T.; Padiya, P. Improving classification using preprocessing and machine learning algorithms on NSL-KDD dataset. In Proceedings of the 2015 International Conference on Communication, Information and Computing Technology (ICCICT), Mumbai, India, 15–17 January 2015. [Google Scholar]
- Nehinbe, J.O. A critical evaluation of datasets for investigating IDSs and IPSs researches. In Proceedings of the 2011 IEEE 10th International Conference on Cybernetic Intelligent Systems (CIS), London, UK, 1–2 September 2016. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In ICISSP; University of New Brunswick: Fredericton, NB, Canada, 2018; pp. 108–116. [Google Scholar]
- Huang, H.; Al-Azzawi, H.; Brani, H. Network traffic anomaly detection. arXiv 2014, arXiv:1402.0856. [Google Scholar]
- Lazarevic, A.; Kumar, V.; Srivastava, J. Intrusion Detection: A Survey, in Managing Cyber Threats. 2005. Available online: https://www.researchgate.net/publication/226650646_Intrusion_Detection_A_Survey (accessed on 21 October 2020).
- Azeez, N.A.; Bada, T.M.; Misra, S.; Adewumi, A.; Van Der Vyver, C.; Ahuja, R. Intrusion Detection and Prevention Systems: An Updated Review; Springer Science and Business Media LLC: Berlin, Germany, 2019; pp. 685–696. [Google Scholar]
- Yeo, L.H.; Che, X.; Lakkaraju, S. Understanding Modern Intrusion Detection Systems: A Survey. arXiv 2017, arXiv:1708.07174. [Google Scholar]
- Fadlullah, Z.M.; Tang, F.; Mao, B.; Kato, N.; Akashi, O.; Inoue, T.; Mizutani, K. State-of-the-Art Deep Learning: Evolving Machine Intelligence Toward Tomorrow’s Intelligent Network Traffic Control Systems. IEEE Commun. Surv. Tutor. 2017, 19, 2432–2455. [Google Scholar] [CrossRef]
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Yuan-Fu, Y. A Deep Learning Model for Identification of Defect Patterns in Semiconductor Wafer Map. In Proceedings of the 30th Annual SEMI Advanced Semiconductor Manufacturing Conference (ASMC), Saratoga Springs, NY, USA, 6–9 May 2019. [Google Scholar]
- Claesen, M.; De Moor, B. Hyperparameter search in machine learning. arXiv 2015, arXiv:1502.02127. [Google Scholar]
- Ryu, J.; Kantardzic, M.; Walgampaya, C. Ensemble Classifier based on Misclassified Streaming Data. In Proceedings of the 10th IASTED International Conference on Artificial Intelligence and Applications, Innsbruck, Austria, 15–17 February 2010. [Google Scholar]
- Elmomen, A.A.; El Din, A.B.; Wahdan, A. Detecting Abnormal Network Traffic in the Secure Event Management Systems. In International Conference on Aerospace Sciences and Aviation Technology; The Military Technical College: Cairo, Egypt, 2011. [Google Scholar]
- BalaGanesh, D.; Chakrabarti, A.; Midhunchakkaravarthy, D. Smart Devices Threats, Vulnerabilities and Malware Detection Approaches: A Survey. Eur. J. Eng. Res. Sci. 2018, 3, 7–12. [Google Scholar] [CrossRef][Green Version]
- Hansen, L.K.; Salamon, P. Neural network ensembles. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 993–1001. [Google Scholar] [CrossRef]
- Ho, T.K. Multiple Classifier Combination: Lessons and Next Steps; World Scientific: Singapore, 2002; pp. 171–198. [Google Scholar]
- Wang, G.; Hao, J.; Ma, J.; Jiang, H. A comparative assessment of ensemble learning for credit scoring. Expert Syst. Appl. 2011, 38, 223–230. [Google Scholar] [CrossRef]
- Koch, R.; Golling, M.; Rodosek, G.D. Towards comparability of intrusion detection systems: New data sets. In Proceedings of the TERENA Networking Conference, Dublin, Ireland, 19–22 May 2014. [Google Scholar]
- Paxson, V.; Floyd, S. Why we don’t know how to simulate the Internet. In Proceedings of the 29th Conference on Winter Simulation, Atlanta, GA, USA, 7–10 December 1997. [Google Scholar]
- Ghorbani, A.A.; Lu, W.; Tavallaee, M. Network Intrusion Detection and Prevention; Springer Science and Business Media LLC: Berlin, Germany, 2009; Volume 47. [Google Scholar]
- Lee, K.-C.; Orten, B.; Dasdan, A.; Li, W. Estimating conversion rate in display advertising from past erformance data. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012. [Google Scholar]
- Beck, J.E.; Woolf, B.P. High-Level Student Modeling with Machine Learning. In Proceedings of the Lecture Notes in Computer Science; Springer: Berlin, Germany, 2000; pp. 584–593. [Google Scholar]
- Karimi, Z.; Kashani, M.M.R.; Harounabadi, A. Feature Ranking in Intrusion Detection Dataset using Combination of Filtering Methods. Int. J. Comput. Appl. 2013, 78, 21–27. [Google Scholar] [CrossRef]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- John, G.; Kohavi, R.; Pfleger, K. Irrelevant features and the subset selection problem. In Machine Learning: Proceedings of the Eleventh International Conference; Morgan Kaufmann: Burlington, MA, USA, 1994. [Google Scholar]
- Biesiada, J.; Duch, W. Feature Selection for High-Dimensional Data: A Kolmogorov-Smirnov Correlation-Based Filter; Springer: Berlin, Germany, 2008; pp. 95–103. [Google Scholar]
- Araújo, N.; De Oliveira, R.; Ferreira, E.; Shinoda, A.A.; Bhargava, B. Identifying important characteristics in the KDD99 intrusion detection dataset by feature selection using a hybrid approach. In Proceedings of the 2010 17th International Conference on Telecommunications, Doha, Qatar, 4–7 April 2010; pp. 552–558. [Google Scholar]
- Chebrolu, S.; Abraham, A.; Thomas, J.P. Hybrid Feature Selection for Modeling Intrusion Detection Systems. In Proceedings of the Computer Vision; Springer: Berlin, Germany, 2004; pp. 1020–1025. [Google Scholar]
- Guennoun, M.; Lbekkouri, A.; El-Khatib, K. Optimizing the feature set of wireless intrusion detection systems. Int. J. Comput. Sci. Netw. Secur. 2008, 8, 127–131. [Google Scholar]
- Talavera, L. An Evaluation of Filter and Wrapper Methods for Feature Selection in Categorical Clustering. Available online: https://www.cs.upc.edu/~talavera/_downloads/ida05fs.pdf (accessed on 21 October 2020).
- Moradi, P.; Gholampour, M. A hybrid particle swarm optimization for feature subset selection by integrating a novel local search strategy. Appl. Soft Comput. 2016, 43, 117–130. [Google Scholar] [CrossRef]
- Liu, Y.; Yu, X.; Huang, J.X.; An, A. Combining integrated sampling with SVM ensembles for learning from imbalanced datasets. Inf. Process. Manag. 2011, 47, 617–631. [Google Scholar] [CrossRef]
- Seo, J.-H.; Kim, Y.-H. Machine-Learning Approach to Optimize SMOTE Ratio in Class Imbalance Dataset for Intrusion Detection. Comput. Intell. Neurosci. 2018, 2018, 1–11. [Google Scholar] [CrossRef]
- Zhai, Y.; Ma, N.; Ruan, D.; An, B. An effective over-sampling method for imbalanced data sets classification. Chin. J. Electron. 2011, 20, 489–494. [Google Scholar]
- Chawla, N.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Yen, S.-J.; Lee, Y.-S. Cluster-based under-sampling approaches for imbalanced data distributions. Expert Syst. Appl. 2009, 36, 5718–5727. [Google Scholar] [CrossRef]
- Hasanin, T.; Khoshgoftaar, T.M.; Leevy, J.L.; Seliya, N. Investigating Random Undersampling and Feature Selection on Bioinformatics Big Data. In Proceedings of the 2019 IEEE Fifth International Conference on Big Data Computing Service and Applications (BigDataService), Newark, CA, USA, 4–9 April 2019; pp. 346–356. [Google Scholar]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A Deep Learning Approach for Network Intrusion Detection System. In Proceedings of the 9th EAI International Conference on Bio-inspired Information and Communications Technologies (Formerly BIONETICS), New York, NY, USA, 3–5 December 2016. [Google Scholar]
- Dhanabal, L.; Shantharajah, S.P. A study on NSL-KDD dataset for intrusion detection system based on classification algorithms. Int. J. Adv. Res. Comput. Commun. Eng. 2015, 4, 446–452. [Google Scholar]
- Hodo, E.; Bellekens, X.; Hamilton, A.; Tachtatzis, C.; Atkinson, R. Shallow and Deep Networks Intrusion Detection System: A Taxonomy and Survey. arXiv 2017, arXiv:1701.02145. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- MeeraGandhi, G. Machine learning approach for attack prediction and classification using supervised learning algorithms. Int. J. Comput. Sci. Commun. 2010, 1, 11465–11484. [Google Scholar]
- Nguyen, H.A.; Choi, D. Application of Data Mining to Network Intrusion Detection: Classifier Selection Model. In Proceedings of the Computer Vision; Springer: Berlin, Germany, 2008. [Google Scholar]
- Darshan, V.S.; Raphael, R. Real Time Call Monitoring System Using Spark Streaming and Network Intrusion Detection Using Distributed WekaSpark. J. Mach. Intell. 2017, 2, 7–13. [Google Scholar] [CrossRef]
- Belavagi, M.C.; Muniyal, B. Performance Evaluation of Supervised Machine Learning Algorithms for Intrusion Detection. Procedia Comput. Sci. 2016, 89, 117–123. [Google Scholar] [CrossRef]
- Hota, H.S.; Shrivas, A.K. Decision Tree Techniques Applied on NSL-KDD Data and Its Comparison with Various Feature Selection Techniques. In Advanced Computing, Networking and Informatics; Springer: Berlin, Germany, 2014; Volume 1, pp. 205–211. [Google Scholar]
- Khammassi, C.; Krichen, S. A GA-LR wrapper approach for feature selection in network intrusion detection. Comput. Secur. 2017, 70, 255–277. [Google Scholar] [CrossRef]
- Abdullah, M.; Alshannaq, A.; Balamash, A.; Almabdy, S. Enhanced intrusion detection system using feature selection method and ensemble learning algorithms. Int. J. Comput. Sci. Inf. Secur. 2018, 16, 48–55. [Google Scholar]
- Chebrolu, S.; Abraham, A.; Thomas, J.P. Feature deduction and ensemble design of intrusion detection systems. Comput. Secur. 2005, 24, 295–307. [Google Scholar] [CrossRef]
- Roli, F.; Kittler, J. Multiple Classifier Systems: Third International Workshop, MCS 2002, Cagliari, Italy, 24–26 June 2002. Proceedings; Springer Science & Business Media: Berlin, Germany, 2002; Volume 2364. [Google Scholar]
- Hansen, J.V.; Lowry, P.B.; Meservy, R.D.; McDonald, D.M. Genetic programming for prevention of cyberterrorism through dynamic and evolving intrusion detection. Decis. Support Syst. 2007, 43, 1362–1374. [Google Scholar] [CrossRef]
- Koza, J.R.; Poli, R. A Genetic Programming Tutorial. 2003. Available online: https://www.researchgate.net/publication/2415604_A_Genetic_Programming_Tutorial (accessed on 21 October 2020).
- Srivats, P. Ostinato Packet Generator. 2018. Available online: https://ostinato.org (accessed on 11 November 2019).
- Najera-Gutierrez, G.; Ansari, J.A. Web Penetration Testing with Kali Linux: Explore the Methods and Tools of Ethical Hacking with Kali Linux; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Sousa, O.F. Analysis of the package dependency on Debian GNU/Linux. J. Comput. Interdiscip. Sci. 2009, 1, 127–133. [Google Scholar] [CrossRef]
- Meidan, Y.; Bohadana, M.; Mathov, Y.; Mirsky, Y.; Shabtai, A.; Breitenbacher, D.; Elovici, Y. N-baiot—Network-based detection of iot botnet attacks using deep autoencoders. IEEE Pervasive Comput. 2018, 17, 12–22. [Google Scholar] [CrossRef]
- Arzhakov, A.V.; Silnov, D.S. Analysis of Brute Force Attacks with Ylmf-pc Signature. Int. J. Electr. Comput. Eng. 2016, 6, 1681–1684. [Google Scholar]
- Sharma, K.; Gupta, B.B. Taxonomy of Distributed Denial of Service (DDoS) Attacks and Defense Mechanisms in Present Era of Smartphone Devices. Int. J. E Serv. Mob. Appl. 2018, 10, 58–74. [Google Scholar] [CrossRef]
- Kirda, E. Getting Under Alexa’s Umbrella: Infiltration Attacks Against Internet Top Domain Lists. In Proceedings of the Information Security: 22nd International Conference (ISC 2019), New York, NY, USA, 16–18 September 2019. [Google Scholar]
- Yan, G.; Brown, N.; Kong, D. Exploring discriminatory features for automated malware classification. In International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment; Springer: Berlin, Germany, 2013. [Google Scholar]
- Lawrence, D. The Hunt for the Financial Industry’s Mostwanted Hacker. 2015. Available online: https://www.bloomberg.com/news/features/2015-06-18/the-hunt-for-the-financial-industry-s-most-wanted-hacker (accessed on 21 October 2020).
- Nagpal, B.; Sharma, P.; Chauhan, N.; Panesar, A. DDoS tools: Classification, analysis and comparison. In Proceedings of the 2015 2nd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 11–13 March 2015. [Google Scholar]
- Goyal, P.; Goyal, A. Comparative study of two most popular packet sniffing tools-Tcpdump and Wireshark. In Proceedings of the 2017 9th International Conference on Computational Intelligence and Communication Networks (CICN), Girne, Cyprus, 16–17 September 2017; pp. 77–81. [Google Scholar]
- Ndatinya, V.; Xiao, Z.; Manepalli, V.R.; Meng, K.; Xiao, Y. Network forensics analysis using Wireshark. Int. J. Secur. Netw. 2015, 10, 91–106. [Google Scholar] [CrossRef]
- Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of encrypted and vpn traffic using time-related. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy (ICISSP), Rome, Italy, 19–21 February 2016; pp. 407–414. [Google Scholar]
- Lashkari, A.H.; Draper-Gil, G.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of tor traffic using time based features. In Proceedings of the ICISSP, Porto, Portugal, 19–21 February 2017; pp. 253–262. [Google Scholar]
- Mahfouz, A.; Abuhussein, A.; Shiva, S. GTCS Network Attack Dataset 2020. Available online: https://www.researchgate.net/publication/344478320_GTCS_Network_Attack_Dataset (accessed on 21 October 2020).
- Amrita, M.A. Performance analysis of different feature selection methods in intrusion detection. Int. J. Adv. Res. Comput. Eng. Technol. 2013, 2, 1725–1731. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Description |
|---|---|
| Flow ID | ID which presents the unique ID calculated from the 5-tuple, i.e., Src IP, Dst IP, Src Port, Dst Port, and protocol number |
| Src IP | IP address of the machine from which the traffic started |
| Src Port | IP address of destination machine |
| Dst IP | IP address of destination machine |
| Dest Port | Destination port number |
| Protocol number | Number of the transaction protocol |
| Timestamp | Date and time of day when the flow occurred |
| Flow Duration | Total duration of flow |
| Tot Fwd/Bwd Pkts | Total packets in forward/backward direction |
| TotLen Fwd/Bwd Pkts | Total size of packet in forward/backward direction |
| Fwd/Bwd Pkt Len | Size of packet in forward/backward direction |
| Flow Byts/Packets | Rate of flow of bytes/packets (i.e., number of bytes/packets transferred each second) |
| Flow IAT | Time between two packets sent in forward/backward direction |
| Fwd/Bwd IAT | Time between two packets sent in forward/backward direction |
| Fwd/Bwd PSH | Number of times that PSH flag was set to packets moving in either forward/backward direction |
| Fwd/Bwd URG | Number of times that URG flag was set to packets moving in either forward/backward direction |
| Active | How long a flow was active before becoming idle |
| Idle | How long a flow was idle before becoming active |
| Fwd/Bwd Pkts/s | Number of transmitted packets per second in forward/backward direction |
| Fwd/Bwd Byts/s | Number of transmitted bytes per second in forward/backward direction |
| Label | Indicates whether traffic is malicious |
| Class | Training Set | Occurrence Percentage |
|---|---|---|
| Normal | 139,186 | 26.98% |
| Botnet | 93,021 | 17.97% |
| Brute Force | 83,858 | 16.20% |
| DDoS | 131,211 | 25.35% |
| Infiltration | 70,202 | 13.56% |
| Total | 517,478 | 100.00% |
| Measure Metric | Explanation |
|---|---|
| True Positive Rate (TP) | Correctly classified anomalous instances as an anomaly |
| True Negative Rate (TN) | Correctly classified normal instances as normal |
| False Negative Rate (FN) | Wrongly classified anomalous instances as normal |
| False Positive Rate (FP) | Wrongly classified normal instances as an anomaly |
| Precision | TP * (TP + FP) |
| Recall | TP * (TP + FN) |
| F1 score | (2 ∗ Precision ∗ Recall) (Precision + Recall) |
| Classifier | Accuracy | TPR | FPR | Precision | Recall | F-Measure | ROC Area |
|---|---|---|---|---|---|---|---|
| NB | 86.81% | 0.869 | 0.116 | 0.912 | 0.864 | 0.885 | 0.921 |
| Logistic | 91.88% | 0.936 | 0.097 | 0.923 | 0.931 | 0.924 | 0.930 |
| MLP | 92.90% | 0.944 | 0.085 | 0.932 | 0.939 | 0.931 | 0.937 |
| SMO | 92.13% | 0.937 | 0.093 | 0.925 | 0.932 | 0.926 | 0.917 |
| IBK | 94.23% | 0.948 | 0.055 | 0.943 | 0.945 | 0.942 | 0.942 |
| J48 | 94.29% | 0.951 | 0.054 | 0.949 | 0.945 | 0.944 | 0.943 |
| Classifier | Accuracy | TPR | FPR | Precision | Recall | F-Measure | ROC Area |
|---|---|---|---|---|---|---|---|
| NB | 89.51% | 0.881 | 0.109 | 0.942 | 0.894 | 0.915 | 0.948 |
| Logistic | 94.58% | 0.948 | 0.091 | 0.953 | 0.961 | 0.954 | 0.966 |
| MLP | 95.60% | 0.956 | 0.077 | 0.96 | 0.969 | 0.962 | 0.964 |
| SMO | 94.83% | 0.949 | 0.086 | 0.955 | 0.962 | 0.956 | 0.944 |
| IBK | 96.93% | 0.960 | 0.050 | 0.971 | 0.973 | 0.971 | 0.969 |
| J48 | 96.99% | 0.962 | 0.048 | 0.974 | 0.975 | 0.972 | 0.970 |
| Classifier | Class | Phase I | Phase II |
|---|---|---|---|
| NB | Normal | 86.00% | 86.90% |
| Botnet | 87.90% | 88.80% | |
| Brute Force | 80.00% | 80.90% | |
| DDoS | 83.80% | 84.70% | |
| Infiltration | 78.96% | 79.86% | |
| Logistic | Normal | 92.50% | 93.40% |
| Botnet | 92.80% | 93.70% | |
| Brute Force | 84.80% | 85.70% | |
| DDoS | 91.58% | 92.48% | |
| Infiltration | 81.30% | 82.20% | |
| MLP | Normal | 93.60% | 94.50% |
| Botnet | 93.50% | 94.40% | |
| Brute Force | 90.00% | 90.90% | |
| DDoS | 98.89% | 99.79% | |
| Infiltration | 82.30% | 83.20% | |
| SMO | Normal | 92.80% | 93.70% |
| Botnet | 93.60% | 94.50% | |
| Brute Force | 83.70% | 84.60% | |
| DDoS | 91.01% | 92.89% | |
| Infiltration | 72.45% | 83.35% | |
| IBK | Normal | 95.50% | 96.40% |
| Botnet | 95.60% | 96.50% | |
| Brute Force | 95.10% | 96.00% | |
| DDoS | 96.32% | 97.22% | |
| Infiltration | 79.67% | 80.57% | |
| J48 | Normal | 94.60% | 95.10% |
| Botnet | 95.30% | 96.20% | |
| Brute Force | 87.70% | 91.60% | |
| DDoS | 95.53% | 96.43% | |
| Infiltration | 83.43% | 84.33% |
| Class | J48 | IBK | MLP | Ensemble Model | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc % | TP | FP | Acc % | TP | FP | Acc % | TP | FP | Acc % | TP | FP | |
| Normal | 95.10 | 0.902 | 0.049 | 96.40 | 0.960 | 0.049 | 93.60 | 0.966 | 0.051 | 98.62 | 0.965 | 0.029 |
| Botnet | 96.20 | 0.913 | 0.038 | 96.50 | 0.967 | 0.046 | 93.50 | 0.951 | 0.053 | 98.87 | 0.972 | 0.018 |
| Brute Force | 91.60 | 0.876 | 0.068 | 96.00 | 0.960 | 0.050 | 90.00 | 0.816 | 0.068 | 96.70 | 0.901 | 0.031 |
| DDoS | 96.43 | 0.964 | 0.035 | 97.22 | 0.973 | 0.039 | 98.89 | 0.976 | 0.038 | 98.99 | 0.979 | 0.016 |
| Infiltration | 84.33 | 0.898 | 0.088 | 80.57 | 0.911 | 0.091 | 82.30 | 0.886 | 0.089 | 88.69 | 0.899 | 0.040 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahfouz, A.; Abuhussein, A.; Venugopal, D.; Shiva, S. Ensemble Classifiers for Network Intrusion Detection Using a Novel Network Attack Dataset. Future Internet 2020, 12, 180. https://doi.org/10.3390/fi12110180
Mahfouz A, Abuhussein A, Venugopal D, Shiva S. Ensemble Classifiers for Network Intrusion Detection Using a Novel Network Attack Dataset. Future Internet. 2020; 12(11):180. https://doi.org/10.3390/fi12110180
Chicago/Turabian StyleMahfouz, Ahmed, Abdullah Abuhussein, Deepak Venugopal, and Sajjan Shiva. 2020. "Ensemble Classifiers for Network Intrusion Detection Using a Novel Network Attack Dataset" Future Internet 12, no. 11: 180. https://doi.org/10.3390/fi12110180
APA StyleMahfouz, A., Abuhussein, A., Venugopal, D., & Shiva, S. (2020). Ensemble Classifiers for Network Intrusion Detection Using a Novel Network Attack Dataset. Future Internet, 12(11), 180. https://doi.org/10.3390/fi12110180