Combined Self-Attention Mechanism for Chinese Named Entity Recognition in Military

Abstract
:1. Introduction
2. Related Works
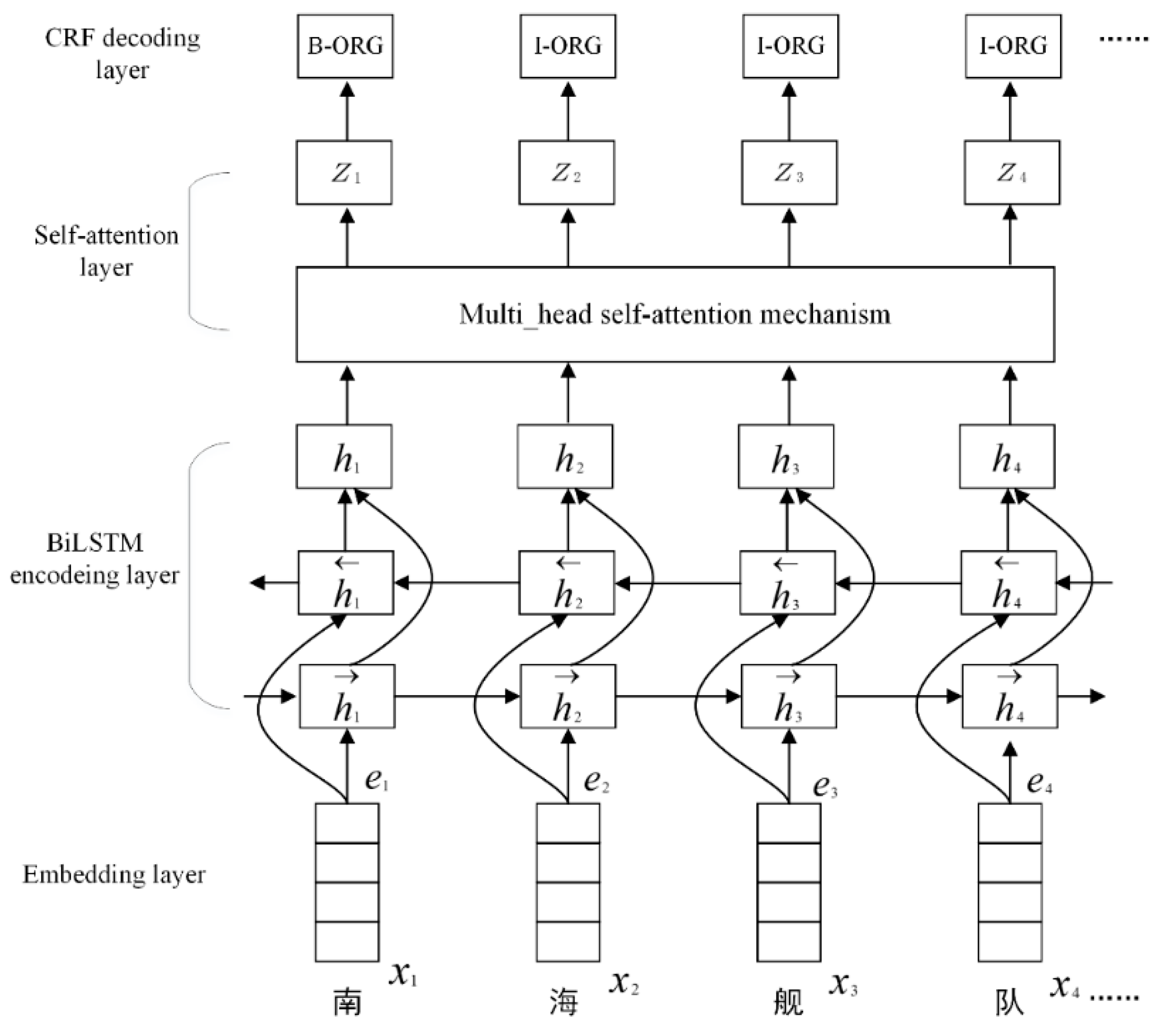
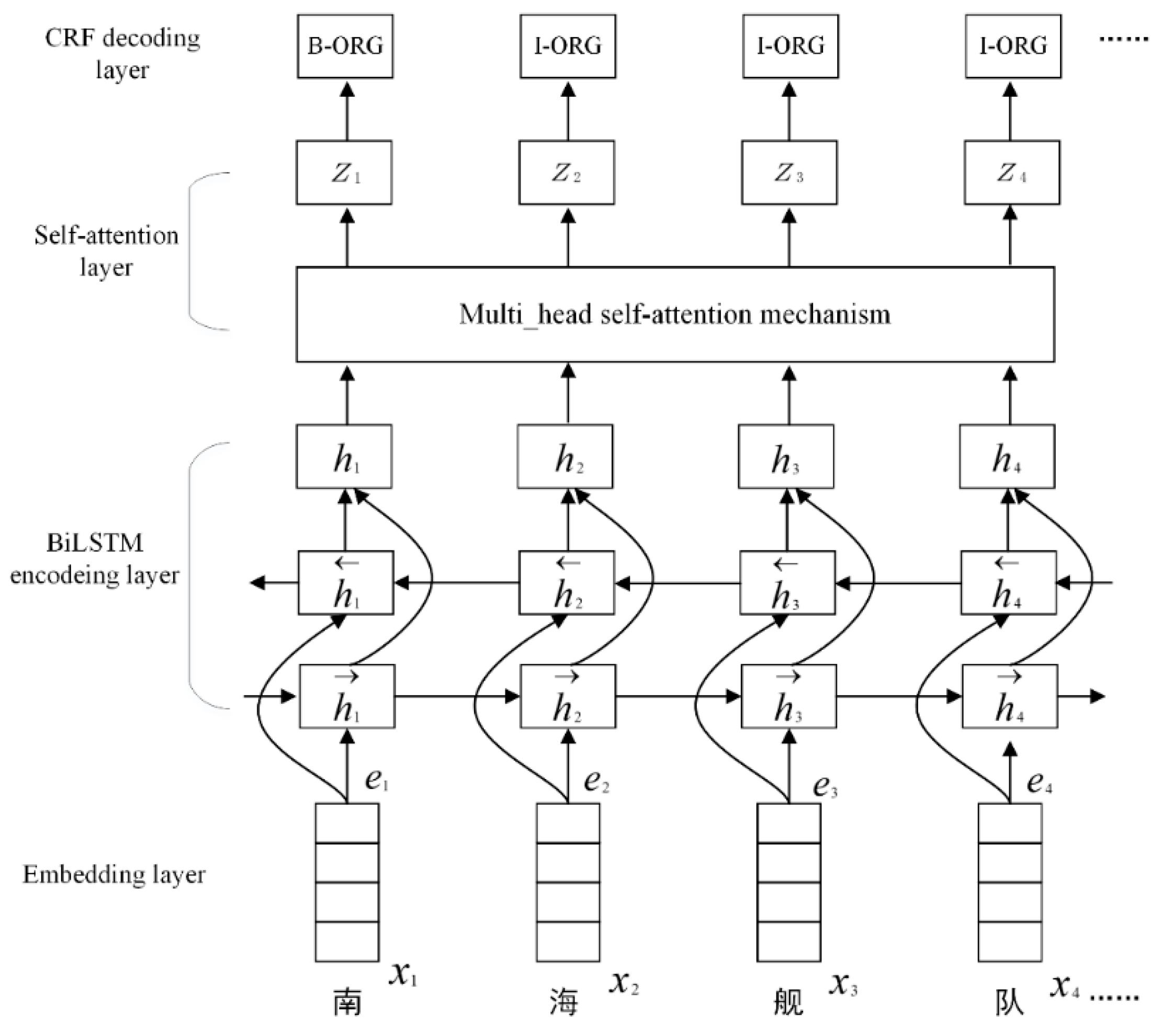
3. BiLSTM-Self-Attention-CRF Model
3.1. Embedding Layer
3.2. Bi-LSTM Encoding Layer
3.2.1. LSTM
3.2.2. BiLSTM
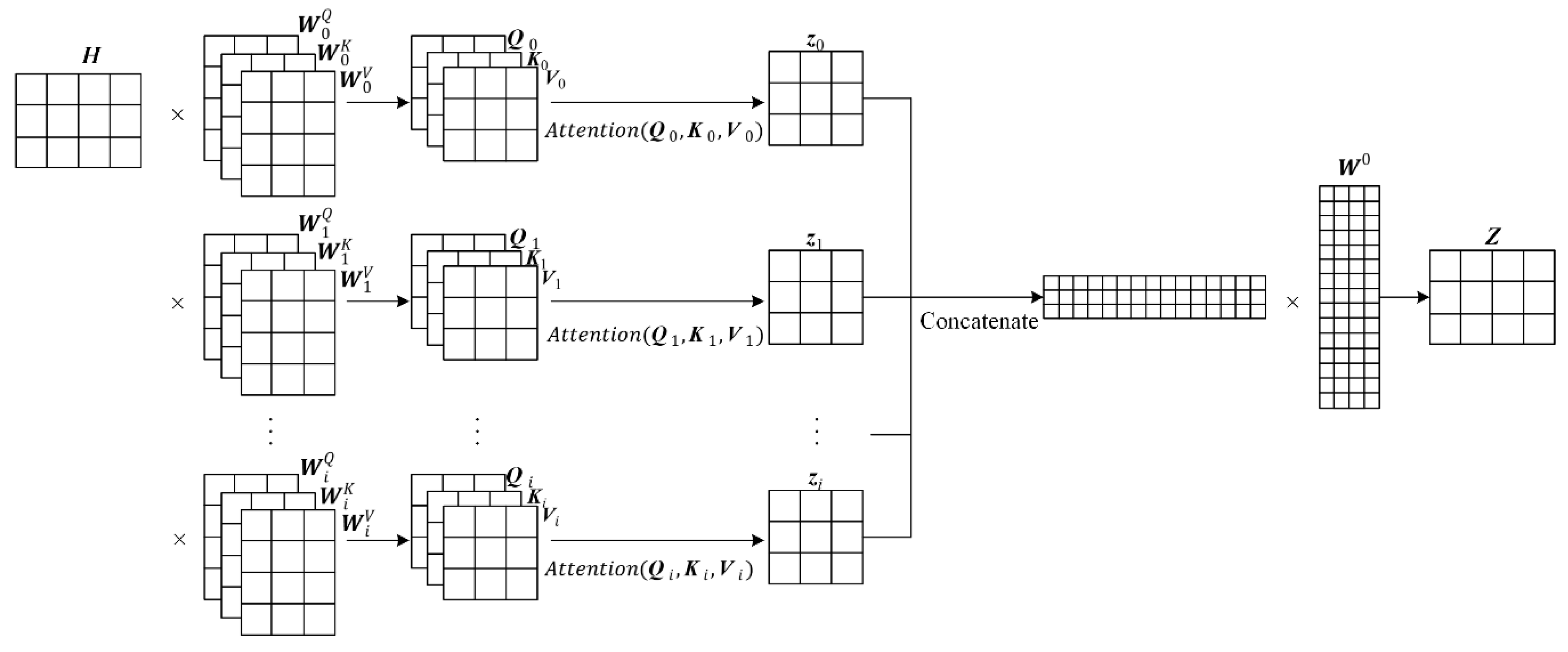
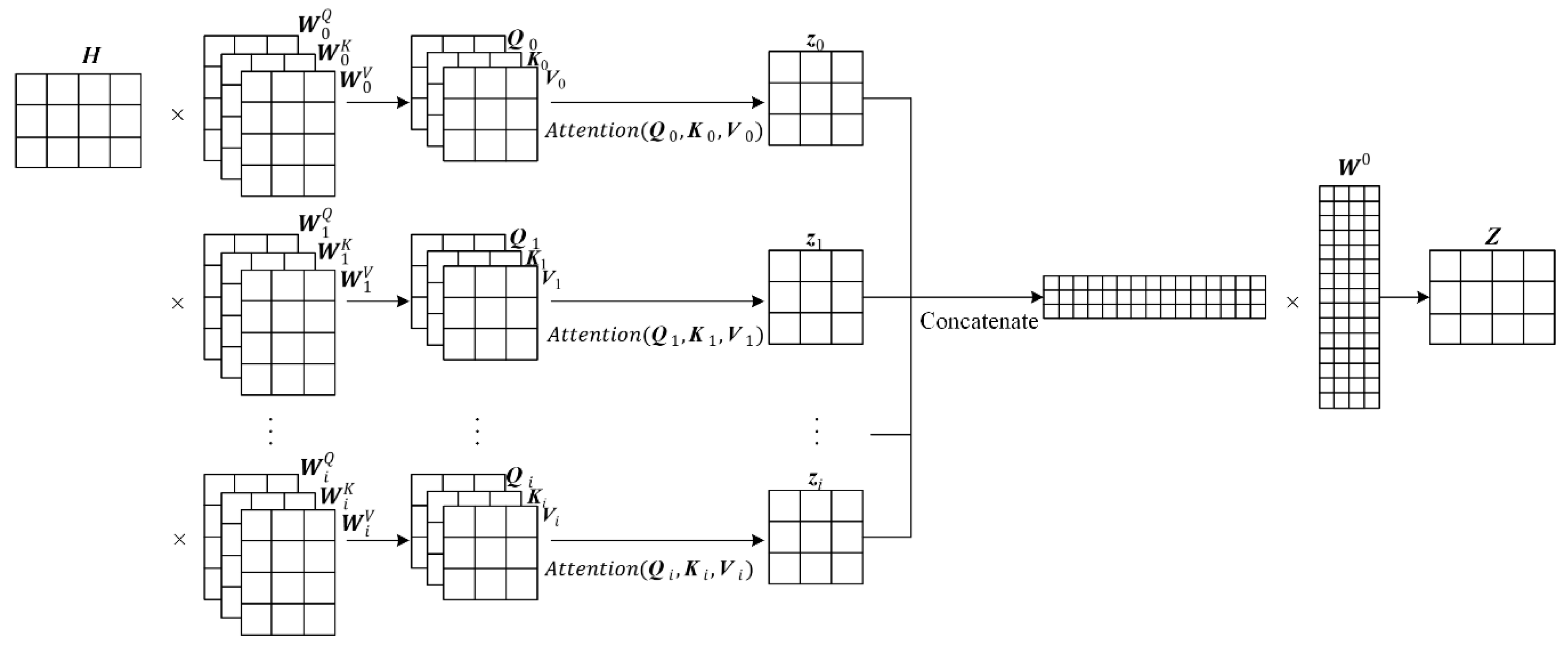
3.3. Self-Attention Layer
3.4. CRF Decoding Layer
4. Experiments
4.1. Data Sets
4.2. Environment and Settings
4.3. Experimental Baselines
4.4. Evaluation Metrics
5. Results and Discussions
5.1. Comparison of Different Architecture
5.2. Comparison with Other Models
5.3. Different Types of Datasets
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Peng, N.; Dredze, M. Named entity recognition for chinese social media with jointly trained embeddings. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 548–554. [Google Scholar]
- Rozi, A.; Zong, C.; Mamateli, G.; Mahmut, R.; Hamdulla, A. Approach to recognizing Uyhgur names based on conditional random fields. J. Tsinghua Univ. 2013, 53, 873–877. [Google Scholar]
- Gayen, V.; Sarkar, K. An HMM based named entity recognition system for Indian languages: JU system at ICON 2013. arXiv 2014, arXiv:1405.7397. [Google Scholar]
- Curran, J.; Clark, S. Language independent NER using a maximum entropy tagger. In Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003, Edmonton, AB, Canada, 21–23 April 2003; pp. 164–167. [Google Scholar]
- Grishman, R.; Sundheim, B. Message Understanding Conference -6: A Brief History. In Proceedings of the 16th International Conference on Computational Linguistics, Copenhagen, Denmark, 5–9 August 1996. [Google Scholar]
- Kravalová, J.; Zabokrtsky, Z. Czech Named Entity Corpus and SVM-Based Recognizer. In Proceedings of the 2009 Named Entities Workshop: Shared Task on Transliteration, Singapore, 7 August 2009; pp. 194–201. [Google Scholar]
- Guo, J.K.; Van Brackle, D.; LoFaso, N.; Hofmann, M.O. Extracting meaningful entities from human-generated tactical reports. Procedia Comput. Sci. 2015, 61, 72–79. [Google Scholar] [CrossRef]
- Shan, H.; Zhang, H.; Wu, Z. A Military Named Entity Recognition Method Based on CRFs with Small Granularity Strategy. J. Armored Force Eng. Inst. 2017, 31, 101–107. [Google Scholar]
- Jiang, W.; Gu, W.; Chu, L. Research on Military Named Entity Recognition Based on CRF and Rules. Command Simul. 2011, 33, 13–15. [Google Scholar]
- Feng, Y.; Zhang, H.; Hao, W. Named Entity Recognition for Military Texts. Comput. Sci. 2015, 42, 15–18. [Google Scholar]
- You, F.; Zhang, J.; Qiu, D. Weapon Name Recognition Based on Deep Neural Network. J. Comput. Syst. 2018, 27, 239–243. [Google Scholar]
- Zhu, J.; Zhang, W.; Liu, W. Identification and Linkage of Military Named Entities Based on Bidirectional LSTM and CRF. Chinese Academy of Command and Control. In Proceedings of the 6th China Command and Control Conference, Beijing, China, 2–4 July 2018. [Google Scholar]
- Zhang, X.; Cao, X.; Gao, Y. Named Entity Recognition of Combat Documents Based on Deep Learning. Command Control Simul. 2019, 3, 121–128. [Google Scholar]
- Peters, M.E.; Ammar, W.; Bhagavatula, C. Semi-supervised sequence tagging with bidirectional language models. arXiv 2017, arXiv:1705.00108. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end sequence labeling via bi-directional lstm-cnns-crf. arXiv 2016, arXiv:1603.01354. [Google Scholar]
- Chiu, J.P.C.; Nichols, E. Named entity recognition with bidirectional LSTM-CNNs. TACL 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- He, J.; Wang, H. Chinese named entity recognition and word segmentation based on character. In Proceedings of the Sixth SIGHAN Workshop on Chinese Language Processing, Hyderabad, India, 11–12 January 2008. [Google Scholar]
- Li, H.; Hagiwara, M.; Li, Q.; Ji, H. Comparison of the Impact of Word Segmentation on Name Tagging for Chinese and Japanese. In Proceedings of the Ninth International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014; pp. 2532–2536. [Google Scholar]
- Liu, Z.; Zhu, C.; Zhao, T. Chinese named entity recognition with a sequence labeling approach: based on characters, or based on words? In Proceedings of the International Conference on Intelligent Computing, Heidelberg, Germany, 19–20 August 2010; pp. 634–640. [Google Scholar]
- Mikolov, T.; Corrado, G.; Chen, K. Efficient estimation of word representations in vector space. In Proceedings of the International Conference on Learning Representations, Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. LSTM can solve hard long time lag problems. Adv. Neural Inf. Process. Syst. 1997, 4, 473–479. [Google Scholar]
- Zhou, P.; Shi, W.; Tian, J. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 207–212. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 2, 5998–6008. [Google Scholar]
- Tan, Z.; Wang, M.; Xie, J. Deep semantic role labeling with self-attention. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Forney, G.D. The viterbi algorithm. Proc. IEEE 1973, 61, 268–278. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Type | Sentences | Characters | MNEs |
|---|---|---|---|
| data set | 4857 | 175426 | 826 |
| train | 3885 | 139652 | 654 |
| test | 972 | 35774 | 172 |
| Type | Sentences | Characters | MNEs |
|---|---|---|---|
| data set | 6849 | 207538 | 1135 |
| train | 5478 | 165937 | 891 |
| test | 1371 | 40601 | 244 |
| Type | Settings |
|---|---|
| OS | Ubuntu 18.04 |
| CPU | i7-8700K 3.70GHz |
| GPU | NVIDIA TITAN Xp (12GB) |
| Tensorflow | 1.12.0 |
| python | 3.6 |
| Hyperparameter name | value |
|---|---|
| Character embedding size | 100 |
| Window size | 5 |
| BiLSTM hidden size | 200 |
| Dropout | 0.5 |
| Maximum number of epochs | 64 |
| Initial learning | 10−4 |
| Number | Model | Data Set | Samples | Identify | Correct | P | R | F1 |
|---|---|---|---|---|---|---|---|---|
| 1 | CRF [10] | MDD | 826 | 819 | 600 | 73.26% | 72.60% | 72.93% |
| NMTD | 1135 | 1075 | 772 | 71.82% | 68.02% | 69.87% | ||
| 2 | CNN-BiLSTM-CRF [13] | MDD | 826 | 824 | 734 | 89.05% | 88.87% | 88.96% |
| NMTD | 1135 | 1130 | 993 | 87.94% | 87.52% | 87.73% | ||
| 3 | BiLSTM-CRF [12] | MDD | 826 | 802 | 700 | 87.30% | 84.78% | 86.02% |
| NMTD | 1135 | 1110 | 952 | 85.78% | 83.86% | 84.81% | ||
| 4 | BiLSTM-Self_Att-CRF | MDD | 826 | 798 | 732 | 91.72% | 88.63% | 90.15% |
| NMTD | 1135 | 1115 | 1005 | 90.13% | 88.56% | 89.34% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, F.; Ma, L.; Pei, J.; Tan, L. Combined Self-Attention Mechanism for Chinese Named Entity Recognition in Military. Future Internet 2019, 11, 180. https://doi.org/10.3390/fi11080180
Liao F, Ma L, Pei J, Tan L. Combined Self-Attention Mechanism for Chinese Named Entity Recognition in Military. Future Internet. 2019; 11(8):180. https://doi.org/10.3390/fi11080180
Chicago/Turabian StyleLiao, Fei, Liangli Ma, Jingjing Pei, and Linshan Tan. 2019. "Combined Self-Attention Mechanism for Chinese Named Entity Recognition in Military" Future Internet 11, no. 8: 180. https://doi.org/10.3390/fi11080180
APA StyleLiao, F., Ma, L., Pei, J., & Tan, L. (2019). Combined Self-Attention Mechanism for Chinese Named Entity Recognition in Military. Future Internet, 11(8), 180. https://doi.org/10.3390/fi11080180