Quality of Experience (QoE)-Aware Fast Coding Unit Size Selection for HEVC Intra-Prediction


Abstract
1. Introduction
2. Background and Related Work
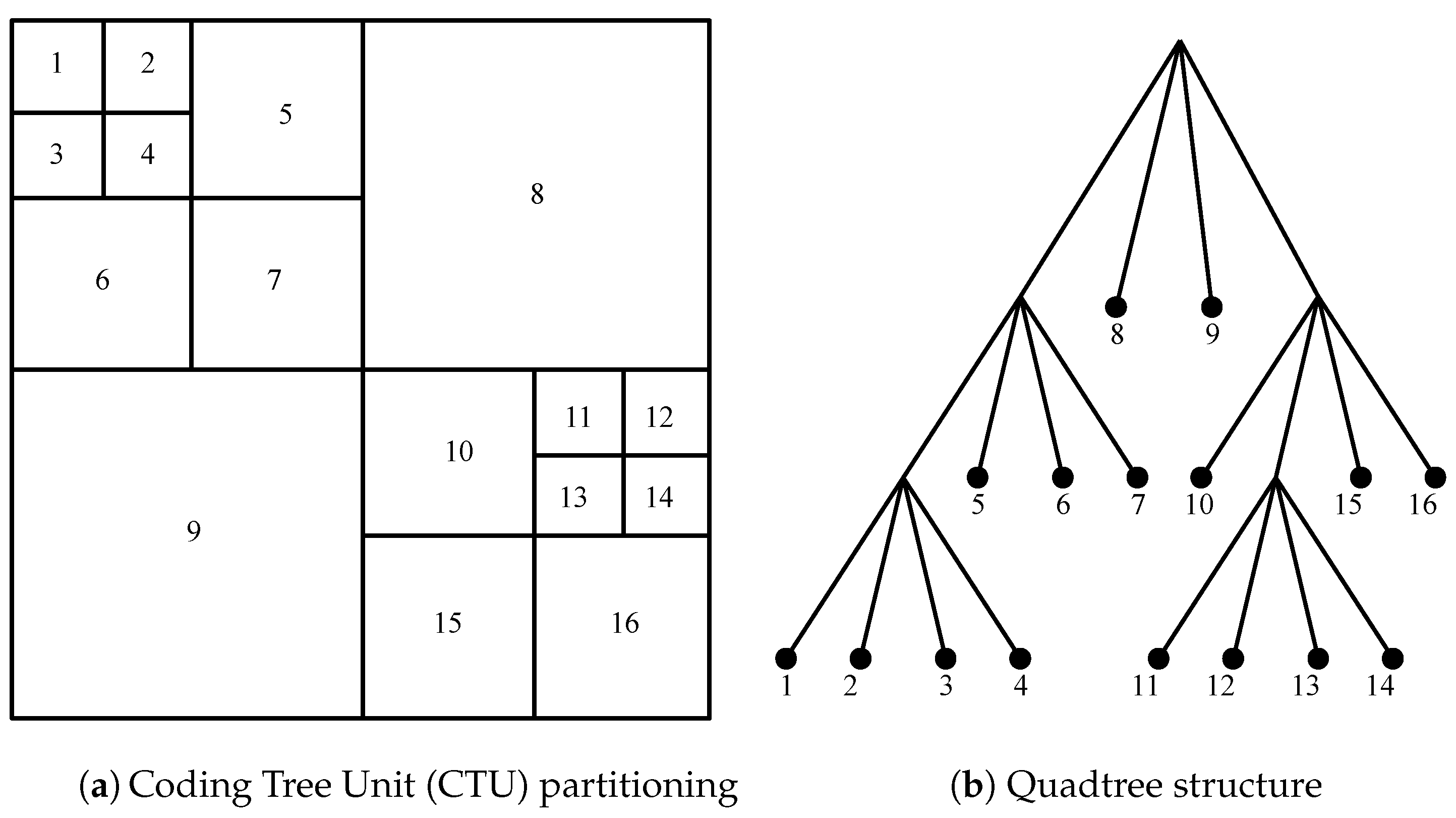
2.1. Background
2.2. Related Work
2.2.1. Statistical Rule-Based Methods
2.2.2. Texture Properties-Based Methods
2.2.3. Machine Learning-Based Methods
3. CU Split Likelihood Modelling Using SVMs
3.1. CU Split Likelihood Modelling
3.1.1. Support Vector Machines (SVMs)
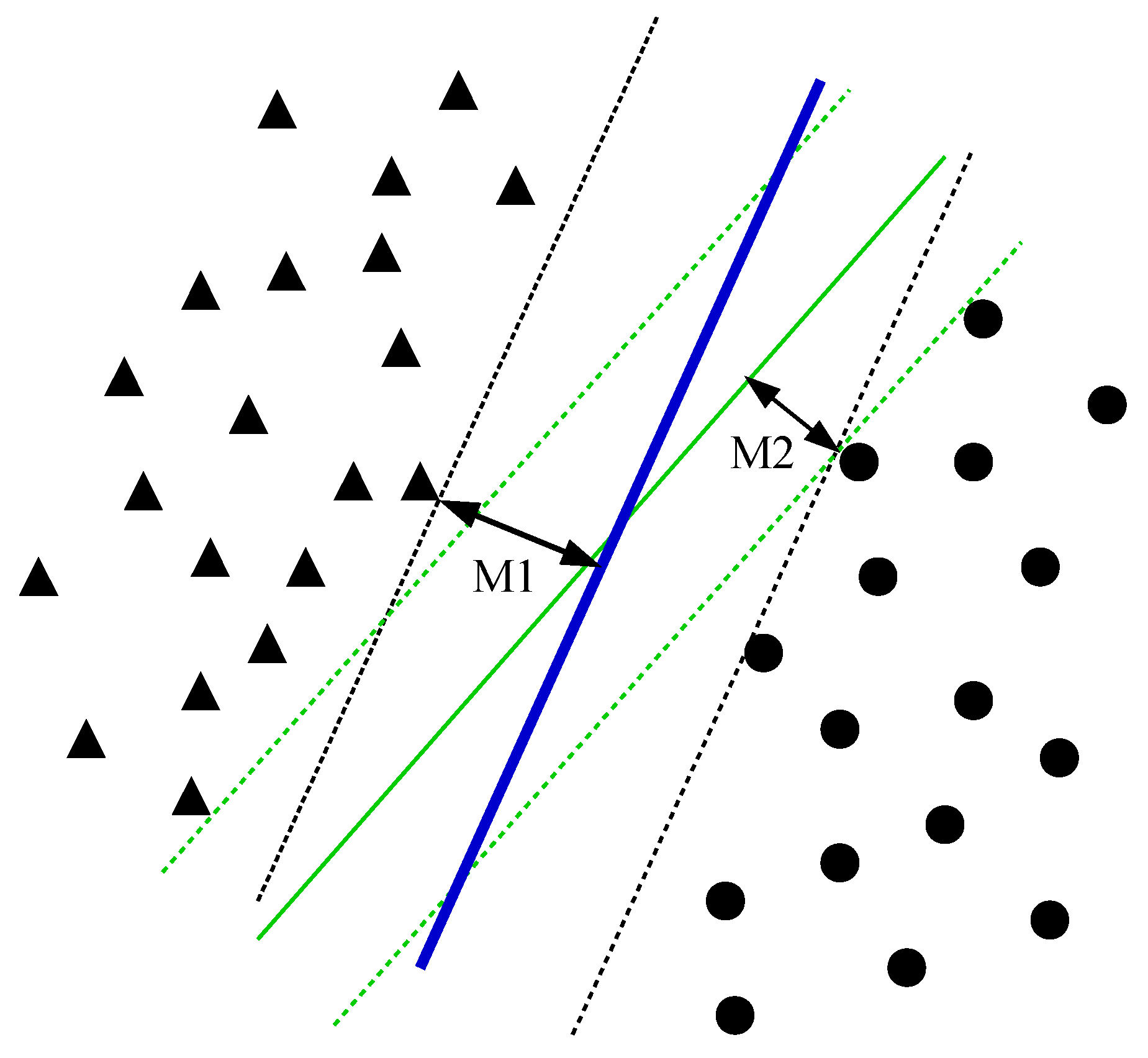
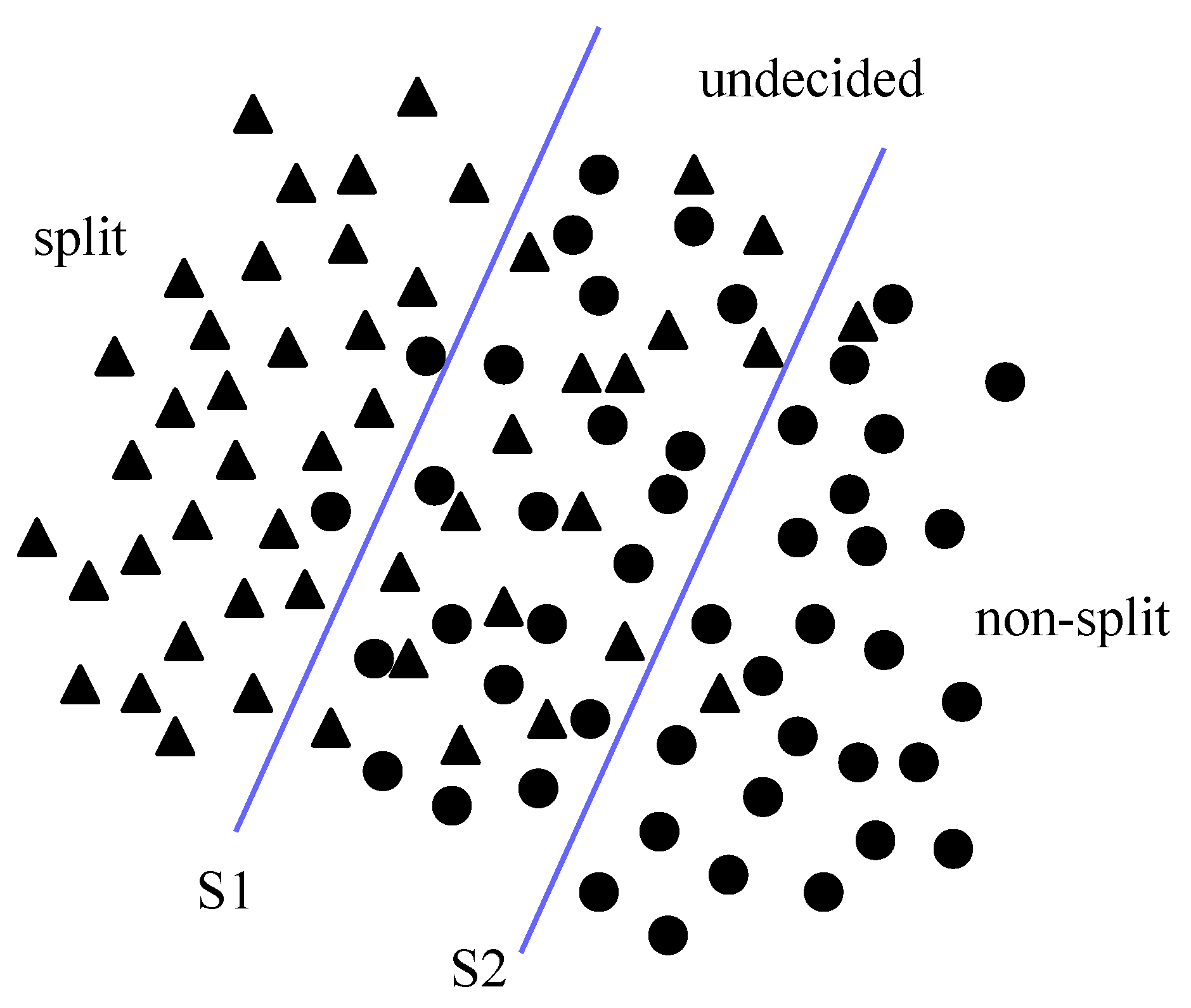
3.1.2. Weighted Support Vector Machines (W-SVMs)
4. Proposed Fast CU Size Selection Algorithm
4.1. Level 1(L-1) SVM Models: Features and Optimal Weight Calculation
4.1.1. Data Collection
4.1.2. Feature Selection
4.1.3. Weight Calculation
4.2. Level 2 SVMs (L-2): Features and Optimal Weight Calculation
4.2.1. Data Collection
4.2.2. Feature Selection
4.2.3. Weight Calculation
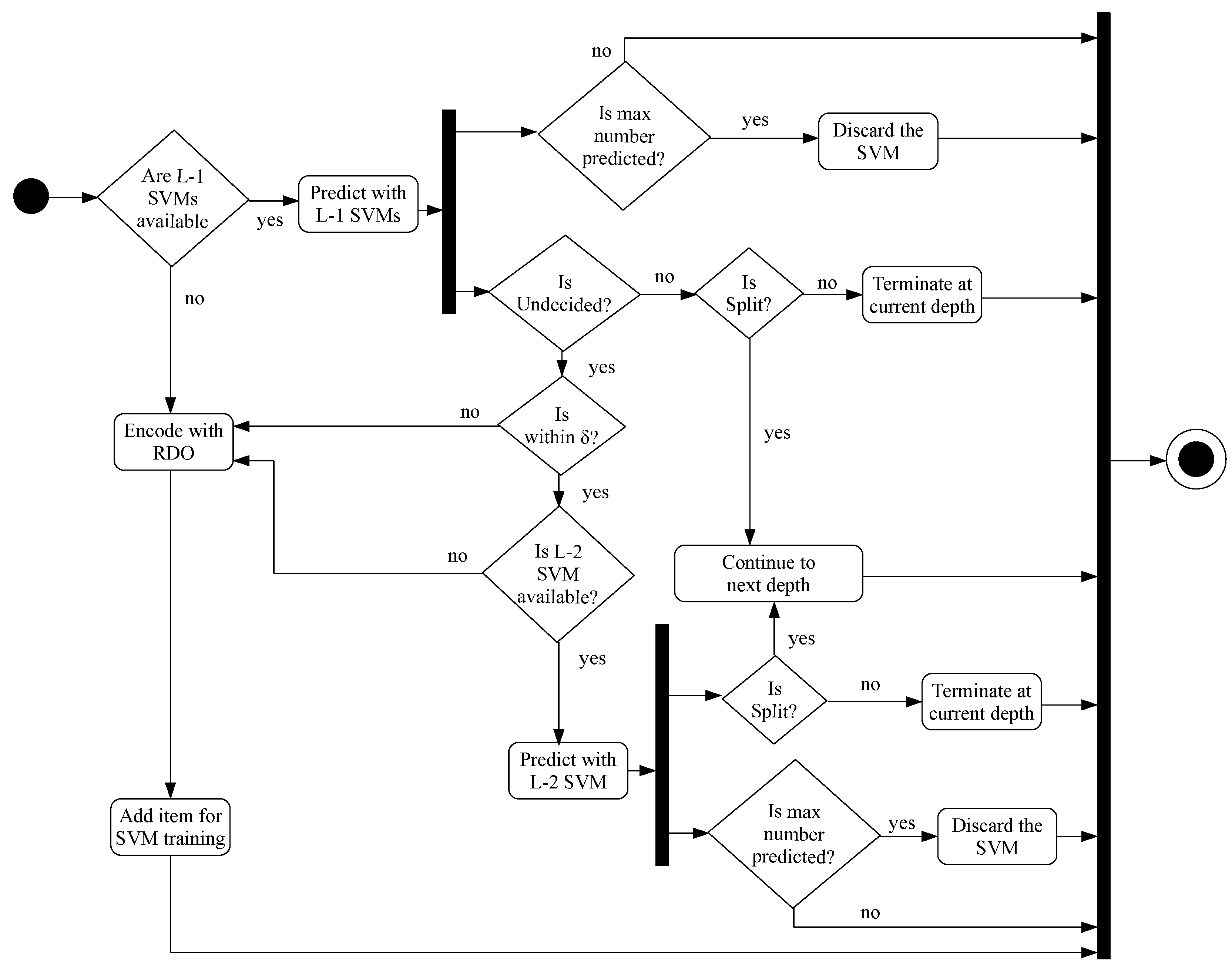
4.3. Overall Encoding Algorithm
Complexity Control Parameter ()
5. Experimental Results and Discussion
5.1. Experimental Setup and Encoding Configurations
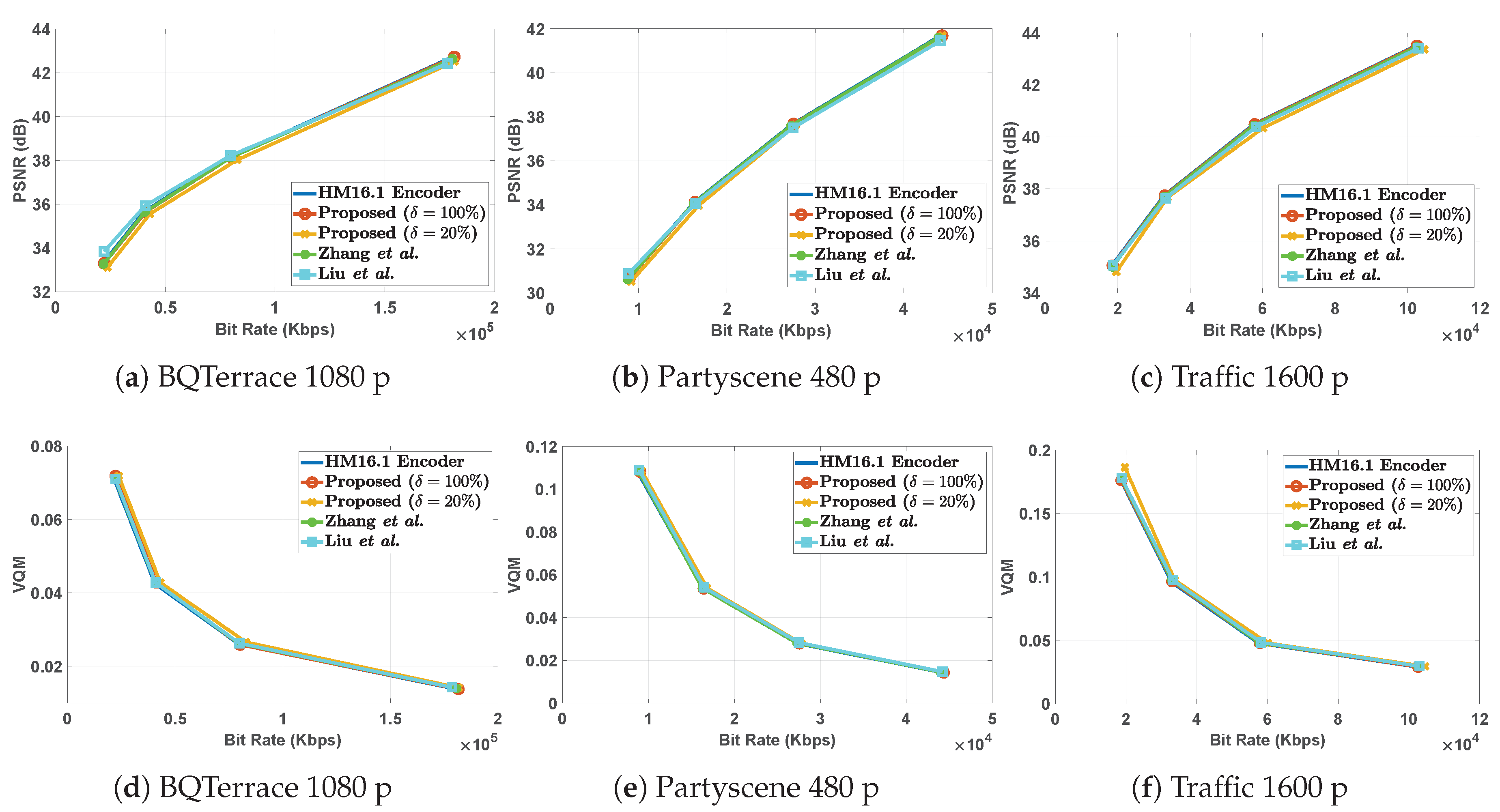
5.2. Results and Performance Analysis
5.2.1. Impact of Complexity Control Parameter
5.2.2. Overall Performance Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cisco. Cisco Visual Networking Index: Global Mobile Data Traffic Forecast Update 2014–2019; White Paper; Cisco: San Jose, CA, USA, 2017. [Google Scholar]
- Segall, A.; Wien, M.; Baroncini, V.; Boyce, J.; Suzuki, T. Draft Joint Call for Proposals on Video Compression with Capability beyond HEVC. In Proceedings of the Joint Video Exploration Team (on Future Video Coding) of ITU-T VCEG and ISO/IEC MPEG, 7th Meeting, Torino, IT, USA, 13–21 July 2017. [Google Scholar]
- Sullivan, G.J.; Ohm, J.; Han, W.J.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Ohm, J.R.; Sullivan, G.J.; Schwarz, H.; Tan, T.K.; Wiegand, T. Comparison of the coding efficiency of video coding standards—Including high efficiency video coding (HEVC). IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1669–1684. [Google Scholar] [CrossRef]
- Bossen, F.; Bross, B.; Karsten, S.; Flynn, D. HEVC complexity and implementation analysis. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1685–1696. [Google Scholar] [CrossRef]
- Kim, I.K.; Min, J.; Lee, T.; Han, W.J.; Park, J. Block Partitioning Structure in the HEVC Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1697–1706. [Google Scholar] [CrossRef]
- Mallikarachchi, T.; Talagala, D.S.; Arachchi, H.K.; Fernando, A. Content-Adaptive Feature-Based CU Size Prediction for Fast Low-Delay Video Encoding in HEVC. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 693–705. [Google Scholar] [CrossRef]
- Baroncini, V.; Ferrara, S.; Ye, Y. Call for Proposals for Low Complexity Video Coding Enhancements; International Organization for Standardization, Coding of Moving Pictures and Audio, ISO/IEC JTC1/SC29/WG11/ N17944; International Organization for Standardization: Geneva, Switzerland, 2018. [Google Scholar]
- Cho, S.; Kim, M. Fast CU splitting and pruning for suboptimal CU partitioning in HEVC intra coding. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1555–1564. [Google Scholar] [CrossRef]
- Zhang, Y.; Pan, Z.; Li, N.; Wang, X.; Jiang, G.; Kwong, S. Effective Data Driven Coding Unit Size Decision Approaches for HEVC INTRA Coding. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 3208–3222. [Google Scholar] [CrossRef]
- Khan, M.U.K.; Shafique, M.; Henkel, J. An adaptive complexity reduction scheme with fast prediction unit decision for HEVC intra encoding. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Melbourne, VIC, Australia, 15–18 September 2013; pp. 1578–1582. [Google Scholar]
- Zhang, Y.; Kwong, S.; Wang, X.; Yuan, H.; Pan, Z.; Xu, L. Machine learning-based coding unit depth decisions for flexible complexity allocation in high efficiency video coding. IEEE Trans. Image Process. 2015, 24, 2225–2238. [Google Scholar] [CrossRef]
- Correa, G.; Assuncao, P.; Agostini, L.V.; Silva, L.A.C. Fast HEVC encoding decisions using data mining. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 660–673. [Google Scholar] [CrossRef]
- Shen, X.; Yu, L. CU splitting early termination based on weighted SVM. EURASIP J. Image Video Process. 2013, 2013, 4. [Google Scholar] [CrossRef]
- HM 16.1. Available online: https://hevc.hhi.fraunhofer.de/trac/hevc/browser/tags/HM-16.1 (accessed on 15 January 2019).
- Lainema, J.; Bossen, F.; Han, W.J.; Min, J.; Ugur, K. Intra coding of the HEVC standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1792–1801. [Google Scholar] [CrossRef]
- Kim, J.; Choe, Y.; Kim, Y.G. Fast coding unit size decision algorithm for intra coding in HEVC. In Proceedings of the IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–14 January 2013; pp. 637–638. [Google Scholar]
- Shen, L.; Zhang, Z.; An, P. Fast CU Size Decision and Mode Decision Algorithm for HEVC Intra Prediction. IEEE Trans. Consum. Electron. 2013, 59, 207–213. [Google Scholar] [CrossRef]
- Zhang, Y.; Kwong, S.; Zhang, G.; Pan, Z.; Hui, Y.; Jiang, G. Low complexity HEVC INTRA coding for high-quality mobile video communication. IEEE Trans. Ind. Inf. 2015, 11, 1492–1504. [Google Scholar] [CrossRef]
- Zuo, X.; Yu, L. Fast mode decision method for all intra spatial scalability in SHVC. In Proceedings of the 2014 IEEE Visual Communications and Image Processing Conference, Valletta, Malta, 7–10 December 2014; pp. 394–397. [Google Scholar]
- Wang, L.L.; Siu, W.C. Novel adaptive algorithm for intra prediction with compromised modes skipping and signaling processes in HEVC. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1686–1694. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, Z. Fast intra mode decision for High Efficiency Video Coding (HEVC). IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 660–668. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, Z. Early Termination Schemes for Fast Intra Mode Decision in High Efficiency Video Coding. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Beijing, China, 19–23 May 2013; pp. 45–48. [Google Scholar]
- Pan, Z.; Qin, H.; Yi, X.; Zheng, Y.; Khan, A. Low complexity versatile video coding for traffic surveillance system. Int. J. Sens. Netw. 2019, 30, 116–125. [Google Scholar] [CrossRef]
- Pan, Z.; Lei, J.; Zhang, Y.; Wang, F.L. Adaptive fractional-pixel motion estimation skipped algorithm for efficient HEVC motion estimation. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2018, 14, 12. [Google Scholar] [CrossRef]
- Lokkoju, S.; Reddy, D. Fast coding unit partition search. In Proceedings of the IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Ho Chi Minh City, Vietnam, 12–15 December 2012; pp. 315–319. [Google Scholar]
- Zhang, Y.; Li, Z.; Li, B. Gradient based fast decision for intra prediction. In Proceedings of the IEEE Visual Communications and Image Processing (VCIP), San Diego, CA, USA, 27–30 November 2012; pp. 1–6. [Google Scholar]
- Tian, G.; Goto, S. Content Adaptive Prediction Unit Size Decision Algorithm for HEVC Intra Coding. In Proceedings of the Picture Coding Symposium (PCS), Krakow, Poland, 7–9 May 2012; pp. 405–408. [Google Scholar]
- Shen, L.; Zhang, Z.; Liu, Z. Effective CU size decision for HEVC intra coding. IEEE Trans. Image Process. 2014, 23, 4232–4241. [Google Scholar] [CrossRef]
- Min, B.; Cheung, R.C.C. A fast CU size decision algorithm for the HEVC intra encoder. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 892–896. [Google Scholar]
- Park, C.S. Efficient intra-mode decision algorithm skipping unnecessary depth-modelling modes in 3D-HEVC. Electron. Lett. 2015, 51, 756–758. [Google Scholar] [CrossRef]
- Zhang, Q.; Huang, X.; Wang, X.; Zhang, W. A fast intra mode decision algorithm for HEVC using sobel operator in edge detection. Int. J. Multimed. Ubiquitous Eng. 2015, 10, 81–90. [Google Scholar] [CrossRef]
- Mallikarachchi, T.; Fernando, A.; Arachchi, H.K. Efficient coding unit size selection based on texture analysis for HEVC intra prediction. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Chengdu, China, 14–18 July 2014; pp. 1–6. [Google Scholar]
- Liu, Z.; Yu, X.; Gao, Y.; Chen, S.; Ji, X.; Wang, D. CU Partition Mode Decision for HEVC Hardwired Intra Encoder Using Convolution Neural Network. IEEE Trans. Image Process. 2016, 25, 5088–5103. [Google Scholar] [CrossRef] [PubMed]
- Hu, N.; Yang, E.H. Fast mode selection for HEVC intra-frame coding with entropy coding refinement based on a transparent composite model. IEEE IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1521–1532. [Google Scholar] [CrossRef]
- Chen, J.; Yu, L. Effective HEVC intra coding unit size decision based on online progressive Bayesian classification. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Du, B.; Siu, W.C.; Yang, X. Fast CU partition strategy for HEVC intra-frame coding using learning approach via random forests. In Proceedings of the 2015 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Hong Kong, China, 16–19 December 2015; pp. 1085–1090. [Google Scholar]
- Coll, D.R.; Adzic, V.; Escribano, G.F.; Kalva, H.; Martínez, J.L.; Cuenca, P. Fast partitioning algorithm for HEVC intra frame coding using machine learning. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4112–4116. [Google Scholar]
- Zhang, T.; Sun, M.T.; Zhao, D.; Gao, W. Fast intra-mode and CU size decision for HEVC. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 1714–1726. [Google Scholar] [CrossRef]
- Shawe-Taylor, J.; Cristianini, N. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000; Volume 204. [Google Scholar]
- Kecman, V. Learning and Soft Computing: Support Vector Machines, Neural Networks, and Fuzzy Logic Models; The MIT Press: Cambridge, MA, USA; London, UK, 2001. [Google Scholar]
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; The MIT Press: Cambridge, MA, USA; London, UK, 2002. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Zhang, X.G. Using class-center vectors to build support vector machines. In Proceedings of the Neural Networks for Signal Processing IX: Proceedings in IEEE Signal Processing Society Workshop, Madison, WI, USA, 25 August 1999; pp. 3–11. [Google Scholar]
- Yang, X.; Song, Q.; Wang, Y. A weighted Support Vector Machines for data classification. Int. J. Pattern Recognit. Artif. Intell. 2007, 2007, 961–976. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 27. [Google Scholar] [CrossRef]
- Bossen, F. Common Test Conditions and Software Reference Configurations. In Proceedings of the Joint Collaborative Team on Video Coding, 10th Meeting, Stockholm, Sweden, 14–23 January 2013. [Google Scholar]
- Bjontegarrd, G. Calculation of Average PSNR Differences Between RD-Curves. In Proceedings of the ITU–Telecommunications Standardization Sector STUDY GROUP 16 Video Coding Experts Group (VCEG), 13th Meeting, Austin, TX, USA, 2–4 April 2001. [Google Scholar]
- Pinson, M.; Wolf, S. A New Standardized Method for Objectively Measuring Video Quality. Electron. Lett. 2004, 50, 322. [Google Scholar] [CrossRef]
- Richardson, I.E. H. 264 and MPEG-4 Video Compression: Video Coding For Next-Generation Multimedia; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Okarma, K. Adaptation of the Combined Image Similarity Index for Video Sequences; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Category | Feature | Depth(s) |
|---|---|---|
| Texture Information | 0, 1, 2, 3 | |
| 0, 1 | ||
| Pre-analysis of current CU | 0, 1, 2, 3 | |
| 0, 1 | ||
| Context Information | 0, 1 | |
| 0, 1 | ||
| 2, 3 |
| Feature Category | Feature | Depth(s) |
|---|---|---|
| Texture Information | 0, 1, 2, 3 | |
| Context Information | 0, 1 | |
| 2, 3 | ||
| Coding Information of Current CU | 0, 1, 2, 3 | |
| 0, 1, 2, 3 |
| Sequence | Proposed ( = 100) vs. HM | Proposed ( = 20) vs. HM | Zhang et al. [10] vs. HM | Liu et al. [34] vs. HM | ||||
|---|---|---|---|---|---|---|---|---|
| T (%) | BD-Rate ★ (%) | T (%) | BD-Rate ★ (%) | T (%) | BD-Rate ★ (%) | T (%) | BD-Rate ★ (%) | |
| Kimono | 72.60 | 2.32 | 81.06 | 5.92 | 80.74 | 4.13 | 70.50 | 2.54 |
| Basketball Pass | 52.68 | 0.56 | 72.15 | 5.99 | 51.84 | 1.21 | 54.55 | 2.80 |
| BQTerrace | 56.17 | 0.91 | 72.94 | 7.52 | 52.03 | 0.80 | 56.78 | 1.95 |
| Traffic | 61.71 | 0.56 | 78.59 | 6.45 | 49.48 | 0.98 | 59.02 | 2.35 |
| RaceHorses | 40.92 | 0.47 | 62.75 | 4.82 | 49.07 | 1.04 | 53.98 | 2.36 |
| BlowingBubbles | 31.78 | 0.28 | 40.21 | 2.81 | 31.33 | 0.41 | 31.59 | 1.93 |
| Johnny | 56.61 | 2.22 | 70.46 | 6.02 | 71.99 | 2.94 | 71.35 | 4.28 |
| KristenAndSara | 59.41 | 1.68 | 66.74 | 4.89 | 62.14 | 2.21 | 68.78 | 3.18 |
| PeopleOnStreet | 49.59 | 2.36 | 75.61 | 13.65 | 44.42 | 1.17 | 56.49 | 2.25 |
| PartyScene | 42.37 | 0.58 | 52.91 | 3.40 | 29.68 | 0.30 | 44.72 | 2.23 |
| Average | 52.38 | 1.19 | 67.34 | 6.15 | 52.27 | 1.52 | 56.78 | 2.59 |
| Sequence | Proposed ( = 100) vs. HM | Proposed ( = 20) vs. HM | Zhang et al. [10] vs. HM | Liu et al. [34] vs. HM | ||||
|---|---|---|---|---|---|---|---|---|
| T (%) | BD-Rate † (%) | T (%) | BD-Rate † (%) | T (%) | BD-Rate † (%) | T (%) | BD-Rate † (%) | |
| Kimono | 72.60 | 1.53 | 81.06 | 4.27 | 80.74 | 4.24 | 70.50 | 2.60 |
| Basketball Pass | 52.68 | 0.45 | 72.15 | 4.01 | 51.84 | -0.73 | 54.55 | 0.03 |
| BQTerrace | 56.17 | 2.58 | 72.94 | 7.28 | 52.03 | 1.68 | 56.78 | 2.03 |
| Traffic | 61.71 | 0.72 | 78.59 | 7.08 | 49.48 | 1.91 | 59.02 | 2.39 |
| RaceHorses | 40.92 | 0.76 | 62.75 | 5.34 | 49.07 | 0.78 | 53.98 | 1.75 |
| BlowingBubbles | 31.78 | 2.20 | 40.21 | 3.79 | 31.33 | 3.83 | 31.59 | 1.68 |
| Johnny | 56.61 | 2.09 | 70.46 | 3.71 | 71.99 | 3.08 | 71.35 | 4.57 |
| KristenAndSara | 59.41 | 1.94 | 66.74 | 6.87 | 62.14 | 2.33 | 68.78 | 3.40 |
| PeopleOnStreet | 49.59 | 2.13 | 75.61 | 10.46 | 44.42 | 1.29 | 56.49 | 1.25 |
| PartyScene | 42.37 | 0.89 | 52.91 | 3.61 | 29.68 | 0.08 | 44.72 | 1.65 |
| Average | 52.38 | 1.52 | 67.34 | 5.64 | 52.27 | 1.84 | 56.78 | 2.13 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Erabadda, B.; Mallikarachchi, T.; Hewage, C.; Fernando, A. Quality of Experience (QoE)-Aware Fast Coding Unit Size Selection for HEVC Intra-Prediction. Future Internet 2019, 11, 175. https://doi.org/10.3390/fi11080175
Erabadda B, Mallikarachchi T, Hewage C, Fernando A. Quality of Experience (QoE)-Aware Fast Coding Unit Size Selection for HEVC Intra-Prediction. Future Internet. 2019; 11(8):175. https://doi.org/10.3390/fi11080175
Chicago/Turabian StyleErabadda, Buddhiprabha, Thanuja Mallikarachchi, Chaminda Hewage, and Anil Fernando. 2019. "Quality of Experience (QoE)-Aware Fast Coding Unit Size Selection for HEVC Intra-Prediction" Future Internet 11, no. 8: 175. https://doi.org/10.3390/fi11080175
APA StyleErabadda, B., Mallikarachchi, T., Hewage, C., & Fernando, A. (2019). Quality of Experience (QoE)-Aware Fast Coding Unit Size Selection for HEVC Intra-Prediction. Future Internet, 11(8), 175. https://doi.org/10.3390/fi11080175