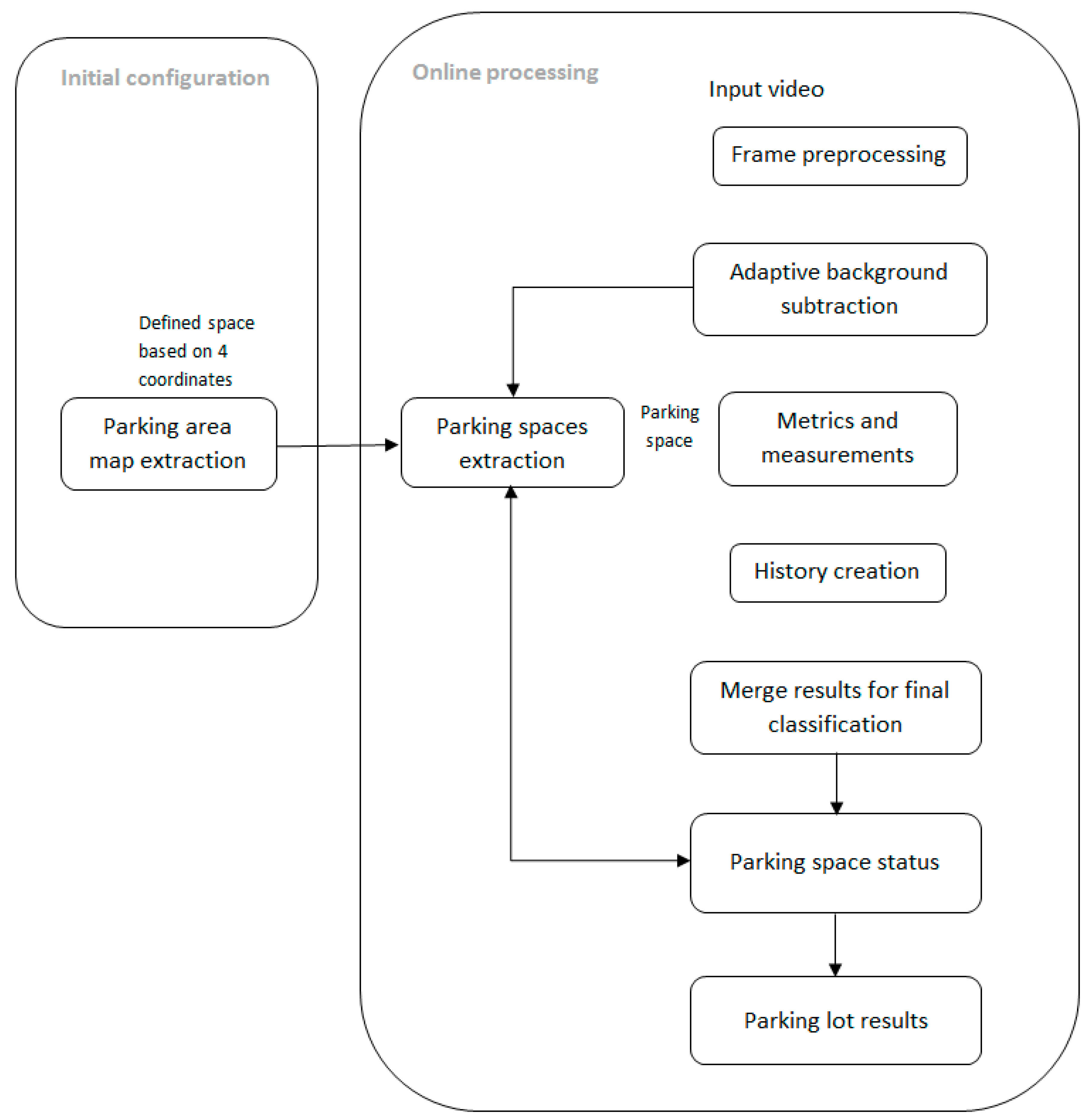
During this stage, the main goal of the proposed algorithm resides in assigning a status to each parking space based on the extraction of several different image features from the map provided in the initial configuration.
2.2.2. Adaptive Background Subtraction
Background subtraction is the first and fundamental step in many computer vision applications, such as traffic monitoring or parking lot occupancy. It is hard to produce a robust background model that works well under a vast variety of situations. A good background model should have the following features: accuracy in terms of form detection and reactivity to changes over time, flexibility under different lighting conditions, and efficiency for real-time delivery.
The mixture-of-Gaussians (MoG) background model is widely used in such applications, in order to segment moving foreground, due to its effectiveness in dealing with gradual lighting changes and repetitive motion. MoG is a parametric method employing statistics by using a Gaussian model for each pixel. Every Gaussian model maintains the mean and the variance of each pixel, with the assumption that each pixel value follows a Gaussian distribution. If considering the swaying of a tree or the flickering of a monitor, the MoG can handle those multi-model changes quite well [
10]. Many improvements on Gaussian mixture model have been implemented like MOG2. An important feature of MOG2 is that it selects the appropriate number of Gaussian distributions for each pixel, providing better adaptability to varying scenes, due to illumination or other changes.
In this approach, the mixture of Gaussians algorithm (MOG2) was used for background subtraction, with the help of which two images were acquired: the background and the foreground. The background model is dynamically updated to compare each pixel with the corresponding distribution, leading to the foreground mask separated from the background. The foreground mask generated is a binary image, where foreground objects are white pixels. One or more objects can be detected in the foreground of a single image. The resulting background image is used as input for the next stage, the extraction of parking spaces.
The system involves the use of a Gaussian mixture model to adjust the probability density function (PDF) of each pixel X(x, y) and create the background model. The probability of observing the value of a pixel is defined as follows [
10]:
with the values of a pixel at any time t, is known as its history [
7]:
where K is the number of Gaussian distributions used to model each pixel, ω
i,t is the weight of the
Gaussian at time t, µ
i,t is the Gaussian average of the
Gaussian at time t,
is the covariance matrix of the
Gaussian probability density function:
Usually, the number of Gaussian distributions used to model each pixel is three or five. These Gaussians are correctly mixed due to the weight factor ωi,t, which is altered (increased or decreased) for each Gaussian, based on how often the input pixel matches the Gaussian distribution.
The covariance matrix is defined as follows:
Once the parameters initialization is made, a first foreground detection can be made and then the parameters are updated. The K distribution are ordered based on the fitness value .
The Gaussian model will be updated by the following update equations [
10]:
where
When the new frame at times t + 1 incomes, a match test is made for each pixel, where K is a constant threshold equal to 2.5. Thus, two cases can occur [
11]:
Case 1: A match is found with one of the K Gaussians. In this case, if the Gaussian distribution is identified as a background one, the pixel is classified as background else the pixel is classified as foreground.
Case 2: No match is found with any of the K Gaussians. In this case, the pixel is classified as the foreground. At this step, a binary mask is obtained. Then, to make the next foreground detection, the parameters must be updated, using Equations (7)–(9).
The following processing steps will use the adaptive background image resulted from the background subtraction algorithm.
2.2.4. Metrics and Measurements Used for Description of the Area of Interest
Based on the resulting images of the parking spaces, various methods and features are used for their detection into available and occupied places.
a. Histogram of Oriented Gradients (HOG)
Prior to applying the algorithm, the edges in the images must be detected and the image resized. The edge detection is done using the Canny algorithm, while the image is resized to 64 × 128 pixels. The histogram of oriented gradients (HOG) is a feature descriptor used to detect objects by counting the occurrences of gradient orientation in areas of interest. In the HOG feature descriptor, the distributions of the gradient orientation histogram are used as a feature, as follows:
Sliding window dimension (winsize) is set to (64, 128). It defines the size of the descriptor.
The size descriptor winSize is first divided into size cell cellSize (8, 8), and for each cell, a histogram of gradient direction or edge orientation is computed. Each pixel in the cell contributes to the histogram based on the gradient values [
8].
Adjacent cell groups are considered 2D regions called blocks, of size (16, 16). A Block uses blockSize.width · blockSize.height adjacent cells in order to estimate a normalized histogram out of the blockSize.width · blockSize.height cell histograms. Grouping the cells into a block is the basis for grouping and normalizing histograms. BlockStride can be used to arrange the blocks in an overlapping manner. BlockStride size is set to (8, 8).
The histogram group constructs the block histogram. All normalized histograms estimated for each block are concatenated, defining the final descriptor vector.
An image gradient represents a directional change in the intensity or color of pixels and it is computed as partial derivatives (Equation (8)).
where
is the derivative with respect to x,
is the derivative with respect to y.
The derivative of an image can be approximated by finite differences. To calculate
one can apply a one-dimensional filter to the image by convolution:
where * denotes the one-dimensional convolution operation.
The gradient direction can be computed as in Equation (13).
while the magnitude is given by the following:
A histogram for each cell was created; with each cell pixel having one vote in the histogram. The interval of the histogram is incremented by a particular pixel is determined by the value of the gradient orientation. Dalal and Triggs [
12] have found that it is enough to have nine histogram intervals, and if the gradient orientation takes values between 0 and 360 degrees, the position in the histogram is calculated by dividing the number by 40. In the polling process, each vote can be weighted with the magnitude of the gradient, with its square root or square magnitude.
To account for the light and contrast variations, the cells are organized into blocks and the normalization is performed for each block [
13]. In [
12], the authors indicate that the L2-norm is suitable for objects detection (Equation (2)).
where v is a non-normalized vector containing all histograms obtained from the block and ε is a constant determined empirically with a low value. The HOG descriptor is the vector resulted from the normalized components of the histograms of each block cell.
The vector obtained from the HOG descriptor is used to compute an arithmetic mean. The values obtained are compared with the threshold defined as 0.03. If the value is bigger than this threshold, the parking space is tagged with 1 (occupied).
b. SIFT corner detector
Scale-invariant feature transform (SIFT) is a descriptor that is expressed as a multidimensional vector in space and it features 128 dimensions. It can be considered a string of numbers assigned to a pixel, which reflects the influence of adjacent elements over the pixel in the image.
A SIFT vector is calculated as the weighted sum of normal values (intensities) over a gradient (pixel groups) considered adjacent to the analyzed pixel, where the weighting factor of the calculated sums is dependent on the distance from said pixel analyzed. It obtains superior results to the Harris corner detector and its features are highly consistent in terms of rotation, scaling, translation. The gray image is used to detect the key points based on the convolution with the kernel:
where (x,y) is the location of the current pixel,
is the standard deviation of Gaussian kernel. Computation of the differences convolutions at different scales σ will be performed.
where k is a natural number, I(x, y) represents the grayscale image.
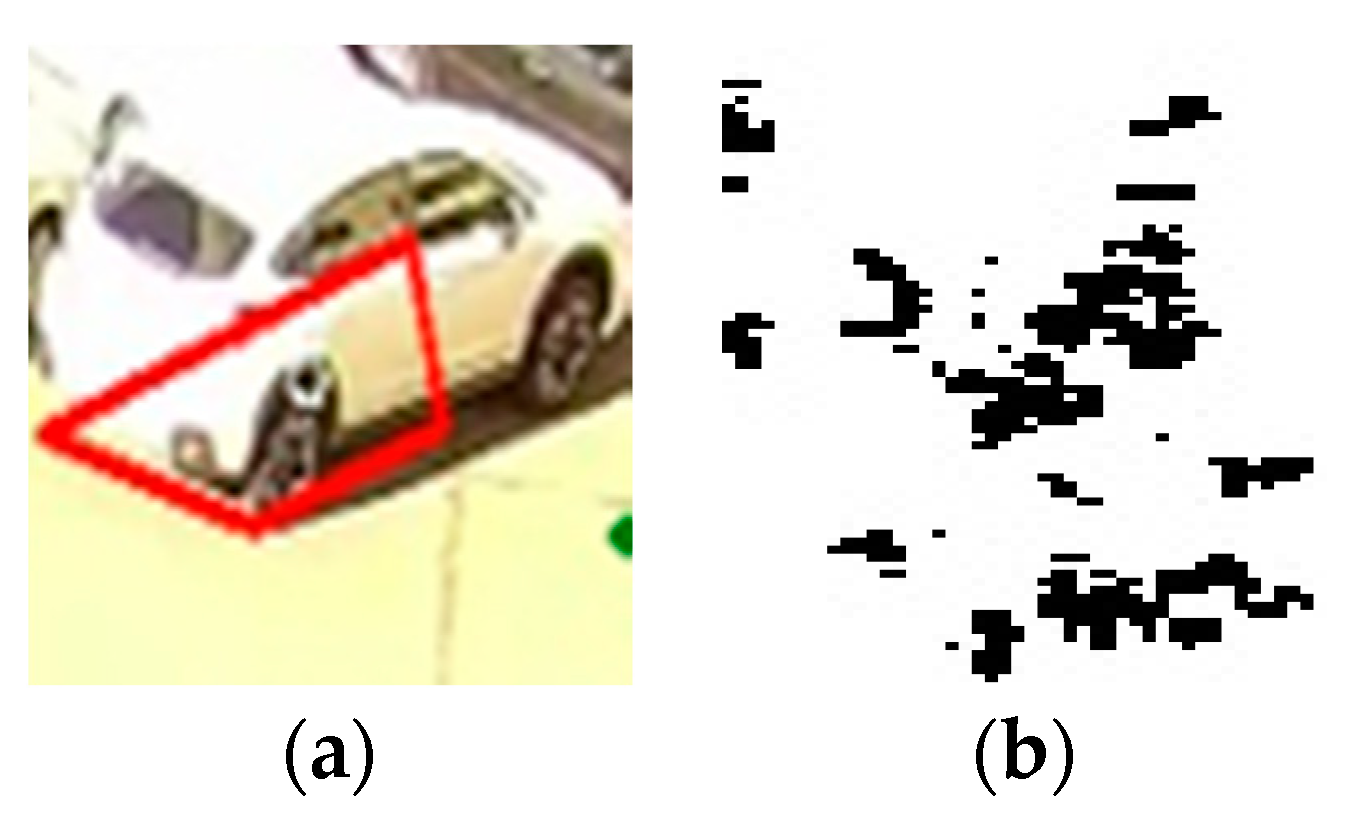
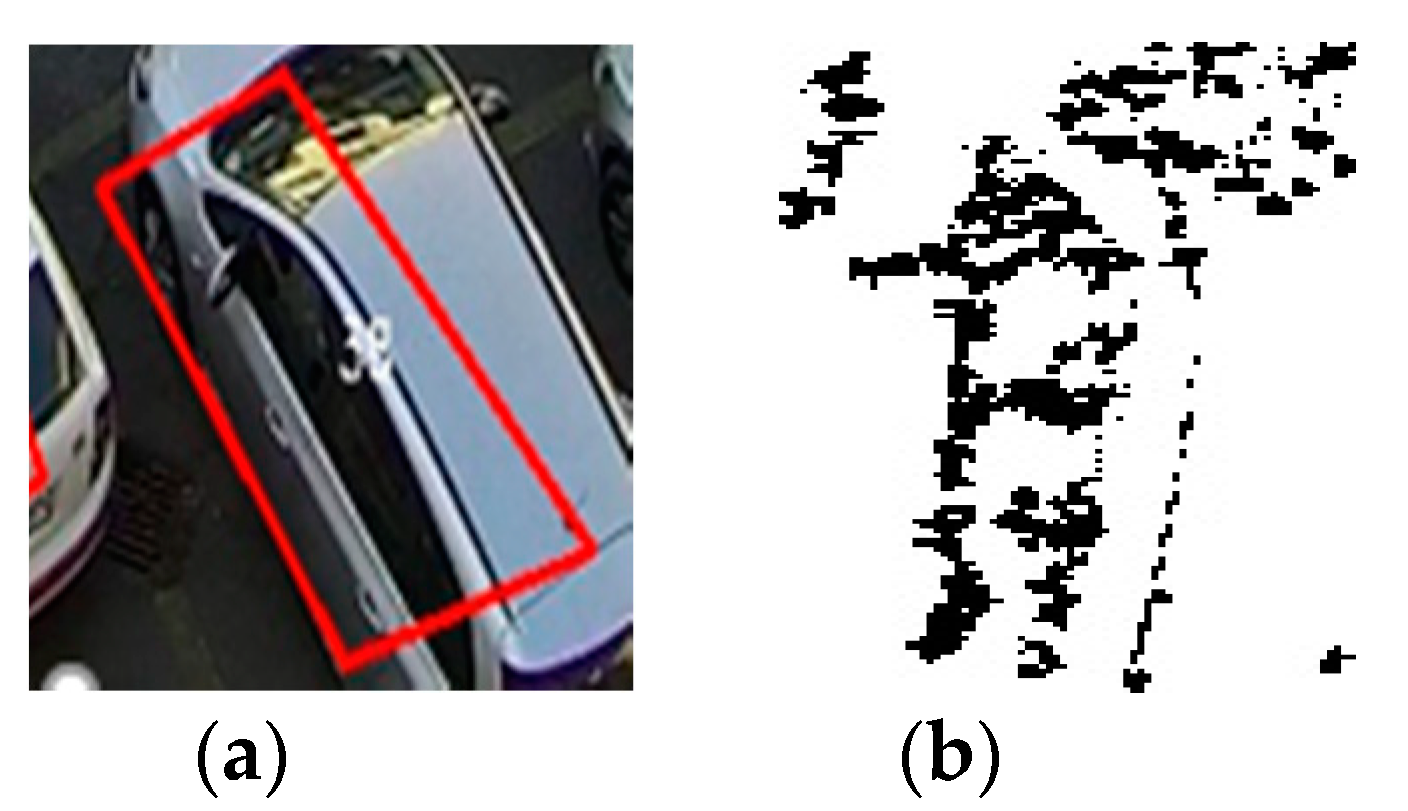
This method extracts feature points, considered to be candidates in the extraction of “key points” used in the description of the image. For each point, the gradient magnitude and orientation will be computed using the following formulas:
An orientation histogram will be created and the maximum values will be retained, together with points containing at least 80% of the maximum value found (eliminating thus over 95% of the points extracted in the previous process). After obtaining the extremes, the points with low contrast and less outlined edges will be eliminated. The remaining points are the points of interest in the image as one can see from
Figure 5,
Figure 6 and
Figure 7.
The number of the points of interest from the SIFT corner detector is compared with threshold = 7 and if the value is bigger than the threshold, then status = 1 (occupied space); otherwise, status = 0 (available space).
The corner detector is combined with the HOG in order to obtain more accurate results.
The parking space status is labeled as occupied if the result of the detection methods employed is mostly “1”, and the parking space status is labeled as available if the result is mostly “0”. In case of various background interferences such as shade, sun, or camouflage, the results are erroneous. In the case of camouflage, no corners are detected for the occupied spaces, and they are labeled as available. In the case of shade or sun, corners are detected in the available spaces, and they are labeled as occupied. To eliminate these background issues, we will add some metrics discussed in the next section.
c. Metrics on Color Spaces YUV, HSV, and YCrCb
YUV defines a color space where U is the color difference between red and blue, and V is the color difference between green and magenta. Y is the weighted values of red, green and blue [
14], and represents the luminance component. U and V stand for the color components. Chrominance is defined as the difference between a color and a shade of gray with the same luminance.
The HSV color space is a uniform one and is a trade-off between a perceptual relevance and computation speed, while in our context, it has been proved to detect the shade more accurately. The theoretical basis for removing shade is that the hues of brightness and saturation are darker than those in the background, but the color remains unchanged when the image is converted to the HSV color space [
15].
YCbCr is a color model which includes a luminance component (Y) and two chrominance components (Cb and Cr), where Cb is the blue chrominance component, and Cr is the red chrominance component.
The measurement used for these metrics is the standard deviation. The vectors obtained from the three color spaces, the standard deviation is calculated on the following channels:
YUV: standard deviation on channel V;
HSV: standard deviation on channel S;
YCbCr: standard deviation on channel Cb;
The values obtained from measurements of metrics are compared with thresholds defined in the system. The thresholds are 1.4 for V component from YUV, 9 for S component from HSV and 1.1 for Cb component from YCbCr. If the value is bigger than the threshold, the parking space is tagged with 1 (occupied). The values of 1 (occupied) and 0 (free) from these measurements are counted and the state of the parking space is set in history in
Section 2.2.5. If the predominant is 1, the parking space is occupied, and otherwise is free.
After combining the YUV, HSV, and YCbCr color spaces with descriptor HOG and SIFT, the results improved significantly. The standard deviations on the three transformations were included in the generated history.
2.2.5. Feature Tracking
The standard deviation values for the three channels V (devSYUV), S (devSHSV), Cb (devSYCrCb) of the color spaces YUV, HSV, YcbCr, the number of corners (noSIFT), and the HOG descriptor mean (meanHOG) were used to create a history, based on predefined thresholds mentioned in
Section 2.2.4. This history tracks the availability of parking spaces.
Each value from metrics and measurements compares with a default threshold. Based on this comparison, the values of 1 (statusOccupied) and 0 (statusAvailable) are counted, and the status is determined by the predominant value.
Function SetStatus (indexParkingLot)
if meanHOG[indexParkingLot] > 0.03 then statusOccupied++;
else statusAvailable++;
end if
if noSIFT[indexParkingLot] >= 7 then statusOccupied++;
else statusAvailable++;
end if
if devSYUV[indexParkingLot] > 1.4 then statusOccupied++;
else statusAvailable++;
end if
if (devSHSV[indexParkingLot] > 9) then statusOccupied++;
else statusAvailable++;
end if
if (devSYCrCb[indexParkingLot] > 1.1) then statusOccupied++;
else statusAvailable++;
end if
if (statusAvailable > statusAvailable) then status = 0
else status = 1
end if
EndStatus
For more accurate results, was have created a history of 20 frames (
Figure 8), that memorizes the status of each parking space, obtained from measured metrics and measurement results. With each new frame, it is tested if the number of frames originally set has been reached. If yes, then adding the status to the list produces the effect of a “sliding window”, which requires the elimination of the first value of the buffer and the addition of the new value in the list, according to the FIFO principle. Thus, this technique allows for the last changes to each parking space to be retained in order to determine the status. Over time, this process helps stabilize changes in the background, such as the gradual change from day to night, different weather conditions.
for parkingSpace=0:totalNumberParkingLot
if(sizeOfBuffer < 20)
Status = SetStatus(parkingSpace)
Add status in buffer
else
SlidingWindow
Status = SetStatus(parkingSpace)
Add status in buffer
end if
if predominat is 1 in buffer StatusParkingSpace = 1
else StatusParkingSpace = 0
end if
end for




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}