1. Introduction
The study of the spreading process on social networks has attracted a lot of attention recently for its great practical value in word-of-mouth marketing or viral marketing [
1,
2]. Domingos et al. [
3] and Kempe et al. [
4] first treated the viral marketing problem as an influence maximization problem, which chooses a limited number of initial nodes to spread information of a product in a social network such that the resulting number of customers that bought the product is maximized. They discarded some important properties of viral marketing in order to simplify the problem. Recently, some properties, such as time, budget and memory networks, have been carefully studied [
5,
6,
7,
8,
9]. However, none of that research considered the memory and social reinforcement effects, which are two common and significant characteristics of social networks.
Memory effect means that previous contacts in a social network could affect the information spread in real time [
10]. Social reinforcement effect means that if more than one neighbor approves the information and transfers it to you, there is a high probability that you will approve it [
11]. For example, in viral marketing, if a person receives a product advertisement recommended by his or her neighbors twice, his/her approval probability for the product should be more than twice as large as the probability with a single recommendation. Once he/she has bought a certain kind of product, the possibility of buying the same product again will be greatly increased.
Online human interactions take place within a dynamic hierarchy, where social influence is determined by qualities such as status, eloquence, trustworthiness, authority and persuasiveness. In this paper, we extend the traditional influence maximization problem to a more realistic viral marketing problem considering memory effect and social reinforcement effect. We first propose a new propagation model, Dependent Cascade Model for Viral Marketing (DCM4VM), to capture the dynamics of memory effect and social reinforcement effect. Then, we present new algorithms to solve the problem under DCM4VM and prove their effectiveness through theoretical and experimental analyses. Finally, we try to explain why the actual effect of current celebrity micro-blogging marketing is not as good as expected through experimental simulation.
The rest of this paper is organized as follows. We introduce related work in
Section 2. In
Section 3, we propose a novel Dependent Cascade Model for Viral Marketing and redefine the influence maximization problem under the model.
Section 4 gives two modified algorithms and a new algorithm to solve the influence maximization problem. In
Section 5, we discuss the corresponding experiments. We make some conclusions and describe our future work in
Section 6.
2. Related Work
Research in the area of viral marketing [
12,
13,
14,
15] takes advantage of social network, wherein friends recommend a product to their friends, who in turn recommend it to others, and so forth, creating a cascade of recommendations. In this way, the ad of the product can spread through the network from a small set of initial nodes to a potentially much larger group.
Domingos and Richardson [
3] first formulated viral marketing on social network as an influence maximization problem. They modelled the problem using Markov random fields and proposed heuristic solutions. Kempe et al. [
4] studies influence maximization as an optimization problem. They showed that the problem is NP-hard under both Independent Cascade (IC) and Linear Threshold (LT) Models, and proposed a greedy algorithm to solve the problem. In an effort to improve the efficiency of greedy algorithms, Leskovec et al. [
16] recognized that not all remaining nodes need to be evaluated in each round and propose CELF. Goyal et al. further proposed CELF++ [
17], that has been shown to run from 35% to 55% faster than CELF. Both CELF and CELF++ are based on sub modularity. In [
18], Chen et al. studied the efficient influence maximization from two complementary directions. One is to propose New Greedy to improve the original greedy algorithm, and the second is to propose Degree Discount heuristics that improves influence spread. Chen et al. devised several heuristic algorithms for influence spread computation [
18,
19,
20]. In Degree Discount [
18], the expected number of additional nodes influenced by adding a node v in the seed set is estimated based on v’s one hop neighborhoods. Chen et al. [
21] proposed a new framework, called community-based influence maximization (CIM), to tackle the influence maximization problem with an emphasis on the time efficiency issue. In [
19,
20], two approximation algorithms, PMIA and LDAG are proposed to compute the maximum influence set under IC and LT models, respectively. In LDAG, it has been proven that under the LT model, computing influence spread in a DAG has linear time complexity, and a heuristic on local DAG construction is provided to further reduce the computation time.
Chen et al. [
5] and Liu et al. [
6] independently proposed the time-critical influence maximization problem, in which the propagation model considers time constrain. They proved the monotonicity and sub modularity of the time constrained influence spread function and propose algorithms to solve the problem. Li et al. [
22] argued that, in more real-world cases, marketers usually target certain products at particular groups of customers. So, they proposed the labeled influence maximization problem, which aims to find a set of seed nodes which can trigger the maximum spread of influence on the target customers in a labeled social network. In order to build a more realistic problem of viral marketing, Huy Nguyen and Rong Zheng further proposed the budgeted influence maximization problem (BIM), which involves selecting a set of seed nodes to maximize the total number of nodes influenced in social networks at a total cost no more than the budget [
7]. Amit Goyal et al. studied influence maximization from a novel data-based perspective. They introduced a new model, which is called credit distribution, that directly leverages available propagation traces to learn how influence flows in the network and uses this to estimate expected influence spread [
23]. Li et al. [
24] proposed a novel network model and an influence propagation model taking influence propagation in both online social networks and the physical world into consideration by using mobile crowd sourced data. Chen et al. [
25] proposed an extension to the Independent Cascade Model (ICM) that incorporates the emergence and propagation of negative opinions which is commonly acknowledged in the social psychology literature. Jing Guo et al. [
26] studied a new interesting problem on social network influence maximization recently. The problem is defined as, given a target user w, finding the top-k most influential nodes for the user (i.e., local optima). Wang et al. [
27] design an independent cascade-based model for influence maximization, called IMIC-OC, to calculate positive influence.
To the best of our knowledge, no existing work on influence maximization considers network dynamic properties such as social reinforcements which are common phenomenon in social network and viral marketing. There are many different types of reinforcement, but when it comes to human beings, one of the most common is the naturally occurring social rein forcers that we encounter all around us every day. Social reinforcement refers to reinforces such as smiles, acceptance, praise, acclaim, and attention from other people. In some cases, simply being in the presence of other people can serve as a natural social reinforcement. Researchers have found that social reinforcement can play a vital role in a variety of areas, including health. The influence of people in our social networks can influence the type of health choices and decisions that we make. Although this simplifies the problem, it results in the disagreement between actual and theoretical situations and discounts the practical value of the theoretical research. Laflin et al. [
28]. discuss the temporal nature of viral marketing in practice on big data with a set of visual accompaniments and novel methodology.
Some researchers also view social reinforcement as a type of affinity [
29], which develops a dynamical information diffusion model referred the affinity of people; however, the research of reinforcement in the reference [
29] is still different from the research in our research, because this method in the reference [
29] only considers three kinds of nodes, and the method in this paper consider the spread reasons.
This paper proposes a new propagation model to capture the dynamic changes of memory effect and social reinforcement effect, and improves this model. Experimental results show that the improved model can capture some important features of viral marketing in social networks and explain some phenomena that cannot be explained by the existing definition of impact maximization problem. What’s more, the improved model also has lower time complexity.
3. Influence Maximization under DCM4VM
3.1. Traditional Influence Maximization Problem
Influence maximization is the problem of finding a small subset of nodes (seed nodes) in a social network that could maximize the spread of influence [
4,
18].
Problem 1. Given a social network modeled as an indirect graph
G = (
V,
E,
PE) (vertical
V representing the individuals in the network, edges E denoting the relationship between individuals, and edge probabilities
PE = {
Pu,
v|
u,
v ∈
V} illustrating the possibility that a node can influence its neighbor on the other side of the edge, and
Pu,
v illustrating the probability of both
u and
v), a specific propagation model called “
M” and a small number called “
k”, the influence maximization problem is to find a initial set called “
S” with k nodes in the graph such that under the propagation model
M, the expected number of nodes influenced by
S is as large as possible. Assume
(
S) represents all influenced nodes, this problem can be formally defined as:
3.2. Dependent Cascade Model for Viral Marketing
Generally, the most commonly used propagation model is Independent Cascade Model (ICM) [
13,
14]. However, there are only two states considered in ICM, namely active and inactive. In addition, the probability that a node changes from inactive to active is independent of the history of the process. This is insufficient for the actual viral marketing problem. In this paper, we propose a new propagation model, namely Dependent Cascade Model for Viral Marketing which is more suitable for the viral marketing problem, which also could be used for viruses spreading and any other living beings spreading.
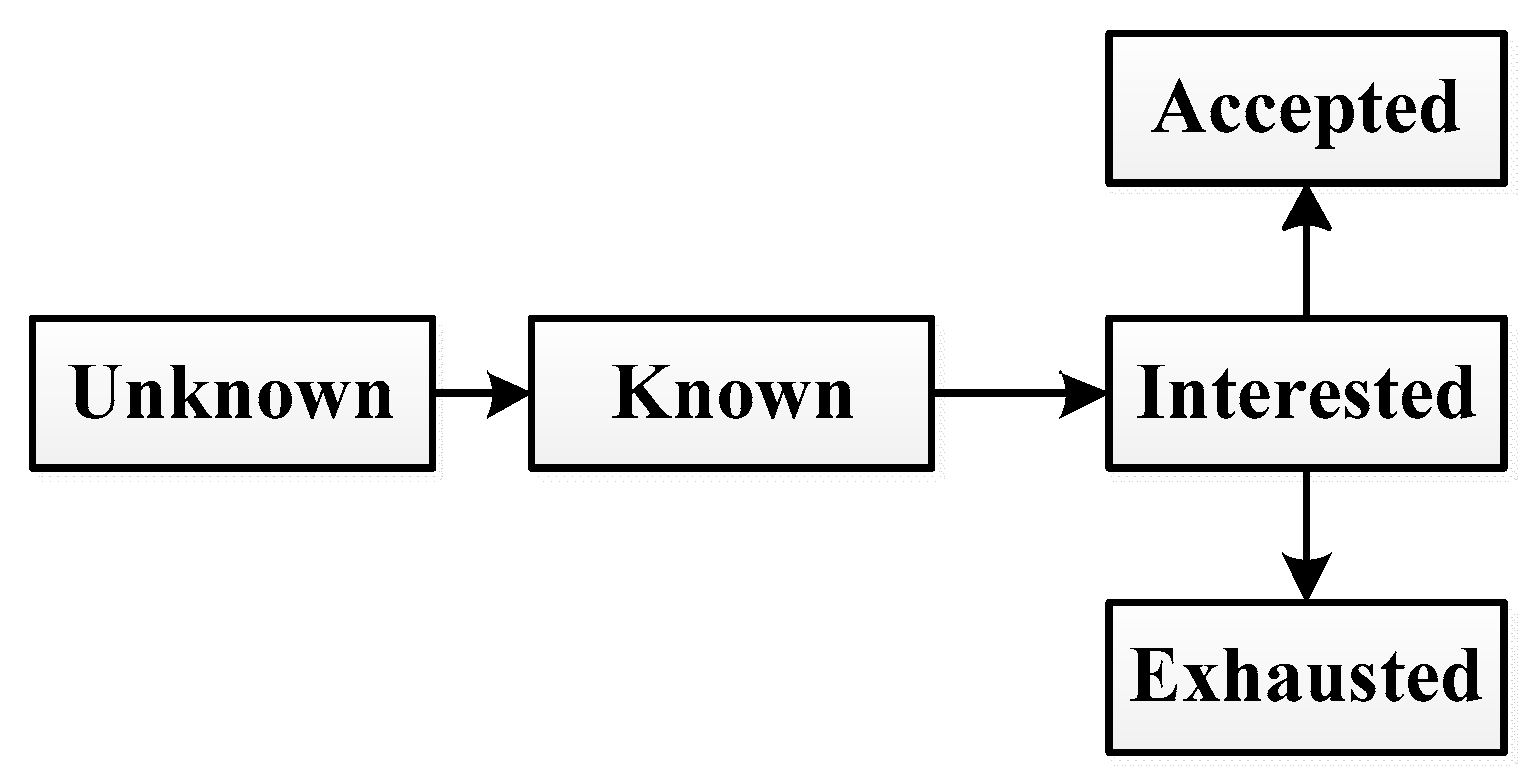
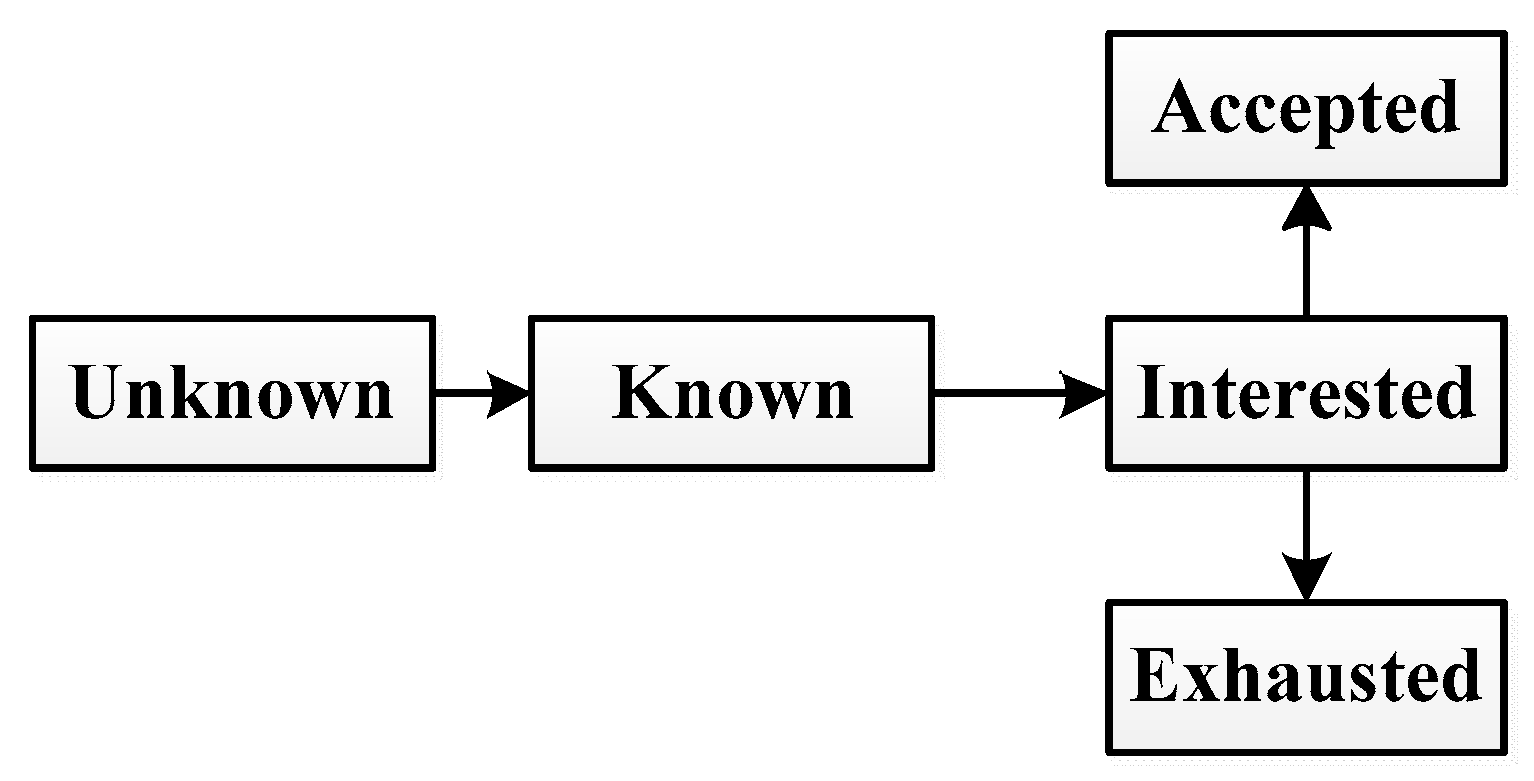
We stipulate that each node has five states: unknown, known, interested, accepted and exhausted. In viral marketing, unknown means that the node never heard about the product advertisement; “known” means that the node hears about the advertisement; “interested” means that the node is interested in the product but may or may not buy the product; “accepted” means that the node is interested in the product and purchases it; “exhausted” means that the node never purchases the product and also loses interest in the product.
The state transition process is shown in
Figure 1. Initially, most nodes are unknown about the product. And a small subset of initial known nodes tries to propagate the product information to their neighbors. Once known about the information, a node
v becomes interested in it with probability
Pu,
v. The interested node will spread the information to its neighbors and become accepted with probability
Pv. After spreading the information, the interested node becomes accepted or exhausted and will not spread it any more.
As shown in
Figure 1, it doesn’t consider time delay [
30], and time delays can be divided into two types, namely, communication delay and processing delay. But In this paper, the propagation problems we study are all concerned with the fact that there is no delay between each node of the network. The research is carried out in the case of average delay, and we will carry out further research in terms of time delay.
We observed that whether a person will buy a product or not relies on two factors: internal factors and external factors. Internal factors reflect a person’s inherent preference for the product. In other words, it is the probability that the person purchases the product without any influence from his/her friends. External factors reflect the effect of outside environment to user purchasing behaviors. For example, social reinforcement effect and memory effect are important external factors. That is, the more friends of a person have bought the product, the more likely the person will buy it.
As shown in
Figure 1, at the beginning, the user does not know the product. After the user knows it, he may become interested, and then the user may accept the product.
Formally, for a given node
v, the probability
Pv(
t) that the node
v purchases a product at time
t is computed as follows [
10]:
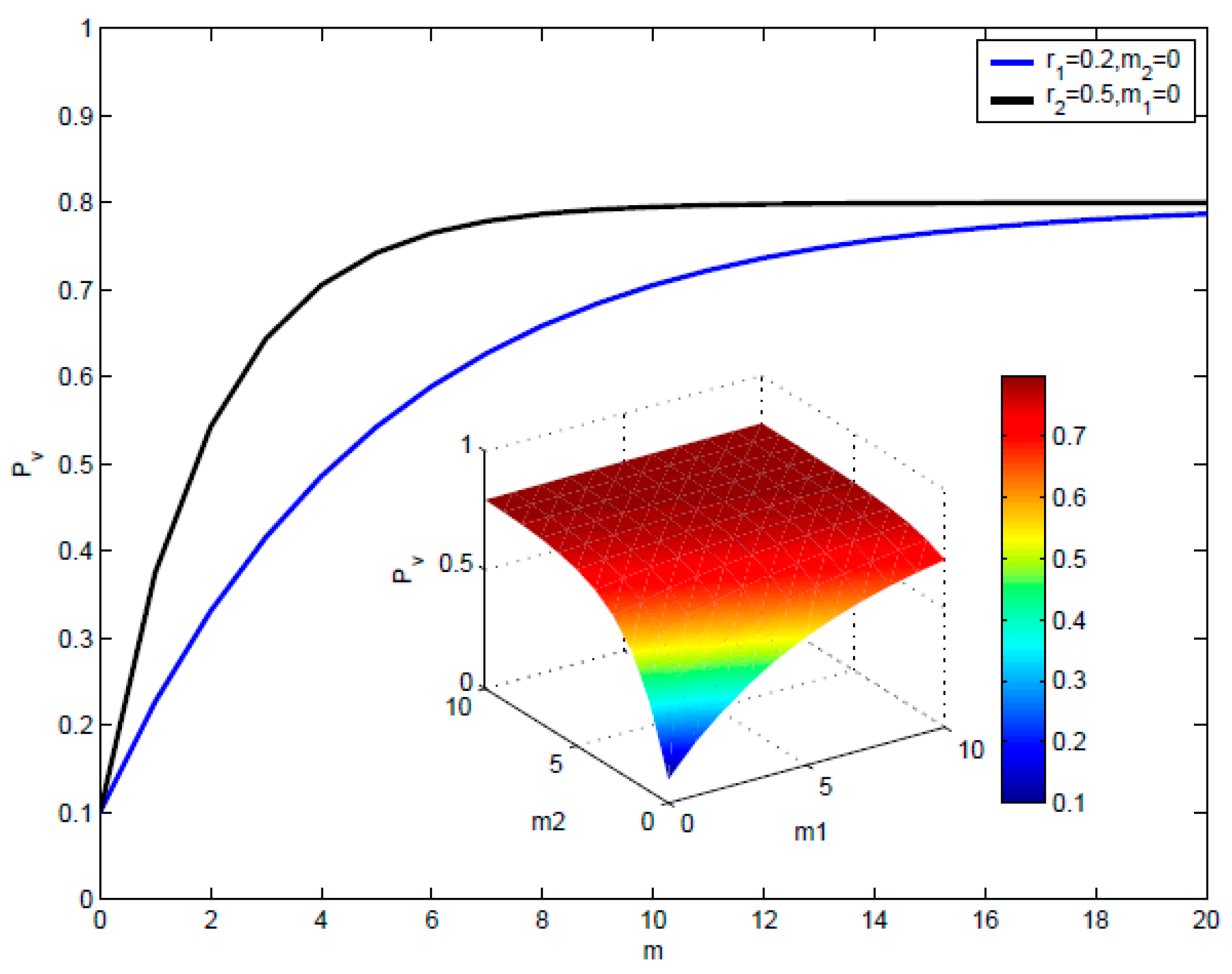
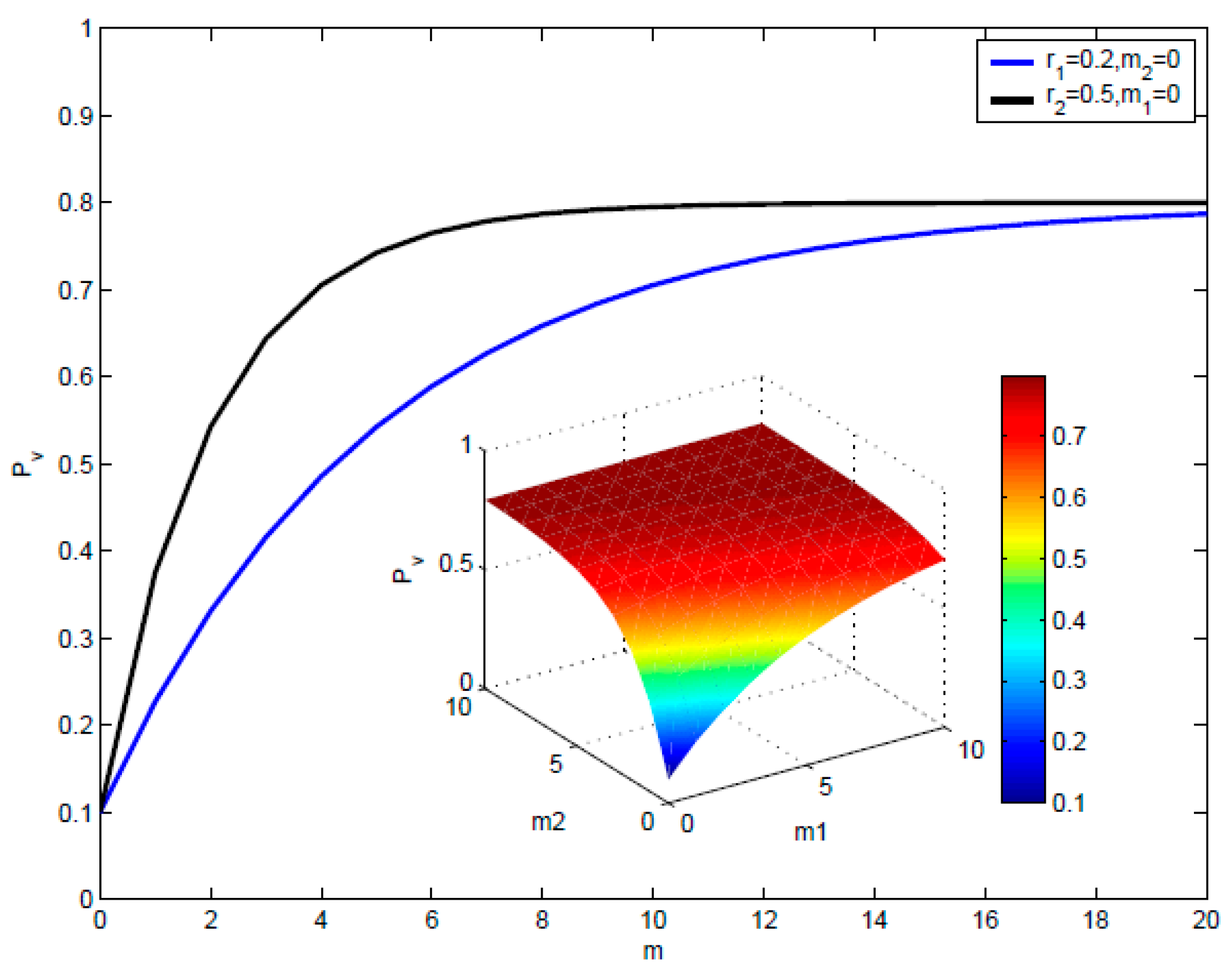
The components of Function (2) are summarized as follows: is the purchasing probability reflecting the internal factors. m1() and m2() are the numbers of neighbors of node v at state interested and accepted until time t respectively, which reflect the memory effect. r1 > 0 and r2 > 0 are parameters which reflect the social reinforcement effect for interested and accepted states respectively. is the upper bound of the probability indicating maximal purchasing probability, which is used to control the maximal effect of social reinforcement effect and memory effect when increasing m1() and m2(), Pv(t) will gradually approach and the speed is determined by the parameters r1 > 0 and r2 > 0.
3.3. Influence Maximization under DCM4VM
In this section, we will redefine the influence maximization problem under DCM4VM and analysis some properties of the problem.
Problem 2. Given a social network graph
G = (
V,
E,
) (
V is the node set,
E is the edge set,
is the node purchase probability set where
denotes node v’s purchase probability, and
is the edge influence probability set where
represents the influence probability on the edge composed by nodes
v and
u), At the very beginning, the propagation model DCM4VM with a small number
k, on the basis, the influence maximization problem under DCM4VM is to find an initial set
S with
k nodes in the graph such that the expected sum of accepted nodes is maximized. Assume T is the final time after which the propagation process is completed,
is the number of accepted nodes the by the time
T, this problem can be formally defined as:
where state (
v,
t) is the state of node
v at time
t,
N(
v) is the outer neighbors of node
v.
There may be more than one optimal solution for problem 2. Undoubtedly, problem 2 is NP-hard. NP [
31] problems are generally problems where the correctness of the solution can be “easily checked,” where “easily checked” refers to the existence of a polynomial check algorithm. If Turing reduces all problems in NP to a certain problem, the problem is NP-hard.
4. Algorithms
In this section, we try to propose algorithms to solve problem 2. The propagation simulation of problem 2 is quite different from that of traditional influence maximization problem. First, we target at those accepted nodes not all nodes that influenced (interested or accepted). Second, once one round of propagation simulation is completed, we must recalculate . We propose a new propagation simulation method according to DCM4VM. Specially, for each round of propagation simulation, we toss a coin to judge whether the known nodes will turn to interested, then for each node that is interested, we toss a coin again to judge whether this node will turn to state of accepted and finally we recalculate of each nodes according to Function 2 to prepare for the next round of propagation simulation. After R rounds of propagation simulation, we average the total accepted nodes as the expected result . The propagation simulation algorithm for problem 2 is described in Algorithm 1.
4.1. General Greedy Algorithm
The
General Greedy [
4] can be extended to solve the
influence maximization problem under
DCM4VM. We consider the expected number of
accepted nodes when estimating the influence spread of certain seeds set. Thus, the expected number of influenced nodes
in the original algorithm is replaced by
. Then the greedy method is the same to select the node
which maximizes the marginal gain of influence spread,
[
]. The
General Greedy Algorithm is described in Algorithm 2.
| Algorithm 1: Propagation Simulation |
Input: network graph, initial seeds
Output: accepted seeds number |
| 1 | , ; |
| 2 | for each nodedo |
| 3 | ; |
| 4 | ; |
| 5 | end |
| 6 | whilenot empty do |
| 7 | ; |
| 8 | ; |
| 9 | //assume all newly interested or accepted nodes spread immediately and simultaneously, is the out neighbors of ; |
| 10 | for each nodedo |
| 11 | for each nodedo |
| 12 | ifthen |
| 13 | continue; |
| 14 | end |
| 15 | ifthen |
| 16 | ; |
| 17 | Ifthen |
| 18 | ; |
| 19 | ; |
| 20 | end |
| 21 | else |
| 22 | ; |
| 23 | end |
| 24 | end |
| 25 | else |
| 26 | ; |
| 27 | end |
| 28 | Ifthen |
| 29 | ; |
| 30 | end |
| 31 | end |
| 32 | end |
| 33 | //whether the newly exposed interested nodes at time t will turn to accepted; |
| 34 | for eachdo |
| 35 | recalculateaccording to (2); |
| 36 | ; |
| 37 | Ifthen |
| 38 | ; |
| 39 | ; |
| 40 | end |
| 41 | end |
| 42 | ; |
| 43 | end |
| 44 | return; |
| Algorithm 2: |
Input: network graph, initial seeds size
Output: accepted seeds |
| 1 | Initializeand; |
| 2 | fortodo |
| 3 | for each node vdo |
| 4 | ; |
| 5 | fortodo |
| 6 | ; |
| 7 | |
| 8 | ; |
| 9 | end |
| 10 | ; |
| 11 | end |
| 12 | return; |
4.2. Degree Discount Algorithm
Degree is frequently used for selecting seeds in
influence maximization. Chen et al. [
18] propose the
Degree Discount heuristic to efficiently find the seed nodes.
Degree Discount considers only one-step neighbor nodes and selects nodes with high degree values, which tends to have higher expectations of influence, to be seeds.
We modified the
Degree Discount heuristic algorithm to solve the viral marketing problem under
DCM4VM, described as Algorithm 3. The central idea is to compute and update the expectations of
accepted nodes (which is influenced nodes in the original algorithm) in each round of selection considering only one-step neighbor nodes. Once a node is chosen as a seed, we discount the potential (represented as
dd in Algorithm 3) of its neighbors to be seeds. Finally, we recalculate
each round according to:
| Algorithm 3: |
Input: network graph , initial seeds size
Output: accepted seeds |
| 1 | Initialize ; |
| 2 | for eachnodedo |
| 3 | compute its degree ; |
| 4 | ; |
| 5 | Initialize to 0; |
| 6 | end |
| 7 | fortodo |
| 8 | ; |
| 9 | |
| 10 | //recalculate ; |
| 11 | update according to (4); |
| 12 | //discount degree; |
| 13 | for eachnodedo |
| 14 | ; |
| 15 | ; |
| 16 | end |
| 17 | end |
| 18 | return; |
4.3. Exchangeable Greedy Algorithm
Both Greedy Algorithms and Heuristic Algorithms are useful in solving influence maximization problems approximately. Actually, we can further improve the result by combining greedy strategies and heuristic strategies. We use two processes to express that. The first process is to generate potential seeds using heuristic methods and the second process is to exchange some of the seeds iteratively to further approximate the optimum. If the potential seeds set are around the global optimum, we are likely to find the optimal solution finally. The algorithm is described in Algorithm 4.
If m = 1 and S is initialized a set of NULL values of k sizes (line 2), then in the next k rounds from t = 1 to t = k, the Exchangeable Greedy Algorithm picks a NULL out of S and puts a node that maximizes [] to S which is exactly the process done by General Greedy Algorithm. That means Exchangeable Greedy Algorithm, which has better potential performance than General Greedy Algorithm.
However, the time complexity can be very expensive. Some strategies must be used to make the algorithm practical.
We find that most of nodes cannot make any improvement though they all have potentials. Experimental results in [
4] showed that selecting nodes with maximum degrees as seeds results in larger influence spread than other heuristics. This is true because most nodes have less out-degrees according to power-law distribution [
32] and are less likely to influence many nodes.
| Algorithm 4: |
Input: network graph , initial seeds size
Output: accepted seeds |
| 1 | Initialize ; |
| 2 | Initialize with nodes using heuristic algorithms; |
| 3 | whilenot converge anddo |
| 4 | pick one node out of with heuristic strategies or simply by order; |
| 5 | ; |
| 6 | for each node do |
| 7 | ; |
| 8 | for to do |
| 9 | ; |
| 10 | end |
| 11 | ; |
| 12 | end |
| 13 | ; |
| 14 | ; |
| 15 | end |
| 16 | return; |
Heuristic strategies have lower time complexity but are less effective. Greedy strategies are just the opposite. In this paper, we propose to combine heuristic strategies and greedy strategies by two processes, namely Sampling and Verification, to make the algorithm more practical. In each round, we only sample fixed number of candidate nodes (Sampling). Once the candidates are produced, we run greedy algorithm to verify the guess (Verification). Specially, each node is chosen as a candidate with a Potential Probability PP which will be increased or decreased due to its performance.
Initially, the probability
PP of each node is set according to its out-degree.
where
is the out-degree of node
.
Then,
is recalculated according to its performance in each round.
where
=
(
S {
v}) −
(
S {
u}) is the increased or decreased
accepted nodes exchanging
u with
v. The more potential a node has, the more likely it is to be selected. With enough iteration, every node has the chance to improve the result. The heuristic update strategy of
PP is very important. If the strategy is good enough, then it is expected to approximate the optimal solution effectively. This is more like the idea of
boosting in machine learning literature which increases the weights of misclassified data and decreases the weights of correctly classified data by last classifier. The
Exchangeable Greedy with Sampling and Verification Algorithm is described in Algorithm 5.
| Algorithm 5: |
Input: network graph , initial seeds size , number of iterations , number of nodes sampled each time
Output: accepted seeds |
| 1 | Initialize ; |
| 2 | Initialize with nodes using heuristic algorithms; |
| 3 | Initialize according to (5); |
| 4 | whilenot converge anddo |
| 5 | pick one node out of with heuristic strategies or simply by order; |
| 6 | ; |
| 7 | Sampling stage: |
| 8 | sample out of randomly; |
| 9 | Verification stage: |
| 10 | for each node do |
| 11 | ; |
| 12 | Fortodo |
| 13 | ; |
| 14 | end |
| 15 | ; |
| 16 | update according to (6); |
| 17 | end |
| 18 | ; |
| 19 | ; |
| 20 | remove from ; |
| 21 | ; |
| 22 | end |
| 23 | return; |
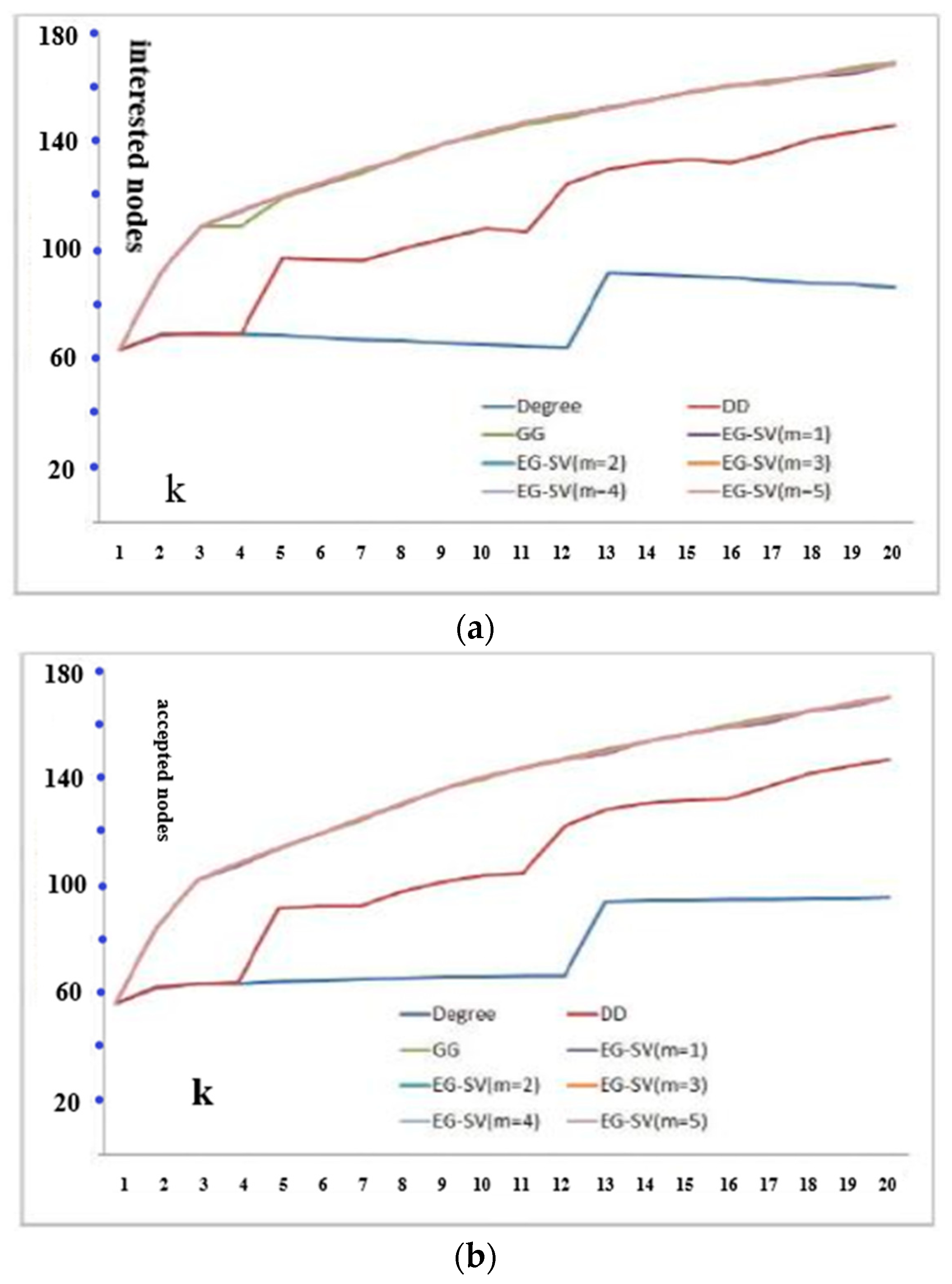
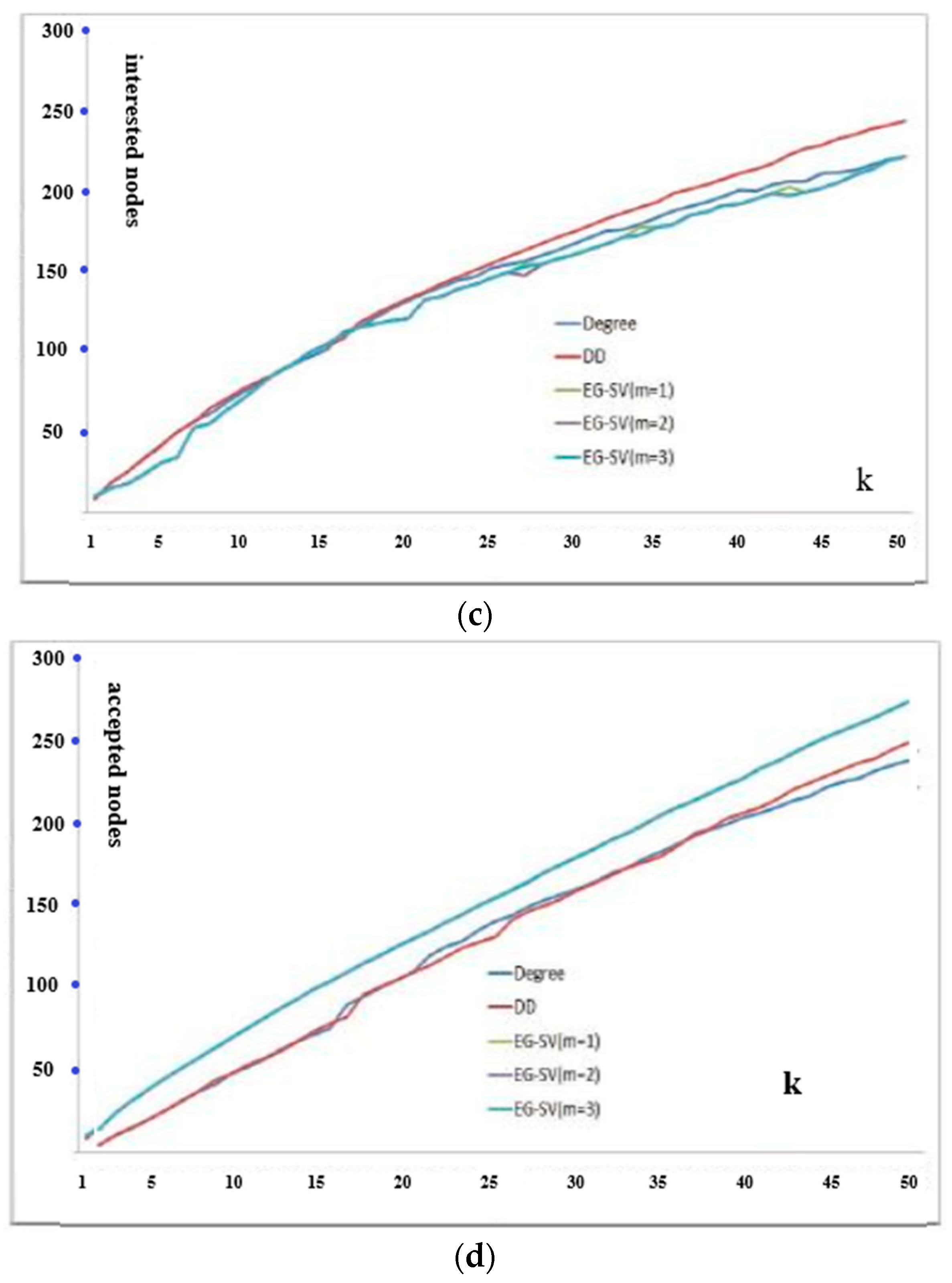
Time complexities of all algorithms in this paper are summarized in
Table 1 for convenience of comparison.
N is the number of nodes,
E is the number of edges and
T is the time complexity of
Propagation Simulation. Note that
m|
n is much less than
N usually and the time complexity of
EG-SV is independent of the size of the network which means we can apply
EG-SV to large networks. Also, we can continue a terminated
EG-SV until a good performance is achieved.
6. Comparison of Propagation Performance
In order to illustrate the effectiveness of the algorithm proposed in this paper in the propagation process, this part compares the DCM4VM method proposed in this paper with the information spreading model based on relative weight in social network (RWSIR) [
33].
6.1. Experimental Data
In this paper, three network topologies of most popular online social network are selected, such as, Twitter [
34], sina microblog [
35] and Epinions [
36], and the relevant data are all from Internet resources [
37,
38]. We assume that the edges of each network are indirect and powerless, and the relevant topological characteristic parameters of each network are shown in
Table 2.
6.2. Experimental Parameters
In this section, two models, DCM4VM and RWSIR, are simulated in the above three network topological models. A random node with low connectivity is selected as the propagation node, and the rest nodes are healthy nodes. Considering the network sizes, the connection degrees of Epinions network, Twitter network and sina microblog are 5, 10 and 10. It should be noted that, considering the characteristics of the real network, the nodes selection did not select the node with the minimum degree of 1, but the node with a small degree of connection. The basic popularity of information was calculated as , and 100 times for each experiment, then the average value was calculated.
6.3. Evaluation Index
Maximum infection rate (MIR), which is the ratio of the number of infected nodes to the total number of network nodes after the completion of the infection process. Since all infected nodes in the model will eventually become immune nodes, we can consider the proportion of the final immune nodes as the final infection rate. MIR is used to characterize the final influence range of propagation nodes on the entire network.
6.4. Results and Analysis of Experiment
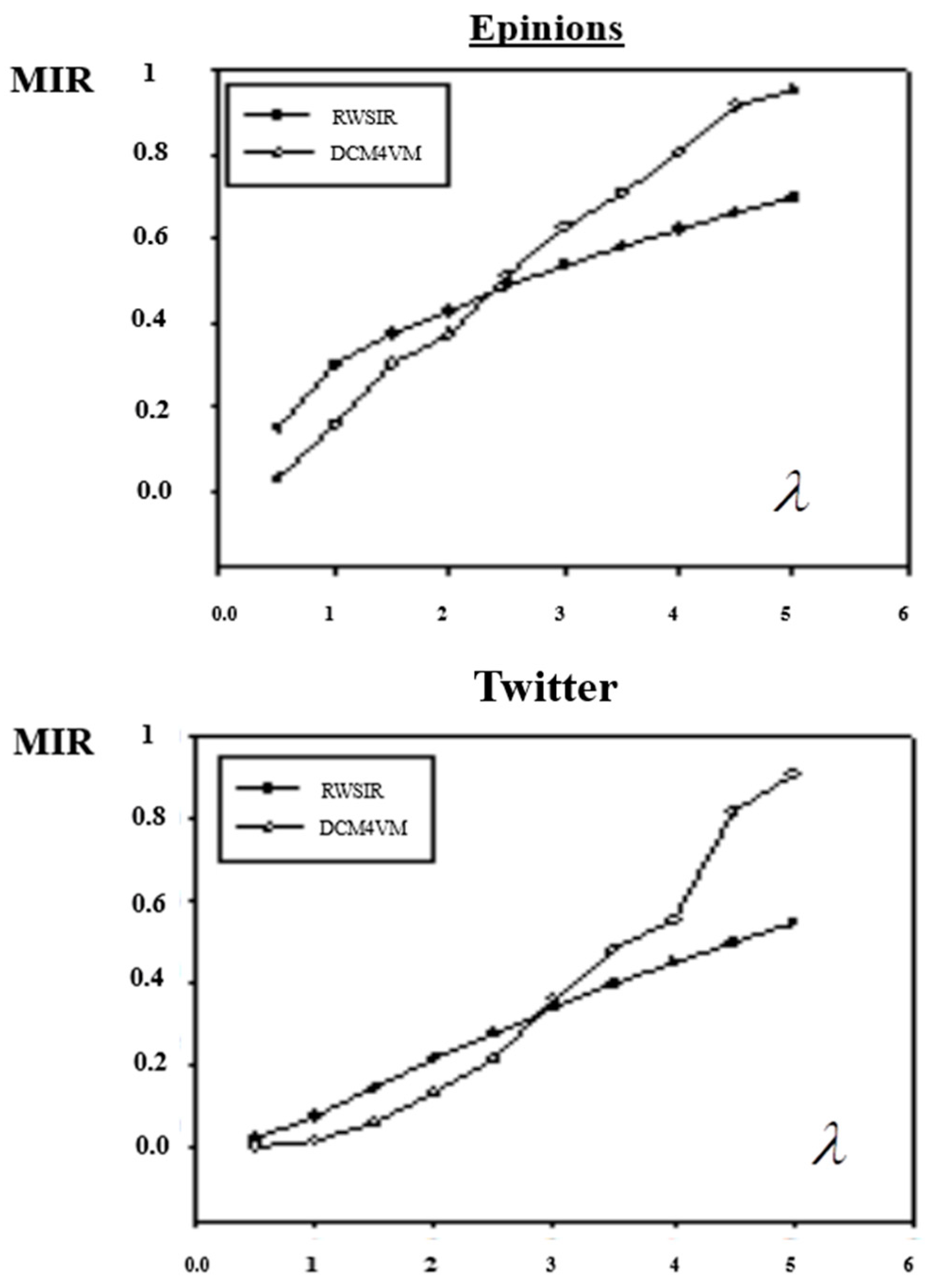
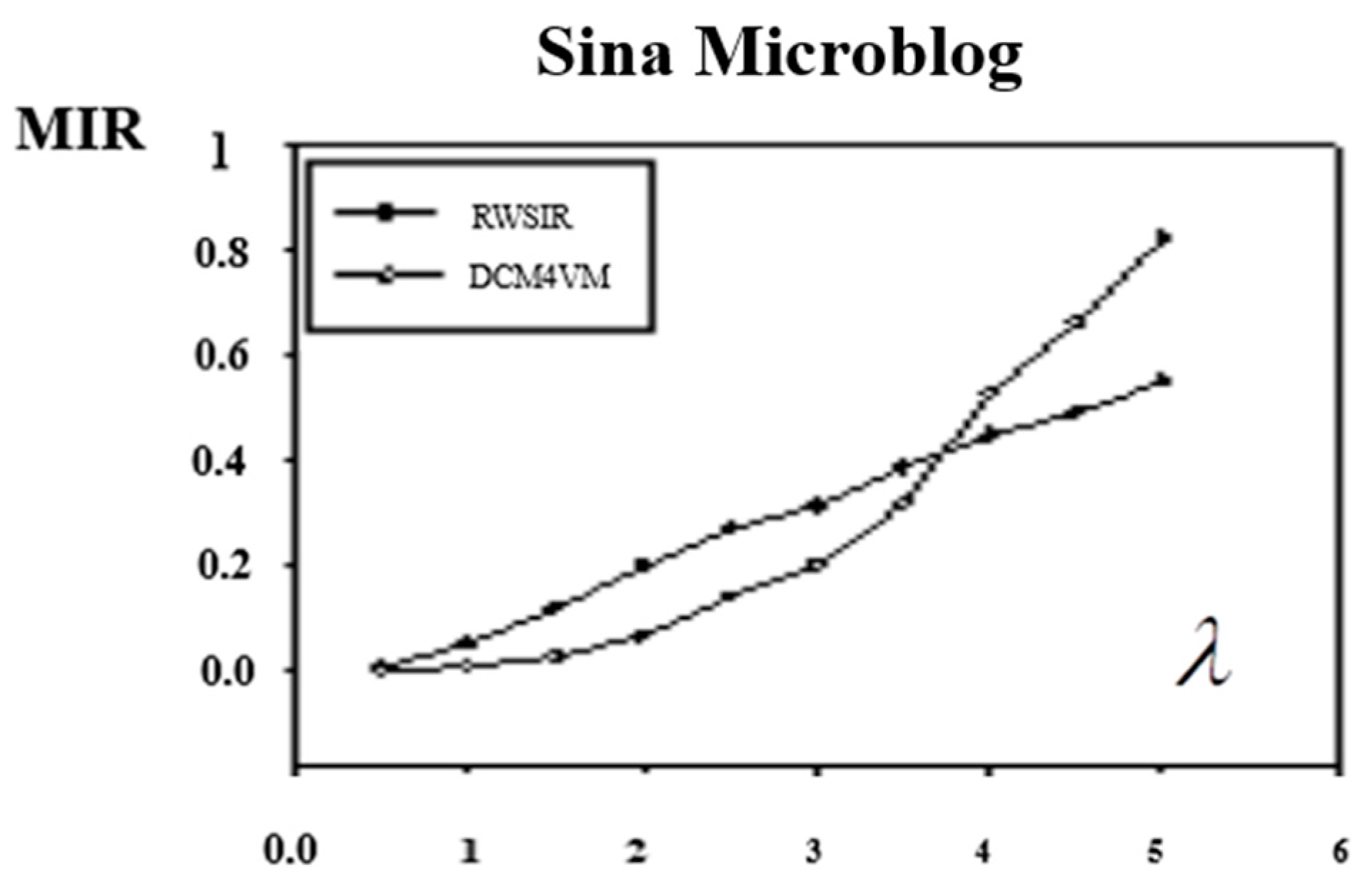
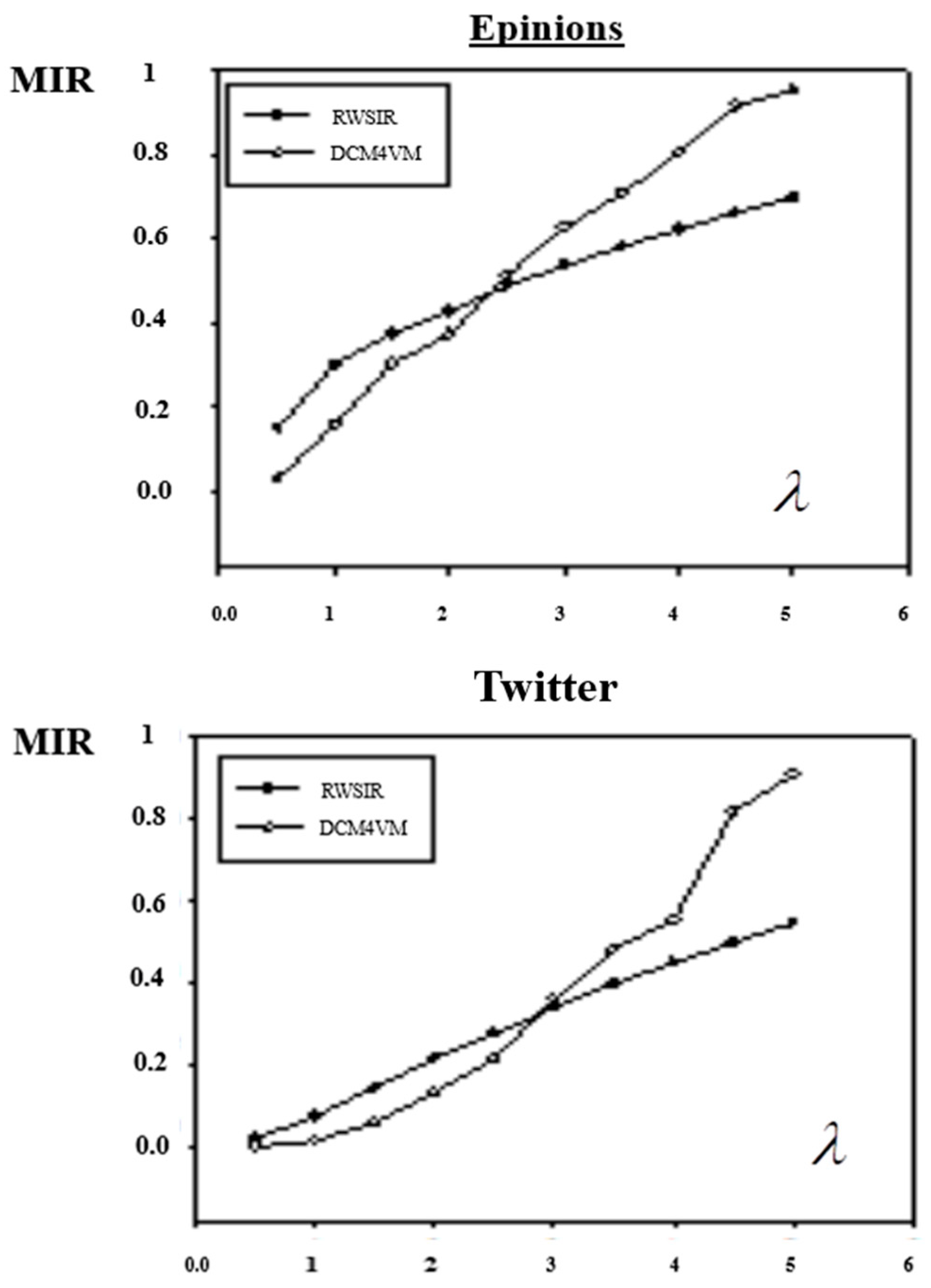
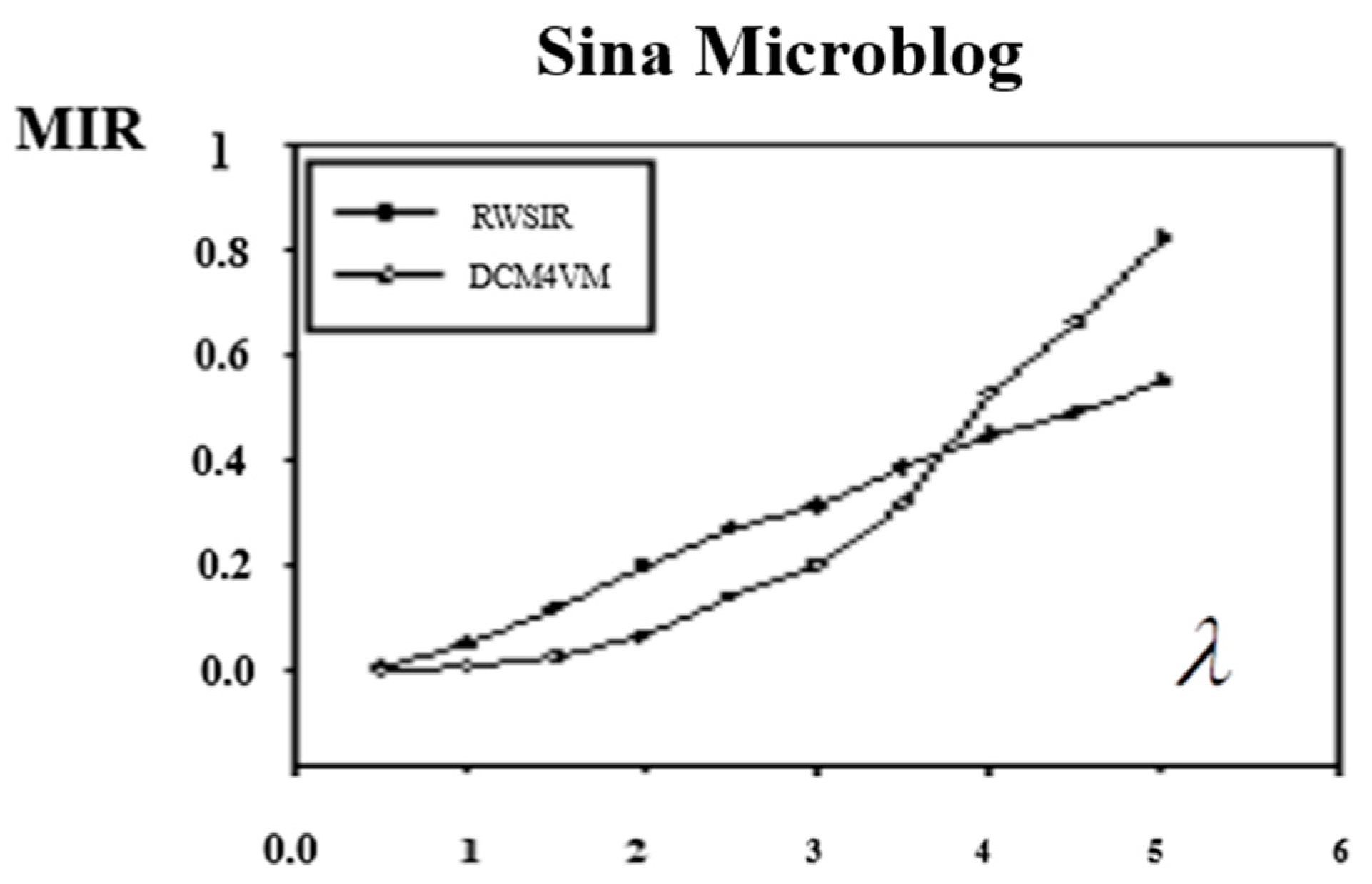
From the experimental results, which are showed in
Figure 4, we could see that the value of MIR increases with the increase of
λ. Except the MIR of Epinions, Twitter and sina weibo in RWSIR model were between 0.4–0.6, the other MIRs were all close to 1, and the information basically covered the whole network.
Compared with the two models, when λ is small, the MIR of RWSIR is lower than DCM4VM, meanwhile, when λ is large, it is the opposite. In other words, with the increase of the importance of the propagation object, the algorithm proposed in this paper could achieve a greater range of influence.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}