Environmental-Based Speed Recommendation for Future Smart Cars †


Abstract
:1. Introduction
- We further explain the details of our original implementation in [14], providing more details about the data analysis (Section 3.2). We also evaluate and compare the presented classification model against existing techniques and we present the results in Section 4.4.
- We introduce a new feature that utilizes route-based information and extracts specific intermediate way-points that dictate change in vehicle’s speed.
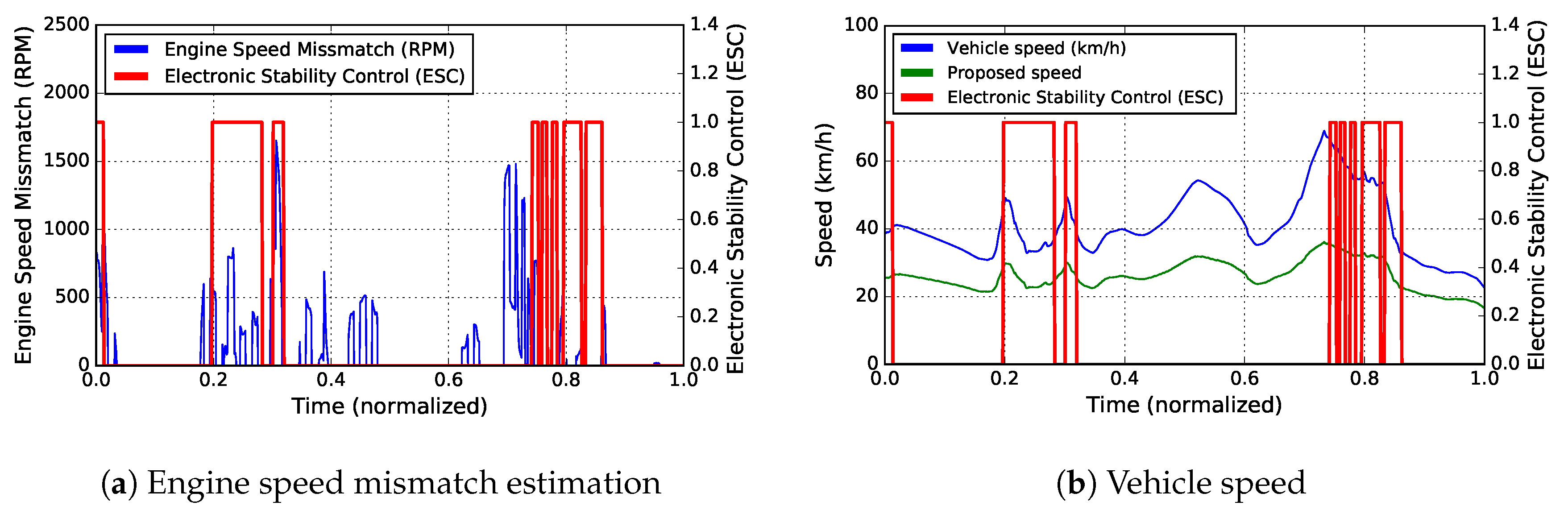
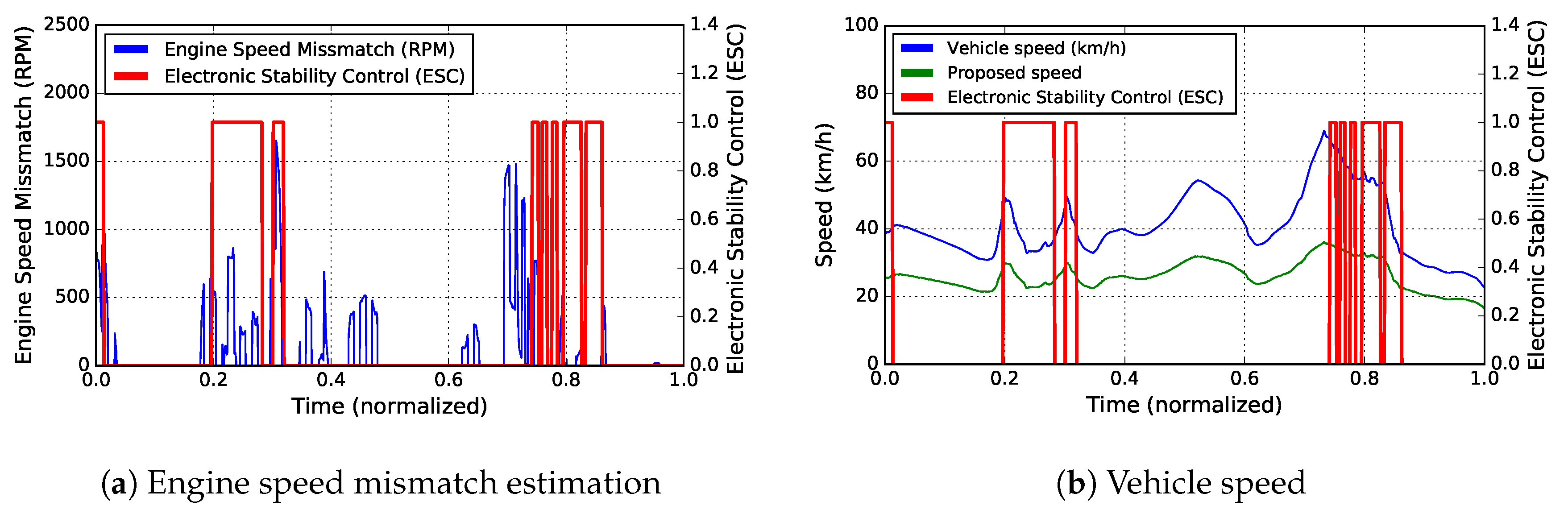
- We utilize vehicle data as a new information source in order to calculate the mismatch between the theoretical engine speed and the actual engine speed of the vehicle. Such mismatch may cause the trigger of advanced driver-assistance systems (e.g., ABS, ESC).
- We validate weather- and route-based information with real-time vehicle data and inform the driver about a recommended (dynamic) speed that the car should adapt to, based on the current road status.
- We developed the overall service on top of Hydra [20], a distributed multi-agent computing framework that targets smart cars and it provides self-management functions such as in-car workload balancing and failure recovery. Section 4.1 further explains the implementation presented in [14] and enhances this work with more technical details regarding the development of the proposed methodology on real computing boards by utilizing the computation infrastructure in [20].
- Hydra is a generic framework that supports the deployment of a variety of applications, and several automotive benchmarks were tested in [20]. However, in this paper, we present a new methodology that we deploy on Hydra for the first time.
- The proposed methodology includes several features that were developed on top of Hydra, which enhances Hydra’s functionality. Specifically, the presented methodology:
- (a)
- gathers environmental information (weather and on-route), in order to create a better understanding about the physical characteristics of the road, and
- (b)
- it combines this information with on-vehicle data in order to suggest a speed limit so as the vehicle achieves a targeted road surface index and reduces the danger of an accident (e.g., loss of traction).
2. Related Work
3. Proposed Approach
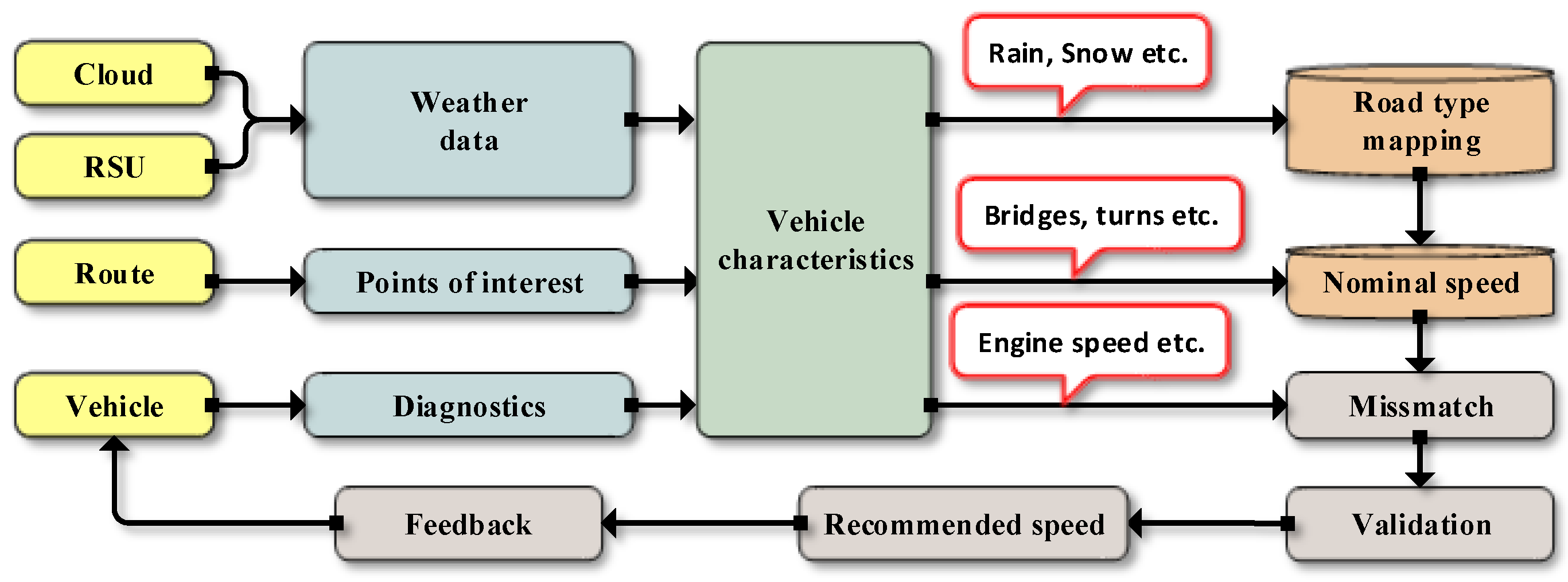
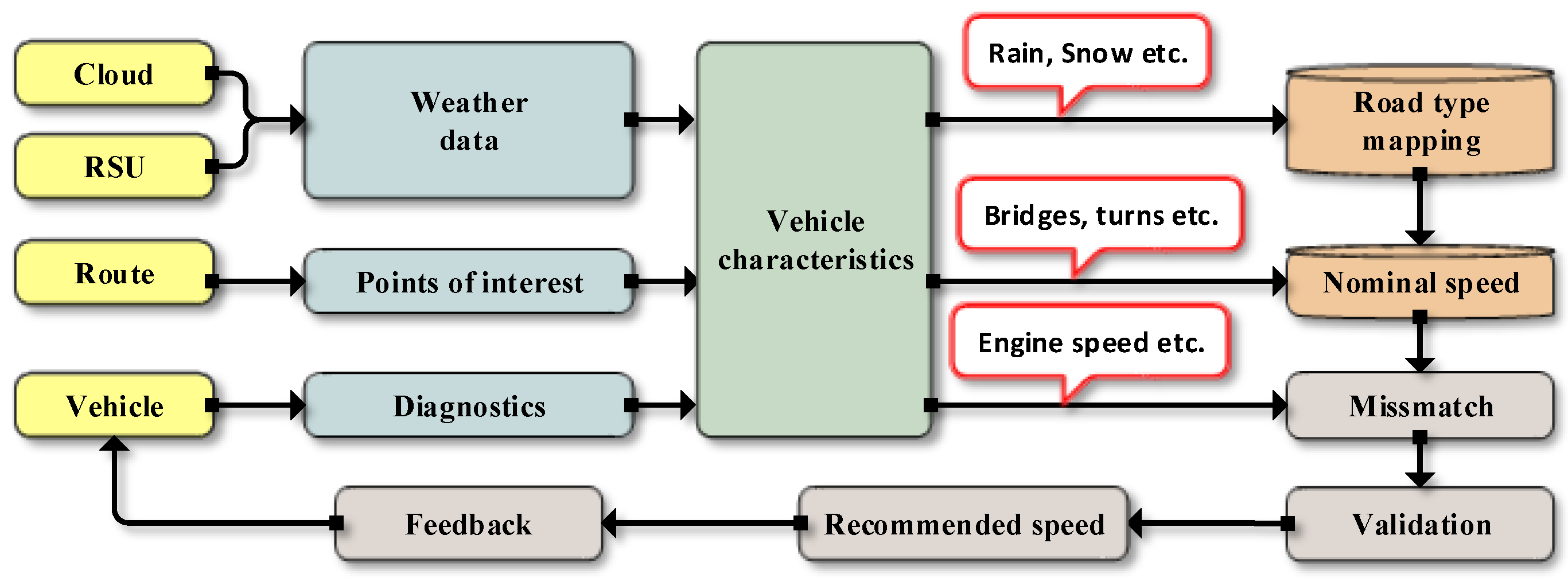
3.1. Overview
3.2. Road Status Estimation Based on Weather Information
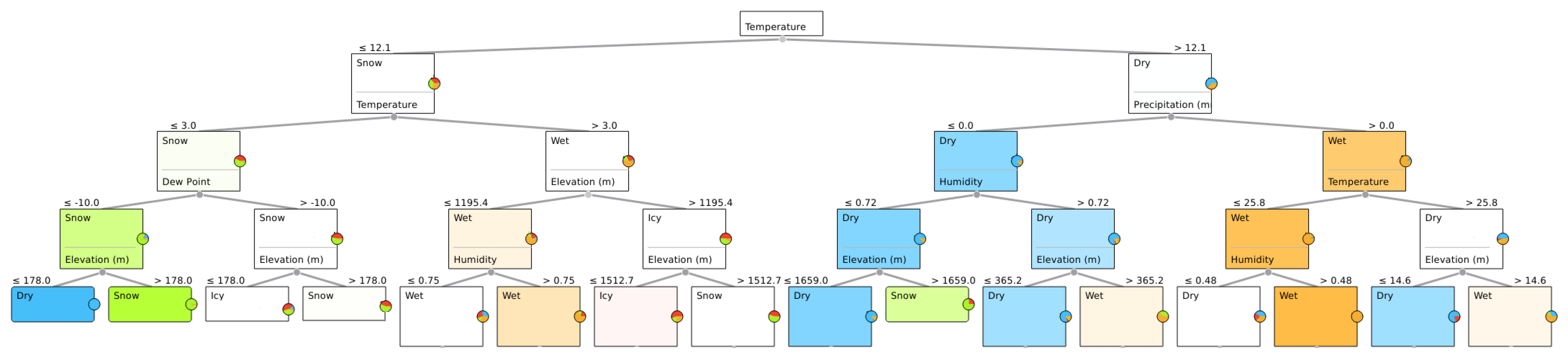
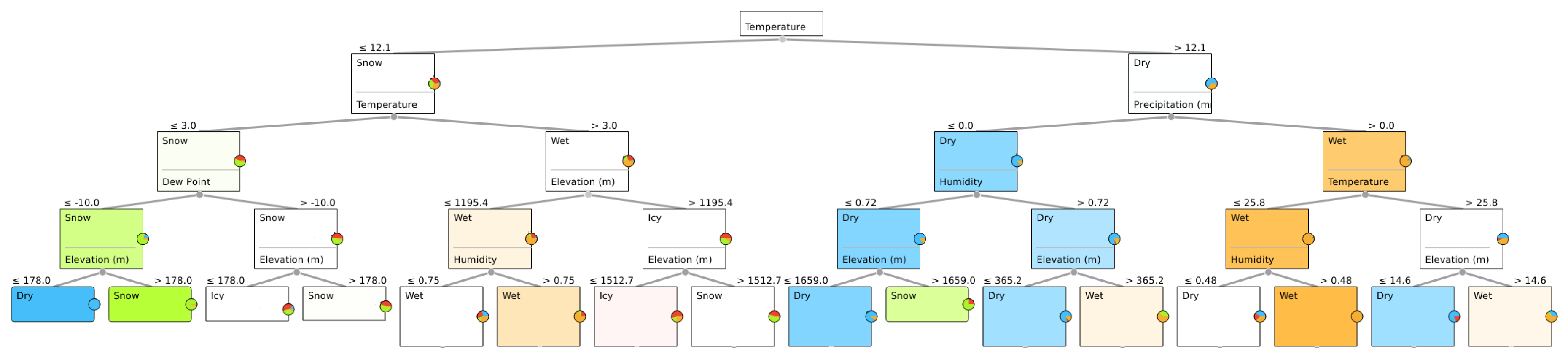
3.2.1. Data Analysis for Road Condition Estimation
| Algorithm 1 Classification Tree Algorithm. |
|
3.2.2. Stages of Execution
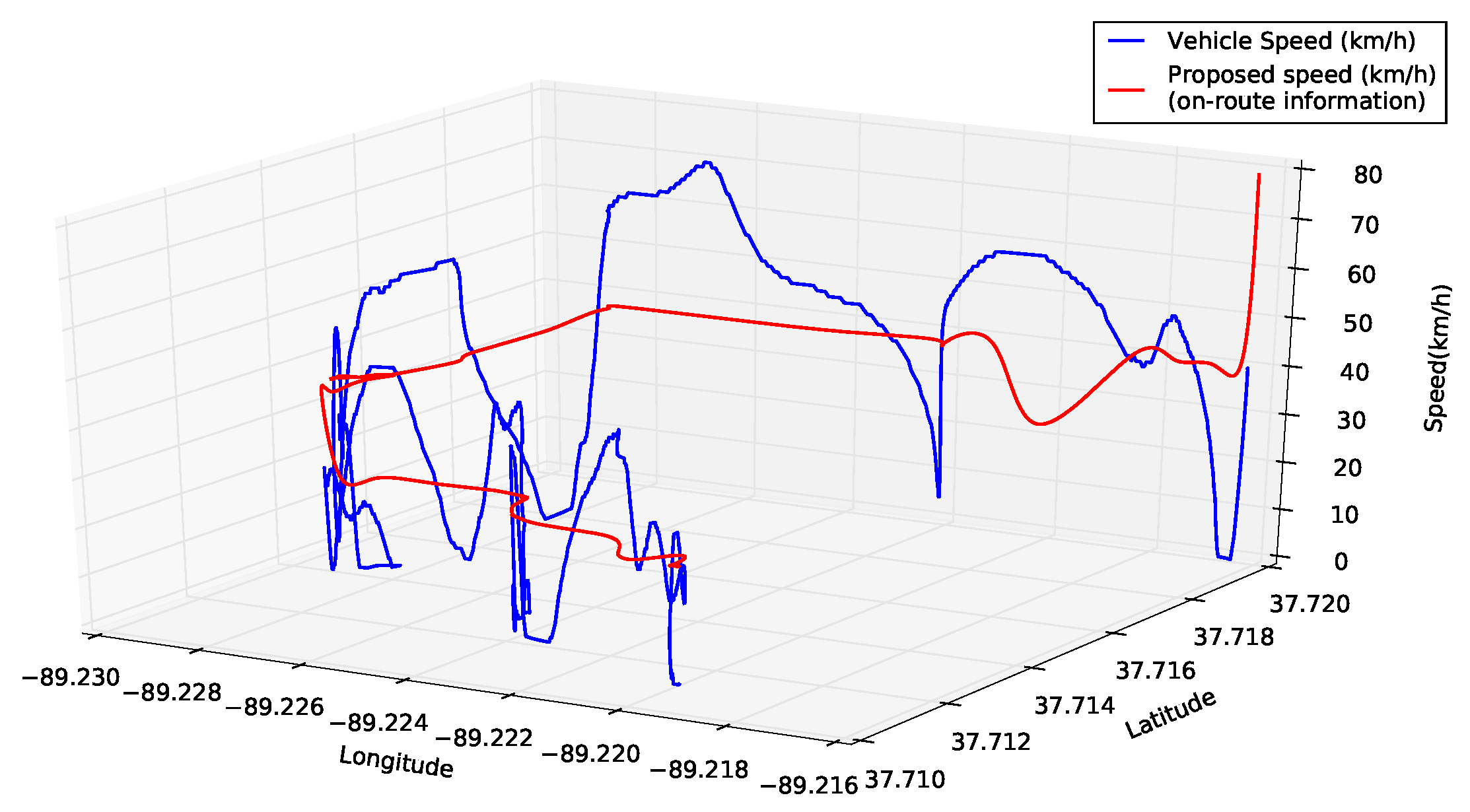
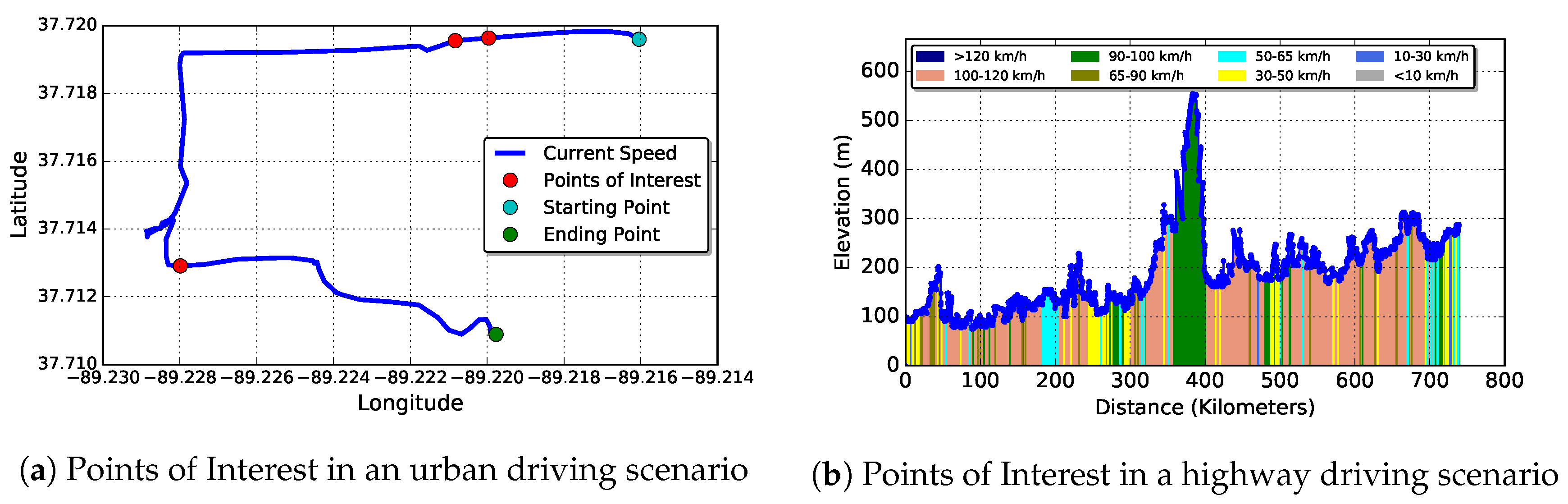
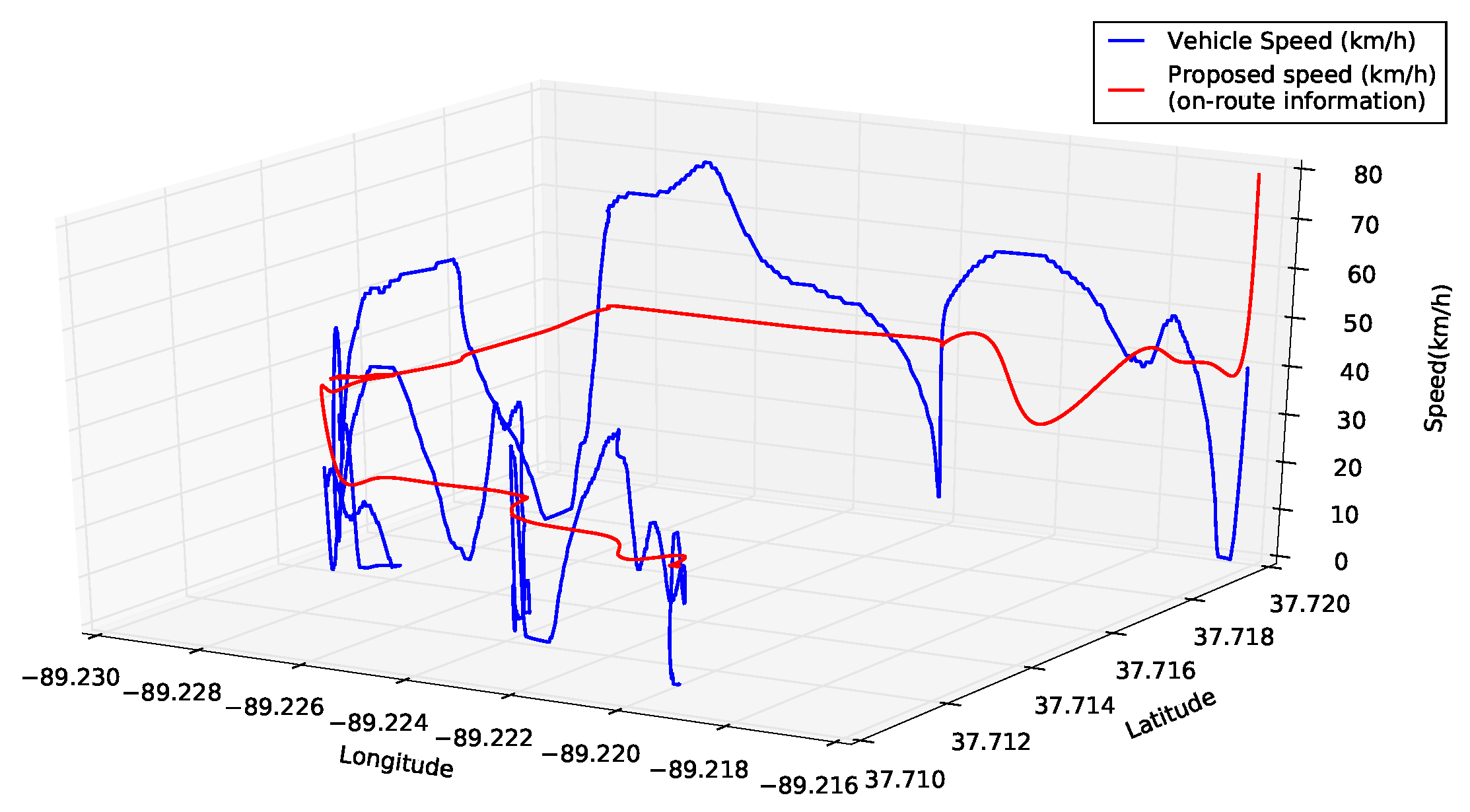
3.3. On-Route Information
3.4. On-Vehicle Information
4. Experimental Results
4.1. System Overview
4.2. Application Evaluation
4.3. Evaluation Scenarios
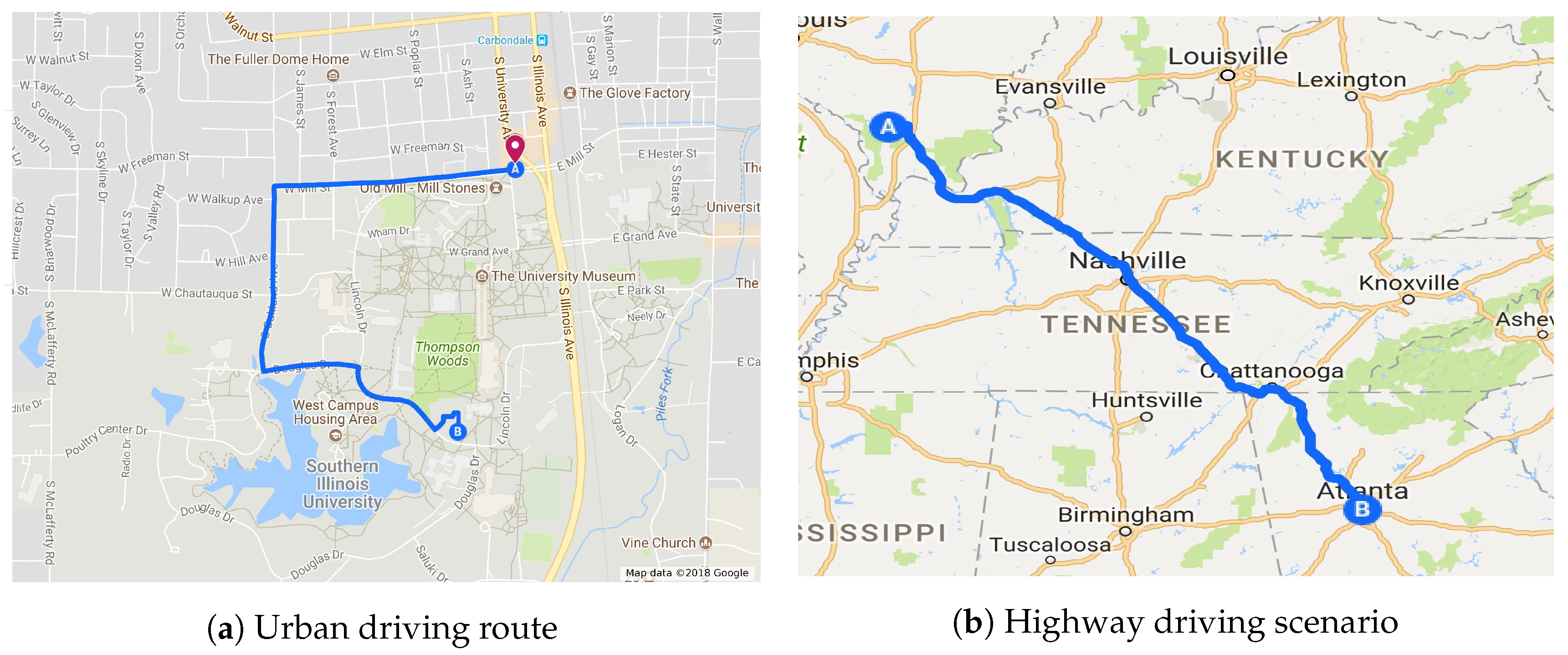
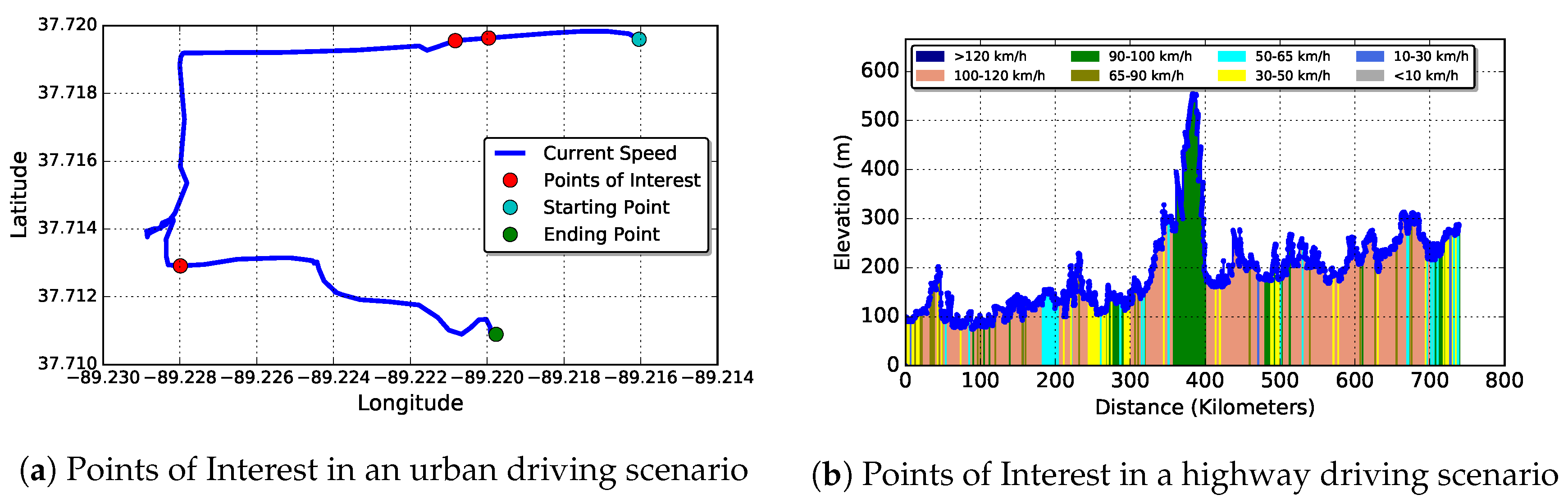
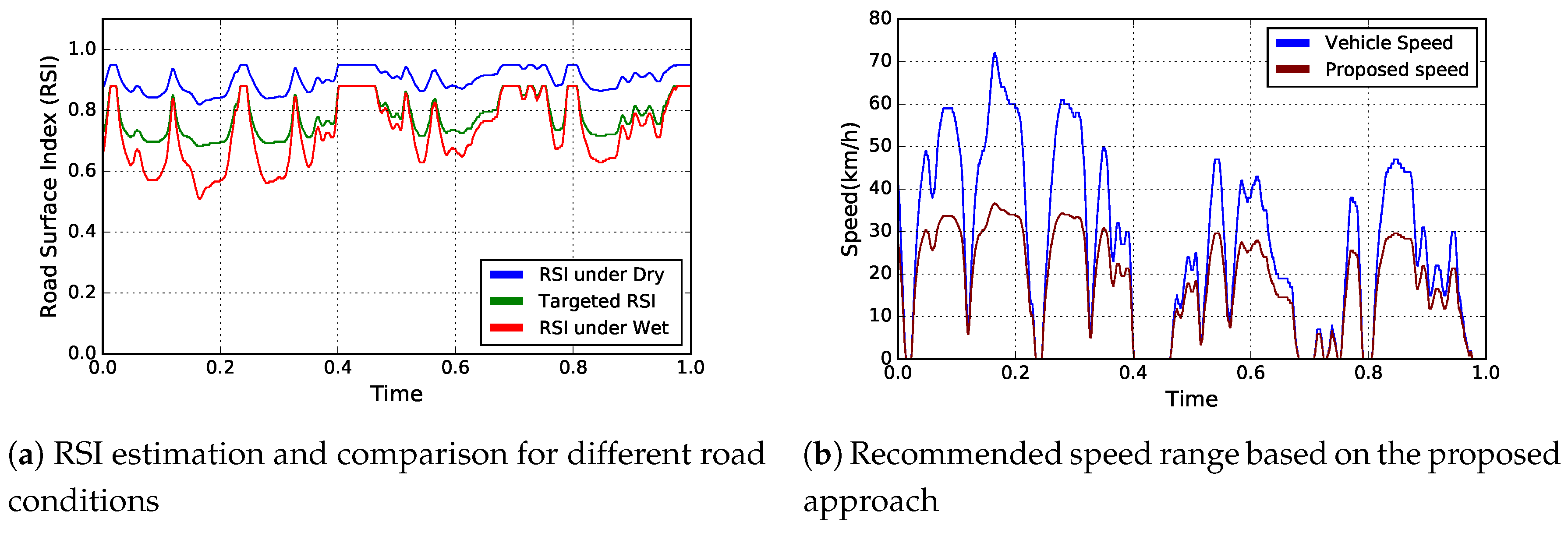
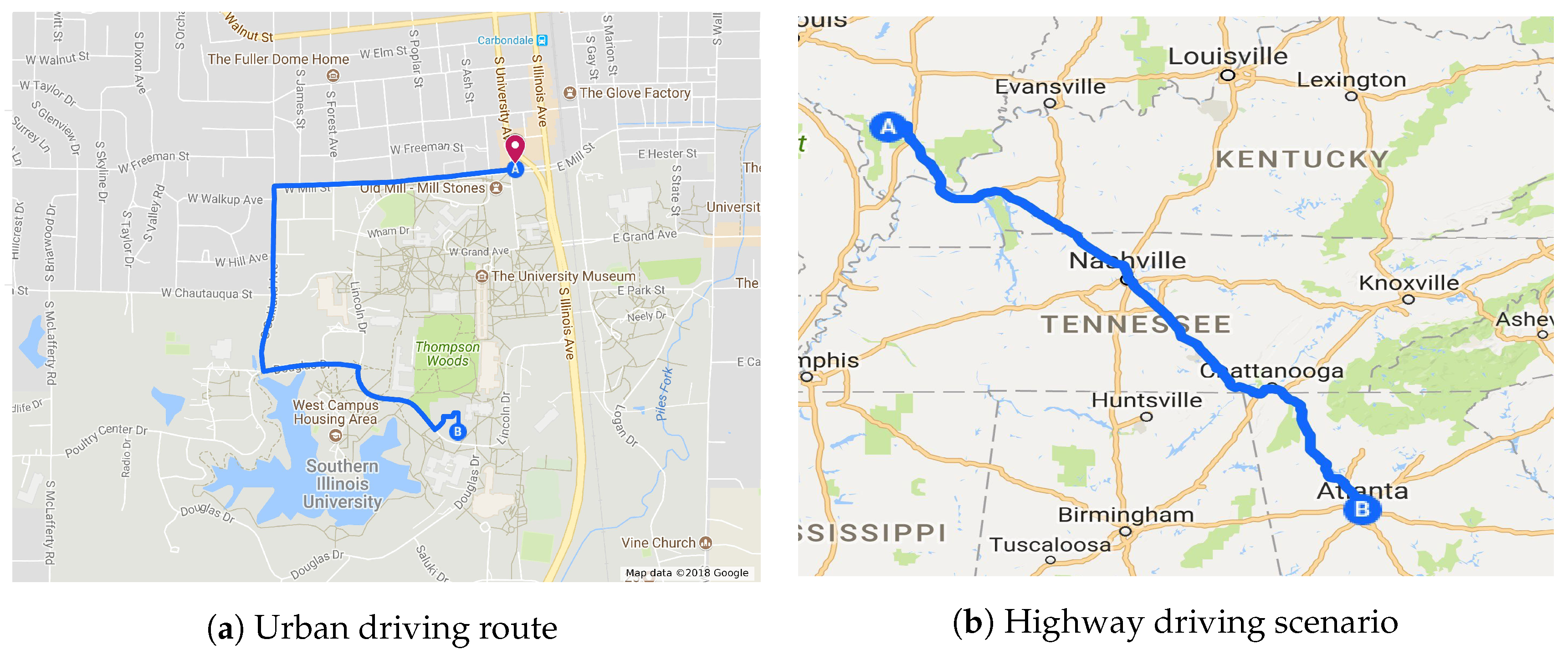
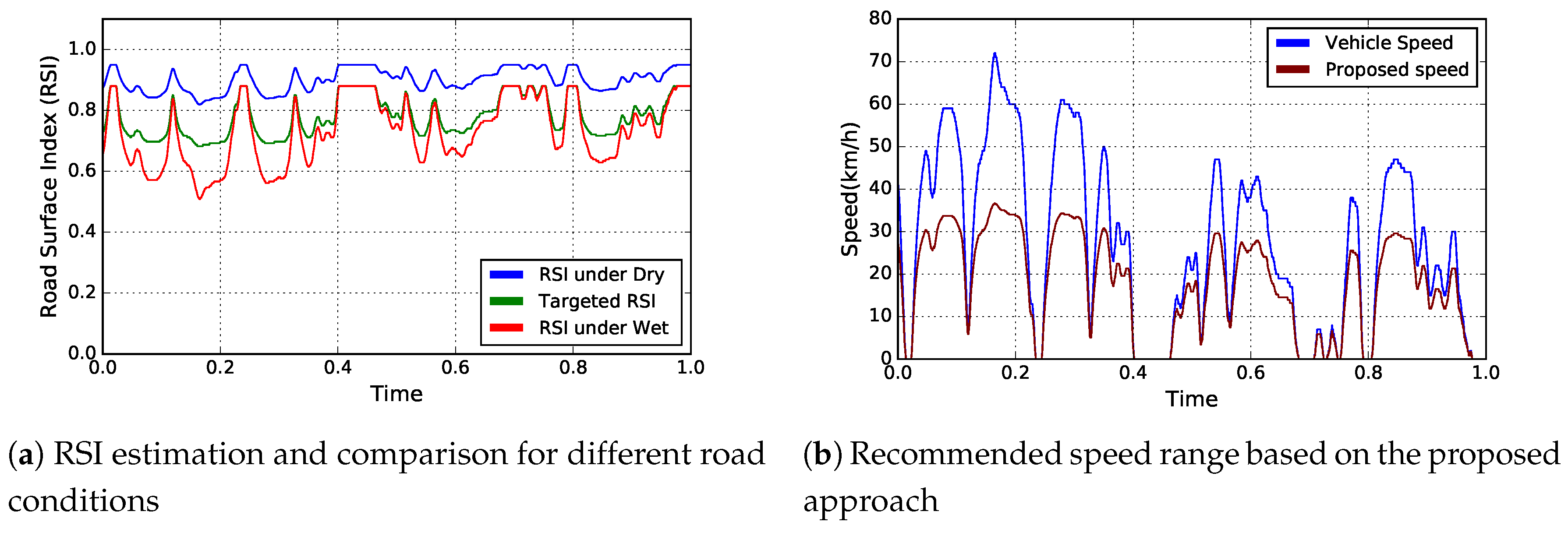
4.3.1. Urban Driving Scenario
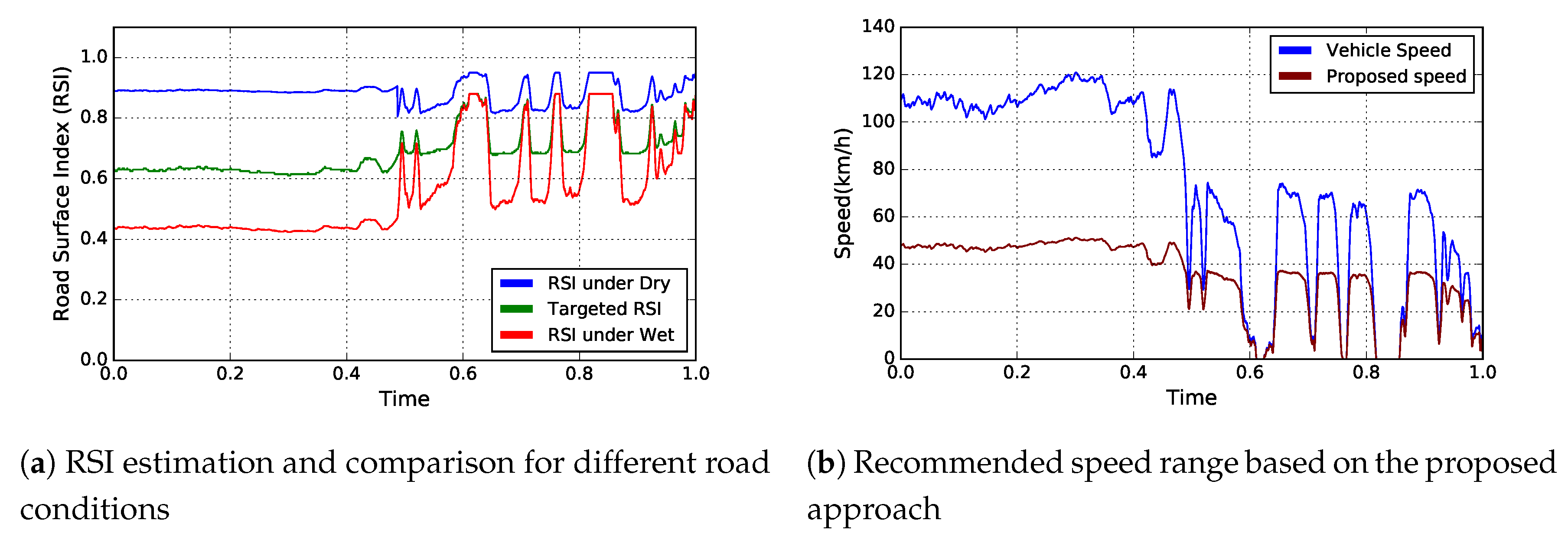
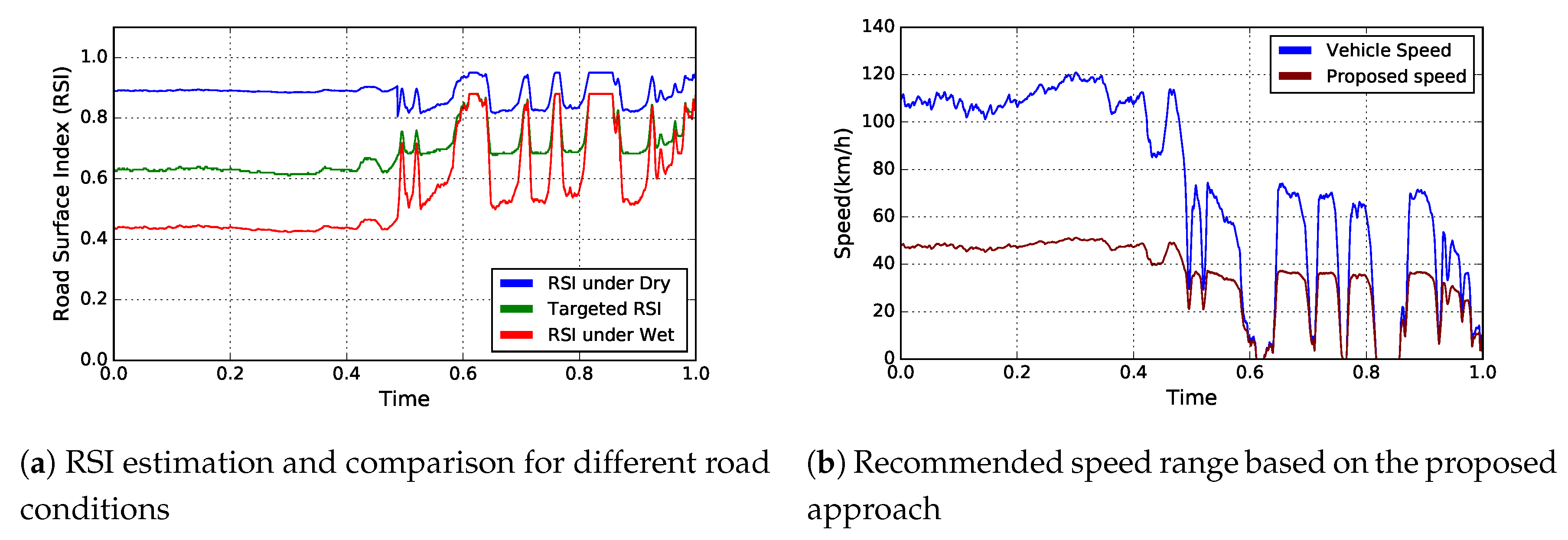
4.3.2. Scenario 2
4.4. Evaluation of the Classification Method
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pelliccione, P.; Knauss, E.; Heldal, R.; Ågren, S.M.; Mallozzi, P.; Alminger, A.; Borgentun, D. Automotive architecture framework: The experience of volvo cars. J. Syst. Archit. 2017, 77, 83–100. [Google Scholar] [CrossRef]
- Traub, M.; Maier, A.; Barbehön, K.L. Future automotive architecture and the impact of it trends. IEEE Softw. 2017, 34, 27–32. [Google Scholar] [CrossRef]
- Adiththan, A.; Ramesh, S.; Samii, S. Cloud-assisted control of ground vehicles using adaptive computation offloading techniques. In Proceedings of the 2018 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 589–592. [Google Scholar]
- Chakraborty, S.; Lukasiewycz, M.; Buckl, C.; Fahmy, S.; Chang, N.; Park, S.; Kim, Y.; Leteinturier, P.; Adlkofer, H. Embedded Systems and Software Challenges in Electric Vehicles. In Proceedings of the Conference on Design, Automation and Test in Europe (DATE), Dresden, Germany, 12–16 March 2012; pp. 424–429. [Google Scholar]
- Brannstrom, M.; Coelingh, E.; Sjoberg, J. Model-based threat assessment for avoiding arbitrary vehicle collisions. IEEE Trans. Intell. Transp. Syst. 2010, 11, 658–669. [Google Scholar] [CrossRef]
- Jiang, Y.; Qiu, H.; McCartney, M.; Sukhatme, G.; Gruteser, M.; Bai, F.; Grimm, D.; Govindan, R. Carloc: Precise positioning of automobiles. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems (SenSys ’15), Seoul, Korea, 1–4 November 2015; ACM: New York, NY, USA, 2015; pp. 253–265. Available online: http://doi.acm.org/10.1145/2809695.2809725 (accessed on 22 March 2019).
- Data is the New Oil in the Future of Automated Driving. Available online: https://newsroom.intel.com/editorials/krzanich-the-future-of-automated-driving/ (accessed on 22 March 2019).
- Paden, B.; Čáp, M.; Yong, S.Z.; Yershov, D.; Frazzoli, E. A survey of motion planning and control techniques for self-driving urban vehicles. IEEE Trans. Intell. Veh. 2016, 1, 33–55. [Google Scholar] [CrossRef]
- Perala, S.S.N.; Galanis, I.; Anagnostopoulos, I. Fog Computing and Efficient Resource Management in the era of Internet-of-Video Things (IoVT). In Proceedings of the IEEE International Symposium on Circuits and Systems, Florence, Italy, 27–30 May 2018. [Google Scholar]
- Arena, F.; Pau, G. An overview of vehicular communications. Future Internet 2019, 11, 27. [Google Scholar] [CrossRef]
- Abbasi, I.; Khan, A.S. A review of vehicle to vehicle communication protocols for vanets in the urban environment. Future Internet 2018, 10, 14. [Google Scholar] [CrossRef]
- NHTSA Calls For V2V Technology In Models Built After 2020. Available online: http://automotivedigest.com/2014/08/nhtsa-eyes-half-million-crashes-prevented-v2v-technology/ (accessed on 22 March 2019).
- Storck, C.R.; Duarte-Figueiredo, F. A 5G V2X Ecosystem Providing Internet of Vehicles. Sensors 2019, 19, 550. [Google Scholar] [CrossRef] [PubMed]
- Galanis, I.; Gurunathan, P.; Burkard, D.; Anagnostopoulos, I. Weather-based road condition estimation in the era of Internet-of-Vehicles (IoV). In Proceedings of the IEEE International Symposium on Circuits and Systems, Florence, Italy, 27–30 May 2018. [Google Scholar]
- Gerla, M.; Lee, E.-K.; Pau, G.; Lee, U. Internet of vehicles: From intelligent grid to autonomous cars and vehicular clouds. In Proceedings of the 2014 IEEE World Forum on Internet of Things (WF-IoT), Seoul, Korea, 6–8 March 2014; pp. 241–246. [Google Scholar]
- Khaleghi, B.; Khamis, A.; Karray, F.O.; Razavi, S.N. Multisensor data fusion: A review of the state-of-the-art. Inf. Fusion 2013, 14, 28–44. [Google Scholar] [CrossRef]
- Lu, N.; Cheng, N.; Zhang, N.; Shen, X.; Mark, J.W. Connected vehicles: Solutions and challenges. IEEE Internet Things J. 2014, 1, 289–299. [Google Scholar] [CrossRef]
- Faezipour, M.; Nourani, M.; Saeed, A.; Addepalli, S. Progress and challenges in intelligent vehicle area networks. Commun. ACM 2012, 55, 90–100. [Google Scholar] [CrossRef]
- Qu, F.; Wang, F.-Y.; Yang, L. Intelligent transportation spaces: Vehicles, traffic, communications, and beyond. IEEE Commun. Mag. 2010, 48, 136–142. [Google Scholar] [CrossRef]
- Galanis, I.; Olsen, D.; Anagnostopoulos, I. A multi-agent based system for run-time distributed resource management. In Proceedings of the IEEE International Symposium on Circuits and Systems, Baltimore, MD, USA, 28–31 May 2017. [Google Scholar]
- Ozatay, E.; Onori, S.; Wollaeger, J.; Ozguner, U.; Rizzoni, G.; Filev, D.; Michelini, J.; di Cairano, S. Cloud-based velocity profile optimization for everyday driving: A dynamic-programming-based solution. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2491–2505. [Google Scholar] [CrossRef]
- Zhang, F.; Xi, J.; Langari, R. Real-time energy management strategy based on velocity forecasts using v2v and v2i communications. IEEE Trans. Intell. Transp. Syst. 2017, 18, 416–430. [Google Scholar] [CrossRef]
- Kim, S.-W.; Liu, W.; Ang, M.H.; Frazzoli, E.; Rus, D. The impact of cooperative perception on decision making and planning of autonomous vehicles. IEEE Intell. Transp. Syst. Mag. 2015, 7, 39–50. [Google Scholar] [CrossRef]
- Jiang, Y.; Qiu, H.; McCartney, M.; Halfond, W.G.; Bai, F.; Grimm, D.; Govindan, A. Carlog: A platform for flexible and efficient automotive sensing. In Proceedings of the 12th ACM Conference on Embedded Network Sensor Systems, Memphis, TN, USA, 3–6 November 2014; pp. 221–235. [Google Scholar]
- Radak, J.; Ducourthial, B.; Cherfaoui, V.; Bonnet, S. Detecting road events using distributed data fusion: Experimental evaluation for the icy roads case. IEEE Trans. Intell. Transp. Syst. 2016, 17, 184–194. [Google Scholar] [CrossRef]
- Orhan, F.; Eren, P.E. Road hazard detection and sharing with multimodal sensor analysis on smartphones. In Proceedings of the 2013 IEEE Seventh International Conference on Next Generation Mobile Apps, Services and Technologies (NGMAST), Prague, Czech Republic, 25–27 September 2013; pp. 56–61. [Google Scholar]
- Garcia, F.; Martin, D.; de la Escalera, A.; Armingol, J.M. Sensor fusion methodology for vehicle detection. IEEE Intell. Transp. Syst. Mag. 2017, 9, 123–133. [Google Scholar] [CrossRef]
- Kumar, S.; Gollakota, S.; Katabi, D. A cloud-assisted design for autonomous driving. In Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing, Helsinki, Finland, 17 August 2012; pp. 41–46. [Google Scholar]
- Jain, A.; Koppula, H.S.; Raghavan, B.; Soh, S.; Saxena, A. Car that knows before you do: Anticipating maneuvers via learning temporal driving models. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3182–3190. [Google Scholar]
- Juga, I.; Nurmi, P.; Hippi, M. Statistical modelling of wintertime road surface friction. Meteorol. Appl. 2013, 20, 318–329. [Google Scholar] [CrossRef]
- Kokogias, S.; Svensson, L.; Pereira, G.C.; Oliveira, R.; Zhang, X.; Song, X.; Mårtensson, J. Development of platform-independent system for cooperative automated driving evaluated in gcdc 2016. IEEE Trans. Intell. Transp. Syst. 2017, 19, 1277–1289. [Google Scholar] [CrossRef]
- Mangharam, R. The car and the cloud: Automotive architectures for 2020. Bridg. Front. Eng. Natl. Acad. Eng. 2012, 42, 25–33. [Google Scholar]
- Khan, S.M.; Dey, K.C.; Chowdhury, M. Real-time traffic state estimation with connected vehicles. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1687–1699. [Google Scholar] [CrossRef]
- Chavez-Garcia, R.O.; Aycard, O. Multiple sensor fusion and classification for moving object detection and tracking. IEEE Trans. Intell. Transp. Syst. 2016, 17, 525–534. [Google Scholar] [CrossRef]
- Popescu, O.; Sha-Mohammad, S.; Abdel-Wahab, H.; Popescu, D.C.; El-Tawab, S. Automatic incident detection in intelligent transportation systems using aggregation of traffic parameters collected through v2i communications. IEEE Intell. Transp. Syst. Mag. 2017, 9, 64–75. [Google Scholar] [CrossRef]
- Silva, C.; Silva, L.; Santos, L.; Sarubbi, J.; Pitsillides, A. Broadening understanding on managing the communication infrastructure in vehicular networks: Customizing the coverage using the delta network. Future Internet 2019, 11, 1. [Google Scholar] [CrossRef]
- Du, W.; Abbas-Turki, A.; Koukam, A.; Galland, S.; Gechter, F. On the v2x speed synchronization at intersections: Rule based system for extended virtual platooning. Procedia Comput. Sci. 2018, 141, 255–262. [Google Scholar] [CrossRef]
- Chen, B.; Gechter, F. A cooperative control method for platoon and intelligent vehicles management. In Proceedings of the 2017 IEEE Vehicle Power and Propulsion Conference (VPPC), Belfort, France, 11–14 December 2017; pp. 1–5. [Google Scholar]
- Zhang, Y.; Loannou, P.A. Ioannou. Combined variable speed limit and lane change control for highway traffic. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1812–1823. [Google Scholar] [CrossRef]
- Zhang, Y.; Ioannou, P.A. Coordinated variable speed limit, ramp metering and lane change control of highway traffic. IFAC-PapersOnLine 2017, 50, 5307–5312. [Google Scholar] [CrossRef]
- Usman, T.; Fu, L.; Miranda-Moreno, L.F. Quantifying safety benefit of winter road maintenance: Accident frequency modeling. Accid. Anal. Prev. 2010, 42, 1878–1887. [Google Scholar] [CrossRef]
- Götzfried, F. Policies and strategies for increased safety and traffic flow on european road networks in winter. In Proceedings of the Final Conference of the COST Action, Delft, The Netherlands, 29–30 October 2008. [Google Scholar]
- Fredriksson, L.-B. Can for critical embedded automotive networks. IEEE Micro 2002, 22, 28–35. [Google Scholar] [CrossRef]
- International Standard. 11898: Road Vehicles—Interchange of Digital Information—Controller Area Network (Can) for High-Speed Communicationa; International Standards Organization: Geneva, Switzerland, 1993. [Google Scholar]
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- ZeroMQ. Available online: http://zguide.zeromq.org/page:all (accessed on 22 March 2019).
- Ting, K.M. Confusion matrix. In Encyclopedia of Machine Learning and Data Mining; Springer: Berlin, Germany, 2017; p. 260. [Google Scholar]
- Kutila, M.; Pyykönen, P.; Kauvo, K.; Eloranta, P. In-vehicle sensor data fusion for road friction monitoring. In Proceedings of the 2011 IEEE International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 25–27 August 2011; pp. 349–352. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | Information Gain |
|---|---|
| Temperature (C) | 0.690 |
| Dew Point | 0.415 |
| Wind chill | 0.414 |
| Humidity (mm) | 0.308 |
| Elevation (m) | 0.289 |
| Precipitation (mm) | 0.283 |
| Snow | 0.147 |
| Precipitation history (mm) | 0.120 |
| Rain | 0.092 |
| Snowfall(mm) | 0.043 |
| Snow depth (mm) | 0.030 |
| Gust Wind | 0.013 |
| Message Type | |||||
|---|---|---|---|---|---|
| ANNOUNCE | UPDATE | BID | WIN BID | ||
| Action type | SET | New agent appears | Require update | Ask for bid | Announce winner |
| GET | Receive information | Send update | Get bids | Assign workload to the winner | |
| Predicted | |||||
|---|---|---|---|---|---|
| Actual | Dry | Wet | Snow | Ice | |
| Dry | 90.2% | 4.0% | 1.4% | 1.7% | |
| Wet | 6.8% | 90.2% | 4.7% | 6.7% | |
| Snow | 1.1% | 2.2% | 82.0% | 16.3% | |
| Ice | 1.8% | 3.6% | 11.9% | 75.3% | |
| Dry | Ice | Snow | Wet | |
|---|---|---|---|---|
| Classification Tree | 90.2% | 75.3% | 82.0% | 90.2% |
| kNN | 79.6% | 65.7% | 69.8% | 80.0% |
| Logistic Regression | 76.9% | 57.9% | 56.3% | 72.4% |
| SVM | 83.5% | 50.0% | 82.3% | 34.6% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Galanis, I.; Anagnostopoulos, I.; Gurunathan, P.; Burkard, D. Environmental-Based Speed Recommendation for Future Smart Cars. Future Internet 2019, 11, 78. https://doi.org/10.3390/fi11030078
Galanis I, Anagnostopoulos I, Gurunathan P, Burkard D. Environmental-Based Speed Recommendation for Future Smart Cars. Future Internet. 2019; 11(3):78. https://doi.org/10.3390/fi11030078
Chicago/Turabian StyleGalanis, Ioannis, Iraklis Anagnostopoulos, Priyaa Gurunathan, and Dona Burkard. 2019. "Environmental-Based Speed Recommendation for Future Smart Cars" Future Internet 11, no. 3: 78. https://doi.org/10.3390/fi11030078
APA StyleGalanis, I., Anagnostopoulos, I., Gurunathan, P., & Burkard, D. (2019). Environmental-Based Speed Recommendation for Future Smart Cars. Future Internet, 11(3), 78. https://doi.org/10.3390/fi11030078