My Smartphone tattles: Considering Popularity of Messages in Opportunistic Data Dissemination

 , , , , , and
, , , , , and
Abstract
1. Introduction
2. Background and Application Scenarios
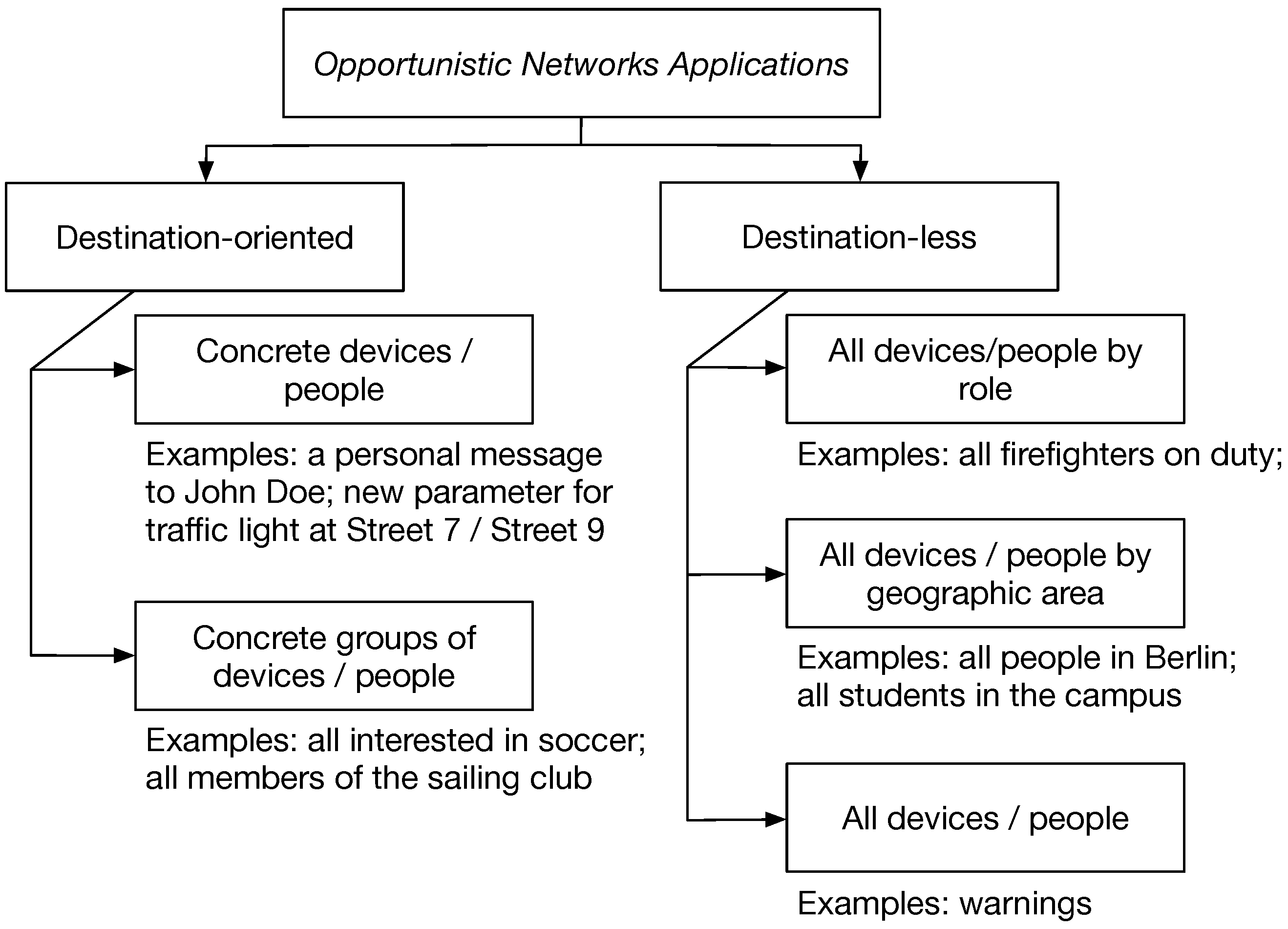
2.1. Application Scenarios
2.2. Real Implementations
3. State of the Art
3.1. Destination-Less Forwarding Protocols
3.1.1. Epidemic Routing
3.1.2. Spray and Wait Routing
3.1.3. Randomised Rumor Spreading (RRS)
3.2. Popularity and Priority
3.3. Summary and Discussion
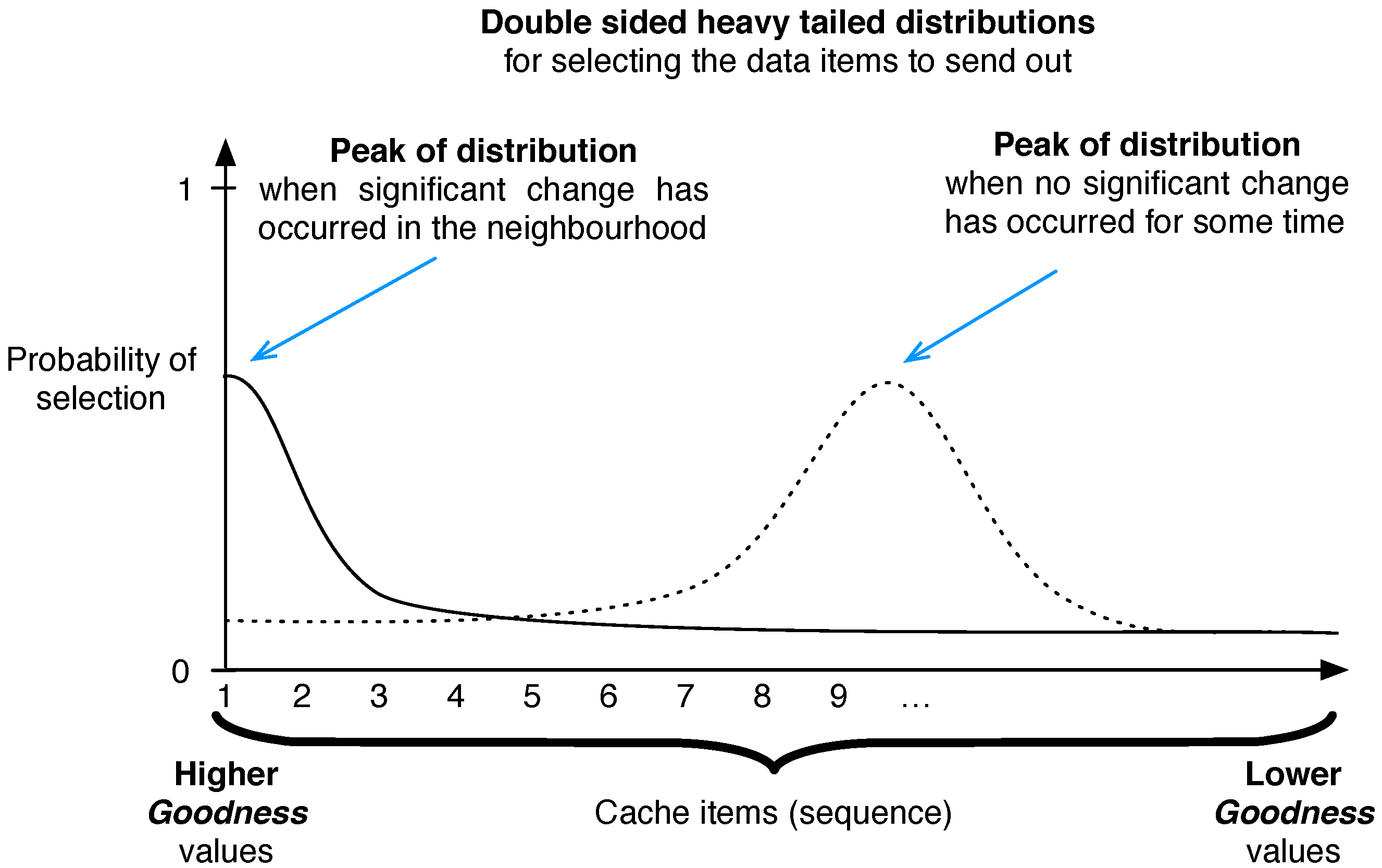
4. Definition of Popularity
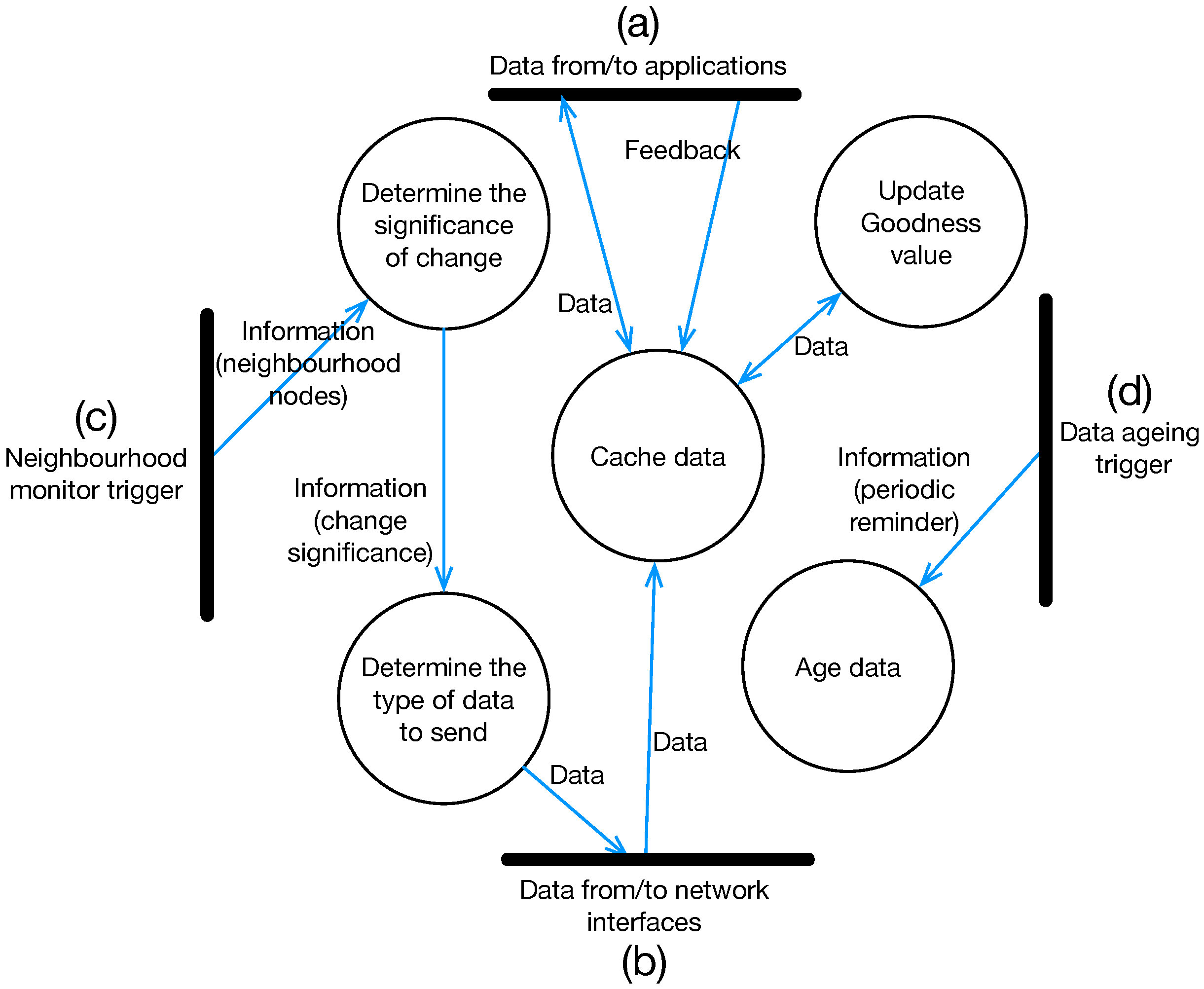
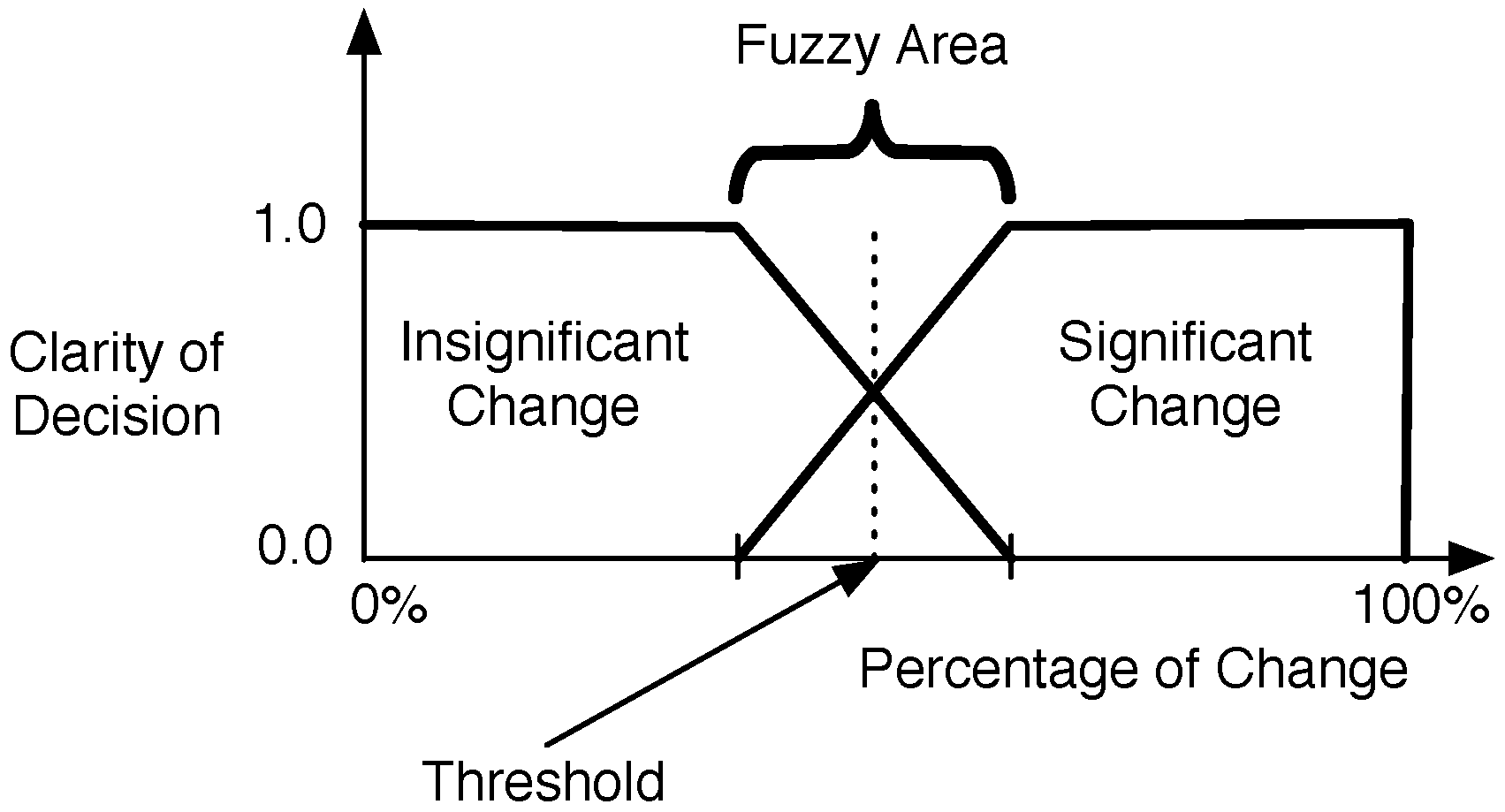
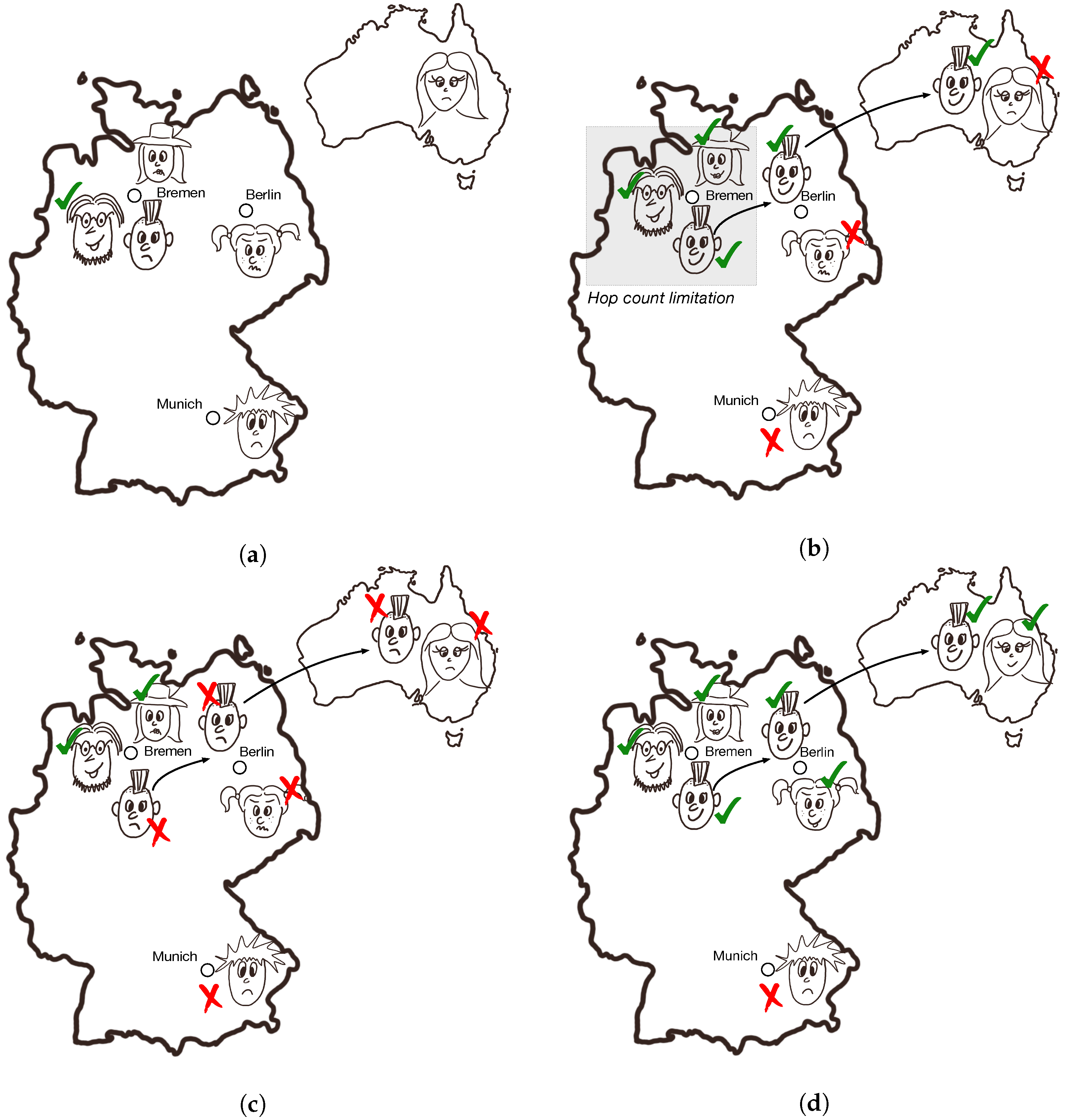
5. Keetchi Forwarding Protocol
Keetchi Algorithm
6. Keetchi—Case Studies
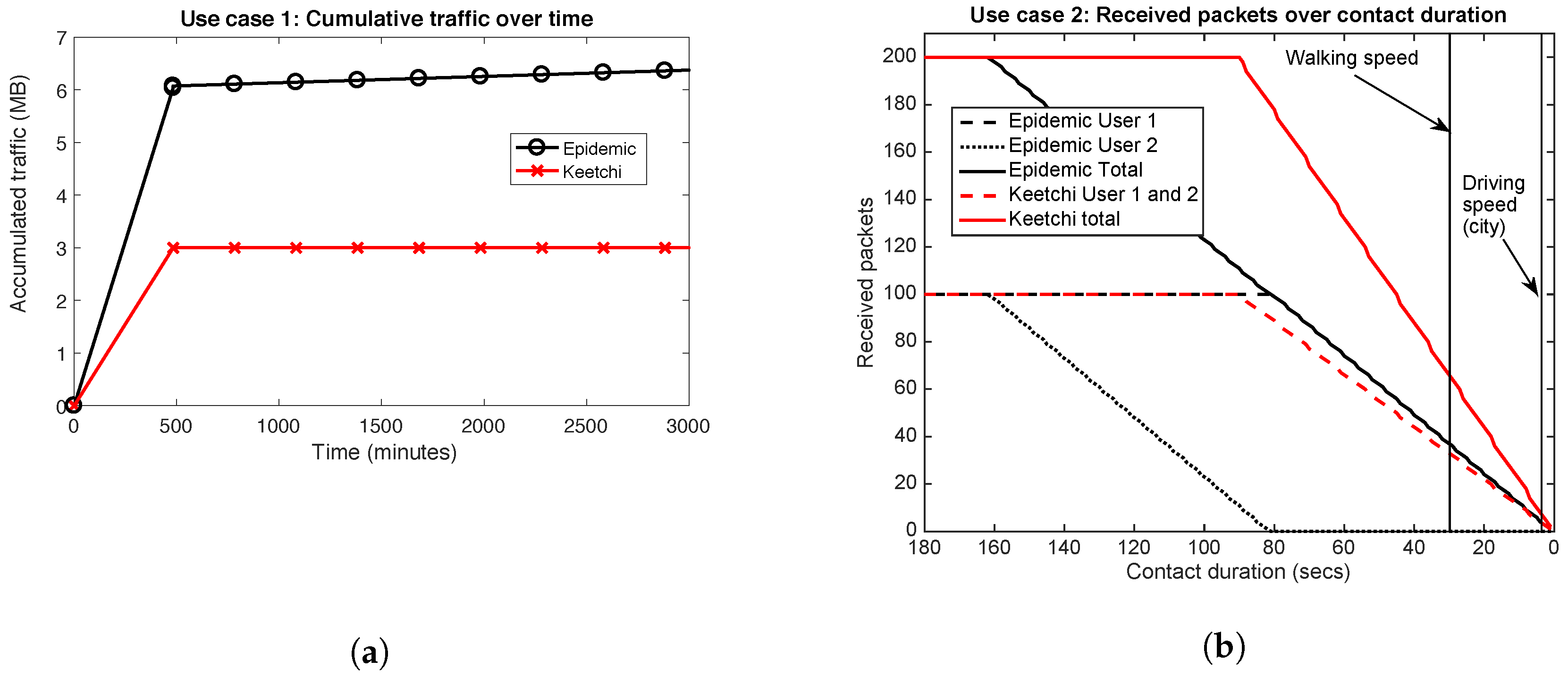
6.1. Use Case 1: Meeting in the Office
6.2. Use Case 2: Two People Passing by on the Street
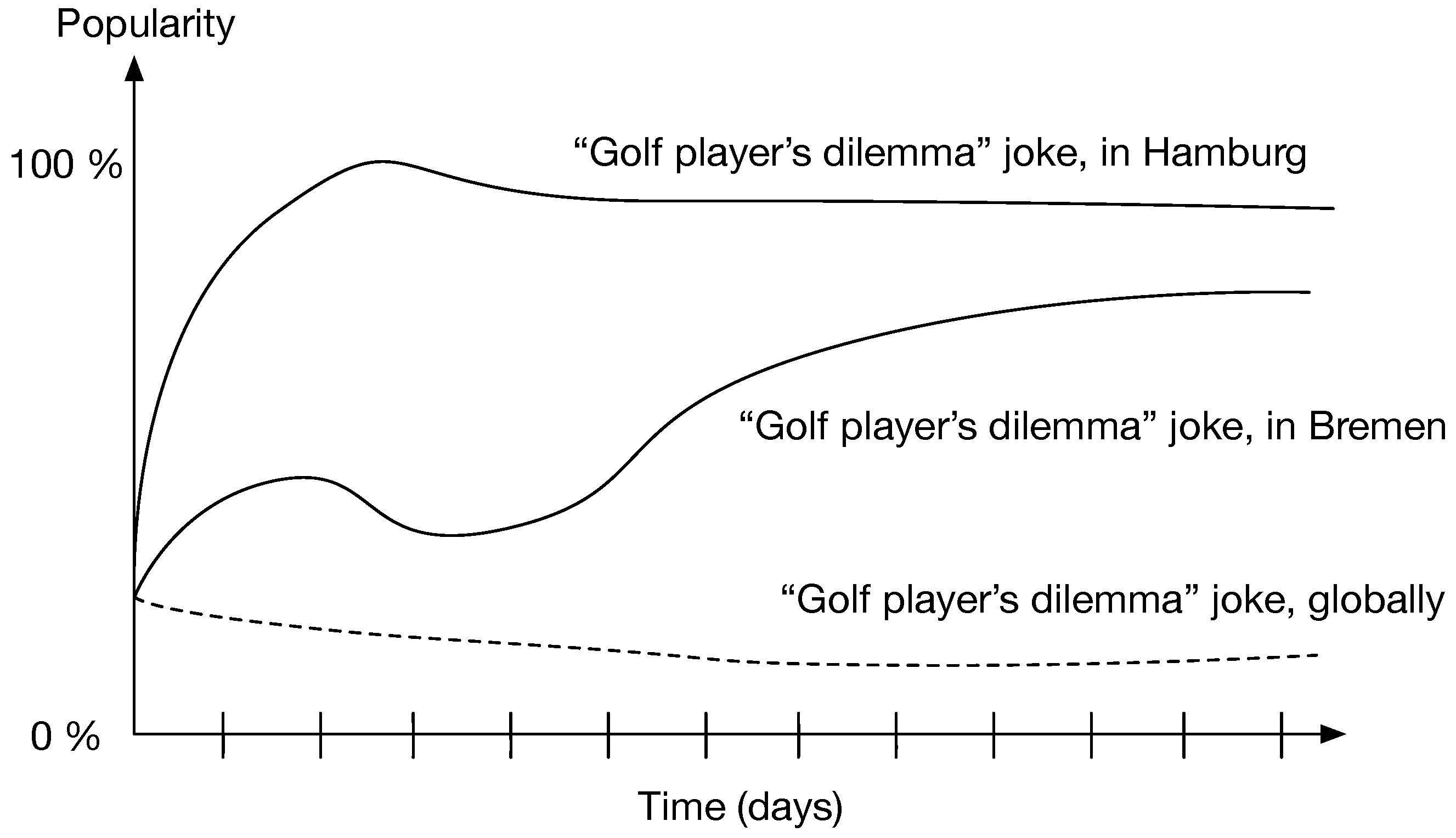
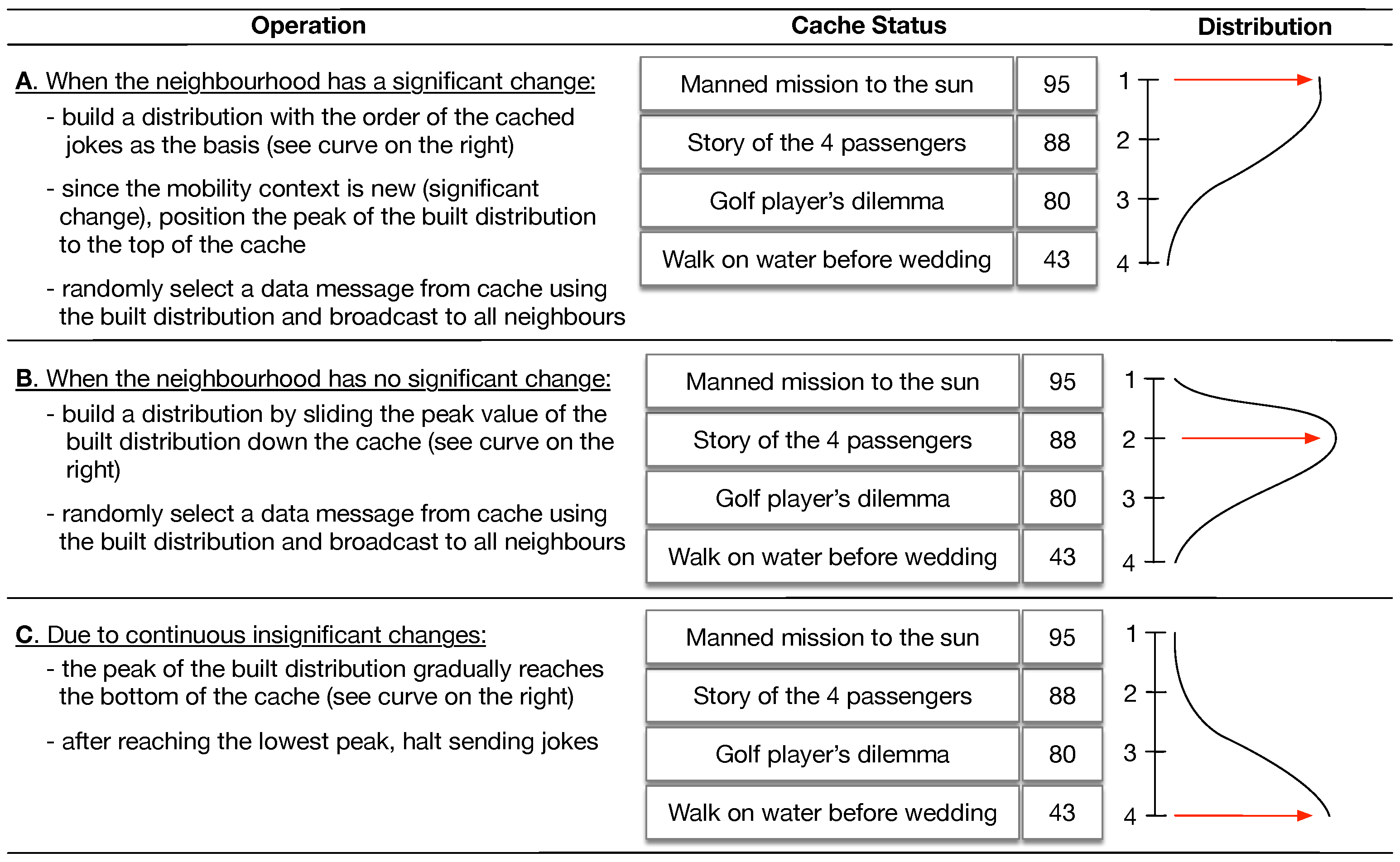
6.3. Use Case 3: The Lifetime of Good and Bad Jokes
7. Performance Evaluation Setup
7.1. Scenario Description
7.2. The OPS Simulation Framework
7.3. Metrics
8. Performance Evaluations
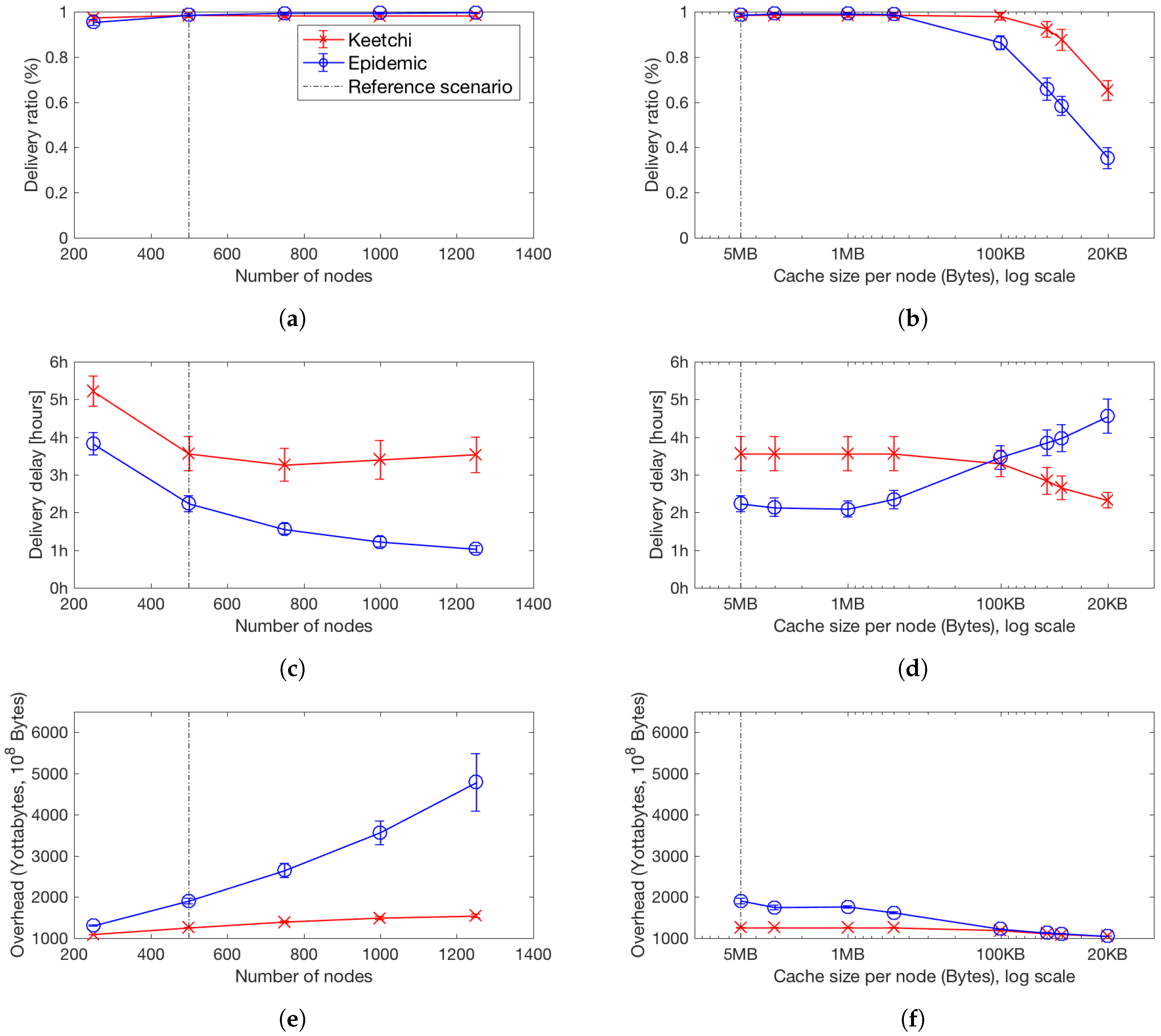
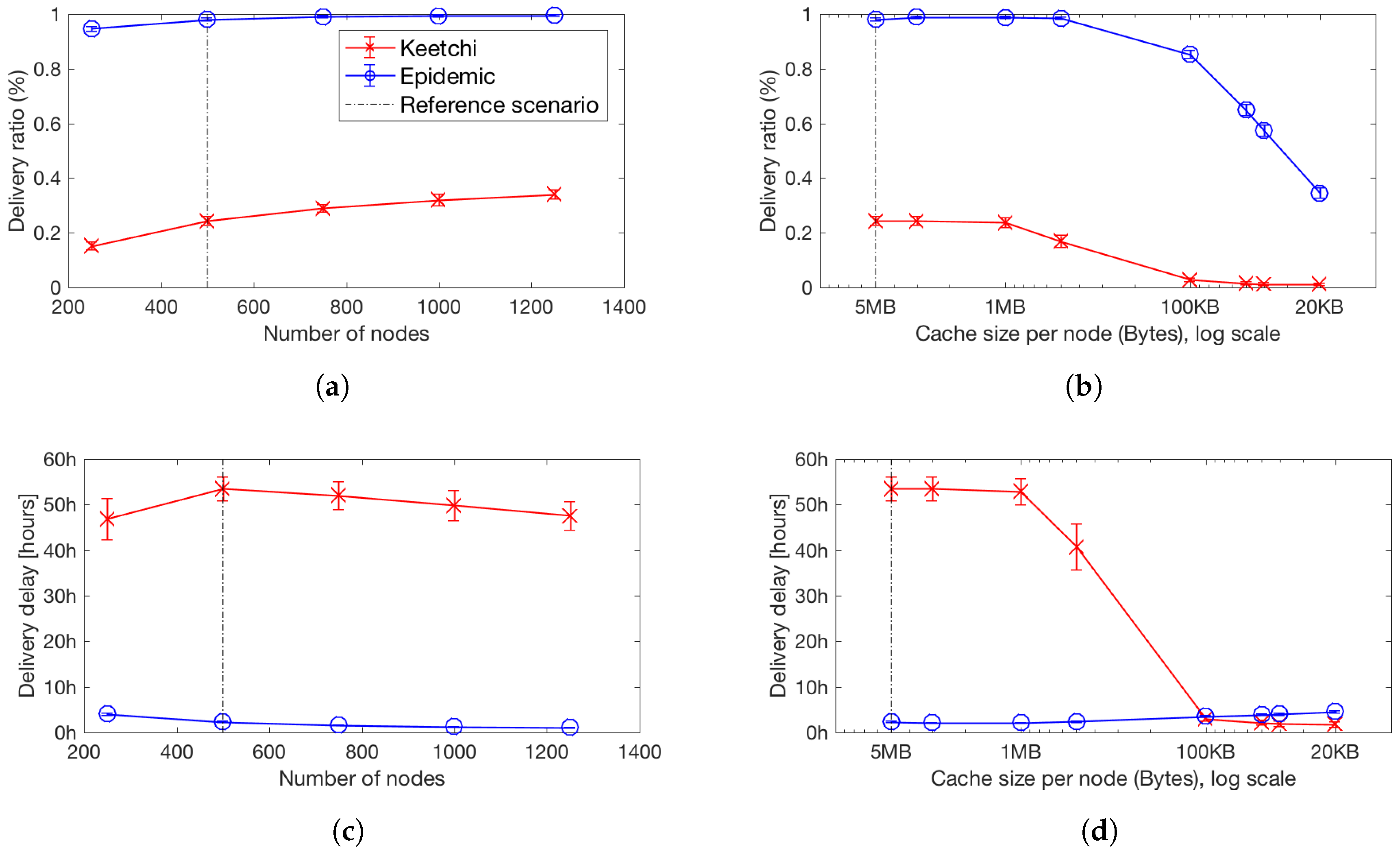
8.1. Impact of Network Size and Density on Popular Messages
8.2. Impact of Cache Size on Popular Messages
8.3. What Happens to the Unpopular Messages?
9. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Appendix A. An Example of the Keetchi Operation


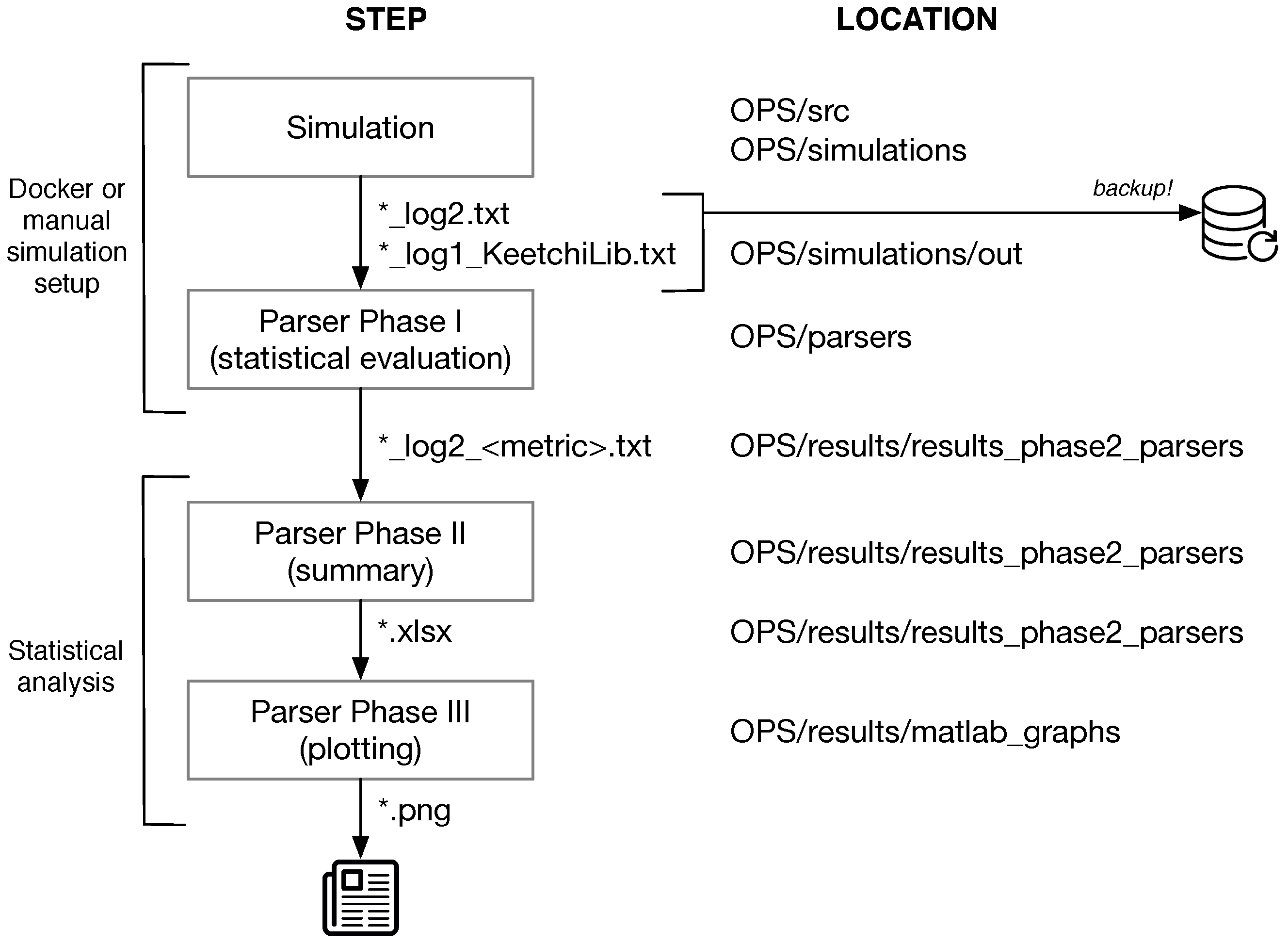
Appendix B. Reproducing Our Results
- Virtualisation technology:Kernel-based Virtual Machine (KVM)
- 48 GB RAM
- 8 CPU cores per virtual machine(Host CPU: Intel(R) Xeon(R) CPU E5-2699)
- File server mounted via Samba
- Operating System: Ubuntu 16.04.4 LTS
- The simulations create log files including all events and log message. These files are quite large (several hundreds of GBs).
- The simulation output log files are parsed using Python scripts to get the main results. This is done automatically after the simulation end. The parsers are located in OPS/parsers. The resulting output of the parsers is located in OPSresults/results_parsers_phase2. (Phase I)
- The next parser is OPS/results/results_ parsers_phase2/parsers-phase2.py. It summarises the text files from Phase I to Excel (.xlsx) files. (Phase II)
- These .xlsx result files are read by Matlab/Octave scripts located in OPS/results/parsers_phase3. These scripts create the graphs used in this work. (Phase III)

Appendix B.1. Using a Docker Image
Appendix B.2. Manual Simulation Setup
Appendix B.3. Statistical Analysis
References
- Sieber, R.E.; Johnson, P.A. Civic Open Data at a Crossroads: Dominant Models and Current Challenges. Gov. Inf. Q. 2015, 32, 308–315. [Google Scholar] [CrossRef]
- Dede, J.; Förster, A.; Hernández-Orallo, E.; Herrera-Tapia, J.; Kuladinithi, K.; Kuppusamy, V.; Manzoni, P.; Muslim, A.B.; Udugama, A.; Vatandas, Z. Simulating Opportunistic Networks: Survey and Future Directions. IEEE Commun. Surv. Tutor. 2018, 20, 1547–1573. [Google Scholar] [CrossRef]
- Vatandas, Z.; Hamm, S.M.; Kuladinithi, K.; Killat, U.; Timm-Giel, A.; Förster, A. Modeling of Data Dissemination in OppNets. In Proceedings of the 19th IEEE International Symposium on a World of Wireless, Mobile and Multimedia Networks, Chania, Greece, 12–15 June 2018. [Google Scholar]
- Vahdat, A.; Becker, D. Epidemic Routing for Partially Connected Ad Hoc Networks; Technical Report; Duke University: Durham, NC, USA, 2000. [Google Scholar]
- Kuppusamy, V.; Thanthrige, U.; Udugama, A.; Förster, A. Survey of Opportunistic Networking Data Forwarding Protocols and Their Evaluation Methodologies. 2019. under review. [Google Scholar]
- Förster, A.; Muslim, A.B.; Udugama, A. Reactive User Behavior and Mobility Models. In Proceedings of the 4th OMNeT++ Community Summit, Bremen, Germany, 7–8 September 2017. [Google Scholar]
- The Jodel Venture GmbH. Jodel—The Hyperlocal App. 2014. Available online: https://www.jodel-app.com (accessed on 1 November 2018).
- Ramanathan, R.; Hansen, R.; Basu, P.; Rosales-Hain, R.; Krishnan, R. Prioritized Epidemic Routing for Opportunistic Networks. In Proceedings of the 1st International MobiSys Workshop on Mobile Opportunistic Networking, MobiOpp ’07, San Juan, PR, USA, 11 June 2007; ACM: New York, NY, USA, 2007; pp. 62–66. [Google Scholar]
- Spyropoulos, T.; Psounis, K.; Raghavendra, C.S. Efficient routing in intermittently connected mobile networks: The single-copy case. IEEE/ACM Trans. Netw. 2008, 16, 63–76. [Google Scholar] [CrossRef]
- Spyropoulos, T.; Psounis, K.; Raghavendra, C.S. Spray and Wait: An Efficient Routing Scheme for Intermittently Connected Mobile Networks. In Proceedings of the 2005 ACM SIGCOMM Workshop on Delay-Tolerant Networking, WDTN ’05, Philadelphia, PA, USA, 26 August 2005; ACM: New York, NY, USA, 2005; pp. 252–259. [Google Scholar]
- Haeupler, B. Simple, Fast and Deterministic Gossip and Rumor Spreading. In Proceedings of the 24th Annual ACM-SIAM Symposium on Discrete Algorithms, SODA ’13, New Orleans, LA, USA, 6–8 January 2013; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2013; pp. 705–716. [Google Scholar]
- Spyropoulos, T.; Turletti, T.; Obraczka, K. Utility-based Message Replication for Intermittently Connected Heterogeneous Networks. In Proceedings of the 2007 IEEE International Symposium on a World of Wireless, Mobile and Multimedia Networks, Espoo, Finland, 18–21 June 2007; pp. 1–6. [Google Scholar]
- Lieser, P.; Alvarez, F.; Gardner-Stephen, P.; Hollick, M.; Boehnstedt, D. Architecture for Responsive Emergency Communications Networks. In Proceedings of the 2017 IEEE Global Humanitarian Technology Conference (GHTC), San Jose, CA, USA, 19–22 October 2017; pp. 1–9. [Google Scholar]
- Müller, S.; Atan, O.; Schaar, M.V.; Klein, A. Context-Aware Proactive Content Caching With Service Differentiation in Wireless Networks. IEEE Trans. Wirel. Commun. 2017, 16, 1024–1036. [Google Scholar] [CrossRef]
- Spyropoulos, T.; Psounis, K.; Raghavendra, C.S. Spray and focus: Efficient mobility-assisted routing for heterogeneous and correlated mobility. In Proceedings of the Fifth Annual IEEE International Conference on Pervasive Computing and Communications Workshops, PerCom Workshops’ 07, White Plains, NY, USA, 19–23 March 2007; pp. 79–85. [Google Scholar]
- Huang, T.K.; Lee, C.K.; Chen, L.J. Prophet+: An adaptive prophet-based routing protocol for opportunistic network. In Proceedings of the 2010 24th IEEE International Conference on Advanced Information Networking and Applications (AINA), Perth, WA, Australia, 20–23 April 2010; pp. 112–119. [Google Scholar]
- Grasic, S.; Davies, E.; Lindgren, A.; Doria, A. The evolution of a DTN routing protocol-PRoPHETv2. In Proceedings of the 6th ACM Workshop on Challenged Networks, Las Vegas, NV, USA, 23 September 2011; ACM: New York, NY, USA, 2011; pp. 27–30. [Google Scholar]
- Burgess, J.; Gallagher, B.; Jensen, D.; Levine, B.N. Maxprop: Routing for vehicle-based disruption-tolerant networks. In Proceedings of the INFOCOM 2006, 25th IEEE International Conference on Computer Communications, Barcelona, Spain, 23–29 April 2006; pp. 1–11. [Google Scholar]
- Hui, P.; Crowcroft, J.; Yoneki, E. Bubble rap: Social-based forwarding in delay-tolerant networks. IEEE Trans. Mob. Comput. 2011, 10, 1576–1589. [Google Scholar] [CrossRef]
- Boldrini, C.; Conti, M.; Jacopini, J.; Passarella, A. Hibop: A history based routing protocol for opportunistic networks. In Proceedings of the IEEE International Symposium on a World of Wireless, Mobile and Multimedia Networks, WoWMoM 2007, Espoo, Finland, 18–21 June 2007; pp. 1–12. [Google Scholar]
- Okamoto, K.; Takami, K. Routing Based on Information about the Routes of Fixed-Route Traveling Nodes and on Destination Areas Aimed at Reducing the Load on the DTN. Future Internet 2016, 8, 15. [Google Scholar] [CrossRef]
- Liu, K.; Chen, Z.; Wu, J.; Xiao, Y.; Zhang, H. Predict and Forward: An Efficient Routing-Delivery Scheme Based on Node Profile in Opportunistic Networks. Future Internet 2018, 10, 74. [Google Scholar] [CrossRef]
- Förster, A.; Udugama, A.; Görg, C.; Kuladinithi, K.; Timm-Giel, A.; Cama-Pinto, A. A Novel Data Dissemination Model for Organic Data Flows. In Proceedings of the 7th EAI International Conference on Mobile Networks and Management (MONAMI), Santander, Spain, 16–18 September 2015; pp. 239–252. [Google Scholar]
- Sang, L.; Kuppusamy, V.; Förster, A.; Udugama, A.; Liu, J. Validating Contact Times Extracted from Mobility Traces. In Proceedings of the 16th International Conference on Ad Hoc Networks and Wireless, ADHOC-NOW, Messina, Italy, 20–22 September 2017; pp. 239–252. [Google Scholar]
- Mikhaylov, K.; Plevritakis, N.; Tervonen, J. Performance Analysis and Comparison of Bluetooth Low Energy with IEEE 802.15.4 and SimpliciTI. J. Sens. Actuator Netw. 2013, 2, 589–613. [Google Scholar] [CrossRef]
- Udugama, A.; Förster, A.; Dede, J.; Kuppusamy, V.; Muslim, A.B. Opportunistic Networking Protocol Simulator for OMNeT++. In Proceedings of the 4th OMNeT++ Community Summit, Bremen, Germany, 7–8 September 2017. [Google Scholar]
- Udugama, A.; Khalilov, B.; Bin Muslim, A.; Förster, A. Implementation of the SWIM Mobility Model in OMNeT++. In Proceedings of the OMNeT++ Summit, Brno, Czech Republic, 15–16 September 2016. [Google Scholar]
- Yuan, P.; Yu, H. A Combinational Buffer Management Scheme in Mobile Opportunistic Network. Future Internet 2017, 9, 823. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Communication range [m] | 30 m (from [24]) |
| Speed of people [m/s] | Walking (1 m/s), Biking (3.6 m/s), Driving city (13.8 m/s), Driving highway (27.7 m/s) |
| Number of data items each user has | 100 |
| Size of each data item [bytes] | 10,000 (text message + some pictures) |
| Size of summary vector [bytes] | 20 |
| Size of data request [bytes] | 20 |
| Data rate [bytes/second] | 12,500 (from [25]) |
| Parameter | Default Value | Explored Parameter Space |
|---|---|---|
| General | ||
| Number of nodes | 500 | 250 … 1250 in steps of 250 |
| Simulation length | 7 days | fixed |
| Area | 1500 m × 1500 m | fixed |
| TTL of Data in days | infinite | fixed |
| Communication range | 30 m | fixed |
| Link layer bandwidth | 100 Kbps | fixed |
| Cache size | 5 MB | 20 KB, 40 KB, 50 KB, 100 KB, 500 KB, 1 MB, 3 MB, 5 MB |
| Size of Data | 10,000 bytes | fixed |
| Data generation | every 900 s | fixed |
| SWIM Mobility | ||
| Number of fixed locations | 200 | fixed |
| Location radius | 2 m | fixed |
| Neighbor location radius | 200 m | fixed |
| Waiting time | 20 min to 8 h | fixed |
| Speed | 1.5 m per second | fixed |
| Alpha | 0.5 | fixed |
| Keetchi | ||
| Focus weight factor | 0.8 | fixed |
| Learning constant | 0.5 | fixed |
| Ageing Interval | 600 s | fixed |
| Neighborhood Change Significance Threshold | 25% or more | fixed |
| Backoff increment factor | 1.5 | fixed |
| Epidemic | ||
| Re-sync period | 300 s | fixed |
| Max. number of hops | 25 | fixed |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Udugama, A.; Dede, J.; Förster, A.; Kuppusamy, V.; Kuladinithi, K.; Timm-Giel, A.; Vatandas, Z. My Smartphone tattles: Considering Popularity of Messages in Opportunistic Data Dissemination. Future Internet 2019, 11, 29. https://doi.org/10.3390/fi11020029
Udugama A, Dede J, Förster A, Kuppusamy V, Kuladinithi K, Timm-Giel A, Vatandas Z. My Smartphone tattles: Considering Popularity of Messages in Opportunistic Data Dissemination. Future Internet. 2019; 11(2):29. https://doi.org/10.3390/fi11020029
Chicago/Turabian StyleUdugama, Asanga, Jens Dede, Anna Förster, Vishnupriya Kuppusamy, Koojana Kuladinithi, Andreas Timm-Giel, and Zeynep Vatandas. 2019. "My Smartphone tattles: Considering Popularity of Messages in Opportunistic Data Dissemination" Future Internet 11, no. 2: 29. https://doi.org/10.3390/fi11020029
APA StyleUdugama, A., Dede, J., Förster, A., Kuppusamy, V., Kuladinithi, K., Timm-Giel, A., & Vatandas, Z. (2019). My Smartphone tattles: Considering Popularity of Messages in Opportunistic Data Dissemination. Future Internet, 11(2), 29. https://doi.org/10.3390/fi11020029