A Novel Neural Network-Based Method for Medical Text Classification


Abstract
1. Introduction
- In order to solve the problem of high-dimensionality of medical texts, we propose a new hierarchical neural network method.
- The method uses the attention mechanism at the word level and sentence level respectively to solve the problem of data sparsity.
- The experimental results show that the proposed method is effective in medical records and medical literature, especially in medical records.
2. Related Work
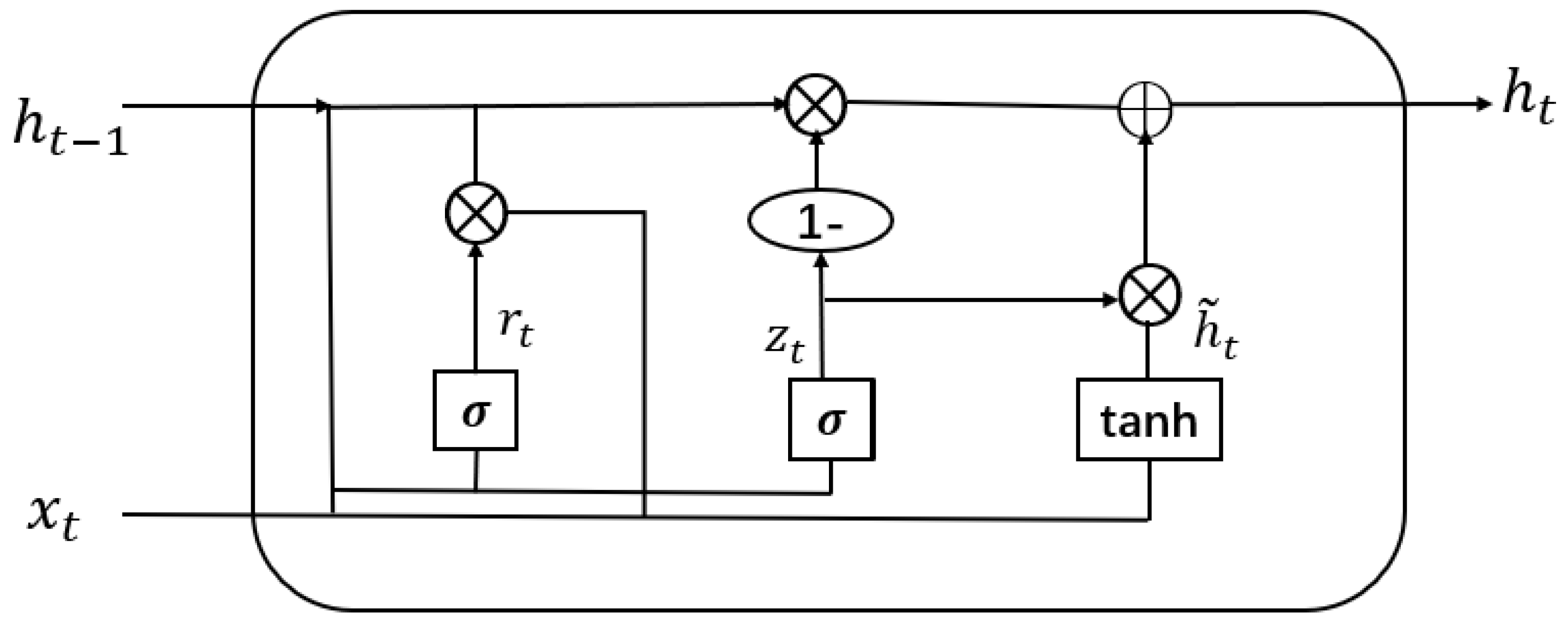
2.1. Gated Recurrent Unit
2.2. Text Classification in General Domain
2.3. Text Classification in Medical Domain
3. Our Work
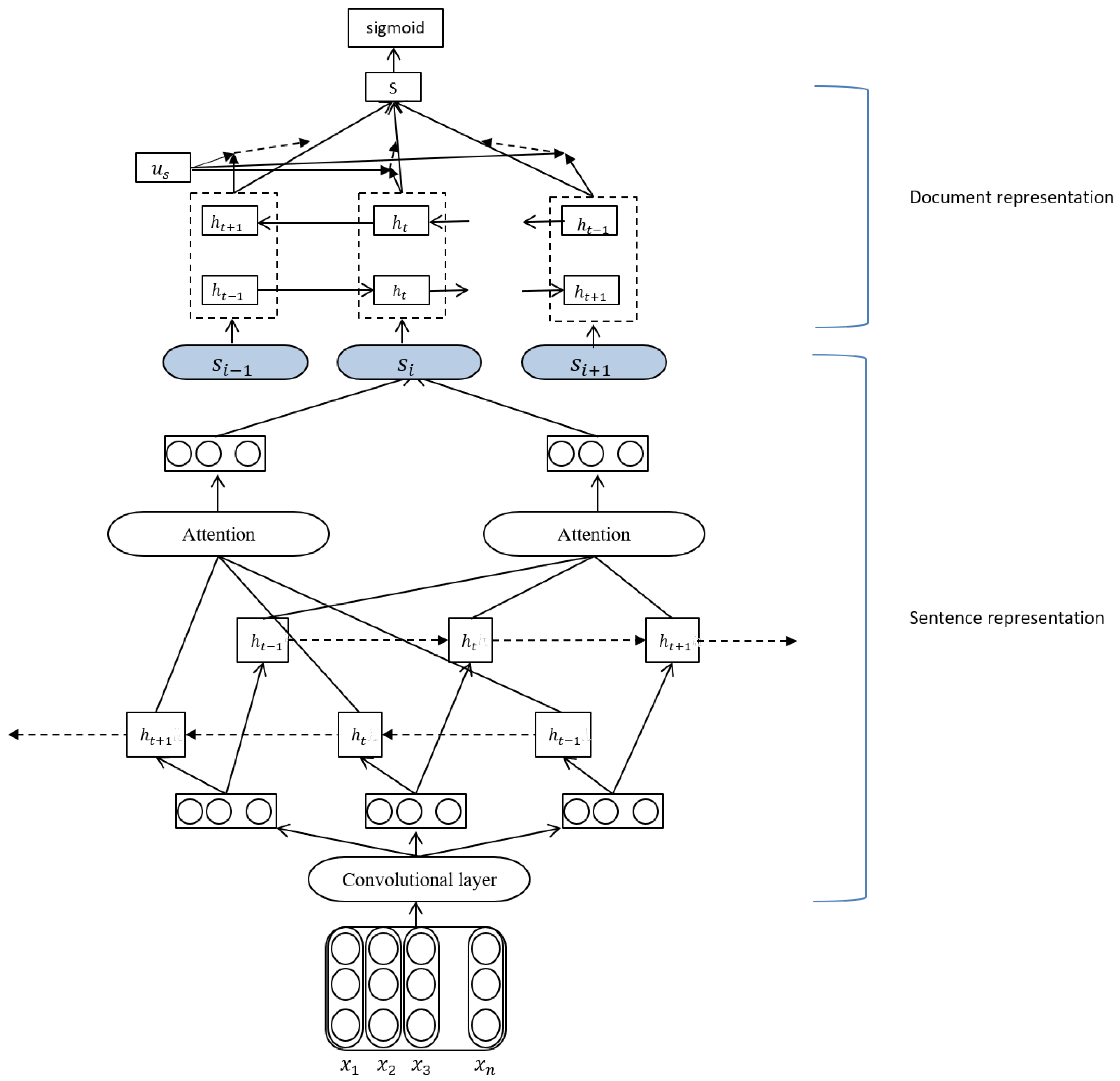
3.1. Sentence Representation
3.1.1. Word Embedding
3.1.2. One Dimension Convolutional Layer
3.1.3. Bidirectional GRU and Attention Mechanism
3.2. Document Representation
3.2.1. Sentence Encoder
3.2.2. Sentence Decoder
- In sentence representation, our method uses convolutional layer to extract features and then through BIGRU and attention mechanism.
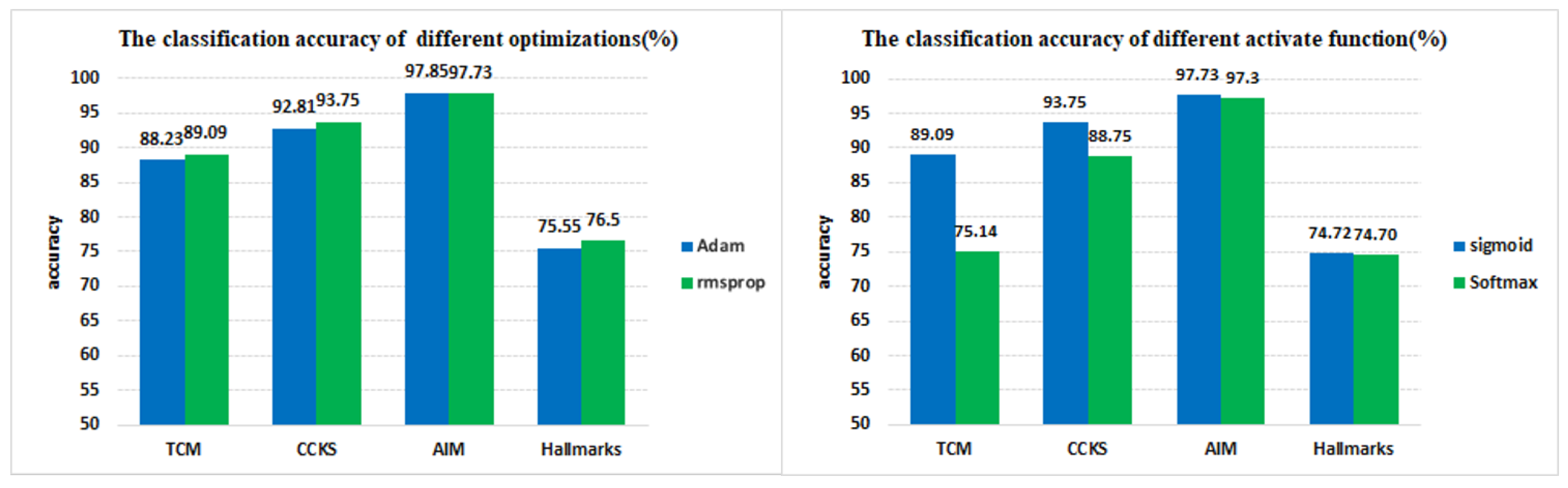
- In model optimization, our method uses RMSProp optimizer to replace Adam which used in HAN.
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Parameter Settings
4.2. Baseline Methods
4.3. Results
4.3.1. Overall Comparison
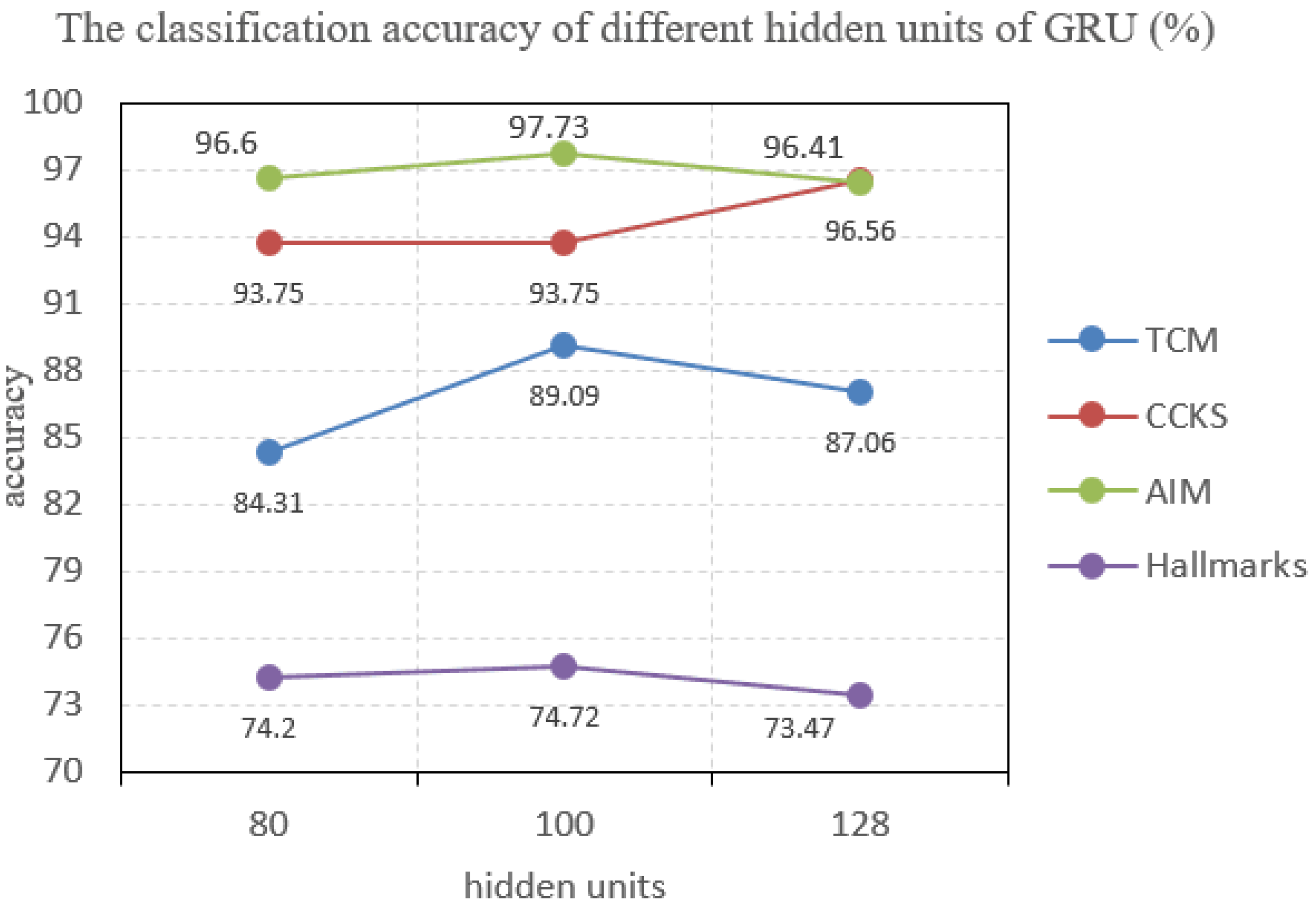
4.3.2. Effect of Parameter Tuning
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Mujtaba, G.; Shuib, L.; Idris, N.; Hoo, W.L.; Raj, R.G.; Khowaja, K.; Nweke, H.F. Clinical text classification research trends: Systematic literature review and open issues. Expert Syst. Appl. 2018, 116, 494–520. [Google Scholar] [CrossRef]
- Kaurova, O.; Alexandrov, M.; Blanco, X. Classification of free text clinical narratives (short review). Bus. Eng. Appll. Intell. Inf. Syst. 2011, 124, 255–266. [Google Scholar]
- Hoang, N.; Patrick, J. Text Mining in Clinical Domain: Dealing with Noise. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 549–558. [Google Scholar]
- Huang, K.; Altosaar, J.; Ranganath, R. ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission. Inf. Sci. 2019, 394–395, 38–52. [Google Scholar]
- Chung, J.; Gülçehre, Ç.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. In Proceedings of the NIPS 2014 Learning and Representation Learning Workshop, Montreal, QC, Canada, 12 December 2014; pp. 1–9. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Wallach, H.M. Topic modeling: Beyond bag-of-words. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 977–984. [Google Scholar]
- Yoon, K. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 19th Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Johnson, R.; Tong, Z. Effective Use of Word Order for Text Categorization with Convolutional Neural Networks. In Proceedings of the HLT-NAACL, San Francisco, CA, USA, 31 May– 5 June 2015; pp. 549–558. [Google Scholar]
- Li, S.; Zhao, Z.; Liu, T.; Hu, R.; Du, X. Initializing Convolutional Filters with Semantic Features for Text Classification. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 1884–1889. [Google Scholar]
- Johnson, R.; Tong, Z. Deep Pyramid Convolutional Neural Networks for Text Categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 9–11 September 2017; pp. 562–570. [Google Scholar]
- Wang, B. Disconnected Recurrent Neural Networks for Text Categorization. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (LongPapers), Melbourne, VI, Australia, 15–20 July 2018; pp. 2311–2320. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent Neural Network for Text Classification with Multi-Task Learning. In Proceedings of the 25th International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2873–2879. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent Convolutional Neural Networks for Text Classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2267–2273. [Google Scholar]
- Zhou, C.; Sun, C.; Liu, Z.; Lau, F. A C-LSTM Neural Network for Text Classification. Available online: https://arxiv.gg363.site/abs/1511.08630 (accessed on 30 November 2015).
- Yao, L.; Zhang, Y.; Wei, B.; Li, Z.; Huang, X. Traditional Chinese medicine clinical records classification using knowledge-powered document embedding. In Proceedings of the 2016 IEEE International Conference on Bioinformatics and Biomedicinee, Shenzhen, China, 15–18 December 2016; pp. 1926–1928. [Google Scholar]
- Hughes, M.; Li, I.; Kotoulas, S.; Suzumura, T. Medical text classification using convolutional neural networks. Stud. Health Technol. 2017, 235, 246–250. [Google Scholar]
- Baker, S.; Korhonen, A.; Pyysalo, S. Cancer hallmark text classification using convolutional neural networks. In Proceedings of the Fifth Workshop on Building and Evaluating Resources for Biomedical Text Mining (BioTxtM2016), Osaka, Japan, 12 December 2016; pp. 1–9. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the NAACL-HLT, San Diego, CA, USA, 17 June 2016; pp. 1480–1488. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. Available online: https://arxiv.org/abs/1301.3781 (accessed on 7 September 2013).
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving Neural Networks by Preventing Co-Adaptation of Feature Detectors. Available online: https://arxiv.org/abs/1207.0580 (accessed on 3 July 2012).
- Graves, A. Generating Sequences with Recurrent Neural Networks. Available online: https://arxiv.org/abs/1308.0850 (accessed on 5 June 2014).
- Baker, S.; Silins, I.; Guo, Y.; Ali, I.; Hogberg, J.; Stenius, U.; Korhonen, A. Automatic semantic classification of scientific literature according to the hallmarks of cancer. Bioinformatics 2016, 32, 432–440. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Liu, Y.; Bi, J.-W.; Fan, Z.-P. A method for multi-class sentiment classification based on an improved one-vs-one (ovo) strategy and the support vector machine (svm) algorithm. Inf. Sci. 2017, 8, 394–395. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. Available online: https://arxiv.org/abs/1607.01759 (accessed on 9 August 2016).
- Genkin, A.; Lewis, D.D.; Madigan, D. Large-Scale Bayesian Logistic Regression for Text Categorization. Technometrics 2004, 49, 291–304. [Google Scholar] [CrossRef]
- Gang, L.; Jiabao, G. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar]
- Kingma, D.P.; Ba, J.A. A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 14–16 April 2014; pp. 1–9. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Classes | Sentence Length | Dataset Size | Vocab Size | Training Set | Validation Set | Test Set |
|---|---|---|---|---|---|---|---|
| TCM | 5 | 428 | 5413 | 99,243 | 3789 | 1082 | 541 |
| CCKS | 4 | 73 | 400 | 2980 | 280 | 80 | 40 |
| Hallmarks | 3 | 833 | 8474 | 29,141 | 5931 | 1694 | 847 |
| AIM | 2 | 833 | 2648 | 29,141 | 1853 | 529 | 264 |
| Methods | TCM | CCKS | AIM | Hallmarks |
|---|---|---|---|---|
| CNN | 73.17 | 89.37 | 95.47 | 70.85 |
| LSTM | 60.00 | 80.62 | 57.36 | 72.73 |
| RCNN | 62.03 | 84.38 | 96.06 | 74.76 |
| HAN | 76.62 | 88.75 | 97.30 | 74.70 |
| SVM | 48.78 | 53.00 | 89.93 | 70.34 |
| Fasttext | 80.00 | 75.01 | 90.28 | 80.45 |
| Logistic Regression | 56.50 | 73.12 | 89.84 | 74.24 |
| AC-BiLSTM | 80.51 | 88.12 | 97.92 | 74.97 |
| Our method | 89.09 | 93.75 | 97.73 | 75.72 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qing, L.; Linhong, W.; Xuehai, D. A Novel Neural Network-Based Method for Medical Text Classification. Future Internet 2019, 11, 255. https://doi.org/10.3390/fi11120255
Qing L, Linhong W, Xuehai D. A Novel Neural Network-Based Method for Medical Text Classification. Future Internet. 2019; 11(12):255. https://doi.org/10.3390/fi11120255
Chicago/Turabian StyleQing, Li, Weng Linhong, and Ding Xuehai. 2019. "A Novel Neural Network-Based Method for Medical Text Classification" Future Internet 11, no. 12: 255. https://doi.org/10.3390/fi11120255
APA StyleQing, L., Linhong, W., & Xuehai, D. (2019). A Novel Neural Network-Based Method for Medical Text Classification. Future Internet, 11(12), 255. https://doi.org/10.3390/fi11120255