1. Introduction
The purpose of network visualization is to assist users to perceive the network structure and understand and explore patterns hidden in the network data [
1,
2]. However, the details of all the nodes and edges, which are shown in their entirety on a limited-size screen, is not a good solution, and it may cause the following problems from a visualization point of view. On the one hand, when a complex network with large numbers of nodes and high-density edges is visualized on a limited-size screen, users fall easily into a chaotic and overlapping node-connection diagram, where it is difficult to identify and perceive the overall structure of the network, and the users cannot easily find elements of interest. On the other hand, the large amount of data inevitably brings greater computational pressure and higher requirements on the algorithms and hardware. In short, inefficient or time-consuming network visualization loses its meaning.
Until now, the existing work of complex networks has been limited to the local scale structure, obtained through statistical distribution, or the macroscopic scale of the overall parameters of the network. However, these two levels can be understood through the intermediate level, which is called the mesoscale structure [
3]. A mesoscale can be understood as a substructure or subgraph. Substructures have their own topological entities, such as motifs, cliques, cores, and loops, but usually they describe the community [
4]. The research of network synchronization processes actually involves studying the evolution process of the dynamic behavior of the network from a small to a large scale, which is inseparable from the mesoscale characteristics of complex networks [
5].
In order to display information effectively and assist users in perceiving the mesoscale structure of the network, a large-scale network must be reduced to bring down the user’s perception complexity and the computational complexity of the layout process. According to the purpose of reduction, the methods of network reduction processing can be divided into three types: filtering, sampling, and compression. Filtering means to filter the nodes and edges that satisfy the condition by a single attribute or a combination of multiple attributes in the network, thereby reducing the number of nodes and the density of the edges. Filtering technology is more about further refinement and exploration of network data, which needs a certain understanding of the network structure. For example, the elements that meet the requirements are selected and displayed on the screen, according to the degree, the intermediate centrality, the intermediate centrality of nodes, the weight of edges, or any other attributes. Sampling is to select the representative nodes and edges according to a certain sampling strategy and to reflect the structural characteristics of the original network with as few nodes and edges as possible. Common sampling strategies [
6] include random node selection, random edge selection, random walk, and sampling strategies based on topological layered models. Compared with filtering and sampling, compression is achieved by aggregating nodes or edges with certain similarities and adopting new nodes instead of aggregation [
7]. While reducing the scale of the nodes, it can also ensure the integrity of the network and display the subgraphs of the network. The composition and other characteristics help users perceive the overall structure of the network from the mesoscale structure [
8].
For the purpose of effectively displaying mesoscale structure characteristics of the network, a method of node layout of a complex network based on community compression is proposed, which combines the force-directed layout algorithm with the method of network compression based on node importance in community structure. The method proposed in this paper can be used to visually observe and analyze the mesoscale structural features of the network, understand the rules and patterns within the network from the mesoscale, and provide support for the research of the synchronization process of the community network.
2. Related Work
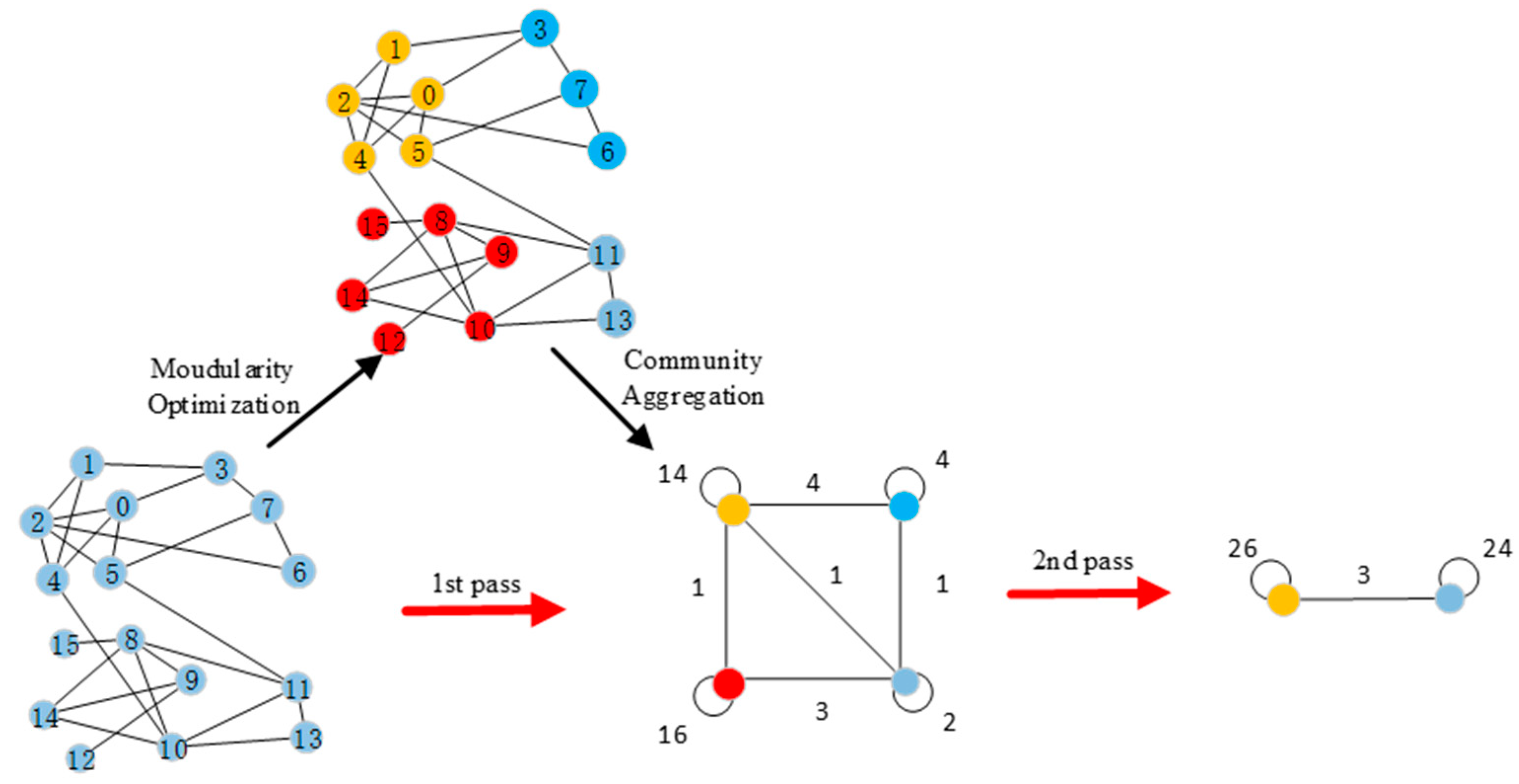
In the field of network visualization compression layout, the spring model [
9] has been most widely explored because of the advantages of simplicity, efficiency, and easy understanding. It simulates the whole network as a spring system, and finally achieves the force balance of the nodes by calculating the force controlled by the distance between different nodes. The KK (Kamada-Kawai) algorithm [
10] introduces Hooke’s law on the basis of the spring model, calculates system energy according to the stress state of the nodes, and transforms the optimal layout problem of nodes into the solution problem of minimizing system energy, which makes the convergence speed of the layout process obviously increase. In the DH (Davidson-Harel) algorithm [
11], the constraints of many aesthetic standards are taken into consideration to construct the energy function, such as node location, length of joints, and the intersection of edges. Different layout effects can be achieved by the parameters of the energy function model. In the FR (Fruchterman-Reingold) algorithm [
12], the nodes are modeled as charged particles in the physical system, and the charge repulsion forces are introduced between particles. The smaller the distance between the particles, the greater the repulsion force is, which can reduce the overlap phenomenon of the dense nodes to a certain extent. The simulated annealing algorithm was adopted by introducing a “cooling function” in order to make the algorithm converge quickly, which can gradually reduce the moving step of the nodes and makes the system energy decrease rapidly, thus realizing the goal of rapid layout [
13,
14].
Compared with the KK and DH algorithms, the rendering results from the FR algorithm have better symmetry and clustering layout effects in most network visualization applications, and are more in line with aesthetic standards. Many scholars have further studied the basis of the FR model. On the one hand, it proposes a fast multi-scale layout [
15], multi-level layout [
16], and FADE [
17] algorithm to reduce visual confusion and accelerate layout. On the other hand, it proposes a network visualization method based on community structure [
18] or subgroup analysis [
19]. The above method shows the community composition of the network to a certain extent, but it is far from sufficient to analyze the mesoscale features.
Studies on network compression are mainly based on the importance of nodes or edges. Saha et al. [
20] studied the nearest neighbor search problem in complex networks by proposing an appropriate concept of proximity degree. Applying it to the problem of network community detection, it can explore the community structure of real networks better. This gave us the idea of studying the reasonable compression layout scheme of community structure. Wang et al. [
21] proposed a sparse representation of network structure based on geometric multi-scale analysis, which effectively helps to analyze the network with as little information as possible. Li et al. [
22] divided network nodes based on the K-core concept in complex networks, and used the force-directed layout algorithm to realize the visualization of a compressed large-scale complex network. However, the above methods evaluate the importance of nodes based on the global network, choose the important nodes as the representative nodes of the overall network structure, and compress the non-important nodes at the same time, so as to achieve the goal of network compression. This kind of method retains the core structure of the network from the node scale (microscale), but it ignores the community structure of the network and cannot show the structural characteristics of the network from the mesoscale.
Based on data fields, the authors of [
23] described the potential values of nodes in the network affected by the nodes themselves and their neighboring nodes by calculating their topological potentials, which can more truly describe the importance of nodes in the network structure. The topological potential is applied to a variety of real network data in [
24] and is compared with traditional node importance measures such as degreed, betweenness, and PageRank. It was pointed out that the topological potential can highlight the difference in node location in the network and reflect the importance of the node, while considering the importance of node degree.
Similarly, the contribution of different nodes in a community is different to the community structure. The greater the degree, and the closer the node is to the community center, the more important it is. Therefore, this paper considers the location of nodes in the community structure, and the importance of the evaluation of nodes based on topological potential is applied to the community structure according to the degree of nodes and the shortest path length between nodes. By choosing the nodes with high importance in the community structure as the representative nodes of the community structure, the compression of the network community structure is realized.
4. Experiments and Analysis
This paper selects three standard data sets in the field of network community analysis: dolphin, football, and karat. Among them, dolphin is the social network of dolphins, football is the social network of the NCAA football league, and karat is the social network of a karate club. The number of nodes and edges of the corresponding network are shown in
Table 1.
The compression layout results of the method of this paper are compared with the network compression layout methods based on node degree value (method 1) and PageRank (method 2). Firstly, the compression effect of different compression methods was quantitatively evaluated through the variations of the number of nodes
, the number of edges
, the average clustering coefficient
, and the number of communities
. The average clustering coefficient indicates the degree of aggregation between nodes in the network, and the calculation formula is
where
is the number of the edges that connect to node
, and
is the degree of node
.
Then, by comparing the visual layout effect of the topological structure before and after compression, the advantages of the method in this paper are qualitatively analyzed. The variation of the number of nodes and the number of edges represents the compression scale of the network. The variation of the average clustering coefficient describes the tightness of connection between nodes in the network. Finally, the variation of the community number reflects whether the compressed network retains the community composition of the original network.
In the experiment, the selected node compression ratio was 0.2. That is, in methods 1 and 2, the network representative nodes were selected according to 20% of the total number of nodes in the whole network, and the method in this paper selected the representative nodes of the community structure according to 20% of the total number of nodes in each community.
The compression results of the different methods are compared in
Table 1. It can be seen that all of the compression methods can reduce the number of nodes and edges to a large extent by merging non-important nodes, thus achieving the purpose of network compression.
In addition, the average clustering coefficient of the compressed network is higher than that before compression, which indicates that the three compression methods above all retain closely connected important nodes, and these nodes and their connecting edges can reflect the skeleton structure of the network. Among them, the average clustering coefficients of the compression networks ranked based on node degree value (method 1) and PageRank (method 2) are relatively close, and both of them are larger than the method in this paper. This is because although the first two methods adopt different node importance evaluation models and the node importance ranking results are not same, for the whole network, important nodes are all distributed in the top ranking region. Therefore, compression results based on the importance of nodes in the global network are the same or basically the same set of representative nodes. In this paper, the importance of nodes in different community structures are sorted respectively. The reserved nodes are important nodes in each community structure and represent the internal structure of each community. Although the average clustering coefficient of the compressed network in this paper is relatively low, the number of communities does not decrease. The community composition of the network is relatively intact, and the overall structure of the network is preserved on the medium scale. The first two methods lost part of the community, resulting in an incomplete overall structure of the network.
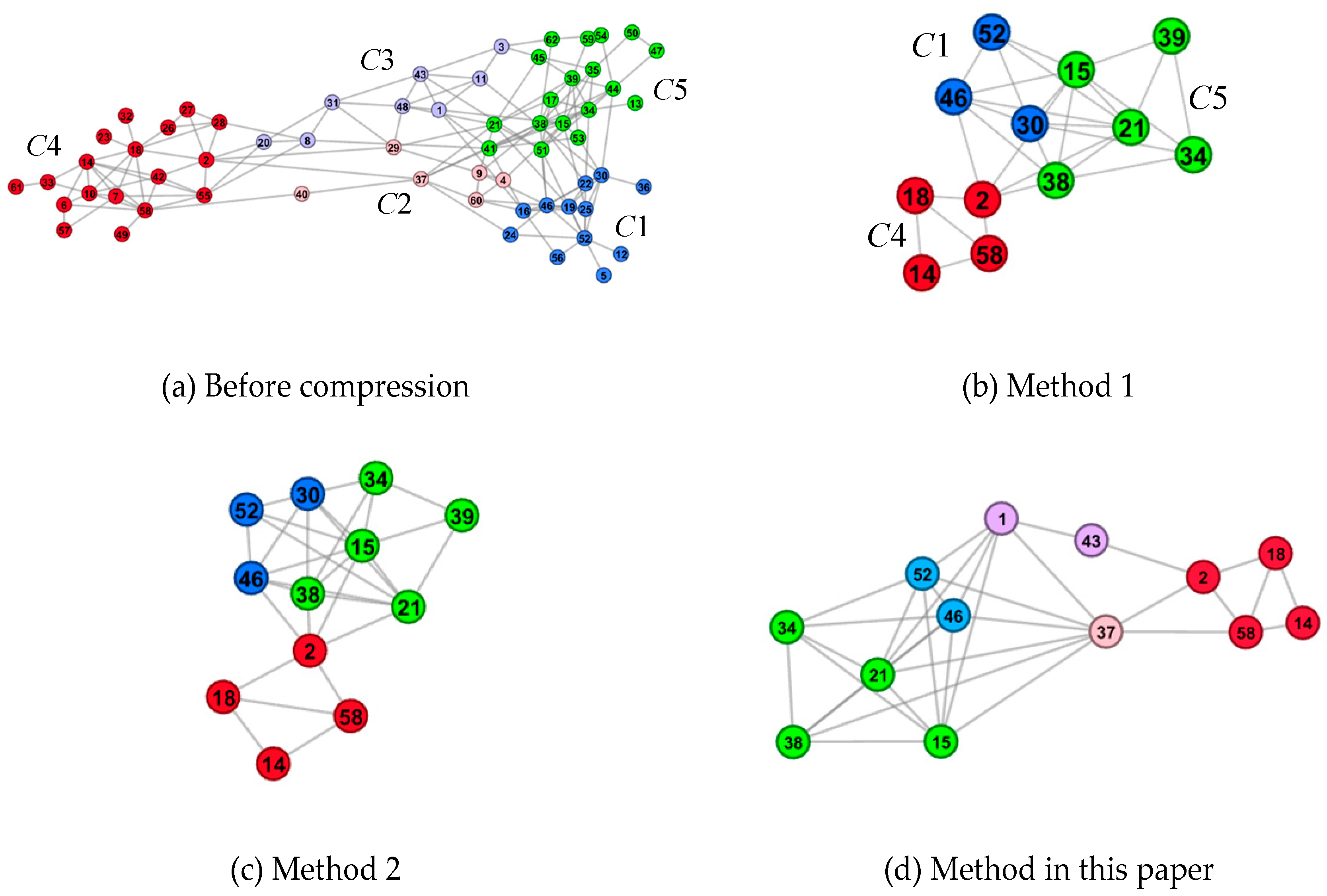
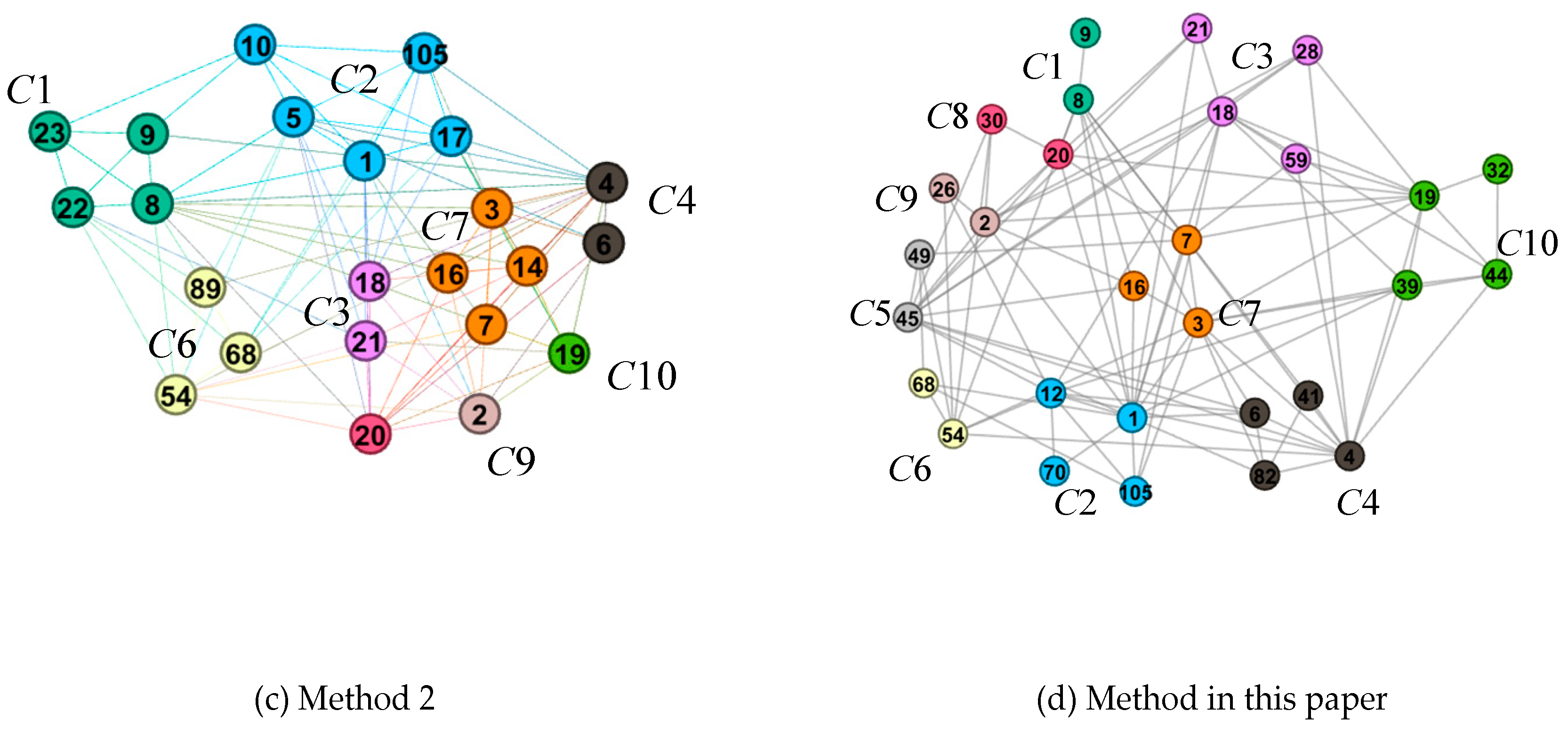
Figure 3,
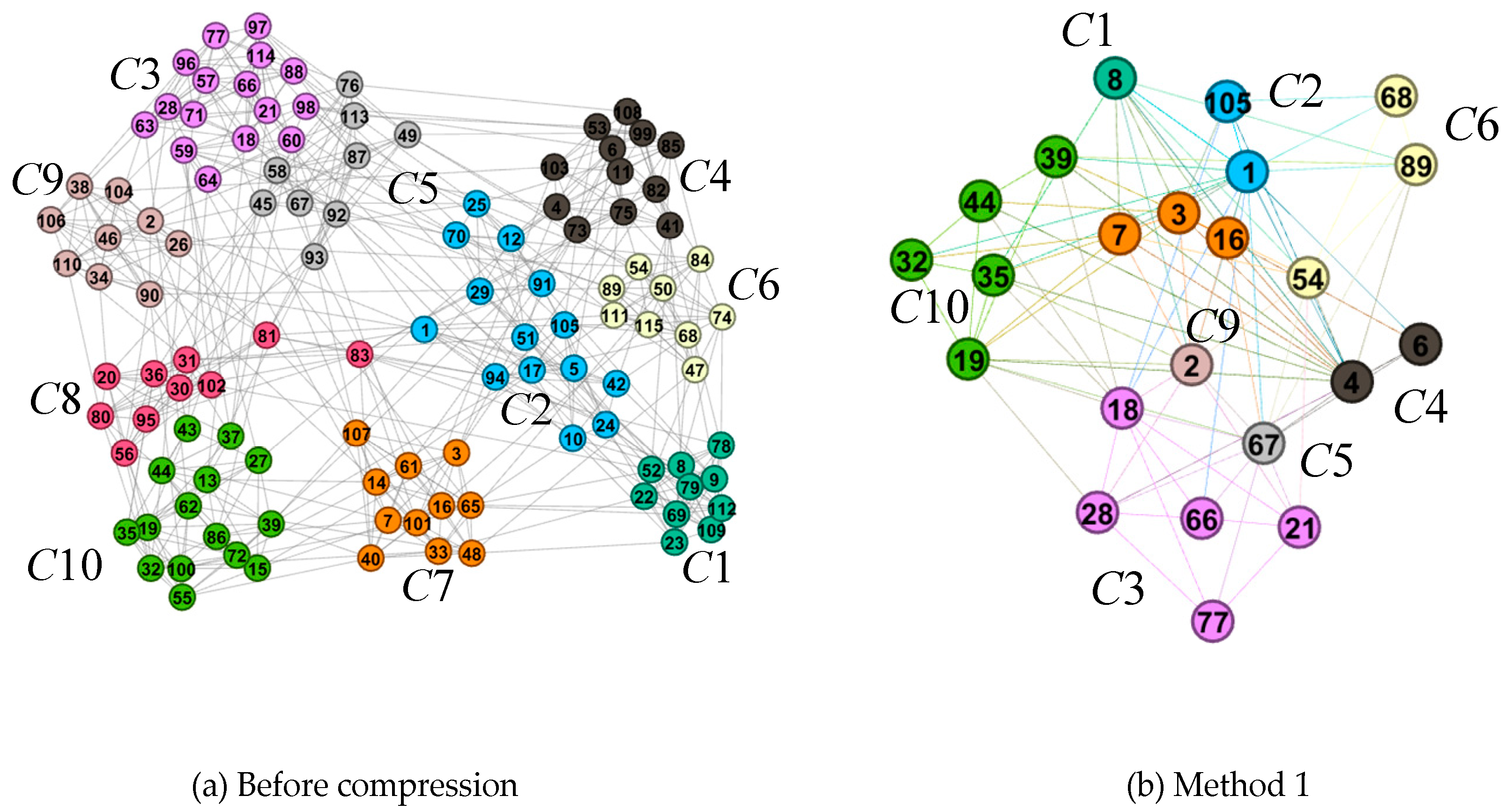
Figure 4 and
Figure 5 show the effect pictures of the three methods used to visually compress the layout of different networks. By comparing the layout effects of different methods, it can be seen that the advantages of the method in this paper are mainly reflected in the following two aspects:
(1) The compression based on the community structure can retain the community composition of the network and highlight the mesoscale structure characteristics.
The sub-graphs (b), (c), and (d) in
Figure 3,
Figure 4 and
Figure 5 show, respectively, the layout results of the compression network in method 1, method 2, and the method in this paper. Compared with the original network layout results in the sub-graph (a), the number of nodes and the number of edges in the sub-graphs (b), (c), and (d) are compressed to a large extent. The original network in sub-graph (a) is limited by the screen size, with small nodes and dense edges, and the overlap of nodes and edges are serious. In the chaotic overlapping view, it is difficult for users to perceive the overall structure of the network. The three methods mentioned above can reduce the visual clutter caused by overlapping of nodes and edges by reducing the scale of nodes and edges. However, because method 1 (subgraph (b)) and method 2 (subgraph (c)) evaluate the importance of nodes and select network representative nodes based on the global structure, no effective representative nodes are reserved for communities with few nodes or relatively sparse edges. In the process of compression, these communities are compressed and merged, resulting in a decrease in the number of communities, which is unable to accurately display the community composition of the original network. However, the method in this paper (subgraph (d)) is compressed based on the community structure to ensure that each community structure has representative nodes, which avoids the loss of the community in the compression process, and reflects the structural characteristics of the network on the community scale.
In addition, compression based on community structure is more conducive to the perception of the overall structure of the network and the interaction between communities. Taking
Figure 3d as an example, it can be found that the original network can be divided into five societies. Among them,
C1 and
C5 contain a large number of nodes, while the other three have a small number. The interaction between
C1 and
C5 is mainly realized through
C2 and
C3. Although there are few nodes in the
C2 and
C3 communities, they play a “bridge” role in the interaction of nodes in the whole network, which is very important to the topology of the network. However,
C2 and
C3 communities are not retained in
Figure 3b,c, which cannot accurately reflect the “bridge” role of the
C2 and
C3 communities.
C4 directly interacts with
C1, which easily causes deviation in users’ understanding of the structural features of the network at the mesoscopic scale.
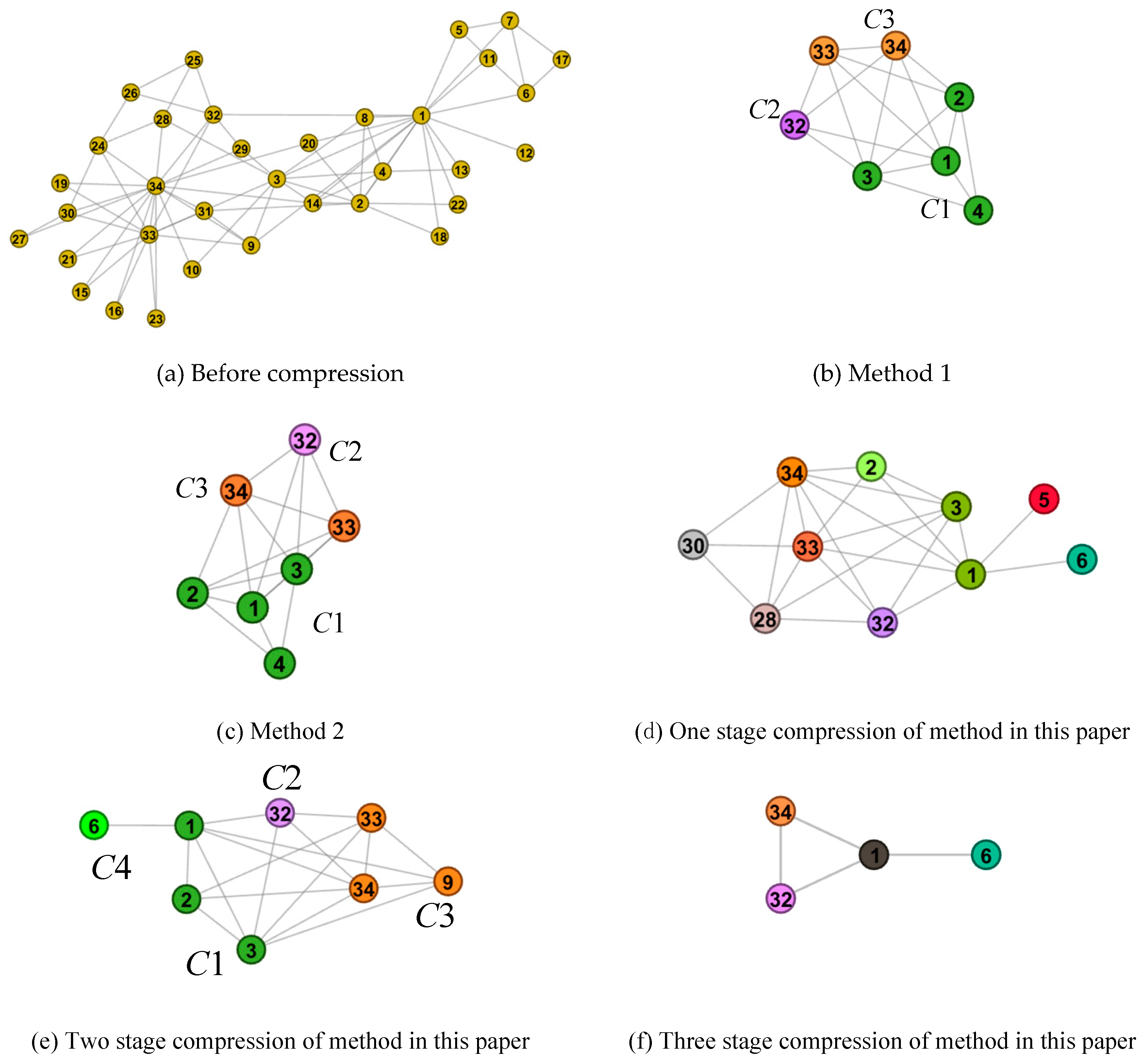
(2) Use of the multi-granularity community structure division algorithm can display the basic structure of the community and realize the multi-granularity compression layout of the network.
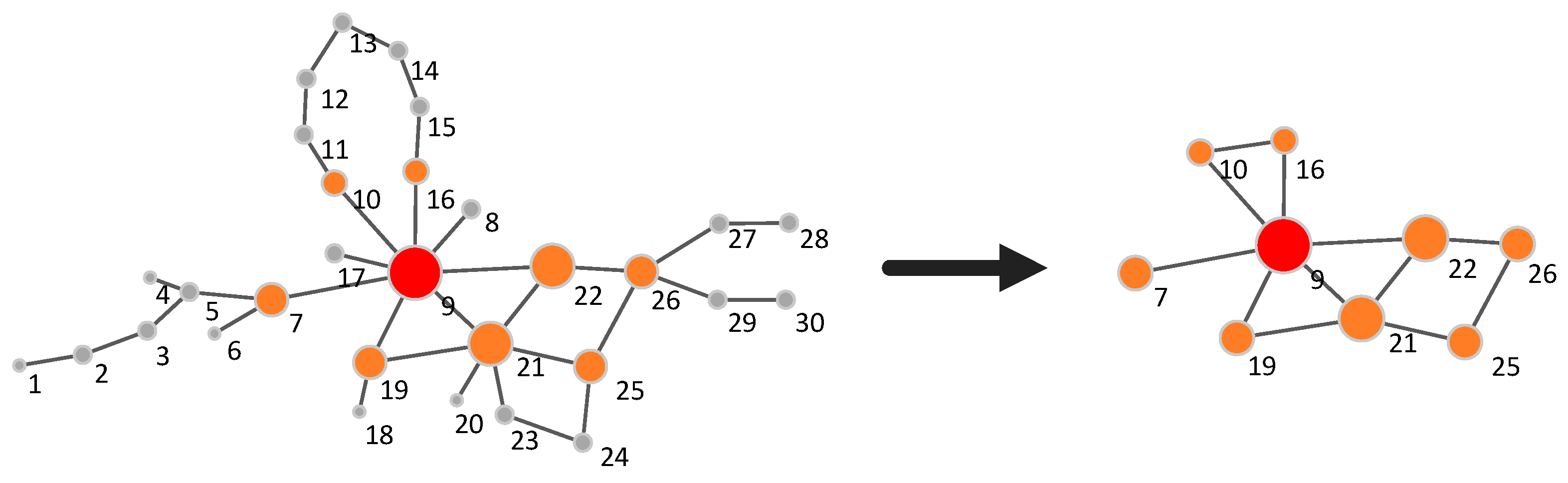
In this paper, the fringe nodes are compressed while the necessary community structure representative nodes are preserved. Based on the analysis of the importance of nodes based on topological potential, the reserved nodes make a greater contribution to the community composition, reflecting the basic structure of the community. By retaining these nodes and connections, the basic structure of the community can be clearly displayed. At the same time, by compressing non-important nodes and deleting repeated edges, the number of edges within the community is reduced, which is conducive to the visual perception of the community structure and the discovery of important nodes in the community or network structure.
According to the granularity of community structure division and compression, the original network can be divided into multi-granularity communities.
Table 2 shows the results of multi-granularity compression, where the reserved nodes are underlined. Based on the method proposed in this paper, the number of nodes and the number of edges can be reduced by compressing and merging fringe nodes, so as to realize the multi-granularity compression layout. Subgraphs (d), (e), and (f) in
Figure 5 show the three-level compression layout for the karat network data.
In stage 1, nodes in the karat network are divided into eight communities based on the Louvain algorithm, while they are divided into four communities in stage 2. Accordingly, the karat network is compressed into eight communities in sub-graph (d) and four communities in sub-graph (e), by compressing each community. In stage 3, nodes in the karat network are also divided into eight communities. However, the network compression ratio can be controlled according to the node compression ratio, and a community can be compressed into one node at most, as shown in stage 3 of
Table 2 and
Figure 5f. In
Figure 5f, each node represents a community, and “nodes” 1, 32, and 34 can interact directly with each other, while “node” 6 can only interact with other “nodes” through “node” 1. It is possible to observe the mesoscale structural features at different granularities of the network topology from subgraphs (d), (e), and (f) in
Figure 5.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}