Forward-Looking Element Recognition Based on the LSTM-CRF Model with the Integrity Algorithm

Abstract
:1. Introduction
2. Related Work
2.1. Rule/Dictionary Methods
2.2. Machine Learning
2.3. Deep Learning Methods
- The dependency syntax can capture the long-range collocation and modification relations between the internal components of a sentence. This feature can be used to solve the problem of integrity;
- Open-element and new entity issues can be solved with the superior recognition performance of the LSTM-CRF model;
- The proposed model meets the requirement of simultaneously identifying different types of elements.
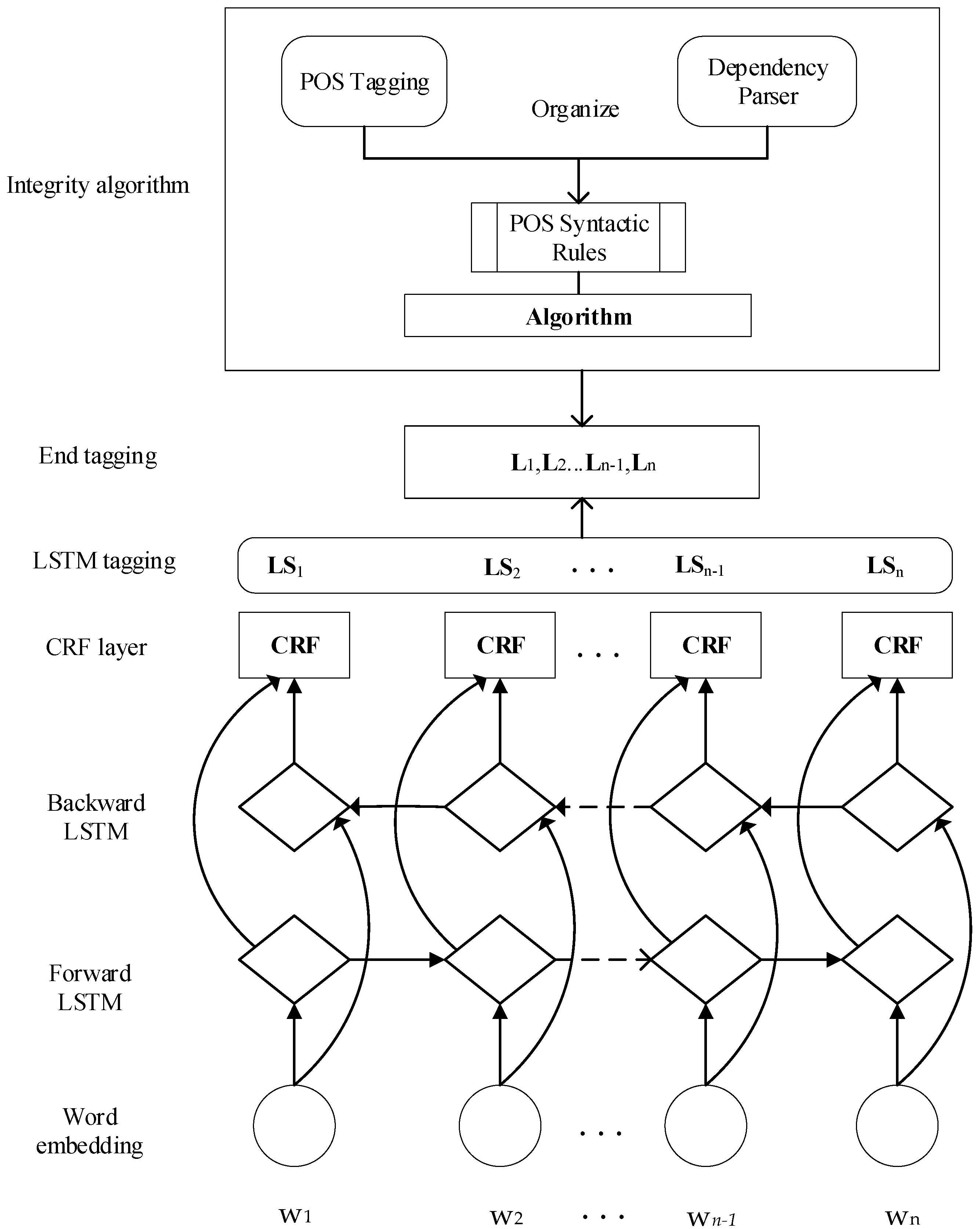
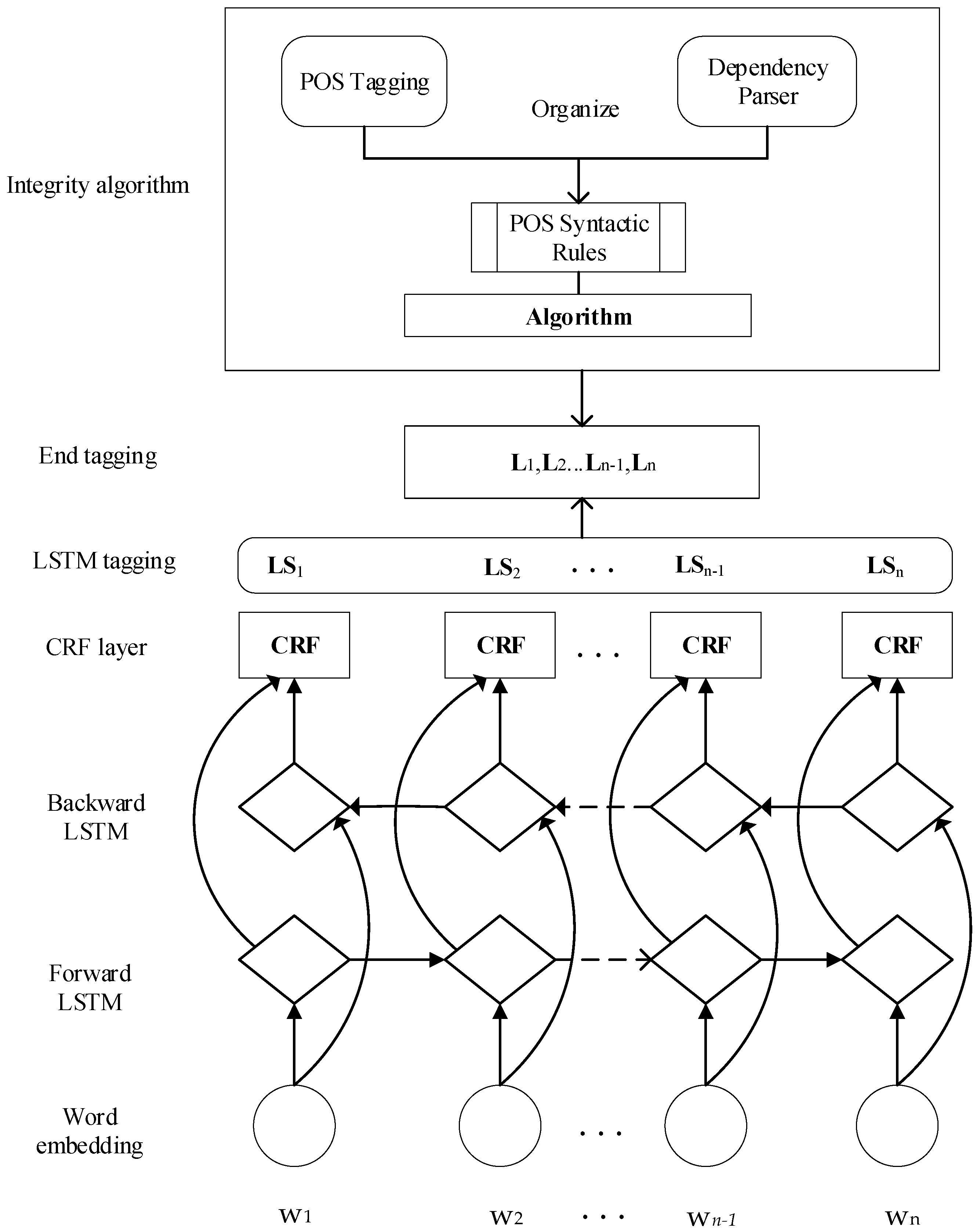
3. LSTM-CRF Model with the Integrity Algorithm
3.1. Model Overview
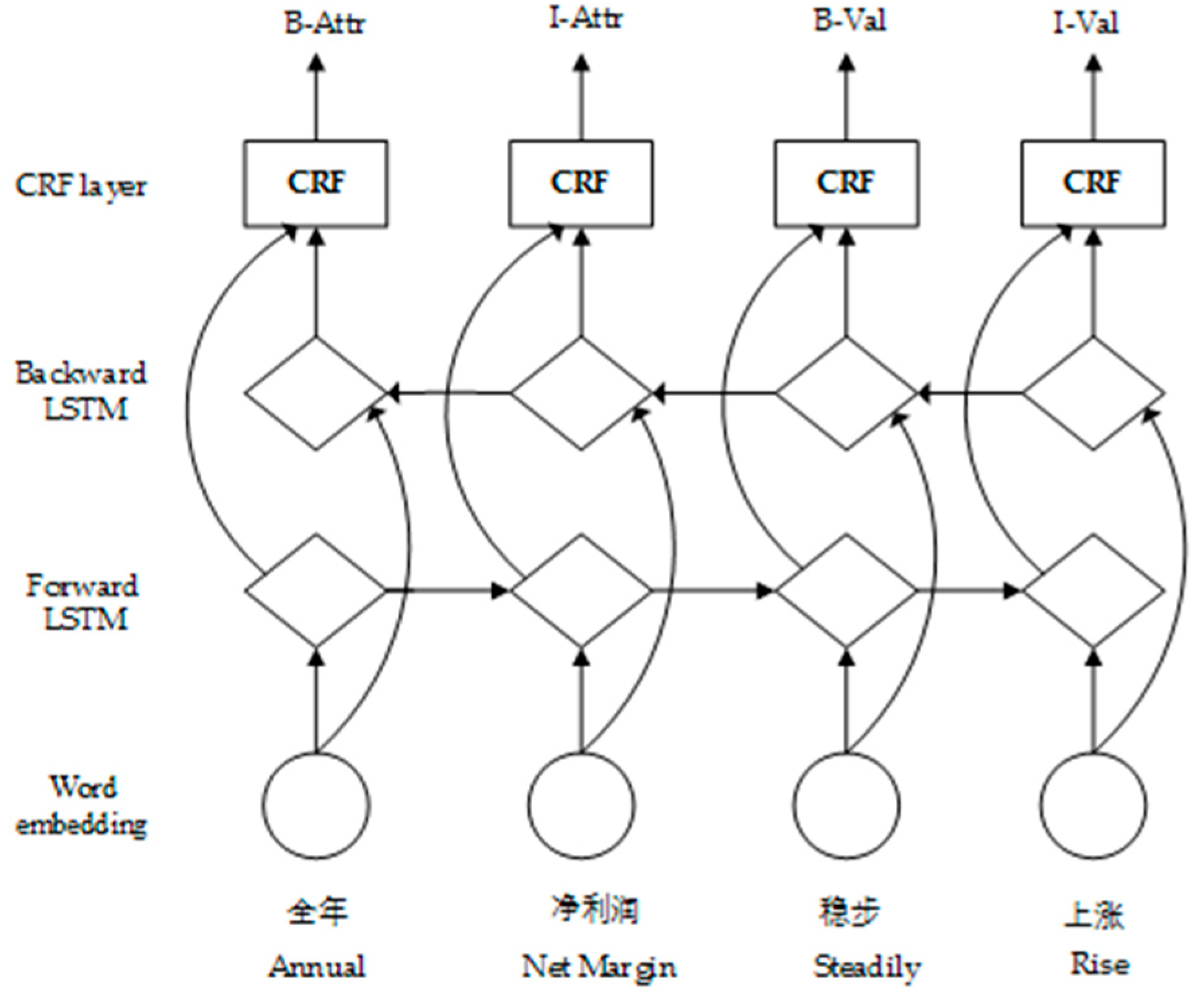
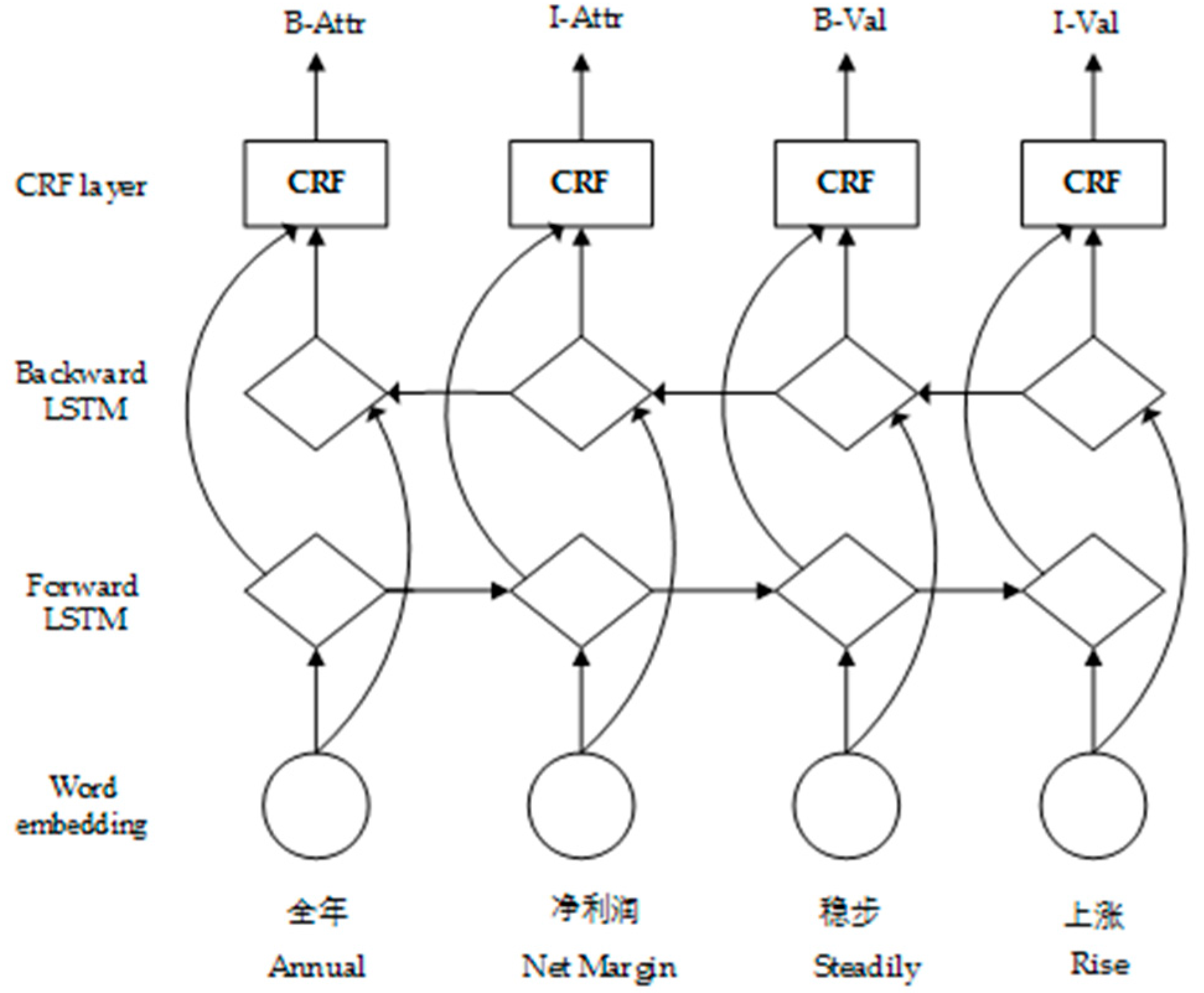
3.2. LSTM-CRF Model
3.3. Integrity Algorithm
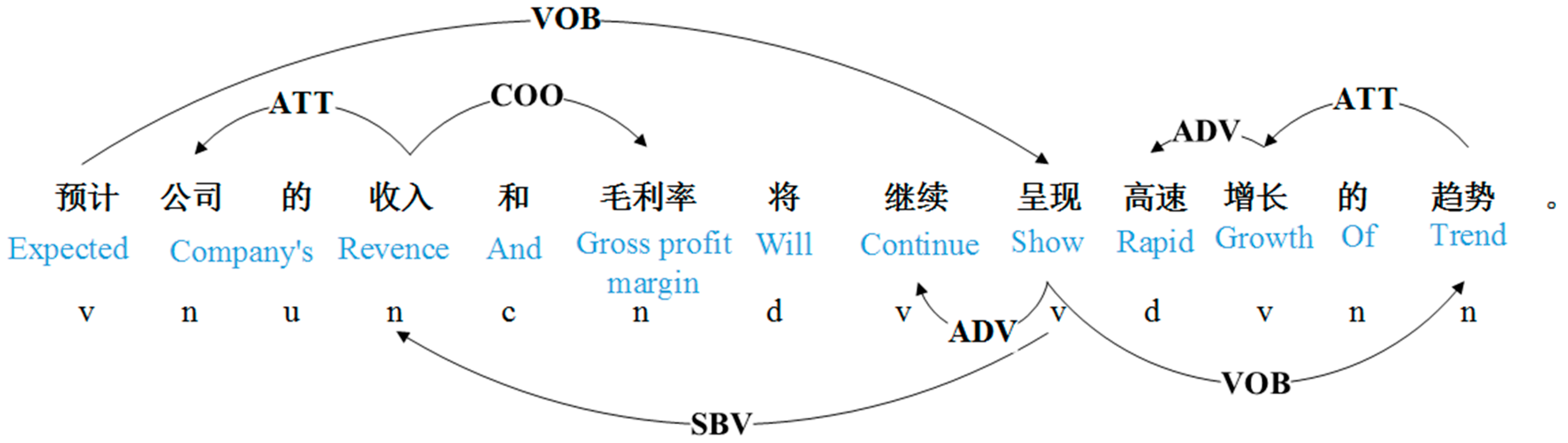
3.3.1. Dependency Syntax
3.3.2. POS Syntactic Rules
3.3.3. Algorithm
- LStag, the result set labeled by the LSTM-CRF model, including {B-Attr (“B-Attr” means the beginning of the attribute element), I-Attr (“I-Attr” means the reminder of attribute element), O (“O” means not belonging to any type of element)};
- Rtag, the result set labeled based on the POS syntactic rules, including {B-Attr, I-Attr, O};
- L, the tags result set;
- Rtag_begin, the subscript of the starting position of each attribute (B-Attr);
- Rtag_end, the subscript of the ending position of each attribute (I-Attr);
- flag, as a flag, its value is true or false;
- i, as a variable to identify the position of each tag.
| Algorithm 1. LSTM-CRF model with integrity algorithm |
| Input: LStag, Rtag, flag, i |
| Output: L |
| 1: Take the result of attribute tagging as an example |
| 2: for (i = 0; i < Rtag.length; i++) |
| 3: set Rtag_begin = 0, Rtag_end = 0 |
| 4: if (Rtag [i]! = O) |
| 5: Rtag_begin = i; |
| 6: while (Rtag [i]! = O) |
| 7: i++; Rtag_end = i; |
| 8: flag = true; |
| 9: for ls ∈ LStag [Rtag_begin: Rtag_end] |
| 10: if ls! = O or ls! = Rtag [i] |
| 11: flag = false; |
| 12: if (flag) |
| 13: LStag [Rtag_begin: Rtag_end] = Rtag [Rtag_begin: Rtag_end] |
| 14: L← LStag |
| 15: return L |
4. Experiment
4.1. Data Description
4.2. Evaluation Indicators
4.3. Experimental Settings
4.4. Experimental Results and Analysis
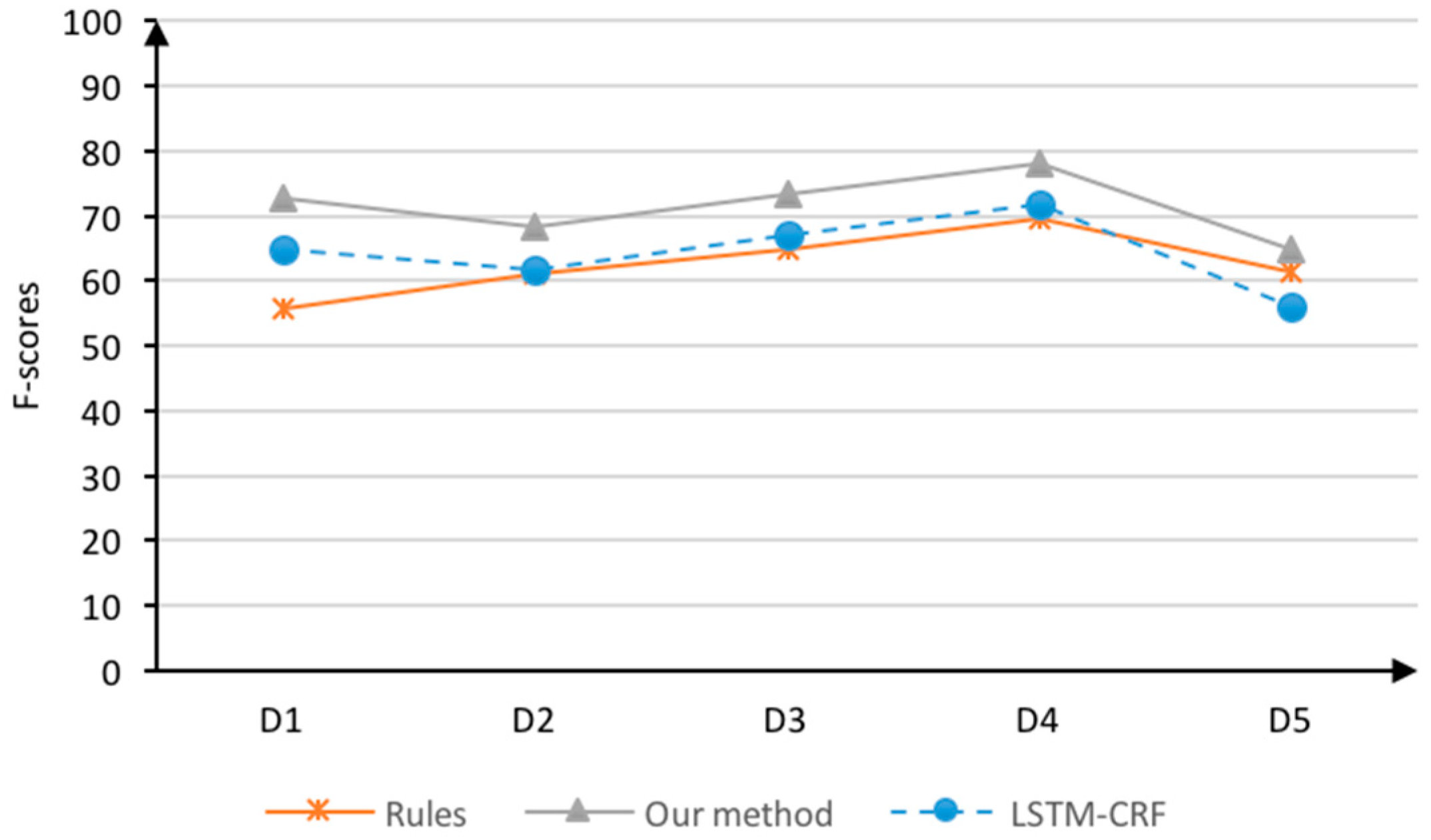
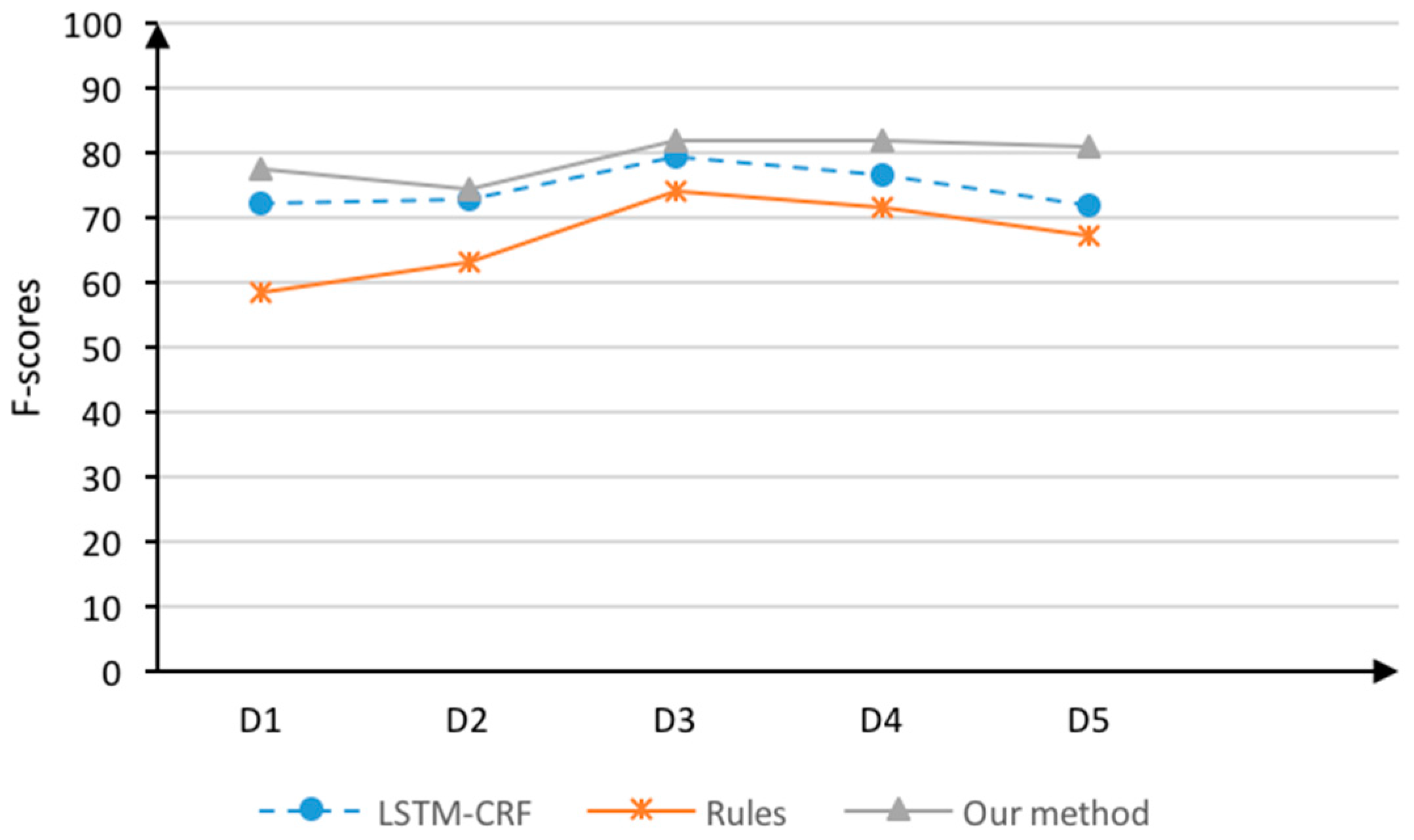
4.4.1. The Results of the Five-Fold Crossover Experiments
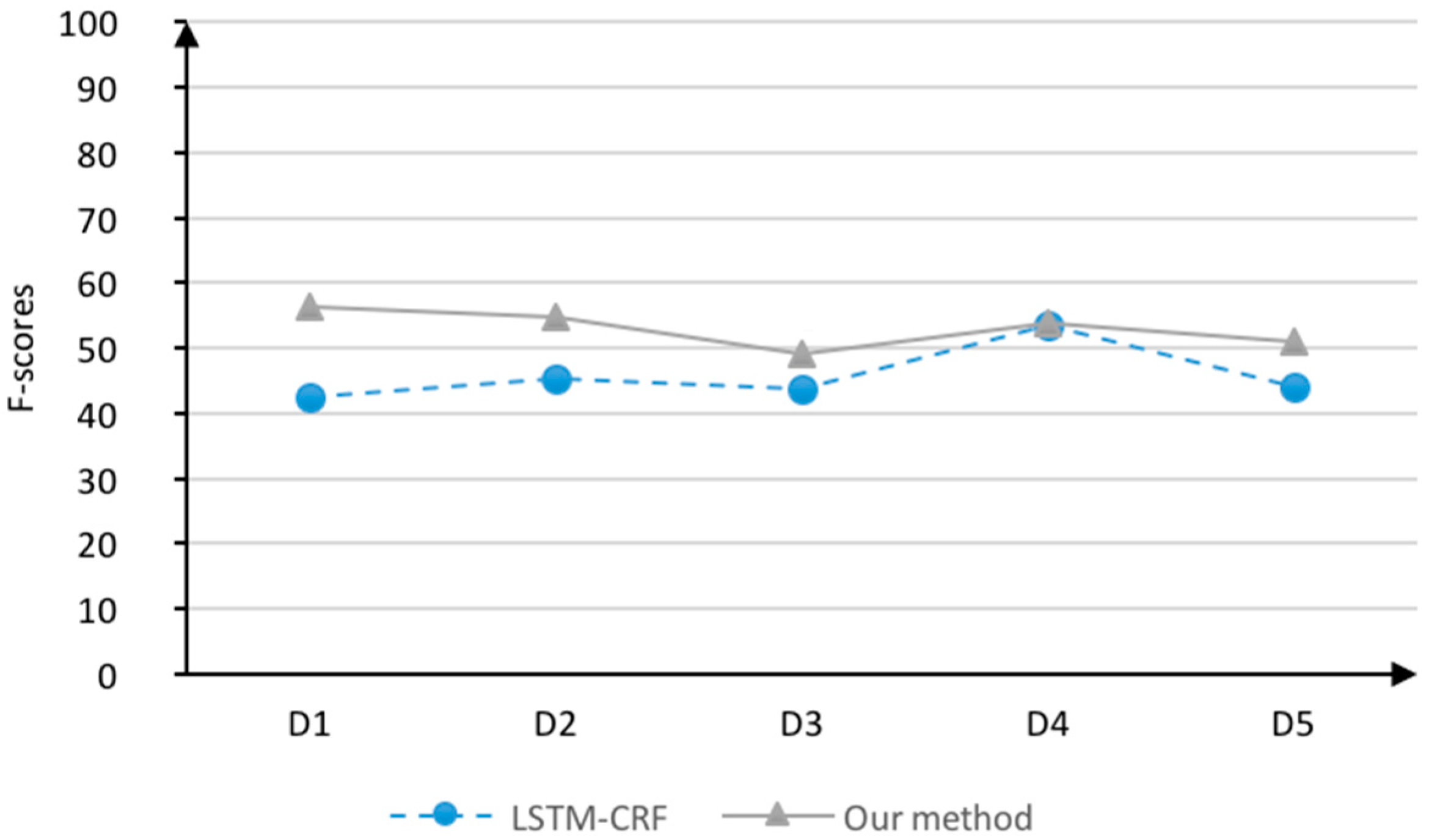
4.4.2. The Field Cross-Recognition Results
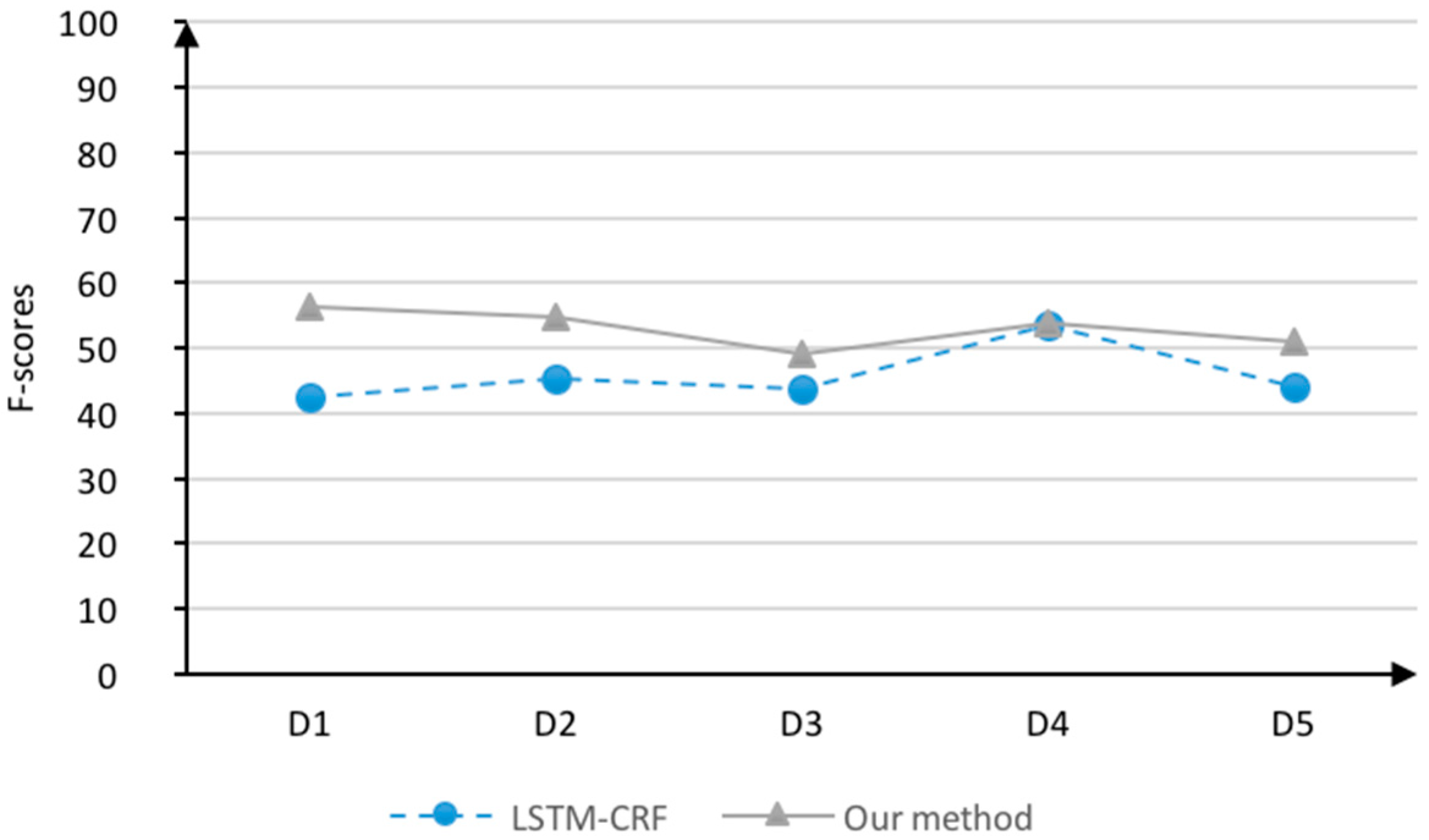
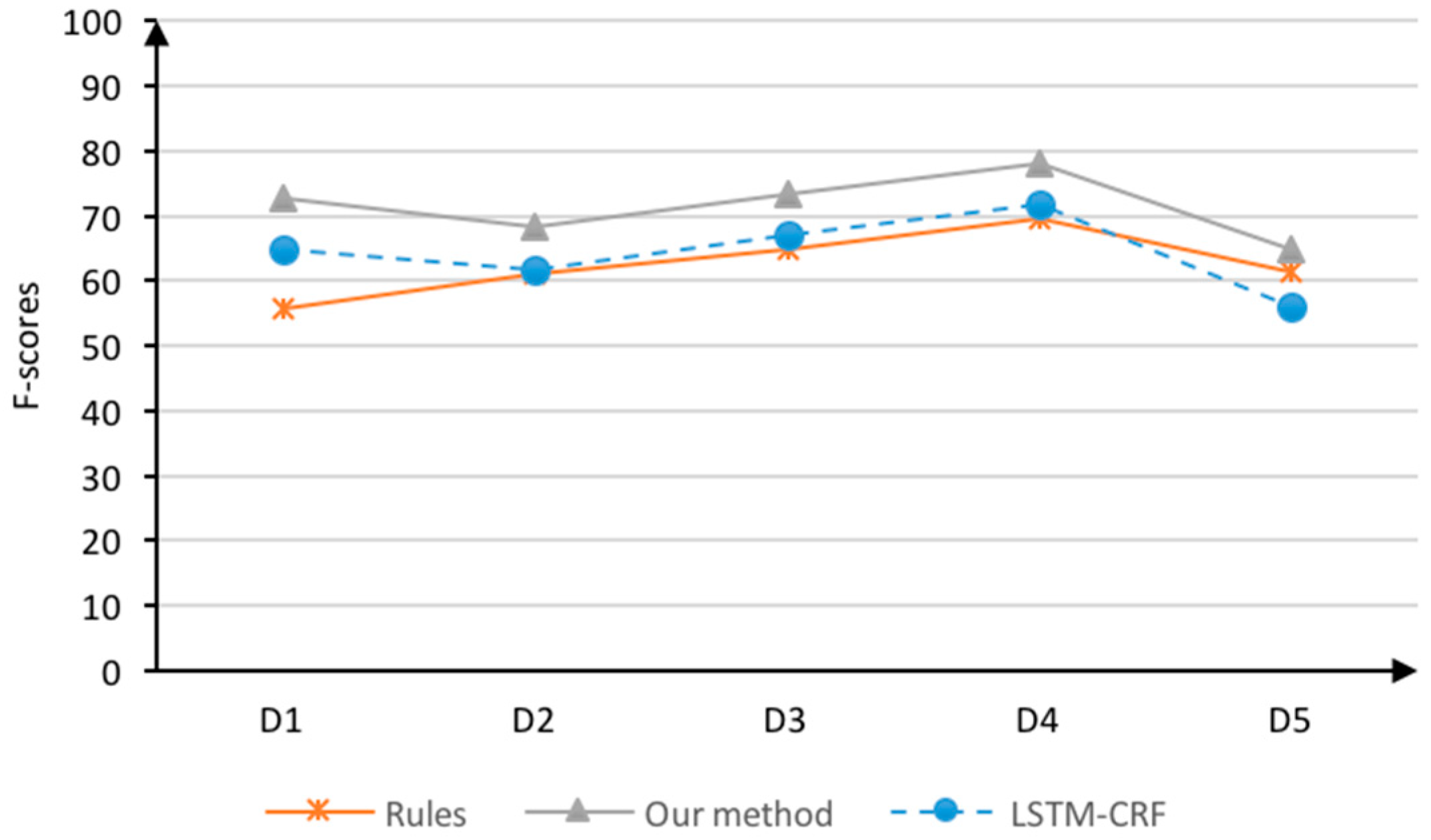
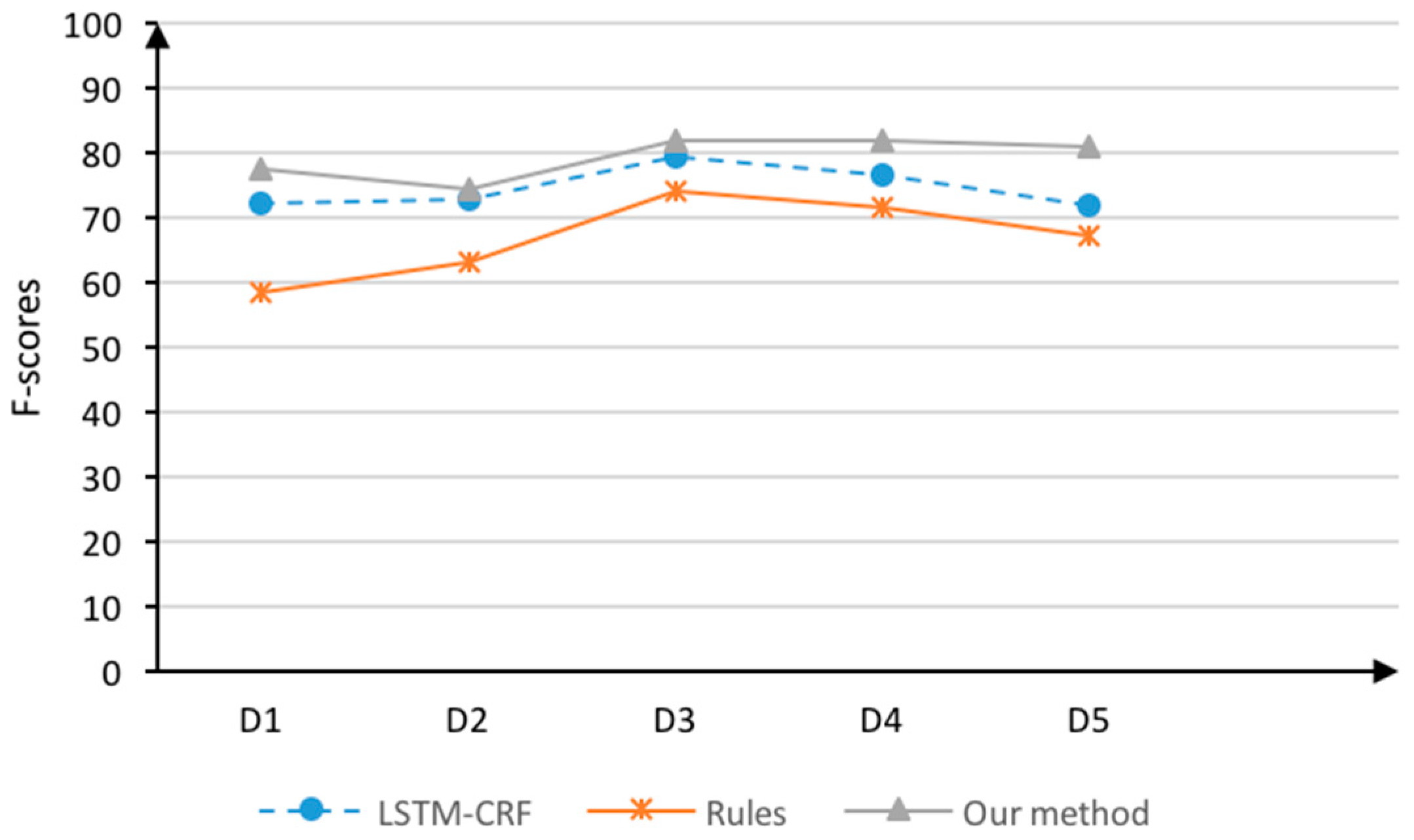
4.4.3. Comparative Experiments
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ding, X.; Zhang, Y.; Liu, T.; Duan, J. Deep learning for event-driven stock prediction. In Proceedings of the International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2327–2333. [Google Scholar]
- Lee, H.; Surdeanu, M.; MacCartney, B.; Jurafsky, D. On the importance of text analysis for stock price prediction. In Proceedings of the LREC 2014, Reykjavik, Iceland, 26–31 May 2014; pp. 1170–1175. [Google Scholar]
- Qiu, X.Y.; Srinivasan, P.; Hu, Y. Supervised learning models to predict firm performance with annual reports: An empirical study. J. Assoc. Inf. Sci. Technol. 2014, 65, 400–413. [Google Scholar] [CrossRef]
- Kumar, A.; Sethi, A.; Akhtar, M.S.; Ekbal, A.; Biemann, C.; Bhattacharyya, P. IITPB at SemEval-2017 Task 5: Sentiment Prediction in Financial Text. In Proceedings of the International Workshop on Semantic Evaluation, Vancouver, BC, Canada, 3–4 August 2017; pp. 894–898. [Google Scholar]
- Kumar, A.; Alam, H.; Werner, T.; Vyas, M. Experiments in Candidate Phrase Selection for Financial Named Entity Extraction-A Demo. In Proceedings of the 26th International Conference on Computational Linguistics: System Demonstrations, Osaka, Japan, 11–16 December 2016; pp. 45–48. [Google Scholar]
- Jiang, T.Q.; Wan, C.X.; Liu, D.X. Evaluation Object-Emotional Word Pair Extraction Based on Semantic Analysis. Chin. J. Comput. 2017, 40, 617–633. [Google Scholar]
- Li, F. The information content of forward-looking statements in corporate filings—A naïve Bayesian machine learning approach. J. Account. Res. 2010, 48, 1049–1102. [Google Scholar] [CrossRef]
- Feldman, R.; Fresco, M.; Goldenberg, J.; Netzer, O.; Ungar, L. Extracting product comparisons from discussion boards. In Proceedings of the IEEE International Conference on Data Mining, Omaha, NE, USA, 28–31 October 2007; pp. 469–474. [Google Scholar]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- Qiu, G.; Liu, B.; Bu, J.; Chen, C. Opinion word expansion and target extraction through double propagation. Comput. Linguist. 2011, 37, 9–27. [Google Scholar] [CrossRef]
- Chieu, H.L.; Ng, H.T. A maximum entropy approach to information extraction from semi-structured and free text. In Proceedings of the Eighteenth National Conference on Artificial Intelligence, Edmonton, AB, Canada, 28 July–1 August 2002; pp. 786–791. [Google Scholar]
- Zhang, S.; Jia, W.J.; Xia, Y.; Meng, Y.; Yu, H. Extracting Product Features and Sentiments from Chinese Customer Reviews. In Proceedings of the 7th LREC, Valletta, Malta, 17–23 May 2010; pp. 17–23. [Google Scholar]
- Finkel, J.R.; Grenager, T.; Manning, C. Incorporating non-local information into information extraction systems by Gibbs sampling. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; pp. 363–370. [Google Scholar]
- Choi, Y.; Cardie, C.; Riloff, E.; Patwardhan, S. Identifying sources of opinions with conditional random fields and extraction patterns. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 355–362. [Google Scholar]
- Pinheiro, P.H.; Collobert, R. Recurrent convolutional neural networks for scene parsing. arXiv, 2013; arXiv:1306.2795. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv, 2015; arXiv:1508.01991. [Google Scholar]
- Limsopatham, N.; Collier, N.H. Bidirectional LSTM for named entity recognition in Twitter messages. In Proceedings of the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; pp. 145–152. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 260–270. [Google Scholar]
- Popescu, A.M.; Etzioni, O. Extracting product features and opinions from reviews. In Natural Language Processing and Text Mining; Springer: London, UK, 2007; pp. 9–28. [Google Scholar]
- Bloom, K.; Garg, N.; Argamon, S. Extracting appraisal expressions. In Proceedings of the Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics, Rochester, NY, USA, 22–27 April 2007; pp. 308–315. [Google Scholar]
- Somprasertsri, G.; Lalitrojwong, P. Mining Feature-Opinion in Online Customer Reviews for Opinion Summarization. J. Univ. Comput. Sci. 2010, 16, 938–955. [Google Scholar]
- Graves, A. Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; ISBN 9783642212703. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning Morgan Kaufmann Publishers, San Francisco, CA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end sequence labeling via bi-directional LSTM-CNNs-CRF. arXiv, 2016; arXiv:1603.01354. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tags | Dependency Relations | Tags | Dependency Relations |
|---|---|---|---|
| SBV | Subject-verb | CMP | Complement |
| VOB | Verb object | COO | Coordinate |
| FOB | Fronting object | POB | Preposition object |
| DBL | Double | LAD | Left adjunct |
| IOB | Indirect object | RAD | Right adjunct |
| ATT | Attribute | IS | Independent structure |
| ADV | Adverbial | HED | Head |
| Ruleid | Description | Output |
|---|---|---|
| R11 | Wi→DS →Wj s.t. Wj∈{context (Wi)}, DS = ATT, POS (Wj, Wi) {(n, n), (v, n), (nl, n)} | Con (Wj ~Wi) |
| R12 | Wi→DS→Wj s.t. Wj∈{context (Wi)}, DS = COO, POS (Wi, Wj) (n, n) | Con (Wi ~Wj) |
| R21 | Wi→DS1→Wj and Wi→DS2→Wk s.t. Wj, Wk∈{context (Wi)}, DS1 = ATT, DS2 = ATT, POS (Wk, Wj, Wi) (n, v, n), (n, n, n)} | Con (Wk~Wj~Wi) |
| R22 | Wi→DS1→Wj and Wj→DS2 →Wk s.t. Wj, Wk∈{context (Wi)}, DS1 = ATT, DS2 = ATT, POS (Wj, Wi, Wk) (n, n, n) | Con (Wj~Wi~Wk) |
| R23 | Wi→DS1→Wj and Wk→DS2→Wi s.t. Wj, Wk∈{context(Wi)}, DS1 = ADV, DS2 = ATT, POS (Wj, Wi, Wk) (a, v, n) | Con (Wj~Wi~Wk) |
| Ruleid | Description | Output |
|---|---|---|
| R11 | Wi→DS→Wj s.t. Wj∈{context (Wi)}, DS = VOB, POS (Wi, Wj) {(v, v), (v, m), (v, n)} | Con (Wi ~Wj) |
| R12 | Wi→DS→Wj s.t. Wj∈{context (Wi)}, DS = ADV, POS (Wj, Wi) {(d, v), (a, v), (d, v), (d, a)} | Con (Wj ~Wi) |
| R13 | Wi→DS→Wj s.t. Wj∈{context (Wi)}, DS = ATT, POS (Wi, Wj) {(a, n), (m, q), (m, m), (b, n)} | Con (Wi ~Wj) |
| R21 | Wi→DS1→Wj→DS2→Wk s.t. Wj, Wk∈{context (Wi)}, DS1 = VOB, DS2 = ADV, POS (Wi, Wk, Wj) (v, d, v) | Con (Wi~Wk~Wj) |
| R22 | Wi→DS1→Wj and Wj→DS2→Wk s.t. Wj, Wk∈{context (Wi)}, DS1 = VOB, DS2 = RAD, POS (Wi, Wj, Wk) (v, m, m) | Con (Wi~Wj ~Wk) |
| R23 | Wi→DS1→Wj and Wj→DS2→Wk s.t. Wj,Wk∈{context(Wi)}, DS1 = VOB, DS2 = ATT, POS (Wi, Wk, Wj) (v, b, n) | Con (Wi ~Wk ~Wj) |
| R24 | Wi→DS1→Wj and Wi→DS2→Wk s.t. Wj,Wk∈{context(Wi)}, DS1 = ADV, DS2 = CMP, POS (Wj, Wi, Wk) (d, v, a) | Con (Wj ~Wi ~Wk) |
| Fields | Articles | FLSs | En | Attr | Val |
|---|---|---|---|---|---|
| Pharmaceutical industry | 600 | 1362 | 1587 | 1887 | 3876 |
| Medical industry | 225 | 594 | 726 | 912 | 1344 |
| Car manufacturer | 225 | 197 | 1026 | 1011 | 1431 |
| Total | 1050 | 2547 | 3339 | 3810 | 6651 |
| Elements | Model | Accurate Evaluation | Coverage Evaluation | ||||
|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | ||
| En | LSTM-CRF | 56.38 | 38.53 | 45.75 | 70.28 | 60.43 | 64.96 |
| Rules | - | - | - | - | - | - | |
| Our method | 64.39 | 45.08 | 52.98 | 77.33 | 65.82 | 71.09 | |
| Attr | LSTM-CRF | 71.35 | 58.67 | 64.19 | 81.79 | 70.57 | 75.69 |
| Rules | 79.72 | 51.57 | 62.47 | 83.26 | 61.88 | 70.65 | |
| Our method | 81.86 | 63.59 | 71.47 | 86.46 | 74.17 | 79.74 | |
| Val | LSTM-CRF | 76.81 | 72.61 | 74.62 | 85.99 | 77.31 | 81.38 |
| Rules | 81.55 | 57.01 | 66.86 | 82.83 | 67.87 | 74.52 | |
| Our method | 86.09 | 73.62 | 79.34 | 90.17 | 81.84 | 85.64 | |
| Test Set | Elements | Accurate Evaluation | Coverage Evaluation | ||||
|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | ||
| 1 | En | 56.25 | 36.00 | 43.90 | 65.35 | 58.06 | 61.49 |
| Attr | 70.15 | 46.53 | 55.95 | 77.34 | 54.87 | 64.20 | |
| Val | 71.83 | 71.83 | 71.83 | 80.82 | 76.39 | 78.20 | |
| 2 | En | 56.92 | 43.79 | 49.50 | 63.32 | 51.80 | 56.94 |
| Attr | 59.58 | 41.94 | 49.23 | 73.25 | 48.62 | 58.45 | |
| Val | 70.25 | 67.82 | 69.01 | 83.18 | 76.03 | 79.44 | |
| Avg | En | 56.59 | 39.90 | 46.70 | 64.33 | 54.93 | 59.22 |
| Attr | 64.87 | 44.24 | 52.59 | 75.30 | 51.75 | 61.33 | |
| Val | 71.04 | 69.83 | 70.42 | 82.00 | 76.21 | 78.82 | |
| Test Set | Elements | Accurate Evaluation | Coverage Evaluation | ||||
|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | ||
| 1 | Attr | 74.28 | 40.13 | 52.11 | 75.52 | 43.37 | 55.10 |
| Val | 78.60 | 53.74 | 63.84 | 82.48 | 60.44 | 69.76 | |
| 2 | Attr | 63.21 | 37.86 | 47.36 | 70.14 | 44.90 | 54.75 |
| Val | 72.93 | 50.54 | 59.70 | 77.36 | 53.02 | 62.92 | |
| Avg | Attr | 68.75 | 39.00 | 49.74 | 72.83 | 44.14 | 54.93 |
| Val | 75.77 | 52.14 | 61.77 | 79.92 | 56.73 | 66.34 | |
| Test Set | Elements | Accurate Evaluation | Coverage Evaluation | ||||
|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | ||
| 1 | En | 57.35 | 41.20 | 47.95 | 65.21 | 50.82 | 57.12 |
| Attr | 80.62 | 58.23 | 67.62 | 85.14 | 67.44 | 75.26 | |
| Val | 83.10 | 72.91 | 77.67 | 88.62 | 75.23 | 81.38 | |
| 2 | En | 53.37 | 39.50 | 45.40 | 61.67 | 45.20 | 52.17 |
| Attr | 69.93 | 43.46 | 53.61 | 79.95 | 61.74 | 69.67 | |
| Val | 78.03 | 79.52. | 78.77 | 84.29 | 80.59 | 82.40 | |
| Avg | En | 55.36 | 40.35 | 46.68 | 63.44 | 48.01 | 54.65 |
| Attr | 75.28 | 50.85 | 60.62 | 82.55 | 64.59 | 72.47 | |
| Val | 80.57 | 76.25 | 78.22 | 86.46 | 77.91 | 81.89 | |
| Model | F |
|---|---|
| CRF | 60.65 |
| LSTM-CRF | 64.19 |
| Char-LSTM-CRF | 72.56 |
| LSTM-CNNs-CRF | 73.09 |
| Our method | 72.87 |
| LSTM-CNNs-CRF + Integrity algorithm | 75.21 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, D.; Ge, R.; Niu, Z. Forward-Looking Element Recognition Based on the LSTM-CRF Model with the Integrity Algorithm. Future Internet 2019, 11, 17. https://doi.org/10.3390/fi11010017
Xu D, Ge R, Niu Z. Forward-Looking Element Recognition Based on the LSTM-CRF Model with the Integrity Algorithm. Future Internet. 2019; 11(1):17. https://doi.org/10.3390/fi11010017
Chicago/Turabian StyleXu, Dong, Ruping Ge, and Zhihua Niu. 2019. "Forward-Looking Element Recognition Based on the LSTM-CRF Model with the Integrity Algorithm" Future Internet 11, no. 1: 17. https://doi.org/10.3390/fi11010017
APA StyleXu, D., Ge, R., & Niu, Z. (2019). Forward-Looking Element Recognition Based on the LSTM-CRF Model with the Integrity Algorithm. Future Internet, 11(1), 17. https://doi.org/10.3390/fi11010017