Mashups: A Literature Review and Classification Framework

Abstract
:1. Introduction
2. Review Methodology
3. Literature Review
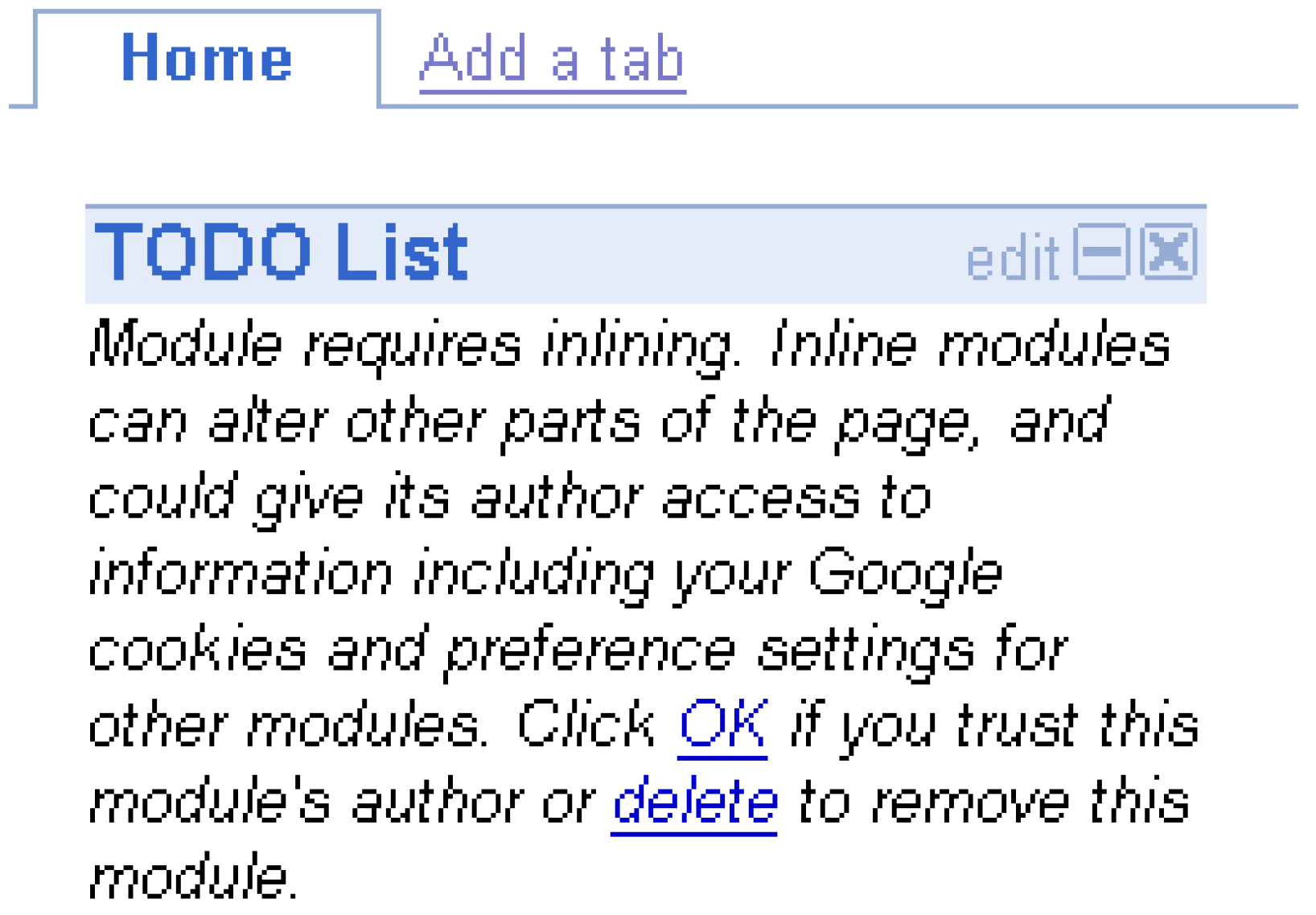
3.1 Access Control and Cross Communication

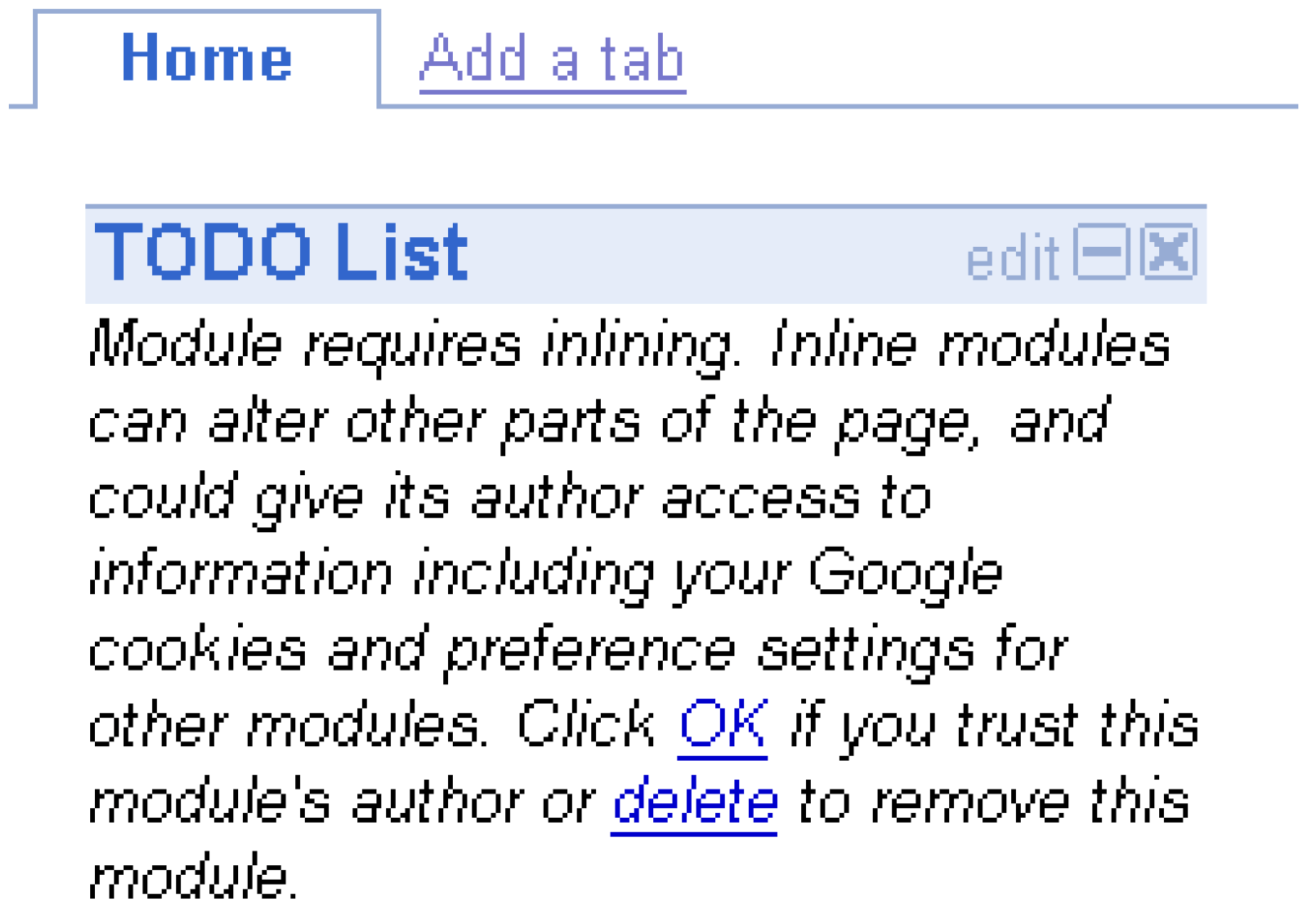{kind=link}
{kind=link}
| Access Control & Cross Communication | Mashups connect disjointed applications to provide unified services, however access control to legacy systems is difficult and hinders a mashup’s potential while increasing security risks to users who have to give their credentials to mashup sites. | [17,18,19] |
| Mashup Integration | Mashups aggregate various different types of data sources (e.g. databases, legacy systems, xml, dynamic web pages, and rss feeds), this area of research addresses the data extraction obstacles presented by these different data sources. | [11,14,20,21,22,23] |
| Mashup Agents | A promising potential of mashups is the ability to semantically determine information sources that are relevant to the user, and autonomously include them in the mashup. | [8,24,25,26,27,28,29] |
| Mashup Frameworks | While mashups are gaining exponential popularity, their individual applications tend to be ad-hoc, partially because of the vast differences in data sources and purpose. Researchers have identified the need for mashup frameworks, to provide developers with a set of best practices. | [4,15,30,31,32,33,34,35,36,37,38,39,40,41,42,43] |
| End User Programming | Enabling the end user to create their own custom mashups is a major reason why mashups have gained such popularity. However this presents an obstacle in that most end users do not obtain the technical expertise to develop mashups, to address researchers are developing end user programming languages and tools, to enable non-technical users to easily create mashups. | [10,28,44,45,46,47,48,49,50,51,52,53,54,55,56] |
| Anonymous | Unrestricted |
| (e.g. public web services) | (e.g. using tags) |
| Full Delegation | Proxy |
| [69,70] | [71] |
| Limited Delegation | Abstracted |
3.2 Mashup Integration
3.3 Mashup Agents
| Machine Learning [28] | Server Based [25,78] |
| Bayesian Networks [29] | |
3.4 Mashup Frameworks
3.5 End User Programming
3.6 Enterprise Mashups
4. Mashup Classification Framework
| Anonymous | Unrestricted | Homogeneous | Machine Learning | Server Based | Consumer | Passive |
| Full Delegation | Proxied | Heterogeneous | Bayesian | Client Based | Enterprise | Proactive |
| Limited Delegation | Abstracted | Application | Natural Language Processing | |||
5. Future Research
| [54] | Anonymous | Unrestricted | Homogeneous | N/A - mobile mashup uses proximity | Server | Consumer | Proactive |
| [9] | Full Delegation | Abstracted | Homogeneous | Semantic Decision Tree | Server | Enterprise | Proactive |
| [26] | Limited Delegation | Proxied | Heterogeneous | N/A – as presented, study focuses on access control | Server | Consumer | Proactive |
| [78] | Anonymous | Abstracted | Homogeneous | Pair-wise Comparisons | Client | Consumer | Passive |
| [39] | Limited Delegation | Abstracted | Heterogeneous | N/A – as presented, study focuses on access control | Client | Consumer | Passive |
| [68] | Limited Delegation | Unrestricted | Homogeneous | Machine Learning | Server | Enterprise | Proactive |
| [70] | Full Delegation | Abstracted | Heterogeneous | Metadata and User Iterations | Server | Consumer | Proactive |
6. Conclusions
References
- O'Reilly, T. What-is-web-2.0. Available at: http://oreilly.com/web2/archive/what-is-web-20.html Accessed September 15, 2009.
- Berners-Lee, T. Originator of the Web and director of the World Wide Web Consortium talks about where we've come, and about the challenges and opportunities ahead. DeveloperWorks Interviews, Available at: http://www-128.ibm.com/developerworks/podcast/dwi/cm-int082206.txt Accessed December 16, 2009.
- Fain, D.C.; Pedersen, J.O. Sponsored Search: A Brief History. In Proceedings of the Second Workshop on Sponsored Search Auctions, Edinburgh, Scotland, May 2006.
- Cayzer, S. Semantic Blogging and Decentralized Knowledge Management. Comm. of the ACM 2006, 47, 47–52. [Google Scholar] [CrossRef]
- Dearstyne, B. Blogs, Mashups, & Wikis: Oh, My! Inf. Management J. 2007, 41, 24–32. [Google Scholar]
- Hester, A. Analysis of Factors Influencing Adoption and Usage of Knowledge Management Systems and Investigation of Wiki Technology as an Innovative Alternative to Traditional Systems. Doctoral Dissertation, University of Colorado at Denver, 2009. [Google Scholar]
- Cold, J. Using Really Simple Syndication (RSS) to Enhance Student Research. SIGITE Newsletter 2006, 3, 6–9. [Google Scholar] [CrossRef]
- Blake, M.B.; Nowlan, M.F. Predicting Service Mashup Candidates Using Enhanced Syntactical Message Management. In IEEE International Conference on Services Computing, Chicago, Illinois, June 2008; pp. 229–236.
- Murugesan, S. Understanding Web 2.0. IT Prof. 2007, 9, 34–41. [Google Scholar] [CrossRef]
- Albinola, M.; Baresi, L.; Carcano, M.; Guinea, S. Mashlight: A Lightweight Mashup Framework for Everyone. In International World Wide Web Conference, Madrid, Spain, April 2009.
- Hornung, T.; Simon, K.; Lausen, G. Mashing Up the Deep Web. In International Conference on Web Information Systems and Technologies, Funchal, Portugal, May 2008; pp. 58–66.
- Merrill, D. Mashups: The New Breed of Web App. IBM Web Architecture Technical Library, 2006. [Google Scholar]
- Tatemura, J.; Chen, S.; Liao, F.; Po, O.; Candan, K.; Agrawal, D. UQBE: Uncertain Query by Example for Web Service Mashup. In International Conference on Management of Data, Vancouver, Canada, May 2008; pp. 1275–1280.
- Sneed, H. Integrating Legacy Software into a Service Oriented Architecture. In Proceedings of the Conference on Software Maintenance and Reengineering, Indianapolis, Indiana, June 2006.
- Vancea, A.; Grossniklaus, M.; Norrie, M. Database-Driven Web Mashups. In International Conference On Web Engineering, Yorktown Heights, New York, July 2008; pp. 162–174.
- Hoyer, V.; Fischer, M. Market Overview of Enterprise Mashup Tools. In International Conference on Service Oriented Computing, Sydney, Australia, December 2008; pp. 708–721.
- Jackson, C.; Wang, H. Subspace: Secure Cross-Domain Communication for Web Mashups. In International World Wide Web Conference, Alberta, Canada, May 2007.
- Keukelaere, F.G.; Bhola, S.; Steiner, M.; Chari, S.; Yoshihama, S. SMash: Secure Component Model for Cross-Domain Mashups on Unmodified Browsers. In International World Wide Web Conference, Beijing, China, April 2008; pp. 535–544.
- Recordon, D.; Reed, D. OpenID 2.0: A Platform for User-Centric identity Management. J. of Comp. Sec. 2007, 15, 11–15. [Google Scholar]
- Blau, B.; Lamparter, S.; Haak, S. Remash! Blueprints for RESTful Situational Web Applications. In International World Wide Web Conference, Madrid, Spain, May 2009.
- Murthy, S.; Maier, D.; Delcambre, L. Mash-o-matic. In ACM Symposium on Document Engineering, Amsterdam, Netherlands, October 2006; pp. 205–214.
- Stonebraker, M.; Hellerstein, J.M. Content Integration for e-Business. In International Conference on Management of Data, Santa Barbara, California, May 2001; pp. 552–560.
- Thor, A.; Aumueller, D.; Rahm, E. Data Integration Support for Mashups. In Proceeding of the International Workshop on Information Integration on the Web, Rio de Janeiro, Brazil, April 2007; pp. 104–109.
- Ennals, R.; Brewer, E.; Garofalakis, M.; Shadle, M.; Gandi, P. Intel Mash Maker: Join the Web. In SIGMOD, Beijing, China, June 2007; pp. 27–33.
- Ikeda, S.; Nagamine, T.; Kamada, T. Application Framework with Demand-Driven Mashup for Selective Browsing. In International Conference on Information Integration and Web-based Applications and Services, Linz, Austria; 2008; pp. 33–40. [Google Scholar]
- Kukka, H.; Ojala, T.; Tiensyrja, J.; Mikkonen, T. panOULU Luotsi: A Location Based Information Mash-up with XML Aggregator and WiFi Positioning. In International Conference on Mobile and Ubiquitous Multimedia, Umea, Sweden, December 2008; pp. 80–83.
- Lizcano, D.; Soriano, J.; Reyes, M.; Hierro, J. EzWeb/FAST: Reporting on a Successful Mashup-based Solution for Developing and Deploying Composite Applications in the Upcoming Web of Services. In International Conference on Information Integration and Web-based Applications and Services, Linz, Austria; 2008; pp. 15–24. [Google Scholar]
- Tatemura, J.; Sawires, A.; Po, O.; Chen, S.; Candan, K.; Argrawal, D.; Goveas, M. Mashup Feeds: Continuous Queries over Web Services. In SIGMOD, Beijing, China, June 2007; pp. 1128–1120.
- Wang, W.; Zeng, G.; Zhang, D.; Huang, Y.; Qiu, Y.; Wang, X. An Intelligent Ontology and Bayesian Network Based Semantic Mashup for Tourism. In IEEE Congress on Services, Honolulu, Hawaii, June 2008; pp. 128–135.
- Abiteboul, S.; Greenshpan, O.; Milo, T. Modeling the Mashup Space. In Workshop On Web Information and Data Management, Napa Valley, California, October 2008; pp. 87–94.
- Ankolekar, A.; Krotzsch, M.; Tran, T.; Vrandecic, D. Two Cultures: Mash Up Web 2.0 and the Semantic Web. In International World Wide Web Conference, Alberta, Canada, May 2007; pp. 825–834.
- Cetin, S.; Altintas, N.; Oguztuzun, H.; Dogru, A.; Tufekci, O.; Suloglu, S. A Mashup-Based Strategy for Migration to Service-Oriented Computing. In Proceedings of the IEEE International Conference on Pervasive Services; 2007; pp. 169–172. [Google Scholar]
- Chen, H.; Ikeuchi, N. Implementation of Ubiquitous Personal Study Using Web 2.0 Mash-up and OSS Technologies. In International Conference on Advanced Information Networking and Applications; 2008; pp. 1573–1578. [Google Scholar]
- Diego, L.; Vazquez, J.; Abaitua, J. A Web 2.0 Platform to Enable Context-Aware Mobile Mash-Ups. In Proceedings of Conference on Ambient Intelligence, Sophia Antipolis, France, September 2007; pp. 266–286.
- Gendarmi, D.; Lanubile, F. A Web Mashup for Social Libraries. In International World Wide Web Conference, Madrid, Spain, April 2009.
- Hartmann, B.; Doorley, S.; Klemmer, S. Hacking, Mashing, Gluing: A Study of Opportunistic Design and Development. Technical Report 2006-14. Stanford HCI Group, 2006. [Google Scholar]
- Iwazume, M.; Kaneiwa, K.; Zettsu, K.; Nakanishi, T.; Kidawara, Y.; Kiyoki, Y. KC3 Browser: Semantic Mash-up and Link-Free Browser. In International World Wide Web Conference, Beijing, China, April 2008; pp. 1209–1210.
- Koschmider, A.; Torres, V.; Pelechano, V. Elucidating the Mashup Hype: Definitions, Challenges, Methodical Guide and Tools for Mashups. In International World Wide Web Conference, Madrid, Spain, April 2009.
- Le-Phuoc, D.; Polleres, A.; Hauswirth, M.; Tummarello, G.; Morbidoni, C. Rapid Prototyping of Semantic Mash-ups through Semantic Web Pipes. In International World Wide Web Conference, Madrid, Spain, April 2009.
- Mostarda, M.; Palmisano, D. MU: An Hybrid Language for Web Mashups. In International World Wide Web Conference, Madrid, Spain, April 2009.
- Raza, M.; Hussain, F.; Chang, E. A Methodology for Quality-based Mashup of Data Source. In International Conference on Information Integration and Web-based Applications and Services, Linz, Austria, November 2008; pp. 528–533.
- Tatsubori, M. Towards an Advertising Business Model for Web Service Mashups. In International World Wide Web Conference, Madrid, Spain, April 2009.
- Wong, J.; Hong, J. What Do We "Mashup" When We Make Mashups? In International Conference on Software Engineering, Leipzig, Germany, May 2008; pp. 35–39.
- Back, G.; Bailey, A. Increasing the Visibility of Web-Based Information Systems via Client-Side Mash-Ups. In International Conference on Digital Libraries, Prague, Czech Republic, August 2008; pp. 418–418.
- Brandt, J.; Klemmer, S. Lash-Ups: A Toolkit for Location-Aware Mash-Ups. In Proceedings of the 19th annual ACM Symposium on User Interface Software and Technology, Montreux, Switzerland, October 2006; pp. 79–80.
- Ennals, R.; Garofalakis, M. Mashmaker: Mashups for the Masses. In International Conference on Management of Data, Beijing, China, June 2007; pp. 1116–1118.
- Ennals, R.; Gay, D. User-Friendly Functional Programming for Web Mashups. In International Conference on Functional Programming, Freiburg, Germany, October 2007; pp. 223–234.
- Huynh, D.; Miller, R.; Karger, D. Potluck: Data Mash-up Tool for Casual Users. In International Conference on World Wide Web, Alberta, Canada, May 2007; pp. 737–746.
- Jones, M.; Churchill, E.; Twidale, M. Mashing up Visual Languages and Web Mash-ups. In Hawaii International Conference on System Sciences, Waikoloa, Hawaii, January 2008; pp. 143–146.
- Kongdenfha, W.; Benatallah, B.; Vayssiere, J.; Saint-Paul, R.; Casati, F. Rapid Development of Spreadsheet-Based Web Mashups. In International World Wide Web Conference, Madrid, Spain, April 2009.
- Lin, J.; Wong, J.; Nichols, J.; Cypher, A.; Lau, T.A. End-User Programming of Mashups With Vegemite. In International Conference on Intelligent User Interfaces, Sanibel Island, Florida, February 2009; pp. 97–106.
- Nestler, T. Towards a mashup-driven end-user programming of SOA-based applications. In International Conference on Information Integration and Web-based Applications and Services, Linz, Austria, November 2008; pp. 551–554.
- Sabbouh, M.; Higginson, J.; Semy, S.; Gagne, D. Web Mashup Scripting Language. In International World Wide Web Conference, Beijing, China, June 2007; pp. 1305–1306.
- Tuchinda, R.; Szekely, P.; Knoblock, C.A. Building Mashups By Example. In International Conference on Intelligent User Interfaces, Canary Islands, Spain, January 2008; pp. 139–148.
- Wang, G.; Yang, S.; Han, Y. Mashroom: End-User Mashup Programming Using Nested Tables. In International World Wide Web Conference, Madrid, Spain, April 2009.
- Wong, J.; Hong, J. Making Mashups with Marmite: Towards End-user programming for the Web. In Conference on Human Factors in Computing Systems, San Jose, California, April 2007; pp. 1435–1444.
- Altinel, M.; Brown, P.; Cline, S.; Kartha, R.; Louie, E.; Markl, V.; Mau, L.; Ng, Y.; Simmen, D.; Singh, A. Damia: A Data Mashup Fabric For Intranet Applications. In Conference on Very Large Data Bases, Vienna, Austria, September 2007; pp. 1370–1373.
- Guinard, D.; Trifa, V.; Pham, T.; Liechti, O. Towards Physical Mashups in the Web of Things. In Proceedings of the 6th International Conference on Networked Sensing Systems, Pittsburgh, Pennsylvania, June 2009.
- Hoyer, V.; Gilles, F.; Fleischmann, K.; Dreiling, A.; Stanoesvka-Slabeva, K. SAP Research Roof Top Marketplace. In International World Wide Web Conference, Madrid, Spain, April 2009.
- Hoyer, V.; Stanoesvka-Slabeva, K.; Janner, T.; Schroth, C. Enterprise Mashups: Design Principles towards the Long Tail of User Needs. In International Conference on Services Computing, Honolulu, Hawaii, July 2008; pp. 601–602.
- Jhingran, A. Enterprise Information Mashups: Integrating Information, Simply. In Conference on Very Large Data Bases, Auckland, New Zealand, July 2008; pp. 3–4.
- Majer, F.; Nussbaumer, M.; Freudenstein, P. Operational Challenges and Solutions for Mashups - An Experience Report. In International World Wide Web Conference, Madrid, Spain, April 2009.
- Makki, S.; Sangtani, J. Data Mashups and Their Applications in Enterprises. In International Conference on Internet and Web Applications and Services, Athens, Greece, June 2008; pp. 445–450.
- Siebeck, R.G.; Janner, T.; Schroth, C. Cloud-based Enterprise Mashup Integration Services for B2B Scenarios. In International World Wide Web Conference, Madrid, Spain, April 2009.
- Simmen, D.; Altinel, M.; Markl, V.; Padmanabhan, S.; Singh, A. Damia: Data Mashups for Intranet Applications. In International Conference on Management of Data, Vancouver, Canada, June 2008; pp. 1171–1182.
- Yang, F. Enterprise Mashup Composite Service in SOA – User Profile Use Case. In IEEE Congress on Services, Honolulu, Hawaii, June 2008; pp. 97–98.
- Zou, J. Towards Accountable Enterprise Mashup Services. In IEEE International Conference on e-Business Engineering, Xi'an, China, October 2008; pp. 205–212.
- Hasan, R.; Winslett, M.; Conlan, R.; Slesinsky, B.; Ramani, N. Please Permit Me: Stateless Delegated Authorization in Mashups. In Proceedings of the Computer Security Applications Conference, Anaheim, California, December 2008; pp. 173–182.
- AuthSub, Google account authentication. Available at: http://code.google.com/apis/accounts/AuthForWebApps.html Accessed September 15, 2009.
- OAuth, Specification 2.0. Available at: http://oauth.net/ Accessed September 15, 2009.
- Johnson, A.D.; Handsaker, R.E.; Pulit, S.L; Nizzari, M.M; O'Donnell, C.J.; Bakker, P. SNAP: A Web-based Tool For Identification and Annotation of Proxy SNPs Using HapMap. Bioinf. Adv. Access 2008, 24, 2938–2939. [Google Scholar]
- Halevy, A.Y. Answering Queries Using Views: A survey. In Conference on Very Large Databases, Rome, Italy, September 2001; pp. 270–294.
- Hull, R. Managing Semantic Heterogeneity in Databases: A Theoretical Perspective. In Symposium on Principles of Database Systems, Tucson, Arizona, May 1997.
- Lenzerini, M. Data Integration: A Theoretical Perspective. In Symposium on Principles of Database Systems, Madison, Wisconsin, June 2002; pp. 233–246.
- Ullman, J.D. Information Integration Using Logical Views. In International Conference on Database Theory, Delphi, Greece, January 1997; pp. 19–40.
- Gruninger, M.; Lee, J. Ontology Applications and Design. Com. of the ACM 2002, 45, 39–41. [Google Scholar] [CrossRef]
- Milanovic, N.; Malek, M. Current Solutions for Web Service Composition. IEEE Int. Comp. 2004, 8, 51–59. [Google Scholar] [CrossRef]
- Lu, B.; Wu, Z.; Ni, Y.; Xie, G.; Zhou, C.; Chen, H. SMash: Semantic-Based Mashup Navigation For Data API Network. In International World Wide Web Conference, Madrid, Spain, April 2009; pp. 1133–1134.
- MacKenzie, M. OASIS - Reference Model for Service Oriented Architecture 1.0. http://www.oasisopen.org/committees/tc_home.php?wg_abbrev=soa-rm Accessed September 15, 2009.
- O’Reilly, T.; Musser, J. Web 2.0 Principles and Best Practices. O’Reilly Radar, Accessed September 15, 2009.
- Walczak, S.; Kellog, D.L.; Gregg, D.G. A Web 2.0 Application to Support Consumer Decision-Making in Multi-Criteria Environments. Int. J. of I.S. in the Serv. Sect. 2009. submitted. [Google Scholar]
- Benslimane, D.; Dustdar, S.; Sheth, A. Services Mashups, The New Generation of Web Applications. IEEE Int. Comp. 2008, 12, 13–15. [Google Scholar] [CrossRef]
- Yu, J.; Benatallah, B.; Casati, F.; Daniel, F. Understanding Mashup Development. IEEE Int. Comp. 2008, 12, 44–52. [Google Scholar] [CrossRef]
- Hoyer, V.; Stanoesvka-Slabeva, K. Towards a Reference Model for grassroots Enterprise Mashup Environments. In 17th European Conference on Information Systems, Verona, Itay, June 2009.
Appendix A. Literature Classification Table.
| [58] | Please Permit Me: Stateless Delegated Authorization in Mashups. | Reviews current mashup access frameworks and discusses their limitations and vulnerabilities, then presents a new access control framework for mashups. | Access Control & Cross Com. |
| [19] | OpenID 2.0: A Platform for User-Centric Identity Management. | Present a proxy-like methodology to provide password protected connections between Identity Providers and Relaying Parties, such as mashups. | Access Control & Cross Com. |
| [18] | Smash: Secure Component Model for Cross-Domain Mashups on Unmodified Browsers. | The security policies of the current generation of web browser prohibits content from different sources to interact, an action required by mashups. A communication abstraction technique is presented, to provide a secure platform for mashups to blend content from differing sources. | Access Control & Cross Com. |
| [17] | Secure Cross-Domain Communications for Web Mashups. | The current web security models states that services can only manipulate data that is from it's same origin. This is a problem for mashup implementations where data from multiple source need to be blended (e.g. aggregated or calculated). Authors propose a mediating frame approach where data from multiple source can be placed and manipulated by the mashup. | Access Control & Cross Com. |
| [20] | Remash! Blueprints for RESTful Situational Web Applications | A system is presented that is designed to harness collective intelligence to support end-user development of service mashups. It enables developers to specify policies about their ingrediential incompatibilities, and then mash services based on their ranking. | Mashup Integration |
| [23] | Data Integration Support for Mashups. | A framework is presented to enhance data integration in web mashup applications. It consists of components for query generation and online matching as well as for additional data transformation. Additionally the framework supports interactive and sequential result refinement to improve the quality of the presented result step-by-step by executing more elaborate queries when necessary. | Mashup Integration |
| [22] | Content Integration for e-Business | While this article was written before the term ‘Mashup’ was coined, it addresses some one the fundamental concepts that enables the development of mashup, namely content integration. | Mashup Integration |
| [21] | Mash-O-Matic | The mashup production process is articulated with an emphasis on the steps needed to clean data from disparate sources and of disparate granularities. | Mashup Integration |
| [11] | Mashup the Deep Web. | A framework is presented that is designed to enable non-expert users to add to deep web sources to mashups by converting them into machine-processable query interfaces. | Mashup Integration |
| [14] | Integrating Legacy Software into a Service Oriented Architecture. | Discusses how to identify legacy systems that are good candidates for being utilized by web services, assess the conversion’s potential business value, and granularize existing logic to be conducive with the web service. | Mashup Integration |
| [28] | Mashup Feeds: Continuous Queries over Web Services. | A collection-based, stream processing, semantic induction method is presented to enable information extraction by monitoring source evolution over time. | Mashup Agents |
| [26] | panOULU Luotsi: A Location Based Information Mashup with XML Aggregator and WiFi Positioning. | A mashup is presented that merges XML content in various forms, such as RSS/ATOM feeds from several content providers, into a database using a flexible XML aggregator. Information relevant to the user’s current location is imposed on a map for a location-based browsing view, which allows the user to learn about nearby services, sites and events of interest. | Mashup Agents |
| [24] | Intel Mash Maker: Join the Web | Mash Maker, a mashing utility included in the current version of the FireFox browser is presented. The utility extracts metadata from pages being viewed by the user, anticipates material that the user might useful, and creates mashups accordingly. | Mashup Agents |
| [29] | An Intelligent Ontology and Bayesian Network Based Semantic Mashup for Tourism. | The authors discuss the importance and present the potential of coupling Semantic Web technologies with Web 2.0 services. A tourism recommendation mashup is presented which uses a Bayesian network to suggest tourist attractions to user, by comparing the user to other users. | Mashup Agents |
| [8] | Predicting Service Mashup Candidates Using Enhanced Syntactical Message Management. | Natural Language Processing is applied as a predictive agent to determine which web services may be related, and thus appropriate for a particular mashup. | Mashup Agents |
| [78] | Smash: Semantic-Based Mashup Navigation For Data API Network. | A semantic based agent is developed to determine which API’s are related that users may couple API’s in effective mashup building. | Mashup Agents |
| [25] | Application Framework With Demand-driven Mashup For Select Browsing. | A mashup development framework is presented. It is based on a data management engine to enable the developer to identify semantic relationships, and then to browse based on semantic relevance. | Mashup Agent |
| [32] | A Mashup-Based Strategy for Migration to Service-Oriented Computing. | Propose a 6 phased methodology to incorporate legacy systems into mashups from a Service Oriented Architecture perspective. Phases include: Model, Analyze, Map (target enterprise model), Design (mashup server), Define (service level agreement), Implement, and Deploy. | Mashup Framework |
| [40] | MU: A Hybrid Language for Web Mashups. | A scripting language is presented that provides support for unification, it is based on the type morphing paradigm, provides user interface induction, and defines both the java runtime environment and java script profiles. | Mashup Framework |
| [15] | Database–Driven Web Mashups. | A database-driven approach to web mashups is presented that allows data integration and mashup logic to be managed within a database to enables developers to work with a uniform abstract model and to have direct access to powerful features of database systems. | Mashup Framework |
| [30] | Modeling the Mashup Space | A mashup model is presented that quantifies the different roles of mashups which are: query data sources, import other mashups, use external Web services, and specify complex interaction patterns between its components. | Mashup Framework |
| [31] | Two Cultures: Mashup Web 2.0 and the Semantic Web. | The differences between Web 2.0 and Semantic Web are disputed by reinforcing their commonalities. The authors advocate a paradigm shift from an overly machine-centered AI view of the Semantic Web towards a more user and community centered approach that draws from the insights of Web 2.0. | Mashup Frameworks |
| [4] | Semantic Blogging and Decentralized Knowledge Management. | Presents a framework to suffice the organizational need of a decentralized, informal, knowledge management system. The framework is a middle ground between blogging and mashups, where multiple users can centrally contribute to decentralized information. | Mashup Frameworks |
| [41] | A Methodology for Quality-based Mashup of Data Source. | A review of mashup literature is conducted, and the need for a mashup framework is identified. The authors present a framework that promotes mashup quality by focusing on inputs. | Mashup Frameworks |
| [34] | A Web 2.0 Platform to Enable Context Aware Mobile Mashups. | Incorporate web 2.0 mashups to ambient intelligence technology environments, to allow users to access services and multimedia data according to their current context (location, identity, preferences). The authors postulate that applying Web 2.0 principles to the development of middleware support for context-aware systems could result into a wider adoption of ambient intelligence. | Mashup Framework |
| [33] | Implementation of Ubiquitous Personal Study Using Web 2.0 Mashup and OSS Technologies. | The authors propose a framework to organize individual information and support information access collaboration for all kinds of users. The framework, Ubiquitous Personal Study (UPS), is independent of service providers and stores personal resources (e.g. profiles and personal activity) and uses tagging to classify and organize information. | Mashup Frameworks |
| [39] | Rapid Prototyping of Semantic Mashups through Semantic Web Pipes. | Semantic Web Pipes is presented to support fast implementation of Semantic data mash-ups while preserving desirable properties such as abstraction, encapsulation, component-orientation, code re-usability and maintainability. | Mashup Frameworks |
| [43] | What Do We “Mashup” When We Make Mashups. | A qualitative review of various mashups is conducted, and mashup categories are discussed in terms of search, visualization, real-time, widget, personalization, folksonomy, and in-situ use. | Mashup Frameworks |
| [37] | KC3 Browser: Semantic Mashup an Link-free Browser. | A framework for a semantic browsing interface called knowledge communication is presented, it integrates multimedia and web services on grid networks, and makes a semantic mashups with various visual gadgets according to user’s contexts. The framework achieves a link-free browsing for seamless knowledge access by generating semantic links based on an arbitrary knowledge models such as ontology and vector space models. | Mashup Frameworks |
| [36] | Hacking, Mashing, Gluing: A Study of Opportunistic Design and Development | Three themes in mash-up design are then evaluated: how components are combined, what the characteristics of the activity of opportunistic design are, and how mash-ups are unique artifacts. | Mashup Framework |
| [42] | Towards an Advertising Business Model for Web Service Mashups. | A business model is presented for online advertising in web service mashups. | Mashup Frameworks |
| [35] | A Web Mashup for Social Libraries. | While social networks are a web 2.0 technology that are benefiting from enhanced user involvement (e.g. folksonomy), their collaborative contributions are restricted to each network, as the social network owners are not providing API to all such content to flow on the web. The authors present a framework to bridge the gap between the disparate social networks. | Mashup Frameworks |
| [38] | Elucidating the Mashup Hype: Definitions, Challenges, Methodical Guide and Tools for Mashups. | A literature review is conducted and a distinction between SOA’s and mashups is postulated. | Mashup Frameworks |
| [10] | Mashlight: A Lightweight Mashup Framework for Everyone. | A mashup building framework is presented that enables non technical users to create process-like mashups using widget like web 2.0 applications. On benefit to the framework is that it does not require a particular web server but can be run on any webkit compliant browser. | End User Programming |
| [54] | Building Mashups By Example. | An end user mashup building approach is presented that combines most problem areas in Mashup building into a unified interactive framework that requires no widgets, and allows users with no programming background to easily create Mashups by example. | End User Programming |
| [56] | Making Mashups With Marmite: Towards End-User Programming for the Web. | An end user mashup tool is presented that is designed to enable end-users to easily extract information from web pages, process extracted data (e.g. exclude certain content, add metadata), integrate multiple data sources, direct the output to a specified location (e.g. DB, map service, text file). | End User Programming |
| [52] | Towards a Mashup-driven End-user programming of SOA-based Applications. | The authors discuss mashup development with a focus on reducing the development cost by empowering specified user groups to create applications that support their daily activities. | End User Programming |
| [28] | UQBE: Uncertain Query by Example for Web Service Mashup. | A query by example mashup tool for non-programmers is presented, it supports query by example over a schema made up by the user without knowing the schema of the original sources. | End User Programming |
| [46] | Mashmaker: Mashups for the Masses. | A tool is presented that allows users to collaboratively share and explore data and queries, the users can share data, widgets, and widget suggestions all using a simple social network that is dynamically maintained. | End User Programming |
| [53] | Web Mashup Scripting Language. | The authors discuss an approach of using an interim web service that can be automatically generated from the pair-wise mappings of legacy web services’ data models. | End User Programming |
| [49] | Mashing Up Visual Languages and Web Mashups. | A recent trend is discussed, detailing the shift away from the desktop computing model where software is installed locally on your machine, towards web applications where personal and public data and services coexist on remote servers distributed across the web. The following cognitive dimensions are then discussed from a mashup perspective: Stability, Robustness, and Share-ability. | End User Programming |
| [48] | Potluck: Data Mashup Tool for Casual Users. | The need and various scenarios of mashups is discussed. An end user mashup tool is presented and empirically evaluated. The results indicated that users were able to quickly learn the user interface and successfully created mashups. | End User Programming |
| [45] | Lash-Ups: A Toolkit for Location-Aware Mash-Ups. | A toolkit is presented that enables smart phone users to create mobile location specific mashups. The toolkit provides two main benefits. Firstly, it provides simple, standard API for mobile user. Secondly, it enables user to distribute their mashups to other users for reuse. | End User Programming |
| [47] | User-Friendly Functional Programming for Web Mashups. | While there are a plethora of different mashups sites currently available, the authors highlight areas where mashups are currently needed. In fact they mention that the number of needed mashups is so great that the only practical solution is to enable end users to create mashups. Thus, an end user mashup tool is presented. | End User Programming |
| [55] | Mashroom: End-User Mashup Programming Using Nested Tables. | An end-user programming model is presented that includes an expressive data structure as well as a set of formally-defined mashup operators. The model uses a table structure to enable users to express complex data objects. An empirical evaluation revealed that users effectively and efficiently used the application to build mashups. | End User Programming |
| [51] | End-User Programming of Mashups With Vegemite. | An end user mashup tool is empirically evaluated, the tool focuses on programming by demonstration, iterative and interactive transformation of data by the user, and mixed-initiative interaction. | End User Programming |
| [44] | Increasing the Visibility of Web-Based Information Systems via Client-Side Mashups. | The common hindrances of mashups are discussed, such as client-side programming, proxy servers, and suitable web service interfaces. A mashup approach is then presented that avoids these three mashup pitfalls. | End User Programming |
| [50] | Rapid Development of Spreadsheet-Based Web Mashups. | The need for web based data mashups is discussed, then a spreadsheet like approach to data mashups is presented that addresses the following mashup obstacles: access, synchronization, re-use, and manipulation. | End User Programming |
| [27] | EzWeb/FAST: Reporting on a Successful Mashup-based Solutions for Developing and Deploying Composite Applications in the Upcoming Web of Services. | The authors elaborated on the synergies between the Web 2.0 and the enterprise application worlds that can be exploited. They then present a model for global user-centric SOA and a novel architecture for enterprise mashup composite applications. | Enterprise Mashups |
| [60] | Enterprise Mashups: Design Principles Towards the Long Tail of User Needs. | The components of Enterprise Mashups are presented as a stack composed of resources, API’s, widgets, mashups, and web applications. The development lifecycle of enterprise mashups is discussed which is perpendicular to traditional lifecycles and resembles the rapid prototyping lifecycle. | Enterprise Mashups |
| [63] | Data Mashups and Their Applications in Enterprises. | The authors discuss web 2.0 mashups in the domain of enterprises. Specifically they compare mashups to traditional applications in terms of having a higher interpretation value and lesser navigational costs. | Enterprise Mashups |
| [65] | Damia: Data Mashups for Intranet Applications | The evolution of the enterprise intranet to a platform for web 2.0 applications is presented as an opportunity for business leaders to exploit information from desktops, the web, and other non-traditional enterprise sources, in order to react to situational business needs. | Enterprise Mashups |
| [61] | Enterprise Information Mashups: Integrating Information Simply. | The need for enterprise mashups is discussed, and a development approach is postulated that focuses on utilizing existing information systems to provide a foundation for enterprise mashup applications. | Enterprise Mashups |
| [67] | Towards Accountable Enterprise Mashup Services. | The legal implications of applying mashups to enterprises is discussed. A model is presented that can be used by information systems developers to understand the roles and responsibilities that need to be accommodated in a mashup service solution. | Enterprise Mashups |
| [60] | SAP Research Rooftop Marketplace. | The authors discuss the lack of consistency in literature concerning the scope, role, and definition of enterprise mashups. The adoption of enterprise mashups is described as a phased approach. | Enterprise Mashups |
| [57] | Damia: A Data Mashup Fabric For Intranet Applications. | An enterprise mashup framework is presented. The framework consists of a browser-based UI to chart data flows, a server-based execution engine, and API's for mashing. | Enterprise Mashups |
| [62] | Operational Challenges and Solutions for Mashups – An Experience Report | The organizational and technical challenges of enterprise mashups are discussed. To address these issues the authors propose that focus be maintained on centralized configuration and monitoring, to enable mediating and managing of disparate components. | Enterprise Mashups |
| [64] | Cloud-based Enterprise Mashup Integration Services for B2B Scenarios | A literature review is presented that distinguishes between consumer and enterprise mashups. The relationship between reach and richness is discussed and a prototype mashup integration service is presented. | Enterprise Mashups |
| [66] | Enterprise Mashup Composite Services in SOA – User Profile Use Case. | Best practices for enterprise mashup development and implementation is discussed. | Enterprise Mashups |
© 2009 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Beemer, B.; Gregg, D. Mashups: A Literature Review and Classification Framework. Future Internet 2009, 1, 59-87. https://doi.org/10.3390/fi1010059
Beemer B, Gregg D. Mashups: A Literature Review and Classification Framework. Future Internet. 2009; 1(1):59-87. https://doi.org/10.3390/fi1010059
Chicago/Turabian StyleBeemer, Brandon, and Dawn Gregg. 2009. "Mashups: A Literature Review and Classification Framework" Future Internet 1, no. 1: 59-87. https://doi.org/10.3390/fi1010059
APA StyleBeemer, B., & Gregg, D. (2009). Mashups: A Literature Review and Classification Framework. Future Internet, 1(1), 59-87. https://doi.org/10.3390/fi1010059